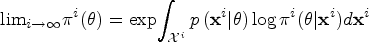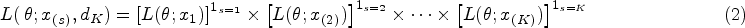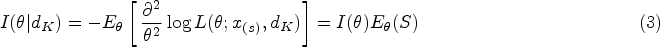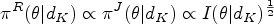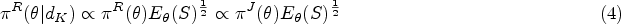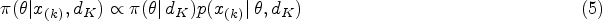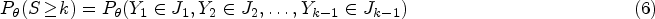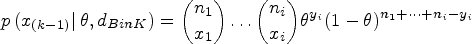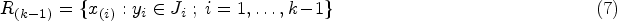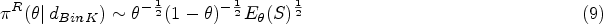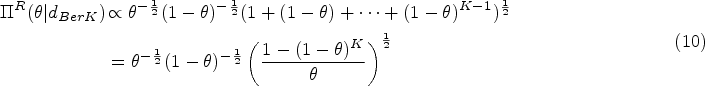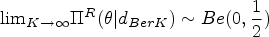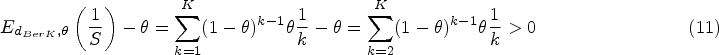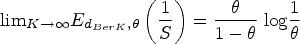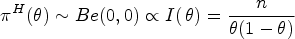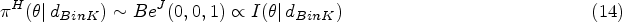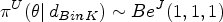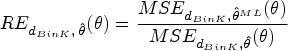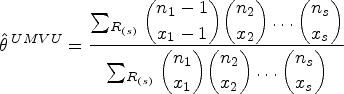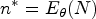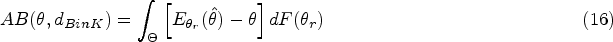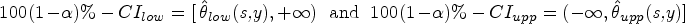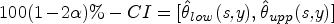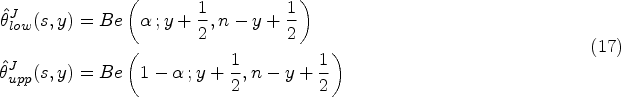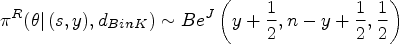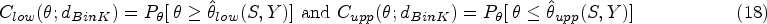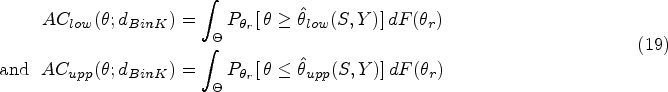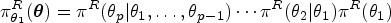This article presents an objective Bayesian approach to estimating the binomial parameter in group sequential experiments with a binary endpoint. The idea of deriving design-dependent priors was first introduced using Jeffreys criterion. Another class of priors was developed based on the reference prior theory. A theoretical framework was established showing that explicit reference to the experimental design in the prior is fully Bayesian justified. Using a design-dependent prior which generalizes the reference prior, I propose a comprehensive and unified approach to the point and the interval estimations in group sequential experiments, and I evidence the good frequentist properties of the posterior estimators through comparative studies with the existing methods. The effect of the prior correction on the posterior estimates is studied in three classical designs of clinical trials. Finally, I discuss the idea of using this approach as a default choice for estimation upon sequential experiment termination.
In the experimental context, the benefits of stopping early can be ethical as well as purely economic. Group sequential designs have become commonplace across all phases of the clinical development. The reasons for an early stopping may be related to efficacy (i.e. strong evidence of the treatment effect) or futility (i.e. absence of treatment effect). In frequentist sequential designs, the adjustments to the stopping boundaries are concerned with controlling the overall type I error rate of a testing procedure. Examples of such adjustments include the Pocock1 and the O’Brien–Fleming2 methods, and the error spending approach.3,4 In Bayesian sequential design, the stopping rule can be based on posterior probability, posterior predictive probability, or a decision-theoretic framework.5–7 Some of these Bayesian designs allow a control of the overall Type I error rate as well.8
As a consequence of the influence of the stopping rule, group sequential designs tend to overestimate the true treatment effect if the trial stops early for efficacy. This trend was observed in a systematic review of clinical trials in cardiology, cancer, and immunodeficiency.9 In another systematic review, authors noted that the published results often fail to adequately report relevant information about the decision to stop early, and sometimes show implausibly large treatment effects.10 Authors also suggested that clinicians should view the results of such trials with skepticism. A reason for this caution is that most of the research undertaken has focused on the study designs and the associated question of maintaining the Type I error.11 In contrast, the question of the estimation of the treatment effect has received comparatively less attention, as reflected in the recent food and drug administration guidance on adaptive designs12 which states: “Biased estimation in adaptive design is currently a less well-studied phenomenon than Type I error probability inflation.”
Nonetheless, the issue of the estimation upon sequential experiment termination has given rise to an abundant literature. The influence of multiple looks at data on the maximum likelihood estimator () is known for a long time13 along with the deficiencies of the coverage probability of the Wald confidence interval14 and the Bayesian credible intervals.15 Various methods have been proposed by authors to estimate the binomial parameter in group sequential experiments with binary endpoint.
The frequentist solutions require ordering the observation space. The reason is that in the binomial case the complete and sufficient statistic is the couple of variables (,) obtained upon stopping, where is the stopping stage and is the experiment outcome which is often the accrued number of successes or responses to a therapeutic intervention. A widely known approach is based on the stage-wise ordering in which results corresponding to earlier termination are more extreme than those which terminate later.16 However, pre-ordering the observation space introduces some subjectivity in the inference.17 Other criticisms are that the solutions are not unique and may depend on the information levels for future (unobserved) stopping stages.
A uniformly minimum variance unbiased estimator () can be derived using Rao–Blackwell’s theorem which states that, given an unbiased estimator and a sufficient and complete statistic, the conditional expectation of the first to the second is UMVU. Accordingly, the conditional expectation of the (unbiased) based on the first stage data given (,) is .18 Another point estimator consists of adjusting the by subtracting the estimate of its bias.19 The bias is calculated at the adjusted estimate using recursive method.
On the Bayesian side, the idea of deriving design-dependent priors was first introduced using Jeffreys’ criterion.20 A Bayesian prior is objective if it has minimal impact on the posterior distribution. In line with this principle, another class of design-dependent priors was developed based on the reference prior theory.21,22 Both the Jeffreys and the reference priors coincide in the one-parameter case. Finally, a design-dependent prior conjugate to the binomial likelihood, namely the beta- prior, was derived for estimation problems based on an extension of the reference prior.23
In this article, I propose a comprehensive and unified approach to the point and the interval estimations of the binomial parameter based on the beta- prior. The method allows a correction for the influence of the stopping rule and applies to any one-arm experiment with a pre-specified stopping rule. The frequentist properties of the posterior estimators are evaluated and compared with the existing methods. The influence of the stopping rule and the effect of the prior correction on the point and the interval estimates are studied in three classical two-stage designs of clinical trials in oncology to test the rate of response to a therapeutic intervention. These are the Simon design24 which allows an early stopping for futility, the Pocock design which allows an early stopping for efficacy, and the O’Brien–Fleming design which allows an early stopping for either futility or efficacy. The estimates obtained using the new approach are compared with the existing alternatives, and recommendations are made about which of them provides results with acceptable interpretation in the experimental practice.
The next section presents key aspects of the reference prior theory in group sequential experiment. In Section 3, I describe the point and the interval estimators and their frequentist properties are investigated. The influence of the experimental design and the effect of the prior correction on the posterior estimates are studied in Section 4. In the conclusion, Section 5, I discuss the idea of using the new approach as a default choice for estimation upon experiment termination. Some technical details to derive the reference prior in sequential experiment are provided in the appendix in Supplemental Material. This document also contains results of simulations to assess the effect of the prior correction on the posterior estimators as the sample size varies and R scripts to produce results reported in this article along with some computational details.
Derivation of the reference prior
Reference prior theory
Descriptions of the reference prior theory and didactic tutorials can be found in the literature.25,26 This section presents some key aspects of the derivation of the reference prior in group sequential experiment while more technical details are given in Section 1 of the appendix in Supplemental Material.
Let us consider the outcome variable and the model parameter, together with the prior specification . The idea behind reference prior is to maximize a distance between the prior and the posterior distributions as data are collected. Formally, the data have maximum influence on the posterior if the Kullback–Leibler (K-L) divergence is maximum. By considering the expectation of the K-L divergence, the reference prior can be defined based on virtual data before experiment.
Let us consider the -dimensional vector with density and consider also the inferential scenario in which the components of are realizations of from independent experiments. Asymptotic theory makes it possible to obtain a convenient form of the reference prior. The problem is reduced to computing:
An analytical solution can be found using the Bernstein Von Mises theorem, sometimes called the Bayesian central limit theorem. It comes that, in the one-parameter problem, the reference prior is identical to the Jeffreys prior, noted , obtained using Jeffreys’ criterion. If we denote by the expected Fisher information, we have:
We now assume that the data are collected in a -stage experiment whose the design is noted . In the general case, the experiment outcome is obtained from a sequence of outcome values observed at the interim analyses, and the analysis times are predefined according to the statistical information available at each analysis. We consider a sequence of outcomes observed until experiment termination and we assume that the density of is known. The likelihood function in the design takes the form:
Based on (2), the expected design-dependent Fisher information can easily be expressed as a function of its naive (i.e. not design-dependent) counterpart:
The introduction of the design information in the reference prior implies rewriting (1) as a function of so that:
Jeffreys’ criterion applied to the likelihood (2) yields an expression of the design-dependent reference prior which depends on the naive Jeffreys prior and the expected stopping time:
Thanks to the component in (4), the prior reflects the degree of certainty associated with the projected design by over-weighing the probabilities about values more likely leading to late termination. The greater the certainty about values, the higher their prior probabilities. By so counterbalancing the expected effect of an early stopping, the reference posterior estimators benefit from a correction for the influence of the stopping rule. These properties were recently evidenced in the normal case.27
Theoretical framework
Taking into account data-dependent stopping rule in experiment has long been a source of controversies among theoretical statisticians. Some are reluctant to transgress the stopping rule principle according to which once the data have been obtained, the reasons for stopping the experiment should have no bearing on the evidence reported about the parameter. The stopping rule principle is the main consequence of the likelihood principle which states that all of the information about the parameter provided by an experiment outcome is expressed in the likelihood function. In turn, the likelihood principle is considered as a direct implication of Bayes’ theorem. However, any applied statistician considers that the design information cannot be ignored because of the bias induced by the stopping rule.
An important breakthrough was made by showing that Bayes’ rule can be expressed with an explicit reference to the experimental design .28 Consequently, the likelihood principle is no longer a direct implication of Bayes’ rule. Let us assume that the sequence of independent outcomes has a known density function which satisfies minimum conditions of regularity, Bayes’ rule becomes:
Formulation (5) holds for any group sequential experiment governed by a proper stopping rule. On this basis, any posterior estimator derived using the design-dependent reference prior (4) is fully Bayesian justified. It also becomes evident that a state of prior ignorance cannot be characterized without reference to the experimental design and Bayesian objectivity cannot ignore such information.
Posterior estimators in sequential experiments
Reference prior in the binomial model
In the one-parameter case, the reference prior is obtained via a straightforward application of Jeffreys’ criterion. Let denote a -stage design (), where is now a sequence of successive binomial trials of fixed sizes () and is the binomial parameter. At stage , the available data are analyzed and a decision whether to continue or to stop the experiment is made based on the accrued number of successes . Let us introduce () which is the continuation region to stage for . So, the stopping stage is the first such that , and the stopping rule is determined by
which is obtained by summing the probabilities
in the dimensional restriction
The restriction in (7) contains all the sequences (or paths) such that all the outcome values () allow the continuation of the experiment to stage . Each interval can be determined based on a given limit value for the observed rate or on a -value if a frequentist testing procedure is planned. In this case, each contains the values of not rejecting an hypothesis, usually the null hypothesis. Practical examples in clinical trials are given in Section 4. In experimental science, it is also common to use designs based on the beta posterior distribution of the parameter wherein the experiment stops, for example, if a given accuracy level which is specified by the credible interval length is reached. Accordingly, each interval contains the values of satisfying the continuation criterion. Other Bayesian designs are based on the posterior predictive distribution of future observations. Therefore, the values of in are determined according to the beta-binomial probabilities of the future outcome values.
Based on (3), the expected Fisher information conditional on the design in the binomial model takes the form:
The design-dependent reference prior can now be expressed in function of the naive prior distribution, as stated in (4), so that:
The properties of the reference prior (9) were first evidenced in the -stage Bernoulli design.29 In the Pascal (or inverse Bernoulli) sampling model, Jeffreys’ criterion results to the improper prior distribution . This improper prior can be approached asymptotically by the proper reference prior (9) in the -stage Bernoulli design using truncation method. A formal proof of the correction for the stopping rule bias is outlined below.
Let us consider the -stage Bernoulli design for an experiment based on successive Bernoulli trials () with early stopping if the outcome is observed (i.e. ). The stopping rule (6) in the design simplifies to . The Pascal sampling model describes the distribution of the outcome in the design when , and the associated stopping rule is infinite (i.e. a.s. when ). Formally, the stopping stage in the design is a truncation of the stopping stage in the Pascal sampling model.
When , the proper density of the reference prior for the design tends to the improper reference prior in the Pascal sampling model, that is,
Compared to the naive prior distribution, in (10) assigns higher probabilities to the low values of as increases. It is easy to show that the prior correction is proportional to the bias induced by the stopping rule on the , which is . The bias of the is:
The bias increases as increases and reaches its maximum when or equivalently in the Pascal sampling model. The maximum bias is the limit of the geometric progression in (11) which is:
Point estimation
In the Bayesian setting, the point estimators are often derived in relation to some given loss functions. Let be the loss incurred in estimating when the estimate is . The quadratic loss is a common loss function. The strategy is to find out a value of which minimizes the expected posterior loss, which is . The condition for is:
Based on (12), is minimized if the value of is the posterior mean, that is, . The mode of the posterior distribution is sometimes used as an alternative point estimator. This approach mimics the principle of likelihood maximization.
The beta- distribution, which is conjugate to the binomial likelihood, was defined in reference to the continuation regions in (6) to allow a flexible use of the components of the reference prior distribution in estimation problems.23 Its density contains the three components in of (9) and depends on the three positive scalars such that:
If , (13) reduces to the beta distribution . Otherwise, if , posteriors are corrected for the influence of the stopping rule. The relation results in the classical form of the reference prior distribution.
We now examine the property of bias correction of priors based on the beta- distribution. In fixed -sample binomial experiment where is the observed outcome value, both the posterior mean based on the Haldane prior and the posterior mode based on the uniform prior coincide with the unbiased , which is .
One can observe that the Haldane prior is proportional to the expected Fisher information, that is,
Extending this relationship to sequential experiments, we define the design-dependent version of the Haldane prior which is proportional to the expected Fisher information conditional on the design (8) so that:
Relation (14) implicitly determines the value which is the extent to which the Haldane prior corrects for the stopping rule bias. This choice of the value may also apply to the design-dependent version of the uniform prior which we define as:
I now denote by the estimator of the posterior mean based on the design-dependent Haldane prior and the estimator of the posterior mode based on the design-dependent uniform prior. In what follows, the biases of and are studied in a two-stage and a three-stage design, namely with , wherein the experiment is based on two or three successive samples of values and stops early if the estimate is equal to or greater than 0.5. I also examine the efficiency relative to which is defined as
into which is the mean square error of .
and are compared to the alternative estimators which are Whitehead’s bias-adjusted estimator () and whose the explicit form is
wherein is the dimensional restriction as defined in (7).
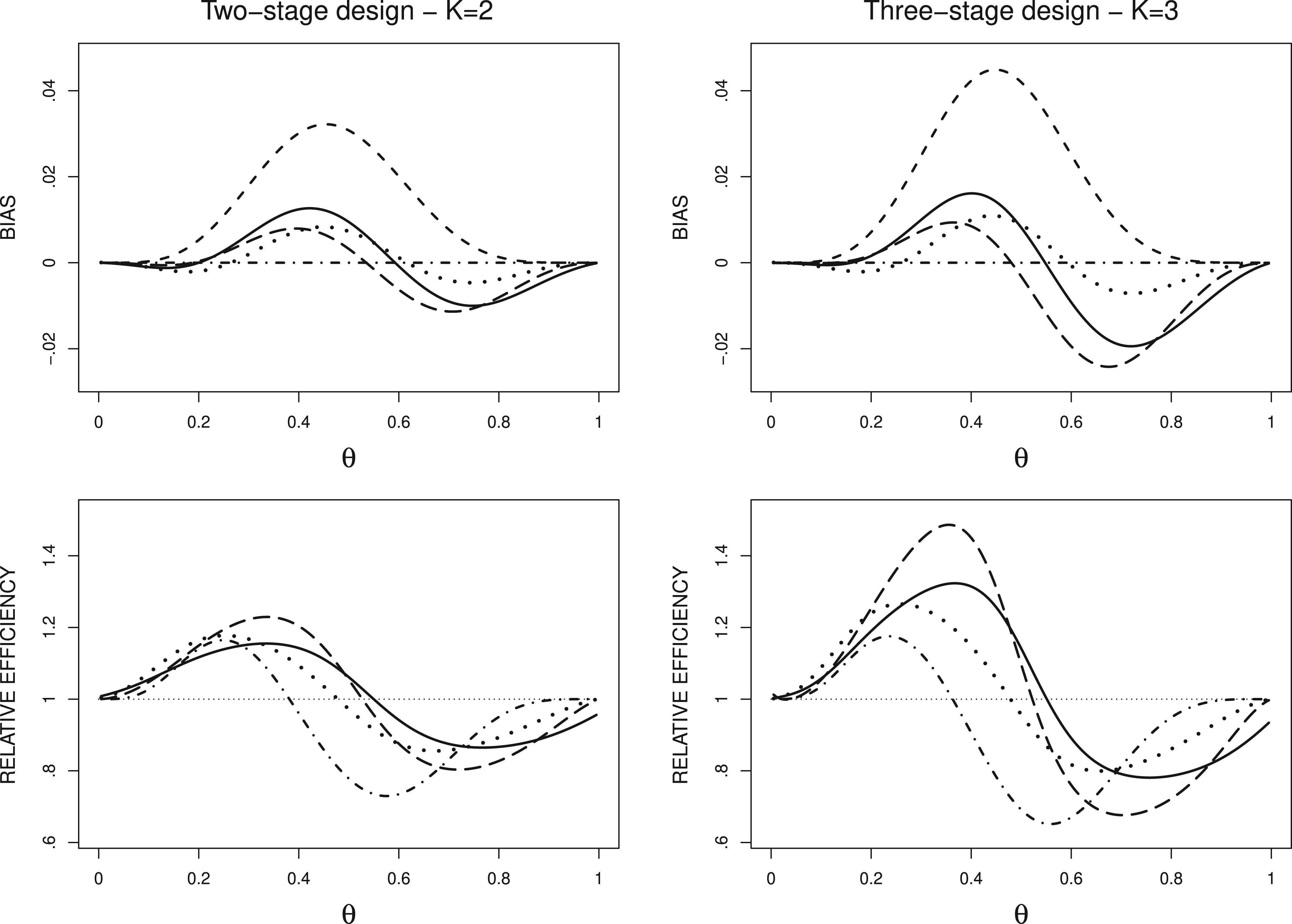
Figure 1 displays the curves of bias and relative efficiency of the estimators in the design with . The stopping rule makes the bias of uniformly positive whereas the magnitude of the bias of the other estimators is substantially lower. In the two-stage design, the range of bias improves from [] with to [] for , [] for , and [] for . In the three-stage design, the range of bias improves from [] with to [] for , [] for , and [] for WHI. For these estimators, the efficiency relative to is positive for the values approximately lower than , and negative otherwise. In return of its unbiasness, exhibits the worst relative efficiency among estimators.
Bias of (- - -), (—), (– –), (), and () and efficiency relative to in the design with . MLE: maximum likelihood estimator; UMVUE: uniformly minimum variance unbiased estimator; WHI: Whitehead’s bias-adjusted estimator.
For Bayesian statisticians, this study based on frequentist criteria has moderate value since the population parameter is summarized by a fixed value. To overcome this, we would like to introduce a reasonable amount of uncertainty about the value of based on the information from the experimental design. To this end, I propose a criterion, namely the so-called average bias, which is obtained via the three-step procedure described hereafter. For the sake of readability, I denote by the accrued sample size at experiment termination and is the actual outcome value. The procedure is as follows:
Calculate the expected sample size at in the design , that is,
Consider that the binomial parameter is now described by a random variable, says , which follows a beta distribution. Consider also as so many pseudo-observations, and define the beta parameters so that
The pseudo-observations are shared between the two beta parameters so that (15) is the posterior distribution obtained with the Haldane prior after observing in a fictitious -sample experiment.
Derive the average bias of at in the design which is the bias averaged over the values of with respect to its distribution, formally,
into which is the cumulative distribution function of in (15).
It is interesting to note that the integral of the difference between the expectation of and (i.e. is replaced by in (16)) also equals since the expectation of in (15) is . The average bias of can be regarded as the bias averaged over the values of after introducing an amount of uncertainty based on the preexperimental evidence given by the design.
A natural value of interest in our example is as it corresponds to the stopping boundary value on the scale. Based on the probability if , it is easy to calculate the expected sample sizes which are in the two-stage design and in the three-stage design. In the two-stage design, the average bias for improves from with to for , for , and for . In the three-stage design, the average bias improves from with to for , for , and for . Combining bias, average bias, and relative efficiency, , , and offer attractive characteristics in both designs.
When using Bayesian estimators, the effect of the prior correction as the sample size varies is an important aspect to be considered. In Section 2 of the appendix in Supplemental Material, I provide the results of simulations to assess the bias, the average bias for , and the relative efficiency of and in the two-stage design with sample size increasing from to , , and . The results show that the effect of the prior correction on the bias and the average bias is proportional to the magnitude of the bias of the and, consequently, the effect decreases as the sample size increases. In the same vein, the range of the relative efficiency does not vary but the interval of the values showing a variation of relative efficiency decreases as the sample size increases.
Interval estimation
In this section, I focus on the one-sided confidence (or credible) intervals () which are used in many applications in the experimental practice. Let us note the one-sided for an observation () as
Of note, the two-sided equal-tailed is the interval defined with the lower limit of and the upper limit of , that is,
The Jeffreys credible interval () is the posterior-based interval obtained using the Jeffreys prior. In the binomial model, the limits are given by and , and otherwise by the following beta distribution quantiles:
As for point estimation, the common thread in the search of a design-dependent credible interval is the correction for the influence of the stopping rule. The Jeffreys interval is known to have good frequentist properties in fixed sample experiment.31 By extension, it is quite possible to derive a design-dependent version of the Jeffreys interval by replacing the distribution in (17) by that of the design-dependent reference posterior which is:
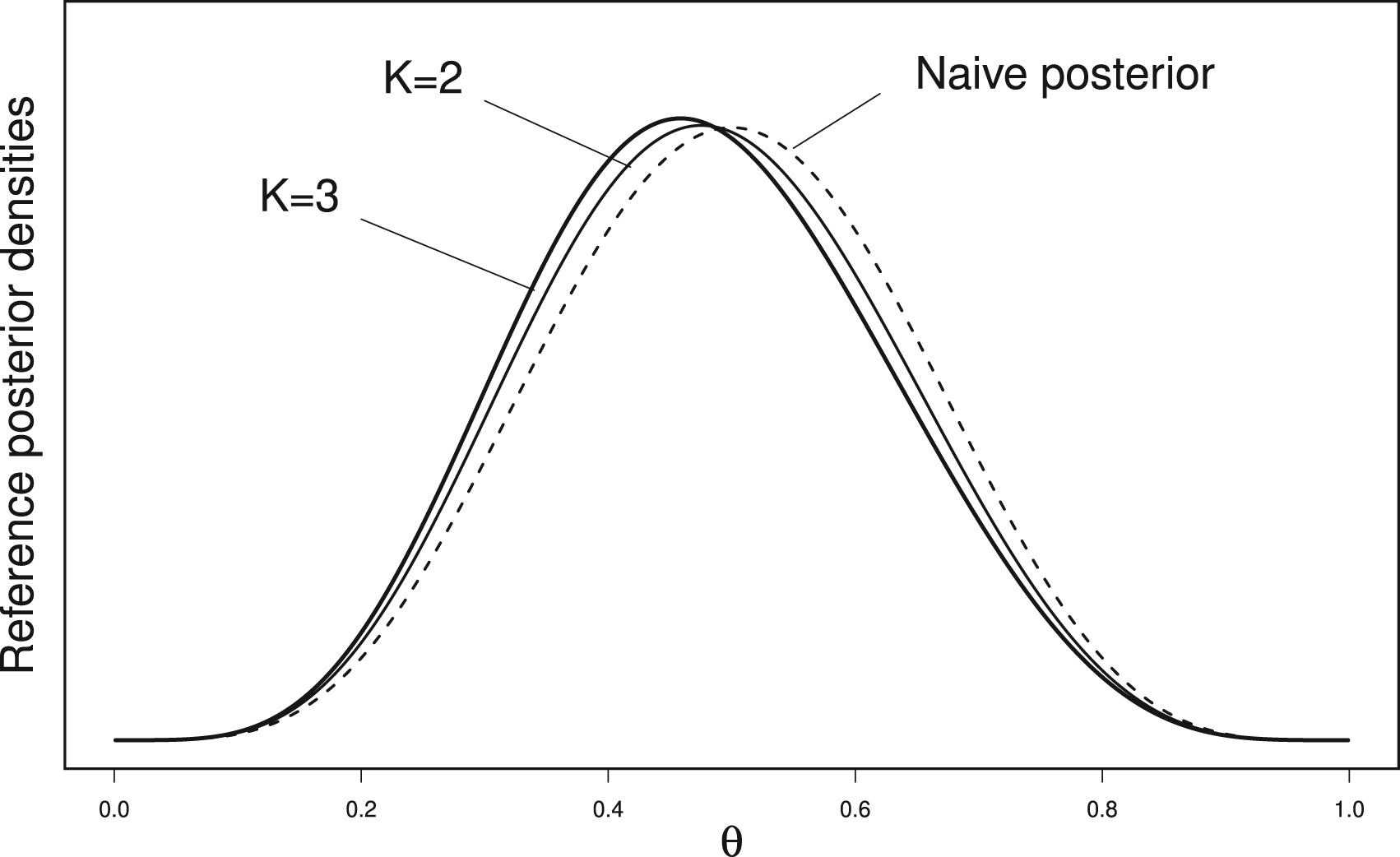
In other words, the naive prior is replaced by the design-dependent prior to derive the posterior distribution. It is worthwhile noting that this posterior benefits from the status of objectivity based on the reference prior theory. However, in what follows we keep the name design-dependent Jeffreys interval that we note , and not design-dependent reference interval, because of the wide use of the first appellation. To figure out the influence of the prior on the interval limits, Figure 2 displays the curves of the posterior densities for the observation obtained with in the design with . It is clear that the mass of the design-dependent posterior density is shifted toward the continuation region on the scale (i.e. ) and the shift increases as increases.
Naive (- - -) and design-dependent (—) posterior densities for the observation with in the design with .
We now investigate the properties of the design-dependent Jeffreys interval. In the long-run frequentist context, the departure of the coverage probability from the confidence level is indicative of the influence of the stopping rule on the interval limits. Given the bivariate variable (), the coverage probabilities of and in the design are defined by
In what follows, the coverage of is compared to that of and the frequentist alternative. The frequentist approach to interval estimation is based on the relation between hypothetical sequences (). The interval limits are determined considering the probabilities of the hypothetical sequences beyond the observed one. Jennison and Turnbull16 described a method based on the stage-wise ordering in which results corresponding to earlier termination are more extreme than those which terminate later. As for the Clopper–Pearson interval for fixed sample experiment,30 the Jennison-Turnbull interval () is directly related to the binomial test as the interval limits result from the inversion of the acceptance zone.
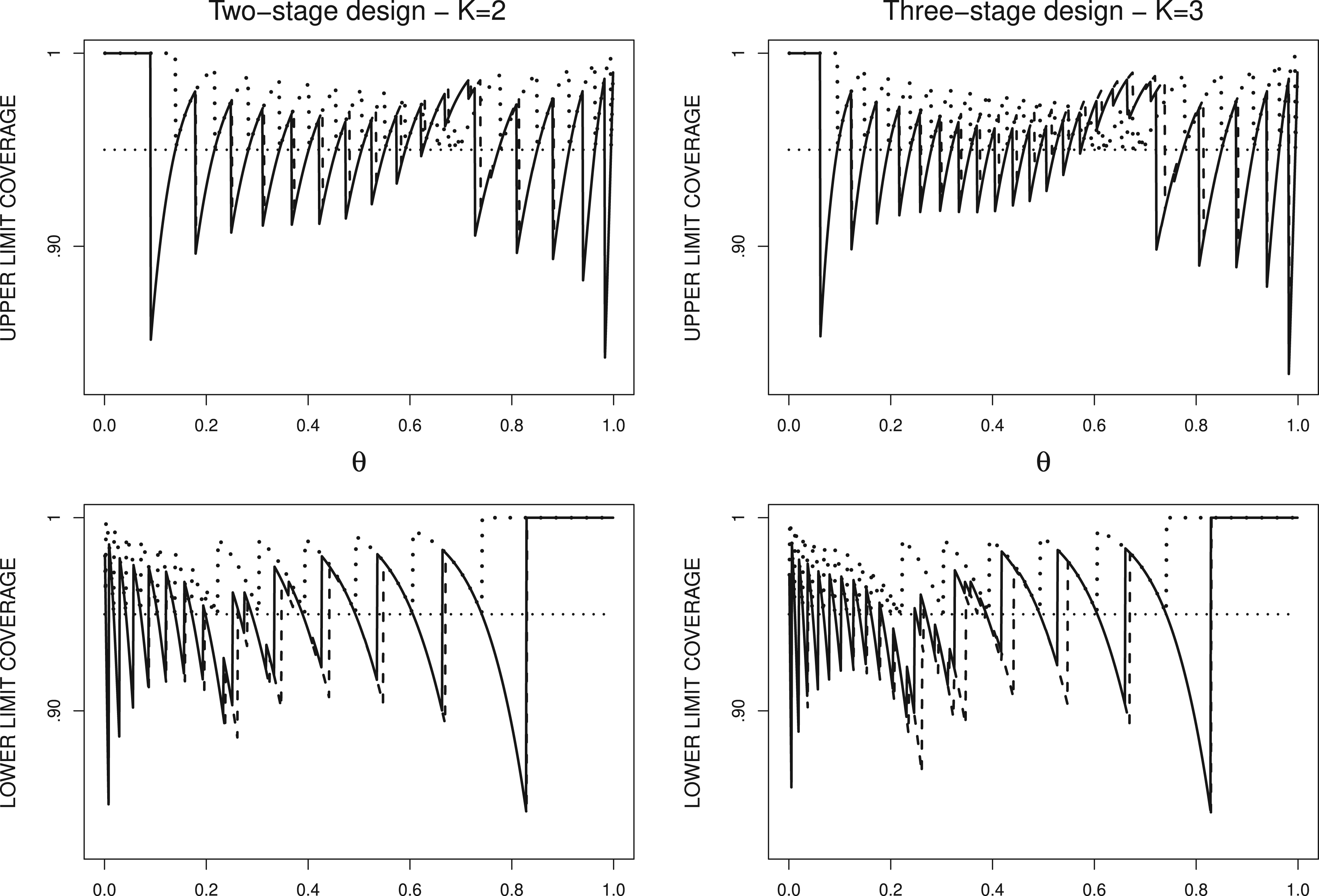
Figure 3 displays the one-sided coverage probabilities of , , and with a confidence level of 95% in the design with . The coverage curves contain non-negligible oscillations as varies that are caused by the lattice structure of the binomial distribution. The one-sided Jeffreys interval was studied in fixed sample experiment.31 Using Edgeworth expansions, it is shown that the Jeffreys interval has no systematic bias in the coverage. However, the sequential nature of the experimental design implies another source of deviation. Figure 3 shows that the stopping rule causes an increase of the coverage probability of for the values around the upper interval limits for the observed rate (i.e. , , and ) and a decrease of the coverage of for the values of around the lower interval limits (i.e. , , and ). One can also observe that the influence of the stopping rule is partially corrected in the design-dependent Jeffreys interval, which exhibits lower magnitude of the spikes in the coverage probability curve. On another side, the Jennisson–Turnbull interval guarantees coverage probability of at least by construction but the actual probabilities are far above the confidence level.
One-sided coverage probabilities of the naive (- - -) and the design-dependent (—) Jeffreys intervals and the Jennison–Turnbull interval () with a confidence level of 95% in the design with .
Due to the oscillation, the influence of the stopping rule on the coverage probability of and the effect of the prior correction in are difficult to be interpreted in Figure 3. To overcome this, I propose a method which resumes some aspects developed for the average bias in the previous section. The variable defined in (15) allows the introduction of an amount of uncertainty around in function of the expected sample size in the experimental design. Now, let us integrate the coverage probabilities in (18) over the values with respect to its distribution, and consider the so-called one-sided average coverage probabilities which are defined as
The average coverage probability is the probability averaged over the values of that the confidence interval contains . Using Fubini’s theorem to interchange the order of integration in a double integral, it is easy to show that the average coverage probabilities considering and not (i.e. is replaced by in (19)) equal the coverage probabilities in (18).
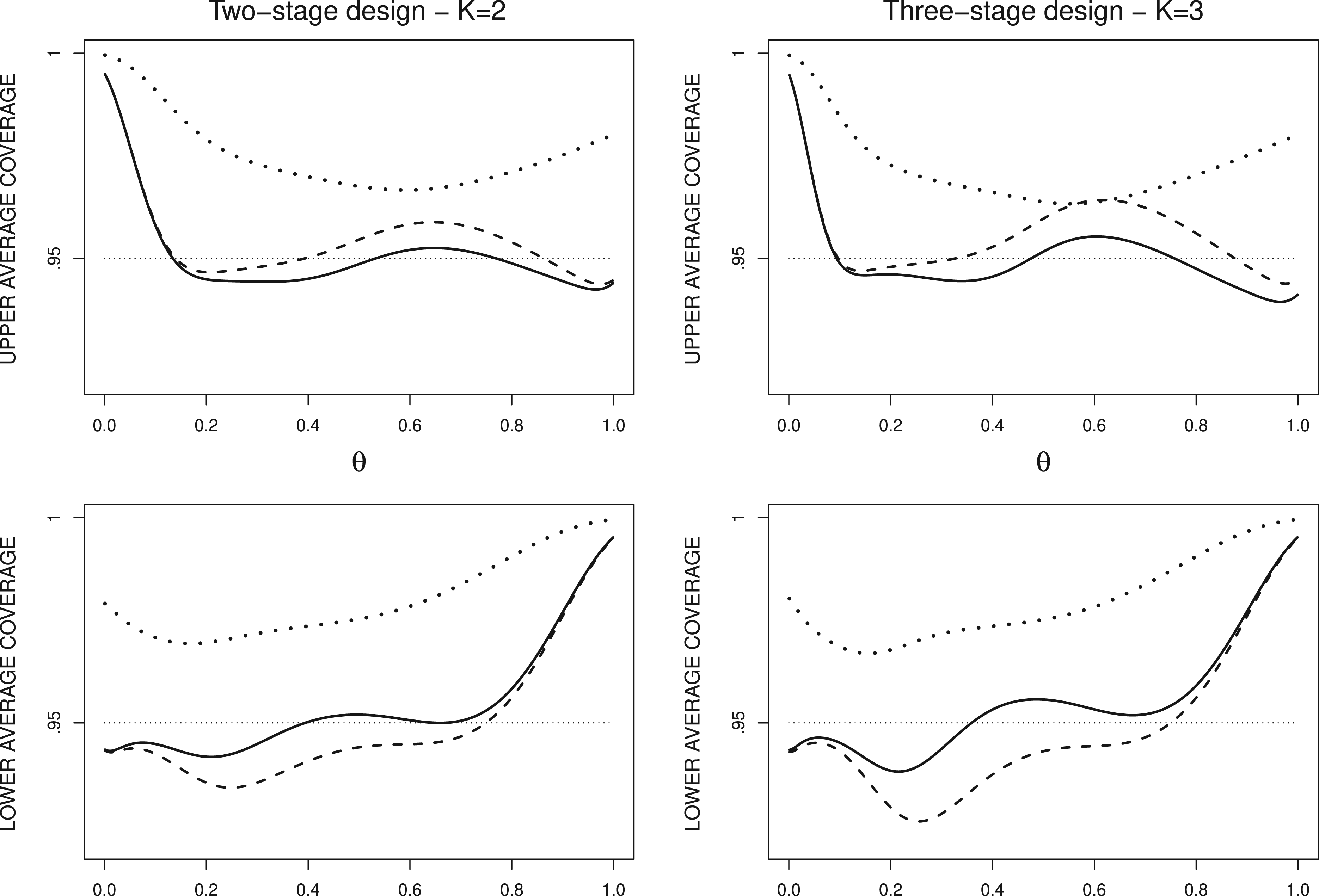
Figure 4 displays the curves of the one-sided average coverage probabilities for , , and with a confidence level of in the design with . The high average coverage of intervals at the extreme values of is caused by the zones of complete coverage, as shown in Figure 3, before the first spike for and after the last spike for . This phenomenon decreases as the sample size increases. It is now clear that the design-dependent Jeffreys interval allows a lower departure of the average coverage probability from than the (naive) Jeffreys interval. This departure is stronger for the values of around the interval limits for the observed rate . If we focus on the values in the range (excluding the zones of complete coverage), the maximum departure of is reached at in the two-stage design and is advanced to in the three-stage design, while the maximum departure of is reached at in the two-stage design and is moved forward to in the three-stage design. The correction for the influence of the stopping rule in , as measured with the raw difference in the average coverage probabilities versus , is stronger near the maximum departure of the average coverage probability of . The maximum correction in is reached at with and with and at with and with in . Regarding the Jennison–Turnbull interval, the average coverage probabilities are far above .
One-sided average coverage probabilities of the naive (- - -) and the design-dependent (—) Jeffreys intervals and the Jennison–Turnbull interval () with a confidence level of in the design with .
This investigation confirms the good frequentist characteristics of the design-dependent Jeffreys interval. It also highlights the relevancy of the average coverage probability as a criterion to appraise the coverage properties of the confidence intervals in group sequential experiment. Section 2 of the appendix in Supplemental Material describes results of simulations to assess the effect of the prior correction on the average coverage of the two-stage design with sample size increasing from to , , and . The results show that the effect of the prior correction on the design-dependent Jeffreys interval is proportional to the influence of the stopping rule on the naive Jeffreys interval as the sample size varies.
Comparison of the estimation approaches in three clinical trial designs
I now study the influence of the stopping rule and the effect of the prior correction on the point and the interval estimates through three classical two-stage designs in oncology clinical trials to test the rate of response to a therapeutic intervention. The parameters of the designs allow testing the one-sided hypotheses versus with the frequentist risks and . The three designs are described hereafter:
In the Simon design, the trial stops early for futility (i.e. is accepted) at the interim analysis if the results are not promising. The minimax Simon design minimizes the maximum number of patients among the admissible Simon designs. This design requires the sample size .
The Pocock design allows an early stopping for efficacy (i.e. is rejected) using an aggressive stopping strategy since it applies a constant boundary on the -value scale at stage 1 and stage 2. The number of patients at stage 1 and stage 2 is set equal so that the sample size is .
The O’Brien–Fleming design combines early stopping for futility and efficacy. In our example, the sample size is the same as in the Pocock design, but the probability to reject at stage 1 is lower and greater at stage 2.
Table 1 gives the estimates obtained using the different approaches at the boundaries to accept and reject at stage and stage for the three experimental designs. Among the Bayesian point estimators, is preferred to , which is not considered anymore in what follows, as the use of the posterior mean is more in accordance with the Bayesian practice than the posterior mode which mimics the methods based on likelihood maximization. Anyway, the estimates given by both Bayesian point estimators are very close. So, is compared to , , and . Table 1 also shows the limits of the two-sided equal-tailed ( (or equivalently the limits of the one-sided () where the value is the significance level of the one-sided test used to reject at each stage. In this manner, the confidence level of the intervals matches with the significance level of the tests. The limits of the design-dependent Jeffreys interval are compared to those of the (naive) Jeffreys interval and the Jennisson–Turnbull interval. Of note, in the Simon and the O’Brien–Fleming designs, the limits at the acceptance boundaries are given for descriptive purpose.
Point and interval estimates at the acceptance and rejection boundaries in the two-stage Simon, Pocock, and O’Brien–Fleming designs for testing versus with and .
* The limits are given for descriptive purpose as the trial stops early for futility.
In the Bayesian approach, the prior correction causes a shift of the posterior density mass toward the region of the experiment continuation to stage 2 on the scale. It is so expected that the prior correction results to an increase of the estimates in the Simon design and a decrease in the Pocock design. In the O’Brien–Fleming design, the continuation region is between the futility and the efficacy stopping boundaries at stage 1. If the observed rate is in, or close to, the continuation region, the posterior density mass will be more concentrated on its central value with the consequence that the design-dependent posterior mean will be close to that of the naive approach while the length of the credible interval will be reduced. Another consequence is that the effect of the prior correction on the posterior estimates is lower in the O’Brien–Fleming design than the Pocock design.
The correction for the influence of the stopping rule differs markedly according to the approach used. For point estimation, estimate is obtained from the estimate by subtracting an estimate of the bias of the at . The correction is a function of only and applies equally whatever the stage number (i.e. without consideration for the actual sample size). Conversely, estimate equals estimate at stage 1 and the correction for the stopping rule bias applies at stage 2 only. For this reason the effect of the correction may appear counter intuitive as the statistical information is maximum at stage 2 and, in some cases, unduly strong. Unlike and , the correction for the influence of the stopping rule on estimates takes into consideration the statistical information: The strength of the correction is inversely proportional to the observed sample size so that the correction is stronger at stage 1 than stage 2.
As for in point estimation, the correction on the limits of the Jennison–Turnbull interval applies at stage 2 only whereas the limits at stage 1 are those of the Clopper–Pearson interval in fixed -sample experiment. The main problem with the Jennison–Turnbull interval is that the limits are conservative due to great interval length. The reason is that this interval was developed with consideration for the preservation of coverage probability. The Jennison–Turnbull interval is usually not a good choice for practical use, unless strict adherence to the prescription that the one-sided coverage is at least is required. In this setting, the design-dependent Jeffreys interval is an appealing alternative since the effect of the prior correction on the limits depends on the statistical information and the interval length is close to that of the naive Jeffreys interval. As previously mentioned, this credible interval also benefits from the objectivity of an approach which is strictly based on the reference prior theory.
This study of the correction for the influence of the stopping rule on the estimates highlights the relevancy of the full Bayesian strategy based on for point estimation and the design-dependent Jeffreys interval for interval estimation.
Concluding remarks and discussion
The idea behind the reference prior theory is to maximize a distance between the prior and the posterior distributions, as data are collected. In return, the “data collected” have maximum influence on the posterior estimates. In sequential experiments, this interpretation can be extended to the “data collected in a given experimental design.” In the fixed sample binomial problem, the reference prior coincides with the prior obtained using Jeffreys’ criterion. The beta- distribution, which generalizes the reference prior distribution in sequential experiment, allows the development of a comprehensive and unified approach to the point and the interval estimations based on posterior estimators with good frequentist properties.
The comparative studies conducted in this article highlight the advantage of using the posterior mean based on the design-dependent Haldane prior in point estimation and the credible interval based on the design-dependent reference prior. The influence of the stopping rule on estimates is corrected depending on the available statistical information. The Bayesian approach provides estimates with coherent interpretation and allows avoiding the issues of pre-ordering in the observation space and non-unicity of the frequentist approach. The good properties of estimators were evidenced using the average bias in point estimation and the average coverage probability in interval estimation. These new criteria allow the introduction of an amount of uncertainty around the parameter value based on the preexperimental evidence given by the design.
Estimation of the binomial proportion upon sequential experiment termination is still a subject that arouses an abundant literature in the applied statistical community.32 This article provides a Bayesian answer to address this issue. The objectivity status of the reference prior combined with the good frequentist properties of the posterior estimators, as well as the easiness of implementation using basic programming, justify to consider this comprehensive approach as one of the default choices in the experimental practice.
In sequential experiments with multiple binomial outcomes, it is natural to consider the use of multivariate binomial models with a dependence structure. However, it is often the case that only one or a subset of parameters is of interest, the others being nuisance parameters. The reference prior theory is particularly well adapted to this context as it allows a hierarchy among parameters. Let us consider the vector where there is a parameter, says , which is more of interest than the others, and suppose that the stopping rule depends on only. The design-dependent reference prior for this problem is the naive reference prior times the expected stopping time,21 that is,
Whereas a Monte Carlo-type algorithm can be used to obtain the reference posterior summaries, the derivation of in (20) is a key aspect of the problem. To handle this, the reference prior theory allows a procedure which comes down to sequentially computing Jeffreys prior in one-parameter problem.25 This approach to nuisance parameter is based on an implicit ordering, for example, (,…,). The reference prior relative to this ordering is obtained after successive conditioning (i.e. assuming each step that the conditional parameter is constant) such that:
Supplemental Material
sj-pdf-1-smm-10.1177_09622802231199160 - Supplemental material for Bayesian estimation of the binomial parameter in sequential experiments
Supplemental material, sj-pdf-1-smm-10.1177_09622802231199160 for Bayesian estimation of the binomial parameter in sequential experiments by Pierre Bunouf in Statistical Methods in Medical Research
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
ORCID iD
Pierre Bunouf
Supplemental material
Supplemental material for this article is available online: Some technical details to derive the reference prior in sequential experiment are provided in the appendix in Supplemental material. This document also contains results of simulations to assess the effect of the prior correction on the posterior estimators as the sample size varies and R scripts to produce Figure 2 and the results reported in along with some computational details.
References
1.
PocockSJ. Group sequential methods in the design and analysis of clinical trials. Biometrika1977; 64: 191–199.
2.
O’BrienPCFlemingTR. A multiple testing procedure for clinical trials. Biometrics1979; 35: 549–556.
3.
LanKKGDeMetsDL. Discrete sequential boundaries for clinical trials. Biometrika1983; 70: 659–663.
4.
SludEWeiLJ. Two-sample repeated significance tests based on the modified Wilcoxon statistic. J Am Stat Assoc1982; 77: 862–868.
5.
BerryDA. Interim analyses in clinical trials: classical vs. Bayesian approaches. Stat Med1985; 4: 521–526.
6.
StallardNToddSRyanEG, et al. Comparison of Bayesian and frequentist group-sequential clinical trial designs. BMC Med Res Methodol2020; 20: 4.
7.
ZhouTJiY. On Bayesian sequential clinical trial designs. New England J Stat Data Sci2023; 1–16 . DOI: 10.51387/23-NEJSDS24.
8.
ZhuHYuQ. A Bayesian sequential design using alpha spending function to control type I error. Stat Methods Med Res2017; 26: 2184–2196.
9.
BasslerDBrielMMontoriVM, et al. Stopping randomized trials early for benefit and estimation of treatment effects: systematic review and meta-regression analysis. J Am Med Assoc2010; 303: 1180–1187.
10.
MontoriVMDevereauxPJAdhikariNK, et al. Randomized trials stopped early for benefit: a systematic review. J Am Med Assoc2005; 294: 2203–2209.
11.
RobertsonDSChoodari-OskooeiBDimairoM, et al. Point estimation for adaptive trial designs I: a methodological review. Stat Med2023; 42: 122–145.
12.
U.S. Food and Drug Administration. Adaptive designs for clinical trials of drugs and biologics: guidance for industry. 2019. https://www.fda.gov/media/78495/download.
13.
ArmitageP. Numerical studies in the sequential estimation of a binomial parameter. Biometrika1958; 45: 1–15.
14.
TsiatisAARosnerGLMehtaCR. Exact confidence interval following group sequential test. Biometrics1984; 40: 797–803.
15.
RosenbaumPRRubinDB. Sensitivity of Bayes inference with data-dependent stopping rules. Am Stat1984; 38: 106–109.
16.
JennisonCTurnbullBW. Group sequential methods with applications to clinical trials. New York: Chapman & Hall, 2000.
17.
WhiteheadJ. The case for frequentism in clinical trials. Stat Med1993; 12: 1405–1413.
18.
JungSKimKM. On the estimation of the binomial probability in multistage clinical trials. Stat Med2004; 23: 881–896.
19.
WhiteheadJ. On the bias of maximum likelihood estimation following a sequential test. Biometrika1986; 73: 573–581.
20.
GovindarajuluZ. The statistical analysis of hypothesis testing, point and interval estimation, and decision theory. Columbus, OH: American Sciences Press, 1981.
21.
SunDBergerJ. Objective Bayesian analysis under sequential experimentation. IMS Collections, Pushing The Limits of Contemporary Statistics: Contributions in Honour of Jayanta K. Ghosh, 2008; 3, 19–32.
22.
BernardoJM. Reference posterior distributions for Bayesian inference. J Roy Statist Soc B1979; 41: 113–147. (with discussion).
23.
BunoufPLecoutreB. On Bayesian estimators in multistage binomial designs. J Stat Plan Inference2008; 138: 3915–3926.
24.
SimonR. Optimal two-stage designs for phase II clinical trials. Control Clin Trials1989; 10: 1–10.
BunoufP. An objective Bayesian approach to estimation in multistage experiments. Stat Methods Med Res2022; 31: 1579–1589.
28.
de CristofaroR. On the foundations of likelihood principle. J Stat Plan Inference2004; 126: 401–411.
29.
BunoufPLecoutreB. Bayesian priors in sequential binomial design. C R Acad Sci Paris, Ser I2006; 343: 339–344.
30.
ClopperCJPearsonES. The use of confidence or fiducial limits illustrated in the case of the binomial. Biometrika1934; 26: 404–413.
31.
CaiTT. One-sided confidence intervals in discrete distributions. J Stat Plan Inference2005; 131: 63–88.
32.
KoyamaTChenH. Proper inference from Simon’s two-stage designs. Stat Med2008; 27: 3145–3154.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.