
Abstract
Situation models—mental representations formed during comprehension—have evolved significantly beyond their origin in text-based research. Situation models are now used in accounts of comprehension across various media, including films, comics, and even real-world events. This article reviews four key developments in comprehension research over the past 25 years: grounded cognition, multitext comprehension, visual media comprehension, and everyday event comprehension. In all these lines of research, situation models continue to play an important role.
One morning, as Gregor Samsa was waking up from anxious dreams, he discovered that in bed he had been changed into a monstrous verminous bug. He lay on his armour-hard back and saw, as he lifted his head up a little, his brown, arched abdomen divided up into rigid bow-like sections. From this height the blanket, just about ready to slide off completely, could hardly stay in place. His numerous legs, pitifully thin in comparison to the rest of his circumference, flickered helplessly before his eyes.
How do we understand events that are relayed to us via language? A quarter of a century ago, I wrote an article on this topic for this journal (Zwaan, 1999). The core concept of the the article was situation models, which were first conceived as mental representations of the state of affairs denoted by a text (Van Dijk & Kintsch, 1983). The article outlined a theory of situation models called the event-indexing model that was described in much greater detail in Zwaan and Radvansky (1998).
Situation models are models of events. Key components of an event are the time at which it occurs, the location where it occurs, and the protagonists that are involved in it. In addition, the physical causes of or psychological motivation for events are also thought to play a role. These indices are used to integrate subsequent event representations.
Consider the opening sentences in the epigraph to this article. The described events show great overlap on the indices I just mentioned. They all take place at the same time (“one morning”) and at the same location (Gregor Samsa’s bed), involve the same protagonist (Gregor Samsa), and show causal connections (e.g., the blanket is about to slide off because of Gregor’s changed size) and motivation (Gregor lifts up his head to see what has happened to him).
Such overlap between events makes them easy to integrate into an evolving situation model. In contrast, integration becomes progressively difficult as the number of situational discontinuities increases, for example, if a new location is introduced, or a new protagonist, or both simultaneously. The more discontinuities the comprehender encounters at any given point, the more difficult integration becomes (Therriault et al., 2006).
In recent decades, situation models have become a powerful tool in the study of comprehension across various domains. Their applicability has expanded beyond text to encompass picture sequences, films, and everyday situations. Moreover, considerable research effort has been devoted to exploring the internal structure of these models.
In this article I highlight four major strands of research on situation models over the past 25 years: grounded cognition, multitext comprehension, visual media comprehension, and everyday event comprehension. The first strand of research is targeted at the internal structure of situation models, whereas the latter three represent extensions of situation modes beyond (single) texts. Figure 1 provides an integrated view of situation model construction extracted from these areas.
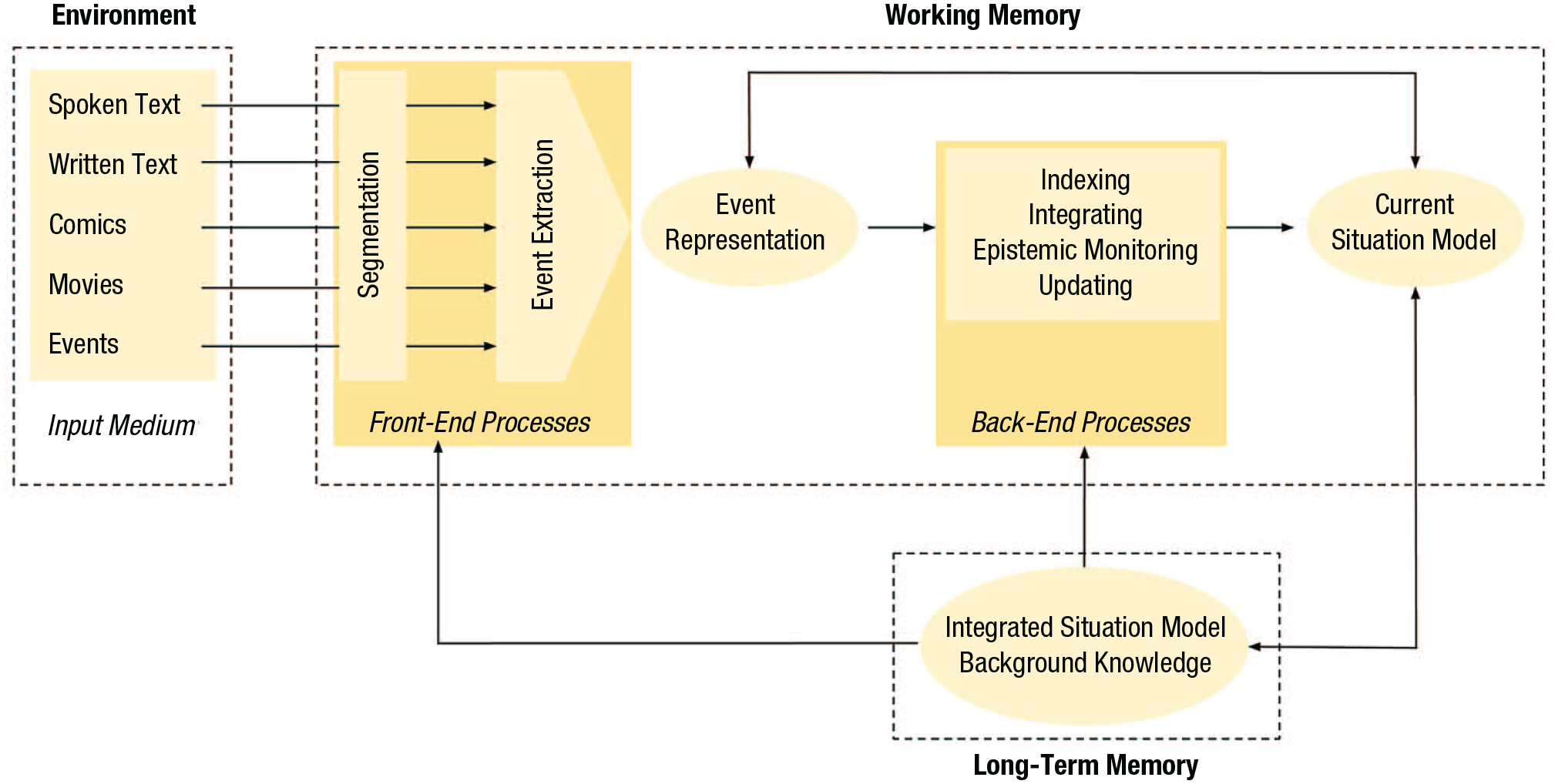
Conceptual representation illustrating the integration of various research areas discussed in this article. This figure describes the processing of a single event. The process is iterative for consecutive events. Comprehension results in the construction of a situation model, which can be acquired through different media or direct experience and is constructed with the aid of episodic and semantic information from long-term memory. Segmentation cues guide the division of continuous information into event units. These cues are specific to each type of input, as is the event-extraction process. Consequently, both segmentation and event extraction vary across media. Both are front-end processes (Magliano et al., 2013). Regardless of the medium, however, their end product is an event representation. Back-end processes (Magliano et al., 2013) operate on the event representation and, unlike front-end processes, function similarly across input types. Event representations are indexed on dimensions such as time, location, and protagonist, facilitating their integration into the current model, which is the active part of the evolving situation model. Typically, the current model consists of the most recently acquired events and is continuously validated against long-term knowledge. Event representations, whether in working memory or long-term memory, may be amodal or take the form of mental simulations, depending on context. The current model can impact the event representation, for example, through anaphoric resolution in language (e.g., if the current sentence contains a pronoun, the current model may contain a representation of the referent so that the reference can be resolved). Long-term memory is involved throughout these processes, contributing semantic, episodic, and procedural knowledge (e.g., segmentation strategies). It is also the neural substrate for the evolving situation model. The bidirectional arrows indicate that comprehension is not only shaped by prior knowledge but also can contribute to knowledge acquisition. Multitext integration follows a similar process as the one described here but includes an additional indexing dimension: information source. Finally, some media require the simultaneous processing of multiple information streams, such as movies with subtitles, that combine visual, spoken, and written linguistic input.
Grounded Cognition
A significant challenge in research on cognition in general and comprehension in particular is the symbol grounding problem (Harnad, 1990). Consider a semantic network: If the labels are removed, the network loses its meaning. As Harnad highlighted, the meaning of such a network—like a situation model—becomes fully dependent on the interpreter’s mental representations. For instance, the labels “insect” within a semantic network lack intrinsic meaning, as does [IN, GREGOR SAMSA, BED] in a propositional network; their meaning is conferred entirely by the human interpreter of the network reading the labels. As a result, semantic networks, along with propositional and event-node networks, are vulnerable to the grounding problem.
It should be noted that it has been argued that abstract symbol systems, such as the ones mentioned above, are able to overcome the grounding problem once the knowledge base is sufficiently large (e.g., Lenat & Feigenbaum, 1991). Indeed, the impressive performance of current large language models, even in tasks that seem to involve perceptual processes, lends support to this idea. However, the performance of such models might tell us little about human performance. The way humans acquire knowledge is fundamentally different from that of large language models. Moreover, the performance of such learning systems might rely on spurious correlations in the data, a phenomenon known as shortcut learning (Mitchell & Krakauer, 2023).
Several researchers have suggested ways to tackle the grounding problem, with seminal contributions from Glenberg (1997) and Barsalou (1999). These articles have given rise to a wave of empirical studies. The primary focus of the subset of these studies that are relevant to this article has been to examine whether and how language comprehension is grounded in perception and action.
Among other things, these studies have examined whether perceptual and action representations are activated during language processing. In a recent consensus review of the literature, Körner et al. (2023) concluded that the empirical evidence for grounded cognition is somewhat mixed. The authors discussed several common criticisms of research on grounded cognition, as well as how these criticisms have been addressed in the literature. On balance, they concluded that there is evidence for grounding at different levels of language, from words to texts, although grounding found in experiments may be more subject to contextual factors than originally thought.
Nevertheless, the authors argued that although sensorimotor simulations may be task-dependent, they may also operate automatically in many normal circumstances. Importantly, outside the laboratory, in naturally produced language, which is not specifically designed to elicit grounded cognition, there are valuable insights into how grounded and embodied processes shape language. Evidence from subword iconicity phenomena and distributional patterns in natural language corpora demonstrates that grounding and embodiment frequently influence language use, suggesting these processes are integral to language and shape it in real-life contexts.
In an article directly relevant to the current discussion, I argued that whether comprehension involves sensorimotor simulations or abstract representations depends on the degree to which comprehension is embedded in the environment (see Zwaan, 2014). Two extremes on this dimension are everyday event comprehension versus the comprehension of a text about an abstract domain. Figure 1 accommodates both representational formats.
Experimental research on grounded cognition could be criticized because of its relative lack of ecological validity. The typical setup of psycholinguistic experiments with large numbers of very short and unrelated texts limits the creation of a fictional world that could enhance grounding processes by providing relevant contextual information, potentially making it more challenging to detect grounding effects (Zwaan, 2024). If this is true, the lack of ecological validity in experiments on grounding might lead us to underestimate the role of sensorimotor representations in comprehension. Larger effects might occur if the comprehender is enabled to build up a more extensive and more detailed referential world, as is the case in novels, extensive news stories, and even short stories such as “The Metamorphosis.”
Thus, there is evidence that the internal structure of event representations is grounded in perception and action, but the extent to which this is context-dependent is a topic for further research. This research should involve naturalistic stimuli.
Multitext Comprehension
To learn about concepts such as climate change or political polarization, people often make use of multiple texts (e.g., multiple news reports, opinion pieces, and Wikipedia articles). A single source is often insufficient to gain an adequate understanding of a concept. The advent of the Internet has dramatically increased the availability and accessibility of multiple texts about the same topic. Along with the rise of the Internet, research on multitext comprehension has increased (List & Alexander, 2017).
A single text is most often written by a single author or group of authors with a single, coherent perspective, ideally leading to a coherent situation model. However, comprehending multiple texts about the same situation poses an extra challenge because such texts do not always neatly combine into a set of cues that allows for the construction of a coherent situation model (Bråten et al., 2011; Saux et al., 2021). Comprehenders have found ways to deal with this.
People who form situation models from multiple texts represent not only the situation that is being described but also the sources from which they obtained the information (Kim & Millis, 2006). In addition to comprehending the referential situation, readers must also comprehend how the documents represent (and sometimes distort) that situation (Britt et al., 2013). Thus, comprehending multiple texts involves creating multiple situation models with links to their sources in what are called document nodes. Together with the situation models gleaned from the individual texts, the document nodes make up the intertext model. One could view the document nodes as a version of the context model as proposed by van Dijk (2024) for single texts because readers also form representations of the communicative situation in single texts.
Whether or not comprehenders engage in extensive multitext integration depends on a great number of factors, one of which is the comprehension context. In an educational task, the emphasis will be on achieving a coherent understanding of a concept. In a news-reading situation, readers may be (more) subject to confirmation bias, causing them to overlook information that contradicts their point of view. In the context of multitext comprehension, the notion of epistemic monitoring has been proposed (Richter & Maier, 2017).
Epistemic monitoring means that comprehenders optimize their processing by monitoring the perceived plausibility of arguments in a text and allocate their resources to the arguments they find the most plausible. As a result, they will construct stronger situation models for information that is consistent with their prior beliefs in trying to integrate multiple texts than for information that is inconsistent with these beliefs. Epistemic monitoring is thought to be a routine aspect of text comprehension. As such, belief-biased processing is not necessarily the result of motivated reasoning. In many cases, it is the outcome of routine comprehension processes to form a coherent situation model.
The notion of situation model construction has informed and is likely to continue to inform research on multitext comprehension. At the same time, research on multitext comprehension has informed theories of situation models, for example, by pointing to the necessity of also mentally representing the documents themselves and by investigating ways in which comprehenders deal with conflicting information.
Visual Media Comprehension
There are fundamental differences between the perceptual and cognitive processes that are engaged during the comprehension of text-born narratives, as discussed in the previous sections, on the one hand and different media on the other hand. Specifically, the front-end processes vary across media. Much work has been done on the front-end processes in sequential picture understanding and how they impact situation model construction (e.g., Cohn, 2020). The comprehender’s assumption here is one of continuity (the sequence of pictures depicts a narrative), as it is with text. But the segmentation of events that form the building blocks of situation models is subject to different rules. For example, where in texts changes in time are indicated by constructs such as time adverbials (e.g., an hour later), sequential picture stories use pictorial cues, such as the change in posture of the protagonists. Learning these cues is necessary to develop the front-end processes that provide fluency in sequential narrative comprehension (Cohn, 2020).
Text and picture sequences are static stimuli. Movies, on the other hand, are dynamic. Given that movies are also complex, directors through the years have developed a repertoire of cues that they use to guide the comprehender’s attention through the narrative world. In experiments in which participants segment movies into event, they are led by such cues and by indices of the situation model, such as time, location, and protagonist discontinuities (Cutting, 2014). Moreover, just as with text, as discussed earlier, Cutting (2014) showed that the number of dimensions on which there is a situational discontinuity has an incremental affect on comprehension
Other research indicates that these cues have a strong influence in that there is a strong convergence among viewers in what they focus on. This is even the case if one group of viewers has been given relevant contextual information, namely the 3 min of film that precede the event of interest, whereas the other group has not (Loschky et al., 2015). One way to interpret these results is to say that because of the complexity of the stimulus, situation model construction has to be strongly—likely more strongly than in text—guided in a bottom-up manner.
Overall, the research on these media suggests that situation model construction is an overarching skill despite the fact that the front-end processes (the memory mechanisms activated by cues and the mechanisms for the extraction of event information) differ widely across media. This conclusion converges with earlier findings that comprehension performance across different media is highly correlated (Gernsbacher et al., 1990).
Everyday Event Comprehension
One of the primary needs of event comprehension is to segment the incoming information into discrete units. In language, events are segmented by clause and sentence markers, in sequential picture understanding by different frames, and in movies by devices such as shots. No such conventional cues are available during everyday event comprehension, making the front end of everyday comprehension very different from the cue-guided segmentation that characterizes the other forms of comprehension.
The lack of external segmentation cues in everyday event comprehension has prompted research into how comprehenders segment visual streams into individual event representations. In this research, event segmentation itself is the major dependent measure (Newtson, 1973; Radvansky & Zacks, 2014; Zacks, 2020). Participants are typically presented with simple animations or more complex video clips that they then segment into bigger or smaller units. Research shows that, just as with text comprehension, changes in time, location, and protagonist play an important role in event segmentation.
Comprehenders rely in part on information that is intrinsic to the events themselves, such as rapid changes in movement or movement direction. In first-person event comprehension, the environment provides additional cues. For example, when comprehenders are moving through a virtual environment, information from a room that they have just passed through is less available to memory than information from the room that they are currently in (Radvansky & Copeland, 2006), which is analogous to what was earlier shown in text comprehension (Bower & Morrow, 1990). In this case the doorway functions as a segmentation cue. “Walking through doorways causes forgetting,” as Radvansky and Copeland put it.
In addition to these visible cues, comprehenders also rely on inferential processes about human intentions. Just as in other forms of comprehension, inferred intentions provide structural information about action sequences. Comprehenders have been found to be very quick at identifying the agent, patient, objects, and their roles in an event segment (Hafri et al., 2018), consistent with this line of reasoning.
These types of cues, visible and inferred, are associated with the events that are to be comprehended. There is evidence that endogenously triggered internal states in the comprehender such as affective states, goal states, and motivational states also play a role in event segmentation (Wang et al., 2023). Thus, even though externally provided segmentation cues are lacking in unmediated everyday event comprehension, people have found additional sources of information for event segmentation.
Conclusion
The comprehension of various media—ranging from text and visual narratives to everyday events—relies heavily on the construction of situation models. Although front-end processes, such as the cues for event segmentation, differ significantly from text to sequential picture narratives, to films, to everyday events, the back-end processes of situation model construction share commonalities. Research shows that sensorimotor representations are involved in these back-end processes, although their involvement may vary depending on the context. Integrating information from different sources into a coherent situation model presents unique challenges. We now have a better understanding of how comprehenders try to overcome them.
Although not as dramatic as Gregor Samsa’s transformation, the evolution of situation model research over the past 25 years has been significant. From its origin in text-based research, it has expanded our understanding of how individuals comprehend events across different media and in everyday life and how we may recruit sensorimotor representations in doing so.
Recommended Reading
Cohn, N. (2020). (See References). Broad-ranging review of visual narratives.
Körner, A., Castillo M., Drijvers, L., Fischer, M. H., Günther, F., Marelli, M., Platonova, O., Rinaldi, L., Shaki, S., Trujillo, J. P., Tsaregorodtseva, O., & Glenberg, A. M. (2023). (See References). Consensus article by a large group of authors with different viewpoints on grounded cognition.
List, A., & Alexander, P. A. (2017). (See References). Useful overview of the literature on multitext comprehension.
Zacks, J. M. (2020). (See References). In-depth review of event comprehension.