
Abstract
Estimating the long-term health impact of air pollution using an ecological spatio-temporal study design is a challenging task, due to the presence of residual spatio-temporal autocorrelation in the health counts after adjusting for the covariate effects. This autocorrelation is commonly modelled by a set of random effects represented by a Gaussian Markov random field (GMRF) prior distribution, as part of a hierarchical Bayesian model. However, GMRF models typically assume the random effects are globally smooth in space and time, and thus are likely to be collinear to any spatially and temporally smooth covariates such as air pollution. Such collinearity leads to poor estimation performance of the estimated fixed effects, and motivated by this epidemiological problem, this paper proposes new GMRF methodology to allow for localised spatio-temporal smoothing. This means random effects that are either geographically or temporally adjacent are allowed to be autocorrelated or conditionally independent, which allows more flexible autocorrelation structures to be represented. This increased flexibility results in improved fixed effects estimation compared with global smoothing models, which is evidenced by our simulation study. The methodology is then applied to the motivating study investigating the long-term effects of air pollution on respiratory ill health in Greater Glasgow, Scotland between 2007 and 2011.
Keywords
1 Introduction
Air pollution has both a financial and a public health impact. The Department for the Environment, Food and Rural Affairs (DEFRA) in the UK estimate that “in 2008 air pollution in the form of anthropogenic particulate matter (PM) alone was estimated to reduce average life expectancy in the UK by six months. Thereby imposing an estimated equivalent health cost of £19 billion”. 1 These estimated effects are based on evidence from large numbers of epidemiological studies, which collectively quantify the impact of exposure over both the short and the long term. The impact of long-term exposure has typically been estimated using individual-level cohort studies, 2 but due to the long-term follow-up required for the cohort, such studies are costly and time consuming to implement. Therefore the recent routine availability of small-area statistics has led to ecological spatio-temporal study designs also being used.3–10 These studies cannot assess the causal health effects of air pollution due to their ecological design, but as they are quick and inexpensive to implement they add to the body of evidence about the long-term health impact of air pollution.
Ecological spatio-temporal studies utilise data relating to K non-overlapping areal units for T consecutive time periods, which include population-level measurements of disease, pollution concentrations and other confounding factors such as socio-economic deprivation and demography. Poisson log-linear models are typically used to estimate the effects of air pollution on health, because the disease data often take the form of counts of the numbers of cases for each areal unit and time period. The simplest such model is a Poisson generalised linear model, where only the available covariates are used to explain the spatio-temporal pattern in the disease data. However, the residuals from such models typically display spatio-temporal autocorrelation, which violates the assumption of independence made in such models. This residual spatio-temporal autocorrelation could be caused by numerous factors, such as unmeasured confounding, neighbourhood effects (where subjects behaviour is influenced by neighbouring subjects), grouping effects (where subjects choose to be close to similar subjects) and the fact that disease counts in consecutive time periods come from largely the same susceptible population. Ignoring this autocorrelation using the naive Poisson model described above can adversely affect both the covariate effect estimates and the coverage probabilities of the corresponding confidence intervals, and models that adjust for this autocorrelation are required.
Purely spatial studies have accounted for this residual autocorrelation using many different approaches, including conditional autoregressive models, 6 simultaneous autoregressive models 3 and geographically weighted regression. 7 However, only one study 10 has allowed for such residual autocorrelation in a spatio-temporal study design, because other existing studies4,5,9 do not relate to contiguous areal units. The main mechanism for modelling this autocorrelation is via a set of random effects, whose prior distribution induces either spatial or spatio-temporal smoothness in their values. However, recent research11,12 in a purely spatial setting has shown the potential for collinearity between spatially smooth covariates such as air pollution and spatially smooth random effects, which may lead to variance inflation and poor fixed effects estimation. 13 Furthermore, the residual spatial autocorrelation from a covariate only model may be too complex to be adequately represented by a set of globally smooth random effects, as some scales of global spatial variation will have been accounted for by covariates included in the model such as air pollution. Thus the unexplained residual spatial variation may be localised, with strong autocorrelation being observed between some pairs of geographically adjacent residuals while other pairs have very different values.
These problems are likely to carry-over to the spatio-temporal setting, and are illustrated by our motivating study of air pollution and health in Glasgow, Scotland, between 2007 and 2011. The data for this study are presented in Section 2, which also presents an initial analysis based on a Poisson generalised linear model which assumes the disease counts are independent conditional on the covariates. The results from this initial analysis illustrate the need for a random effects model that can account for localised residual spatio-temporal variation, and the goal of this paper is to develop such a model. Our approach builds on recent work on localised smoothing in a purely spatial context,14,15 and is the first paper to consider this problem in a spatio-temporal rather than a purely spatial domain. Our general approach is based on Gaussian Markov random field (GMRF) models, which are extended so that the spatio-temporal adjacency structure of the data is estimated rather than being fixed. This general approach allows random effects that are geographically or temporally adjacent to be autocorrelated or conditionally independent, corresponding to either smoothing or not smoothing their values. However, the price of this flexibility is a large increase in the number of partial correlation parameters, and a critique of the existing solutions to this problem in a purely spatial context is presented in Section 3. This Section also summarises the spatio-temporal random effect models commonly used in a disease data context, and provides the background for the methodology we propose in Section 4. A simulation study is presented in Section 5 to evidence the improved estimation performance of our proposed model compared with commonly used alternatives, and the results of the Greater Glasgow study are presented in Section 6. Finally, Section 7 discusses the implications of our findings and avenues for future work.
2 Study design and initial analysis
The methodology developed in this paper is motivated by an epidemiological study investigating the health impact of long-term exposure to air pollution in the Greater Glasgow and Clyde Health Board in Scotland, for the five year period spanning 2007 to 2011. Glasgow is the largest city in Scotland, and the health board had a population of between 1,187,062 and 1,205,334 people during the study. The health board is split into K = 271 administrative units called intermediate geographies (IGs), which contained populations of between 2468 and 9517 people. The layout of the health board is presented in Figure 1, and the city of Glasgow is the set of small IGs in the east of the figure. The data are described below, and both the disease and confounder data are available from the Scottish Neighbourhood Statistics (SNS) database (http://www.sns.gov.uk), while the modelled pollution concentrations are available from the DEFRA (http://uk-air.defra.gov.uk/data/pcm-data).
Maps displaying the standardised incidence ratio (SIR) for respiratory disease in 2007 (top left panel) and 2011 (top right panel) and the annual mean concentration for particles less than 10 µm (PM10) in 2006 (bottom left panel) and 2010 (bottom right panel).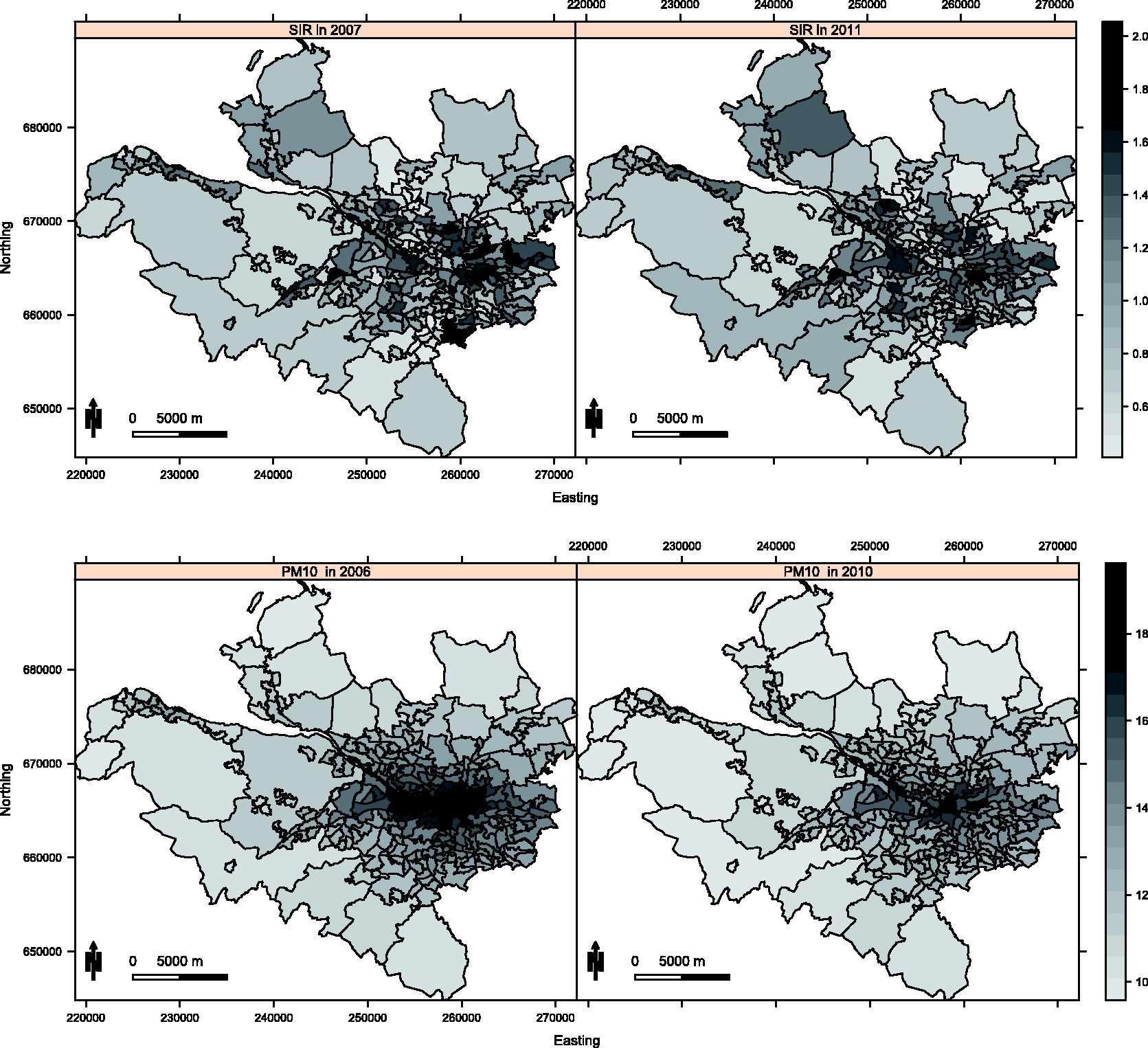
2.1 Description of the data
The disease data are yearly counts of the numbers of people in each IG admitted to non-psychiatric and non-obstetric hospitals with a primary diagnosis of respiratory disease, which corresponds to the International Classification of Disease tenth revision (ICD-10) codes J00-J99 and R09.1. However, the set of IGs have different population sizes and demographic structures, so external standardisation was used to compute the expected numbers of disease cases in each area and year, using age and sex specific disease rates for the entire population. An exploratory estimate of disease risk is given by the standardised incidence ratio (SIR, observed cases/expected cases), which is displayed for the first and last years of the study in the top row of Figure 1. The figure shows that the risks are highest in the heavily deprived east end of Glasgow (east of the study region) and along the southern bank of the river Clyde (which starts as an estuary in the west and moves south east across the study region). While the main spatial pattern in disease risk has not changed over the five year period, there are IGs that exhibit elevated and reduced risks in 2011 compared with 2007, suggesting that the spatio-temporal correlation structure in these data is likely to be non-separable.
Summary of the spatio-temporal variation in the data between year 1 (2007) and year 5 (2011) of the study, presented as the mean (standard deviation) value across the study region. a
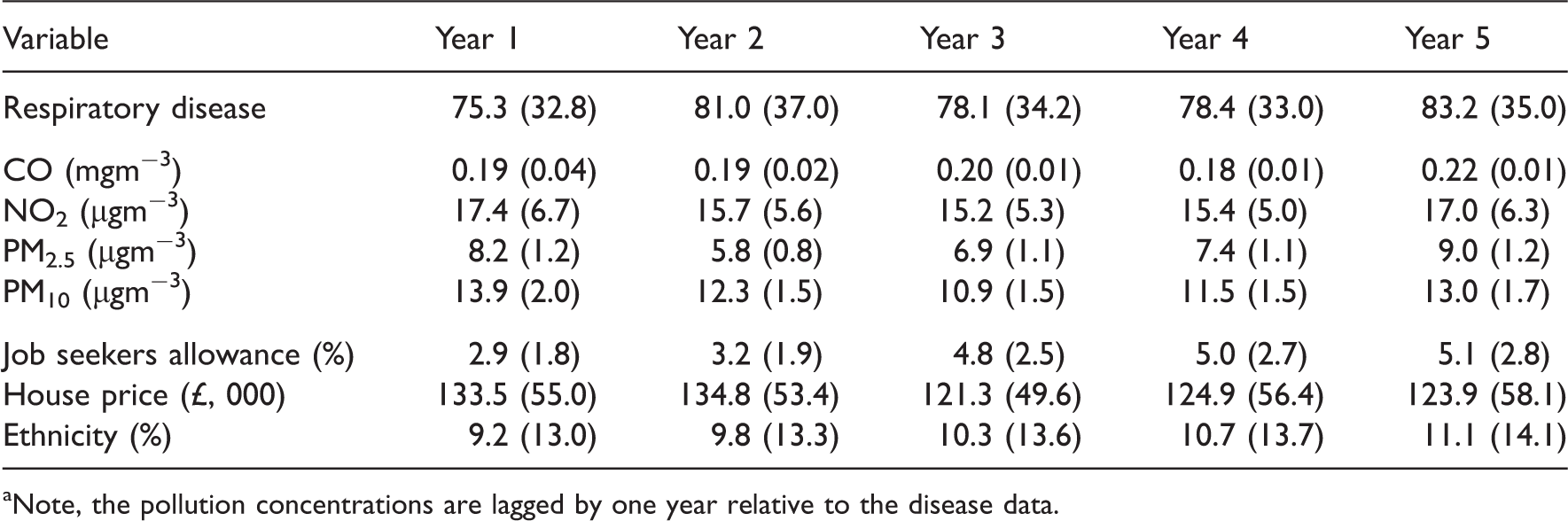
Note, the pollution concentrations are lagged by one year relative to the disease data.
The main confounding factor in ecological health studies is socio-economic deprivation, 17 and data on median property price and the percentage of people who are in receipt of job seekers allowance (JSA) are available. In the current study, where the response is a measure of respiratory ill health, the level of socio-economic deprivation in an IG is likely to be acting as a proxy measure of smoking prevalence, which is the major risk factor for respiratory health. Yearly smoking prevalence data for each IG are not available, and existing studies 18 have shown area level measures of socio-economic deprivation to be good proxy measures. The other potential confounder considered in this study is a measure of ethnicity, because different rates of respiratory disease have been observed for people from different ethnic backgrounds. 19 The only variable available to measure ethnicity is the percentage of school children living in each IG who are non-white, which we appreciate is imperfect as it does not differentiate between people of different non-white ethnicities.
2.2 A generalised linear model analysis
The study region is partitioned into
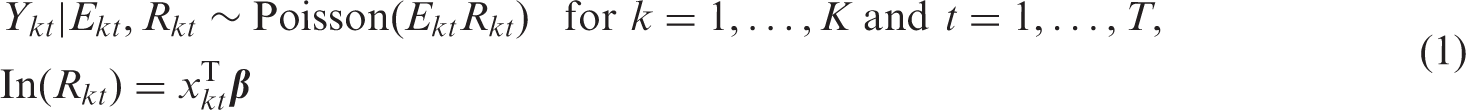
To assess the appropriateness of this model the raw residuals were computed, and are displayed in Figure 2 for 2007 and 2011. The residuals exhibit substantial overdispersion with respect to the Poisson distribution, with estimated overdispersion parameters ranging between 4.39 and 4.92 depending on the pollutant included in the model. To assess the presence of residual spatial autocorrelation, a permutation test based on Moran's I statistic
20
using 10,000 random permutations was conducted for each year of the study separately. Statistically significant spatial autocorrelation was observed for each year, with p values ranging between 0.0101 and 0.0000999. The space–time separability of the residuals was then assessed, by computing correlation coefficients between residual spatial surfaces for each year. The correlations ranged between 0.335 and 0.646, suggesting that this residual autocorrelation is non-separable in space and time, a result which is visually corroborated by Figure 2. The figure also shows that the residual spatial autocorrelation is localised in both years, with some pairs of adjacent areal units having similar values suggesting spatial smoothness, while others have very different values suggesting a lack of smoothness.
Maps displaying the residuals from the Poisson generalised linear model for 2007 and 2011.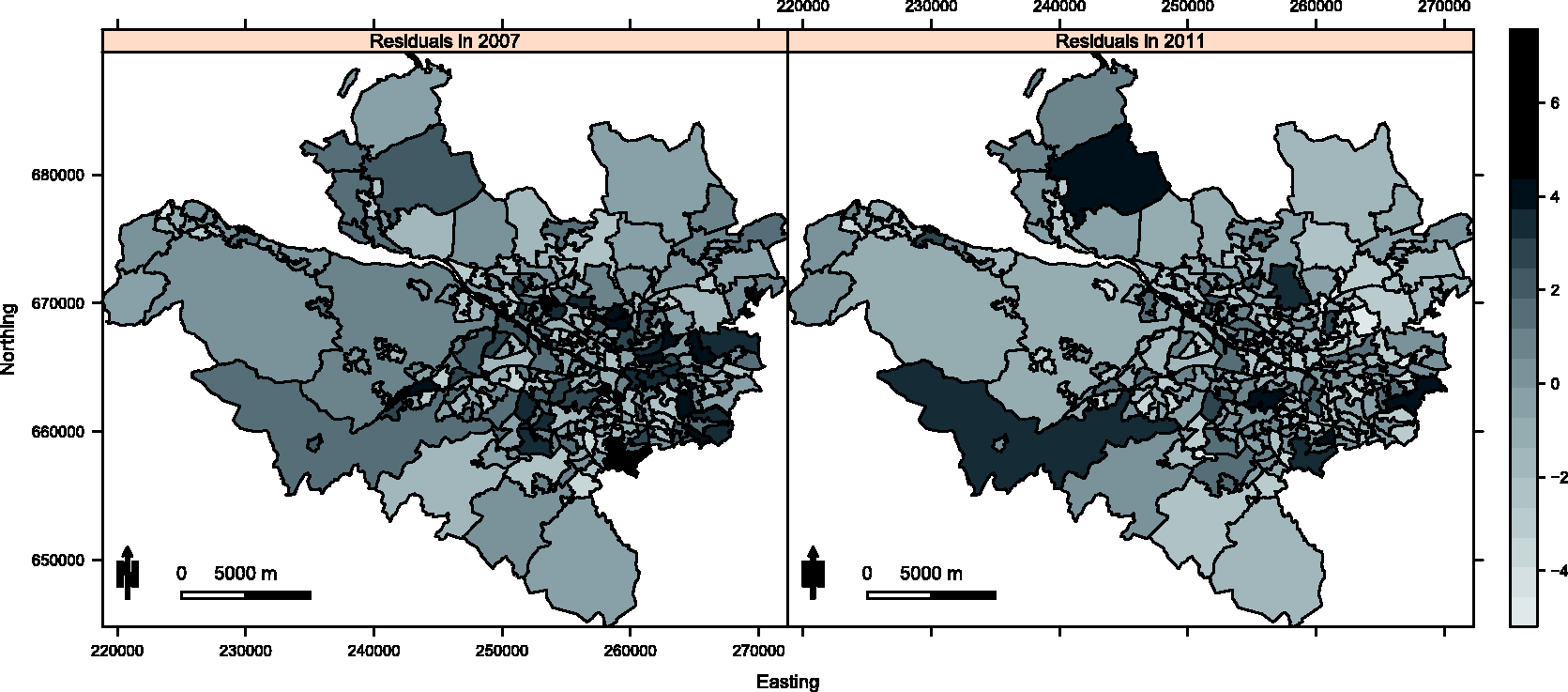
3 Spatio-temporal autocorrelation models
3.1 Existing models
Models that account for the spatio-temporal autocorrelation in the data extend equation (1) by adding in a set of random effects to the linear predictor, and the first level of such a model is given by
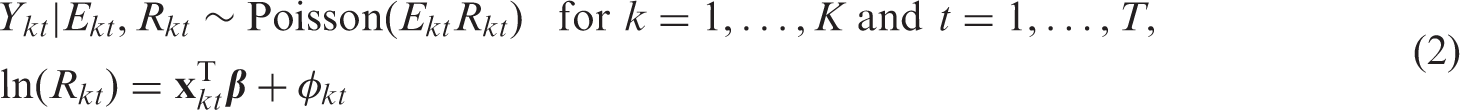
Here the spatio-temporal pattern in the log risk is represented by covariates
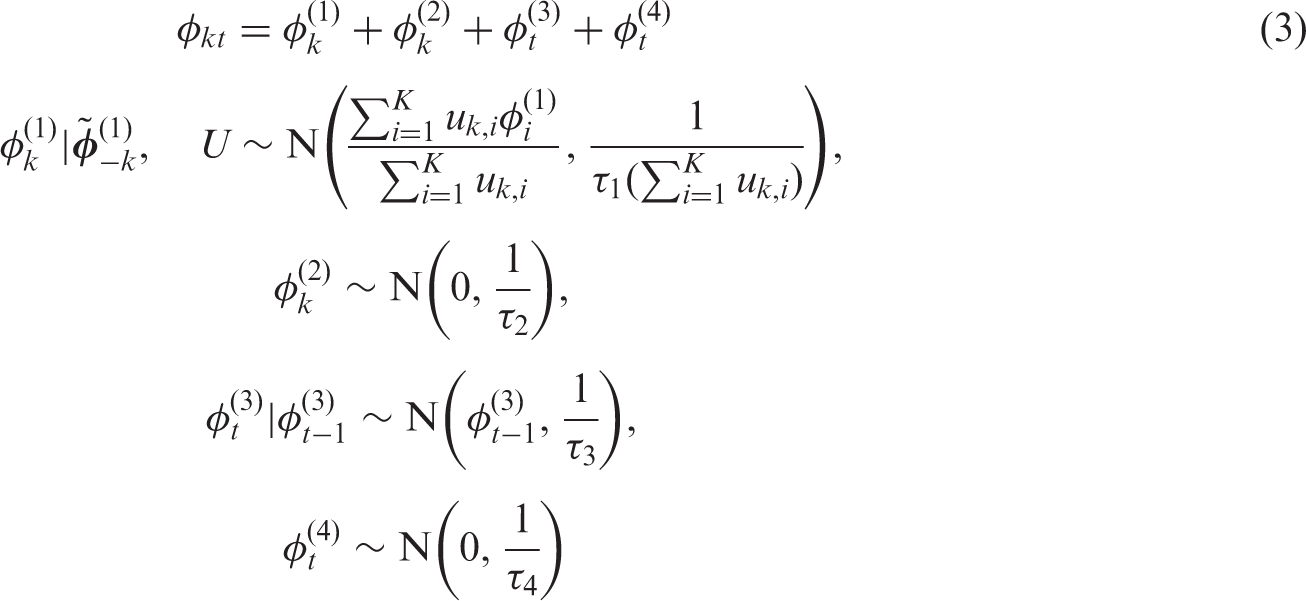
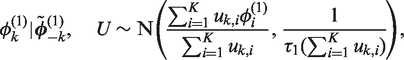
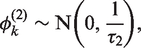
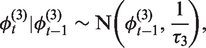
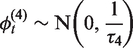
In this model,
However, as illustrated in Section 2 the residual spatio-temporal autocorrelation in the Glasgow respiratory disease data is unlikely to be separable, and one of the first non-separable extensions to equation (3) added a fifth set of spatio-temporal random effects.
24
This model was used in a disease mapping context with no covariates, where the spatio-temporal random effects were of direct interest. In contrast, in the ecological regression context considered here they are only included to account for residual spatio-temporal autocorrelation, and are not of direct interest. Therefore a simpler, in terms of the number of random effects terms, non-separable spatio-temporal extension of the BYM model is given by
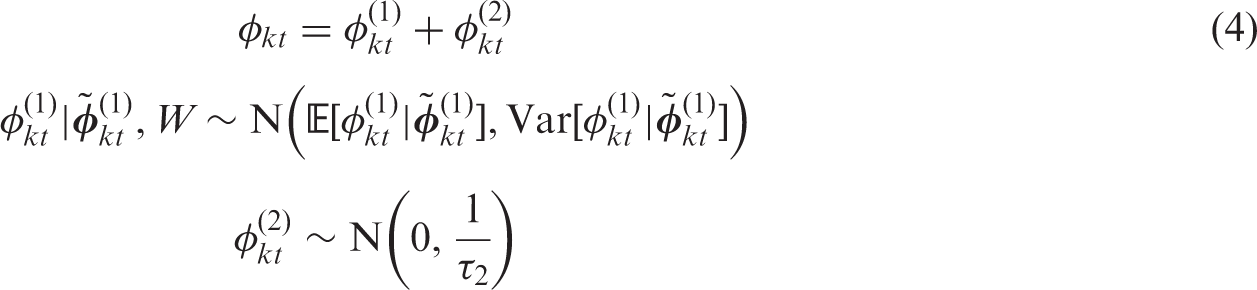
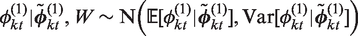
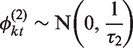
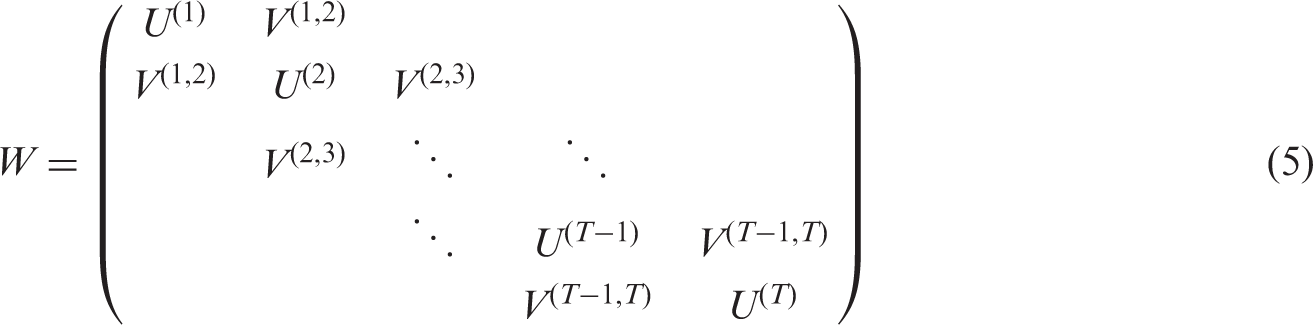
Here
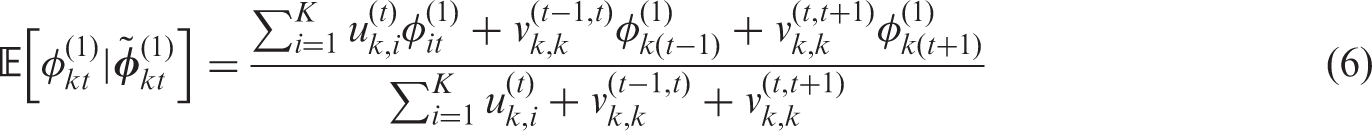
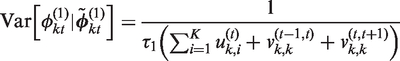
3.2 Global smoothing models and their limitations
Both the separable and non-separable models force global levels of spatial and temporal smoothness on the random effects, which are determined by the relative sizes of the precision parameters controlling the independent and autocorrelated processes. This is because the partial correlation between the autocorrelated random effects (
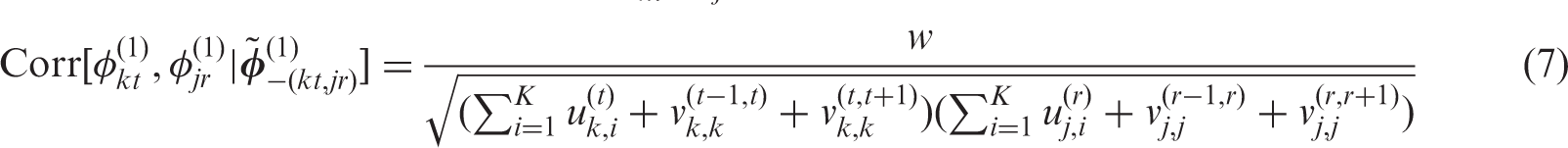
A small number of papers have proposed localised smoothing approaches using GMRF priors in a purely spatial context, but no work has been done to extend these ideas to the spatio-temporal domain. The majority of the purely spatial approaches have treated the elements of the spatial adjacency matrix U corresponding to adjacent areal units as binary random quantities, rather than being fixed equal to one. Equation (7) shows that estimating an element of the adjacency matrix equal to one induces correlation between the random effects and smoothes their values towards each other, where as if it is estimated as zero then they are conditionally independent and no such spatial smoothing is enforced. Methods have been proposed for estimating the elements in U using measures quantifying the dissimilarity between pairs of areal units, 26 but their approach was aimed at a disease mapping context, where as in the ecological regression context considered here covariate information would be included in the regression model. Therefore an iterative algorithmic approach has also been proposed, 14 which deterministically updated the spatial adjacency matrix U based on the joint posterior distribution of the remaining model parameters. Finally, data on disease risk prior to the study period have been used to elicit a set of candidate spatial structures for the random effects, 15 which are then used as the elements in a discrete prior distribution for U in an extended hierarchical model.
4 Methodology
The localised spatio-temporal smoothing model we propose follows the general approach of the existing literature in a purely spatial domain,26,14,15 and treats the elements of W relating to spatially or temporally adjacent observations as binary quantities to be estimated rather than fixed equal to one. From equation (7) it is clear that this allows adjacent random effects to be autocorrelated (if the element
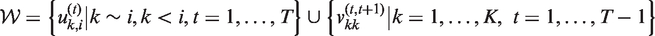
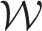 is large. For example, in the Greater Glasgow study there are 1355 data points (K = 271 and T = 5), while
is large. For example, in the Greater Glasgow study there are 1355 data points (K = 271 and T = 5), while
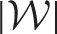 equals 4644. Therefore we do not treat each element in a Bayesian manner with a Bernoulli prior distribution, but instead propose an algorithm that iteratively re-estimates the localised spatio-temporal structure in the random effects until a convergence criterion is satisfied. The drawback of our proposed approach is that only a final estimate of each
equals 4644. Therefore we do not treat each element in a Bayesian manner with a Bernoulli prior distribution, but instead propose an algorithm that iteratively re-estimates the localised spatio-temporal structure in the random effects until a convergence criterion is satisfied. The drawback of our proposed approach is that only a final estimate of each
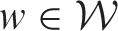 is provided, where as the
is provided, where as the
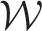 in the estimation process which we acknowledge is a limitation of our method, but it does enable localised smoothing to be undertaken without the need for additional data unlike existing approaches.26,15 The next section proposes a new random effects model based on a fixed neighbourhood structure
in the estimation process which we acknowledge is a limitation of our method, but it does enable localised smoothing to be undertaken without the need for additional data unlike existing approaches.26,15 The next section proposes a new random effects model based on a fixed neighbourhood structure
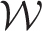 , while the iterative estimation algorithm is presented in Section 3.2. The model proposed here is an extension of the non-separable BYM model given by equation (4), because as has already been discussed the Glasgow data are likely to exhibit non-separable residual structure. However, separable residual spatio-temporal autocorrelation is possible in some applications, so the Supplementary material describes the analogous local smoothing extension of the separable BYM model (3).
, while the iterative estimation algorithm is presented in Section 3.2. The model proposed here is an extension of the non-separable BYM model given by equation (4), because as has already been discussed the Glasgow data are likely to exhibit non-separable residual structure. However, separable residual spatio-temporal autocorrelation is possible in some applications, so the Supplementary material describes the analogous local smoothing extension of the separable BYM model (3).
4.1 A random effects model based on a fixed
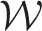
The model we propose combines equation (2) with a single KT × 1 vector of spatio-temporal random effects
 is a set of binary random quantities it is possible that
is a set of binary random quantities it is possible that
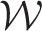 , is given by
, is given by

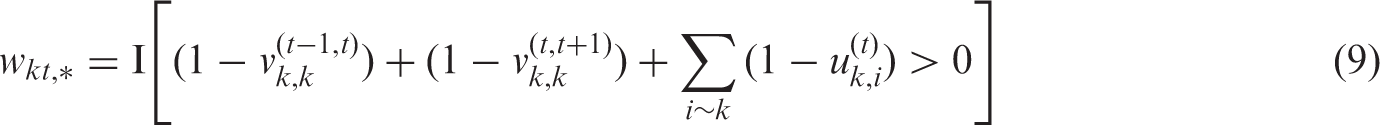
Here
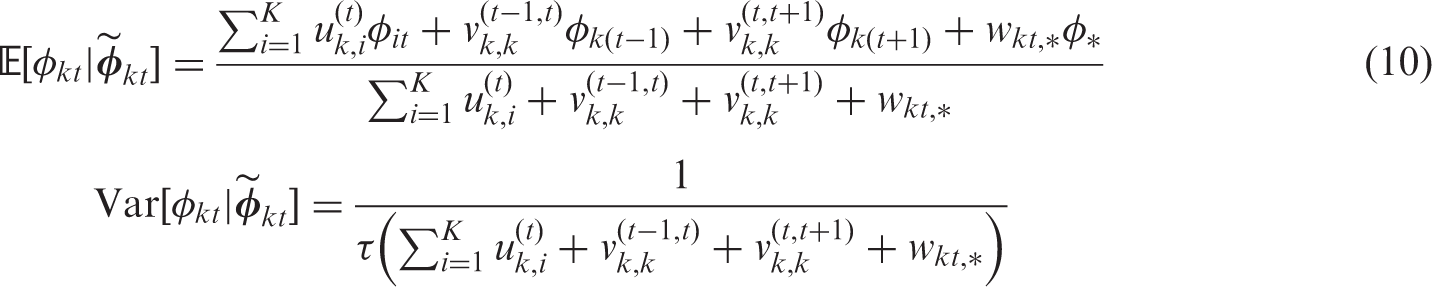
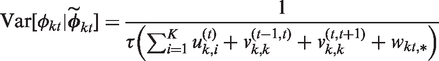
The conditional expectation is a weighted average of the global random effect
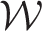 . This model can represent both spatio-temporal smoothing extremes, because if all elements in
. This model can represent both spatio-temporal smoothing extremes, because if all elements in
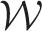 are estimated as one then the model is equivalent to just having the autocorrelated random effects
are estimated as one then the model is equivalent to just having the autocorrelated random effects
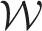 equal zero then the model is equivalent to just having the independent random effects
equal zero then the model is equivalent to just having the independent random effects
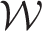 is given by
is given by


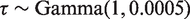
4.2 Estimation algorithm for localised spatio-temporal smoothing
The parameters
Set w = 0 if the marginal 95% posterior credible intervals for the two random effects do not overlap, because there is evidence that they are substantially different. Set w = 1, if the marginal 95% posterior credible intervals for the two random effects do overlap, because there is no substantial difference between them. conditional on the other in turn until a termination criterion is met. Conditional on
conditional on the other in turn until a termination criterion is met. Conditional on
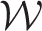 model (11) is fully Bayesian, and inference is implemented using INLA rather than McMC simulation for reasons of computational speed. This is because the estimation algorithm proposed here iteratively re-fits the model based on different neighbourhood structures
model (11) is fully Bayesian, and inference is implemented using INLA rather than McMC simulation for reasons of computational speed. This is because the estimation algorithm proposed here iteratively re-fits the model based on different neighbourhood structures
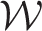 , which would make an McMC approach to estimation computationally prohibitive. In contrast,
, which would make an McMC approach to estimation computationally prohibitive. In contrast,
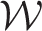 is updated deterministically at each iteration of the algorithm based on the current posterior distribution of Θ. Consider an element
is updated deterministically at each iteration of the algorithm based on the current posterior distribution of Θ. Consider an element
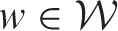 , which determines the partial correlation between two spatially or temporally adjacent random effects. Its value is updated based on the posterior distribution of Θ using the following deterministic rule.
, which determines the partial correlation between two spatially or temporally adjacent random effects. Its value is updated based on the posterior distribution of Θ using the following deterministic rule.
This approach induces spatio-temporal smoothing between the next estimates of spatially or temporally adjacent random effects if the current estimates are similar, whereas no such smoothing is enforced if the current estimates are substantially different. The full iterative estimation algorithm proposed here is given below.
Algorithm
1: Estimate a starting posterior distribution
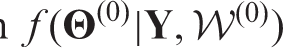 for Θ using INLA. For this initial model the random effects are assumed to be independent.
for Θ using INLA. For this initial model the random effects are assumed to be independent.
2: Iterate the following two steps for
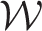 , outlined in step 3, are met.
, outlined in step 3, are met.
a: Estimate
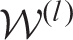 deterministically from the current posterior distribution
deterministically from the current posterior distribution
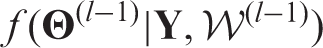 . Set
. Set
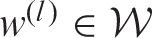 equal to one if the marginal 95% posterior credible intervals for the two corresponding random effects overlap. Otherwise, set
equal to one if the marginal 95% posterior credible intervals for the two corresponding random effects overlap. Otherwise, set
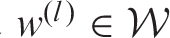 equal to zero.
equal to zero.
b: Estimate the posterior distribution
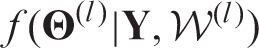 using INLA.
using INLA.
3: After l* iterations one of the following two termination conditions will apply.
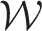 estimates is such that
estimates is such that
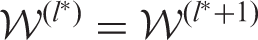 , which is the estimated neighbourhood structure
, which is the estimated neighbourhood structure
 .
.
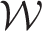 estimates forms a cycle of k different states
estimates forms a cycle of k different states
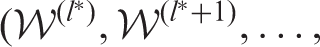
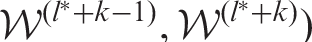 , where
, where
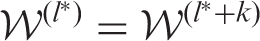 . In this case, the estimated neighbourhood structure
. In this case, the estimated neighbourhood structure
 is the value from the cycle of k states that has the minimal level of residual spatio-temporal autocorrelation, as measured by the absolute value of Moran's I statistic.
is the value from the cycle of k states that has the minimal level of residual spatio-temporal autocorrelation, as measured by the absolute value of Moran's I statistic.
When one of these termination conditions has been met
 is the estimated spatio-temporal structure of the random effects, and Θ is summarised by the posterior distribution
is the estimated spatio-temporal structure of the random effects, and Θ is summarised by the posterior distribution
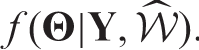 .
.
The algorithm is initialised by assuming the random effects are independent, because this does not enforce any initial spatio-temporal smoothing constraints on the random effects surface. One of the two termination conditions outlined in the algorithm is guaranteed to apply after a sufficiently large number of iterations l*, because each
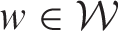 is binary and hence the sample space for
is binary and hence the sample space for
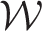 is large but finite. In practice however, the algorithm almost always terminates under case 1 in a small number of iterations.
is large but finite. In practice however, the algorithm almost always terminates under case 1 in a small number of iterations.
5 Simulation study
This section presents a simulation study, which compares the performance of an overdispersed Poisson generalised linear model (1) with the global BYM model (4) and localised smoothing model (11) that account for non-separable spatio-temporal autocorrelation. In addition, the separable global BYM model (3) and a localised extension of it (described in the Supplementary material) are also compared, to see the impact that specifying an inappropriate autocorrelation structure has on fixed effects estimates.
5.1 Study design
Simulated data are generated for the 271 areal units that comprise the Greater Glasgow and Clyde health board for 2007–2011, which is the study region and time frame for our motivating study. Disease counts are generated from model (2), where the expected numbers Ekt are uniform random draws from one of the following three intervals: (i) [10, 25], (ii) [50, 100] and (iii) [150, 200]. These values allow us to assess the robustness of our methodology when applied to disease data with different prevalences. The log risk surface is generated from a linear combination of covariates and random effects, the former including PM (PM10) and the other three covariates used in the Glasgow study. The regression parameters for the non-pollution covariates were fixed at the estimates obtained from the motivating study, where as the relative risk associated with a one standard deviation increase in PM10 was fixed at 1.03 to be similar to both this and existing studies.
The random effects are included to induce residual spatio-temporal autocorrelation into the log risk surface, which mimics its presence in the real data study. They are generated from a multivariate Gaussian distribution with a piecewise constant mean and a spatially and temporally smooth precision matrix, the latter being based on the neighbourhood matrix (5). Localised spatio-temporal structure is induced by the piecewise constant mean, which for the first year of the study follows the template shown in Figure 3. This template only has three distinct values {−1, 0, 1}, which are multiplied by a constant M to obtain the mean surface. Values of M = 0.5 and M = 1 are considered in this study, which respectively correspond to small and large localised structure. Finally, we consider scenarios where the random effects are separable and non-separable, with the former being achieved by using the same piecewise constant mean (given by Figure 3) for each year of the study. In contrast, non-separable random effects were generated by allowing the piecewise constant mean spatial surface given by Figure 3 to evolve each year, with the restriction that it still consisted of a series of spatial clusters.
A map showing the piecewise constant mean function (with possible values {−1, 0, 1}) for the random effects that generate localised spatial autocorrelation in the first year of the simulation study.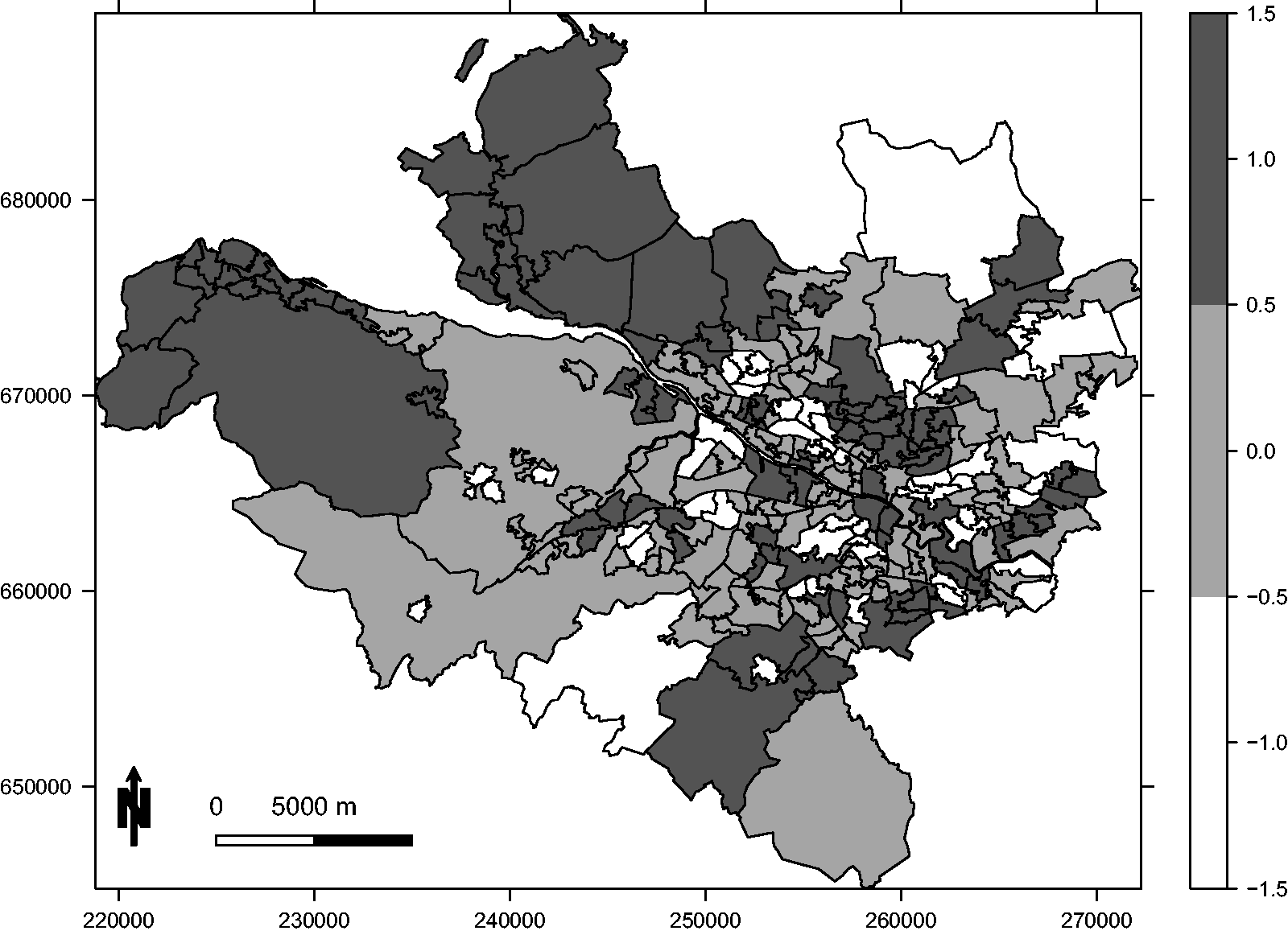
5.2 Results
Five hundred data sets are generated under each of 12 different scenarios, which include all pairwise combinations of: (i) M = 0.5, 1 (strength of the localised structure); (ii)
Root mean square error (RMSE) for the estimated regression parameter β for different values of M and Coverage probabilities for the estimated regression parameter β for PM10 from each of the following models: (a) Poisson GLM, (b) BYM separable, (c) localised separable, (d) BYM non-separable, (e) localised non-separable.
a
The top half of the table corresponds to data containing separable spatio-temporal autocorrelation, while the bottom half has non-separable structure. In both cases, the results are presented for different levels of localised structure (via M) and different disease prevalences (via 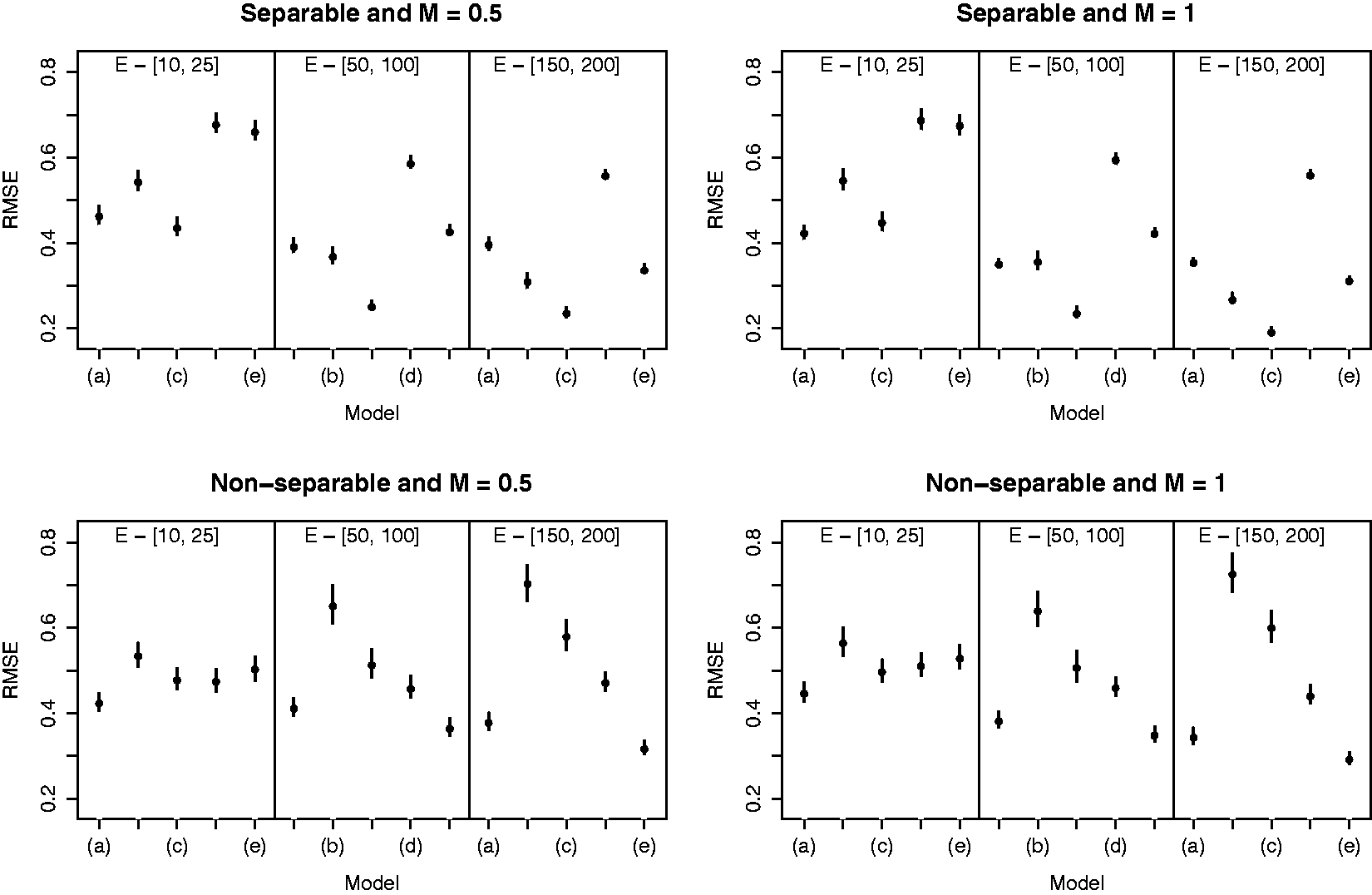
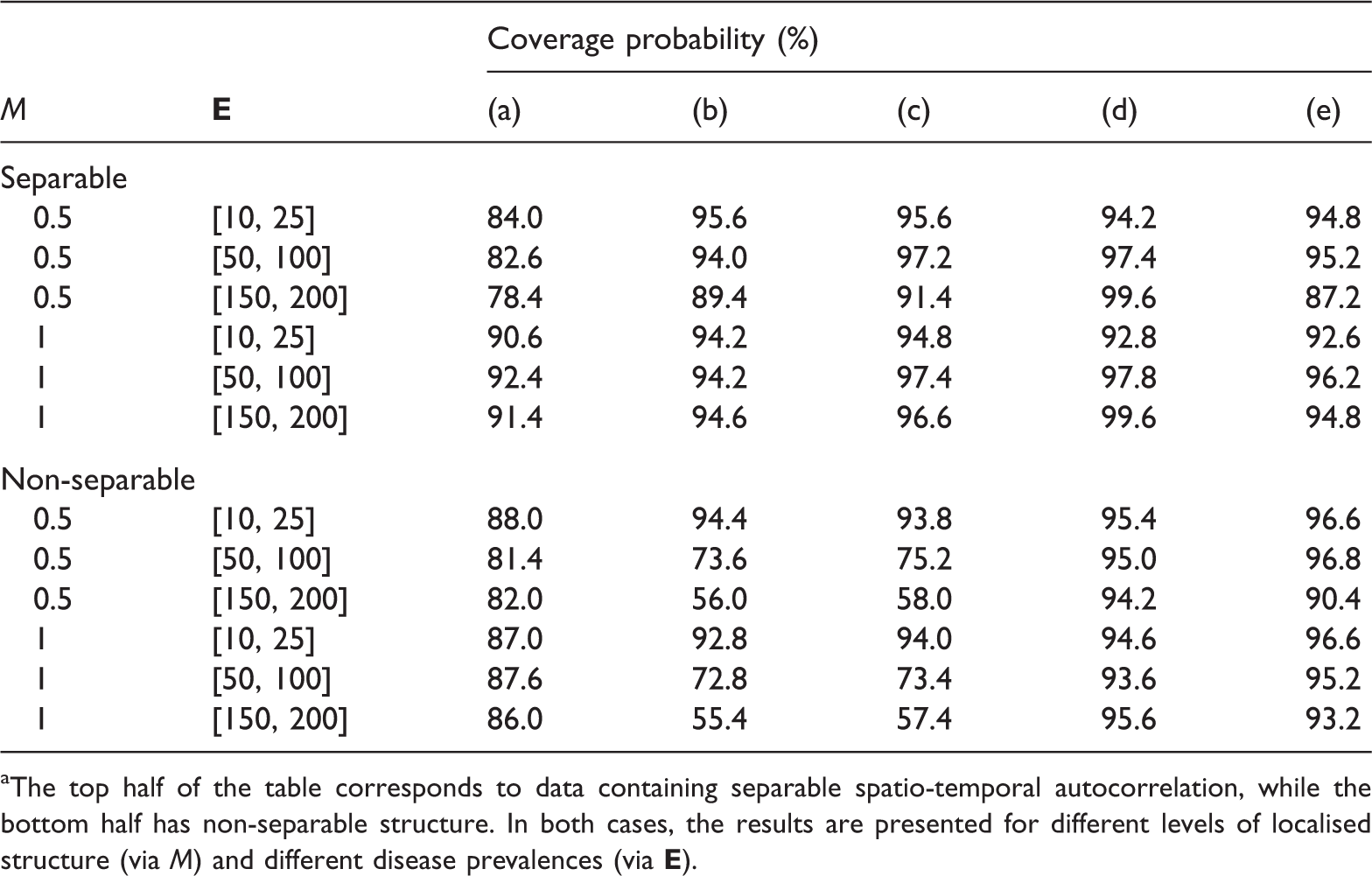
In Figure 4, the RMSE values are represented by a black dot for each scenario and model, while the vertical lines are bootstrapped 95% uncertainty intervals based on 1000 bootstrapped samples. The figure presents three main findings. Firstly, both separable and non-separable localised smoothing models generally outperform their BYM global smoothing counterparts even when the magnitude of the localised structure is small, exhibiting RMSE values that are substantially lower (the uncertainty intervals rarely overlap). These findings are consistent for diseases with moderate to large prevalences (
5.3 Results – algorithm convergence
The empirical convergence properties of the localised smoothing algorithm show that it terminates under case 1 in 93.5% of cases for the separable model and 99.9% of cases for the non-separable model. For both models the median number of iterations taken to converge is 4, which taken with the above result suggests that the algorithm typically converges quickly to a final value of
 .
.
6 Glasgow study
The non-separable localised spatio-temporal smoothing model (11) proposed in Section 4 is now applied to the data from the Greater Glasgow study presented in Section 2, together with the non-separable global BYM smoothing model given by equations (2) and (4). We have not applied the separable variants of these two models to the Glasgow data because the initial analysis in Section 2 suggests that the residuals exhibit highly non-separable structure.
6.1 Model comparison
The overall fit of both non-separable models to the Glasgow respiratory data was compared using a number of different metrics, including the Deviance Information Criterion
27
(DIC), the Conditional Predictive Ordinate (CPO), and the extent to which they adequately controlled for the spatio-temporal autocorrelation in the data. Both models have successfully accounted for this autocorrelation, as evidenced by Moran's I permutation tests on the residuals for each year yielding non-significant p values. The DIC for the BYM global smoothing model is 10,556 compared with 10,430 for the localised model, suggesting an improvement in in-sample fit to the data for the localised model proposed here. Conversely, the CPO for each observation is its predictive distribution conditional on the remainder of the data, that is
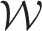 ) as being conditionally independent, which is 7.2% of the total number of adjacencies in the study region.
) as being conditionally independent, which is 7.2% of the total number of adjacencies in the study region.
6.2 Estimated covariate effects
The results are presented as relative risks, for a one standard deviation increase in each covariates value, which are: CO – 0.024, NO2 – 5.87, PM2.5 – 1.56, PM10 – 1.96, job seekers allowance (JSA) – 2.57%, house price – £ 54,800 and ethnicity – 13.5%.
7 Discussion
This paper has proposed a new GMRF model for capturing localised spatio-temporal autocorrelation in areal unit health data, which combines existing methods14,15 and extends both into the spatio-temporal domain. Models for both separable and non-separable spatio-temporal autocorrelation have been proposed, and have been shown by simulation to outperform their global smoothing counterparts when the magnitude of the localised autocorrelation is either small or large. The increased flexibility offered by these methods naturally comes at the cost of a large increase in the number of parameters to estimate, and an estimation algorithm is proposed which iteratively updates the structure of the spatio-temporal autocorrelation conditional on the remaining parameters until a convergence criterion is reached. The key advantage of this and other localised smoothing approaches is that temporally or spatially adjacent random effects are allowed to be autocorrelated or conditionally independent, which does not enforce smoothing between their values if the data suggest such smoothing is inappropriate. However, the downside of localised smoothing approaches is their increased complexity in terms of the numbers of parameters, and the main drawback of our solution to this problem is that the uncertainty in
 is ignored in the estimation process.
is ignored in the estimation process.
The main message from the simulation study is that the estimation of regression parameters for spatially and temporally smooth covariates is difficult, due to the presence of spatio-temporal autocorrelation in the data that is unexplained by the covariates. This autocorrelation is typically modelled by a set of random effects, and our study has shown that enforcing an inappropriate spatio-temporal structure on these effects is likely to lead to poor fixed effects estimation. In fact, ignoring this autocorrelation can lead to better fixed effects in a RMSE sense than modelling it with an inappropriate spatio-temporal structure, although such an approach does lead to 95% confidence intervals that are too narrow in terms of their coverage probabilities. However, models including spatio-temporal random effects are not without problems, as they have the potential for collinearity between the covariates and the random effects. The impact of this collinearity has previously been investigated in a purely spatial context,11,12 and an extension of this research into the spatio-temporal domain is urgently required. This paper has shown that the development of more flexible localised smoothing models is likely to be beneficial in this regard, because locally smooth rather than globally smooth autocorrelation can be represented which is less likely to be collinear to globally smooth covariates.
The Glasgow study presented here is one of the most up to date studies of the long-term effects of air pollution on human health in a UK urban environment, and shows that even though pollution concentrations are relatively low they still represent a substantial public health problem. In particular, we have found that elevated concentrations of NO2 and PM10 are associated with increased risks of respiratory disease of 3.4% and 5.3% if the pollutants increased by 5.78 µgm−3 (NO2) and 1.96 µgm−3 (PM10), respectively. However, the limitations of data availability mean that we have assumed the impact of smoking can be accounted for by proxy measures of socio-economic deprivation, such as average property price and the proportion of people claiming JSA. Furthermore, the pollution data are modelled concentrations and thus subject to error, which could impact upon the analysis. Finally, this is a population level observational study, and the results must not be interpreted in terms of individual level cause and effect (ecological bias). Even so, as small-area studies are cheaper and quicker to implement than individual-level cohort studies, they form an important component of the evidence base quantifying the health effects of long-term exposure to air pollution.
There are many avenues for future work arising from this paper. The most obvious one from an epidemiological perspective would be to extend the present study to the whole of the United Kingdom, as it would give the UK government a national rather than a regional picture of the extent of the air pollution problem. As highlighted above there is also the problem of error in the modelled pollution concentrations, so an avenue of future work will be to combine the model considered here with a measurement error model for the pollution concentrations. Finally, the methodology proposed here would also be useful in the related field of disease mapping, whose aim is to estimate the spatio-temporal pattern in disease risk. Within this context our methodology would be especially suited to the identification of risk boundaries, which separate spatially or temporally adjacent data points that exhibit large differences in their disease risks. In this context, our approach would identify a set of disjoint risk boundaries that do not enclose a group of areal units and time points. Therefore, extending the algorithm so that it identifies closed boundaries that completely enclose a group of areal units and time points would be a useful tool in the cluster detection literature, where the identification of high-risk disease clusters is the main goal.
Supplementary material
This paper is accompanied by supplementary material which includes details of a separable localised smoothing model and the data and software to partially reproduce the analysis in Section 6.
Footnotes
Acknowledgements
The authors gratefully acknowledge the helpful comments from the editor and a referee, which have improved the content and presentation of this paper. The health and covariate data as well as the shapefiles were provided by the Scottish Government through the Scottish Neighbourhood Statistics database, while the pollution data were provided by the DEFRA.
Funding
This work was funded by the Engineering and Physical Sciences Research Council (EPSRC) grant number EP/J017442/1.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.