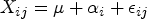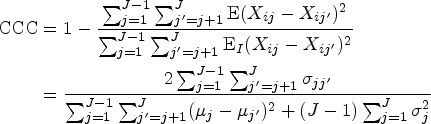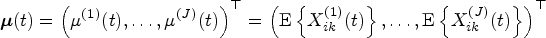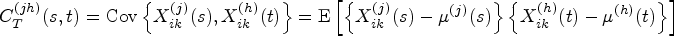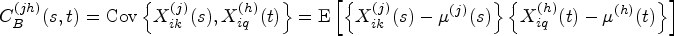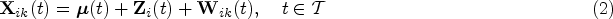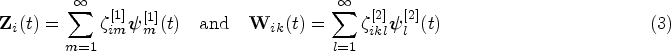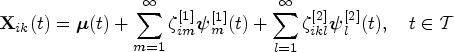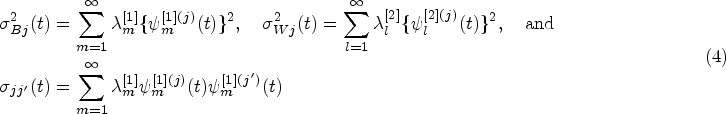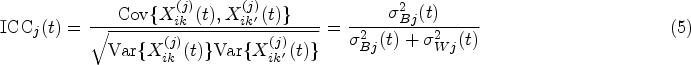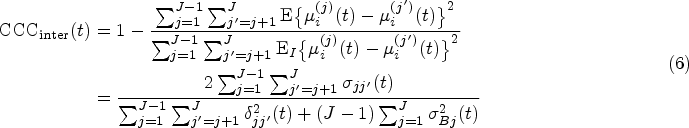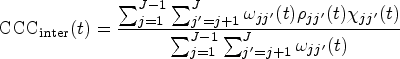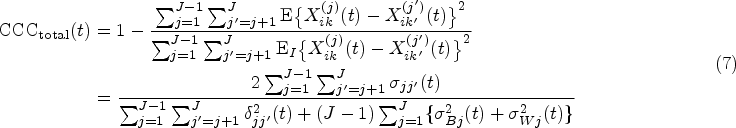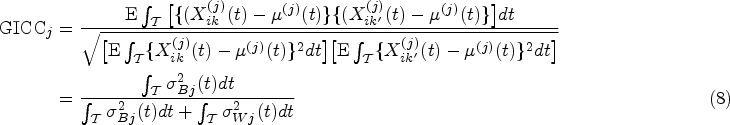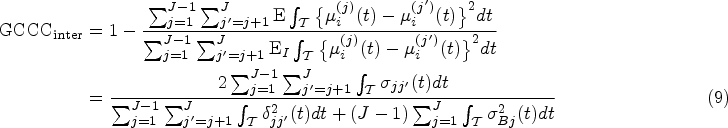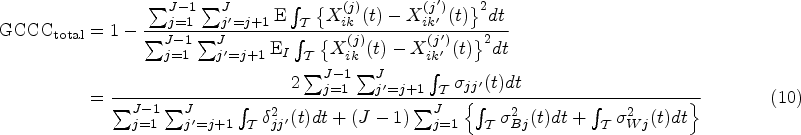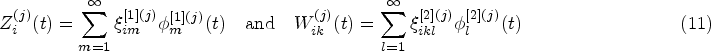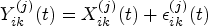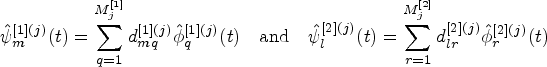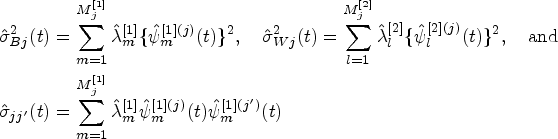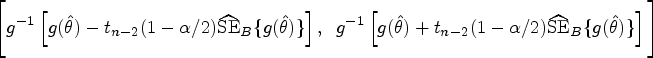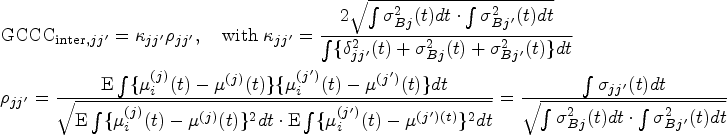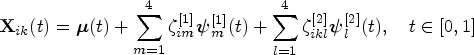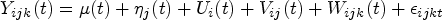Modern medical devices are increasingly producing complex data that could offer deeper insights into physiological mechanisms of underlying diseases. One type of complex data that arises frequently in medical imaging studies is functional data, whose sampling unit is a smooth continuous function. In this work, with the goal of establishing the scientific validity of experiments involving modern medical imaging devices, we focus on the problem of evaluating reliability and reproducibility of multiple functional data that are measured on the same subjects by different methods (i.e. different technologies or raters). Specifically, we develop a series of intraclass correlation coefficient and concordance correlation coefficient indices that can assess intra-method, inter-method, and total (intra + inter) agreement based on multivariate multilevel functional data consisting of replicated functional data measurements produced by each of the different methods. For efficient estimation, the proposed indices are expressed using variance components of a multivariate multilevel functional mixed effect model, which can be smoothly estimated by functional principal component analysis. Extensive simulation studies are performed to assess the finite-sample properties of the estimators. The proposed method is applied to evaluate the reliability and reproducibility of renogram curves produced by a high-tech radionuclide image scan used to non-invasively detect kidney obstruction.
In biomedical studies, clinical measurements provide an objective means of diagnosing, monitoring, or refuting a patient’s physiological condition, state of health, and disease. The recent advancement in technology has led to introduction of many new clinical measurement scales that could potentially offer deeper insights into disease and pathological mechanisms. To ensure that scientific conclusions derived from a new clinical measurement scale are trustworthy, it is necessary to evaluate its reliability and reproducibility. From a statistical standpoint, this amounts to assessing agreement among target clinical measurements produced by several methods, technologies, or raters on a common subject/unit.1
Various statistical methods have been developed to assess agreement among multiple methods when clinical measurements are continuous. Intraclass correlation coefficient (ICC) is one of the popular measures of agreement for continuous measurements.2,3 Let denote the clinical measurement of the th subject produced by the th method (; ). The ICC is based on the following linear mixed model:
where fixed effect denotes the grand mean of the measurements over all methods, is a random subject effect with mean zero and variance , and denotes a random interaction effect between rater and subject with mean zero and variance . Then assuming and are uncorrelated, the ICC is defined as
The index is scaled between 0 and 1, and the closer the index value is to 1, the better the agreement among different methods. One major limitation of ICC is that it assumes measurements produced by different methods share the common mean and variance (the exchangeable assumption), which is often not true in practice.
Concordance correlation coefficient (CCC) is another popular measure of agreement for continuous readings.4,5 The basic idea is to quantify the degree of concordance among measurements from methods by the sum of their pairwise expected squared differences . Then the index is constructed by scaling by its counterpart under the assumption that all methods are independent; that is,
where denotes the expectation conditional on the assumption that and are independent, and . A value of denotes perfect concordance (discordance); a value of zero denotes no concordance. Unlike the ICC, no statistical model is assumed, and measurements from different methods can have different means and variances. Several extensions of CCC have been proposed to assess agreement under different contexts: a weighted CCC for a repeated measures design,6 a robust version of the CCC,7 and a series of indices (intra-ICC, inter-CCC, and total-CCC) that can assess intra-method, inter-method, and total (inter intra) agreement when there are replicated readings taken by each of the multiple methods on a given subject.7
With advancements in technology, modern medical devices are increasingly producing complex data that could offer deeper insights into physiological mechanisms underlying diseases and aid in improving diagnostic capabilities. One such type of data that arises frequently in medical imaging studies is functional data, whose sampling unit is a smooth continuous function defined over a time, space, or other continuum. To date, many functional data analysis methods have been developed to analyze functional data and translate their rich structural information into clinically useful applications.8
However, there is limited work on the development of statistical methods for assessing agreement of functional data measurements. One ad hoc approach to evaluate agreement of functional data is to compute pointwise ICCs or CCCs across the time points. This approach, however, produces highly variable (non-smooth) ICC or CCC curves that are hard to interpret and not applicable to irregular functional data. An alternative naive approach is to project the functions on the space spanned by a set of pre-specified basis functions (e.g. B-splines, Fourier basis, wavelets, etc.) and extract the corresponding basis coefficients as low-dimensional representations of the functions. Then, treating the extracted basis coefficients as continuous readings, one can compute the existing ICC and CCC indices7 to assess intra-method, inter-method, and total agreement. This approach, however, has two major drawbacks: (i) the pre-specified set of basis functions may not capture important aspects of the data, resulting in loss of information; and (ii) a loss of efficiency occurs as smoothing of functions is done for each observational unit independently, without borrowing information from other observations. Another approach utilizing a weighted CCC6 for repeated measures is not appropriate for functional data because observation for each subject is very dense, more like a set of curves over time rather than a multi-dimensional vector of repeated measurements.
More recently, three approaches that are specifically tailored to assess agreement of functional data were introduced. Initially, an extended CCC index that can assess agreement between functional data produced by two different methods was proposed.9 The index is defined based on a modified inner product in some probability functional space and is estimated via a method of moments. Next, an extended ICC index that is appropriate for assessing the agreement of images (two-dimensional functions) was developed.10 Here, the index is formulated based on the traces of variance component operators—which are extensions of and in (1) to the functional space—and are estimated based on multilevel functional principal component analysis (FPCA) .11 More recently, a functional CCC index that can evaluate agreement of functional data produced by two or more different methods was introduced.12 To facilitate parsimonious modeling and stable estimation of the index, the method utilizes multivariate FPCA13 to represent the measurements using a small number of method-specific principal components. Unlike the first two extended CCC9 and ICC10 indices, this functional CCC itself is a function of time and provides insight into how the degree of agreement changes over time.
The aforementioned agreement studies for functional data, however, assume that only one functional data measurement is produced by each method on a single subject. The problem here is that the index formulated under such a design can only evaluate total agreement that contains both intra- and inter-method agreement, without being able to separate the two. In order to assess intra-method, inter-method, and total agreement separately, a development of a series of ICC and CCC indices formulated under a design with replicated functional data measurements from each of the several methods on each subject (i.e. multivariate multilevel functional data) is required but has not yet been pursued; our article aims to fill this important gap.
Our work is motivated by the renal study conducted at Emory University. One of the study goals is to evaluate the reliability and reproducibility of a high-tech medical imaging device called Technetium-99m mercaptoacetyltriglycine (MAG3) renography, which is widely used to non-invasively detect kidney obstruction.14 The data collection experiment begins with an intravenous injection of MAG3, a gamma-emitting tracer, that is absorbed by the kidneys and then travels down the ureters from the kidney to the bladder. During the process, the MAG3 photons are imaged and quantified on a user-defined region of interest (ROI) in the kidney, and a renogram curve, which represents the MAG3 photon counts detected at 100 time points (every 12–15 s) during a period of 1428 s on the ROI, is produced. There are two methods for specifying the ROI in the kidney. In the first method, a radiologist specifies an ROI within a whole region of the kidney and is called a “whole-kidney ROI method.” In the second method, a radiologist focuses exclusively on the outer layer of the kidney (renal cortex), where the nephrons begin, and specifies an ROI within it; this method is called the “cortical-kidney ROI method.” The top panel of Figure 1 shows renogram curves (with time-varying MAG3 photon counts expressed as dots) produced by the whole-kidney ROI method (left panel) and the cortical-kidney ROI method (right panel) on a representative kidney in the data set. The bottom panel simultaneously presents the renogram curves of five selected kidneys from the data set.
The top panel presents the renogram curves (dots representing the series of MAG3 photon counts/1000 quantified over 1428 s) produced by the whole-kidney ROI method (left panel) and the cortical-kidney ROI method (right panel) on a representative kidney from the Emory renal study data set. The bottom panel presents the renogram curves of five selected kidneys in the data set. MAG3: mercaptoacetyltriglycine; ROI: region of interest.
The specific research question pertaining to the evaluation of the reliability and reproducibility of MAG3 renography is two-fold. First, are the renogram curves produced by each of the methods on the same kidney reproducible across multiple ROI specification attempts by the practicing radiologist? Investigating this question by assessing intra-method agreement can help establish the reliability of clinical measurements produced by MAG3 renography for detecting and monitoring kidney obstruction. Second, is the renogram curve produced by one method reproducible by another method (inter-method agreement)? If so, the diagnostic procedure can be simplified as a practicing radiologist can focus on interpreting a renogram curve produced by one of the two methods.
To answer these research questions, we develop a set of ICC and CCC indices that can assess intra-method, inter-method, and total agreement of functional data measurements. Two types of indices are proposed. The first type consists of “time-dependent” ICC and CCC indices that can quantify degree of agreement varying smoothly over time. These time-dependent indices are particularly useful for cases where identifying a subset of the domain with high agreement or delineating the trend of agreement is of interest. The second type comprises “global” indices that summarize agreement over the entire time domain using a single measure.
We use a model-based approach for defining and estimating the indices. Specifically, we begin by formulating a multivariate multilevel functional mixed effects model, under which functional data measurements produced by multiple methods are written as a sum of multivariate grand mean function, subject-specific random effect function, and residual subject- and replication-specific random effect function. Such a formulation allows us to write the indices as functions of within- and between-subject variance components, which in turn can be expressed as truncated multivariate Karhunen–Loéve (KL) expansions. This leads to the following three-step procedure for estimating the indices: (i) we estimate the terms (scores, eigenvalues, and eigenfunctions) of the univariate multilevel KL expansion based on the univariate multilevel FPCA11 and then combine them in a way that produces the consistent estimates for the terms of the multivariate multilevel KL expansion; (ii) use the estimated terms of the multivariate multilevel KL expansion to produce the estimates of within- and between-subject variance components; and (iii) use the estimated variance components to produce the estimates of the indices. For inference, we propose to construct the confidence bands and intervals of the indices based on an non-parametric bootstrap at the subject level.
The remainder of the article is organized as follows. In Section 2, we first introduce a multivariate multilevel functional mixed effects model for functional data measurements produced by multiple methods. We then introduce ICC and CCC indices for assessing intra-method, inter-method, and total agreement of functional data and provide an efficient estimation strategy based on FPCA. In Section 3, we conduct simulation studies to evaluate the performance of the proposed approach. The application of our methods to the Emory renal study is described in Section 4. Concluding remarks are in Section 5.
Methods
Data object
Let denote a th replication of a square-integrable random function measured over a continuous variable by method on subject for , and . In our application, a function denotes a renogram curve, is a renal scan time, is a renal scan period (in seconds), is a kidney, and stands for either a “whole-kidney ROI method” ( or “cortical-kidney ROI method” (.
Combining the functions across different methods for each replicate and subject, we obtain the multivariate functional object with the multivariate mean function
for all . For , the matrix of total covariance functions is defined as , whose th row and th column () element is
For , the matrix of covariance function between the replicates within the same subject is defined as , whose th row and th column element is
Note that does not depend on and , implying that the common covariance structure is imposed between any pair of replicates.
Modeling of data
We introduce the following multivariate multilevel functional mixed effects model for the agreement analysis:
where is the subject-specific random effect function (level 1 function), and is the residual subject- and replication-specific random effect function (level 2 function). This model is a multivariate extension of the two-way functional analysis of variance model11 and a multilevel extension of the uncentered multivariate KL expansion.15 We make the following assumptions for the model: (a) is a fixed function; (b) each is a mean zero stochastic process with between-subject variance ; (c) each is a mean zero stochastic process with within-subject variance ; (d) ’s are correlated across the methods with ; (e) ’s are independent across the replicates and methods; and (e) and are mutually uncorrelated.
To facilitate the estimation of the variance components , , and , which constitute the agreement measures introduced in the next section, we decompose both level 1 and level 2 functions in (2) based on the following multivariate multilevel KL expansion
Here, for , are level 1 multivariate eigenfunctions corresponding to the non-decreasing eigenvalues from the spectral decomposition of the “between” covariance function: . Note that forms an orthonormal basis of the space of multivariate functions ; that is, . The coefficients are random variables (called level 1 scores) with , and for any . For , are level 2 multivariate eigenfunctions corresponding to the non-decreasing eigenvalues from the spectral decomposition , where . The set also forms an orthonormal basis of , and the coefficients are level 2 scores with , , and for any . We further assume that are uncorrelated with .
Model (2) with the multivariate multilevel KL expansion (3) becomes
which gives the following expressions for the variance components of main interest:
for , and .
Agreement measures
Based on the multivariate multilevel functional mixed effects model (2), we introduce three types of agreement indices for functional data: (i) ICC that measures agreement among repetitions of a single method (intra-method agreement); (ii) inter-CCC that quantifies agreement among different methods based on the true readings of each method without replication error (inter-method agreement); and (iii) total-CCC that measures total (intra inter) agreement based on any observed individual reading from each method. We first introduce a “time-dependent” version of the indices, which quantifies the degree of agreement varying smoothly over time . These time-dependent indices are particularly useful for cases where identifying a subset of the domain with high agreement or delineating the trend of agreement is of interest.
For a given method, say , we have and for any under model (2); that is, the replicates of a given method are interchangeable. As such, the following ICC index can be used to quantify the degree of concordance between the replicated readings of method at each time point (intra-method agreement):
For each method, the ICC measures the proportion of variance that is attributable to the subjects, and it is heavily dependent on the total variability (total data range).
At each , the inter-CCC quantifies the degree of concordance among different methods (inter-method agreement) based on the true readings of each method, , which are not obscured by the within-method replication error:
Here, denotes the expectation conditional on the assumption that and are independent, and . Note that the inter-CCC depends on the between-subject variability but not on the within-subject variance , thus capturing the pure agreement among the methods while effectively denoising the intra-method differences. Note that we can rewrite the inter-CCC (6) as
where , , and , with and . Here, denotes Pearson’s correlation coefficient representing the degree of “precision” between methods and . The degree of “accuracy” between the two methods is quantified by , which contains representing scale shift and representing location shift relative to the scale.4,16 This formulation allows us to investigate the source of disagreement between a particular pair of methods. That is, a low value of implies that the disagreement is due to lack of precision, while high values of and suggest that the disagreement is due to scale shift and location shift, respectively.
The total CCC quantifies the total agreement containing both intra-method agreement and inter-method agreement. The index is formulated based on any individual reading from each method, given that the replicated readings from the same method are independently and identically distributed (iid). Thus, the total CCC does not depend on the number of replicates and is defined as
where denotes the expectation conditional on the assumption that and are independent. Note that the total CCC, which is defined at the level of observed readings, consists of both and ; that is, the index takes into account both the intra- and inter-method variabilities in the readings for assessing agreement.
In some cases, we may be interested in the “global” agreement measure that summarizes the agreement of functional data over the entire domain . The following agreement indices, global ICC (), global inter-CCC () and global total-CCC (), respectively, summarize the intra-method, inter-method, and total agreement of functional data over their entire domain :
Note that these indices are constructed using the moments based on the inner product , where and belong to a space of square-integrable random functions.
Estimation and inference
In this section, we introduce our approach for smoothly estimating the time-dependent indices (5)-(7) and estimating the global indices (8)-(10). Note that all indices are functions of the variance components , , and , which, in turn, can be expressed as linear combinations of the KL expansion terms as in (4). Accordingly, the proposed estimation scheme comprises the following three steps.
The first step is to estimate the terms of the multivariate multilevel KL expansion (3), namely, , , , and (i.e. level 1 and 2 eigenvalues and multivariate eigenfunctions). To achieve this, we derive the univariate multilevel KL expansion of the level 1 and 2 functions in (2) separately for each th element as
Here, for , are level 1 univariate eigenfunctions corresponding to eigenvalues from the spectral decomposition . The coefficients are mutually uncorrelated level 1 scores with and . For , are level 2 univariate eigenfunctions corresponding to eigenvalues from the spectral decomposition , where . The coefficients are mutually uncorrelated level 2 scores with and . Note that the univariate multilevel KL expansion (11) uses information from readings of only one method (single ) at a time, while the multivariate counterpart (3) leverages information within and across different methods (multiple 's) simultaneously.
We now introduce an estimation framework based on FPCA that first estimates univariate multilevel KL expansion terms—namely, , , , , , and —and then combines them in a way that produces the estimates of the multivariate multilevel KL expansion terms , , , and . The framework consists of the following four sub-steps.
In practice, each function is measured at a set of grid points . Let denote the collection of observed readings of functional data produced by method . Perform univariate multilevel FPCA11 separately on data from each method to estimate the univariate KL expansion terms. That is, for each , obtain , , , , , and . Here, () denote the optimal truncation lags for the univariate multivariate KL expansion (11), which can be chosen based on the percentage of variance explained; that is, such that the leading eigenfunctions explain (e.g. 90% or 95%) of total variability. Note that the univariate multilevel KL expansion terms are obtained based on the eigenanalyses of the univariate covariance functions estimated by the method of moments: , , and , where . In many applications, functional data are observed with error (residual noise), that is
where denotes the independent residual noise process with mean zero and variance . There are three ways to handle error-prone functional data. The first approach is to smooth the data prior to applying the FPCA.17 The second is to represent the functions using a set of basis functions (e.g. B-splines) and control their smoothness by introducing a penalty term.18 The third is to smooth the covariance functions.19 The detailed estimation procedure for the univariate multilevel FPCA based on the covariance smoothing approach is described in Section 2.3 of Di et al.’s paper.11
Let (). Firstly, create the matrix , where each row contains all estimated level 1 scores for a single subject. Define . Secondly, create the matrix , where each row contains all estimated level 2 scores for each replicate. Define .
Firstly, perform an eigenanalysis of to obtain the eigenvalues of interest and the corresponding orthonormal eigenvectors , with for (). Secondly, perform an eigenanalysis of to obtain the eigenvalues of interest and the corresponding orthonormal eigenvectors , with for (). Here, and are truncation lags that can be chosen to explain a certain amount of variance; that is, .
Estimate the multivariate level 1 and 2 eigenfunctions, respectively, as
for , and .
The sub-steps 3 and 4 above, which combine the univariate multilevel functional principal components to produce the estimates of the multivariate multilevel counterparts, extend and enrich the recent estimation framework for multivariate FPCA13 to the multilevel setting with additional complexity induced by functional clustering. Note that here we assume level 1 and 2 functions are mutually independent.
In the second step, we plug the estimates , , , and obtained in the previous step into (4) to obtain the estimates of the variance components. That is,
for and .
In the third step, we plug the estimates of the variance components , , and into formulas (5) to (10) to obtain the corresponding ICC and CCC estimates. For estimation of , the method of moments can be used: . Given measurement error-prone functional data, can be estimated using the method of moments after smoothing the curves or by applying penalized spline smoothing.20 Note that the integrals in the global measures can be approximated by Riemann sums.
Next, we describe the procedure for constructing confidence intervals (CIs) or bands for the proposed ICC and CCC indices. Let represent one of the proposed indices, and let denote its estimate obtained from the aforementioned steps. Since the indices range between and 1, we may apply the Fisher -transformation for their estimates, , to obtain a better normal approximation. To construct a CI, a non-parametric bootstrap21 can be performed. Specifically, one can draw (e.g. ) bootstrap cluster samples with replacement from ’s (, where contains all functional data on the th subject, and the unit of cluster is subject. Note that such a cluster sampling allows adjustment for correlation among multiple readings made on the same subject. Then, we compute for each bootstrap sample , and obtain the bootstrap estimate of the standard error, that is, , where . This allows us to construct pointwise confidence bands for time-dependent indices (5) to (7) and CIs for global indices (8) to (10) as
where denotes the percentile of the distribution.
Given a notable overall agreement among the methods, possibly based on the CI of not containing zero, one may be interested in further investigating which specific pair of methods exhibits significant agreement. This amounts to testing the hypothesis: versus , where denotes the pairwise global inter-CCC between methods and . Noting that the pairwise global inter-CCC can be written as
that is, the functional correlation coefficient9 scaled by , one can conduct a permutation test, similar in spirit to that for the correlation, to test this hypothesis.22 However, performing a permutation test using may result in an inflated Type I error rate as permutation and sampling distributions converge to different distributions.23 One remedy is to perform the test on the studentized statistic22, where is the estimator of with , assuming and . To summarize, permute the data from method at the subject level, compute the studentized statistic, repeat the permutation multiple times (e.g. 10,000), and obtain the -value as the proportion of permutations with an absolute value of the statistic at least as large as the observed one. One can compare the -value to the significance level adjusted for multiple pairwise comparisons.
Simulations
In this section, we conduct simulation studies to examine the finite-sample performance of the proposed procedure for estimating the ICC and CCC indices for functional data.
We generate functional data according to the following multivariate multilevel model whose level 1 and 2 functions are expressed using respective multivariate multilevel KL expansion with four components for each level:
for and , where the domain of functional data is a unit interval , , , and .
In the first setting, we consider functional data produced by two methods (). The level 1 multivariate eigenfunctions are set as , for and . The level 2 multivariate eigenfunctions are set to and for and . Two different specifications of the multivariate mean functions are considered: and . Here the former mean function is constant over , while the latter is a linear function of . In the second setting, functional data are produced by three methods (). The level 1 multivariate eigenfunctions are set as , for and . The level 2 multivariate eigenfunctions are set to and for and . Two different specifications of the multivariate mean functions that we consider are and .
In both settings, the scores and are independently generated from and , respectively, where , and . Sample sizes are set as and , and the number of replicates produced by each method on each subject is set to . All functional data are generated on a grid of equidistant time points , with and . In sum, we consider 16 scenarios (two different specifications of .
The accuracy of the CCC and ICC estimates computed using the procedure described in Section 2.4 is measured by “average bias” for the time-dependent indices and “bias” for the global indices. The biases are calculated and averaged across 500 simulated data sets. We also report the coverage rates of pointwise 95% bootstrap confidence bands (averaged across time points) and 95% bootstrap CIs on 500 simulated data sets. Here, the intervals are constructed using bootstrap resamples at the subject level. Note that during estimation and inference, the numbers of level 1 and 2 components to retain ( and ) are chosen to preserve 95% of the total variability in each simulated data set.
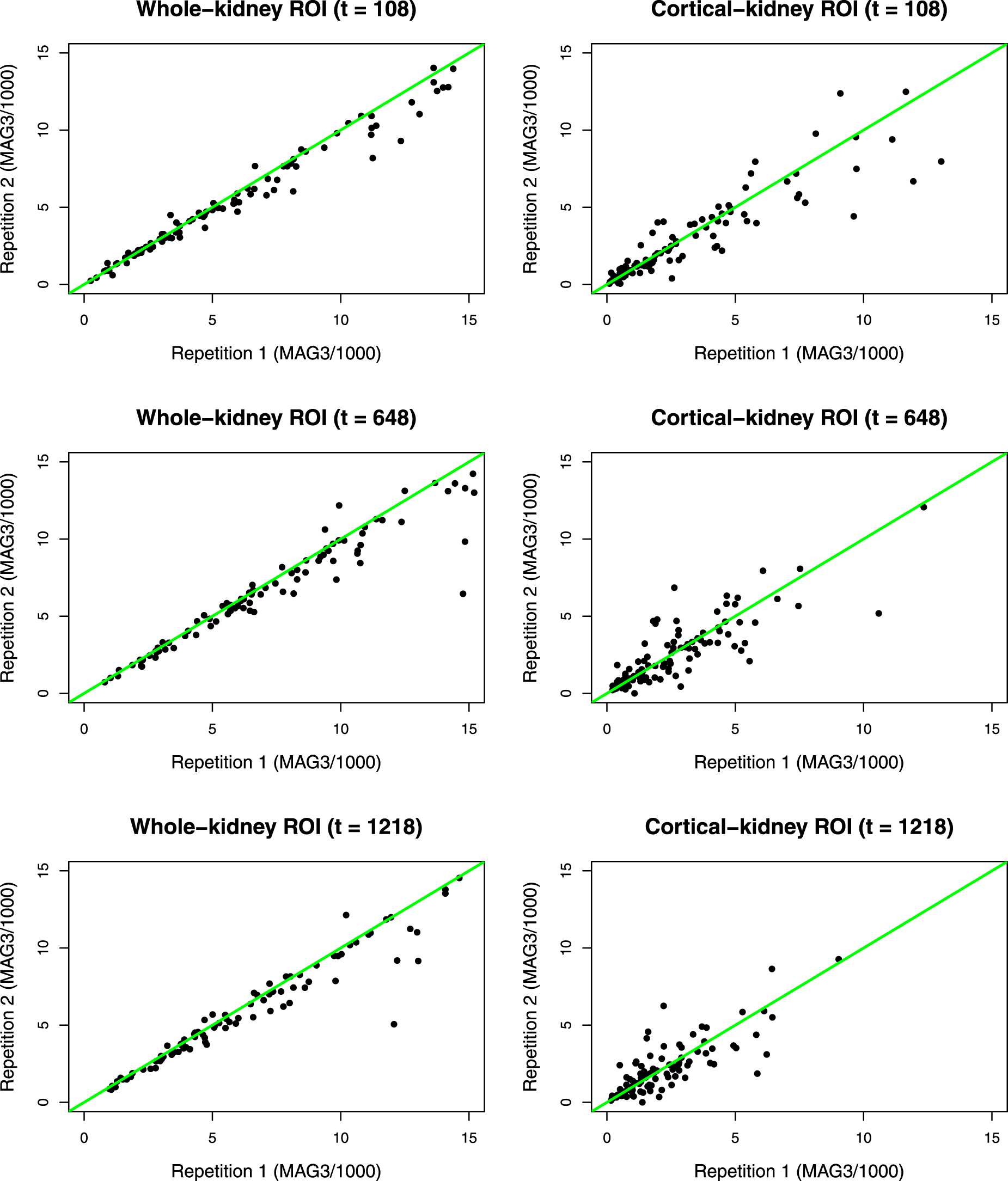
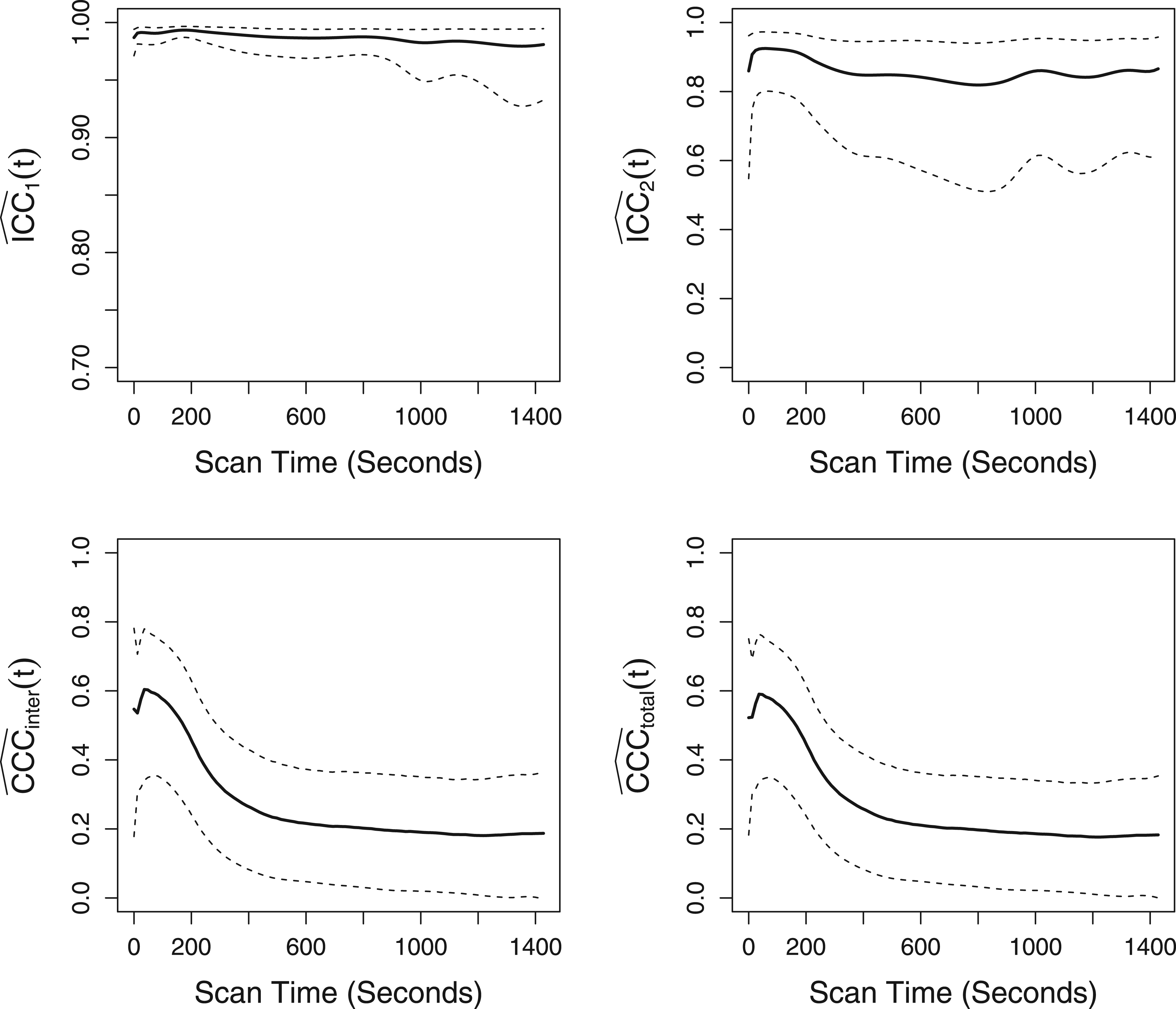
Tables 1 and 2 present the simulation results for the two settings with and methods, respectively. We immediately see that, in all configurations, the biases of all estimated indices are small and approach 0 as the sample size () and number of time points () increase, demonstrating the adequate accuracy and consistency of our estimation procedure. Note that both time-dependent and global inter-CCC indices ( and ) exhibit slightly higher bias (but still reasonably low) compared to other indices. This is mainly because the inter-CCC indices are based on the squared expected difference between the true readings that are not directly observed, further complicating their estimation task. However, we do see that their biases quickly approach 0 as the sample size and number of time points increase. The coverage rates of the pointwise 95% bootstrap confidence bands for time-dependent indices and the 95% bootstrap CIs for global indices are all close to 0.95. Again, the coverage rate of is slightly lower (but still over 0.92) than those of other indices when and , but it quickly approaches the nominal level as and increase. In summary, our simulation studies demonstrate the satisfactory finite-sample performance of the proposed estimation and inference schemes.
Simulation results with methods.
Index
Bias
CR
Bias
CR
Bias
CR
Bias
CR
Mean function: =
−0.0018
0.944
−0.0016
0.944
−0.0001
0.947
0.0001
0.948
0.0006
0.944
0.0007
0.946
0.0008
0.946
0.0009
0.948
−0.0103
0.944
−0.0094
0.945
−0.0039
0.948
−0.0031
0.952
−0.0045
0.939
−0.0040
0.939
−0.0014
0.946
−0.0009
0.949
0.0004
0.938
0.0003
0.938
0.0008
0.954
0.0008
0.952
0.0018
0.936
0.0017
0.938
0.0014
0.954
0.0013
0.954
−0.0104
0.922
−0.0096
0.926
−0.0039
0.942
−0.0032
0.954
−0.0036
0.928
−0.0032
0.932
−0.0010
0.948
−0.0006
0.948
Mean function: =
−0.0018
0.944
−0.0016
0.944
−0.0001
0.947
0.0001
0.948
0.0006
0.944
0.0007
0.946
0.0008
0.946
0.0009
0.948
−0.0120
0.942
−0.0110
0.944
−0.0046
0.945
−0.0037
0.951
−0.0049
0.939
−0.0043
0.939
−0.0015
0.946
−0.0009
0.948
0.0004
0.938
0.0003
0.938
0.0008
0.954
0.0008
0.952
0.0018
0.936
0.0017
0.938
0.0014
0.954
0.0013
0.954
−0.0114
0.924
−0.0105
0.926
−0.0044
0.944
−0.0035
0.950
−0.0038
0.930
−0.0034
0.932
−0.0010
0.946
−0.0006
0.946
ICC: intraclass correlation coefficient; CCC: concordance correlation coefficient; GICC: global ICC; GCCC: global CCC. Bias denotes a mean of 500 “average biases” for time-dependent indices and a mean of 500 “biases” for global indices. CR denotes coverage rates of pointwise 95% bootstrap confidence bands averaged over time points for time-dependent indices and coverage rates of 95% bootstrap confidence intervals for global indices; results are based on 500 simulated data sets.
Simulation results with methods.
Index
Bias
CR
Bias
CR
Bias
CR
Bias
CR
Mean function: =
0.0020
0.945
0.0021
0.948
0.0011
0.948
0.0013
0.952
−0.0005
0.944
−0.0004
0.944
0.0005
0.946
0.0006
0.947
−0.0022
0.943
−0.0021
0.943
−0.0003
0.947
−0.0002
0.946
−0.0098
0.941
−0.0091
0.943
−0.0037
0.951
−0.0030
0.954
−0.0040
0.938
−0.0035
0.939
−0.0011
0.947
−0.0007
0.948
0.0027
0.936
0.0026
0.938
0.0015
0.956
0.0015
0.956
0.0011
0.938
0.0010
0.938
0.0011
0.954
0.0011
0.952
−0.0005
0.938
−0.0005
0.938
0.0004
0.954
0.0004
0.952
−0.0093
0.934
−0.0087
0.940
−0.0034
0.944
−0.0029
0.946
−0.0032
0.936
−0.0029
0.936
−0.0008
0.950
−0.0005
0.952
Mean function: =
0.0020
0.945
0.0021
0.948
0.0011
0.948
0.0013
0.952
−0.0005
0.944
−0.0004
0.944
0.0005
0.946
0.0006
0.947
−0.0022
0.943
−0.0021
0.943
−0.0003
0.947
−0.0002
0.946
−0.0107
0.943
−0.0099
0.944
−0.0040
0.950
−0.0033
0.953
−0.0041
0.937
−0.0037
0.938
−0.0012
0.945
−0.0008
0.948
0.0027
0.936
0.0026
0.938
0.0015
0.956
0.0015
0.956
0.0011
0.938
0.0010
0.938
0.0011
0.954
0.0011
0.952
−0.0005
0.938
−0.0005
0.938
0.0004
0.954
0.0004
0.952
−0.0096
0.928
−0.0090
0.930
−0.0036
0.940
−0.0030
0.948
−0.0033
0.934
−0.0030
0.934
−0.0008
0.950
−0.0005
0.952
ICC: intraclass correlation coefficient; CCC: concordance correlation coefficient; GICC: global ICC; GCCC: global CCC. Bias denotes a mean of 500 “average biases” for time-dependent indices and a mean of 500 “biases” for global indices. CR denotes coverage rates of pointwise 95% bootstrap confidence bands averaged over time points for time-dependent indices and coverage rates of 95% bootstrap confidence intervals for global indices; results are based on 500 simulated data sets.
Furthermore, we perform additional simulation studies with error-prone functional data; that is, , where true signals are generated under the aforementioned data generation scenarios, and is an independent residual noise iid . The errors are handled by representing the functions using B-splines with 25 basis functions and controlling their smoothness by introducing a roughness penalty term (integral of the square of the second derivative). The same evaluation scheme as above is applied. The simulation results are presented in Tables S1 and S2 of the Supplemental Materials, and they demonstrate the satisfactory finite-sample performance of the proposed estimation and inference schemes with error-prone functional data.
Application to Emory renal study
In this section, we apply the proposed methodology to the Emory renal study described in Section 1. The study collected renogram data from kidneys of patients who were referred to the Emory University Hospital with suspected kidney obstruction from 1 May 1994 to 4 July 2015. For each kidney, renogram curves, which consist of MAG3 photon counts detected at 100 time points (every 12–15 s) over a period of 1428 s on the ROI, were produced by different methods: the “whole-kidney ROI method” () and “cortical-kidney ROI method” (). Each method was repeated two times by the attending radiologist, who manually specified the ROI on the kidney on each occasion. In sum, four renogram curves (two curves produced by the whole-kidney ROI method plus two curves produced by the cortical-kidney ROI method) were available for each kidney, and accordingly the collection of observed renogram curve data can be expressed using mathematical notation as with each .
One of the main goals of the study is to evaluate the reproducibility and reliability of MAG3 renography, which is a state-of-the-art medical device widely used to non-invasively detect kidney obstruction. Specifically, the researchers aim to achieve this goal by answering the following two scientific questions: (i) do twice-repeated renogram curves produced on the same kidney by each method agree (intra-method agreement); and (ii) do renogram curves produced by the two methods agree (inter-method agreement). To address these two questions, the proposed indices are estimated based on the procedure introduced in Section 2.4. Note that the eigenanalyses of the smoothed covariance function estimates are performed to account for residual noise in the renogram curves. We also note that the numbers of level 1 and 2 components to retain ( and ) are chosen to preserve 95% of the total variability in the data, and the pointwise 95% bootstrap confidence bands and 95% bootstrap CIs are constructed based on bootstrap resamples at the kidney level. Web Figures S1 and S2 of the Supplemental Materials, respectively, present the estimated mean functions, and , and the estimated variance components, , , , , and .
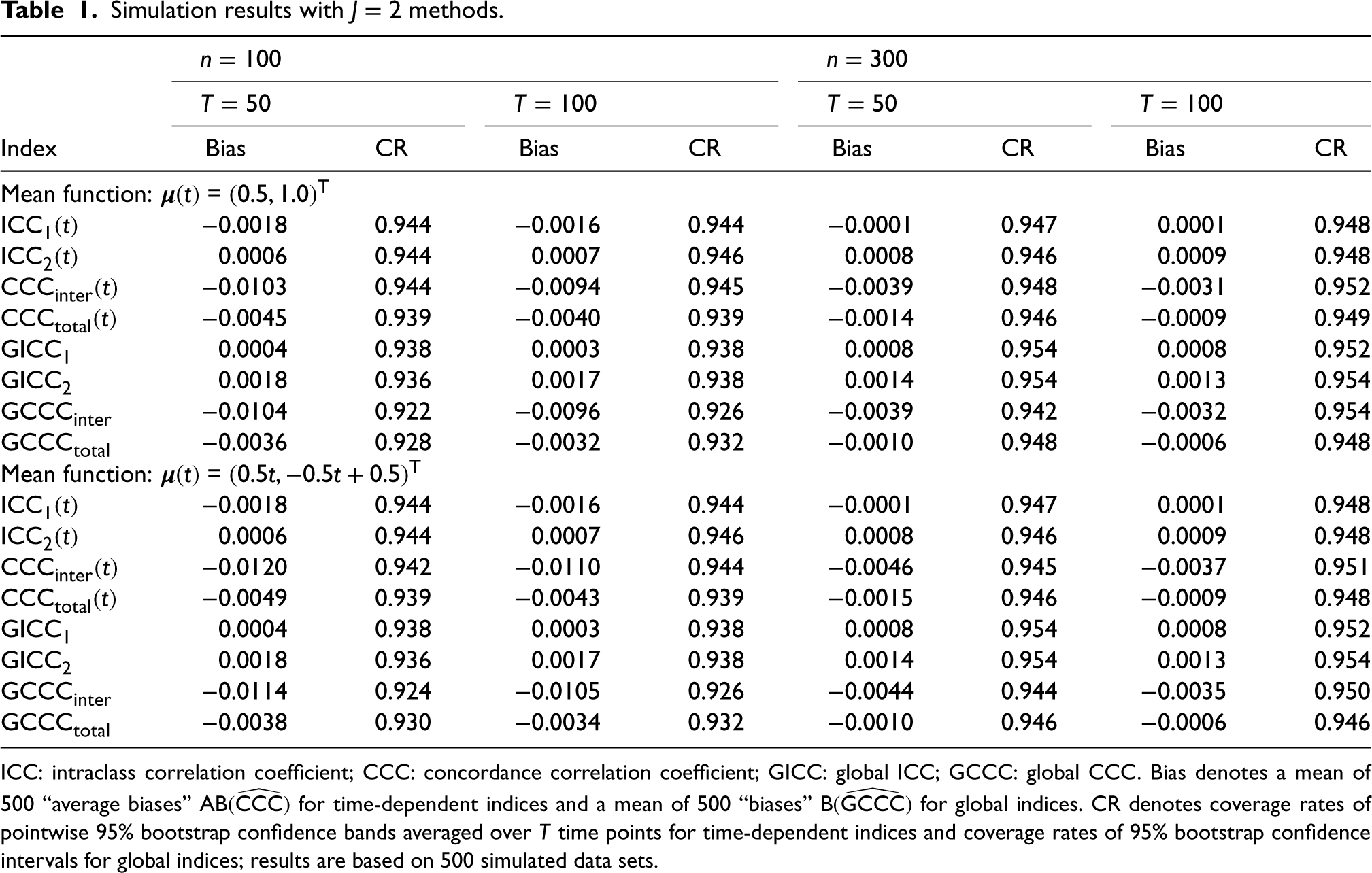
Regarding the first question, we first examine the scatterplots whose horizontal and vertical axes are MAG3 photon counts of the first and second repetitions, respectively, produced by each method at scan times , , and 1218; see Figure 2. At all time points, we see that the points are more tightly clustered around the 45-degree line for the whole-kidney ROI method, suggesting its superior intra-method agreement compared to the cortical-kidney ROI method.
Scatterplots whose horizontal and vertical axes respectively represent the MAG3 photon counts (divided by 1000) of the first and second repetitions, respectively, produced by each of the methods (left panel: whole-kidney ROI method; right panel: cortical-kidney ROI method at scan times (top panel), (middle panel), and (bottom panel). MAG3: mercaptoacetyltriglycine; ROI: region of interest.
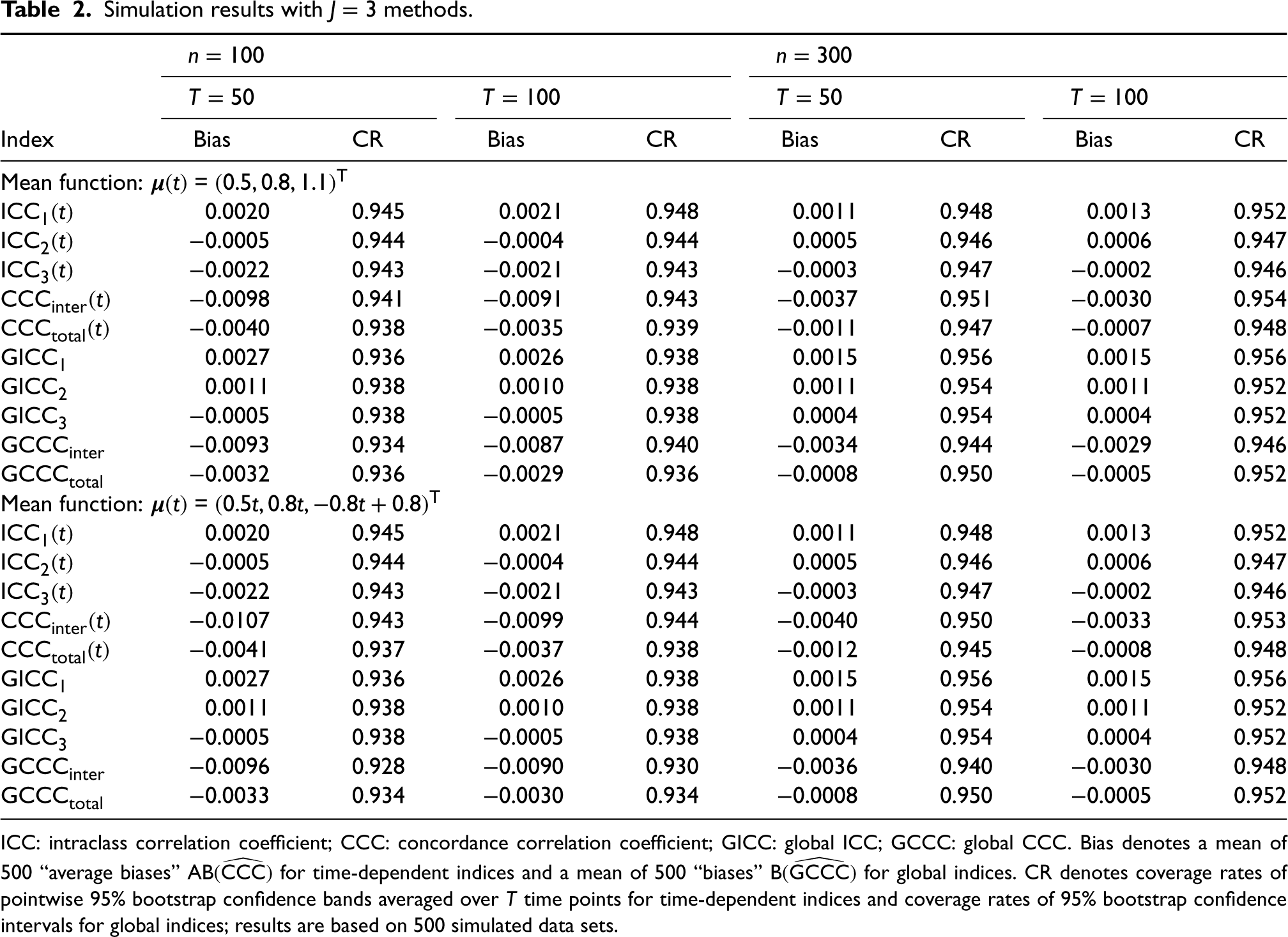
To formally assess intra-method agreement, the proposed ICC indices, and , are estimated and displayed in the top panel of Figure 3. The estimated time-dependent ICC for the whole-kidney ROI method, , hovers above 0.95 over the entire scan period. Accordingly, a high global ICC () value of 0.986 (95% CI: ) is obtained. This high intra-method agreement suggests that the whole-kidney ROI method is robust to and reproducible across multiple ROI specification tasks performed by a practicing radiologist. For the cortical-kidney ROI method, hovers over 0.8 over the entire scan period, and the corresponding global ICC value (95% CI: ). This suggests that the cortical-kidney ROI method has moderate intra-method agreement and is not as reproducible as the whole-kidney ROI method over repeated ROI specification tasks by a practicing radiologist.
The top panel presents the estimated time-dependent ICC indices (bold line) for the whole-kidney ROI method (left) and the cortical-kidney ROI method (right), along with their pointwise 95% bootstrap confidence bands (dashed line). The bottom panel presents the estimated time-dependent inter-CCC index (left; bold line) and total-CCC index (right; bold line) between the whole-kidney ROI and cortical kidney ROI methods, along with their pointwise 95% bootstrap confidence bands (dashed line). Note the differing scale on the vertical axes for the top left panel. ICC: intraclass correlation coefficient; ROI: region of interest.
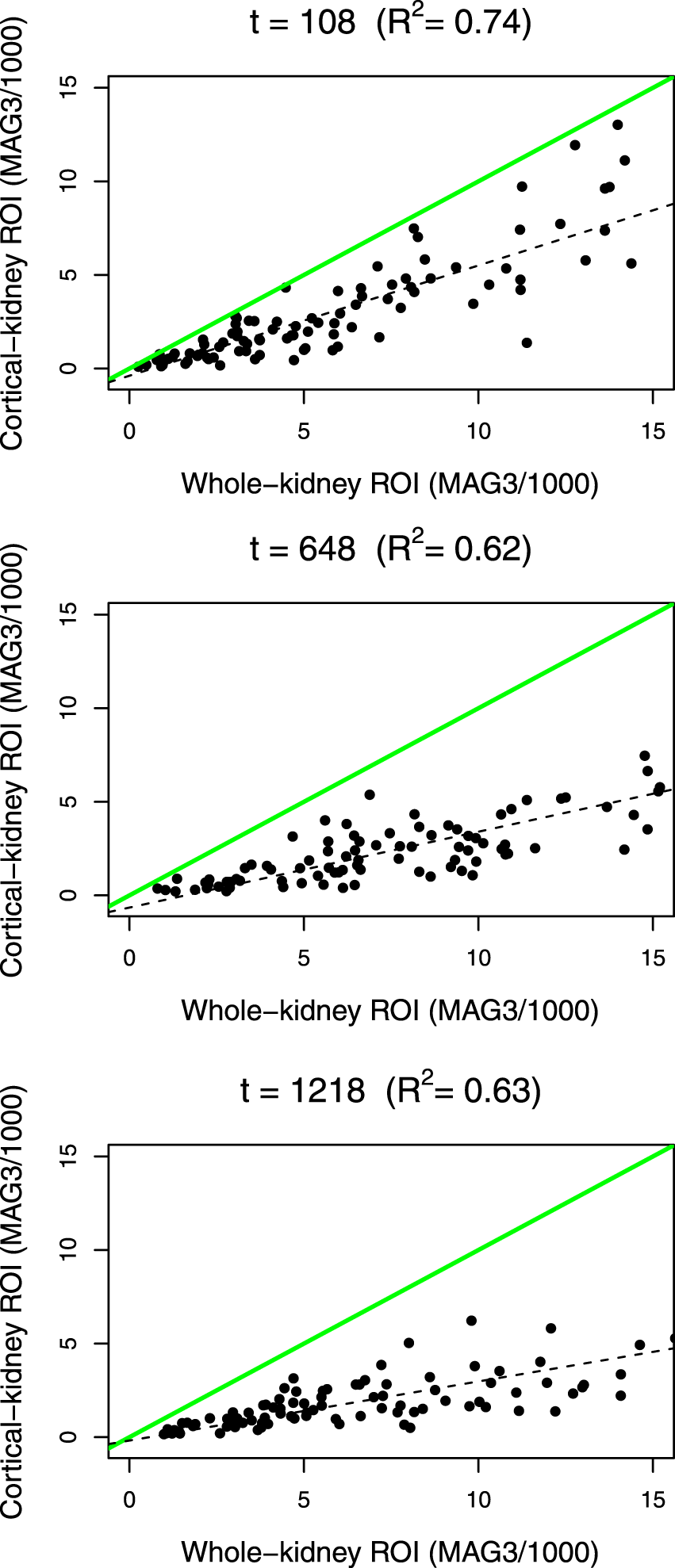
Regarding the second question, we first examine the scatterplot of MAG3 counts between the first replications of the whole-kidney ROI (horizontal axis) and cortical-kidney ROI (vertical axis) methods at scan times , , and ; see Figure 4. At each of the time points, we see that the paired measurements are positively correlated with an R-squared value >0.6, but the deviation of the least-squares line (dashed line) from the 45-degree line (solid line) increases as the photon count increases, suggesting a location and scale shift of one method from the other.
Scatterplots of MAG3 photon counts (divided by 1000) between the first replications of the whole-kidney ROI method (horizontal axis) and the cortical-kidney ROI method (vertical axis) at time points (top panel), (middle panel), and (bottom panel). The green (gray in print) solid line denotes the 45-degree line. The black dashed line represents the least-squares line. denotes the R-squared value between the measurements from the two methods at each time point. MAG3: mercaptoacetyltriglycine; ROI: region of interest.
To formally assess inter-method agreement between the whole-kidney ROI and cortical-kidney ROI methods, we estimate and obtain its pointwise 95% bootstrap confidence band. In the bottom right panel of Figure 3, we see that the degree of inter-method agreement between the two methods hovers below 0.3 during most of the scan period except the initial phase of 0–250 s. Accordingly, the global CCC is low (; 95% CI: ). To investigate the source of disagreement between the two methods, we estimate , and , which, respectively, measure the degrees of precision, scale shift, and location shift; see Figure S3 of the Supplemental Materials. The trajectory (top panel) starts around 0.8, gradually decreases to approximately 0.5 until , and then stabilizes afterward, indicating a moderate precision (correlation) between the true readings of the two methods. The major source of disagreement is the shift in scale and location. Specifically, the trajectory (middle panel) starts around 2 and then gradually increases up to 2.8, indicating that the scale of the whole-kidney ROI method is larger than that of the cortical-kidney ROI method. The trajectory (bottom panel) hovers between 1 and 1.5 during most of the scan period after the initial phase of 0–250 s and shows that the measurements of the whole-kidney ROI method are shifted right relative to those of the cortical-kidney ROI method. These results suggest that the agreement between the two methods is not acceptable, and one method cannot completely replace the other. The estimated total agreement indices, (see bottom right panel of Figure 3) and (95% CI: ), which contain both intra- and inter-method agreement, show similar trends, though they are slightly lower than the inter-agreement counterparts.
In conclusion, the moderate to high intra-method agreement suggests that both whole-kidney ROI and cortical-kidney ROI methods generate renogram curves that are quite reproducible across multiple ROI specification tasks manually performed by a practicing radiologist. These results lend support to establishing both methods as a robust basis for diagnostic evaluation of kidney obstruction. Between the two methods, we found that the whole-kidney ROI method produces more consistent and thus more reliable renogram curves across multiple ROI specifications compared to the cortical-kidney ROI method. This is possibly because the renogram curves produced by the cortical-kidney ROI method can be relatively more noisy on the region overlying the liver (a very vascular organ), where the MAG3 in the blood may be superimposed on the cortical curve.24 Thus, given the high/moderate but imperfect intra-method agreement, a practicing radiologist may produce and study multiple renogram curves from each method (especially for the cortical-kidney ROI method with relatively low intra-method agreement) to safeguard against possible inconsistency in its readings across multiple attempts. Furthermore, the low inter-method agreement between the two methods (i.e. one method cannot completely replace the other) indicates that both renogram curves should be studied and interpreted by a practicing radiologist to diagnose kidney obstruction. In fact, this conclusion aligns with that of previous research,14,24 which states that each method captures unique physiological mechanisms linked to kidney obstruction, and the best practice to capture all relevant physiological mechanisms and maximize diagnostic accuracy is to simultaneously examine pharmacokinetic features of renogram curves from both methods (e.g. whole-kidney ROI postvoid/max count ratio and cortical-kidney ROI time-to-maximum).
Discussion
In this paper, we introduced a set of time-dependent ICC and CCC indices that quantify the degrees of intra-method, inter-method, and total agreement varying smoothly over time and global counterparts that summarize such agreement over time using a single measure. We take a model-based approach for defining and estimating the proposed indices. Specifically, the functional data measurements are modeled using a multivariate multilevel functional mixed effects model, which enables us to express the indices as variance components and smoothly estimate them by FPCA. An extensive simulation study was performed to demonstrate that our estimation and inference procedures produce consistent estimators and CIs with adequate coverage, respectively. In application to renal study data, the proposed unscaled indices were computed to obtain new and interesting insights into the reliability and reproducibility of modern diuresis renography for kidney obstruction diagnosis. We note that the proposed methodology is generally applicable and transferable to quantify the reliability and reproducibility of any modern medical device producing various functional data measurements including images and tensors (two- or three-dimensional functional data).
In our work, we expressed the random effect functions and variance components of the multivariate multilevel functional mixed model (2) in finite-dimensional forms using principal components (eigenfunctions). Using principal components as data-driven basis functions has several advantages compared to using pre-specified basis functions (e.g. B-splines, Fourier basis, etc.). Firstly, principal components represent the directions of the data that capture most of the between- and within-subject variabilities, enabling us to derive the indices that can assess the agreement of functional data while focusing on their most important features. Secondly, the principal component scores which are used as lower-dimensional representations of the random effect functions—see (3)—are estimated simultaneously using all data, facilitating borrowing of information across different observation units and coherent characterization of uncertainty.
One limitation of the FPCA approach is that if measurements generated by different methods differ considerably in domain, range, or variation, there is a possibility that FPCA components are dominated by data from one or few methods with larger variances. However, the main goal of our study (as in other agreement studies) is to quantify the degree of reproducibility among methods/raters that generate clinical measurements of the same unit representing a certain common biological or disease mechanism, in which case clinical measurements from different methods do not usually differ in domain, range, or variation to a degree that one or few methods completely dominate the FPCA components. In the past FPCA literature, multivariate FPCA has been successfully applied to identify any major co-varying patterns of multivariate functional data without scaling when their measurements are in the same unit and do not grossly differ in range, domain, or variation.15,13
In some rare cases, researchers might have to assess agreement among methods that generate functional clinical measurements that grossly differ in domain, range, or variation. One simple remedy is to scale the data so that each of the multivariate functions has integrated variance equal to 1.13 This approach, however, prevents our indices from identifying and incorporating disagreement due to scale shift; they can only identify disagreement due to lack of precision and location shift. Another possible approach is to model the clinical measurements based on recently introduced “structured FPCA”25 as following
where is denotes the th repeated functional clinical measurement from method for subject , is a deterministic overall mean function, is a deterministic method-specific mean function, is a subject-specific random function with covariance operator , is a subject-method-specific random function with covariance , is a random function representing the remaining variation in not explained by the first two random functions and has covariance , and is a white noise. To ensure identifiability, the random processes , and are assumed to have mean-zero and be uncorrelated. This approach is free from the problem of one or a few methods with larger variances dominating the FPCA components. However, a major limitation of this approach is that it requires the between-subject variance , within-subject variance and between-subject covariance are shared across all methods and thus severely restricts the applicability of the ICCs and CCCs formulated based upon them. Specifically, under this formulation, the ICC (5) takes on common values across all methods, and the inter-CCC (6) and total-CCC (7) can only capture discrepancies in the means (location shifts). Given these limitations of the current approaches, our future research direction is to develop a model framework under which agreement indices can not only capture discrepancies due to various disagreement types (lack of precision, scale shift, and location shift), but also admit an estimation scheme that is unaffected by extreme differences of multivariate functional measurements in domain, range, or variation.
Supplemental Material
sj-pdf-1-smm-10.1177_09622802231219862 - Supplemental material for Assessing intra- and inter-method agreement of functional data
Supplemental material, sj-pdf-1-smm-10.1177_09622802231219862 for Assessing intra- and inter-method agreement of functional data by Ye Yue, Jeong Hoon Jang and Amita K. Manatunga in Statistical Methods in Medical Research
Supplemental Material
sj-r-2-smm-10.1177_09622802231219862 - Supplemental material for Assessing intra- and inter-method agreement of functional data
Supplemental material, sj-r-2-smm-10.1177_09622802231219862 for Assessing intra- and inter-method agreement of functional data by Ye Yue, Jeong Hoon Jang and Amita K. Manatunga in Statistical Methods in Medical Research
Supplemental Material
sj-r-3-smm-10.1177_09622802231219862 - Supplemental material for Assessing intra- and inter-method agreement of functional data
Supplemental material, sj-r-3-smm-10.1177_09622802231219862 for Assessing intra- and inter-method agreement of functional data by Ye Yue, Jeong Hoon Jang and Amita K. Manatunga in Statistical Methods in Medical Research
Footnotes
Acknowledgment
The authors thank Dr Andrew Taylor and his research team from the Department of Radiology and Imaging Sciences at Emory University School of Medicine for providing the renal study data set.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Heart, Lung, and Blood Institute (R01HL159213), National Institute of Diabetes and Digestive and Kidney Diseases (R01DK108070), and the Yonsei University Research Fund (2022-22-0137).
ORCID iDs
Jeong Hoon Jang
Amita K. Manatunga
Supplemental material
Supplemental material for this article is available online.
References
1.
LinLSHASinhaBet al. Statistical methods in assessing agreement: Models, issues and tools. J Am Stat Assoc2002; 97: 257–270.
2.
BartkoJJ. The intraclass correlation coefficient as a measure of reliability. Psychol Rep1966; 19: 3–11.
LinLI. A concordance correlation coefficient to evaluate reproducibility. Biometrics1989; 45: 255–268.
5.
KusunokiTMatsuokaJOhtsuHet al. Relationship between intraclass and concordancecorrelation coefficients: Similarities and differences. Jpn J Biom2009; 30: 35–53.
6.
ChinchilliVMMartelJKKumanyikaTet al. A weighted concordance correlation coefficient for repeated measurement designs. Biometrics1996; 52: 341–353.
7.
LinLHedayatASWuW. A unified approach for assessing agreement for continuous and categorical data. J Biopharm Stat2007; 17: 629–652.
8.
KokoszkaPReimherrM. Introduction to functional data analysis. Boca Raton, FL: CRC Press, 2017.
9.
LiRChowM. Evaluation of reproducibility for paired functional data. J Multivar Anal2005; 93: 81–101.
10.
ShouHEloyanALeeSet al. Quantifying the reliability of image replication studies: The image intra-class correlation coefficient (I2C2). Cogn Affect Behav Neurosci2013; 13: 714–724.
11.
DiCZCrainiceanuCMCaffoBSet al. Multilevel functional principal component analysis. Ann Appl Stat2009; 3: 458–488.
12.
De SilvaGSRRathnayakeLNetal. Modeling and analysis of functional method comparison data. Commun Stat Simul Comput2022; 51: 7298–7318.
13.
HappCGrevenS. Multivariate functional principal component analysis for data observed on different (dimensional) domains. J Am Stat Assoc2018; 113: 649–659.
14.
BaoJManatungaABinongoJNGet al. Key variables for interpreting 99mTc-mercaptoacetyltriglycine diuretic scans: Development and validation of a predictive model. AJR Am J Roentgenol2011; 197: 325–333.
15.
ChiouJMChenYTYangYF. Multivariate functional principal component analysis: A normalization approach. Stat Sin2014; 24: 1571–1596.
16.
BanhartHXHaberMSongJ. Overall concordance correlation coefficient for evaluating agreement among multiple observers. Biometrics2002; 58: 1020–1027.
17.
RamsayJODalzellCJ. Some tools for functional data analysis. J R Stat Soc Series B Stat Methodol1991; 53: 539–572.
18.
RamsayJOSilvermanBW. Functional data analysis. New York, NY: Springer, 2005.
19.
YaoFMüllerHGWangJL. Functional data analysis for sparse longitudinal data. J Am Stat Assoc2005; 100: 577–591.
20.
RuppertDWandMPCarrollRJ. Semiparametric regression. Cambridge, UK: Cambridge University Press, 2003.
21.
EfronBTibshiraniRJ. An introduction to the bootstrap. New York, NY: Chapman and Hall, 1993.
22.
HutsonADYuH. A robust permutation test for the concordance correlation coefficient. Pharm Stat2021; 20: 696–709.
23.
DiCiccioCJRomanoJP. Robust permutation tests for correlation and regression coefficients. J Am Stat Assoc2017; 112: 1211–1220.
24.
TaylorAT. Radionuclides in nephrourology, part 2: Pitfalls and diagnostic applications. J Nucl Med2014; 55: 786–798.
25.
ShouHZipunnikovVCrainiceanuCMet al. Structured functional principal component analysis. Biometrics2015; 71: 247–257.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.