
Abstract
Counterfactual inference at the distributional level presents new challenges with censored targets, especially in modern healthcare problems. To mitigate selection bias in this context, we exploit the intrinsic structure of reproducing kernel Hilbert spaces (RKHS) harnessing the notion of kernel mean embedding. This enables the development of a non-parametric estimator of counterfactual survival functions. We provide rigorous theoretical guarantees regarding consistency and convergence rates of our new estimator under general hypotheses related to smoothness of the underlying RKHS. We illustrate the practical viability of our methodology through extensive simulations and a relevant case study: The SPRINT trial. Our estimatort presents a distinct perspective compared to existing methods within the literature, which often rely on semi-parametric approaches and confront limitations in causal interpretations of model parameters.
Keywords
Introduction
Estimating treatment effects using survival endpoints is a critical concern in the field of statistical methodology and translational research within the biomedical domain. However, the challenges related to obtaining data from randomized controlled trials hinder the establishment of robust experimental designs that aim to address questions related to treatment effects. Consequently, observational studies play a central role in medicine, and the development of new methods to accommodate the diverse sampling design problems that often arise is a major methodological concern. Personalized healthcare 1 serves as an exemplary case in point, where planning tailored interventions is imperative to guide optimal treatments, and randomization may not be feasible due to ethical and resource constraints.
In the context of observational data, the cornerstone of statistical analysis revolves around the potential outcomes framework, which forms the foundation for causal assertions regarding treatment effects.2–4 As a general rule, we observe only one response per patient following a specific treatment arm, making it impossible to directly compare the effectiveness of multiple treatment strategies on the same individuals. This limitation leads to the need for inferential methods that can bridge this gap. In the field of counterfactual inference, the prevailing approach in the literature is based on the concept of average treatment effect (ATE). The ATE is a parameter of paramount importance as it quantifies the difference in means of potential outcomes distributions between arms,5–7 harmonizing with the principles of causal inference outlined by Pearl et al. 8
A distinctive feature of survival analysis is that users are interested in modeling the conditional distribution of the response, rather than focusing solely on its specific characteristics, such as the conditional mean. This is because the conditional expectation often provides a limited picture of patients’ responses, given the significant variability and heterogeneity across individuals to a fixed therapeutic strategy. 9 Furthermore, the presence of censoring complicates estimation and increases the bias of estimators, making the design of robust and efficient estimators a crucial task, given the limited availability of patient response data particularly when dealing with clinical treatments.
In practical terms, practitioners have widely employed estimators based on a hazard ratio. However, many of these strategies face challenges in terms of causal interpretation, as is the case with Cox’s 10 model. This has sparked considerable debate regarding the advantages and real-world possibilities that these models offer in practice.11–13 There has also been a question about the need to develop new models that overcome these limitations while remaining interpretable. Furthermore, a poorly specified selection of semiparametric estimators can lead to clinical conclusions that are far removed from the reality of treatment effects.14,15
Chernozhukov et al. 16 proposed seminal methodology for regressing counterfactual distributions in censoring-free contexts. Reciprocally, in survival analysis under randomization it would suffice to fit one Kaplan–Meier 17 curve per arm. However, in observational studies (or randomized experiments with imperfect compliance), this type of analysis becomes challenging. 18 In this line, distributional extensions of the ATE have been considered in the literature through multiple lenses. For example, 19 considers a bootstrap strategy to test distributional treatment effects while 20 base their work on the theory of reproducing kernel Hilbert spaces (RKHSs).
In this line, estimating potential outcomes distributions directly is straightforward in randomized settings but becomes challenging in observational studies due to distributional disparities between group characteristics.
10
Our approach focuses directly on a parameter that directly captures the gap between potential outcomes on the scale of survival probabilities. Let
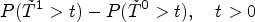
We embrace a framework for estimating counterfactual distributions under right-censoring, leveraging the power of inference within a RKHS. Inspired by classical econometric concepts in the absence of censoring,16,22,23 we offer a way to dissect the differences between observational distributions24,25 through disentangling the various components contributing to these discrepancies: whether they arise from treatment effectiveness, baseline characteristics, or a combination of both. It provides a structured mechanism for rigorously assessing the origins of observed disparities between treatment groups.
To delve into specifics, we introduce the concept of Causal Survival Embeddings (CSEs). While building upon prior work designed for non-censored data, our methodology goes a step further by not only estimating kernel embeddings of counterfactual distributions 20 but also enhancing their interpretability in terms of survival functions. Our method introduces a fresh perspective for comprehending treatment effects in observational studies. They quantify the contributions of various factors and surmount the interpretation limitations often encountered with traditional distributional survival models, such as those seen in the Cox model.
From a practical standpoint, our estimators offer several advantages. They exhibit favorable statistical properties in terms of convergence rates. Additionally, they are versatile enough to accommodate diverse sources of information, having the potential to encompass techniques like functional data analysis and address the intricate structures prevalent in contemporary medical research.
Our results and contributions
We introduce a general non-parametric estimator under right-censoring of counterfactual survival functions based on statistical inference on RKHSs.
Our estimation procedure is a model-free approach based on embedding counterfactual distributions in RKHSs. This extends the prior work of Muandet et al.
20
to handle censored data-generation environments, being our proposal the first strategy in the literature that adjusts for confounding in non-parametric estimation of survival functions. Traditional non-parametric survival estimators like Beran’s
26
typically rely on strong smoothness conditions such as differentiability of density functions. In general, our approach does not require these hypotheses (only mild conditions on the moments of the kernel function). This makes our method more flexible and applicable to a wider range of scenarios. Theoretically, we are able to provide asymptotic behavior guarantees for our estimator and compute its convergence rate by employing techniques from Empirical Process Theory. We utilize these techniques to deduce the Hadamard-differentiability of an operator that takes values in a RKHS. While the Functional Delta Method
27
is widely known for its application to general operators in Banach spaces, the interplay between the geometry of RKHSs and von Mises calculus remains relatively unexplored in the literature, with little research delving into this aspect.28,29 Our procedure is computationally efficient since the main challenge lies in the estimation of conditional mean embeddings, a process that traditionally requires non-severe computational resources. Furthermore, our approach exclusively uses Kaplan–Meier weights, which are implemented in a highly efficient manner in widely recognized software packages, such as R’s survival. In addition, the framework of kernel embeddings allows for a natural reconstruction of probability measures from information encoded in elements belonging to Hilbert spaces of functions.
30
The Supplemental material includes a brief explanation of how to recover counterfactual distributions from estimators of their kernel mean embedding. We display the potential and interpretability of our new estimator through its application to a pioneer analysis of the SPRINT trial,
31
a celebrated governmental medical study tackling cardiovascular morbidity and mortality in the United States. We demonstrate that CSEs outperform existing and well-known methods in the literature, as showcased by simulations in Section 5.1. Specifically, our method surpasses the Adjusted Kaplan–Meier Estimator (AKME)
32
and Causal Survival Forests.
33
Related work
Different methods exist for treatment effect estimation in presence of censoring. A general procedure that can be found across the literature consists of the following steps. First, the ATE is causally identified without censoring and then a so-called Censoring Unbiased Transformation34,35 is used to create a pseudopopulation from the observed data in which the conditional mean survival time is the same as in the uncensored population. Second, methodology from semiparametric inference adapts the estimators to the censoring mechanisms. 36 Alternative estimators of treatment effect include standardizing expected outcomes to a given distribution of the confounders (Robins’ g methods 37 ), inverse probability of treatment weighting (IPTW) estimators38,39 and doubly robust estimators, 40 which combine the two latter lines. In Xue et al., 41 the authors balance the covariates over an RKHS to avoid directly modeling the propensity score for estimating causal effects.
The utilization of tools from the RKHS framework for right-censored data is relatively limited, with a primary focus on hypothesis testing,42–44 albeit outside the context of counterfactual inference. There have also been efforts to perform hypothesis testing using RKHS’s in other incomplete information schemes such as missing reponses. 45
Organisation of the paper
The paper is structured as follows. In Section 2 we rigorously introduce the formal elements that constitute the basis of our work by specifying: The fundamental random variables playing a role, which of them are observable and which are not, how they interact between them to generate incomplete information, and notation for their distribution functions. A self-contained description of the parameters of interest is presented next, accompanied by an opening introducing the notion of counterfactual distributions in survival analysis. Then we define their counterparts in a Hilbert space, leading to the notion of counterfactual mean embedding. Naturally, in Section 3 we develop the estimation theory that is needed in our setting, involving M-estimation on a space of functions that themselves take values in another space of functions. The asymptotic properties of our proposal estimator are investigated in Section 4, starting with preliminary definitions needed for its formalization followed by sufficient conditions for consistency and a convergence rate of non-parametric counterfactual inference under censoring. Detailed and extensive simulation studies can be found in Section 5, being Section 6 concerned with the workflow of our proposal in medical contexts, illustrating the usefulness of our methodology in a real application case related to cardiology. Finally, Section 7 closes the document with a discussion on the consequences of relaxing the censoring assumptions and other concerns regarding open directions.
Population elements
Setup
We start with a collection of random variables in the potential outcomes framework:
46
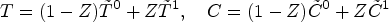
We define
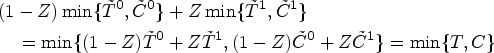
In practice, we observe an i.i.d sample
Counterfactual survival functions
A key consideration for understanding counterfactual inference is that
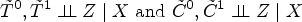
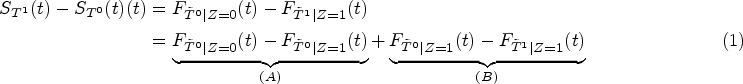
It is important to note again that
We now see how these distributions related to potential outcomes that appear in distributional causal effects are related to the notion of counterfactual distribution, defined below. In the following,
Whenever support
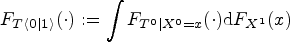
An important result in Muandet et al.
20
establishes a link between arm-conditioned and counterfactual distributions. It asserts that, in general,
If assumptions of Lemma 1 are fulfilled, then term (A) in (1) satisfies
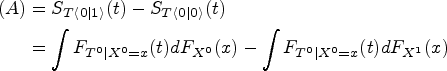
Kernel embeddings
Let
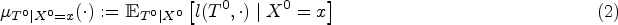
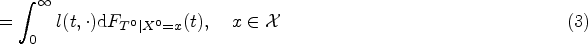
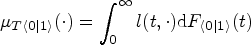
We first discuss how to estimate
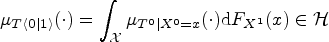
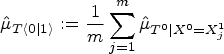
We have by the generalized conditional Jensen’s inequality
51
and iterated expectations lemma:
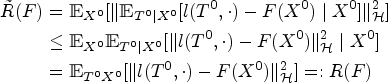
Now the problem is that, because of censoring, we do not have access to a sample from the joint distribution of
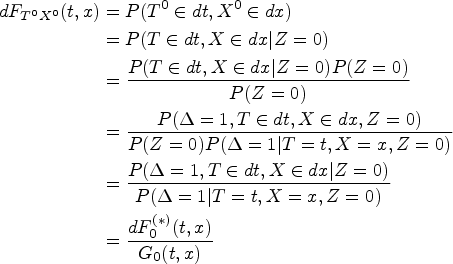
Note that if we assume
Let
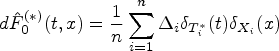
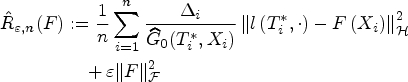
A minimizer of the empirical risk
See Supplemental material. □
Choosing
The counterfactual mean embedding is computed by taking the average of the previous row:
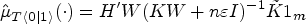
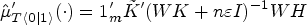
Computing an estimator of
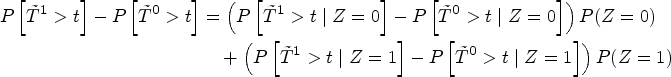

This section comprises the main theoretical contribution of our work. Let us get started by a couple of definitions needed to reexpress parameters and their estimators in a more convenient way regarding proofs.
Population and empirical covariance operators
We need to introduce the following definitions20,54 in order to state theoretical results regarding asymptotic properties of our estimator.
Let
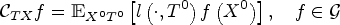
Substituting in the measure
Let
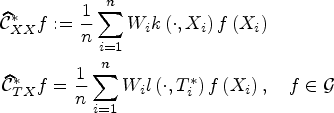
The following result shows that we can write
Let
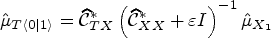
See Supplemental material. □
In the following, we introduce the assumptions needed for establishing consistency of our proposed estimator. Recall that The distribution
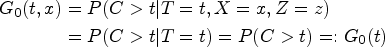
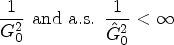
Consistency and convergence rate
Our main theoretical contribution is the convergence rate of the stochastic error in RKHS norm in Theorem 1. Once established, we use it to establish consistency in Corollary 1 and find the final convergence rate in Corollary 2.
Convergence rate of the stochastic error
Consider the CSEs estimator
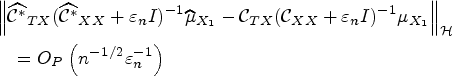
See Supplemental material. □
Suppose that Assumptions (i.) to (vi.) are satisfied. Let the regularization constant
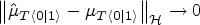
See Supplemental material. □
Suppose that Assumptions (i.) to (vi.) in our paper and Assumptions 3 and 4 in Muandet et al.
20
hold with
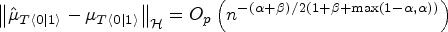
See Supplemental material. □
Informally,
In this section, we thoroughly evaluate the effectiveness of CSEs through three focused analyses. First, we conduct an empirical comparison with state-of-the-art methods to benchmark CSEs against existing techniques (Section 5.1). Second, we assess the asymptotics of our estimator itself at the RKHS scale, examining its performance across various sample sizes and simulation runs (Section 5.2). Third, we evaluate the reconstruction of counterfactual survival functions through CSEs at the raw distributional scale under different levels of censoring and distributional shifts (Section 5.3). This structured approach allows us to demonstrate the advantages of the new method compared to existing approaches and subsequently verify its convergence properties.
Empirical comparison with the literature
We present a comparative analysis of four methods—CSEs, Counterfactual Mean Embeddings
20
considering uncensored observations, AKME, and Causal Survival Forests (GRF)—in estimating survival functions. We simulate
Causal survival forests
Recall the parameter of interest,
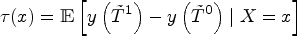
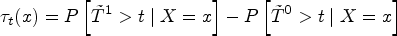
Choosing a different value of
Inverse probability of treatment weighting is among the various approaches that leverage the treatment assignment mechanism to adjust for confounding. Specifically, Xie and Liu 32 proposed an IPTW-based Kaplan–Meier estimator, referred to as the AKME estimator, which applies weights derived from the inverse probability of group assignment to adjust survival estimates.
Counterfactual mean embeddings (Naive)
The Naive method we define involves fitting Counterfactual Mean Embeddings 20 using only non-censored observations. This approach is commonly adopted when attempting to apply methods originally designed for complete (non-censored) data to survival analysis settings. 59 Have into account that the Naive method does not borrow information from censored observations and results therefore in an inefficient estimator.
Simulation setup
We generated synthetic data to compare the performance of the described methods with our approach. A single dataset consists of two groups: A control group with
Each observation includes three covariates
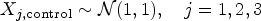
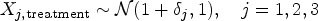
The population conditional survival functions for the control and treatment groups are non-linear functions of the covariates, incorporating complex interactions to reflect realistic scenarios. For the control group:

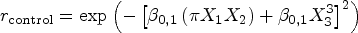
For the treatment group, we apply a time shift factor
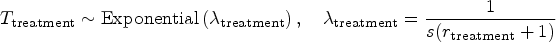
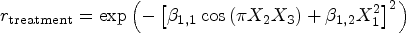
For both groups, censoring times follow exponential distributions:

All estimates are assessed by comparison with the true counterfactual survival difference
Following Klein and Moeschberger,
61
we consider the mean-squared error (MSE) between the estimated and true survival curves. For a given simulation run,
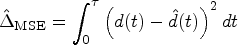
We compute the arithmetic mean and standard deviation of
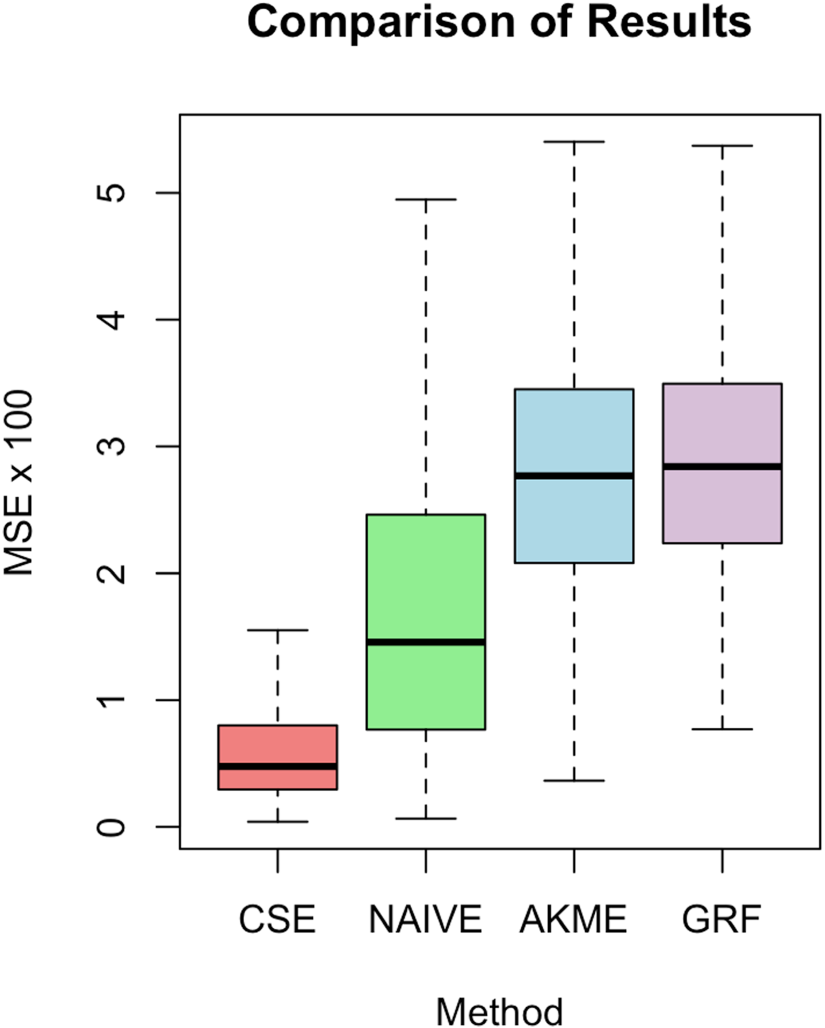
Comparison of our approach with the three methods described in Section 5.1.
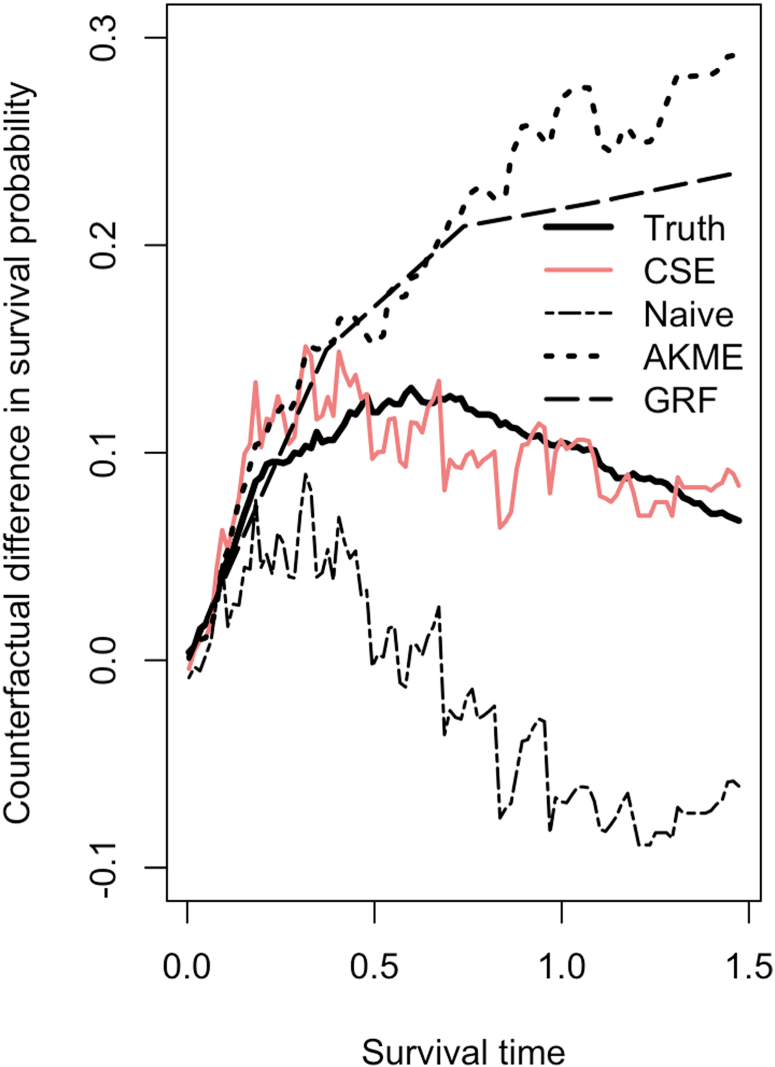
The true difference between counterfactual survival functions,
Comparison of results: MSE average and standard deviation.
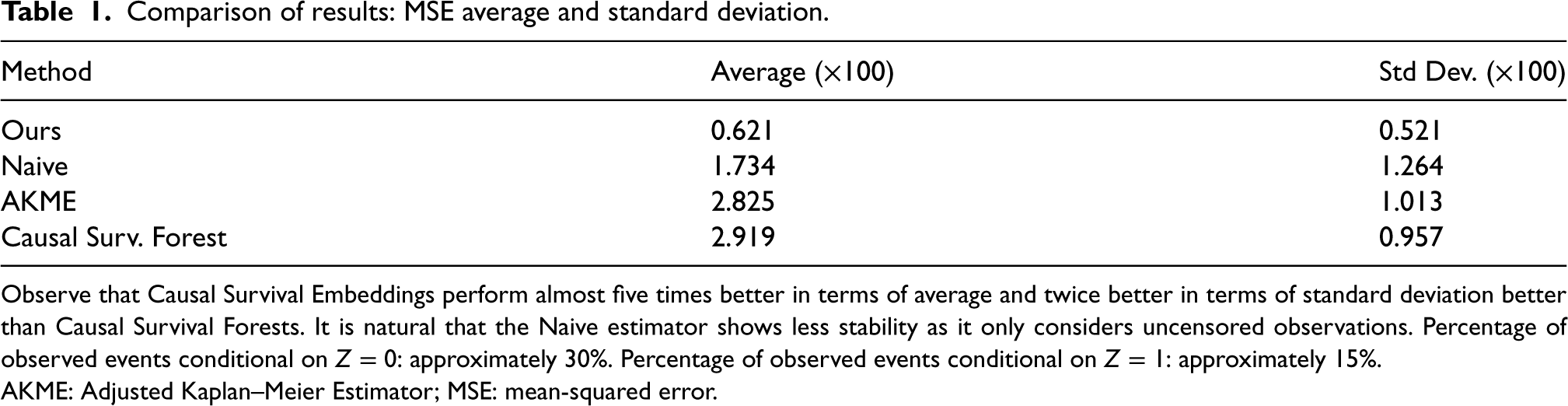
Observe that Causal Survival Embeddings perform almost five times better in terms of average and twice better in terms of standard deviation better than Causal Survival Forests. It is natural that the Naive estimator shows less stability as it only considers uncensored observations. Percentage of observed events conditional on
The superior performance of CSE can be attributed to several factors. While both CSE and GRF utilize flexible, non-parametric approaches to model the survival function and capture complex relationships between covariates and survival times, there are some notable distinctions in their underlying assumptions and analytical frameworks.
CSE directly employs conditional mean embeddings without requiring specific functional assumptions about the propensity score. GRF, built on the random forest framework, also models complex relationships through an ensemble of decision trees that partition the feature space. While random forests are technically non-parametric, their theoretical analysis often involves simplifying assumptions. Specifically, for studying the asymptotic properties of random forests, an additive regression model for the response is frequently assumed. 62 This assumption helps to establish theoretical guarantees regarding asymptotics but can limit the flexibility of the model when applied to data with non-additive or non-linear interactions between covariates and outcomes. As detailed in Scornet et al., 62 this additive assumption aids in understanding the behavior of random forests in large samples but may not always align with the model’s practical application, especially when the true relationships are more complex.
Secondly, unlike AKME, which uses IPTW to adjust for treatment assignment, CSE does not require reweighting with propensity-to-treatment scores. Reweighting can introduce additional variance, especially in regions with few data or extreme propensity scores.
Thirdly, CSE inherently accounts for censoring without excluding censored observations. This contrasts with the Naive method, which only considers uncensored data, leading to higher variability because of small sample sizes, particularly at larger time horizons. The ability to incorporate censored data allows CSE to maintain accuracy across the entire range of observed times.
In conclusion, our proposal demonstrates clear advantage over the other methods evaluated in this setting.
We perform estimation of CSEs for
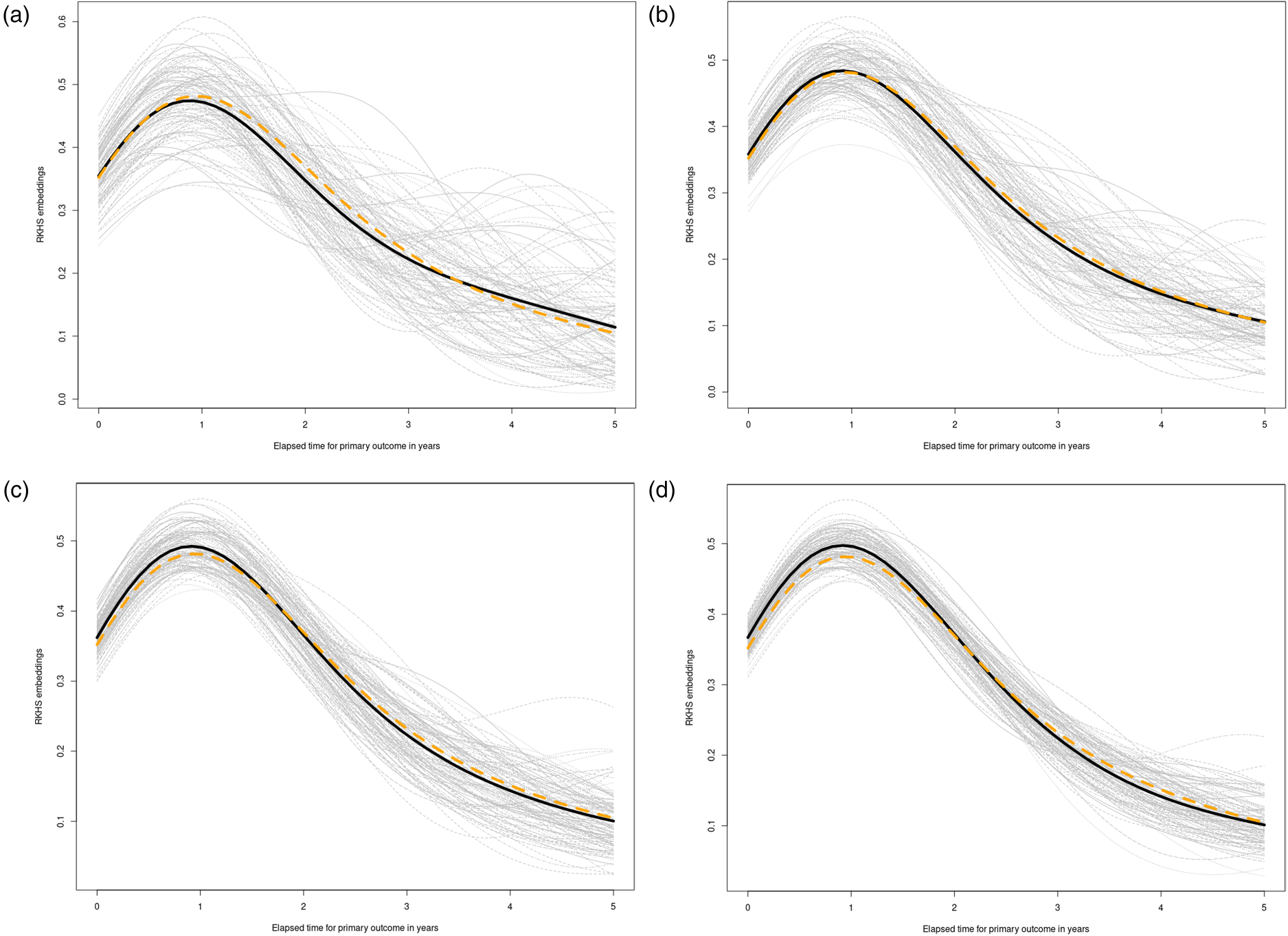
Simulation results for subsection 5.2. See setup details in the Supplemental material (subsection 7.2). (a)
We undertake an examination of the impact of varying levels of censoring percentage on the reconstruction of counterfactual survival functions. To achieve this, we maintain a fixed sample size—
Our simulation design encompasses two distinct scenarios, each representing a fundamental aspect of observational studies. In the first scenario, we delve into cases where observational differences across treatment groups are primarily driven by distributional variations within the treated arm, corresponding (Case I in the Supplemental material). In the second scenario, we consider situations where disparities in survival outcomes between treatment arms arise predominantly from shifts in the covariate distribution (Case II in Supplemental material).
Results are displayed in Table 2 and a graphical depiction of the simulation results is in Figure 4. Further details on the simulation process can be found in Supplemental material 7.3.
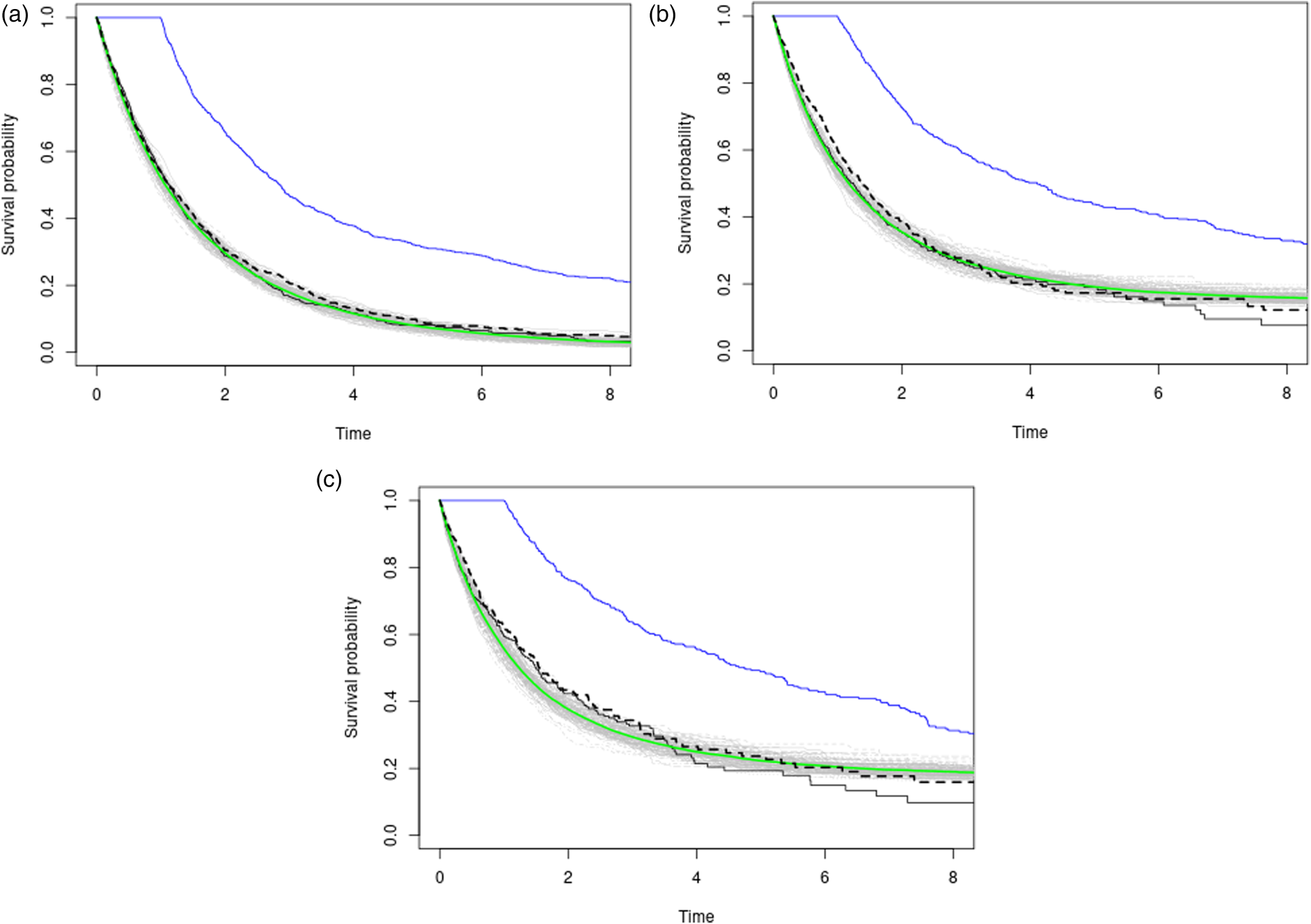
Three plots with varying censoring percentages (approx. 25%, 50%, 65% in descending order) in a no-confounding scenario on a fixed grid of time-points. The black and blue curves represent observational Kaplan–Meier estimates for the placebo and treatment arms, respectively. The gray lines depict
Performance metrics for different censoring percentages.
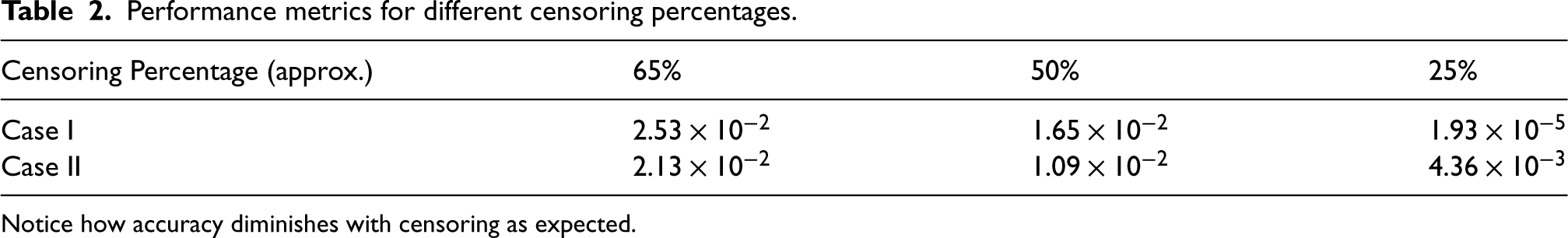
Notice how accuracy diminishes with censoring as expected.
NIH’s Systolic Blood Pressure Intervention Trial (SPRINT) was conducted to inform the new blood pressure medication guidelines in the US by testing the effects that a lower blood pressure target has on reducing heart disease risk. Observational studies had shown that individuals with lower systolic blood pressure (SBP) levels had fewer complications and deaths due to cardiovascular disease (CVD). Building on this observation, the NIH’s Systolic Blood Pressure Intervention Trial (SPRINT) was designed to test the effects of a lower blood pressure target on reducing heart disease risk. Specifically, SPRINT aimed to compare treating high blood pressure to a target SBP goal of less than 120 mmHg against treating to a goal of less than 140 mmHg.
However, it has been seen in major clinical trials that a reduction of SBP is intimately connected to a reduction of diastolic blood pressure (DBP). Despite this association, it is debated whether low DBP leads to undesirable cardiovascular outcomes, such as a reduction of coronary flow, myocardial infarction, heart failure, or cardiovascular death.63–65 This suggests that intensive SBP therapy may result in an excessive reduction of DBP and therefore result in an undesired increase in cardiovascular risk. Nevertheless, SPRINT showed that intensive treatment was clearly associated with a reduced risk of CVD and was even finished early because its results were so convincing. 31 Given the conclusions drawn by SPRINT, the research question is now whether it is possible to decompose the total effect of treatment on the primary outcome into a (natural) direct effect and a (natural) indirect effect through low DBP (induced by the treatment).
The debate on intensive blood pressure therapy is ongoing. Lee et al. 66 set out to ascertain whether there is an association between the onset of diastolic hypotension during treatment and negative outcomes. To achieve this, they utilized a conventional Cox PH model, using DBP as a time-varying exposure and adjusting for certain baseline factors. Stensrud et al. 67 aimed to explore whether a formal mediation analysis, utilizing the SPRINT data, could identify whether intensive SBP treatment impacts cardiovascular outcomes via a pathway that involves DBP below 60 mmHg. They claim that the association between treatment-induced DBP and cardiovascular outcomes suffers from confounding. 68
We illustrate how our methodological contribution manages to perform the desired effect decomposition both across pathways and, importantly, across time thanks to the RKHS formulation. A consensus answer to the problem would be relevant to the medical community because, as mentioned, SPRINT ultimately informed the new blood pressure guidelines by demonstrating that a lower blood pressure target can significantly reduce heart disease risk.
Naive analysis of SPRINT
We might start by stratifying the observations into two groups: One with DBP
The estimates provided by the model fit would confirm the original suspicions of the medical community, stating that low DBP leads to increased cardiovascular risk. This is because the estimate of the hazard ratio exp(coef)=1.326
The second step we take is to fit two Kaplan–Meier curves, one for each arm of the SPRINT trial (INTENSIVE=0 target SBP of 140 mmHg, INTENSIVE=1 target SBP of 120 mmHg) and produce the black and blue lines respectively displayed in Figure 5. This serves as a quantitative basis for three facts. First, the paradox we are facing becomes empirically confirmed because now treatment defined as SBP lowering intervention seems to be effective (the blue curve therein estimating the survival function of the treatment population is higher after one year). Second, the estimates of the survival functions are crossing. This is a well-known problem in the field of time-to-event analysis, 69 directly invalidating the proportional hazards assumption. Third, this would confirm observationally the overall positive results of the SPRINT trial, asserting that intensive SBP control results in cardiovascular benefit.
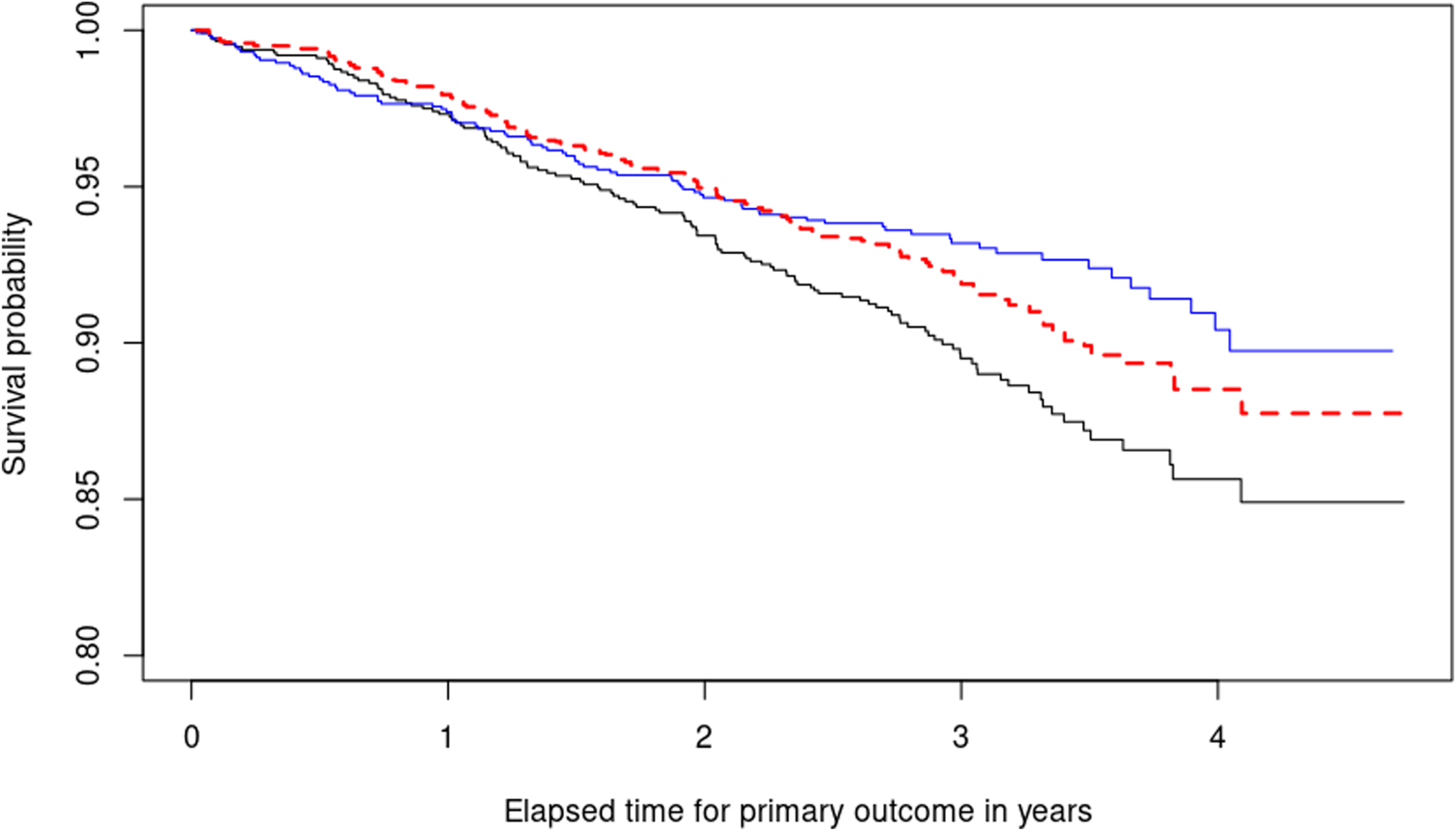
Illustrating the decomposition of treatment effects using equation (1). Two Kaplan–Meier survival curves are shown: The blue curve represents the estimated survival probability
Our response variable T_PRIMARY is observed time-to-primary outcome in days. The treatment indicator for each patient INTENSIVE is encoded such that 1 indicates lower SBP target of 120 mmHg and 0 indicates standard treatment (target SBP: 140 mmHg). The vector of covariates for each patient includes ‘‘DBP.1yr’’ (DBP one year after randomization) and baseline characteristics we want to adjust for: ‘‘DBP.rz’’ DBP at randomization and ‘‘AGE’’
Our results agree with Stensrud and Strohmaier
67
and Beddhu et al.
70
: The increased risk in subjects with diastolic pressure below 60 cannot be fully explained by the intensive treatment itself, but may be due to other factors. A complete description of the results is included in Figure 5. For most of the study duration (approximately from year 1 onwards), intensive reduction of SBP counteracts the harmful consequences of reduced DBP, leading to increased survival in the treatment arm, as evidenced by the blue curve being above the black one. However, the difference between
Specifically, our novel estimator provides valuable insights that support the findings in Stensrud and Strohmaier, 67 which suggest that the association between treatment-induced DBP and cardiovascular outcomes may be confounded. This corroborates similar findings reported in the literature, as mentioned in the study, 70 which align with our own results.
When comparing our proposed method with existing non-parametric estimators in the SPRINT trial application case, we benchmark CSEs against Causal Survival Forests. 33 We selected a fully non-parametric estimator to avoid the need for specifying a propensity score model.
In Figure 6, we display in gray the differences between the arm-conditioned Kaplan–Meier (KM) estimators (blue minus black lines in Figure 5) alongside an estimate
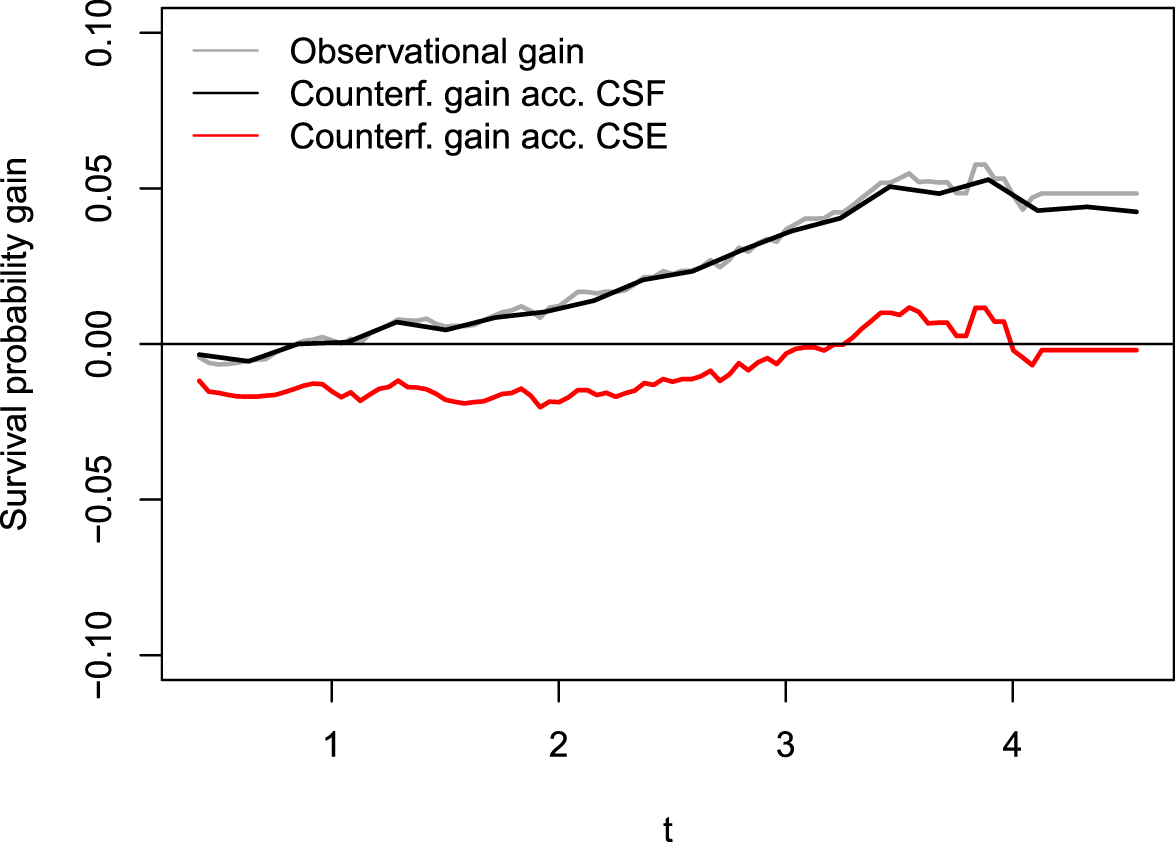
Difference between conditional KM estimators (gray) and estimations of counterfactual survival probability gain,
In conclusion, the reduced risk of cardiovascular complications is primarily due to the accompanying reduction in DBP from an SBP intervention, with SBP itself having a positive impact only in the long term. This analysis demonstrates the practical performance of CSEs, showing that our algorithm’s results closely align with established findings in the literature.
It is important to note that while Causal Survival Forests are designed to estimate conditional treatment effects, they can recover marginal effects only by averaging over covariates, making them less suitable for directly estimating marginal effects. Additionally, the additive model assumption often used in the theoretical analysis of random forests 62 may not hold in complex settings like the SPRINT trial, potentially limiting their practical utility.
The main contribution of this paper is the introduction of a novel framework that enables model-free counterfactual inference in survival analysis, opening the doors to many tasks including uncertainty quantification and hypothesis testing. The key advantage of our method is its model-free nature, allowing for learning of complex non-linear relationships between predictors and response variables, given certain smoothness and moment conditions. Many existing models in counterfactual inference are semi-parametric in nature, like the Cox model, which may involve parameters that do not have a causally valid interpretation. 11 The adaptation of such estimators to the fully non-parametric context faces technical difficulties, as seen with the k-NN algorithm and Beran’s estimator. However, by adopting the kernel embedding toolset, we can create model-free estimators without technical difficulties.
From a theoretical standpoint, let us discuss the implications of using weights involving just marginal Kaplan–Meier estimators. Roughly speaking, these weights assume independence between survival and censoring times, as well as conditional independence of the censoring indicator and the covariates given the realized times (Assumption v.). Let us briefly depict the consequences of relaxing these hypotheses. A regular estimator is efficient if it achieves the lowest possible variance among regular estimators, and this optimality notion is established with tools from semiparametric inference.
71
Specifically, the Kaplan–Meier integral is asymptotically efficient only under the assumption of independence between survival and censoring times with respect to the covariates.52,72 This is intuitive because the covariate values of the censored times are never observed in empirical estimates. However, if we relax this hypothesis and consider a scenario where
To address this issue, we could use a Cox model to estimate
We utilized a RKHS approach for estimating counterfactual survival distributions with censored outcomes, leveraging the benefits of inverse censoring probability weighting due to its established history and compatibility with our chosen framework. Regarding potential inaccuracies linked to censoring distribution estimation, it is worth noting that certain techniques, such as targeted maximum likelihood (TMLE), 76 have gained traction in recent studies addressing similar problems.72,77 Future explorations might delve into the integration of TMLE with our framework, refining CSEs with a targeting step and providing a comparative assessment.
The proportional hazards model is the prevailing regression model used in survival analysis. However, a standard Cox analysis does not provide insight into how the effects evolve over time, potentially resulting in loss of valuable information. With the usual Cox analysis, coefficients are typically assumed to remain constant over time, making it challenging to incorporate any deviations from this assumption. There exist a number of alternatives, for instance Aalen’s additive regression model. 78 It offers the benefit of permitting covariate effects to vary independently over time. However, Aalen’s model performs repeated regressions at each event time, running into instability and overfitting problems when not many events (understood as uncensored observations) are present in the data. Figure 5 illustrates the importance of our estimator as a tool to assess relative risk between treatment arms across time in a natural way without involving time-dependent hazard ratios. All being said, reliably answering inferential questions about time-varying causal effects is a true milestone in contemporary statistics, even reaching areas like Reinforcement Learning. 79
In conclusion, our proposed estimator offers a flexible and powerful tool for estimating counterfactual distributions in observational studies with right-censored data. The model-free nature of our approach makes it applicable to diverse scenarios where traditional methods may be unsuitable. Our estimator can be used in combination with or as an alternative to existing parametric and semiparametric causal survival models, further expanding the range of options available for researchers and practitioners.
Supplemental Material
sj-zip-1-smm-10.1177_09622802241311455 - Supplemental material for Causal survival embeddings: Non-parametric counterfactual inference under right-censoring
Supplemental material, sj-zip-1-smm-10.1177_09622802241311455 for Causal survival embeddings: Non-parametric counterfactual inference under right-censoring by Carlos García Meixide and Marcos Matabuena in Medical Research
Supplemental Material
sj-pdf-2-smm-10.1177_09622802241311455 - Supplemental material for Causal survival embeddings: Non-parametric counterfactual inference under right-censoring
Supplemental material, sj-pdf-2-smm-10.1177_09622802241311455 for Causal survival embeddings: Non-parametric counterfactual inference under right-censoring by Carlos García Meixide and Marcos Matabuena in Medical Research
Footnotes
Acknowledgements
The authors acknowledge the valuable insights and suggestions provided by Professor David Ríos Insua and Professor Peter Bühlmann, which significantly contributed to the quality of this work. Gratitude is extended to Fundación Barrié for their thorough and invaluable support during this research. This manuscript was prepared using SPRINT POP Research Materials obtained from the NHLBI Biologic Specimen and Data Reppsitory Information Coordinating Center and does not necessarily reflect the opinions or views of the SPRINT POP or the NHLBI.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors didnot receive any financial support for the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.