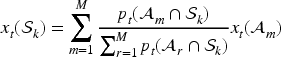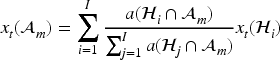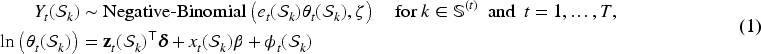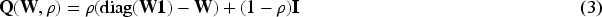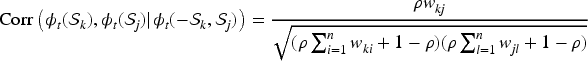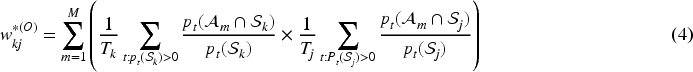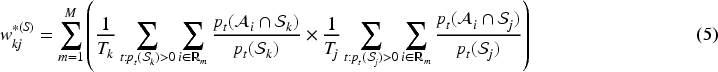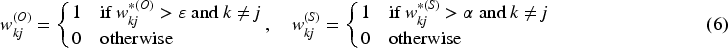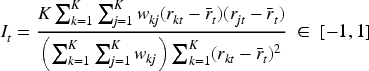Quantifying the effects of air pollution on respiratory ill health treated in primary care when the locations of the populations at risk are partially unknown
Open accessResearch articleFirst published online 2026
Quantifying the effects of air pollution on respiratory ill health treated in primary care when the locations of the populations at risk are partially unknown
Most air pollution and health studies focus on severe outcomes such as hospitalisations and deaths, overlooking the impact that air pollution may have on non-hospitalised respiratory ill health treated in primary care. This paper presents a new study investigating the effects of NO2, PM10 and PM on the prescription rates of respiratory medications in Scotland between 2016 and 2020 at a monthly resolution. To enhance the spatial accuracy of the exposure estimates, air pollution predictions at a 1 km resolution are realigned to General Practioner (GP) surgery patient populations by accounting for where patients are likely to live rather than just where the GP surgery is. A Bayesian spatio-temporal conditional autoregressive model is utilised to account for spatial and temporal dependencies in the data, and this paper proposes two novel spatial neighbourhood matrices to better represent the spatial closeness among the patient populations registered at each GP surgery. These matrices improve model performance in capturing spatial correlation compared to standard distance-based approaches, such as using -nearest neighbours approach. The results of the study suggest that particulate matter pollution has a significant impact on prescription rates for inhaled corticosteroids that are taken to prevent the symptoms of respiratory ill health, while NO2 demonstrates no such association.
Air pollution is a complex mixture of numerous components, including gases such as nitrogen dioxide (NO2), and particulate matter which is commonly classified as particles 10 m (PM10) or 2.5 m (PM) in aerodynamic diameter. These and other air pollutants are some of the most important environmental risk factors for non-communicable diseases, affecting global health and well-being. In 2019, ambient air pollution was estimated to have caused 4.2 million premature deaths worldwide.1 In the UK it remains the leading environmental risk to public health, contributing to between 28,000 and 36,000 deaths per year.2 The financial burden is also substantial, with air pollution expected to cost the National Health Service and social care system £1.6 billion between 2017 and 2025.3 Research shows that long-term exposure to air pollutants can affect lung function, trigger asthma and chronic obstructive pulmonary disease (COPD) exacerbations, and increase the risk of lung cancer, imposing a considerable social and economic burden.4–6 The UK has one of the highest asthma prevalence rates globally, with approximately 5.4 million people receiving treatment.7 Additionally, COPD affects around 3 million individuals in the UK and accounts for approximately 1.4 million general practice (GP) consultations per year.8
Most of the epidemiological research on air pollution and health has focused on severe health outcomes, such as hospital admissions9–11 and mortalities.12 Large international collaborative studies have examined these severe end points, including the World Health Organisation-led Estimating the Morbidity from Air Pollution and its Economic Costs (EMAPEC) and Health Risks of Air Pollution in Europe (HRAPIE-2) projects. However, this almost exclusive focus on severe disease cases may underestimate the full burden of air pollution, because it overlooks its effects on non-hospitalised illness treated in primary care where disease cases with relatively mild symptoms are managed. An exception is Blangiardo et al.,13 who linked NO2 concentrations to respiratory medication prescriptions issued in general practice (GP, doctors) surgeries in England, using prescription rates as a proxy for the prevalence of respiratory illness not requiring hospitalisation. They found a very small association between NO2 and GP prescribing rates, with an estimated increase in prescribing rates of 0.07% when NO2 increased by 10 g/m. In a later study, Lee14 separately modelled data on medications that relieve (i.e. short-acting agonists) and prevent (i.e. corticosteroids) the symptoms of respiratory ill health in Scotland, and found that increased concentrations of both PM10 and PM by 2 g/m were significantly associated with around 1% to 3% increases in prescribing rates.
These studies, although valuable, are not very recent and have a short temporal duration, which highlights the need for updated epidemiological evidence to inform current public health policies. For example, Blangiardo et al.13 analysed prescribing data from August 2010 to November 2012 in England, while Lee14 used data from October 2015 to August 2016 in Scotland. Both studies are at the population level, and have the drawback that they relate prescription rates for each GP surgery to estimate pollution concentrations at or near the GP surgery location. They are thus likely to suffer from exposure measurement error, due to the spatial misalignment between each GP surgery’s location and where its registered patient population actually live. Blangiardo et al.13 estimated air pollution concentrations at the GP surgery location, while Lee14 estimated average concentrations in arbitrary circular buffer zones around each surgery, both of which assume that all patients live very close to their GP surgery which is unrealistic. Furthermore, these studies utilised standard distance-based spatial neighbourhood matrices to model the residual spatial correlation structure in the GP-level prescribing data, which only took account of the distances between each pair of GP surgeries. This again may not accurately reflect the real-world spatial proximity and interactions between patients attending different GP surgeries, as patients do not live at the surgery itself and may not even attend their nearest surgery.
Therefore, this paper provides two novel contributions to the literature that addresses these limitations. Firstly, it presents a new Scotland-wide study quantifying the effects of air pollution on the prescribing rates of respiratory medications in primary (non-hospitalised) care, using more recent and long-term data from 2016 to 2020. We focus on the effects that NO2, PM10 and PM have on prescription rates for medications that relieve and prevent the symptoms of respiratory disease such as asthma and COPD. Additionally, we compare the results from the pre-pandemic period (2016–2019) and the full study period (2016–2020), allowing us to examine whether pandemic-related disruptions altered the association between air pollution and respiratory prescription rates. Secondly, we propose novel binary neighbourhood matrices to capture the spatial adjacencies between the GP surgery patient populations, which are used in conjunction with conditional autoregressive (CAR)15 models to account for the residual spatial correlations present in the data. We show that these new adjacency structures better account for the spatial correlation in the data compared to simpler distance-decay based structures that only account for the GP surgery locations and not where their registered patients actually live. In a similar vein we enhance the spatial accuracy of the air pollution exposure estimates compared to the above studies, by again developing estimates based on where each surgery’s patient population are likely to live.
These new methodological developments are set within the Bayesian spatio-temporal random effects model proposed by Rushworth et al.,16 which is fitted using an integrated nested Laplace approximation (INLA) approach17 with variational Bayes approximations. Full details of our proposed methodology are given in Section 3, while the motivating study is presented in Section 2. Section 4 presents the results of the study, focusing on how the newly proposed neighbourhood matrices capture residual spatial autocorrelation, and the estimated effects of air pollution on chronic respiratory prescription rates. Finally, Section 5 summarises the study contributions and directions for future research.
Motivating study
The study is based in Scotland, UK, and utilises monthly data between 2016 and 2020. Our goal is to quantify the impact that air pollution exposure has on the prevalence of less severe cases of respiratory ill health that are treated in primary (non-hospitalised) care. In Scotland, primary care is provided by doctors who work in small groups co-located in GP surgeries, who are responsible for prescribing medications for alleviating and managing the symptoms of disease. Prescribing data were collected from a total of distinct GP surgeries that were operational at some points between January 2016 and December 2020, with 964 being present in 2016 compared to 928 in 2020. This decrease is a result of the trend for surgeries to merge into larger entities,18 and illustrates that the number of spatial data points change over the study period. Figure 1(a) presents the spatial distribution of the surgeries that were operational at any point during the study, and shows that most surgeries are located within the central belt of Scotland containing Glasgow in the west and Edinburgh in the east.
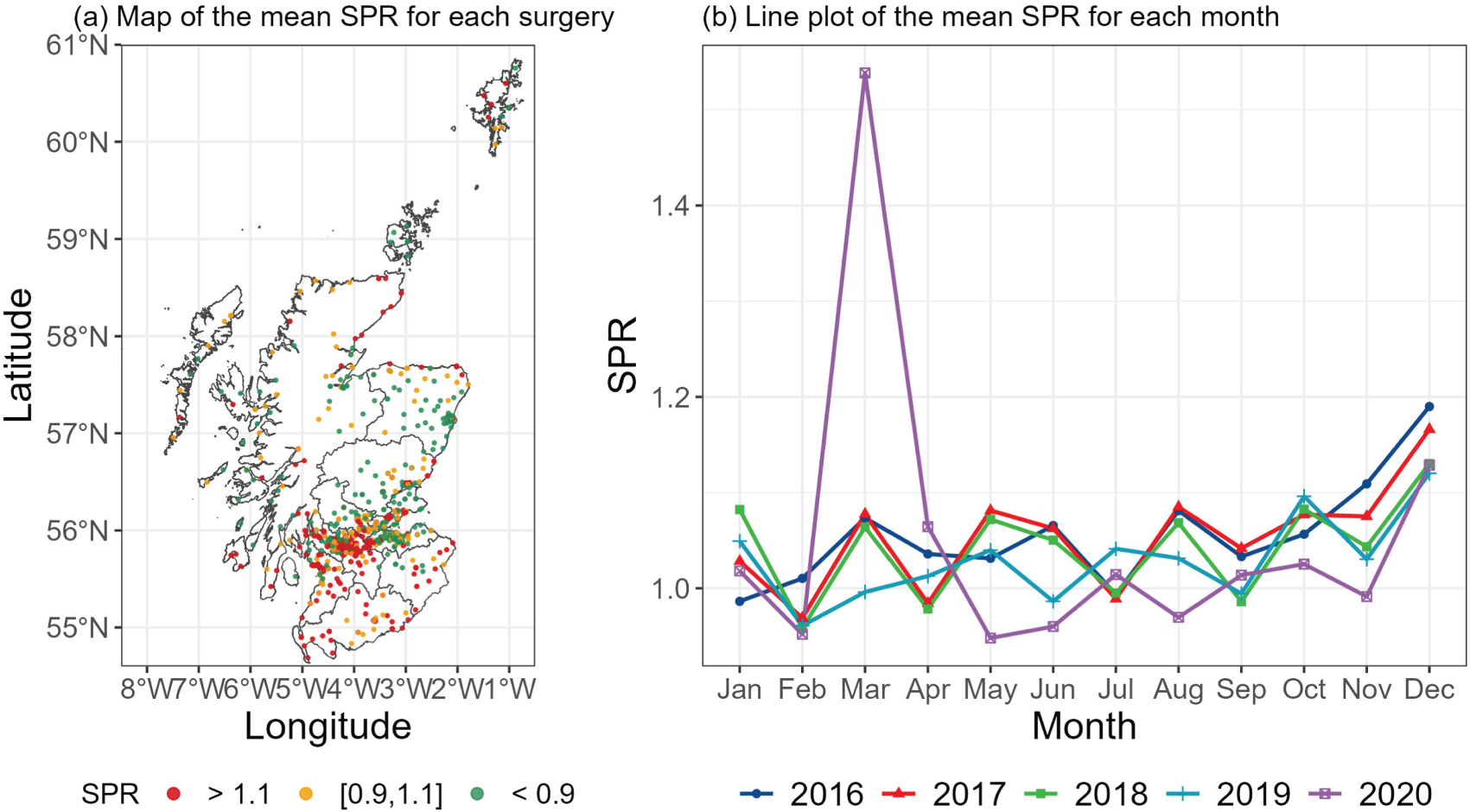
Spatial and temporal trends in the standardised prescription ratios for respiratory medications (the combined Both medication type) in Scotland. Panel (a) displays a map showing the spatial distribution of the mean SPR for each GP surgery between 2016 and 2020, while panel (b) displays a line plot showing the monthly variation in the mean SPRs over all GP surgeries in Scotland. For the former the SPR has been categorised into low (<0.9), medium () and high (>1.1) to aid clarity. SPR: standardised prescription ratio; GP: general practice.
Prescription data
In this study, we use the number of respiratory-related medications prescribed by each GP surgery as a proxy measure for the prevalence of less severe respiratory ill health that does not require hospitalisation. Monthly prescription counts for asthma and COPD medications were collected from the Prescribing Information System database of Public Health Scotland, including medications prescribed for both relieving and preventing the symptoms of these diseases. Following Blangiardo et al.13 and Lee,14 these medications comprise bronchodilators (see British National Formulary (BNF) Chapter 3.1) that relieve the symptoms of respiratory ill health (hereafter Reliever) and inhaled corticosteroids (BNF Chapter 3.2) that prevent the symptoms of respiratory ill health (hereafter Preventer). Additionally, we also consider counts of both medication types jointly (hereafter Both) to assess the sensitivity of our results. To adjust for demographic differences across GP surgeries, expected prescription counts were calculated using indirect standardisation. Specifically, the numbers of male and female patients registered at each surgery in age groups (0–4, 5–14, 15–24, 24–44, 45–64, 65–74, 75–84 and 85+) were multiplied by national age-sex specific prevalence rates of asthma and COPD from the Scottish Primary Care Information Resource database (see Section S1.1 of the Supplemental materials), and then summed to estimate the expected numbers of patients living with respiratory disease at each surgery. These expected numbers were then rescaled to ensure that the total observed and expected prescription counts across all spatio-temporal units are equal.
The standardised prescription ratio (SPR) for each GP surgery and month is computed by dividing the observed prescription count by the expected count, and is analogous to computing the standardised mortality ratio when modelling death data. A value above one indicates a higher risk of respiratory disease compared to the national average, with an SPR of 1.2 corresponding to a 20% increased risk. The spatial distribution of the SPRs for the combined Both medication type averaged between January 2016 and December 2020 is depicted in Figure 1(a), which categorises them into three groups for reasons of clarity in the figure: below average (<0.9); around average (); and above average (>1.1). Areas in Glasgow, southern Scotland, and along some parts of the coast typically exhibit higher SPRs, while Edinburgh and Aberdeen stand out as having lower risks. The monthly temporal trend in the mean SPR (again the Both medication type) across all GP surgeries is displayed in Figure 1(b), which generally exhibits somewhat random fluctuations with a little apparent trend. The exceptions to this are the peaks in SPRs in December each year and in March 2020, which is likely to be because patients stock up on medications while their GP surgeries are closed during the Christmas vacation and again following the national lockdown at the start of the Covid-19 pandemic. The spatial and temporal trends for the Preventer and Reliever medication types are broadly similar and are not shown for brevity.
Air pollution data
The geographical region and monthly temporal resolution of our study aligns with the spatio-temporal resolution used in a recent air pollution prediction study by Zhu et al.19 The aim of this work is to compare the predictive accuracy of a number of different methodologies, including simple linear and additive models, spatio-temporal smoothing models and machine learning algorithms. Each model was applied to the set of monthly average pollution concentrations measured by a network of fixed-site monitors across Scotland, which numbers 94 (NO2), 93 (PM10) and 79 (PM) sites in total across the 60-month study period. The covariates used in these models included numerical pollution and meteorological model outputs at a 1 km resolution, as well as other covariates quantifying population density and distance to the nearest road. The best-performing model for each pollutant was assessed by quantifying its out-of-sample predictive performance, which was achieved by splitting the measurement data into an 80% training set and a 20% test set by site. Each model was fitted to the training set (tuning parameters were optimised via a 10-fold cross validation procedure applied to this training set), before being used to predict observations in the test set. This process was repeated 10 times to ensure that the results were not affected by a single choice of training and test split.
The accuracy of the point predictions were measured by their root mean squared error (RMSE) and median absolute error (MAE), while the appropriateness of their 95% prediction intervals was assessed by their coverage proportions and average interval widths. This model comparison resulted in a random forest being the best prediction algorithm for both NO2 and PM, while a simple linear model performed best for PM10. The RMSE and MAE values from these best-performing models are: NO2: , ; PM10: , ; and PM: , ; which compares to the original monthly average measurement data that have the following ranges: NO2: [1.1, 76.5]; PM10: [2.8, 38.5]; PM: [1.3, 23.9]. The above-mentioned best-performing models were subsequently used to predict monthly average concentrations on a 1 km grid covering all of Scotland for all 60 months, which we use here as the basis for our air pollution exposure metrics. Further details on these predictions are given in Zhu et al.19
Confounders
Data on a number of important confounding factors were collected for this study, the first of which is socio-economic deprivation that strongly correlates with the risk of respiratory disease.14,20 In Scotland, socio-economic deprivation is quantified using the Scottish Index of Multiple Deprivation (SIMD),21 and here we use the index for 2020. The index includes indicators in seven domains such as income, employment, education, health, access to services, crime, and housing, and it is constructed for 6976 small non-overlapping areal units called data zones (DZs). The indicators in the health domain were removed to avoid circularity, that is, using health indicators to model health outcomes. Additionally, some pairs of SIMD indicators show high correlations, so only a subset of the SIMD indicators were selected in the models. Further details are provided in Section S1.2 of the Supplemental materials.
Epidemiological studies have consistently found that both extreme heat and cold are linked to increased respiratory morbidity and mortality in asthma and COPD cases.22–25 Although humidity is not typically considered a health risk factor, high humidity can promote mould growth, producing spores that, when inhaled, can trigger respiratory symptoms such as coughing and wheezing, particularly in individuals with mould allergies.26 This can exacerbate asthma and COPD symptoms and pose increasing risks for patients.11,27 Therefore, in this study we include temperature and humidity as meteorological confounders in the model. These monthly data were collected from the HadUK-Grid data sets28 at a 1 km grid square resolution over Scotland.
Disparities in the prevalence and severity of asthma and COPD by ethnicity have been identified,29,30 so we obtained ethnicity data from the 2022 Scottish census (the closest year of data available). For each DZ the ethnicity data include the percentage of the population belonging to the following ethnic groups: (i) White; (ii) South Asian (Indian/Pakistani/Bangladeshi) descent; (iii) Chinese descent; and (iv) Black. The percentages in each of these groups sum to nearly 100 for most data zones, inducing collinearity between these four covariates. Therefore, the percentage White variable is not included in the analysis. The correlations among the remaining three ethnic groups (Chinese, South Asian, and Black) are relatively low, ranging between 0.25 and 0.29, and are hence included as covariates in the model.
Spatial realignment
The study consists of data for consecutive months between January 2016 and December 2020, and collectively the prescription, air pollution and covariate data relate to three different spatial scales. Prescription data were recorded at GP surgeries, but recall that not all surgeries were operational for all 60 months, leading to different numbers of spatial data points for each month. The th GP surgery is located at , while the spatial extent of its patient catchment area is denoted by . Patients do not necessarily attend their nearest GP surgery, which means that the set of patient catchment areas constitute a set of overlapping areal units. The spatial extent of catchment area is partially unknown, because the only information available to quantify it measures its population intersections with each data zone. Here, we denote the data zones by . The specific population intersection data provided by Public Health Scotland are denoted by , which quantifies the number of people who live in data zone and are registered at the th GP surgery in month . Note, each person can only be registered at one GP surgery. Thus, while these data provide some information on the spatial extents of the GP surgery catchment areas, they do not give an exact geographical boundary as we do not know where in each data zone each patient lives.
The SIMD and ethnicity confounders are available at the data zone scale, while the air pollution concentrations and the meteorological confounders are available at a third spatial scale, namely the set of 1 km grid squares across Scotland denoted here by . As these grid squares and the data zones have fixed geographical boundaries, we computed their areas of intersection, which for grid square and data zone is denoted by . Therefore, the first statistical challenge we face when modelling these data is the spatial change of support problem, as we need all the variables to be on a common spatial scale. The spatial scale used for inference is the GP surgery scale, because that is the scale at which the disease count data are available. Thus, any covariate at the DZ scale was spatially realigned to the GP scale by population weighted averaging, that is, by computing
Note, the population intersect data are only available on an annual basis, so we assume that these population intersections apply for all months within the year. Finally, the 1 km gridded pollution exposures and meteorological confounders were spatially rescaled to the DZ scale and then subsequently to the GP scale. The DZ to GP scale realignment is achieved using the population-weighted averaging outlined above, while the grid square to DZ realignment is achieved using area-weighted averaging via
Exploratory analysis
We fitted overdispersed negative binomial count data models to six separate prescription data sets, which include the three different medication types (reliever, preventer and both) for two time periods: (i) the full study period from 2016 to 2020; and (ii) the pre-pandemic period from 2016 to 2019 to remove any pandemic effects. Each model includes the expected prescription counts as an offset term as well as the set of potential confounders described in Section 2.3. To check for the presence of multicollinearity, we computed the variance inflation factors (VIFs) for this covariate set, and sequentially removed covariates that had VIF values above 5, which is a commonly used rule of thumb for when collinearity is likely to adversely affect the model results. This procedure was applied separately for each data set, and resulted in the removal of six confounders in all cases (see Section S1.2 of the Supplemental materials). The confounders removed include those summarising employment deprivation and no school qualifications (correlated with income deprivation), housing overcrowding (correlated with no central heating in housing) and public transport travel times to a post office, GP surgery and retail centre (correlated with the drive time equivalents).
Upon selecting this confounder set we then added a single pollutant to each model, as well as a set of temporal trend terms. The latter includes year (5 levels) and month-of-year (12 levels) indicator variables, together with an additional indicator for March 2020. This specification adjusts for year to year temporal variation and seasonality, while explicitly allowing for the anomalous spike in prescriptions observed in the first month of the Covid-19 lockdown (see Figure 1) that was likely due to people stocking up on medications due to the uncertainty surrounding the national lockdown that was introduced on 24th March 2020. Note, the data do not support the addition of a longer-term Covid effect indicator for the months succeeding March 2020, which is probably due to the fact that after stocking up in March there was no need to stock up on further medications again in subsequent months.
We then examined the presence of spatial correlation in the residuals using Moran’s statistic,31 where a binary neighbourhood matrix based on the five nearest neighbours method (Euclidean distances were calculated between the GP surgery locations ) was used to compute the indicator. Similarly, residual temporal correlation was examined using the lag 1 autocorrelation function. The results of this correlation analysis presented below relate to when NO2 is the pollutant included in the model, but the results for the remaining pollutants are analogous and are not shown for brevity. We found that for each of the six prescription data sets all of the 60 months exhibit significant positive residual spatial correlation at the 5% level, indicating that spatial correlation is pervasive and needs to be accounted for. Additionally, residual temporal correlation is also consistently present, with between 23.05% and 27.31% of the GP surgeries exhibiting significant temporal correlation at lag 1 across the different medication types.
Methodology
This section proposes a novel Bayesian hierarchical spatio-temporal model for quantifying the effects of air pollution on GP prescribing rates, where the novel contribution concerns how to construct a spatial neighbourhood matrix for capturing the spatial closeness between the patient populations registered at each pair of GP surgeries. Inference for this model is based on INLAs with variational Bayes approximations, using the R package INLA.17 The model is presented in stages below, beginning with the data likelihood component.
Data likelihood model
Letting index the complete set of GP surgeries that appears at least once throughout the -month study period, the negative binomial likelihood model is given by
As previously described, not all GP surgeries are operational at each month of the study, and hence denotes the set of indices for the GP surgeries that are operational in month . The response variable denotes a count of the number of prescriptions issued by the GP surgery with catchment area in month , while denotes the indirectly standardised expected count (accounting for demographics) that is included in the model as a fixed offset. The expected value of this distribution is the product of the expected count and the (relative) risk of disease , while the hyperparameter is the overdispersion parameter of the negative binomial distribution. Here, is assigned a penalised complexity Gamma prior distribution (pc.mgamma, default in INLA software), which is chosen to be weakly informative and hence let the data inform on the level of overdispersion. The risk of disease is modelled on the natural log scale by a vector of confounders , the pollution exposure , and a spatio-temporal random effect to allow for residual spatio-temporal correlation. The regression parameters for the confounders () and the pollution exposure () are assigned weakly informative independent Gaussian priors with mean 0 and precision 0.001, again to let the data inform on their value. Finally, we only incorporate a single pollutant in each model run, due to the collinearity between the three pollutants considered in this study.
Spatio-temporal random effects model
A range of prior distributions have been proposed for modelling the correlations among the spatio-temporal random effects , and in this analysis we utilise the multivariate first-order autoregressive process model with CAR spatial structure proposed by Rushworth et al.16 The model is expressed by
where denotes the complete set of spatial random effects for all GP surgeries during month . Thus, has the same length for all months , and is a time-invariant precision matrix. For any given month where a particular GP surgery is not operational, its corresponding data values from (1) are treated as missing values. Temporal correlation is captured through the mean via , while spatial correlation is captured through the covariance structure via . The parameters control the level of temporal () and spatial () correlation among the random effects, with values of zero corresponding to independence in time and space, while values close to one correspond to strong positive correlation. The spatial dependence parameter is assigned a weakly informative Gaussian prior on the logit scale, that is, . Similarly, the temporal dependence parameter is assigned a weakly informative Gaussian prior on the transformed scale, . The level of uncertainty in the random effects is controlled by the precision parameter , which is assigned a weakly informative half-normal prior on the standard deviation scale, that is, , following the recommendation by Gelman.32 Further details about these prior specifications are provided in Section S2 of the Supplemental materials.
The spatial correlation structure in the data is modelled by the CAR prior proposed by Leroux et al. (2000),33 which has the precision matrix
where denotes a vector of ones while denotes a identity matrix. The spatial closeness between each pair of GP surgeries is captured by the non-negative neighbourhood matrix , where typically if the patient populations represented by surgeries are close together, and otherwise (). A binary specification is commonly assumed for this matrix, because it encourages sparsity in and hence fast model fitting. Under either a binary or a non-binary construction, multivariate Gaussian theory shows that the partial correlations implied by the Leroux CAR model are given by
where denotes all the random effects at time period except . Thus, if then are modelled as conditionally independent given the remaining random effects at time , while if then they are modelled as marginally correlated.
Neighbourhood matrix
The novel methodological contribution of this paper is how to construct the spatial neighbourhood matrix for use in the spatio-temporal CAR model, which is crucial because the previous equation (3) shows that it controls the spatial correlation structure assumed for the random effects . The most common approach to defining in spatial areal unit data is through the border sharing rule, which specifies a binary neighbourhood matrix whose values are determined by whether or not each pair of areal units shares a common border. However, the GP surgery catchment areas overlap and have partially unknown spatial extents, so this approach is not feasible. The second most common approach is to use a nearest neighbours structure, where if the th GP surgery location is one of the nearest neighbours of the th GP surgery location , and is zero otherwise. This matrix is then made symmetric by setting if under this construction . The choice of in this setting is somewhat arbitrary, and typically values around are chosen as this tends to match the average numbers of neighbours each areal unit would have under the commonly used border sharing rule. In the present context this nearest neighbours construction would define the spatial correlation structure based solely on where the GP surgeries are located, rather than on where their patient populations live and the extent to which they overlap and interact. As it is the patient populations rather than the GP surgery buildings that have respiratory disease and use the medications, this construction seems inappropriate.
Therefore, here we propose two novel binary specifications for denoted by and , which account for the extent to which the patient populations from two GP surgeries overlap and are spatially close together. The only data available to quantify these population overlaps are at the data zone level, and comprise population counts defined earlier. The first matrix (‘O’ for overlap) only considers direct population overlaps, that is, the extent to which the patient populations from two GP surgeries live in the same data zones. For the GP surgeries with catchment areas the th element of the matrix is based on
where denotes the total size of the patient population for the th GP surgery. Additionally, and denote the number of time periods that GP surgeries and are operational. This construction first computes the product of the (time-averaged) proportions of the two GP surgery’s patient populations who live in the same data zone , before summing these products over all data zones in Scotland. Note, most of these time-averaged products will be zero. Thus, two GP surgeries will have a higher value of if their populations are generally located in the same data zones, and lower values if they are distributed across different data zones. In the extreme, if the patient populations from the GP surgeries located at are both all located in the same data zone for all time periods, then . Conversely, if they have no data zone level population overlaps then . The above construction only considers patient population overlaps in the same data zone, and thus our second novel specification (‘S’ for spatial) considers population overlaps in the same and spatially neighbouring data zones. Here, spatially neighbouring means that two data zones share a common border. This construction naturally extends (4) and is given by
where denotes the set of indices that include the target data zone , along with all data zones that share a border with . Thus, population overlaps between two GP surgeries are aggregated over each individual data zone and its spatial neighbours, giving a more comprehensive picture of the spatial closeness between two GP surgery’s patient populations.
The constructions are inherently non-binary, and also contain a large number of very small non-zero values corresponding to two GP surgeries that only have a small number of patients living in the same or neighbouring data zones. These very small non-zero values may not be representative of the closeness of the two surgeries in question, and will lead to a less sparse neighbourhood matrix which will increase the model fitting time. Additionally, initial analyses showed that a binary matrix constructed based on performed much better than a non-binary one in the motivating study (see the next section for details), which is likely to be due to a number of reasons. Firstly, a non-binary matrix would lead to some of the row sums being very small (minimum = 0.0001, mean = 0.12, maximum = 0.997), and in CAR models this results in division by very small numbers in the mean and variance of the conditional distribution of , which would lead to numerical instability and unreliable smoothing. Additionally, the degree of spatial smoothing would be highly uneven, because some values are close to one while others are close to zero, meaning that a few large weights dominate the smoothing process which will pull some random effects strongly towards only one neighbour while effectively ignoring the others. To address these limitations we create binary neighbourhood matrices based on , and additionally apply a threshold ( or ) so that very small values are set to zero. Specifically, we define the elements in the neighbourhood matrices as follows
We consider a range of thresholds and for the motivating study in the next section, and illustrate the impact of these choices on the number of neighbours (non-zero elements) for each GP surgery in Section S3 of the Supplemental materials. The optimal threshold is the one that minimises the levels of spatial correlation in the model residuals across the 60 months of the study, because the role of the neighbourhood matrix in conjunction with the random effects is to capture these correlations in the data.
Measuring residual spatial correlation
The level of spatial correlation in the residuals for each month is measured by Moran’s statistic,31 which, based on a generic neighbourhood matrix , is given by
where . A value of zero corresponds to spatial independence, while values respectively above and below zero correspond to positive and negative spatial correlation. A permutation-based hypothesis test (based on 10,000 random permutations of the data) can be constructed to test the significance of the residual spatial correlation, whose null hypothesis represents independence via . The alternative hypothesis could be or , and while the former is the most obvious as data typically exhibit positive spatial correlation, spatial random effects models can over-smooth the data and induce negative spatial correlation into the residuals that can be identified by the latter hypothesis. Therefore, we measure the ability of each neighbourhood matrix at capturing the spatial correlation in the data by computing the following three metrics:
Positive spatial autocorrelation indicator (PSAI): The percentage of the months that have statistically significant Moran’s values at the 5% level based on .
General spatial autocorrelation indicator (GSAI): The percentage of the months that have statistically significant Moran’s values at the 5% level based on .
Mean absolute Moran’s (MAI): The mean absolute value of Moran’s over all months computed by .
The first two of these metrics are used to assess how well each neighbourhood matrix has modelled the spatial correlation in the data (ideal values are 5%), while the last metric should be as small as possible and is used to pick the optimal threshold.
Results of the motivating study
The results of the study are presented below, and focus on the ability of the different neighbourhood matrices to capture the spatial correlation in the data (see Section 4.2), and the estimated effects of air pollution on prescribing rates for respiratory medications (see Section 4.3).
Study design
The study comprises 18 pollutant–outcome pairs, which are all possible combinations of three respiratory disease measures (preventer, reliever and both), three pollutants (NO2, PM10, PM), and two time periods (2016–2020 and 2016–2019). This dual study period allows us to assess the impact of the Covid-19 pandemic on the associations between air pollution and respiratory ill health. For each of these 18 analyses we fit the model with 11 different neighbourhood matrices, which includes one constructed using the five nearest neighbours method (hereafter ), as well as fitted separately with thresholds , and fitted separately with thresholds .
Assessment of residual spatial correlation
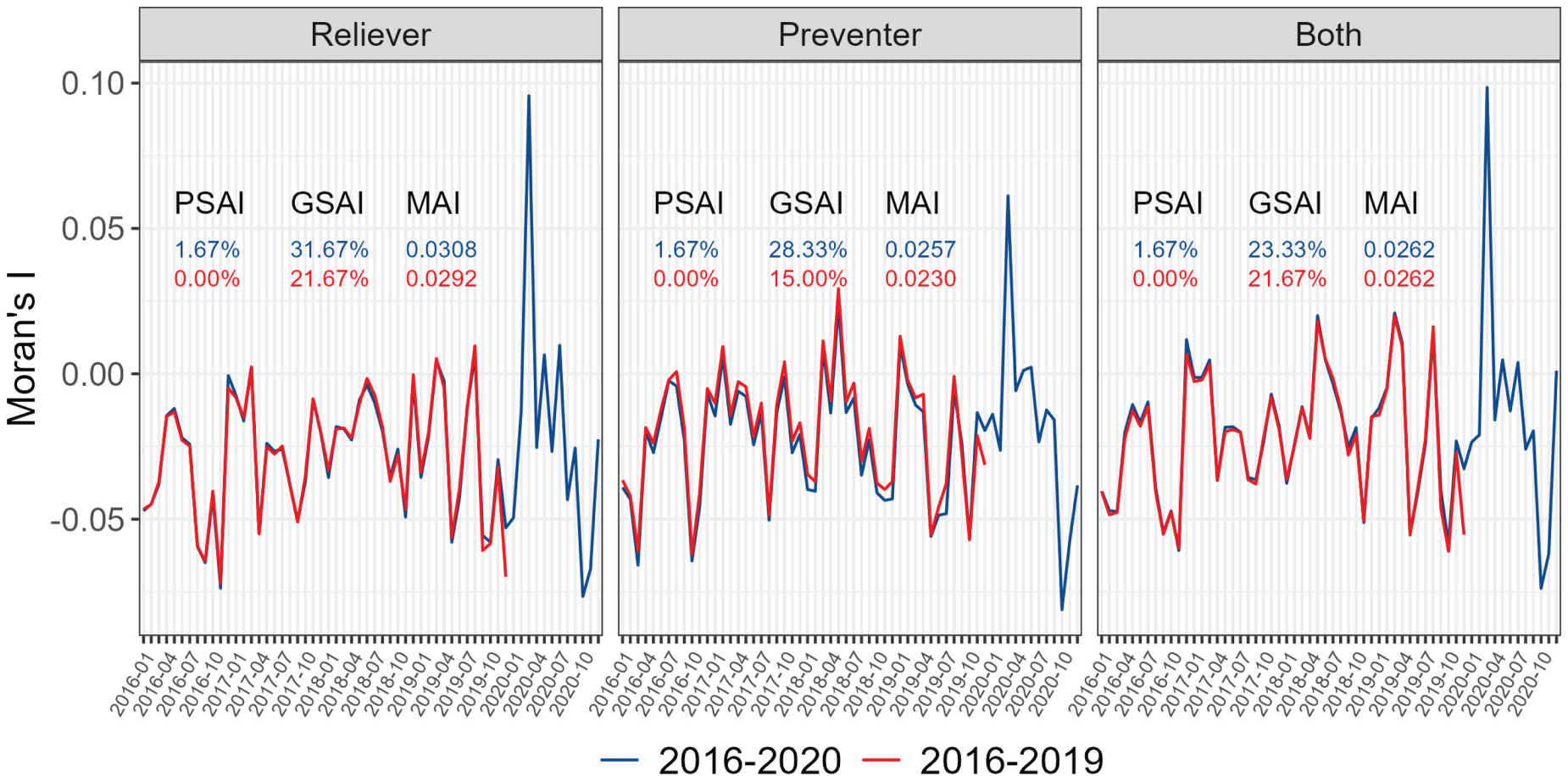
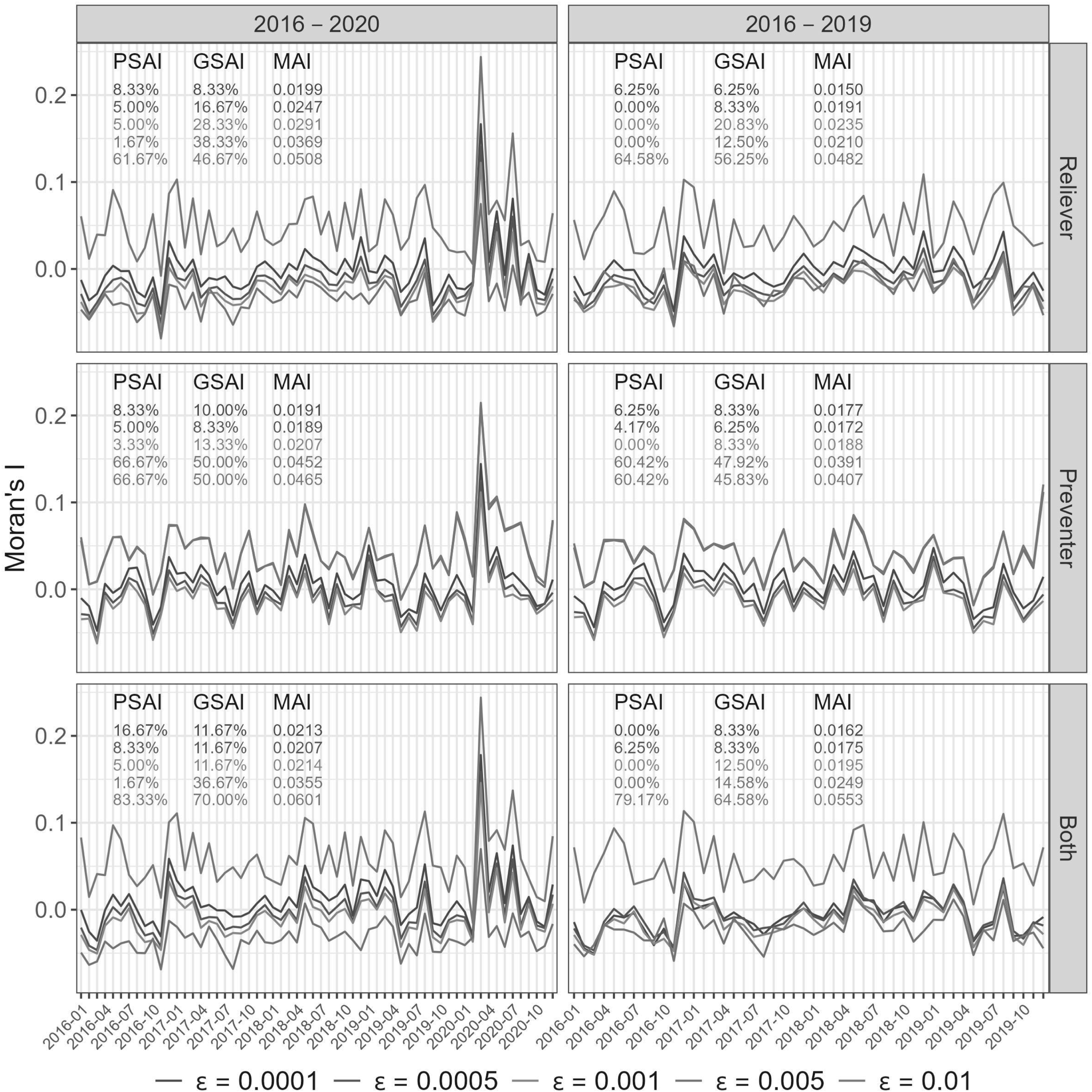
Figures 2 and 3 present the levels of spatial correlation in the model residuals over all 60 months when using (Figure 2) and (Figure 3) for each medication type and study period. The corresponding plot for is provided in Section S4.1 of the Supplemental materials. These plots are based on the models fitted including NO2 as the single pollutant, and the results when including the other pollutants are almost identical and not shown for brevity. Each plot presents the Moran’s statistic for each month of the study and for each threshold (for ), and the PSAI/GSAI/MAI metrics are given in each panel to summarise these residual correlations.
Moran’s statistics quantifying the level of spatial correlation in the residuals for each month when using as the neighbourhood matrix. Each panel represents a different disease outcome, while red lines relate to the 2016–2019 study period while the blue lines relate to 2016–2020. PSAI, GSAI and MAI indicators are listed in each case. PSAI: positive spatial autocorrelation indicator; GSAI: general spatial autocorrelation indicator; MAI: mean absolute Moran’s .
Moran’s statistics quantifying the level of spatial correlation in the residuals for each month when using as the neighbourhood matrix. Each panel represents a different disease outcome and time period, while the coloured lines relate to the different thresholds . PSAI, GSAI and MAI indicators are listed in each case. PSAI: positive spatial autocorrelation indicator; GSAI: general spatial autocorrelation indicator; MAI: mean absolute Moran’s .
Figure 2 highlights that for both study periods (red: 2016–2019; blue: 2016–2020) fails to adequately capture the spatial correlation in all three medication types. The models typically induce negative spatial correlation into the residuals as a result of over-smoothing, which is evident because almost all of the Moran’s values are negative. The exception to this is during the start of the Covid-19 pandemic in March 2020, where there is still positive residual correlation for all three medication types. The induced negative spatial correlations are generally statistically significant, as the GSAI indicator ranges between 15% and 32% across the medication types and study periods, when under independence it should be close to 5%. Conversely, the newly proposed binary neighbourhood matrices are much better at capturing the spatial correlation in the data, because in both cases at least one threshold gives a GSAI value relatively close to 5% for each medication type and study period (see Figure 3 and Supplemental Figure S5).
For , small threshold values seem to provide the best model fit, with typically yielding the lowest MAI values between 0.0150 and 0.0213. In contrast, larger values of tend to either over or under smooth the data, resulting in either more positive or negative correlations in the residuals. For , the middle threshold values (e.g. ) seem to most appropriately capture the spatial correlation in the data, because they result in the smallest MAI values between 0.0153 and 0.0229 across all data sets. Therefore, and seem to be the optimal thresholds for and , because they typically minimise the GSAI and offer the lowest MAI values thus providing the best control for residual spatial correlation. Based on these optimal threshold and perform similarly, having similar GSAI, PSAI and MAI values. They both however provide a substantial improvement on , because their MAI values range between (: 0.0150–0.0213) and (: 0.0158–0.0208) compared to (0.0230–0.0308) for . Finally, we also investigated using non-binary versions of , but these performed very poorly and the results are displayed in Section S4.2 of the Supplemental materials.
Pollution-health effects
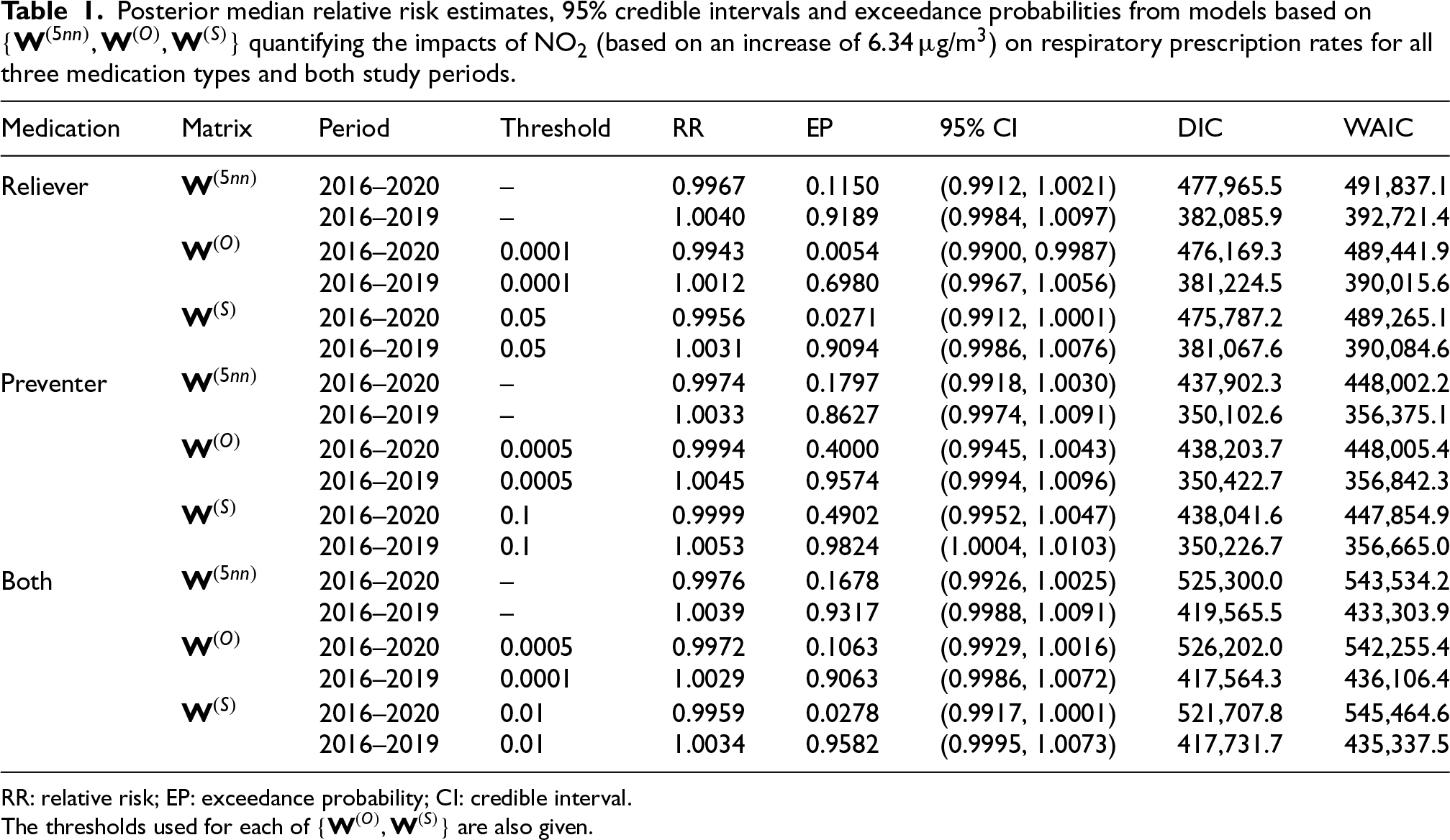
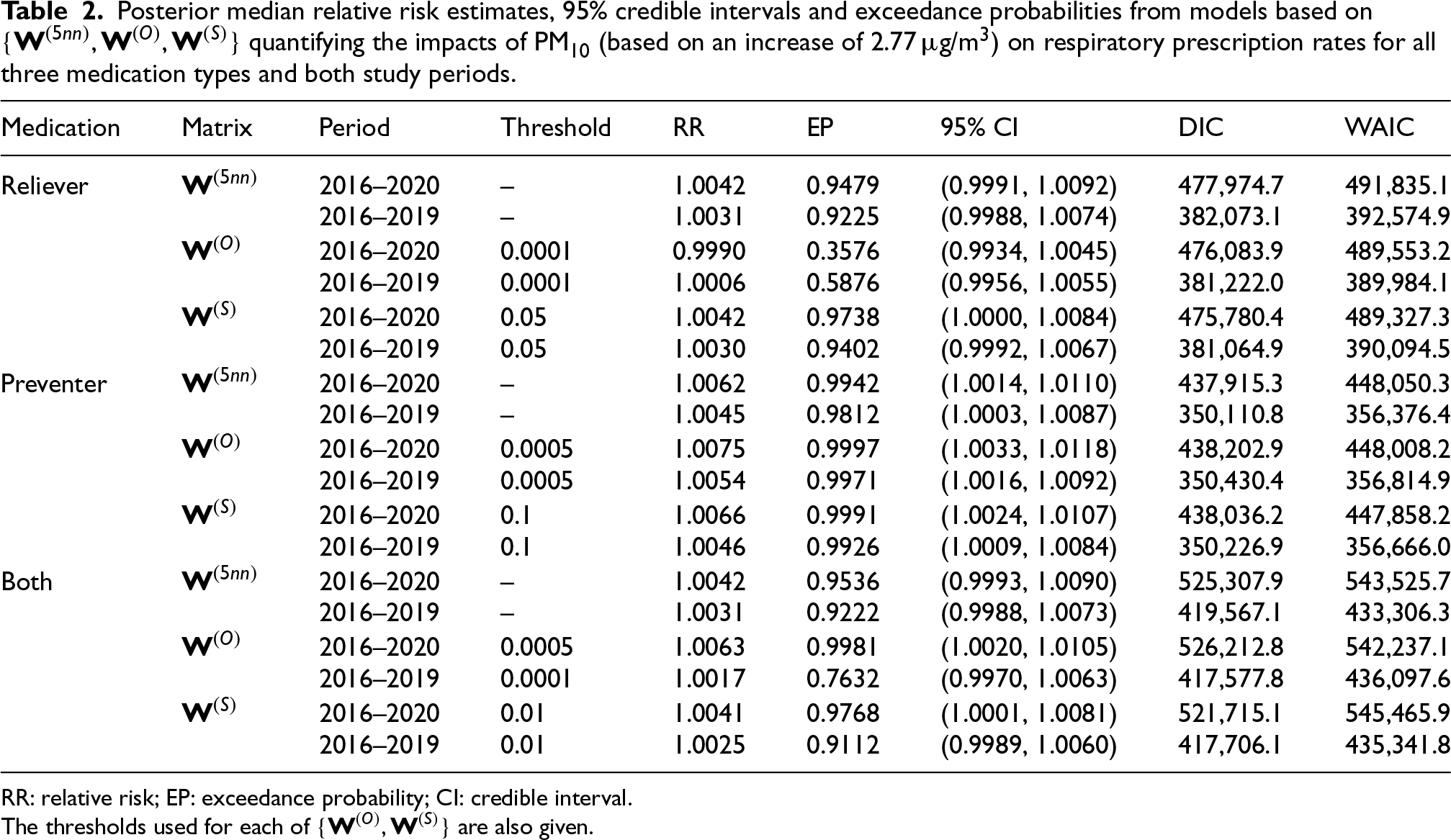
The effect of each pollutant on each medication outcome is presented as a relative risk (RR), where a value of one corresponds to no association between air pollution concentrations and respiratory prescription rates. An RR greater than one indicates that increased concentrations are associated with an increased rate of respiratory prescriptions, while an RR less than one indicates a protective effect. Each relative risk presented here is computed for a one standard deviation increase in each pollutant, because this represents a realistic increase in the concentrations that could be observed in the present study. Specifically, these standard deviations are: NO2: 6.34 g/m, PM10: 2.77 g/m, and PM: 1.68 g/m. The relative risk results for NO2 and PM10 are displayed in Tables 1 and 2, respectively, while those for PM are presented in Section S4.3 of the Supplemental materials. Each table presents the results from 18 model runs, which include all combinations of the three medication types, three neighbourhood matrices (, and , the latter two using the optimal thresholds) and two time periods. The results for each model run comprise the posterior median relative risk and a 95% credible interval, the exceedance probability that the estimated relative risk is greater than one, and the Deviance Information Criterion (DIC) and Watanabe-Akaike Information Criterion (WAIC) model fit metrics.
Posterior median relative risk estimates, 95% credible intervals and exceedance probabilities from models based on quantifying the impacts of NO2 (based on an increase of 6.34 g/m) on respiratory prescription rates for all three medication types and both study periods.
Posterior median relative risk estimates, 95% credible intervals and exceedance probabilities from models based on quantifying the impacts of PM10 (based on an increase of 2.77 g/m) on respiratory prescription rates for all three medication types and both study periods.
Table 1 shows that NO2 does not exhibit a strong association with respiratory medication prescriptions, because all RR estimates are very close to one across all medication types and time periods, while all but one of the 95% credible intervals include the null RR of one. The table also shows that for the pre-pandemic period (2016–2019) all relative risks are above one, while for the full time period (2016–2020) they are all below one. While the absolute differences in these posterior median relative risk are small between the two time periods the exceedance probabilities are typically substantially different, ranging between 0.6980 and 0.9824 for 2016–2019 and between 0.0054 and 0.4902 for 2016–2020.
The results for PM10 are shown in Table 2, and demonstrate that there are significant effects of PM10 on preventer medications for all models and time periods as all of the 95% credible intervals are wholly greater than one. The posterior median relative risks for this pollutant–outcome pair range between 1.0045 and 1.0075, suggesting that if PM10 increases by around 2.77 g/m then the rate of preventer medication usage will increase by around 0.5%. This significant effect is reinforced by the exceedance probabilities, which are all above 98%. In contrast, there are no significant effects of PM10 on reliever medications, as all of the 95% credible intervals contain the null relative risk of one. However, there is some evidence of a potential effect, as the exceedance probabilities range between 0.3576 and 0.9738. Moreover, considering both medications jointly shows results in the middle of the previous two as expected, with relative risks ranging between 1.0017 and 1.0063 and exceedance probabilities ranging between 0.7632 and 0.9981. But in this case only two of the six estimates are statistically significant at the 0.05 level. Comparing the two data spans shows that the relative risks for the entire time period (2016–2020) are generally larger than those for the shorter time period (2016–2019), which is the opposite result observed for NO2. However, these differences do not generally affect the statistical significance.
The results for PM are shown in Section S4.3 of the Supplemental materials for brevity, and are similar but slightly weaker than those for PM10. Additionally, the Supplemental materials present two further analyses for PM10, focusing on lagged effects (see Section S4.4) and the incorporation of exposure uncertainty when estimating the health effects (see Section S4.5). Finally, the tables of results also display the DIC and WAIC model fit metrics for each neighbourhood matrix. The tables show that for the reliever and both medication types and generally outperform in terms of both DIC and WAIC, while for the preventer medication type the results are much closer and typically performs better. Thus, while our proposed neighbourhood matrices do not always provide the best model fit they do so in the majority of situations, which taken together with their improved modelling of spatial correlation suggests that they are a superior approach compared to using the five nearest neighbours method.
Discussion
This study has developed spatio-temporal models to quantify the effects of air pollution on the volume of medications prescribed to treat chronic respiratory ill health like asthma and COPD within a primary care setting, and applied the models in a new study based in Scotland. This study extends the work of Blangiardo et al.13 and Lee14 to a longer and more recent time period, while examining multiple respiratory medications (reliever, preventer and both) and pollutants (NO2, PM10 and PM) to provide a comprehensive assessment of how air pollution influences chronic respiratory ill health that is managed in a non-hospitalised setting. Additionally, this study estimates population-level pollution exposures based on where the GP surgery patient populations are likely to live, rather than simply estimating the concentration at each GP surgery itself.
From a methodological standpoint, this study adjusts existing spatial areal unit smoothing models for the situation where the spatial extents of the areal units (i.e. GP surgery catchment areas) are partially unknown and overlapping. The challenge here is how to determine the spatial adjacency between these areal units, and this study proposes novel spatial adjacency structures based on population overlap data obtained on a second set of areal units (i.e. data zones) that have known geographical boundaries. We propose two specifications here, which measure spatial closeness based on whether the patient populations from two GP surgeries occupy the same () or the same/spatially neighbouring () data zones. These neighbourhood matrices thus consider where each GP surgery’s patient population actually live, rather than just considering the exact locations of the surgeries themselves. As a result, these neighbourhood matrices are better able to capture spatial dependencies and prevent over-smoothing of the spatial random effects than a commonly used five nearest neighbours approach is, which is evidenced by lower MAI and GSAI values. For example, the MAI values reduce by between 20.99% and 48.63% when using or in the model compared with using . For other researchers modelling the type of data considered here, we recommend fitting models with both and initially, so that the consistency of the results can be observed. Here, the results are fairly consistent, but this may not always be the case. In practice, we recommend choosing between and using the MAI, as the role of the spatial random effects is to capture the unmeasured correlation in the data.
This study provides robust evidence that PM10 has a consistent significant association with prescriptions of medications used to prevent respiratory ill health events, as the exceedance probabilities exceed 98% across all spatial structures and both data spans (2016–2019 and 2016–2020). The posterior median relative risks suggest that the rate of prescriptions of such medications increases on average by 0.5% when PM10 increases by 2.77 . Although this estimated effect size is small, the population at risk of air pollution is large. For example, over the study period about 2,002,720 items of this type of medication were prescribed on average across the entire country each year, which when multiplied by the above relative risk equates to an additional 10,014 items of preventer medication each year. In contrast, there are no consistent associations between medications used to relieve the symptoms of respiratory ill health and PM10, while the results when both medications are combined show weak evidence of an effect as their results are a compromise between those for the two medication types. Additionally, the effects of PM on respiratory prescription rates are weaker than the corresponding effects of PM10, with smaller exceedance probabilities and posterior median relative risks in most cases. In contrast, across all models and medication types NO2 consistently demonstrates no association with prescription rates, with relative risk estimates being close to one and 95% credible intervals that almost always include one.
Comparing the two data spans highlights the potential influence of the Covid-19 pandemic on the relationship between air pollution and respiratory prescription rates. The most notable difference is observed for NO2, where the exceedance probabilities are substantially higher for the pre-pandemic period compared to the whole time period, while the corresponding relative risks are generally above one and below one respectively. That said, in all cases the associations are not significant at the 0.05 level. For PM10, the differences between the two data spans are smaller, with slightly weaker associations in the pre-pandemic period, although this does not alter the statistical significance of the findings. In contrast, PM exhibits almost no differences, suggesting that its impact on prescriptions remained stable despite pandemic-related disruptions. There are a number of possible reasons for these pandemic-related differential health impacts, including changes in the lifestyle and healthcare-seeking behaviours which may have affected the respiratory prescription counts. For example, the spike in prescription rates in March 2020 (see Figure 1) suggests that people stocked up on medications just before the first national lockdown. Additionally, the pandemic led to a reduction in pollution levels as a result of national lockdowns and other travel restrictions that reduced vehicle and other emissions. For example, based on pollution predictions used in this study, the mean concentrations across Scotland in March 2020 reduced by 0.12 g/m (NO2), 0.07 g/m (PM10) and 0.16 g/m (PM) compared to the corresponding concentrations for March 2019. These reductions were still evident later that year, as a result of the additional national and regional lockdowns imposed by the Scottish Government.
A limitation of this study is that the proposed approach to modelling the spatial correlation structure is crucially dependent on additional population distribution data that may not be available in all countries. For instance in developing countries like China, where primary healthcare is less structured, patients often visit multiple hospitals or pharmacies without adequate registration systems, making it challenging to construct a meaningful neighbourhood matrix based on GP registration data. A further limitation is that the spatio-temporal model used assumes that the length of the random effects vector and the neighbourhood structure captured by remains constant throughout the 60-month study period, and thus does not dynamically adjust to potential changes in GP surgery locations or shifts in patient registration patterns over time. Therefore, in future work we will explore alternative random effects models with adaptive neighbourhood structures that can evolve over time to reflect changes in patient distribution and differing numbers of GP surgeries. The study also assumes that the spatial distribution of the set of registered patients from each GP surgery to the surrounding data zones matches the distribution of those subset of patients actually receiving respiratory related prescriptions. This assumption may lead to potential misclassification, since disease prevalence and thus prescription rates differ across data zones served by a GP surgery. In the future we will explore a more flexible Bayesian hierarchical modelling approach, which will allow the proportions of patients receiving prescriptions from a GP surgery in each data zone to be treated as an unknown random vector and modelled using a Dirichlet distribution, at a latent level. This random vector can be informed by the observed proportions of registered patients in each data zone, with the mean of the Dirichlet distribution depending on these proportions.
Supplemental Material
sj-pdf-1-smm-10.1177_09622802261439259 - Supplemental material for Quantifying the effects of air pollution on respiratory ill health treated in primary care when the locations of the populations at risk are partially unknown
Supplemental material, sj-pdf-1-smm-10.1177_09622802261439259 for Quantifying the effects of air pollution on respiratory ill health treated in primary care when the locations of the populations at risk are partially unknown by Qiangqiang Zhu, Duncan Lee and Oliver Stoner in Statistical Methods in Medical Research
Footnotes
Acknowledgements
The authors would like to thank the editor and reviewers for their constructive comments and suggestions that helped improve the quality of this manuscript.
ORCID iD
Qiangqiang Zhu
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work of the first author, Qiangqiang Zhu, is supported by the China Scholarship Council (CSC, No. 202208060260) as part of his PhD studies at the University of Glasgow.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online. The Supplemental materials contain additional data description, analysis and results. Code and data used in this paper are available at .
ChenXZhouCWFuYYet al.Global, regional, and national burden of chronic respiratory diseases and associated risk factors, 1990–2019: results from the Global Burden of Disease Study 2019. Front Med2023; 10: 1066804.
LeeDMukhopadhyaySRushworthAet al.A rigorous statistical framework for spatio-temporal pollution prediction and estimation of its long-term impact on health. Biostatistics2017; 18: 370–385.
10.
HuangGLeeDScottEM. Multivariate space-time modelling of multiple air pollutants and their health effects accounting for exposure uncertainty. Stat Med2018; 37: 1134–1148.
11.
CaillaudDLeynaertBKeirsbulckMet al.Indoor mould exposure, asthma and rhinitis: findings from systematic reviews and recent longitudinal studies. Eur Respir Rev2018; 27: 170137.
12.
KhomenkoSCirachMPereira-BarbozaEet al.Premature mortality due to air pollution in European cities: a health impact assessment. Lancet Planet Health2021; 5: e121–e134.
13.
BlangiardoMFinazziFCamelettiM. Two-stage Bayesian model to evaluate the effect of air pollution on chronic respiratory diseases using drug prescriptions. Spat Spatiotemporal Epidemiol2016; 18: 1–12.
14.
LeeD. A locally adaptive process-convolution model for estimating the health impact of air pollution. Ann Appl Stat2018; 12: 2540–2558.
15.
BesagJYorkJMolliéA. Bayesian image restoration with two applications in spatial statistics. Ann Inst Stat Math1991; 43: 1–59.
16.
RushworthALeeDMitchellR. A spatio-temporal model for estimating the long-term effects of air pollution on respiratory hospital admissions in Greater London. Spat Spatiotemporal Epidemiol2014; 10: 29–38.
17.
RueHMartinoSChopinN. Approximate Bayesian inference for latent Gaussian models by using integrated nested Laplace approximations. J R Stat Soc SeriB (Stat Methodol)2009; 71: 319–392.
ZhuQLeeDStonerO. A comparison of statistical and machine learning models for spatio-temporal prediction of ambient air pollutant concentrations in Scotland. Environ Ecol Stat2024; 31: 1085–1108.
20.
LeeD. Identifying boundaries in spatially continuous risk surfaces from spatially aggregated disease count data. Ann Appl Stat2023; 17: 3153–3172.
LinSLuoMWalkerRJet al.Extreme high temperatures and hospital admissions for respiratory and cardiovascular diseases. Epidemiology2009; 20: 738–746.
23.
Hayes JrDCollinsPBKhosraviMet al.Bronchoconstriction triggered by breathing hot humid air in patients with asthma: role of cholinergic reflex. Am J Respir Crit Care Med2012; 185: 1190–1196.
24.
NadiaNHanselMCMKimV. The effects of air pollution and temperature on COPD. COPD: J Chronic Obstr Pulm Dis2016; 13: 372–379.
25.
D’AmatoMMolinoACalabreseGet al.The impact of cold on the respiratory tract and its consequences to respiratory health. Clin Transl Allergy2018; 8: 1–8.
26.
KosmidisCHashadRMathioudakisAGet al.Impact of self-reported environmental mould exposure on COPD outcomes. Pulmonology2023; 29: 375–384.
27.
MuZChenPLGengFHet al.Synergistic effects of temperature and humidity on the symptoms of COPD patients. Int J Biometeorol2017; 61: 1919–1925.
TranHNSiuSIribarrenCet al.Ethnicity and risk of hospitalization for asthma and chronic obstructive pulmonary disease. Ann Epidemiol2011; 21: 615–622.
30.
GilkesAHullSDurbabaSet al.Ethnic differences in smoking intensity and COPD risk: an observational study in primary care. NPJ Prim Care Respir Med2017; 27: 50.
31.
MoranPA. Notes on continuous stochastic phenomena. Biometrika1950; 37: 17–23.
32.
GelmanA. Prior distributions for variance parameters in hierarchical models (comment on article by Browne and Draper). Bayesian Anal2006; 1: 515–534.
33.
LerouxBLeiXBreslowN. Estimation of disease rates in small areas: a new mixed model for spatial dependence. In: Halloran M and Berry D (eds) Statistical models in epidemiology, the environment and clinical trials. New York: Springer-Verlag, 2000, pp.135–178.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.