
Abstract
Artificial intelligence (AI) is suggested as a support for virtual collaboration. We conducted a between-subjects experiment (N = 151) to compare two AI summarizers using the Human-Agent Teaming on Intelligence Tasks (HATIT) platform. Participants reviewed study-created documents, with the HATIT AI summarizer providing either an informative or an indicative summary. Dispositional trust in AI influenced learned trust in the AI summarizer and greater trust developed in the informative condition. Compared to the indicative condition, participants in the informative condition also displayed some evidence of faster but less frequent attention to newly arrived teammate information. Problem-solving accuracy was comparable across conditions.
Keywords
Knowledge workers, such as scientists, bankers, consultants, and intelligence analysts, increasingly tackle complex analytical tasks that require collaboration with individuals with complementary information and expertise (Baber et al., 2016; Gartin, 2019; Hackman, 2011; Wuchty et al., 2007). To access information across time and place, team members increasingly collaborate virtually, using reports, documents, and other digital files (Handke et al., 2020). Virtual collaborative analysis has become increasingly challenging as the data involved has exploded in volume, velocity and variety, among other characteristics of “big data” (Fan et al., 2010; Jin et al., 2015).
Partnering with others has long been advocated to address the needs of complex tasks, and psychologists have been studying effective teaming for decades (McGrath, 1984). From this research, we know that interacting teams can collectively process information (Hinsz et al., 1997; Kane, 2010; Mesmer-Magnus & DeChurch, 2009). When such teams work well, members combine what they have gleaned from their own information processing with what they learn from attending to information provided by their teammates (Gupta & Woolley, 2021; Kane et al., 2023). However, these collaborative analysis processes can break down. Members may be caught up in their own analysis and be slow to attend to teammates’ contributions (Fan et al., 2010). Overloaded with information to synthesize, members may only cursorily review teammates’ information and not return for a second or third look (Baber et al., 2016; Kang et al., 2014).
Artificial intelligence (AI) has been suggested as a way of meeting the demands of high volume, rapid velocity information processing tasks, such as those encountered by a team of intelligence analysts monitoring a border (Gartin, 2019; Kane et al., 2023; Kane et al., in press). In the comparable high-information contexts of medicine and academia, AI summarizer tools have emerged to help doctors track hospital patients’ progress (Goldstein & Shahar, 2016) and scientists “surf a paper flood” (Brainard, 2023). These types of single purpose, virtual AI tools that provide onscreen text are among the many types of AI that are becoming a part of teamwork in workplaces (Bezrukova et al., 2023, Figure 3, p. 634). Similarly, AI that supports team members as they conduct their work has been identified as key to the collective intelligence of teams (Gupta & Woolley, 2021; Gupta et al., 2023, 2024).
The goal of the current research is to experimentally test the effects of two different AI summarizers on virtual collaborative analysis. The tested AIs are (1) an indicative summarizer that outlines the contents of the text, versus (2) an informative summarizer that provides a condensed version of a text (explained below). Specifically, we examine their effects in the virtual collaborative analysis context of intelligence analysis. Our study makes several contributions. We responded to calls from the National Academies of Sciences, Engineering, and Medicine (2022) to experimentally test different AIs on human-AI teaming. Our study contributes to this evolving literature by highlighting that the tested AI summarizers influence attitudes towards AI, namely learned trust in the AI summarizer, as well as the speed and frequency of switching attention (attention-switching) to teammates’ information. Finally, we advance the automated text summarization literature by providing an in-use evaluation of informative and indicative summaries in a novel and important team context.
Theoretical Framework
Automated Text Summarizers
Text summaries, whether an abstract, synopsis, or precis, are critical for effective idea dissemination and collaboration (Luo et al., 2024; Rowley, 1982). However, creating useful summaries often requires significant time and effort from busy individuals (Rush et al., 1971). Recognizing this problem, Luhn (1958) made a first attempt at computer-generated abstracts, measuring word significance and frequency to extract the most important sentences from a piece of text. While efforts in automated text summarization (ATS) continued, Paice (1980) declared that “the production of well-constructed abstracts is an artificial intelligence problem, and therefore unlikely to be either feasible or worthwhile until well into the future” (p. 172). Indeed, the early rules-based, extractive approaches did not yield much until they were replaced with neural network and deep learning approaches that by 2010 had begun to support abstractive summarization (see Khan et al., 2023, their Figure 1 for a timeline).
While significant advances in ATS have been made, computer-generated summaries often miss relevant information. For example, Yang et al. (2020) found state-of-the-art models (i.e., deep reinforcement learning, generative adversarial network, and multi-task learning framework) to be only at the midpoint on a five-point scale in terms of capturing relevant information in CNN and Daily Mail news stories (Yang et al., 2020, Table 8, p. 58). Advances in AI models, such as the Generative Pre-trained Transformer commonly used in large language models, show promise in terms of improved accuracy and efficiency of ATS (Khan et al., 2023; Luo et al., 2024).
Technical advances in ATS coincide with research exploring their practical utility across domains where information overload occurs. Notably, researchers made significant advances in ATS systems that consolidate electronic health records and clinical documents (Goldstein & Shahar, 2016; Moen et al., 2016; Moradi et al., 2020); synopsize lengthy legal documents (Jain et al., 2021; Kanapala et al., 2019); and summarize news (Egonmwan & Chali, 2019; Yang et al, 2020). This research largely focuses on how accurately specific technical approaches capture the content of the summarized documents (e.g., Yang et al., 2020). We contend that to effectively bring ATS into virtual collaboration, more research is needed that evaluates the utility of the summarizers—in other words, that examines how different kinds of summaries support team members who use them (e.g., Goldstein & Shahar, 2016).
This study thus focuses on evaluating AI summaries on their utility to team members. We examine two types, indicative summaries and informative summaries, that fulfill defined roles (see Table 1). The first, indicative summaries, describe the document and seek to convey the principal idea of the text (Khan et al., 2023; Sharma & Sharma, 2023). An indicative summary allows the reader to determine whether they want to read the entire document (Rush et al., 1971; Saggion & Lapalme, 2000) and tends to comprise about 5% of the original text (Tas & Kiyani, 2017). For example, Hallet and Scott (2005) used a natural language generator to produce indicative summaries of the clinical history of cancer patients that take less than a minute to read, “fit entirely on a computer screen” (p. 33), and are accompanied by the entire medical record should the practitioner wish to read further.
AI Summarizer Types.

The second, an informative summary, is a “condensed version of the text” (Altmami & Menai, 2022), ideally containing all relevant information, or as much as possible (Saggion & Lapalme, 2000). An informative summary is about 20% of the original text (Tas & Kiyani, 2017) and functions as a replacement for the original document (Pivovarov & Elhadad, 2015). For example, Goldstein and Shahar (2016) developed CliniText, an ATS system that generated informative summaries for discharging a patient. These summaries aim to include all relevant information about the patient’s symptoms, diagnoses, and treatment. CliniText summaries were found to help doctors answer questions about patients 40% faster than doctor-written summaries. However, CliniText summaries more often missed crucial information than those written by doctors.
AI Summarizers for Intelligence Analysis
This study evaluates informative versus indicative AI summarizers in an important type of virtual collaborative analysis conducted by members of the intelligence community tasked with assessing threats and making recommendations. Intelligence analysis is a sensemaking process that requires analysts to sift through data to identify key facts, assemble facts into models, test models against data, and report to policy makers (Doppler Haider et al, 2019; Pirolli & Card, 2005). Intelligence analysts often work collaboratively to ensure 24/7 monitoring of critical events, like troop movements by adversarial nations near allied borders (Baber et al., 2016; Bier et al., 2008; Kane et al., 2023). Virtual collaborative analysis involves iterating between teammate provided information and one’s own evolving perspective (Baber et al., 2016; Bier et al., 2008). Importantly, analyst teams must process vast amounts of data (e.g., news reports, social media), which are continuously collected at scale (Lowenthal, 2023).
In intelligence analysis, both indicative and informative summarizers may be helpful in different ways. Faced with hundreds of documents, an indicative summary would help analysts decide which are worth reading. An informative summary would allow analysts to grasp the contents of documents more quickly. We know from research on ATS that the specific information that makes a summary informative is context-dependent (e.g., Pivovarov & Elhadad, 2015). Prior research on intelligence analysis indicates that information processing is “made easier if it is organized around entities (people, places, things, times, etc.)” (Bier et al., 2008, p. 99). Including such information in informative AI summaries would help with quickly understanding and synthesizing documents about unfolding events, such as through news media and historical reports. By calling out specific people, places, things, and times, the attention of the reader can be focused on the key narrative aspects of actors, events, and locations to better understand causes and effects.
Attitudes Toward and Trust in AI
Attitudes are generally positive or negative opinions that individuals develop about people, activities, and things (Albarracín & Johnson, 2018). Because of their mutability and connection to behavior, attitudes are an active area of research in applied domains. Attitudes are central in technology use (Lee & See, 2004). In the domain of AI and teams, Bezrukova et al. (2023) developed a model in which attitudes feature prominently. Specifically, they postulate that attitudes shape team members’ engagement with AI, such that engagement is likely to be highest when members evaluate AI positively and have discretion over how much they use the AI to do their collaborative work (Bezrukova et al., 2023).
Among attitudes toward AI that are likely to impact collaborative analysis, trust is a particularly important and active area of research (Bezrukova et al., 2023; Carter-Browne et al., 2021; National Academies of Sciences, Engineering, and Medicine, 2022; Wildman et al., 2024). Glikson and Woolley (2020) identified trust as central in “human–AI relationships because of the perceived risk embedded in them, due to the complexity and nondeterminism of AI behaviors, and its future role in the workplace” (p. 630). To define trust in AI, we integrate seminal work in management and human factors. In management, trust has been defined as an inclination “to be vulnerable to the actions of another party based on the expectation that the other will perform a particular action important to the trustor, irrespective of the ability to monitor or control that other party” (Mayer et al., 1995, p. 712). In human factors regarding automation, trust is “the attitude that an agent will help achieve an individual’s goals in a situation characterized by uncertainty and vulnerability” (Lee & See, 2004, p. 54). From these we suggest that trust in AI may be defined as the human trustor’s expectations that the trustee, an AI agent over which the human teammate has limited control, will help them achieve their work goals in a situation characterized by uncertainty. These expectations likely include beliefs about the trustee’s performance, their process, and their purpose (Lee & See, 2004).
In line with the established conceptualization of trust in automation as interrelated expectations, Chien et al. (2017, 2018, 2020) developed and cross-culturally validated questionnaires. This universal trust in automation instrument, which flexibly applies to different automation technologies, consists of two scales: one for generalized trust in the broader class of automation (e.g., AI), and one for trust in the specific instance of the technology (e.g., an AI summarizer) that participants encounter. Chien et al. (2020) characterized the general trust measure also as dispositional trust, and the specific trust measure as learned trust, in line with Hoff and Bashir (2015). Accordingly, the formation of trust in AI will likely depend on properties of the trustor as well as on properties of the trustee that are learned through experience as outlined next.
Dispositional Trust in AI in General
Trust formation can be understood as arising in part from relatively stable characteristics of the trustor, termed dispositional trust, generalized trust, or trust propensity (Glikson & Woolley, 2020; Mayer et al., 1995). For various reasons ranging from childhood experiences to cultural norms, individuals vary in their baseline propensity to trust others. Dispositional trust, arising from norms, culture, demographics, and personality, applies to automation and AI as well (see Hoff & Bashir, 2015, for a review). For example, American participants displayed stronger generalized trust in a decision tool automation than did Turkish participants (Chien et al., 2020). It is natural to expect that dispositional trust in AI in general will similarly affect the trust individuals initially develop toward a specific AI, leading to our first hypothesis.
Hypothesis 1: Dispositional trust in AI in general will positively influence learned trust in the specific AI summarizer.
Learned Trust in AI as a Function of the Type of AI Summarizer
Trust in AI depends on task-specific expectations that develop with experience with the technology. This type of learned trust has been identified across models of human trust (Mayer et al., 1995) and trust in automation (Hoff & Bashir, 2015). In human-AI teaming, trust in the AI is a key collaboration output (O’Neill et al., 2023, see their Table 2, p. 915) and an emergent state (Carter et al., in press).
Key to the development of learned trust in AI is the expectation that the AI will help the user perform well enough to meet the challenges of their specific context. How well an AI summarizer is perceived to perform may be related to whether it is indicative or informative. As noted previously, in the context of intelligence analysis, entity-based summaries are likely to be more informative. In a study supported by the National Institute for Standards and Technology involving four intelligence analysts, participants used digital notebook tools to keep track of people and places and reported that they found an entity-based approach to be helpful (Bier et al., 2008, p. 104). For information overloaded analysts, we argue that informative summaries that do not require review of the document to understand its contents are likely to be viewed as more helpful than indicative ones that require reading the document.
These insights are related to two additional features that can influence the perceptions of an AI’s utility and trust: demonstrability and transparency. From research on work groups and teams, we know that when the merits of information shared by teammates is demonstrable and apparent, groups are more likely to use that information in their work (Bonner et al., 2021; Kane, 2010; Laughlin & Ellis, 1986; Mesmer-Magnus & DeChurch, 2009). Making summaries demonstrable has conceptual overlap with the concept of information transparency. Here, we focus on information transparency as it refers to the clarity of the content provided by a technology, rather than on other types, such as system transparency that relates to clarity about the inner workings of the technology (e.g., Hoff & Bashir, 2015; Glikson & Woolley, 2020). Informative summarizers, which provide details from the original text, can be considered more transparent than indicative summaries, which provide a general idea of the original text without going into specifics (see Table 1). A transparent summarizer may have an easy-to-read format, such as bullet points (Wang et al., 2023).
Over time, as an analyst gains experience with an informative, entity-based AI summarizer that presents information in a relatively transparent and demonstrable way, we predict that trust will increase. The information will be useful in that context, so the more the analyst sees the summarizer across different documents, the more they will trust it. Whereas additional experience with an indicative summarizer of limited utility that is neither entity-based nor presents information in a bulleted, transparent way should not increase trust. Taken together, an informative, entity-based AI summarizer that lists people, places, and events in bullet points is likely to be perceived as more trustworthy over time than an indicative AI summarizer that provides the document’s main content in a phrase. Accordingly, we provide the following hypothesis:
Hypothesis 2: Over time, stronger trust in a specific AI summarizer will develop for those conducting collaborative analysis using an informative versus indicative AI summarizer.
Collaborative Analysis and Attention
Collaborative analysis teams are rarely bounded in the way an airplane cockpit crew or surgical team all comes together for a defined performance period. Rather, membership and work tend to be fluid, with some members working synchronously and others replacing one another (Kane et al., 2023; Kang et al., 2014; Paletz & Schunn, 2011). This team structure means that the work of collaborative analysis is, by its nature, virtual and distributed.
The interpreting, analysis, and sensemaking of information in these teams is a challenging distributed cognition problem. Analyst team members collaborate to make sense of complex situations, developing, testing, and updating models as new information becomes available (Bier et al., 2008; Lowenthal, 2023). Observations of military intelligence professionals reveals that experienced analysts review data broadly, testing multiple hypotheses iteratively (Baber et al., 2016). These processes can occur sequentially or synchronously.
Key to both individual and collaborative analysis is attention. Because people have limited attention (Newell & Simon, 1972; Simon, 1996), its allocation and focus within teams is an important consideration (Bernstein et al., 2024). Information can flow from teammates via messages or email, and be received synchronously or asynchronously (Handke et al., 2020). The speed of responsiveness to new teammate information versus the frequency of returning to that information can be behavioral markers of attention, including collective attention (e.g., Mayo & Woolley, 2021). For complex analysis tasks, team members face a trade-off between reviewing existing information or considering the information provided by their teammates. It is challenging to know ex ante the value of newly arrived teammate information. High velocity intelligence data from teammates, such as social media and breaking news, may be irrelevant and interrupt current work. However, while continuing to engage in one’s own analysis supports refinement of one’s current model, new information collected by teammates may provide a new take on the situation (Bernstein et al., 2018; Duncan et al., 2023). A study of visualization supports for intelligence analysis revealed that successful analysts jumped between files, returning to some multiple times, ostensibly to validate evolving representations of the situation (Doppler Haider et al., 2019). We therefore note the importance of two types of attention-switching: the responsiveness to new information versus the frequency of returning to existing information again and again.
Technological tools can have an impact on attentional processes, providing representations and shaping information flows as part of a sociotechnical system (Hutchins, 1995). A key concern is understanding the effect that different AI may have on the allocation of team member’s attention (Gupta et al., 2023). In a high-volume, high-velocity information scenario, different AI summarizers likely influence the extent that team members allocate attention to teammates’ proffered information. We argue that an informative, entity-based summarizer, being more complete, may make the analyst think that they need not review information in documents beyond understanding the summaries, and so then free up the analyst to be able to review new documents when suddenly delivered. In other words, an informative summarizer may encourage participants to attend to high-velocity information newly arrived from teammates but discourage them from frequently attending to teammate-provided documents that contain a high volume of information. Whereas an indicative summarizer may be recognized as insufficient, such that the analyst may focus on working through the existing information contained in documents before having the capacity to turn to new information from synchronous teammates. We further expect that the attentional processes shaped by an indicative summarizer will include returning multiple times to lengthy documents to overcome memory issues and validate their understanding (Doppler Haider et al., 2019).
In the context of our study, we expect that the details provided in an informative summarizer will render it less critical that analyst participants read existing documents in detail, which opens attentional resources for rapid attention switching as detailed in Hypothesis 3a. By contrast, an indicative AI summarizer is expected to require analyst participants to return their attention more frequently to teammates’ information, leading to Hypothesis 3b.
Hypothesis 3a: Participants in the informative AI condition will more quickly switch attention to newly arrived teammate information than in the indicative condition.
Hypothesis 3b: Participants in the indicative condition will more frequently switch attention to teammates’ information than in the informative condition.
Team Performance in Collaborative Analysis: Problem-Solving Accuracy
In collaborative analysis tasks, problem-solving success may be achieved in numerous ways. From observations of teams at work, including bankers developing financial products, Hackman (1990) identified three normative criteria for effective teaming; namely, members need to bring the requisite knowledge and skills to complete their task, exert enough effort to achieve a reasonable performance, and use appropriate strategies for the task and context (p. 9). Consistent with this perspective, problem-solving success in intelligence tasks is associated with several variables, including domain knowledge and task engagement behavioral variables (Mellers et al., 2015). The current study uses a complex problem-solving task with simulated virtual teamwork and randomly assigns participants to AI conditions. The question, then, is whether the different AI summarizers might affect problem-solving success—here, accuracy, because the task was created to have a correct answer—as a main effect. We could make an argument in either direction, mainly because (1) problem-solving accuracy in virtual teams is caused by many factors and is a distal variable (Handke et al., 2020), and (2) the motivation and actions necessary to engage in problem solving are not necessarily influenced in only one way by the different AI conditions. As noted previously, indicative and informative summarizers may both be helpful. Indicative summaries could help analysts decide which of the many documents to read, whereas informative summaries may allow analysts to grasp the contents of each document more quickly (Pivovarov & Elhadad, 2015; Saggion & Lapalme, 2000). Consequently, we take an abductive approach and do not make any a priori directional hypotheses regarding the effects of the informative and indicative AI summarizer condition on problem-solving accuracy. Doing so follows recommendations by researchers (Aguinis & Vanderberg, 2014; Mathieu, 2016) to incorporate distal outcomes, like performance, to set the stage for subsequent research to build theory capable of tackling real-world challenges.
Method
Design
We conducted a between-subjects (AI Summarizer: indicative, informative) experiment using the Human-Agent Teaming on Intelligence Analysis Task (HATIT) online testbed. 1 As detailed below, researchers designed HATIT for controlled experiments on the effects of AI on virtual collaborative analysis (Paletz et al., in press).
Participants
Participants were recruited via the Prolific (https://www.prolific.com) online pool with the qualifications that they be 18 years or older, fluent in English, have completed high school/A-levels or more education, use a laptop or desktop computer with internet access, and be willing to work for 25 min on a training phase and, if eligible and interested, up to 75 additional minutes on a subsequent task.
In total, 171 participants took part in both phases. In return, they received $5 for completing the training phase and $15 for completing the main phase. For “good faith” efforts in the main phase, 154 participants received an additional $3 bonus. The final sample included main phase participants who passed both reading comprehension checks, worked for at least 30 min on the main task, and were not duplicate participants. The 151 participants that met our inclusion criteria were randomly assigned to either the indicative AI summarizer condition (n = 82) or the informative AI condition (n = 69). 2
Of the 151 participants, 107 (70.9%) self-identified as men, 39 (25.8%) as women, 3 (2%) as non-binary or third gender, and 2 (1.3%) preferred not to answer. The participants’ average age was 33.2 years old (SD = 12.7, range 19–79 years old). In terms of race (non-exclusive codes), 116 (76.8%) self-identified as Caucasian or White, 17 (11.3%) as Black, 11 (7.3%) as Asian (including East, South, and Southeast Asian), 2 (1.3%) as Middle Eastern or North African, and 7 (4.6%) as Other. Twenty-two (14.6%) self-reported their ethnicity as Hispanic or Latino, with 126 (83.4%) as not and 3 (2%) preferred not to answer.
The largest group of the participants reported living in the United Kingdom (n = 37, 24.5%), with the next living in the United States (n = 28, 18.5%), Portugal (n = 20, 13.2%), South Africa (n = 16, 10.6%), Poland (n = 14, 9.3%), and Spain (n = 6, 4.0%). Five participants (3.3%) listed their locations as Mexico or Hungary, four participants (2.6%) were from Greece, three (2.0%) from Germany, and then two or one were from Australia, Belgium, Canada, Chile, the Czech Republic, Estonia, Ireland, Italy, and the Netherlands.
Procedure
All research procedures were approved by and conducted in compliance with Institutional Review Boards (UMD Protocol 1758081-4, ARL Protocol 22-045). During recruiting and in the informed consent form, participants were informed that if they choose to take part in this study, they would be asked to imagine that they were working in a team of intelligence analysts in a fictional country.
Participants completed the experiment using the online HATIT platform (Paletz et al., in press). HATIT is an externally valid online system, developed via interviews with intelligence analysts, for examining how AI interventions may impact collaborative analysis. HATIT houses digital task materials in a repository (as asynchronous information, e.g., memos), collects unobtrusive measures of participant attention (see Measures), displays document summaries generated in advance by the researchers (either manually or by using an ATS—see AI Summarizer Manipulation), and enables the collection of participant-reported data through integration with the Qualtrics online survey platform.
HATIT simulates asynchronous and synchronous virtual collaboration as the participant and their teammates collectively monitor media, agency reports, and other documents to identify threats to their own fictional country, Vorgaria. The other teammates, including Kalev, the analyst on the shift prior, and Magda, who delivers social media data, are electronic confederates of the experimenter. The use of confederates, who act in scripted ways, renders the experience similar across participants, enhancing the validity of causal claims. The approach dates to seminal work on social influence (Asch, 1956) and has been used to explore contemporary virtual collaboration (Kang et al., 2014; Leavitt et al., 2019). In the fictional world of the HATIT task, Vorgaria shares borders with three countries, Unkaroa, Rozania, and Stradikovia, which had previously been an empire that encompassed the other three. In their role working for the Vorgarian Intelligence Agency (VIA), participants reviewed documents to solve a straightforward analysis task in the training phase and a significantly more complex collaborative analysis task in the main phase.
Training Phase
The 25-min training/screening phase began with an informed consent procedure, in which participants were informed that if they answered certain questions correctly, they may qualify for the main study. Next, participants were asked about their computer setup to ensure they could use the platform (e.g., type of browser) and provided some demographic information (e.g., language fluency). Participants then entered the HATIT platform, which was populated with an introduction to the world, maps, and country reports. They also received a shift handover document from Kalev, the VIA teammate they were replacing for the next shift. Kalev asks the participant to solve a relatively simple intelligence task. The participants were then given 10 min to review the materials and determine a solution, after which they were assessed on their performance (see Table 2).
Study Variables.
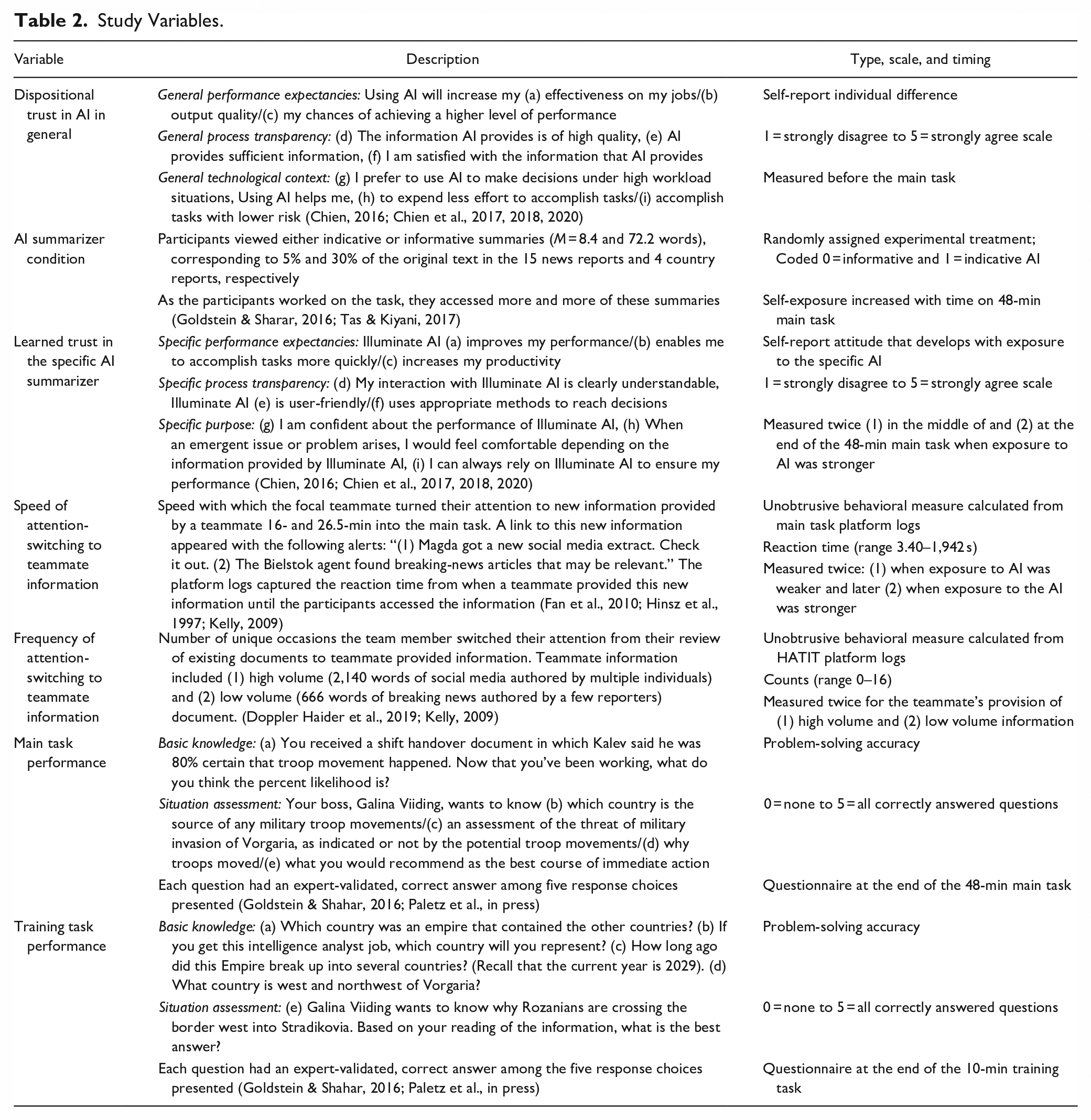
In addition to familiarizing participants with HATIT, the training phase allowed us to screen out inattentive or fraudulent participants (Paletz et al., in press). For this study, the threshold we used to determine who would be invited included correctly answering at least two of five training task performance questions (a 40% solve rate) and accessing at least two of the documents loaded in the HATIT directory (e.g., one of the four country reports or the map).
Main Phase
Before the main task began, participants completed an online informed consent procedure followed by a brief survey where they indicated their dispositional trust in AI in general, answered the same computer setup questions as in training, and provided demographic items (e.g., race/ethnicity). In this phase, participants worked with the assistance of a virtual AI called “Illuminate AI,” whose document summaries appeared above each document next to a sun icon (see Figure 1). In this phase’s shift handover document, Kalev introduced Illuminate AI and outlined their VIA team’s priority task, which was to investigate a possible troop movement within Stradikovia, Vorgaria’s larger, aggressive neighbor. While Kalev suspected that Stradikovia was readying troops due to animosity with their neighbor Unkaroa, multiple narratives were seeded in the documents, including a Stradikovian invasion of Vorgaria and a terrorist attack.
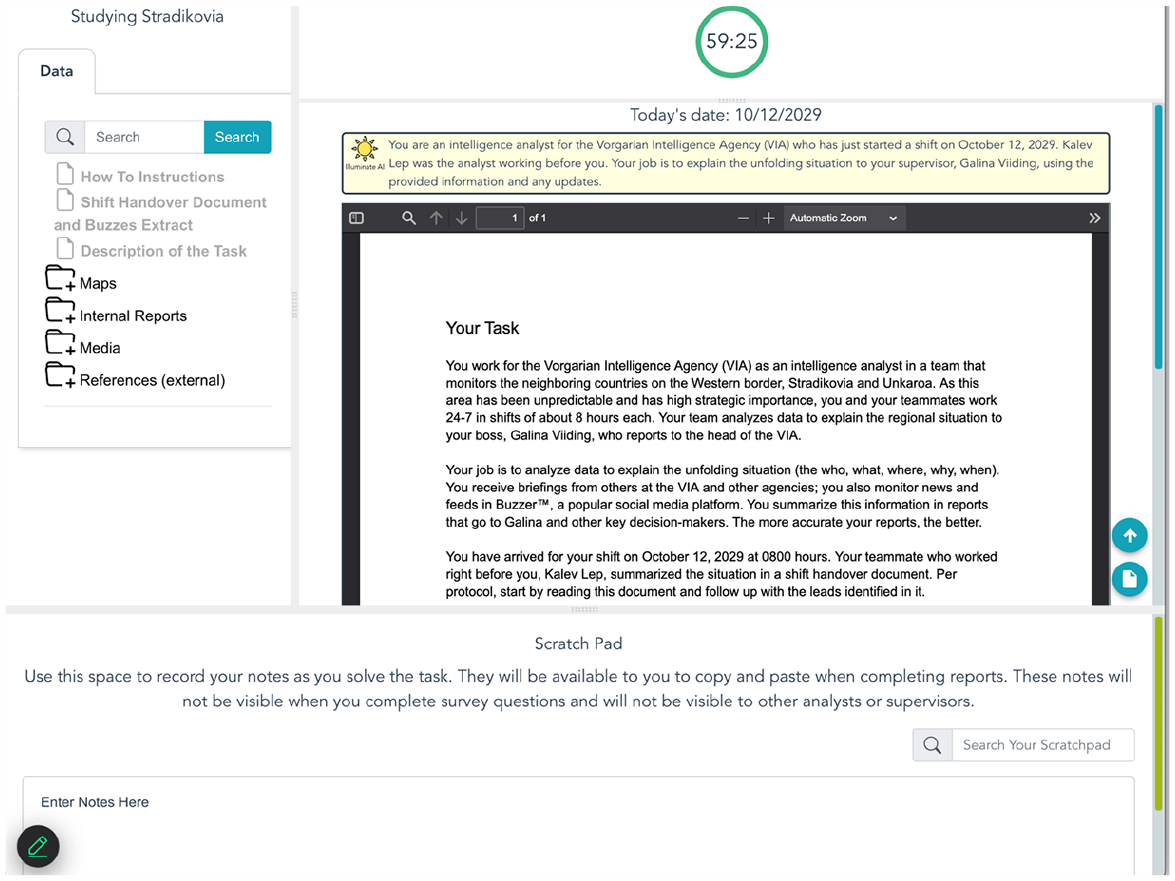
HATIT platform displaying the description of task document.
To simulate synchronous collaboration and the flows of information that characterize intelligence analysis in an externally valid way, teammates provided the analyst with documents that varied in their velocity, volume and variety. As intelligence events unfold, social media reporting arrives faster and in greater volume and variety than does traditional media reporting (Lowenthal, 2023). Accordingly, 16 min into the task a teammate provided a 2,140-word social media file authored by multiple individuals. Eleven minutes later another teammate provided a 666-word file containing six breaking news articles (see Figure 2 for a detailed timeline).
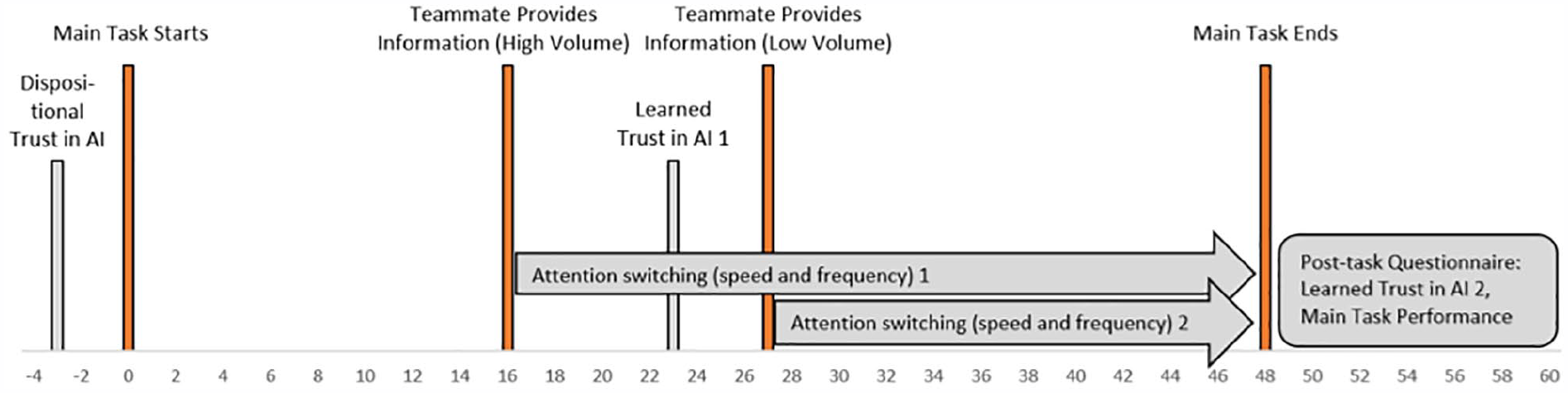
Experimental timeline.
The potentially relevant information that the analyst could review included 60 study-created documents (containing 188,615 words). These news reports, country reports, social media, orienting files, agency reports and references, averaged 3,143.6 words (SD = 5,200.1, Min = 13, Max = 24,704). Once selected from a searchable directory, each document appeared in a scrollable viewing pane with an Illuminate AI summary displayed above it (see Figure 1).
AI Summarizer Manipulation
We developed “Illuminate AI,” an AI agent branded with a sun icon. As participants selected a document, such as the Description of the Task, its summary appeared at the top of the viewer panel (see Figure 1). All 60 documents had a static, pre-generated summary that the research team developed and presented as coming from Illuminate AI. This type of Wizard of Oz approach, where experimenters simulate a technology for experimental control, has a long history in human-computer interaction research (Green & Wei-Hass, 1985).
As shown in Table 3, Illuminate AI provided either a short indicative or an informative entity-based summary of news reports and country reports, Ms = 8.4 and 72.2 words, corresponding to 5% and 31% of the original text, respectively. We varied the summaries of these 19 documents because intelligence analysis benefits from information about entities, such as people, places, and events, which are included in news reporting and country reports in greater frequency than in the other types of documents. For the 41 remaining documents, Illuminate AI provided the participants a baseline summary, either indicative or informative, that did not vary by condition, M = 70.2, corresponding to 11% of original text length. These baseline summaries, fixed across AI condition, helped keep the word count comparable across conditions (for details see Tables 3 and 4). 3
Overview of the Summary Types in Each AI Summarizer Condition.
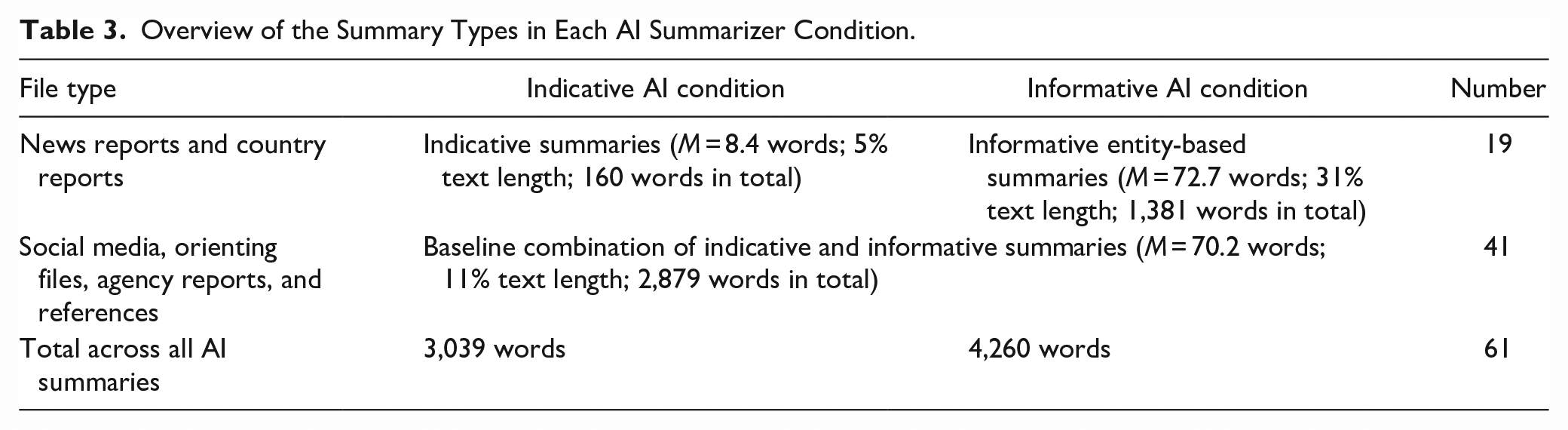
Illustrative Summaries for Each Type with Conditional Presentation Noted.
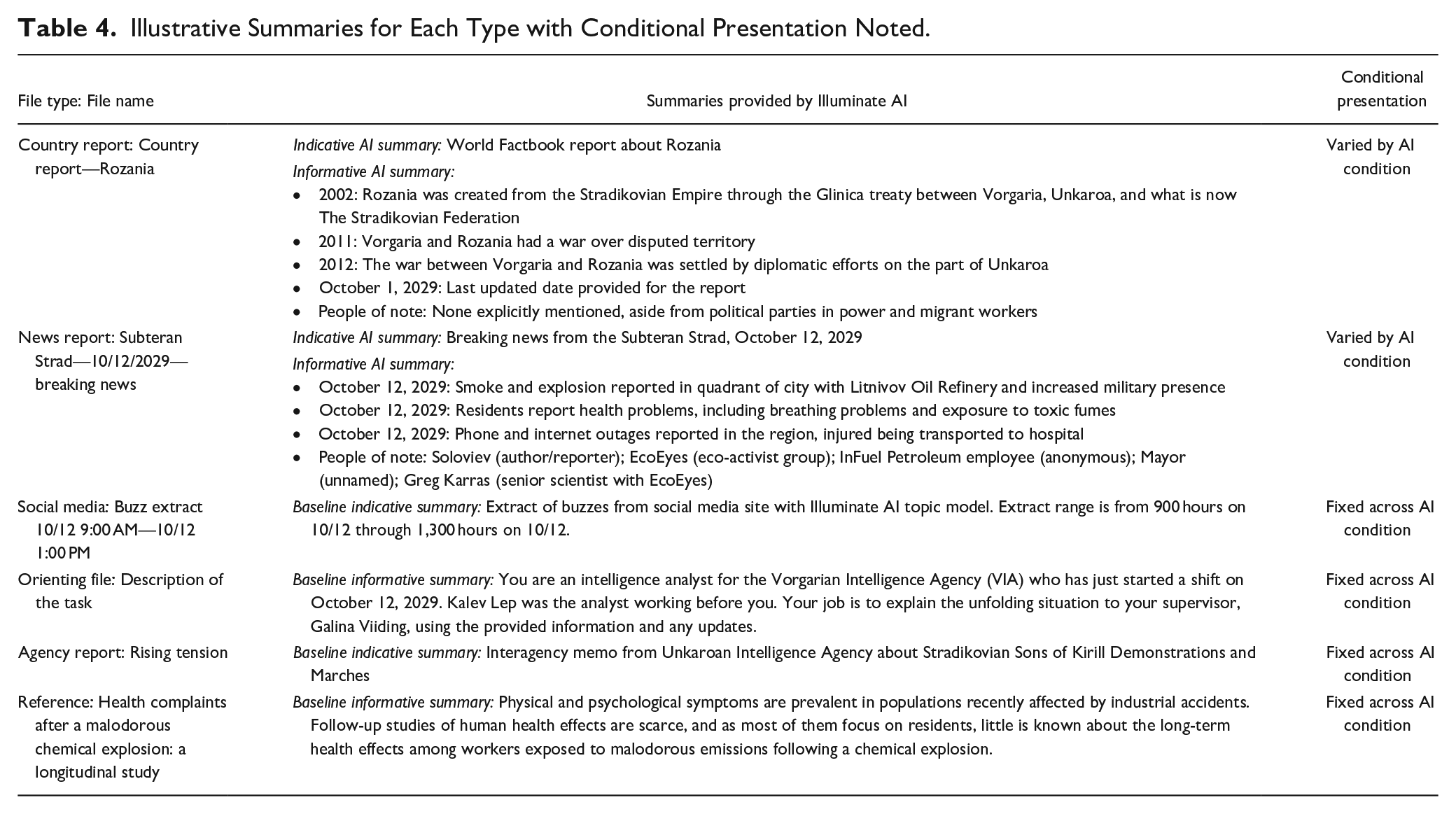
To examine a best-case version of an AI summarizer, we carefully constructed each summary (for a full list see the Supplemental materials detailed in Footnote 1). Members of the research team wrote the indicative summaries for the 19 news and country reports and the baseline summaries for the other 41 documents and checked their accuracy. To create the informative entity-based summaries for the news and country reports, we wrote a Python script that extracted the text from each news and country report and, using the ChatGPT API, generated a text summary. We used ChatGPT model gpt-3.5-turbo (the latest model available at the time) and the prompt: “List key events (with dates if available), and people from the following text: [extracted news article or country report text].” We captured each resulting summary, reviewed it for accuracy, and then included it in our task materials. See Table 4 for illustrative summaries for each file type.
As the participants worked through the task, they accessed more and more of the manipulated summaries that varied according to indicative versus informative AI summarizer condition. Notably, participants had accessed twice as many news reports and country reports by the second teammate information provision when compared with the first teammate information provision, t(150) = 11.47, p < .001, Ms = 8.38 and 4.25, SDs = 5.46 and 7.06, respectively. Participants also accessed significantly more of these manipulated summaries by the end compared to the midpoint of the task, t(150) = 17.43, p < .001, Ms = 17.65 and 6.93, SDs = 9.34 and 6.51, respectively. These data indicate participants’ sustained task engagement and increased exposure to the differences in the AI summarizer condition over time.
Measures
Table 2 provides detail for each measure, including the type, scale, and timing, which is also illustrated in the timeline in Figure 2.
Trust in AI Measures
To assess trust in AI, we used the universal trust in automation instrument, comprised of two psychometrically sound scales (detailed below) used in experiments where trust is expected to develop with technology use (Chien, 2016; Chien et al., 2017, 2018, 2020).
Dispositional Trust in AI in General
To measure dispositional trust in AI, we used the general trust in automation scale, validated on more than 1,000 respondents across at least three cultures and two languages (Chien et al, 2017). The referent is the general class of automation (i.e., smart phone [Chien et al., 2018] and “a decision aid” [Chien et al., 2020]) that participants will later encounter. With three items each, the scale captures three key constructs, here called components: (1) performance expectancies, (2) process transparency, and the (3) technological context. To adapt the scale, we replaced “smart phone/a decision aid” with the term “AI” (detailed in Table 2). Following Chien et al. (2018) we formed a composite measure from the mean values of the three components, α = .82.
Learned Trust in the Specific AI Summarizer
We measured learned trust in the specific AI summarizer during and after the task using the specific trust in automation scale, the second part of the universal trust in automation instrument (Chien, 2016; Chien et al., 2017, 2018, 2020). Construct definition, item refinement, and validity tests support the approach of measuring learned trust by soliciting expectancies about the encountered automation around three constructs, here called components (1) performance, (2) process, and (3) purpose (see Chien et al., 2017, 2018, 2020). To use the scale, we replaced their specific automation technology (e.g., GPS [Chien et al., 2018], conflict detector [Chien et al., 2020]) with our specific technology, “Illuminate AI,” in each item (see Table 2). Following Chien et al. (2018) we formed a composite measure from the mean values of the three components, which formed a reliable measure at Time 1, α = .85, and at Time 2, α = .80.
Attention-Switching to Teammates’ Information: Speed and Frequency
HATIT unobtrusively and automatically recorded participants’ behavior as they worked through the task, a general practice with information systems that goes back decades (Penniman & Dominick, 1980). Specific behaviors within information systems, such as click throughs (e.g., Kelly, 2009) and dwell time on pages (e.g., Yi et al., 2014) have previously been used to represent cognitive processes such as attention. In this study, these traces represent fine-grained, interpersonal behaviors that reflect underlying participant cognition (attention) in response to information coming directly from teammates. The HATIT platform logs document access behaviors including the specific documents that participants opened and when the document was open on their screen (a proxy measure by analyzing the timestamps of the platform events; Paletz et al., in press). From these logs, we created objective measures of the participants’ attention based on their reactions to two documents shared during the task by their virtual teammates (see Figure 2). For external validity and as described in the Main Phase subsection of the Procedure section, early in the task (16 min), a teammate provided a high-volume document (2,140 words of social media authored by multiple individuals). Later in the task (27 min), another teammate provided a low-volume document (666 words of breaking news authored by a few reporters). Participants had no reason to expect these documents to appear when they did.
From these data, we created two separate variables: the speed with which participants turned their attention to these two documents, and the frequency with which they returned to these documents (see Table 2). Lower values on the speed variable indicate quicker responsiveness and faster attention switching to the information provided by their teammates (Fan et al., 2010). Frequency was calculated by counting logs of the number of separate occasions each participant clicked on the documents shared by their virtual teammates. This represents an attention-switch because only one document can be viewed at a time (see Doppler Haider et al., 2019, for a similar approach).
Problem-Solving Accuracy
Prior research on team decision-making has involved distributing different pieces of information across participants such that a correct answer on the task requires synthesis of that information (e.g., Stasser & Titus, 1985). Analogously, for this study, participants had to synthesize information across many documents to determine a correct answer. At the end of the task, participants completed five task solution questions, four of which were multiple choice. The questions asked the percentage chance that troops were moving (we set an a priori threshold for correctness), the source of the troop movement, the level of threat of military invasion to Vorgaria, why the troops moved (if they did), and a recommendation for the best course of immediate action, the answer of which required an understanding of the situation. Correct answers to these questions were summed to form a task solution score from 0 to 5.
Prior research also testing ATS similarly used questions with correct answers to measure performance (Goldstein & Shahar, 2016). To confirm the validity of this performance measure, we recruited an expert with 14 years of experience working in intelligence analysis to complete the main HATIT task without the support of any AI. The expert participant’s five responses to the task solution questions aligned exactly with what the researchers deemed to be the correct responses (Paletz et al., in press), providing convergent evidence that these answers reflect accurate problem solving for this task.
Results
The confirmatory factor analyses were conducted using the laavan package 0.6-19 in R Studio Version 2024.12.1+563. All other statistical analyses were conducted using SPSS Version 28.0.1.0. Table 5 provides correlations among the key study variables as well as descriptive statistics. We report one-tailed tests for directional hypothesis and two-tailed test for exploratory analyses. This approach implements the advice of researchers who highlight the precision gained from such an approach and the logical congruity between a one-tailed test and a directional research hypothesis (Cho & Abe, 2013; Cohen, 1994; Mell et al., 2020). We note each one-tailed test, following the example of other team researchers (e.g., Mell et al., 2020; Gupta et al., 2024).
Correlations, Means, and Standard Deviations.
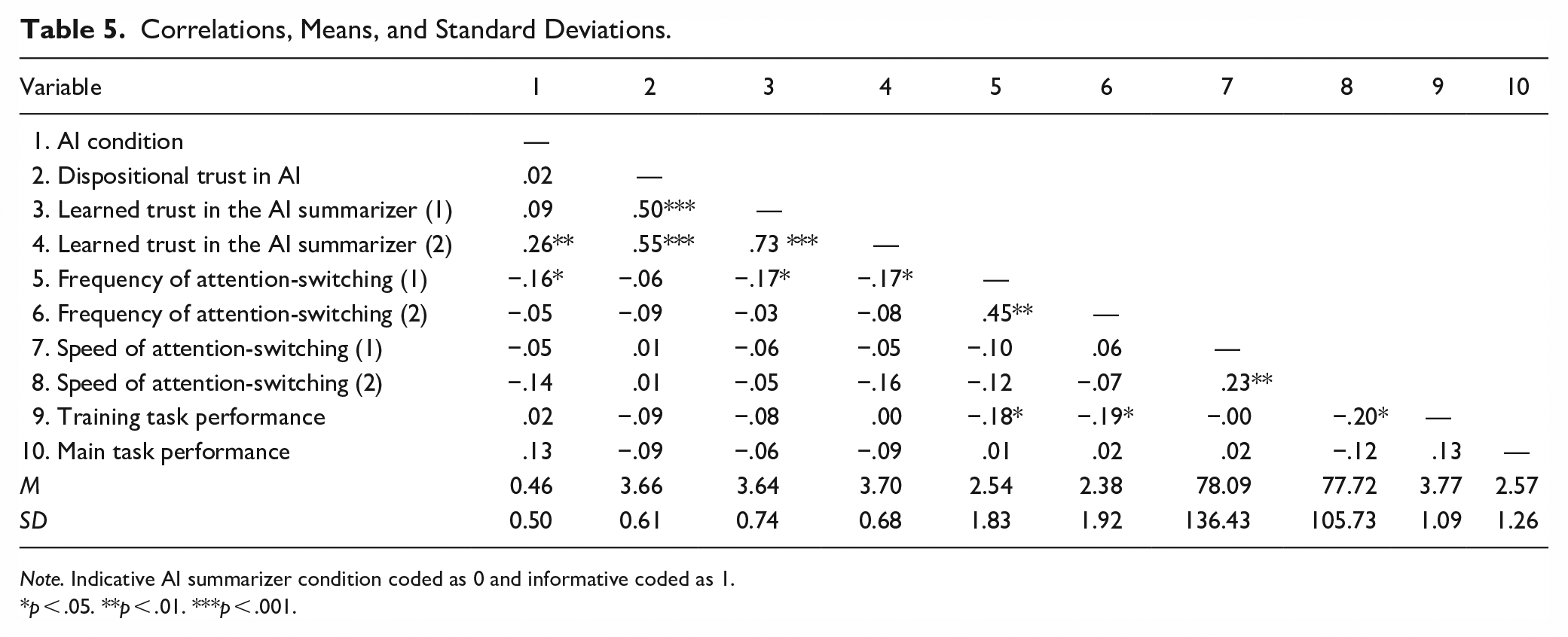
Note. Indicative AI summarizer condition coded as 0 and informative coded as 1.
p < .05. **p < .01. ***p < .001.
Dispositional Trust in AI in General and Learned Trust in the Specific AI Summarizer
We measured dispositional trust in AI in general and learned trust in our specific AI summarizer with carefully constructed, psychometrically sound scales (Chien et al., 2017, 2018, 2020). For added rigor, we conducted a confirmatory factor analysis to check the dimensionality of the six components (i.e., general performance, process, context; and specific performance, process, purpose) used to create the composite two measures of pre-task dispositional trust and post-task learned trust. We found that the expected two-factor model, which assumes dispositional and learned trust are distinguishable factors, fits the data well (χ2 = 27.39, df = 8, SRMR = .05, RMSEA = .13, TLI = .90, CFI = .95, AIC = 1581.21, BIC = 1619.64). We also evaluated a one factor model that assumes the two were not distinguishable factors. However, this model did not fit the data well (χ2 = 70.57, df = 9, SRMR = .09, RMSEA = .22, TLI = .90, CFI = .82, AIC = 1622.39, BIC = 1657.86). In addition, a Chi-square difference test shows the two-factor model fits the data significantly better than the one factor model (χ2 difference = 43.18, p < .001). Given the empirical support for the two distinguishable factors, we proceed with the analysis of Hypothesis 1.
We conducted a 2 (AI Summarizer: Indicative, Informative) by 2 (Time: 1, 2) repeated-measures analysis of variance (RM-ANOVA) on learned trust in AI summarizer with dispositional trust in AI as a covariate. The assumption of sphericity was met, Greenhouse-Geisser epsilon ε = 1, indicating that no corrections to F-statistics were needed. First, the main effect of dispositional trust on learned trust was significant, F(1, 133) = 58.01, p < .001, η2p = .30. The interaction between dispositional trust and time was not significant, F(1, 133) = 0.05, p = .83, η2p = .00. Increases in dispositional trust in AI were positively associated with learned trust in AI summarizer at Time 1, r(143) = .50, p < .001, and at Time 2, r(142) = .55, p < .001. Hypothesis 1 was confirmed.
Second, the main effect of AI condition on learned trust in the AI summarizer, F(1, 133) = 4.63, p = .03, η2p = .03, was conditional on time: The interaction between AI condition and time was significant, F(1, 133) = 6.04, p = .02, η2p = .04. As shown in Figure 3, Trust in AI increased over time in the informative AI summarizer condition but not in the indicative AI summarizer condition. To further quantify these patterns, we conducted paired sample t-tests that compared the Time 1 and Time 2 learned trust. In the informative summarizer condition, trust in AI developed over time such that the later measure of trust in AI was significantly greater than the initial measure, t(60) = 2.77, p = .004, one-tailed, Cohen’s d = 0.36. By contrast, in the indicative summarizer condition, trust in AI was not significantly different in Time 2 and Time 1, t(74) = −0.57, p = .29, one-tailed, Cohen’s d = −0.07. Hypothesis 2 was confirmed. 4
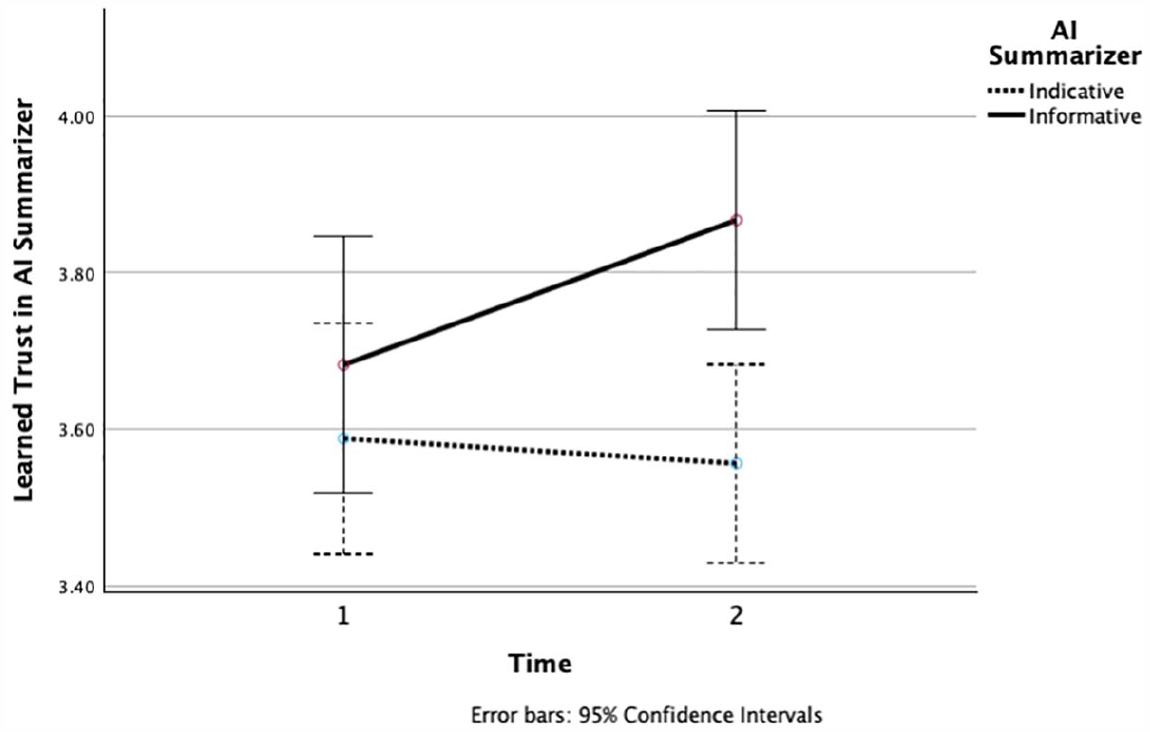
Learned trust in the AI summarizer as a function of time on task and AI summarizer condition.
Attention-Switching to Teammate Information: Speed and Frequency
Table 6 displays the means and standard deviation for the attention variables, which were measured twice: (1) at minute 16 when exposure to AI was weaker and the teammate provided a high-volume document and (2) at minute 27 when exposure to the AI was stronger and the teammate provided a low-volume document.
Attention-Switching to Teammate Information in the Summarizer Conditions and Overall.
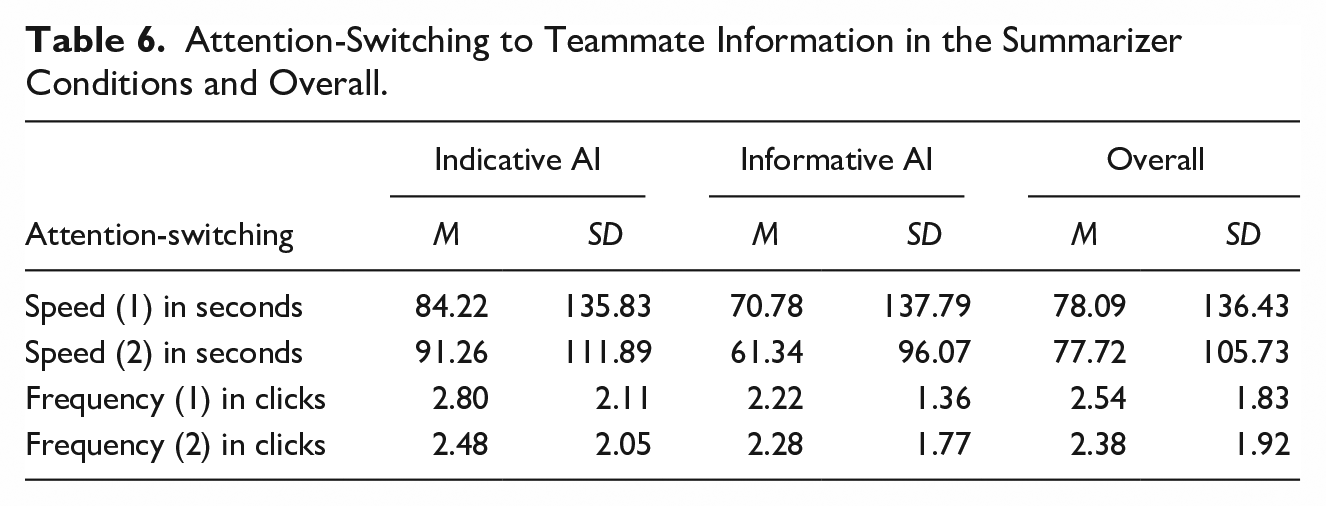
Speed
As shown in Table 6, participants in the indicative AI summarizer condition were slower to attend to the new teammate information. To test H3a and assess the significance of these differences, we conducted survival analyses, which use log functions to model the distribution of the speed with which an event occurs, also known as elapsed time (Kragh Andersen et al., 2021; Singer & Willett, 1993). In a related team study, researchers used survival analysis to examine software issue resolution speed (Newton et al., 2024). We used Cox proportional hazards regression analysis (Cox, 1972) to estimate the effect of AI condition on the attention-switching to teammate information, which was provided twice.
Speed of attention-switching to the first provision of teammate information did not vary as hypothesized due to the AI summarizer condition (B = 0.04, SE = 0.17, p = .41, one-tailed). As shown at the top of Figure 4, the survival curves for the two conditions are practically on top of one another, indicating no difference in speed. As hypothesized in H3a, participants switched their attention to the second teammate information faster in the informative than in the indicative AI summarizer condition (B = 0.32, SE = 0.17, p = .03, one-tailed). 5 As shown in the bottom panel of Figure 4, participants displayed faster attention-switching in informative AI summarizer condition (shown with the quickly descending lower solid line) than in the indicative AI summarizer condition (shown with the higher dashed line). An examination of where the curves cross the .20 cumulative probability mark reveals that 80% of the participants accessed the second teammate information faster in the informative (within 100 s) than the indicative condition (within 180–190 s). 6 Together these results provide partial support for Hypothesis 3a.
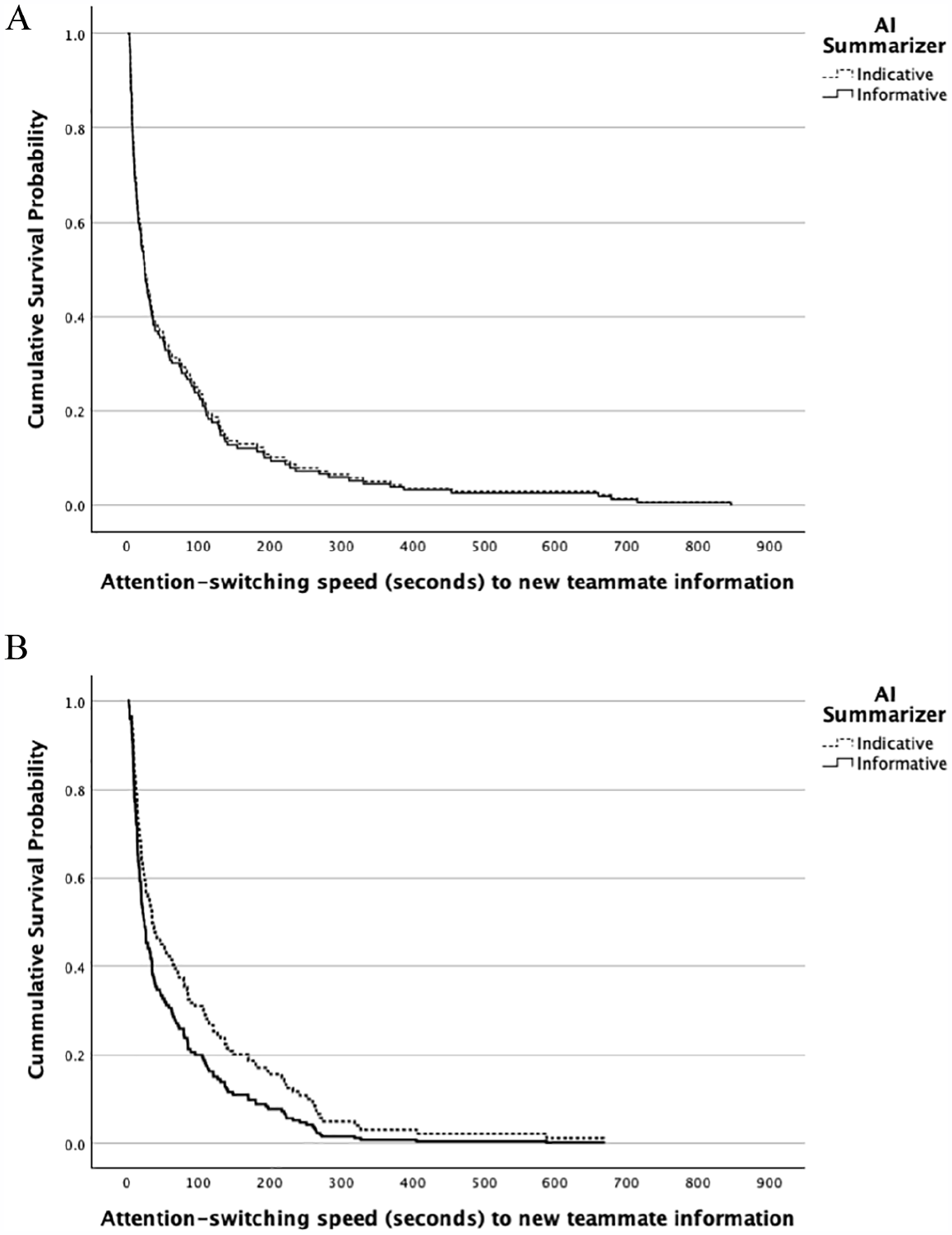
Survival analysis displaying the speed of attention-switching as function of the AI condition. (A) First teammate provided document. (B) Second teammate provided document.
Frequency
As shown in Table 6 (bottom rows), in the indicative compared to the informative AI summarizer condition, participants attended somewhat more frequently to an initial and a subsequent teammate information provision. However, these count data violated normality assumptions. Therefore, we conducted, for each measure, a non-parametric Mann–Whitney U test. As hypothesized in H3b, participants in the indicative AI condition more frequently switched attention to the first document provided by a teammate than the participants in the informative condition (Mean ranks = 82.15 and 68.69, respectively, Mann–Whitney U = 2324.50, p = .03, one-tailed). However, the frequency of attention-switching to the subsequent teammate-provided document was no greater in the indicative versus the informative AI condition (Mean ranks = 76.49 and 75.42, respectively, Mann–Whitney U = 2789.00, p = .44, one-tailed). 7 Together these results provide partial support for Hypothesis 3b.
Problem-Solving Accuracy
Participants performed moderately well, correctly answering approximately half of the main phase problem solving questions, M = 2.57, SD = 1.26. To explore whether this finding varied as a function of the AI condition, we conducted an analysis of variance (ANOVA) on problem-solving accuracy and included training task performance as a baseline control covariate. Problem-solving performance in the training phase, where there was no AI, did not differ as a function of the randomly assigned AI condition that participants would encounter in the main phase, verifying the strength of random assignment, F(1, 149) = 0.09, p = .77, η2p = .001. Neither was there a significant effect for training task performance, F(1, 142) = 2.55, p = .11, η2p = .02, on problem-solving in the main phase. The analysis revealed no significant effect of AI condition, F(1, 142) = 2.41, p = .12, η2p = .02. Problem-solving accuracy did not differ in the informative compared to the indicative AI summarizer conditions, Ms = 2.74 and 2.42, SDs = 1.23 and 1.27, respectively.
Discussion
AI tools are increasingly used by knowledge workers (Lee et al., 2025), but the research on how these tools affect workplace teaming is in its infancy (Bezrukova et al., 2023; O’Neill et al., 2023). The current study contributes to an emerging understanding about how different AI tools affect virtual collaboration. To recap, compared to the indicative AI summarizer, the informative AI summarizer resulted in higher levels of learned trust. Dispositional trust in AI influenced learned trust in the AI summarizer, regardless of the type of summarizer encountered. The informative AI summarizer, when compared to the indicative AI summarizer, was also related to faster attention-switching to new information delivered by a teammate later in the task (news stories), but not to faster attention-switching to an earlier, high-volume information delivery. The indicative summarizer, by contrast, resulted in relatively more frequent attention to the earlier, higher-volume teammate-delivered social media document. Our exploration of team performance revealed no effect of the AI summarizer on problem-solving accuracy.
Implications
Implications for Theory on Collaborative Analysis
Collaboration has long been suggested to meet knowledge work demands, which can be aided by working with diverse others (Jehn & Bezrukova, 2004), transferring best practices (Kane, 2010), and collaborating in a collectively intelligent way (Woolley et al., 2015). Historically, sociotechnical systems have also provided support (Hutchins, 1995; Kang et al., 2014), but the relative import of the technological component of these systems has increased with advances in machine learning. Our study imitated a collaborative virtual team composed of both simulated human teammates and an AI summarizer assistant, all working towards solving a time-sensitive, high-stakes intelligence task with information overload. The informative and indicative AI summarizers differentially influenced attention to information delivered by teammates, which has implications for how people go about a collaborative analysis within the context of distributed and virtual team cognition. The lack of differences in performance suggests that it is a distal outcome, influenced by a broader variety of factors than trust in AI and teammate attention processes alone.
This study also has implications for attention allocation under information overload and human-AI teaming more broadly (O’Neill et al., 2023). In addition to the obvious benefits to an individual team member of using an accurate AI, this study implies that AI features affect both an individual’s information processing and how they deal with teammate information. Given that teams collectively process information (Hinsz et al., 1997) and the importance of unique information (e.g., Mesmer-Magnus & DeChurch, 2009), this study helps to unpack specific, fine-grained processes related to how teammates attend to proffered information. These findings thus have implications related to how team cognition is built up as an emergent property of information in different individuals’ minds (Grand et al., 2016).
One question is why participants using the informative AI summarizer attended faster to the second provision of new information but not the first. This finding is likely due to the participants having exposed themselves to significantly more AI summaries—in this case informative ones—later in the task compared to earlier. In addition, participants in the indicative condition more frequently switched back to attend to the initial teammate information, but not to the later teammate information. This finding could be due to the relatively higher-volume nature of the initial information compared to the later information (2,140 words for the first teammate-delivered document, on social media, versus 666 words for the second teammate-delivered document, which contained breaking news stories). Future research will be necessary to separately and experimentally vary the amount of information and the topic of information to tease out potential moderators.
Implications for Theory on AI and Trust
There exists a broad, cross-disciplinary literature on AI and trust (e.g., Glikson & Woolley, 2020; Hoff & Bashir, 2015; Lee & See, 2004; McNeese et al., 2021; National Academies of Sciences, Engineering, and Medicine, 2022; Shneiderman, 2020). While there are similarities across these theories in definitions of trust and AI, there are differences in the category schemes and foci. To keep a manageable scope, we drew on the cognitive approach and identified hypotheses regarding both the truster (dispositional trust, Hoff & Bashir, 2015) and a feature of the trustee (Lee & See, 2004). Our first test confirmed the importance of dispositional trust on learned trust (H1, also see Hoff & Bashir, 2015; Chien et al., 2020). This study’s second hypothesis focused on a specific feature that was primarily functional—informative versus indicative summaries. But this feature also varied the AI summarizers’ levels of demonstrability (Bonner et al., 2021) or information transparency (Wang et al., 2023). Our study found that learned trust can increase for informative summarizers, suggesting the utility of information transparency and demonstrability in AI tools for teaming. In addition to practical implications, our findings suggest making explicit and testing information versus system transparency on trust and performance over repeated exposure to an AI.
As AI technologies improve and as teams gain greater trust in it (Bezrukova et al., 2023), there is a growing concern that workers will become overly trusting on the AI tools, ceding their authority, doubting their own judgment, and incorporating incorrect or unethical AI suggestions. The issue of appropriate human reliance on AI (Lee & See, 2004) is particularly timely because knowledge workers have self-reported that they often use large language model (LLM)-based AI tools without engaging in the critical thinking needed to identify the inaccuracies that are part of LLM output (Lee et al., 2025). We need further research into approaches and tools that effectively balance human verification of AI against the need to minimize interruptions and manage human workload.
Design Suggestions for AI in Collaborative Environments
Our study suggests several practical design implications. Avoiding overreliance, for instance, may require improved explainability or system transparency that enables teams to spot AI mistakes, and/or require teams to periodically verify the AI’s output. Informative and indicative AI summarizers each influenced attention-switching to teammate information, though in different ways. AI summarizers for collaboration might include a toggle feature on an indicative versus an informative summarizer (Saggion & Lapalme, 2000). Given that there are benefits to each type, enabling this choice could enable team members to optimize the benefits of both.
Current trends in AI summarizers include multi-document, multimodal, and real-time summarizers. A multi-document summarizer uses multiple (and usually related) documents as sources and then creates an overarching summary (Gambhir & Gupta, 2017). Multimodal summarizers can ingest and summarize inputs beyond simple text (e.g., videos, audios). Real-time summarizers provide updates to the existing summaries when new information becomes available. A real-time summarizer could be a valuable tool to help address the information velocity challenge, but it may be difficult for collaborators to track the changes (and identify which new information resulted in the changes) when coupled with a multi-document source. If new information triggers automatic updates from real-time and/or multi-document summarizers, knowledge workers may not notice new information provided by their teammates, which may reduce awareness of the teammates’ contributions.
Participants developed trust over time in the informative entity-based AI summarizer, which was specialized to the intelligence analysis context. Instead of having one such AI tool, knowledge workers could use multiple AI agents (effectively different team members), each with a specialized information processing focus or utility. For instance, different AI tools/teammates could be specialized to specific domains, performing different functions such as translation, summarization, and checking the results of other AI agents (Kane et al., in press). Further research is needed to understand what processes are needed to compose and continuously adapt the appropriate team of AI agents to complement virtual collaborative analysis teams.
Limitations and Future Research Directions
While a strength of this study is the variety of measures (e.g., self-report measure of trust in AI, unobtrusive behavioral measures of attention), each has limitations. For instance, the study’s measures of trust in AI largely focused on cognitive trust. Future research might examine emotional components of trust in AI (Glikson & Woolley, 2020; Hoff & Bashir, 2015) and multi-referent and team-level trust (Carter et al., in press; Wildman et al., 2024). Additionally, attitudes toward AI will likely depend on whether the team has discretion over the AI (Bezrukova et al, 2023), suggesting the importance of considering who makes the choices about which AI teams use in their work. The study’s behavioral measures capture attention-switching speed and frequency at the level of the document. Future research might employ within-document unobtrusive measures, such as reading more than 50% of the document (Lagun & Lalmas, 2016) and mouse/cursor tracking associated with eye tracking data (Navalpakkam & Churchill, 2012), which can provide a fine-grained measure of attention.
Another set of limitations is the generalizability of our results in terms of sample, setting, and task. The sample was mostly White men, all recruited using Prolific. Although diverse in terms of nationality, they were still primarily from the United States and Western Europe. It made sense to recruit participants fluent in English given the task requirements. The study did not control for how noisy the participants’ environments were, although the requirements (i.e., participants allocate 75 min to the main task, have a steady internet connection, and use a laptop or desktop computer) were likely to have limited the setting to primarily homes and offices. The task, while reflective of intelligence analysis, cannot generalize to all virtual knowledge work. The results on trust and attention were found for an assistive AI in the context of a difficult collaborative analysis task involving uncertainty and information overload. Future work could examine whether findings generalize to more diverse samples, in controlled settings, and with more straightforward tasks and other types of AI supports, such as team effort visualization dashboards (Glikson et al., 2019).
This study used an AI summarizer that may not generalize to the universe of AI summarizers, their results, or other types of AI interventions: While it provided experimental control and helped to establish causality, there was a tradeoff with external validity. LLM-based summarizers may include inaccuracies (Lee et al., 2025). LLM-based AI summarizers also allow users to interrogate document(s) using different prompts (e.g., summarize based on a certain focus or identify similarities in two documents) and maintain and consider a user’s prompt history in generating their results. All of these differences and issues can exacerbate biases as well as lead to teammates obtaining different outputs, despite making seemingly similar queries. Future research is needed to understand how these types of variations in AI use and outputs may impact collaborative analysis. Various promising research directions could be explored, including the effects of tracking LLM queries and making them available to team members working on a collaborative analysis task so they can confirm, refute, or complement teammates’ results. Cultural differences in team and organizational norms, as well as responses to different AI, could also be studied (e.g., Chien et al., 2020).
Conclusion
Collaborative analysis occurs in sociotechnical systems with high uncertainty and complexity and, increasingly, information overload. Our study highlights how AI can be developed to work with humans and within teams, in a user-centered manner.
Footnotes
Acknowledgements
We are grateful to Andrej Rasevic and Jeronimo Cox for platform development; Aayushi Roy, Alexandra Cooper, Neshell Francois, and Selena Hamilton for task, materials, and questions creation and management and QA testing. We are also thankful for Phillip Thompkins for assistance with data collection, Sarah Vahlkamp for assistance with the creation of the precursor experiment, Joel Chan for sharing expertise on behavioral measures, and Yeonjeong (YJ) Kim for sharing expertise on confirmatory factor analysis.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Research was sponsored by the United States Government Army Research Office (ARO) grant #W911NF-20-1-0214. The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the Army Research Office, the U.S. Government, University of Maryland, Duquesne University, or Fraunhofere USA Mid-Atlantic. The U.S. Government is authorized to reproduce and distribute reprints for Government purposes notwithstanding any copyright notation herein.