
Abstract
Estimands can help clarify the interpretation of treatment effects and ensure that estimators are aligned with the study's objectives. Cluster-randomised trials require additional attributes to be defined within the estimand compared to individually randomised trials, including whether treatment effects are marginal or cluster-specific, and whether they are participant- or cluster-average. In this paper, we provide formal definitions of estimands encompassing both these attributes using potential outcomes notation and describe differences between them. We then provide an overview of estimators for each estimand, describe their assumptions, and show consistency (i.e. asymptotically unbiased estimation) for a series of analyses based on cluster-level summaries. Then, through a re-analysis of a published cluster-randomised trial, we demonstrate that the choice of both estimand and estimator can affect interpretation. For instance, the estimated odds ratio ranged from 1.38 (p = 0.17) to 1.83 (p = 0.03) depending on the target estimand, and for some estimands, the choice of estimator affected the conclusions by leading to smaller treatment effect estimates. We conclude that careful specification of the estimand, along with an appropriate choice of estimator, is essential to ensuring that cluster-randomised trials address the right question.
Keywords
Introduction
An estimand is a precise definition of the treatment effect investigators want to estimate.1–3 Defining the estimand at the study's outset helps to clarify the appropriate interpretation of treatment effects and ensure that statistical methods are aligned with the study's objectives (i.e. that statistical methods are chosen to estimate the right treatment effect).1–11 Because of the clarity that estimands provide, they are becoming increasingly popular in randomised trials. The standard framework for defining an estimand requires specification of the following five attributes: (i) the population of participants; (ii) the treatment conditions; (iii) the endpoint; (iv) the summary measure (e.g. odds ratio (OR), difference, etc); and (v) how intercurrent events, such as treatment non-adherence, are handled. Importantly, the above attributes are defined in relation to the target treatment effect (e.g. the population to whom the treatment effect applies).
However, cluster-randomised trials (CRTs) (where groups of participants, such as schools or hospitals, are randomised instead of individual participants12–18) require the specification of additional attributes compared to individually randomised designs.4,19 For example, investigators must decide between marginal (sometimes called population-averaged) and cluster-specific (sometimes called conditional) treatment effects, which differ in whether outcomes are summarised overall or by cluster.14,15,20–22 Separately, they must also decide between participant-average and cluster-average treatment effects, which differ in how participants are weighted. 4
Proper consideration of these attributes is important to ensure that CRTs are designed to answer the most clinically relevant question, as different estimands provide fundamentally different interpretations, and choosing the wrong estimand and/or estimator could provide misleading evidence. For instance, if interest lies in an intervention's effect across the population of participants (e.g. the number of participants that would be saved by using the intervention vs. using control), this is provided through a participant-average estimand. Hence, an estimator that targets a cluster-average estimand (such as an analysis of unweighted cluster-level summaries, which is a commonly recommended estimator in CRTs14,15,18,23,24), may provide a biased answer. It is therefore essential in CRTs to clearly define the estimand and then choose an appropriate estimator that targets this estimand.
The concept of marginal versus cluster-specific treatment effects has been discussed previously,14,15,20–22 as has the issue around how to weigh patients (i.e. participant- vs. cluster-average effects).4,19,25–29 However, to our knowledge, cluster-specific effects have not been formally defined using potential outcomes notation. Further, to our knowledge, these two issues have not been considered together, meaning there are currently no formal definitions for estimands which encompass both concepts nor any guidance on how these attributes differ for the construction of estimands. Finally, because these estimands have only been considered separately, the literature around estimation has also typically focused on only a single attribute of the estimand (e.g. estimation of a marginal effect, or estimation of a participant-average effect), meaning there is currently no guidance on estimation of estimands which incorporate both the marginal versus cluster-specific and participant- versus cluster-average attributes unique to CRTs.
The purpose of this paper is therefore to resolve these issues by (i) defining estimands which incorporate both attributes together (e.g. marginal, participant-average estimands; cluster-specific, participant-average estimands; etc.), and demystifying these interconnected concepts and terminology; and (ii) describing estimators that can be used for each of these estimands.
Estimands
In this section, we describe the difference between marginal and cluster-specific estimands (Section 2.2), and then separately we describe the difference between participant-average and cluster-average estimands (noting when the different estimands will coincide) (Section 2.3). A summary is provided in Table 1.
Difference between marginal/cluster-specific and participant-/cluster-average attributes of estimand.

Difference between marginal/cluster-specific and participant-/cluster-average attributes of estimand.
We then merge the two concepts to define estimands incorporating both attributes; because there are two options for each concept, this leads to four total estimands: (i) marginal, participant-average; (ii) marginal, cluster-average; (iii) cluster-specific, participant-average; and (iv) cluster-specific, cluster-average. These are defined for both a difference in means or proportions and an OR in Section 2.4, and Table 2.
Overview of estimands for cluster-randomised trials.a

aM and N represent the total number of clusters and the total number of participants, respectively,
bUnder the super-population perspective, each cluster is assumed to be an independent random sample from a hypothetical infinite population of clusters, and the expectation for each estimand is defined with respect to that super-population of clusters. Under the finite-population perspective, the trial sample itself is considered as the finite target population, and so the estimand is defined for these clusters. Mathematically, the difference between the two frameworks is that one uses population expectation for the estimand while the other considers a finite-sample estimand.
cIn order to be fully defined, estimands require further specification of the (i) population; (ii) treatment conditions; (iii) endpoint; (iv) summary measure; and (v) handling of intercurrent events.
dFor differences, marginal and cluster-specific estimands coincide.
e
We note that to be fully defined, each of the estimands described below would require specification of the other attributes encompassing an estimand (i.e. population, treatment conditions, endpoint, summary measure, and handling of intercurrent events1,30). Some of these attributes may require additional consideration in CRTs; for instance, the population of interest would need to be described for clusters as well as participants, and investigators may need to differentiate whether interest lies in the population of all eligible participants versus just those that would enrol in the study if provided the opportunity.31,32 Similarly, in some CRTs, investigators may need to describe the duration of the implementation of the intervention (e.g. the average effect over three vs. six months of implementation33,34) when describing the treatment conditions of interest. Similarly, because non-adherence could occur both at the participant or cluster level, they may need to define intercurrent events at both the individual and cluster levels. To our knowledge, there are unlikely to be any additional considerations in CRTs when defining the endpoint or summary measure attributes (apart from the cluster-specific vs. marginal distinction discussed in this paper). To facilitate a clearer description of our main message, we do not further address these additional considerations below.
We describe each estimand using the potential outcomes framework. We do this under two different perspectives that have been used for defining causal effects in CRTs: (i) a super-population perspective, where each cluster is assumed to be an independent random sample from a hypothetical infinite population of clusters26,29,35; and (ii) a finite-population perspective, where the clusters in the trial are themselves considered as the target population. 28 The key difference between these is that under the super-population perspective, the estimand is written in terms of a population expectation (taken over the infinite population of clusters), while under the finite-population perspective, the estimand is written as an empirical average across the observed clusters and participants in the study. Though the concepts behind the participant- versus cluster-average and marginal versus cluster-specific aspects are the same under each perspective, we provide both for completeness. For simplicity, however, we focus on describing the estimands under the finite-population perspective in what follows and include those under the super-population perspective in Table 1.
We begin by introducing the notation that will be used to define both the estimands and the estimators below. Let
Under the potential outcome framework, 
We provide formal definitions for marginal and cluster-specific estimands below. Briefly, the difference between marginal and cluster-specific estimands is based on how the potential outcomes are summarised.
A marginal estimand is calculated using the following steps:
Overall summaries are obtained by summarising the potential outcomes separately by treatment condition using all participants (e.g. the mean potential outcome is calculated under the intervention and control, respectively). The summaries are contrasted between treatment conditions to calculate an overall marginal treatment effect. Cluster-specific summaries are obtained by summarising the potential outcomes within each cluster (e.g. the mean potential outcome is calculated under intervention and control, respectively, in cluster 1, cluster 2, etc.). The cluster-specific summaries are contrasted between treatment conditions within each cluster to calculate a cluster-specific treatment effect. An average of these cluster-specific effects is calculated to provide the overall cluster-specific estimand (note this average can be taken in different ways; see Section 2.3. on participant- vs. cluster-average estimands below).
Conversely, for a cluster-specific estimand, the following steps are taken:
Thus, the difference between marginal and cluster-specific estimands is whether an overall summary measure is calculated within each treatment arm before the arms are contrasted (marginal estimand), or whether summary measures are contrasted within each cluster first (cluster-specific estimand).
For certain summary measures, the overall cluster-specific estimand may average over some function of the cluster-specific effects. For instance, when defining an estimand based on an OR, the average of the log OR may be taken across clusters, then back-transformed after to obtain the overall cluster-specific OR. This example will be further discussed in Section 2.4.
We note that marginal and cluster-specific estimands can be written as either participant-average or cluster-average treatment effects (depending on how each individual or cluster will be weighted, described in Section 2.3); for simplicity, we describe the differences between marginal and cluster-specific estimands below in terms of participant-average effects.
For a difference in means or proportions, a marginal participant-average estimand is defined under the finite-population perspective as:
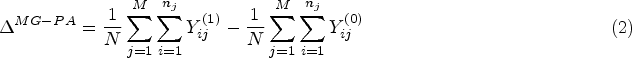
The cluster-specific estimand for a difference in means/proportions can be defined under the finite-population perspective as follows. First, let 
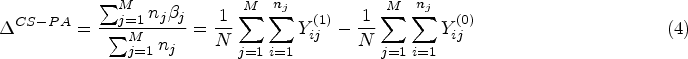
We use the term collapsible to indicate that the values of the two estimands will coincide, and non-collapsible to mean that the values of the two estimands will differ. 36
Whether the marginal and cluster-specific estimands will coincide or not depends on the summary measure (e.g. difference and OR) being used. For differences (e.g. difference in means and difference in proportions), these two estimands will coincide (i.e.
For ratio summary measures (e.g. risk ratios and ORs), in general, the two estimands will differ. This is because of the function used which transforms the summaries (e.g. by taking the log or logit transformation of the marginal or cluster-specific summaries); this feature renders the mathematical equivalency stated above invalid; that is, a ratio of overall summaries is generally not the same as an average of the ratios within each cluster (except in a few specific settings, e.g. if the risk ratio is identical across all clusters). Because the marginal and cluster-specific estimands are different, ‘ratio’ summary measures are non-collapsible, except in special circumstances.
Participant- and cluster-average estimands
We provide formal definitions for participant- and cluster-average estimands under the finite-population perspective below. Briefly, the difference between the participant- and cluster-average estimands is in how the potential outcomes are weighted. 4 Under the participant-average estimand, a general principle is that each participant is given equal weight. Under the cluster-average effect definition, a general principle is that each cluster is given equal weight (implying that participants from smaller clusters are given more weight than participants from larger clusters). 4
We note that both the participant- and cluster-average treatment effects can be written as either marginal or cluster-specific estimands; however, in this section, we write them as marginal estimands for simplicity.
Participant-average estimands
For a difference in means, or difference in proportions, the marginal participant-average estimand is given in equation (2) above (as we defined marginal estimands above as participant-average for simplicity). We repeat this equation here for completeness:
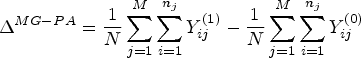
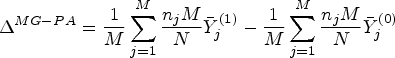
Cluster-average estimands
For a difference in means/proportions, the marginal cluster-average estimand is defined as:
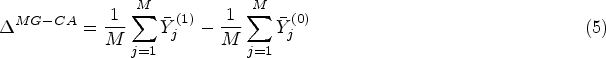
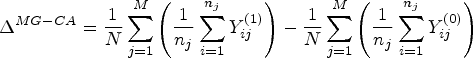
Whether the participant- and cluster-average estimands will differ depends on two things: (i) whether the estimand summary measure being used is collapsible (e.g. a difference in means or proportions) or non-collapsible (e.g. a ratio, except in specific circumstances); and (ii) whether informative cluster size is present. Informative cluster size occurs when either the potential outcomes or potential outcome contrasts (i.e.
For collapsible summary measures, such as the difference in means/proportions, the participant- and cluster-average estimands will differ when the second type of informative cluster size is present, that is, when the potential outcome contrasts differ according to cluster size. 4
For non-collapsible summary measures, such as the OR, the participant- and cluster-average treatment effect will typically differ when either the first or second type of informative cluster size is present, that is, when either the outcomes or the treatment effects differ depending on the cluster size. 4
Estimands encompassing both attributes (marginal vs. cluster-specific attribute and participant- vs. cluster-average attribute)
Estimand definitions incorporating both attributes (marginal vs. cluster-specific attribute and participant- vs. cluster-average attribute) are described below and summarised in Table 2. Because there are two options for each attribute, this leads to four total estimands. Below we describe the construction of these estimands for both a difference and an OR summary measure.
Marginal participant-average estimand
The marginal participant-average estimand for a difference is given in equation (2) above, and we repeat it here for convenience:
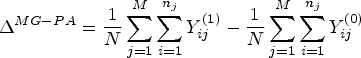
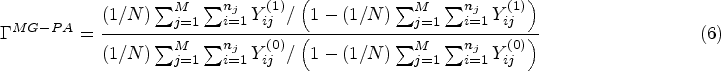
For a difference in means/proportions, the marginal cluster-average estimand is given in equation (5); we repeat it here for convenience:
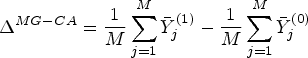
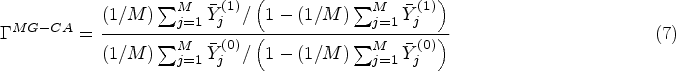
The cluster-specific participant-average estimand for a difference in means/proportions is given in equation (4); we repeat it here for convenience:
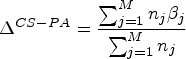
For the cluster-specific participant-average OR, one can first let 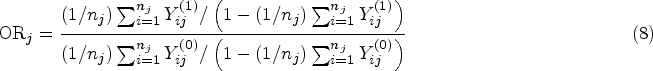

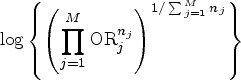
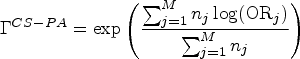
In general, cluster-specific estimands (participant- or cluster-average) are only well defined when the cluster-specific treatment effects are well defined, for example, for an OR this would require the potential outcome proportion to be bounded away from 0 or 1 in each cluster so that a cluster-specific ORs from equation (8) can be defined without ambiguity.
The cluster-specific cluster-average estimand for a difference in means/proportions is defined as:

The cluster-specific cluster-average OR can be defined by giving equal weight to each cluster-specific summary:

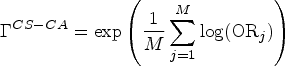
We now describe some familiar estimators that can be used to estimate each of the estimands described previously for a parallel-arm CRT. We focus on the following estimators: (a) independence estimating equations (IEEs)4,19; (b) the analysis of cluster-level summaries4,15,18; (c) mixed-effects models with a cluster-level random intercept; and generalised estimating equations (GEEs) with an exchangeable working correlation structure. We focus on the simple scenario without baseline covariate adjustment for each estimand. When covariate adjustment is of interest to obtain more efficient estimators, we refer readers to Su and Ding 28 for related development under a finite-population perspective, Balzer et al.,39,40 Benitez et al., 25 and Wang et al. 29 for related developments under a super-population perspective; although these prior developments often focus only on a subset of estimands we have covered. Below, we address commonly used estimators for CRTs in the absence of covariate adjustment, and then explain which estimands they target, along with the key assumptions required for consistency (i.e. asymptotically unbiased estimation). A summary is given in Table 3.
Overview of estimators for each estimand.

Overview of estimators for each estimand.
GEE: generalised estimating equation; IEE: independence estimating equation.
aStandard assumptions are: (a) the consistency assumption (sometimes termed the stable unit treatment value assumption), which requires that
bThe cluster size
In general, the assumptions required to consistently estimate the target estimand are similar under both perspectives (super-population vs. finite-population), except for some technical differences in conceptualising the asymptotic regime and versions of the Central Limit Theorems invoked41,42; for simplicity, we do not distinguish between these two perspectives and only discuss the necessary assumptions with easy-to-understand terms.
We note that this list of estimators we describe is not intended to be comprehensive. In particular, we focus on the standard implementations of mixed-effects models and GEEs with an exchangeable correlation structure, in which the estimated treatment effect is taken from the model parameter corresponding to the assigned treatment. However, there are other implementations that could be used (e.g. model-based g-computation estimators based on linear-mixed models and GEEs in Section 3 in Wang et al., 29 and propensity score weighting estimators in Zhu et al. 43 ), which can consistently estimate the participant-average and cluster-average estimands even when the associated working models are misspecified.
In general, all estimators described above require the following assumptions: (i) the consistency assumption (sometimes termed the cluster-level stable unit treatment value assumption), which requires that
In addition, estimators for cluster-specific estimands with a binary outcome will also require the assumption that the average potential outcome in each cluster is bounded away from 0 or 1. We discuss additional assumptions required for mixed-effects models and GEEs with an exchangeable correlation structure below.
Of note, we slightly abuse the notation throughout this section such that
IEEs are a class of estimators which is applied to individual participant outcomes and use an independent working correlation structure in conjunction with cluster-robust standard errors (SEs). 45 Briefly, IEEs make a working assumption that outcomes within a cluster are independent; in practice, this assumption will almost always be false for CRTs; however, it helps ensure consistent (asymptotically unbiased) estimation in the presence of informative cluster size. 4 The cluster-robust SEs then serve to ensure estimated SEs are asymptotically valid despite the incorrect working independence assumption. 46
IEEs can be used to estimate marginal, participant-average effects, as well as marginal, cluster-average effects (using different specifications of weights). However, they cannot be used to estimate cluster-specific effects. They do not require any assumptions beyond those specified earlier.
Marginal, participant-average estimator
For a difference in means, IEEs can be implemented to estimate the marginal, participant-average effect by applying the following model to individual participant data:

Similarly, the marginal, participant-average OR can be estimated through the following model:

Because the models in equations (12) and (13) give equal weight to each participant, they correspond to a participant-average effect, and because the models first summarise outcomes within treatment groups before applying any transformations, they correspond to marginal effects.
IEEs can be used to estimate a marginal, cluster-average effect using models (12) and (13) above; however, each individual observation is additionally weighted by the inverse cluster size
Because these models give equal weight to each cluster, they correspond to a cluster-average effect. As above, because they summarise outcomes within treatment groups before applying any transformations, they correspond to marginal effects. In the case of an OR summary measure, a simple modification of the proof in Web Appendix 1 of Zhu et al. 43 can be used to show that this weighted IEE estimator is consistent.
Analysis of cluster-level summaries
The analysis of cluster-level summaries involves two steps: (i) a summary measure is taken in each cluster (e.g. the mean observed outcome across all participants in the cluster) and (ii) the analysis is performed on the cluster-level summaries.
The analysis of cluster-level summaries can be used to estimate all four estimands described previously (marginal, participant-average effects; marginal, cluster-average effects; cluster-specific participant-average effects; and cluster-specific, cluster-average effects). For illustration, we describe the different implementations below for an OR summary measure (we note that for a difference in means/proportions, implementations of marginal and cluster-specific estimators are identical; this is because no transformation of the marginal/cluster-specific summaries needs to be taken). They require the standard assumptions specified earlier. Further, the cluster-specific estimators require the same assumption as required for the cluster-specific estimand, that is, that the potential outcome proportions need to be bounded away from 0 or 1 in each cluster so that an OR summary within each cluster is well defined. We provide proof of consistency (i.e. asymptotically unbiased estimation) for each cluster-level summary approach described below in the Appendix.
Marginal, participant-average estimator
This estimator uses a two-step procedure. In the first step, the proportion of events in each cluster is calculated, represented by 
Because this model gives equal weight to each participant, it corresponds to a participant-average effect. Furthermore, because this model summarises outcomes within the treatment group before applying any transformations, it estimates a marginal effect.
Cluster-level summaries can be used to estimate a marginal, cluster-average effect, using model (14) above; however, the cluster-level summaries are unweighted in order to give equal weight to each cluster. The final OR parameter is calculated by
Cluster-specific, participant-average estimator
This estimator uses a three-step procedure, as follows:
As above, the proportion of observed events in each cluster ( The proportions from Step 1 are transformed according to the summary measure being used; for instance, an OR would require calculating the log odds in each cluster, that is, Finally, the cluster-level summaries calculated in step 2 (e.g. the

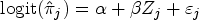
The treatment effect estimate is then back-transformed as appropriate (e.g. the OR is then calculated as
Because this estimation procedure weights each cluster-specific summary by the cluster size (hence intuitively giving each participant the same weight), it corresponds to a participant-average effect. Furthermore, because it applies transformations to the cluster-level summaries directly (rather than summarising the entire treatment arm before applying the transformation) it targets a cluster-specific effect. As above, we sketch the proof for consistency in Section A.3.
Cluster-level summaries can be used to estimate a cluster-specific, cluster-average effect, using model (15) above; however, the cluster-level summaries are unweighted in order to give equal weight to each cluster. A proof of consistency is given in Section A.4.
Mixed-effects models
Mixed-effects models are applied to participant level data and involve specifying a random intercept term for the clusters. For a difference in means, a linear mixed-effects model takes the form:

For estimating an OR, a logistic mixed-effects model with a random intercept is:

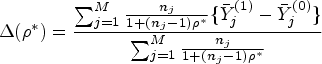
However, in the absence of informative cluster size, linear mixed-effects models can provide a consistent estimator for the ‘difference’ summary measure for all four estimands, as in this case, the values of all estimands,
However, these results do not easily generalise to other link functions such as the logistic mixed-effects models, since the marginal likelihood and the score equations are analytically intractable. Therefore, the requirement for consistent estimation of the OR estimands (defined in Section 2) with logistic mixed-effects models is likely more stringent compared to linear mixed-effects models. To this end, an important area of future research is around whether deviations from model assumptions (e.g. that the normality assumption for the random effects in the logistics mixed-effects model is misspecified) may affect the consistent estimation of all four OR estimands.
GEEs are applied to individual participant data.
45
They involve specifying a working correlation structure in conjunction with cluster-robust SEs. Typically, for CRTs, an exchangeable working correlation structure is specified, that is, the correlation is assumed to be constant between any two participants in the same cluster, and 0 between participants from different clusters. The use of the cluster-robust SE ensures consistent variance estimation, even when the working correlation structure is misspecified. For a difference in means, GEEs take the following mean model:

For an OR summary measure, the following form is used:

The RESTORE trial was a CRT that compared protocolised sedation with usual care in critically ill children who were mechanically ventilated for acute respiratory failure. 48 Thirty-one clusters were randomised, with the number of participants in each cluster ranging between 12 and 272. In total, 2449 participants were enrolled.
We focus on the adverse event ‘post-extubation stridor’, which denoted the presence of inspiratory noise indicating the narrowing of the airway (yes vs. no). Our aims were (i) to compare estimators for the same estimand, to determine to what extent different choices may impact results; and (ii) to compare estimators across different estimands, to evaluate to what extent choice of estimand may affect interpretation of trial results.
We implemented each of the estimators described in Section 3. For IEEs and GEEs, we calculated cluster-robust SEs using the Fay–Graubard small-sample correction. 49 For the analysis of cluster-level summaries, we used Huber–White SEs, and for mixed-effects models, we used model-based SEs.
Difference between estimators
Results are shown in Table 4 and Figure 1. The estimated OR ranged substantially across different estimands, from 1.38 (95% CI 0.87 to 2.19, p = 0.17) for the marginal cluster-average effect, to 1.83 (95% CI 1.06 to 3.14, p = 0.03) for the cluster-specific participant-average effect.
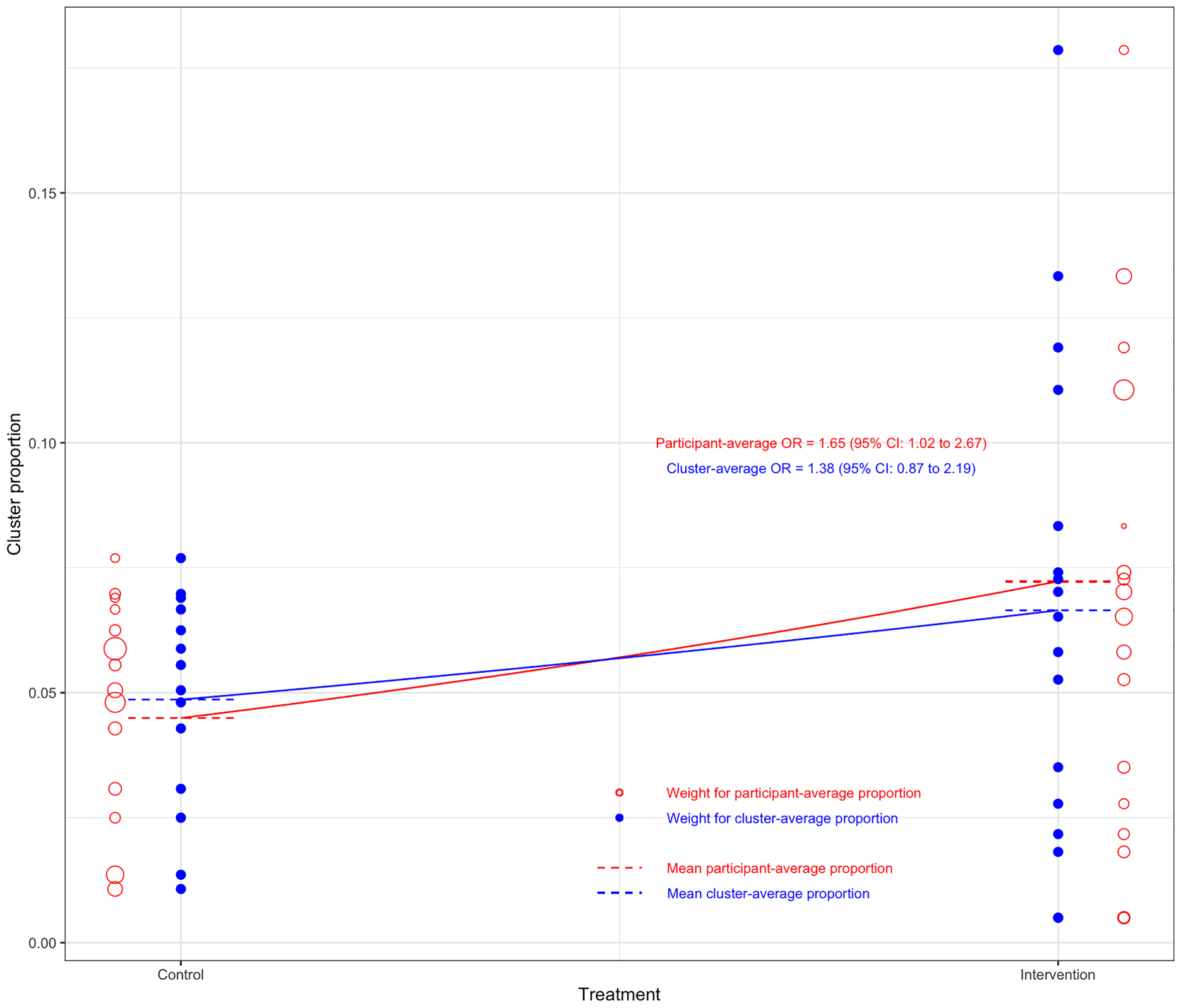
Difference between marginal participant- versus cluster-average odds ratio for ‘post-extubation stridor’ in the randomised evaluation of sedation titration for respiratory failure (RESTORE) trial. Each bubble denotes the proportion of events in that cluster. The size of the bubbles represents the weight given to each cluster, with hollow bubbles representing the participant-average weighting, and solid bubbles denoting the cluster-average weighting. The overall treatment group means are closer together under the cluster-average weighting than the participant-average weighting, owing to the cluster-average weighting giving more weight to smaller clusters with smaller between-group differences.
Re-analysis results for the RESTORE trial for the outcome ‘post-extubation stridor’.

RESTORE: randomised evaluation of sedation titration for respiratory failure; 95% CI: 95% confidence interval; GEE: generalised estimating equation; IEE: independence estimating equation.
Odds ratios are for the comparison of intervention versus control. This trial enrolled 31 clusters, and the event rate was 7.2% in the intervention versus 4.5% in the control. Intra-class correlation coefficient = 0.03. P-value for interaction between treatment and cluster size ≥100 = 0.21. Marginal, participant-average odds ratio = 1.15 (0.56 to 2.36) in clusters of size <100, and 2.26 (1.49 to 3.43) in clusters of size ≥100.
aCIs were calculated using cluster-robust standard errors with the Fay–Graubard correction.
bCIs were calculated using Huber–White standard errors.
The choice of both estimand and estimator impacted conclusions. Estimates for the participant-average estimands (both marginal and cluster-specific) were larger than those for the cluster-average estimands and were statistically significant (based on a 0.05 significance level), while those for the cluster-average estimands were not.
However, only specific estimators for the two participant-average estimands demonstrated statistical significance. In particular, mixed-effects models and GEEs with an exchangeable correlation structure produced smaller estimates of treatment effect than IEEs or the analysis of cluster-level summaries, and, as a consequence, results from mixed-effects models and GEEs with an exchangeable correlation structure were not statistically significant, while those from IEEs and cluster-level summaries were. For example, for the marginal participant-average effect, IEEs provided an estimated OR of 1.65 (95% CI 1.02 to 2.67, p = 0.04), while GEEs with an exchangeable correlation structure produced an estimated OR of 1.57 (95% CI 0.98 to 2.50, p = 0.06). Similarly, for the cluster-specific participant-average effect, the use of weighted cluster-level summaries provided an OR of 1.83 (95% CI 1.06 to 3.14, p = 0.03), while a mixed-effects logistic regression model gave an estimated OR of 1.54 (95% CI 0.97 to 2.44, p = 0.07).
The participant-average effects were larger than the corresponding cluster-average effects, which is consistent with the implication of informative cluster size. 50 Smaller clusters had numerically smaller treatment effects than larger clusters: the participant-average OR was 1.15 (95% CI 0.56 to 2.36) in the 24 clusters of size <100, while it was 2.26 (95% CI 1.49 to 3.43) in the seven clusters of size ≥100. We also observed attenuated estimates from mixed-effects models and GEEs with an exchangeable correlation structure. Although often thought to estimate participant-average effects, in fact, these models can give more weight to smaller clusters. Hence, they may give an estimate ‘shifted’ towards the cluster-average effect, in this case, a smaller overall treatment effect. 4 However, the interaction between small and large clusters was not statistically significant (p = 0.21), so we cannot definitively conclude there was informative cluster size in this setting.
The use of estimands to clarify the interpretation of treatment effects and ensure that estimators are aligned with study objectives has rapidly been gaining attention in randomised trials; however, most research has been focused on individually randomised trials. CRTs have unique features that require additional specification in the estimand definition. In this paper, we have: (i) defined estimands that encompass both the marginal versus cluster-specific and participant- versus cluster-average attributes together; and (ii) described commonly used, simple estimators for each of these estimands.
Our re-analysis of the RESTORE trial demonstrated the value of careful consideration of both the estimand and the estimator. Different estimands led to different conclusions around the effect of treatment (e.g. OR = 1.38, p = 0.17 for the marginal cluster-average effect vs. OR = 1.83, p = 0.03 for the cluster-specific participant-average effect). Similarly, different estimators of the same estimand also affected interpretation. Mixed-effects models and GEEs with an exchangeable correlation structure, which may be considered for estimation of participant-average effects (cluster-specific and marginal, respectively), provided lower estimates of treatment effect that were closer to the cluster-average effect than either IEEs or the analysis of cluster-level summaries. This also led to a change in statistical significance. As such, careful consideration around the plausibility of the assumptions required by each estimator is essential.
The choice of estimand should be driven by the trial objectives. We anticipate all four estimands described in Table 2 may be of interest, depending on the specific study objectives. For instance, if interest lies in understanding how well clusters have implemented the intervention (as measured by adherence), a cluster-specific and/or cluster-average estimand may be more appropriate. Conversely, if interest lies in understanding the absolute number of patients that would be saved by the intervention, a marginal participant-average estimand may be most appropriate. 4 We acknowledge that the choice of estimand may not always be straightforward, but this should not discourage conversations between the statisticians and investigators around which estimands may be most appropriate in a given CRT. Further work describing when different estimands would be most appropriate, and using case studies to describe how investigators chose their estimand, would be of value. 4
In this paper, we have defined four estimands that could be used in CRTs. However, the estimands described here are not exhaustive; alternative estimands could be defined, for instance, by using different weighting schemes than those proposed here. While we feel that the participant- and cluster-average estimands (which give equal weight to participants or clusters) lead to clinically interpretable treatment effects that align well with standard estimators used in CRTs, we acknowledge that other approaches may be of interest to investigators. It is not our intention that investigators must use one of the estimands defined within this paper; in our view, the most important thing is to have a well-defined estimand that is clinically justified based on the study's objectives, and, importantly, this paper provides a coherent framework with standard terminology to enable investigators to describe their estimand, regardless of whether it is one of those described here.
This article suggests a number of areas of future research. For example, we have focused on leveraging the asymptotic properties of each estimator. However, many CRTs only enrol a small number of clusters. 23 Thus, evaluation of the properties of these estimators for well-defined estimands in small-sample settings would be useful, for instance, by extending previous simulation studies to evaluate these estimators under settings that include informative cluster size15,18,24,51). In particular, it may be useful to undertake a comprehensive comparison of the benefits and drawbacks of estimators that require an assumption of ‘non-informative cluster size’ (i.e. mixed-effects models and GEEs with an exchangeable correlation structure) versus those that do not (i.e. IEEs and cluster-level summaries). In addition, we have primarily focused on simple parallel-arm CRTs, but longitudinal CRTs with multiple periods are increasingly common. The extension of the estimands in this article to more complex designs, such as the stepped wedge designs,52,53 may be of interest.
It would also be useful to evaluate the performance of individual methods. For example, evaluation of different variance estimators along with small-sample corrections for the cluster-level analysis approaches would be useful given the model-based variance functions may be misspecified. Additionally, the marginal cluster-level summary estimator we have described has not been extensively studied, and empirical evaluation using simulations (with and without baseline covariates) would be useful.
Conclusions
Estimands can help clarify research objectives and ensure appropriate statistical estimators are chosen. In CRTs, additional attributes of the estimand must be specified compared to individually randomised trials (including whether treatment effects are marginal or cluster-specific, and whether they are participant-average or cluster-average). The choice of these attributes should be based on clinical considerations, and an estimator targeted to the chosen estimand should be used to ensure estimand-aligned statistical analysis of CRTs.
Footnotes
Data availability
Data from the RESTORE trial was obtained from the U.S. National Heart, Lung and Blood Institute, Biologic Specimen and Data Repository Information Coordinating Center (BioLINCC) (![]() ). The authors do not have permission to share this data directly; however, the data are available to researchers upon request and approval from BioLINCC.
). The authors do not have permission to share this data directly; however, the data are available to researchers upon request and approval from BioLINCC.
Author contributions
B.C.K. developed the idea for the manuscript, analysed the data, and wrote the first draft. F.L. derived the proofs in the appendix and assisted with analyses. F.L., B.B., V.J., A.J.C., S.J., and M.O.H. provided feedback on the manuscript structure and content and provided edits. All authors approved the final submitted manuscript.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: BCK. and A.J.C. are funded by the UK Medical Research Council (grant nos. MC_UU_00004/07 and MC_UU_00004/09). M.O.H. was supported by the National Heart, Lung, and Blood Institute of the United States National Institutes of Health (NIH) under the award R00HL141678. M.O.H. and F.L. were also supported by the Patient-Centered Outcomes Research Institute (PCORI) Awards (ME-2022C2-27676 and ME-2020C1-19220). All statements in this report are solely those of the authors and do not necessarily represent the views of the NIH, PCORI, its Board of Governors or the Methodology Committee.
Appendix
For completeness, we sketch the proof for consistency of each estimator based on the cluster-level summary statistics in Section 3.2. Of note, the consistency of the IEE estimators in Section 3.1 is provided in Wang et al. 19 (for difference in means) and Zhu et al. 43 (for OR), and therefore we omit them for brevity. Furthermore, the proof we provide below is based on the super-population perspective as the steps are simpler, relatively more standard in the CRTs literature, and are more intuitive to understand. The proof under the finite-population perspective requires taking an expectation over the randomisation distribution and invoking the less familiar finite-population, design-based results. 41 Therefore, we only focus on the super-population proof. The consistent results, however, do not change regardless of which of these two perspectives is used.