
Abstract
We consider income-source-dependent tax evasion and show that this is a generalisation of the well-known endowment effect. We show that loss aversion, moral costs, mental accounting and risk preferences play a role in explaining key features of source-dependent tax evasion. We provide evidence of the first direct link between subject-specific loss aversion and tax evasion, which is central to most successful modern theoretical accounts of tax evasion. We provide some evidence that risk aversion strengthens the cautionary effect of loss aversion and risk loving behaviour attenuates, or reverses, it. However, the underlying effect is also influenced by the source of income. Evasion is increasing in the tax rate and decreasing in the audit penalty, as predicted. Our study provides novel theoretical insights; proposes new methods in the estimation of the underlying behavioural parameters; and confirms the central predictions of the theory, while pointing out challenges for further developments that existing theory is unable to account for.
Keywords
Introduction
Tax evasion is an important area of research within public economics with significant welfare consequences. 1 This problem has attracted a great dea of academic interest. 2 The Allingham-Sandmo (1972) model established the basic framework, based on expected utility, but the empirical success of this framework has been questionable, giving rise to the well-known tax evasion puzzles. The puzzles are both quantitative 3 and qualitative 4 By contrast, non-expected utility theories such as prospect theory provide a better explanation of the tax evasion evidence (Bernasconi, 1998; Yaniv, 1999; Bernasconi & Zanardi, 2004; Dhami & al-Nowaihi, 2007, 2010; Eide et al., 2011). 5
Loss Aversion and Tax Evasion
The key features in the success of prospect theory in explaining the qualitative and quantitative puzzles in tax evasion are reference dependence and loss aversion. This is true of the theoretical models (Bernasconi, 1998; Yaniv, 1999; Bernasconi & Zanardi, 2004; Dhami & al-Nowaihi, 2007, 2010; Eide et al., 2011; Alm & Torgler, 2012) and of empirical studies that use data from field observational studies (Engström et al., 2015; Rees-Jones, 2018). Loss aversion also influences much human and primate behaviour and is also well supported by neuroeconomic evidence (Dhami, 2019, Vol. 1).
Despite the key importance of loss aversion, we are not aware of empirical work that rigorously and directly measures loss aversion for 'individual' taxpayers and relates it to their tax evasion behaviour. 6 Observational studies and studies based on administrative data attempt to study indirect implications of reference dependence and loss aversion, such as bunching of taxpayers where there are kinks in the marginal tax/subsidy rates. Direct measurement of loss aversion at the level of each taxpayer is a specialised, complex and time consuming, task and requires measurement of all parameters of prospect theory in one fell swoop. 7
The 'main aim' of our study is to provide a direct examination of the underlying mechanisms of prospect theory-based explanations of tax evasion, by directly measuring individual-specific loss aversion in lab experiments. We then relate individual-specific loss aversion with the tax evasion decisions of the same individual.
Source-Dependent Evasion
Extensive evidence shows that humans experience different levels of entitlements from earned and unearned incomes. 8 In the classic endowment effect studies, entitlements are themselves caused by loss aversion (Kahneman & Tversky, 2000; Dhami, 2019, Vol. 1). We wish to examine the income-source-dependence of tax evasion (source dependent evasion) when the different income sources are identical in their tax/deterrence treatment. In particular, we compare labour income, earned in a tedious experimental task, relative to non-labour income which is unearned during the experiment, for example, bequests, gifts, lottery wins, unexpected capital gains. Our proposed theory allows for potentially any difference in the two income sources, provided the individual feels more entitled to one income source over the other.
If taxpayers evade different amounts from the two different sources of incomes, then this may also indicate a form of mental accounting. Thaler (1999, p. 186) gave a general definition of mental accounting: 'I wish to use the term 'mental accounting' to describe the entire process of coding, categorizing, and evaluating events'. 9 Source-dependent tax evasion behaviour, if confirmed, potentially indicates mental accounting because tax evaders then appear to code and categorise different income sources, identical in their tax/deterrence treatment, differently. 10
It is an interesting research question to see if there is any interaction between the source of income, loss aversion and risk aversion. This is the second objective of our study.
Following the earlier literature, cited above, we hypothesise that people feel more entitled to (earned) labour income relative to (unearned) non-labour income. We conjecture two effects, working in opposite directions, through which entitlements to income might influence tax evasion. (i) First, loss aversion arising from being caught evading taxes is greater from income that one feels more entitled to (earned income) relative to unearned income, and our data supports it. Our theoretical model shows that higher loss aversion reduces evasion. Hence, individuals should evade less earned income as compared to unearned income. (ii) Second, we hypothesise that there are lower moral cost from evading earned labour income. In some sense, individuals feel less guilty from evading income they are more entitled to. Our theoretical model predicts that lower moral costs from evasion will result in more evasion of labour income. There is no satisfactory method of directly measuring income source-specific moral costs for each taxpayer, but we provide indirect evidence, consistent with moral costs. 11
From (i) and (ii) above, greater loss aversion reduces evasion and lower moral costs increase evasion of earned income. Thus, the overall treatment effect, which determines the relative tax evasion from labour and non-labour income, is an empirical question. 12 We note that, nevertheless, a predicted ambiguous result is also an important theoretical result that needed to be demonstrated rigorously. Furthermore, the sign of the treatment effects, based on our empirical analysis, speaks to the relative strengths of the two opposite effects.
Loss Aversion and Risk Aversion
Traditional analyses of risky situations, based on expected utility theory, highlight the importance of risk aversion in explaining individual choices. 13 By contrast loss aversion is a property of the utility function under prospect theory, not related to its curvature, and it arises in riskless choices as well as risky choices. Risk aversion and loss aversion are distinct, yet related, entities in prospect theory. 14
There are claims that once loss aversion is accounted for, there is 'no' remaining risk aversion (Novemsky & Kahneman, 2005). In other words, the claim is that observed risk aversion is likely to be mostly on account of loss aversion, but unless one separately measures them, results may be confounded. There is no simple relation between risk aversion and loss aversion under prospect theory if there are outcomes in, both, the domains of gains and losses. However, we measure risk aversion in lotteries that are only in the domain of gains, while loss aversion is measured with both gain and loss lotteries; this removes the confounding role of loss aversion.
A third aim of our study is to measure risk aversion for each individual taxpayer and relate it to evasion behaviour, while also considering the interactions between risk aversion and loss aversion.
Theoretical Model
We use the framework in Dhami & al-Nowaihi (2007, 2010) to derive the implications of loss aversion and income-source dependence of tax evasion, using prospect theory. Since these results follow in a straightforward manner from their model, we relegate the detailed model to the supplementary section, and only list the two main propositions in the text as a guide to the predictions of the relevant model.
Experiments and Findings
We ran a between-subjects experiment over Zoom with Indian University students. Subjects are randomly assigned to either a primed or an unprimed group. The primed group is shown data about tax evasion in India. Within each group, subjects are assigned to two treatments. In the first treatment (T1), taxpayers have only non-labour, experimenter-provided, unearned income. In the second treatment (T2), the only source of income for taxpayers is labour income, earned by solving a set of timed and tedious experimental tasks. We control for taxpayer-specific preference characteristics (e.g. loss aversion, risk attitudes), economic characteristics (e.g. education) and demographic characteristics (e.g. age, gender, marital status, religion). In addition, we explore the effects of varying the tax and detection/enforcement parameters on tax evasion. 15
Several empirical results support the predictions of our theoretical model. In the simplest estimation, under a linear utility function, the mean loss aversion for our data is 1.83. For a non-linear utility function, the mean loss aversion is 1.37 for non-labour income and 1.53 for labour income. This supports our conjecture on source dependent loss aversion.
Even when there is an effective 100% subsidy to evasion, taxpayers declare, on average, 35% of their income, which is consistent with the presence of moral costs of evasion. 16 Moreover, in the presence of a subsidy to evasion, unprimed subjects declare, on average, more of their non-labour income, which is consistent with our hypotheses on income-specific differences. However, we do not measure moral costs for different sources of income, and it is not clear how to do so. 17
In terms of 'direct effects' in a Tobit regression, those who are loss averse declare 18.1% more of their income, relative to those who are loss seeking. This is consistent with our theory. It also provides the first direct empirical evidence, using subject-specific, directly measured, loss aversion, for the underlying transmission channel in most 'prospect theory-based' explanations of tax evasion, as described above.
We also show that the effects of loss aversion are more complicated than anticipated. They are influenced by the source of income (as postulated), but also by risk preferences, in a manner which is a new result that cannot be accommodated within the predictions of our theoretical model, or any other decision theory model that we are aware of. Loss averse and risk averse taxpayers declare 7.6% more labour income relative to non-labour income. However, loss averse and risk loving subjects declare 19.3% less labour income, relative to non-labour income. It is 'as if' risk loving behaviour reverses the cautionary effects of loss aversion on declared incomes for labour income. Loss seeking and risk averse subjects declare 3.6% more labour income as compared to non-labour income. In this case, the cautionary effects of risk aversion seem to overweight the effects arising from loss seeking behaviour. However, this is not a general finding, as we also report exceptions depending on the source of incomes.
In conjunction, our results show that tax evasion behaviour is driven not just by loss aversion, but also by moral costs, mental accounting and risk preferences.
Finally, we confirm some of the standard effects that have already been identified or tested in other models. Our model predicts that tax evasion is decreasing in the deterrence parameters, audit probability and penalty rate, as in models based on expected utility theory, and we confirm this with our data. We also show that evasion is decreasing in the tax rate, as predicted by prospect theory, where no Yitzhaki puzzle arises.
Schematic Outline of Paper
Section II presents our model and summarises the theoretical predictions. Section III outlines our theoretical approach to measuring loss aversion and risk attitudes. Section IV describes the experimental design. Section V provides the descriptive statistics for the model and the findings on loss aversion and risk attitudes. Section V tests our comparative static predictions of the amount evaded with respect to the audit penalty rate and the tax rate. Section VI gives a Tobit analysis of the proportion of declared income and highlights its determinants. Section VII concludes. We provide the details of all the theoretical results in the study and some additional statistical findings in a separate supplementary section.
The Model
We use the generic Allingham-Sandmo-Yitzhaki model of tax evasion, adapted to prospect theory by Dhami & al-Nowaihi (2007). We relegate the full model and the derivations to the supplementary section. 18 We summarise the essential features of the model in this section, and the theoretical predictions in the next section.
We distinguish between the source of the taxable income, that is either labour income, L, or non-labour income, N. We write the income of the taxpayer from source
Each source of income is taxed at the identical constant marginal rate t, 0 < t < 1. The taxpayer chooses to declare income
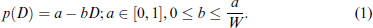
The restrictions on a,b ensure that
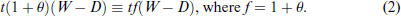
We call f the fine rate per unit of evaded taxes. A tax evader experiences morality costs
We use prospect theory in our analysis. In prospect theory, taxpayers are either in the domain of gains (income greater than reference point) or in the domain of losses (income lower than the reference point). The 'status-quo' serves as a powerful reference point for humans, animals and plants (Kahneman & Tversky, 1979; Kahneman & Tversky, 2000; Dhami, 2019, Vol. 1). Furthermore, the legal framework (e.g. legal tax liabilities) provides a useful, and empirically satisfactory, reference point and enhances the status-quo in applications, particularly tax evasion (Dhami & al-Nowaihi, 2007, 2010).
21
For this reason, we define the reference income, R, of the taxpayer to be the legal after-tax income
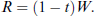
Dhami & al-Nowaihi (2007) show that this is the 'unique' reference point such that for any level of declared income,
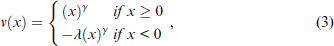
where x is an outcome relative to a reference point. The typical restriction on the two parameters in (3) are
As discussed in the introduction, earned labour income may create greater entitlements relative to unearned non-labour income through differences in loss aversion and moral costs of evasion. A formal statement of this assertion requires us to temporarily invoke the subscript

and relatively higher loss aversion from labour income (giving up a unit of income that one feels more entitled to, is more aversive).

We allow for individual-specific and income-source-specific heterogeneity in preference parameters, but suppress it in the formal notation.
We now directly give the theoretical predictions of the model. The details of the derivations are in the supplementary section. There are two states of the world. (1)
(a) (Effectiveness of deterrence) (b) (Loss aversion) (c) (Explanation of Yitzhaki puzzle) (d) (Morality costs)
Discussion of the results: An increase in the probability of detection (the parameter 'a'), or an increase in the audit penalty, θ, reduces the expected marginal returns from evasion, which reduces evasion (Proposition 1a). An increase in loss aversion increases the losses that arise in the state
Recall from (4) and (5) our hypotheses that for earned labour income, loss aversion is relatively higher
We now show how the result in Proposition 1 is modified with an exogenous probability of detection,
However, the intuition for the comparative static effects is as in Proposition 1, which we do not repeat here.
(a) (Exogenous probability of detection, a) Let
(b) (Penalty rate, θ) Let
(c) (Tax rate, t) There exists a critical value of the tax rate
(d) (Loss aversion, λ) There exists a critical value of the parameter of loss aversion
We split the discussion in this section into (1) the theory behind our elicitation of loss aversion, based on a lottery choice task, that is separate from the tax evasion task 26 and (2) the bisection method for generating indifference between lotteries applied to our problem. We also compute the risk attitudes of subjects.
Theoretical Framework for Estimating Loss Aversion
Suppose that the income of the subject is y, which could either be in treatment T1 or T2. We assume that the reference income, r, of the subject is the status-quo income, so r = y (and this is made salient in the experimental instructions). We fix an experimenter-provided outcome z > 0 and a probability p > 0. We then elicit the outcome value x > 0 for which the subject expresses indifference between the following two lotteries:
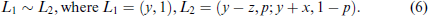
Lottery L1 allows the subject to keep the income y for sure. In lottery L2, the subject gains an amount
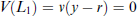
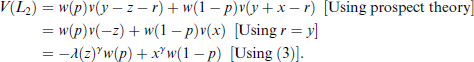
Thus, the indifference in (6) implies that
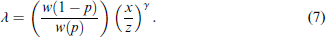
In particular, for the case p = 0.5, that we use in our experimental design, we have

We obtain an identical result using linear probability weighting
In Equation (8), there are two unknowns on the RHS, x and γ (recall that z was chosen by the experimenter in Equation (6)). We now show how to elicit the preference parameter, γ, of a subject with income y and then we show how to estimate x.
We now describe our theoretical framework for the calculation of γ. We elicit the certainty equivalent value C such that a subject exhibits the following indifference

The lottery (y,0.5;2y,0.5 offers a 50-50 chance of 'keeping the status-quo income y ' or 'doubling the status-quo income y ' (indeed, such framing, which we use in the experimental instructions, makes the status-quo income salient). The reference income equals the status-quo income y (r = y), so
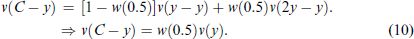
The two-parameter Prelec probability weighting function
Using Equation (3), and the approximation

Esstimation of x Using the Bisection Procedure
In this section, we outline the subjective estimation of x in Equation (8) following the bisection method. Consider the two lotteries L1 and L2 in Equation (6), where y,z, and p are fixed. It is clearer to denote L2 by L2(x). Our objective is to find x after offering subjects a series of 6 lottery choices of the following form.
Choice 1: Subjects are given a choice between
(1.1) If
(1.2) If L1 is chosen over
Choice 2: Subjects are given a choice between
(2.1) If
(2.2) If L1 is chosen over
Choice
Estimation of γ Using the Bisection Procedure
In order to estimate λ in Equation (8), we first need to estimate x (which was done above). Then, in order to approximate γ in Equation (11), we elicit the value C such that the indifference in Equation (9) holds. We employ the bisection method with 6 iterations, as in Section III.
Risk Attitudes
The estimation of γ in Section III allows us to elicit data on the subject's risk attitudes as well. The reason is that we have elicited the certainty equivalent C of the lottery
Our experiments were conducted between March and November 2022 over one-on-one zoom sessions with the experimenter. 30 We recruited 525 students from various universities in India. The experiment was programmed in LIONESS, developed by Giamattei et al. (2020).
The payments to the subjects consisted of three components: a show-up fee of Rs. 100 and two incentive-based payments, which were contingent on their choices in the two tasks—the lottery choice task and the tax payment task. On average, subjects took 35 minutes to complete the experiment. The average payment per subject was Rs. 244; thus, the per hour payment, on average, was Rs. 418. 31 Subjects were assured of strict anonymity of their choices. All subjects were paid in private after the experiment through an automated process which excluded the experimenter, and subjects knew this.
We used a between-subjects design to derive the contrast between our treatments. Subjects are randomly assigned to primed and unprimed groups. 32 Subjects in the primed group are asked to read a factually accurate but fairly extreme description of tax evasion in India, with potentially important implications for the provision of critical public services in India. 33 Priming subjects might highlight tax-relevant information and engage descriptive norms of behaviour (e.g. if others evade, I might as well evade) or have an effect on the underlying behavioural parameters. On the other hand, if the information provided in the primed treatment is already readily available to the subjects in the unprimed treatment through their outside-the-lab experiences, then we would expect little effect of priming.
Within the primed and unprimed groups, subjects were randomly allocated to one of the two treatments. 34 In treatment T2, subjects could earn 'labour income' by performing a tedious task that required them to count the number of 7s and 9s in different sequences of densely packed numbers in 225 seconds. Based on the number of correct answers, subjects could earn one of the following levels of labour income: 25, 50, 75, 100, 125. To keep the distribution of subjects for each income level comparable in the two treatments, in treatment T1 we randomly allocated subjects to unearned non-labour income levels of 25, 50, 75, 100, 125, using an earlier pilot. This successfully ensured comparable frequencies of subjects for each income level in the two treatments.
Once the income of the subjects was determined (Task 1), they participated in the following two main tasks (Tasks 2 and 3) whose order was randomised. (1) A lottery task that was designed to elicit loss aversion, and (2) a tax payment task in which subjects made a tax evasion decision. We now explain these tasks.
The lottery task was conducted using the income of the subjects from Task 1 (non-labour income in T1 and labour income in T2). The elicitation of the loss aversion parameter, for each subject, is implemented using the process described in Section III.
Using either their non-labour income (T1) or labour income (T2), we asked subjects to declare their income for tax purposes in response to the following 7 questions. The order of these questions was randomised through a Latin Square Design. For the audit probability function in (1),
Questions Q1-Q3 ask subjects to declare their income for 3 different values of the tax rate (5, 30, and 60%). The audit probability is held fixed at 3% and the fine rate at f = 2, where f = 1 + θ is defined in (2); these are empirically realistic values.
Questions Q4-Q6 ask subjects to declare their income for 3 different values of the fine rate
Question Q7 asks subject to declare their income under an endogenous detection probability,
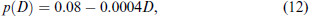
so a = 0.08 and b = 0.0004, which satisfies the restrictions in (1). Thus, starting with an exogenous probability of detection of, say, 8%, for every increase in declared income, D, of 25, the probability of detection decreases continuously by 1%. As an example, for someone with an income of 125, who declared their entire income, the detection probability is 3%.
Since the probability of detection is kept fixed for Q1-Q6, the relevant predictions of our model are contained in Proposition 2. Q7 enables us to test the prediction of our more general model (see Proposition 1) based on an audit probability that is decreasing in the amount declared.
Several illustrative examples were given to the subjects to enhance their understanding of the experiments. Subjects also had to answer non-trivial test questions correctly to proceed in the experiment.
In this section, we first give general descriptive statistics, followed by our estimates of loss aversion and risk aversion.
Basic Data on Participation and Evasion
Out of 525 people who completed the experiment, 31 people participated twice and we only considered their first attempt. For 3 subjects we have some NAs due to software issues and 14 subjects were not students. Dropping these individuals, we have a sample size of 477.
The number of subjects in each category of income (25, 50,75, 100, 125) for each treatment is shown in Table 1. There is a reasonably similar frequency of subjects in each treatment and the median of income is the same across all 4 treatment arms.
The Number of Subjects in Each Income Category for Each Treatment.
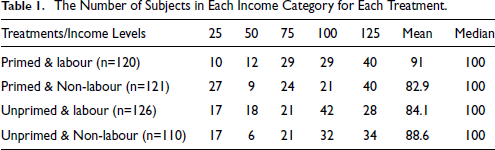
The Number of Subjects in Each Income Category for Each Treatment.
In Table 2, we report the mean and the medians of the percentage of declared incomes, across all subjects, in all income categories, for each of our 7 questions (see Section IV for a detailed description of the questions). The supplementary section provides details on the corner solutions (D = 0, D = W) and shows that no order effects were found.
Percentage of Declared Income for Each Question.
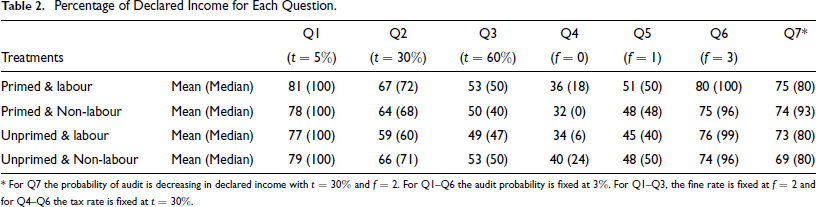
* For Q7 the probability of audit is decreasing in declared income with t = 30% and f = 2. For QI-Q6 the audit probability is fixed at 3%. For QI-Q3, the fine rate is fixed at f = 2 and for Q4-Q6 the tax rate is fixed at t = 30%.
As noted earlier, due to the opposing effects of loss aversion and morality, the overall treatment effects are an empirical question (for an econometric analysis, with controls, see Section VI below). Yet, positive treatment effects (lower evasion for labour income) will indicate to us that loss aversion plays a relatively more important role than moral costs of evasion. In Table 2, there are examples of significant differences in evasion across treatments that should not arise in the absence of source-dependent evasion, or mental accounting. In Q2, and for unprimed subjects, there is a statistically significant difference in declared incomes across the two income sources (3 rd and 4 th rows of column labeled Q2) with p = 0.0396. 36 In Q6, and for primed subjects, there is a statistically significant difference in declared incomes across the two income sources (1 st and 2 nd rows of column labelled Q6) with p = 0.0458.
Across all questions, once primed, subjects declare more labour income (58%) as compared to non-labour income (51%). Among the unprimed group, subjects declare more non-labour income as compared to labour income in Q1-Q5. 37
In order to compare the differences in declared incomes arising from exogenous and endogenous probabilities of detection (respectively the cases a > 0, b = 0 and a,b > 0), keeping fixed tax rates and penalties at empirically realistic levels (30% tax rate and a fine rate of 3), we compare the results for Q2 and Q7. For the unprimed group, the difference between declared incomes in Q7 and Q2 is greater for labour income as compared to non-labour income (73-59 = 14 in 3 rd row as compared to 69-66 = 3 in 4 th row) suggesting source-dependent tax evasion.
Loss Aversion and Risk Aversion
Our measurement of loss aversion is described in Section III; see Equation (8). Our estimates of mean and median loss aversion are 1.46 and 1.06 respectively. 38 This figure is lower than other estimates of loss aversion in the literature that assume a linear utility function. Most estimates of the prospect theory utility function report close to a linear utility function, at least for small stakes (Dhami, 2019, Vol. 1). Under a linear utility function, the mean of loss aversion for our data is 1.83. Chapman et al. (2024) report median values of loss aversion between 1.5 and 2.5 in their survey of the literature. For our data, and employing a non-linear utility function as described above in Section III, the median value of loss aversion is 1.05 for non-labour income (T1) and 1.17 for labour income (T2). The mean value of loss aversion, under a non-linear utility function, in our data, is 1.37 in T1 (non-labour income) and 1.53 in T2 (labour income). 39 These figures are consistent with our first conjecture about higher loss aversion for labour income (see (5)).
Chapman et al. (2024) use data for 2000 US respondents on MTurk to measure loss aversion using a new procedure (DOSE). They find a nearly equal split between loss averse (λ > 1) and loss tolerant (λ ≤ 1) individuals. By contrast, a comparison of 8 lab studies shows that loss averse subjects range from 70 to 83% of the total; the rest, 13% to 30%, are loss tolerant.
40
We find that 52% of our student subjects in T1 and 58% in T2 are loss averse. We follow the Chapman et al. (2024) binary distinction between loss averse (
Recall that our risk aversion measure was obtained by using lotteries in the gains domains only so as not to confound its measurement with loss aversion. 42 We have the following contingency values. Of the loss averse subjects, 193 are risk averse and 69 are risk loving. Of the loss tolerant subjects, 104 are risk averse and 111 are risk loving. The value of Cramér's V (a measure of association between two categorical variables) is 0.2596, indicating low association between risk aversion and loss aversion, allowing for their simultaneous use in the Tobit regressions in Section VI.
Comparative Static Results for t,θ
In this section, we analyze the effect on declared income as we vary the tax rate, t, and the penalty rate, θ. The relevant questions are Q1-Q6, with an exogenously fixed probability of detection
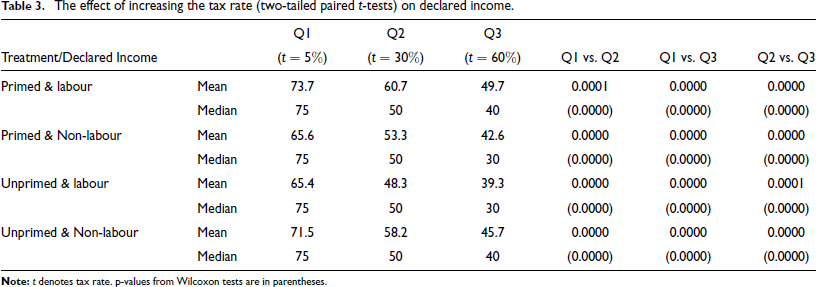
The Effect of Increasing the Tax Rate
Table 3 shows the average of declared incomes across all treatments for Q1-Q3, with respective tax rates t = 5%,30% and 60%. We keep fixed the penalty rate θ = 1 and the audit probability p = a = 3%, b = 0). We find that the declared income goes down with an increase in the tax rate, which is consistent with our model. Thus, there is no Yitzhaki puzzle under prospect theory (Proposition 2c), in line with the evidence, while there is a predicted Yitzhaki puzzle under expected utility theory and under reasonable attitudes to risk. There is a significant fall in the declared income when the tax rate goes up from 5 to 30%; from 5 to 60%; and from 30 to 60% (
The effect of increasing the tax rate (two-tailed paired t-tests) on declared income.
Effect of Increasing the Penalty Rate
Table 4 compares declared income across treatments as the fine rate
The Effect of Increasing the Fine Rate, f (Two-Tailed Paired t-Tests) on Declared Income.
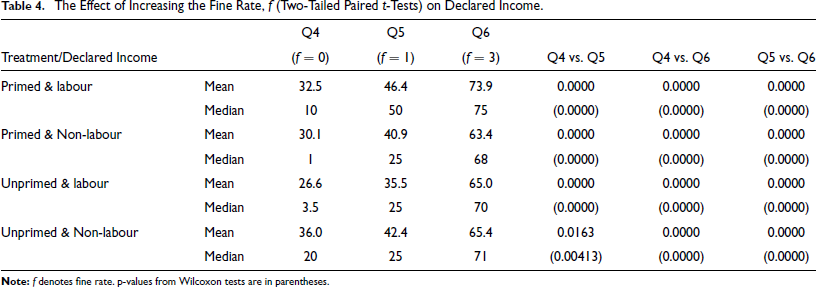
In pairwise comparisons of the declared incomes for Q4, Q5 and Q6, there is a significant increase in the declared incomes when the fine rate increases from 0 to 1, and 3 (
Table 6 gives the results of the Tobit regression analysis with robust standard errors for data that is pooled across all questions.
44
Since we have 5 different levels of incomes, and taxpayers make their declaration decision based on their level of income, we use the proportion of declared income,

where u is normally distributed with mean zero and variance normalised to unity; X is a vector of explanatory variables and β is a vector of coefficients. The explanatory variables used in (13), with the corresponding names given in Table 6, and the basic data on the individual categories, are as follows.
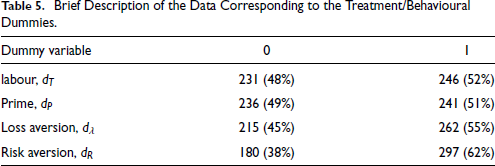
Table 5 gives the data on the different categories of the dummy variables listed above. We have a fairly even distribution across the relevant categories.
Brief Description of the Data Corresponding to the Treatment/Behavioural Dummies.
Probability of detection: Dummy variable that equals to 1 for endogenous audit probability (
Income: Continuous variable corresponding to different level of income received during the experiment.
We also use the interaction terms:
'Time' indicates the length of time taken for the completion of the experiment.
'Age' gives the self-reported age of subjects. The minimum age is 18, the maximum is 37, mean age is 21.6, median is 20, and the standard deviation is 2.80.
'Gender' is a dummy for gender and takes the value 1 for female and 0 for male; Two hundred forty-five out of four hundred seventy seven subjects (51%) are males and
'Marital' is a dummy for marital status and takes the value 0 for single and 1 otherwise. Since our sample consists of students, most are single 464/477 (97%). Seven subjects are married, 2 subjects are in a domestic relationship and 4 have indicated 'other' for their marital status.
'Religion' is a dummy for religion. It equals 1 for Hindu subjects and 0 otherwise. The majority of our sample is Hindus 335/477 (70%) (Hindus are approximately 80% of the Indian population). Others in the sample subscribe to Islam (4%), Christianity (3%), Jainism (4%), Sikhism (
'Education' is a dummy variable. It equals 1 for Masters/PhD students, and 0 otherwise. 221/477 subjects (46%) are graduate students, and 256/477 subjects (54%) are undergraduates.
In the supplementary section, we successfully demonstrate the robustness of our results to the following extensions. (1) Measurement of the loss aversion parameter on a continuous scale. (2) Different parameters for the probability weighting function used to estimate loss aversion. (3) Using a continuous measure of risk aversion. (4) Using different model specifications.
In Table 6, we describe 3 successively more complex econometric models. In Model 1, we only include the deterrence parameters, loss aversion, risk aversion and the treatment dummies (labour and Prime) as the explanatory variables. None of the treatment dummies are significant at 5%. In Model 2, we add several individual-specific covariates, such as time, age, gender, marital, education and religion. In our most general specification, in Model 3, we also include the interaction terms between various dummy variables (these are
Tobit Regression Results.
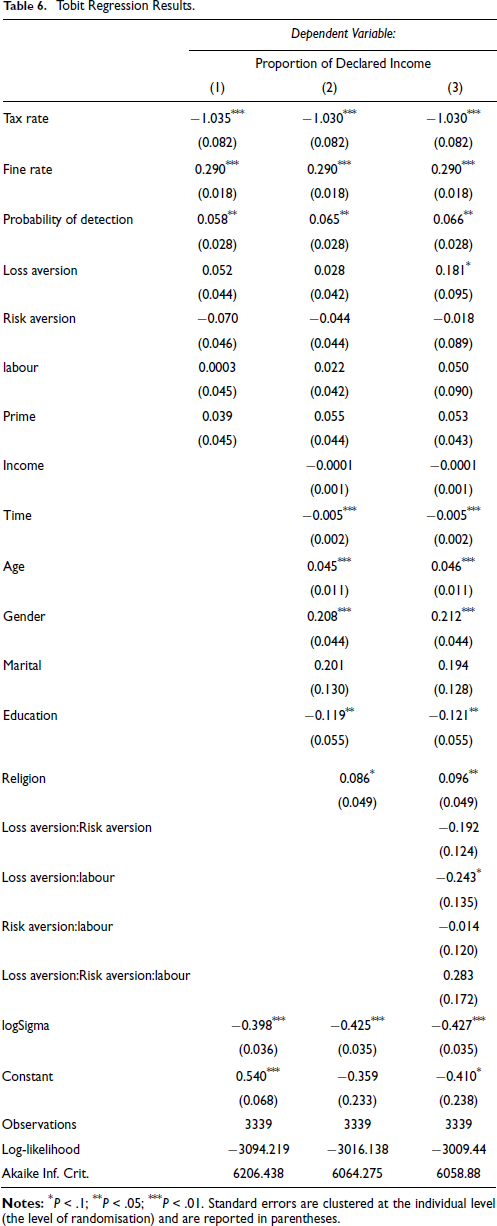
We first verify two effects that we have already demonstrated in Section V above, and are predicted by our model (Proposition 1 and Proposition 2). An increase in the tax rate reduces declared income, which is consistent with prospect theory, but not with expected utility theory (Yitzhaki puzzle). An increase in the fine rate increases declare income. Both are statistically significant at 1%.
Recall our discussion about ambiguous treatment effects predicted by economic theory, hence, the treatment effect is an empirical question. We find that taxpayers declare 5% more labour income relative to non-labour income. Thus, overall and in terms of the direct effect, loss aversion dominates morality costs in inducing greater declaration of labour income. Taxpayers declare, on average,
The more educated students declare less income; Masters/PhD students reduce declared income by
Loss aversion, on its own, is significant and increases declared incomes. In terms of the direct effect, those who are loss averse declare
We now use Table 6 to identify several effects arising from the interaction of the dummy variables in our model. We use the notation
The main result of interest, from a treatment effect point of view, is the average differences in the declared amounts of loss averse subjects
Loss averse taxpayers,
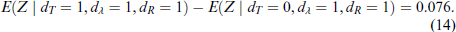
From (14), restricting attention to loss averse
Loss averse taxpayers,
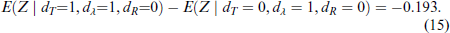
From (15), loss averse subjects, who are also risk loving, declare 19.3% less of their labour incomes as compared to their non-labour incomes. Comparing (14) and (15), risk aversion strengthens the cautionary effect of loss aversion, while risk loving behaviour attenuates, and even reverses the effect of loss aversion. As far as we are aware, this is the first demonstration of such a result in the literature on decision making under risk and uncertainty, based on directly measured subject-specific loss aversion and risk aversion.
The results in (14) and (15), since they directly reveal evasion differences for two different sources of income, that are identical in all other respects, support our claims on source-dependent mental accounting in this study. A similar comment applies to the results below.
Loss seeking taxpayers,
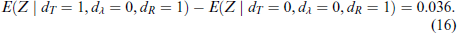
From (16), restricting attention to loss seeking
Loss seeking taxpayers,
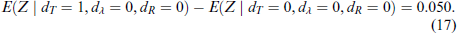
From (17), restricting attention to loss seeking
Our main contribution is to provide the first rigorous demonstration of a link between subject specific loss aversion and tax evasion, which lies at the heart of many modern theories of tax evasion.
There are several novel features of our analysis. First, we derive theoretical predictions for tax evasion by exploiting the link between loss aversion, risk aversion, mental accounting and moral costs in a prospect theory framework. Second, we propose a theoretical framework for measuring subject-specific loss aversion; and empirically determine a strategy to measure it that is independent of risk aversion. Third, a combination of loss aversion, moral costs and risk aversion is essential for an understanding of tax evasion that depends on the source of income. For instance, it appears that risk aversion strengthens the cautionary effect of loss aversion, while risk loving behaviour attenuates the effect of loss aversion. However, a third dimension, the source of income, makes it difficult to present truly generalised findings. Fourth, our empirical results show that entitlements to income influence the degree of evasion (source-dependent evasion). Fifth, we show that the effectiveness of loss aversion in reducing evasion is income-source specific. The interactions of the treatment effect with loss/risk attitudes are significant. These findings suggest the importance of mental accounting. Sixth, we confirm the predicted comparative static effects of the probability of detection, the penalty rate and the tax rate on tax evasion for the same set of subjects, for two different sources of income.
While we are able to explain most of our results, our model is unable to provide explanations of some of the results. This is the case with our finding of new and unknown interaction effects of risk aversion with loss aversion that are income source dependent. This requires further developments in the relevant theory.
Footnotes
Acknowledgement
We are extremely grateful to James Alm, Junaid Arshad, Michele Bernasconi, and Alex ReesJones for their comments and suggestions on earlier versions of the paper. We are grateful to the Centre for Social and Behaviour Change (CSBC), Ashoka University for their facilities. The experiments were run and funded by the CSBC Lab at Ashoka and we thank Bijoyetri Samaddar and Aayush Agarwal for their superb assistance in designing and in the running of experiments.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The authors received no financial support for the research, authorship and/or publication of this article.
Supplementary Materials
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.