
Abstract
Music is increasingly used as a cue for autobiographical memories in psychological research and clinical interventions. Despite the burgeoning body of evidence on the phenomenology of music-evoked autobiographical memories (MEAMs), few previous studies have focused in detail on how the capacities and experiences of individual listeners impact features of MEAMs. The present work examined the relationship of individual differences in visual and auditory imagery, musical familiarity and engagement, musical reward sensitivity, musical training, and gender to MEAM features. Participants (N = 304, ages 18–25 years, 156 female) completed a self-selected MEAM task, in which they described an autobiographical memory they often associate with a piece of music of their choice, and a cued MEAM task, in which they described and rated autobiographical memories evoked by 16 chart-topping pop songs, alongside a series of questionnaires assessing individual differences in mental imagery and musical behaviors. In the cued MEAM task, memories elicited by more familiar songs were more frequent, more vivid, and more positive, whilst general engagement with pop music also positively impacted the vividness and emotionality of these memories. The amount of visual imagery within MEAMs was positively related to individual capacities to generate vivid visual and auditory imagery, and higher scores in musical reward sensitivity were associated with greater emotional intensity of MEAMs. Formal musical training did not predict any MEAM features. Results are discussed in relation to how such findings can maximize the efficacy and rigor of experiments and interventions that use music as an autobiographical memory cue.
Keywords
Music-evoked autobiographical memory, the experience whereby listening to music brings back memories of people, places, and events from one’s life, is a topic of increasing empirical interest (Belfi & Jakubowski, 2021). Previous studies have sought to characterize music-evoked autobiographical memories (MEAMs), revealing, for instance, that MEAMs are common everyday experiences that often occur involuntarily and evoke primarily positive emotions (Jakubowski & Ghosh, 2021; Janata et al., 2007). Another strand of research has focused on comparing the quantity and qualities of autobiographical memories evoked by music versus other retrieval cues, such as photographs, words, food, or environmental sounds (Belfi et al., 2016; Jakubowski & Eerola, 2022; Jakubowski et al., 2021, 2023; Zator & Katz, 2017). Such work has demonstrated that music may be particularly effective in evoking vivid and positive lifetime memories (Belfi et al., 2016; Jakubowski & Eerola, 2022; Jakubowski et al., 2021). Several studies have probed the musical reminiscence bump, revealing that songs that were released or frequently listened to during adolescence are typically the most effective music for cueing autobiographical memories (Jakubowski et al., 2020; Platz et al., 2015; Rathbone et al., 2017; Schulkind et al., 1999). Finally, a body of research on MEAMs in clinical populations has found evidence of preservation of MEAMs in some conditions such as early-stage Alzheimer’s disease (Baird et al., 2018; El Haj et al., 2012), although MEAMs may be impaired in other populations, such as patients with medial prefrontal cortex damage (Belfi et al., 2018).
Despite the accumulating evidence on the experience of MEAMs and their relationship to other autobiographical memories, few studies have systematically probed how MEAMs vary across healthy individuals. The handful of studies that have considered individual differences in MEAMs have limited their focus to age and/or gender comparisons. These studies have shown that, on the whole, age and gender differences that are found in other autobiographical memory experiences, such as the age-related shift in positivity of memories (Mather & Carstensen, 2005; Reed et al., 2014), are replicated in MEAMs (Belfi et al., 2016; Cady et al., 2008; Cuddy et al., 2017; Ford et al., 2016; Jakubowski et al., 2021, 2023; Jakubowski & Ghosh, 2021; Mehl et al., 2024). However, other individual differences that may impact MEAM experiences remain largely unexamined. Understanding how different people vary in the degree to which music elicits autobiographical memories, and how the qualities of such memories vary, is important for several reasons. For example, such research can inform therapeutic work aiming to provoke autobiographical recollections via music, by providing an indicator as to whether some individuals might be more responsive to such interventions than others. In addition, individual differences that affect MEAM qualities should be controlled for within studies that utilize between-group designs (e.g., Cady et al., 2008; Zator & Katz, 2017), to ensure the results of such studies cannot simply be explained by preexisting differences between the participant groups.
In the present work we investigated several individual cognitive and behavioral traits we expected could impact the quantity and qualities of MEAM experiences. First, we investigated the relationship between visual and auditory imagery and MEAM experiences, given the significant relationship that has been found between mental imagery capacities and autobiographical memories cued by other stimuli (e.g., Rubin et al., 2003). Second, we investigated the potential role of music-specific behaviors, including formal training in music, music listening behaviors, and musical reward sensitivity. Below, we provide a brief overview of relevant literature in each of these two areas.
Mental imagery and autobiographical memories
Several previous studies have shown that qualities of autobiographical memories evoked by non-musical cues (most commonly, word cues) are positively related to mental imagery abilities. The majority of such research has focused on visual imagery (Palombo et al., 2018), and has shown that the extent to which one is able to generate a vivid visual image of a scene is a strong significant predictor of the degree of reliving attributed to an autobiographical memory experience (Rubin, 2005; Rubin et al., 2003). Damage to visual imagery-related brain areas also impairs episodic memory recall (Greenberg et al., 2005; Greenberg & Rubin, 2003), while sustained visual imagery training can lead to enhancements in the retrieval of episodically detailed autobiographical memories (Ernst et al., 2013). Individuals with a greater capacity to generate vivid visual imagery, as assessed by the Vividness of Visual Imagery Questionnaire (VVIQ) (Marks, 1973), have been found to generate more detailed autobiographical memories (D’Argembeau & van der Linden, 2006; Vannucci et al., 2016) as well as more detailed imagined future events (D’Argembeau & van der Linden, 2006).
Previous studies have also revealed a positive relationship between auditory imagery and the degree of reliving within autobiographical memory experiences, although such correlations are typically smaller in magnitude than the correlation between visual imagery and autobiographical reliving (Rubin, 2005; Rubin et al., 2003). Here, we also consider individual differences in the vividness of auditory imagery, given that MEAMs often inherently contain auditory imagery (i.e., the reliving of a previous experience of hearing a particular song). We therefore anticipated that both the capacity for vivid visual imagery and the capacity for vivid auditory imagery would predict MEAM vividness.
Potential impacts of musical behaviors on MEAMs
Musical training has been linked to enhancements in auditory processing (e.g., Barrett et al., 2013; Kraus & Chandrasekaran, 2010), and a recent meta-analysis revealed that musicians perform better on a range of memory tasks than non-musicians (Talamini et al., 2017). One previous study found no significant correlation between musical training (as measured via the Musical Training subscale of the Goldsmiths Musical Sophistication Index; Müllensiefen et al., 2014) and the frequency, emotionality, or involuntary nature of MEAMs, although the correlation with MEAM vividness was close to statistical significance, r(29) = .34, p = .058, (Jakubowski & Ghosh, 2021). However, this study had a relatively small sample size (N = 31) and did not recruit participants specifically based on their musical experience, thus further research in this area is warranted.
There are several reasons to suppose individual differences in musical training might impact MEAM experiences. Music may be a more effective autobiographical memory cue for musically trained individuals due to their enhanced ability to remember particular pieces of music, or the wider range of music to which they may have been exposed (Groussard et al., 2010). In addition, the content of MEAMs may vary between more versus less musically trained individuals. For example, many musicians may experience MEAMs involving performing music, which may invoke fewer peripheral details (due to the intense focus required during music performance) or more negatively valenced emotions (due to the stress and anxiety that often accompany performance situations; Kenny, 2011) than MEAMs of non-performance situations.
Beyond formal training, other musical behaviors may influence the MEAM experience. Frequent music listening may increase the range of autobiographical events that are associated with music, thereby increasing the potential for MEAM experiences. However, very frequent listening to the same piece of music could decrease its cue-item discriminability, such that it becomes associated with many different events and is therefore no longer an effective cue for one particular event (Berntsen et al., 2013; Rubin, 1995). In addition to considering overall music listening frequency, it is also important to consider individual musical preferences and habits, as it may be less likely, for instance, that a completely unfamiliar genre of music is strongly associated to autobiographical memories (Jakubowski & Francini, 2023).
Finally, individuals differ in how they respond to music. For instance, consistent variations in emotional responsivity to music can be found across individuals (Müllensiefen et al., 2014; Vuoskoski & Eerola, 2011). Such differences may have an impact on MEAM experiences, such that greater emotional responses to the music itself may facilitate the recall of more emotional memories (Holland & Kensinger, 2010). Individual differences in the use of music as a social surrogate (temporary substitute for social interaction) might also impact the degree to which music evokes autobiographical memories of other people (Schäfer & Eerola, 2018). These and other components of how people respond to music have been considered within the framework of musical reward sensitivity. One of the most common measures in this domain, the Barcelona Music Reward Questionnaire (BMRQ) (Mas-Herrero et al., 2013), captures individual differences in five facets of musical reward behaviors (Musical Seeking, Emotion Evocation, Mood Regulation, Social Reward, and Sensory-Motor). Research using the BMRQ has shown that individuals who experience greater reward in response to music also perform better in memory tests for newly learned music and word lists encoded in a highly pleasant musical context (Ferreri & Rodriguez-Fornells, 2022). Thus, musical reward sensitivity is linked not only to musical memory, but also episodic memories associated with music.
The present study
The aims of the present study were to investigate how individual mental imagery capacities and musical behaviors are associated with the frequency and qualities of MEAM experiences. Two MEAM tasks were used. The first asked participants to think of a song/piece of music they often associated with an autobiographical memory and describe the memory in detail (hereafter self-selected MEAM task). The second used 16 chart-topping pop songs from 2014 to 2021 as cues for autobiographical memories (hereafter cued MEAM task). To control for other differences between individuals, we constrained our sampling to participants aged 18–25 years, who were both born in and currently residing in the United Kingdom. This also enabled us to maximize the potential familiarity of our pop music stimuli. Gender was included as a control variable in our analyses, given some previous gender differences found in MEAMs (Belfi et al., 2016; Jakubowski et al., 2021).
We predicted that the vividness and visual imagery within MEAMs would be positively associated with individual differences in vividness of visual and auditory imagery, given related findings on other autobiographical memories (e.g., Rubin et al., 2003). We also predicted that musical training, musical engagement, and musical reward sensitivity would be positively related to various features of MEAMs (e.g., frequency, vividness, emotionality), although we did not make strong predictions about which features would be implicated, given the lack of previous research in this area. This study represents a novel and essential step in understanding the potential behaviors and component processes that underpin the relationship between music and memories from across our lives.
Method
Participants
In total, 330 participants completed the study, who were recruited online via Prolific. We excluded 17 participants who failed the attention check, three who experienced technical difficulties with sound playback, and six who fell outside the desired age range. This left 304 participants for our main analyses, aged 18–25 years (M = 22.29, SD = 2.15; 156 female, 135 male, 11 other, two preferred not to respond to the gender question). All were of UK nationality, who were both born in and currently living in the United Kingdom. In terms of educational background, 24% had attained a high school or A-Level certificate as their highest qualification, 56% were currently pursuing or had completed an undergraduate degree, and 19% were currently pursuing or had completed a postgraduate degree. Five participants (1.6%) reported mild hearing impairments that did not currently require any corrective measures, and nine (3.0%) reported mild visual impairments (seven were wearing glasses, one had partial blindness in one eye, one had anisometropia). To ensure a good spread of musical training scores, around half of the sample were recruited in relation to having answered “Yes” to the Prolific screening question on “Experience with musical instruments” with at least two years of musical training reported. All participants received £4.50 for completing the study.
Materials/stimuli
MEAM tasks
All tasks were hosted on Qualtrics. Participants were given a definition of an autobiographical memory (“An autobiographical memory occurs when you remember personal experiences from your past. These memories may contain details about events, people, places, and time periods from your life”), and were asked to give an overall estimate of how often music evokes autobiographical memories for them (see Appendix 1). They then completed the self-selected MEAM task. In this task, they were asked to think of a specific song/piece of music that they often associate with an autobiographical memory. Once they had a song/piece in mind, they were asked to record the name and performer of the song/piece and then provide a detailed written description of the memory associated with the music (see Appendix 1 for exact wording).
The cued MEAM task used 16 pop songs from 2014 to 2021. Specifically, the top two songs from the UK year-end charts for each year were selected (see Appendix 2 for song list). Song clips of 20 s each were created, which contained the chorus or other highly recognizable parts of the song (following Belfi et al., 2016). Participants were presented with all 16 clips in this task and were asked to use each clip as a cue to think of an autobiographical memory. If a memory came to mind during a clip, they were asked to press a button reading “I have recalled a memory” as soon as the memory came to mind. If no memory came to mind during the 20-s clip they were asked simply to refrain from pressing the button, and the experiment automatically advanced to the next question at the end of the song clip. For clips that did trigger autobiographical memories, they were asked to rate, on 7-point scales, the vividness, visual imagery, emotional valence, emotional intensity, and importance of the memory. These questions were derived from the Autobiographical Recollection Test (ART) (Berntsen et al., 2019; Gehrt et al., 2022) (see Appendix 1 for wording). They were also asked to provide a short (one-sentence) written description of the memory. Regardless of whether the music evoked a memory, they were asked to rate the familiarity of each music clip (on a 5-point scale). A practice trial (using the top-ranked chart song from 2013, “Blurred Lines”) was presented before the main task to familiarize participants with the procedure.
The use of two MEAM tasks afforded several advantages. The self-selected MEAM task was relatively unconstrained, and thereby allowed us to examine MEAM experiences across genres and tailored to each participant’s individual experiences and preferences. In contrast, the cued MEAM task focused on pop songs and followed closely from the protocols used in several previous MEAM studies (Belfi et al., 2022; Belfi et al., 2016; Janata et al., 2007; Zator & Katz, 2017), facilitating comparisons with existing literature and allowing for the examination of MEAMs elicited by the same cues across all participants.
Questionnaires
The 16-item Vividness of Visual Imagery Questionnaire (VVIQ) (Marks, 1973) and 14-item Vividness subscale of the Bucknell Auditory Imagery Scale (BAIS-V) (Halpern, 2015) were used to measure individual differences in the vividness of visual imagery and auditory imagery, respectively. Both questionnaires require a participant to conjure up mental images of scenes/sounds, respectively, and rate the degree to which those mental scenes/sounds replicate the vividness of a perceptual experience. Formal training in music was measured with the 7-item Musical Training subscale of the Goldsmiths Musical Sophistication Index (Gold-MSI-MT) (Müllensiefen et al., 2014), which probes such factors as years of practice and lessons on an instrument/voice, music theory training, and self-assessed musicianship. Musical reward sensitivity was measured via the 20-item Barcelona Music Reward Questionnaire (BMRQ) (Mas-Herrero et al., 2013), which includes five subscales (Musical Seeking, Emotion Evocation, Mood Regulation, Social Reward, and Sensory-Motor). We also included questions on participants’ frequency of (both deliberate and incidental) engagement with and preferences for pop music from the charts, given that this was the style of music utilized in our cued MEAM task; these three questions are listed in Appendix 1.
Procedure
After giving informed consent, participants completed basic (non-music) demographic questions (e.g., age, gender). They then completed the self-selected MEAM task. Next, a sound check was administered, during which participants were asked to adjust their device to a comfortable volume. This was followed by the cued MEAM task, which commenced with a practice trial, followed by the 16 pop music cues presented in a randomized order across participants. Participants then completed the two imagery questionnaires (VVIQ and BAIS-V) in a counterbalanced order, followed by the music questionnaires (Gold-MSI-MT, BMRQ, pop music listening and liking) in a counterbalanced order. The questionnaires were always administered at the end of the study to avoid any carry-over effects on the MEAM tasks (e.g., participants who responded that they had low musical training or imagery vividness feeling they should perform less well on the MEAM tasks).
Analysis
In the cued MEAM task, we excluded three cases of MEAM reports for which participants wrote that they had accidentally clicked the button when they did not have a MEAM, and one case where a memory was forgotten during the task. This left 2,145 total MEAMs reported in the cued MEAM task. All 304 participants were able to generate a self-selected MEAM.
MEAM descriptions from both the cued and self-selected MEAM tasks were coded following the procedures of the Autobiographical Interview (AI; Levine et al., 2002). Briefly, each memory was segmented into details (single pieces of information) that were coded as either internal or external. Internal details pertain to the central memory and reflect episodic reexperiencing, and include details about the event (e.g., actions, happenings), time (e.g., year, season, day), place (e.g., city, building, room), perceptions (e.g., auditory, tactile, visual details), and thoughts or emotions (e.g., emotional states). External details do not directly pertain to the memory and primarily reflect semantic content (e.g., general knowledge or facts), but also can include external events (e.g., details from other unrelated incidents), repetitions (e.g., repeating details already stated), or metacognitive statements. To maintain consistency in scoring, memory descriptions were coded by a single trained rater who was blind to the nature of the research question. After coding each detail, internal and external composite scores were created by counting the total number of internal and external details for each memory. The internal and external composite scores were then used to calculate a ratio of internal/total details. This ratio provides a measure of episodic detail that is unbiased by the total number of details (Levine et al., 2002). We included both the composite internal and external scores, as well as the ratio of internal/total details, in our subsequent statistical analyses (Belfi et al., 2016, 2022).
For the self-selected MEAM descriptions we also performed an automated sentiment analysis using the Bing sentiment lexicon as implemented in the R package syuzhet (Jockers, 2015). For each MEAM description, each word was classified as positive, negative, or neither. Each positive word received a score of +1 and each negative word received a score of –1; these scores were then summed and divided by the total number of words in each MEAM description, to control for the varying lengths of the descriptions. Thus, each description could attain a total sentiment score ranging from –1 to +1. This method of automatically classifying the sentiment or other psychological properties of a text on a word-level basis has revealed a range of useful insights in previous autobiographical memory studies about the emotionality or cognitive processes underlying a memory experience (see overview in Belfi et al., 2020).
For the cued MEAM task, mean ratings and mean AI scores were computed across all MEAMs reported by a participant (e.g., the MEAM vividness score for a participant was the mean vividness rating across all MEAMs they reported for the cued MEAM task). Questionnaire responses (VVIQ, BAIS-V, Gold-MSI-MT, BMRQ) were reverse scored and summed where relevant, following published guidelines, to obtain a single score for each participant for each subscale.
The relationships of all variables of interest were first explored via correlations. Pearson’s correlations were run for all variable pairings except those including gender; gender was coded dichotomously (male/female) and thus point-biserial correlations were run for pairings involving this variable. A series of conditional inference tree models were then run with each of the cued and self-selected MEAM features as dependent variables. Conditional inference trees are non-parametric, recursive binary partitioning models that can flexibly handle a large number of predictors, both categorical and continuous, and do not need to meet the distributional assumptions of parametric methods such as linear regression. The recursive splitting method also provides information about the relative importance of significant predictors; the root node (at the top of the tree) is the most important significant predictor, with the next split down representing the next most important predictor and so on. Predictors included in the analysis that are not selected in the final tree are considered unimportant predictors (Hothorn et al., 2006).
We included VVIQ, BAIS-V, BMRQ (total), Gold-MSI-MT scores, and gender as predictor variables in all tree models. For the models predicting cued MEAM task variables we also included pop music engagement (computed as a mean score across the ratings of deliberate pop music listening, incidental pop music listening, and pop music liking) and mean song familiarity (mean familiarity ratings with the songs used in the cued MEAM task) as predictors. We fitted nine separate tree models for the cued MEAM task dependent variables. As such, we adopted a conservative, Bonferroni-corrected critical p value of .05/9 = .0056; predictors in the tree models were only considered statistically significant if p < .0056. For the self-selected MEAM task we fitted four models and thus used a Bonferroni-corrected statistical significance criterion of p < .0125. All analyses were conducted in RStudio (version 2022.02.0), conditional inference trees were fitted using the partykit package (Hothorn & Zeileis, 2015; Zeileis et al., 2008), and significance tests for the tree models were conducted using the strucchange package (Zeileis et al., 2002); for a similar application of these methods to a music psychological data set see Kreutz and Cui (2022). Data are available on the Open Science Framework: https://osf.io/w7pkn/
Results
Cued MEAM task
On the cued MEAM task, 297 participants (97.7%) reported at least one MEAM and, on average, participants reported 7.06 MEAMs (SD = 3.64, range = 0–16). All 16 songs cued some MEAMs, with each song cueing MEAMs in 28% to 60% of participants. Written MEAM descriptions ranged from one to 98 words in length (M = 22.8, SD = 12.67). Descriptive statistics for the questionnaires used are reported in Table 1.
Descriptive statistics for the four questionnaires.

Figure 1 visualizes the correlations between all individual difference measures and cued MEAM features. The BMRQ subscales were moderately positively correlated with each other and also, unsurprisingly, correlated with the BMRQ total score (rs > .25). Vividness of visual and auditory imagery were also correlated (VVIQ and BAIS-V), r(302) = .55, p < .001. The various subjective features of the MEAMs (e.g., vividness, emotional intensity) were moderately positively correlated (rs > .27), but the frequency of MEAMs was not highly correlated with any of these subjective features of MEAMs (–.06 < rs < .14).
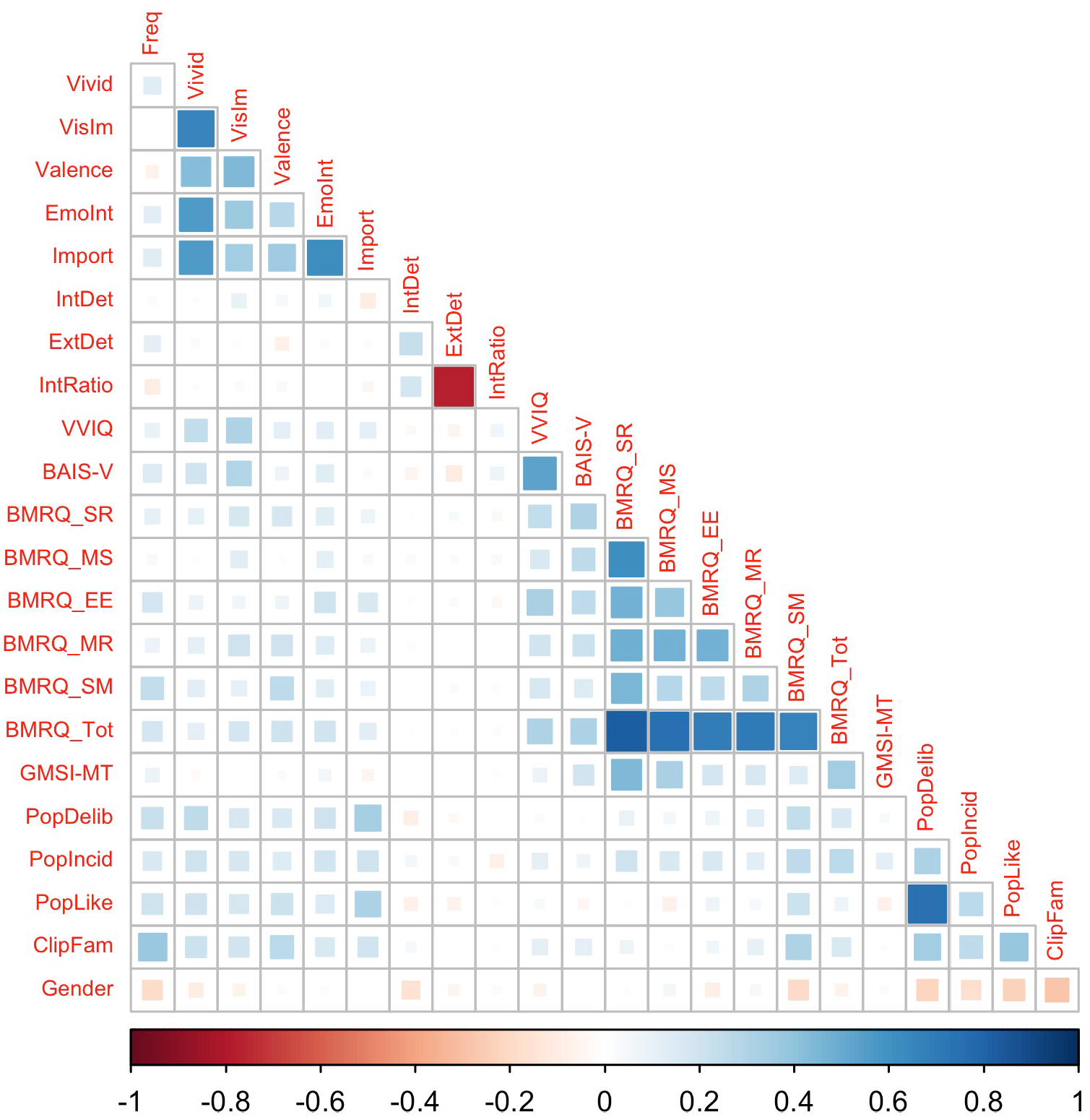
Correlations between cued MEAM task features and individual difference measures.
Of more direct relevance to the current study is the relationship of the individual difference measures and the cued MEAM features. Visual and auditory imagery vividness (VVIQ and BAIS-V) were most substantially correlated with MEAM vividness and strength of visual imagery in MEAMs (rs > .19). The BMRQ subscales were weakly to moderately positively correlated with several MEAM features; the strongest correlations between BMRQ total scores and MEAM features were with MEAM valence and MEAM emotional intensity (rs > .19). Musical training, as measured via the Gold-MSI subscale, was not substantially correlated with any of the MEAM features (–.06 < rs < .09). Rating of pop music listening frequency (both deliberate and incidental), pop music liking, and familiarity with the songs used in the study were correlated with each other, and also correlated weakly to moderately with MEAM frequency and subjective ratings of MEAM features (.14 < rs < .38). The highest correlation between gender and MEAM features was with MEAM frequency (r = –.19), indicating men reported fewer MEAMs, although this may potentially be explained by the negative correlations between gender and the four measures of pop music familiarity/engagement (rs < –.18). The three measures derived from the AI scoring of MEAM descriptions (internal details, external details, ratio of internal details to total details) were not substantially correlated with any of the individual difference measures (–.11 < rs < .08).
We then fitted nine conditional inference tree models, one for each of the cued MEAM task dependent variables. All tree models with more than one statistically significant predictor are presented as figures (to show the relationship of the different predictors) and described in the text below; those with one significant predictor or no significant predictors are described in the text only.
The conditional inference tree predicting MEAM frequency contained one significant predictor, which was the familiarity of the specific songs we used (p < .001); participants with mean ratings above 3.438 on the 5-point song familiarity rating scale (n = 230) reported more MEAMs than those with lower mean song familiarity ratings (n = 74). Figure 2 shows the tree model predicting MEAM vividness ratings. The most important predictor in this model, as denoted at the top of Figure 2, was pop music engagement (p < .001), with scores of 3.667 or less leading to less vivid MEAMs than higher pop music engagement scores. 1 For participants with pop music engagement scores above 3.667, the second node in the tree, familiarity ratings of the specific songs we used (p = .001), becomes a further significant differentiator of MEAM vividness, with higher song familiarity ratings (>4) predicting more vivid MEAMs. Thus, general engagement with the style of music used in this task is a key predictor of MEAM vividness; for those who engage to a certain degree with this music style, familiarity with the specific pop songs used then becomes a further positive predictor of MEAM vividness.
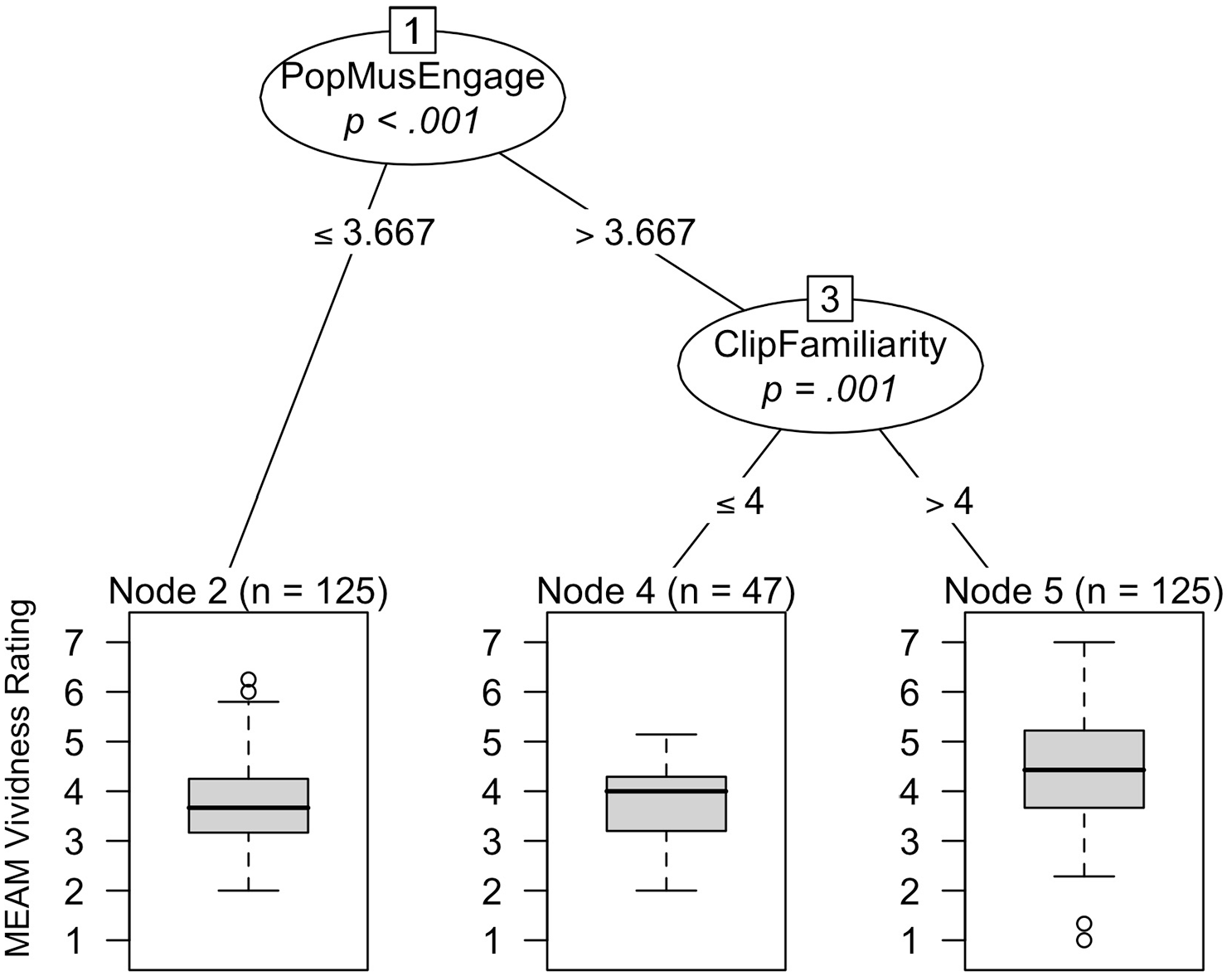
Conditional inference tree visualizing significant predictors of MEAM vividness ratings. Terminal (bottom) node boxplots show MEAM vividness values predicted by the preceding nodes. Pop music engagement scores can range from 1 to 6.33 and clip familiarity from 1 to 5.
Figure 3 shows the model predicting visual imagery ratings of MEAMs. VVIQ scores (p < .001) were the most important predictor in this model, with higher VVIQ scores predicting higher visual imagery ratings. For those with VVIQ scores above a certain threshold (>32), BAIS-V scores (p < .001), then become a significant predictor, with BAIS-V scores above 70 predicting higher visual imagery ratings. For those participants with BAIS-V scores of 70 or lower, there is further differentiation depending on their level of pop music engagement (p = .001), with pop music engagement scores of above 5 predicting more visual imagery in MEAMs.
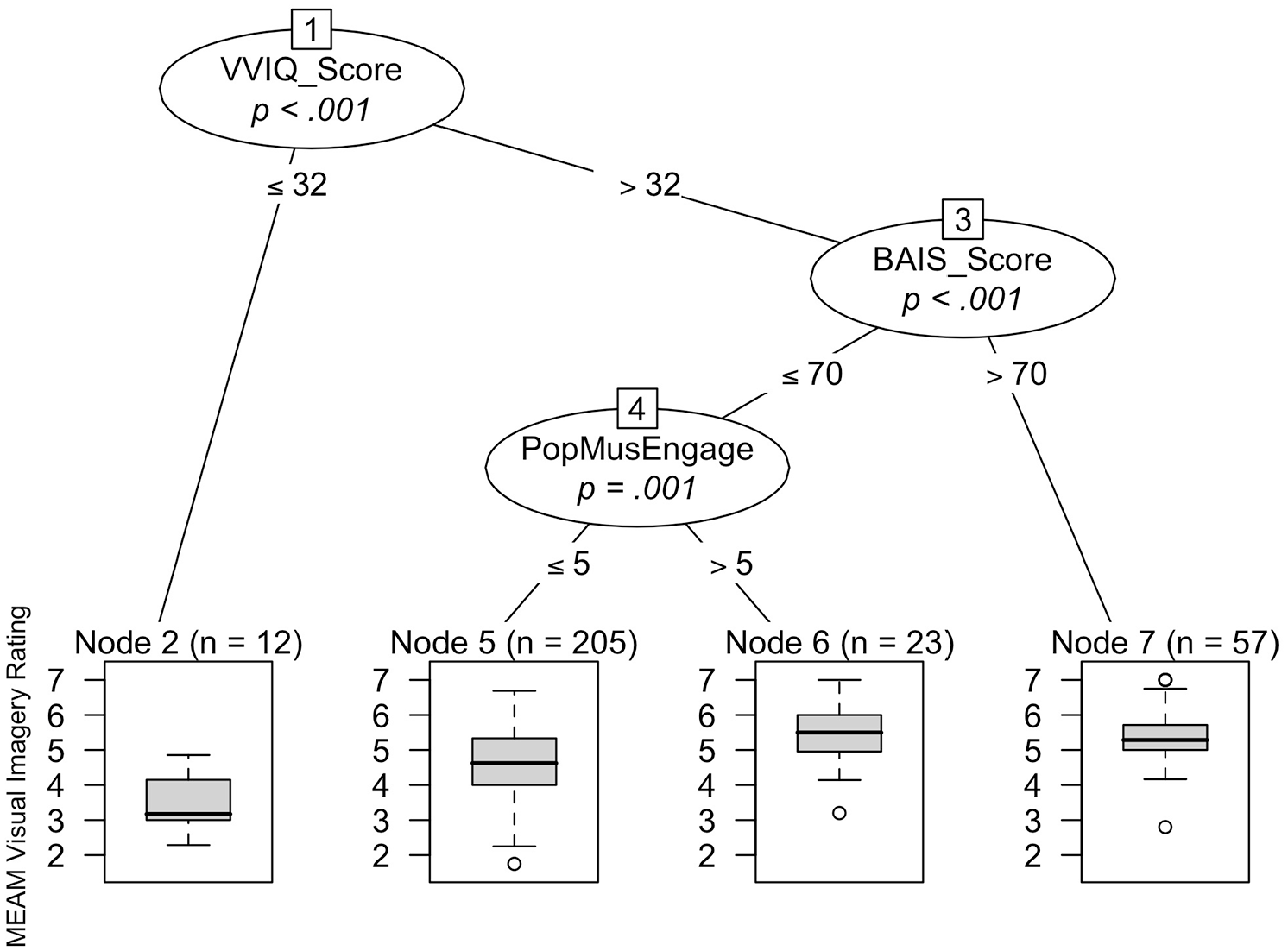
Conditional inference tree visualizing significant predictors of MEAM visual imagery ratings. Terminal node boxplots show MEAM visual imagery values predicted by the preceding nodes. VVIQ scores can range from 16 to 80, BAIS-V scores from 14 to 98, and pop music engagement scores from 1 to 6.33.
The only statistically significant predictor in the model predicting MEAM valence was mean song familiarity ratings (p < .001), with familiarity ratings above 4.188 on the 5-point scale (n = 154) predicting more positive MEAMs than familiarity ratings of 4.188 or less (n = 143). Higher pop music engagement scores (p = .002) were the most important predictor of greater emotional intensity of MEAMs. For those participants with pop music engagement scores above 2.667, higher BMRQ total scores (>78; p = .004) then predicted greater emotional intensity of MEAMs (see Figure 4).
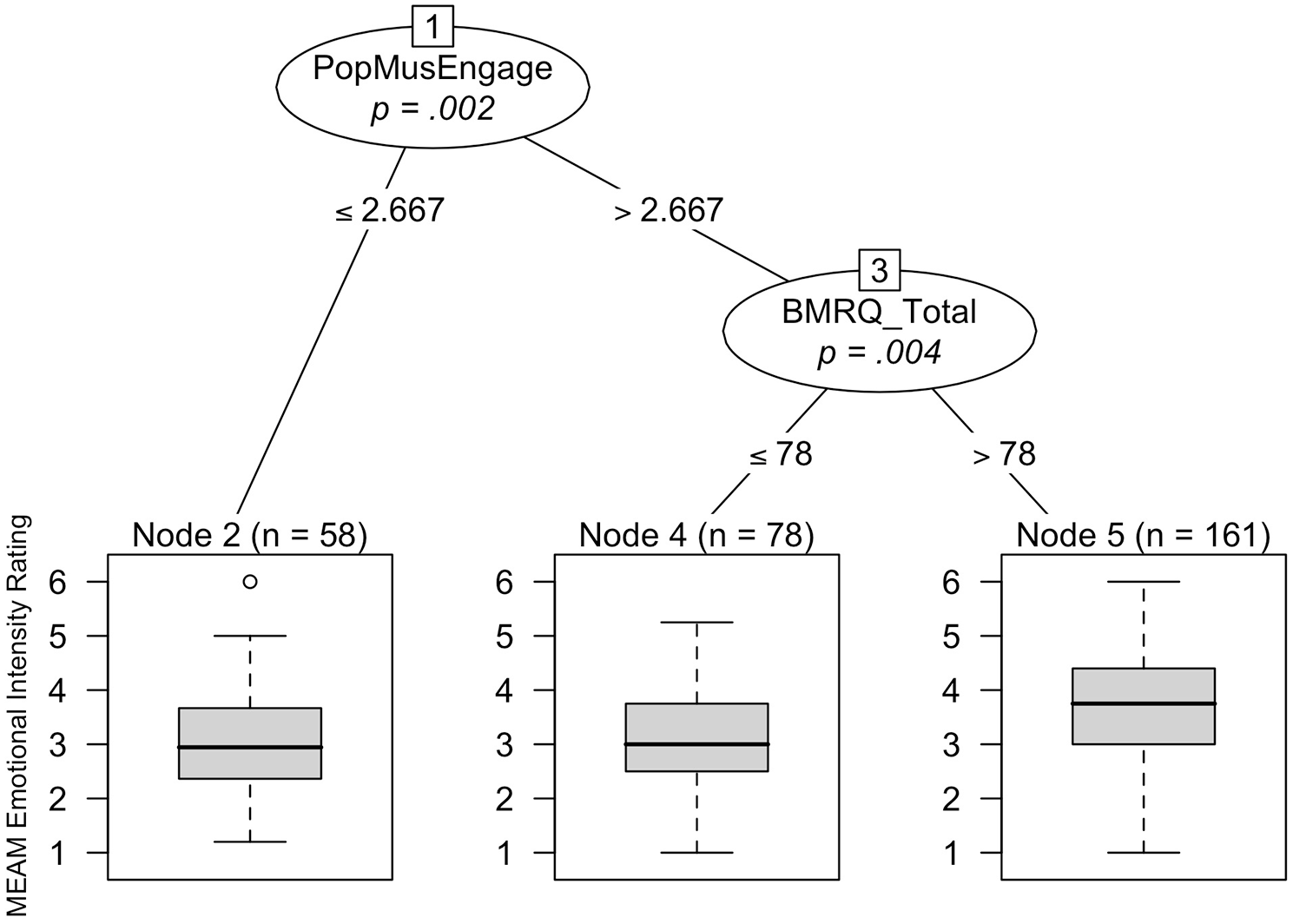
Conditional inference tree visualizing significant predictors of MEAM emotional intensity ratings. Terminal node boxplots show MEAM emotional intensity values predicted by the preceding nodes. Pop music engagement scores can range from 1 to 6.33 and BMRQ total scores from 20 to 100.
The only statistically significant predictor in the model predicting the importance of MEAMs to the participant’s life story was pop music engagement scores (p < .001), with pop music engagement scores above 3.667 (n = 172) predicting more important MEAMs than scores of 3.667 or lower (n = 125). No statistically significant predictors emerged for the analyses considering the MEAM description content (specifically, the mean number of internal details, mean number of external details, and mean ratio of internal to total details reported in the memory descriptions).
Self-selected MEAM task
A wide range of pieces of music were selected as cues of frequent MEAMs, primarily from pop, rap/hip-hop, classical, and film/musical genres. The most frequently reported performers of these selections were Beyoncé, Taylor Swift, George Ezra, Ed Sheeran, and Twenty One Pilots. Written MEAM descriptions in this task ranged from six to 143 words in length (M = 48.8, SD = 24.8).
Figure 5 shows the correlations between the individual difference measures and the four measures derived from the MEAM descriptions (number of internal details, number of external details, ratio of internal details to total details, sentiment score). In general, correlations of the individual difference measures with these MEAM features were low. The measures most substantially correlated with the number of internal details were some of the BMRQ scales (SR scale: r = .13, MS scale: r = .12) and the Gold-MSI (r = .15). The sentiment scores were most correlated with VVIQ scores (r = .11) and BMRQ-SM (r = .12). The number of external details and ratio of internal details to total details in the MEAM descriptions were not highly correlated with any of the individual difference measures (–.07 < rs <.07).
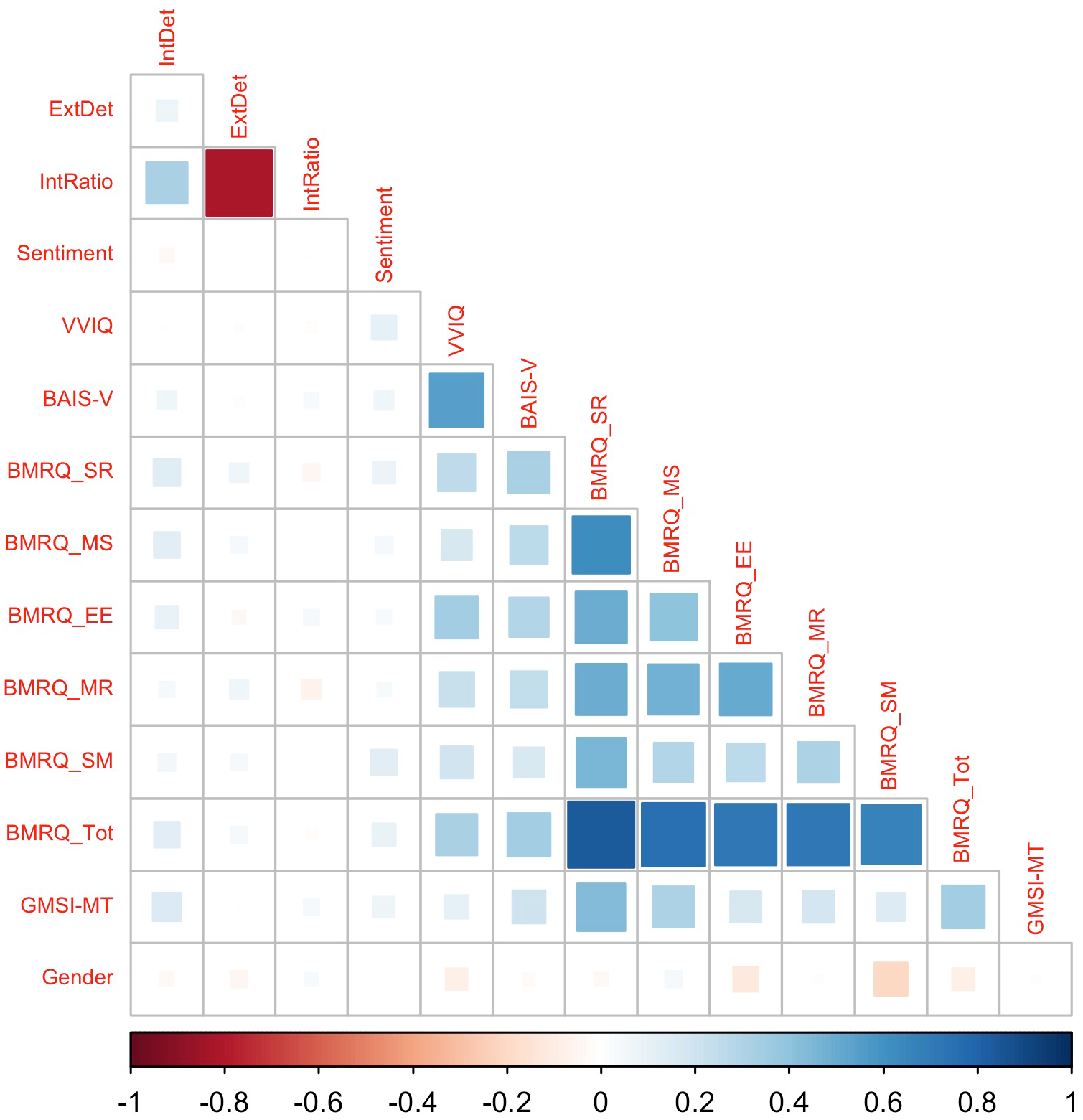
Correlations of self-selected MEAM task features and individual difference measures.
None of the four measures derived from the self-selected MEAM descriptions were significantly predicted by any of the individual difference measures in conditional inference tree models (all ps > .06).
Correlation between measures across MEAM tasks
There were some correlations between measures across the two MEAM tasks. In particular, the number of internal details in the self-selected MEAM task was moderately correlated with the mean number of internal details in the cued MEAM task, r(295) = .40, p < .001. The number of external details, r(295) = .16, p = .005, and the ratio of internal to total details, r(295) = .18, p = .002, measures showed smaller significant correlations across the two tasks.
Discussion
The present work examined the relationship of individual differences in mental imagery and musical behaviors with the frequency and qualities of autobiographical memories evoked by music. Results indicate that different features of MEAMs are differentially impacted by music-specific and domain-general capacities and experiences.
The frequency of MEAMs reported in the cued MEAM task was positively related to familiarity ratings for the specific pop songs we used. This parallels several previous studies that have found a positive relationship between song familiarity and MEAM occurrence (Jakubowski et al., 2020; Jakubowski & Francini, 2023; Janata et al., 2007). This result also highlights that individual familiarity with a song appears to be the primary determining factor in whether it evokes an autobiographical memory. Such results have implications for practical applications of music, for instance in clinical contexts, suggesting that music selection aimed at eliciting autobiographical recall should be personally tailored (El Haj et al., 2012; Jakubowski et al., 2020; Rao et al., 2021). But beyond this personalization, individuals do not seem to require particularly strong engagement with music via formal training or to be exceptionally sensitive to musical reward for music to be an effective cue for personal memories. Interestingly, MEAM frequency was not substantially related to the subjective features of MEAMs (e.g., vividness ratings) or the amount of detail contained within the memory descriptions, indicating that the propensity to experience MEAMs and the propensity to experience these in vivid and emotional detail are relatively independent.
The most important predictor of visual imagery within MEAMs (“While remembering the event, I can see it in my mind”) in the tree model was the capacity for vivid visual imagery, followed by the capacity for vivid auditory imagery. This aligns with findings from the general autobiographical memory literature that the ability to construct vivid mental visual and auditory images is related to more detailed reliving of autobiographical memories (Rubin, 2005; Rubin et al., 2003). This result also aligns with previous research showing that the vividness of visual imagery evoked by music (including both imagined narratives and memories) correlates with one’s general capacity for vivid visual imagery, as measured via the VVIQ (Hashim et al., 2023, 2024), suggesting that music-evoked imagery is underpinned by domain-general mental imagery abilities. Interestingly, the question we used from the Autobiographical Recollection Test to index MEAM vividness (“My memory of this event has lots of details”) was not significantly predicted by VVIQ and BAIS-V scores in the conditional inference tree model, suggesting that this question taps into a somewhat different aspect of the memory experience than the visual imagery rating question.
Vividness and visual imagery ratings of MEAM experiences in our cued MEAM task were also positively related to pop music engagement. In addition, for those with a moderate level of pop music engagement, familiarity ratings of the specific songs we used also became a significant positive predictor of MEAM vividness. This suggests that regular engagement with and/or preferences for pop music may enhance the level of detail in mental representations of life memories retrieved in response to such music. Some previous studies have found that music evoked more vivid autobiographical memories than other cues, such as photographs of famous faces or TV shows (Belfi et al., 2016, 2022; Jakubowski et al., 2021). Given the repeated-measures designs used in these studies, this result cannot be explained by group-level differences in mental imagery capacities. But our findings on pop music engagement offer one possible explanation for such results, that is, that participants in these studies may have had greater preference for or more regular engagement with the music styles utilized in comparison to the non-musical cues. Furthermore, the fact that pop music engagement independently predicted MEAM vividness beyond general visual/auditory imagery capacities suggests a potential alternative route to elicit vivid MEAMs in practical and clinical contexts. That is, even if a person does not exhibit high trait mental imagery vividness, choosing music from a genre with which they regularly engage and prefer may increase the occurrence of vivid and detailed memories.
Emotional responses to the cued MEAMs (valence and emotional intensity) and the importance of each memory to one’s life story were also assessed. All three of these MEAM features were positively related to pop music engagement or song familiarity ratings, suggesting a possible reinforcing cycle, whereby music that is regularly engaged with becomes associated with positive and important life events, which may then drive listeners to reengage with such music to reconnect with these memories. In addition, for those participants meeting a certain threshold of pop music engagement scores (>2.667 out of 6.33), BMRQ total scores predicted more emotionally intense memories. This suggests that, for people who have some moderate level of engagement with pop music, those who have greater reward sensitivity to music also experience more emotional impact from their MEAMs. The correlational nature of this study precludes us from making conclusions about the direction of this relationship, but possible explanations include that more reward-sensitive individuals project their heightened emotional responses to music onto their MEAM experiences, or that people who have more emotional memories associated with music tend to engage in more regular music seeking and use of music for functions such as mood regulation (e.g., “Music keeps me company when I’m alone”; Mas-Herrero et al., 2013) due to these existing associations.
Formal training in music was not significantly related to any MEAM features across the two tasks. Our findings instead suggest that individual music listening habits and preferences are more crucial factors to consider in relation to both the efficacy and experience of autobiographical retrieval in response to musical cues. It is likely that more nuanced patterns of differentiation exist in relation to musical training, for instance in terms of the precise content of MEAMs. In future we aim to perform content analysis on MEAM descriptions from musicians and non-musicians to assess potential differences in particular scenarios that are recalled and whether memories of performing music differ systematically to memories of listening to music.
We also did not find any of our individual difference measures to be significant predictors of the measures derived from the written MEAM descriptions (the AI and sentiment scores). Taken together, our results thereby indicate a dissociation between self-report ratings of MEAMs and scoring methods based on written texts about these memories. Whereas participants’ general imagery abilities and music-related behaviors were significant predictors of ratings of the phenomenology of these memories, such as the degree to which participants could “see” the events in their minds and the intensity of their emotional experience, this was not the case for measures of the amount of detail within the memory and the sentiment of the memory as derived directly from these textual descriptions. Similarly, the text-derived measures were not substantially correlated with the subjective ratings of MEAMs (see Figure 1). Future research should seek to compare systematically possible reasons for discrepancies between these two types of measures (see also Pearson et al., 2023 for an additional example of such a dissociation).
As we deliberately chose to focus on a UK young adult sample in this study to control for other differences such as familiarity with the pop songs we used, the findings of this research require further exploration and replication in other demographic groups. Other limitations of this research include the use of a single memory description to assess self-selected MEAM experiences. We choose this approach to limit the overall time required of participants to complete the online study. Nevertheless, the relative lack of significant results stemming from the self-selected MEAM task may be related to a lack of variance across this task. That is, it may be that many participants recalled one particularly vivid, emotional, and salient memory in response to the task instructions, thereby resulting in a lack of clear differentiation across participants in relation to their personal imagery abilities and musical behaviors.
In addition, in the cued MEAM task we asked participants to write one sentence describing each MEAM. This meant the MEAM descriptions in this task were comparatively shorter (M = 22.8 words) than other previous studies using the AI (e.g., Pearson et al., 2023 reported a mean word count of 39.0 and 97.8 in their two tasks). As such, the number of external details per memory was relatively low (M = 0.52), which also meant the ratio of internal to total details was skewed toward 1, with relatively low variance across participants (although there was good variation in the number of internal details across participants). Thus, our lack of significant results in relation to the AI measures may be at least partially due to the limited variation in two of these measures (external details and ratio). Finally, we used an automated sentiment analysis protocol that assigns a sentiment score for each individual word in a text. Although such approaches have proved fruitful in previous research on MEAMs and other memories (e.g., Belfi et al., 2020), various advances afforded by recent developments in natural language processing and large language models could be incorporated in future research to better account for the context of each word within the text (e.g., to detect negations, words being used sarcastically, etc.).
In conclusion, we found that features of MEAMs are influenced by individual differences in visual and auditory imagery, musical familiarity and engagement, and musical reward sensitivity. These results have key implications for the design of experiments and clinical interventions using music as cues for autobiographical memories.
Footnotes
Appendix 1: List of questions used in MEAM tasks and pop music engagement questions
Appendix 2: Songs used as stimuli in cued MEAM task
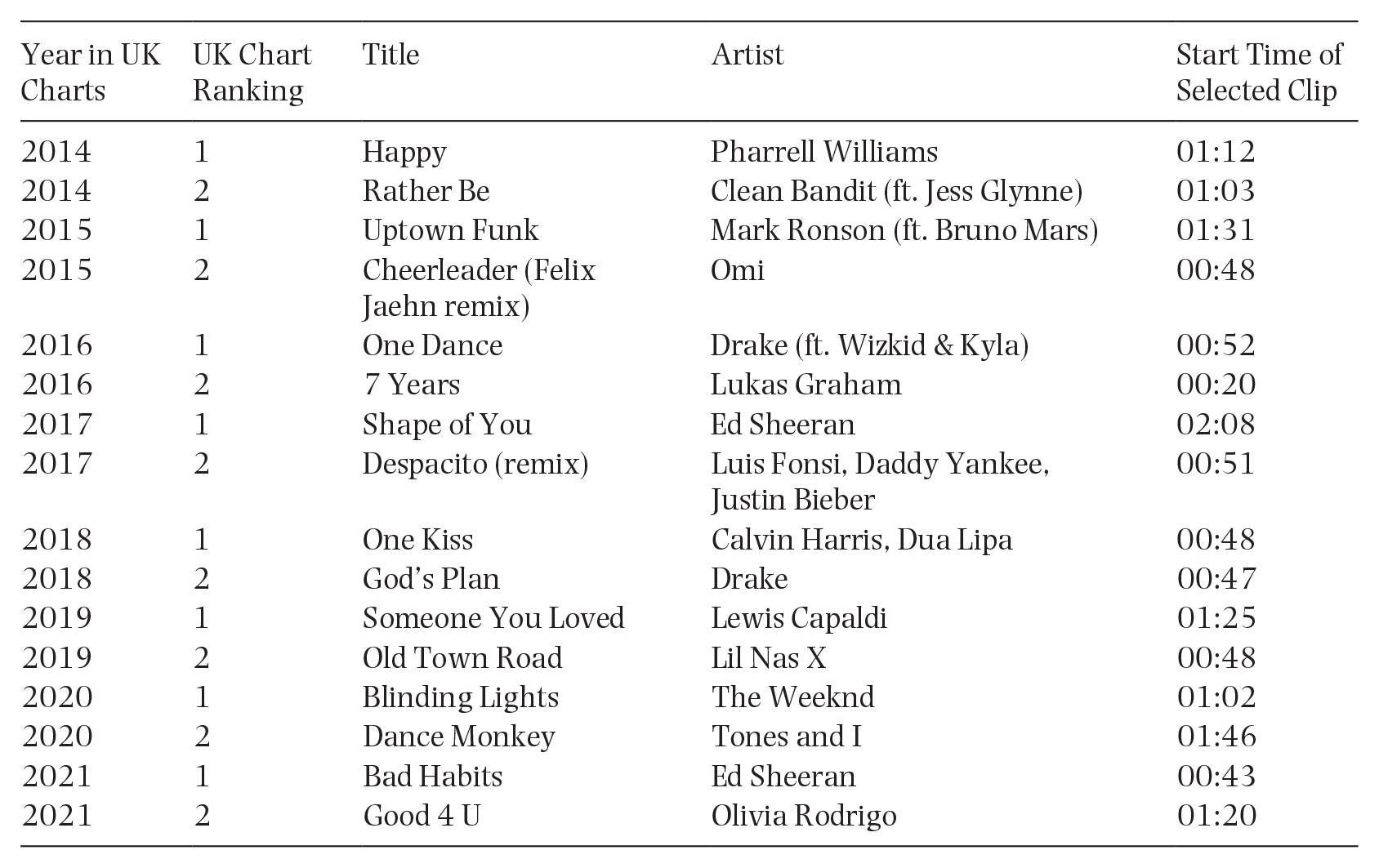
| Year in UK Charts | UK Chart Ranking | Title | Artist | Start Time of Selected Clip |
|---|---|---|---|---|
| 2014 | 1 | Happy | Pharrell Williams | 01:12 |
| 2014 | 2 | Rather Be | Clean Bandit (ft. Jess Glynne) | 01:03 |
| 2015 | 1 | Uptown Funk | Mark Ronson (ft. Bruno Mars) | 01:31 |
| 2015 | 2 | Cheerleader (Felix Jaehn remix) | Omi | 00:48 |
| 2016 | 1 | One Dance | Drake (ft. Wizkid & Kyla) | 00:52 |
| 2016 | 2 | 7 Years | Lukas Graham | 00:20 |
| 2017 | 1 | Shape of You | Ed Sheeran | 02:08 |
| 2017 | 2 | Despacito (remix) | Luis Fonsi, Daddy Yankee, Justin Bieber | 00:51 |
| 2018 | 1 | One Kiss | Calvin Harris, Dua Lipa | 00:48 |
| 2018 | 2 | God’s Plan | Drake | 00:47 |
| 2019 | 1 | Someone You Loved | Lewis Capaldi | 01:25 |
| 2019 | 2 | Old Town Road | Lil Nas X | 00:48 |
| 2020 | 1 | Blinding Lights | The Weeknd | 01:02 |
| 2020 | 2 | Dance Monkey | Tones and I | 01:46 |
| 2021 | 1 | Bad Habits | Ed Sheeran | 00:43 |
| 2021 | 2 | Good 4 U | Olivia Rodrigo | 01:20 |
Acknowledgements
The authors thank Elizabeth Kickbusch for her assistance in scoring memory data.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by a Leverhulme Trust Early Career Fellowship (ECF2018-209) awarded to K.J. and by the National Institute on Aging of the National Institutes of Health under Award Number R15AG075609 awarded to A.B.
Ethical approval statement
Ethical approval was granted by the Durham University Music Department Ethics Committee.