
Abstract
Cluster randomized trials are widely used in healthcare research for the evaluation of intervention strategies. Beyond estimating the average treatment effect, it is often of interest to assess whether the treatment effect varies across subgroups. While conventional methods based on tests of interaction terms between treatment and covariates can be used to detect treatment effect heterogeneity in cluster randomized trials, they typically rely on parametric assumptions that may not hold in practice. Adapting existing permutation tests from individually randomized trials, however, requires conceptual clarification and modification due to the multiple possible interpretations of treatment effect heterogeneity in the cluster randomized trial context. In this work, we develop variations of permutation tests and clarify key causal definitions in order to assess treatment effect heterogeneity in cluster randomized trials. Our procedure enables investigators to simultaneously test for effect modification across a large number of covariates, while maintaining nominal type I error rates and reasonable power in simulation studies. In the Pain Program for Active Coping and Training (PPACT) study, the proposed methods are able to detect treatment effect heterogeneity that was not identified by conventional methods assessing treatment–covariate interactions.
Keywords
Introduction
Cluster randomized trials (CRTs) are conducted because the treatment naturally occurs at the group level, to limit the risk of within-cluster treatment contamination, and for logistical reasons. 1 In a CRT, outcome observations are often measured at the individual level, while randomization occurs at the cluster level. Because of this, individual observations within the same group generally have a positive intracluster correlation and it is recommended that statistical analyses of CRTs account for this correlation. 2 While the average treatment effect has been the main target of estimation and inference in many published CRTs and the corresponding methodological literature, interest is growing in investigating treatment effect heterogeneity across subpopulations. Such analyses can reveal crucial insights at both the individual and cluster levels, providing a more nuanced understanding of intervention efficacy and informing the design of tailored strategies.
In this article, we consider treatment effect heterogeneity that refers to nonrandom, explainable treatment effects which vary across individual or cluster subpopulations. These differences may arise due to biological mechanisms, differences in access to services, and potentially adverse effects, among others, and can occur both at the cluster and individual level. At the cluster level, for example, hospitals may vary in terms of their quality of care and physician experiences, leading to differential responses to treatment. On the individual level, a surgical intervention may lead to greater benefit in younger participants, while being less effective in older or more frail participants, due to the presence of comorbidities. Exploring such variation of treatment effects at the cluster- or individual-level in CRTs can provide finer-resolution evidence beyond an average treatment effect, and carries important policy implications for scaling up interventions in target populations.
A common practice for exploring treatment effect heterogeneity is to test for treatment-by-covariate interactions. In CRTs, this can be done by postulating a linear mixed model or a marginal model fitted by generalized estimating equations in order to incorporate the clustering effect. 3 Either procedure facilitates statistical testing of treatment-by-covariate interaction terms based on asymptotic theory. For example, a likelihood ratio (LR) test, which compares the likelihood of a given mean model specification with the likelihood of a nested specification, can be used to assess the presence of interaction effects in a linear mixed model. When conducting a statistical test for one or more effect modifiers, one can either consider an omnibus test of all interactions or individual tests of each interaction separately. For individual tests, as with more general tests for subgroup differences, there is a high risk of false positive results due to multiplicity. It is generally recommended to use a priori knowledge to limit the number of subgroups considered. 4 Once the subgroups are pre-specified, investigators may use a multiple testing procedure, such as a Bonferonni correction, to reduce the risk of false positives. 5 However, both omnibus and Bonferonni-corrected model-based tests often lack power to effectively detect meaningful subgroup differences, especially when the interaction terms are modelled incorrectly.
Different versions of permutation tests have been developed and compared for CRTs, but with a strict focus on the average treatment effect. To conduct a permutation test, we generally shuffle parts of the data, consistent with the null hypothesis, and compute the portion of re-samples that have a test statistic larger than the observed data. Such tests can better maintain the type I error rates in small samples and require less distributional assumptions than model-based tests. For exponential family outcomes, Braun and Feng 6 derived uniformly and locally most powerful permutation test statistics for detecting a non-zero treatment effect. Wang and De Gruttola 7 proposed efficient permutation tests for time-to-event outcomes and stepped wedge CRTs by using a weighted average of pair-specific treatment effect estimates, with the optimal choice of weights dependent on the intracluster correlation coefficient and degree of cluster size heterogeneity. Methods have also been developed to account for CRTs which employ constrained randomization, an allocation technique used for ensuring covariate balance. 8 By way of estimation, Rabideau and Wang 9 proposed a general method to construct permutation-based confidence intervals for the average treatment effect using individual-level data from a CRT. Watson et al. 10 investigated permutation-based methods for CRTs in settings with multiple outcomes by adapting various p-value corrections, including Bonferroni, Holm, and Romano–Wolf adjustments. They found that the Romano–Wolf procedure controlled family-wise error rates with efficiency gains over other methods under certain dependence structures. Despite its potential, to the best of our knowledge, no permutation tests have been proposed for detecting treatment effect heterogeneity in CRTs.
Permutation tests generally rely on the exchangeability of observations under a specified null hypothesis. In individually randomized trials, permutation procedures for detecting treatment effect heterogeneity involve first removing the main effect of treatment from the outcome of interest to create exchangeable observations under the null. Then, the treatment indicators are permuted in accordance with the randomization scheme and the effect of treatment is added back into the outcome. In this context, Wang et al. 11 proposed a test statistic which compares the mean squared error of a model relating outcome, treatment indicators, and all the covariates to a series of similar treatment-specific models. They apply variable selection within the computation of each test statistic. Wolf et al. 12 used a Virtual Twins approach, extending the methods of Foster et al. 13 They considered machine learning techniques, such as random forests or Super Learner, to estimate the conditional average treatment effect for each individual. For each permutation, test statistics are based on a single decision tree relating the conditional average treatment effects of the permutation distribution with candidate covariates. Rather than permuting the treatment indicators directly, Foster et al. 4 permuted the residuals of a flexible model accounting for effect measure modification. Ding et al. 14 proposed first constructing a confidence interval for the average treatment effect, repeating the permutation procedure point-wise over that interval and then taking the maximum p-value. This procedure guarantees test validity as long as the confidence interval is valid. Chung and Olivares 15 propose a permutation test for heterogeneous treatment effects that addresses the challenge of an estimated nuisance parameter, employing a martingale transformation to stabilize the empirical process and ensure asymptotic control of type I error. Unlike Ding et al. 14 , who take a conservative pointwise approach by constructing a confidence interval around the nuisance parameter and using the maximum p-value across this interval, the method of Chung and Olivares 15 directly neutralizes the impact of the nuisance parameter, resulting in a less conservative, more powerful test. These methods, however, are all designed for individually randomized trials, where the concept of treatment effect heterogeneity is typically narrowly defined at the individual level. In the context of a CRT, treatment effect heterogeneity can be defined at the cluster or individual level, with each having distinct implications. Neglecting this conceptual distinction may result in needlessly inferior policy and treatment recommendations.
In this article, we describe a new permutation test for detecting treatment effect heterogeneity in CRTs. The contribution of this work is two-fold. Firstly, we make explicit the various definitions of treatment effect heterogeneity in CRTs. This is crucial as, unlike in individually randomized trials, treatment effect heterogeneity can have different meanings in a CRT. For example, treatment may be more effective in females (individual level), or treatment may be more effective in clusters with a larger female population (cluster level). Ignoring this distinction may render the analysis less interpretable. We outline testing procedures for both cluster- and individual-level heterogeneity, with a specific focus on the latter, given that the former is a straightforward extension of Ding et al. 14 Secondly, we enhance the methods proposed by Ding et al. 14 by incorporating semiparametric modeling techniques to enhance the efficiency of adjusting for baseline covariates. We assess the finite-sample validity and empirical power of our proposed test under various scenarios in Section 3. In Section 4, we use the proposed method to identify treatment effect heterogeneity in the PPACT (Pain Program for Active Coping and Training) study. In Section 5, we discuss practical recommendations and future directions of our development.
Methods for detecting treatment effect heterogeneity in CRTs
Notation and null hypotheses
We define treatment effect variation using the potential outcomes framework. Let

We define the individual-specific treatment effect as

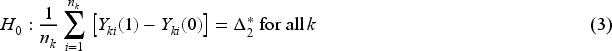
To clarify the differences between the two null hypotheses: the individual-level null hypothesis assumes that treatment effects are constant across all individuals. In contrast, the cluster-level null hypothesis focuses on the average treatment effect across clusters being constant. The individual-level hypothesis is sharper because it implies the cluster-level hypothesis, but not vice versa. In the analysis of CRTs, the choice of null hypothesis depends on the research objectives. For cluster-level interventions, such as implementing a new healthcare program across different hospitals, researchers may prioritize treatment effect variation between clusters. In this case, a cluster-level null hypothesis would be appropriate as a primary pursuit. On the other hand, when studying individual-level interventions that were cluster-randomized for practical reasons, the variation in treatment effects across individual patients may be of primary interest (and variation in treatment effects across clusters could still be secondary interest), making an individual-level null hypothesis more suitable. It’s worth noting that researchers aren’t limited to choosing between these approaches. Studies could examine both null hypotheses to investigate both between-cluster and between-individual heterogeneity, regardless of the level at which the intervention is delivered.
We may also consider various definitions of the finite-sample average treatment effect.
17
The first definition considers the average treatment effect across the entire study population of individuals, or the individual-average treatment effect given by
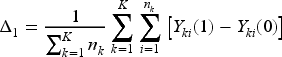

In general, the individual-level null hypothesis, described in (2), and the cluster-level null hypothesis, described in (3), are not equivalent. Any randomization test valid for the cluster-level null is also valid for the individual-level null, because the latter implies the former. The converse, however, does not hold. As such, careful consideration must be made to determine which testing procedures are appropriate. To test for constant treatment effects across clusters under the cluster-level null, we can apply the randomization inference framework of Ding et al.,
14
treating clusters as the units of analysis. We can compute cluster-level means,
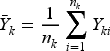
To test the null (2), we first present a general permutation testing framework for the idealized scenario when Calculate a specified test statistic based on the observed data, defined as Enumerate all possible treatment assignments in accordance with the randomization scheme (accounting for appropriate restrictions at the design stage such as stratification or covariate-constrained randomization). Typically, there would be too many possible schemes to list so one can take a random sample by simulating a large number ( For Compare the observed test statistic

When
Specifically, we operationalize the plug-in method in CRTs by replacing


In the CRT setting, as
Further, we clarify the difference between the sharp null hypothesis evaluated by our testing procedure and the conventional null hypothesis of constant average treatment effect across predefined subgroups. The latter tests the null hypothesis that the treatment effect is consistent across subgroups defined by one or more covariates. This null hypothesis requires pre-specifying covariates of interest and specifically targets the form of effect modification by the resulting subgroups. In contrast, our permutation-based test evaluates a sharper null hypothesis: it assesses whether the treatment effect is constant across all subgroups defined by any combination of covariates, regardless of whether they are observed or unobserved. That is, rather than conditioning on a specific set of covariates, our procedure tests whether treatment effect heterogeneity exists across all possible covariate combinations.
When the sharper null hypothesis—that the treatment effect is constant for all individuals—does not hold, it is still possible that the conventional null hypothesis—that the average treatment effect is constant across pre-specified subgroups—does hold. In such cases, the proposed test procedure, which is designed to test the sharper null, would not be appropriate for testing the conventional null, as it may lead to inflated type I error rates. Specifically, if the conventional null holds while the sharper null does not, the proposed test may still reject, detecting finer-scale variations in treatment effects that do not necessarily translate into differences in subgroup-level averages. Compared to the tests for the conventional null, the proposed procedure is more sensitive to detect treatment effect heterogeneity because it is designed to identify any form of variation in treatment effects across individuals. It does not rely on pre-specified subgroup definitions but instead evaluates heterogeneity in a more flexible and global manner.
There are many possible choices for the test statistic
Shifted Komologorov–Smirnov (SK–S) statistics
We first consider a test statistic that relies solely on the Stable Unit Treatment Value Assumption and exchangeability, without making any additional distributional assumptions about our observed data and potential outcomes. Let
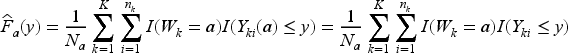
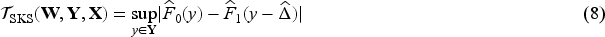
In order to improve testing power, we may allow the chosen test statistic to account for the relationship between covariates and outcome. As long as the covariates are predictive of the outcome, such an adjustment will often improve power to detect treatment effects by explaining at least some baseline variation.22,23 We conjecture that this observation may be generalized to testing for treatment effect heterogeneity in CRTs, and propose to integrate baseline covariate adjustment into the test statistics. Importantly, since the validity of the test relies only on cluster randomization and the correct estimation of the average treatment effect, adjusting for baseline covariates does not compromise the test validity. To allow for flexible functional forms of the baseline covariates, we create a generalized additive mixed model (GAMM)-adjusted K–S (GK–S) test statistic by comparing the CDFs of the residuals of a GAMM fit of
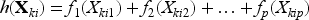
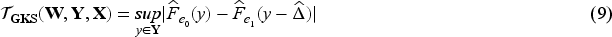
We conducted a simulation study to assess the validity and empirical power of the proposed permutation testing frameworks under a range of scenarios.
Validity
We first investigate the empirical type I error rate for different permutation tests under the null hypothesis of no treatment effect heterogeneity. In order to do this, we use the following steps to generate synthetic CRTs for evaluation.
Generate a synthetic CRT with Simulate potential outcomes consistent with the constant treatment effect assumption that For each choice of the test statistic and method to address the nuisance parameter
Specifically, we compare our three proposed methods with one existing method. The three proposed methods are the permutation tests with either the true average treatment effect
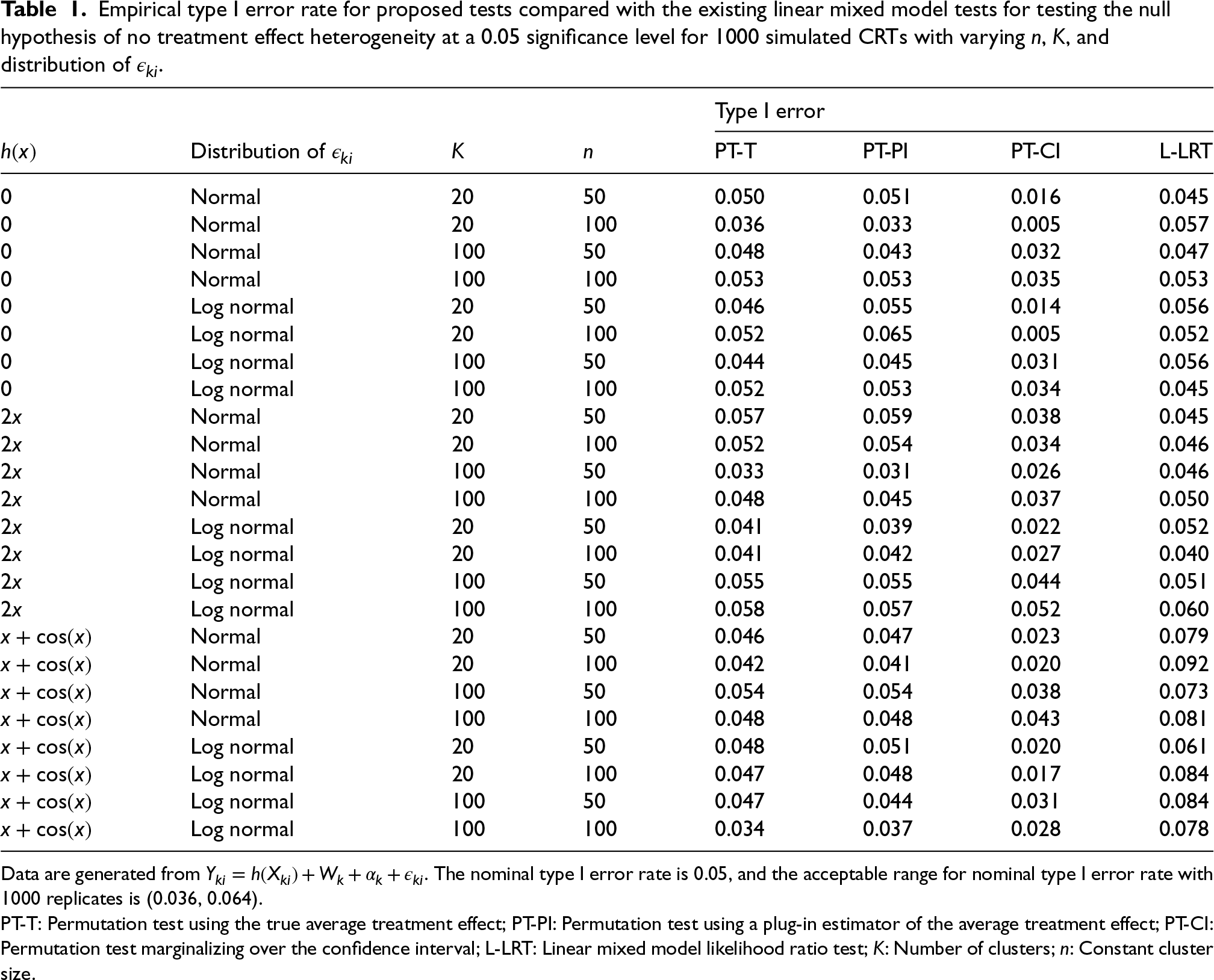
Table 1 shows the empirical type I error rates based on these simulations. Although the LR test relies on correct distributional assumptions, it maintains the correct size even when the error distribution is misspecified in our simulations. However, when
Empirical type I error rate for proposed tests compared with the existing linear mixed model tests for testing the null hypothesis of no treatment effect heterogeneity at a 0.05 significance level for 1000 simulated CRTs with varying
,
, and distribution of
.
Empirical type I error rate for proposed tests compared with the existing linear mixed model tests for testing the null hypothesis of no treatment effect heterogeneity at a 0.05 significance level for 1000 simulated CRTs with varying
Data are generated from
PT-T: Permutation test using the true average treatment effect; PT-PI: Permutation test using a plug-in estimator of the average treatment effect; PT-CI: Permutation test marginalizing over the confidence interval; L-LRT: Linear mixed model likelihood ratio test;
Next, we carry out simulations to compare the power to detect heterogeneous treatment effects for each of the above tests in CRTs. For each simulation iteration, we generate a synthetic CRT with
Functional form of effect modification for simulation study. For all settings, the constant effect is
.
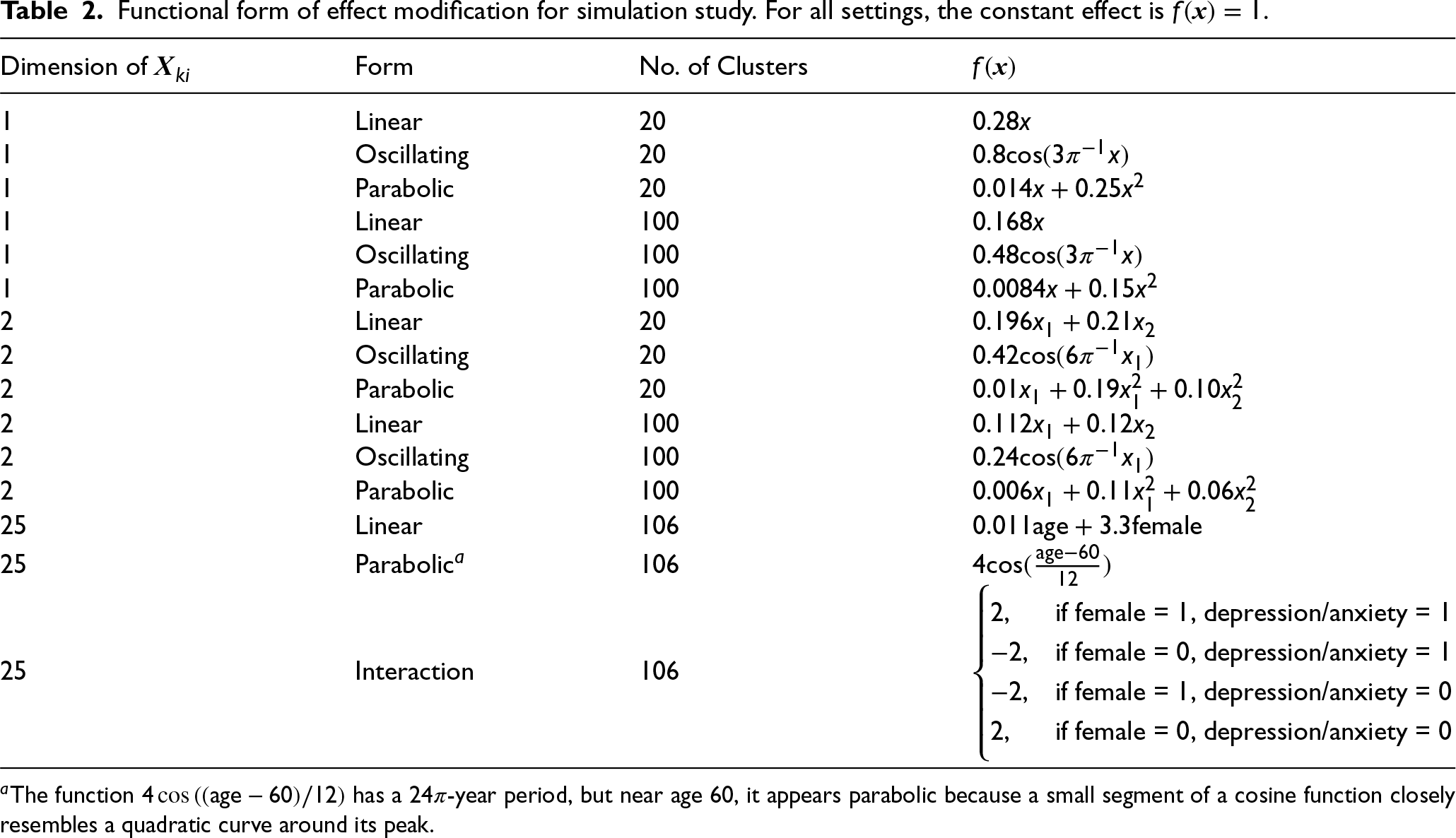
Functional form of effect modification for simulation study. For all settings, the constant effect is
We additionally consider multivariate scenarios with 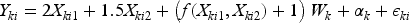
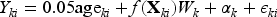
Finally, at the end of each simulation iteration, we calculate the test statistic and p-value for each of the three proposed approaches (PT-T, PT-PI, and PT-CI) and the existing L-LRT and NS4-LRT approach. The smoothed likelihood ratio test (NS4-LRT) follows a similar approach but incorporates a smoothing mechanism to improve stability and power in detecting treatment effect heterogeneity. Instead of modeling the covariates linearly, NS4-LRT represents all continuous covariates using natural splines with four degrees of freedom, allowing for flexible, nonlinear relationships with the outcome. The test compares a model that includes interactions between the treatment and the spline-transformed covariates with a model that only includes main effects. We consider two different test statistics (SK–S and GK–S) for each of PT-T, PT-PI, and PT-CI, totaling six different testing procedures. The specific procedures used for the permutation tests with the SK–S test statistic and the existing L-LRT approach are described in Section 3.1. For the permutation tests using the GK–S test statistic, we use the function
A total of
Tables 3 and 4 show the empirical type I error and power of the three proposed tests (PT-T, PT-PI, PT-CI) and the existing L-LRT and NS4-LRT to detect treatment effect heterogeneity for three different functional forms of effect measure modification at a significance level of 0.05. Table 3 includes simulation results for a single effect modifier. Type I error rates for all tests are well-controlled at the nominal 0.05 level, with the CI methods being slightly conservative as in Table 1. For Normally distributed errors, the model-based LR test always has highest power when its assumptions are met, i.e. when the form of effect modification is linear. When the its functional assumptions are not met, power of the LR test becomes substantially lower than that of the GAMM-adjusted permutation test. As expected, the tests which use the GAMM-adjusted test statistics have similar or higher empirical power than their corresponding unadjusted counterparts, capitalizing on the information embedded in baseline covariates. Further, the confidence interval methods have slightly lower power than the plug-in and true average treatment effect methods, for the permutation tests. We note that the effect of covariate adjustment on the permutation test is more pronounced in the case of linear effect modification. Results were similar for non-Normally distributed errors, indicating that the model-based LR test is much more sensitive to misspecification of the conditional mean structure than the misspecification of the error distribution. The NS4-LRT, which incorporates spline-based effect modification modeling, achieves the highest power across all scenarios, including those where the true effect modification is nonlinear. Unlike the standard L-LRT, which suffers from power loss when functional forms are complex, the NS4-LRT maintains robust performance, effectively capturing complex, nonlinear effect modifications such as oscillatory and parabolic patterns.
Empirical power and type I error (T1E) for the three proposed tests (PT-T, PT-PI, PT-CI) compared with the existing L-LRT and NS4-LRT for testing the null hypothesis of no treatment effect heterogeneity at a 0.05 significance level for 1000 simulated CRTs with varying
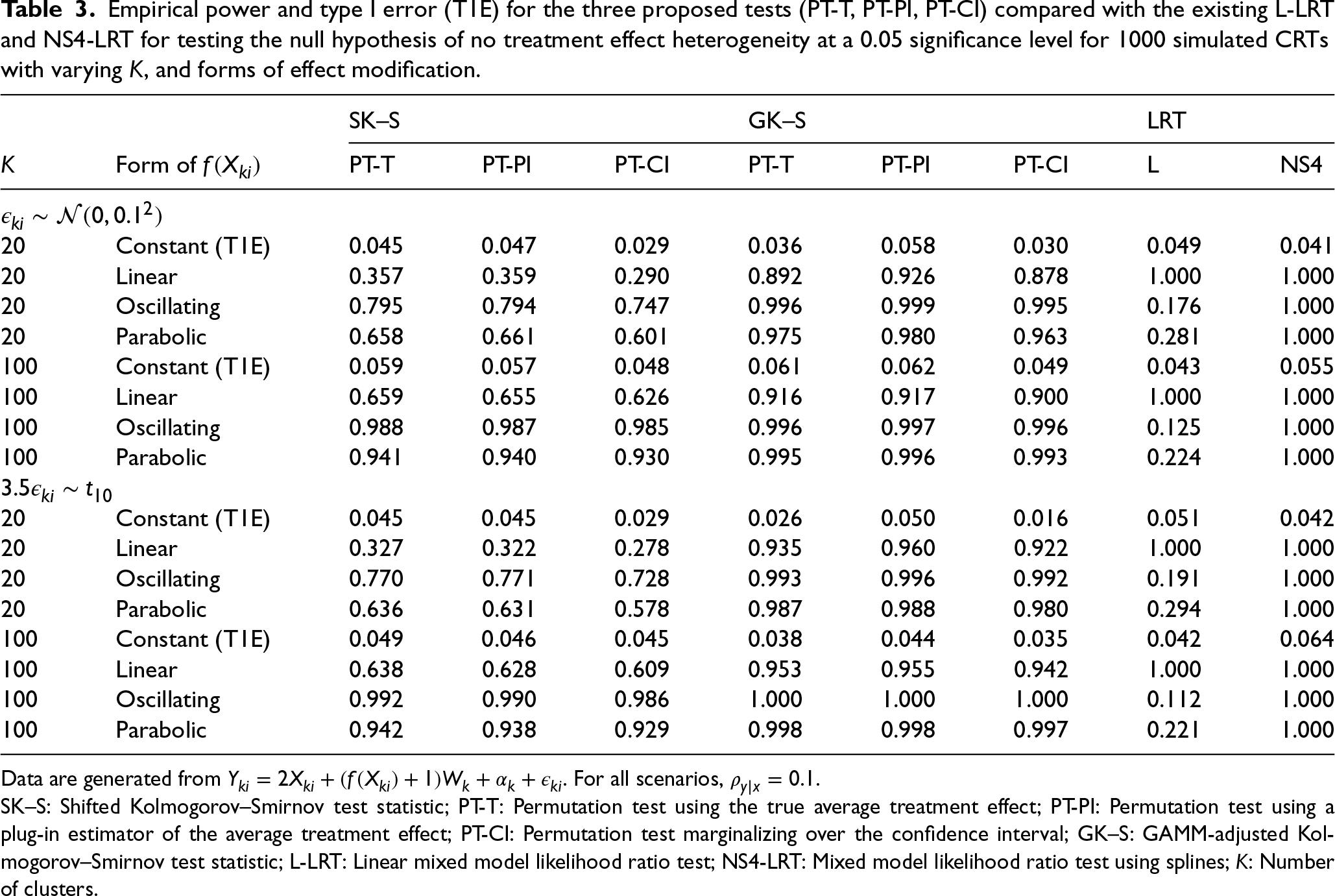
Data are generated from
SK–S: Shifted Kolmogorov–Smirnov test statistic; PT-T: Permutation test using the true average treatment effect; PT-PI: Permutation test using a plug-in estimator of the average treatment effect; PT-CI: Permutation test marginalizing over the confidence interval; GK–S: GAMM-adjusted Kolmogorov–Smirnov test statistic; L-LRT: Linear mixed model likelihood ratio test; NS4-LRT: Mixed model likelihood ratio test using splines;
In the presence of multiple effect modifiers (Table 4), type I error rates were well-controlled at the nominal 0.05 level for the permutation tests; however, when
The PPACT (Pain Program for Active Coping and Training) study was a parallel-arm CRT to evaluate non-pharmaceutical strategies for treatment of chronic pain (ClinicalTrials.gov: NCT02113592). 29 In response to the lack of research on such interventions for chronic pain, investigators aimed to compare cognitive behavioral therapy (CBT) embedded in primary care settings versus usual care for treating chronic pain among patients receiving long-term opioid therapy. The study was conducted from 2014 to 2016 at Kaiser Permanente health care systems in Georgia, Hawaii, and the Northwest. Participants included adults aged 18 and older with mixed chronic pain conditions receiving long-term opioid therapy. The primary outcome, self-reported pain impact as measured by the PEGS scale (pain intensity and interference with enjoyment of life, general activity, and sleep), and was assessed quarterly over 12 months. For the purposes of this illustration, we focus on the embedded cross-sectional CRT comparing intervention to standard-of-care at 12 months.
At the 12-month visit, 816 patients in 106 clusters of primary care providers completed assessments. In the intervention arm, CBT clusters had a reduced mean PEGS score (5.52) compared with the standard-of-care arm (6.15), indicating a modest but sustained reduction in pain compared with usual care. A remaining question is whether summary measures are a sufficient representation of the effectiveness of CBT in the treatment of chronic pain. We use the proposed permutation test with 2000 Monte Carlo samples to assess the null hypothesis of no treatment effect heterogeneity and compare with the existing LR test based on a linear mixed model with prespecified effect modifiers. For the purposes of illustration, we consider all available baseline variables as potential effect modifiers and investigate whether there is treatment effect variation along any of these baseline covariates (or equivalently the existence of effect modification); see Table 5 for an entire list of baseline covariates.
Empirical power and type I error (T1E) for the three proposed tests (PT-T, PT-PI, PT-CI) compared with the existing L-LRT and NS4-LRT for testing the null hypothesis of no treatment effect heterogeneity at a 0.05 significance level for 1000 simulated CRTs with varying
,
,
, and forms of effect modification.
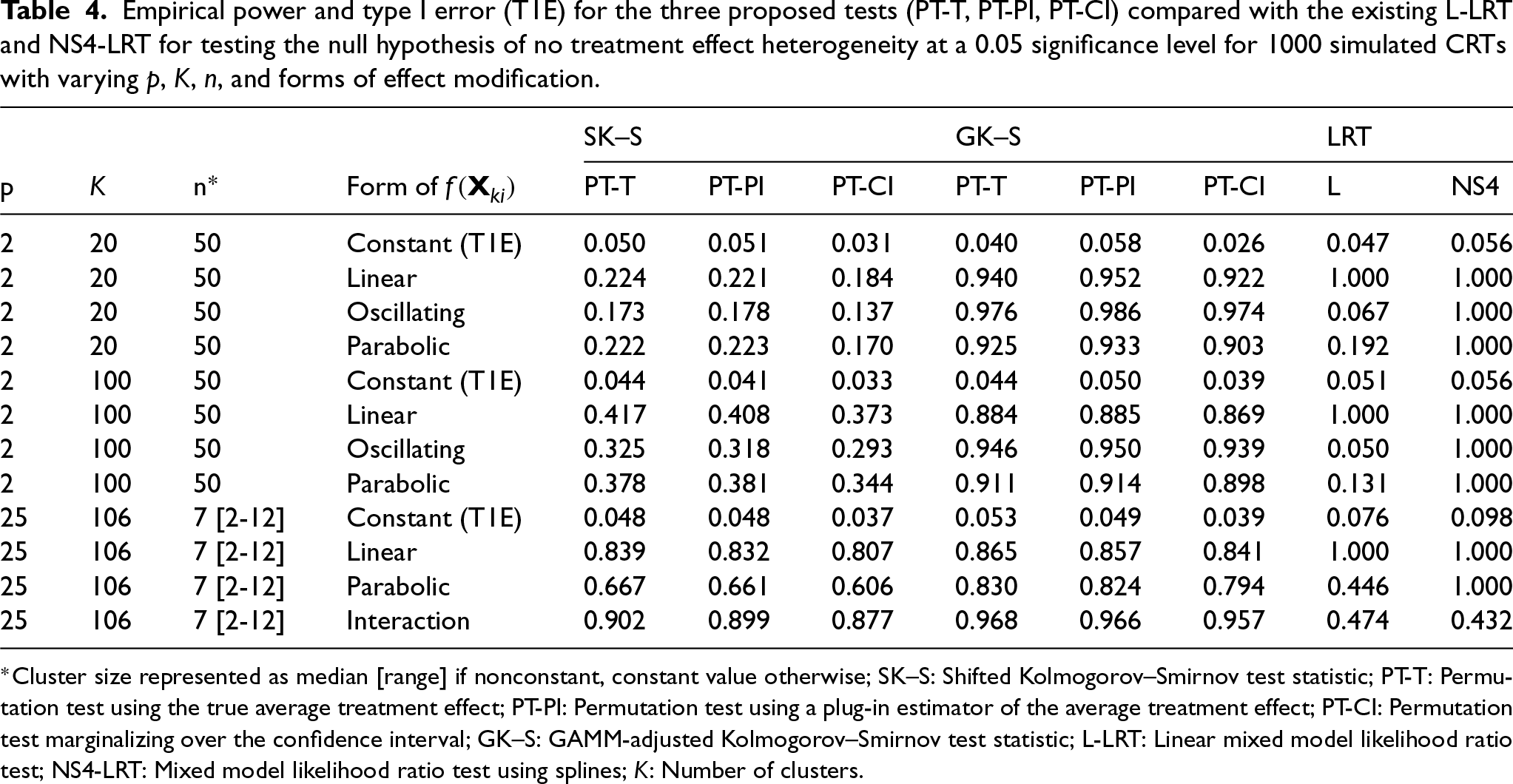
Empirical power and type I error (T1E) for the three proposed tests (PT-T, PT-PI, PT-CI) compared with the existing L-LRT and NS4-LRT for testing the null hypothesis of no treatment effect heterogeneity at a 0.05 significance level for 1000 simulated CRTs with varying
p-Values assessing the presence of an interaction between given effect modifier and treatment for various linear mixed models.
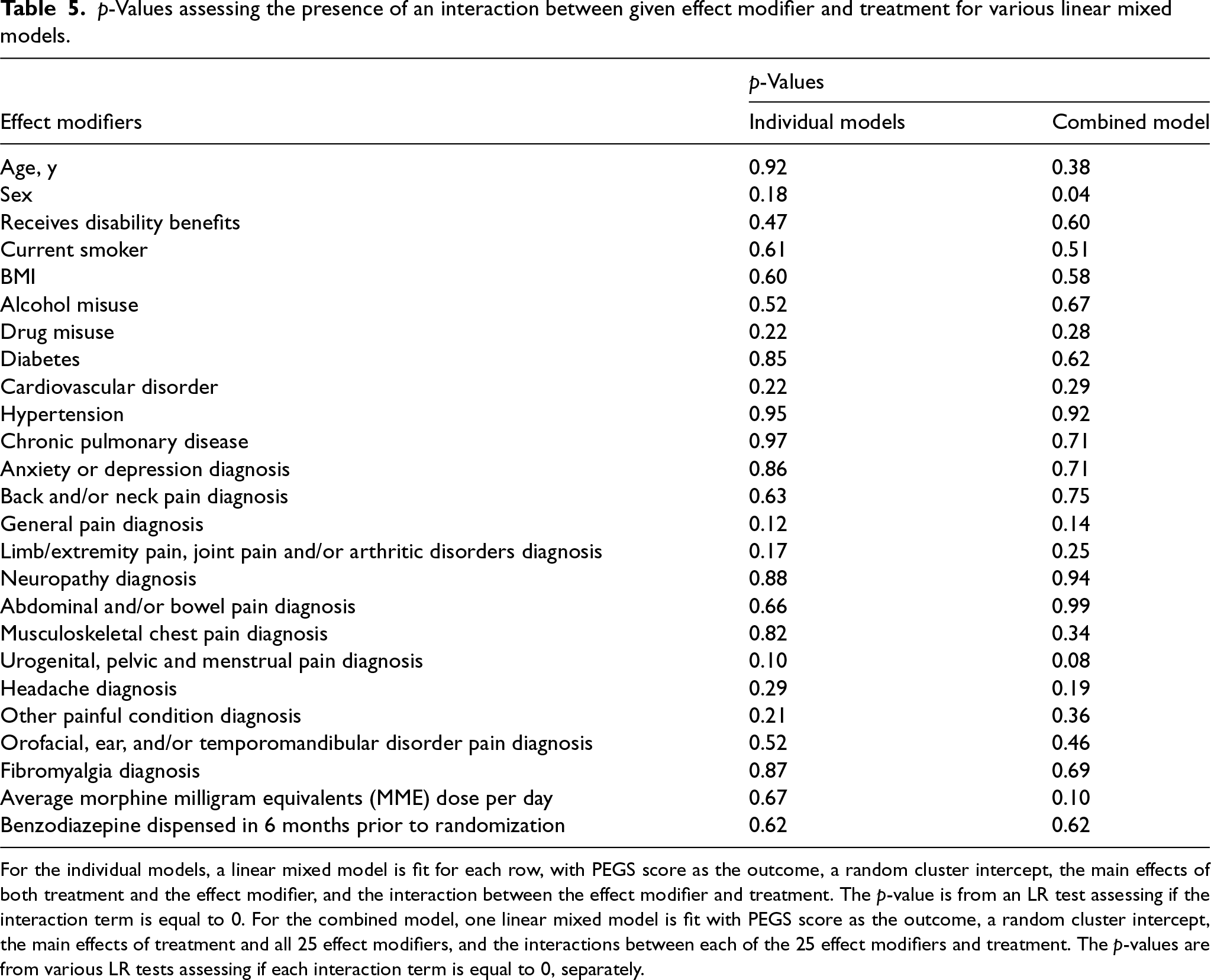
For the individual models, a linear mixed model is fit for each row, with PEGS score as the outcome, a random cluster intercept, the main effects of both treatment and the effect modifier, and the interaction between the effect modifier and treatment. The p-value is from an LR test assessing if the interaction term is equal to 0. For the combined model, one linear mixed model is fit with PEGS score as the outcome, a random cluster intercept, the main effects of treatment and all 25 effect modifiers, and the interactions between each of the 25 effect modifiers and treatment. The p-values are from various LR tests assessing if each interaction term is equal to 0, separately.
As an exploratory analysis, we first fit separate linear mixed models to model the interaction effect between CBT and each of the 25 effect modifiers. Here, the p-values range from 0.10 to 0.97. We then fit one linear mixed model with all possible interactions and individually tested for each interaction within the combined model. Here, the p-values range from 0.04 to 0.99 (sex is the only effect modifier with
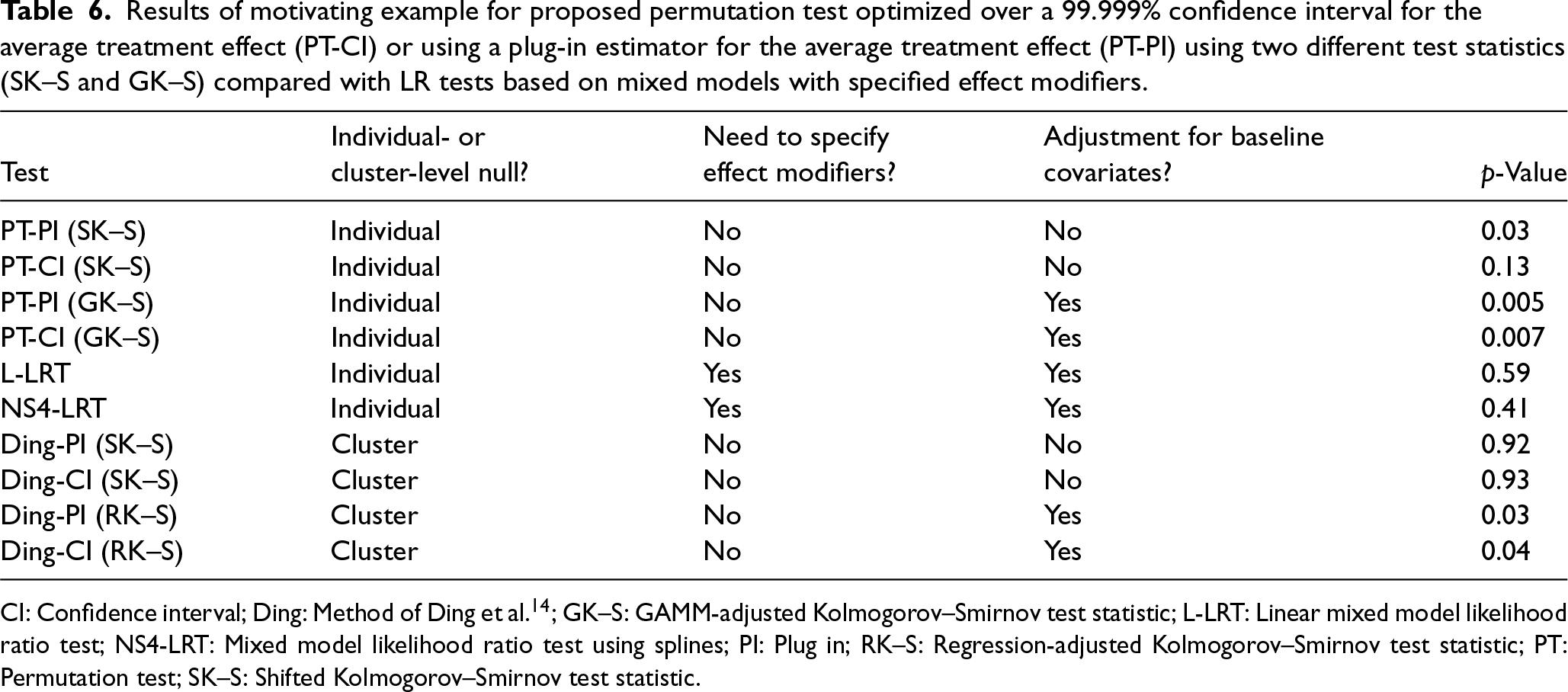
To formally test for treatment effect heterogeneity, we proceed with the proposed permutation tests. We consider the SK–S test statistic, which does not adjust for any covariates, and the GK–S test statistic, which adjusts for a the covariates in Table 5. The p-values for the permutation tests using the confidence interval method are 0.13 and 0.007 for the SK–S and GK–S statistics, respectively. The p-values for the permutation tests using the plug-in method are 0.03 and 0.005 for the SK–S and GK–S statistics, respectively. In sharp contrast, the p-values for the LR tests, which assesses treatment effect variation by any of the effect modifiers using an omnibus test are 0.59 (linear) and 0.41 (spline). Table 6 summarizes the results from each test. As expected, testing using the covariate-adjusted GK–S test statistic yields a smaller (and statistically significant at a 0.05 level) p-value compared to that of the SK–S test statistic, which emphasizes the importance of leveraging baseline covariates to improve precision when detecting treatment effect variation across individuals.
Results of motivating example for proposed permutation test optimized over a 99.999% confidence interval for the average treatment effect (PT-CI) or using a plug-in estimator for the average treatment effect (PT-PI) using two different test statistics (SK–S and GK–S) compared with LR tests based on mixed models with specified effect modifiers.
CI: Confidence interval; Ding: Method of Ding et al. 14 ; GK–S: GAMM-adjusted Kolmogorov–Smirnov test statistic; L-LRT: Linear mixed model likelihood ratio test; NS4-LRT: Mixed model likelihood ratio test using splines; PI: Plug in; RK–S: Regression-adjusted Kolmogorov–Smirnov test statistic; PT: Permutation test; SK–S: Shifted Kolmogorov–Smirnov test statistic.
We additionally assess cluster-level treatment effect heterogeneity using the methods of Ding et al. 14 For this permutation test, we consider the SK–S test statistic, which does not adjust for any covariates, and a linear regression-adjusted K–S test statistic (RK–S), which adjusts for all 25 available variables using a simple multiple linear regression. Instead of testing the individual-level null hypothesis, we test the cluster-level null hypothesis and use the cluster-level average treatment effect. We define the outcome as the mean PEGS score within each cluster and estimate the average treatment effect by computing the difference in mean cluster-level PEGS scores between the treatment and control groups. For the regression-adjusted test statistic, we use the residuals from a linear regression where the cluster mean is the outcome and the predictors are the cluster-level mean of each covariate. The p-values for the permutation tests using the confidence interval method are 0.93 and 0.04 for the SK–S and RK–S statistics, respectively. The p-values for the permutation tests using the plug-in method are 0.92 and 0.03 for the SK–S and RK–S statistics, respectively.
In this setting, the LR tests did not detect any treatment effect heterogeneity based on 25 effect modifiers at the 0.05 level, whereas both cluster-level (only significant after adjustment for covariates) and individual-level permutation tests did detect the existence of treatment effect heterogeneity at the 0.05 level. Although permutation tests do not pinpoint the precise source of treatment effect heterogeneity, they highlight the need for further data-driven exploration of subgroups with enhanced treatment effects. To explore which covariates contribute most to treatment effect heterogeneity, we adopt a leave-one-out variant of the treatment effect variable importance measure (TE-VIM) as introduced by Hines et al. 30 In this approach, we begin by fitting a flexible spline model (as in NS4-LRT) that includes interaction terms between treatment and all baseline covariates. We then iteratively refit the model, each time removing a single treatment–covariate interaction. After each refit, we re-estimate the variation in the conditional average treatment effect (CATE). Comparing the CATE variation from the full model to that from the reduced models allows us to assess how much each interaction contributes to overall treatment effect heterogeneity. This leave-one-out TE-VIM procedure helps identify key effect modifiers and enhances interpretability of heterogeneity in personalized treatment effects. Figure 1 displays the percent change in the estimated treatment effect when each interaction term is removed. Larger deviations indicate variables that contribute more to treatment effect heterogeneity. The results suggest that BMI, age, general pain diagnosis, and morphine dose per day and sex have the largest influence on the estimated treatment effect, while the impact from other variables appears relatively smaller. More broadly, flexible semi-parametric and non-parametric methods have been developed to identify subgroups and tailor treatment recommendations in individually randomized trials.13,31,32 The extension of these methods to CRTs is an active area of research and will be considered in future work.
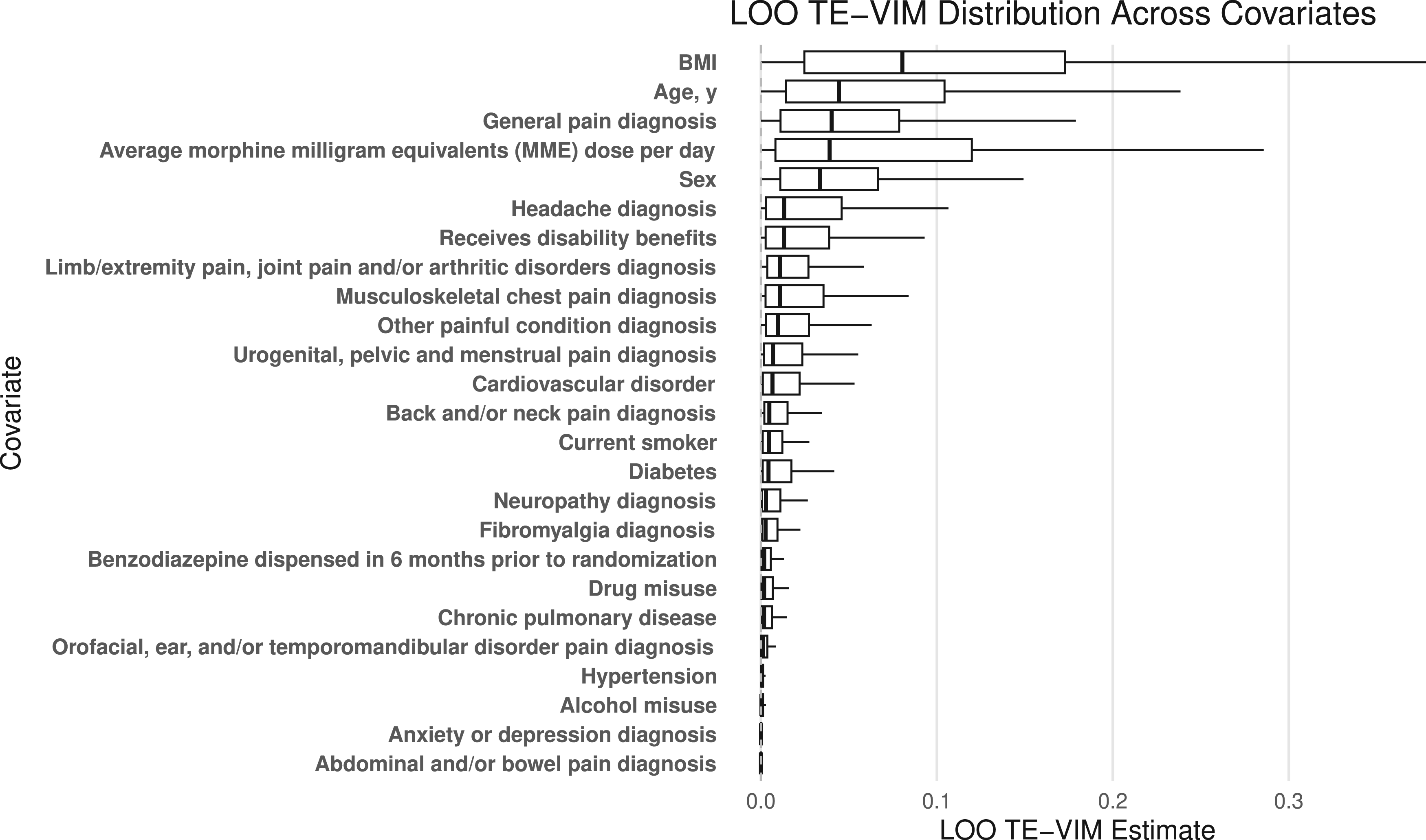
The percent change in the variation in treatment effect estimates when each interaction term is removed (leave one out treatment effect variable importance measure; LOO TE-VIM). Larger deviations indicate variables that contribute more to treatment effect heterogeneity.
As interest grows in assessing differential treatment effectiveness in subgroups, we propose new permutation testing methods for detecting treatment effect heterogeneity in CRTs. Standard methods for testing for treatment effect heterogeneity in CRTs typically involve specifying effect modifiers and using linear mixed models or marginal models to perform a model-based test for the appropriate parametric interaction terms. However, these tests require a priori specification of effect modifiers, rely on parametric assumptions which may not be met in practice, and may have low power to detect non-linear effects. Our new methods improve upon this existing testing paradigm by circumventing the need for effect modifier specification and the need for specifying the functional forms of the interactions. In simulation studies, the proposed permutation test maintains desired type I error rates for various error distributions and baseline covariate effects. Compared with the model-based LR test, the GAMM-adjusted permutation test has higher empirical power when the functional form of effect modification is non-linear. Finally, we illustrate these methods using real data from the PPACT study.
In practice, when effect modifiers have an unknown form, we recommend using the proposed permutation test to detect treatment effect heterogeneity. The methods of Ding et al. 14 are appropriate for a cluster-level null hypothesis and our new developments are appropriate for an individual-level null hypothesis. These permutation methods require marginalization over a range of the average treatment effect estimates. Marginalizing over a wide confidence interval for the average treatment effect will ensure test validity, while there are no theoretical guarantees for the plug-in method. 11 Consistent with the theory, Ding et al. 14 found the plug-in method to have an inflated type I error rate in simulation studies. In our simulations for individual-level heterogeneity, however, the plug-in method maintains empirical validity and the confidence interval method is overly conservative. Furthermore, we recommend employing a GAMM to leverage baseline variables, which can improve statistical power for detecting heterogeneous treatment effects. 33
The proposed method provides an omnibus test for the null hypothesis that treatment effect is constant across individual participants in a CRT and serves as a first step in searching for subgroup effects. If the overall test is statistically significant at a pre-specified level, a natural next step would be to identify subgroups with enhanced treatment effects to inform personalized interventions; to this end, model-robust methods for detecting enhanced treatment effects have been proposed in individually randomized trials,30,31,34 and may be worthwhile to generalize to accommodate the clustered data structure in CRTs. In particular, flexible exploratory procedures that assess the marginal contribution of each covariate to heterogeneity—such as those used in our application which correspond to leave-one-out treatment effect variable importance measures—can help identify the most influential modifiers and guide future hypothesis generation. 30 We view such analyses as valuable complements to the proposed global testing framework, and formalization of these strategies for CRTs will be pursued in future work.
Although we have developed the permutation tests in the context of two-arm CRTs, it can be adapted to multi-arm CRTs. With three or more arms, the null must be carefully specified. 35 Potential options include simultaneously testing if there is treatment effect heterogeneity between any arms, and pairwise hypotheses assessing heterogeneous effects of each treatment with respect to usual care. In both settings, multiple average treatment effect values may need to be estimated. This would necessitate the estimation of more nuisance parameters and may require more intensive computations to execute the permutation procedure. For testing treatment effect heterogeneity between each intervention arm and usual care separately, one possible solution is to consider mini sub-trials nested within the CRT and apply our methods directly. For testing treatment effect variation across all arms simultaneously, we can consider the trial in its entirety and construct a permutation distribution consistent with the given allocation scheme, with appropriate specifications of the test statistics. In this latter case, rejecting the null does not provide information about the source of the treatment effect heterogeneity and additional analyses to identify arms that contribute to treatment effect variation would be necessary.
It is possible to further expand the permutation testing methods to stepped wedge CRTs, where clusters are randomized into distinct treatment sequences and clusters are repeated assessed over time. 7 However, due to the staggered roll-out of treatment, the definition of treatment effect variation is naturally more complicated because the average treatment effects can vary both across exposure time and subpopulation defined by baseline covariates. 36 Maleyeff et al. 37 proposed permutation tests specifically for addressing exposure-time specific treatment effect heterogeneity in stepped wedge CRTs. However, investigators may be interested in testing for additional subgroup differences. As in multi-arm CRTs, careful consideration must be made when adapting our methods to stepped wedge CRTs. A full development of this testing framework will be pursued in a separate work.
Footnotes
Acknowledgments
Lara Maleyeff is supported by a trainee award from the Canadian Network for Statistical Training in Trials (CANSTAT) funded by Canadian Institutes of Health Research (CIHR) grant #262556. Research in this article was in part supported by the National Institute of Allergy and Infectious Diseases of the National Institutes of Health (NIH) T32 AI007358 and R01 AI136947, and a Patient-Centered Outcomes Research Institute Award® (PCORI® Award ME-2020C3-21072). The statements presented in this article are solely the responsibility of the authors and do not necessarily represent the views of the NIH, PCORI® or its Board of Governors or Methodology Committee.
Data availability
The R code to execute the proposed permutation test and to reproduce the results of this paper can be found at https://github.com/laramaleyeff1/permutation_teh_crt. The data that were used to illustrate the proposed approach in Section 4 are freely available at ![]() .
.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical approval
Not applicable.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Informed consent
Not applicable.