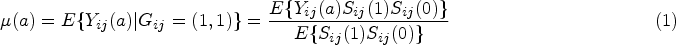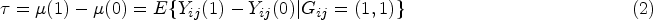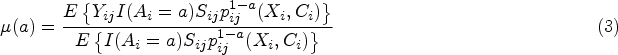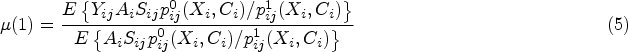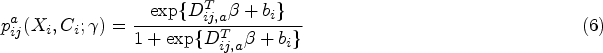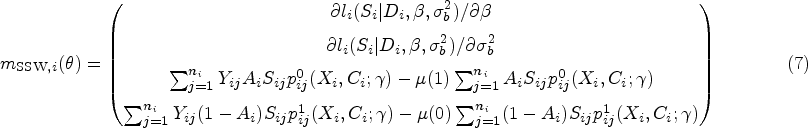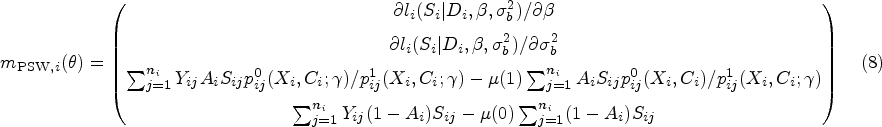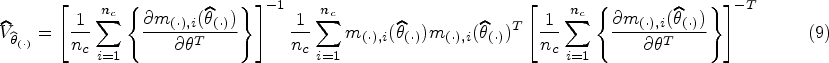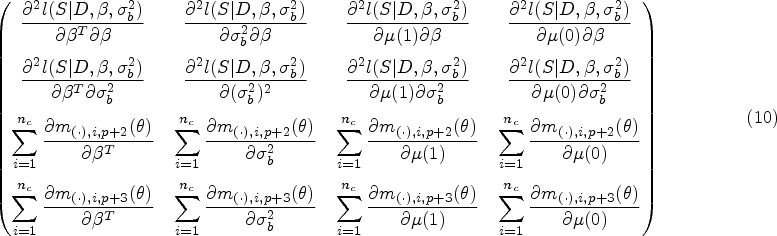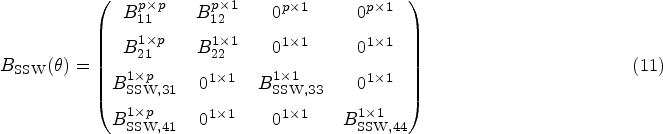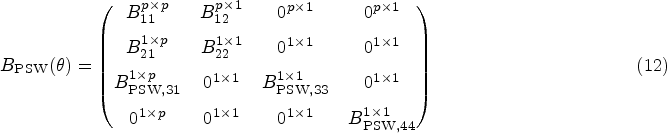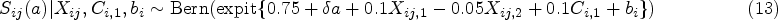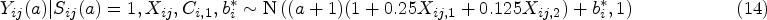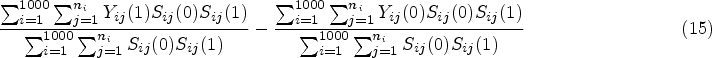Patient-centered outcomes, such as quality of life and length of hospital stay, are the focus in a wide array of clinical studies. However, participants in randomized trials for elderly or critically and severely ill patient populations may have truncated or undefined non-mortality outcomes if they do not survive through the measurement time point. To address truncation by death, the survivor average causal effect has been proposed as a causally interpretable subgroup treatment effect defined under the principal stratification framework. However, the majority of methods for estimating the survivor average causal effect have been developed in the context of individually randomized trials. Only limited discussions have been centered around cluster-randomized trials, where methods typically involve strong distributional assumptions for outcome modeling. In this article, we propose two weighting methods to estimate the survivor average causal effect in cluster-randomized trials that obviate the need for potentially complicated outcome distribution modeling. We establish the requisite assumptions that address latent clustering effects to enable point identification of the survivor average causal effect, and we provide computationally efficient asymptotic variance estimators for each weighting estimator. In simulations, we evaluate our weighting estimators, demonstrating their finite-sample operating characteristics and robustness to certain departures from the identification assumptions. We illustrate our methods using data from a cluster-randomized trial to assess the impact of a sedation protocol on mechanical ventilation among children with acute respiratory failure.
In cluster-randomized trials (CRTs), groups of individuals, such as schools, communities, or health facilities, are randomly assigned to treatments.1 CRTs are a favorable alternative to individually randomized trials when the intervention must be administered to entire groups, there are concerns about contamination (i.e. individuals can gain access to treatment(s) to which they were not assigned), and/or individual random assignment is logistically challenging.2 In CRTs, researchers may be interested in studying the causal effect of a binary treatment on a non-mortal outcome like quality of life. However, in some applications, individual participants may die before the time when their non-mortal outcome would be measured, and death acts as an intercurrent event. Mortality rates can be substantial in CRTs among vulnerable populations such as the critically ill or elderly patients.
Death prior to follow-up is a post-randomization event that precludes the complete measurement of a non-mortal outcome. However, estimation of treatment effects among observed survivors can introduce selection bias when survival status is impacted by treatment because such conditioning disrupts the balance of confounders, measured and unmeasured, afforded by randomization. Bias due to conditioning on post-randomization variables such as death is a well-documented issue in the causal inference literature.3,4 To address this problem from a causal perspective, Frangakis and Rubin5 proposed the principal stratification framework which partitions populations with respect to cross-classified potential outcomes of a binary post-randomization variable. These latent strata are thus unaffected by treatment assignment and can be considered as pre-treatment covariates that define relevant subpopulations. In the context of truncation by death, a common causal estimand of interest is the mean difference in potential outcomes among individuals who would survive under either treatment received (referred to as the always-survivors), named the survivor average causal effect (SACE).6,7 This is precisely the subpopulation where the pair of non-mortality potential outcomes are well-defined without truncation by death.
For the setting of individually randomized trials, several methods have been proposed to point identify and estimate SACE. For example, Zhang et al.8 introduced a mixture model approach for empirical identification of SACE, which relies on correctly specifying the joint distribution of principal strata and non-mortal outcomes conditional on covariates. While likelihood inference leads to efficient estimators under correct model assumptions, accurate specification of the conditional outcome models is usually more challenging than the principal strata model. In addition, empirical identification under the mixture model requires sufficient distance between the mixture components and may be numerically less stable otherwise.9 Alternatively, leveraging information from baseline covariates, Hayden et al.10 and Ding and Lu11 considered different formulations of ignorability assumptions that allow for non-parametric point identification of SACE. These assumptions result in simple weighting methods for these estimands. Employing a similar set of assumptions to Ding and Lu,11 Zehavi and Nevo12 analogously developed matching estimators for SACE. Despite the simplicity of the weighting methods, they were designed for independent and identically distributed (iid) data and may not be directly applicable to the multilevel data structure present in CRTs. In CRTs, individuals within the same group tend to have positively correlated outcomes, even after conditioning on measured individual-level covariates. Failing to properly account for this correlation may result in underestimated variances and anti-conservative inference.13 Moreover, if there are unobserved cluster-level characteristics that simultaneously affect survival statuses and non-mortal outcomes of individuals, the existing SACE estimators based only on individual covariate information for non-parametric identification (as with iid data) would not suffice even under cluster randomization. The role of clustering effects on causal identification of the SACE, particularly from potentially unmeasured sources, has not been sufficiently explored for CRTs.
In this article, we survey the application of weighting estimators for addressing truncation by death in CRTs. We pursue the principal stratification framework and tackle the additional complications associated with the hierarchical data structure imposed by cluster randomization. While there are a number of likelihood-based methods that exist for CRTs with truncation by death,14–16 the more intuitive weighting estimators for SACE have not been fully studied. To dispense with the need to model the outcome distributions, we provide two weighting estimators derived under different sets of identification assumptions inspired by Hayden et al.,10 Ding and Lu,11 and Zehavi and Nevo.12 While the estimators are distinct, they turn out to be functions of the exact same working models to predict survival status, and we provide a conceptual and numerical comparison between these estimators. Furthermore, for each estimator, we consider both conditional and marginal logistic regression paradigms for modeling survival status as they are commonly used in analyses of CRTs.1 To accomplish this, we solve for the SACE estimators and construct their sandwich variance expressions using cluster-indexed estimating equations per the M-estimation method17–19 that are specific to each modeling paradigm.
We have organized the remaining sections as follows. In Section 2, we define notation, provide two sets of identification assumptions, and present the corresponding weighting estimators for SACE in CRTs, along with their variance estimators. In Section 3, we conduct a simulation study to empirically assess the performance of our estimators under different data generating mechanisms which adhere to each set of assumptions. Moreover, we assess the necessity of explicitly modeling for latent group-level effects by comparing the inferential performance of the conditional to the marginal model for survival status in the SACE estimators. Although the proposed marginal model does not incorporate these effects directly, the cluster-indexed M-estimation results in a sandwich variance estimator that aims to correct for this in inference. We also directly compare the computing time and coverage of our proposed asymptotic confidence intervals against bootstrap confidence intervals. In Section 4, we apply our methods to SACE estimation in a CRT that evaluates the impact of a sedation protocol on mechanical ventilation duration among children with acute respiratory failure. In the data application, we consider the analysis of a duration outcome defined within a specific time frame and ascribe to it no parametric assumptions. However, we leave a full time-to-event analysis, which includes addressing censoring in causal assumptions as well as estimation, for future development of the survival framework for SACE in CRTs. Section 5 concludes with a discussion. To facilitate implementation of the proposed methods, we provide a companion R package, PtSaceCrts, for implementing our weighting estimators in CRTs, available at https://github.com/abcdane1/PtSaceCrts.
Methods
Notation, survivor average causal effect estimand, and assumptions
We use the following notation for CRTs. Let denote the number of clusters in a study. The subscript refers to the cluster such that . Let be the size of cluster , and be the binary treatment assigned to cluster . The double subscript “” refers to the individual, , in the cluster. In the observed data, let be individual survival status before the measurement of the non-mortal outcome, and let be the non-mortal outcome. Under the potential outcomes framework, we let and be the potential values of the survival status and non-mortal outcome, respectively, of individual in cluster had cluster been assigned to . Under truncation by death, potential outcomes are connected to observed outcomes under received treatment assignment through the cluster-level SUTVA (the stable unit treatment value assumption), where and if , then . If , then we denote since it is not completely measured following established notation for SACE in the independent data setting.7,8 In addition, we define , and .
Under the principal stratification framework,5 we denote the prinicipal strata in terms of the joint variables, . These strata partition the population into subgroups defined with potential post-randomization events (sometimes referred to as intercurrent events) and since they are no longer functions of , stratum membership can be viewed as a pre-treatment covariate. The strata are always-survivors when , protected patients when , harmed patients when , and never-survivors when . For studying the treatment effect on the non-mortality outcome, we define the estimand within the sub-population of always-survivors. We restrict the estimand to this stratum because it is the only subgroup for which and are both unambiguously defined (or equivalently without impact of the intercurrent event of death). These effects are represented as functions where for ,
Possible functions may be the mean difference or risk ratio. We primarily focus on the SACE expressed in mean difference (although the methods apply directly to other summary measures) defined as
This estimand represents the expected difference in response had an individual received the active treatment as compared to the control given their membership in the sub-population of always-survivors—that is, a subset of healthier patients for whom the definition of non-mortality potential outcomes is not affected by the intercurrent event of death.
Because stratum membership is only partially observed, the estimand cannot be directly identified without additional assumptions. We consider assumptions that require leveraging information from observed baseline covariates. Let the variables denote vectors of individual-level covariates such that is the covariate matrix for all individuals in cluster , and let the variables denote vectors of cluster-level covariates. In addition to the cluster-level SUTVA, we require that for all and that . In other words, every individual within every cluster has some possibility of either survival or mortality under both treatments. The remaining assumptions are as follows:
(Between-cluster independence)
The potential outcomes and cluster-level baseline variables are independent across clusters and drawn from a common distribution for a given cluster size.
(Randomization)
Treatment assignment is independent of all cluster-level variables such that , and .
(Non-informative cluster-size)
Within each cluster , the vector of the individual-level potential outcomes have the same marginal distribution that is independent of the cluster size .
Assumptions 1 and 2 are standard assumptions for CRTs. Assumption 3 prevents the size of each cluster from possibly affecting individuals’ survival status and non-mortal outcomes, a phenomenon referred to as informative cluster size.20 This assumption thus allows us to define as a ratio of marginal expectations of individual-level potential outcomes without ambiguity. We provide a further discussion of informative cluster size in Section 5. In addition to the aforementioned assumptions, we need one of the following two additional sets of assumptions to identify SACE in CRTs. Set 1 extends the explainable non-random survival assumptions of Hayden et al.,10 and Set 2 refers to the Ding and Lu11 and Zehavi and Nevo12 assumptions based on the survival monotonicity and principal ignorability. Both Sets 1 and 2 rely on cross-world assumptions,21 which make claims about survival and/or non-mortal outcome distributions across different interventions. The Set 1 assumptions are defined as follows.
Set 1 Assumption 4 (S1A4):(Conditional Survival Independence).For each individual in a cluster, .
Set 1 Assumption 5 (S1A5):(Strong Partial Principal Ignorability).For each individual in a cluster and for, .
Assumption S1A4 means that an individual’s survival status under one treatment is independent of their survival status under the other treatment given observed information within each cluster. In other words, a patient’s survival under one treatment provides no additional knowledge about their survival under the other treatment once a sufficient set of individual-level covariates (such as age, and other baseline clinical characteristics) and cluster-level covariates (geographical location such as urban or non-urban) is controlled for. Similarly, the conditional independence statement of S1A5 signifies that an individual’s non-mortal outcome under one treatment, contingent on surviving to have this recorded, is not informed by their survival status under the other treatment given a set of measured baseline characteristics within a cluster. To parallel the Set 1 assumptions, the Set 2 assumptions are defined as follows.
Set 2 Assumption 4 (S2A4):(Survival Monotonicity).For each individual in a cluster, such that there is no harmed patients stratum in the study population.
Set 2 Assumption 5 (S2A5):(Partial Principal Ignorability).For each individual in a cluster, .
Assumption S2A4 says that survival under the active treatment is no worse than survival under the control, therefore, leaving only three possible principal strata in the study population. S2A5 is a weaker version of S1A5 in that the relationship described need only hold under the active treatment. In their initial conception, Ding and Lu11 provided the stronger assumption of generalized principal ignorability, whose equivalent here would be for . The purpose in that more general context is to allow for the identification of estimands defined in additional principal strata, for example, in the presence of treatment noncompliance as an intercurrent event. Under monotonicity, however, it is sufficient to consider S2A5 for identification of the SACE, as pointed out previously.12
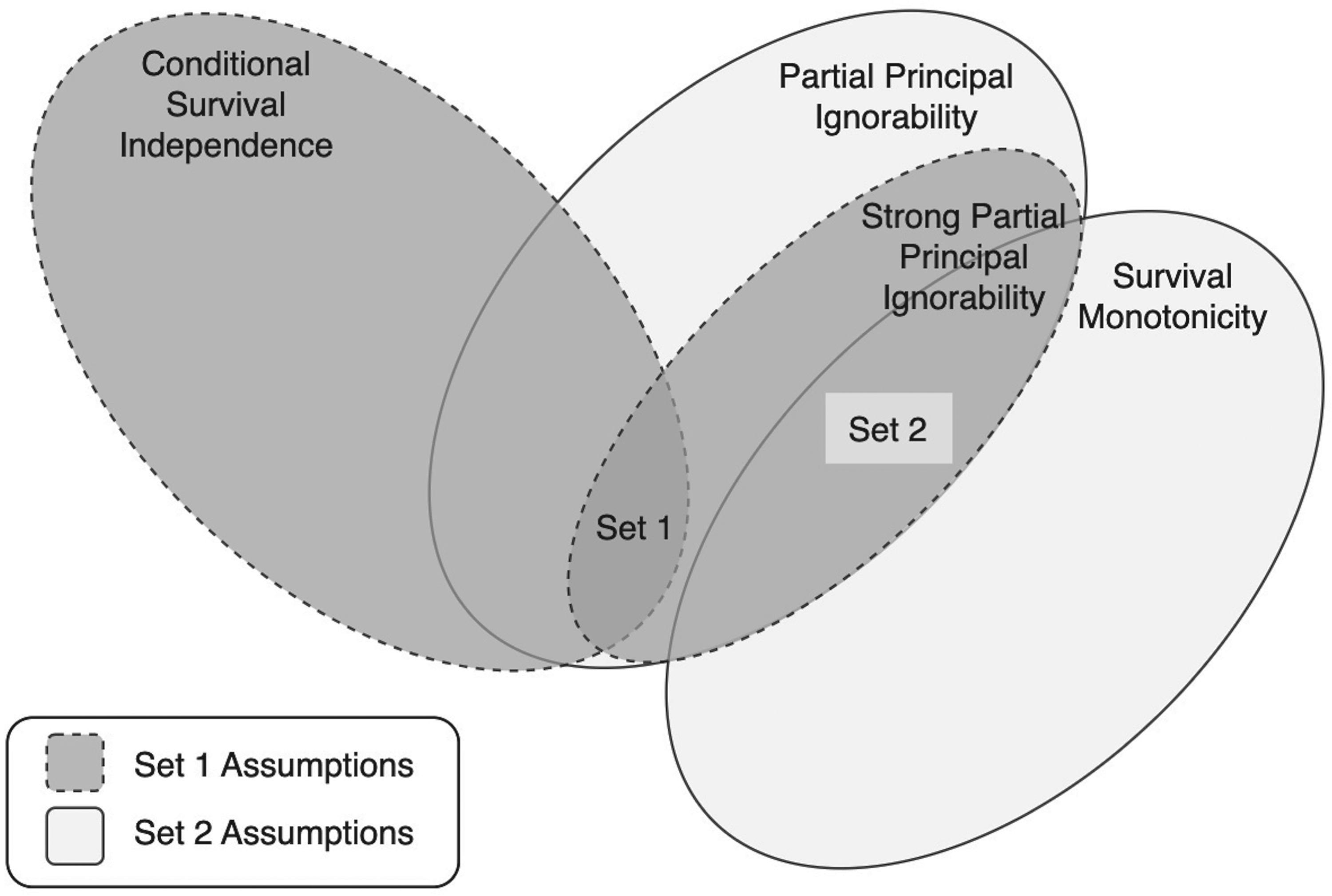
As we explain later, each set of assumptions motivate a distinct weighting estimator to identify SACE in CRTs. Given their seeming similarity to one another, it is important to conceptually distinguish between the Set 1 and Set 2 assumptions. We visualize their relationships in Figure 1, which is meant to demonstrate two salient features. First, S2A4 and S2A5 imply S1A5. For the case of , S2A5 directly implies S1A5, and for the case of , survival monotonicity, S2A4, means the event implies (i.e. a constant), which induces the stated conditional independence.12 Second, the Set 1 and Set 2 assumptions are mutually exclusive due to the relationship between S1A4 and S2A4. If S1A4 and S2A4 are simultaneously true, we would have for each individual and , , which is prohibited by the assumption of non-trivial survival, , under . In summary, these two sets of assumptions live disjointly within the condition S1A5.
Diagram of relationship between Set 1 and Set 2 assumptions for identification of SACE. Each assumption set is satisfied within the intersection of their respective conditions (where they are both preceded by Assumptions 1 to 3, non-trivial survival, and SUTVA). S1A4 conditional survival independence, S1A5 strong partial principal ignorability, S2A4 survival monotonicity, and S2A5 partial principal ignorability. SACE: survivor average causal effect; SUTVA: stable unit treatment value assumption.
The above framework puts forth the necessary causal assumptions for non-parametric identification supposing that we have a sufficient set of observed individual-level and cluster-level characteristics. However, in reality, even after conditioning on a rich set of baseline covariates, individuals’ outcomes within the same cluster tend to be positively correlated. If the source of this correlation is not accounted for in the assumptions, then the conditional independence statements of Set 1 (S1A4 and S1A5) and of Set 2 (S2A5), which hold across all individuals, may not be sufficiently strong to enable identification. To accommodate this complexity, we extend the above assumptions by having (wherever it appears) be comprised of two components, where denotes the component of whose values can be observed and , a parametric random intercept for cluster, which induces the within-cluster correlation. The caveat of this extension is that identification requires specification of the distributions of the latent variables and restricts the form of unmeasured confounding between survival and the final outcome. Similar latent cluster-level confounding assumptions have also been proposed in earlier work on clustered observational studies without truncation by death.22,23 Specifically, as described in the next sections, we make a Gaussian specification for the enabling parametric survival status modeling according to conventional mixed effects logistic regression for binary survival status. Nevertheless, we also evaluate, using simulations, the consequence of ignoring the cluster-level random intercept for survival status modeling to generate practical recommendations.
Two identification formulas
We next present Identity 1 and Identity 2, which represent how SACE is point identified with estimable parameters with intuitive weighting under the Set 1 and Set 2 assumptions respectively. Importantly, for the two SACE quantities, any appearance of the non-mortal outcome will be predicated on survival (due to a product term). Interestingly, while different in form, they will both depend on the exact same models for survival status.
Identity 1. The parameters for under Set 1 assumptions are identified with:
where . The weight means that the observed survivors within one treatment group are up-weighted by their probability of survival under the alternative treatment, which in turn signifies that individuals whose probability of being an always-survivor is higher are weighted more heavily. In the context of a CRT, the proof of Identity 1 is provided in Supplemental Material 1.1.
Identity 2. The parameters under Set 2 assumptions are identified with:
and
By cluster-level SUTVA, S2A4, and , we have . Therefore, the weights of are straightforward because those who are observed to have survived treatment 0 are always-survivors. The Set 2 assumptions also imply that . Since , the terms in of re-weight the observed survivors in the treated group, which are comprised of both always-survivors and protected patients, to reflect the population of always-survivors. In the context of a CRT, the proof of Identity 2 is presented in Supplemental Material 1.2.
It is critical to emphasize that the quantities, , are expectations conditioned on so, at the outset, it may seem as though the identified estimands would necessarily rely on models for with , referred to as “principal score models.”11 However, both the Set 1 and Set 2 assumptions, which contain cross-world conditions, allow for identification of by separating the survival statuses and the non-mortal outcomes across treatments. As a result, we see that identification leads to products of survival status terms (as in equations (3) and (5) above)—one term that is observed and one that needs to be predicted given covariates and random effects under a given treatment. In contrast, the full likelihood based approaches, while avoiding these assumptions, require having to target the principal score models. From a practical point of view, modeling binary survival statuses is generally more straightforward than simultaneously modeling at least three principal strata.
Model specifications and weighting estimators
For our working survival modeling, we first consider that the data, , arise from each cluster independently. Given our beliefs about the mechanism of clustering effects, we will suppose that within each cluster , an individual’s survival status is drawn according to where with , and is a finite vector of observed regressors involving . In practice, we often make a convenience choice that such that the survival of each individual only depends on the characteristics of that individual but not those from other individuals in the same cluster (apart from shared cluster-level information). Therefore, for , each individual’s probability of survival is represented as follows:
where represents setting . The effect of treatment and observable baseline covariates on survival is captured in , and the unobserved effects of clustering on survival are represented via the random intercept with variance , so that is of finite dimension. Although we do not consider this possibility, can also include treatment-by-covariate interactions as well as summary measures of individual-level covariates through (e.g. ) as in a contextual-effects model.24
Two common parametric approaches for analyzing survival status data from parallel-arm CRTs—that we will use for survival status modeling for our SACE estimators—are to (i) fit a GLMM, specifically a mixed effects logistic regression model with a random intercept for cluster membership and (ii) fit a GLM, specifically a logistic regression model (accounting for clustering only in the robust sandwich variance expression) where both models must include a treatment effect indicator.13 Since the GLMM relies on modeling the distribution of survival status conditional on the random effects (as well as any observed covariates), it is referred to as a conditional model. In contrast, the GLM, for which no random effects are modeled, is referred to as a marginal model under working independence.
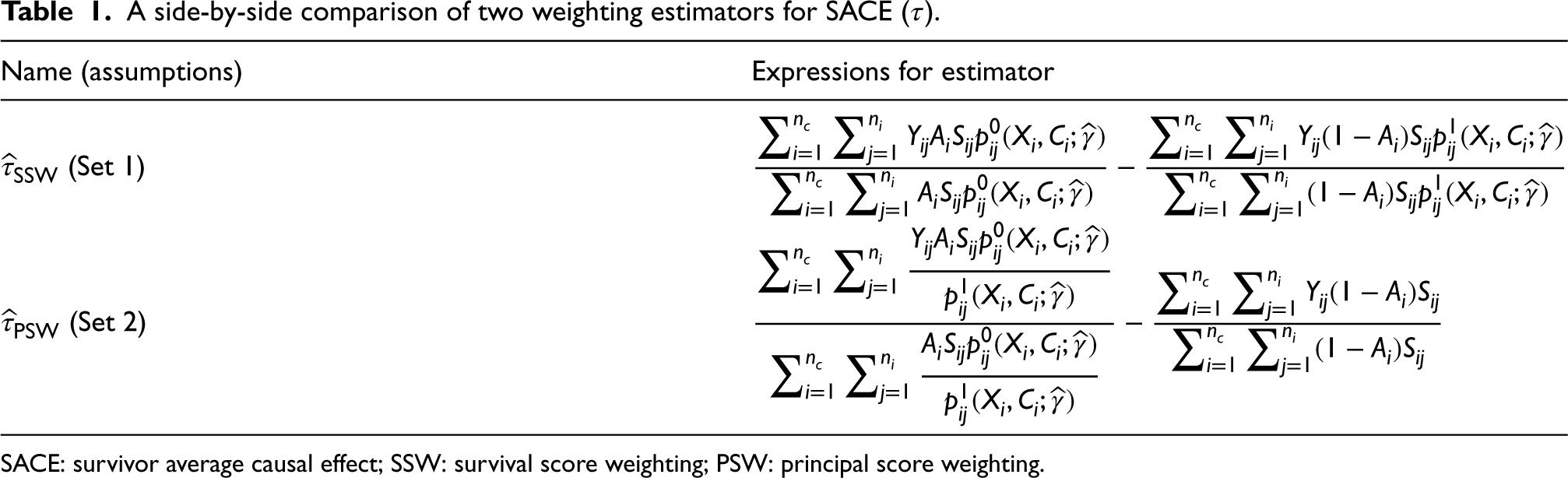
We will denote the estimators derived from Set 1 and Set 2, respectively, as the survival score weighting (SSW) estimator, , and the principal score weighting (PSW) estimator, . Their forms are summarized in Table 1. Although neither estimator fits principal scores directly, Set 2 uses that under monotonicity, the always-survivors principal stratum is comprised of exactly those that survive under treatment 0, whereas Set 1 relies on S1A4 breaking up the principal strata distributions (hence the naming convention). As discussed in Supplemental Material 1.3 and 1.4, and are consistent for SACE if and are a solution to unbiased estimating equations indexed by cluster, and if under the regularity conditions for which these , we have correct specification of the working survival modeling such that reflects the truth.19 With latent cluster-level confounding, to achieve consistency, we would in principle fit the GLMM model (i) as it directly controls for as a random intercept.
A side-by-side comparison of two weighting estimators for SACE ().
Name (assumptions)
Expressions for estimator
(Set 1)
(Set 2)
SACE: survivor average causal effect; SSW: survival score weighting; PSW: principal score weighting.
According to the proposed identification assumptions, the marginal GLM model (ii), which assumes independence given observed covariates, is inherently mis-specified for predicting survival status. Only under the setting for which we are able to assume that there are absolutely no unobserved sources of within-cluster correlation of potential outcomes might this model be appropriate. Nonetheless, because cluster-indexed unbiased estimating equations are used to derive the GLM model parameters and SACE estimators, the asymptotic distribution of the SACE estimators have a sandwich variance, as demonstrated in Section 2.4 and in Supplemental Material 1.6, that can account for extra variation in the observed outcomes induced by clustering effects. Since the parameters of the survival status models themselves do not need to be interpreted, we juxtapose the small-sample performances of these two common modeling paradigms in the simulation study (Section 3) under data generation that explicitly includes a cluster-level random intercept as per the working model assumptions. Therefore, the marginal modeling strategy is considered in our simulations to elucidate the consequence of ignoring the latent cluster-level confounding under realistic levels of clustering observed in CRTs where intracluster correlation coefficients (ICCs) typically do not exceed 0.3.25
Variance estimation
In this section, we approximate the variance of the weighting estimators, and , by establishing their asymptotic distributions through the theory of M-estimation.17–19 Our motivation for using asymptotic variance expressions stems from the limitations of the cluster bootstrap despite its conceptual simplicity. Specifically, cluster bootstrapping generally requires re-sampling entire clusters with replacement from the original data set to preserve the unknown within-cluster correlation structure, so it tends to work better for a large number of clusters.26 However, for even a moderate number of clusters, the computational time for the bootstrap approach with an acceptable number of replicates can be prohibitive since it requires fitting regression models repeatedly (such as generalized linear mixed model (GLMM)) to each bootstrapped data set. To this end, our proposed variance estimators serve as computationally efficient alternatives to re-sampling-based methods.
Recall we suppose that the available data are mutually independent by cluster randomization (where the observable elements of are for observed survivors). Suppose that each and thus have dimension . Our focus is on the space of parameters of the form of dimension since our target estimand is simply the linear combination , where . For each , we define a function of observable data, , which matches the dimension of , such that (for any ). Then, for the included number of clusters in the study , the solution to is the M-estimator, . However, since the identification of and are distinct for the Set 1 and Set 2 assumptions, the corresponding unbiased estimating equations must themselves be distinct with functions, and , and solutions, and .
To obtain the unbiased estimating equations, we stack the score functions used to maximize the (marginalized) log-likelihood induced by the GLMM conditions, (see Supplemental Material 1.4), which will be common to both the SSW and PSW estimators, and the functions that enable solving for and if the GLMM parameters, , were known. The form of estimating functions corresponding to the Set 1 assumptions is
and for the Set 2 assumptions
Using first-order Taylor approximations coupled with certain regularity conditions for these independent data, applications of Slutsky’s and continuous mapping theorems give us that and converge in distribution to .19 Under correct specification, and are the true parameters, and is the true asymptotic variance as written out in Supplemental Material 1.3 (equation (20)). Note, we only subscript estimators with SSW and PSW and not parameters because parameters cannot be simultaneously identified under Set 1 and Set 2. The form of the estimator of the asymptotic variance, often termed a cluster-robust sandwich variance estimator, is
The regularity conditions under which is consistent for are posited by Iverson and Randles.27 The full expressions for the estimating functions (including the derivative of the log-likelihood) and a more thorough sketch of the asymptotic arguments are in Supplemental Material 1.3 and 1.4.
Now, we must determine the components of the sandwich variance for each estimator. We denote the middle matrices with and . The estimating functions that are required to find the middle matrices are already written above. We must also find the outer matrices, which we will denote by and . The general form of the outer matrices, , is
where the third index of represents the -th component of the -th vector function. Due to the nature of the stacked estimating equations, for which the score equations are solved independently, we have matrix structures and that are relatively sparse. However, they have different forms since under the Set 2 assumptions is not identified with a parameter that involves a model for survival events. For the SSW estimator, we have outer matrix:
for the PSW estimator,
where the superscripts denote the dimension of the submatrices ( on the RHS is suppressed for notation simplicity). Using the estimator of the asymptotic variance as in equation (9), we can approximate the variances for the SACE estimators, and , with and , respectively. These expressions assume that and are non-singular, which will generally be the case for a sufficiently large sample of clusters. Each non-zero entry of and is fully written out in Supplemental Material 1.4. Estimates of the GLMM parameters can be obtained from standard statistical software. However, both the outer and middle matrices involve integrals, as a byproduct of marginalizing over the random intercept in the likelihood, that are not solvable analytically. Computing these integrals numerically is not a trivial exercise as shown in prior work.28 Since the entries in the matrices are complex (particularly in the outer matrix), just keeping track of the integral expressions and ensuring that they are numerically integrable is a cumbersome task. After accounting for these integrals, we employ a numerical integration technique that is well-suited to integrals representing Gaussian expectations. In the Supplemental Material 1.5, we present all integrals involved in variance estimation as well as outline our choice and usage of adaptive Gauss-Hermite quadrature (AGQ)29 for the required numerical integration. Despite the necessity of said numerical methods, for the cases in our simulation study where the non-parametric cluster bootstrap is viable, the variance estimates using the asymptotic distributions are not meaningfully different than those using the bootstrap but the computation times are reduced substantially (for reference, see Table S4 of Supplemental Material 2).
The process for determining asymptotic distributions under the GLMM for survival status requires a similar formulation to the above, but the random intercept terms and row for are removed from the estimating functions as outlined in Supplemental Material 1.6; accordingly, no numerical integration is required for estimation. Therefore, for clarity of notation, we will henceforth distinguish the SACE estimated using the GLM from the GLMM by using parameter estimators denoted with a tilde, which so far include , , , , , , and for . We note that Table 1 omits this notational distinction for continuity and succinctness. Since the parameter estimates for SACE are conceived as solutions to estimating equations that sum with respect to the cluster index, we obtain a sandwich variance expression that accounts for clustering when using the GLM. More specifically, the analogous sub-matrix of corresponding to the estimated variance matrix for the model coefficients is precisely the sandwich variance estimate that we would achieve by solving a GEE30 with mean and variance models as in logistic regression with a working correlation matrix for independence (Supplemental Material 1.6). In terms of interpretation and estimation, solving GEEs (marginal) are often compared to and viewed as a standard alternative to fitting GLMMs (conditional).13,31 Although in this setting the parameters of the survival status models are not of interest, we emphasize that marginal and conditional logistic regression models are separate conceptual frameworks, whose parameters do not necessarily coincide (due to a lack of collapsibility).32 As it pertains to inference, these two approaches may also perform differently with CRTs for a binary response depending on the study conditions, for example, the number of clusters and the strength of the within-cluster correlation,33 and we compare the effect of these modeling choices for SACE estimation across various scenarios in the simulation study in Section 3.
There are well-documented issues with small-sample inference associated with sandwich variance estimators, either from marginal or conditional modeling, for the analysis of CRTs. These estimators tend to underestimate the true variance in small samples and lead to anticonservative inference.34,35 As such, we suggest employing a bias-corrected version of the proposed sandwich variance estimators (whether or not conditioning on random effects). For our simulation study and data application, we use a simple degrees of freedom correction,36 multiplying the variance terms by , where “params” refers to all survival status model parameters as well as and ; note, for the GLMM, we have one additional parameter for the random effect variance. While this proved sufficient for achieving near nominal coverage in our simulations and thus suitable to our motivating application, alternative corrections to the sandwich variance estimates may warrant future research.
Lastly, it may be that for the fitted GLMM, is estimated to be 0 when using statistical software. This estimate arises due to the fact that convergence to a maximum is restricted by the boundary condition on the parameter space, where the variance of the random intercept must be at least 0; for further treatment of this phenomenon including asymptotics, see Self and Liang.37 Therefore, constrained optimization algorithms will permit estimates of 0 for the variance, which is the default for the prevailing GLMM fitting package lme4 in R.38 When this phenomenon occurs, it produces (virtually) the same coefficient estimates as the GLM, and thus can be constructed as the solution to the corresponding estimating equations (i.e. those which drop the random intercept); nonetheless, we treat it as a separate case from the marginal model approach because we penalize for the extra variance parameter. There are options to explicitly avoid a zero variance estimate such as changing the optimizer or putting a prior on the variance parameter that pulls it away from 0,39 but we adopt the most standard application of the existing R software allowing for a zero variance component estimate.
Simulation study
In our simulation study, we assess the performance of the SACE estimators under different data generating mechanisms. We follow the ADEMP (Aims, Data-generating mechanisms, Methods, Estimands, Performance measures) schema defined by Morris et al.40 to describe our simulation study. There are two primary goals for these simulations. The first goal is to evaluate the two weighting SACE estimators when the data generation adheres to either the Set 1 assumptions or the Set 2 assumptions in terms of their empirical bias and coverage (see Section 3.2 for more details). We recall that these are technically mutually exclusive data generating mechanisms because S1A4, conditional survival independence, and S2A4, the deterministic requirement of survival monotonicity, cannot exist simultaneously. Because of S1A4, it is natural to define a data generating mechanism that adheres to the Set 1 assumptions but operates on the survival terms separately. For the Set 2 assumptions, we follow the approach of Jiang et al.41 by imposing stochastic monotonicity,42 where we make the probability of survival under treatment greater than under treatment conditional on covariates. For our simulation, we increase the magnitude of the treatment effect on survival substantially so as to drive the empirical incidence of harmed patients to near 0. Of note, it is also possible to simulate data which achieves deterministic survival monotonicity and maintains the target marginal survival status models by specifying models for given values of .43 This approach is also equivalent to an ordinal representation of the principal strata model, where stratum membership is assigned by thresholding a latent continuous response variable with cut-points that represent the treatment effect on survival, but such ordering of stratum membership is not intrinsic. The results for this ordinal approach as presented in Table S3 (Supplemental Material 2) are consistent relative to the other data generating mechanisms, so we save this exploration for Supplemental Material 1.7.
The second aim is to evaluate how well our SACE estimators handle latent clustering effects, represented by unobserved cluster-level random intercepts in the data generating process for the mortality and non-mortality outcomes. To this end, we compare the performance of the estimators with GLMM survival status modeling, and , to those with GLM survival status modeling (with cluster-robust variance), and . Variance expressions and confidence -intervals are computed based on the asymptotic distributions discussed in Section 2 and in Supplemental Material 1.
Data generating process
We consider scenarios for which we choose the number of clusters . The number of individuals in each cluster is drawn from a discrete uniform distribution, . We generate two individual-level covariates for each cluster, and and one cluster-level covariate, . We incorporate latent cluster-level effects via the variables and for survival status and the non-mortal outcome respectively, where we suppose and ; given , we see that this setup induces a source of unobservable correlation between individuals’ non-mortal and survival events within each cluster. These variables differ from the observed covariates because we only propose their distributional form and relationship to other variables, but their actual values are unknown to us. For , we generate survival status and non-mortal outcomes according to:
For treatment effect, we consider . The values of and represent Set 1 data generation and represents Set 2 data generation because the treatment effect is large enough to induce near empirical monotonicity.
We quantify the strength of the latent clustering effects for each data generating mechanism via the ICC. For the continuous non-mortal outcomes, the ICC or equivalently the correlation among individuals within the same cluster is given by , which is set equal to . We define the ICC for survival as . This standard representation for ICC for mixed effects logistic regression is motivated via a latent variable model, which creates a dichotomous outcome by thresholding an underlying continuous variable with a standard logistic distribution.44,45 We briefly show how it is derived as a note in Supplemental Material 1.7. This definition of the ICC for GLMMs then allows for an analogous interpretation to the ICC for linear mixed models (LMMs), except that it is defined on the latent or log-odds scale. Since , we choose values of such that .
For finding the true parameters, we generate the data using a large number of clusters, , as if to represent the population of clusters. We define the true SACE estimand within each simulation as
For the results presented in the next section, the percentage of always-survivors under ranges from to , where larger values of and smaller induce higher rates of this subgroup.
For each data generating mechanism, the observed data are obtained after random allocation of clusters to treatment where . For example, if cluster is assigned to treatment 1, the observed data are with cluster size . In the next section, we report the performance of SACE estimates on these observed data under the different data generation assumptions and modeling techniques as described above. The results for the additional values of and as well as the scenarios for deterministic monotonicity are presented in Supplemental Material 2.
Simulation results
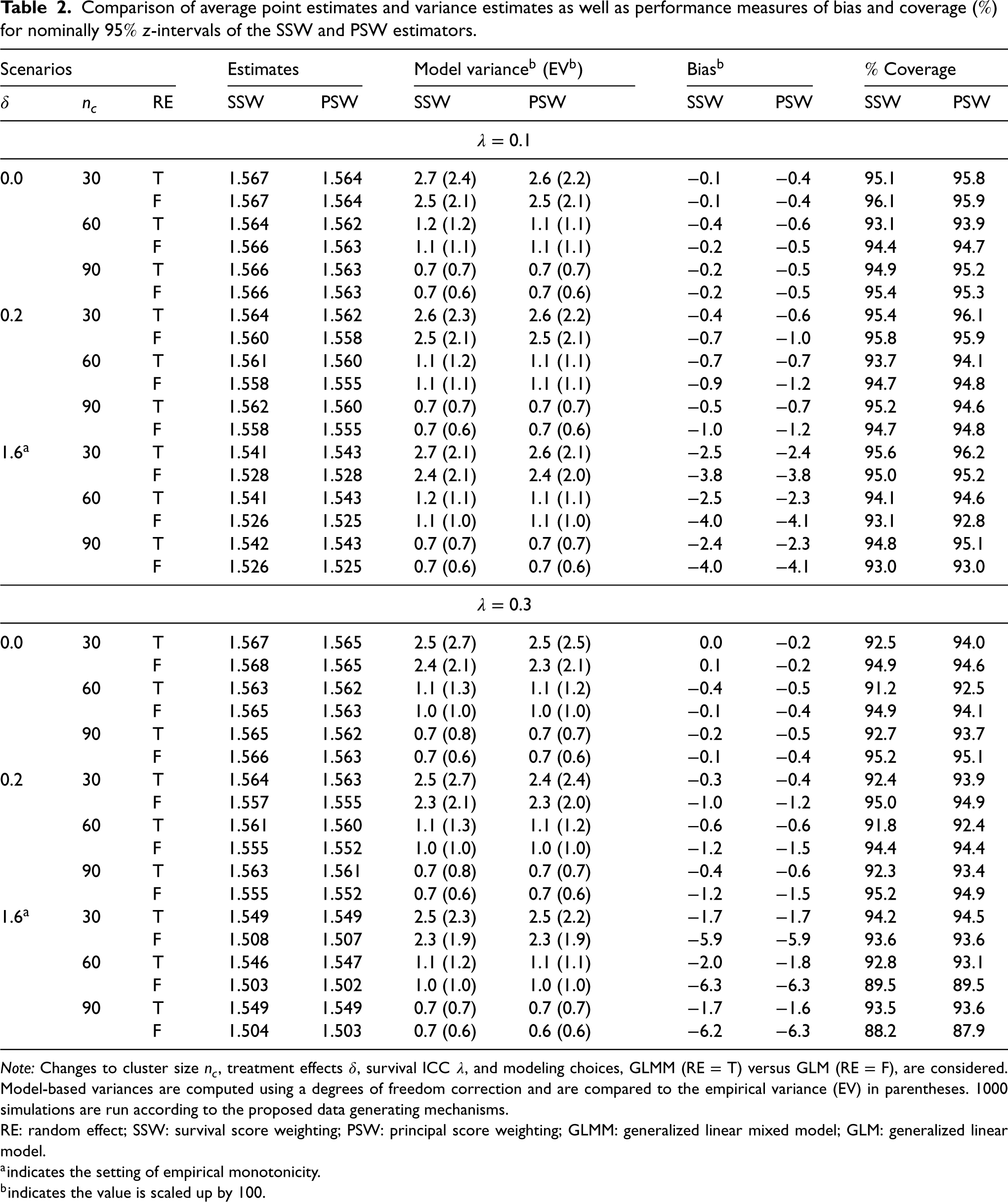
We include four measures to evaluate the performance of the estimators under the various simulation scenarios: empirical bias, empirical variance, average of the estimated variance, and coverage of the confidence interval. The empirical or Monte Carlo variance is included in parentheses as a benchmark for the average of the estimated variance. Results for 1000 simulations are presented in Table 2, where the bias and variance metrics are scaled by 100.
Comparison of average point estimates and variance estimates as well as performance measures of bias and coverage () for nominally -intervals of the SSW and PSW estimators.
Scenarios
Estimates
Model variance (EV)
Bias
Coverage
RE
SSW
PSW
SSW
PSW
SSW
PSW
SSW
PSW
0.0
30
T
1.567
1.564
2.7 (2.4)
2.6 (2.2)
−0.1
−0.4
95.1
95.8
F
1.567
1.564
2.5 (2.1)
2.5 (2.1)
−0.1
−0.4
96.1
95.9
60
T
1.564
1.562
1.2 (1.2)
1.1 (1.1)
−0.4
−0.6
93.1
93.9
F
1.566
1.563
1.1 (1.1)
1.1 (1.1)
−0.2
−0.5
94.4
94.7
90
T
1.566
1.563
0.7 (0.7)
0.7 (0.7)
−0.2
−0.5
94.9
95.2
F
1.566
1.563
0.7 (0.6)
0.7 (0.6)
−0.2
−0.5
95.4
95.3
0.2
30
T
1.564
1.562
2.6 (2.3)
2.6 (2.2)
−0.4
−0.6
95.4
96.1
F
1.560
1.558
2.5 (2.1)
2.5 (2.1)
−0.7
−1.0
95.8
95.9
60
T
1.561
1.560
1.1 (1.2)
1.1 (1.1)
−0.7
−0.7
93.7
94.1
F
1.558
1.555
1.1 (1.1)
1.1 (1.1)
−0.9
−1.2
94.7
94.8
90
T
1.562
1.560
0.7 (0.7)
0.7 (0.7)
−0.5
−0.7
95.2
94.6
F
1.558
1.555
0.7 (0.6)
0.7 (0.6)
−1.0
−1.2
94.7
94.8
1.6
30
T
1.541
1.543
2.7 (2.1)
2.6 (2.1)
−2.5
−2.4
95.6
96.2
F
1.528
1.528
2.4 (2.1)
2.4 (2.0)
−3.8
−3.8
95.0
95.2
60
T
1.541
1.543
1.2 (1.1)
1.1 (1.1)
−2.5
−2.3
94.1
94.6
F
1.526
1.525
1.1 (1.0)
1.1 (1.0)
−4.0
−4.1
93.1
92.8
90
T
1.542
1.543
0.7 (0.7)
0.7 (0.7)
−2.4
−2.3
94.8
95.1
F
1.526
1.525
0.7 (0.6)
0.7 (0.6)
−4.0
−4.1
93.0
93.0
0.0
30
T
1.567
1.565
2.5 (2.7)
2.5 (2.5)
0.0
−0.2
92.5
94.0
F
1.568
1.565
2.4 (2.1)
2.3 (2.1)
0.1
−0.2
94.9
94.6
60
T
1.563
1.562
1.1 (1.3)
1.1 (1.2)
−0.4
−0.5
91.2
92.5
F
1.565
1.563
1.0 (1.0)
1.0 (1.0)
−0.1
−0.4
94.9
94.1
90
T
1.565
1.562
0.7 (0.8)
0.7 (0.7)
−0.2
−0.5
92.7
93.7
F
1.566
1.563
0.7 (0.6)
0.7 (0.6)
−0.1
−0.4
95.2
95.1
0.2
30
T
1.564
1.563
2.5 (2.7)
2.4 (2.4)
−0.3
−0.4
92.4
93.9
F
1.557
1.555
2.3 (2.1)
2.3 (2.0)
−1.0
−1.2
95.0
94.9
60
T
1.561
1.560
1.1 (1.3)
1.1 (1.2)
−0.6
−0.6
91.8
92.4
F
1.555
1.552
1.0 (1.0)
1.0 (1.0)
−1.2
−1.5
94.4
94.4
90
T
1.563
1.561
0.7 (0.8)
0.7 (0.7)
−0.4
−0.6
92.3
93.4
F
1.555
1.552
0.7 (0.6)
0.7 (0.6)
−1.2
−1.5
95.2
94.9
1.6
30
T
1.549
1.549
2.5 (2.3)
2.5 (2.2)
−1.7
−1.7
94.2
94.5
F
1.508
1.507
2.3 (1.9)
2.3 (1.9)
−5.9
−5.9
93.6
93.6
60
T
1.546
1.547
1.1 (1.2)
1.1 (1.1)
−2.0
−1.8
92.8
93.1
F
1.503
1.502
1.0 (1.0)
1.0 (1.0)
−6.3
−6.3
89.5
89.5
90
T
1.549
1.549
0.7 (0.7)
0.7 (0.7)
−1.7
−1.6
93.5
93.6
F
1.504
1.503
0.7 (0.6)
0.6 (0.6)
−6.2
−6.3
88.2
87.9
Note: Changes to cluster size , treatment effects , survival ICC , and modeling choices, GLMM (RE = T) versus GLM (RE = F), are considered. Model-based variances are computed using a degrees of freedom correction and are compared to the empirical variance (EV) in parentheses. 1000 simulations are run according to the proposed data generating mechanisms.
RE: random effect; SSW: survival score weighting; PSW: principal score weighting; GLMM: generalized linear mixed model; GLM: generalized linear model.
indicates the setting of empirical monotonicity.
indicates the value is scaled up by .
Overall, the simulation study reveals that both of the proposed SACE estimators, where the mortality outcome is modeled using mixed effects logistic regression, exhibit low bias across all data generating scenarios. The -intervals constructed using the asymptotic variance expressions with a degrees of freedom adjustment in general get close to nominal rates. In summary, regardless of the assumptions underlying the data generating mechanism, and tend to perform similarly and well, where there may be a slight advantage to the latter estimator. This empirically shows that and are relatively robust to certain departures from their requisite identification assumptions in CRT settings, that is, when the identification assumptions underlying the other estimator hold and when data generating process mimics realistic CRTs. Performance instead appears to be most affected by modeling choice, where we see analogous patterns for the SSW and PSW estimators.
The results demonstrate that there is usually benefit relative to bias for explicitly accounting for clustering effects in modeling the mortality event via a GLMM as opposed to a GLM. The differences in their bias are relatively negligible in most scenarios, but the bias of and becomes more pronounced when the treatment effect on survival status further deviates from zero. In general, the fixed effects parameters in marginal logistic models tend to be attenuated towards zero,46 which accords with the opposite sign bias we see with the GLM when there are larger treatment effects. For the most part, when there are small treatment effects, the coverage rates are comparable across these modeling techniques, and they all are near to the nominal rate. However, when the value of is higher, such as 0.3 (and occasionally 0.15), the constructed confidence intervals for and tend to suffer from undercoverage as compared and even though the variance estimates of the former are higher on average (regardless of small-sample corrections). Discrepancies here might be explained by the inferential trade-offs of using a marginal model in lieu of a conditional model in the presence of certain values of ICC.13,33,47,48 Given our observations in the small treatment effect scenarios, opting for and may suffice even if they cost some in terms of bias. However, the story for inference is different when the treatment effect on survival is large, particularly for higher values of . The interval estimates for and achieve closer to nominal coverage as opposed to and , which demonstrate noticeable undercoverage. In our simulations, all of the average estimated variances are close to their empirical counterparts signifying that our variance estimators perform adequately in finite samples, and bias, particularly for the GLM, is mostly driving the coverage results. The results for additional treatment effects and survival ICC are shown in Tables S1 to S3 of Supplemental Material 2 and in general are consistent with those presented above.
In selected scenarios, we have also examined the performance of the cluster bootstrap for generating variance estimates and confidence intervals, presented in Table S4 of Supplemental Material 2. We observe that the results are similar (if not slightly worse in terms of coverage) to the proposed variance estimators. However, the computation time required by our variance estimators is on average reduced by more than 10-fold for GLMM modeling and more than 60-fold for GLM modeling relative to the corresponding non-parametric bootstrap methods with 250 replicates.
Application to the RESTORE trial
We apply the weighting methods to estimate SACE in the Randomized Evaluation of Sedation Titration for Respiratory Failure (RESTORE) trial, a CRT investigating the effect of protocolized sedation on mechanical ventilation for children with acute respiratory failure, first analyzed by Curley et al.49 In this study, 31 pediatric intensive care units (PICUs) were randomized in parallel to one of two treatment arms pertaining to sedation practices. Following the necessary training, intervention PICUs (17 sites) managed sedation according to a goal-directed nurse-implemented comfort algorithm informed by illness trajectory, pain and arousal assessments, extubation readiness testing, sedation reevaluation every 8 hours, and weaning status. Control PICUs (14 sites) administered sedation per their usual care and in the absence of a protocol. The cluster sizes range from 12 to 272 with a median size of 57, and there are a total of 2449 children with 1225 in intervention and 1224 in control. There are 110 (4.5) observed deaths of which 47 (3.8) are in the intervention group and 63 (5.1) are in the control group.
In our analysis of RESTORE, the non-mortal outcome of interest is duration in days on a mechanical ventilator for a 28-day period. Duration on a ventilator not only has potential implications for the length of convalescence and overall health and well-being of a patient but may also impact resource availability in healthcare systems.50 Patients who do not reach their follow-up due to ICU-death within a 28-day period are considered to have their outcome truncated because their duration on mechanical ventilation, had they in fact survived on their assigned treatment, cannot be fully defined. Restricting only to those individuals observed to have complete duration measurements could introduce survivor bias, but the SACE is a valid causal estimand in this context. Moreover, because our weighting methods impose no distributional assumption on the non-mortal outcome, issues about model mis-specification for this length-of-stay type outcome51 over a specific time frame are avoided. This approach, however, does not explicitly allow for simultaneous SACE estimation over a continuous time domain (although it can be repeated at each restriction time), and we also assume, given strict oversight of care for critically-ill children, that if neither extubation occurs nor 28 days is reached, there are no sources of incomplete measurements outside of death, such as dropout or human error. Handling these additional considerations would necessitate a continuous-time principal stratification approach in CRTs as discussed briefly in Section 5.
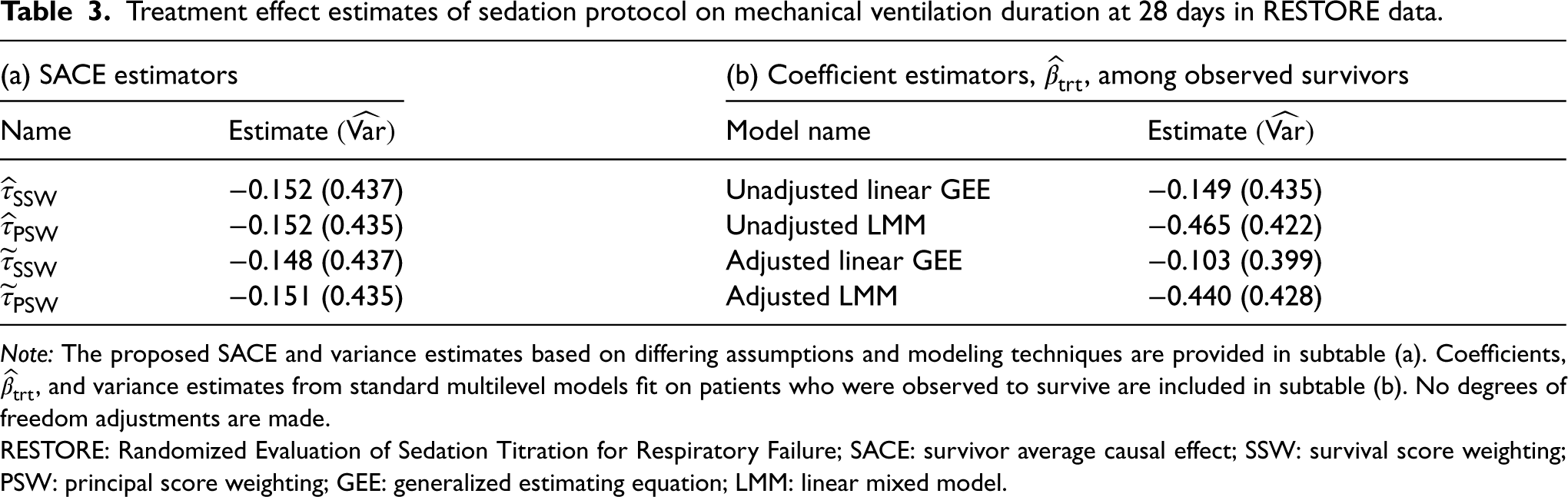
We apply our weighting estimators of SACE to the RESTORE data, where the survival status models adjust for variables suggested in the initial analysis.49 The covariates are age in years, Pediatric Risk of Mortality (PRISM) III-12 score (on log-scale), an aggregated measure of physiological status,52 and Pediatric Overall Performance Category (POPC) > 1, an assessment of functional morbidity and cognitive impairment,53 and for the GLMM, there is a random intercept for PICU facility. The SACE estimates where survival status is modeled using a mixed effects logistic regression model are and . The SACE estimates where survival status is modeled using a logistic regression model are similar and . All standard errors are computed using the proposed sandwich variance estimators with a degrees of freedom correction. As displayed in Table 3, differences between the sandwich variance estimates (uncorrected) are negligible, which is expected because the estimated ICC for survival is small, only . The point estimates suggest that the protocolized sedation reduces duration on mechanical ventilation among always-survivors on average by 3.6 hours, but this effect is not statistically significant at the 0.05 level.
Treatment effect estimates of sedation protocol on mechanical ventilation duration at 28 days in RESTORE data.
(a) SACE estimators
(b) Coefficient estimators, , among observed survivors
Name
Estimate
Model name
Estimate
−0.152 (0.437)
Unadjusted linear GEE
−0.149 (0.435)
−0.152 (0.435)
Unadjusted LMM
−0.465 (0.422)
−0.148 (0.437)
Adjusted linear GEE
−0.103 (0.399)
−0.151 (0.435)
Adjusted LMM
−0.440 (0.428)
Note: The proposed SACE and variance estimates based on differing assumptions and modeling techniques are provided in subtable (a). Coefficients, , and variance estimates from standard multilevel models fit on patients who were observed to survive are included in subtable (b). No degrees of freedom adjustments are made.
RESTORE: Randomized Evaluation of Sedation Titration for Respiratory Failure; SACE: survivor average causal effect; SSW: survival score weighting; PSW: principal score weighting; GEE: generalized estimating equation; LMM: linear mixed model.
Due to conditional survival independence and survival monotonicity, the Set 1 and Set 2 identification assumptions are mutually exclusive, so from a causal perspective, it is instructive to consider which set is more suited to this data application (supposing correct representation of the randomization scheme). Given that sedation practices are not meant to directly treat the conditions associated with acute respiratory failure, the causal assertion that survival under the active treatment is no worse than under the control treatment may not be easily justified. On the other hand, the conditional independence assumptions for Set 1 may be plausible since the key covariates that potentially impact and differentiate patient survival events are identified in the original analysis plan. All that said, while the Set 2 assumptions seem reasonable for this particular CRT, they nor those for Set 1 are testable using the observed data alone, but the nearly identical results for SSW and PSW estimators lend empirical credence to their robustness relative to whichever underlying identification assumptions hold.
As a follow-up illustration, we fit unadjusted and adjusted standard multilevel models to the RESTORE data removing patients whose death was reported prior to 28 days. The models are a generalized estimating equation (GEE) with Gaussian-type mean and variance functions with an independence working correlation, also known as linear regression with cluster-robust standard errors, and a LMM with a random intercept for PICU. We consider these models as they are among the commonly used regression methods for analyzing CRTs but may not produce causal estimates in the presence of truncation by death. In Table 3, the non-mortal treatment effect estimate, which is the coefficient of treatment in the models, is reported alongside the variance estimate, . These values are juxtaposed with the estimates for SACE. We observe that the results for the unadjusted GEE are similar to those that we have with the SACE estimators. However, does not target a clearly interpretable causal estimand because conditioning on survival breaks the balance of confounders across treatment groups and can lead to comparisons defined on different subpopulations. The similarity in estimates alone does not support the general application of such methods due to the ambiguity in the target estimand and may likely be attributed to the relatively low mortality rates in the RESTORE trial. Moreover, we see that the estimates for the remaining models, in particular the LMMs, are not comparable to those that we obtained for our SACE estimators. These differences may in fact be related to the selection bias introduced by conditioning on survivors and any distributional assumptions about the observed outcome. In contrast, the weighting methods avoid the need to consider outcome models that are often difficult to correctly specify, and they only require selecting a binary regression model to capture the likelihood of survival until the time of outcome measurement.
Discussion
For randomized trials targeting the effect of a binary treatment on a non-mortal outcome, participants who do not survive to their follow-up visit will have truncated outcome measurements. Estimating effects conditional on realizations of post-treatment variables such as survival status is a well-known potential source of selection bias that depends on underlying causal pathways. Moreover, when clusters are the randomization unit as in CRTs, there is an additional source of variation in patient outcomes due to within-group correlation. For this multifaceted problem, we target the SACE, a treatment effect conditional on individuals who would survive under either treatment received, and we discuss two sets of assumptions that allow for point identification of the SACE, notably accounting for unobservable sources of variation via a group-level latent variable. We develop two corresponding estimators for the SACE, denoted by SSW and PSW, based on the theory of M-estimation, where their asymptotic distributions have sandwich variance expressions enabling cluster-robust variance estimation.
Results of the simulation studies, which vary both the magnitudes of the within-cluster correlation and the treatment effect for survival status, suggest that the SACE estimators perform well in terms of empirical bias, and their confidence intervals generally achieve nominal coverage even for a small to modest number of clusters. There are occasional issues in undercoverage, but sources of this phenomenon have been documented in the past and may simply be remedied by other choices of small-sample corrections. Critically, both the SSW and PSW estimators prove to be robust to violations to one of their identifying assumptions—conditional survival independence for SSW and survival monotonicity for PSW. Furthermore, for these estimators, we consider models to predict survival status that do and do not explicitly address within-cluster correlation : mixed effects logistic regression (a type of GLMM) and logistic regression (a type of GLM), respectively. Performance in simulations across these modeling decisions is similar. Nevertheless, from the standpoint of addressing latent cluster-induced variation, the GLMM is a more principled approach compared to the GLM, and the simulation study shows that the empirical bias for the SACE estimator is in general smaller when the former is used. But, we demonstrate that in finite samples where the ICC for survival is also relatively low, the choice to use a GLMM may not be as stable (due in part to numerical methods), and one may prefer the GLM with a cluster-robust variance expression for inference, except if there is a previously known large effect of the treatment on survival. The above observations bear out in our application to the RESTORE data, where there are negligible differences in SACE interval estimates across the assumption sets and modeling choices. However, the SACE estimates may differ from estimation of treatment effects among observed survivors, which have no causal interpretation, and the magnitude of this difference may be amplified by (incorrect) assumptions when modeling the outcome distribution. To enable users to implement our methods, we provide an R package, PtSaceCrts, for computing SACE interval estimates based on choices of the set of assumptions and survival status model, available at https://github.com/abcdane1/PtSaceCrts. While we have a non-parametric bootstrap option in this package, the default estimation of asymptotic variances is computationally more efficient than bootstrapping and avoids complications of model fitting on bootstrapped samples when there is a small number of clusters.
The limitations and future considerations for our work relate to assumptions on and utilization of the data. For our analysis of the RESTORE study, we only consider the impact of the sedation protocol on mechanical ventilation duration over a fixed period of time, which does not make maximal use of the available data. Viewed as a time-to-extubation outcome, we could have performed a survival analysis examining treatment effect changes over time and accounting for censoring mechanisms. There has been recent literature on estimating SACE within the semi-competing risks framework for individually randomized data.54–56 Aside from requiring causal censoring assumptions to be estimable, these estimands can be viewed as continuous time extensions of our target estimand but in the iid context. For identification of continuous time SACE estimands, all the existing approaches also include some framing of assumptions that allow teasing apart non-mortal and survival times across treatments, which enable specifying a likelihood from observable data and thus a range of estimation strategies. For example, Xu et al.56 employed a Set 1 like approach, replacing the conditional survival independence assumption with a slightly weaker Gaussian copula formulation with correlation parameter that allows defining the survival status models marginally and is identified for a fixed correlation (e.g. , as in our case). In this article, we do not pursue an extension of the aforementioned continuous time methods to estimate SACE in the CRT context which would require fully specifying a likelihood for estimation; instead we focus on simpler weighting estimators that are able to be applied to a variety of non-mortal outcomes (continuous, binary, and count). An extension of our methods to estimate continuous time SACE in CRTs with application to the RESTORE study is a direction for future research.
Additionally, the proposed estimation of the SACE estimand relies on cross-world identification assumptions, that is, worlds defined by intervening on and . This is a debated framework in causal inference because there is no setting, even hypothetically, where simultaneous interventions could occur and assumptions across them are able to be verified.21 As an alternative framework, Stensrud et al.57 proposed estimands based on the notion of separable effects which avoid these cross-world assumptions and can be applied to the truncation by death problem. But, separable effects requires a significant conceptual exercise itself—one of decomposing treatment disjointly into its effect on survival and its effect on the non-mortal outcome. Despite the inherent untestability of cross-world assumptions, we opt for them because we feel that these assumptions as well as the SACE estimand that they identify are more easily translated to language accessible to practitioners. We have also assumed that there is no (marginal) dependence between the individual-level survival and non-mortal outcomes and cluster size (i.e. no informative cluster size), which can impact the validity of the proposed estimators for targeting individual-level effects.20 When informative cluster size is present, cluster-average and individual-average causal estimands may not overlap, necessitating a more principled approach to defining identification assumptions and compatible estimators as others have ventured at in recent literature in the absence of truncation by death.58 Another fundamental assumption is related to the mechanism of randomization, where we suppose that our data come from parallel-arm CRTs. However, a comprehensive review of analyses of CRTs in critical care units shows that less than half of them are based on true parallel-arm trials with the remaining being crossover or stepped wedge.59 The emergence of these types of randomized trials, motivated by practical, ethical, and statistical reasons, warrants an exploration of estimands for SACE that can accommodate different randomization designs.
Supplemental Material
sj-pdf-1-smm-10.1177_09622802241309348 - Supplemental material for Weighting methods for truncation by death in cluster-randomized trials
Supplemental material, sj-pdf-1-smm-10.1177_09622802241309348 for Weighting methods for truncation by death in cluster-randomized trials by Dane Isenberg, Michael O Harhay, Nandita Mitra and Fan Li in Statistical Methods in Medical Research
Footnotes
Acknowledgements
The data example was prepared using the RESTORE Research Materials obtained from the National Heart, Lung, and Blood Institute (NHLBI) Biologic Specimen and Data Repository Information Coordinating Center (BioLINCC) and does not necessarily reflect the opinions or views of the RESTORE study investigators or the NHLBI.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Research in this article was supported by the Patient-Centered Outcomes Research Institute® (PCORI® Award ME-2020C1-19220), and the United States National Institutes of Health (NIH), National Heart, Lung, and Blood Institute (grant number R01-HL168202). All statements in this report, including its findings and conclusions, are solely those of the authors and do not necessarily represent the views of the NIH or PCORI® or its Board of Governor or Methodology Committee.
ORCID iDs
Dane Isenberg
Fan Li
Supplemental material
Supplemental material for this article is available online.
References
1.
TurnerELLiFGallisJA, et al. Review of recent methodological developments in group-randomized trials: part 1 –design. Am J Public Health2017; 107: 907–915.
RosenbaumPR. The consequences of adjustment for a concomitant variable that has been affected by the treatment. J R Stat Soc Ser A: Stat Soc1984; 147: 656–666.
4.
WangCScharfsteinDOColantuoniE, et al. Inference in randomized trials with death and missingness. Biometrics2017; 73: 431–440.
5.
FrangakisCERubinDB. Principal stratification in causal inference. Biometrics2002; 58: 21–29.
6.
RubinDB. Causal inference without counterfactuals: comment. J Am Stat Assoc2000; 95: 435–438.
7.
ZhangJLRubinDB. Estimation of causal effects via principal stratification when some outcomes are truncated by “death”. J Educ Behav Stat2003; 28: 353–368.
8.
ZhangJLRubinDBMealliF. Likelihood-based analysis of causal effects of job-training programs using principal stratification. J Am Stat Assoc2009; 104: 166–176.
9.
MercatantiALiFMealliF. Improving inference of Gaussian mixtures using auxiliary variables. Stat Anal Data Mining: The ASA Data Sci J2015; 8: 34–48.
10.
HaydenDPaulerDKSchoenfeldD. An estimator for treatment comparisons among survivors in randomized trials. Biometrics2005; 61: 305–310.
11.
DingPLuJ. Principal stratification analysis using principal scores. J R Stat Soc Ser B (Stat Methodol)2017; 79: 757–777.
12.
ZehaviTNevoD. Matching methods for truncation by death problems. J R Stat Soc Ser A: Stat Soc2023; 186: 659–681.
13.
TurnerELPragueMGallisJAet al. Review of recent methodological developments in group-randomized trials: part 2 –analysis. Am J Public Health2017; 107: 1078–1086.
14.
TongGLiFChenX, et al. A Bayesian approach for estimating the survivor average causal effect when outcomes are truncated by death in cluster-randomized trials. Am J Epidemiol2023; 192: 1006–1015.
15.
HeLWangYBBridges JrWC, et al. Bayesian framework for causal inference with principal stratification and clusters. Stat Biosci2023; 15: 114–140.
16.
WangWTongGHiraniSP, et al. A mixed model approach to estimate the survivor average causal effect in cluster-randomized trials. Stat Med2024; 43: 16–33.
17.
HuberPJ. Robust estimation of a location parameter. Ann Math Stat1964; 35: 73–101.
18.
HuberPJ. The behavior of maximum likelihood estimates under nonstandard conditions. In: Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability, volume 1, University of California Press, 1967, pp.221–233.
19.
StefanskiLABoosDD. The calculus of M-estimation. Am Stat2002; 56: 29–38.
20.
KahanBCLiFCopasAJ, et al. Estimands in cluster-randomized trials: choosing analyses that answer the right question. Int J Epidemiol2023; 52: 107–118.
21.
RichardsonTSRobinsJM. Single world intervention graphs (swigs): a unification of the counterfactual and graphical approaches to causality. Center Stat Soc Sci Univer Washington Ser Work Paper2013; 128: 2013.
22.
LiFZaslavskyAMLandrumMB. Propensity score weighting with multilevel data. Stat Med2013; 32: 3373–3387.
23.
YangS. Propensity score weighting for causal inference with clustered data. J Causal Inference2018; 6: 20170027.
24.
RaudenbushSW. Statistical analysis and optimal design for cluster randomized trials. Psychol Methods1997; 2: 173.
25.
CampbellMKFayersPMGrimshawJM. Determinants of the intracluster correlation coefficient in cluster randomized trials: the case of implementation research. Clin Trials2005; 2: 99–107.
26.
RabideauDJLiFWangR. Multiply robust generalized estimating equations for cluster randomized trials with missing outcomes. Stat Med2024; 43: 1458–1474.
27.
IversonHRandlesR. The effects on convergence of substituting parameter estimates into U-statistics and other families of statistics. Probab Theory Relat Fields1989; 81: 453–471.
28.
WuMYucelRM. Model-based inference on average causal effect in observational clustered data. Health Serv Outcomes Res Methodol2019; 19: 36–60.
29.
LiuQPierceDA. A note on Gauss-Hermite quadrature. Biometrika1994; 81: 624–629.
30.
LiangKYZegerSL. Longitudinal data analysis using generalized linear models. Biometrika1986; 73: 13–22.
31.
HubbardAEAhernJFleischerNL, et al. To GEE or not to GEE: comparing population average and mixed models for estimating the associations between neighborhood risk factors and health. Epidemiology2010; 21: 467–474.
32.
NeuhausJMKalbfleischJDHauckWW. A comparison of cluster-specific and population-averaged approaches for analyzing correlated binary data. Int Stat Review/Revue Int de Stat1991; 59: 25–35.
33.
ThompsonJALeyratCFieldingKL, et al. Cluster randomised trials with a binary outcome and a small number of clusters: comparison of individual and cluster level analysis method. BMC Med Res Methodol2022; 22: 1–15.
34.
LiPReddenDT. Small sample performance of bias-corrected sandwich estimators for cluster-randomized trials with binary outcomes. Stat Med2015; 34: 281–296.
35.
KahanBCForbesGAliY, et al. Increased risk of type I errors in cluster randomised trials with small or medium numbers of clusters: a review, reanalysis, and simulation study. Trials2016; 17: 1–8.
36.
MacKinnonJGWhiteH. Some heteroskedasticity-consistent covariance matrix estimators with improved finite sample properties. J Economet1985; 29: 305–325.
37.
SelfSGLiangKY. Asymptotic properties of maximum likelihood estimators and likelihood ratio tests under nonstandard conditions. J Am Stat Assoc1987; 82: 605–610.
ChungYRabe-HeskethSDorieV, et al. A nondegenerate penalized likelihood estimator for variance parameters in multilevel models. Psychometrika2013; 78: 685–709.
40.
MorrisTPWhiteIRCrowtherMJ. Using simulation studies to evaluate statistical methods. Stat Med2019; 38: 2074–2102.
41.
JiangZYangSDingP. Multiply robust estimation of causal effects under principal ignorability. J R Stat Soc Ser B: Stat Methodol2022; 84: 1423–1445.
42.
SmallDTanZLorchS, et al. Instrumental variable estimation when compliance is not deterministic: the stochastic monotonicity assumption. arXiv preprint arXiv:14077308 2014.
43.
SassonAWangMOginoS, et al. The subtype-free average causal effect for heterogeneous disease etiology. ArXiv preprint arXiv:220600209 2022.
44.
GoldsteinHBrowneWRasbashJ. Partitioning variation in multilevel models. Underst Stat: Stat Issu Psychol Educ Soc Sci2002; 1: 223–231.
45.
EldridgeSMUkoumunneOCCarlinJB. The intra-cluster correlation coefficient in cluster randomized trials: a review of definitions. Int Stat Rev2009; 77: 378–394.
46.
ZegerSLLiangKYAlbertPS. Models for longitudinal data: a generalized estimating equation approach. Biometrics1988; 1049–1060.
47.
RodríguezGGoldmanN. An assessment of estimation procedures for multilevel models with binary responses. J R Stat Soc: Ser A (Stat Soc)1995; 158: 73–89.
48.
HuangFLiX. Using cluster-robust standard errors when analyzing group-randomized trials with few clusters. Behav Res Methods2022; 54: 1–19.
49.
CurleyMAWypijDWatsonRS, et al. Protocolized sedation vs usual care in pediatric patients mechanically ventilated for acute respiratory failure: a randomized clinical trial. Jama2015; 313: 379–389.
50.
HillADFowlerRABurnsKE, et al. Long-term outcomes and health care utilization after prolonged mechanical ventilation. Ann Am Thoracic Soc2017; 14: 355–362.
51.
FaddyMGravesNPettittA. Modeling length of stay in hospital and other right skewed data: comparison of phase-type, gamma, and log-normal distributions. Value Health2009; 12: 309–314.
52.
PollackMMHolubkovRFunaiT, et al. The pediatric risk of mortality score: update 2015. Pediat Crit Care Med: J Soc Crit Care Med World Feder Pediat Inten Crit Care Soc2016; 17: 2.
53.
FiserDH. Assessing the outcome of pediatric intensive care. J Pediat1992; 121: 68–74.
54.
CommentLMealliFHaneuseS, et al. Survivor average causal effects for continuous time: a principal stratification approach to causal inference with semicompeting risks. ArXiv preprint arXiv:190209304, 2019, pp.1–28.
55.
NevoDGorfineM. Causal inference for semi-competing risks data. Biostatistics2022; 23: 1115–1132.
56.
XuYScharfsteinDMüllerP, et al. A Bayesian nonparametric approach for evaluating the causal effect of treatment in randomized trials with semi-competing risks. Biostatistics2022; 23: 34–49.
57.
StensrudMJRobinsJMSarvetA, et al. Conditional separable effects. J Am Stat Assoc2022; 118: 1–13.
58.
WangBParkCSmallDS, et al. Model-robust and efficient covariate adjustment for cluster-randomized experiments. J Am Stat Assoc2024; 119: 1–13.
59.
CookDJRutherfordWBScalesDC, et al. Rationale, methodological quality, and reporting of cluster-randomized controlled trials in critical care medicine: a systematic review. Crit Care Med2021; 49: 977–987.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.