
Abstract
A sequential multiple assignment randomized trial, which incorporates multiple stages of randomization, is a popular approach for collecting data to inform personalized and adaptive treatments. There is an extensive literature on statistical methods to analyze data collected in sequential multiple assignment randomized trials and estimate the optimal dynamic treatment regime. Q-learning with linear regression is widely used for this purpose due to its ease of implementation. However, model misspecification is a common problem with this approach, and little attention has been given to the impact of model misspecification when treatment effects are heterogeneous across subjects. This article describes the integrative impact of two possible types of model misspecification related to treatment effect heterogeneity: omitted early-stage treatment effects in late-stage main effect model, and violated linearity assumption between pseudo-outcomes and predictors despite non-linearity arising from the optimization operation. The proposed method, aiming to deal with both types of misspecification concomitantly, builds interactive models into modified parametric Q-learning with Murphy’s regret function. Simulations show that the proposed method is robust to both sources of model misspecification. The proposed method is applied to a two-stage sequential multiple assignment randomized trial with embedded tailoring aimed at reducing binge drinking in first-year college students.
Keywords
Introduction
A sequential multiple assignment randomized trial (SMART)1,2 is a trial in which some or all participants undergo multiple stages of randomization. The data collected in such trials can be used by investigators to construct and improve dynamic treatment regimes (DTRs).3,4 A DTR is a sequence of decision-making functions, one at each stage, which map from a subject’s history of characteristics, interventions, and responses to previous interventions to a recommended intervention. Making treatment decisions dynamically based on evolving patient information has become an important clinical practice that takes treatment effect heterogeneity into account and effectuates personalized medicine.
Q-learning with linear regression5,6 is a widely used backward induction algorithm 7 to identify the optimal DTR. For each stage of treatment, Q-learning requires the correct specification of a Q-function, 3 which is a parametric model for the expected outcome conditional on past history while assuming that the optimal interventions are followed thereafter. To ease implementation and interpretation, the Q-function is commonly modeled using linear regression, with a main effect component and a treatment effect component. The main effect component characterizes variation in the outcome that can be explained by pre-treatment covariates, whereas the treatment effect component characterizes the average effect of the observed/assigned treatment at the relevant stage allowing for variation with pre-treatment covariates.
Decision making at a single stage, for example, using data from a randomized controlled trial, does not depend on the main effect model as the treatment effect model fully defines the estimated optimal rule. This is not the case for a backward induction process over multiple stages like Q-learning. The standard Q-learning algorithm is susceptible to model misspecification of the main effect component of the Q-function. Heterogeneous treatment effects at an earlier stage on a final outcome are in fact part of the main effects at later stages (either as the earlier treatment-covariate interaction or as an intermediate measurement which depends on prior treatment). In practice, early-stage treatment interactions are usually omitted in late-stage main effect model, probably out of consideration for interpretability, overfitting and convergence issues, and doing so will result in biased estimation of the treatment effects at early stages. This is an example of (informative) residual bias in optimizing over multiple stages and is problematic in identifying the optimal DTR. Existing methods that deal with residual bias are modified Q-learning, 8 A-learning, 9 and robust Q-learning. 10 A-learning takes a propensity score approach and allows for flexible modeling of the main effects. Robust Q-learning as well takes a propensity score approach, but obviates the need to specify the main effect model. Nonparametric methods are usually used to estimate the main effects in A-learning and the expected outcome in robust Q-learning. Nonparametric methods work ideally for nonlinearity between outcomes and covariates, but are less straightforward to interpret and implement. Moreover, model checking and residual diagnostics for Q-learning with linear regression can be easily performed using standard approaches.11,12 Therefore, we advocate the use of modified Q-learning, a parametric approach that takes account of stage 2 residuals, for dealing with misspecification of the main effect model.
Additionally, a nonzero treatment effect at a later stage results in biased estimation of early-stage linear models. 13 Although the treatment effect component of a Q-function is assumed to be correctly specified with no unmeasured confounders, a nonlinear relationship between early-stage pseudo-outcome and predictors arises from the optimization operation when the late-stage treatment effects are nonzero. Therefore, late-stage heterogeneous treatment effects, if present, may bias the estimation of early-stage Q-function because the treatment effects are highly likely to be nonzero across all patients, especially when the associated patient characteristic is on a continuous scale. To deal with violation of the linearity assumption, Laber et al. 13 proposed an interactive model building of Q-learning to correct the bias caused by the misspecified linearity between pseudo-outcome and predictors.
For a two-stage SMART, the two types of misspecification described above are associated with heterogeneous treatment effects at stage 1 and stage 2, respectively. Both of them result in a nonnegligible bias in the prediction of stage 1 optimal rule using Q-learning and have been addressed individually with the carefully constructed methods as discussed earlier. However, investigators of many SMART studies would expect heterogeneous treatment effects at both stages and thus these two sources of model misspecification need to be addressed together. Our motivating example is the M-bridge study,14,15 a two-stage SMART that develops and evaluates the DTRs to reduce binge drinking and related consequences among first-year college students. The investigators recorded at baseline a comprehensive set of covariates, including demographics, pre-college drinking norms, intention for college drinking, and pre-college drinking habits, which would potentially moderate the intervention effect at both stages. In a standard analysis using Q-learning,
16
we typically are reluctant to include heterogeneous treatment effects from earlier stages in the current-stage Q-function because, first, inclusion of all interactions between baseline covariates and earlier treatments may cause overfitting problems, and second, Q-learning works backwards and we cannot have identified important interactions from earlier stages to include in the current-stage estimation. If we have multiple stages, then the overfitting problem would accumulate because the Q-function at the
We begin with an introduction of the data structure and a further elaboration on the importance of the problem using the M-bridge study as an example in Section 2. We then discuss the integrative impact of late-stage unadjusted residuals and early-stage nonlinearity on the prediction of optimal rules, with mathematical formulation in Section 3 to help understand the statistical aspects of the problem. Specifically, we outline the proof of residual bias in the Supplemental Materials to fill the gaps in the DTR literature. We then propose to build interactive models into modified parametric Q-learning with Murphy’s regret function in Section 4. Simulations are performed in Section 5 to show the robustness of our proposed algorithm with heterogeneous treatment effects at both stages. We then demonstrate its application on SMARTs with embedded tailoring using the M-bridge data in Section 6. Finally, we conclude with a discussion in Section 7.
Background
Data and framework
We use the M-bridge study as a data example to illustrate the problem. As shown in Figure 1, the M-bridge study has two stages of intervention. At stage 1, enrolled students were randomized to receive a combined universal preventive intervention consisting of personalized normative feedback and self-monitoring (PNF+SM), either starting prior to attending college (early intervention) or in the first month of Semester 1 (late intervention). Two intermediate measures of alcohol use, namely, the frequency of binge drinking (consuming 4/5+ drinks in a row for women/men) and the frequency of high-intensity drinking (consuming 8/10+ drinks in a row for women/men) in the past two weeks, were reported by students in four self-monitoring surveys. Students were flagged as a “heavy drinker” if they reported at any self-monitoring survey two or more occasions of binge drinking, or one or more occasion of high-intensity drinking. The self-monitoring period ended once a student was flagged as a heavy drinker. At stage 2, heavy drinkers were re-randomized to either an automated email or an invitation to online health coaching so as to bridge these eligible students to indicated interventions, whereas non-heavy drinkers continued self-monitoring for the rest of Semester 1. Binge drinking (primary outcome) and negative drinking-related consequences (secondary outcome) were measured at the end of Semester 1 for all students.
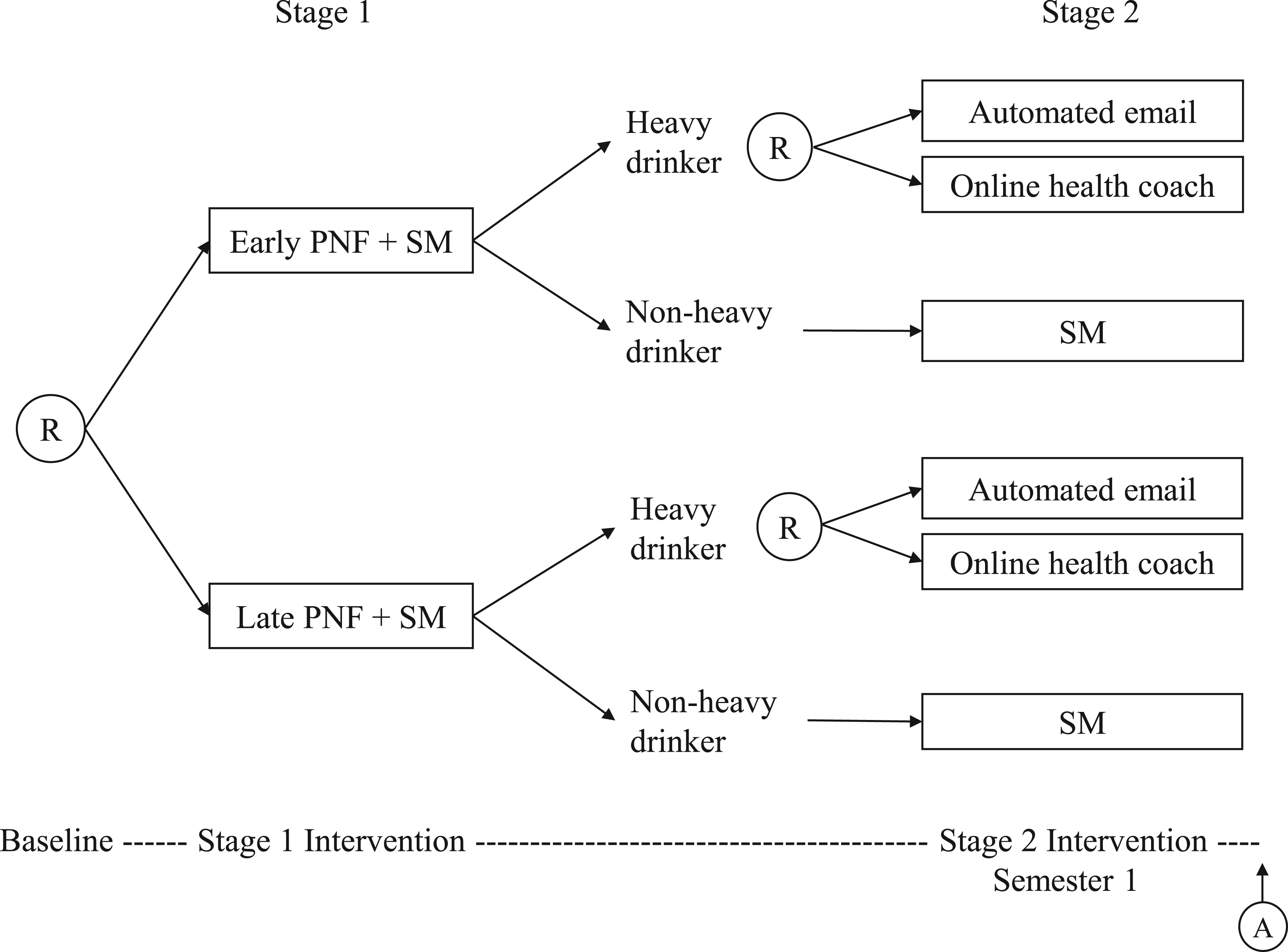
The M-bridge study: a sequential, multiple assignment, randomized trial. This figure is adapted from the figure of study design by Patrick et al. 14 Ⓡ indicates a randomization stage with arrows pointing to available treatment options, and Ⓐ indicates an assessment of outcomes. Note that this design only considers a final outcome measured at the end of the treatment course.
Our scientific question is to identify the DTR that minimizes the maximum number of drinks consumed within a 24-hour period, and the total number of alcohol-related consequences in the past 30 days, which was measured using 24 items from the Brief Young Adult Alcohol Consequences Questionnaire (B-YAACQ), respectively. In other words, our aim is (1) to determine whether a student should receive PNF+SM early or late, conditional on their baseline characteristics, and (2) whether a student should receive an automated email or online health coaching if they are a heavy drinker but continue self-monitoring if they are not a heavy drinker, so that the combined regime minimizes problematic drinking. In the M-bridge study, the investigators hypothesize that pre-college alcohol use norms and pre-college intentions for college drinking are the treatment effect moderators at stage 1, and intermediate binge drinking is the treatment effect moderator at stage 2. We also evaluate effect moderation with respect to demographics and pre-college drinking habits.
We assume a two-stage setting throughout the paper, although the following could be generalized to multiple decision points. Suppose that the data collected from a SMART are represented by a sequence of independent and identically distributed random variables
In the M-bridge study,
Optimization of DTRs relies on the concept of potential outcomes, and therefore the following causal assumptions are necessary: (i) consistency: the potential outcome under the observed treatment agrees with the observed outcome; (ii) no unmeasured confounders, also known as sequential ignorability:
We describe the algorithm of standard Q-learning with linear regression to identify the optimal DTR. Starting from stage 2, the Q-function is specified as
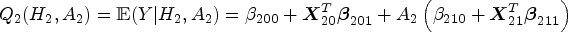
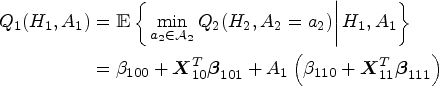
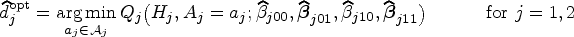
Misspecification with treatment effect heterogeneity
In this section, the integrated impact of the two sources of model misspecification caused by heterogeneous treatment effects are formulated mathematically and discussed in detail. We use uppercase to denote random variables and lowercase to denote a realization of the corresponding random variable. Suppose
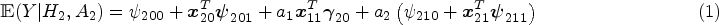
In the backward induction setting, stage 1 optimization is contingent on compliance with the optimal rule at stage 2, so the true optimal pseudo-outcome at stage 1 is
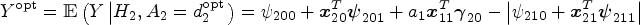
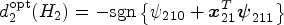
Omitted stage 1 heterogeneous treatment effects in the stage 2 main effect model may cause a loss in the power to correctly predict stage 1 optimal rules. Investigators may miss the importance of properly adjusting for stage 1 treatment effects in the stage 2 model as only the (heterogeneous) treatment effects of stage 2 intervention impact the stage 2 optimal rule. In fact, Q-learning with linear regression is often implemented using a linear predictor function such that the same design matrix is used for both the main effect and treatment effect models. Moreover, three-way interactions are rarely included in the stage 2 treatment model, so
To understand the problem thoroughly, we provide a full argument of residual bias based on the omitted variable bias theorem in Supplemental Appendix A. Equation (1) is a special case of equation (A.1). Suppose the stage 2 Q-function,
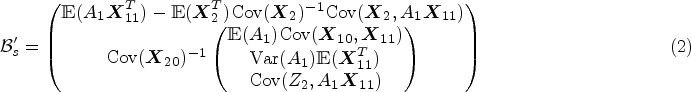
To simplify subsequent notation, we define

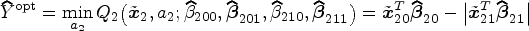
Now we derive an expression for stage 1 bias from model misspecification associated with heterogeneous treatment effects at both stages. First, we rewrite the stage 1 Q-function as
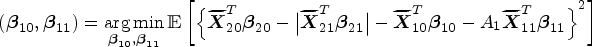
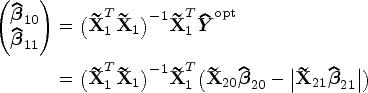
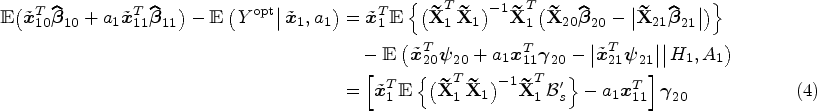
The modified interactive Q-learning algorithm
Interactive Q-learning
13
was proposed to address the misspecified linearity in stage 1 estimation by separately regressing stage 2 main effects on stage 1 predictors and estimating the conditional distribution of stage 2 treatment effects conditional on stage 1 predictors, and then combining the former and the expected absolute value of the latter to get the estimated stage 1 Q-function. To address both types of bias simultaneously, our proposed method follows the virtue of interactive Q-learning and modifies the main effect portion of the algorithm to account for any informative residuals from stage 2 estimation. The modified interactive Q-learning (mIQ) algorithm comprises the following steps:
Regress Regress Estimate the conditional distribution Obtain the estimator of
The optimal DTR is identified as
The pseudo-outcome in the stage 1 estimation,
We conducted a simulation study to show the predictive performance of the proposed method (mIQ) in the context of small samples, and compared mIQ with standard Q-learning (Q), modified Q-learning (mQ),
8
and interactive Q-learning (IQ).
13
Two metrics were used to assess these methods: probability of correctly identified (PCI) stage 1 optimal rules, and bias of the estimated optimal value. Biased estimators of treatment effects may lead to incorrect decision making. Though we have discussed extensively the bias of parameter estimators using Q-learning, eventually we care about identifying the correct decision rules. The optimal value,
22
We assumed that a sequence of observations from a SMART study was
For a data generative process with specifications of
Bias (mean (SD)) of the estimated optimal value using standard Q-learning (Q), modified Q-learning (mQ), interactive Q-learning (IQ), and the proposed method (mIQ), based on a set of the population data (
) and 1000 simulations of the sample data (
).
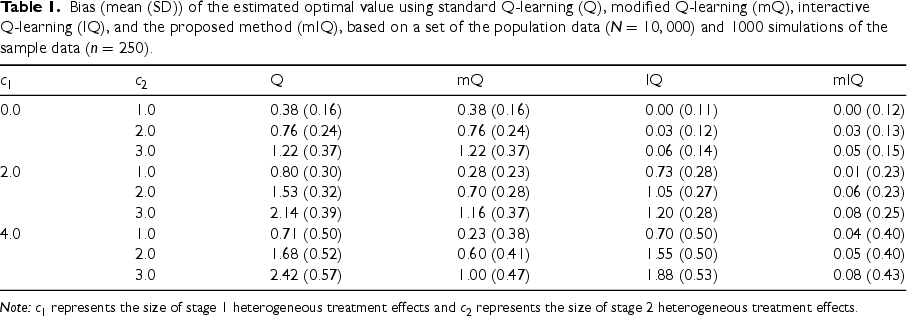
Bias (mean (SD)) of the estimated optimal value using standard Q-learning (Q), modified Q-learning (mQ), interactive Q-learning (IQ), and the proposed method (mIQ), based on a set of the population data (
Note:
To specify heterogeneous treatment effects at both stages, we set
We considered three values of
We used the M-bridge data (
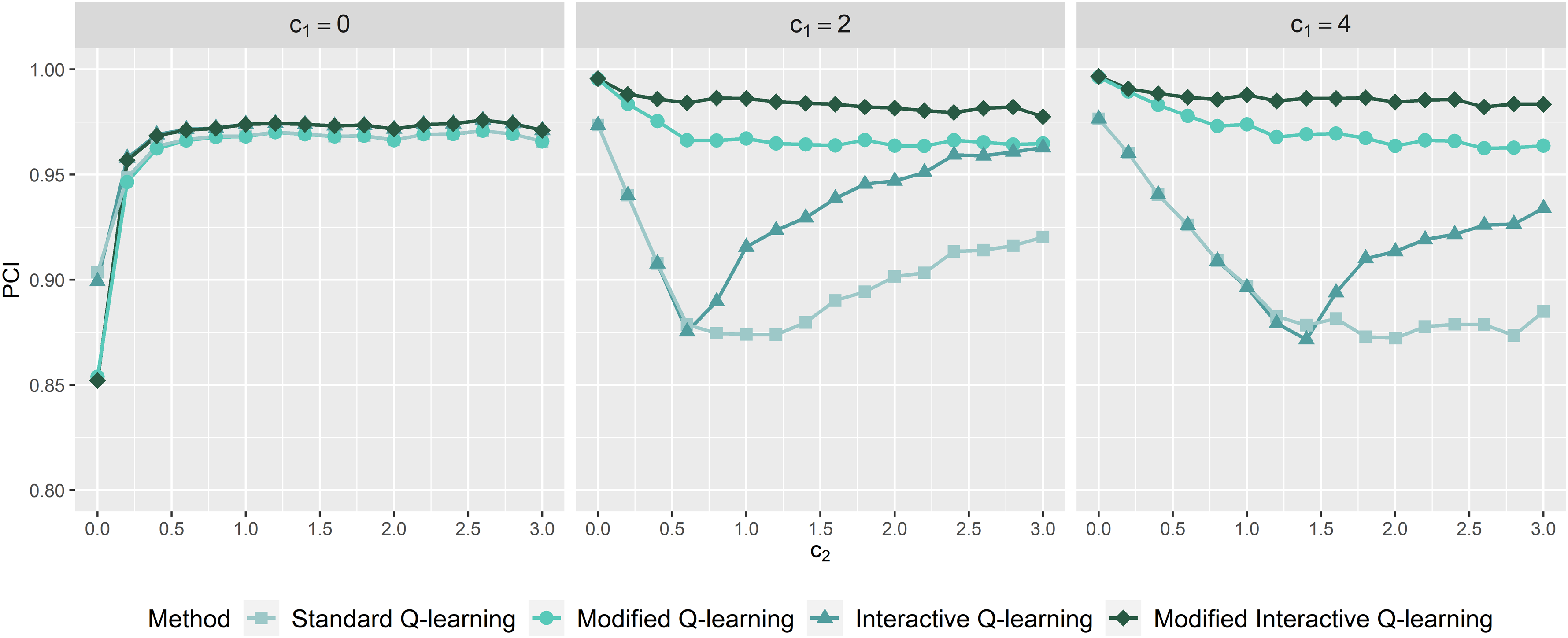
Probability of correctly identified stage 1 optimal rules as a function of
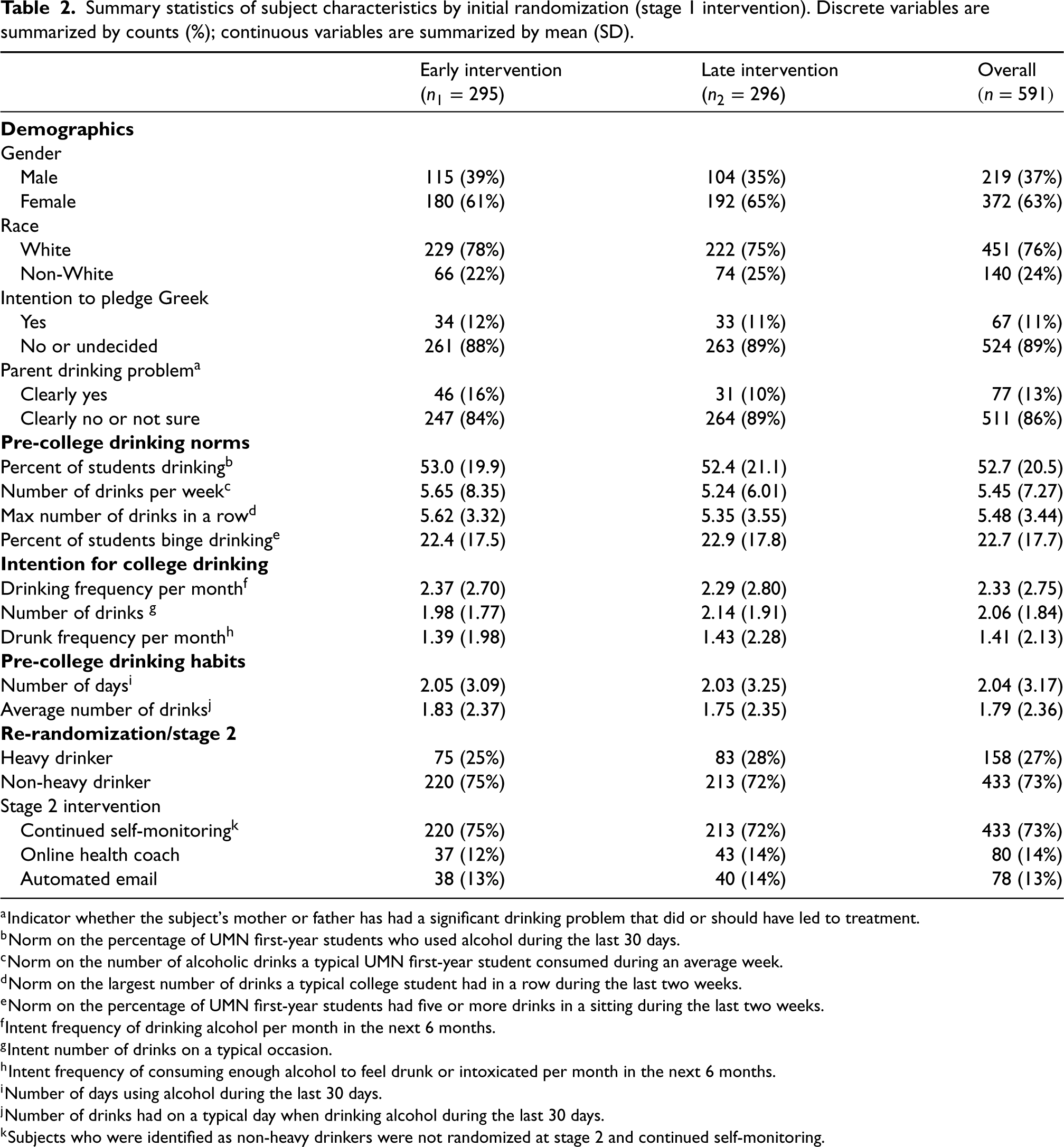
The stage 2 model adjusted for baseline characteristics, including race, gender, intention to pledge Greek, whether a parent had a significant drinking problem, pre-college norms and intention for college drinking, and pre-college drinking habits, as well as their interactions with stage 2 intervention. The stage 1 model included the same baseline characteristics as well as their interaction with stage 1 intervention. The embedded tailoring variable “heavy drinker” determined the subset of re-randomized students which should be included in the stage 2 analysis. A summary of the covariates and outcomes used in the model is presented in Table 2. Among the 591 participants (219 males and 372 females), 11% intended to pledge Greek after attending college, and 13% indicated that a parent had a significant drinking problem. Pre-college drinking norms, intention, and habits were assessed using several metrics via questionnaires. At the end of stage 1 intervention, 158 participants were flagged as heavy drinkers.
Summary statistics of subject characteristics by initial randomization (stage 1 intervention). Discrete variables are summarized by counts (%); continuous variables are summarized by mean (SD).
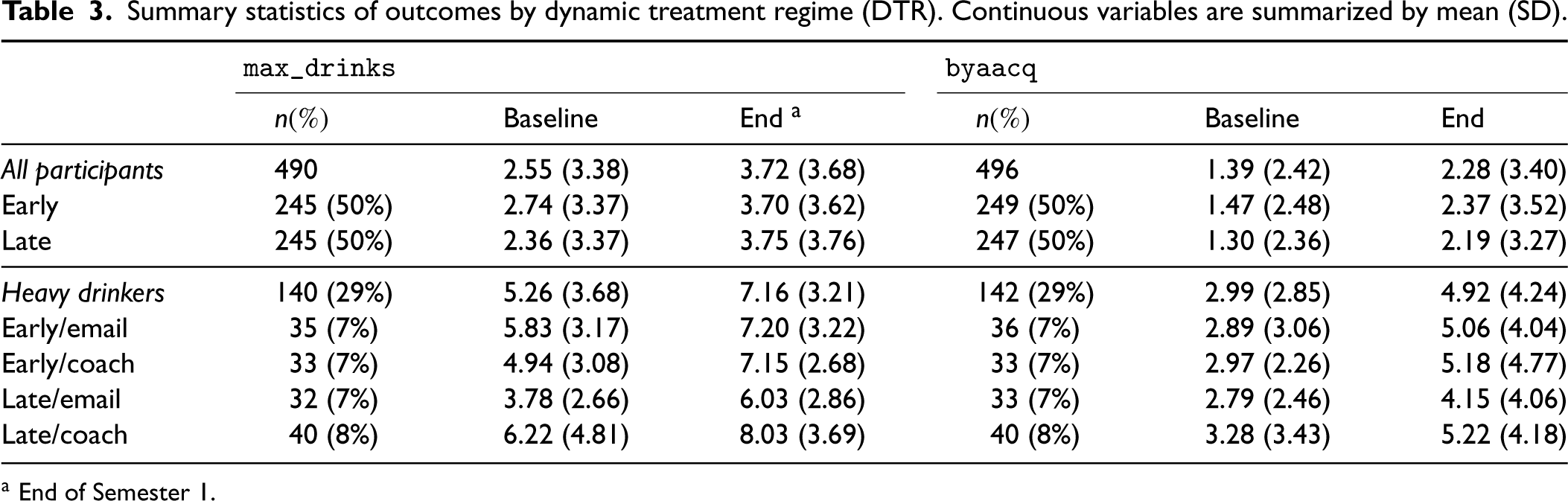
We used complete-case data for model estimation, thus assuming that any missingness in outcome measurements is not informative, i.e. outcomes are missing at random given baseline covariates. Table 3 summarizes outcomes by the assigned DTR. The missing rate of outcomes is around 16%. For the primary outcome (
Summary statistics of outcomes by dynamic treatment regime (DTR). Continuous variables are summarized by mean (SD).
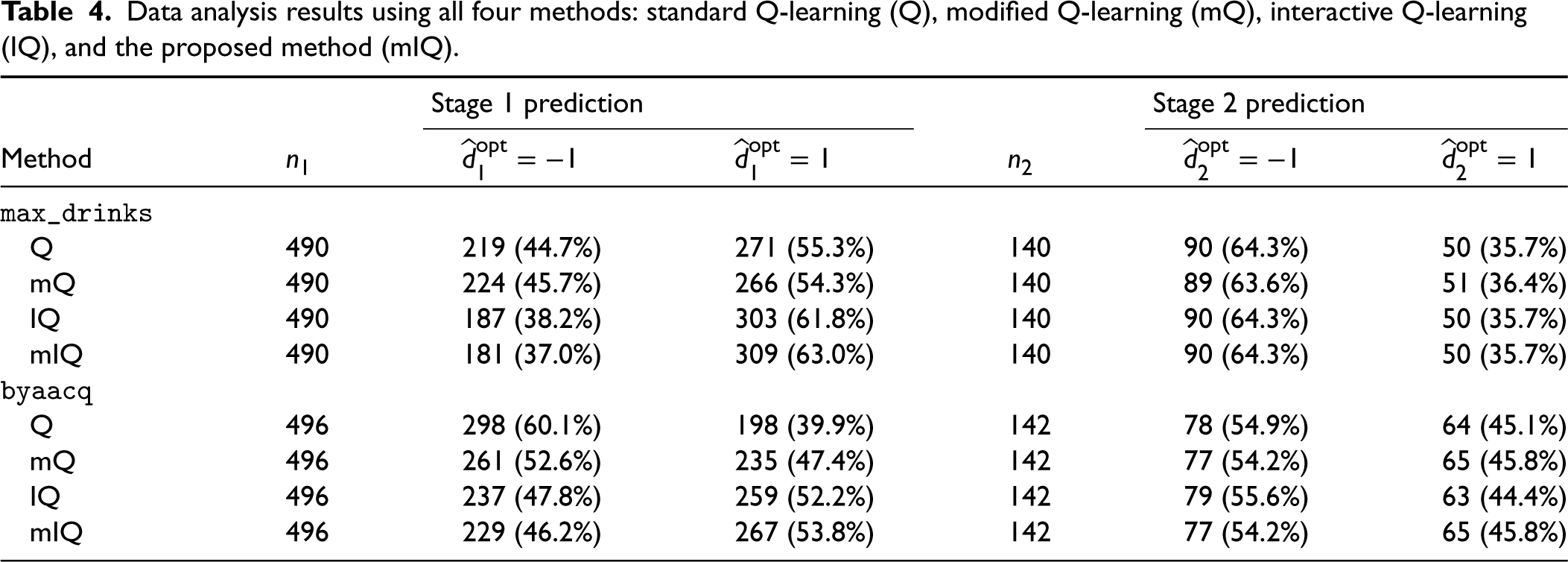
We applied and compared all four methods discussed (Q, mQ, IQ, and mIQ) and summarized the analysis results in Table 4. Q-learning is able to make different recommendations to subjects by virtue of treatment effect heterogeneity. Table 4 does not reveal very distinctive recommendations across the methods. For the primary outcome (
Data analysis results using all four methods: standard Q-learning (Q), modified Q-learning (mQ), interactive Q-learning (IQ), and the proposed method (mIQ).
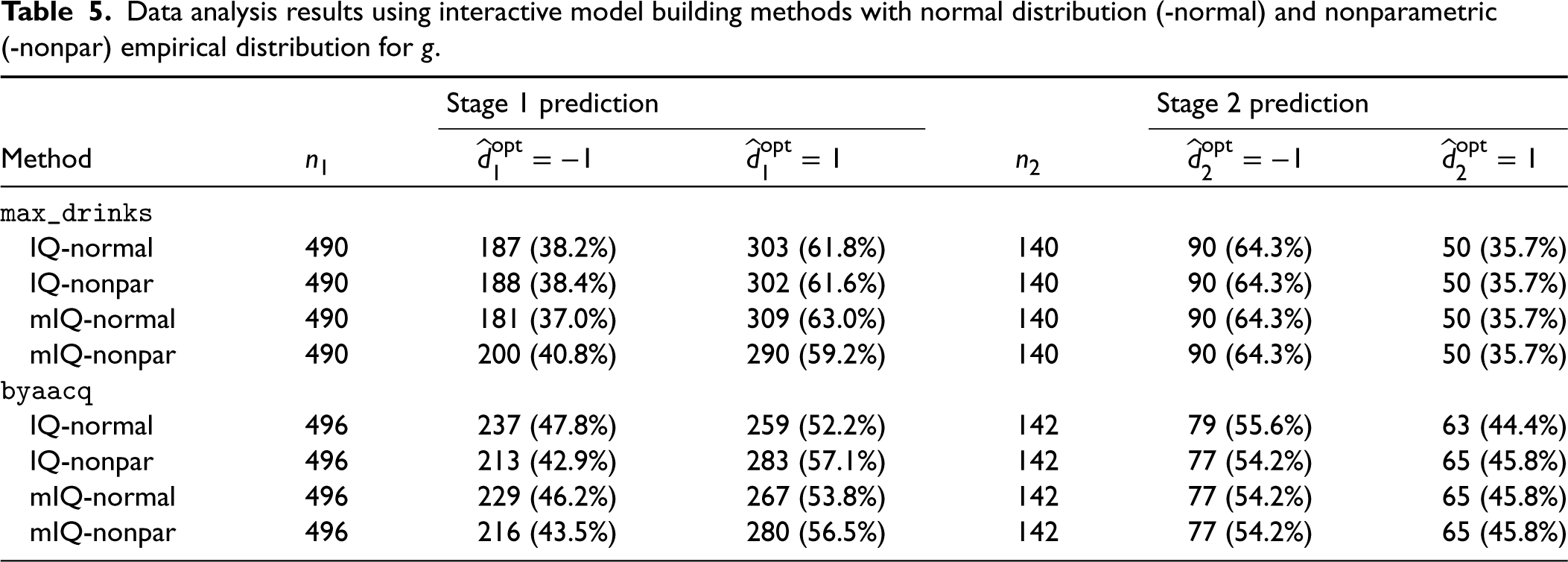
Note that we assumed normality of stage 2 heterogeneous treatment effects for the interactive model building of Q-learning, that is,
Data analysis results using interactive model building methods with normal distribution (-normal) and nonparametric (-nonpar) empirical distribution for
To better describe the treatment effect heterogeneity and understand which variables are contributing to the heterogeneity, we applied a random forest technique 26 to identify the significant predictors driving different recommendations (more details in Supplemental Appendix C). For the aim of minimizing the primary outcome, the analysis results show that students with the intention and habit of drinking more would benefit more from late intervention at stage 1, and heavy drinkers whose parent had a significant drinking problem would benefit more from online health coach at stage 2. For the aim of minimizing the secondary outcome, in contrast, non-white students may benefit more from late intervention at stage 1, and heavy drinkers who intended to pledge Greek would benefit more from automated email at stage 2.
In this article, we proposed a modified interactive Q-learning algorithm to attenuate the impact of model misspecification as a result of heterogeneous treatment effects at multiple stages. A major contribution we make to the literature is the attempt to understand and quantify the part of the bias caused by misspecified main effect model of the stage 2 Q-function, specifically, omitting an unmeasured variable, and we confirmed the existence of bias when the unmeasured variable correlates with the treatment at stage 1. To address this bias, we modified the Q-learning algorithm with Murphy’s regret function to account for the unexplained residuals. This modification was then built into interactive Q-learning, which corrects the bias generated by stage 2 heterogeneous treatment effects and the optimization operation, to improve the overall performance where both stage 1 and 2 treatment effects are believed to be heterogeneous. In the conventional practice of Q-learning, stage 1 heterogeneous treatment effects might be a significant predictor at stage 1 but are usually overlooked in the stage 2 main effect model. By reasoning the bias associated with heterogeneous treatment effects and developing the proposed solution, we would like to draw the attention of clinical investigators and policy makers to the high possibility of model misspecification in analyzing data collected from a SMART with possible treatment effect moderators. We do not claim to “eliminate” the bias of standard Q-learning because the impact of heterogeneous treatment effects might not be exhaustively explored in the sequentially randomized design. Rather, we attenuate the bias by addressing the two known sources simultaneously. Future work on identifying other sources of bias due to the interplay of heterogeneous treatment effect and multiple stages of treatment would be valuable.
Omission of unmeasured variables in the main effect model is an intrinsic problem in Q-learning, especially for high-dimensional moderators or SMARTs with more than two stages, where it is impractical to include all important higher-order interactions with treatment from previous stages in the current Q-function. A significant advantage of our proposed method is that, for model building at a specific stage, there is no need to assume all earlier-stage treatment effects are correctly captured and included in the main effect model at the current stage, which is unverifiable due to the backward nature of Q-learning. In practice, existence of high-dimensional covariates may be computationally problematic and we can apply regularization or dimension reduction techniques (e.g. principal component analysis or variable selection based on random forest) to select important moderators into the treatment effect model at each stage without worrying about the main effect model, where any residual bias caused by omitting important interactions from previous stages could be taken care of by our proposed method. In contrast, standard Q-learning requires investigators to include all these important interactions in the main effect model to obtain unbiased estimators.
The trial setting in which our proposed method could be applied is not limited to the M-bridge study design where two treatment arms are considered at each stage. This method is generalizable to comparison among multiple treatment options by rewriting the framework using dummy treatment variables, representing heterogeneous treatment effects using contrasts, and estimating the optimal decision rule by searching through the available treatment options for which treatment minimizes the Q-function at each stage. A difficulty with this generalization, however, is that the treatment component of
Both the simulation study and the trial design in our application have equal/balanced allocation of the randomization arms, but this is not required to ensure unbiased estimation of the treatment effects. All that is required is perfect randomization, that is, the “no unmeasured confounders” assumption, and a fixed treatment allocation so that the treatment variable can be specified to have expectation zero. As evidenced by Supplemental Theorem A.2, it is necessary to have
The M-bridge study monitored participant outcomes repeatedly at stage 2, but we only considered the single measurement immediately following stage 2 intervention. Further study of our proposed method in the context of full utilization of the outcome trajectory, that is, analysis of repeated-measures outcomes using generalized estimating equations 27 instead of linear regression is needed.
Supplemental Material
sj-pdf-1-smm-10.1177_09622802231206471 - Supplemental material for Modified interactive Q-learning for attenuating the impact of model misspecification with treatment effect heterogeneity
Supplemental material, sj-pdf-1-smm-10.1177_09622802231206471 for Modified interactive Q-learning for attenuating the impact of model misspecification with treatment effect heterogeneity by Yuan Zhang, David M Vock, Megan E Patrick and Thomas A Murray in Statistical Methods in Medical Research
Footnotes
Acknowledgements
The authors would like to thank Grace Lyden and Nicole Morrell for their help in data access and setup.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Research reported in this article was supported by the National Cancer Institute (awards 5P30CA077598-22 to T.M., R01CA225190, R01CA214825, and P30CA077598 to D.V.) and the National Center for Advancing Translational Sciences (award UL1TR002494 to D.V.), and the National Institute on Alcohol Abuse and Alcoholism (award R01AA026574 to M.P.). The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.