
Abstract
We consider the analysis of longitudinal data of multiple types of events where some of the events are observed on a coarser level (e.g. grouped) at some time points during the follow-up, for example, when certain events, such as disease progression, are only observable during parts of follow-up for some subjects, causing gaps in the data, or when the time of death is observed but the cause of death is unknown. In this case, there is missing data in key characteristics of the event history such as onset, time in state, and number of events. We derive the likelihood function, score and observed information under independent and non-informative coarsening, and conduct a simulation study where we compare bias, empirical standard errors, and confidence interval coverage of estimators based on direct maximum likelihood, Monte Carlo Expectation Maximisation, ignoring the coarsening thus acting as if no event occurred, and artificial right censoring at the first time of coarsening. Longitudinal data on drug prescriptions and survival in men receiving palliative treatment for prostate cancer is used to estimate the parameters of one of the data-generating models. We demonstrate that the performance depends on several factors, including sample size and type of coarsening.
Keywords
Introduction
This article considers estimation of parameters of a discrete time multivariate longitudinal model, such as a competing risk survival model, an illness-death model, a progressive three-state model with an intermediate transient state, or a more general multi-state model,1,2 where data on some events are occasionally observed only on a coarser level than required. In this case, it may only be known that an event in a particular group of events has occurred during certain parts of the follow-up, for example, because some events are not recorded, resulting in gaps in the event history. This can occur by design, when subjects fail to self-report, or when data on events is registered in different linked data registers that cover different calendar periods. For example, data on drug prescriptions in Sweden is not available prior to the initiation of the Swedish Prescribed Drug Register in 2005, and consequently the start and duration of treatment(s) may be unknown for some study subjects. Historical data can be lost because it is not allowed to be stored indefinitely according to privacy and security laws (e.g. the General Data Protection Regulation [GDPR]) or because old hardware is upgraded (e.g. floppy disks to hard disk drives) without copying the old data to the new hardware. A register’s variable definitions may be updated, allowing a higher level of details to be recorded, and some events may only be distinguished from each other after this update. For example, the type of radiotherapy may only be known after one begins to register whether radiotherapy was curative or palliative. If there is an administrative lag of the assessment and registration of the cause of death, then the cause is not available for those dying during the latest calendar period.
When certain events are indistinguishable or not observable, we say that the data on events is coarsened. The concept of coarsened data is more general than missing data and describes several incomplete-data problems such as heaped and censored data.3,4 Multi-state models under different censoring mechanisms have been extensively studied both in continuous time5–7 and in discrete time.8–12 A special case of coarsening of counting process models in continuous time is the notion of a filtered counting process where no events can be observed during parts of the follow-up. 6 Data coarsening can also occur on the time-scale due to the discretization of time into intervals.13–15 Whenever past events may affect the probability of future events, the coarsening of data on events simultaneously introduces missing data on events and time-dependent covariates defined by the history of the process. This is problematic since missing data may introduce bias and loss of efficiency unless appropriately dealt with.16,17 One approach to parameter estimation in continuous time models of recurrent events with gaps is to use a hot-deck imputation procedure that samples information from subjects with completely recorded history.18,19 To our knowledge, there are no previous studies that explicitly consider parameter estimation in more general coarsened discrete-time longitudinal models.
The aims of this article are to (1) introduce a representation of coarsened multivariate longitudinal data, (2) discuss estimators of the parameters of a general class of discrete-time coarsened longitudinal models, (3) study the performance of the estimators in a series of simulation studies, and (4) provide code for transparency and reproducibility. In particular, we focus on a coarsening process that, at each time, either coarsens the events into disjoint groups of events where it is only known if an event in a group occurred or not, or that right-censors the entire counting process. We derive the likelihood function under the assumption that the coarsening process is independent of the longitudinal process possibly given an observed external covariate process. We then restrict attention to models where the event probabilities are linked to linear predictors through a baseline category model and derive the score and observed information. The simulation studies involve three data-generating models of progressive type with either three or four states, where the coarsening generates gaps in the event history in different ways. Estimators based on full data maximum likelihood, the Monte Carlo Expectation Maximization (MCEM) algorithm,20,21 ignoring the coarsening and consequently acting as if no event occurred, and artificially right censoring at the first time of coarsening, 19 are compared in terms of bias, empirical standard errors, and confidence interval coverage. For MCEM, importance sampling is used for approximating the expectations, and we show how to construct a proposal that generates nonzero weights for a certain class of models and coarsening.
The discrete-time longitudinal event process
In this section, we define the latent data
First, let
Let
When an absorption occurs during the follow-up, let
In addition to the above, we need to keep track of the history of
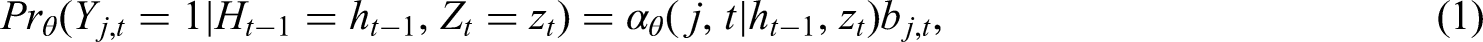
Since
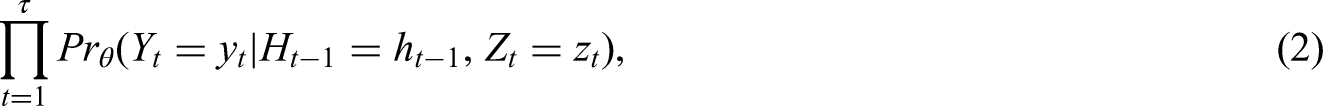
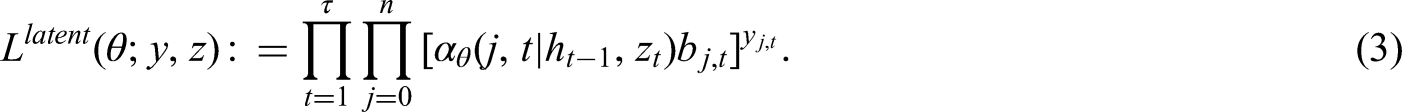
In this section, we define and describe how
Let
The observed version of
Continuing the previous example, we further assume that there are two registers, one that records drug prescriptions (events 1 and 2) and one that records date and cause of death (events 3 and 4) or date of emigration. Assume that the register that records drug prescriptions stops collecting information from time
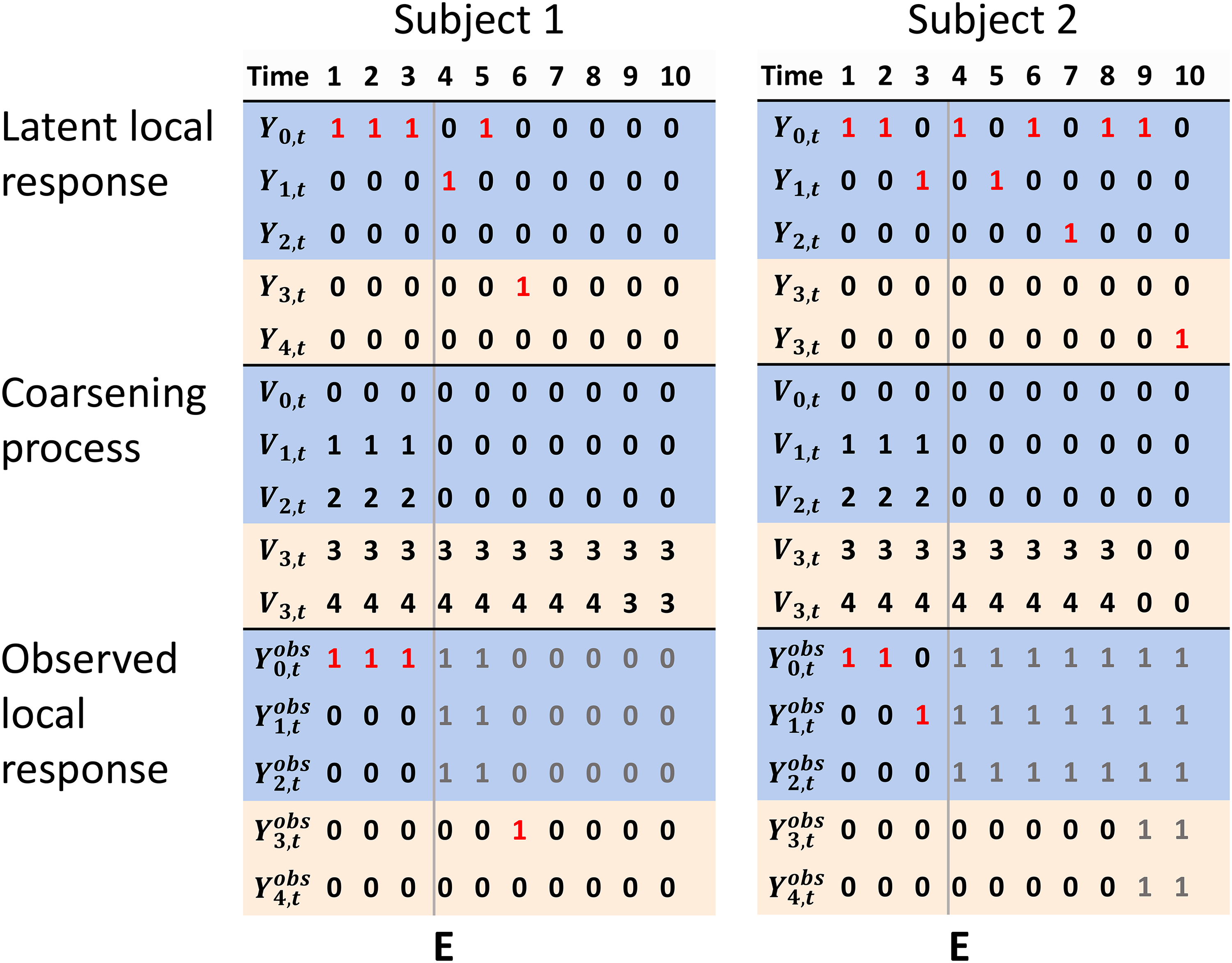
Examples of the latent local response, the coarsening process, and observed local response, for a coarsening process
The groups that define the coarsening may vary over time (e.g. become larger and/or smaller) and subjects. In the previous example, this would correspond to a situation where the register that records drug prescriptions starts and stops collecting data at several different times. Figure 2 illustrates another situation with a different randomly generated time-varying coarsening process
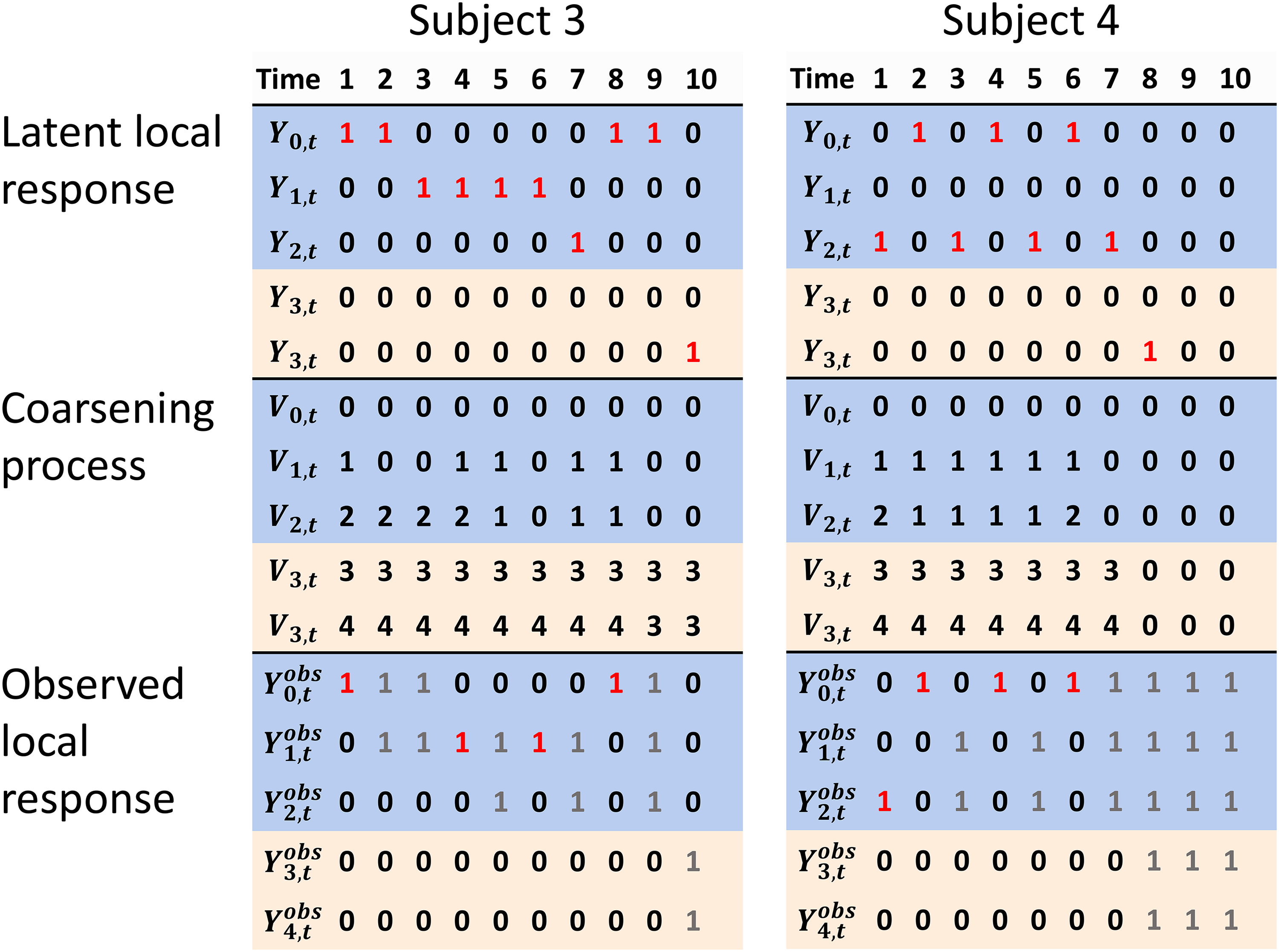
Examples of the latent local response, the coarsening process, and observed local response, for a randomly generated time-varying coarsening process
It is important to stress that event though
We derive the ignorable likelihood function that only depends on the observed data and
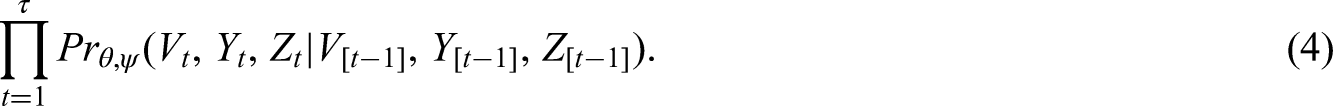
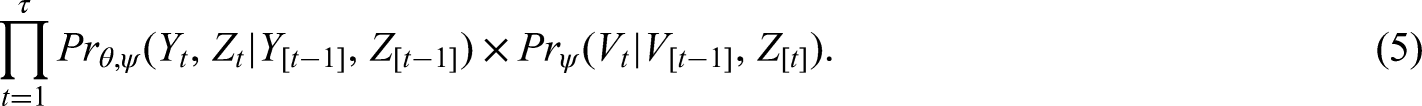
The joint probability mass function of the observed data is
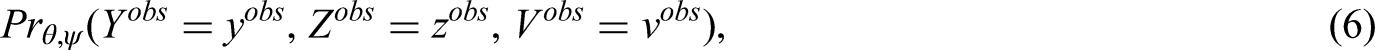
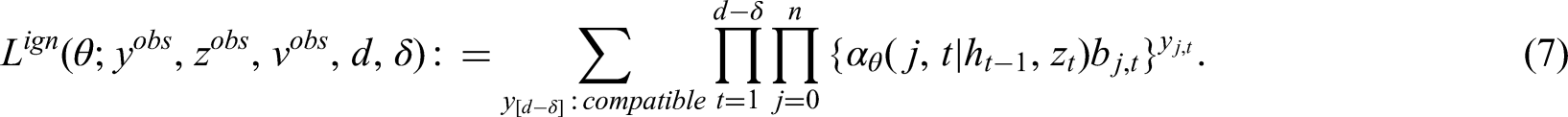
The likelihood contribution is in other words the latent likelihood (3) evaluated up until the last time of follow-up
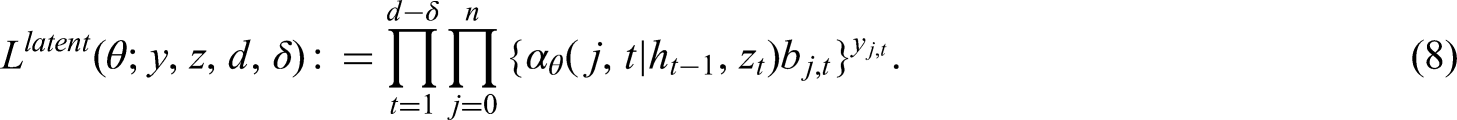
An estimate of
We assume that the reference event 0 always can occur whenever the subject has not been absorbed with positive probability given the past, for example when it indicates that the subject stayed alive. We restrict our attention to the conditional (on the past) baseline category model.
9
For
Maximum likelihood using Monte Carlo Expectation Maximization (MCEM)
Direct maximization of the ignorable likelihood involves a large number of sums and products on the form (7) to be computed, which can become computationally intensive, for example, when the sample size
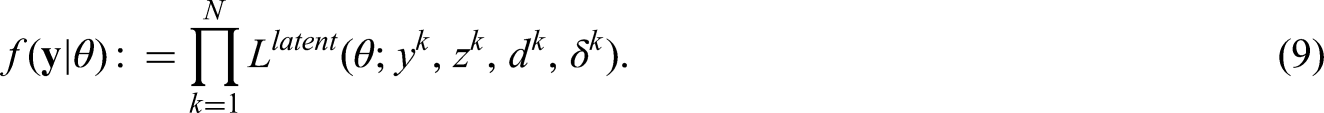

Importance sampling is a procedure to approximate a (conditional) expectation.21,24 It involves two probability mass functions (pmfs). For each individual with some coarsened data, one samples the latent data
In our case, the target pmf is proportional to
Model restrictions
From hereon, we consider a relatively general type of longitudinal model and coarsening process for which it is computationally cheap to find the support of the target pmf and straightforward to construct a proposal pmf whose support matches the target pmf. In short, the support of
For each subject, sampling is performed sequentially from
Generating a sample and a weight.

Generating a sample and a weight.
Further details regarding the MCEM implementation are provided in Appendix B in the Supplemental Material.
We considered three different data-generating models with different properties in a set of simulation studies. All models were based on the above specified discrete time conditional baseline category model. The first (model 1) concerned a study of men diagnosed with advanced prostate cancer assigned to palliative treatment with either AA or GnRH as in the examples in the previous sections. However, we only considered death from any cause instead of death from prostate cancer and other causes separately. During the follow-up a man could receive one or several doses of AA, and possibly switch to GnRH, or initiate GnRH treatment first without having received any AA. An initiation of a new drug, indicated by a prescription, was interpreted as a proxy for disease progression, and hence, in this study, a prescription of AA never followed a prior GnRH prescription. Therefore, the data-generating model included four events: reference 0 (Alive), 1 (AA), 2 (GnRH), and 3 (Death). The states were S0 (no prior treatment and alive), S1 (have received AA), S2 (have received GnRH). The discrete time hazards are shown in Figure 3 and indicate that most men initiated a treatment quite early on and frequently receive a dose of the same treatment.
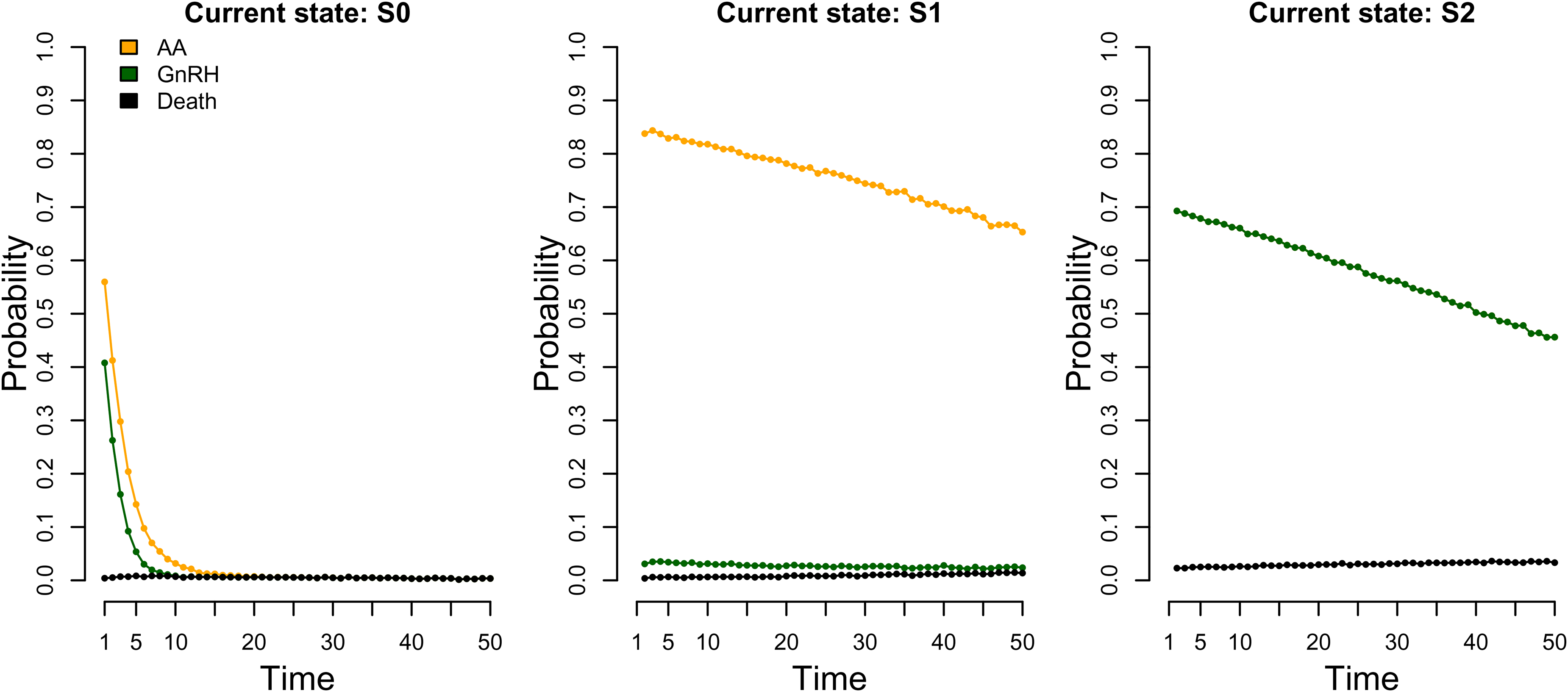
Approximate event probabilities (discrete time hazards) for data-generating model 1 at times
The data-generating model parameters are shown in Supplemental Table 2. These were obtained by fitting the model on observed data on 16,312 men diagnosed with prostate cancer between 2006 and 2016, assigned to palliative treatment, and registered in Prostate Cancer data Base Sweden (PCBaSe). 26 In short, PCBaSe contains linkages between the National Prostate Cancer Register of Sweden, the Prescribed Drug Registry, and the Cause of Death Registry. Follow-up extended to the first of the date of death, migration, or 2016-12-31. Data on dates of GnRH and AA prescriptions were obtained from the Prescribed Drug Registry, and the time was discretized using a 90-day time window. The study was approved by the Research Ethics Board in Uppsala (2016-239).
For model 1, we considered three scenarios with different follow-up and types of coarsening. A hypothetical blackout was simulated for some of the subjects independently of their event histories, during which no drug prescriptions were registered. In scenarios 1 and 2, prescriptions of GnRH were not registered, so events 0 and 2 were coarsened to the same group
Models 2 and 3 had three events: 0 (Alive), 1 (Treatment), and 2 (Death), and were designed to explore two other qualitatively different dynamics, see Supplemental Figures 1 and 2 and Supplemental Tables 3 and 4 for visualizations of the discrete hazards and model parameters. For model 2, follow-up ended at
The full data MLE (MLE*) was computed before coarsening the data. We considered four estimators used after coarsening. The first (EarlyCensor) is an MLE on a modified dataset obtained by artificially right censoring each subject at the first time
For all the above estimators, the inverse of the negative Hessian of the corresponding log-likelihood at convergence was computed based on the (modified data) and its diagonal elements were used as estimates of the standard error and to construct 95% approximate confidence intervals under the assumption of asymptotic normality. 27
The last estimator was based on MCEM and importance sampling, as described in the previous section. The parameter sequence
MCEM.

MCEM.
We assessed bias, empirical standard error (EmpSE), and confidence interval coverage (%) for each parameter and estimator, along with corresponding Monte Carlo standard errors (MC-SE), as described in Morris et al. 28
For model 1, scenarios 1 and 3, the number of repetitions was set to
For models 2 and 3, similar reasoning was used to determine the settings for model 2 (
Results
The bias of all estimators decreased for each parameter with increasing sample size, except for IgnoreV for some parameters. Although all estimators were biased for one or many parameters at a sample size
For model 1, scenario 1, the biases of DirectML were similar to the MLE without coarsening (MLE*), while EarlyCensor had larger bias for some parameters at
Model 1, scenario 1. Bias of each parameter by estimator. MLE* is the MLE obtained without coarsening.
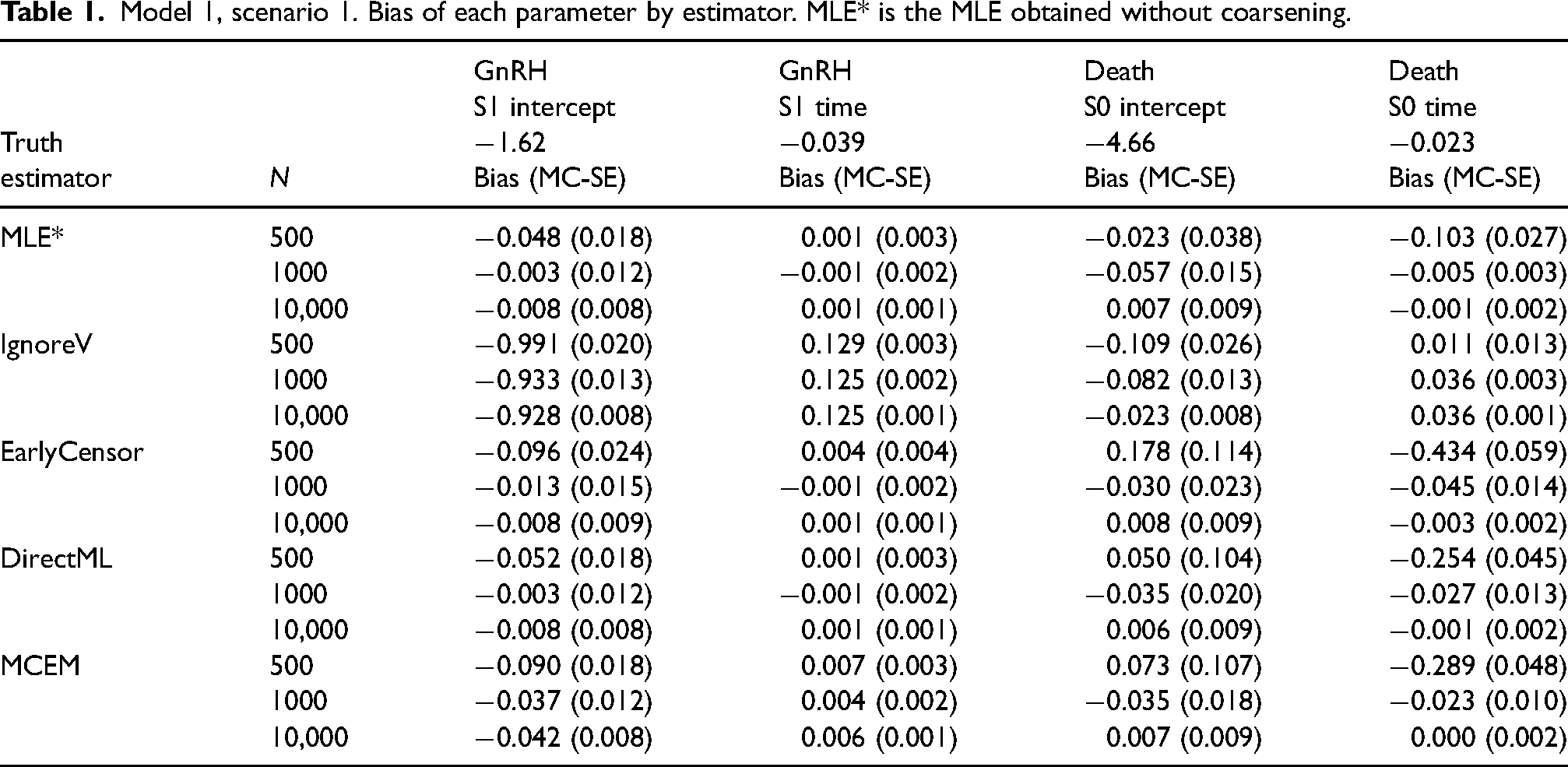
Model 1, scenario 1. Bias of each parameter by estimator. MLE* is the MLE obtained without coarsening.
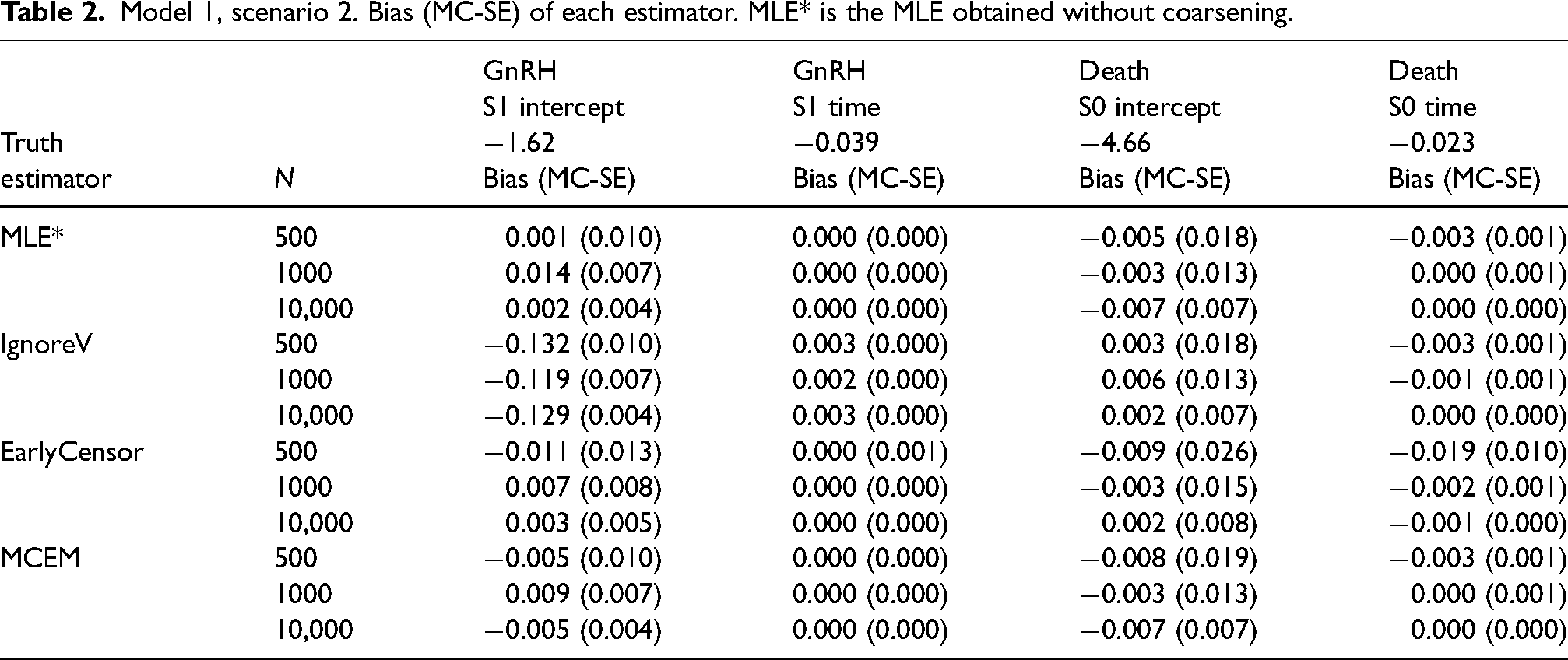
For model 1, scenario 2, the follow-up was longer (
Model 1, scenario 2. Bias (MC-SE) of each estimator. MLE* is the MLE obtained without coarsening.
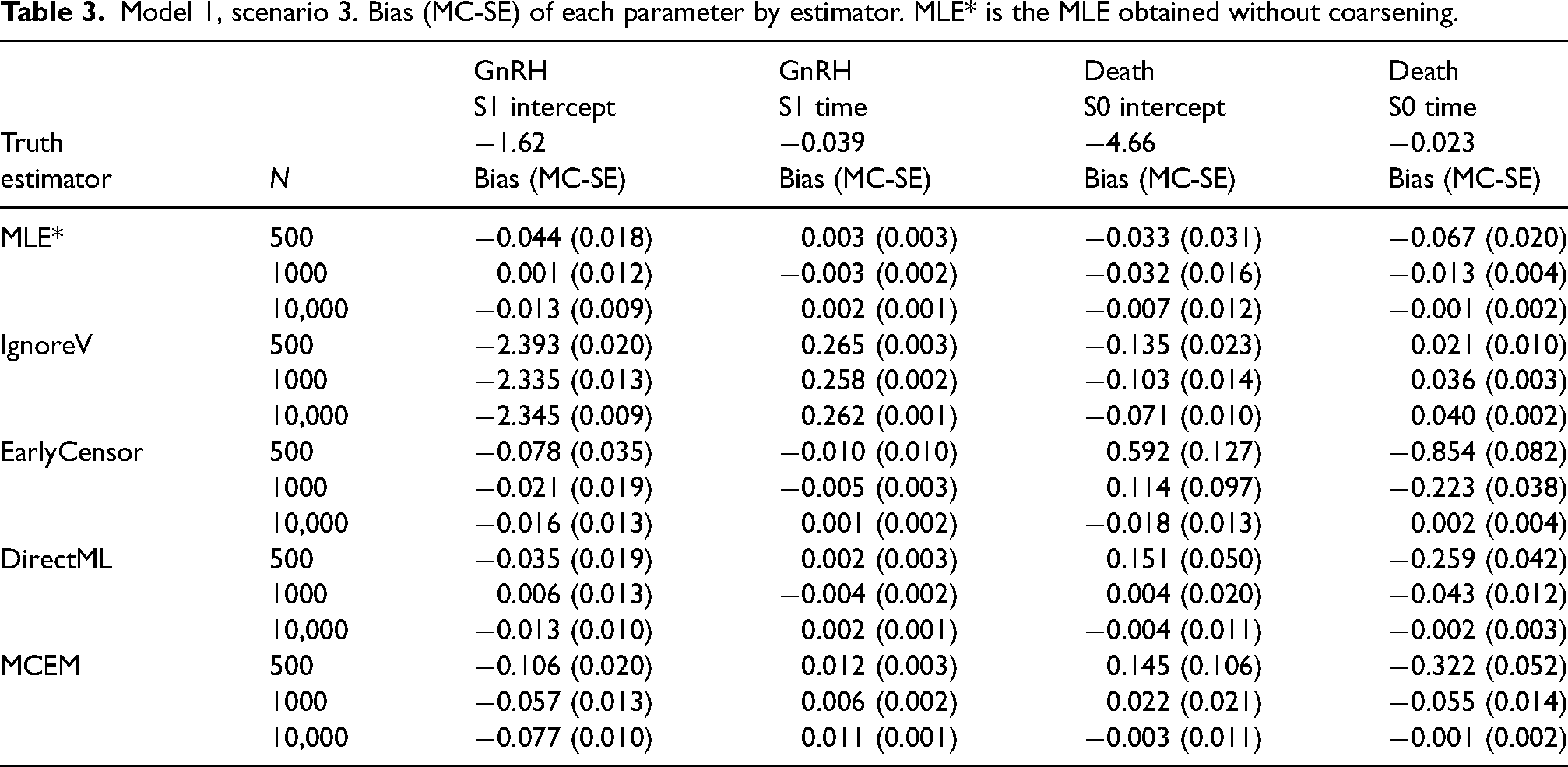
For model 1, scenario 3, both the events GnRH and AA were coarsened instead of only GnRH as in scenarios 1 and 2. Biases were significantly larger for IgnoreV and larger for EarlyCensor in scenario 3 compared to scenario 1, in particular for parameters S1 intercept and S1 time for all events AA, GnRH, and Death, Table 3 and Supplemental Figure 5. Coverage for IgnoreV was far below 95% for most parameters (except e.g. Death, S0 intercept). MCEM had larger biases and EmpSE’s for
Model 1, scenario 3. Bias (MC-SE) of each parameter by estimator. MLE* is the MLE obtained without coarsening.
In contrast to model 1, models 2 and 3 have three events instead of four, and these two models have different parameter values and follow-up (
In this article, we derived the likelihood function for discrete time counting process models under independent and noninformative coarsening, and compared the performance of several estimators through a series of simulation studies, focusing on bias, empirical standard error, and 95% confidence interval coverage. Our article adds to the literature on discrete time counting process modelling by providing the appropriate set-up, expressions for the likelihood with a coarsening process, and expressions for derivatives including the score and observed information under the conditional baseline category model. We derived and implemented the direct maximum likelihood estimator, and showed how to construct a proposal distribution used in an importance sampling MCEM algorithm for certain models and coarsening.
We saw that the maximum likelihood estimation for discrete time counting process models in the absence of a coarsening process (MLE*) was biased in smaller samples but 95% CIs still reached approximately 95% coverage. The bias shrunk more slowly for DirectML, MCEM and EarlyCensor with increasing sample size, which is expected due to the loss of information due to data coarsening. Ignoring the coarsening (IgnoreV) introduced mild to strong bias in varying direction and magnitude, depending on the data-generating model and the timing and amount of coarsening, and confidence interval coverage was generally poor. For example, relative to scenario 1, the bias of IgnoreV increased when the coarsening became coarser in scenario 3. For model 2, where follow-up was long (
Directly maximizing the likelihood (DirectML) gave the smallest empirical standard errors as expected (where it was used), often closely followed by MCEM, and these were occasionally significantly larger for EarlyCensor. This was not surprising since EarlyCensor disregards all information after first time of censoring while the other two estimators use all available information. In particular, both EarlyCensor and MCEM performed better in terms of bias and EmpSE for model 1 in scenario 2 compared to 1, which is expected since (a) event 2 (GnRH) most likely occurred before coarsening (prior to time 5) in scenario 2, (b) the follow-up was longer, and (c) the coarsening process acted later during the follow-up and at that time fewer men were alive.
An important limitation of the DirectML estimator is the need to not only compute all possible realizations that are compatible with the observed data, but also to propagate the history of events forward in time when computing each such realization. The number of computations required for the first operation scales exponentially with the number of time points where the event is unknown and polynomially in the number of possible events that could have occurred at each such time point. Although these computations only need to be performed once before optimization, each realization requires some computational time and storage. Thus, for large sample sizes where events are frequently coarsened into one of few large groups over a long time of follow-up, DirectML may quickly become computationally expensive.
In this regime, the limitations of DirectML can be accommodated using an instance of MCEM with importance sampling which is less computationally intensive. Whenever both can be used, we saw that it performed similarly to DirectML. In practice, the performance of MCEM can be improved further by increasing the number of Monte Carlo samples and iterations, for convergence guarantees to hold, 21 to alleviate the occasional bias and poor coverage of MCEM that was observed. With some further optimization of code, use of convergence criteria, and automation of MCEM, for example, by dynamically increasing the number of MC samples at each iteration, 31 we expect there to be many situations where MCEM is computationally feasible but where DirectML is not. Alternative approaches with potentially more optimal use of the computational budget include Markov Chain Monte Carlo methods and stochastic version of the EM algorithm.22,32
It could be attractive to increase the time-interval width when discretizing time in order to reduce computational complexity, but the use of large widths may lead to biased inferences.13–15 Future work should therefore instead investigate ways to reduce the computational cost using state of the art Monte Carlo methods in combination with the EM algorithm instead of importance sampling-based MCEM. We speculate that artificial right censoring (EarlyCensor) could be a viable option worth attention when sample size is very large, especially if coarsening occurs for the first time late during the follow-up relative to the model under consideration, and at many time points. In this regime, we expect that EarlyCensor may have negligible bias and the loss in precision to be moderate. However, the artificial censoring time was conditionally independent of
In conclusion, we have proposed several useful estimators of model parameters in discrete time coarsened counting process models, with partially complementary areas of use. From our experience, coarsened data and missing event types are common problems encountered in studies based on data collected from multiple registers and inappropriate handling of such data can lead to biased inference as demonstrated.
Supplemental Material
sj-pdf-1-smm-10.1177_09622802231155010 - Supplemental material for Estimation in discrete time coarsened multivariate longitudinal models
Supplemental material, sj-pdf-1-smm-10.1177_09622802231155010 for Estimation in discrete time coarsened multivariate longitudinal models by Marcus Westerberg in Statistical Methods in Medical Research
Supplemental Material
sj-zip-2-smm-10.1177_09622802231155010 - Supplemental material for Estimation in discrete time coarsened multivariate longitudinal models
Supplemental material, sj-zip-2-smm-10.1177_09622802231155010 for Estimation in discrete time coarsened multivariate longitudinal models by Marcus Westerberg in Statistical Methods in Medical Research
Supplemental Material
sj-zip-3-smm-10.1177_09622802231155010 - Supplemental material for Estimation in discrete time coarsened multivariate longitudinal models
Supplemental material, sj-zip-3-smm-10.1177_09622802231155010 for Estimation in discrete time coarsened multivariate longitudinal models by Marcus Westerberg in Statistical Methods in Medical Research
Supplemental Material
sj-zip-4-smm-10.1177_09622802231155010 - Supplemental material for Estimation in discrete time coarsened multivariate longitudinal models
Supplemental material, sj-zip-4-smm-10.1177_09622802231155010 for Estimation in discrete time coarsened multivariate longitudinal models by Marcus Westerberg in Statistical Methods in Medical Research
Footnotes
Acknowledgements
The anonymous reviewer is thanked for its efforts that lead to a substantial improvement of the manuscript. MW is also grateful to his former supervisors Rolf Larsson and Hans Garmo for helpful suggestions and comments, and to an anonymous colleague for proofreading assistance.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The author received support from the Centre of Interdisciplinary Mathematics (CIM) at Uppsala University. The sponsors had no involvement with the planning, execution or completion of the study.
Supplemental material
The reader is referred to the online Supplemental Material for technical appendices and additional results from the simulation studies. R code, along with comments and examples, is also provided as supplemental digital content. This code allows a user to generate data from a specified data-generating model, estimate model parameters, with and without coarsening, and reproduce the results of this study.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.