
Abstract
We examine the capabilities of large language models (LLMs) in evaluating early-stage ventures. In pre-registered experiments, we prompt selected LLMs to generate investment evaluations and survival predictions for an archival dataset of 171 new venture pitches under systematically varied information cues. We compare these LLM-generated evaluations with realized fundraising outcomes, post-campaign survival rates, and evaluations provided by a benchmark sample of human investors. LLMs show strong capabilities in mirroring real fundraising outcomes. In contrast, their apparent accuracy in predicting venture survival largely reflects prior exposure to some ventures’ digital footprints rather than genuine reasoning under uncertainty. Providing LLMs with scientific, contextual, and social information cues can improve their evaluations, but can also activate human-like heuristics, including anchoring and herding. Our study highlights LLMs’ potential in venture evaluations while cautioning that unobserved influences can mislead interpretations of their capabilities.
Introduction
“Venture firms fueled the rise of artificial intelligence startups that promise to reshape how companies operate. Now those firms are ramping up their own use of AI.”
Evaluations under uncertainty lie at the heart of entrepreneurship (McMullen & Shepherd, 2006; Townsend et al., 2018). Early-stage investors routinely confront such evaluations when deciding whether to fund new ventures that typically lack track records, market presence, or proven business models (Fisher & Neubert, 2023; Packard et al., 2017; Stinchcombe, 1965). Given that most new ventures fail within 5 years (Kerr & Nanda, 2009; Yang & Aldrich, 2017), these evaluations are both consequential and inherently challenging. Accordingly, extensive research has examined how early-stage investors form evaluations, providing important insights into the information cues and heuristics they employ in their judgments (Huang & Pearce, 2015; Nagy et al., 2012; Shepherd, 1999).
Recent advances in generative AI—particularly general-purpose large language models (LLMs)—introduce a potentially transformative tool for venture evaluation (Obschonka et al., 2025). 1 Trained on vast amounts of text, LLMs have shown strong performance in creative and analytical tasks, including idea generation (Girotra et al., 2023), strategic problem-solving (Dell’Acqua et al., 2023), and narrative creation (Doshi & Hauser, 2024). These capabilities have attracted the attention of early-stage investors (Vismara et al., 2025), who are increasingly experimenting with LLMs as “guides to decision-making” (WSJ, 2024). While not explicitly designed to emulate expert judgment, initial evidence suggests that LLMs can simulate domain expertise, for instance, by ranking business models similarly to strategy experts (Doshi et al., 2025). Yet how LLMs perform in the high-uncertainty evaluations central to early-stage investing remains unclear. Such evaluations require judgments under severe information asymmetry (Amit et al., 1998) and the ability to envision plausible but unrealized future scenarios (Huang & Pearce, 2015)—a challenge even for human experts (Kahneman & Tversky, 1973), and potentially more so for LLMs, which rely on historical data. This challenge is intensified by the Knightian uncertainty inherent to early-stage investing, where, as Townsend et al. (2025, p. 425) observe, AI models may struggle due to “future possibilities that are neither analyzable nor predictable using statistical analysis and probabilistic reasoning.” Compounding these issues is the documented sycophancy tendency of LLMs, which often leads them to provide overly positive or agreeable responses (Sharma et al., 2023) and raises further concerns about their ability to produce accurate evaluations. Thus, the capabilities of LLMs in early-stage venture evaluations remain an open question.
Understanding LLM capabilities in this context requires examining not only their outputs but also how they process information and arrive at judgments. The black box nature of LLM reasoning (Hutson, 2024) complicates this task and mirrors broader concerns about AI-based decision-making (Obschonka et al., 2025). Because LLMs are designed to mimic human language patterns (Dillion et al., 2023), they may be sensitive to the same information cues that influence human judgment. For example, prior research shows that human evaluations are influenced by the application of decision-making frameworks (Zacharakis & Meyer, 2000), the availability of benchmark information (Simonson & Tversky, 1992), and endorsements provided by other decision-makers (Zhang & Liu, 2012). However, LLMs may additionally rely on internal cues, specifically prior exposure to a venture’s digital footprints during training. As many startups leave digital footprints online (Fisch & Block, 2021), LLMs may “know” more about some ventures than others. This raises the possibility that their evaluations reflect recalled information (memory) rather than forward-looking reasoning (inference). Accordingly, we explore the following research questions: To what extent can LLMs accurately evaluate early-stage ventures? How do different types of information cues influence these evaluations?
To address these questions, we build on research in entrepreneurial finance (Mollick & Nanda, 2016; Vismara, 2018) and foundational work on decision-making under uncertainty (Banerjee, 1992; Tversky & Kahneman, 1974; Spence, 1973). We conceptualize evaluations as overarching judgments about a venture’s quality and prospects (Shepherd, 1999) and examine two related types of evaluations: investment evaluations (i.e. judgments of investment attractiveness) and survival predictions (i.e. assessments of long-term venture viability). We then examine how different types of information cues shape LLM evaluations. Scientific cues convey venture-independent evaluation criteria from expert investors (Bapna, 2019) and may guide LLMs toward more structured assessments of factors relevant for venture success. Contextual cues, such as evaluating multiple ventures next to each other, provide benchmarks for assessments but may also lead to order or anchoring effects (Simonson & Tversky, 1992). Social cues, such as signals of investor interest, can convey venture quality yet risk-triggering herding behavior (Banerjee, 1992). Finally, ventures’digital footprints embedded in LLM training data may improve apparent accuracy, but may also reduce sensitivity to other information cues. These cues thus present both opportunities and risks for shaping AI judgment.
Our empirical analysis draws on pre-registered experiments in which we prompt selected LLMs—GPT-4, GPT-4o, and Gemini 2.5 Pro—to evaluate new ventures under systematically varied information conditions and compare these evaluations with realized outcomes. The evaluations are based on an archival dataset of 171 real early-stage ventures, using original pitch materials from equity crowdfunding campaigns conducted on the UK platform Crowdcube between 2017 and 2018. We examine how LLM investment evaluations align with realized fundraising success as a proxy for real investor behavior, and how LLM survival predictions align with observed 5-year post-campaign survival as a proxy for long-term venture viability. As a benchmark, we collect corresponding evaluations from a sample of 900 human investors recruited via Prolific, comparable to samples used in prior research (Wesemann Lekkas et al., 2025; Zunino et al., 2022). For LLMs, we implement a series of experimental manipulations, including baseline prompts, scientific cues (i.e. providing decision-making frameworks), contextual cues (i.e. presenting ventures in groups), and social cues (i.e. disclosing investor interest/fundraising outcomes). To account for potential prior knowledge embedded in LLM training data, we directly test for exposure to ventures’ digital footprints. Depending on the model, LLMs exhibit prior exposure to approximately 15% to 48% of the ventures, whereas human investors report familiarity with only about 4%. We therefore conduct analyses of LLM evaluations on the full sample as well as split-sample analyses comparing ventures with versus without prior exposure. We further report results on evaluations for anonymized ventures. In total, we collect 4,617 LLM-generated evaluations for the main analyses, along with additional evaluations for supplementary tests.
This study makes two key contributions to the understanding of AI in new venture evaluations (Obschonka et al., 2025; D. A. Shepherd & Majchrzak, 2022; Townsend et al., 2025). First, we extend initial research on LLMs in strategic evaluations (Doshi et al., 2025) by showing that LLM capabilities in early-stage venture evaluations are mixed. LLMs perform well in reflecting realized fundraising outcomes, thereby mirroring actual investor preferences and behavior. In contrast, accurate survival predictions are confined to ventures for which LLMs had prior exposure and collapse for ventures without such exposure, indicating that apparent capabilities in our setting reflect recall rather than genuine reasoning under uncertainty. This digital footprint effect highlights boundaries of current generative AI models as autonomous evaluators and warns that observed performance can mislead true capabilities. Second, we test theories of human decision-making (Banerjee, 1992; Tversky & Kahneman, 1974; Spence, 1973) in the novel context of AI judgment. We show that generative AI responds to information cues in ways similar to humans, sometimes improving the accuracy of evaluations, but also reproducing heuristic biases such as anchoring and herding. Our findings thereby underscore the value of integrating theories of human judgment into the study of AI-driven evaluation and decision-making.
Theoretical Background
New Venture Evaluations and Generative AI
Uncertainty lies at the core of the entrepreneurial process, characterized by multiple possible outcomes and limited knowledge about the probabilities associated with those outcomes (Fisher & Neubert, 2023; Townsend et al., 2018). Entrepreneurs must nevertheless make evaluations under such uncertainty, which ultimately determine their actions (McMullen & Shepherd, 2006). For example, Casson (1982, p. 22) defines the entrepreneur as “someone who specializes in taking judgmental decisions” to allocate scarce resources under conditions where outcomes cannot be predicted with confidence. However, entrepreneurs are not alone in facing these challenges. Resource providers, too, must evaluate under uncertainty to determine how scarce resources should be allocated among competing ventures (Nagy et al., 2012). For external resource providers such as early-stage investors, these evaluations are particularly difficult, as they often lack the insider knowledge that entrepreneurs possess (Ko & McKelvie, 2018). This asymmetry creates a dilemma: entrepreneurs depend on external resource providers to succeed, as they are “dependent on marshalling resources and support from a diverse array of external actors” (Fisher et al., 2017, p. 52). Yet, only a limited number of resource providers are willing or able to make decisions under conditions of high uncertainty. For instance, poor access to debt financing from banks is often attributed to their reluctance to fund new ventures in such uncertain circumstances (Colombo & Grilli, 2007). Similarly, Amit et al. (1998) argue that this necessity has led to the emergence of venture capitalists, who possess the “specialized abilities” required for such assessments under uncertainty. Thus, evaluations under uncertainty are a fundamental yet challenging task for entrepreneurs and their stakeholders.
AI technologies are currently transforming the entrepreneurial process (Obschonka et al., 2025; D. A. Shepherd & Majchrzak, 2022), with significant potential to augment decision-making (Lebovitz et al., 2022). Among these technologies, generative AI—and particularly general-purpose LLMs like OpenAI’s GPT or Alphabet’s Gemini—represents the most advanced tools currently available. These models, trained on extensive textual data, generate human-like language by predicting plausible next words based on statistical correlations in billions of sentences (Biever, 2023). By leveraging a variety of sources and reflecting the breadth of human thinking and decision-making, LLMs effectively access a wide range of knowledge embedded in linguistic sources, making them highly versatile. Recent work has highlighted the capabilities of LLMs in various management-related tasks, such as creativity and strategic problem-solving (Boussioux et al., 2024; Dell’Acqua et al., 2023; Doshi & Hauser, 2024; Girotra et al., 2023). Prior research has also shown that LLMs are particularly adept at simulating human behavior in areas like marketing preferences (P. Li et al., 2024), moral judgments (Dillion et al., 2023), and risk aversion (Mei et al., 2024). A recent study by Doshi et al. (2025) shows that LLMs can also mirror human experts (e.g. strategy professors) in uncertain strategic decisions, for instance, selecting the more promising of two business models in pairwise comparisons. This raises the possibility that they could also contribute to early-stage venture evaluations.
Yet uncertainty in the entrepreneurship context presents distinct and particularly challenging characteristics. It is often Knightian, that is, fundamentally indeterminate rather than merely probabilistic (Townsend et al., 2018). As Townsend et al. (2025, p. 416) observe, AI models trained on historical data may be poorly equipped to address “the Knightian uncertainty […] endemic to the business venturing process.” Consequently, findings from strategy and related domains may not translate easily to the forward-looking evaluations required in early-stage investing. This is why Obschonka et al. (2025, p. 623) specifically call for research in the entrepreneurship context: “these tasks remain largely unexplored by entrepreneurship scholars despite the growing ubiquity of generative AI applications.” This gap raises important questions about whether current generative AI models can effectively support core entrepreneurial tasks such as evaluations of new ventures from the perspective of early-stage investors.
The Role of Information Cues for Evaluations by Generative AI
To develop a theoretically grounded understanding of how generative AI models, such as LLMs, evaluate new ventures, we draw on theories of human decision-making under uncertainty (Banerjee, 1992; Tversky & Kahneman, 1974; Spence, 1973). Establishing a theoretical foundation is critical for addressing the persistent black box problem associated with LLMs, whose internal reasoning processes remain largely opaque (Hutson, 2024). This opacity has led AI researchers to emphasize the “paramount importance of understanding the mechanisms through which LLMs reason and make decisions” (Hagendorff et al., 2023, p. 833). By design, LLMs reflect human knowledge and cognitive structures as represented in publicly available text. Moreover, to manage computational constraints during training and inference, LLMs adopt architectural features that parallel human cognitive functions, such as working memory and attentional focus (Bubeck et al., 2023). If one assumes that such sources (often plain text) accurately reflect human thinking and decision-making (Pinker, 2007), theoretical insights from research on human judgment can provide useful reference points for interpreting, and potentially demystifying, LLM reasoning. Specifically, such insights can help us determine whether, with the right input and guidance, LLMs can approximate human evaluative capabilities in uncertain contexts—such as assessing new ventures—an area likely underrepresented in their training data.
When theories of human decision-making turn out to be applicable, they allow us to understand not only whether LLMs leverage information in ways similar to humans but also whether and how they reproduce human biases. This is an issue of particular importance when considering LLMs both as tools for simulating human judgment and as potential aids for improving decision-making. Accordingly, to ground our investigation, we rely on seminal ideas from information and behavioral economics, which have illuminated how information cues shape human decision-making under uncertainty (Banerjee, 1992; Simon, 1987; Tversky & Kahneman, 1974; Spence, 1973). Building on this literature, we examine three distinct types of information cues: scientific, contextual, and social. These cues differ substantially in their nature and informational content, ranging from generic to specific. Given their demonstrated influence on human evaluations, we expect these cues to also shape how LLMs evaluate new ventures.
Scientific cues offer evaluation frameworks grounded in evidence-based knowledge (Kuhn, 1962; Popper, 1959). In contrast to intuition-driven or heuristic judgments, which often result in subjective and inconsistent assessments (Simon, 1987), scientific cues guide decision-makers toward validated criteria, leading to more objective evaluations (Rousseau, 2006). In early-stage investing, such objectivity is critical, as investors frequently overlook important dimensions due to information asymmetries and cognitive biases (Butticè et al., 2022; Huang & Pearce, 2015). Extensive research has identified factors—ranging from product-market fit to team composition and financial viability—that drive venture success and funding decisions (Petty & Gruber, 2011; Shepherd, 1999). For instance, Bapna (2019) synthesizes this literature into a comprehensive framework of 15 evaluation criteria used by expert investors. While specialized models could be fine-tuned on such expert knowledge (X. Li et al., 2023), general-purpose LLMs are not explicitly trained on structured investor decision-making frameworks. Instead, they function as aggregated reflections of human knowledge and may, like human investors, rely on a few salient or intuitive features when making decisions (Huang & Pearce, 2015). Scientific cues may counteract this tendency by guiding LLMs toward more systematic, expert-like evaluations. However, because these cues often contain general best-practice advice, their influence may be limited if the LLM has already developed generalized evaluative capabilities from diverse training data, including its access to academic research.
Contextual cues serve as benchmarks for evaluations (Tversky & Kahneman, 1974; Tversky & Simonson, 1993). Scholars have long recognized the pivotal role of context in decision-making processes (Blaseg & Schwienbacher, 2024; N. G. Shepherd & Rudd, 2014; Trueblood et al., 2013), noting that “choice is often influenced by the context, defined by the set of alternatives under consideration” (Simonson & Tversky, 1992, p. 281). Contextual cues may also be relevant for LLMs by enabling them to evaluate new ventures relative to their peers rather than in isolation. In early-stage financing, context in the form of the competitive landscape and available investment alternatives is particularly salient. Early-stage investors typically screen hundreds of ventures but invest in only about one percent on average (Gompers et al., 2020). Without knowing competing options, LLMs might struggle to determine whether a new venture outperforms its competitors and should be evaluated more favorably. Contextual cues may thus provide valuable comparative information that helps refine LLM evaluations. However, while these cues provide relative benchmarks, they do not offer specific insights into the venture itself, which may limit their effectiveness in addressing incomplete information concerns. Additionally, insights from research on human evaluations reveal that contextual cues can introduce biases, particularly through order or anchoring effects (Tversky & Kahneman, 1974). When an initial evaluation establishes a reference point, it may cause LLMs to under- or overestimate the attractiveness of subsequently evaluated similarly promising companies.
Social cues convey information derived from the actions and judgments of others and play a critical role in shaping evaluations under uncertainty (Banerjee, 1992; Bikhchandani et al., 1992). They influence a wide range of decisions, from consumer behavior like movie ratings and lending preferences to institutional responses like media coverage (Lee et al., 2015; Rao et al., 2001; Zhang & Liu, 2012). In early-stage investing, such cues are particularly influential, as others who may possess relevant knowledge about a venture’s prospects (Vismara, 2018). Social cues can also function as credible quality signals (Spence, 1973). For example, endorsements by sophisticated investors or the ability of a startup to attract a large number of backers can reduce uncertainty and increase perceived legitimacy (Roma et al., 2017; Wang et al., 2019). LLMs may be inherently responsive to such cues, as they are trained on human-generated text that encodes patterns of preference, endorsement, and popularity. Social cues may thus enhance LLMs’ evaluations by providing specific, venture-level information. Yet this potential comes with risks. Overreliance on social cues may lead LLMs to mirror human tendencies toward imitation rather than engage in independent assessment. Similar to human decision-makers, LLMs may therefore exhibit herding behavior, which could ultimately undermine the quality of their evaluations (Banerjee, 1992).
Data and Methods
Our research design includes pre-registered experiments and exploratory analyses using various general-purpose LLMs: GPT-4 (February 2024), GPT-4o (June 2025), and Gemini 2.5 Pro (September 2025). 2 At the time of this research, these models are among the most advanced LLMs available (Doshi et al., 2025; Hagendorff et al., 2023) and enable us to test differences within models and across models. For parsimony, we refer to these three models collectively as LLMs, unless stated otherwise. The primary goal of our study was to explore the capabilities of LLMs in evaluating new ventures and how evaluations are influenced by scientific, contextual, and social cues. To this end, we developed a variety of prompts in which we manipulated the information and instructions given to the LLMs for evaluating a large number of new ventures. We assessed LLM performance by comparing their evaluations, that is, investment evaluations and survival predictions, with objective venture outcomes, focusing on realized fundraising success and 5-year venture survival. To enable the assessment of current LLM models, we rely on ventures with historical outcomes, which introduces the possibility of more pronounced digital footprint effects than would be present in a prospective prediction setting. We address this concern through systematic tests of prior exposure and by conducting additional analyses using anonymized venture information. Our main analyses draw on 4,617 LLM-generated evaluations of investment pitches from 171 new ventures. To benchmark the evaluations produced by the LLMs, we also conducted pre-registered experiments involving human investors. 3 We obtained evaluations from 900 human investors of the same ventures, using identical instructions as for the LLMs. Three key components are essential to our design: (a) the dataset of new ventures used for evaluation, including tests of LLMs’ potential prior exposure to some ventures; (b) the experimental setup with treatments varying in instructions and additional information provided to the LLMs; and (c) the data collection procedures for both LLMs and human investors. We explain these components in the following sections.
The New Venture Dataset
New Venture Dataset for Evaluations
To compare LLM evaluations with those of real early-stage investors in actual fundraising processes, and to assess the accuracy of LLM survival predictions, our empirical design requires a dataset that includes venture investment pitches, fundraising outcomes, and long-term survival information. We draw on equity crowdfunding data for this purpose. Equity crowdfunding has become an increasingly important source of early-stage financing (Zunino et al., 2022) and provides rich, and comparable data on venture descriptions and fundraising outcomes. This setting is particularly well-suited to our research goals because funding decisions are made by a crowd of investors including more and less professional ones (Wang et al., 2019), allowing for aggregated early-stage investor evaluations to be compared with those generated by the LLMs. Furthermore, equity crowdfunding platforms offer a pool of ventures that compete simultaneously for funding and present their investment pitches in a standardized format, typically detailing the venture’s idea, product, team, and financials (Ahlers et al., 2015). Specifically, we use publicly available data from Crowdcube, a UK-based equity crowdfunding platform and one of the market leaders in Europe.
Because our analysis focuses not only on fundraising but also on venture survival, we require a time horizon over which survival outcomes are both meaningful and comparable across ventures. Prior research shows that many new ventures fail within their first years and that a substantial share is no longer operating within 5 years (D. A. Shepherd et al., 2000; Song et al., 2008; Yang & Aldrich, 2017). We therefore focus on ventures that launched equity crowdfunding campaigns between 2017 and 2018, which corresponds to approximately 5 years prior to our initial data collection. This yields an initial sample of 245 companies. We complemented the venture data with data from UK Companies House—the official register for records of companies in the UK—to collect survival and Standard Industrial Classification (SIC) codes. We excluded companies not listed in UK Companies House (e.g. a few campaigns on Crowdcube are from outside the UK) or those with ambiguous status such as “in administration” or “proposal to strike off,” reducing our sample to 214 companies. The remaining ventures were categorized as active, dissolved, or in liquidation. Because ventures that are acquired and integrated into other firms are typically recorded as dissolved despite not having failed, we complemented Companies House data with information from two startup databases, PitchBook and Crunchbase (Ko & McKelvie, 2018), which explicitly indicate whether ventures are active, acquired, or out of business. At the end of 2023, based on information from all three sources, we classified ventures as surviving if they were listed as active or, in a small number of cases (three ventures), dissolved due to acquisition. Ventures were classified as failed if they were listed as dissolved or liquidated in Companies House and identified as out of business in PitchBook and Crunchbase.
In the next step, we applied a distance filter to create a more homogeneous set of ventures used as evaluation targets. Without such matching, LLMs might infer survival outcomes from salient structural differences (e.g. industry affiliation or firm size) rather than from cues embedded in the venture descriptions themselves. We implemented a k-nearest-neighbor matching approach based on company valuation, funding goal, and firm age. In addition, we required that each broad industry category (first two digits of the SIC code) included at least two ventures: one that survived and one that failed. This procedure resulted in a final sample of 171 new ventures. Within this sample, 54.39% of ventures successfully reached their fundraising goals, and 57.89% survived for at least 5 years following the crowdfunding campaign. These base rates are consistent with those reported in prior studies of UK equity crowdfunding platforms such as Crowdcube and Seedrs. For example, Ralcheva and Roosenboom (2020) report average fundraising success rates of 62.3% in 2017 and 49.6% in 2016. With respect to longer-term outcomes, Rossi et al. (2023) document a 5-year survival rate of 60.4% for ventures that conducted equity crowdfunding campaigns between 2011 and 2020, while Crowdcube (2025) itself cites survival rates of approximately 60% for campaigns launched in 2017. Thus, our final sample used for LLM and human evaluation provides a realistic reflection of ventures from equity crowdfunding.
Assessment of LLM Prior Exposure to New Ventures
To assess whether the LLMs had prior exposure to the ventures in our sample—and whether their training processes encoded sufficiently detailed knowledge of these ventures that could influence subsequent evaluations—we conducted a structured, multi-stage verification test. 4 For each venture, we first asked the LLMs whether they had “heard of a UK-based venture called [venture name].” To control for false positives, we included 30 fictitious, plausible-sounding venture names alongside the ventures from our dataset. Both GPT models reported no familiarity with any fictitious ventures, while Gemini 2.5 Pro claimed familiarity with one. To further distinguish genuine familiarity from potential hallucination, we followed the initial inquiry with requests for venture-specific information that would be inaccessible without true prior exposure. Specifically, we asked the LLMs to name the founder(s) of the venture, and we cross-verified these responses against the original venture descriptions. 5 The results showed that self-reported familiarity frequently exceeded actual recall of venture-specific information. For GPT-4, self-reported familiarity was 32.75%, while correct founder recall was only 14.62%. Corresponding figures for GPT-4o were 41.52% versus 42.69%, and for Gemini 2.5 Pro, 57.31% versus 47.95%. Interestingly, GPT-4o failed to indicate familiarity with one venture despite correctly identifying its founder(s). These discrepancies underscore the risks of relying on LLMs’ self-reported familiarity as an indicator of prior exposure. Accordingly, we use the correct identification of at least one founder as a more reliable indicator of genuine prior exposure and the presence of sufficiently detailed venture-specific knowledge embedded in the model. 6
The Experimental Setup and Prompt Design
We presented LLMs with nine experimental treatments, implemented through distinct prompts. 7 For human investors, we replicated the baseline experimental treatment. Each treatment followed the same structure and included three elements: (a) instructions, (b) evaluation questions, and (c) venture descriptions. The baseline case served as the control group, while subsequent treatments introduced scientific, contextual, and social cues (see Table 1). Figure 1 illustrates the baseline case treatment, and Online Supplementals A and B report all other treatments.
Overview of Main Treatments.
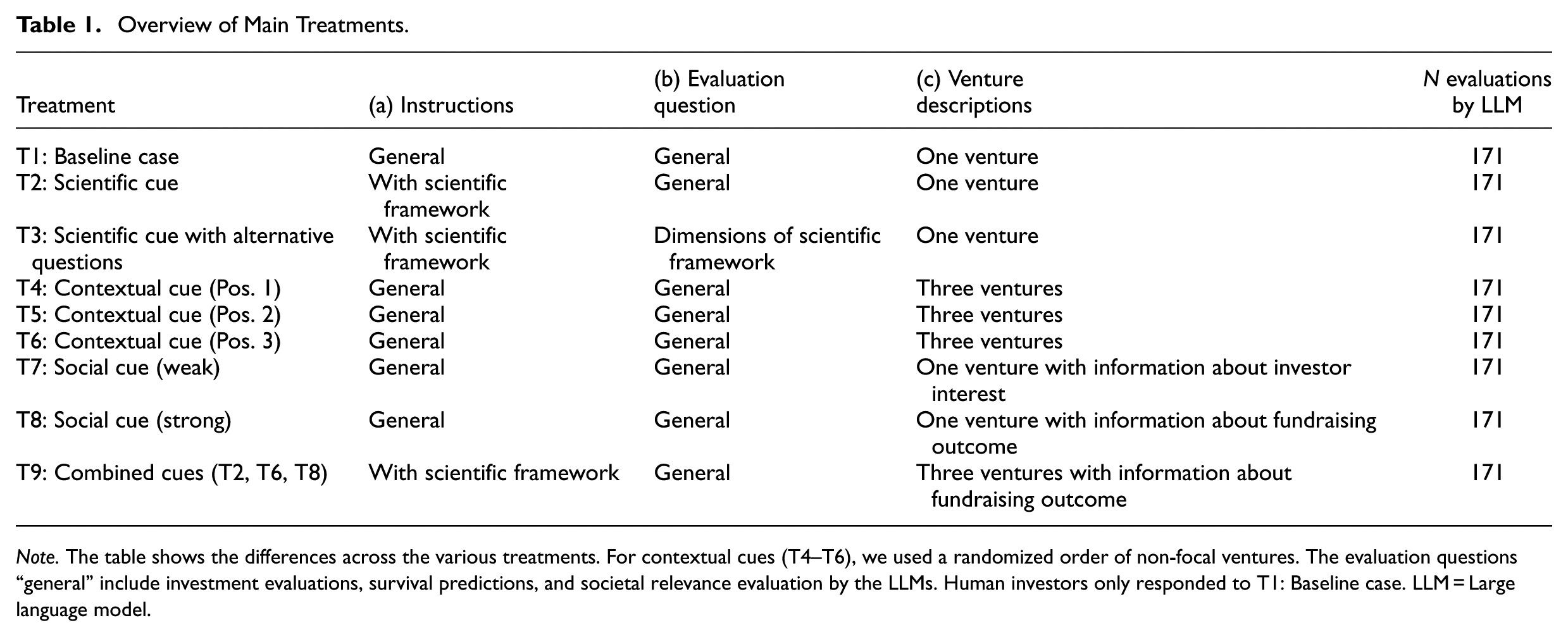
Note. The table shows the differences across the various treatments. For contextual cues (T4–T6), we used a randomized order of non-focal ventures. The evaluation questions “general” include investment evaluations, survival predictions, and societal relevance evaluation by the LLMs. Human investors only responded to T1: Baseline case. LLM = Large language model.

Baseline case instructions as shown to LLMs and human investors.
Baseline Case
The baseline case (Treatment 1) followed typical research designs from experimental entrepreneurial finance research used to collect data on evaluations from early-stage investors (Mollick & Nanda, 2016; Murnieks et al., 2011; Shepherd, 1999). First, in the instructions, we prompted LLMs and humans to adopt the perspective of an early-stage investor and critically evaluate new ventures as investment opportunities. We also clarified that the new venture descriptions were investment pitches used to attract investors in equity crowdfunding. Second, we presented three different sets of venture evaluation questions relating to investment evaluations, survival predictions, and societal relevance evaluations.
Questions on Investment Evaluation
We asked three questions regarding the investment attractiveness of each venture. The goal of these questions was not to explicitly request simulations of investment decisions by early-stage human investors but observe the extent to which LLMs and humans would independently arrive at similar evaluations. We adopted an established three-item measure used to test investment evaluations by early-stage investors (Murnieks et al., 2011). The first item evaluated the likelihood of considering an investment, the second item assessed the likely investment amount, and the third item gauged the anticipated satisfaction with the investment. All three items were rated on a Likert scale from 1 to 7 (low to high). For LLMs, Pearson correlations among the three items ranged from .77 to .95, and we used their average as the investment evaluation measure (Cronbach’s α = .94 for all LLMs). For human investors, Pearson correlations ranged from .70 to .81 (with Cronbach’s α = .89).
Question on Survival Prediction
We asked LLMs and human investors to predict the survival probability of each venture over the 5 years following the campaign, using a scale from 0 to 100. Given the low survival rates of new ventures, survival serves as a relevant and objective proxy for success (Yang & Aldrich, 2017) and is commonly used by VCs as an indicator of venture performance (Shepherd, 1999).
Question on Societal Relevance Evaluation
To differentiate investment attractiveness (e.g. financial returns) from other measures that potentially reflect attractiveness of a venture, we included an additional question on the societal relevance of the venture. We instructed LLMs and human investors to evaluate the societal relevance of each venture on a Likert scale from 1 to 7 (low to high).
Third, after the instructions and evaluation questions, we presented the venture descriptions as presented to real investors on the equity crowdfunding platform. The venture descriptions included a comprehensive investment pitch of the new venture in plain text, starting with its funding terms such as funding goal, equity offering and valuation, followed by an explanation of its idea, product, team, and financial situation. In the baseline case, each evaluation contained only one venture description. Thus, 171 ventures were evaluated independently, one venture per human evaluator and one per LLM prompt.
Scientific Cue
For the scientific cue (Treatments 2 and 3), we instructed LLMs to apply an established evaluation framework based on scientific knowledge on venture evaluations (see Online Supplementals A and B). We selected the framework proposed by Bapna (2019), which synthesizes entrepreneurial finance research on evaluation criteria used by expert early-stage investors such as VCs and business angels. The framework comprises 15 dimensions across 4 domains: product, market, team, and financial characteristics. In Treatment 2, we retained the baseline evaluation questions and the single-venture presentation but prompted LLMs to use the framework when forming their evaluations. In Treatment 3, we modified the evaluation questions to require a structured assessment of each dimension, thereby explicitly enforcing application of the framework. In this treatment, LLMs evaluated one venture at a time by scoring each of the 15 dimensions. Following Åstebro and Elhedhli (2006), each dimension was classified as a critical flaw, average, or very good. Our data revealed that LLMs were conservative in identifying “critical flaws” (occurring in only 5% of evaluations), whereas at least one dimension was rated as “very good” in 12% of evaluations. Accordingly, we focus on the “very good” scores as a proxy for the LLM’s perception of venture quality.
Contextual Cue
For the contextual cue (Treatments 4, 5, and 6), we presented LLMs with three venture descriptions simultaneously and asked to produce corresponding three evaluations within a single prompt. Thus, presenting multiple ventures side by side allowed the additional ventures to serve as benchmarks for evaluation (Simonson & Tversky, 1992). From the full sample of 171 ventures, we created 57 venture sets, each consisting of 3 ventures. To ensure that LLMs had the opportunity to differentiate ventures based on quality, each set was designed to include a mix of better- and poorer-performing ventures. Specifically, for each set, we randomly selected at least one non-surviving venture, one surviving venture, and one additional venture selected at random. We created prompts representing all possible orderings to ensure that ventures were evaluated in every position (i.e. positions 1, 2, or 3). For the analyses of positional effects, we relied on a randomized order of the additional ventures in a set, which ensured that we have a single randomized rather than multiple observations for ventures across treatments.
Social Cue
For the social cue (Treatment 7 and 8), LLMs received information about how other investors evaluated the venture. In Treatment 7, we implemented a weak social cue by modifying the venture descriptions to include real-world investor interest (Vismara, 2018). We added the following sentence to the venture descriptions, alongside the investment conditions: “Investor interest: Based on these investment conditions and the pitch deck, [number] investors declared interest in investing.” This statement conveyed an endorsement by other investors without revealing actual fundraising outcomes, thereby providing a subtle cue of perceived quality. In Treatment 8, we implemented a strong social cue that provided a more explicit signal of quality, consistent with prior work (Roma et al., 2017; Wang et al., 2019). The added sentence stated: “Fundraising [successful/unsuccessful]: With these investment conditions and pitch deck, the company was [successful/unsuccessful] in attracting equity funding from the crowd. Overall [number] invested £[amount] so that the company could [not] achieve its funding goal.” This strong social cue disclosed realized fundraising outcomes and thus provided a salient performance signal that could be readily incorporated into LLM evaluations.
Combination of Cues
For the combined cues (Treatment 9), we integrated the potentially strongest combination of external cues of scientific, contextual, and social cues into a single prompt. Specifically, the instructions included the scientific framework (as in Treatment 2), the prompt presented three venture descriptions simultaneously (as in Treatment 6), and each venture description contained information on fundraising outcomes (as in Treatment 8). As in the contextual cue treatments, each prompt included three ventures, but we focused our analysis on the venture presented in the third position, assuming that it is the most informative given the accumulation of contextual information from the preceding ventures.
The Data Collection Process with LLMs and Human Investors
Data Collection Process with LLMs
To collect LLM evaluations of the 171 ventures across nine experimental treatments, we used R and its embedded facilities to access the LLMs’ Application Programming Interfaces (APIs). We set the temperature parameter to 0, because we were interested in the most reasonable evaluations rather than the creativity of LLMs and wanted to reduce randomness in LLM responses as much as possible (cf. Girotra et al., 2023). To facilitate reproducibility, we set the seed parameter to 432. We collected the data at different points in time: GPT-4 (February 2024), GPT-4o (June 2025), Gemini 2.5 Pro (September 2025). 8 By using the APIs, we also ensured that the LLMs did not access the internet in response to the prompts.
Data Collection Process with Human Investors
To benchmark LLM performance, we recruited a convenience sample of human investors to evaluate the same 171 ventures using the same instructions provided to the LLMs in the baseline case (Treatment 1, see Table 1). 9 Participants were recruited through Prolific, a widely used platform for behavioral research and particularly common in studies involving early-stage investors (Antretter et al., 2025; Kleinert, 2024; Van Balen et al., 2019; Zunino et al., 2022). We conducted two waves of data collection. In August 2024, we recruited a general sample of potential equity crowdfunding investors. We screened participants based on prior investment experience in at least one of the following asset classes: exchange-traded commodities or funds, government bonds, stocks, unit trusts, angel (syndicate) investing, private equity funds, VC funds, options, or crowdfunding. In May 2025, we targeted a more specialized sample of early-stage investors, restricting participation to individuals with experience in angel (syndicate) investing, private equity funds, or VC funds. In both waves, we applied general screening criteria, including a minimum Prolific approval rate of 90%, UK residence, and fluency in English. To ensure data quality, we also implemented multiple attention checks to filter out unreliable responses. In total, the combined data collection resulted in a sample of 900 participants with 500 from the first and 400 from the second wave.
Each participant was randomly assigned to evaluate 1 of the 171 new ventures. Across the 900 participants, the resulting number of evaluations per venture ranged from 2 to 10. In addition to the evaluation questions, we asked participants whether they were familiar with the venture they evaluated. Only 3.44% of respondents reported prior familiarity (corresponding to 3.72% on the venture level based on averaged responses). Moreover, 34.44% participants identified as female, and the average age was 41.76 years, 43.11% held a bachelor’s degree, and 27.44% had a master’s degree or higher. Across the sample, 50.55% reported experience in angel (syndicate) investing, private equity funds, or VC funds, while the rest reported investment experience only in other asset classes. To assess whether differences in the investment experience influenced evaluations, we compared these groups with respect to investment evaluations and survival predictions (see Online Supplemental C). As we observed no substantive differences, we do not distinguish between these groups in the main analyses. For analyses conducted at the venture level, we use the average human evaluation per venture. This approach allows for direct comparison with the 171 LLM evaluations and enables statistical tests with a consistent sample size.
Main Results
Descriptive Statistics
Table 2 reports the descriptive statistics and correlations for the key variables at the venture, human investor, and LLM levels. At the venture level, we observe a positive correlation of .29 (p < .01) between fundraising success and survival, indicating that ventures that successfully raise funds are also more likely to survive. At the human investor level, the average investment evaluation is 3.72, and the average survival prediction is 54.52. At the LLM level, average investment evaluations are 4.53, 4.15, and 3.59, and average survival predictions are 67.63, 55.01, and 41.21 for GPT-4, GPT-4o, and Gemini 2.5 pro, respectively. LLMs’ prior exposure to ventures is positively correlated with venture success, including both fundraising success (r = 0.21, 0.36, 0.41) and survival (r = 0.12, 0.28, 0.25), which likely reflects the greater digital footprint of more successful ventures (Fisch & Block, 2021). Similarly, LLMs tend to assign higher scores to ventures they know, both for investment evaluations (r = 0.21, 0.45, and 0.45) and survival predictions (0.22, 0.42, and 0.42). We also observe substantial correlations across LLMs in investment evaluations (0.71, 0.56, and 0.68) and survival predictions (0.74, 0.58, and 0.72). Online Supplemental D reports further descriptive statistics across experimental treatments.
Descriptive and Correlation Statistics of Key Variables.
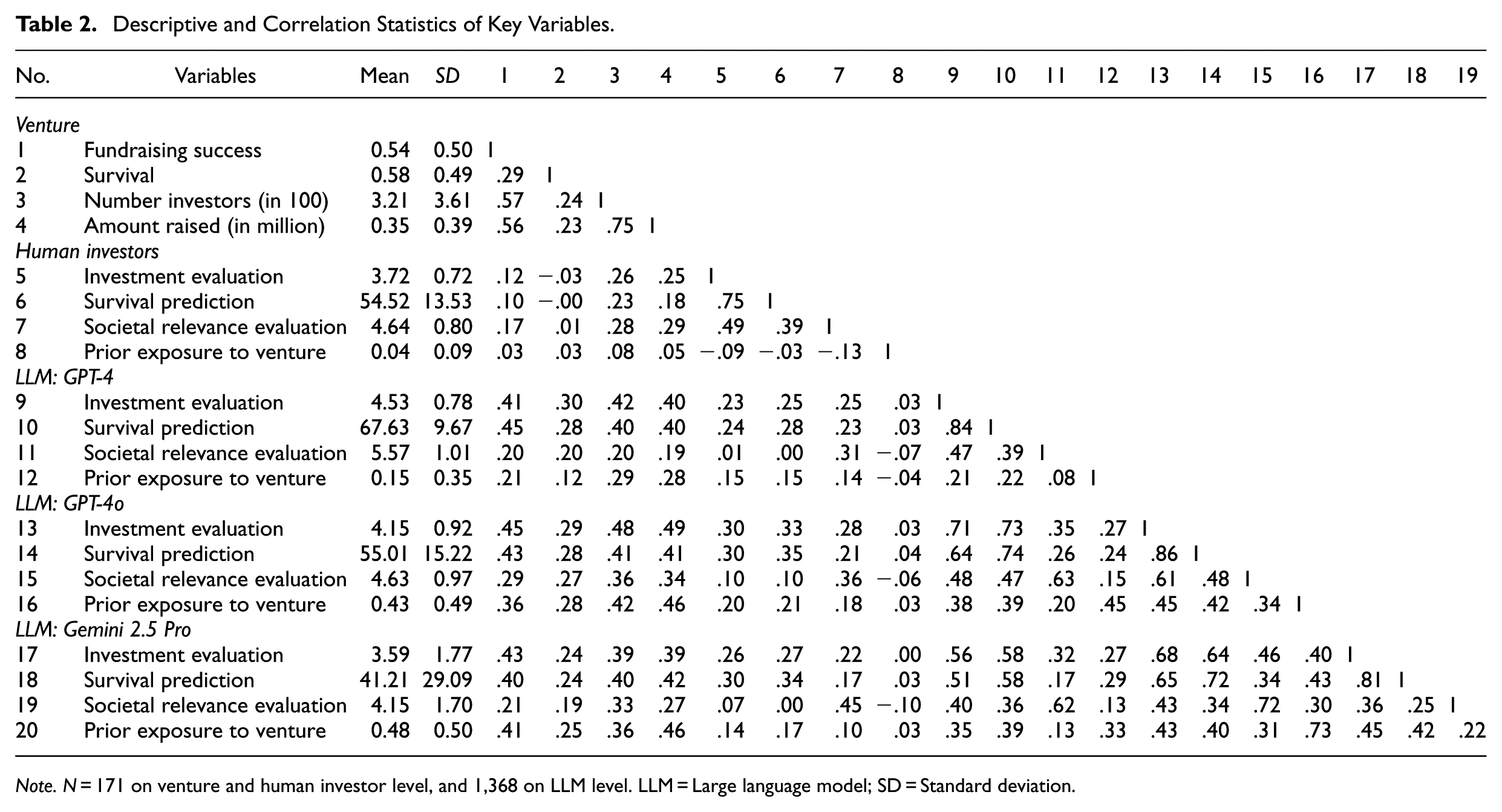
Note. N = 171 on venture and human investor level, and 1,368 on LLM level. LLM = Large language model; SD = Standard deviation.
To gain an initial understanding of how LLM evaluations relate to actual venture performance, Figure 2 visualizes two relationships: (a) investment evaluations and the frequency of fundraising success, and (b) survival predictions and the frequency of actual survival. For this analysis, we pooled all treatments that included both types of evaluations across the LLMs (n = 8 × 171 × 3). Panel (a) shows a strong and positive monotonic relationship, indicating that higher investment evaluations by LLMs are associated with a greater likelihood of fundraising success. This pattern suggests that LLMs effectively mirror the preferences of real early-stage investors. In contrast, Panel (b) reveals a weaker and less consistent relationship between LLM survival predictions and actual survival outcomes. Although higher predicted survival probabilities are generally associated with higher survival rates, LLMs appear less reliable in identifying ventures that ultimately fail. Online Supplemental E reports the same figures separately for the three LLMs.
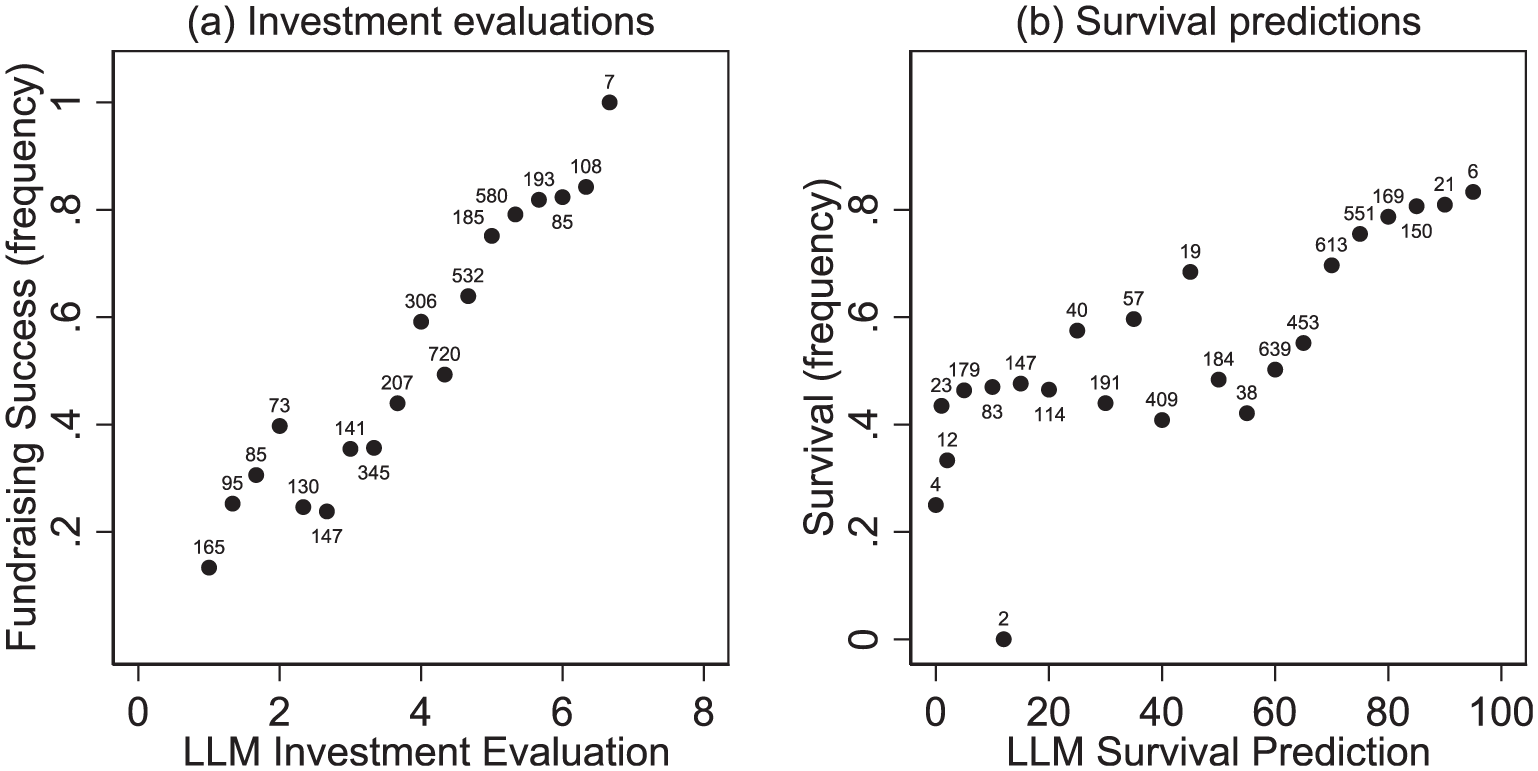
LLMs’ (a) investment evaluations and average fundraising success and (b) survival predictions and average survival.
LLMs’ Capabilities in Venture Evaluations
To assess LLMs’ capabilities in evaluating new ventures and the extent to which information cues improve these evaluations, we compare evaluations for ventures that ultimately succeeded or failed. Figures 3 and 4 present our main findings and display sets of bars representing LLM and human investor investment evaluations or survival predictions for the 171 ventures, grouped by actual venture outcomes, successful fundraising versus failed fundraising and survived versus failed. Both figures report t-tests of differences in evaluations between successful and failed ventures. Appendices A and B report corresponding regression analyses and show comparisons of differences across treatments.
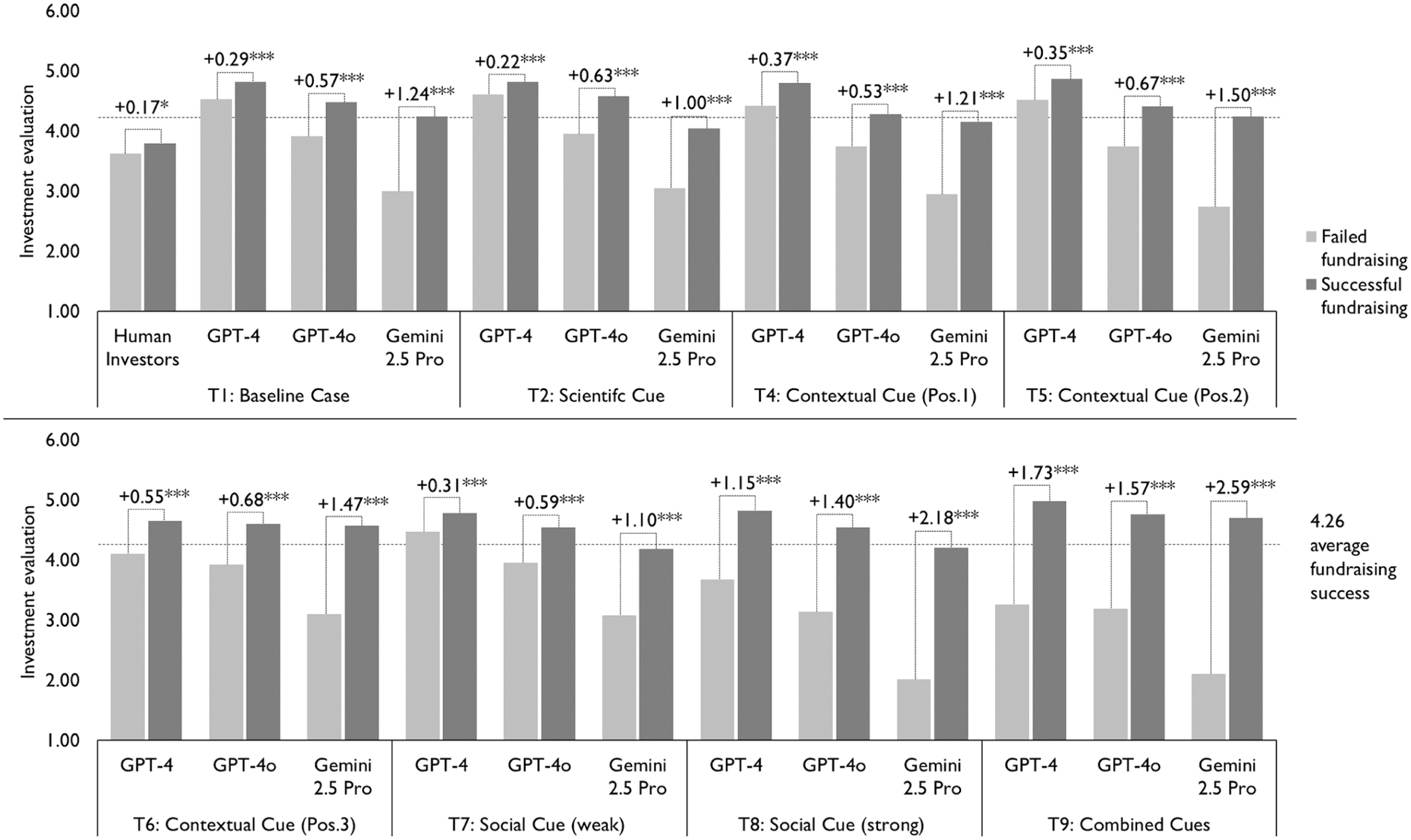
Investment evaluations and fundraising success across information cues.
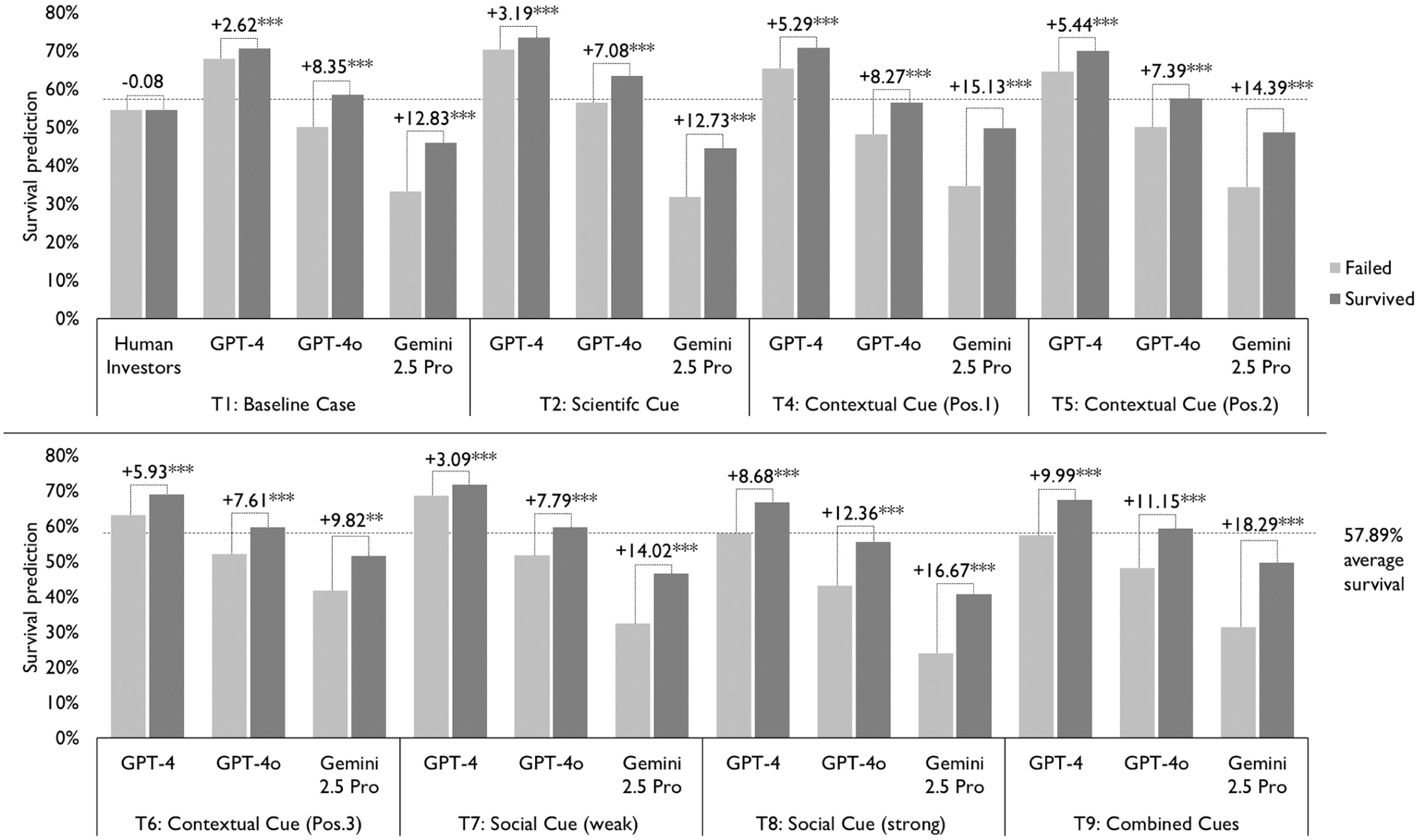
Survival predictions and survival across information cues.
In the investment evaluations, LLMs significantly outperform the human investor benchmark. In the baseline condition, all LLMs provide substantially higher investment evaluations for ventures that achieved successful fundraising compared with those that failed. Among the LLMs, Gemini 2.5 Pro shows the largest difference in evaluations between ventures with successful and failed fundraising (+1.24), followed by GPT-4o (+0.57) and GPT-4 (+0.29). In contrast, human investors exhibit a smaller difference in evaluations between ventures with successful and failed fundraising (+0.17). 10 The effects of information cues on LLM investment evaluations are mixed. Among the cues, the strong social cue substantially improves evaluations relative to the baseline condition. With this cue, the differences in evaluations between ventures with successful and failed fundraising increase for Gemini 2.5 Pro (+1.24 + 0.94 = +2.18), GPT-4o (+0.57 + 0.83 = +1.40), and GPT-4 (+0.29 + 0.86 = +1.15). The contextual cue yields mixed effects, improving evaluations when ventures are presented in positions 2 and 3, but not when presented in position 1. The scientific cue does not improve investment evaluations. The combined cue strongly improves evaluations, this effect appears to be driven primarily—though not exclusively—by the strong social cue.
We observe similar patterns for survival predictions. LLMs outperform human investors in predicting venture survival. Among the LLMs, Gemini 2.5 Pro again performs best, showing the strongest discrimination between survived and failed ventures (+12.83), followed by GPT-4o (+8.35) and GPT-4 (+2.62). Human investors do not discriminate between survived and failed ventures (−0.08). Among the information cues, the strong social cue and the combined cues again provide significant improvements in the accuracy of survival predictions, with effects that are statistically different from the baseline condition (Appendix B). Contextual cues yield minor and inconsistent improvements across LLMs and across venture positions within a set. The scientific cue does not improve survival predictions.
Across both investment evaluations and survival predictions, we observe notable differences across models. The oldest model, GPT-4, not only performs weakest overall but also tends to provide unrealistically positive assessments, consistent with well-documented sycophancy tendencies (Sharma et al., 2023). GPT-4o aligns more closely with realized fundraising success and survival outcomes, whereas Gemini 2.5 Pro is substantially more critical in its evaluations. At the same time, information cues appear relatively more effective in improving GPT-4’s performance, which is weaker in the baseline condition. By contrast, GPT-4o and Gemini 2.5 Pro already exhibit considerably stronger baseline evaluations and therefore benefit less from additional informational cues.
The Boundary Condition of LLM Prior Exposure to Ventures
To examine the extent to which LLMs’ strong capabilities in evaluating new ventures are driven by prior exposure to specific ventures in their training data, we split venture evaluations based on whether an LLM had prior exposure to a venture (Prior exposure = 1) or not (Prior exposure = 0). Tables 3 and 4 present regression results for the associations between LLM investment evaluations and fundraising success, and between LLM survival predictions and realized survival, respectively. Two key insights emerge from these analyses.
Investment Evaluations Across Information Cues by Fundraising Success and Prior Exposure to Ventures.
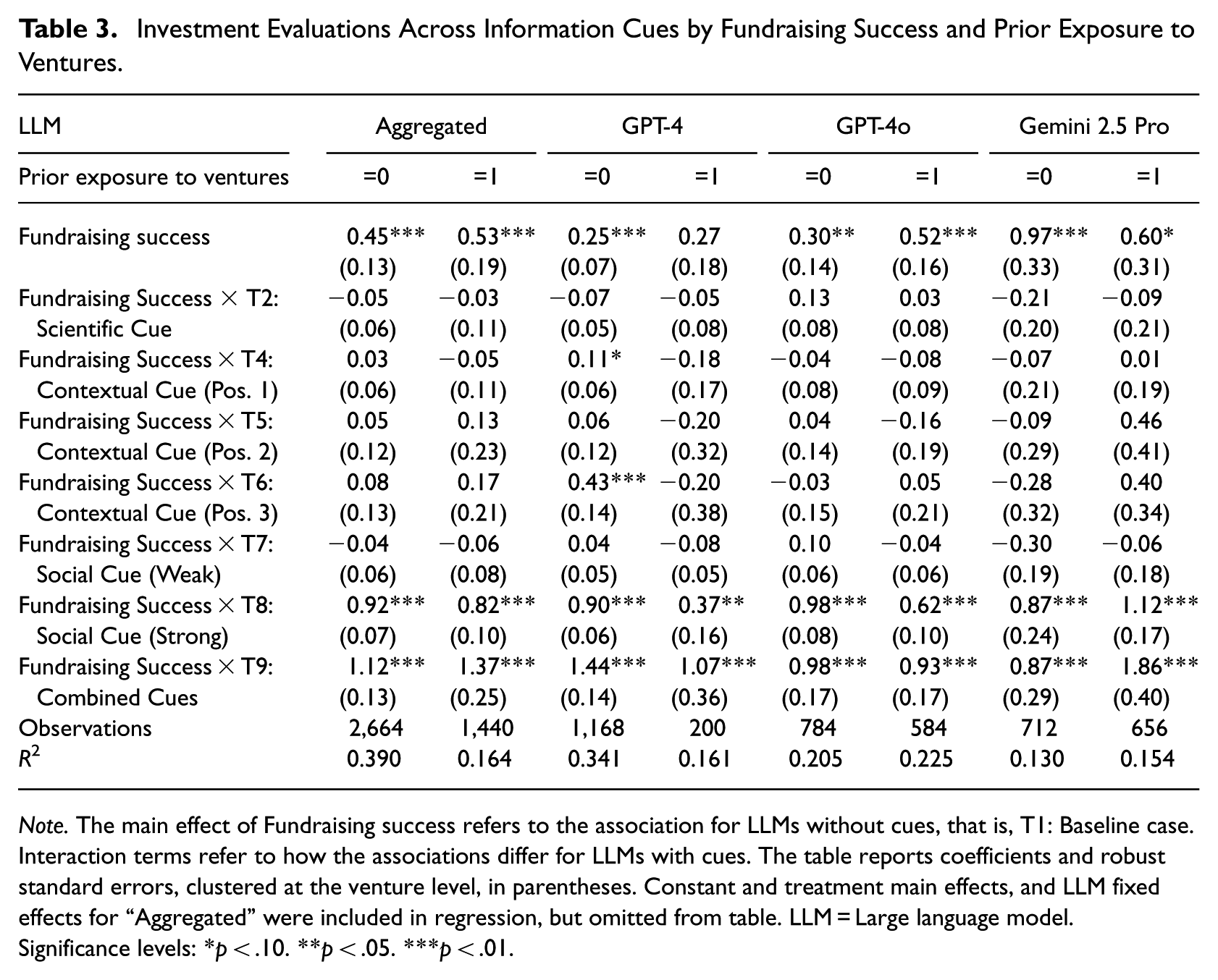
Note. The main effect of Fundraising success refers to the association for LLMs without cues, that is, T1: Baseline case. Interaction terms refer to how the associations differ for LLMs with cues. The table reports coefficients and robust standard errors, clustered at the venture level, in parentheses. Constant and treatment main effects, and LLM fixed effects for “Aggregated” were included in regression, but omitted from table. LLM = Large language model.
Significance levels: *p < .10. **p < .05. ***p < .01.
Survival Prediction Across Information Cues by Survival and Prior Exposure to Ventures.
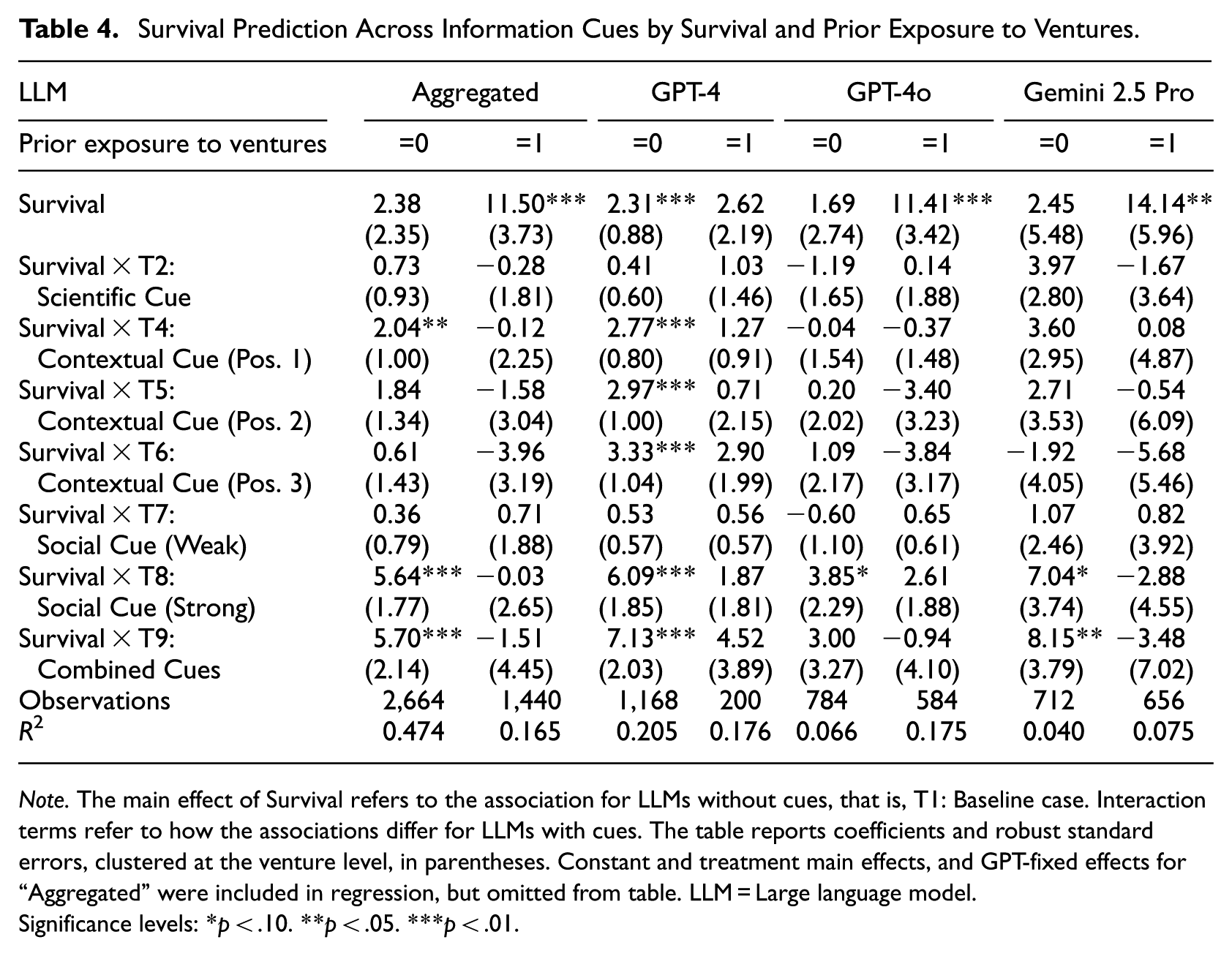
Note. The main effect of Survival refers to the association for LLMs without cues, that is, T1: Baseline case. Interaction terms refer to how the associations differ for LLMs with cues. The table reports coefficients and robust standard errors, clustered at the venture level, in parentheses. Constant and treatment main effects, and GPT-fixed effects for “Aggregated” were included in regression, but omitted from table. LLM = Large language model.
Significance levels: *p < .10. **p < .05. ***p < .01.
First, prior exposure explains a substantial share of LLMs’ apparent ability to predict venture survival. When aggregating across LLMs, we observe a strong and statistically significant relationship between realized survival and LLM survival predictions when prior exposure is present (Table 4: b = 11.50, p < .01). By contrast, this relationship becomes statistically insignificant when LLMs had no prior exposure to the venture (Table 4: b = 2.38, p = .31). This pattern is particularly pronounced for GPT-4o and Gemini 2.5 Pro, which also exhibit higher rates of prior exposure. Importantly, prior exposure does not fully account for LLMs’ strong ability to mirror real investor preferences. Even in the absence of prior exposure, fundraising success remains significantly associated with LLM investment evaluations across models (Table 3: b = 0.45, p < .01).
Second, information cues matter more for survival predictions when prior exposure is absent than when it is present. For example, survival predictions incorporating the strong social cue, the combined cue, and, in some cases, the contextual cues are significantly related to actual survival when LLMs had no prior exposure. This pattern suggests that such cues are particularly valuable when LLMs must form judgments under greater uncertainty. In contrast, survival predictions that incorporate these cues do not significantly relate to actual survival when prior exposure is present, consistent with the notion that recalled information dominates inference in these cases. Notably, information cues appear especially important for survival predictions generated by GPT-4, which also exhibits the lowest rates of prior exposure. These cue effects are smaller for investment evaluations, for which prior exposure appears to play a more limited role overall.
Exploration of the Role of Information Cues
So far, we have examined how information cues influence LLM performance in venture evaluations. We now turn to underlying patterns in how LLMs form evaluations. Specifically, we examine whether seemingly ineffective scientific cues become effective when enforced, whether contextual cues induce order and anchoring biases, and whether social cues trigger herding behavior in LLM evaluations.
Scientific Cues: Do LLMs Effectively Apply Decision-Making Frameworks for Evaluations?
Our main findings indicate that the scientific cue does not improve LLM investment evaluations or survival predictions. There are several possible explanations. One possibility is that LLMs already respond in ways similar to expert early-stage investors and therefore implicitly follow the framework even when it is not explicitly included in the prompt. Alternatively, LLMs may fail to apply the scientific framework altogether, some dimensions of the framework such as product, market, team, or financials may be less relevant, or the framework itself may not effectively explain fundraising success or survival outcomes. To further investigate these possibilities, we implemented an enforced application of the scientific framework by prompting LLMs to explicitly evaluate ventures along each of the 15 framework dimensions (Treatment 3 in Table 1). We construct both an aggregate measure across all 15 dimensions and domain-specific sub-scores for product, market, team, and financial characteristics. Table 5 reports regression results examining the association between the number of “very good” scores and fundraising success (Panel A) as well as venture survival (Panel B). To assess whether enforcing the scientific framework improves evaluations beyond the original scientific cue, we control for the investment evaluation or survival prediction from the scientific cue treatment (Treatment 2), in which application of the framework was not enforced.
Results on Enforced Application of Scientific Cue.
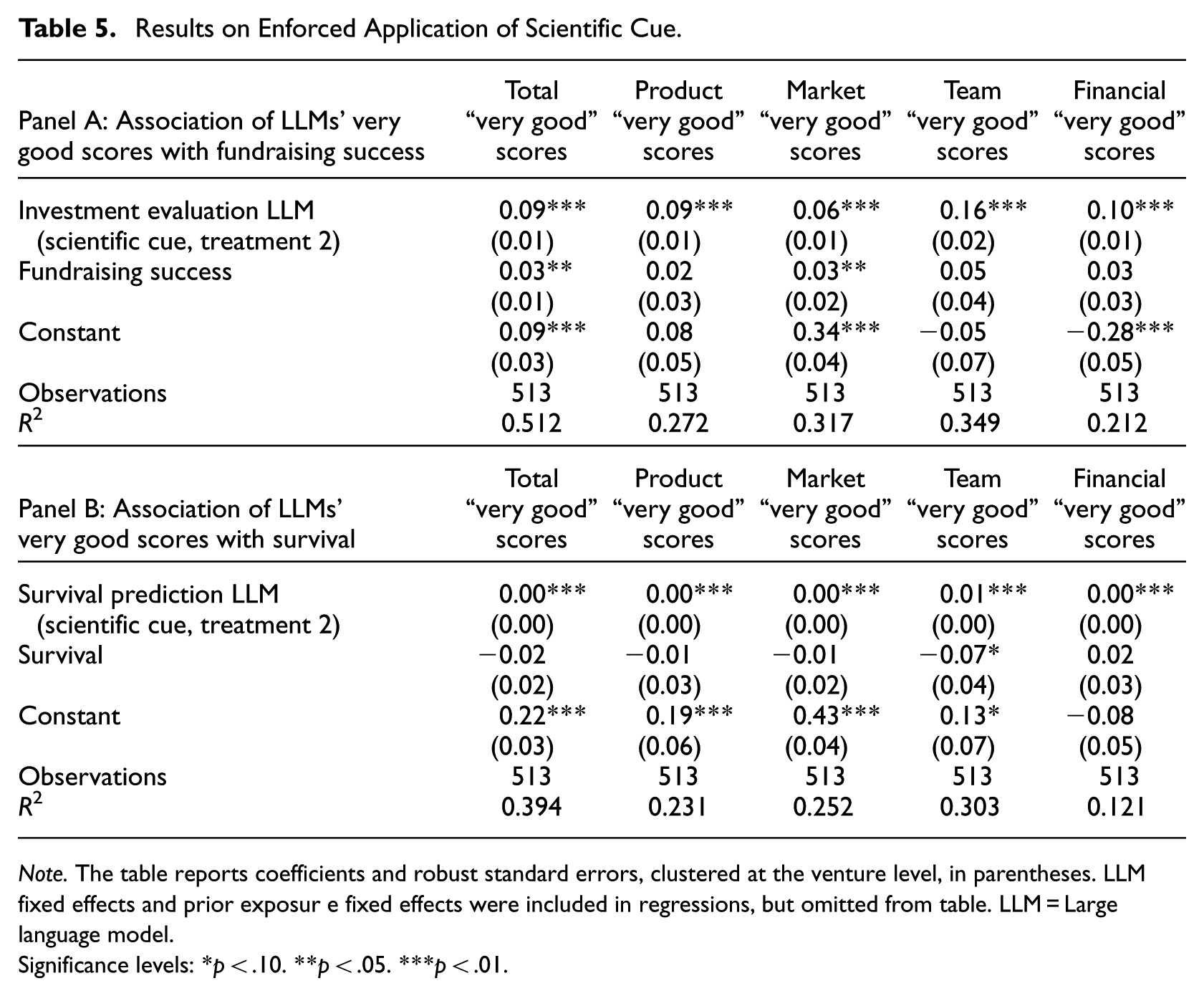
Note. The table reports coefficients and robust standard errors, clustered at the venture level, in parentheses. LLMfixed effects and prior exposur e fixed effects were included in regressions, but omitted from table. LLM = Large language model.
Significance levels: *p < .10. **p < .05. ***p < .01.
Table 5, Panel A, shows that fundraising success is positively associated with the total number of “very good” scores (b = 0.03, p = .01), indicating additional explanatory power even after controlling for the investment evaluation from Treatment 2, that is, the scientific cue with general evaluation questions. Among the individual dimensions, the largest coefficient is observed for the team dimension, although only the market dimension is statistically significant. In contrast, the results in Table 5, Panel B, reveal no significant association between survival and the total number of “very good” scores (b = −0.02, p = .33). We observe an even larger negative association between survival and the number of “very good” scores in the team dimension (b = −0.07, p = .07). Taken together, these findings suggest that enforcing the application of the scientific framework helps LLMs more closely reflect real investor preferences, but does not improve their ability to predict survival. 11
Contextual Cues: Are LLMs Prone to Order and Anchoring Effects?
Our main findings indicate that contextual cues partially improve LLM evaluations. At the same time, such cues may also shape evaluations by inducing cognitive biases commonly observed in human judgment, particularly order and anchoring effects. To examine these potential biases, we pool all observations from Treatments 4 to 6 across LLMs (n = 513 × 3) and analyze how venture position within a set and evaluations of prior ventures relate to both investment evaluations and survival predictions. To account for unobserved venture-level heterogeneity, prior exposure to ventures, and the fact that each venture is evaluated three times at different positions, we include venture fixed effects. We also include LLM fixed effects to control for systematic differences across models. Table 6 reports the results.
Results on Order and Anchoring Effects in Contextual Cue.
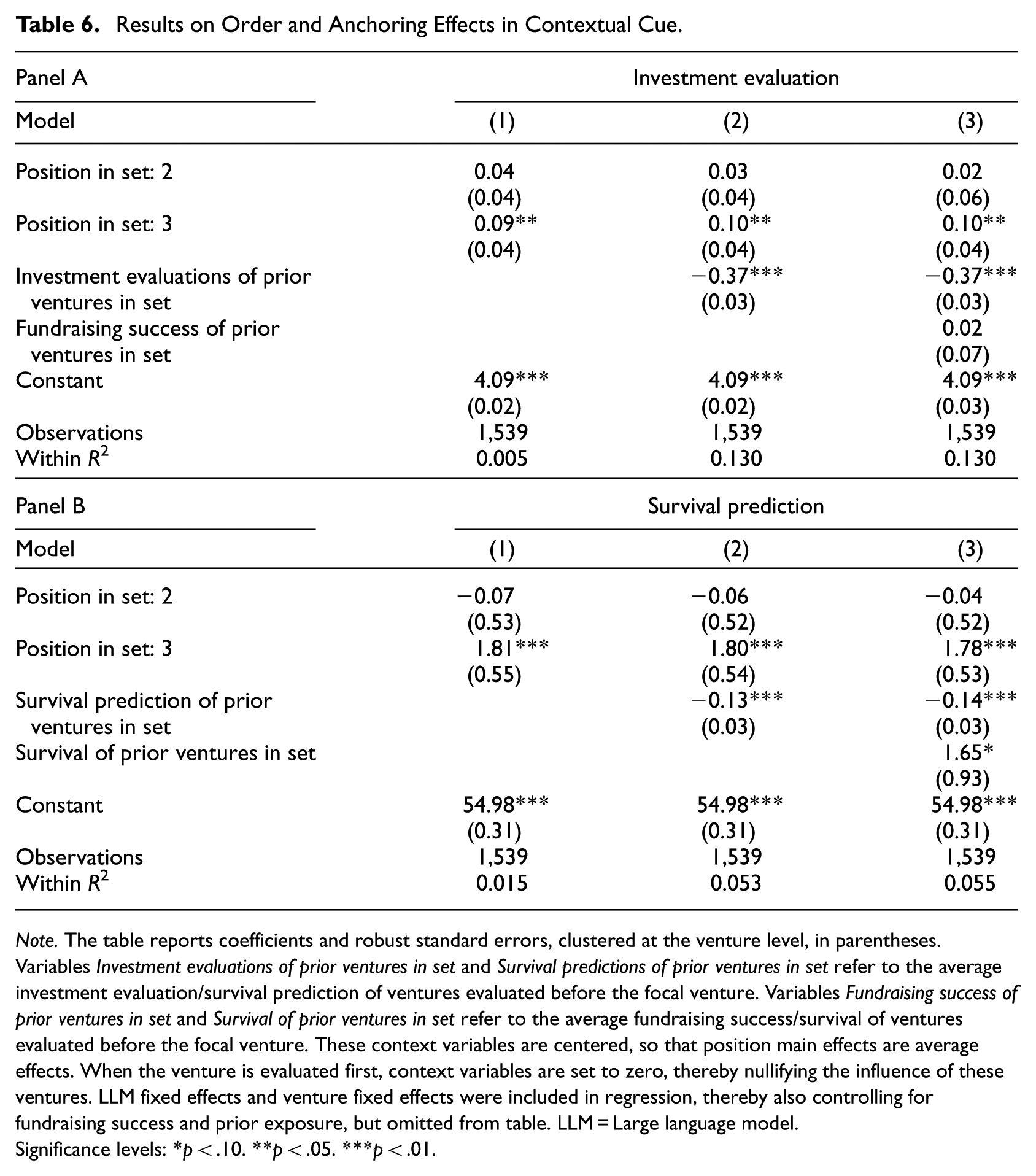
Note. The table reports coefficients and robust standard errors, clustered at the venture level, in parentheses. Variables Investment evaluations of prior ventures in set and Survival predictions of prior ventures in set refer to the average investment evaluation/survival prediction of ventures evaluated before the focal venture. Variables Fundraising success of prior ventures in set and Survival of prior ventures in set refer to the average fundraising success/survival of ventures evaluated before the focal venture. These context variables are centered, so that position main effects are average effects. When the venture is evaluated first, context variables are set to zero, thereby nullifying the influence of these ventures. LLM fixed effects and venture fixed effects were included in regression, thereby also controlling for fundraising success and prior exposure, but omitted from table. LLM = Large language model.
Significance levels: *p < .10. **p < .05. ***p < .01.
Table 6, Model 1, shows that a venture’s position within a set has a significant effect on both LLM investment evaluations (Panel A) and survival predictions (Panel B). Ventures evaluated in the third position receive more favorable assessments. Because the order of ventures within each set is randomized, this pattern indicates a systematic order effect in LLM evaluations. The magnitude of the effects is meaningful. For example, being evaluated last increases survival predictions by nearly two percentage points, suggesting that evaluation order can bias LLM outputs.
Model 2 examines anchoring effects, that is, whether evaluations of a focal venture are influenced by evaluations of prior ventures within the same set. We find that more positive evaluations of earlier ventures reduce both LLM investment evaluations (Panel A) and survival predictions (Panel B) for subsequently evaluated ventures. This pattern indicates that LLM evaluations within a set are not independent but instead depend on preceding assessments. To address the possibility that these effects reflect the actual quality of ventures within a set rather than contextual framing, Model 3 additionally controls for the fundraising success or survival of prior ventures. The results remain unchanged, supporting the conclusion that LLMs anchor their assessments on evaluations of earlier ventures within a set.
The order and anchoring effects are also independent of LLMs’ prior exposure to ventures (see Online Supplemental M). However, estimating the models separately for each LLM (Online Supplemental N) reveals substantial model-specific differences in these contextual effects. For example, GPT-4 evaluates ventures at position 2 more favorably, GPT-4o evaluates ventures at position 3 most favorably, whereas Gemini 2.5 Pro evaluates ventures at position 2 least favorably. These inconsistent patterns further support heterogeneity in how different LLMs respond to contextual information, consistent with the results reported in the main analysis.
Social Cues: Do LLMs Exhibit Herding Behavior?
Our main findings indicate that social cues play a crucial role in LLM investment evaluations and survival predictions. Two mechanisms may explain this pattern. LLMs may interpret signals such as investor interest or successful fundraising as indicators of inherent venture quality. Alternatively, they may echo positive human sentiment in a manner consistent with herding behavior. As a test for herding, we estimate regressions with LLM investment evaluations and societal relevance evaluations as dependent variables. 12 We focus on observations from Treatment 7, which includes the weak social cue, and Treatment 8, which includes the strong social cue. We examine how specific social cue information displayed in these treatments’ influences LLM evaluations, namely the number of investors in the weak social cue and fundraising success, number of investors, and amount raised in the strong social cue. Table 7 reports the corresponding analyses.
Results on Herding Effects in Social Cues.
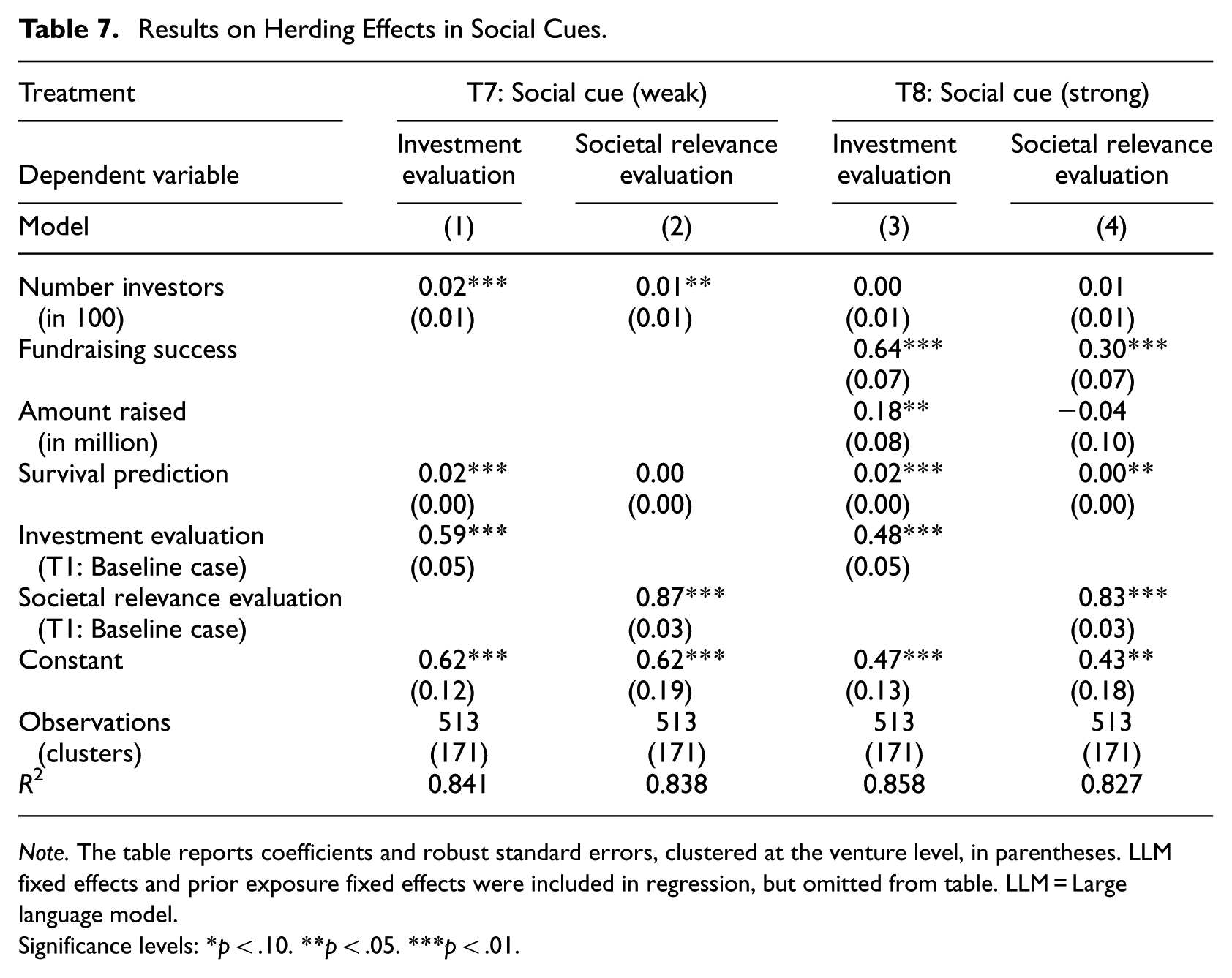
Note. The table reports coefficients and robust standard errors, clustered at the venture level, in parentheses. LLMfixed effects and prior exposure fixed effects were included in regression, but omitted from table. LLM = Large language model.
Significance levels: *p < .10. **p < .05. ***p < .01.
We first assess whether the variables displayed in the social cues affect LLM investment evaluations after accounting for general perceived venture quality. General quality is proxied by LLM survival predictions. To ensure that the observed effects are attributable to the social cues rather than baseline tendencies, we also control for investment evaluations from the baseline condition without information cues. In Table 7, Model 1, the number of investors has a significant effect on LLM investment evaluations even after controlling for these quality proxies. In Model 3, we observe a similar pattern for the strong social cue, where fundraising success and amount raised significantly influence investment evaluations beyond the baseline assessments. These results indicate that social cues shape LLM investment evaluations over and above the models’ own assessments of venture quality.
To further distinguish between information-based updating and herding, we examine the effect of social cue information on a different outcome variable, that is, LLM evaluations of ventures’ societal relevance. Equity crowdfunding investors primarily seek financial returns (Ahlers et al., 2015), and societal relevance is only loosely connected to equity crowdfunding investment outcomes (Vismara, 2018). Reliance on social cues (from return-oriented investors) when evaluating societal relevance therefore suggests herding rather than informative updating. The results show that even after controlling for LLMs’ baseline societal relevance evaluations from Treatment 1, LLMs rely strongly on social cue information. In the weak social cue treatment, the number of investors significantly drives societal relevance evaluations (Model 2), while in the strong social cue treatment, fundraising success significantly drives societal relevance evaluations (Model 4). Because societal relevance is not directly related to financial scale, it is not surprising that the amount raised does not influence societal relevance evaluations. Taken together, these findings support the conclusion that LLMs tend to uncritically mimic human endorsements, consistent with herding behavior. 13
Additional Analyses
Alternative Context Manipulation
We additionally examined an alternative manipulation of the contextual cue that increases the amount of contextual information provided to the LLMs. Specifically, prior to evaluating a focal venture, we presented LLMs with a broader set of venture pitch decks, namely 2, 5, or 10 ventures. At the time of running the experiment, the LLM applications did not reliably return responses when required to evaluate ten ventures within a single prompt. Hence, in contrast to Treatments 4 to 6, LLMs were not asked to evaluate these contextual ventures. The ventures used as context in this treatment were randomly drawn from our broader population of new ventures that were not included in the final sample. The results reported in Online Supplemental Q are consistent with our earlier findings in showing that these contextual cues do not reliably improve evaluation quality and only occasionally yield performance gains. Gemini 2.5 Pro exhibits improved survival prediction when provided with ten additional contextual ventures, whereas GPT-4o shows improved investment evaluations when exposed to two contextual ventures. This latter effect attenuates as the number of contextual ventures increases, which may indicate limits to effective attentional capacity. In contrast to our earlier results, GPT-4 does not benefit from these contextual cues. This pattern may reflect the model’s comparatively smaller attention window and a reduced tendency to attend to contextual information when it is not directly required for task completion. Taken together, these analyses further support the robustness of our main findings regarding the fragile and inconsistent impact of contextual information on LLM-based venture evaluations.
Additional Tests on the Effect of Prior Exposure
Our results indicate that LLM evaluations, and survival predictions in particular, for the ventures in our archival dataset are influenced by prior exposure to some of these ventures. Although we explicitly test and document the effects of such prior knowledge in our main analyses, two additional considerations warrant attention. First, prior exposure effects may extend beyond venture-specific familiarity (as captured by our measure of prior exposure based on correct identification of a venture’s founder) to include broader factors such as market dynamics. Second, it remains an open question whether such prior exposure effects can be actively reduced in LLM-based evaluations. To address these issues, we conduct two additional sets of tests.
First, we implemented two additional treatments to examine whether LLMs provide more accurate evaluations when explicitly prompted to consider or to ignore more recent information that they could, in principle, leverage. In the first additional treatment, we instructed LLMs to consider recent market dynamics since the time of the fundraising campaign by adding the following instruction to the prompt: “Evaluate the startups from the perspective of an early-stage investor today in 2024 and consider all relevant contextual factors and information that have occurred since 2017/18, such as major events like the coronavirus pandemic or other market dynamics.” In the second additional treatment, we used a contrasting prompt that explicitly instructed LLMs to ignore such post-2017/18 developments. For the analyses reported in Appendix C, we pool observations from the baseline condition (Treatment 1) with these additional treatments and estimate regression models examining the relationship between investment evaluations and fundraising success (Panel A) and between survival predictions and actual survival (Panel B), conditional on whether LLMs were instructed to consider or ignore recent market dynamics.
Appendix C shows that investment evaluations are slightly less strongly related to fundraising success when LLMs are prompted to ignore market dynamics relative to the baseline condition. However, the baseline association between LLM investment evaluations and fundraising success remains robust. More importantly, for survival predictions, explicitly prompting LLMs to consider recent market dynamics significantly strengthens the relationship between predicted and actual survival. This finding suggests that, in the baseline condition and main analyses, LLMs do not, by default, incorporate potentially relevant post-2017/18 information when forming survival predictions. Once more, this indicates that potential information encoded in LLMs needs be activated by corresponding prompts. We further explore how such prompting of market dynamics interacts with prior exposure to ventures. When we further split the sample based on whether LLMs had prior exposure to a venture, we find that the effect of prompting LLMs to consider market dynamics for survival predictions is stronger for ventures with prior exposure. Conversely, the effect weakens when LLMs are prompted to ignore market dynamics. This pattern suggests that prompting LLMs to consider recent market dynamics also encourages LLMs to draw more fully on their existing familiarity with a venture. In contrast, explicitly instructing LLMs to ignore such dynamics may partially mitigate the influence of prior exposure. Hence, prompts designed to suppress prior knowledge could be effective when familiarity is a concern.
Second, we implement a third additional treatment, in which we rerun the baseline treatment using anonymized venture descriptions. Specifically, we anonymize venture names, founder names, employee names, and product or service names, replacing them with generic labels (e.g. venture names replaced with “Venture” and founder names with “Founder”). By removing identifiable information, this treatment reduces the likelihood that LLM evaluations rely on the ventures’ digital footprints. The results reported in Appendix C show that anonymization substantially weakens the associations between LLM evaluations and venture outcomes for ventures with prior exposure to the LLM (investment evaluation: 0.53−0.21 = 0.32); survival predictions: 11.47−7.32 = 4.16). For ventures without prior exposure, anonymization does not meaningfully change these associations. This pattern suggests that anonymization can partially counteract the effects of prior exposure. At the same time, we observe that the association between venture evaluations and fundraising success may—counterintuitively—be stronger for ventures without prior exposure than for ventures with prior exposure but anonymized (0.46 vs. 0.32). Moreover, anonymization generally leads to more positive evaluations, even for ventures without prior exposure. One possible explanation is that anonymized ventures, which may closely resemble known ventures, are not recognized as such and instead are implicitly treated as competitors, thereby introducing additional influences on evaluations. While anonymization in LLM-based evaluations represents a promising avenue for future, more methods-oriented research, our main analyses deliberately avoid anonymization in order to prevent such ambiguous evaluation conditions.
Discussion
This study examines the capabilities of generative AI—specifically the general-purpose LLMs GPT-4, GPT-4o, and Gemini 2.5 Pro—to evaluate new ventures in the early-stage investment context and how information cues shape these evaluations. Across a range of experimental manipulations, we examine how investment evaluations (judgments of investment attractiveness) relate to realized fundraising success in equity crowdfunding campaigns, and how survival predictions (assessments of long-term venture viability) relate to observed 5-year post-campaign venture survival.
Our findings reveal a double-edged performance of LLMs in the evaluation of new ventures. On the one hand, LLMs generate evaluations that align closely with realized outcomes. Both their investment evaluations and survival predictions distinguish between ventures that successfully raised funding or survived and those that did not, with associations that are stronger than those observed for a benchmark sample of human investors. These strong associations between LLM evaluations and real venture outcomes suggest that LLMs are effective at capturing signals that reflect investor preferences and venture viability. On the other hand, our split-sample analyses reveal that prior exposure to ventures’ digital footprints (i.e. familiarity with the venture, but not its outcomes) shape some of these apparent capabilities. Whereas LLMs’ investment evaluations continue to mirror real investor behavior even in the absence of prior exposure, their apparent ability to predict venture survival in our archival dataset is confined to ventures for which they had prior exposure. These survival predictions therefore appear to reflect venture-specific information embedded in training data rather than independent reasoning about future viability based solely on pitch content. Although this pattern is particularly salient given our research design, which relies on historical outcomes, it reflects a broader challenge: most companies leave digital traces, making it difficult to assess whether LLMs form truly independent evaluations.
Our findings regarding information cues present a mixed picture. Among the cues we examine, the strong social cue is the most influential. It consistently improves investment evaluation accuracy and survival prediction accuracy across LLMs and model versions. This pattern is unsurprising, as the strong social cue provides venture-specific information, whereas the other cues are more generic in nature. At the same time, our results point to herding in response to social cues, whereby LLMs evaluate ventures more favorably simply because they are framed as successful or endorsed. By contrast, the other cues are less consistently effective. The scientific cue improves evaluations only when its use is explicitly enforced through structured prompting, and even then, its effect is limited to investment evaluations. Contextual cues generally exert weaker effects, although their influence varies across prompts. Importantly, contextual cues induce order and anchoring effects. Despite randomized ordering, venture position within a set and evaluations of other ventures systematically influence LLM evaluations. These patterns suggest that LLM evaluations are sensitive to the specific informational context in which venture descriptions are presented.
We also observe notable differences across LLMs. Overall, Gemini 2.5 Pro performs better than the GPT models in discriminating between successful and unsuccessful ventures. Interestingly, however, differences in underlying response patterns are more pronounced across model versions, such as GPT-4 versus GPT-4o, than across model families, such as GPT-4o versus Gemini 2.5 Pro. The most recent GPT and Gemini models exhibit similar levels of prior exposure and similar responses to information cues. For these models, information cues are less impactful because baseline performance is already strong. By contrast, the older GPT-4 model performs markedly differently. It exhibits stronger sycophancy tendencies and produces overly positive, less realistic evaluations. In this case, information cues play a more substantial role in offsetting weaker baseline performance. The lower performance of this older model appears to stem from overall reduced capability and less granular retained knowledge, reflected in its significantly lower rate of prior exposure to ventures. Consistent with this pattern, prompting strategies and information cues are considerably more important for the older model, that is, when evaluations must be made under greater uncertainty in the absence of sufficient prior exposure. Contextual cues that have minimal effects on the most recent models are substantially more influential for this earlier version.
Theoretical Contributions
We make several contributions to research on AI in entrepreneurship and provide corresponding future research directions. First, we show that LLM capabilities in new venture evaluation are task-dependent and critically shaped by prior exposure to ventures’ digital footprints. Specifically, we demonstrate that LLMs show promise in mirroring evaluations by real early-stage investors, while highlighting prior exposure to ventures’ digital footprints as a critical boundary condition for LLMs’ ability to assess long-term venture viability. This contributes to the emerging literature on AI in entrepreneurship (Blohm et al., 2022; Chalmers et al., 2021; Lévesque et al., 2022), which has largely overlooked the role of generative AI in high-uncertainty tasks such as venture evaluation (Obschonka et al., 2025). In doing so, we depart from recent work by Doshi et al. (2025), who study LLM-generated rankings of business models in strategic contexts and assess performance based on agreement with expert raters. In contrast, we examine holistic investment judgments of real early-stage ventures that involve greater uncertainty, require forward-looking reasoning, and span multiple venture attributes (Amit et al., 1998; Fisher & Neubert, 2023). Rather than relying on subjective alignment with human judgments obtained in survey-like settings, we assess LLM performance against objective venture outcomes—fundraising success as an indicator of real investor behavior and venture survival as an indicator of economic viability. In doing so, we directly respond to Doshi et al.’s (2025, pp. 605–606) call to “investigate how generative AI evaluations compare with both human evaluations and an outside outcome, when the latter is available.”
Our study shows that LLMs perform particularly well in mirroring realized fundraising outcomes and thus in reflecting actual investor preferences. This suggests that LLMs are well-suited to simulating early-stage investor decision-making, a capability of particular relevance for entrepreneurial finance research that seeks to study and test investor judgment and behavior (Ademi et al., 2023; Svetek, 2023; Van Balen et al., 2019; Zunino et al., 2022). Future research may therefore consider LLM-based evaluations as a complementary methodological tool for generating insights into such behaviors. At the same time, we show that LLMs’ ability to predict venture survival—that is, to assess long-term venture viability under uncertainty—is weak, except in cases where specific venture-related information is available in the LLM’s training data. Given this weak performance even in our archival setting, where digital traces are particularly pronounced, our findings raise doubts about how well LLMs can predict venture performance in truly novel settings with limited digital footprints, such as nascent entrepreneurs pitching in venture capital contexts.
More broadly, our study contributes to debates on AI performance in high-uncertainty tasks (Ramoglou et al., 2025; Townsend et al., 2025) by showing that apparent evaluative capability may conflate reasoning with exposure. Because digital footprints are pervasive yet unevenly distributed across ventures (Fisch & Block, 2021; Obschonka et al., 2017), prior exposure constitutes a critical but largely unobservable boundary condition for the use of generative AI as an evaluator. Thus, it can be difficult to determine whether an LLM’s output reflects reasoning based on the information provided or a plain retrieval of previously encountered content. This ambiguity challenges existing interpretations of LLM accuracy in evaluative and decision-making tasks (Doshi et al., 2025), as observed performance may reflect retrieval of previously encountered patterns rather than genuine task competence. Relatedly, prior exposure may also help explain why LLMs tend to generate business ideas that appear high in quality but low in novelty (Boussioux et al., 2024; Girotra et al., 2023), for example by reproducing patterns associated with historically successful business models. While our study focuses on evaluation rather than ideation and strongly amplifies exposure effects due to its reliance on historical outcomes, it underscores the need for future theorizing to systematically examine how even limited digital traces shape LLM outputs and how such effects can be detected. At the same time, an open question is whether such effects should be mitigated at all. LLMs may leverage relevant prior information that improves evaluative accuracy, yet this capability also raises concerns about opaque black box assessments and potential incentives for entrepreneurs to strategically curate their digital footprints. Exploring these dynamics represents a promising avenue for future research.
Second, we test and elaborate foundational decision-making theories by examining how they apply to AI-based judgments. Specifically, we borrow well-established theories developed to explain human decision-making under uncertainty and contrast how these theories account for evaluations produced by LLMs when assessing new ventures. Our overarching finding is that core evaluation and judgment patterns based on information cues and heuristics, well documented in research on human decision-making (Bapna, 2019; Huang & Pearce, 2015; Nagy et al., 2012; Petty et al., 2023; Vismara, 2018; Zacharakis & Meyer, 2000), also shape LLM evaluations, although they operate through partially different mechanisms.
Consistent with theories of decision-making under uncertainty (Tversky & Kahneman, 1974), we find that context-based biases such as anchoring are present in LLM evaluations. Randomized venture position systematically affects LLM judgments, and evaluations of earlier ventures within a set shape subsequent assessment. Unlike human judgment, however, where the first option often establishes a positive benchmark, the first venture evaluated by an LLM has a negative effect on subsequent evaluations. This pattern suggests that LLMs may implicitly treat ventures within a set as zero-sum competitors rather than as independent reference points, pointing to a departure from standard anchoring mechanisms. In line with theories of information cascades and herding (Banerjee, 1992; Bikhchandani et al., 1992), LLMs also place disproportionate weight on others’ observed actions or endorsements. Both weak and strong social cues shift LLM evaluations in the direction implied by human endorsement, even when controlling for general quality proxies. The mechanism underlying this pattern differs from the one typically assumed in information cascade research. Whereas such theories emphasize rational inference from others’ actions, an assumption that finds some support in early-stage funding contexts where investors follow more sophisticated investors (Vismara, 2018), LLMs’ mimicking behavior does not appear to reflect informational learning. Instead, social cues activate tendencies to overweight endorsement-like information, potentially linked to documented forms of over-agreeableness or sycophancy in LLMs (Sharma et al., 2023). Our findings are also partially consistent with signaling theory and its applications in entrepreneurship (Bafera & Kleinert, 2023; Spence, 1973). When LLMs are provided with strong social cues, such as fundraising success and associated metrics, these cues generate the largest improvements in alignment with realized outcomes and enable more accurate survival predictions, even in the absence of prior exposure. At the same time, these effects may still be driven by mimicry rather than by an assessment of signal credibility. This raises questions about how LLMs respond to different types of quality signals. Future research could examine whether LLMs similarly value other signals commonly used in entrepreneurship, such as team characteristics or patents, or whether endorsement-based signals are systematically over-weighted relative to other relevant signals.
Our theory testing and elaboration provides a starting point for future research at the intersection of decision-making theories developed for human evaluators and AI-based judgments. Prior scholars have called for a “theory-based research process” in entrepreneurial AI research (Lévesque et al., 2022, p. 803), and our study illustrates how established theories can serve as useful points of departure while also requiring refinement. Two implications for theory development in AI contexts follow from our study. One concerns model heterogeneity. More recent LLMs exhibit stronger baseline evaluative capabilities and weaker responses to generic cues, whereas older models benefit more from additional structure. Identical cues and potentially other theoretical lenses may therefore have different relevance depending on model capability. A second implication concerns the role of digital footprints in evaluation. Whereas human decision-makers rely on memory and experience when interpreting information (Ciuchta et al., 2018), LLMs draw on latent patterns embedded in training data. Information cues appear particularly influential when such latent traces are weak or absent, underscoring the need to adapt decision-making theories to account for how AI systems store and retrieve prior information.
Together, these insights open several avenues for future research. Future studies could examine a broader set of information cues and assess whether LLMs replicate other human biases, such as stereotype-based judgments that are known to affect entrepreneurial finance decisions (Eddleston et al., 2016). Research might also explore strategies to debias LLM evaluations (Blaseg & Schwienbacher, 2024) and systematically map the biases to which specific LLMs are most susceptible. Finally, it remains unclear how early-stage investors integrate AI-generated evaluations into their decision-making processes. In our study, we treat LLMs as autonomous evaluators, whereas in practice, investors may use these tools as part of their own screening efforts. It is therefore important to understand whether investors treat LLM recommendations as substitutes for, or complements to, their own judgments, and under which conditions they rely on or disregard them. For example, future research could replicate our study using different configurations of evaluators, such as human-only, AI-only, and combined human–AI decision-making groups. Addressing these questions is essential for understanding the growing interplay between human and generative AI in entrepreneurial decision-making.
Practical Implications
Our study offers timely practical implications into the growing use of generative AI in early-stage investing. Anecdotal evidence and reports from multiple VC firms suggest that LLMs such as GPT and Gemini are increasingly being integrated into the investment process (WSJ, 2024). 14 These tools support a range of tasks, including summarizing pitch materials, scoring startups, and automating the initial screening process (4 Degrees, 2025). VCs cite several advantages. First, LLMs substantially increase the speed of deal evaluation (see also Vismara et al., 2025). For example, Forum Ventures reviews around 8,000 deals annually and employs generative AI to guide and streamline decision-making. Second, LLMs enable investors to evaluate startups outside their core domain expertise, including those in technical or highly regulated sectors. Third, LLMs can surface promising ventures that might otherwise be overlooked. Sierra Ventures, for instance, made an investment based on an AI-generated assessment, and firms like Nauta Capital and Signal Fire have similarly used LLM tools to surface high-potential startups (LTSE, 2025). Despite these benefits, concerns persist. Some VCs, such as Amplify Partners and Ulu Ventures, question AI’s ability to replace direct founder interactions or warn of AI reinforcing existing biases (Global Corporate Venturing, 2025; WSJ, 2024). Overall, these examples indicate that while interest is high, there is no standardized or validated approach to using AI in early-stage investing.
Our study provides insight into how LLMs perform in venture evaluations. We find that models such as GPT and Gemini can generate structured and informative assessments that align with real-world outcomes, including fundraising success. These capabilities may assist investors during early-stage screening and help entrepreneurs refine their fundraising materials. However, our findings also reveal important limitations. In particular, LLM performance may appear stronger than it truly is. We show that seemingly strong survival predictions are largely driven by ventures’ existing digital footprints—that is, information the models may have encountered during training. Although our study likely overestimates the role of prior exposure because it relies on historical success outcomes (e.g. venture survival up to 2024), in practice, most early-stage ventures are likely to have some digital footprint, such as a company website, social media presence, or media mentions, in addition to their pitch materials. When such information exists, it may be incorporated into an LLM’s assessment in ways that are not transparent to users. As a result, investors may receive evaluations without clear insight into the sources underlying the model’s judgment, effectively rendering the assessment a black box. Such dynamics may even create incentives for entrepreneurs to strategically curate or manipulate their digital presence (see also Rutherford et al., 2009), potentially altering how ventures seek funding and how they are evaluated in turn. Such concerns are particularly salient in settings like equity crowdfunding, where less experienced investors may overestimate the objectivity of LLM-based evaluations.
To guide more effective use of LLMs in early-stage investing, we offer several recommendations related to prompting and context generation. First, investors should incorporate explicit digital footprint checks to determine whether and to what extent an LLM has prior exposure to a venture. Doing so requires developing systematic approaches to detect exposure. Our study provides an initial step by querying the model separately about whether it recognizes venture-specific information that would be inaccessible without prior knowledge. Additional analyses further suggest that LLMs can be prompted to rely less on prior exposure when forming evaluations. Second, investors can prompt LLMs to evaluate discrete dimensions, such as the market or founding team, when these are of particular interest. Targeted prompts help isolate specific evaluation criteria and reduce the risk of overly general responses. Third, investors should remain cautious about LLMs’ susceptibility to biased responses, including tendencies to mirror endorsements or display excessive agreeableness. Finally, human oversight remains essential to ensure that LLMs function as decision-support tools rather than substitutes for expert judgment.
Limitations and Constraints on Generality
We acknowledge several limitations and constraints on generality in our study (Simons et al., 2017). First, our research design relies on LLM-generated investment evaluations and survival predictions for ventures with historical outcomes (i.e. fundraising success and 5-year survival). This design does not allow us to perfectly isolate the predictive performance of LLMs, as doing so would require evaluating contemporary pitch information and then observing how ventures subsequently develop. Although such a prospective design would be ideal for assessing predictive accuracy, it would require a long-time horizon during which LLM capabilities would likely continue to evolve, rendering results based on outdated technologies. By contrast, our retrospective approach enables us to examine the performance of current state-of-the-art models, but it is inherently susceptible to digital footprint effects that may have accumulated over time. These footprint effects may play a different role when analyzing contemporary pitch materials, for which post-pitch information is not yet available and thus cannot have entered training data. Throughout our analyses, we therefore carefully measure and test the effects of prior exposure, operationalized as the correct identification of a venture’s founder. While identifying founders likely reflects relatively detailed knowledge of a specific venture, this measure is subject to potential measurement error. For example, LLMs may possess other venture-specific information without identifying founders, or may recognize founders without access to other relevant venture-specific information. Such unobserved exposure could influence some results beyond what is captured in our reported analyses. Importantly, even within our retrospective design, accounting for prior exposure reveals clear limits to LLM predictive capabilities. For ventures without prior exposure, we find no statistical relationship between LLM survival predictions and actual survival outcomes, indicating that LLMs do not accurately predict survival under genuine uncertainty. While this pattern likely generalizes to settings in which relevant information is neither encoded in the model nor publicly available, our findings would benefit from complementary research designs. Future research could address these limitations by evaluating contemporary ventures and tracking outcomes in real time, for example by observing performance or survival over subsequent years. We further recommend that such studies explicitly measure differences in ventures’ digital footprints, as these may constitute an alternative basis for forward-looking prediction accuracy
Second, to assess the capability of LLMs to evaluate new ventures, we focus on selected state-of-the-art models available at the time of data collection, including GPT-4 (February 2024), GPT-4o (June 2025), and Gemini 2.5 Pro (September 2025). Our findings therefore generalize to these specific models at these specific points in time. It remains unclear to what extent our results extend to other LLMs, such as Llama (Meta), Grok (xAI), or Claude (Anthropic). Prior research documents notable similarities across models, including shared tendencies toward sycophancy across providers (Sharma et al., 2023), and our results similarly reveal fundamental evaluation patterns (e.g. herding and anchoring effects) that are broadly consistent across GPT and Gemini models. At the same time, we observe meaningful differences in baseline performance and contextual effects (e.g. order effects), both across and within models, indicating that model-specific characteristics matter. More broadly, our analysis captures LLM behavior at particular moments in time in 2024 and 2025. As generative AI technologies continue to evolve rapidly, future model generations may differ substantially in their evaluative capabilities. Accordingly, future research could extend our analyses to additional models and newer generations.
Third, we benchmark LLM evaluations against a sample of early-stage investors recruited via the Prolific platform. Prolific has been widely used in entrepreneurship research to study entrepreneurs and early-stage investors (Antretter et al., 2025; Kanze, 2025; Wesemann Lekkas et al., 2025; Zunino et al., 2022), but online panels have increasingly been criticized for low-quality and AI-generated responses (Westwood, 2025). Compared to other online panels, Prolific is generally considered to provide higher-quality data (Douglas et al., 2023) and employs extensive measures to detect and prevent AI participation, including more than 50 onboarding verification steps, identity checks, live video verification, and continuous behavioral monitoring (Prolific, 2026). Although it remains difficult to fully rule out such concerns, we conducted several robustness checks. Specifically, we compared response patterns across our two waves of human investor data collected in 2024 and 2025—when the risk of AI-generated responses may have increased—and found no meaningful differences. We also examined whether evaluations varied systematically with completion time (Online Supplemental S) and observed no notable patterns. Nonetheless, limitations related to sample representativeness cannot be entirely excluded. Relatedly, our Prolific sample includes both generalist investors, such as individuals with stock market experience, and participants with specific early-stage investment experience, including venture capital. We therefore believe our findings are most directly generalizable to equity crowdfunding contexts, where investor populations are typically diverse in experience and sophistication (Wang et al., 2019). While the results for our benchmark sample may offer tentative insights into the behavior of investors with some venture capital experience, generalizability to highly sophisticated investors, such as active professional venture capitalists or experienced angel investors, remains limited and represents an important avenue for future research.
Fourth, we use venture descriptions derived from equity crowdfunding campaigns, which enhances realism, especially relative to AI-generated business models used in other work (Doshi et al., 2025). While these descriptions resemble executive summaries often sent from entrepreneurs to investors (Krukowski et al., 2023), they may not generalize to more detailed business plans typically reviewed by VCs, which could, for instance, include more extensive financial data (Collewaert et al., 2021). Additionally, ventures that pursue equity crowdfunding may differ systematically from those targeting other investor types (Walthoff-Borm et al., 2019), constraining generalizability beyond this context. Future research could therefore examine LLM evaluations in alternative settings, such as reward-based crowdfunding or professional venture capital decision-making, and using different information formats, including pitch videos, venture websites, or detailed business plans.
Conclusion
Our study examines how generative AI, specifically LLMs, evaluates new ventures and how different information cues shape these evaluations. In doing so, we contribute to emerging research at the intersection of artificial intelligence, decision-making, and entrepreneurial finance. Our findings suggest that general-purpose LLMs, in their current form, can provide practical value in early-stage venture evaluation, but that their capabilities are bounded and must be applied with caution. Theoretically, our work extends established insights from research on human judgment and decision-making to artificial evaluators. We show that mechanisms long studied in human cognition, such as the use of heuristics and informational cues, also shape LLM evaluations. While these mechanisms can improve evaluations, they can simultaneously introduce systematic biases, including herding behavior and anchoring effects. Practically, our results offer guidance for the use of LLMs in entrepreneurial contexts. Entrepreneurs, for example, may use LLMs to simulate investor feedback and iteratively refine pitch materials before engaging with actual funders. At the same time, our findings underscore important limitations. LLMs often rely on recall rather than inference, and their evaluations are sensitive to contextual framing and prior exposure. As a result, LLM outputs should be viewed as complementary inputs to human judgment rather than as substitutes for expert evaluation.
Supplemental Material
sj-docx-1-etp-10.1177_10422587261430320 – Supplemental material for Startup Evaluations with Generative Artificial Intelligence: An Exploratory Study on Early-Stage Investments and Survival Predictions by Large Language Models
Supplemental material, sj-docx-1-etp-10.1177_10422587261430320 for Startup Evaluations with Generative Artificial Intelligence: An Exploratory Study on Early-Stage Investments and Survival Predictions by Large Language Models by Simon Kleinert and Diemo Urbig in Entrepreneurship Theory and Practice
Footnotes
Appendix A
Investment Evaluations Across LLMs, Human Investors, and Information Cues by Fundraising Success.
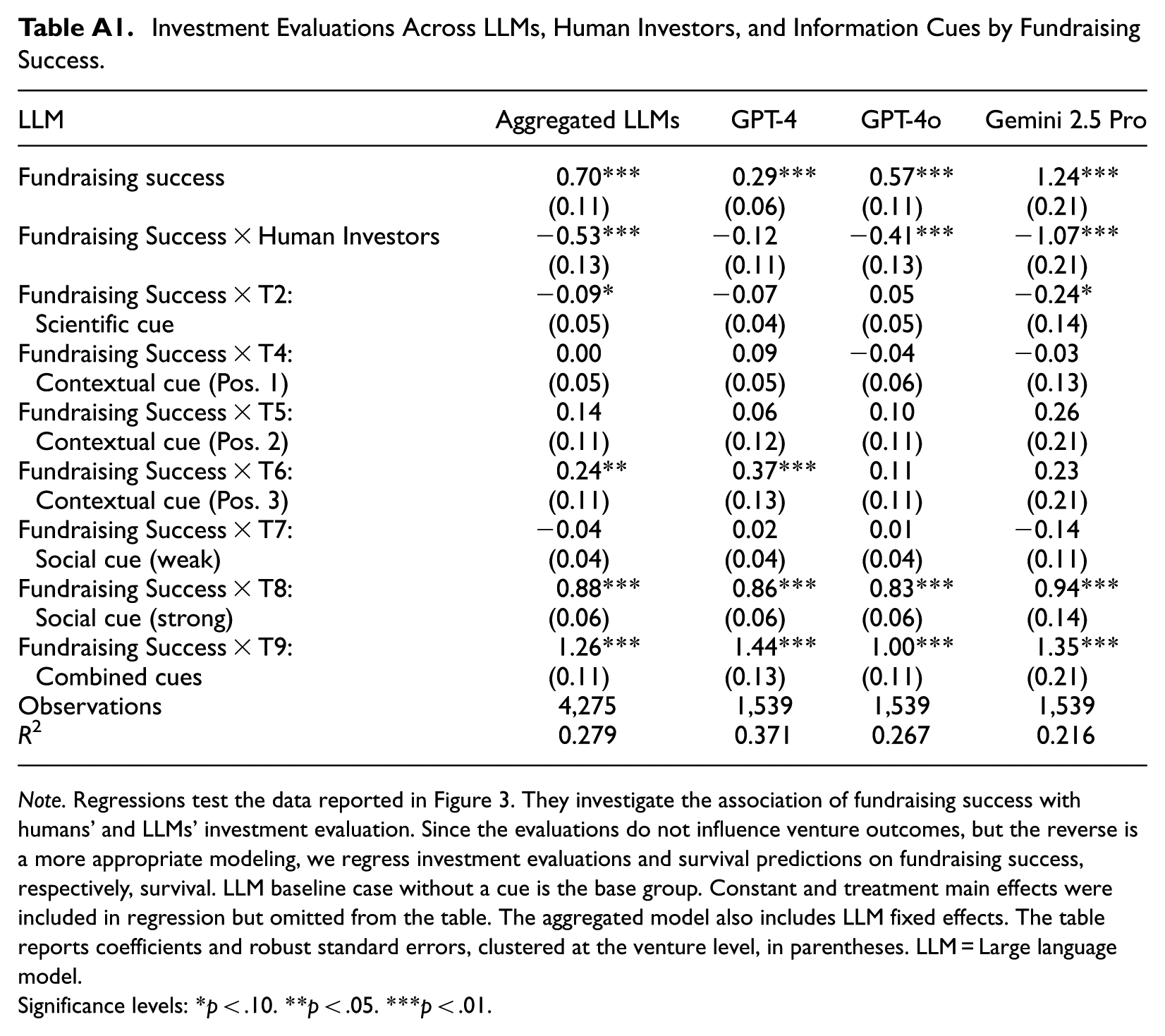
| LLM | Aggregated LLMs | GPT-4 | GPT-4o | Gemini 2.5 Pro |
|---|---|---|---|---|
| Fundraising success | 0.70*** (0.11) | 0.29*** (0.06) | 0.57*** (0.11) | 1.24*** (0.21) |
| Fundraising Success × Human Investors | −0.53*** (0.13) | −0.12 (0.11) | −0.41*** (0.13) | −1.07*** (0.21) |
| Fundraising Success × T2: Scientific cue | −0.09* (0.05) | −0.07 (0.04) | 0.05 (0.05) | −0.24* (0.14) |
| Fundraising Success × T4: Contextual cue (Pos. 1) | 0.00 (0.05) | 0.09 (0.05) | −0.04 (0.06) | −0.03 (0.13) |
| Fundraising Success × T5: Contextual cue (Pos. 2) | 0.14 (0.11) | 0.06 (0.12) | 0.10 (0.11) | 0.26 (0.21) |
| Fundraising Success × T6: Contextual cue (Pos. 3) | 0.24** (0.11) | 0.37*** (0.13) | 0.11 (0.11) | 0.23 (0.21) |
| Fundraising Success × T7: Social cue (weak) | −0.04 (0.04) | 0.02 (0.04) | 0.01 (0.04) | −0.14 (0.11) |
| Fundraising Success × T8: Social cue (strong) | 0.88*** (0.06) | 0.86*** (0.06) | 0.83*** (0.06) | 0.94*** (0.14) |
| Fundraising Success × T9: Combined cues | 1.26*** (0.11) | 1.44*** (0.13) | 1.00*** (0.11) | 1.35*** (0.21) |
| Observations | 4,275 | 1,539 | 1,539 | 1,539 |
| R 2 | 0.279 | 0.371 | 0.267 | 0.216 |
Note. Regressions test the data reported in Figure 3. They investigate the association of fundraising success with humans’ and LLMs’ investment evaluation. Since the evaluations do not influence venture outcomes, but the reverse is a more appropriate modeling, we regress investment evaluations and survival predictions on fundraising success, respectively, survival. LLM baseline case without a cue is the base group. Constant and treatment main effects were included in regression but omitted from the table. The aggregated model also includes LLM fixed effects. The table reports coefficients and robust standard errors, clustered at the venture level, in parentheses. LLM = Large language model.
Significance levels: *p < .10. **p < .05. ***p < .01.
Appendix B
Survival Prediction Across LLMs, Human Investors, and Information Cues by Survival.
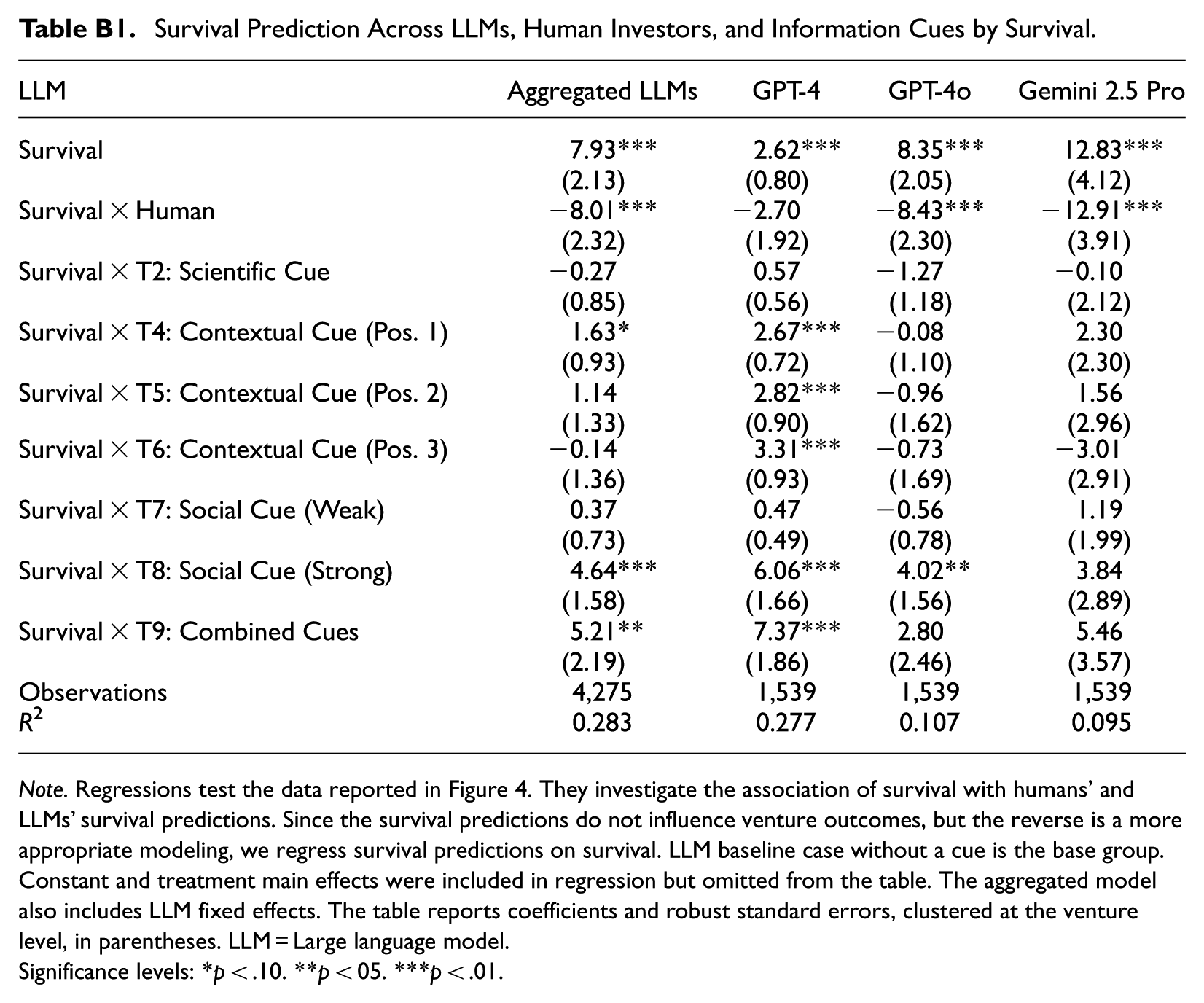
| LLM | Aggregated LLMs | GPT-4 | GPT-4o | Gemini 2.5 Pro |
|---|---|---|---|---|
| Survival | 7.93*** (2.13) | 2.62*** (0.80) | 8.35*** (2.05) | 12.83*** (4.12) |
| Survival × Human | −8.01*** (2.32) | −2.70 (1.92) | −8.43*** (2.30) | −12.91*** (3.91) |
| Survival × T2: Scientific Cue | −0.27 (0.85) | 0.57 (0.56) | −1.27 (1.18) | −0.10 (2.12) |
| Survival × T4: Contextual Cue (Pos. 1) | 1.63* (0.93) | 2.67*** (0.72) | −0.08 (1.10) | 2.30 (2.30) |
| Survival × T5: Contextual Cue (Pos. 2) | 1.14 (1.33) | 2.82*** (0.90) | −0.96 (1.62) | 1.56 (2.96) |
| Survival × T6: Contextual Cue (Pos. 3) | −0.14 (1.36) | 3.31*** (0.93) | −0.73 (1.69) | −3.01 (2.91) |
| Survival × T7: Social Cue (Weak) | 0.37 (0.73) | 0.47 (0.49) | −0.56 (0.78) | 1.19 (1.99) |
| Survival × T8: Social Cue (Strong) | 4.64*** (1.58) | 6.06*** (1.66) | 4.02** (1.56) | 3.84 (2.89) |
| Survival × T9: Combined Cues | 5.21** (2.19) | 7.37*** (1.86) | 2.80 (2.46) | 5.46 (3.57) |
| Observations | 4,275 | 1,539 | 1,539 | 1,539 |
| R 2 | 0.283 | 0.277 | 0.107 | 0.095 |
Note. Regressions test the data reported in Figure 4. They investigate the association of survival with humans’ and LLMs’ survival predictions. Since the survival predictions do not influence venture outcomes, but the reverse is a more appropriate modeling, we regress survival predictions on survival. LLM baseline case without a cue is the base group. Constant and treatment main effects were included in regression but omitted from the table. The aggregated model also includes LLM fixed effects. The table reports coefficients and robust standard errors, clustered at the venture level, in parentheses. LLM = Large language model.
Significance levels: *p < .10. **p < 05. ***p < .01.
Appendix C
Additional Tests on LLMs Prompted to Consider and Ignore Market Dynamics and Anonymized Venture Descriptions.
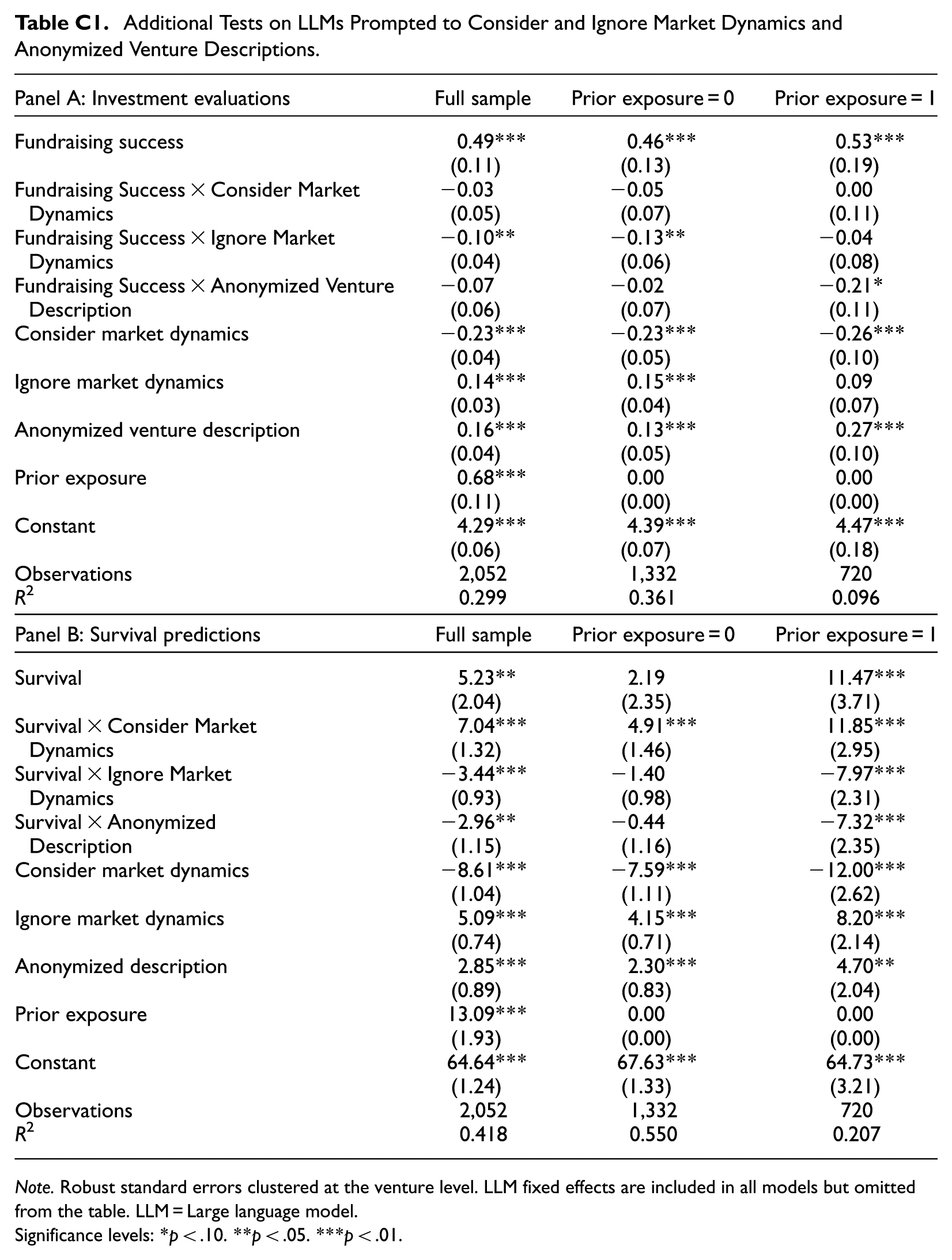
| Panel A: Investment evaluations | Full sample | Prior exposure = 0 | Prior exposure = 1 |
|---|---|---|---|
| Fundraising success | 0.49*** (0.11) | 0.46*** (0.13) | 0.53*** (0.19) |
| Fundraising Success × Consider Market Dynamics | −0.03 (0.05) | −0.05 (0.07) | 0.00 (0.11) |
| Fundraising Success × Ignore Market Dynamics | −0.10** (0.04) | −0.13** (0.06) | −0.04 (0.08) |
| Fundraising Success × Anonymized Venture Description | −0.07 (0.06) | −0.02 (0.07) | −0.21* (0.11) |
| Consider market dynamics | −0.23*** (0.04) | −0.23*** (0.05) | −0.26*** (0.10) |
| Ignore market dynamics | 0.14*** (0.03) | 0.15*** (0.04) | 0.09 (0.07) |
| Anonymized venture description | 0.16*** (0.04) | 0.13*** (0.05) | 0.27*** (0.10) |
| Prior exposure | 0.68*** (0.11) | 0.00 (0.00) | 0.00 (0.00) |
| Constant | 4.29*** (0.06) | 4.39*** (0.07) | 4.47*** (0.18) |
| Observations | 2,052 | 1,332 | 720 |
| R 2 | 0.299 | 0.361 | 0.096 |
| Panel B: Survival predictions | Full sample | Prior exposure = 0 | Prior exposure = 1 |
| Survival | 5.23** (2.04) | 2.19 (2.35) | 11.47*** (3.71) |
| Survival × Consider Market Dynamics | 7.04*** (1.32) | 4.91*** (1.46) | 11.85*** (2.95) |
| Survival × Ignore Market Dynamics | −3.44*** (0.93) | −1.40 (0.98) | −7.97*** (2.31) |
| Survival × Anonymized Description | −2.96** (1.15) | −0.44 (1.16) | −7.32*** (2.35) |
| Consider market dynamics | −8.61*** (1.04) | −7.59*** (1.11) | −12.00*** (2.62) |
| Ignore market dynamics | 5.09*** (0.74) | 4.15*** (0.71) | 8.20*** (2.14) |
| Anonymized description | 2.85*** (0.89) | 2.30*** (0.83) | 4.70** (2.04) |
| Prior exposure | 13.09*** (1.93) | 0.00 (0.00) | 0.00 (0.00) |
| Constant | 64.64*** (1.24) | 67.63*** (1.33) | 64.73*** (3.21) |
| Observations | 2,052 | 1,332 | 720 |
| R 2 | 0.418 | 0.550 | 0.207 |
Note. Robust standard errors clustered at the venture level. LLM fixed effects are included in all models but omitted from the table. LLM = Large language model.
Significance levels: *p < .10. **p < .05. ***p < .01.
Acknowledgements
We are very grateful to the editor and the anonymous reviewers for their developmental feedback. We also thank participants at Maastricht University, Tilburg University, the University of Bergamo, the 2025 Academy of Management Annual Meeting, and the 2025 G-Forum Conference for their valuable feedback.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.