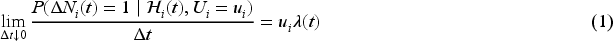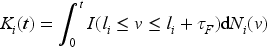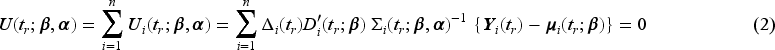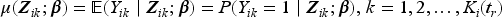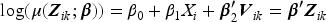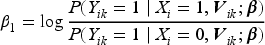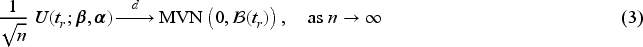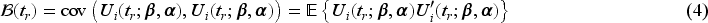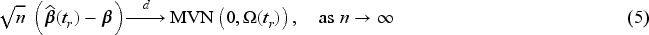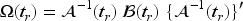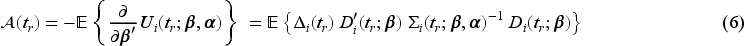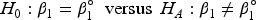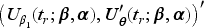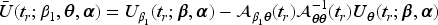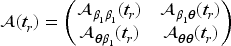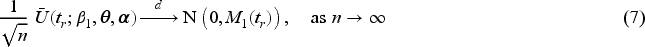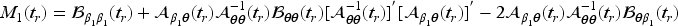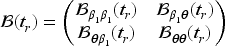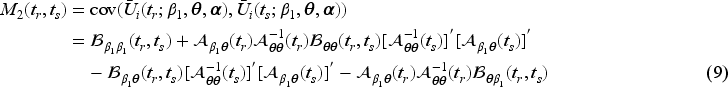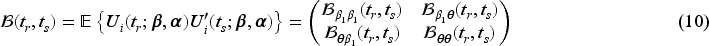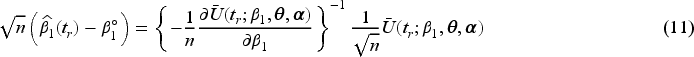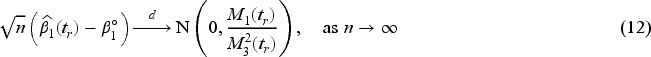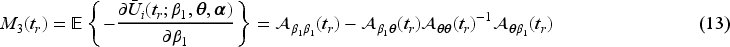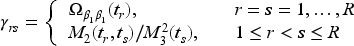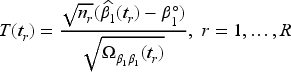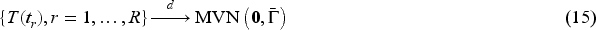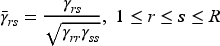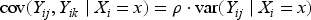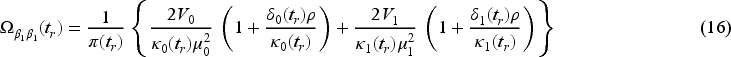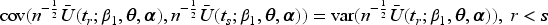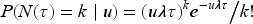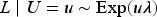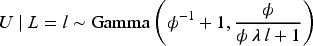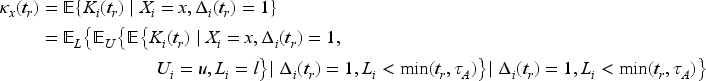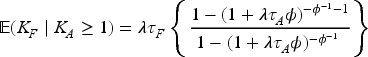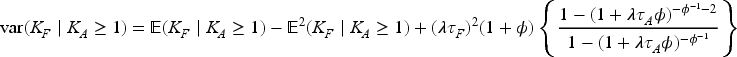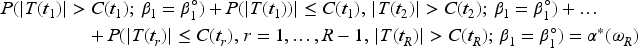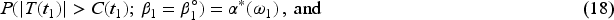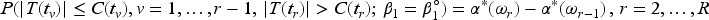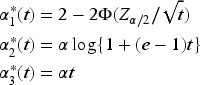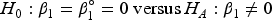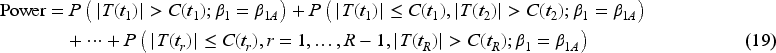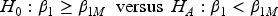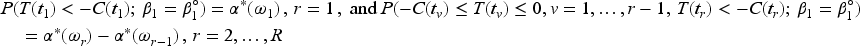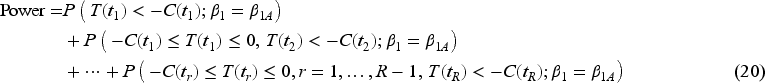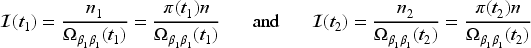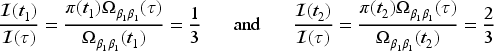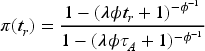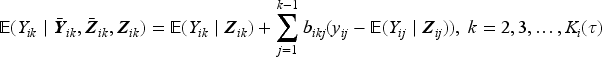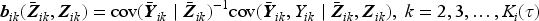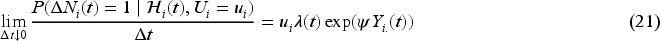Plasma donation plays a critical role in modern medicine by providing lifesaving treatments for patients with a wide range of conditions like bleeding disorders, immune deficiencies, and infections. Evaluation of devices used to collect blood plasma from donors is essential to ensure donor safety. We consider the design of plasma donation trials when the goal is to assess the safety of a new device on the response to transfusions compared to the standard device. A unique feature is that the number of donations per donor varies substantially so some individuals contribute more information and others less. The sample size formula is derived to ensure power requirements are met when analyses are based on generalized estimating equations and robust variance estimation. Strategies for interim monitoring based on group sequential designs using alpha spending functions are developed based on a robust covariance matrix for estimates of treatment effect over successive analyses. The design of a plasma donation study is illustrated where the focus is on assessing the safety of a new device with serious hypotensive adverse events as the primary outcome.
Large clinical trials are now routinely designed to incorporate interim analyses to monitor the safety and effectiveness of experimental interventions. Early termination of trials showing unexpected adverse effects of a new treatment minimizes exposure to harm, while early termination when treatments are found to be effective facilitates rapid dissemination of findings and deployment of more useful treatments to affected individuals. In addition to these ethical reasons, trials with planned interim analyses can be expected to reduce costs due to early termination when large treatment effects are seen since fewer participants may need to be recruited and follow-up can be shortened for enrolled participants. The statistical challenge involves control of the experimental type I error rate when conducting repeated significance tests on data accumulating over the course of the study.1
In early work on group sequential trials, Pocock2 proposed controlling the type I error rate through the derivation of a single critical value, which can be used to guide stopping decisions and determine the statistical significance of the trial results. O’Brien and Fleming3 later proposed a design wherein different critical values could be used at successive interim analyses with greater thresholds for early analyses leading to designs which are more conservative for early stopping. These methods all require the specification of a fixed number of interim analyses timed at roughly equal amounts of information under the assumption that data accumulated between successive analysis times are independent of the past data. The so-called independent increment structure enables the use of a recursive integration method1,4 to compute standard group sequential boundaries for repeated significance tests. Slud and Wei5 generalized the approach to sequential monitoring to allow for departures from the independent increments assumption, greatly expanding the range of analyses for which group sequential analyses could be planned. Lan and DeMets6 proposed a more general concept of an alpha spending function which enables a much more flexible and adaptive way to compute critical values for interim tests where the number and timing of analyses can be modified during the course of the study. In trials involving responses based on repeated measures, the independent increments structure for successive test statistics is violated because of the serial dependence of the responses within individuals. Lee and DeMets7 proposed to address this for continuous responses based on random-effects models while Wei et al.8 and Lee et al.9 used generalized estimating equations10 to develop a framework applicable to a broader range of data types. Many of these methods however are based on designs in which the repeated measurements are taken at specified fixed time points following randomization.
In many areas interest lies in assessing the effect of an experimental device or intervention which is delivered repeatedly over time but at times determined by the individual and hence which cannot be specified a priori. Examples are ubiquitous and arise in neurology when interest lies in the evaluation of therapies for acute migraine which are only administered when migraines develop,11 in respirology where bronchodilators are administered for the resolution of symptoms in recurrent exacerbations in asthma,12 and in transfusion medicine where therapeutic transfusion of platelets or red cell products are only given when the need is identified (i.e. platelets are transfused when thrombocytopenia is sufficiently severe that patients are at risk of serious bleeds).13 A similar data structure arises in blood donation research in which healthy donors give blood repeatedly over time. Here interest may lie in studying the occurrence of adverse events upon blood donation—in particular in comparing whether two methods of blood collection lead to similar adverse event profiles in donors. In all such settings one can think of the data as arising from a marked point process where the point is the time an intervention is administered and the mark is the response to the intervention. We consider the setting where individuals are randomized to one of two intervention arms and will receive the assigned intervention whenever it is required during the course of follow-up. Our work is motivated by the setting of a blood donation study so here the points are the times that donors arrive at a donation center to give blood and the mark is an indicator of whether an adverse reaction occurred. We consider the setting where the number of donations per donor varies substantially with some individuals contributing more information than others. In particular, we focus on the scenario where donors recruited earlier tend to donate more frequently than those enrolled later. This varying rate of information acquisition introduces a unique dependence structure among successive test statistics.
The remainder of this article is organized as follows. In Section 2, we define notation and give the generalized estimating functions used for estimation and large sample theory for analyses. The joint distribution of the sequential test statistics is then derived. The precise forms of the large sample distributions are given which identify the terms needed to facilitate sample size calculations for a two-arm clinical trial where there is no covariate adjustment and the marginal models for treatment effect simply involve the binary treatment indicator. One element of this large sample distribution involves the distribution of the number of transfusions during the follow-up period. Section 3 proposes the use of a zero-truncated negative binomial process for the need for transfusions. We consider a nuance whereby donors giving more frequent blood donations will tend to be encountered sooner than those donating less frequently. In probabilistic terms, we allow the intensity for transfusions to be higher for those individuals who are recruited earlier in the course of the accrual period—the impact of this is explored in Section 3. Alpha spending functions are reviewed in Section 4. Sample size calculations for the study with interim analyses are given. Both superiority and non-inferiority study designs are considered in Sections 4.2 and 4.3, respectively. Section 5 gives a simulation study demonstrating the good control of the type I error rate and the power for the derived sample sizes. In Section 5.3, we illustrate an example of a plasma donation study design with interim analyses. Discussions and concluding remarks are given in Section 6.
Statistical formulation and methods
Notation and generalized estimating equations
Let denote the cumulative number of donations over a window of calendar time for individual in the donor population of interest. Let be a right-continuous counting process that records the cumulative number of donations from individual over the period of calendar time with indicating a donation took place at calendar time , and otherwise. With the history of donations over given by , we assume donations occur in the population according to a mixed Poisson process with conditional intensity14
where is the number of donations over the interval , is a random effect with mean one, variance , and realization , and is a baseline population average rate function.
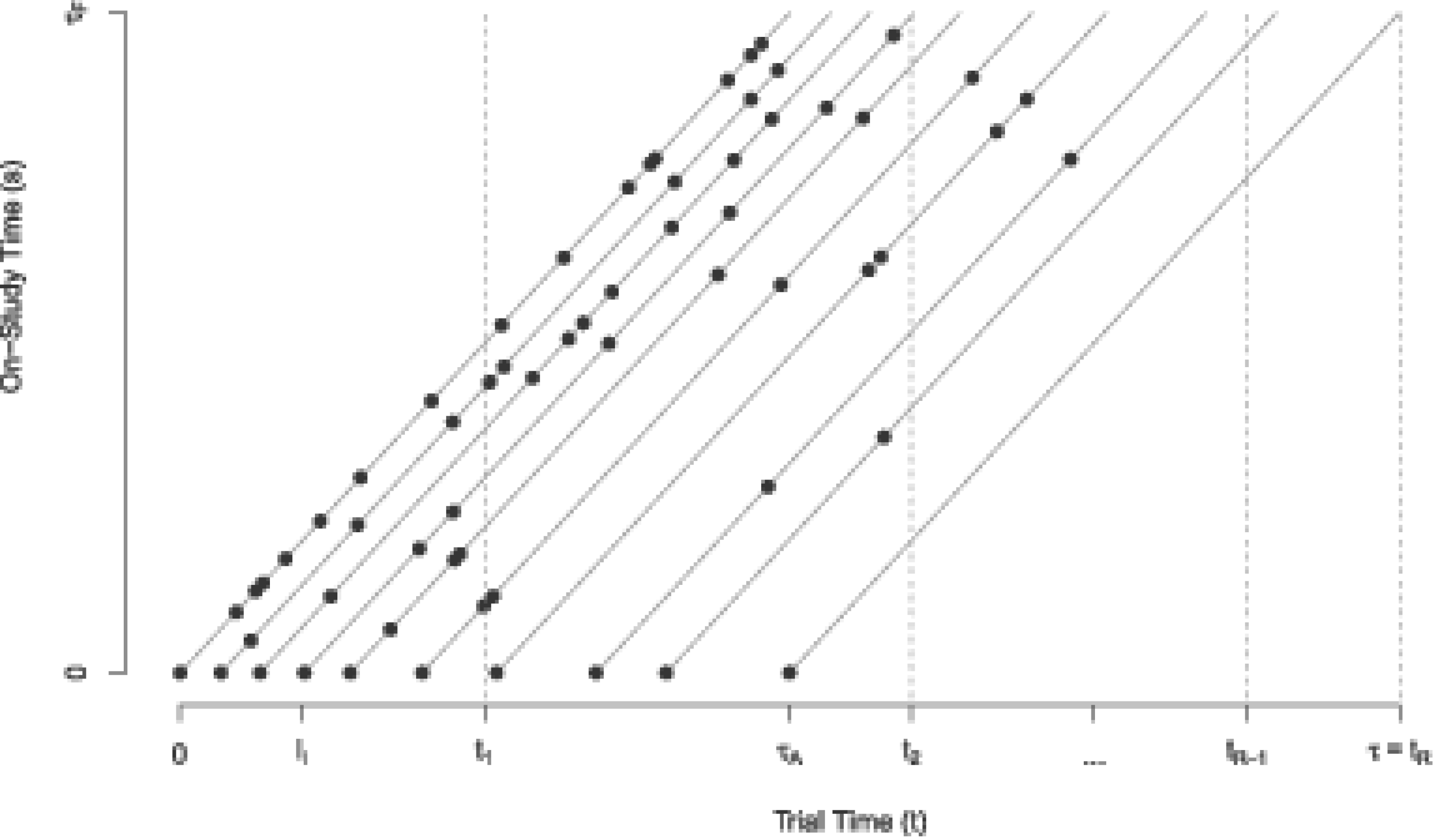
We consider a study with an accrual period of length and a follow-up period for each recruited individual of length making the total study duration . It is helpful to consider two time scales with denoting the time from the start of the accrual period of the trial with and the time from recruitment for an individual with . We may refer to the former as “trial time” (which is the calendar time with the time origin for defined as the start of the accrual period), and the latter as “study time” (for time on study for an individual). If is the random recruitment time for individual and is its realization then provided individual has been on study for a length of time at . Figure 1 contains a Lexis diagram depicting the accrual and study follow-up periods which define the trial duration, as well as the relation between time-scales on the horizontal axis and on the vertical axis. The lines emanate from the horizontal axis at the time of recruitment with 10 hypothetical individuals depicted. We assume that the first donation of each subject occurs at their study recruitment time . The donation process in (1) plays an important role in study planning as it determines the distribution of the random accrual time as well as the associated event intensity during the study period among recruited individuals. In brief the heterogeneity in the rate of donations among individuals in the donor population means that frequent donors will be encountered and recruited early during the accrual period, and as the time from the start of the accrual period passes more donors with lower donation rates will be encountered. This is depicted in Figure 1 by the more frequent donations (represented by the dots on the lines) in the individuals recruited earlier compared to individuals recruited later in the period . We consider the implications of this in more detail in Section 3.
An illustration of the recruitment process for 10 subjects along with their repeated measurements. Interim analyses are planned at study times , , , , and a final analysis at . The length of the accrual period is , the length of the follow-up period is for each individual, and the entire study duration is .
Consider the setting where consenting donors are recruited and randomized upon encountering them during the accrual period. The total number of donations received from the recruited individual by time from the start of the trial is
where indicates that individual is under observation. Let be the response measured at the th donation during study follow-up which is observed at time if and ; we can refer to this as the mark associated with the th donation and here we consider the case where is a binary response indicating the occurrence of an adverse event where denotes that an adverse event occurs and otherwise. Ultimately we may observe the set of marks for individual , . Let indicate the treatment arm where if individual is assigned to the experimental arm and otherwise. If represents a covariate vector measured at the time of the th donation we let be the covariate vector, , , .
Suppose interim analyses are planned at trial times , with a final analysis at study completion (i.e. ); see Figure 1. Let indicate that individual entered the study by time and denote the total number of such individuals contributing to the th analysis, , with . Specifically the vector of responses is the set of indicators from the donations observed by the time of the th analysis with the corresponding matrix of covariates. The generalized estimating equations10 at each interim analysis include subjects recruited by the time of that analysis, so at the th interim analysis it is given by
where is the vector of means with
indexed by , , and is the working covariance matrix indexed by a parameter vector . The marginal probability that is very small in the motivating study since serious hypotensive adverse events are very rare in blood donation.15 The natural log link function can therefore be specified under the “Poisson” approximation giving the generalized linear model16 of the form
where and the estimate of can be obtained by solving (2). This generalized linear model gives
as the log relative rate of an adverse event for the experimental arm compared to the control arm conditional on the covariate but we note that if then this retains the same interpretation if we do not adjust for auxiliary covariates by setting .
The covariance parameter can be estimated using the moment estimator based on Pearson residuals,10 or through second-order estimating equations.17–19 Liang and Zeger10 showed that is asymptotically equivalent to if is -consistent, and is estimated based on the data accumulated by study time and updated at each interim analysis. Next we present asymptotic results necessary for developing the joint distribution of sequential test statistics in Section 2.2. By the central limit theorem, we have
where
is the asymptotic covariance matrix.
The solution to (2) is the estimate of at the th interim analysis and is denoted by . Our interest lies primarily in , the estimated coefficient of , since is an estimate of the relative rate of an adverse event in the experimental to control arms. Note
where the robust covariance matrix is
and
Joint distribution of sequential test statistics
In this section, we derive the joint distribution of sequential test statistics based on , . Here we are interested in the effect of the experimental device and aim to test
We consider the group sequential setting where analyses are planned at . The -dimensional generalized estimating functions in (2) can lead to a -dimensional joint multivariate normal distribution of .9 Since our primary interest is and for ease of derivation of the joint distribution of sequential test statistics, we adopt the approach proposed by Lee et al.9 in which is partitioned as follows:
where is the one-dimensional estimating function for , and contains the remaining regression parameters (i.e. excluding ). Then is the -dimensional estimating function with respect to . Lee et al.9 proposed using “profile score function” or profile estimating function of to construct the sequential test statistics and derive its asymptotic joint distribution. The profile estimating function9,20 is written as follows:
where , , , and are submatrices defined conformably with as
By asymptotic multivariate normality and using a linear transformation of (3), we have
with asymptotic variance
where , , , and are submatrices of , and
The asymptotic variance can be simplified to if the working covariance matrix is correctly specified since in this case .
The -dimensional vector of profile estimating functions over all analyses times,
is asymptotically multivariate normal with zero mean and covariance at any two study times and is given by the following equation:
It can be shown that , where is the first diagonal entry of the asymptotic variance in (5) corresponding to . Based on (8), (11), and (12) the sequential estimators
follow a multivariate normal distribution with mean and covariance matrix , , where
The test statistic of interest for the th analysis can then be written as follows:
We reject at the th interim analysis if the test statistic exceeds the corresponding critical value. The serial critical values for the sequential test statistics can be obtained either through standard values directly if the independent increments structure (IIS)21 of the statistics holds (see Section 2.3), or through the derivation based on the multivariate joint distribution of sequential test statistics as discussed in Section 4.
If we constrain (i.e. do not adjust for covariates) and assume an exchangeable pairwise correlation for responses within individuals, we obtain
Then when taking the expectation of the product of estimating functions in (4) and (10) under the working independence covariance matrix with the Poisson variance function we have
in a simple two-arm trial with equal allocation , where , is the expected number of donations for a subject in group for the th interim analysis, , , is the variance of the number of donations for a subject in group for the th interim analysis, and , . The asymptotic variance of is obtained by dividing (16) by . See Sections A and B of the Supplemental Material for the details of the derivation of (16).
The independent increments structure
The independent increments structure (IIS) refers to a property of sequential test statistics where the random variables providing data between the current analysis time at and the next analysis time are statistically independent of random variables providing the current data.21 Lee et al.9 proved that has the asymptotic IIS if the covariance function is correctly specified. Based on (11), the asymptotically IIS of the sequentially computed test statistics can be assessed by the following equation:
through
If the independent increments property holds then the established critical values for standard group sequential boundaries of sequential test statistics can be used; these are computed through recursive univariate integration as described by Armitage et al.1 If the IIS does not hold, the joint distribution of the sequential test statistics, and in particular the covariance matrix of successive test statistics in (15) must be used to obtain critical values which enables control of the type I error rate. We show how this can be carried out in practice in Section 4.
Modeling the accrual time and subsequent donation process
As shown in (16) in Section 2.2, the mean and variance of the number of measurements per individual are required to evaluate the joint distribution of the sequential test statistics for the sample size calculation. Suppose the number of donations per individual over a period of duration is . As noted in Section 2.1, if the number of donations per individual varies according to a mixed time-homogeneous Poisson process, then conditionally on , , and
where and . We consider a negative binomial process for which . Suppose the recruitment time of a random subject in the population given its random effect follows an exponential distribution with
where the random effect . We note that subjects who have a higher frequency of donations in calendar time will tend to be recruited earlier in the accrual period. Thus for the trial design with interim monitoring we need to consider the recruitment time of the individual when modeling the number of donations they have by each interim analysis time. The conditional distribution of the random effect given recruitment time then follows a modified gamma distribution with
With this reflects the fact that individuals with an earlier recruitment time tend to have larger random effects, which contributes to them providing a larger number of repeated measurements during the follow-up period compared to those recruited at a later time.
To compute the expected number of donations over the course of the trial to time we average over the recruitment time for recruited individuals. The mean of the number of donations per individual by study time with is denoted by and given as follows:
The variance of the number of donations per individual by study time , , can then be obtained as , which is a function of , , , , and . Similarly, the mean number of donations per individual between study time and in group can be calculated via , where , . The explicit forms of , , and with detailed derivations are given in (C.10) to (C.16) in Supplemental Material C. Since the number of donations per recruited individual does not depend on the treatment arms here we have , , and , . With , , and derived we can evaluate the joint distribution of sequential test statistics which is the key for the calculations of the group sequential boundaries and sample size for interim monitoring.
For a study design with a single analysis at study completion (i.e. a study without interim analysis), let denote the number of donations from a random subject during the accrual period of length , and be the number of donations from the subject in the follow-up window of length . Li15 has shown that the mean of given that subject has at least one donation during the recruitment phase () is
and the variance of given is
It can be shown that and which means that in a sequential study that does not terminate early, the expected number of donations per individual by the end of the study and their variance remain the same as in a fixed study without interim analysis. Hence the modeling of the recruitment time on number of donations is a special case for the design of sequential analysis.
Sample size and group sequential testing
Alpha spending functions
Let be the critical value or group sequential boundary at such that if we reject and may consider the termination of the study. Let be an increasing function with and where is the predetermined significance level. The alpha spending function proposed by Lan and DeMets6 allocated the significance level over the interim analyses, and based on the alpha spending function the group sequential boundaries can be determined by solving
or
where is the information fraction for the th interim analysis, . There are three common ways to define the information fraction. The first is using the statistical information which is the inverse of the variance of the estimated effect (e.g. for the th interim analysis). If the maximum information is known or can be specified at the design stage based on historical research, the information fraction can be defined as , where . This can also be used as the guidance of determining the time of interim analysis. If the maximum information is unknown we can instead use the second approach based on the expected number of subjects/measurements (i.e. ), The third is to specify it in terms of the expected study duration (i.e. .
Lan and DeMets6 proposed the use of alpha spending functions which allow for flexible interim monitoring of clinical trials. Examples of commonly used alpha spending functions include
The boundaries generated by function and are similar to the boundaries obtained by O’Brien and Fleming3 and Pocock,2 respectively, and we refer them to the O’Brien-Fleming and Pocock type alpha spending functions, respectively. The third one is the uniform alpha spending function as it allocates the type I error rate evenly over time.6
Sample size calculation for a sequential superiority trial
For a superiority trial, we consider a two-sided test with the aim to test
where the true effect is denoted as . Interest lies in one direction (i.e. typically ) but we consider a two-sided test as is standard practice, and conventionally we take the probability of rejection in the opposite direction to the true effect as negligible. Using the joint distribution of the sequential test statistics in (15) and assumptions about the response process, accrual, and transfusions discussed in Sections 2.1 and 3, it is possible to determine the times of interim analyses that will give a dependence structure aligned with the independent increments property by verifying (17). This will enable the use of established critical values directly.9 The times of interim analysis can also be determined based on the proportions of the maximum information, for example, times corresponding to 1/3, 2/3 of the maximum information for a study with two interim analyses and one final analysis. In such cases or more generally for analyses planned at any key times of interest, the critical values can be derived through (18) to ensure the control of the type I error rate at for the specified alpha spending function. The sample size for a sequential superiority study can be calculated by solving (19) with the desired power,
Sample size calculation for a sequential non-inferiority trial
For a non-inferiority design, we consider a one-sided test with the aim to test
where is the non-inferiority margin of , that is, , and for we can claim non-inferiority on the relative rate scale. This corresponds to the case where the relative rate of an adverse event for the blood donation using the experimental system versus the standard system is no greater than . Based on (18), the critical values for the sequential tests for the non-inferiority trial can be solved through
Once the critical values have been determined, the sample size for the study with interim analyses can be calculated by solving (20) such that the desired power requirement is met,
Simulation studies
Empirical validation with sequential trials
In this section, we report on the results of simulation studies designed to validate the derivations. Let , , , , , , , and type I error rates are controlled at the significance level of . Also let for the superiority study, and for the non-inferiority study. The sample sizes are then calculated to ensure adequate power of trials (at least 80% or 90%). Suppose we plan for two interim analyses with a final analysis at the end of the study so . The times of two interim analyses are determined based on the proportions of the maximum information where the first and second analysis are at the times corresponding to and of the maximum information, and the times of interim analyses can be determined without knowing the actual maximum information but the asymptotic variance of , that is, , and the probability of being recruited by time , that is, . In this example, suppose the information for the two interim analyses is the inverse of the asymptotic variance of , that is,
and the maximum information at the end of the study is . By taking the ratio of the information at and with the maximum information, respectively, gives two information fractions (i.e. and ), and the times of two interim analyses are chosen at the times such that the information fractions equal to 1/3 and 2/3, respectively, that is, and are determined such that
where
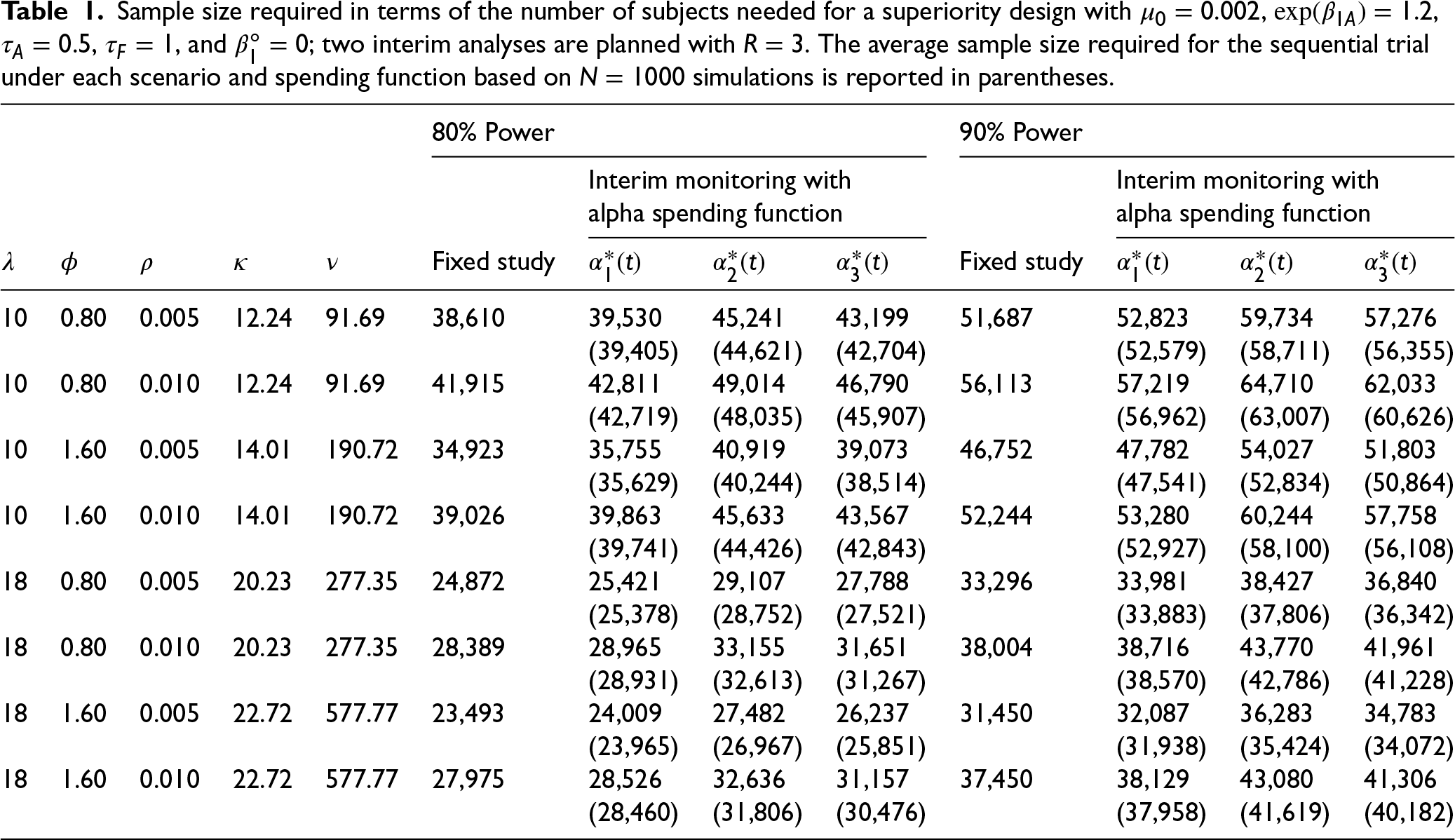
Once the interim analyses times are determined, the group sequential boundaries can be derived and sample sizes needed for the study with two interim analyses can be calculated as described in Sections 4.2 and 4.3. Three different alpha spending functions are considered. The required sample sizes for each scenario are provided in Table 1 for the superiority study design, and Table 2 for the non-inferiority study. The “Fixed study” columns of Tables 1 and 2 record the sample sizes required for a fixed study without any interim analysis. The columns after “Fixed study” record the sample sizes required for the study with interim monitoring using different alpha spending functions. The sample size needed for a study with interim analyses increases compared to a fixed sample size study in order to reach the same desired power since the critical value is higher.
Sample size required in terms of the number of subjects needed for a superiority design with , , , , and ; two interim analyses are planned with . The average sample size required for the sequential trial under each scenario and spending function based on simulations is reported in parentheses.
80% Power
90% Power
Interim monitoring with
Interim monitoring with
alpha spending function
alpha spending function
Fixed study
Fixed study
10
0.80
0.005
12.24
91.69
38,610
39,530
45,241
43,199
51,687
52,823
59,734
57,276
(39,405)
(44,621)
(42,704)
(52,579)
(58,711)
(56,355)
10
0.80
0.010
12.24
91.69
41,915
42,811
49,014
46,790
56,113
57,219
64,710
62,033
(42,719)
(48,035)
(45,907)
(56,962)
(63,007)
(60,626)
10
1.60
0.005
14.01
190.72
34,923
35,755
40,919
39,073
46,752
47,782
54,027
51,803
(35,629)
(40,244)
(38,514)
(47,541)
(52,834)
(50,864)
10
1.60
0.010
14.01
190.72
39,026
39,863
45,633
43,567
52,244
53,280
60,244
57,758
(39,741)
(44,426)
(42,843)
(52,927)
(58,100)
(56,108)
18
0.80
0.005
20.23
277.35
24,872
25,421
29,107
27,788
33,296
33,981
38,427
36,840
(25,378)
(28,752)
(27,521)
(33,883)
(37,806)
(36,342)
18
0.80
0.010
20.23
277.35
28,389
28,965
33,155
31,651
38,004
38,716
43,770
41,961
(28,931)
(32,613)
(31,267)
(38,570)
(42,786)
(41,228)
18
1.60
0.005
22.72
577.77
23,493
24,009
27,482
26,237
31,450
32,087
36,283
34,783
(23,965)
(26,967)
(25,851)
(31,938)
(35,424)
(34,072)
18
1.60
0.010
22.72
577.77
27,975
28,526
32,636
31,157
37,450
38,129
43,080
41,306
(28,460)
(31,806)
(30,476)
(37,958)
(41,619)
(40,182)
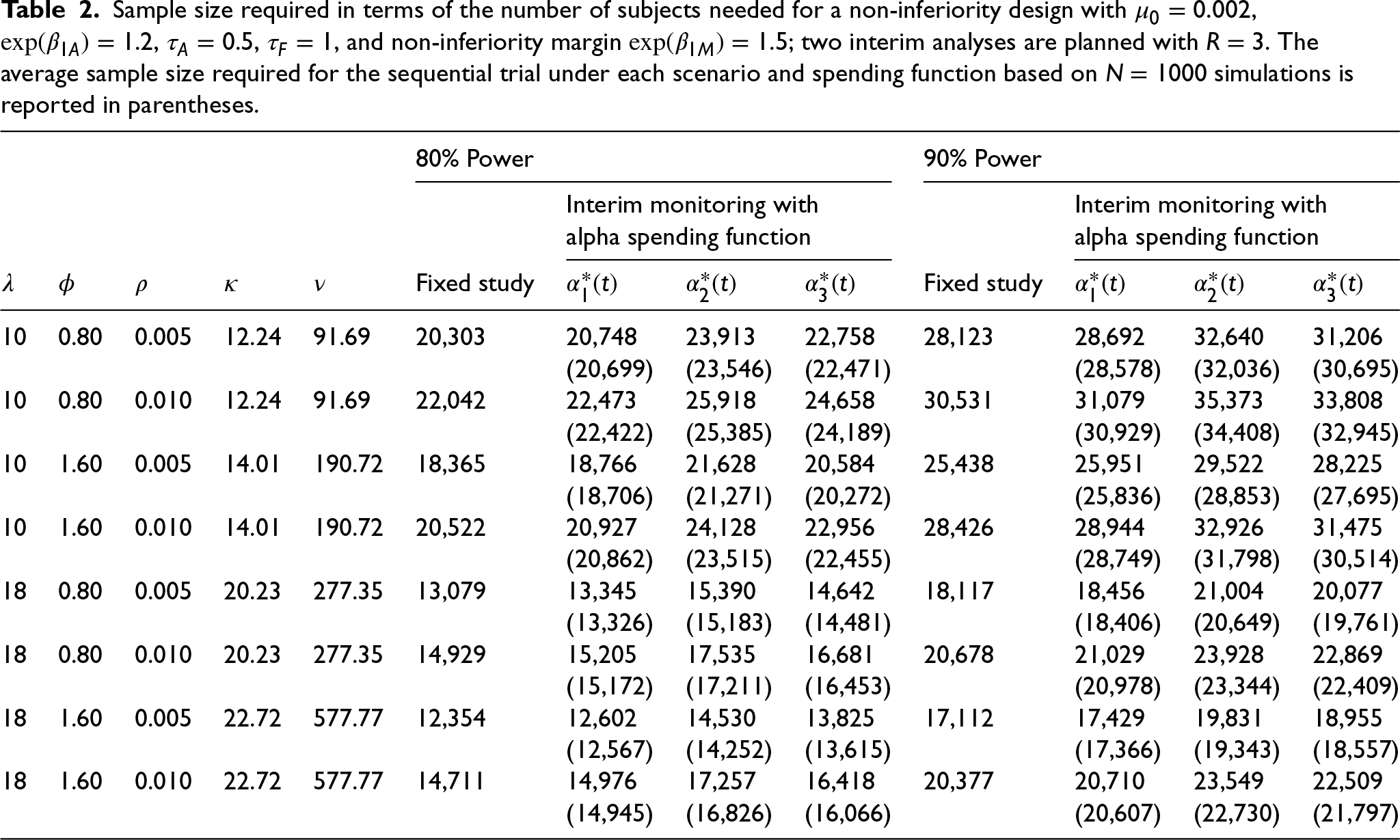
Sample size required in terms of the number of subjects needed for a non-inferiority design with , , , , and non-inferiority margin ; two interim analyses are planned with . The average sample size required for the sequential trial under each scenario and spending function based on simulations is reported in parentheses.
80% Power
90% Power
Interim monitoring with
Interim monitoring with
alpha spending function
alpha spending function
Fixed study
Fixed study
10
0.80
0.005
12.24
91.69
20,303
20,748
23,913
22,758
28,123
28,692
32,640
31,206
(20,699)
(23,546)
(22,471)
(28,578)
(32,036)
(30,695)
10
0.80
0.010
12.24
91.69
22,042
22,473
25,918
24,658
30,531
31,079
35,373
33,808
(22,422)
(25,385)
(24,189)
(30,929)
(34,408)
(32,945)
10
1.60
0.005
14.01
190.72
18,365
18,766
21,628
20,584
25,438
25,951
29,522
28,225
(18,706)
(21,271)
(20,272)
(25,836)
(28,853)
(27,695)
10
1.60
0.010
14.01
190.72
20,522
20,927
24,128
22,956
28,426
28,944
32,926
31,475
(20,862)
(23,515)
(22,455)
(28,749)
(31,798)
(30,514)
18
0.80
0.005
20.23
277.35
13,079
13,345
15,390
14,642
18,117
18,456
21,004
20,077
(13,326)
(15,183)
(14,481)
(18,406)
(20,649)
(19,761)
18
0.80
0.010
20.23
277.35
14,929
15,205
17,535
16,681
20,678
21,029
23,928
22,869
(15,172)
(17,211)
(16,453)
(20,978)
(23,344)
(22,409)
18
1.60
0.005
22.72
577.77
12,354
12,602
14,530
13,825
17,112
17,429
19,831
18,955
(12,567)
(14,252)
(13,615)
(17,366)
(19,343)
(18,557)
18
1.60
0.010
22.72
577.77
14,711
14,976
17,257
16,418
20,377
20,710
23,549
22,509
(14,945)
(16,826)
(16,066)
(20,607)
(22,730)
(21,797)
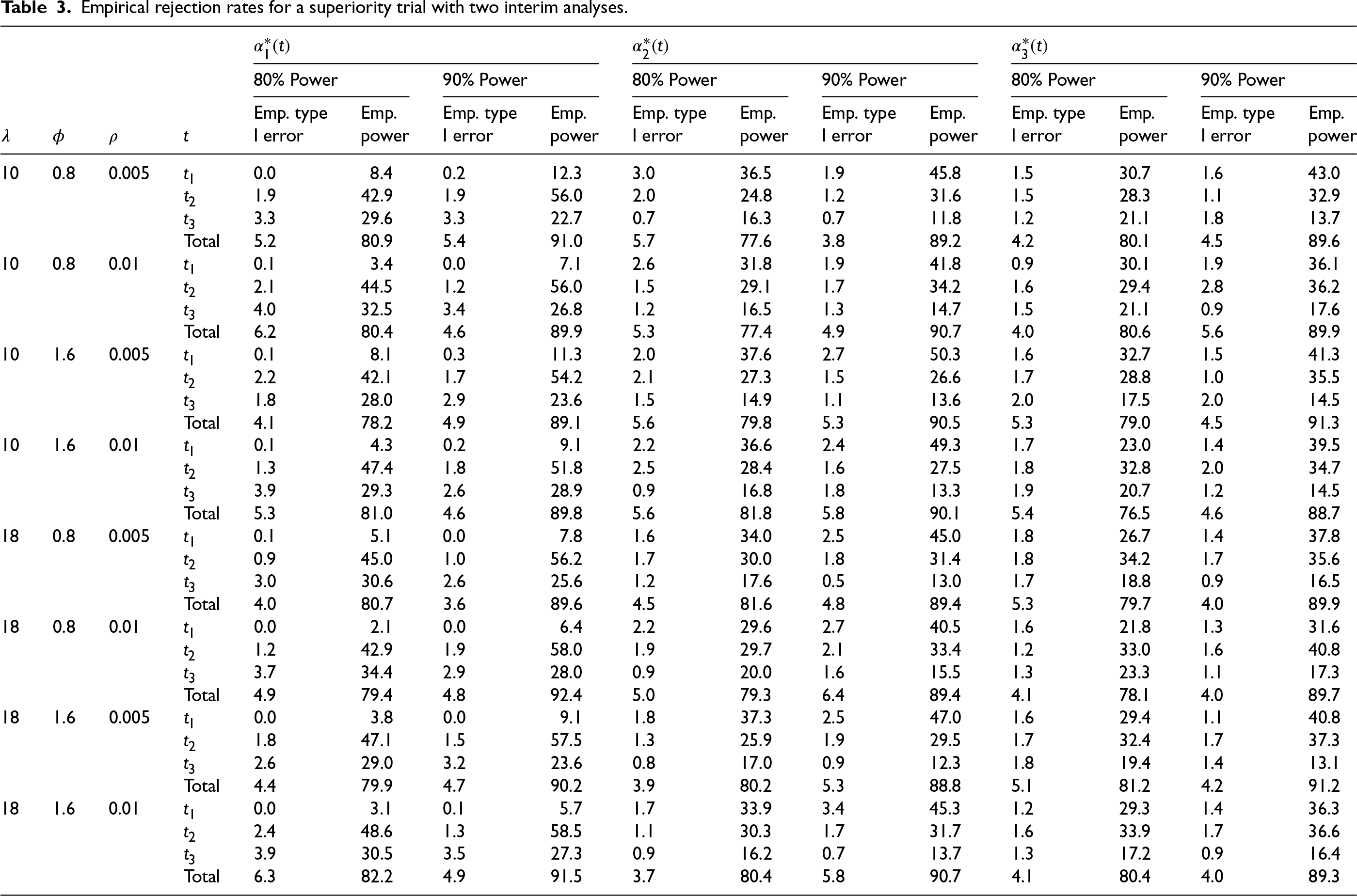
Empirical rejection rates for a superiority trial with two interim analyses.
80% Power
90% Power
80% Power
90% Power
80% Power
90% Power
Emp. type
Emp.
Emp. type
Emp.
Emp. type
Emp.
Emp. type
Emp.
Emp. type
Emp.
Emp. type
Emp.
I error
power
I error
power
I error
power
I error
power
I error
power
I error
power
10
0.8
0.005
0.0
8.4
0.2
12.3
3.0
36.5
1.9
45.8
1.5
30.7
1.6
43.0
1.9
42.9
1.9
56.0
2.0
24.8
1.2
31.6
1.5
28.3
1.1
32.9
3.3
29.6
3.3
22.7
0.7
16.3
0.7
11.8
1.2
21.1
1.8
13.7
Total
5.2
80.9
5.4
91.0
5.7
77.6
3.8
89.2
4.2
80.1
4.5
89.6
10
0.8
0.01
0.1
3.4
0.0
7.1
2.6
31.8
1.9
41.8
0.9
30.1
1.9
36.1
2.1
44.5
1.2
56.0
1.5
29.1
1.7
34.2
1.6
29.4
2.8
36.2
4.0
32.5
3.4
26.8
1.2
16.5
1.3
14.7
1.5
21.1
0.9
17.6
Total
6.2
80.4
4.6
89.9
5.3
77.4
4.9
90.7
4.0
80.6
5.6
89.9
10
1.6
0.005
0.1
8.1
0.3
11.3
2.0
37.6
2.7
50.3
1.6
32.7
1.5
41.3
2.2
42.1
1.7
54.2
2.1
27.3
1.5
26.6
1.7
28.8
1.0
35.5
1.8
28.0
2.9
23.6
1.5
14.9
1.1
13.6
2.0
17.5
2.0
14.5
Total
4.1
78.2
4.9
89.1
5.6
79.8
5.3
90.5
5.3
79.0
4.5
91.3
10
1.6
0.01
0.1
4.3
0.2
9.1
2.2
36.6
2.4
49.3
1.7
23.0
1.4
39.5
1.3
47.4
1.8
51.8
2.5
28.4
1.6
27.5
1.8
32.8
2.0
34.7
3.9
29.3
2.6
28.9
0.9
16.8
1.8
13.3
1.9
20.7
1.2
14.5
Total
5.3
81.0
4.6
89.8
5.6
81.8
5.8
90.1
5.4
76.5
4.6
88.7
18
0.8
0.005
0.1
5.1
0.0
7.8
1.6
34.0
2.5
45.0
1.8
26.7
1.4
37.8
0.9
45.0
1.0
56.2
1.7
30.0
1.8
31.4
1.8
34.2
1.7
35.6
3.0
30.6
2.6
25.6
1.2
17.6
0.5
13.0
1.7
18.8
0.9
16.5
Total
4.0
80.7
3.6
89.6
4.5
81.6
4.8
89.4
5.3
79.7
4.0
89.9
18
0.8
0.01
0.0
2.1
0.0
6.4
2.2
29.6
2.7
40.5
1.6
21.8
1.3
31.6
1.2
42.9
1.9
58.0
1.9
29.7
2.1
33.4
1.2
33.0
1.6
40.8
3.7
34.4
2.9
28.0
0.9
20.0
1.6
15.5
1.3
23.3
1.1
17.3
Total
4.9
79.4
4.8
92.4
5.0
79.3
6.4
89.4
4.1
78.1
4.0
89.7
18
1.6
0.005
0.0
3.8
0.0
9.1
1.8
37.3
2.5
47.0
1.6
29.4
1.1
40.8
1.8
47.1
1.5
57.5
1.3
25.9
1.9
29.5
1.7
32.4
1.7
37.3
2.6
29.0
3.2
23.6
0.8
17.0
0.9
12.3
1.8
19.4
1.4
13.1
Total
4.4
79.9
4.7
90.2
3.9
80.2
5.3
88.8
5.1
81.2
4.2
91.2
18
1.6
0.01
0.0
3.1
0.1
5.7
1.7
33.9
3.4
45.3
1.2
29.3
1.4
36.3
2.4
48.6
1.3
58.5
1.1
30.3
1.7
31.7
1.6
33.9
1.7
36.6
3.9
30.5
3.5
27.3
0.9
16.2
0.7
13.7
1.3
17.2
0.9
16.4
Total
6.3
82.2
4.9
91.5
3.7
80.4
5.8
90.7
4.1
80.4
4.0
89.3
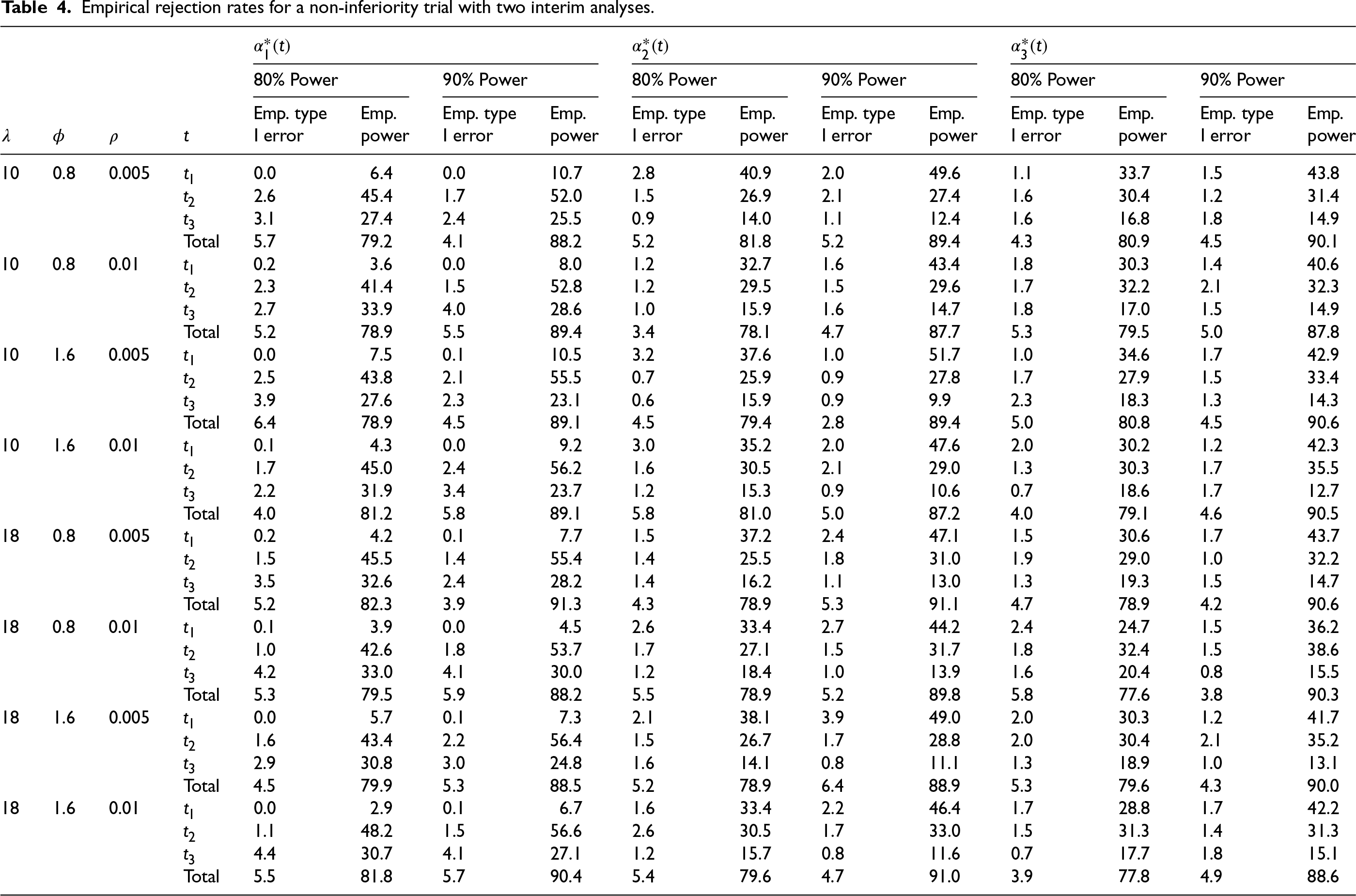
Empirical rejection rates for a non-inferiority trial with two interim analyses.
80% Power
90% Power
80% Power
90% Power
80% Power
90% Power
Emp. type
Emp.
Emp. type
Emp.
Emp. type
Emp.
Emp. type
Emp.
Emp. type
Emp.
Emp. type
Emp.
I error
power
I error
power
I error
power
I error
power
I error
power
I error
power
10
0.8
0.005
0.0
6.4
0.0
10.7
2.8
40.9
2.0
49.6
1.1
33.7
1.5
43.8
2.6
45.4
1.7
52.0
1.5
26.9
2.1
27.4
1.6
30.4
1.2
31.4
3.1
27.4
2.4
25.5
0.9
14.0
1.1
12.4
1.6
16.8
1.8
14.9
Total
5.7
79.2
4.1
88.2
5.2
81.8
5.2
89.4
4.3
80.9
4.5
90.1
10
0.8
0.01
0.2
3.6
0.0
8.0
1.2
32.7
1.6
43.4
1.8
30.3
1.4
40.6
2.3
41.4
1.5
52.8
1.2
29.5
1.5
29.6
1.7
32.2
2.1
32.3
2.7
33.9
4.0
28.6
1.0
15.9
1.6
14.7
1.8
17.0
1.5
14.9
Total
5.2
78.9
5.5
89.4
3.4
78.1
4.7
87.7
5.3
79.5
5.0
87.8
10
1.6
0.005
0.0
7.5
0.1
10.5
3.2
37.6
1.0
51.7
1.0
34.6
1.7
42.9
2.5
43.8
2.1
55.5
0.7
25.9
0.9
27.8
1.7
27.9
1.5
33.4
3.9
27.6
2.3
23.1
0.6
15.9
0.9
9.9
2.3
18.3
1.3
14.3
Total
6.4
78.9
4.5
89.1
4.5
79.4
2.8
89.4
5.0
80.8
4.5
90.6
10
1.6
0.01
0.1
4.3
0.0
9.2
3.0
35.2
2.0
47.6
2.0
30.2
1.2
42.3
1.7
45.0
2.4
56.2
1.6
30.5
2.1
29.0
1.3
30.3
1.7
35.5
2.2
31.9
3.4
23.7
1.2
15.3
0.9
10.6
0.7
18.6
1.7
12.7
Total
4.0
81.2
5.8
89.1
5.8
81.0
5.0
87.2
4.0
79.1
4.6
90.5
18
0.8
0.005
0.2
4.2
0.1
7.7
1.5
37.2
2.4
47.1
1.5
30.6
1.7
43.7
1.5
45.5
1.4
55.4
1.4
25.5
1.8
31.0
1.9
29.0
1.0
32.2
3.5
32.6
2.4
28.2
1.4
16.2
1.1
13.0
1.3
19.3
1.5
14.7
Total
5.2
82.3
3.9
91.3
4.3
78.9
5.3
91.1
4.7
78.9
4.2
90.6
18
0.8
0.01
0.1
3.9
0.0
4.5
2.6
33.4
2.7
44.2
2.4
24.7
1.5
36.2
1.0
42.6
1.8
53.7
1.7
27.1
1.5
31.7
1.8
32.4
1.5
38.6
4.2
33.0
4.1
30.0
1.2
18.4
1.0
13.9
1.6
20.4
0.8
15.5
Total
5.3
79.5
5.9
88.2
5.5
78.9
5.2
89.8
5.8
77.6
3.8
90.3
18
1.6
0.005
0.0
5.7
0.1
7.3
2.1
38.1
3.9
49.0
2.0
30.3
1.2
41.7
1.6
43.4
2.2
56.4
1.5
26.7
1.7
28.8
2.0
30.4
2.1
35.2
2.9
30.8
3.0
24.8
1.6
14.1
0.8
11.1
1.3
18.9
1.0
13.1
Total
4.5
79.9
5.3
88.5
5.2
78.9
6.4
88.9
5.3
79.6
4.3
90.0
18
1.6
0.01
0.0
2.9
0.1
6.7
1.6
33.4
2.2
46.4
1.7
28.8
1.7
42.2
1.1
48.2
1.5
56.6
2.6
30.5
1.7
33.0
1.5
31.3
1.4
31.3
4.4
30.7
4.1
27.1
1.2
15.7
0.8
11.6
0.7
17.7
1.8
15.1
Total
5.5
81.8
5.7
90.4
5.4
79.6
4.7
91.0
3.9
77.8
4.9
88.6
With the calculated sample size for study with the planned interim analyses for each scenario we assess the empirical rejection rates to verify the sample size calculation. Under each parameter setting, for each subject we generate random effect and treatment assignment . The recruitment time for subject is generated from . We repeat the above steps and keep the subjects with until we get the calculated sample size . Next we generate the waiting times between measurements for each subject according to . The number of donations for each subject is then determined by the accumulated waiting time for the donations within . Note that the first donation of each subject is assumed to occur at the entry time of the study so the number of donations will be added by one for each subject. The correlated binary response of subject for the th measurement is generated given the pre-specified marginal means and pairwise associations based on the method of Qaqish.22 The response is generated from Bernoulli distribution with mean , and response , , can be generated sequentially though
where , , and is the th element of
Following the above simulation procedure we have the recruitment times, repeated measurement times and responses generated for all individuals in the sample. We next plan 2 interim analyses at and with a final analysis at the end of study. The average sample size required for the sequential trial under each parameter setting based on simulations is reported in parentheses in Tables 1 and 2. The average sample size for the sequential design is slightly larger than that of a fixed study because under the current design framework—with 2 interim analyses planned at information fractions of 1/3 and 2/3—the majority of donors are recruited before the first interim analysis occurs. Nonetheless, conducting group sequential analyses remains valuable as early termination of the trial can lead to a reduction in the average sample size overall, and the average sample size remains lower than the analytically calculated sample size required for a sequential trial. The empirical rejection rates under and , respectively, based on the simulated data using the computed critical values are calculated and repeated for times. The averaged empirical rejection rates for each scenario are summarized in Table 3 for the superiority study and in Table 4 for the non-inferiority study. From the summary tables, we see that the empirical type I errors (empirical rejection rate under ) for most of the scenarios are within 5%. Similarly for the empirical power (empirical rejection rate under ), the empirical powers reach the desired power at either 80% or 90% settings for most of the scenarios, and some cases have empirical powers slightly below the target power due to randomness. The overall empirical rejection rates are satisfying which verify our sample size calculation method for the study with interim analyses for the cluster data.
Empirical study with dependence between response and donation intensity
The derivations in Section 2 are based on the assumption that donations occur in the population with a conditional intensity given by (1) which does not depend on the response. Here we conduct simulation studies to examine the sensitivity of estimators to violations of this assumption in the setting where the event rate for the control arm is , as specified in Section 5.1. To allow the response to influence the intensity of future events, we consider the modified intensity function
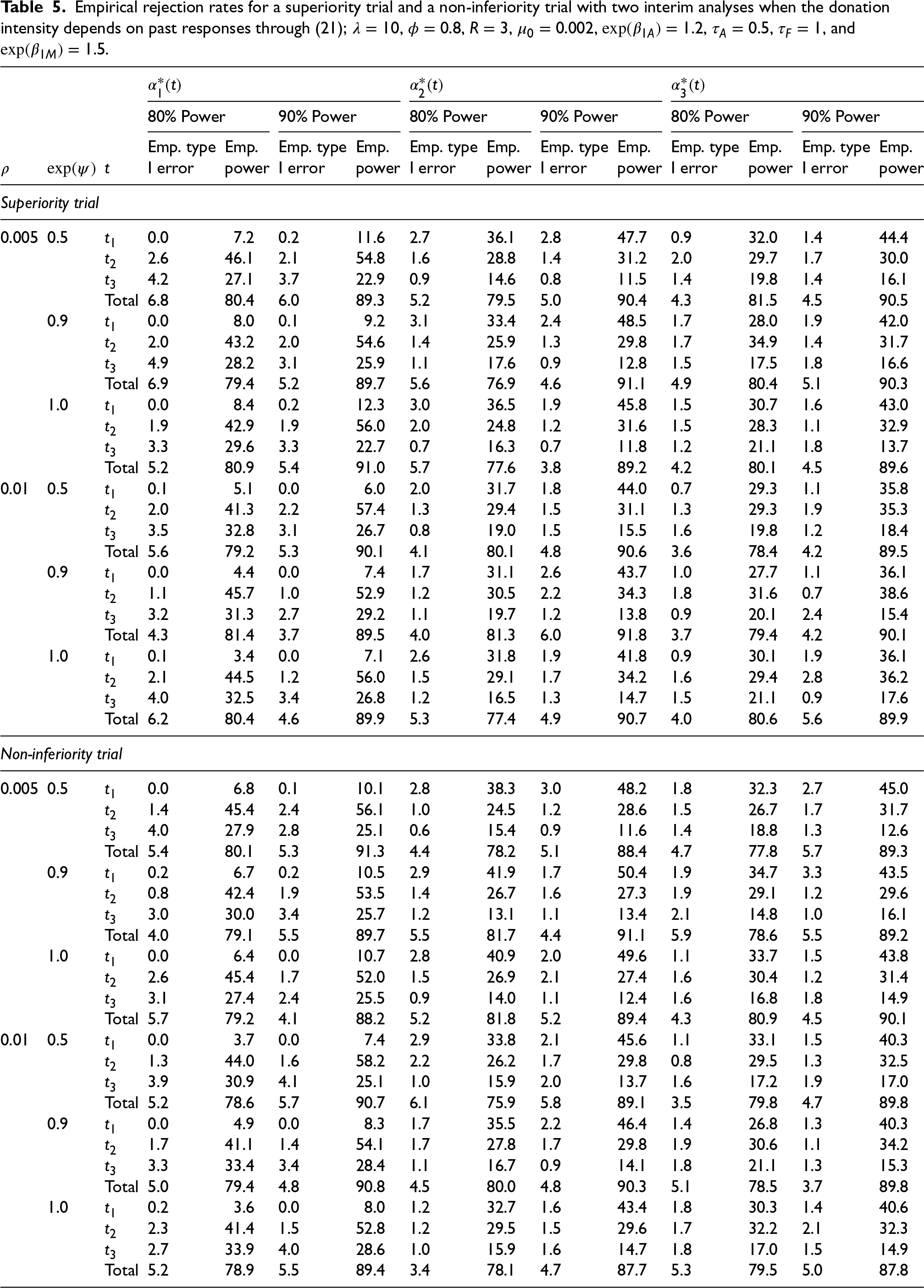
where is the total number of adverse events observed by study time for subject , . According to (21), the donation intensity decreases by a factor of every time an event occurs. We report simulation results for both superiority and non-inferiority trials in Table 5, where , , and , while all other parameters have the same settings as in Section 5.1. The simulations demonstrate excellent control of the type I error rate at around 5% with no appreciable loss in empirical power given that the event rate is very low. These findings suggest that when adverse events are rare, the impact of the association between adverse events and the propensity to donate is negligible on the study power. Therefore assuming independence between the donation response and donation frequency is reasonable for study planning purposes.
Empirical rejection rates for a superiority trial and a non-inferiority trial with two interim analyses when the donation intensity depends on past responses through (21); , , , , , , , and .
80% Power
90% Power
80% Power
90% Power
80% Power
90% Power
Emp. type
Emp.
Emp. type
Emp.
Emp. type
Emp.
Emp. type
Emp.
Emp. type
Emp.
Emp. type
Emp.
I error
power
I error
power
I error
power
I error
power
I error
power
I error
power
Superiority trial
0.005
0.5
0.0
7.2
0.2
11.6
2.7
36.1
2.8
47.7
0.9
32.0
1.4
44.4
2.6
46.1
2.1
54.8
1.6
28.8
1.4
31.2
2.0
29.7
1.7
30.0
4.2
27.1
3.7
22.9
0.9
14.6
0.8
11.5
1.4
19.8
1.4
16.1
Total
6.8
80.4
6.0
89.3
5.2
79.5
5.0
90.4
4.3
81.5
4.5
90.5
0.9
0.0
8.0
0.1
9.2
3.1
33.4
2.4
48.5
1.7
28.0
1.9
42.0
2.0
43.2
2.0
54.6
1.4
25.9
1.3
29.8
1.7
34.9
1.4
31.7
4.9
28.2
3.1
25.9
1.1
17.6
0.9
12.8
1.5
17.5
1.8
16.6
Total
6.9
79.4
5.2
89.7
5.6
76.9
4.6
91.1
4.9
80.4
5.1
90.3
1.0
0.0
8.4
0.2
12.3
3.0
36.5
1.9
45.8
1.5
30.7
1.6
43.0
1.9
42.9
1.9
56.0
2.0
24.8
1.2
31.6
1.5
28.3
1.1
32.9
3.3
29.6
3.3
22.7
0.7
16.3
0.7
11.8
1.2
21.1
1.8
13.7
Total
5.2
80.9
5.4
91.0
5.7
77.6
3.8
89.2
4.2
80.1
4.5
89.6
0.01
0.5
0.1
5.1
0.0
6.0
2.0
31.7
1.8
44.0
0.7
29.3
1.1
35.8
2.0
41.3
2.2
57.4
1.3
29.4
1.5
31.1
1.3
29.3
1.9
35.3
3.5
32.8
3.1
26.7
0.8
19.0
1.5
15.5
1.6
19.8
1.2
18.4
Total
5.6
79.2
5.3
90.1
4.1
80.1
4.8
90.6
3.6
78.4
4.2
89.5
0.9
0.0
4.4
0.0
7.4
1.7
31.1
2.6
43.7
1.0
27.7
1.1
36.1
1.1
45.7
1.0
52.9
1.2
30.5
2.2
34.3
1.8
31.6
0.7
38.6
3.2
31.3
2.7
29.2
1.1
19.7
1.2
13.8
0.9
20.1
2.4
15.4
Total
4.3
81.4
3.7
89.5
4.0
81.3
6.0
91.8
3.7
79.4
4.2
90.1
1.0
0.1
3.4
0.0
7.1
2.6
31.8
1.9
41.8
0.9
30.1
1.9
36.1
2.1
44.5
1.2
56.0
1.5
29.1
1.7
34.2
1.6
29.4
2.8
36.2
4.0
32.5
3.4
26.8
1.2
16.5
1.3
14.7
1.5
21.1
0.9
17.6
Total
6.2
80.4
4.6
89.9
5.3
77.4
4.9
90.7
4.0
80.6
5.6
89.9
Non-inferiority trial
0.005
0.5
0.0
6.8
0.1
10.1
2.8
38.3
3.0
48.2
1.8
32.3
2.7
45.0
1.4
45.4
2.4
56.1
1.0
24.5
1.2
28.6
1.5
26.7
1.7
31.7
4.0
27.9
2.8
25.1
0.6
15.4
0.9
11.6
1.4
18.8
1.3
12.6
Total
5.4
80.1
5.3
91.3
4.4
78.2
5.1
88.4
4.7
77.8
5.7
89.3
0.9
0.2
6.7
0.2
10.5
2.9
41.9
1.7
50.4
1.9
34.7
3.3
43.5
0.8
42.4
1.9
53.5
1.4
26.7
1.6
27.3
1.9
29.1
1.2
29.6
3.0
30.0
3.4
25.7
1.2
13.1
1.1
13.4
2.1
14.8
1.0
16.1
Total
4.0
79.1
5.5
89.7
5.5
81.7
4.4
91.1
5.9
78.6
5.5
89.2
1.0
0.0
6.4
0.0
10.7
2.8
40.9
2.0
49.6
1.1
33.7
1.5
43.8
2.6
45.4
1.7
52.0
1.5
26.9
2.1
27.4
1.6
30.4
1.2
31.4
3.1
27.4
2.4
25.5
0.9
14.0
1.1
12.4
1.6
16.8
1.8
14.9
Total
5.7
79.2
4.1
88.2
5.2
81.8
5.2
89.4
4.3
80.9
4.5
90.1
0.01
0.5
0.0
3.7
0.0
7.4
2.9
33.8
2.1
45.6
1.1
33.1
1.5
40.3
1.3
44.0
1.6
58.2
2.2
26.2
1.7
29.8
0.8
29.5
1.3
32.5
3.9
30.9
4.1
25.1
1.0
15.9
2.0
13.7
1.6
17.2
1.9
17.0
Total
5.2
78.6
5.7
90.7
6.1
75.9
5.8
89.1
3.5
79.8
4.7
89.8
0.9
0.0
4.9
0.0
8.3
1.7
35.5
2.2
46.4
1.4
26.8
1.3
40.3
1.7
41.1
1.4
54.1
1.7
27.8
1.7
29.8
1.9
30.6
1.1
34.2
3.3
33.4
3.4
28.4
1.1
16.7
0.9
14.1
1.8
21.1
1.3
15.3
Total
5.0
79.4
4.8
90.8
4.5
80.0
4.8
90.3
5.1
78.5
3.7
89.8
1.0
0.2
3.6
0.0
8.0
1.2
32.7
1.6
43.4
1.8
30.3
1.4
40.6
2.3
41.4
1.5
52.8
1.2
29.5
1.5
29.6
1.7
32.2
2.1
32.3
2.7
33.9
4.0
28.6
1.0
15.9
1.6
14.7
1.8
17.0
1.5
14.9
Total
5.2
78.9
5.5
89.4
3.4
78.1
4.7
87.7
5.3
79.5
5.0
87.8
Design of a plasma donation study
Source plasma is crucial in life-saving treatments for various medical conditions and the demand for it has consistently exceeded its supply, especially during the COVID-19 pandemic.23 For a potential increase in average plasma collection volume, the trial named IMPACT (IMproving PlasmA CollecTion)24 was conducted between 6 January and 26 March 2020 at three plasma collection centers (i.e. Charlotte, NC; Spokane, WA; and Wichita, KS) in the United States. It is a randomized controlled trial to assess the non-inferiority of a new “percent plasma nomogram” (PPN) compared to the standard nomogram in terms of the incidence of significant hypotensive adverse events.24 The PPN nomogram was developed to personalize the target plasma volume for each donor, allowing for adjustment of the target plasma volume upward or downward based on individual characteristics. Donors were recruited between 6 January and 26 March 2020 at three plasma collection centers: Charlotte, NC; Spokane, WA; and Wichita, KS. Here we demonstrate how the proposed design framework can be applied to plan a plasma donation study with interim analyses in this context.
To design the study based on the aims of the IMPACT trial, we assume so that donors are randomized into two groups with a 50:50 allocation to either the PPN or the standard nomogram arm. Based on Canadian plasma donor data on the expected annual number of donations per donor is 21 so we set . To account for variability in donation frequency among donors we set . The rate of significant hypotensive adverse events in the control arm using the standard nomogram is set to . For the experimental arm, we anticipate a 50% increase in the event rate, so we let . Given the low event rate we set a non-inferiority margin of , and consider trial planning with versus with significant level and target power at 80%. We assume an exchangeable within-donor serial correlation of across repeated donations. Furthermore, we plan for a 6-month recruitment duration () and follow each donor for 6 months ().
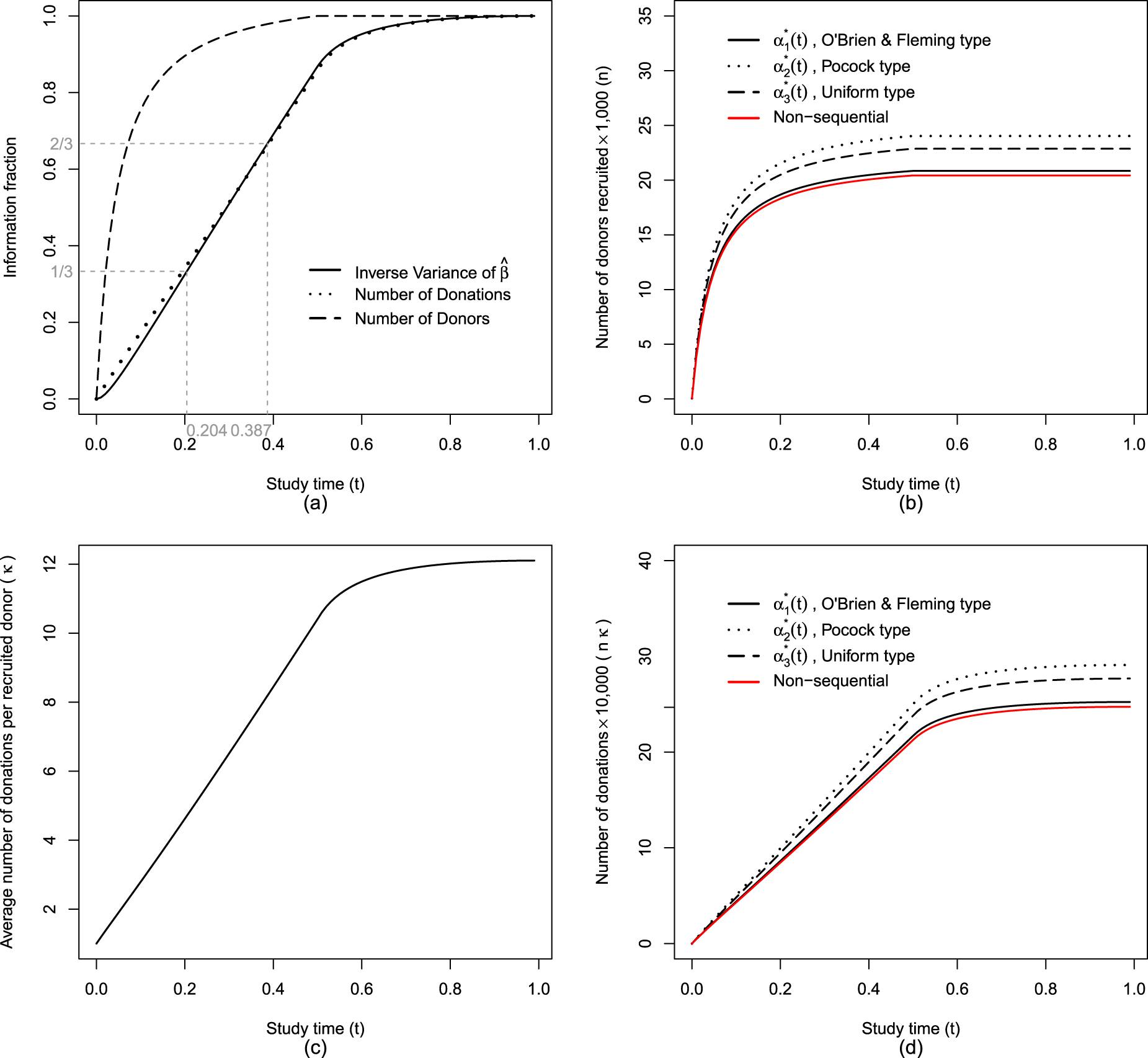
We plan to conduct two interim analyses at times and , along with a final analysis at the end of the study, . The timing of the interim analyses can be determined by the amount of information accumulated up to each point in the study. Figure 2(a) illustrates the growth of the information fraction over the course of the study based on the inverse variance of the estimator . For example, interim analyses can be conducted at study times approximately and which corresponds to and of the maximum information expected by the end of the study. If the estimated variance of is unavailable, alternative metrics such as the proportion of donors recruited, donations accumulated, or simply the passage of study time can be used to approximate the information fraction and guide the timing of interim analyses. The critical values for three analyses, that is, first interim analysis at , second interim analysis at , and final analysis at , are provided in Table D1 in the Supplemental Material. These critical values are calculated based on the information fraction defined as the fraction of inverse variance of . Here for a fixed design the critical value is around 1.64 for a one-sided test with significant level . Using an O’Brien and Fleming alpha spending function , the critical values at , , and are 3.25, 2.09, and 1.70, respectively. For a Pocock-type spending function , the corresponding critical values are 2.01, 1.96, and 1.98, while for a uniform spending function they are 2.14, 1.96, and 1.88; see Table D1 in the Supplemental Material. The O’Brien-Fleming alpha spending function heavily protects against early stopping by setting a very strict (high) critical value for the first interim analysis with more relaxed critical values toward the final analysis. Pocock type alpha spending function provides more balanced critical values across all interim analyses, potentially allowing for earlier termination of the trial since the first interim analysis has a considerably lower critical value compared to the O’Brien-Fleming type. The uniform alpha spending function allocates the type I error rate uniformly across all interim analyses and it falls between O’Brien-Fleming and Pocock in terms of conservatism on early stopping.
Study progression over time in a non-inferiority trial of information fraction, number of donors recruited, average donations per donor, and total donations with , , , , , , , , and target power=80%.
Figure 2(b) shows the number of donors recruited over time. Under the same setting a non-sequential study requires the fewest donors () to achieve 80% power and a study planned using Pocock type alpha spending function requires the largest number of donors (). If the study is terminated early following interim analyses, the total number of recruited donors will be fewer than the sample size originally planned for the end of the study. The average number of donations per recruited donor (Figure 2(c)) and number of donations (Figure 2(d)) increase rapidly during the recruitment period as the frequent donors are encountered and recruited earlier.
Discussion
We have developed a framework for the design and analysis of large scale trials involving marked point processes where there is inter-individual variation in the rate of events. The events are the occasions in which a therapeutic intervention is warranted and the trial is planned such that the same intervention is applied each time an event occurs during the course of follow-up. We consider the setting where the response is available relatively soon after the therapy is administered and it does not affect the intensity for future events. This is suitable for the study of chronic conditions with recurrent episodic flares or acute exacerbations that warrant treatment and in the introduction we listed example settings.
The methodological development here is specifically motivated by challenges in blood donation research where the goal, like that of Hartmann et al.24 is to show that a new device or algorithm is used to extract blood in donors is safe. For this specific setting, we use a binary response indicating the occurrence of a serious hypotensive adverse event wherein the probability of such an event is very rare—this, along with the desire to estimate the relative rate of events, leads us to the use of a log link function. A working independence assumption means the dependence structure does not need to be specified but protection against misspecification of the variance function (implicit from the use of the Poisson approximation and log link) and serial dependence in responses is ensured by use of a robust covariance matrix. While we formulate our method based on a binary response, other types of responses could be considered provided they are measurable soon after the donation.
The problem we address has similarities with the problem of group sequential monitoring of cluster-randomized trials with variable cluster sizes (e.g. Grayling et al.25), but it differs in several key respects. First in our setting clusters are defined by individuals, and the number of donations within an individual arises from a point process, rather than the way individuals might be organized in static clusters. Second, we deal with the correlation of responses over successive donations using marginal models for correlated binary data rather than mixed effect modeling. Third, heterogeneity in the donation rate in the target population can be characterized using historical data in the donation setting and it represents a meaningful population parameter (e.g. the variance of the random effect in the mixed Poisson process) when modeling the donation process. This heterogeneity helps trialists anticipate that the donation rate among donors recruited earlier during the accrual period will tend to be higher than those recruited towards the end of the accrual period. A consequence of this phenomenon is that the rate of information acquisition is very much higher early in the course of the study than a later phase when the highest frequency of donors were already recruited and may have completed their follow-up—less frequent donors being followed at this point would be yielding less information per unit of calendar time. The derivations of the joint distributions of successive test statistics and specification of alpha spending functions are exploited here to ensure interim analyses and stopping rules are possible while ensuring control of the type I error rate. This has significant implications on the optimal timing of interim analyses, and trials aiming to plan analyses at roughly equal increments of information must ensure that data collection, validation and reporting is possible soon after the launch of the trial to ensure that safety can be effectively monitored.
The derivations we provide can also be exploited when interest lies in conditional power26 calculations. If there is a concern that sample size calculations were inadequate due to misspecification of one or more parameters (e.g. the baseline event rate determined by ) then the joint distribution of the current and a future test statistic can be useful to calculate the probability that the trial at the planned or some later end of study will lead to rejection of the null hypothesis. This may be done in the context of a fixed sample trial or a sequential trial, and can be used as a basis for sample size re-estimation27 or stochastic curtailment28 of a trial.
Supplemental Material
sj-pdf-1-smm-10.1177_09622802251350263 - Supplemental material for Group sequential analysis of marked point processes: Plasma donation trials
Supplemental material, sj-pdf-1-smm-10.1177_09622802251350263 for Group sequential analysis of marked point processes: Plasma donation trials by Kecheng Li and Richard J Cook in Statistical Methods in Medical Research
Footnotes
Data availability
The simulated data generated for this study are available from the corresponding author upon reasonable request.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was funded by the Natural Sciences and Engineering Research Council of Canada through Discovery Grants to Dr Richard J Cook (RGPIN-2017-04207). Dr Richard Cook is a university professor and Faculty of Mathematics Research Chair at the University of Waterloo and an associate faculty member with the Michael G. DeGroote Centre for Transfusion Research at McMaster University.
ORCID iDs
Kecheng Li
Richard J Cook
Supplemental material
Supplemental material for this article is available online.
References
1.
ArmitagePMcPhersonCKRoweBC. Repeated significance tests on accumulating data. J R Stat Soc Ser A (Gen)1969; 132: 235–244.
2.
PocockSJ. Group sequential methods in the design and analysis of clinical trials. Biometrika1977; 64: 191–199.
3.
O’BrienPCFlemingTR. A multiple testing procedure for clinical trials. Biometrics1979; 35: 549–556.
4.
ReboussinDMDeMetsDLKimKM, et al.Computations for group sequential boundaries using the Lan-DeMets spending function method. Control Clin Trials2000; 21: 190–207.
5.
SludEWeiLJ. Two-sample repeated significance tests based on the modified Wilcoxon statistic. J Am Stat Assoc1982; 77: 862–868.
6.
LanKKGDeMetsDL. Discrete sequential boundaries for clinical trials. Biometrika1983; 70: 659–663.
7.
LeeJWDeMetsDL. Sequential comparison of changes with repeated measurements data. J Am Stat Assoc1991; 86: 757–762.
8.
WeiLJSuJQLachinJM. Interim analyses with repeated measurements in a sequential clinical trial. Biometrika1990; 77: 359–364.
LiangKYZegerSL. Longitudinal data analysis using generalized linear models. Biometrika1986; 73: 13–22.
11.
PascualJFalkRMPiessensF, et al.Consistent efficacy and tolerability of almotriptan in the acute treatment of multiple migraine attacks: results of a large, randomized, double-blind, placebo-controlled study. Cephalalgia2000; 20: 588–596.
12.
WilsonRAllegraLHuchonG, et al.Short-term and long-term outcomes of moxifloxacin compared to standard antibiotic treatment in acute exacerbations of chronic bronchitis. Chest2004; 125: 953–964.
13.
WebertKCookRJSigouinCS, et al.The risk of bleeding in thrombocytopenic patients with acute myeloid leukemia. Haematologica2006; 91: 1530–1537.
14.
CookRJLawlessJF. The statistical analysis of recurrent events. Springer, 2007.
15.
LiK. Design and analysis of studies assessing exposure effects in complex settings. University of Waterloo, 2024
16.
McCullaghP. Generalized linear models. Routledge, 2019.
17.
PrenticeRL. Correlated binary regression with covariates specific to each binary observation. Biometrics1988; 44: 1033–1048.
18.
ZhaoLPPrenticeRL. Correlated binary regression using a quadratic exponential model. Biometrika1990; 77: 642–648.
19.
PrenticeRLZhaoLP. Estimating equations for parameters in means and covariances of multivariate discrete and continuous responses. Biometrics1991; 47: 825–839.
20.
RotnitzkyAJewellNP. Hypothesis testing of regression parameters in semiparametric generalized linear models for cluster correlated data. Biometrika1990; 77: 485–497.
21.
SpiessensBLesaffreEVerbekeG, et al.An overview of group sequential methods in longitudinal clinical trials. Stat Methods Med Res2000; 9: 497–515.
22.
QaqishBF. A family of multivariate binary distributions for simulating correlated binary variables with specified marginal means and correlations. Biometrika2003; 90: 455–463.
23.
CovingtonMLVomaCStowellSR. The impact of the COVID-19 pandemic on source plasma donations. J Clin Apher2023; 38: 644–646.
24.
HartmannJRagusaMJBurchardtER, et al.Personalized collection of plasma from healthy donors: a randomized controlled trial of a novel technology-enabled nomogram. Transfusion2021; 61: 1789–1798.
25.
GraylingMJWasonJMManderAP. Group sequential designs for stepped-wedge cluster randomised trials. Clin. Trials2017; 14: 507–517.
26.
LachinJM. A review of methods for futility stopping based on conditional power. Stat Med2005; 24: 2747–2764.
27.
ManoHTanakaYOriharaS, et al.Application of sample size re-estimation in clinical trials a systematic review. Contemp Clin Trials Commun2023; 36: 101210.
28.
XieTZhangPShihWJ, et al.Dynamic monitoring of ongoing clinical trials. Stat Biopharm Res2022; 14: 580-591.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.