
Abstract
Social workers often find themselves in situations where they have to speak in public or give a presentation. Therefore, social workers need to have good presentation skills. Among the social workers’ clients, some people have to speak in public and are affected by problems in this area, too. Nervous habits that can occur in public speaking are filler words (such as the senseless use of the word “like”), filled pauses (consisting of utterances such as “um,” holding a vowel for a longer time, or stuttering) or tongue clicks (Mancuso & Miltenberger, 2016, p. 188). Perrin et al. (2021) summarize these as speech disfluencies. Frequent use of speech disfluencies can affect the credibility of the speaker (Clark & Fox Tree, 2002; Duvall et al., 2014) and make the speaker look unprepared and uncertain (Bell, 2011). Listeners may be distracted by frequent use (Bell, 2011; Clark & Fox Tree, 2002). Mancuso and Miltenberger (2016) considered filled pauses similar to nervous habits such as stuttering or nail biting.
Habit reversal training is a method developed by Azrin and Nunn (1973) to treat both nervous behavior habits and tic disorders. The central element of the training is that an incompatible alternative behavior, also called a competing response, should be shown instead of the problematic behavior. Habit reversal training is based on four components: awareness training, competing response practice, habit control motivation, and generalization training (Azrin & Nunn, 1973). The first component is awareness training. Clients should first develop an awareness of behaviors or tics. The awareness training component is again divided into five phases. The first phase of awareness training is the response description procedure. Clients should describe the topography of the behavior as accurately as possible. In the second phase, the response detection procedure, clients should learn to recognize each movement involved in the behavior. The third phase aims at recognizing early signs or preceding movements; therefore, it is also called an early warning procedure. The fourth phase and, at the same time, the second component is the competing response training. This phase involves practicing a behavior that is opposite and incompatible with the problem behavior, a competing response. In the fifth phase, situation awareness training, the clients are supposed to gain an awareness of situations, persons, or places in which the nervous habit occurs. The third component, habit control motivation, represents building motivation for change. The last and fourth component is generalization training. This component involves instruction of the target behavior in natural settings. (Azrin & Nunn, 1973).
The complexity of the original protocol led researchers to investigate whether simplified protocols could achieve similar outcomes. Rapp et al. (1998) showed that a simplified version of habit reversal training is sufficient in most cases to get the problem behavior under control. This simplified or brief habit reversal (BHR) essentially only includes a shortened form of awareness training and competing response training. In the meantime, the brief habit reversal training is so widespread that it has replaced the original habit reversal training in most cases.
Mancuso and Miltenberger (2016) evaluated the effect of a brief habit reversal procedure, consisting of awareness training and competing response practice on the frequency of filled pauses in public speaking. The awareness training included the response description and response detection procedure. Results showed that the training reduced speech disfluencies and that the results were maintained on a follow-up survey. The study (see also Bördlein & Sander, 2020) provides evidence that self-awareness training as a sole component may be sufficient to reduce the use of speech disfluencies. Therefore, Spieler and Miltenberger (2017) extended these findings and investigated whether awareness training alone was sufficient. The study confirmed the findings that awareness training alone led to a reduction in speech disfluencies, but booster sessions were necessary. This alteration reduced the required effort and time only marginally. Therefore, there may be no benefit in eliminating the competing response practice. Montes et al. (2019) conducted a systematic replication of the two previous studies. The procedure of the awareness training was divided into two phases: video training and in vivo training. All subjects showed a reduction in speech disfluencies, and no competing response training was required. The study provided evidence that separate video and in vivo training may be helpful. Previous findings suggested that instruction of a competing response may produce better results. Participants in a study by Pawlik and Perrin (2020) received awareness training and then instruction for a competing response but no formal competing response practice. The rates of speech disfluencies of the participants decreased, and the rates of competing responses increased, supporting the findings that habit reversal training can be effective even without formal competing response practice. Since habit reversal was still time-consuming, Montes et al. (2021) investigated whether it is necessary to conduct both components of awareness training (video and in vivo training) or whether one component is sufficient. Results showed that awareness training, consisting of both video and in vivo training, resulted in the most sustained effects. To extend previous research, Ortiz et al. (2022) conducted a study on the independent and additive effects of awareness training components. Their participants first went through the response description, and when a specific criterion was met, they proceeded directly to the postsurvey. The study provided evidence that response description as a sole component may lead to reductions, but further research is needed. Perrin et al. (2021) investigated whether training in a small group can reduce the duration of BHR. The purpose of the study was to examine the efficacy of BHR in a small group with an interdependent group contingency and the efficacy of instructing a competing response. The study suggests that brief habit reversal in a small group is effective in reducing speech disfluencies. However, it is unclear whether the small group format is more effective than individual training, as individuals had to remain in a phase longer than they would have in individual training due to the group contingency. In addition, the study provides findings that competing response practice is likely more effective than instruction alone.
Luiselli 2022 reviewed the research on this topic. Since then, other studies have highlighted different implementation variants of habit reversal training applied to speech disfluencies. For example, Perrin et al. 2024 demonstrated that computer-based asynchronous awareness training could reduce speech disfluencies in four participants.
The current study on brief habit reversal in a group format is derived from the findings of the study by Perrin et al. (2021). The group setting most closely represents the actual situation of public speaking and may be more time efficient. In addition, the study by Perrin et al. (2021) is the methodologically most advanced study. Therefore, the aim of the present study was to replicate and extend the work of Perrin et al. (2021) by (a) investigating the efficiency of group training versus individual training, (b) exploring the importance of response and reduction criteria, and (c) investigating the instruction of a competing response without formal competing response practice.
Method
Participants, Setting, Materials
Nine female social work students participated in this study. All participants expressed an interest in improving their public speaking skills after the first author had recruited participants for the study in the lectures of the second author. The participants delivered a speech using a procedure similar to the baseline to verify that they met the inclusion criterion. They had to give a speech lasting 5 min. Topics were based on opinions or personal experience and from a list of 25 topics, which was used later, too. During the 5 min, speech disfluencies were counted. As specified by Mancuso and Miltenberger (2016) and Spieler and Miltenberger (2017), participants could be included in the study if they used at least two speech disfluencies per minute. The participants were assigned to three groups. Group 1 (participants 1, 2, and 3) and Group 2 (participants 4, 5, and 6) were undergraduate students of social work. Group 3 (participants 7, 8, and 9) were social work students in a master's degree program. All of them speak German as their mother tongue, and all presentations were held in German. All participants signed informed consent and were informed that all personal data was anonymized and stored according to the national data protection regulations.
Participant 5 dropped out of the study after the first session of BHR. She gave personal psychological and health reasons for her withdrawal. She explained that the training was too much of a burden due to the upcoming exams. It is assumed that there is no connection between the training and the personal concerns, only additional mental stress. Therefore, no more data could be collected on Participant 5 after the first session of BHR.
Sessions occurred in seminar rooms at the University. At each session, the rooms were equipped with tables and chairs. During some of the sessions, a podium was used for the presentations. The student giving the presentation stood in front of the audience (the other two students), who sat in chairs facing the person giving the presentation. The researcher sat at a table that was equipped with data collection sheets and a list of presentation topics. In addition, the table was equipped with two smartphones, one to record the presentations and one to use as a stopwatch. Furthermore, a white and a red card (25 cm × 19.7 cm) were placed on the table and served as signal cards. Holding up the white card signaled that 4 min of the assigned presentation time were over and 1 min remained. The red card signaled that 5 min were over, and the participant had to end the presentation.
Target Behaviors, Interobserver Agreement
Frequency data were collected on three nervous habits occurring during public speaking: filled pauses, tongue clicks, and inappropriate word use, collectively referred to as filler words. The three nervous habits are similar to the dependent variables in Perrin et al. (2021) combined into one single measure: speech disfluencies. Operational definitions were identical to those described by Perrin et al. (2021) with one exception: Data were also collected on the inappropriate use of the words exactly, yes, so, and quasi. The competing response was defined as a silence of at least 3 s between one speech sound and the onset of the following speech sound, meaning that during competing response training, the participant had to remain silent for 3 s whenever she used a speech disfluency or felt the urge to use one.
All sessions were recorded. During the sessions, the experimenter documented the number of speech disfluencies on a data collection sheet. The names of the participants were anonymized, and each participant was assigned a number from 1 to 9 (P1–P9).
For data analysis, the frequency data of speech disfluencies were converted into a rate. The total number of speech disfluencies was divided by the duration of the speech. The speech duration was 5 min for each talk, and it was calculated from the time the speech started until the experimenter held up the red card. That way, an average value of speech disfluencies per minute could be calculated. For the data analysis of each group, the speech disfluencies of the participants were first added to get a total frequency. This total frequency of speech disfluencies was converted into a rate by dividing the total group frequency by the sum of the speech durations of the individual participants. Using this calculation, the group mean for each phase could be calculated.
In addition, during BHR, frequency data were also collected for response identification. The number of identified speech disfluencies was converted to a percentage by dividing the number of responses identified correctly by the total number of speech disfluencies and then multiplying by 100.
Data on competing responses were collected using a similar principle as Perrin et al. (2021). Using the audio analysis and editing software “Wondershare Filmora 11®,” data on the competing responses can be collected (Wondershare Technology Co., Ltd, 2022). First, the videos were imported into the program. The settings ‘Volume threshold 15%’ and ‘3-second pauses’ were selected. The silent pauses (competing responses) in the individual videos were then determined using the ‘silence detection’ function in the program. The first author cross-checked the outputs of the silent pauses of the program to verify its reliability.
To calculate interobserver agreement (IOA), two additional observers collected data for approximately 33% of the sessions in each phase of the study. The two reliability observers watched 16 videos from the baseline, 15 videos of brief habit reversal, 10 videos of postsurvey, and three videos of follow-up. The videos were randomly selected and distributed to the two observers. They were given a data collection sheet. Exact agreement was calculated for speech disfluencies by dividing the sessions into 15 s intervals and dividing the number of intervals with agreement by the number of intervals with agreement plus disagreement. Then, the result was multiplied by 100. The mean agreement was 85,2%.
Social Validity
Participants completed three questionnaires during the study. Prior to the beginning of the study and after the last session, all participants completed a public-speaking abilities rating scale. A treatment rating scale was used to assess social validity. The questionnaires are identical to Perrin et al. (2021) and have only been translated into German.
The public-speaking abilities rating scale includes seven questions for self-assessment regarding one's comfort with public speaking, assessment of confidence and anxiety in giving a speech in public, and self-assessment regarding the use of speech disfluencies. The scale uses a five-point Likert-type scale. Seven additional items were added to assess the skills before and after the training (see Table 1).
Summary of Responses on the Public Speaking Rating Scale.
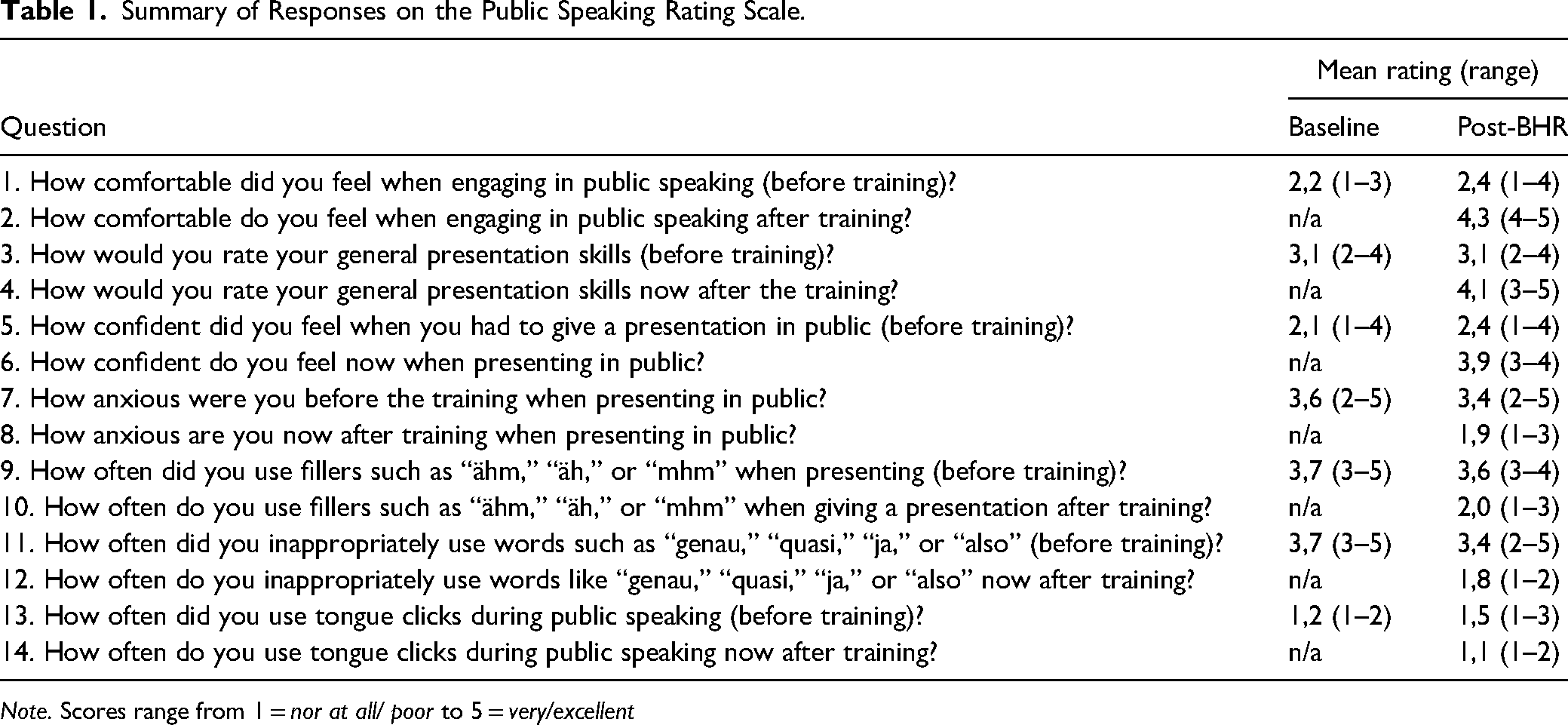
Note. Scores range from 1 = nor at all/ poor to 5 = very/excellent
The treatment rating scale (Table 2) was also a five-point Likert-type scale to measure acceptance, willingness to participate in the training, advantages and disadvantages, and difficulties of the training.
Summary of Responses on the Treatment Acceptability Rating Scale.

Note. Scores range from 1 = not at all/none to 5 = very/many
The data analysis method was a descriptive mean calculation. The mean was calculated by counting the number of responses for each answer choice and then multiplying it by the value of that answer. The result was then divided by the number of answered questionnaires to calculate the mean. Because one participant ended the study prematurely, poststudy questionnaire data are based on the ratings of 8 participants only.
Design and Procedure
As in Perrin et al. (2021), a concurrent multiple baseline design across groups was used. In addition, an interdependent group contingency was used to examine the effectiveness of BHR training in reducing speech fluencies.
This study is a replication of Perrin et al. (2021); therefore, the procedure is identical, with a few exceptions. Unlike the original study, participants had 3 min to prepare a 5-min speech. In Perrin et al. (2021), the participants were asked to give a speech of 3–5 min. In addition, the participants in this study were not given a red card to signal the end of their talk, as in Perrin et al. (2021), only the experimenter had a red card. Perrin et al. (2021) set the criterion for ending the BHR as either all group members identify 100% of speech disfluencies during their speech, all group members identify at least 85% during two consecutive speeches, or a group member identified 84% or fewer speech disfluencies for three consecutive speeches. In addition to these criteria, the groups had to meet an 80% reduction compared to baseline rates. 80% reduction was also the criterion in the original study (Perrin, personal communication).
In the study of Perrin et al. (2021), during BHR, the participants watched 1-min videos from the baseline. In contrast, the participants in the present study only listened to the 1-min videos from the baseline but did not watch the videos. Another difference refers to the follow-up probes. In the original study, a group of 14 persons consisting of the three groups and the experimenters were present. In the present study, the follow-up probes were conducted in small groups, such as during baseline and BHR. In addition, the period between the last post-BHR session and the follow-up probe was longer compared to Perrin et al. (2021), as they took place after 47, 43, and 20 days.
Baseline
During baseline, the experimenter met with all groups separately. At the beginning, the procedure of the session was explained, which was identical for each group and baseline session. The experimenter randomly selected two topics from a list of 25 topics. As in Perrin et al. (2021), speech topics were (a) identical to those used during both Spieler and Miltenberger (2017) as well as Pawlik and Perrin (2020) and (b) based on opinion or personal experience. The group chose one of the topics. The participants had 3 min to prepare a 5-min talk. They were allowed to talk about anything relevant to the topic. Furthermore, the participants were allowed to take notes and use the Internet. The notes were allowed to be used during the presentation, but the participants were instructed to give a free presentation and not to read from the notes. Even though the sessions were conducted in a group format, each person gave a speech of their own. The experimenter counted down from three, started the camera and the stopwatch, and the participant began her speech. After 4 min, the experimenter held up the white card, indicating that there was 1 min left. After 5 min, the red signal card was held up by the experimenter, signalizing the end of the time. If the participant stopped speaking for 15 s during the presentation, the experimenter stated, “Please continue.” This procedure was then repeated for all participants, and all groups underwent several sessions—each time, a new topic was chosen, and the order of presentation of the subjects varied. The baseline ended when the rate of speech disfluencies of the subjects was stable.
Brief Habit Reversal
For the BHR, the experimenter met again with the groups. The first phase of the BHR corresponds to the response description procedure. In the beginning, the three forms of speech disfluencies (pause fillers, filler words, tongue clicks) were operationalized. For example, the experimenter stated, similar to Perrin et al. (2021): “One common speech disfluency is what we refer to as a filled pause. We have defined filled pauses as speech sounds including ‘ähm,’ ‘äh,’ or ‘mhm’ that are not grammatically or semantically meaningful to the speech.” The participants were explained which speech disfluencies had been used by which participant during the baseline. Next, participants should practice recognizing speech disfluencies. This phase corresponds to the response detection procedure (video training). The groups watched a 1-min sample of each of the participants’ baseline speeches that contained representative examples of the speech disfluencies. Participants were instructed to raise their hands each time they heard a speech disfluency. The experimenter also raised her hand but waited a few seconds after the speech disfluency occurred. This way, the subjects themselves had a chance to recognize the speech disfluency. If a subject failed to recognize a speech disfluency, the video was played again. After each group watched all of the baseline videos, the group members were asked if they felt confident in recognizing the speech disfluencies or if they wanted to continue practicing. All groups reported feeling confident and that it was possible to proceed to the next step, which was the response detection procedure (in vivo training). The procedure was the same as in the baseline, except that the same topic was used for each talk during the BHR. The groups were instructed to raise their hand each time they used a speech disfluency or when the experimenter raised her hand. The researcher raised her hand while the first five speech disfluencies occurred, only when the participant did not recognize the speech disfluency. The other two participants in the group were asked to discreetly practice recognizing the speech fluencies by noting speech disfluencies on a separate sheet of paper as they occurred. In addition to the instruction to raise their hand, the subjects were given an instruction for the competing response, similar to Perrin et al. (2021): “A 3-s pause can serve as a competing response, which can replace the speech disfluency making it less likely to occur. While speaking, if you feel yourself about to emit a speech disfluency, stop talking and count to three silently.” Practice speeches continued until two criteria were met. The group had to achieve an 80% decrease in speech disfluencies compared to the group's baseline mean. Once this criterion was met, practice speeches continued until one of the following occurred: (a) all group members identified 100% of their speech disfluencies during a speech, (b) all group members identified at least 85% of their speech disfluencies during two consecutive speeches, and (c) one group member identified 84% or less of their speech disfluencies during three consecutive speeches. Participants were not informed of the criteria or progress toward meeting them. Instead, they were told during the sessions that they would continue to practice giving speeches.
Post-BHR
Post-BHR sessions took place at least 24 hr but up to three days after the completion of BHR. The post-BHR procedure was identical to the baseline procedure. The subjects no longer had to raise their hand to identify speech disfluencies, and the experimenter no longer raised her hand when speech disfluencies occurred. Post-BHR ended when the group had a decreasing or stable trend of speech disfluencies, with a reduction of at least 80% compared to baseline rates.
Booster Sessions
Booster sessions were conducted if a group did not meet an 80% reduction in speech disfluencies compared to baseline within the first two post-BHR sessions or if an increasing trend was observed. The first booster session took place at least 24 hr after the last post-BHR session. The procedure and criteria for booster sessions were the same as for BHR. The only exception was that the participants did not practice identifying speech disfluencies while listening to the videos.
Follow-up
Follow-up probes were conducted in each group separately. For Group 1, they were conducted 47 days after the last post-BHR session, 43 days for Group 2, and 20 days for Group 3. The follow-up procedure was identical to the baseline. Each participant gave one 5-min presentation.
Results
Figure 1 shows the rates of speech disfluencies for all treatment conditions for all participants. At baseline, all participants showed moderate to high rates of speech disfluencies. Group 1 showed the highest rate with M = 5.95 (range, 2.85–10.75) speech disfluencies per minute. Group 2 showed the second highest rate (M = 4.79 speech disfluencies per minute; range, 2.64–5.88). Group 3 showed the lowest rate with an average of M = 4.45 (range, 2.71–6.69). All groups showed moderate mean frequency of speech disfluencies during baseline.
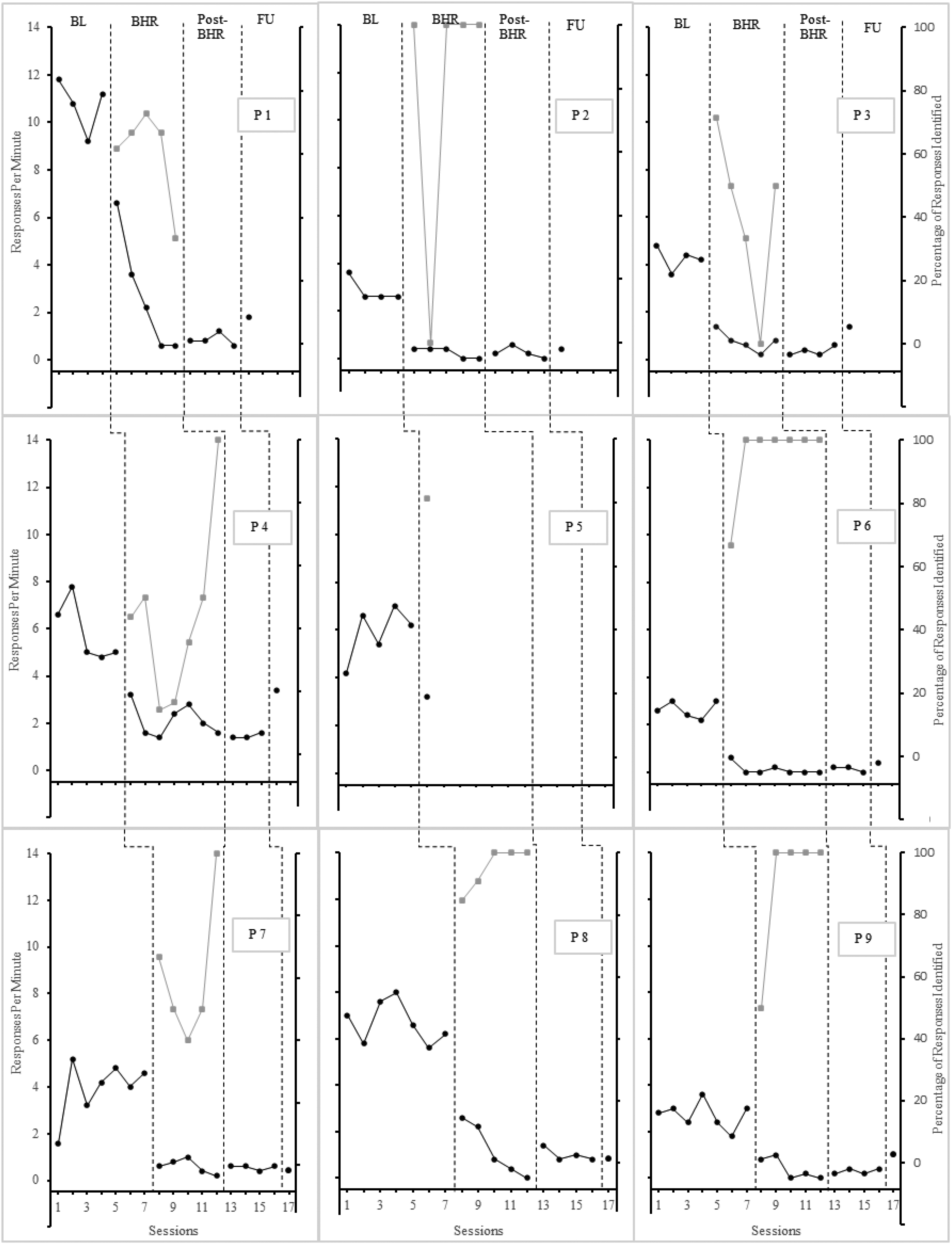
Speech disfluencies and response identification across conditions
During BHR, speech disfluencies decreased for all participants in groups 1–3. At the end of the BHR, all groups achieved a reduction in frequency of at least 80% compared to baseline rates. Group 1 showed a reduction already in the first session of the BHR (M = 2.8; range, 0.4–6.6) and a further reduction by the last session (M = 0.46; range, 0.0–0.8). Group 2 showed a reduction in speech disfluencies (M = 2.3; range, 0.6–3.2) that decreased further to a mean of M = 0.8 (range, 0.0–1.6) in the last session of the BHR. In Group 3, the number of speech disfluencies also decreased with M = 1.3 (range, 0.6–2.6) in the first session and M = 0.07 (range, 0.0–0.2) in the last session.
Levels of response identification varied among participants. P1 showed moderate levels of response identification. P2 always identified 100% of her speech disfluencies except for one speech. P3 showed large fluctuations in levels of response identifications. P4 showed low to moderate levels of response identification. P5 showed a high level of response identification, but no more data was collected after that. After the first speech, P6 identified 100% of speech disfluencies in each session. In Group 3, P7 showed moderate to high levels of response identification. P8 and P9 showed high levels of response identification and mostly identified 100% of speech disfluencies. Each group had at least one person who could not identify 100% of speech disfluencies in one session or 85% in two consecutive sessions at all or only after a few sessions. As a result, four of the nine participants had to give an average of 3.25 (range, 2–5) additional speeches due to the interdependent group contingency, even though they had already met the criterion of identifying 100% of speech disfluencies.
Group 1 showed low and stable rates of speech disfluencies at post-BHR. In the post-BHR sessions, the group showed a mean between M = 0.4 and M = 0.6 speech disfluencies per minute. In addition, the group achieved an average reduction in speech disfluencies of 91.85% (range, 89.9%–93.2%), so no booster sessions were necessary. Group 2 remained below criterion with a constant mean of M = 0.8 speech disfluencies per minute and a reduction of 81.1% in the post-BHR sessions and did not require booster sessions. With a mean between M = 0.53 and M = 0.73 in the first sessions of the post-BHR, Group 3 achieved a reduction to baseline in all sessions with an average of 86.2% (range, 83.6%–88.1%). This group also did not require booster sessions.
At follow-up, all participants continued to show low rates of speech disfluencies. Some participants showed higher rates than in post-BHR or BHR sessions, but no participant reached values above the baseline rate. Group 1 showed low rates at follow-up with M = 1.2, achieving a 79.8% reduction from baseline. With a mean of M = 1.9, Group 2 showed an increase in speech disfluencies, and the rate of speech disfluencies is substantially above post-BHR. Even though the group as a whole remained below baseline rates, a reduction of 80% to baseline could not be maintained, and the group only achieved a reduction of 55.2% to baseline. Group 3 showed overall low rates in the combined total frequency of speech disfluencies, and with a mean of M = 0.73, the group achieved a reduction of speech disfluencies by 83.6% to baseline.
Figure 2 shows the rates of competing responses. At baseline, all participants showed competing responses at low rates. P3, P4, and P5 used no competing response, and the rates of the other participants varied between 0 and 1 competing response per minute. During BHR, the rates of competing responses increased for all participants except P6. However, the rates remained low and varied between M = 0.06 and M = 0.6. At post-BHR, rates of competing responses decreased in all participants, with only P8 showing a minimally higher rate at this phase. P2, P3, and P4 showed no more competing responses. Except for P8 and P9, all participants showed low rates of competing responses again. At the follow-up probe, none of the participants except P3 and P9 used competing responses anymore.
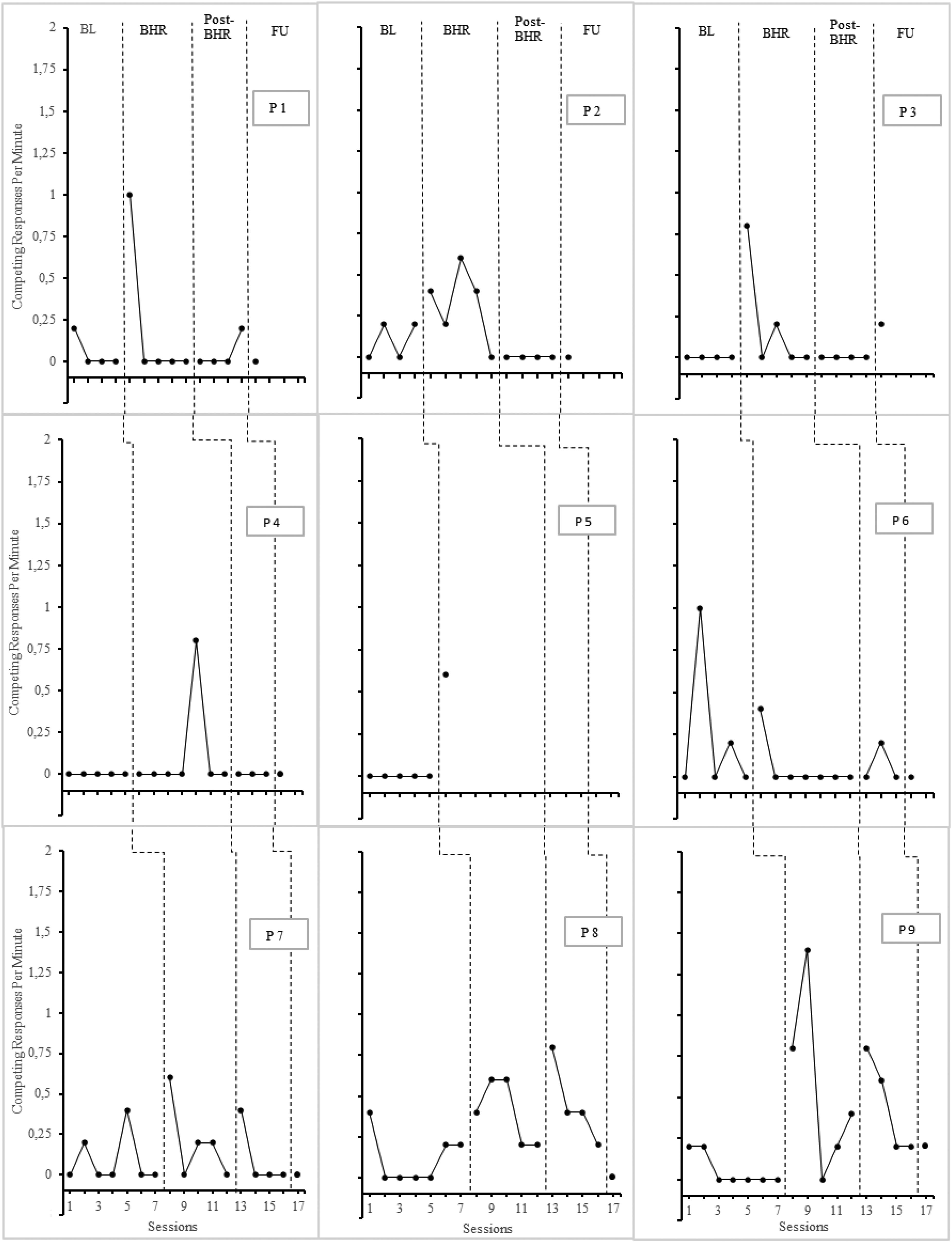
Competing responses across conditions
Table 1 depicts the results of the public speaking rating scale. Prior to baseline, the participants reported a low level of comfort while speaking in public. Their abilities are rated as medium, and the participants reported low self-confidence while feeling more anxiety when speaking in public. Participants reported moderate to high levels of speech disfluencies. Following BHR, the level of comfort is higher, and participants also rated their abilities higher. After training, participants reported feeling more confident and less anxious. The use of speech disfluencies is rated lower after the training. The results of the treatment rating scale show a medium to high social validity (Table 2). The participants stated that they enjoyed the training, that it was hardly or only slightly challenging to participate in, and that it did not cause any disadvantages. The effectiveness of the training was rated at a medium to high level. All participants would recommend the training to others.
Discussion and Applications to Practice
The results of this study could replicate the findings from Perrin et al. (2021) that BHR in a small group is effective in reducing speech disfluencies. At post-BHR, all participants reduced the usage of speech disfluencies by at least 80% compared to baseline levels. Booster sessions were not required. However, in the follow-up probes, not all participants were able to fulfill the mastery criterion, although they still showed a reduction of at least 55.2%.
Even if this replication provides consistent results, it has yet to be conclusively clarified whether the application in a small group is more efficient than on an individual basis. In total, the training for the Groups lasted from 400 to 570 min, of which the BHR took up to 175 to 225 min. These durations are consistent with Perrin et al. (2021). However, the time is approximately the same as in studies in which the participants underwent the training separately (Luiselli 2022). Due to the interdependent group contingency, some subjects had to stay in a phase longer, even though they had already reached a criterion. As other participants in the group still needed to meet this criterion, the group as a whole remained in the phase, which means that training in a small group appears to be not more efficient and timesaving than individual training.
Nevertheless, training in a small group has advantages compared to individual training. The group setting corresponds more closely to the real-life situation of social workers and their clients. In addition, the group setting includes the social and motivational components described by Azrin and Nunn (1973). Perrin et al. (2021) suggest conducting the training in a group with an independent group contingency. Then, the participants would go through the BHR in a group, but individual responses would determine when a participant moves to post-BHR. This procedure has the advantages of a group setting, and the training could be more time efficient. This consideration by Perrin et al. (2021) should be pursued further.
Another purpose of this study was to evaluate further whether both of the mastery criteria are necessary for the success of the training, the reduction of the speech disfluencies, and the identification of those. The initial level of identification of speech disfluencies was mixed among the participants. Most participants showed medium to high rates of identification (four of nine reached 100% immediately); others had more difficulties and initially showed only low rates. Due to the interdependent group contingency, seven participants were required to give an average of 3.1 speeches (range: 2–5) after they had already achieved the 80% reduction of speech disfluencies. This result is consistent with the results of Perrin et al. (2021). Therefore, it is recommended that only the effectiveness of the 80% reduction criterion should be tested.
Competing responses were generally used at a low rate. At baseline, the participants showed no or meager rates of competing responses. During BHR, the rates increased but decreased post-BHR, and they continued to be low in follow-up probes. Therefore, this study supports the findings of Perrin et al. (2021) that the instruction of a competing response is less effective than teaching a competing response. The study by Mancuso and Miltenberger (2016) provides evidence that awareness training alone may be effective. Other studies (Montes et al., 2019, 2021; Oritz et al., 2022; Spieler & Miltenberger, 2017) also support this conclusion. These results leave the impression that the competing responses are less critical for the success of the training than the awareness component.
In the social validity questionnaire, the test subjects rated their public speaking skills lower before the training. They stated that they were less self-confident, felt less at ease, and were afraid of public speaking. After the training, all subjects stated that they felt more confident and less anxious when speaking in public. Their sense of well-being was also higher. Social validity ratings were generally medium to high. Participants found the treatment acceptable and would recommend it to others. They also stated that the training did not have any disadvantages. Overall, the question about the effectiveness of the training achieved a medium to high score, which indicates a high social validity of the training.
There are a few differences in results compared to Perrin et al. (2021). In the present study, no booster sessions were necessary because the groups met the criterion without. Booster sessions at follow-up could have been helpful in maintaining the treatment effect. In contrast to Perrin et al. (2021), the follow-up was conducted after a more extended period. The rates of participants remained low; therefore, this study can provide results on the long-lasting effects of BHR training in a group setting. Participant 5 dropped out of the study due to personal problems. It cannot be excluded that the training triggers fears or similar reactions. Compared to previous studies, this was the first drop-out. A screening for social anxiety and similar issues before the start of the training is recommended. Clients who are particularly affected may then require customized training. Especially with regard to social work clients, who often have to deal with psychological problems, the training should be adapted, and it should be ensured that the training does not have any mental disadvantages.
Despite the promising results and the improvements in all participants, there are several limitations. The first limitation is that no generalization training was conducted, so it was not possible to determine whether the results could be transferred to other settings. This limitation is of specific consideration because a presentation in front of an unfamiliar group may cause more anxiety. In addition, only female social work students took part in the study, which may limit the generalizability of the results. Although the group setting is ecologically valid, as speeches usually have to be given in front of different people, the interdependent contingency resulted in four of the nine participants giving additional speeches despite already having fulfilled the mastery criterion. This also corresponds to the results of a study by Perrin et al. (2021) in which five participants had to give more speeches after meeting the criteria. Another limitation is that this study design does not address the aim of investigating the efficiency of group training versus individual training. The study provides some evidence, but it still needs to be determined whether habit reversal training should be used in casework or group work settings.
The strengths of this study include the fact that BHR training is an easily implementable treatment. Social workers can easily benefit from this training and significantly improve their public speaking skills. The successful replication with different populations demonstrates generalizability to different populations, enhancing the external validity of previous results.
The data from the study provides implications for future research. The group setting should be studied using only the mastery criterion of reducing speech disfluencies by 80%. This criterion may be more effective and less time-consuming. An independent group contingency could be investigated in which the performance of each individual determines their progress, as suggested by Perrin et al. (2021). Furthermore, conditions (such as the type and magnitude of the audience) could be changed to create a situation similar to real life. This change would foster the generalization of treatment effects. As current studies have only been conducted with students, future research should focus on training with social workers and their clients.
Social workers need good presentation skills in many situations in their daily work. They have to work together in interdisciplinary teams, and there is much exchange with other professional groups, and information has to be communicated to different target groups. In addition, social workers often lead workshops or seminars on essential topics such as addiction prevention, integration, and conflict resolution. Good presentation skills help to convey knowledge clearly and increase learning success. Since speech disfluencies are common in public speaking and, therefore, also common among social workers, this study provides data demonstrating the effectiveness of using BHR to reduce speech disfluencies. BHR in a small group with an interdependent group contingency is effective and provides some advantages over individual training. This study also provides implications for adjustments for the group design. Further research could make the training more efficient. Essential is the adaption to the field of social work so that social workers and their clients can benefit.
Supplemental Material
sj-docx-1-rsw-10.1177_10497315241301372 - Supplemental material for Using Brief Habit Reversal to Decrease Speech Disfluencies in Public Speaking. A Systematic Replication
Supplemental material, sj-docx-1-rsw-10.1177_10497315241301372 for Using Brief Habit Reversal to Decrease Speech Disfluencies in Public Speaking. A Systematic Replication by Anja Göhring and Christoph Bördlein in Research on Social Work Practice
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.