
Abstract
Often patients may require treatment on multiple occasions. The re-randomisation design can be used in such multi-episode settings, as it allows patients to be re-enrolled and re-randomised for each new treatment episode they experience. We propose a set of estimands that can be used in multi-episode settings, focusing on issues unique to multi-episode settings, namely how each episode should be weighted, how the patient's treatment history in previous episodes should be handled, and whether episode-specific effects or average effects across all episodes should be used. We then propose independence estimators for each estimand, and show the manner in which many re-randomisation trials have been analysed in the past (a simple comparison between all intervention episodes vs. all control episodes) corresponds to a per-episode added-benefit estimand, that is, the average effect of the intervention across all episodes, over and above any benefit conferred from the intervention in previous episodes. We show this estimator is generally unbiased, and describe when other estimators will be unbiased. We conclude that (i) consideration of these estimands can help guide the choice of which analysis method is most appropriate; and (ii) the re-randomisation design with an independence estimator can be a useful approach in multi-episode settings.
Keywords
Introduction
In many clinical settings, patients may require treatment on multiple occasions. For example, patients who experience acute sickle cell pain crises will require treatment for each pain crisis they experience; patients who experience severe asthma exacerbations will require treatment for each new exacerbation; and patients who develop febrile neutropenia as a result of chemotherapy would require treatment for each new round of chemotherapy leading to a neutropenic episode.1–3 In these settings, patients would typically be given the same treatment for each new episode. We refer to these as ‘multi-episode’ settings.
Re-randomisation trials have been used to evaluate interventions in multi-episode settings.4–6 The re-randomisation design involves re-enrolling and re-randomising patients for each new episode they experience; overviews of this design are available in references.1,4,5,7 Importantly, the number of times each patient is enrolled in the trial is not specified in advance, but depends on how many treatment episodes they experience during the trial. 5
The re-randomisation design has been applied to trials of acute sickle cell pain crises, 2 severe asthma exacerbations, 3 influenza vaccination, 8 platelet transfusions for thrombocytopenia, 9 complications of cirrhosis, 10 febrile neutropenia, 11 ambient light to perform biophysical profiles, 12 pre-term births, 13 and in-vitro fertilisation. 14 These trials are typically analysed by comparing all episodes allocated to the intervention versus all episodes allocated to the control, for instance using a t-test or linear regression model on the individual episodes 1 (counterintuitively, the approach of ignoring within-patient correlation between episodes can provide valid standard errors under certain assumptions, e.g. see Dunning and Reeves 4 and Kahan et al., 5 although robust standard errors which allow for clustering may be more appropriate in case these assumptions fail 15 ).
With the publication of the ICH-E9 addendum, 16 there is growing recognition of the importance of estimands17–22 (a precise definition of the treatment effect to be estimated), as careful consideration of the estimand can clarify research objectives and ensure the trial design and statistical methods are aligned with those objectives. However, estimands have not yet been defined for the re-randomisation design, or for multi-episode settings more generally. Therefore, it is not immediately clear what estimand the analysis approach discussed above corresponds to, or whether this estimand is in line with trial objectives.
In this article, we (i) propose a set of estimands that can be used for multi-episode settings; (ii) show that the analysis approach used in previous re-randomisation trials corresponds to one of these proposed estimands (the ‘per-episode added-benefit’ estimand); (iii) propose a set of estimators for the re-randomisation design which correspond to the proposed estimands; (iv) discuss the bias of these estimators; and (v) discuss these estimands in the context of a trial of sickle cell pain crises. We focus on independence estimators (where estimates are obtained using a working independence correlation structure, often in conjunction with robust standard errors). For simplicity, we limit ourselves to the setting where the interventions under study do not affect whether future episodes occur; that is, patients would experience the same number of episodes during the trial period regardless of which treatments they receive. We note that re-randomisation trials could still be used if treatment affects the occurrence of future episodes (e.g. see Nason and Follmann 6 ), but that some of the estimands specified in this article would not be directly applicable. However, we do allow for non-enrolment in this article (where future episodes do occur, but patients are not re-enrolled into the trial).
Notation
Let i index patient, and j index the episode number within the trial.
Let
Let
Estimands
An estimand ‘summarises at a population level what the outcomes would be in the same patients under different treatment conditions being compared’. 16 It consists of five components: (1) the treatment regimens; (2) the population; (3) the outcome; (4) a population-level summary denoting how outcomes between treatment arms will be compared; and (5) how intercurrent events which may influence the interpretation of the treatment effect, such as treatment discontinuation, will be handled.
All of these components will need to be defined for re-randomisation trials. For some components, the considerations will generally be the same in a re-randomisation trial as in a parallel group or alternate trial design (e.g. the outcome definition, or how treatment discontinuation is handled), and so we do not discuss those here; instead, we focus on the aspects that are unique to multi-episode settings, and thus to re-randomisation trials.
The three aspects we focus on in this article are (i) whether each episode or each patient is given equal weight in the estimand; (ii) how the patient's ‘treatment history’ (i.e. the treatments they were allocated to in previous episodes) is handled; and (iii) the set of episodes included in the estimand.
Weighting by episode or by patient: Per-episode versus per-patient estimands
Here we discuss whether to give equal weight to each episode or to each patient in calculating the treatment effect.
Consider a setting where patients with more severe underlying diseases are pre-disposed to experience a larger number of episodes, but are less likely to respond to intervention than other patients. Imagine the treatment effect is
In this section, we define two different approaches to weighting: the per-episode estimand, and the per-patient estimand. The approach we use to define these estimands is based on a sampling scheme framework, as has been used to define estimands in other settings (notably in the informative cluster size setting).23–29
Per-episode estimands
The per-episode estimand (denoted by
Let I and J be random variables, where
Then, let
Then, the estimand is defined as
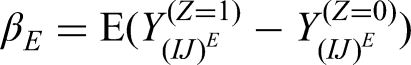
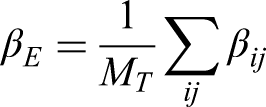
Per-patient estimands
The per-patient estimand (denoted by
Let
The estimand is defined as
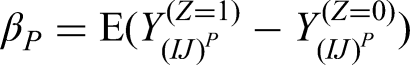
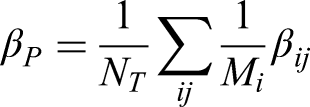
Treatment history: Added-benefit versus policy-benefit estimands
One key difference in the multi-episode setting compared to many other settings with clustered data is that in the multi-episode setting episodes occur sequentially in time, and outcomes or treatment effects in a patient's current episode may depend on the treatments they received in previous episodes. For example, imagine that patient outcomes follow the model

In this section, we define two different approaches for incorporating treatment history into the estimand definition: the policy-benefit estimand, and the added-benefit estimand. For the moment, we do not distinguish between per-episode and per-patient sampling schemes, and instead, use
The policy-benefit estimand (denoted by
We define the policy-benefit estimand as the expected difference in potential outcomes for a randomly selected episode (based either on a per-episode or per-patient basis), which has been allocated intervention for the current and all previous episodes versus control for the current and all previous episodes. It can be thought of as the average effect of always versus never treating.
The estimand can be written as
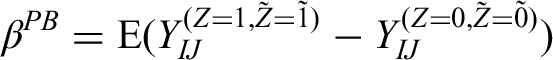
This estimand can be related to the potential outcomes by the expression
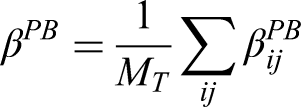
Added-benefit estimands
The added-benefit estimand (denoted by
We define the added-benefit estimand as the expected difference in potential outcomes for a randomly selected episode (based either on a per-episode or per-patient basis), based on both the intervention and control potential outcomes sharing the same treatment history.
The estimand can be written as
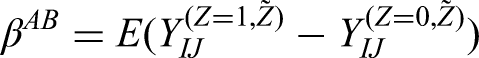
The estimand can be related to the potential outcomes as follows
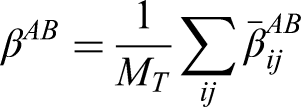
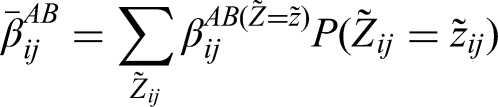
There are several important implications that follow on from this definition. The first is that the estimand depends on the distribution of
Another implication of this definition is that the estimand excludes episodes corresponding to treatment histories for which the patient would not be enrolled in the trial. For instance, if a patient would re-enrol in the trial for their second episode if they received intervention in the first episode, but not if they received control, then
The set of episodes to include: Average effects across all episodes versus episode-specific estimands
In the previous sections, we defined estimands that included all enrolled episodes. These provide a single overall average treatment effect across all episodes (with the type of average being defined by whether a per-episode or per-patient approach is used). This is in line with common practice in randomised trials, where a single average effect is typically provided for the main estimand, recognising that this average effect will not necessarily correspond to the true effect within each specific subgroup.
In multi-episode settings, it may sometimes be useful to define episode-specific estimands (denoted by
Under the added-benefit framework, the episode-specific estimand is
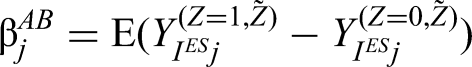
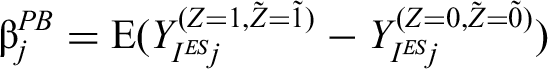
Of note, if we want to know whether the intervention is more effective the first time it is used versus the second time, a comparison between
An alternate way to define episode-specific estimands is to restrict the subset of patients for each
Comparison between estimands
A full set of the estimands described is shown in Table 1. We now discuss some of the differences between the per-episode versus per-patient, and the added- versus policy-benefit estimands.
Summary of estimands for multi-episode settings.

Summary of estimands for multi-episode settings.
Whether the per-episode and per-patient estimands coincide will depend on whether there is ‘informative cluster size’,23–29 where the patient acts as the cluster, and the size is determined by
For collapsible treatment effect measures (such as a difference in means, risk difference, or risk ratio), the per-episode and per-patient estimands should coincide unless the second type of informative cluster size occurs (where the treatment effect depends on
For non-collapsible effect measures (such as an odds ratio), the per-episode and per-patient will coincide in the absence of both types of informative cluster size; if either type occurs (either the outcome or treatment effect depends on
A simple way to evaluate whether the cluster size is informative under a particular data generating model (for a difference in means) is to take the mean of the potential outcomes and the mean of the potential treatment effects (either
We provide a number of examples in the supplementary material of scenarios where these estimands either coincide or are different (for a difference in means).
We note that identifying informative cluster size can be more challenging for non-collapsible treatment effect measures, such as the odds ratio (OR). For instance, consider the setting where patients for whom
Comparison between added-benefit versus policy-benefit estimands
The added-benefit and policy-benefit estimands will coincide if
We provide a number of examples in the supplementary material of scenarios where these estimands either coincide or are different.
Independence estimators
In this section, we describe a set of independence estimators that can be used in re-randomisation trials for the estimands described in Table 1. Independence estimators use a working independence correlation structure (i.e. they are based on a working assumption that episodes from the same patient are uncorrelated). We focus on a difference in means for a continuous outcome, however, the approaches in this section can be extended to estimate different types of treatment effects for different outcomes. They can be used in conjunction with robust standard errors which allow for clustering. 30 We do not explicitly define estimators for the episode-specific estimands, though these can be easily adapted from the estimators listed.
Estimators are summarised in Table 2, along with an example Stata code to implement these estimators.
Independence estimators.

Independence estimators.
Policy-benefit estimators are based on a maximum of two episodes per patient; this is because different causal models would need to be specified for the setting of ≥3 episodes. Added-benefit estimators can be used for any number of maximum episodes. For Stata code (version 15), ‘y’ denotes patient outcome, ‘z’ denotes treatment allocation, ‘id’ is a unique identifier for a patient, ‘m_i’ denotes the number of episodes for which the patient is enrolled in the trial, ‘z_prev’ denotes the patient's treatment allocation in their previous episode (and is set to 0 if it is the patient's first episode), ‘x_ep’ is an indicator for episode 2, ‘prop_1st_ep’ and ‘prop_2nd_ep’ represent the proportion of episodes in the trial which are first and second episodes, respectively, and ‘prop_has_1ep’ and ‘prop_has_2ep’ denote the proportion of patients enrolled in the trial for one and two episodes, respectively. In order to run the above code in Stata, ‘prop_1st_ep’, ‘prop_2nd_ep’, ‘prop_has_1ep’, and ‘prop_has_2ep’ must be saved as Stata local macros.
We provide some mathematical results evaluating the bias of the per-episode added-benefit and per-patient added-benefit estimators in the Supplemental Material and discuss when the policy-benefit estimators may be biased in the following sections.
The independence estimator for per-episode added-benefit estimand is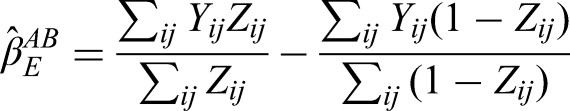
In the Appendix, we show that this estimator is unbiased under a wide variety of different data-generating mechanisms.
Per-patient added-benefit estimator
The per-patient estimator can be obtained by weighting each patient by the inverse of their number of episodes, that is, 
Differential non-enrolment occurs when different types of patients from the intervention and control groups re-enrol for their next episode. For example, in a setting where patients enrol for a maximum of two episodes, differential non-enrolment could occur if in the episode 1 intervention group, healthier patients were more likely to re-enrol in the trial for episode 2 than sicker patients, but in the episode 1 control group, sicker patients are more likely to re-enrol.
Per-episode policy-benefit estimator
To estimate the per-episode policy-benefit treatment effect, we must first estimate the 
After obtaining estimates for
We can then use these estimates to get an overall estimate of 
This estimator will be unbiased if (a) we correctly specify the causal model in (2); and if (b) we are able to obtain unbiased estimates of the causal parameters (e.g.
We note that even if the causal model in (2) is correctly specified, we may still obtain biased estimates of the causal parameters; for example, under differential non-enrolment, the parameter estimate of
For the per-patient policy-benefit estimator we need to obtain estimates from model (2) using weighted least-squares, where each patient is weighted by the inverse of their number of episodes, 
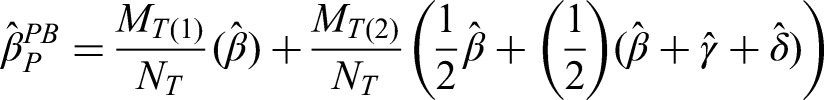
This estimator will be biased in the same settings as the per-episode policy-benefit estimator 15 (incorrectly specified causal model, biased parameter estimates due to differential non-enrolment), and in the same settings as the per-patient added-benefit estimator (differential non-enrolment based on the outcome from the previous episode).
Example: Trial in acute sickle cell pain crises
An example of a setting where re-randomisation has been used is trials in acute pain crises in patients with sickle cell disease. 2 Pain crises can be recurring, and so some patients may experience more than one pain crisis in a given period of time. 5
Patients who experience sickle cell pain crises typically require hospitalisation and treatment to manage symptoms. Treatment generally consists of morphine, which can have unwanted side effects. Therefore, alternative treatment options would be useful; for example, one trial assessed the use of high-dose ibuprofen compared to a placebo to reduce the amount of morphine required to manage pain symptoms. 31 We note that the interventions under study in this example (ibuprofen, placebo) will not affect the occurrence of future episodes (e.g. ibuprofen would not prevent future pain crises from occurring).
There are two important considerations when choosing the most estimand. First, the distribution of pain crises across patients is often skewed, where most patients may experience only one or two episodes during the course of the trial, but a small number of patients will experience a much larger number of episodes. 5 Therefore, differences between the per-episode and per-patient estimands may be large if the treatment effect differs in patients predisposed to experience a large number of pain crises. Both estimands address clinically important questions. The per-episode has the interpretation ‘the average effect across each time the intervention is used’. It gives more weight to patients who experience frequent pain crises, and it could be argued that it is more important that the intervention work well in these patients compared to those who experience infrequent crises (as they will undergo the intervention more frequently). However, it may also be useful to know how well the intervention works for the average patient; for instance, if the intervention works well for the 80% of patients in the trial who experience only one or two pain crises, this would still be clinically important to know, even if it worked less well in the other 20% of patients who experienced more frequent pain crises. Therefore, both estimands could be used, one as the primary and the other as a secondary estimand. Given that per-episode effects can be estimated under less restrictive assumptions (i.e. it does not require the assumption of no differential non-enrolment, unlike the per-patient estimator), we suggest this could be considered for the primary estimand, though this choice largely depends on the overall goals of the trial.
Second, the interventions used to treat symptoms from acute sickle cell pain crises (e.g. ibuprofen 5 ) are unlikely to influence either the outcome or treatment effect in subsequent episodes. Therefore, the added-benefit and policy-benefit estimands should be similar. Given the additional complexity of estimating policy-benefit effects, we suggest an added-benefit approach be used here. Coupled with a per-episode approach, this estimand provides an interpretation of ‘the additional benefit of the intervention averaged across all pain crises for which it would be used’, and can be easily estimated using the difference between all interventions episodes versus all control episodes.
Discussion
We have proposed a set of estimands that can be used in multi-episode settings, as well as a set of independence estimators that can be used in re-randomisation trials. Our main result is to show that the analytical approach most commonly used in re-randomisation trials (comparing all intervention vs. all control episodes directly) corresponds to a per-episode added-benefit estimand. This implies these trials have been estimating the average effect of the intervention across episodes, over and above any benefit conferred from the intervention in previous episodes. We have found the per-episode added-benefit estimator to be generally unbiased, which suggests results from trials using this approach are valid.
However, other estimands we have proposed here may also be useful in future trials. For instance, in trials for which some patients experience a large number of episodes, per-patient estimands may give a better idea of how well the intervention works for the average patient in such settings. Similarly, in trials for which the treatments are expected to influence outcomes or treatment effects in subsequent episodes, policy-benefit estimands may provide a better picture of the overall benefit to adopting such interventions into routine practice.
Our derivations show that while the per-episode added-benefit estimator is generally unbiased in re-randomisation trials, other estimands (per-patient added-benefit and policy-benefit estimands) require untestable assumptions for unbiasedness. Sometimes we can determine that the assumptions are plausible based on subject matter knowledge (e.g. the assumptions underpinning the policy-benefit estimator in the sickle cell example given earlier), but in other settings, the required assumptions might be quite strong (e.g. it may be unlikely we are able to determine an appropriate causal model for the policy-benefit estimator under complex carryover mechanisms, or when carryover or treatment effects interact with disease progression). In these settings, it may be desirable to specify policy-benefit or per-patient as secondary estimands, with the per-episode added-benefit used as the primary (as it can be reliably estimated without strong assumptions). Alternatively, if policy-benefit is the main question of interest and it is anticipated that a plausible causal model cannot be identified, then it may be useful to consider alternative trial designs which can more easily estimate this type of estimand, such as a cluster design where participants are assigned to receive the same treatment for each episode; however, only limited research has been undertaken on this type of trial design to date, and further research is warranted before it is used regularly.
One drawback of the added-benefit estimand is that it averages over different (randomised) treatment histories, which will not reflect the treatment histories seen in clinical practice. If the treatment effect is not modified by treatment allocation in previous episodes (as would be expected in the sickle cell example given earlier), then the added-benefit estimand will generalise to clinical practice, as the treatment histories will not affect the value of the estimand. Otherwise, the added-benefit estimand will be less generalisable, though depending on the specific study objectives, it may still be useful (as it is the only way of addressing the question ‘how much additional benefit is conferred by the intervention in this episode, over and above any previous episodes’ which can be estimated without strong assumptions).
As with any treatment effect which is an average over different patients or data points, the estimands defined here may not be representative of the treatment effect for a particular episode. For instance, the treatment effect may decrease in later episodes compared to earlier ones (for instance, in the case of progressive disease, where patients’ health status gradually worsens for each new episode they experience, and there is a treatment-by-disease status interaction, or if the treatment itself loses efficacy the more often it is given). It may be of interest to explore supplementary estimands here, particularly to help identify whether treatment should be given for each new episode, or whether there is a certain point at which it becomes no longer useful. This could be done using episode-specific estimands (i.e. the treatment effect the first time a treatment is given vs. the second time, etc.), though we note this may not be sufficient to answer the question on its own. For instance, consider the example of progressive disease given above; the episode-specific effects will show the treatment becoming less effective in later episodes, though it won’t be clear whether this is due to the treatment itself becoming less effective, or because of an interaction with disease progression. Therefore, in this type of setting it may also be worth exploring subgroup analyses (e.g. the episode-specific effect in patients whose disease has progressed vs. those where it has not), which may provide a more complete picture of which patients or episodes should receive treatment.
The re-randomisation design is a new type of trial design, and as such, there has been little methodological research to date. Future extensions to the work in this article would be useful, for instance, to evaluate alternatives to independence estimators (such as mixed-effects models), or alternative designs (such as a cluster design where patients are allocated to receive the same treatment for all episodes). Sample size requirements will likely differ for each of the estimands described (e.g. sample size requirements for the per-patient estimands will likely be based on recruiting a specified number of patients, whereas the per-episode estimands will likely require a specified number of episodes, irrespective of patients 5 ), and so further research in this area is warranted. Further work to implement new packages in routine statistical software (such as Stata or R) to automate estimation of the policy-benefit estimands (which can be challenging to implement manually, due to the need to specify a different causal model depending on the number of episodes, and then to average over different parameters in the causal model) would be useful. More generally, further work on the estimation of policy-benefit estimands would be useful, particularly in the setting where some patients experience a large number of episodes, where including an indicator variable for each episode may lead to computational issues. Finally, in this paper, we considered the setting where treatment allocation does not affect the occurrence of subsequent episodes. In some clinical settings, this may not be the case, and so it would be useful to extend the estimands here to the setting where treatment allocation may prevent subsequent episodes from occurring.
Conclusions
Consideration of the proposed estimands can help guide the choice of an appropriate analytical method. The re-randomisation design in conjunction with an independence estimator can be a useful approach in multi-episode settings.
Supplemental Material
sj-docx-1-smm-10.1177_09622802221094140 - Supplemental material for Re-randomisation trials in multi-episode settings: Estimands and independence estimators
Supplemental material, sj-docx-1-smm-10.1177_09622802221094140 for Re-randomisation trials in multi-episode settings: Estimands and independence estimators by Brennan C Kahan, Ian R White, Richard Hooper and Sandra Eldridge in Statistical Methods in Medical Research
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
Brennan Kahan is funded by a National Institute for Health Research Doctoral Research Fellowship (DRF-2016-09-005). This article presents independent research funded by the National Institute for Health Research (NIHR). The views expressed are those of the authors and not necessarily those of the NHS, the NIHR, or the Department of Health. Ian White and Brennan Kahan are grateful for support from the UK Medical Research Council, grants MC_UU_00004/07and MC_UU_00004/09.
Supplemental material
Supplementary material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.