
Abstract
The human mind engages with repetition both in the form of external stimulation and as an internal psychological phenomenon. I studied these two facets of repetition in 111 musically untrained participants. The investigation was in two parts. In the first part, I looked at the speech-to-song (STS) illusion by comparing ratings of musicality for identical looped (repeated) spoken phrases and for looped spoken phrases including pitch transpositions. Contrary to previous evidence, the stimuli containing transposed presentations were rated more song-like. I attribute this finding to the particular patterns of transpositions used and the fact that the interval of transposition was a major second as opposed to the fractions of semitones used in previous studies. In the second part of the investigation, I partially adopted the stimulus design of the STS illusion paradigm, presenting participants with looped phrases and single phrases. Participants were asked to suppress them and click a button if they thought of them. An increase in button clicks suggests that participants found it significantly harder to suppress the looped phrases than the single phrases. As the stimuli in the second part had been shown in previous research not to induce the STS illusion when repeated, I attribute the differences between participants’ responses to the two kinds of stimuli to the repetition of the phrases rather than their being perceived as song-like. I consider these findings in the light of research on earworms, or involuntary musical imagery. Future directions for a more in-depth exploration of the STS illusion in conjunction with auditory imagery are also briefly discussed.
Repetition is ubiquitous in music but relatively rare in language (Margulis, 2013), with notable exceptions including public speeches (Ehrensberger, 1945), poetry (Ribeiro, 2007), and child-directed speech (Hoff-Ginsberg, 1985; McRoberts et al., 2009; Schwab et al., 2018). Given listeners’ focus on semantic content rather than surface structure in everyday conversation, repetition appears irrelevant in naturally occurring speech in contrast to its central role in music (Margulis, 2013). An artificial form of speech has the potential to blur the boundaries between music and language (Deutsch et al., 2008): a spoken phrase played in a loop, or repeated several times. I built on previous research in the first part of the study, exploring the effects of exact repetition and deviations from it on a well-known musical illusion. I brought together previously disparate strands of research in the second part, looking at the effects of repetition on involuntary mental imagery.
Acoustic repetition in the speech-to-song illusion
It has been long known that single spoken phrases repeated several times in quick succession come to be perceived as sung, a phenomenon referred to as the speech-to-song (STS) illusion (Deutsch et al., 2008). There has been extensive inquiry into the acoustic features of speech that may contribute to it (Falk et al., 2014; Groenveld et al., 2020; Rathcke et al., 2021; Tierney et al., 2018) as well as some work demonstrating the generalizability of the illusion to nonspeech stimuli (Margulis & Simchy-Gross, 2016; Rowland et al., 2019; Simchy-Gross & Margulis, 2018). With regard to speech, it has been postulated that the mechanisms underpinning pitch perception may be less active, so as to facilitate the processing of phonological and, in turn, semantic information, but such mechanisms may be activated following consecutive repetitions (Deutsch et al., 2011). In other words, when speech perception is divorced from the taxing process of extracting meaning, attentional resources may be directed to the perception of pitch information.
Although the effects of repetition on the extent to which a stimulus is perceived as music-like have been well studied, less is known about the effect of deviations from exact repetition on the STS illusion. In previous studies, researchers have transposed some of the repetitions in a sequence and looked at how this affects listeners’ ratings of musicality (Deutsch et al., 2011; Vanden Bosch Der Nederlanden et al., 2015). Transposition—the shifting of notes in a melody up or down while the same series of intervals is preserved—is processed in a relative rather than absolute fashion, with only perfect pitch possessors perceiving transposed melodies as distinct (Dowling & Harwood, 1986). The processing of tonal patterns in this relative way is a part of music cognition emerging very early in human development (Chang & Trehub, 1977; Trehub et al., 1984), and our auditory world abounds with transposed melodies, with transposed themes being prevalent in Western music (Kamien & Wagner, 1997; Mason, 1962; Ricci, 2017; Russ, 2012; Yust, 2018). Given the widespread presence of the device in compositional practice, the question arises as to whether pitch transposition in the context of the STS illusion reinforces the notion that listeners shift, when they hear it, to perceiving the stimulus as music rather than speech. The STS illusion is less likely to occur when the stimulus is transposed, at least by small non-tempered intervals such as two-thirds of a semitone, with participants rating transposed versions as less song-like than untransposed ones (Deutsch et al., 2011; Vanden Bosch Der Nederlanden et al., 2015). It is yet to be established whether transposing the stimulus by an interval more likely to be heard in everyday life, such as an equal-tempered major second, also reduces the likelihood of producing the illusion. Aside from the magnitude and precision of the transposition, the resulting pattern may be less or more musical depending on whether the locus of the manipulation mirrors compositional practice; this was an additional concern in this study. In the case of an ostinato, a short musical phrase is repeated and, in some cases, transposed to another pitch (Encyclopaedia Britannica, 2013). Phrases may also take a question-and-answer form, the question being played or sung at a higher pitch and the answer at a lower pitch (Snoman, 2012). Employing such manipulations in the context of the STS illusion can help address the question of whether any deviation from exact repetition compromises the illusion, as previously shown (Deutsch et al., 2011; Vanden Bosch Der Nederlanden et al., 2015), or whether the type of transposition and the extent to which it is perceived as music-like may also have a bearing on the listener’s experience.
Perceived repetition in earworms (involuntary musical imagery)
A separate body of literature shows that repetition can be experienced as an internal or imagined phenomenon in the form of an earworm, or involuntary (and typically musical) imagery. Earworms have been referred to anecdotally in literature dating back to the 19th and early 20th century (Sacks, 2007) and are described as snippets of music playing in a loop in one’s head beyond conscious control (Beaman & Williams, 2010). They seem to be prevalent in the general population (Liikkanen, 2008), but engagement in musical activities has been positively associated with increased frequency or duration of earworms in several studies (Beaty et al., 2013; Floridou et al., 2015; Hyman et al., 2013; Liikkanen, 2012b; Liptak et al., 2022; Moeck et al., 2018). More generally, repeated exposure to the music that is the source of the earworm may lead to more persistent imagery (Byron & Fowles, 2015; Killingly & Lacherez, 2023; Liikkanen, 2012b; Liptak et al., 2022). The findings of these studies of earworms could thus be taken as an indication of a relationship between two apparently distinct types of repetition. The first type of repetition is contained within the external stimulus itself (e.g., repetitive music); the second type of repetition is imagined and involuntary (i.e., an earworm).
Verbal earworms equivalent to musical earworms but involving snippets of speech playing in a loop remain comparatively understudied. Verbal earworms have been found to be less prevalent than musical earworms (Halpern & Bartlett, 2011; Tillmann et al., 2023). One possible explanation is that musical earworms derive from a richer tapestry of acoustic information than speech and are thus activated by a wider variety of cues; another is that people are more likely to be exposed to music than to public speeches or recitations of poetry, the purported sources of verbal earworms (Halpern & Bartlett, 2011). Despite the scarcity of research on verbal earworms, the majority of musical earworms reported in some previous work originated in music containing lyrics (Halpern & Bartlett, 2011; Liikkanen, 2012b; Tillmann et al., 2023). Furthermore, participants report the most vivid components of musical imagery to be not only melody but also lyrics (Bailes, 2007), and exposure to music with lyrics has been associated with longer earworm episodes (Liptak et al., 2022). Hence, although it is music that is typically presumed to be sticky, verbal content appears to be a common component of musical imagery.
If repetition contained within an external stimulus and repetition experienced as an earworm are somehow connected, as suggested above, it may be the repetition itself that causes the involuntary musical imagery rather than some other feature of the stimulus. On the basis of what is known about the longer-term effects of repeated exposure to musical content (Byron & Fowles, 2015; Killingly & Lacherez, 2023; Liikkanen, 2012b; Liptak et al., 2022), it might be predicted that repetition of a stimulus would produce more persistent involuntary imagery than the same stimulus presented once, and this prediction could be tested in controlled conditions. Moreover, evidence linking earworms with a stimulus presented recently (Bailes, 2007; Byron & Fowles, 2015; Floridou et al., 2012; Halpern & Bartlett, 2011; Hyman et al., 2013; Liikkanen, 2012a; Williamson et al., 2012) suggests that involuntary imagery is even more likely to be induced if a stimulus is presented in controlled conditions and the participant is tested immediately afterwards. Earworms have been elicited and studied experimentally in previous research (e.g., Beaman et al., 2015; Hyman et al., 2013; Killingly et al., 2021; Liikkanen, 2012a). Even more relevant to the present investigation is the study of earworms in the lab by intending to induce thought suppression, or the deliberate attempt to ignore a thought (Beaman et al., 2015). This approach was borrowed from earlier studies showing that mental images remain active in consciousness even when people are instructed to suppress them (Wegner et al., 1987). Given the evidence of the role of lyrics in imagery discussed earlier (Bailes, 2007; Halpern & Bartlett, 2011; Liikkanen, 2012b; Liptak et al., 2022; Tillmann et al., 2023), a spoken phrase could serve as a source of involuntary imagery if repeated several times in quick succession. To explore this possibility, I used the thought-suppression paradigm in the second part of this study to compare participants’ ability to mentally control and ignore single phrases, on one hand, and as repeated repetitions of the same phrases, on the other; in the latter case, I adopted the stimulus presentation mode employed in the STS-illusion literature. In this way, I looked at whether repeated repetitions of a spoken phrase can produce a verbal earworm, albeit only in the short term. In an effort to disentangle the effect of repetition per se from listeners’ perception of stimuli as music-like, I used as stimuli only spoken phrases that had already been found by Tierney et al. (2013) not to yield the STS illusion when repeated.
This study was the first, so far as I know, to examine repetition contained within an external stimulus in conjunction with repetition experienced involuntarily in the imagination. My first aim was to find out if the two kinds of repetition are linked; my second aim was to lay the ground for further exploration. Although I used pitch transpositions only in the first part of the study, they could also be used in future research similar to the second part of this study to test the effects of different types of repetition on short-term involuntary imagery.
Method
Ethics
The study received ethical approval from the local ethics officer at the Department of Linguistics at University College London (approval no. LING-2023-04-06). Participants gave informed consent prior to taking part in the study and were treated according to the ethical standards of the Declaration of Helsinki.
Participants
All participants were recruited online on Prolific (https://www.prolific.co). Exclusion criteria included formal music training and/or a diagnosis of dyslexia, other literacy difficulties, and autism. These exclusion criteria were set to ensure that no unwarranted variability in speech and music processing would affect the results. A total of 111 English-speaking monolingual individuals (69 female, 41 male) aged between 19 and 36 years (M = 27.48, SD = 4.39) took part in the study. Each participant carried out the same two tasks, one in each of the two parts of the study. The tasks were administered and completed online via Gorilla Experiment Builder (for more details on this platform, see Anwyl-Irvine et al., 2020).
Materials and procedure
Task I
The raw stimuli for this task were taken from Tierney et al. (2013) with permission from the first author. The stimuli consisted of spoken phrases of varying lengths that were found to be perceived as sung when repeated eight times (Tierney et al., 2013), such as “I have had nothing since breakfast” and “Snags and sandbars.” 1 For the purposes of the present task, target phrases were looped to produce a total of eight repetitions separated by 800 ms pauses.
The task comprised three conditions with stimuli presented as follows: sequences made up of eight identical presentations (original repetitions), sequences whereby the second, third, fourth, fifth, sixth, and seventh presentations were transposed up by two semitones (intervening transpositions), and sequences in which the second, fourth, sixth, and eighth presentations were transposed up by two semitones (alternating transpositions). The intervening-transpositions condition had been used in previous research (Deutsch et al., 2011; Vanden Bosch Der Nederlanden et al., 2015); I added the alternating-transpositions condition to find out if question-and-answer patterns reminiscent of question-and-answer musical stimuli are perceived as even more song-like, as discussed above. The transpositions were applied using the overlap-add method in Praat software.
The experimental manipulations were counterbalanced so that each spoken phrase served as a stimulus for all three conditions (original repetitions, intervening transpositions, and alternating transpositions). A total of 72 stimuli were generated and three stimulus lists were created, each including 24 stimuli presented in fixed random order.
Participants were randomly assigned to one of the three lists and required to rate target stimuli on a 5-point Likert-type scale from 1 (exactly like speech) to 5 (exactly like song) by clicking the appropriate button on the computer screen. They were reminded of the meaning of each of the rating scale categories in every trial. As the stimuli had previously been shown to induce the illusion when repeated (Tierney et al., 2013), participants in this study were required only to provide a single rating at the end of each trial so that I could compare the mean ratings per stimulus obtained in each of the three conditions.
Task II
Again, the raw stimuli used in this task were taken from Tierney et al. (2013). The stimuli consisted of spoken phrases previously found to be heard as speech—not song—when repeated. This task included two conditions: spoken phrases presented once (single presentation) and spoken phrases repeated eight times, the repetitions separated by 800 ms pauses (repeated presentation), as in Task I (original repetitions).
The experimental manipulations were counterbalanced so that the same spoken phrases served both as single presentations and repeated presentations. A total of 28 stimuli were generated and two stimulus lists were constructed, each including 14 stimuli presented in fixed random order. Participants were randomly assigned to one of the lists. Due to the passive nature of the task (see below), not all the raw stimuli from Tierney et al. (2013) were used, to ensure that participants would remain focussed on the task throughout the session.
Participants were explicitly asked to try not to form mental images of (i.e., suppress) the stimuli presented, in line with the thought-suppression conditions described by Wegner et al. (1987) and an earworm study by Beaman et al. (2015). This paradigm was adopted to provide a baseline for the two conditions; I assumed that participants would be able to suppress the stimuli to some extent regardless of condition, but a greater number of clicks would indicate more persistent imagery. After being exposed to each stimulus, participants were asked not to form a mental image of it for one minute but to click a button if it came to mind.
Results
Task I
A linear mixed-effects model was fitted to analyze the data from the first task. The type of manipulation (original repetitions, intervening transpositions, and alternating transpositions) was modeled as a fixed effect. Participants and trials were modeled as random effects. Significance testing was conducted using the lmerTest (Kuznetsova et al., 2017) and lme4 (Bates et al., 2015) packages. Effect sizes were computed using the effectsize (Ben-Shachar et al., 2020) package. Post-hoc tests applying the false discovery rate (FDR) for multiple comparisons were carried out using the emmeans package (Lenth, 2020).
Analysis of variance revealed that the type of manipulation was statistically significant, F(2, 2460) = 15.40, p < .001, ηp2 = .01, albeit with a small effect size. Post-hoc pairwise comparisons with FDR corrections showed that alternating transpositions were perceived as more song-like than original repetitions, p < .001, d = .11; intervening transpositions were perceived as more song-like than original repetitions, p < .001, d = .08. There was no significant difference between alternating and intervening transpositions, p = .11, d = .03. Figure 1 shows the corresponding boxplots for the data broken down by type of manipulation.
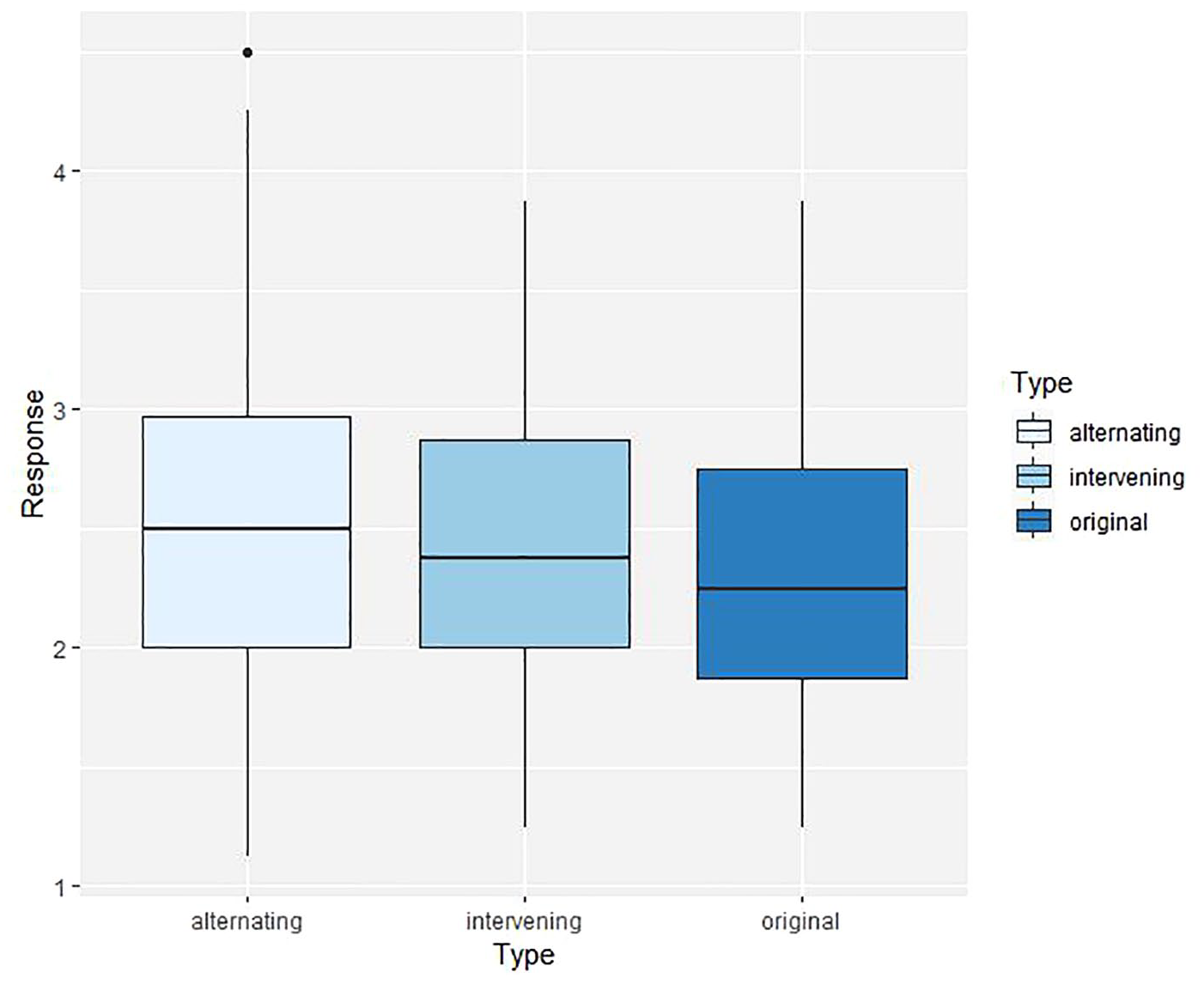
Boxplots showing participants’ responses, that is, mean ratings for all phrases by type (alternating, intervening, and original), with higher values indicating stimuli perceived as more song-like. Post-hoc pairwise comparisons showed that both alternating and intervening repetitions were perceived as more song-like than the original version including verbatim repetitions, *** p < .001. Thick horizontal lines represent the medians; black dots represent outliers.
Analysis of mean ratings per stimulus revealed variation in the extent to which the stimuli in the three conditions were perceived as song-like (see Figure 2. Stimuli appear in the same order as in Tierney et al., 2013). Stimuli 1, 2, 3, and 11 (“Here is no less,” “Gave the houses,” “Snags and sandbars,” and “People in the neighbourhood” respectively) were perceived as more musical. Stimuli 4, 14, 16, and 23 (“And his two sisters,” “Linen of this sort in public,” “I have had nothing since breakfast,” and “The prince continued to struggle”) were perceived as least song-like.
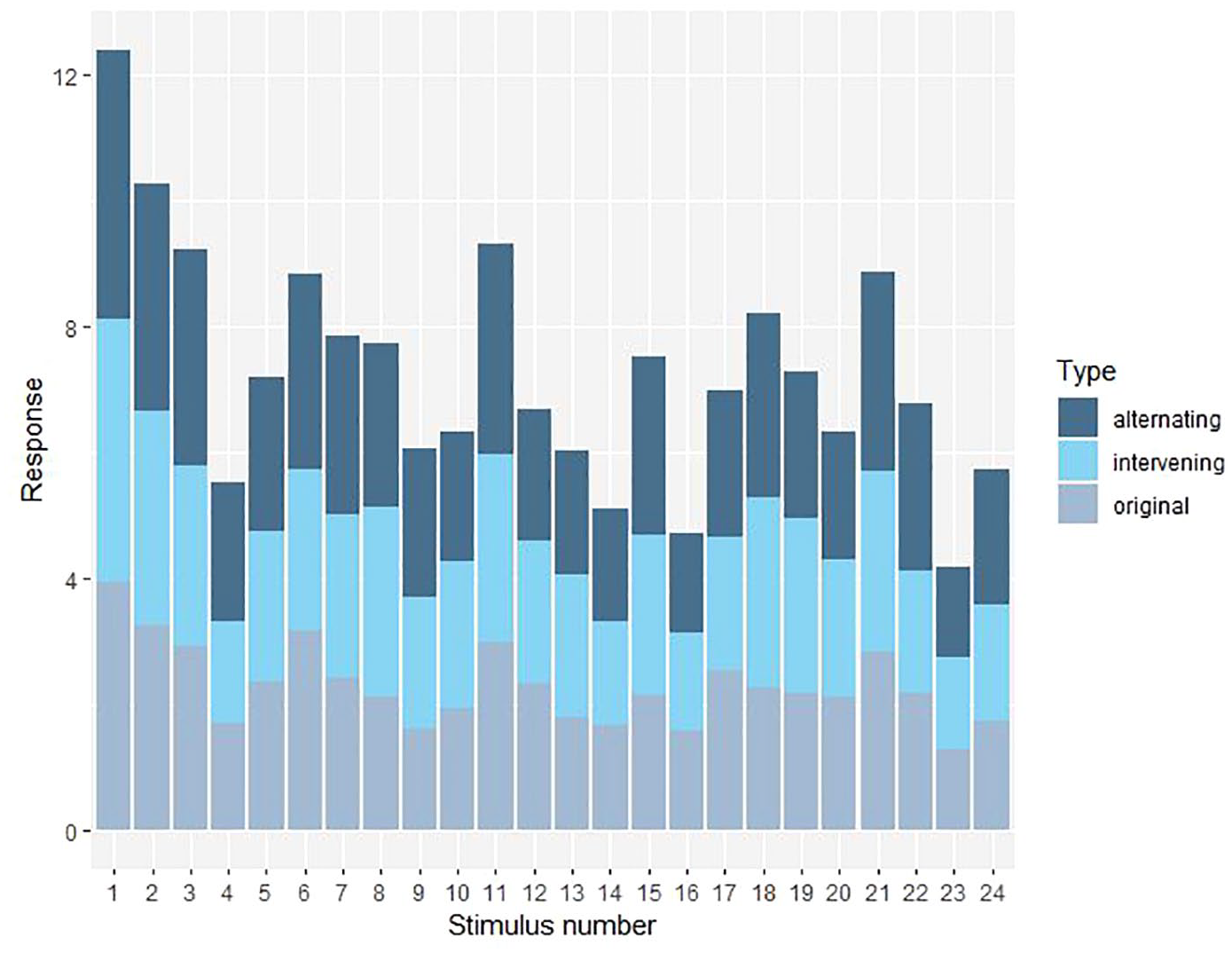
Stacked barplots depicting responses (mean ratings), with different colors in each bar representing different manipulation types and higher ratings indicating stimuli perceived as more song-like. To listen to the original sentences created by Tierney et al. (2013), follow the link to the supplementary data in their article.
Task II
A Poisson regression was originally selected for the second task but due to the overdispersion of the data, a negative binomial regression was fitted to model the number of times participants clicked a button as a function of the type of presentation (single vs. repeated). Results including zero counts showed that repeated presentations were associated with a statistically significantly higher rate of clicks compared to single presentations, β =.48, SE = .06, z-value = 7.20, p < .001. The exponentiated value of the regression coefficient, e0.48 = 1.61, points to a 61% increase in clicks for repeated presentations compared to single presentations (see Figure 3 for boxplots comparing the two conditions).
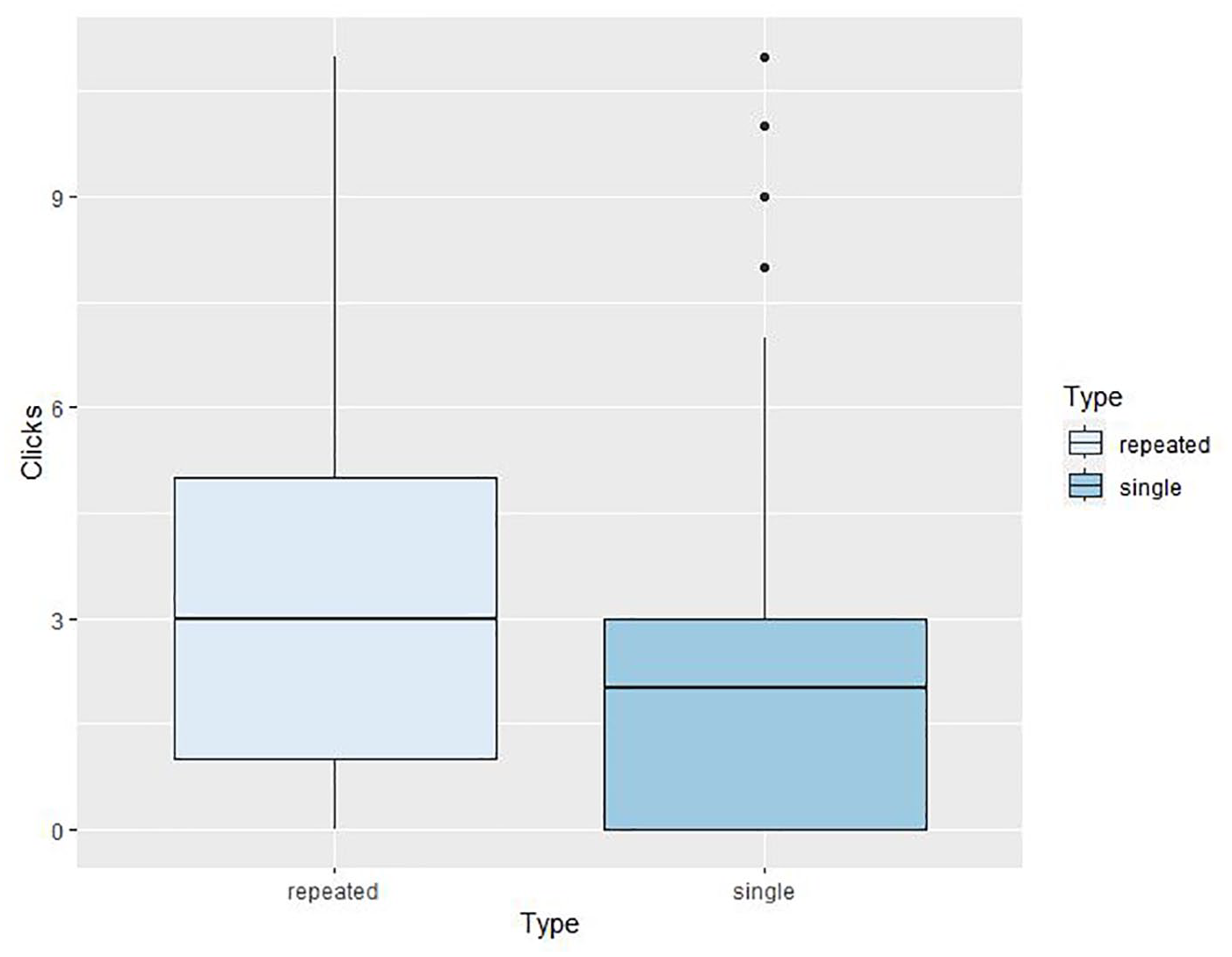
Boxplots displaying mean numbers of clicks for repeated and single presentations, *** p < .001. Thick horizontal lines represent the medians; black dots represent outliers.
Some phrases were associated with a larger mean number of clicks when repeated than others, as shown in the top panel of Figure 4. This does not include zero counts, however, and should be read in conjunction with the bottom panel, which shows that zero-count clicks were primarily associated with single presentations. Single presentations were also more frequently associated with one or two clicks, while repeated presentations were more frequently associated with larger numbers of clicks.
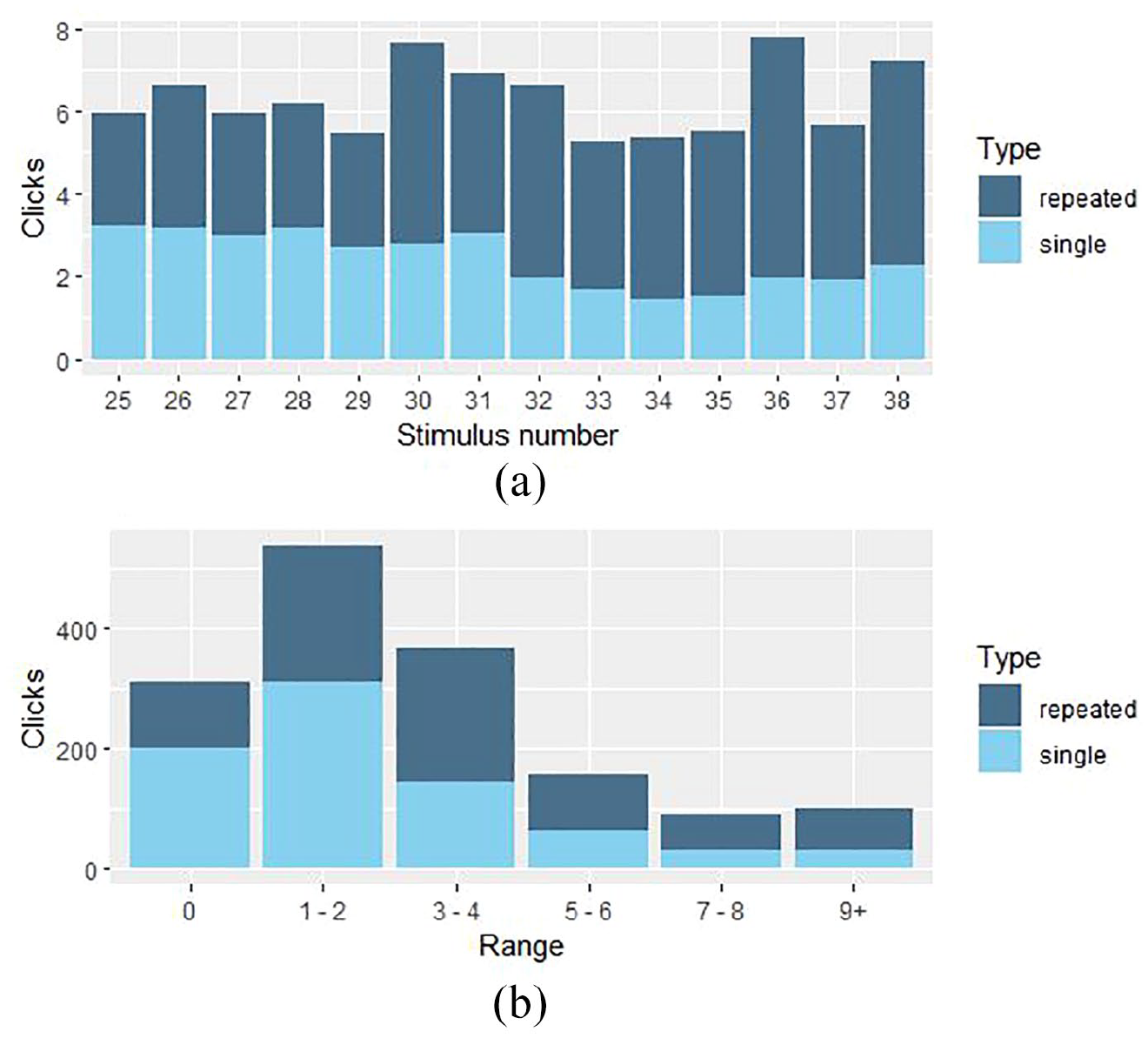
(a) (Upper panel): Stacked barplots depicting mean numbers of clicks corresponding to single and repeated presentations. Note that this panel does not take zero counts into consideration. Figure 4(b) (lower panel): Total number of clicks per condition for different count ranges including zero counts. For more information about the stimuli, follow the link to the supplementary data by Tierney et al. (2013) and see Table S1 in the supporting information file. They did not number the stimuli but Stimulus 1 in this study corresponds to the first phrase of the Song stimuli in Table S1 and Stimulus 25 in this study corresponds to Stimulus 1 of the Speech stimuli in Table S1.
Discussion
In the first part of the study, I demonstrated that transposing repetitions of a looped spoken phrase up by two semitones not only did not disrupt the STS illusion, but actually enhanced it; listeners perceived the stimuli containing transposed repetitions as significantly more song-like than those comprising exact repetitions. The locus of the transposition, intervening (whereby only the first and last repetitions remained at the original pitch) and alternating (whereby original and transposed presentations alternated), was not associated with statistically significantly different ratings of perceived musicality. Having borrowed the structure of the stimuli from the STS illusion paradigm, I found that repeated repetitions led to more persistent involuntary mental imagery in the second part of the study; participants found it significantly harder to suppress looped phrases than phrases presented in isolation.
The findings of the first part of this study contrast with those of previous studies suggesting that repeated repetitions of the same stimulus are perceived as more music-like than transposed ones (Deutsch et al., 2011; Vanden Bosch Der Nederlanden et al., 2015). I explain this discrepancy by reference to the type of transposition applied; I transposed repetitions by a standard musical interval instead of fractions of semitones and used patterns of manipulations (question-and-answer) that could be considered more musical. I can only speculate on the psychological mechanisms underlying participants’ responses at this point. Regarding untransformed repetitions, Deutsch et al. (2011) showed that, having heard a spoken phrase in a looped form, listeners distort the original pitch content when they sing it back, presumably for perceptual reasons. The authors further reasoned that repetition helps listeners access pitch more easily and draw on their stored memories for music.
In similar vein, listeners may draw on common transpositions they have already absorbed; this may partially account for the present results regarding transposed repetitions. Transposition is a device prevalent in compositional practice (Kamien & Wagner, 1997; Mason, 1962; Ricci, 2017; Russ, 2012; Yust, 2018), contributing to a soundscape in which transposed melodies are linked to the perception of musicality. Yet the size of the transposition interval and the precision of the interval, in terms of Western tonality, may be crucial; musical themes are more likely to be transposed by an equal-tempered major second than, say, two-thirds of a semitone. If transpositions by standard musical intervals are part of listeners’ stored representations, the perception of musicality that they confer may be transferred into the speech domain. Moreover, alternations between a transposed phrase and its lower-in-pitch original version may mirror question-and-answer patterns heard in music (Snoman, 2012), thus sounding more musical than the sequences of transpositions used in previous research (Deutsch et al., 2011; Vanden Bosch Der Nederlanden et al., 2015), although I found no significant difference between the extents to which intervening and alternating transpositions were perceived as song-like.
Further methodological differences that may have contributed to the differences between the present findings and those of previous studies must be considered. First, I used raw stimuli that had been shown in previous research to produce the STS illusion when repeated (Tierney et al., 2013), but instead of collecting ratings after each presentation, I only collected ratings after each trial. This allowed me to compare the three conditions without requiring participants to rate every single repetition. However, the phenomenological experience of the participants in the two studies may have been different, since listening to an intact stimulus (as in this study) is not the same as listening to a stimulus requiring multiple ratings (as in Tierney et al., 2013). Second, the direction of the transposition may have also had a bearing on the results, as I only transposed the original stimuli up, and not down. It is worth emphasizing that repetitions were rated more song-like when they were transposed up than when they were transposed down in the study by Vanden Bosch Der Nederlanden et al. (2015), even though it is still of note that their high transpositions did not boost the illusion. Finally, the discrepancy between my findings and those of previous studies may or may not be attributable to the use of equal-tempered transpositions; this would need to be addressed in future research using a more fine-grained design. Overall, the current findings do not support the suggestion, based on previous results, that the STS illusion can only occur if repetitions are exact (Deutsch et al., 2011; Vanden Bosch Der Nederlanden et al., 2015). They suggest, rather, that the illusion may be enhanced when there is deviation from an exact repetition, depending on type of transposition and the musicality of the pattern it produces.
Repetition is understood to be at the heart of the STS illusion, as non-speech sounds, as well as speech sounds, can be perceived as more like music when they are repeated (Margulis & Simchy-Gross, 2016; Rowland et al., 2019; Simchy-Gross & Margulis, 2018). Music is typically highly repetitive (Ockelford, 2009); however, further work is warranted to find out if repetition explains the STS illusion fully or only in part. Although the illusion is thought to stem from repetition, it could be that listeners perceive sequences of non-musical stimuli as musical whenever the structure of the sequence parallels a particular musical device. Repetition can be understood as an ostinato, with examples including phrases that are repeated (as in all studies on the STS) or transposed by an equal-tempered interval (as in the current study). It remains to be seen whether other musical devices that do not involve repetition produce a similar illusion.
The results of the second part of the study show that participants found it harder to suppress spoken phrases when they were repeated than when they were presented in isolation. Even though the literature on earworms describes different settings and time windows, frequent or repeated material is associated with greater imagery (Byron & Fowles, 2015; Killingly & Lacherez, 2023; Liikkanen, 2012b; Liptak et al., 2022). Recent exposure also increases musical imagery (Bailes, 2007; Byron & Fowles, 2015; Floridou et al., 2012; Halpern & Bartlett, 2011; Hyman et al., 2013; Liikkanen, 2012a; Williamson et al., 2012), as suggested by my findings. This was not the focus of my inquiry, however, so I did not include a control condition that would have enabled me to test length of exposure. Nevertheless, I used stimuli previously rated non-musical, insofar as they had not produced the STS illusion in previous research (Tierney et al., 2013), so it is likely that higher involuntary imagery (inferred from button clicks representing hard-to-suppress stimuli) was the result of repetition rather than perceived musicality. Future research is warranted to find out if the set of stimuli found to induce the illusion would also produce higher involuntary imagery, or not. A potential practice effect precluded testing for this in the present study, as my participants had already been exposed to the illusion-inducing sentences in the first part of the study.
Verbal earworms are the phenomenon closest to the type of involuntary verbal imagery identified in this study. They seem to be rarer than musical earworms (Halpern & Bartlett, 2011; Tillmann et al., 2023). In the past, this has been explained by reference to the range of possible activation cues afforded by music (e.g., pitch, harmony, timbre, and lyrics), which is wider than that afforded by speech, and the relative lack of exposure to sources of verbal earworms (e.g., speeches, poetry) in comparison to exposure to music (Halpern & Bartlett, 2011). I propose a novel explanation on the basis of the current results: as repetition is rare in everyday speech (Margulis, 2013), fewer episodes of involuntary imagery stem from speech. Future research could find out if hearing looped phrases, as in this study, produces verbal earworms in listeners (i.e., they are stored in long-term memory) if participants were followed up.
The findings of previous studies have shown that verbal content in the form of song lyrics is a common component of musical imagery (Bailes, 2007; Halpern & Bartlett, 2011; Liikkanen, 2012b; Liptak et al., 2022; Tillmann et al., 2023). The findings of this study show that the verbal content of repeated spoken phrases can produce involuntary imagery at least in the short term. People with congenital amusia, a neurogenetic disorder affecting music and speech processing, have recently been found also to report musical earworms (Loutrari et al., 2022; Tillmann et al., 2023). Interestingly, verbal earworms seem to be more prevalent in people with congenital amusia than neurotypical controls (Tillmann et al., 2023), but people with amusia, when asked to imagine musical, vocal, and environmental sounds, find it harder than neurotypical controls to control the transition from imagining one sound to another (Loutrari et al., 2022). It would therefore be interesting to explore the effects of repeated repetitions of speech on people with amusia and find out if they can suppress involuntary imagery given their difficulty to control imagined sound transitions
In conclusion, this study replicated previous research in which repeated repetitions of a spoken phrase produce the STS illusion, but my findings suggest that the illusion can be enhanced by presenting not verbatim repetitions but patterns of repetition that deviate in a musical way. Further research is warranted to determine more precisely the kinds of deviation that are more or less likely to produce the illusion. I also used the STS illusion paradigm to test whether repeated repetitions of a spoken phrase are associated with more persistent involuntary auditory imagery in the short term. Further research is needed to find out if involuntary imagery is a function of the extent to which the repetitions of a spoken phrase are perceived as song-like or whether it is a function of repetition per se. This could be achieved in a future thought-suppression study using both illusion-inducing and non-inducing stimuli to compare musical and verbal involuntary imagery.
All the original stimuli are available in the supplemental materials by Tierney et al. (2013). Readers can also access the transcribed sentences corresponding to the stimuli; the second table in the supporting information file contains the phrases that were shown to be perceived as song-like in the original study.