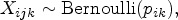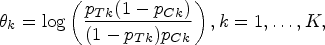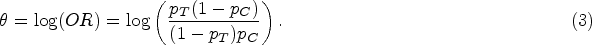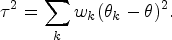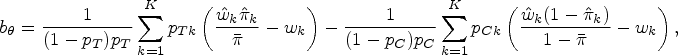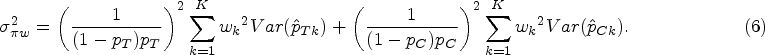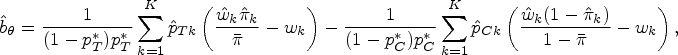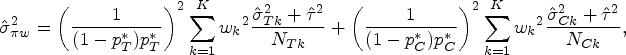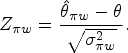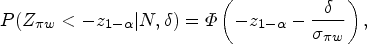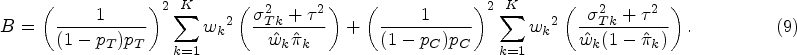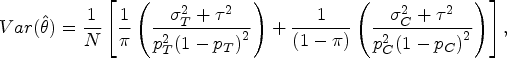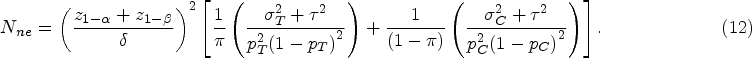Multiregional clinical trials (MRCTs) have become a standard strategy for pharmaceutical product development worldwide. The heterogeneity of regional treatment effects is anticipated in an MRCT. For a two-group comparative study in an MRCT, patient assignments, including regional weights and treatment allocation ratios, are predetermined under the same protocol. In practice, the observed patient assignments at the final analysis stage are often not equal to the predetermined patient assignments, which may impact the accuracy of estimating the overall treatment effect and may lead to a biased estimator. In this study, we use a discrete random effects model (DREM) to account for the heterogeneous treatment effect across regions in an MRCT and propose a bias-adjusted estimator of the overall treatment effect through a naïve estimator conditioned on ancillary statistics based on the observed patient assignments at the final analysis stage in the trial. We also perform power analysis for the overall treatment effect and determine the overall sample size for the bias-adjusted estimator with the DREM. Results of simulation studies are given to illustrate applications of the proposed approach. Finally, we provide an example to demonstrate the implementation of the proposed approach.
With the development of global pharmaceutical products, multiregional clinical trials (MRCTs) have become a standard strategy. In an MRCT, patients are recruited from multiple geographical regions under the same protocol. Ensuring the accuracy of effect estimates is crucial for demonstrating the clinical benefits of test drugs.
Traditionally, the same treatment effects are assumed for all participating regions in an MRCT. However, in reality the treatment effects show regional variations, which are often due to differences in race, diet, environment, culture, and medical practice among regions. Therefore, when regional heterogeneity is anticipated, the assumption that regional treatment effects are not identical would be more appropriate in the design of MRCTs.1,2 To address this issue, Lan and Pinheiro3 proposed the discrete random effects model (DREM) to account for heterogeneous treatment effects across regions. The DREM framework is applicable in practical situations. For example, Liu et al.4 used the DREM with a continuous endpoint for the design and evaluation of MRCTs. Moreover, Lan et al.5 extended the application of the DREM from a continuous endpoint to time-to-event and binary endpoints.
In a two-group comparative study of an MRCT, patients are recruited from each region according to regional weights and then randomly assigned to the two groups. During the design stage, the regional weights are predetermined based on the population size, market size, prevalence of disease, and cost-effectiveness. Under a common protocol, it is generally assumed that the same treatment allocation ratio is used for all participating regions during the design stage. However, at the final analysis stage, the observed patient assignments are often not the same as the predetermined ones. That is, the regional weights and treatment allocation ratios vary among regions. For instance, differences in the observed treatment allocation ratios across regions in practice may be due to patients lost to follow-up, dropout rate, drug side effects, or other reasons. Therefore, the accuracy of estimating the overall treatment effect may be compromised, resulting in a biased estimator. Ignoring the potential bias in an estimator may lead to overestimation or underestimation of the overall treatment effect.
To quantify the potential bias caused by the differences between the observed patient assignments and the predetermined ones, Tian et al.6 used a conditional distribution, which enhances our understanding of the efficiency augmentation procedure, in the stratified analysis. Of note, a conditional distribution with reasonable auxiliary statistics can be more informative than an unconditional distribution.7,8 In this article, we extend the approach of Tian et al.6 to obtain a bias-adjusted estimator for the overall treatment effect. Furthermore, we conduct power analysis for the overall treatment effect and determine the overall sample size by adjusting for the potential impact caused by these differences.
The odds ratio (OR) is a common measure for the binary endpoint in two-group comparative studies. In this study, we adopt the OR as an example to illustrate our approach. Additionally, both the observed regional weights and the observed treatment allocation ratios are considered as auxiliary statistics.
We organize the rest of this article as follows. In Section 2, we introduce the DREM and propose to construct a bias-adjusted estimator for the overall treatment effect under the DREM. In Section 3, we describe the hypothesis for our proposed approach using the DREM, derive the power functions for the resulting test statistic and the naïve estimator, and determine the required sample sizes. In Section 4, we provide simulation studies that investigate the performance of the proposed approach. An example is illustrated in Section 5, and some concluding remarks are given in Section 6.
Adjusting the naïve estimator under the DREM
DREM with binary endpoints
To address the heterogeneous treatment effect across regions in an MRCT, the DREM was proposed by Lan and Pinheiro.3 In this section, we present the application of the DREM to binary endpoints5 by taking the OR as an example.
We consider the patient population to be partitioned into K disjointed clinical regions. The regional weight of region k is represented by with where is a parameter rather than a random variable.3 In a randomized control trial, patients are randomly assigned to either the treatment group or the control group. Suppose that the patient-allocation ratio of the treatment group and the control group is and let , which represents the overall treatment allocation ratio. The treatment allocation ratio for region k is denoted as where is a parameter rather than a random variable.3 Note that the overall treatment allocation ratio can be expressed as the weighted sum of , i.e., .
When the primary endpoint is binary, to compare the treatment effect in the treatment group and the control group, the overall treatment effect is estimated by the event rates of the two groups. The Bernoulli random variable is used to indicate whether the event occurs or not for the jth patient in the kth region for group We assume that
where represents the true event rate of group i in the kth region. The regional treatment effect is defined as:
which is the log(OR) for the kth region. Let us now consider the overall treatment effect. It is important to note that the event rates for the treatment group overall and the control group overall are defined as follows:
where and are modified weights reflecting both the regional weight and the treatment allocation ratio . Thus, we can define the overall treatment effect as
Assuming that a lower event rate represents a better outcome, a log(OR) of less than zero would favor the treatment group.
Under the DREM, the treatment effect for a randomly selected patient in the population is a random variable with the distribution defined by the possible values and their respective probabilities . The mean is and the between-region variance () is expressed as
To demonstrate how to calculate , we provide an example of an MRCT with three regions in Table 1. By considering and , Table 1 exhibits the between-region variance for different event rates. As shown in the first row of Table 1, given for the treatment group and for the control group, we obtain , , and .
Between-region variance for event rates and , given and .
0.50
0.60
0.60
0.65
0.70
0.70
0.0071
0.55
0.60
0.65
0.70
0.75
0.80
0.0024
0.40
0.40
0.45
0.60
0.60
0.60
0.0088
When a patient from the population is randomly selected, the variance of his/her treatment effect should not only consider the between-region variance , but also take into account the within-region variance. For a patient from region k in group i, the within-region variance is the variance of , which is denoted as . As a result, we define the variance of the random variable as
Let the sample size of region k be and the total sample size across all K regions be . Within region k, let the sample size for group i be If the sample size is reasonably large, the event rate can be adequately estimated by . The observed regional weight is with , the observed treatment allocation ratio is , in the kth region, and the observed overall treatment allocation ratio is . The event rates for the treatment group overall and the control group overall are estimated by and , respectively. Therefore, according to Tian et al.6 we can obtain the naïve estimator of the overall treatment effect as
The estimator of treatment effect for region k is , and the variance is estimated by
Adjusting the naïve estimator
So far, we have defined the overall treatment effect (Eq. (3)) and have obtained the naïve estimator (Eq. (5)). We will now discuss the potential bias of and how to quantify it. As a common protocol is used in an MRCT, we generally assume that the overall treatment allocation ratio is applied across all K regions, meaning that . However, in practice, at the final analysis stage, the treatment allocation ratios and the regional weights may differ from those predetermined at the design stage. This reduces the accuracy of estimating the overall treatment effect. In this article, we take into account the gap between the design stage and the actual implementation results with the following assumptions:
the observed regional weights are possibly different from the predetermined regional weights in the protocol, and
the observed treatment allocation ratios are possibly different across regions.
Although efforts are made to enroll patients from each region to achieve predetermined regional weights and a predetermined treatment allocation ratio , they are often different in practice. We recognize this “real-world” challenge and attempt to fully understand its impact on the overall treatment effect. We anticipate that the observed naïve estimator would not be equal to based on the predetermined patient assignments.
One approach to empirically quantify the bias of is to use conditional inference with ancillary statistics for .6,9 There is a vast amount of literature on how to adjust the estimator based on baseline covariate information under unconditional inference.10–13 In this study, we focus on the conditional distribution of given appropriate ancillary statistics, as it is more informative than unconditional inference to study the stochastic behavior of .7,8 Here, both the observed regional weights and the observed treatment allocation ratios are ancillary statistics.
We consider the naïve estimator to be generated through random sampling, but of each sample would be the same as the observed patient assignment. We also assume random sampling of patients from each region and then their random assignment to one of two groups. Within the framework of the DREM, we extend the method proposed by Tian et al.6 By the Central Limit Theorem, it can be readily shown that the conditional distribution of is approximately normal, with the mean of
and the variance of
It is worth noting that the variance of accounts for both between-region and within-region variations. According to Eq. (4), the variance of can be derived as
Next, let be another estimator of (Eqs. (1) and (2)). Note that if and , then the estimator is equal to the estimator . Following Tian et al.,6 define and . Using the aforementioned notation, we construct an estimator of as
and an estimator of as
where . By adjusting directly, we can obtain
The bias-adjusted estimator is the sum of and a function of . Note that is a consistent estimator of . Moreover, the conditional distribution under the null hypothesis is approximately normal with mean 0 and variance .
Power analysis and sample size determination under the DREM
Sample size calculation for the bias-adjusted estimator
The hypothesis test for the overall treatment effect under the DREM is
versus.
Here, if the overall treatment effect (Eq. (3)) is less than 0, it indicates that the treatment is effective, since we assumed that an OR of less than 1 is in favor of the treatment group (when the event rate represents death or disease recurrence, etc.). Utilizing the proposed estimator , the test statistic is given by
It is easily seen that the conditional distribution of the test statistic under the null hypothesis is approximately standard normal. The efficacy of the treatment group is claimed beneficial if the test statistic , where represents the percentile of the standard normal distribution. Thus, the power function is
where , is the cumulative distribution function of the standard normal distribution, and if one-sided . In order to calculate the total required sample size N to detect , we converted the variance (Eq. (6) and Eq. (7)) into an expression involving N using and . It can be obtained that , where
As shown in Eq. (9), B is the combination of regional variances, which include the variance of the Bernoulli random variable between-region variance , observed regional weights , observed treatment allocation ratio , and predetermined regional weights . Given the significance level and the power at the design stage, the total sample size required for is
Sample size calculation for the naïve estimator
In this section, we introduce the distribution of the naïve estimator and derive the required sample size. The estimator follows an approximately normal distribution with the mean of and the variance of . To calculate the variance , let , which is the log odds function of the event rate p. Then, through Taylor's expansion, . Taking the variance on both sides, we obtain
Under the DREM, substituting Eq. (7) into Eq. (11) and considering the log(OR) of the treatment and control groups, we obtain
where Therefore, the test statistic for the naïve estimator is given by , and the required sample size for is
We have thus derived the sample sizes (Eq. (10)) and (Eq. (12)) for and , respectively.
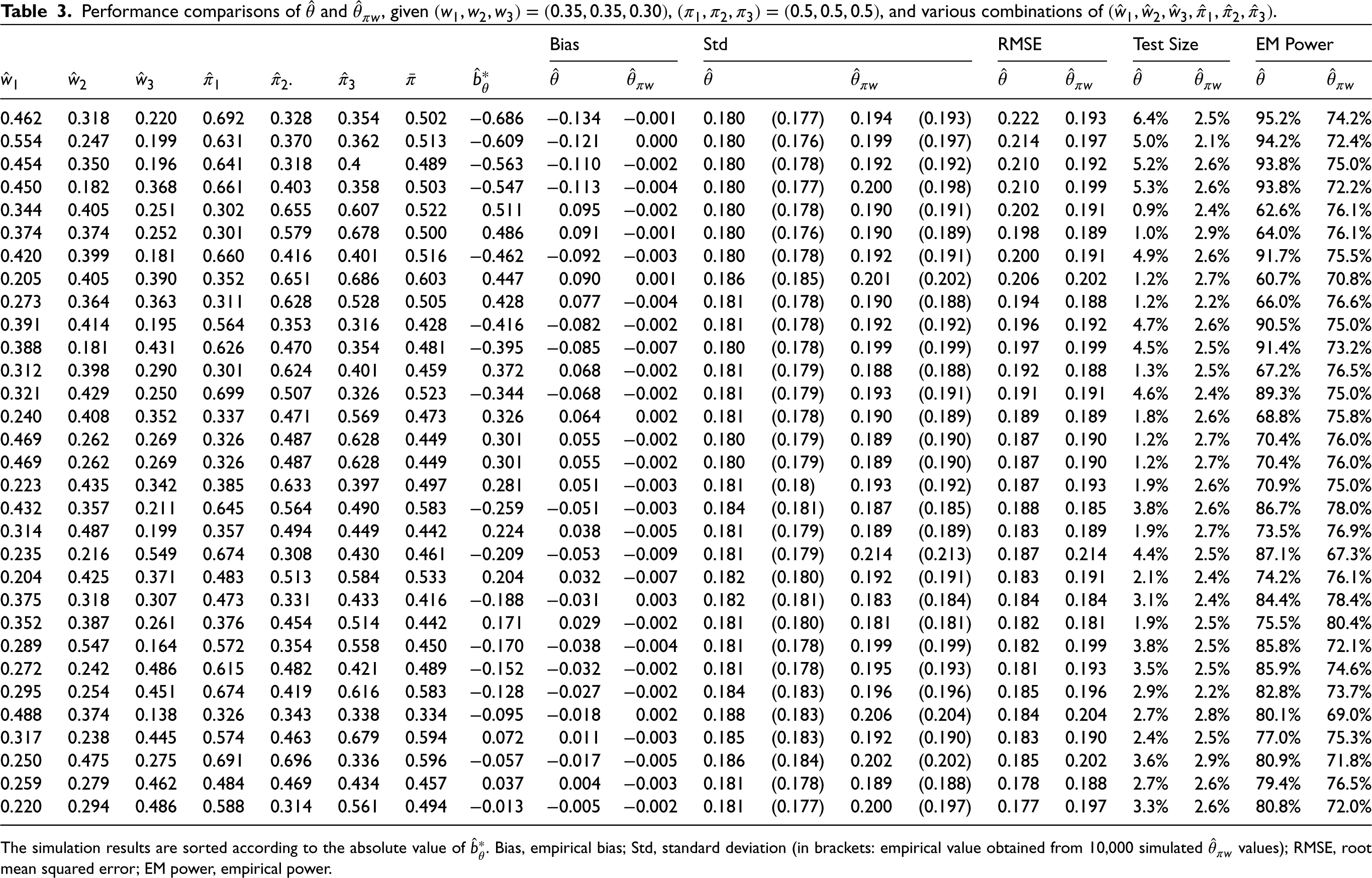
With , , , , and , along with , Table 2 shows the sample sizes and required for given observed patient assignments . Although a treatment allocation of is common in an MRCT, there may be a higher proportion in the treatment arm in some clinical trials.14,15 Therefore, we considered two cases: and , as shown in the top and bottom halves of Table 2, respectively. In both cases, the first row shows that the observed patient assignments were equal to the designed ones, i.e., and for all regions k, . Since there are infinitely many combinations of , the subsequent rows show some randomly generated as described below. The observed regional weights were generated from a uniform distribution in the range with . For and , the observed treatment allocation ratios were randomly generated from the ranges and , respectively.
The required sample size for and with using and .
0.350
0.350
0.300
0.500
0.500
0.500
554
551
0.462
0.318
0.220
0.692
0.328
0.354
554
651
0.235
0.216
0.549
0.674
0.308
0.430
554
789
0.352
0.387
0.261
0.376
0.454
0.514
554
566
0.350
0.350
0.300
0.700
0.700
0.700
677
674
0.526
0.260
0.214
0.606
0.555
0.599
677
640
0.216
0.591
0.193
0.672
0.694
0.672
677
805
0.339
0.310
0.351
0.661
0.683
0.778
677
696
In the case of , while and for all k, the required sample sizes are and . Moreover, regardless of the combination of , the sample size remains the same. On the other hand, depending on the given , the sample size will be different accordingly. For instance, given , we obtained for the desired power level of . In contrast to the proposed estimator , does not take into account the difference in patient assignments between the design stage and the final analysis stage. Therefore, when calculating the sample size , it will not change with . In the case of , a similar result was observed. As shown in Table 2, may be greater or less than , depending on the combination of . When considering the predetermined patient assignments at the design stage and the possible observed patient assignments, it becomes evident that conducting a trial with the sample size may not guarantee adequate statistical power. This deficiency in power can be attributed to the bias of the naïve estimator . This study addresses the issue of loss of statistical power by hypothetically adjusting the required sample size at the design stage.
Simulation
To evaluate the performance of the proposed approach under the DREM, we compared the bias-adjusted estimator with the naïve estimator . For simplicity, we considered three regions. Let the event rates of the treatment group and the control group be and , respectively. The regional treatment effects are . At the design stage, we set the patient assignments as and . The between-region variance was 0.0071. To detect the expected treatment effect in favor of the treatment group at a significance level of and power of , the required sample size was . It is important to note that both and were evaluated using a sample size of for comparison. The true parameter is .
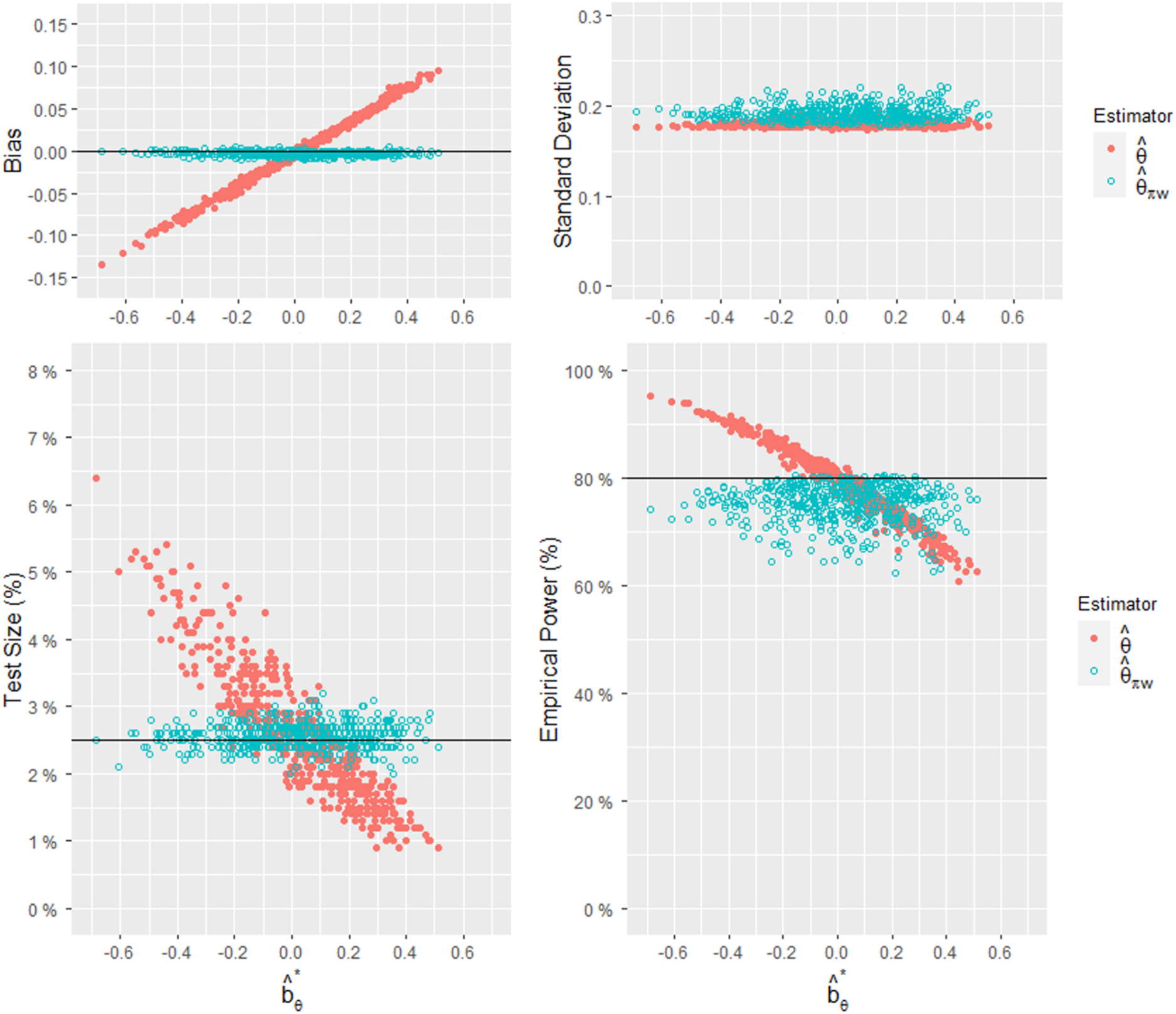
In order to investigate various scenarios that may occur in practice, we generated different combinations of . The observed regional weights were randomly generated from a uniform distribution within the range of with a constraint on . This wide range allows us to cover a diverse set of possible values for the observed regional weights. The observed treatment allocation ratios were randomly generated from a uniform distribution with the mean of 0.5 and the range of . By bounding the observed treatment allocation ratio between this range, we avoid values that are too large or too small, as this indicates a very poor randomization scheme, which is rarely the case in practice. For each combination of , we performed 10,000 simulations to assess the performance of the two estimators. The simulation results shown in Table 3 include empirical bias, standard deviation, root mean squared error (RMSE), empirical test size, and empirical power. To interpret the size of the biases, we considered the standardization of and defined it as
Performance comparisons of and , given , and various combinations of .
Bias
Std
RMSE
Test Size
EM Power
.
0.462
0.318
0.220
0.692
0.328
0.354
0.502
−0.686
−0.134
−0.001
0.180
(0.177)
0.194
(0.193)
0.222
0.193
6.4%
2.5%
95.2%
74.2%
0.554
0.247
0.199
0.631
0.370
0.362
0.513
−0.609
−0.121
0.000
0.180
(0.176)
0.199
(0.197)
0.214
0.197
5.0%
2.1%
94.2%
72.4%
0.454
0.350
0.196
0.641
0.318
0.4
0.489
−0.563
−0.110
−0.002
0.180
(0.178)
0.192
(0.192)
0.210
0.192
5.2%
2.6%
93.8%
75.0%
0.450
0.182
0.368
0.661
0.403
0.358
0.503
−0.547
−0.113
−0.004
0.180
(0.177)
0.200
(0.198)
0.210
0.199
5.3%
2.6%
93.8%
72.2%
0.344
0.405
0.251
0.302
0.655
0.607
0.522
0.511
0.095
−0.002
0.180
(0.178)
0.190
(0.191)
0.202
0.191
0.9%
2.4%
62.6%
76.1%
0.374
0.374
0.252
0.301
0.579
0.678
0.500
0.486
0.091
−0.001
0.180
(0.176)
0.190
(0.189)
0.198
0.189
1.0%
2.9%
64.0%
76.1%
0.420
0.399
0.181
0.660
0.416
0.401
0.516
−0.462
−0.092
−0.003
0.180
(0.178)
0.192
(0.191)
0.200
0.191
4.9%
2.6%
91.7%
75.5%
0.205
0.405
0.390
0.352
0.651
0.686
0.603
0.447
0.090
0.001
0.186
(0.185)
0.201
(0.202)
0.206
0.202
1.2%
2.7%
60.7%
70.8%
0.273
0.364
0.363
0.311
0.628
0.528
0.505
0.428
0.077
−0.004
0.181
(0.178)
0.190
(0.188)
0.194
0.188
1.2%
2.2%
66.0%
76.6%
0.391
0.414
0.195
0.564
0.353
0.316
0.428
−0.416
−0.082
−0.002
0.181
(0.178)
0.192
(0.192)
0.196
0.192
4.7%
2.6%
90.5%
75.0%
0.388
0.181
0.431
0.626
0.470
0.354
0.481
−0.395
−0.085
−0.007
0.180
(0.178)
0.199
(0.199)
0.197
0.199
4.5%
2.5%
91.4%
73.2%
0.312
0.398
0.290
0.301
0.624
0.401
0.459
0.372
0.068
−0.002
0.181
(0.179)
0.188
(0.188)
0.192
0.188
1.3%
2.5%
67.2%
76.5%
0.321
0.429
0.250
0.699
0.507
0.326
0.523
−0.344
−0.068
−0.002
0.181
(0.179)
0.193
(0.191)
0.191
0.191
4.6%
2.4%
89.3%
75.0%
0.240
0.408
0.352
0.337
0.471
0.569
0.473
0.326
0.064
0.002
0.181
(0.178)
0.190
(0.189)
0.189
0.189
1.8%
2.6%
68.8%
75.8%
0.469
0.262
0.269
0.326
0.487
0.628
0.449
0.301
0.055
−0.002
0.180
(0.179)
0.189
(0.190)
0.187
0.190
1.2%
2.7%
70.4%
76.0%
0.469
0.262
0.269
0.326
0.487
0.628
0.449
0.301
0.055
−0.002
0.180
(0.179)
0.189
(0.190)
0.187
0.190
1.2%
2.7%
70.4%
76.0%
0.223
0.435
0.342
0.385
0.633
0.397
0.497
0.281
0.051
−0.003
0.181
(0.18)
0.193
(0.192)
0.187
0.193
1.9%
2.6%
70.9%
75.0%
0.432
0.357
0.211
0.645
0.564
0.490
0.583
−0.259
−0.051
−0.003
0.184
(0.181)
0.187
(0.185)
0.188
0.185
3.8%
2.6%
86.7%
78.0%
0.314
0.487
0.199
0.357
0.494
0.449
0.442
0.224
0.038
−0.005
0.181
(0.179)
0.189
(0.189)
0.183
0.189
1.9%
2.7%
73.5%
76.9%
0.235
0.216
0.549
0.674
0.308
0.430
0.461
−0.209
−0.053
−0.009
0.181
(0.179)
0.214
(0.213)
0.187
0.214
4.4%
2.5%
87.1%
67.3%
0.204
0.425
0.371
0.483
0.513
0.584
0.533
0.204
0.032
−0.007
0.182
(0.180)
0.192
(0.191)
0.183
0.191
2.1%
2.4%
74.2%
76.1%
0.375
0.318
0.307
0.473
0.331
0.433
0.416
−0.188
−0.031
0.003
0.182
(0.181)
0.183
(0.184)
0.184
0.184
3.1%
2.4%
84.4%
78.4%
0.352
0.387
0.261
0.376
0.454
0.514
0.442
0.171
0.029
−0.002
0.181
(0.180)
0.181
(0.181)
0.182
0.181
1.9%
2.5%
75.5%
80.4%
0.289
0.547
0.164
0.572
0.354
0.558
0.450
−0.170
−0.038
−0.004
0.181
(0.178)
0.199
(0.199)
0.182
0.199
3.8%
2.5%
85.8%
72.1%
0.272
0.242
0.486
0.615
0.482
0.421
0.489
−0.152
−0.032
−0.002
0.181
(0.178)
0.195
(0.193)
0.181
0.193
3.5%
2.5%
85.9%
74.6%
0.295
0.254
0.451
0.674
0.419
0.616
0.583
−0.128
−0.027
−0.002
0.184
(0.183)
0.196
(0.196)
0.185
0.196
2.9%
2.2%
82.8%
73.7%
0.488
0.374
0.138
0.326
0.343
0.338
0.334
−0.095
−0.018
0.002
0.188
(0.183)
0.206
(0.204)
0.184
0.204
2.7%
2.8%
80.1%
69.0%
0.317
0.238
0.445
0.574
0.463
0.679
0.594
0.072
0.011
−0.003
0.185
(0.183)
0.192
(0.190)
0.183
0.190
2.4%
2.5%
77.0%
75.3%
0.250
0.475
0.275
0.691
0.696
0.336
0.596
−0.057
−0.017
−0.005
0.186
(0.184)
0.202
(0.202)
0.185
0.202
3.6%
2.9%
80.9%
71.8%
0.259
0.279
0.462
0.484
0.469
0.434
0.457
0.037
0.004
−0.003
0.181
(0.178)
0.189
(0.188)
0.178
0.188
2.7%
2.6%
79.4%
76.5%
0.220
0.294
0.486
0.588
0.314
0.561
0.494
−0.013
−0.005
−0.002
0.181
(0.177)
0.200
(0.197)
0.177
0.197
3.3%
2.6%
80.8%
72.0%
The simulation results are sorted according to the absolute value of . Bias, empirical bias; Std, standard deviation (in brackets: empirical value obtained from 10,000 simulated values); RMSE, root mean squared error; EM power, empirical power.
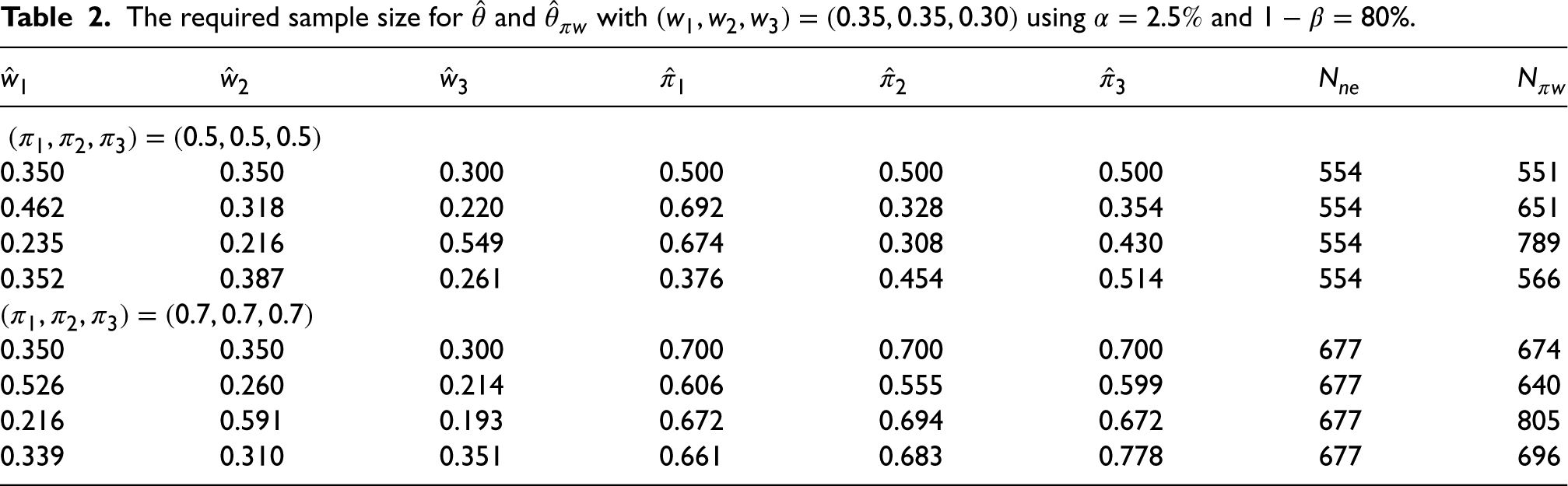
The value of is also provided in Table 3. Note that the results presented in Table 3 are sorted by the absolute values of .
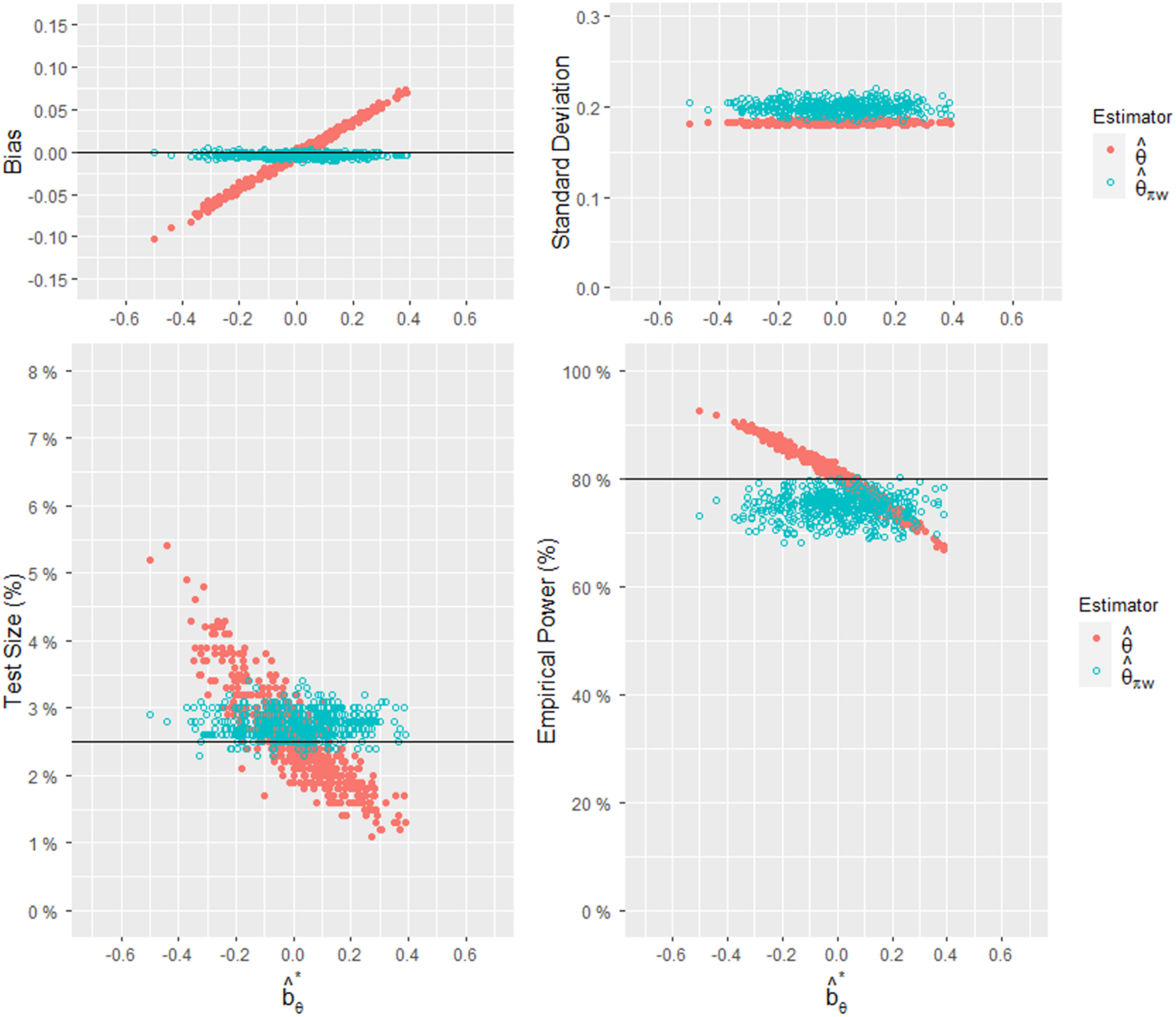
We started with scenarios where the value of is negative, taking the first row of Table 3 as an example. It can be observed that has a bias of , while is almost unbiased. This indicates that our approach successfully corrected the bias. Considering a significance level of , the empirical test size of is , and the empirical test size of is . The inflated test size of is primarily due to its large negative bias. In terms of standard deviation, has a slightly higher value of 0.193 compared to 0.177 for . The RMSE of is 0.193, which is less than the value of 0.222 for . The estimator has the empirical power of , while has the empirical power of . To explain the unusually high empirical power of , we need to look at its corresponding test size and standard deviation. When the test size is as high as , such high power is not meaningful.
Next, let's turn our attention to the scenarios where the value of is positive, taking the fifth row of Table 3 as an example. The naïve estimator is overestimated with a bias of 0.095, resulting in the empirical test size of , which is well below . The excessively small test size of leads to the empirical power of , which is well below the desired power of . In contrast, is nearly unbiased with the empirical test size of and the empirical power of .
Across all the combinations of presented in Table 3, regardless of the value of , it is evident that our proposed estimator is almost unbiased. When the observed patient assignments remarkably deviate from the designed assignments , indicated by being far from 0, the proposed estimator clearly outperforms the naïve estimator. The empirical test size of is always close to compared to that of . The empirical power of is more meaningful when the test size is stable and close to compared to that of . However, the standard deviation of is slightly greater than that of . This is because our approach sacrifices some precision in the process of bias adjustment. Therefore, when there is almost no bias ( is close to 0), the RMSE of will be slightly larger than that of .
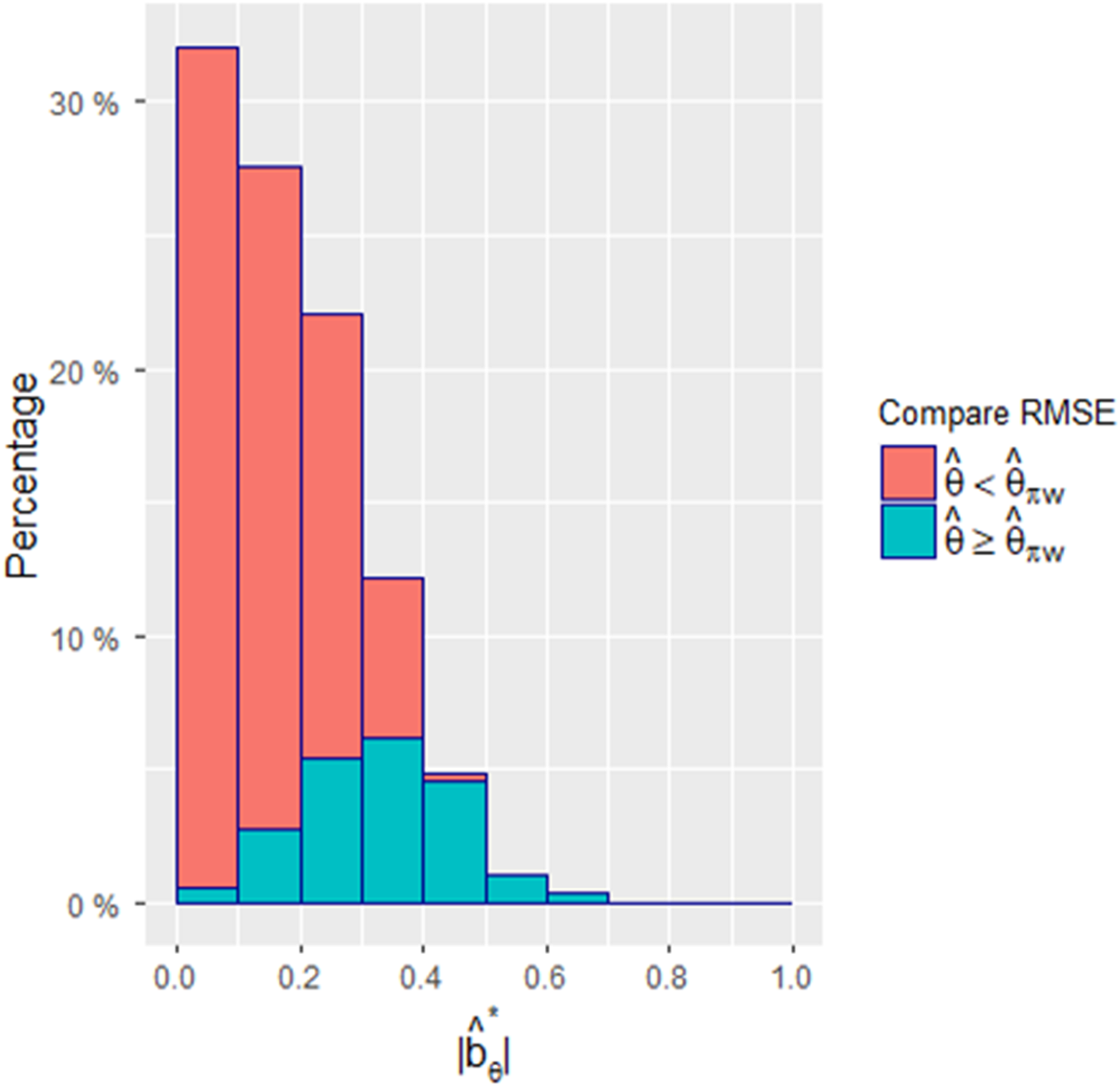
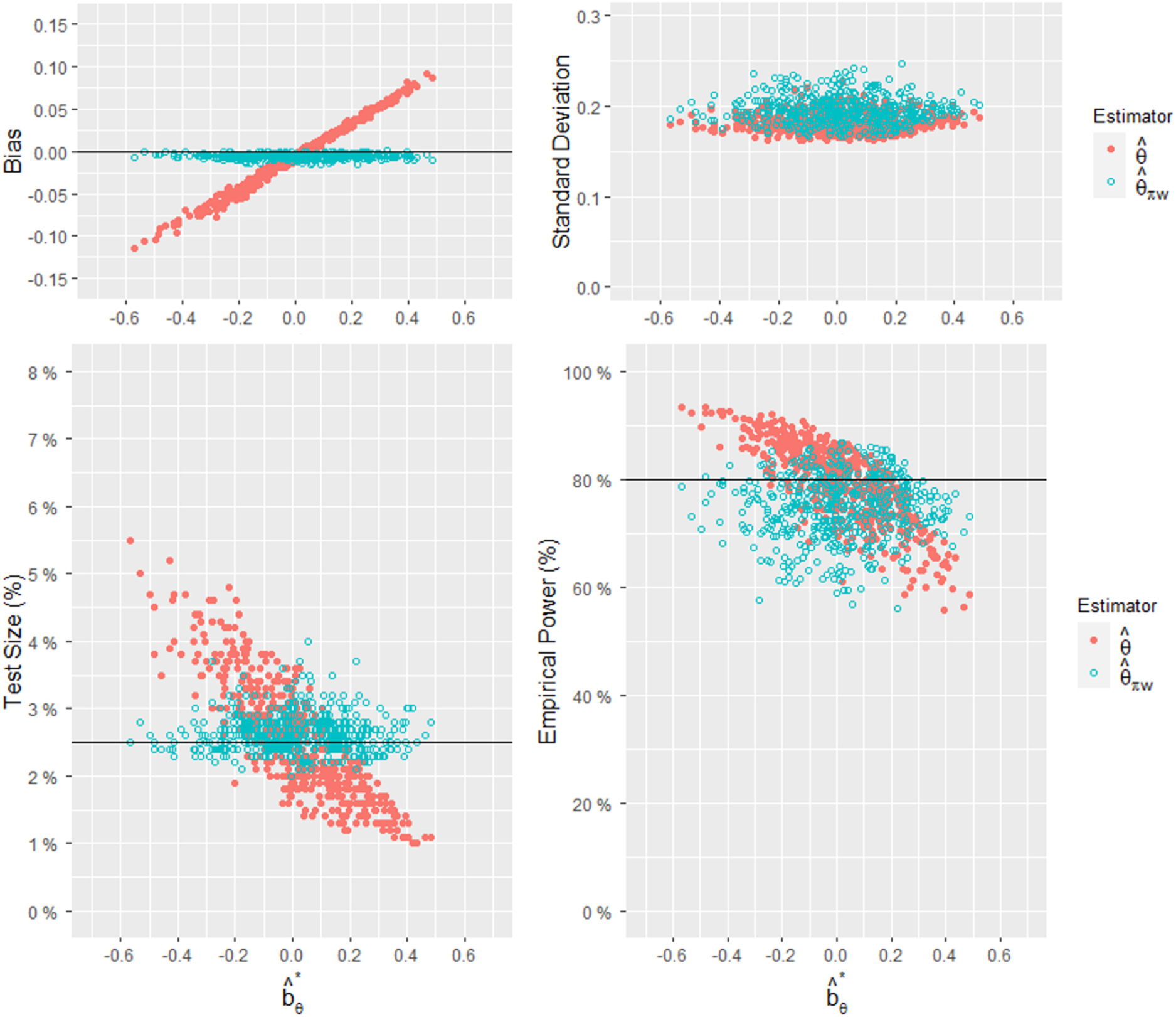
These results can also be clearly seen in Figure 1, where the x-axis represents and each dot represents a combination of . A total of 500 combinations were compared between the two estimators, and each combination represents the result of 10,000 simulations. Figure 1 depicts the relationships between and the empirical bias, standard deviation, test size, and power. When the size of bias is far from 0, the empirical test size of is far from and the empirical power of is far from . On the other hand, since the empirical test size of the biased-adjusted estimator is stable around , the empirical power of is statistically informative. Figure 2 displays a histogram comparing the RMSEs of the two estimators for the 500 combinations. Since the RMSE is affected by the bias and standard deviation and our approach sacrifices some precision in the process of adjusting the bias, our approach will show a greater advantage when is large.
Comparisons of the empirical bias, standard deviation, test size, and power of and , given , and 500 combinations of .
Comparisons of the RMSEs of and when and . The absolute values of were obtained from 500 combinations of . The darker area means that the RMSE value of is greater than or equal to ; otherwise, it is represented by the lighter area.
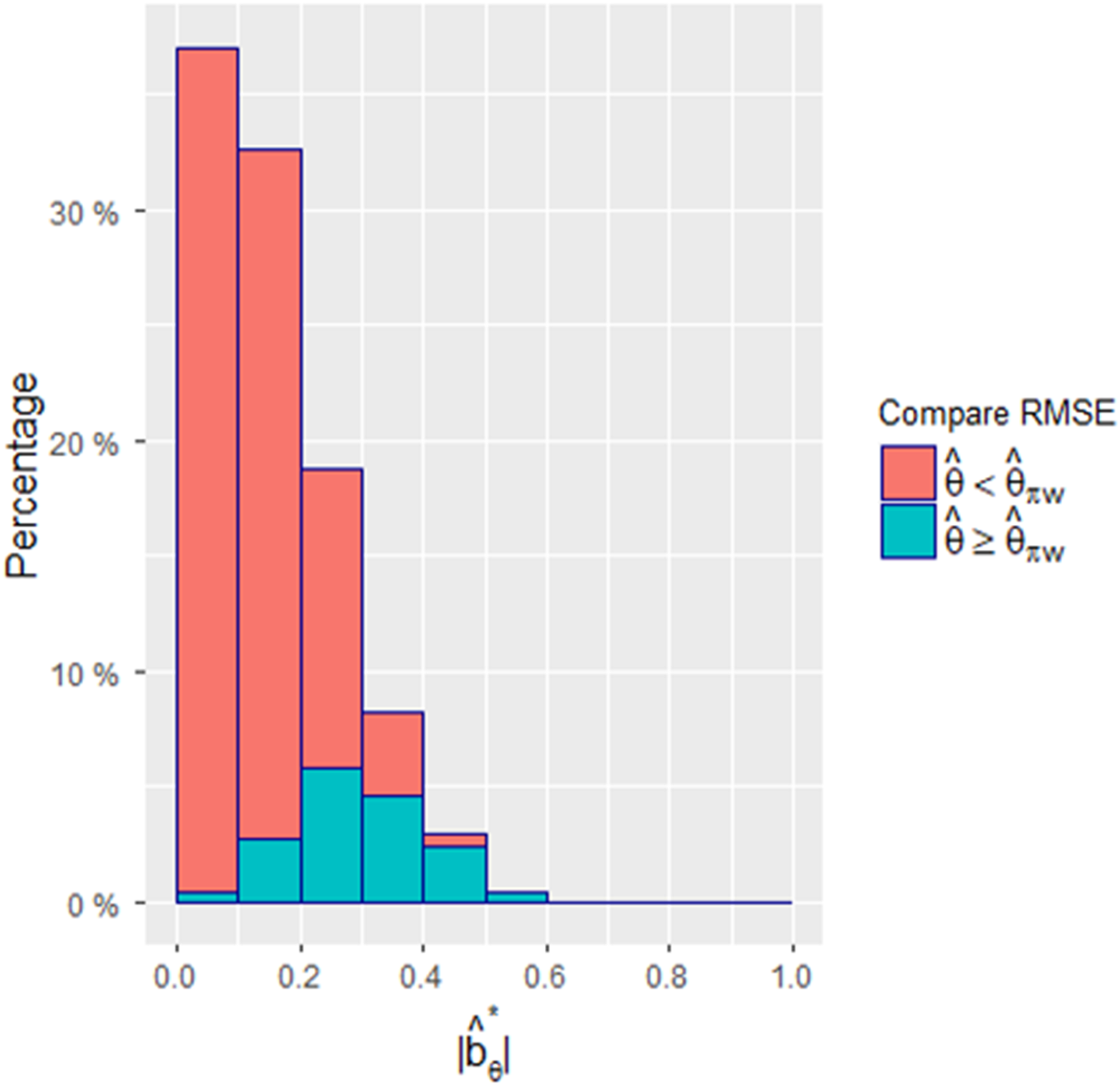
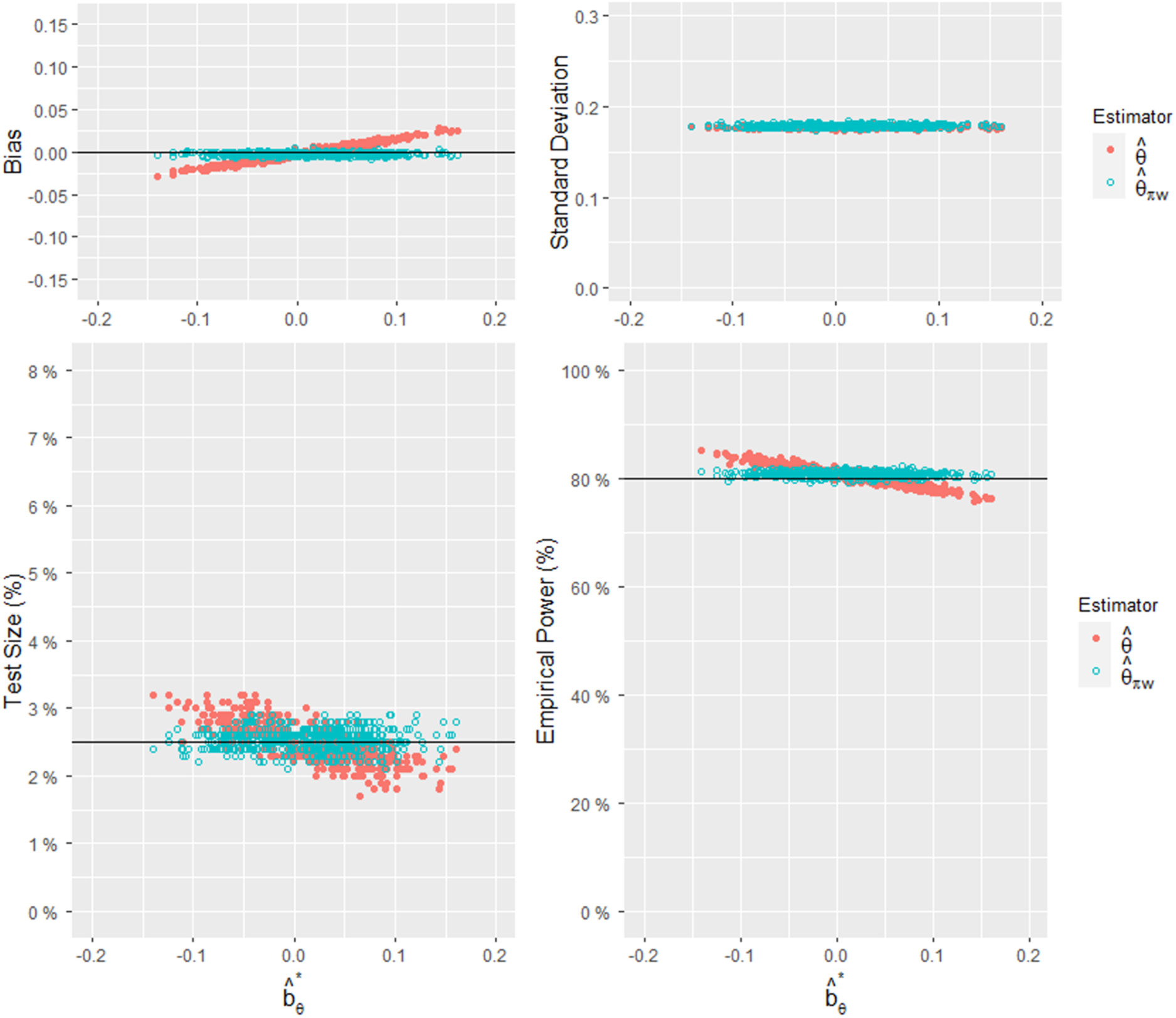
In the second set of predetermined patient allocation settings, we have and . We conducted 10,000 simulations for each combination , considering a total of 500 combinations for analysis. For this set, the observed regional weights were randomly generated from a uniform distribution within the range of with a constraint on . The observed treatment allocation ratios were randomly generated from a uniform distribution with the mean of 0.7, and the range of . The required sample size was determined to be 667. The results of the simulation study are presented in Figures 3 and 4. Figure 3 illustrates the relationships between and the bias, standard deviation, test size, and power for the two estimators and . Figure 4 presents a histogram comparing the RMSEs of the two estimators for the 500 combinations of . Similar to the previous analysis, the findings shown in Figures 3 and 4 align with the conclusions drawn from Figures 1 and 2.
Comparisons of the empirical bias, standard deviation, test size, and power of and , given , and 500 combinations of .
Comparisons of the RMSEs of and when and . The absolute values of were obtained from 500 combinations of . The darker area means that the RMSE value of is greater than or equal to ; otherwise, it is represented by the lighter area.
When the observed regional weights and treatment allocation ratios closely align with the design, the bias of is close to 0, and our proposed estimator demonstrates its advantages by reducing bias, maintaining a stable test size close to , and providing informative empirical power. To demonstrate this, we adopted the same designed set as the first set in this section, and assumed the observed regional weights were randomly generated from a uniform distribution within the range of , the observed treatment allocation ratios were randomly generated from a uniform distribution within the range of . Such assumptions about the range of observed values and are not exceptional but rather represent a common scenario. The results are summarized in Figure 5, which illustrates the relationships between and the bias, standard deviation, test size, and power for the two estimators and . The stability is demonstrated by the consistent performance of our method despite the variability of . Therefore, our method demonstrates better performance.
Comparisons of the empirical bias, standard deviation, test size, and power of and , given , and 500 combinations of , where and .
In the third set of predetermined patient allocation settings, we considered seven regions to investigate the scenario with a larger number of regions. Let the event rates of the treatment group and the control group be and respectively. At the design stage, we set the patient assignments as and . The between-region variance was 0.0077. At a significance level of and a power of , the required sample size was determined to be 523. The observed regional weights were randomly generated from a uniform distribution within the range of with a constraint on . The observed treatment allocation ratios were randomly generated from a uniform distribution with the mean of 0.5, and the range of . The results of the simulation study are presented in Figure 6, which illustrates the relationships between and the bias, standard deviation, test size, and power for the two estimators and . Since our approach sacrifices some precision in the process of bias adjustment, this effect appears to be more pronounced as the number of regions increases. However, the performance of our proposed estimator remains stable, across different values of .
Comparisons of the empirical bias, standard deviation, test size, and power of and , given and and 500 combinations of .
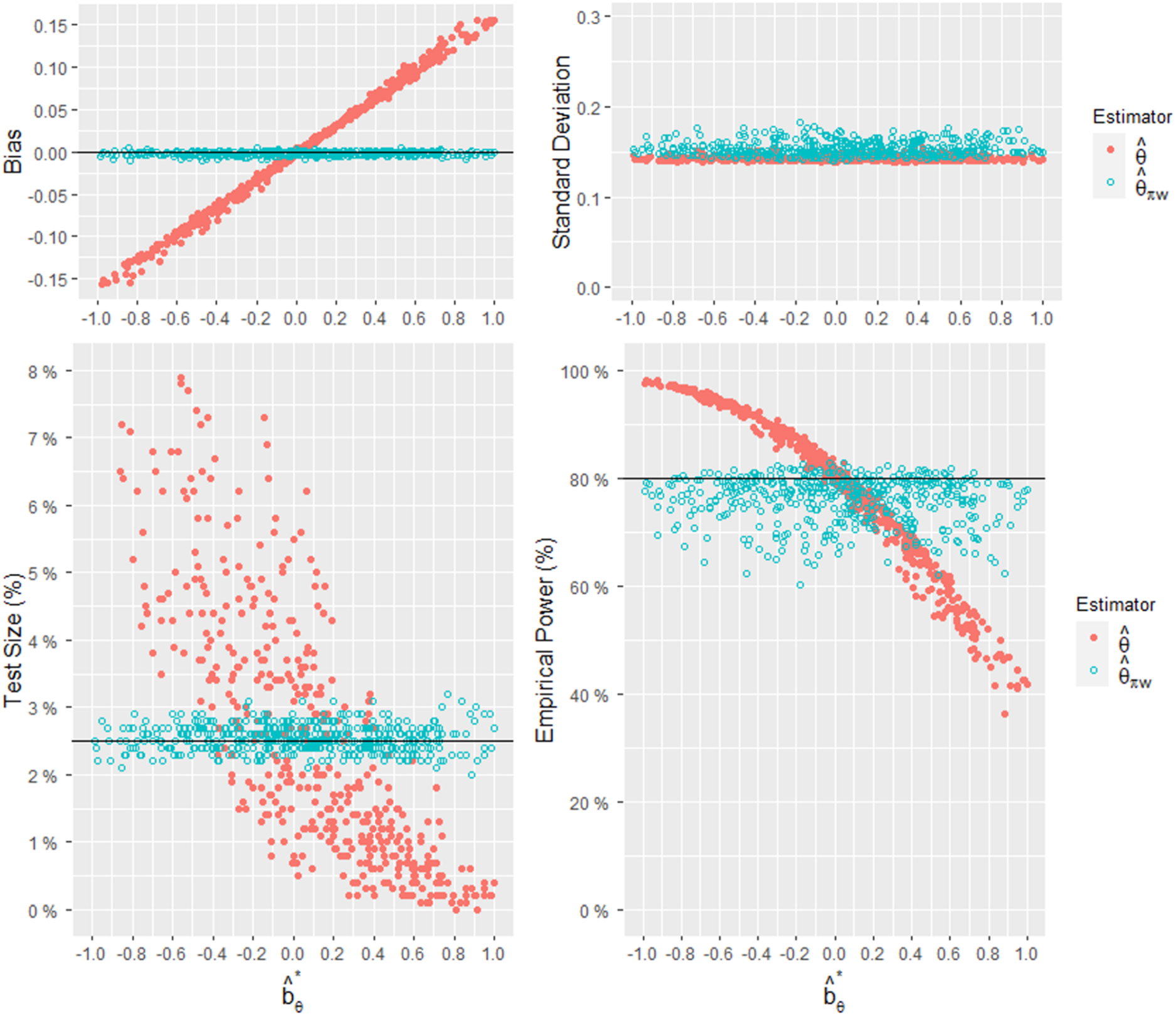
Finally, we considered the scenario with noticeable treatment effect heterogeneity in the case of three regions with and . At the design stage, we set the patient assignments as and . The between-region variance was 0.0280. Notably, this value is nearly four times greater than in the first designed set. At a significance level of and a power of , the required sample size was determined to be 839. The observed regional weights were randomly generated from a uniform distribution within the range of . The observed treatment allocation ratios were randomly generated from a uniform distribution with the mean of 0.5 and the range of . The results of the simulation study are presented in Figure 7, which illustrates the relationships between and the bias, standard deviation, test size, and power for the two estimators and . In this scenario with obvious treatment effect heterogeneity, our method continues to demonstrate advantages in reducing bias, ensuring that the test size is stable at around 2.5%, and providing meaningful empirical power.
Comparisons of the empirical bias, standard deviation, test size, and power of and , given , and 500 combinations of .
In summary, the simulation study provides evidence that the bias-adjusted estimator outperforms the naïve estimator by reducing the bias, maintaining a stable test size close to 2.5%, and yielding informative empirical power. The larger the bias is, the more advantageous the proposed method is.
Example
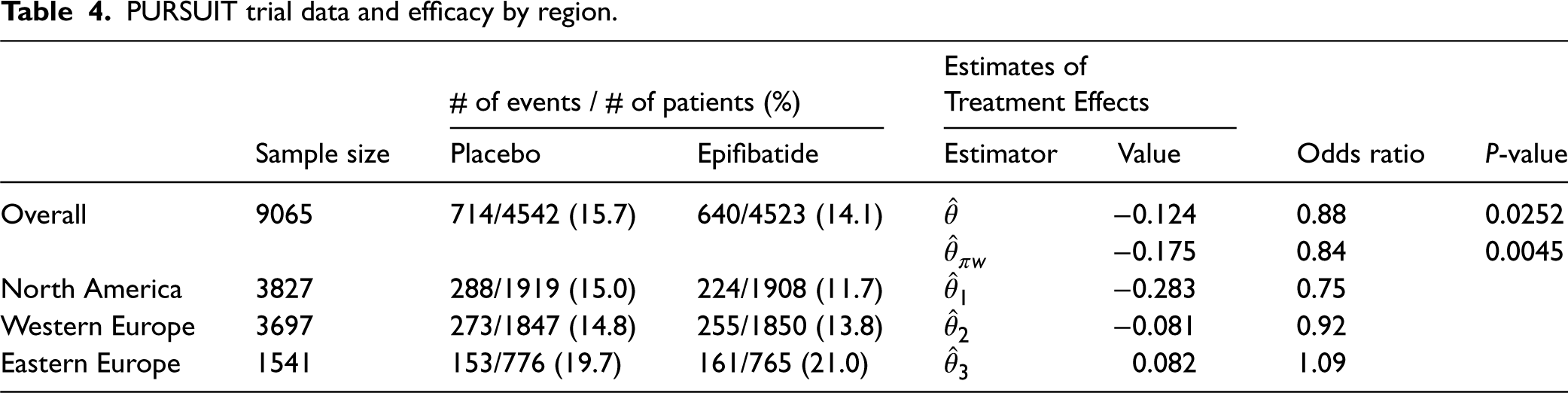
In this section, we provide a real-data example to illustrate the proposed approach. We utilized partial information from the Platelet Glycoprotein IIb/IIIa in Unstable Angina: Receptor Suppression Using Integrilin Therapy (PURSUIT) trial.16,17,18 The PURSUIT trial was a randomized, double-blind, add-on, MRCT that enrolled a total of 10,948 patients with acute coronary syndrome from 726 hospitals across 28 countries. The data is available online at https://doi.org/10.1056/NEJM199808133390704. In this example, we focused on 9065 patients who participated in the trial from three geographical regions: North America (NA), Western Europe (WE), and Eastern Europe (EE). In addition to standard therapy, the patients received eptifibatide or placebo in a 1:1 treatment allocation ratio. The primary endpoint was a composite of death and nonfatal myocardial infarction (MI) at 30 days after study initiation. Table 4 shows the event rates (death or MI) and the number of patients for the overall trial population as well as the individual regions (NA, WE, and EE). Based on this information, the observed regional weights were and the observed treatment allocation ratios were . The treatment allocation ratio for each region was approximately 0.5, indicating that the randomization scheme worked well. Additionally, the overall treatment allocation ratio was .
PURSUIT trial data and efficacy by region.
# of events / # of patients (%)
Estimates of Treatment Effects
Sample size
Placebo
Epifibatide
Estimator
Value
Odds ratio
P-value
Overall
714/4542 (15.7)
640/4523 (14.1)
−0.124
0.88
0.0252
−0.175
0.84
0.0045
North America
3827
288/1919 (15.0)
224/1908 (11.7)
−0.283
0.75
Western Europe
3697
273/1847 (14.8)
255/1850 (13.8)
−0.081
0.92
Eastern Europe
1541
153/776 (19.7)
161/765 (21.0)
0.082
1.09
Table 4 also provides the estimates of the treatment effects both overall and by region. Note that the treatment effect is defined as the log(OR) of the eptifibatide group compared to that of the placebo group, with a lower value indicating a better result. Based on the DREM with the regional treatment effect estimates , the between-region variance estimate was 0.0187. In addition, the naïve estimate for log(OR) was , with the standard error of 0.063 and the P-value of 0.0252. The corresponding estimate of OR was 0.88. For our purpose, we assumed that predetermined regional weights in the protocol were Using these regional weights, the bias-adjusted estimate was calculated to be , with the standard error of 0.067 and the P-value of 0.0045. The corresponding estimate was 0.84. Notably, the P-value for is much less than that for , indicating a more significant overall treatment effect when the bias-adjusted estimate was used. In principle, if we use for testing the significance of the treatment effect, did not lead to the conclusion of significance. However, the proposed method concluded a high significance.
Discussion
With the framework of the DREM, we expanded the approach proposed by Tian et al.6 to evaluate an MRCT. Specifically, we proposed the adjusted estimator that quantifies the bias of the naïve estimator through conditional inference. The bias-adjusted estimator improves the accuracy of the treatment effect estimation, as it is stochastically closer to the true treatment effect . This conditional correction of bias further strengthens our understanding of the process of enhancing the accuracy.
In this work, we also derived the required sample sizes and for and , respectively, to achieve the desired power level. Through simulation analysis considering different combinations of observed patient assignments, we evaluated the performance of the two estimators. The bias-adjusted estimator exhibited a reduced bias, maintained a stable test size close to the target significance level, and provided meaningful empirical power. These findings emphasize the importance of bias correction in MRCTs and highlight the effectiveness of our proposed approach for obtaining accurate treatment effect estimates. Our approach is especially valuable when there is noticeable bias in patient assignments. Furthermore, our approach is flexible and can be applied to MRCTs with different numbers of regions () and other types of endpoints, such as continuous or survival outcomes.
There are numerous challenges in the design and evaluation of MRCTs. The “Basic Principles of Global Clinical Trials” issued by the Japanese Ministry of Health, Labour and Welfare (MHLW),19 provides some guidelines for the planning and implementation of global clinical studies. These guidelines raise concerns regarding the consistency of efficacy for patients in a specific region and the overall population. In future research, incorporating the bias-adjusted estimator proposed in this paper may contribute to exploration of this topic and aid in the design of MRCTs. Of note, some informative studies by Tsong et al.,20 Tsou et al.,21 and Liu et al.4 have investigated the consistency of efficacy across regions, providing valuable insights.
Footnotes
Acknowledgements
The authors are grateful to the reviewer for their constructive and helpful comments, which led to a much improved version of the manuscript.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Ministry of Education, Taiwan, ROC.
ORCID iDs
Hsiao-Hui Tsou
Suojin Wang
References
1.
HungHJWangSJO'NeillRT. Consideration of regional difference in design and analysis of multi-regional trials. Pharm Stat2010; 9: 173–178.
2.
WangSJJames HungHM. Ethnic sensitive or molecular sensitive beyond all regions being equal in multiregional clinical trials. J Biopharm Stat2012; 22: 879–893.
3.
LanKGGPinheiroJ. Combined estimation of treatment effects under a discrete random effects model. Stat Biosci2012; 4: 235–244.
4.
LiuJTTsouHHGordon LanKK, et al.Assessing the consistency of the treatment effect under the discrete random effects model in multiregional clinical trials. Stat Med2016; 35: 2301–2314.
5.
LanKKGPinheiroJChenF. Designing multiregional trials under the discrete random effects model. J Biopharm Stat2014; 24: 415–428.
6.
TianLJiangFHasegawaT, et al.Moving beyond the conventional stratified analysis to estimate an overall treatment efficacy with the data from a comparative randomized clinical study. Stat Med2019; 38: 917–932.
7.
SennSJ. Covariate imbalance and random allocation in clinical trials. Stat Med1989; 8: 467–475.
8.
PocockSJAssmannSEEnosLE,et al.Subgroup analysis, covariate adjustment and baseline comparisons in clinical trial reporting: current practice and problems. Stat Med2002; 21: 2917–2930.
9.
KalbfleischJD. Sufficiency and conditionality. Biometrika1975; 62: 251–259.
10.
ZhangMTsiatisAADavidianM. Improving efficiency of inferences in randomized clinical trials using auxiliary covariates. Biometrics2008; 64: 707–715.
11.
TsiatisAADavidianMZhangM,et al.Covariate adjustment for two-sample treatment comparisons in randomized clinical trials: a principled yet flexible approach. Stat Med2008; 27: 4658–4677.
12.
MooreKLvan der LaanMJ. Covariate adjustment in randomized trials with binary outcomes: targeted maximum likelihood estimation. Stat Med2009; 28: 39–64.
13.
TianLCaiTZhaoL,et al.On the covariate-adjusted estimation for an overall treatment difference with data from a randomized comparative clinical trial. Biostatistics2012; 13: 256–273.
14.
FalseyARSobieszczykMEHirschI, et al.Phase 3 safety and efficacy of AZD1222 (ChAdOx1 nCoV-19) COVID-19 vaccine. N Engl J Med2021; 385: 2348–2360.
15.
HsiehSMLiuMCChenYH, et al.Safety and immunogenicity of CpG 1018 and aluminium hydroxide-adjuvanted SARS-CoV-2 S-2P protein vaccine MVC-COV1901: interim results of a large-scale, double-blind, randomised, placebo-controlled phase 2 trial in Taiwan. Lancet Respir Med2021; 9: 1396–1406.
16.
PURSUIT Trial Investigators. Inhibition of platelet glycoprotein IIb/IIIa with eptifibatide in patients with acute coronary syndromes. N Engl J Med1998; 339: 436–443.
17.
AkkerhuisKMDeckersJWBoersmaE, et al.Geographic variability in outcomes within an international trial of glycoprotein IIb/IIIa inhibition in patients with acute coronary syndromes. Results from PURSUIT. Eur Heart J2000; 21: 371–381.
18.
MahaffeyKWHarringtonRAAkkerhuisM, et al.Disagreements between central clinical events committee and site investigator assessments of myocardial infarction endpoints in an international clinical trial: review of the PURSUIT study.Curr Control Trials Cardiovasc Med2001; 2: 187–194.
19.
Ministry of Health, Labour and Welfare of Japan (MHLW). “Basic principles on global clinical trials,” Available at: http://www.pmda.go.jp/files/000153265.pdf. 2007.
20.
TsongYChangWJDongX,et al.Assessment of regional treatment effect in a multiregional clinical trial. J Biopharm Stat2012; 22: 1019–1036.
21.
TsouHHJames HungHMChenYM, et al.Establishing consistency across all regions in a multi-regional clinical trial. Pharm Stat2012; 11: 295–299.