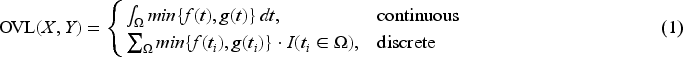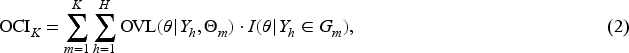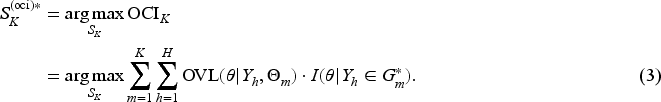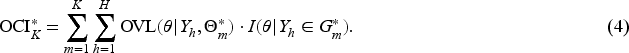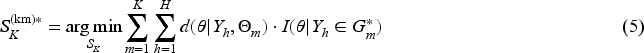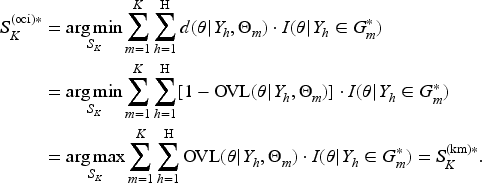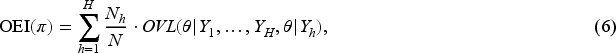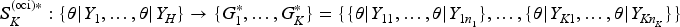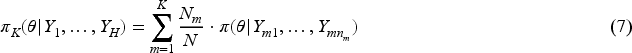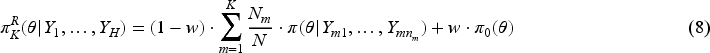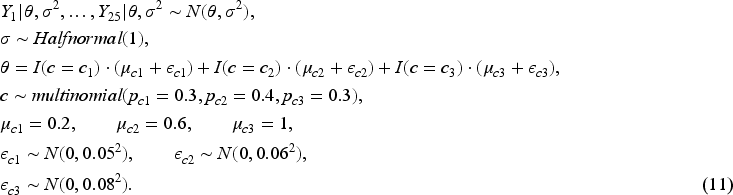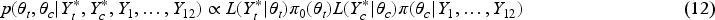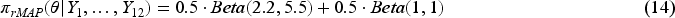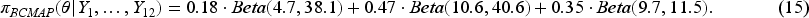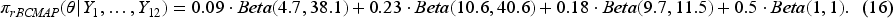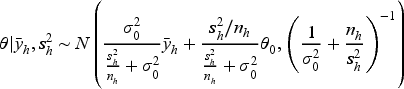The use of external data in clinical trials offers numerous advantages, such as reducing enrollment, increasing study power, and shortening trial duration. In Bayesian inference, information in external data can be transferred into an informative prior for future borrowing (i.e. prior synthesis). However, multisource external data often exhibits heterogeneity, which can cause information distortion during the prior synthesizing. Clustering helps identifying the heterogeneity, enhancing the congruence between synthesized prior and external data. Obtaining optimal clustering is challenging due to the trade-off between congruence with external data and robustness to future data. We introduce two overlapping indices: the overlapping clustering index and the overlapping evidence index . Using these indices alongside a K-means algorithm, the optimal clustering result can be identified by balancing this trade-off and applied to construct a prior synthesis framework to effectively borrow information from multisource external data. By incorporating the (robust) meta-analytic predictive (MAP) prior within this framework, we develop (robust) Bayesian clustering MAP priors. Simulation studies and real-data analysis demonstrate their advantages over commonly used priors in the presence of heterogeneity. Since the Bayesian clustering priors are constructed without needing the data from prospective study, they can be applied to both study design and data analysis in clinical trials.
Incorporating multisource external data into the design and analysis of clinical trials has become a field of significant interest. U.S. Food and Drug Administration (FDA) has issued the guidance, “Use of Real-World Evidence to Support Regulatory Decision-Making for Medical Devices,”1 to encourage the integration of external data in new studies. This practice aims to enhance the efficiency of clinical trials by leveraging real-world data (RWD) to inform study parameters, potentially reducing sample size, increasing the statistical power and precision of testing or estimating study outcomes, and accelerating trial timelines.2 In the Bayesian framework, a critical component of incorporating RWD is the construction of informative priors from external data, a process commonly referred to as evidence synthesis. Methods of synthesizing informative priors have been extensively studied. For instance, the meta-analytic predictive (MAP) prior3,4 uses meta-analysis to summarize information from external data into an informative prior. The power prior (PP)5,6 adjusts the influence of external data on the analysis of new data by applying a likelihood discounting approach based on the relevance and reliability of the external data. Commensurate priors7,8 and multisource exchangeability models (MEMs)9 modulate the degree of information borrowing from external data according to their relevance and congruence to the new data. The elastic prior10 dynamically borrows information from external data using a monotonic function of a congruence measure between external and new data.
The use of prior information is critical in both trial design and data analysis. During the trial design stage, where new trial data is not yet available, prior information is typically derived from domain knowledge or external data. In the data analysis stage, once new trial data is available, priors can be refined by evaluating the similarity between the external and new trial data. Constructing an informative prior that is suitable for both trial design and data analysis is challenging. For example, with the exception of the MAP prior, all of the aforementioned priors require the new trial data, which limits their applicability during the trial design stage.
Another challenge arises from the diversity and heterogeneity of multiple data sources, including differences in study design, population characteristics, eligibility criteria, outcome measures, etc.4 Such variability complicates the accurate transferring or borrowing of information from external data into a prior, potentially leading to information distortion and adversely affecting the analysis of the new trial. Therefore, it is crucial to accurately identify the heterogeneity across external datasets. MAP (or rMAP) prior accommodates this heterogeneity by using the linear mixed model with a random effect parameter.11 However, a single parameter may not adequately capture complex heterogeneity structures, such as scenarios where external datasets include multiple clusters with varying degrees of homogeneity. The MEM approach attempts to address this challenge by measuring pairwise exchangeability among the interested random parameters (associated with external datasets). However, it does not explicitly construct a prior that adapts to the heterogeneity structure. in this paper, we focus on clustering methods, where heterogeneity is identified by partitioning the interested random parameters (associated with external datasets) into distinct clusters. Bayesian nonparametric clustering with Dirichlet process12 is a widely used approach. For example, based on it, Chen and Lee13 proposed a Bayesian clustering hierarchical model to dynamically partition sub-trials into clusters for efficient information borrowing in basket trials. Nevertheless, in their model, the number of clusters is determined by a hyperparameter, making it challenging to establish an interpretable and unified criterion for selecting the optimal hyperparameter value across different applications.14 Additionally, based on our knowledge, this approach has not been applied to prior synthesis with multisource external data.
To address these challenges, we propose a novel approach for synthesizing informative priors from multisource external data, leveraging the concept of overlapping coefficients.15,16 Specifically, we introduce the overlapping clustering index (OCI) and employ a K-means algorithm to identify heterogeneity across external datasets. To measure the congruence between the synthesized prior and external data, we define an overlapping evidence index (OEI). A higher OEI indicates more accurate information transferred from external data to the prior, reflecting stronger congruence between them. There is, however, an inherent trade-off between maximizing OEI and ensuring the robustness of the prior to new data. To address this, we propose an OEI-based criterion that balances this trade-off, enabling accurate heterogeneity identification through optimal clustering. Compared to existing nonparametric clustering methods,17,18 our criterion is more interpretable and maintains a consistent standard across different applications. Using the optimal clustering results, we introduce the Bayesian clustering prior, a flexible framework for prior synthesis. By integrating the MAP and robust MAP priors within this framework, we develop the Bayesian clustering MAP (BCMAP) and robust Bayesian clustering MAP (rBCMAP) priors. They exhibit desirable properties and are applicable in both trial design and data analysis stages.
Section 2 introduces the notations, assumptions, and key challenges of Bayesian evidence synthesis with multisource external data. In Section 3, we propose two overlapping indices, explore the trade-off between evidence congruence and robustness, and present a K-means algorithm to achieve optimal clustering for accurate heterogeneity identification. Section 4 details the construction of Bayesian clustering priors, provides a sensitivity analysis and OEI-based threshold selection guidelines, and includes an illustrative example. Simulation studies comparing our method with existing approaches are presented in Section 5. Section 6 demonstrates the application of the proposed method to two real-world external datasets, featuring binary and continuous endpoints. Section 7 concludes with a brief discussion. To facilitate reading and referencing, Table 5 in the Appendix lists the symbols and abbreviations used in this paper.
Bayesian evidence synthesis from multisource external data
Let denote external data from multiple sources. Assume to be the common parameter of interest. Bayesian evidence synthesis aims to create an informative prior of from , denoted as . Then, for any new data , the inference of can borrow information from through , where is the likelihood function. In this paper, we assume is unknown; in other words, has no effect on the construction of . In Bayesian inference, the prior distribution represents the beliefs or information about a parameter before observing the new data. Avoiding “use the data twice”19 is fundamental for maintaining the integrity of the Bayesian updating process. Compared to the most existing methods, such as the MEM and power prior, which use first in the prior and then in the likelihood, our approach strictly follows the rule that do not use the data twice. It makes applicable in both trial design (without ) and data analysis (with ). Another assumption in this paper is the exclusion of covariate information. This assumption stems from the practical challenges of obtaining such information. For instance, patient-level data may be restricted from the public access, even for research purposes. Even when this information is accessible, the available covariates often vary across data sources. For example, data source 1 includes covariates , data source 2 include , and data source 3 include , leaving only as a common covariate. In such cases, inference relying solely on may lead to questionable conclusions.
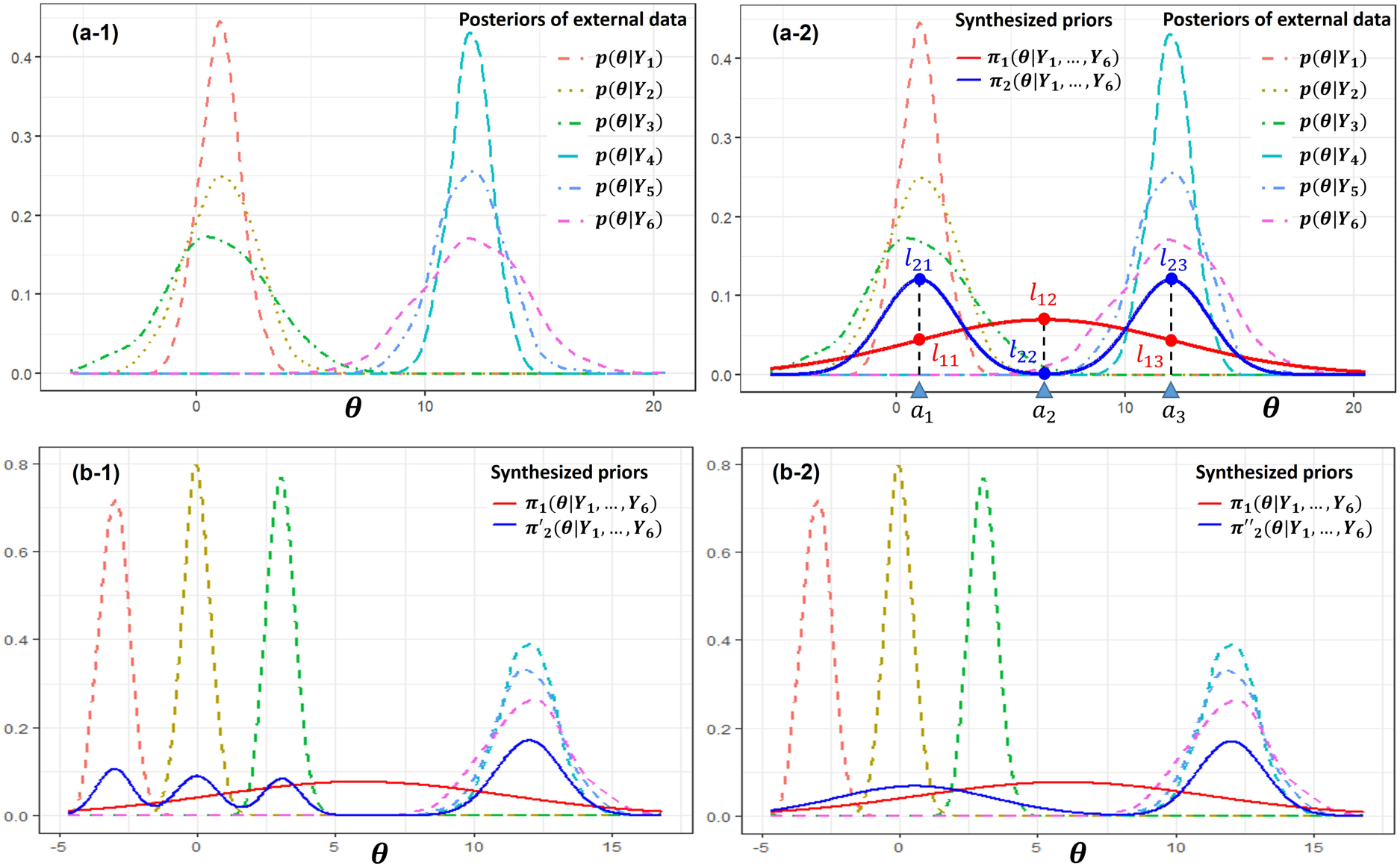
In practice, heterogeneity often exists among data sources, such as multi-regional data or data from multiple health centers. One approach to address this issue is to filter out certain datasets to achieve homogeneity. However, without knowledge of covariate information or the new data , this method risks losing valuable information, furthermore it is hard to determine which data sources should be excluded. An alternative approach is to include all external datasets. In this scenario, the evidence synthesis model used to construct the prior must be capable of effectively identifying the heterogeneity across the various data sources and be able to handle it well. Otherwise, it may distort the information transferred from to . The information of in is contained in where , , is obtained through , and can be either a weakly informative or an informative prior of . (Note: Instead of using , we utilize the posteriors to reflect the heterogeneity of the external data. This notation emphasizes the congruence between the external data and the synthesized prior .) The information distortion can be illustrated by the example shown in Panels (a-1) and (a-2) of Figure 1. The example includes six external datasets with corresponding posteriors as shown in Panel (a-1). It is obvious that these datasets are heterogeneous and can be partitioned into two clusters. In Panel (a-2), we examine information transfer at three points: , , and . The transferred information is quantified using the likelihood under priors and . The corresponding likelihoods are for and for . According to the posteriors , it is clear that the likelihoods at and should be greater than the likelihood at . However, performs oppositely, with . This occurs because the synthesizing method of fail to identify the heterogeneity, thus distorting the information in the external data. Conversely, correctly captures the heterogeneity and accurately reflects the information in the external data, with .
Information distortion and the trade-off between evidence congruence and robustness. Panel (a-1) shows an example with the posterior distributions of six external datasets. Panel (a-2) illustrates the distortion of information due to heterogeneity, demonstrating that prior , which correctly accounts for heterogeneity, is more appropriate than prior . Panels (b-1) and (b-2) demonstrate the trade-off between evidence congruence and robustness. In Panel (b-1), the prior has stronger evidence congruence but weaker robustness. In Panel (b-2), the prior has weaker evidence congruence but stronger robustness.
As discussed above, the quality of a synthesized prior can be evaluated by the congruence of information about between and . We refer to this congruence as the evidence congruence of with respect to . In Panel (a-2) of Figure 1, it is clear that has stronger evidence congruence than . However, higher evidence congruence is not always better. Robustness is another crucial criterion for evaluating the quality of a synthesized prior.4 As shown in Panels (b-1) and (b-2), is constructed by identifying four clusters in the external datasets, whereas assumes two clusters. It is easy to check that the evidence congruence of is greater than that of . But we prefer because it is more robust. In sum, both criteria of evidence congruence and robustness are closely related to the heterogeneity identification. Since contain all the information about , an accurate clustering of can strike a good balance between evidence congruence and robustness, thereby helping to create a high-quality informative prior.
Overlapping indices
Overlapping coefficient (OVL) is a measure of the intersection area between two probability density or mass functions. Let and be two random variables with probability density or mass functions and , respectively. is the common support of and . OVL can be defined by equation (1). (Note: the integral expression is used in this paper without loss of generality)
Based on the concept of OVL, we propose two overlapping indices for the clustering of to address the challenges discussed in Section 2.
Overlapping clustering index and K-means clustering
Let , , be the probability density function (pdf) or probability mass function (pmf) of posterior distributions obtained from the external datasets . The corresponding random variables are denoted as , . A partition groups them into clusters , . For each cluster , , let be a Gaussian random variable with density function , which is the maximum likelihood estimation (MLEs of mean and variance) obtained from the samples of the random variables in cluster . Then, the overlapping clustering index (OCI) of this partition is defined as follows:
where is a indicator function. The random variables in the same cluster are assumed to be exchangeable. denotes the centroid of cluster , and it is modeled as a Gaussian random variable. This assumption is justified by the central limit theorem, which implies that as the size of increases, the mean of the all posteriors within the cluster will approximate a Gaussian distribution, regardless of the differences among , .
measures the overall within cluster homogeneity of the K-partition. Based on it, we can define the optimal for K partition as follows:
With , we can calculate the corresponding :
An optimal clustering can be found through the following K-means algorithm:
where is a distance measure between two random variables and . The equivalence between and is shown as follows:
The above mentioned K-means algorithm closely resembles the standard K-means algorithm. The differences lie in the definitions of the centroid and the distance . A detailed description of the proposed K-means algorithm in the form of pseudo-code can be found in Algorithm 1 in the Appendix.
Overlapping evidence index and trade-off between evidence congruence and robustness
For any fixed , the heterogeneity among ,…, can be effectively identified through . As demonstrated by Figure 1 in Section 2, the evidence congruence increases as increases, and the information distortion reduces. However, the robustness of the synthesized prior weakens as increases because the clusters become more and more specific and the amount of data in each cluster tends to decrease. It is desirable to find an optimal to strike a good balance for this trade-off. To help identifying the optimal , we introduce the concept of overlapping evidence index (OEI).
Let denote the random variable corresponding to the synthesized prior . The OEI of is defined as the weighted sum of overlapping coefficients between the random variable and each for .
where is the sample size of dataset and .
lies within the interval . It measures the congruence of synthesized prior with the information of external data. The higher the , the more congruent information transfers to from external data, and the less information distortion occurs. An OEI-based criterion for selecting the optimal number of clusters , aimed at balancing evidence congruence and robustness, is introduced in Section 4.
Bayesian clustering prior
The formulation of bayesian clustering prior
For a fixed , let us assume the optimal partition is denoted as follows:
where is the number of random variables in cluster , .
Based on , the Bayesian clustering prior with clusters can be constructed as a weighted sum of informative priors synthesized from clusters, , .
where is the number of observations in cluster , and is the size of all external data. Moreover, the prior in equation (7) can be made more robust by adding a weighted weakly informative prior. We refer to this as the robust Bayesian clustering prior:
where is a weakly informative prior, is the weight of .
In equations (7) and (8), can be estimated through various methods, such as traditional Bayesian hierarchical models (BHM), MAP, or power priors. In this article, we choose MAP and robust MAP (rMAP) priors because they can be used in both trial design and data analysis stages. We refer to the resulting priors as Bayesian clustering MAP (BCMAP) and robust Bayesian clustering MAP (rBCMAP), respectively. Weber et al.11 developed the R package “RBesT” to implement the sampling of MAP and rMAP through Markov chain Monte Carlo (MCMC). To represent the MAP prior in parametric form, an expectation maximization (EM) algorithm is conducted to approximate the MCMC samples with a parametric mixture distribution. Since BCMAP (rBCMAP) is a weighted sum of MAPs, it can naturally be represented by a parametric mixture distribution as well. Thus, when conjugate MAP priors exist, a mixture of conjugate BCMAP priors can be applied (see the real data example in Section 6.1.1).
The BCMAP prior can be constructed based on for each . Then, we can obtain a sequence of , , which monotonically increase as increases, that is . The proof of monotonicity can be found in Theorem 1 in Appendix. We can scale the sequence by the maximum and refer to , , as . The sequence of , , denotes the percentage of evidence congruence under each relative to the extreme case where each distribution is a cluster. A threshold balancing the trade-off of maximizing evidence congruence and minimizing the number of clusters for robustness can be used to determine the optimal . Then, is the finalized optimal Bayesian clustering prior (see an example in Section 4.3 below). The main advantages of this OEI-based threshold optimizing approach are two-fold: (i) it is straightforward and easy to interpret, as the threshold reflects a balance between the congruence of the synthesized prior with the external data and the robustness to new data, and (ii) a fixed threshold offers a consistent and unified interpretation across various applications. These contrasts with Bayesian nonparametric clustering approaches, where the value of hyperparameters used to determine the number of clusters are often challenging to select and interpret, and may lack consistency across different applications.
Sensitivity analysis and practical guidelines
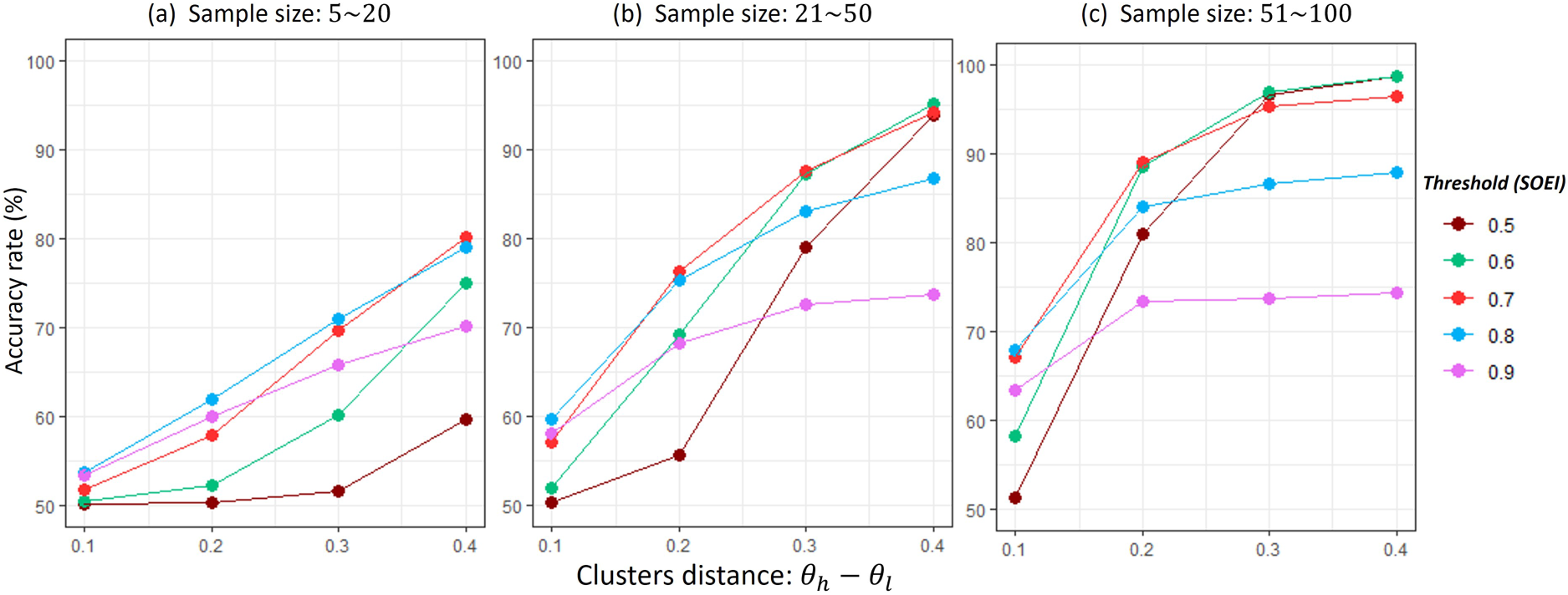
To provide guidelines for selecting an appropriate threshold, it is essential to understand how the threshold affects clustering performance. We answer this question through a simulation study. The simulation setup consists of two clusters representing low and high parameter values, each containing five subgroups. Specifically, the data are generated as follows: and for . We fixed and varied to create increasing levels of separation between the two cluster, . To examine the effects of the threshold under different sample sizes, three settings for and are considered, where values are drawn from , , and , respectively. We evaluate five threshold values: . For each configuration (i.e., a combination of , sample size, and threshold), we simulate 1000 datasets and compare the average clustering accuracy rate.
The clustering accuracy rate is defined as follows. Suppose there are objects partitioned into clusters. For each pair of objects, we assign a label of 1 if they belong to the same cluster and 0 otherwise, resulting in a total of labels for any given clustering. We then compare the labels from the estimated clustering (based on a given threshold) to those from the true clustering. Let denote the number of matching labels between the two. The accuracy rate is then calculated as .
Several insights emerge from the simulation results in Figure 2. (a) accuracy improves as the sample size increases. (b) Low thresholds (0.5, 0.6) tend to reduce accuracy when clusters are close together and/or the sample size is small. (c) High thresholds (0.9) decrease accuracy when clusters are well separated. Base on these insights, the general guidelines for selecting the threshold are:
Choose a threshold in the range ;
Use values closer to 0.7 when the sample size of each study or the average sample size are small () or when the gap of clusters is small ();
Use values closer to 0.6 when the sample size of each study or the average sample size are large () or when the gap of clusters is large ().
Sensitivity analysis of the scaled OEI (SOEI) threshold.
An illustrative example
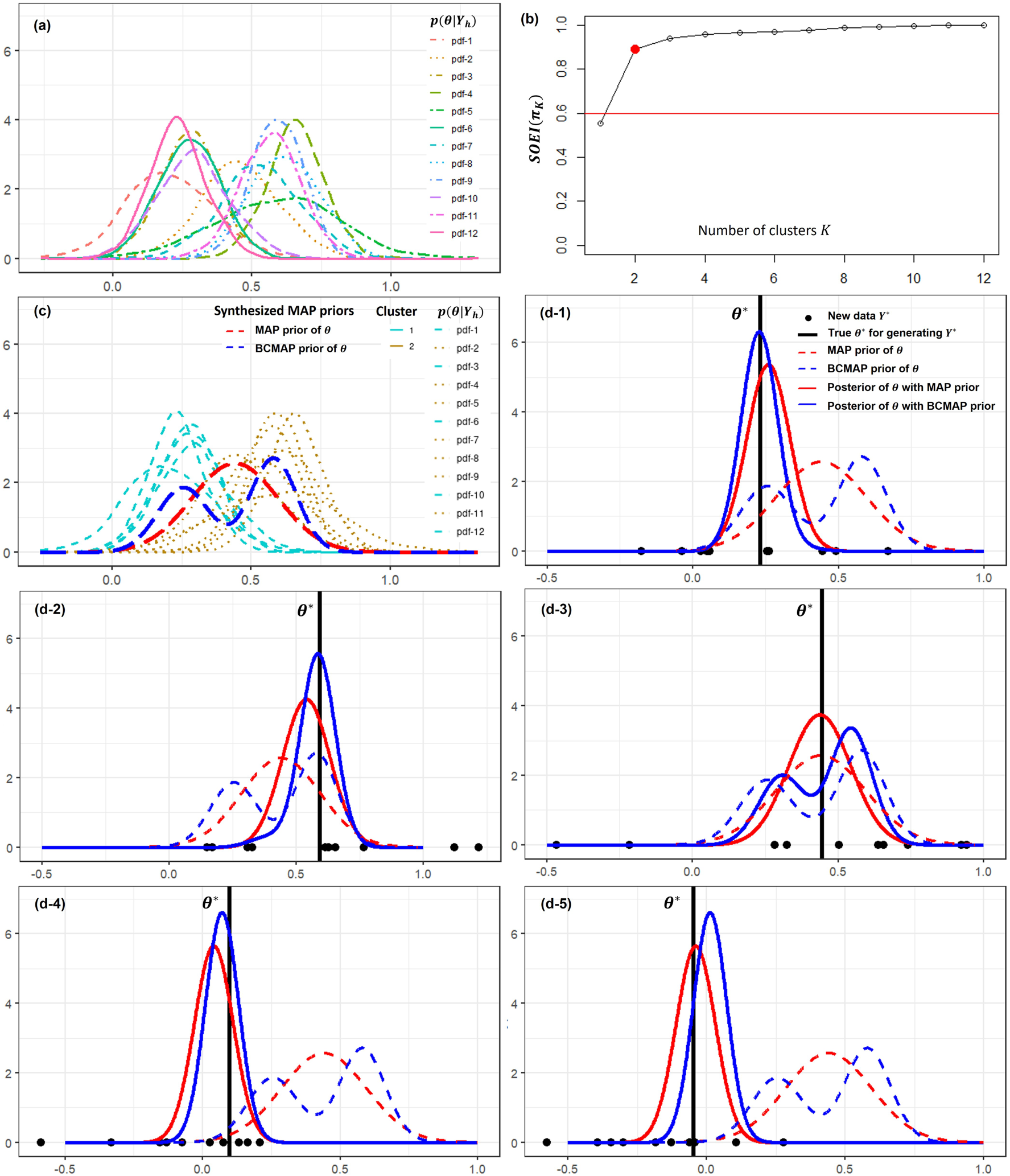
The following example provides an intuitive understanding of the questions: how is BCMAP constructed and how and why does it work? In this example, 12 external datasets were generated by using the model (9). The summary of these datasets is provided in Table 6 in Appendix. It is easy to find the heterogeneity among these datasets that contains two clusters centered at 0.2 and 0.6.
The posteriors , , are shown in Panel (a) of Figure 3. The weakly informative prior is constructed as: , where and . Given that the average size of the external data is 55, we set the threshold at 0.6 in accordance with the proposed guidelines. Thus, the optimal number of clusters is identified as as shown in Panel (b). The BCMAP prior is presented in Panel (c), where the corresponding MAP prior is also provided for comparison. The BCMAP prior is congruent with external data, that is RWD. Therefore, if the new data is congruent with the RWD too, which is reasonable, the estimation of will benefit from the information borrowing with the BCMAP prior. To illustrate this, two examples are shown in Panels (d-1) and (d-2) with the new datasets (black dots) generated from . (black vertical line) is generated following the defined in (9), maintaining congruence between the new data and the external data. We compare the performance of BCMAP and MAP in estimating . In Panel (d-1), is near the center at 0.2. The posterior with BCMAP prior outperforms MAP prior in the estimations of both location (bias) and scale (variance). In Panel (d-2), is near the center at 0.6. BCMAP prior again outperforms MAP priors in both location and scale estimation. However, when the new data is incongruent with the external data in a certain way, BCMAP may perform worse than MAP, as illustrated in Panel (d-3). Notably, this does not imply that BCMAP consistently underperforms in all incongruent scenarios. For example, in Panel (d-4), BCMAP still outperforms MAP despite the presence of incongruence. In Panel (d-5), although MAP provides a more accurate estimate of the location, BCMAP exhibits a smaller variance.
The example of BCMAP and comparisons with MAP. Panel (a) shows the posteriors , , with a weakly informative prior . Panel (b) presents the identification of optimal number of clusters . Panel (c) exhibits the clustering result and corresponding BCMAP prior, where MAP prior is also provided for comparison. Panels (d-1), (d-2), (d-3), (d-4), and (d-5) show the posteriors, which are obtained by using the new data with various congruence and incongruence to the external data. Panels (d-1) and (d-2) demonstrate the cases that the new data is congruence with the external data. Panels (d-3), (d-4), and (d-5) demonstrate the cases that the new data is incongruence with the external data.
The example highlights the strengths and limitations of the proposed Bayesian clustering prior. Specifically, the superiority of this approach depends on two key conditions, which are commonly met in practice.
Heterogeneity among external datasets: The Bayesian clustering MAP (BCMAP) prior is particularly advantageous when there is heterogeneity among the external datasets. In the absence of heterogeneity, BCMAP typically identifies a single cluster, causing the BCMAP prior to degenerate to the MAP prior (see Figure 8 in Appendix).
Congruence between new data and external data: For the BCMAP to perform well, the new data must be congruent with the external data. Specifically, the data generating process of should align with that of the external datasets, even if it is not identical. For example, may follow a distribution that corresponds to one of the components in the mixture distribution of the external data. If this condition is not met, the BCMAP may not work well. In fact, none of the priors will work well if there are severe prior-data conflicts. In this case, the rBCMAP can provide a partial remedy by incorporating robustness into the prior construction (see Section 5.1).
Simulation studies
In this section, we conduct comprehensive simulation studies to demonstrate the advantages of BCMAP (rBCMAP) in both parameter estimation and hypothesis testing compared to commonly used priors, such as MAP, rMAP, NPP (Normalized Power Prior), and MEM. Note: for both rBCMAP and rMAP, the weight for robustness (weight of weakly informative component) is set to 0.5.
Parameter estimation
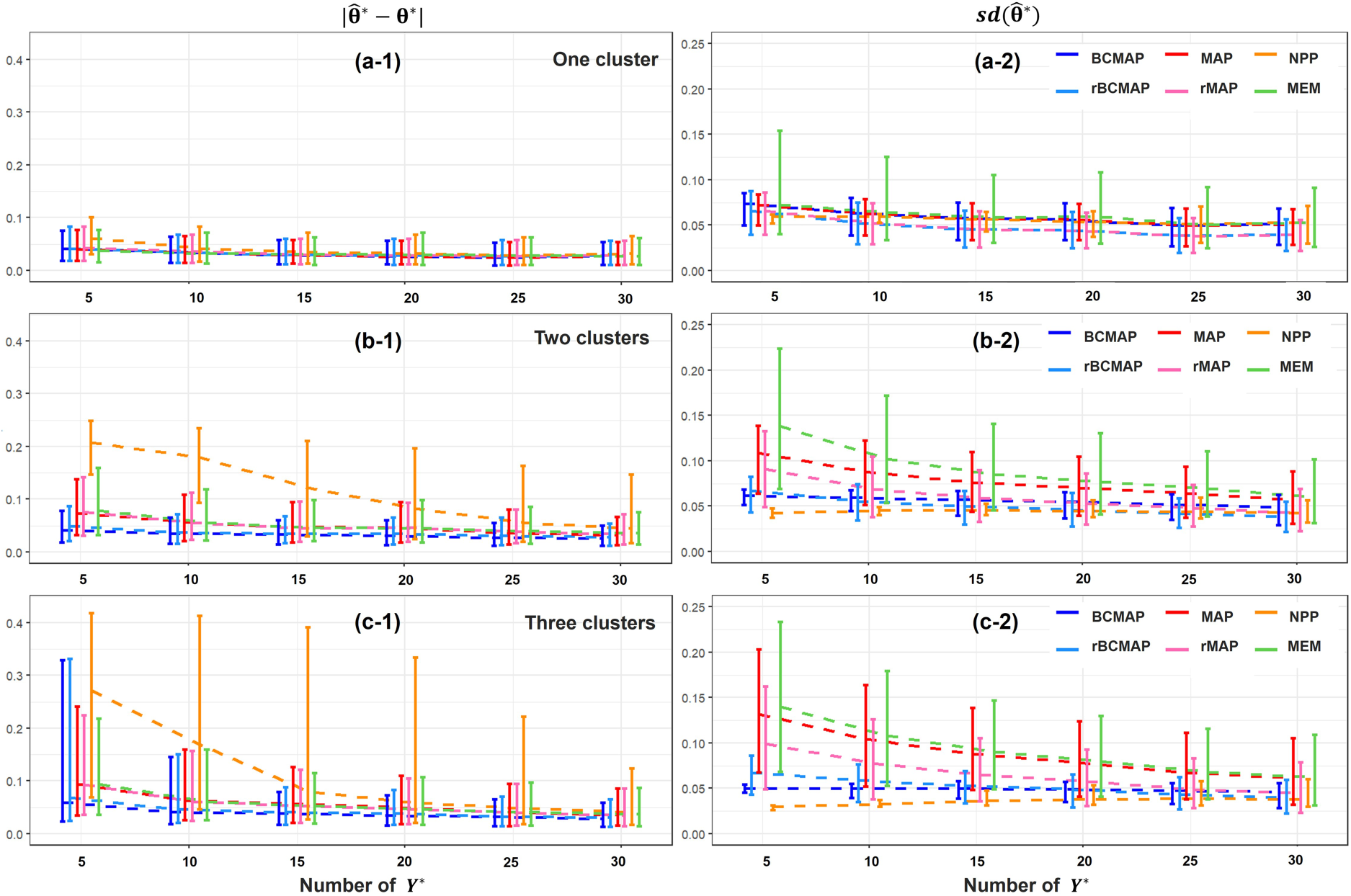
The simulation study for parameter estimation follows the prior comparison framework described in Section 4.3. We examine external data under three different heterogeneity scenarios: one, two, and three clusters. For each scenario, we conduct 1000 simulation runs. In each run, we generate new data samples and compute the posterior distributions using various priors.
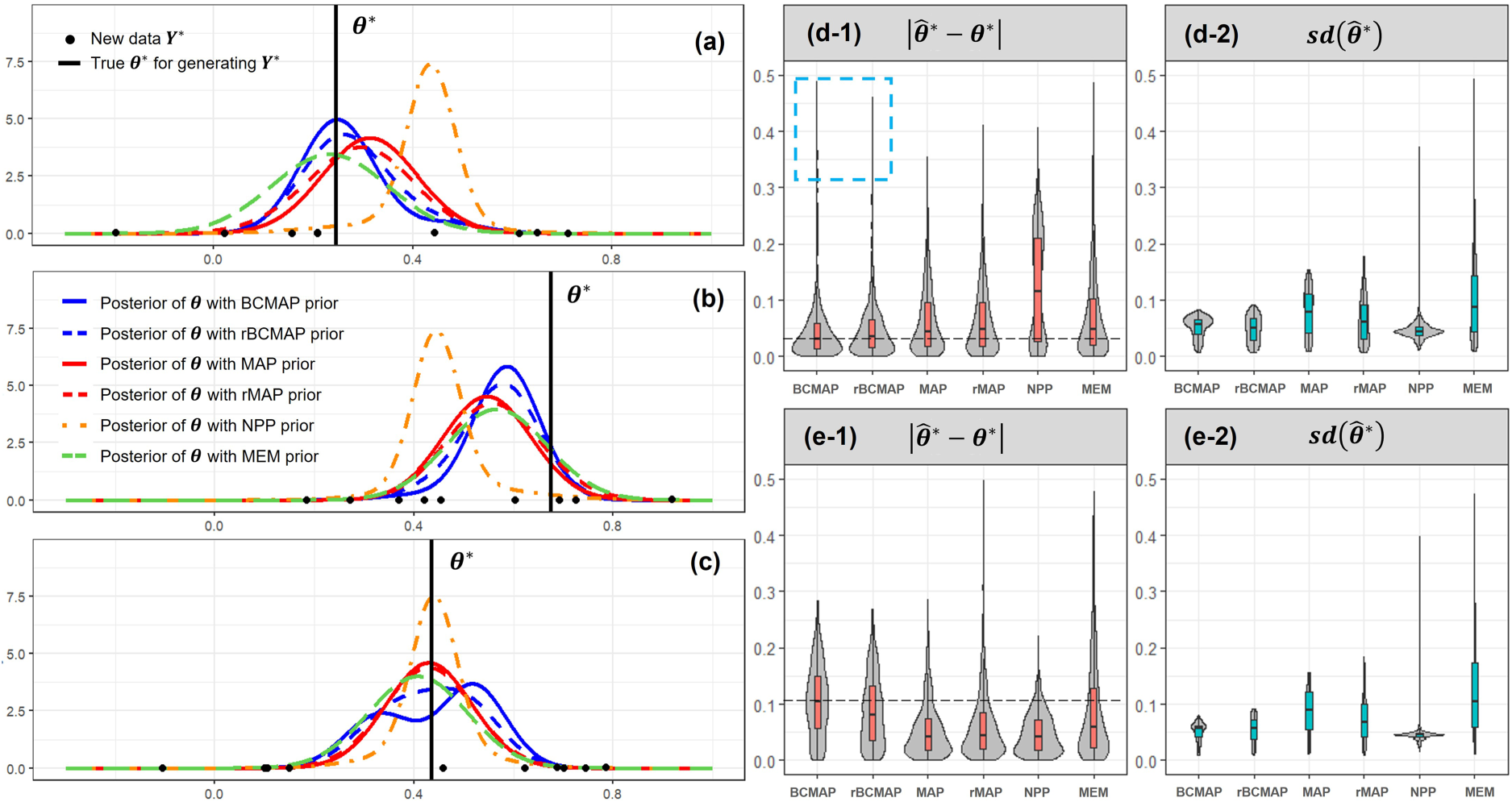
In the two-cluster scenario, we use the 12 external datasets described in Section 4.3, whose posteriors are displayed in Panel (a) of Figure 3. The new data consists of 10 observations generated from a normal distribution , where is drawn from the model (9). Then, the posteriors are then calculated based on using different priors. Intuitive comparison can be conducted by considering the posterior estimation of the location (bias) and scale (standard deviation) of estimate . Let us examine three examples shown in Panels (a), (b), and (c) of Figure 4. In Panels (a) and (b), is close to the centers 0.2 or 0.6, indicating the congruence of the new data with the external data. BCMAP and rBCMAP outperform other methods with less bias and lower variance of the estimate . However, Panel (c) exhibits the opposite scenario where is located in the middle of the two centers, indicating the incongruence between the new data and the external data. This results in a worse performance of BCMAP compared to the other methods. But, such scenarios as in Panel (c) are rare under the assumption that the new data is congruent with the external data, i.e., RWD. A valuable observation in Panel (c) is that rBCMAP can enhance the robustness of BCMAP when the assumption of congruence is violated. The results from 1000 simulation runs under both congruent and incongruent scenarios are presented in Panels (d-1) through (e-2). Panels (d-1) and (d-2) correspond to the congruent scenario. Panel (d-1) shows the empirical distribution of the absolute bias, , where is the mode of the posterior. In this setting, BCMAP and rBCMAP exhibit lower bias compared to the other methods. Panel (d-2) displays the empirical distribution of the standard deviation, . Excluding NPP, BCMAP and rBCMAP perform better than all other methods. Although NPP has the lowest standard deviation, it has the highest bias in Panel (d-1). In the incongruent scenarios shown in Panels (e-1) and (e-2), BCMAP exhibits the highest bias among all methods. However, with a robustness weight of 0.5, rBCMAP effectively reduces this bias, consistent with the observation in Panel (c).
Estimation of new from posteriors computed with different priors. In Panels (a) and (b), is congruent with the external data, located near the cluster centers at 0.2 and 0.6, respectively. In contrast, Panel (c) illustrates an incongruent scenario, where lies between the two cluster centers. Panels (d-1) and (d-2) present the bias and standard deviation of the estimator under the congruent cases. Panels (e-1) and (e-2) show the corresponding results for the incongruent case, where is positioned between the two centers. All results in (d-1) through (e-2) are based on 1000 simulations, each with 10 observations of .
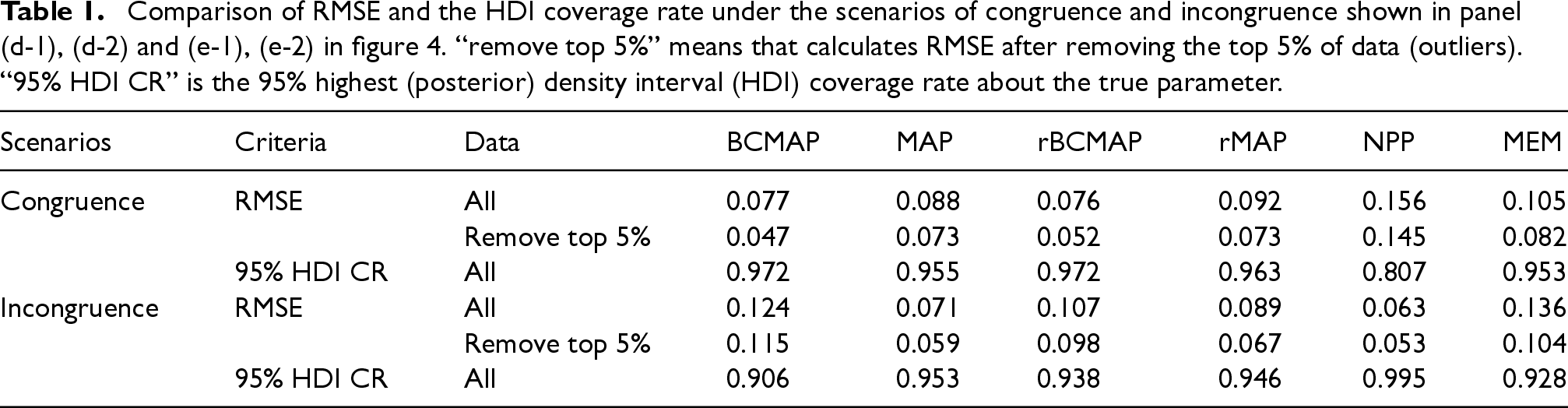
The summary of the estimation results for both the congruence and incongruence scenarios is presented in Table 1. Regarding the root mean square error (RMSE) criterion, both BCMAP and rBCMAP shows a smaller RMSE (0.077 and 0.076) compared to the MAP and rMAP (0.088 and 0.092) in the congruence scenario, aligning with the results shown in Panels (d-1) and (d-2) of Figure 4. Sometimes, the influence of outliers, as highlighted in Panel (d-1) of Figure 4 (indicated by the blue dashed rectangle), may cause inflation of the RMSE ( see Tables 7 and 8 in Appendix). In these case, we can remove the top 5% or 10% of data (outliers) to reduce the inflation. Regarding the coverage rate of the 95% highest (posterior) density interval (HDI), in the congruence scenario, both BCMAP and rBCMAP outperform all other methods. In the incongruence scenario, however, the HDI coverage of BCMAP experiences a significant drop, falling below that of other methods. Nevertheless, the rBCMAP provides a substantial remedy for this issue.
Comparison of RMSE and the HDI coverage rate under the scenarios of congruence and incongruence shown in panel (d-1), (d-2) and (e-1), (e-2) in figure 4. “remove top 5%” means that calculates RMSE after removing the top 5% of data (outliers). “95% HDI CR” is the 95% highest (posterior) density interval (HDI) coverage rate about the true parameter.
Scenarios
Criteria
Data
BCMAP
MAP
rBCMAP
rMAP
NPP
MEM
Congruence
RMSE
All
0.077
0.088
0.076
0.092
0.156
0.105
Remove top 5%
0.047
0.073
0.052
0.073
0.145
0.082
95% HDI CR
All
0.972
0.955
0.972
0.963
0.807
0.953
Incongruence
RMSE
All
0.124
0.071
0.107
0.089
0.063
0.136
Remove top 5%
0.115
0.059
0.098
0.067
0.053
0.104
95% HDI CR
All
0.906
0.953
0.938
0.946
0.995
0.928
The simulation presented in Figure 4 focuses solely on the two-cluster heterogeneity scenario of the external datasets and keeps the new data with 10 observations. To enable a more comprehensive comparison, we extend the study in two directions: (1) in addition to the two-cluster scenario, we examine cases with one and three clusters; (2) we evaluate the effect of varying the size of , considering sizes of 5, 10, 15, 20, 25, and 30. In the one-cluster scenario, 10 external datasets are generated from the model (10), representing homogeneity among the datasets.
While the three-clusters scenario includes 25 external datasets generated from the model (11), reflecting different heterogeneity from the two-clusters scenario.
A summary of the three scenarios, including the number of clusters, number of datasets, and sample sizes within each dataset, is provided in Table 9 in the Appendix. The posteriors (with a weakly informative prior), clustering results, and synthesized BCMAP and rBCMAP priors for the one-cluster and three-cluster scenarios are presented in Figures 8 and 9, respectively, in the Appendix.
The simulation results are presented in Figure 5. The Panels in the left and right columns illustrate the comparison of bias and variance , respectively. In the one-cluster scenario, the MAP and rMAP priors are identical to the BCMAP and rBCMAP priors, respectively, as shown in Panels (a-1) and (a-2). In the two- and three-clusters scenarios, when the new data is congruent with the external data, the BCMAP and rBCMAP priors outperform other methods. Notably, the NPP exhibits poor performance, characterized by the smallest but the largest bias. An interesting observation is that as the size of increases, all methods tend to converge to similar results because the new data begins to dominate the prior. The summary (RMSE and 95% HDI coverage rate) for the two clusters and three clusters scenarios (excluding the one cluster scenario, as BCMAP and rBCMAP are equivalent to MAP and rMAP in this case) is presented in Table 7 and Table 8, respectively.
Comparison of parameter estimation under different heterogeneous scenarios with various size of new observations . Panels in left and right columns present the bias and standard deviation of estimate , respectively. Panels in top row show the result under homogeneous scenario. Panels in middle row present the result under two clusters scenario, where the true new is near the cluster centers 0.2 or 0.6. Panels in bottom row exhibit the result under three clusters scenario, where the true new is near the cluster centers 0.2, 0.6, or 1.
In summary, if the new data is congruent with external data that exhibits heterogeneity, BCMAP and rBCMAP priors provide more accurate parameter estimation, with lower bias and variance, than commonly used methods. When the new data is incongruent with the external data, both BCMAP and rBCMAP may perform worse than alternative methods. But, rBCMAP can provide a partial remedy, as demonstrated in Panel (e-1) of Figure 4 and Tables 1, 7, and 8.
Hypothesis testing
In this section, we compare the performance of different priors in hypothesis testing. All priors are constructed from the external datasets used in the illustrative example (see Panel (a) of Figure 3) in Section 4.3. We design a prospective trial with two groups: control and treatment. Observations are generated from and , where and . Since the possible values of are centered at 0.2 and 0.6 by the model (9), we consider two scenarios: and . Correspondingly, we are interested in two hypothesis tests:
.
In the simulation, we investigate both frequentist and Bayesian methods. The frequentist method is a one-sided two-sample t-test. We considered two control vs. treatment recruitment ratios, and . For Bayesian methods, to study the effect of information borrowing from synthesized priors, we use the same data with control vs. treatment ratio and evaluate the gain in power by incorporating external control data. Corresponding to the two hypothesis tests, the decision rule (reject ) and operational characteristics in Bayesian methods are defined as follows:
Decision rule:
;
Type 1 error rate:
;
Power:
.
Decision rule:
;
Type 1 error rate:
;
Power:
,
where is an adjustable threshold used to control the type 1 error rate under 5%. In the calculation of and , we need to find the joint posterior , where and . Since and are independent, the joint posterior can be expressed as follows:
where is a weakly informative prior indicating trivial prior knowledge about the treatment group, and denotes the synthesized priors from the 12 external datasets.
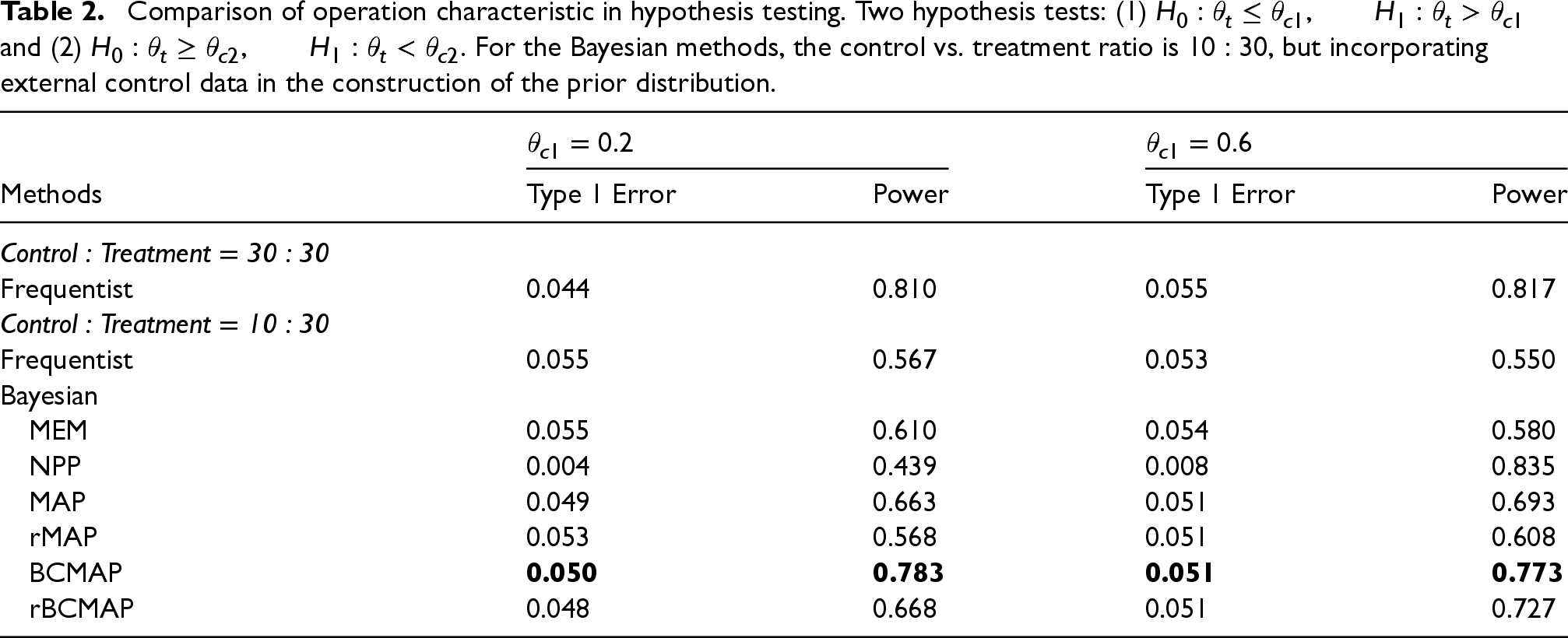
The simulation results are shown in Table 2. For the frequentist method, the results of both hypothesis tests (1) and (2) show a dramatic reduction in power as the size of the control group decreases from 30 to 10. (Note: the frequentist method does not involve clustering or information borrowing.) Regarding Bayesian methods, except for the case of NPP in hypothesis test (1), information borrowing from synthesized priors can improve the test power compared to the frequentist 10:30 trial. However, the simulation results also illustrate that the quality of the prior plays a critical role. NPP performs best in test (2) but worst in test (1). MEM and rMAP perform similarly, offering only modest gains in power. MAP provides a greater improvement but remains less effective than rBCMAP and BCMAP. Overall, BCMAP achieves the highest performance, increasing power by more than 35%, and is comparable to the frequentist 30:30 trial. In sum, Bayesian cluster priors enable the incorporation of accurate information from heterogeneous external data. When the new data is generally congruent with the external data, borrowing information from Bayesian cluster priors can effectively improve the operational characteristics of hypothesis testing.
Comparison of operation characteristic in hypothesis testing. Two hypothesis tests: (1) and (2) . For the Bayesian methods, the control vs. treatment ratio is , but incorporating external control data in the construction of the prior distribution.
Methods
Type 1 Error
Power
Type 1 Error
Power
Control : Treatment 30 : 30
Frequentist
0.044
0.810
0.055
0.817
Control : Treatment 10 : 30
Frequentist
0.055
0.567
0.053
0.550
Bayesian
MEM
0.055
0.610
0.054
0.580
NPP
0.004
0.439
0.008
0.835
MAP
0.049
0.663
0.051
0.693
rMAP
0.053
0.568
0.051
0.608
BCMAP
0.050
0.783
0.051
0.773
rBCMAP
0.048
0.668
0.051
0.727
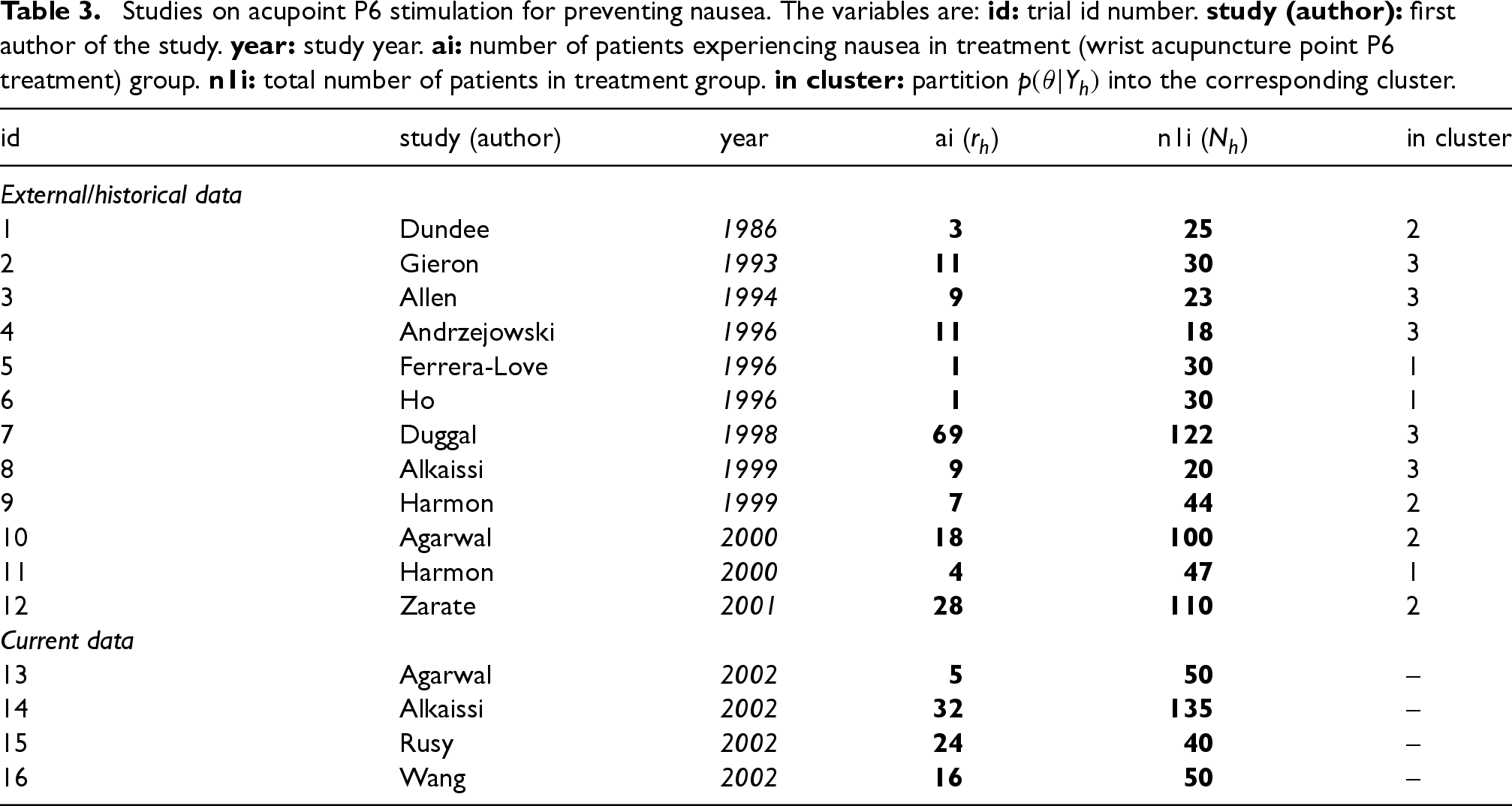
Studies on acupoint P6 stimulation for preventing nausea. The variables are: id: trial id number. study (author): first author of the study. year: study year. ai: number of patients experiencing nausea in treatment (wrist acupuncture point P6 treatment) group. n1i: total number of patients in treatment group. in cluster: partition into the corresponding cluster.
id
study (author)
year
ai ()
n1i ()
in cluster
External/historical data
1
Dundee
1986
3
25
2
2
Gieron
1993
11
30
3
3
Allen
1994
9
23
3
4
Andrzejowski
1996
11
18
3
5
Ferrera-Love
1996
1
30
1
6
Ho
1996
1
30
1
7
Duggal
1998
69
122
3
8
Alkaissi
1999
9
20
3
9
Harmon
1999
7
44
2
10
Agarwal
2000
18
100
2
11
Harmon
2000
4
47
1
12
Zarate
2001
28
110
2
Current data
13
Agarwal
2002
5
50
–
14
Alkaissi
2002
32
135
–
15
Rusy
2002
24
40
–
16
Wang
2002
16
50
–
Real data examples
Acupuncture trials
Postoperative nausea and vomiting are common complications following surgery and anesthesia. As an alternative to drug therapy, acupuncture has been studied as a potential treatment in several trials.20 The dataset “dat.lee2004” in the R package “metadat”21 contains the results from 16 clinical trials examining the effectiveness of wrist acupuncture point P6 treatment for preventing postoperative nausea. Patient level (covariate) information is not available. A detailed description of the dataset is provided in Table 3. The columns “ai” and “n1i” correspond to and , respectively, where denotes the number of patients in study , and indicates the number of patients who experienced postoperative nausea. The data are modeled using a Binomial distribution: , where represents the probability of a patient experiencing nausea. We denote the observed data for study as . There are four studies (id 13, 14, 15, and 16) were conducted in 2002. To illustrate the application of the proposed prior in data analysis, we treat each of these four datasets as the current data, and the other 12 studies conducted before 2002 as external (historical) data.
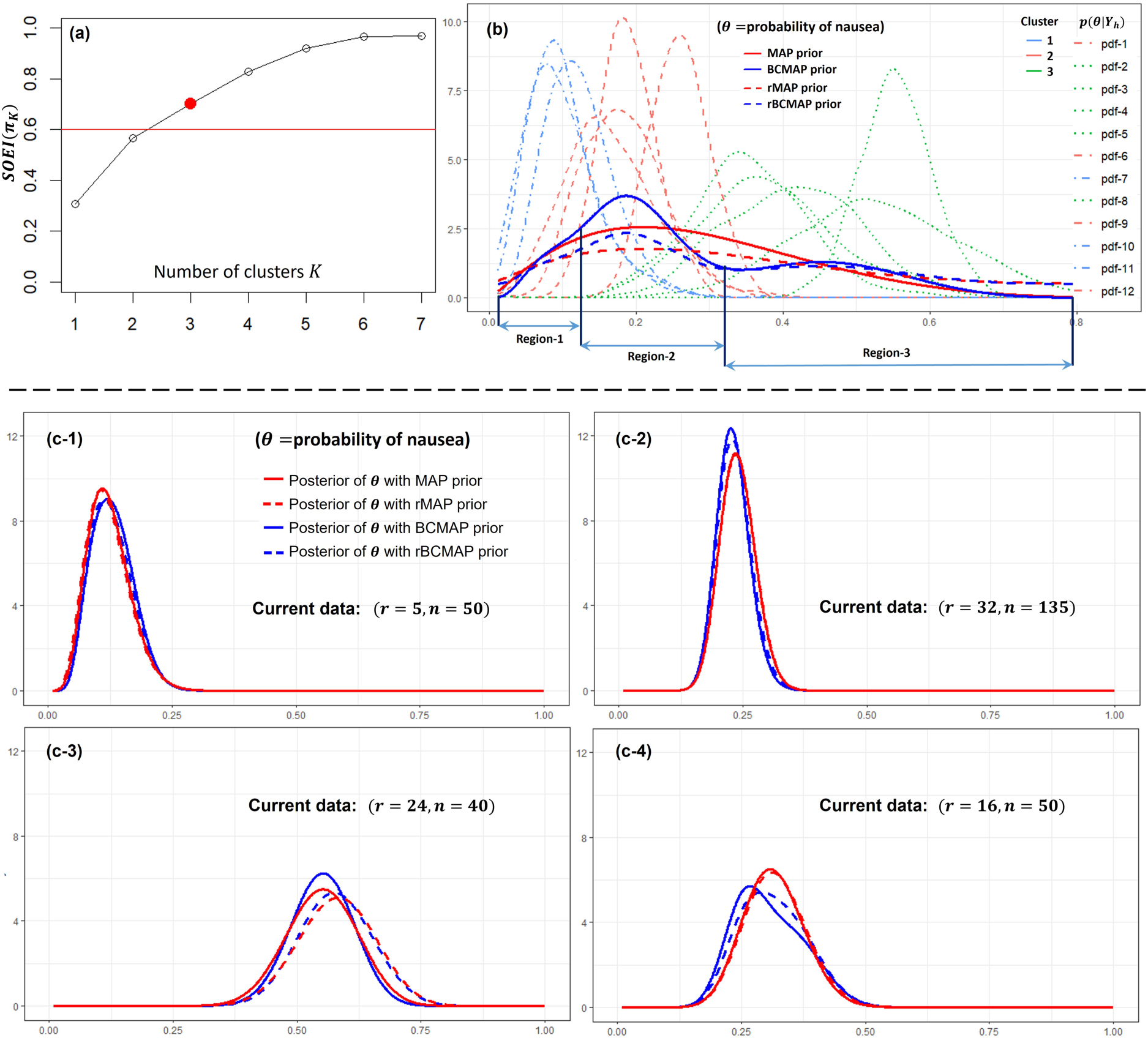
Studies on the effectiveness of wrist acupuncture point P6 treatment for preventing postoperative nausea. Panel (a): the optimal number of cluster . Panel (b) the corresponding BCMAP, rBCMAP, MAP, and rMAP. Panels (c-1) to (c-4): the posteriors with different priors and current data.
Prior for study design
In trial design study, our goal is to construct an informative prior from the external data to provide useful prior information for the new trial. To achieve this goal, we begin by examining the posteriors of the external data using a vague conjugate prior, . The posterior distributions are straightforward to derive: , as shown in Panel (b) of Figure 6. The results reveal substantial heterogeneity across the studies, making this dataset well-suited for applying the Bayesian clustering prior. Next, we determine the optimal number of clusters. Given that the average sample size is approximately 50, we set the threshold at 0.6 in accordance with the guidelines outlined in Section 4.2. The optimal number of clusters is identified as 3 as shown in Panel (a). The corresponding BCMAP and rBCMAP priors are presented in Panel (b), alongside the MAP and rMAP priors for comparison. Their parameterized forms are listed below:
Based on equations (13) and (15), compared to MAP prior, the BCMAP prior has the advantage that its effective sample size (ESS) can be estimated in a finer way. From equation (13), we know that the ESS of over the entire region [0,1] is . Let us check the ESS of from equation (15) and Panel (b): in region 1, ; in region 2, ; in region 3, . This offers valuable prior information for the design of future trials. For example, acupuncture treatment appears more likely to reduce the probability of postoperative nausea to below 30%, with a concentration in the range of 15% to 30%. For the rMAP and rBCMAP priors, the effect of robustification results in an ESS of .
Prior for data analysis
Applying the constructed priors to the current datasets (id = 13, 14, 15, and 16), we can obtain the posteriors of as shown in Panels (c-1) to (c-4). Overall, the resulting posteriors are not substantially affected by the choice of prior, likely because the relatively large sample sizes in the current datasets dominate the posterior inference. However, in Panel (c-4), the BCMAP prior noticeably shifts the posterior toward the middle cluster (around 0.2), while the rBCMAP prior slightly counteracts this effect, drawing the posterior closer to those obtained under the MAP and rMAP priors.
Potassium supplementation to reduce diastolic blood pressure
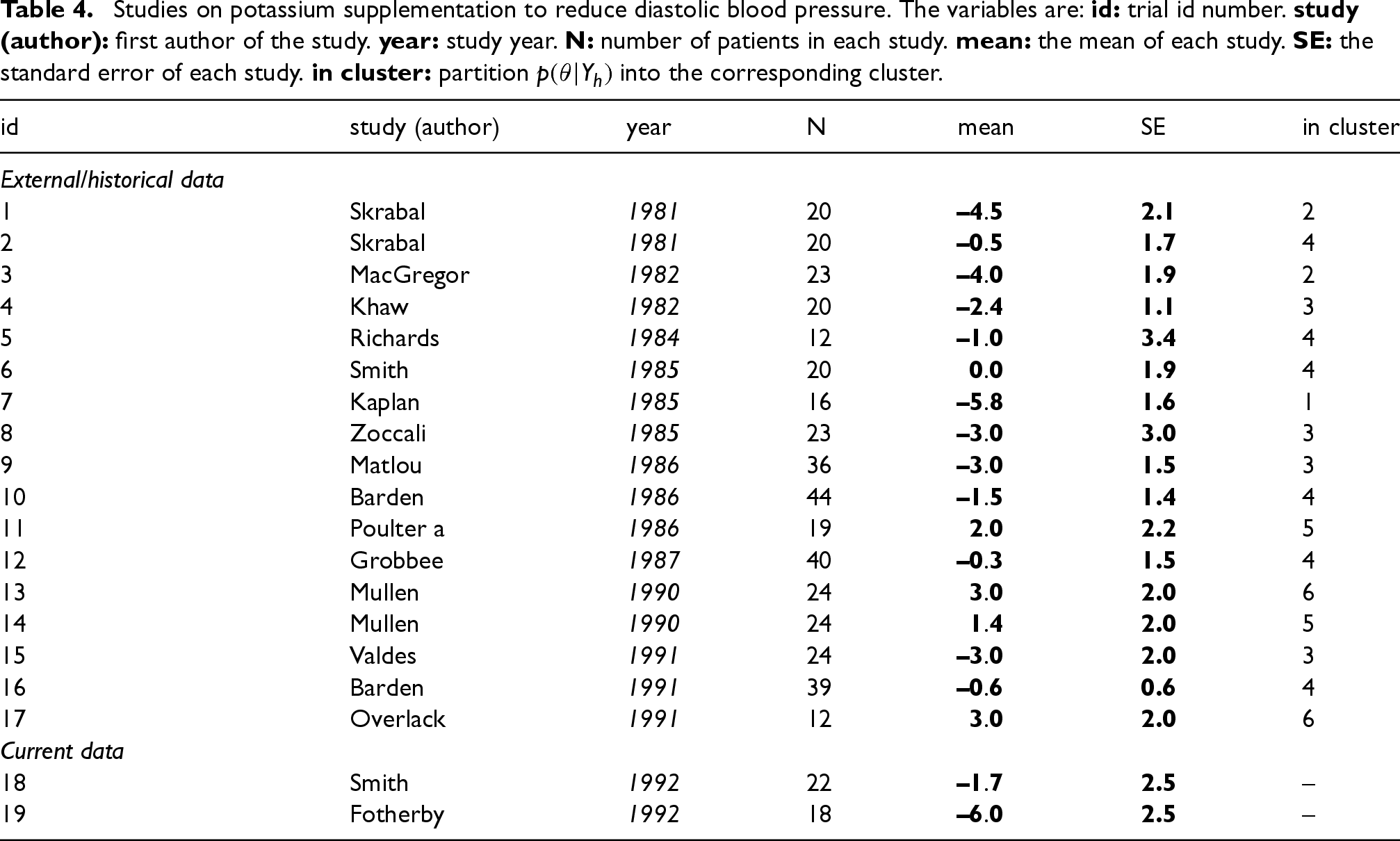
In this section, we consider continuous endpoint data with the normal distribution. We use the dataset “dat.curtin2002” from the R package “metadat”, which includes 21 cross-over studies evaluating the effect of potassium supplementation on reducing diastolic blood pressure. This dataset does not contain patient-level information. We perform a preliminary data cleaning step by removing two outlier studies with mean values of and . The resulting cleaned dataset is provided in Table 4.
Studies on potassium supplementation to reduce diastolic blood pressure. The variables are: id: trial id number. study (author): first author of the study. year: study year. N: number of patients in each study. mean: the mean of each study. SE: the standard error of each study. in cluster: partition into the corresponding cluster.
id
study (author)
year
N
mean
SE
in cluster
External/historical data
1
Skrabal
1981
20
–4.5
2.1
2
2
Skrabal
1981
20
–0.5
1.7
4
3
MacGregor
1982
23
–4.0
1.9
2
4
Khaw
1982
20
–2.4
1.1
3
5
Richards
1984
12
–1.0
3.4
4
6
Smith
1985
20
0.0
1.9
4
7
Kaplan
1985
16
–5.8
1.6
1
8
Zoccali
1985
23
–3.0
3.0
3
9
Matlou
1986
36
–3.0
1.5
3
10
Barden
1986
44
–1.5
1.4
4
11
Poulter a
1986
19
2.0
2.2
5
12
Grobbee
1987
40
–0.3
1.5
4
13
Mullen
1990
24
3.0
2.0
6
14
Mullen
1990
24
1.4
2.0
5
15
Valdes
1991
24
–3.0
2.0
3
16
Barden
1991
39
–0.6
0.6
4
17
Overlack
1991
12
3.0
2.0
6
Current data
18
Smith
1992
22
–1.7
2.5
–
19
Fotherby
1992
18
–6.0
2.5
–
Similar to the acupuncture example, in order to simulate data analysis, we pick out the two studies from 1992 (id = 18, 19) as the current data and those conducted before 1992 as external data (17 external datasets). Given a prior , the corresponding posteriors can be computed as follows:
where, , , and denote the sample size, sample mean, and sample variance for dataset , respectively. We set the prior mean and variance as and , in order to specify a weakly informative prior . The resulting posterior distributions are shown in Panel (b) of Figure 7.
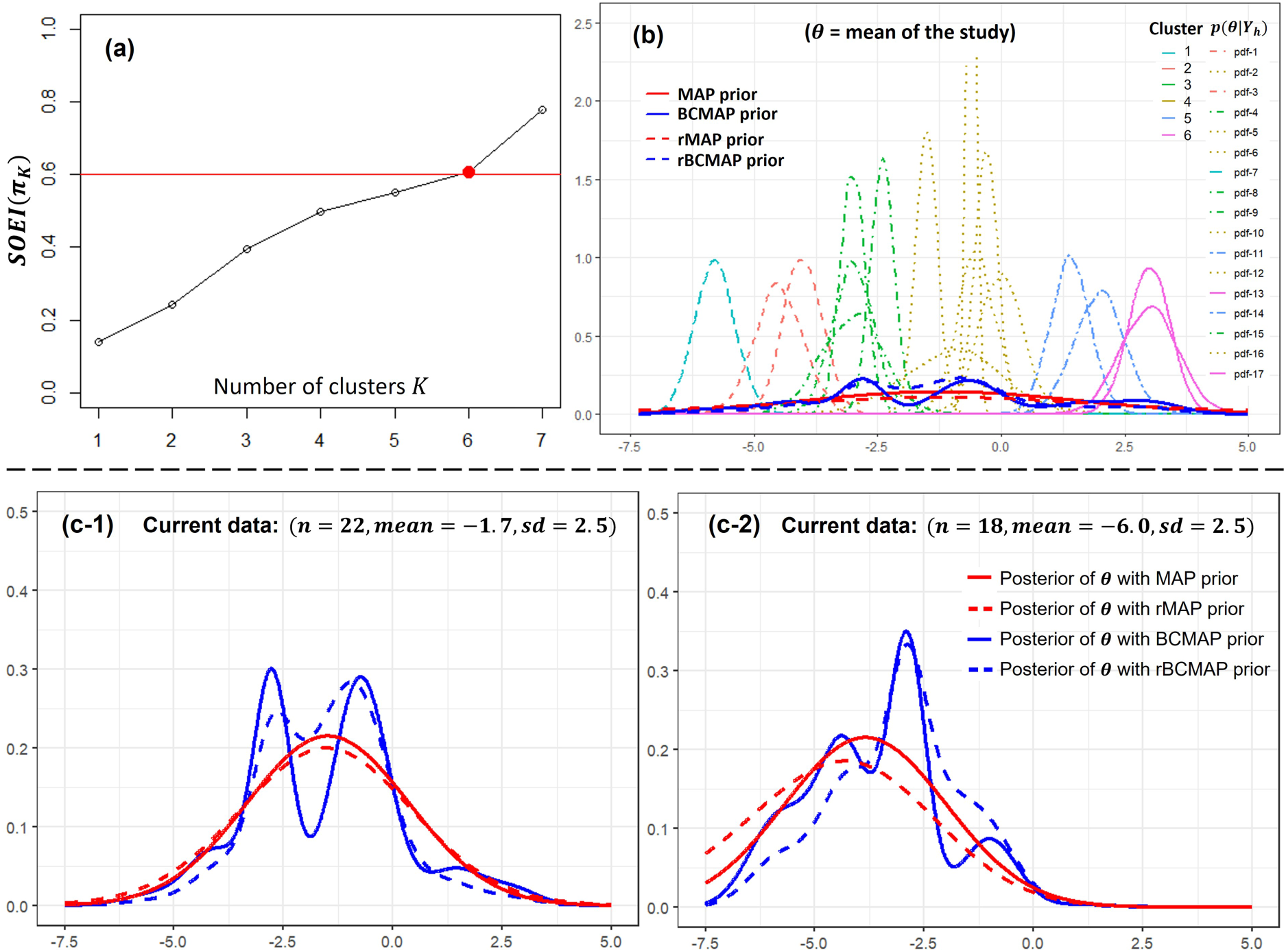
Studies on potassium supplementation to reduce diastolic blood pressure. Panel (a): the optimal number of cluster . Panel (b) the corresponding BCMAP, rBCMAP, MAP, and rMAP. Panels (c-1) and (c-2): the posteriors with different priors and current data.
Since the posterior distributions are well spread, indicating substantial separation between potential clusters, we select a threshold of 0.6 in accordance with the guidelines in Section 4.2. The optimal number of clusters is identified as as shown in Panel (a) of Figure 7. The corresponding BCMAP and rBCMAP priors are shown in Panel (b), alongside MAP and rMAP for comparison. Compared to MAP and rMAP, the BCMAP and rBCMAP priors exhibit more pronounced concentration around the cluster centers, particularly near -0.7 and -2.8. This prior information suggests that future studies are more likely to observe the values of pressure reduction centered around these two values.
The posterior distributions of , based on the constructed priors and current data, are displayed in Panels (c-1) and (c-2). Unlike the acupuncture example, the current data in this case are relatively small, which leads the prior to exert a stronger influence on the posterior. The rBCMAP serves to moderate the impact of the BCMAP, yielding a smoother posterior distribution closer to MAP and rMAP.
Discussion
Clustering plays a crucial role in synthesizing informative priors from heterogeneous multisource external data. Leveraging the concept of the overlapping coefficient, we introduce the OCI, OEI, K-Means algorithm, and an OEI-based criterion to identify the optimal clustering. Based on it, a Bayesian clustering prior can be constructed and applied during both the trial design and data analysis stages. Simulation studies validate its advantages.
Effectively borrowing information from external (historical) data remains an active area of research. The proposed Bayesian clustering prior represents an effort to address the challenges of information borrowing from heterogeneous multisource external data. Several potential research directions of this approach merit further investigation:
First, this study focuses on the case where is one-dimensional. Since the definition of the overlapping coefficient (OVL) extends naturally to higher dimensions, We believe the proposed method can also be extended to multi-dimensional . However, the computational aspects of OVL in higher dimensions, which impact the calculation of OCI and OEI, require more careful consideration.
Second, we do not incorporate covariate information in the current study. However, in the era of precision medicine, covariates are becoming increasingly important. A straightforward way to integrate covariates into the Bayesian clustering prior is through their inclusion in posterior estimation, for instance via the MAP approach. Further research is needed to explore more advanced strategies for incorporating covariates, such as regression-based adjustments or propensity score matching.
Third, this paper adopts a fixed weight of , representing an equal balance between the informative prior derived from external data and a weakly informative component. While convenient, this choice may not be optimal across all scenarios. Data-driven methods for estimating the weight dynamically could offer greater flexibility and potentially enhance performance.
Finally, beyond the K-Means-based approach used here, alternative clustering techniques, such as Gaussian mixture models, could be employed to simultaneously perform clustering and prior construction. These alternatives deserve further exploration and comparative evaluation.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
ORCID iDs
Xuetao Lu
J Jack Lee
Appendix
Description of symbols and abbreviations.
Symbol / Abbreviation
Description
,
External datasets.
Posterior distribution of given external data
The random variable corresponding to the posterior .
Constructed prior distribution of given external data .
The random variable corresponding to the posterior .
Overlapping coefficient between random variables and .
Overlapping clustering index of a partition.
-partition of , .
The cluster in the partition .
The centroid random variable of cluster .
The optimal partition identified by maximizing .
The optimal partition identified by K-Means clustering algorithm.
Overlapping evidence index of the prior .
The Bayesian clustering prior with clusters given the external data.
The robust Bayesian clustering prior with clusters given the external data.
The sequence of scaled overlapping evidence index.
For the BCMAP priors , , the sequence increases monotonically with the increase of , i.e., .
Without losing generality, let us compare and , . Correspondingly, we need to consider the difference between and . For an arbitrary cluster in , say , we split it to two clusters say and , where . The new partition is denoted as . In each cluster, we assume that the random variables are homogeneous and use them to construct a MAP prior. For , the corresponding MAP random variable is denoted as . For and , they are presented as and . Since the homogeneity of cluster and cluster are greater than that of cluster , it follows that:
By equation (6) in the definition of OEI, we know that
By definition of the Overlapping Clustering Index (OCI), denotes the partition that maximizes the overall within-cluster homogeneity among all K+1 partitions (including ). This implies:
Therefore, holds. Note: This proof is applied to the rBCMAP as well.
References
1.
US Food and Drug Administration. Use of real-world evidence to support regulatory decision-making for medical devices: guidance for industry and food and drug administration staff. Silver Spring, 2017.
2.
SpiegelhalterDJDJAbramsKRKRMylesJP. Bayesian approaches to clinical trials and health-care evaluation. Statistics in practice. Chichester: John Wiley & Sons, 2004.
3.
NeuenschwanderBCapkun-NiggliGBransonM, et al.Summarizing historical information on controls in clinical trials. Clinical Trials2010; 7: 5–18.
4.
SchmidliHGsteigerSRoychoudhuryS, et al.Robust meta-analytic-predictive priors in clinical trials with historical control information. Biometrics2014; 70: 1023–1032.
5.
ChenMHIbrahimJGShaoQM. Power prior distributions for generalized linear models. J Stat Plan Inference2000; 84: 121–137.
6.
IbrahimJGChenMHSinhaD. On optimality properties of the power prior. J Am Stat Assoc2003; 98: 204–213.
7.
HobbsBSargentDCarlinB. Commensurate priors for incorporating historical information in clinical trials using general and generalized linear models. Bayesian Anal2012; 7: 639–674.
8.
HobbsBPCarlinBPMandrekarSJ, et al.Hierarchical commensurate and power prior models for adaptive incorporation of historical information in clinical trials. Biometrics2011; 67: 1047–1056.
9.
KaizerAMKoopmeinersJSHobbsBP. Bayesian hierarchical modeling based on multisource exchangeability. Biostatistics2017; 19: 169–184.
10.
JiangLNieLYuanY. Elastic priors to dynamically borrow information from historical data in clinical trials. Biometrics2023; 79: 49–60.
11.
WeberSLiYSeaman JWIII, et al.Applying meta-analytic-predictive priors with the R Bayesian evidence synthesis tools. J Stat Softw2021; 100: 1–32.
12.
GershmanSJBleiDM. A tutorial on Bayesian nonparametric models. J Math Psychol2012; 56: 1–12.
13.
ChenNLeeJJ. Bayesian cluster hierarchical model for subgroup borrowing in the design and analysis of basket trials with binary endpoints. Stat Methods Med Res2020; 29: 2717–2732.
14.
LuXLeeJJ. Overlapping indices for dynamic information borrowing in Bayesian hierarchical modeling. 2023, https://arxiv.org/abs/2305.17515v1.
15.
SchmidFSchmidtA. Nonparametric estimation of the coefficient of overlapping-theory and empirical application. Comput Stat Data Anal2006; 50: 1583–1596.
16.
WeitzmanMS. Measures of overlap of income distributions of white and negro families in the united states. Technical Report 22, US Department of Commerce, 1970.
17.
FraleyCRafteryAE. Model-based clustering, discriminant analysis, and density estimation. J Am Stat Assoc2002; 97: 611–631.
18.
TehYWJordanMIBealMJ, et al.Hierarchical dirichlet processes. J Am Stat Assoc2006; 101: 1566–1581.
19.
CarlinBPLouisTA. Empirical bayes: past, present and future. J Am Stat Assoc2000; 95: 1286–1289.
20.
LeeADoneM. Stimulation of the wrist acupuncture point p6 for preventing postoperative nausea and vomiting. Cochrane Database Syst Rev2004. DOI: 10.1002/14651858.CD003281.pub2.