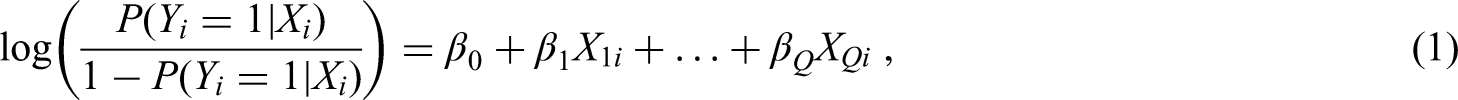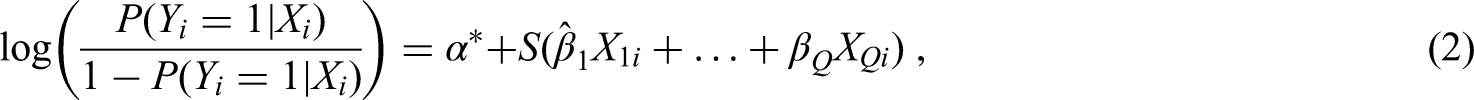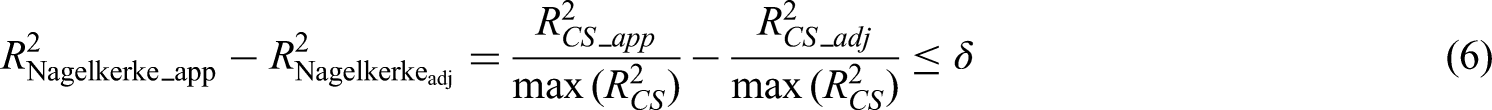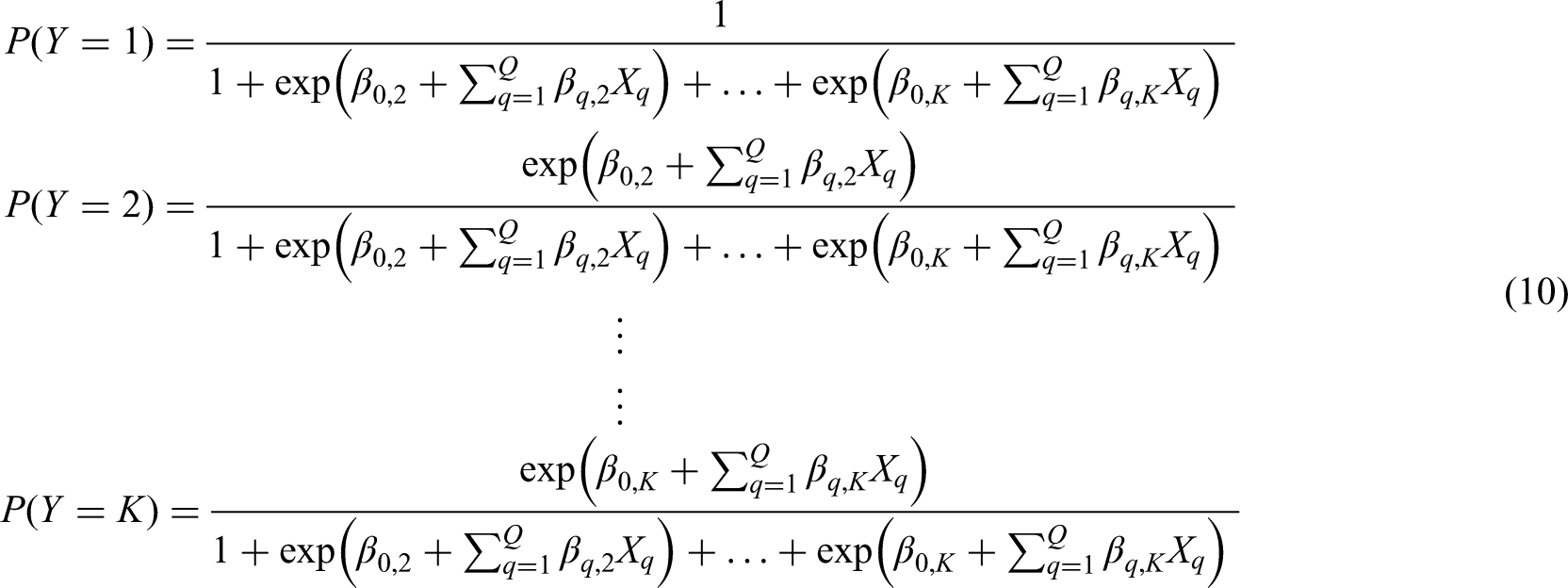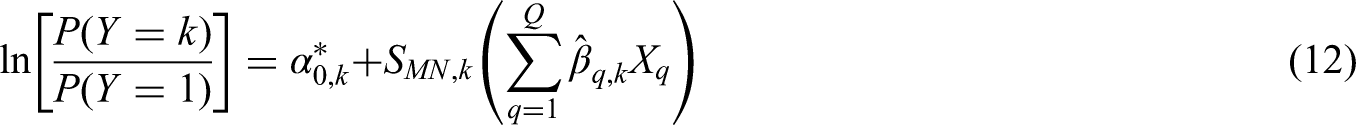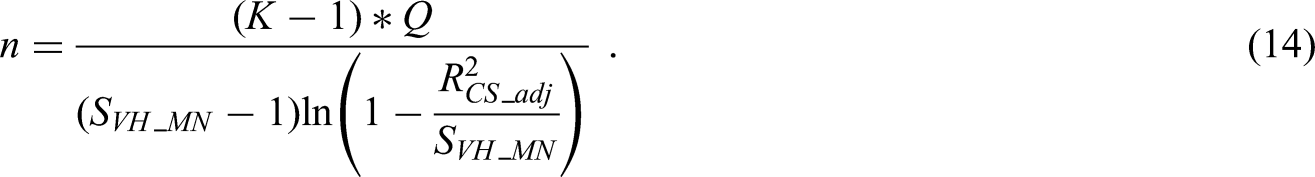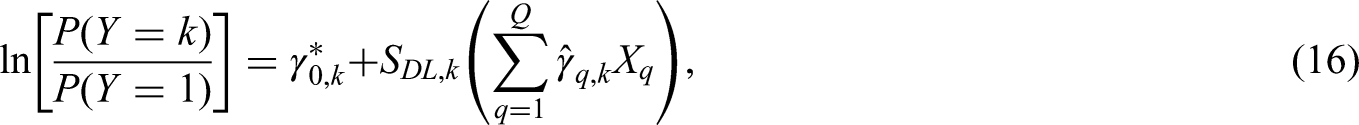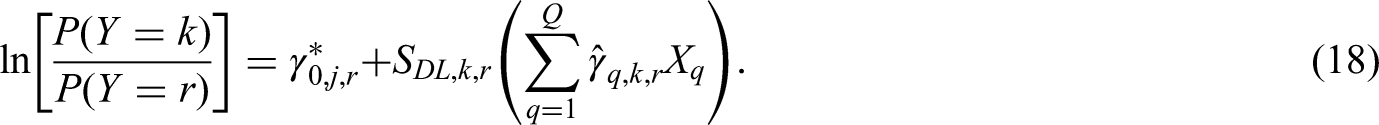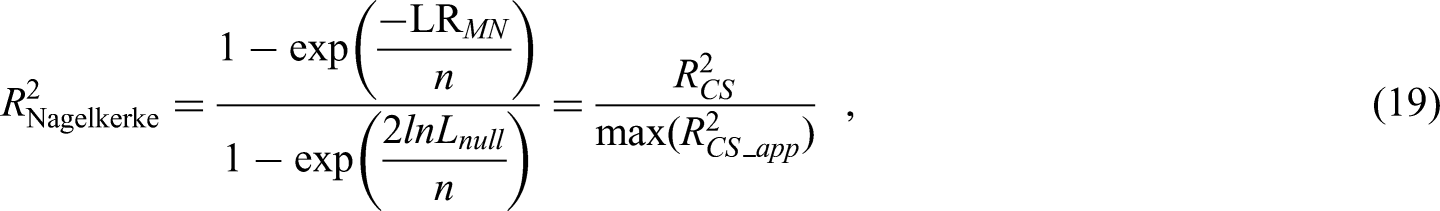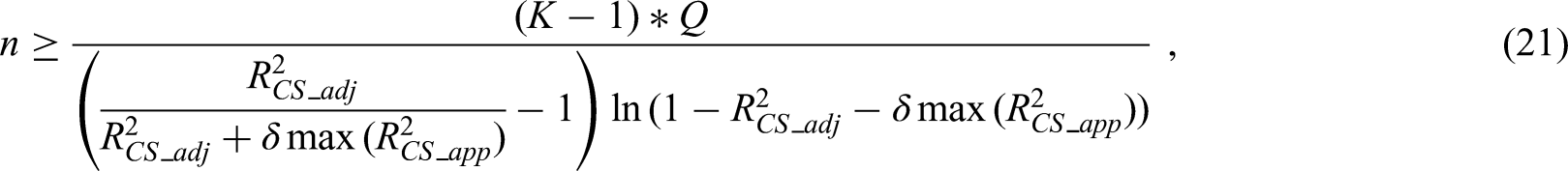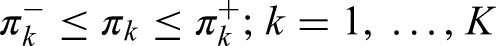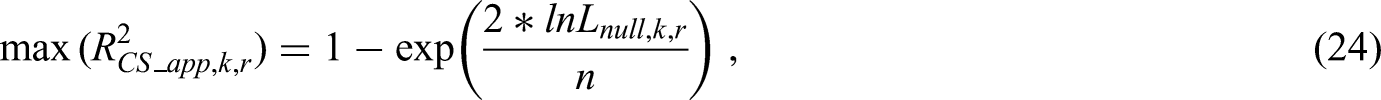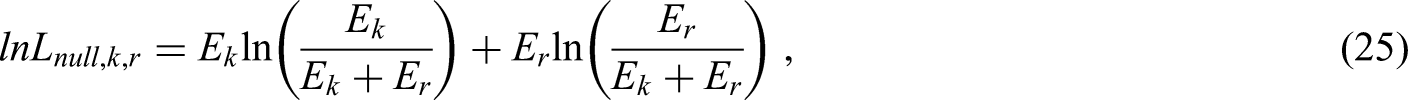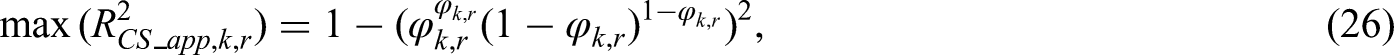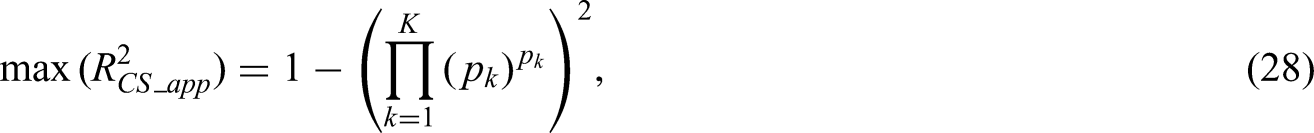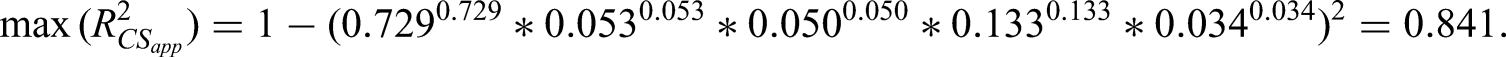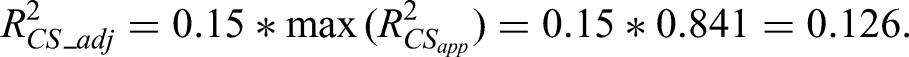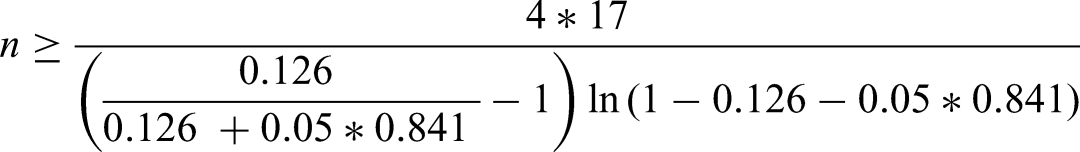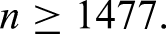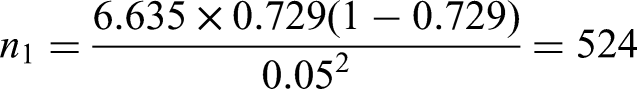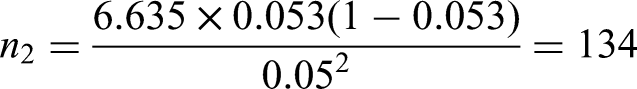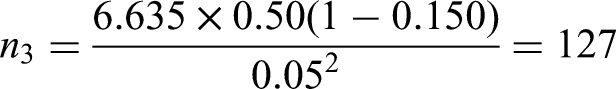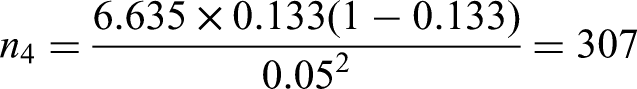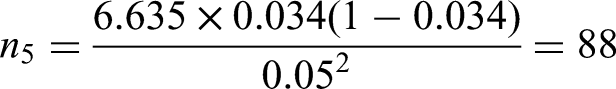Multinomial logistic regression models allow one to predict the risk of a categorical outcome with > 2 categories. When developing such a model, researchers should ensure the number of participants () is appropriate relative to the number of events () and the number of predictor parameters () for each category k. We propose three criteria to determine the minimum n required in light of existing criteria developed for binary outcomes.
Proposed criteria
The first criterion aims to minimise the model overfitting. The second aims to minimise the difference between the observed and adjusted Nagelkerke. The third criterion aims to ensure the overall risk is estimated precisely. For criterion (i), we show the sample size must be based on the anticipated Cox-snell of distinct ‘one-to-one’ logistic regression models corresponding to the sub-models of the multinomial logistic regression, rather than on the overall Cox-snell of the multinomial logistic regression.
Evaluation of criteria
We tested the performance of the proposed criteria (i) through a simulation study and found that it resulted in the desired level of overfitting. Criterion (ii) and (iii) were natural extensions from previously proposed criteria for binary outcomes and did not require evaluation through simulation.
Summary
We illustrated how to implement the sample size criteria through a worked example considering the development of a multinomial risk prediction model for tumour type when presented with an ovarian mass. Code is provided for the simulation and worked example. We will embed our proposed criteria within the pmsampsize R library and Stata modules.
Clinical prediction models (CPMs) are developed to predict expected health outcomes, such as an individual's probability that a specific disease or condition is present (diagnostic models) or that a specific event will occur in the future (prognostic models).1,2 Logistic regression is typically used for developing CPMs to predict a single binary outcome. Often though, healthcare outcomes have multiple levels (multi-category/ polytomous outcomes), such as cancer grade or Likert scales. Then, the natural extension is to use multinomial logistic regression to develop the CPM. Multinomial models have been used to develop CPMs across a range of clinical settings,3–8 and it has been argued they should be used to develop prediction models more often.9 It has also been shown that multinomial logistic regression is preferred over multiple binary logistic regression when predicting multiple correlated binary outcomes to estimate their joint probability.10
An important design aspect when developing any prediction model is ensuring the sample size of the development dataset is appropriate to minimise overfitting and ensure sufficiently precise predictions. Sample size guidance for developing prediction models with continuous, binary and time-to-event outcomes have recently been developed.11–15 However, there is a paucity of guidance for multinomial prediction models. Work by de Jong et al.,16 highlighted the importance of considering the number of events per predictor for each outcome category when choosing the sample size, and showed that multinomial logistic regression models were susceptible to overfitting when fit in development data of small-to-medium sample size. However, there is no evidence to support events per predictor rules-of-thumb for calculating the required sample size,13,17 and more tailored guidance is required.
Therefore, the aim of this study was to extend the existing sample size criteria by Riley et al.,11,12 to cater for multinomial logistic regression prediction models predicting nominal polytomous outcomes. The remainder of this paper is structured as follows: the ‘Existing sample size proposal for developing prediction models using binary logistic regression’ section briefly reviews the minimum sample size criterion outlined by Riley et al.12 for binary CPMs, and the ‘Extending the sample size formula to multinomial logistic regression’ section uses these as the foundation for our proposed sample size criteria for developing a multinomial logistic regression model. A detailed description of the simulation used to verify one of the proposed sample size criteria is given in Appendix S1. The ‘Practical recommendations for implementing criteria in practice (estimating and dealing with large required sample sizes)’ and ‘A worked example of calculating sample size criteria for a multinomial logistic regression model’ sections illustrate and advise on how to implement the proposed criteria in practice. Finally, in the ‘Discussion’ section we summarise the findings.
Existing sample size proposal for developing prediction models using binary logistic regression
We use the sample size criteria proposed by Riley et al.12 as the basis for our extensions into multinomial logistic regression. In this section, we introduce the notation required for our proposals, but refer readers to previous literature11,12 for a full discussion.
Consider a binary outcome, (), which takes the value 1 if observation i has the outcome and is 0 otherwise. CPMs for such outcomes aim to estimate the probability of conditional on a set of Q (candidate) predictor parameters, denoted as for collectively in the vector . Note that predictor parameters refer to the number of coefficients that must be estimated in the model, rather than the number of covariates included in the model. This can be modelled using logistic regression to estimate , as
where are a set of predictor coefficients (conditional log odds ratios), which are estimated through maximum likelihood estimation to give estimates .
The Riley et al. sample size criteria for developing a binary CPM based on equation (1) have three components detailed in Table 1:
Three component for deriving a minimum sample size for a binary logistic regression model.
Criterion (i): targeting the global shrinkage factor to be above a pre-defined threshold
Criterion (ii) targeting a small absolute difference in the apparent and adjusted Nagelkerke's ()18
Criterion (iii) targeting a precise estimate of overall risk (model intercepts).
We explain these in more detail and introduce the necessary notation for the rest of the manuscript in this section, and extend each criterion to multinomial logistic regression in the “Extending the sample size formula to multinomial logistic regression” section.
Overview of criterion (i): Sample size to target the global shrinkage factor to be above a pre-defined threshold
The first sample size criterion of Riley et al.12 assesses overfitting on the multiplicative scale by considering shrinkage of predictor effects. This is when regression coefficients are shrunk towards zero to help mitigate against risk of overfitting. Criterion (i) is based on a global shrinkage factor (S) that is applied to all predictor effects. Specifically, one multiplies of equation (1) by S, giving,
where is the revised intercept to ensure the mean predicted risk matches the mean observed risk.19 For the sample size criteria,12 the van Houwelingen and Le Cessie's heuristic shrinkage factor ()20 is used to estimate :
where Q is the number of candidate predictors parameters considered for inclusion prior to any variable selection, and is the likelihood ratio statistic.
Criterion (i) of Riley et al.,12 calculates a sample size n to target the shrinkage () to be above a pre-specified threshold (commonly taken as 0.9 or above, to target an overfitting of 10% or less, which leads to greater model stability21,22). For binary logistic regression, the required sample size to target a shrinkage factor , is calculated as:
where , is an optimism-adjusted estimate of the Cox-Snell23.
Overview of criterion (ii): Ensuring small absolute difference in the apparent and adjusted
The second sample size criterion of Riley et al.12 is defined to ensure a small difference () between the apparent and adjusted Nagelkerke . It requires pre-specifying a value for that one would tolerate, with small values preferred to improve model stability.21,22 For any generalised linear model, Nagelkerke is expressed as
where could be the apparent or optimism-adjusted estimate of . The maximum value of is calculated as , where is the log-likehood of the intercept-only model. It then follows that
holds if the required level of shrinkage () is such that:
For binary logistic regression, the sample size for criterion (ii) is then calculated by substituting the minimum that satisfies equation (7) into equation (4).
Overview of criterion (iii): Ensure precise estimate of overall risk
The third sample size criterion of Riley et al.12 is to ensure a precise estimate of overall risk. For binary logistic regression, an approximate 95% confidence interval for the estimate of the overall outcome proportion () can be expressed as
Therefore, to target a pre-specified absolute margin of error of , the following sample size is required:
The final (minimum) sample size is then taken to be the maximum sample size across criterion (i), (ii) and (iii).
Extending the sample size formula to multinomial logistic regression
In this section, we extend each of the criteria from the previous section to the situation where the outcome has multiple categories, and we wish to develop a CPM using multinomial logistic regression. As such, hereto we consider an outcome, (), which has K nominal categories, where for if individual i has the th outcome category. All other notation introduced in the ‘Existing sample size proposal for developing prediction models using binary logistic regression’ section remains the same.
Introducing the multinomial logistic regression model and its calibration framework
A multinomial logistic regression model24 predicting outcome, , with K nominal categories (taking the first category as the reference, without loss of generality), and Q the number of candidate predictor parameters in each sub-model k, is expressed by the following set of equations (dropping the subscript i for brevity):
which equates to the following submodels:
for , alongside the constraint .
Sub-model specific shrinkage factors can be defined for a multinomial logistic regression based on the recalibration framework outlined by Van Hoorde et al.25 Specifically, after fitting a multinomial logistic regression using maximum likelihood (equation (11)), a separate shrinkage factor is applied to all the 's for each sub-model k, and each intercept updated (to ensure calibration-in-the-large), as follows:
for , where are the maximum likelihood estimates from the multinomial logistic regression (equation (11)), and are the re-estimated intercepts.
Extending criterion (i) to multinomial logistic regression
Direct application of criterion (i) to multinomial logistic regression models
A natural starting point for criterion (i) from binary logistic regression to multinomial logistic regression, would be to again base the required sample on targeting the single heuristic shrinkage factor of van Houwelingen and Le Cessie20 to be at or above the chosen threshold. If we let
be the heuristic shrinkage factor of the multinomial model, where is like likelihood ratio test statistic for the multinomial model, is the total number of candidate predictor parameters across all sub-models, and is the apparent estimate of the Cox-Snell generalised definition of for the multinomial model, then equation (4) could again be used to define a minimum required sample size to target to be at a pre-specified threshold:
However, this approach has issues. While the van Houwelingen and Le Cessie20 heuristic shrinkage factor is an estimator of the (true) S for binary logistic regression, there is no clear relationship between and the multinomial sub-model specific shrinkage factors in equation (12). Therefore, simply ensuring that surpasses a pre-specified threshold (using equation (14)) would not necessarily result in the required level of shrinkage in each sub-model (i.e. in equation (12)). This is undesirable because it would mean that some sub-models of the multinomial model could be overfit. Therefore, we propose another approach to extend criterion (i), which targets all sub-model shrinkage factors to be at or above the desired threshold.
Alternative suggestion for criterion (i), utilising distinct logistic regression models
Equation (11) can be expressed as a set of distinct logistic regression models fitted separately, in the subset of the cohort which has either outcome k or outcome 1 (the reference). That is, the following binary logistic regression model can be fitted,
on the subset of individuals where , separately for . These are also referred to as ‘one vs one’ models.6
Crucially, a separate shrinkage factor for each distinct logistic regression model can then be calculated,26–28 such that
where are the coefficients estimated from equation (15), are the re-estimated intercepts, and is the shrinkage factor for distinct logistic regression model k, defined in the same way as S from the ‘Overview of criterion (i): Sample size to target the global shrinkage factor to be above a pre-defined threshold’ section (now referred to as ‘distinct logistic shrinkage factors’). This means that if an estimate of is available for each distinct logistic regression model k, then using the process summarised in the ‘Overview of criterion (i): Sample size to target the global shrinkage factor to be above a pre-defined threshold’ section, equation (4) can be used to derive a sample size to target a particular distinct logistic shrinkage factor for each model. Importantly, it has been shown that the sub-models of the multinomial logistic regression, and the distinct logistic regression models, are parametrically equivalent ().29 Given the asymptotically unbiased property of the maximum likelihood estimators, it follows that as , and hence as . Therefore, deriving a sample size to target the shrinkage factor of each distinct logistic regression () is above the desired value using equation (4),12 will also target the multinomial sub-model specific shrinkage factors () to be above the desired threshold. A separate sample size calculation must therefore be done for each pair of outcomes, taking the maximum to ensure criterion (i) is satisfied for each sub-model. One further point, this strategy relies on the fact that as . For the sample size criteria to work, we need close agreement between and at the value of N that satisfies the sample size criteria. We therefore report the agreement between and in the simulation carried out in the supplementary material, at a sample size N that meets said criteria.
Consideration of the choice of reference category
So far, the first outcome category has been taken as the reference. During model development, changing the reference category will not have an impact on the risk scores generated from the model. However, upon validating a multinomial CPM, the choice of reference category will change which of the multinomial sub-model specific shrinkage factors are calculated (i.e. what is estimated from equation (12)). Therefore, for the purposes of criterion (i), one must ensure that the shrinkage of every possible sub-model across all reference categories at model validation is above a certain level. Not doing so (i.e. only focusing on one outcome category), would potentially create over-confidence in the model's ability to distinguish between some of the outcome categories. In other words, one must aim to minimise optimism in all pairwise performance metrics. While calculating criterion (i) with taking each outcome category as a reference in turn may lead to high required sample sizes (e.g. see the ‘A worked example of calculating sample size criteria for a multinomial logistic regression model’ section), this would be reflective of one trying to develop a CPM to predict multinomial outcomes that require a lot of statistical power; this should be viewed as valuable information rather than a hindrance (as with any sample size calculation). We, therefore, outline our final approach in the following section, to ensure overfitting is minimised across all pairs of outcomes.
Final proposal for criterion (i)
Let be the sub-model specific shrinkage factor from the van Hoorde et al.25 framework, for sub-model k with the reference category r. The following approach will target every to be above the pre-specified threshold. The proposal is to follow the approach outlined in the ‘Alternative suggestion for criterion (i), utilising distinct logistic regression models’ section for every possible reference category, and take the maximum sample size across all reference categories. That is for each distinct logistic regression model where ,
we can obtain a corresponding shrinkage factor, , each defined in the same way as from equation (16); that is,
Define as the number of individuals with outcome category k or r that is required to target the shrinkage factor to be above some pre-defined threshold (e.g. 0.9). Here, can be calculated using the existing formula for binary logistic regression12; specifically, using equation (4). To do so, appropriate estimates of (Cox-Snell for distinct logistic regression model ), Q (the number of candidate predictor parameters considered for inclusion in each sub-model), and (the proportion of individuals from the cohort expected to have outcome ) must each be pre-specified. Suggestions of how to pre-specify are given in the ‘Practical recommendations for implementing criteria in practice (estimating and dealing with large required sample sizes)’ section. Note that because the logistic regression models for and are equivalent, we can reduce this to only consider the combinations where .
The total number of individuals required in the whole cohort () to ensure there are individuals with outcome categories , can then be calculated as , where is the proportion of individuals from the whole cohort expected to have outcome categories . Finally, the required sample size n to satisfy our criterion (i) is taken to be .
The proposed approach to implementing criterion (i) are evaluated in a simulation study with full details provided in Appendix S1.
Extending criterion (ii) to multinomial logistic regression
As noted in the ‘Overview of criterion (ii): Ensuring small absolute difference in the apparent and adjusted ’ section, the second criterion outlined by Riley et al.,12 is defined to ensure a small difference between the observed and expected proportion of variance explained () for the overall model.
As outlined in de Jong et al.,16 the apparent for a multinomial logistic regression model is defined in the same as for a binary logistic model:
where is defined as previously, and is the log-likelihood of an intercept only multinomial model. Therefore, given the definition of in equation (13), to ensure a difference of less than between the apparent and adjusted the following equation must hold:
Plugging this into equation (14), and noting that n is a monotonically increasing function of , we get the following requirement for criterion (ii) for multinomial logistic regression prediction models:
Given is similarly defined for binary logistic and multinomial logistic regression models, this criterion is directly transferable from binary logistic regression to multinomial models. In line with the criterion (the ‘Overview of criterion (ii): Ensuring small absolute difference in the apparent and adjusted ’ section) for binary logistic regression, we recommend a difference of = 0.05.11,12
We note that for criterion (ii), we focus on the fit of the overall multinomial logistic regression model, in contrast to criterion (i) where we focused on each sub-model. The reason for this is that (and hence ) is not typically expressed for the sub-models of a multinomial logistic regression. While we could ensure that criterion (ii) holds for each distinct logistic regression model, it is not clear what this would achieve with respect to the sub-models of the multinomial logistic regression model.
Extending criterion (iii) to multinomial logistic regression
As outlined in the ‘Overview of criterion (iii): Ensure precise estimate of overall risk’ section, the third criterion of Riley et al.,12 is to ensure a precise estimate of overall risk (i.e. model intercept). To mimic the approach for binary logistic regression, for a multinomial model, this can be approximated by calculating the margin of error in the outcome proportion estimates.
Let be the proportion of individuals from the entire cohort with outcome category , with the number of events in outcome category k. If is the underlying multinomial probability of outcome category k, then it can be shown through the work of Quesenberry and Hurst,30 and Goodman,31 that the simultaneous % confidence interval limits for :
can be estimated by
where denotes the Chi-squared distribution with 1 degree of freedom. Therefore, the sample size to ensure an absolute margin of error (say 0.05) at a % confidence level is
We choose to target simultaneous confidence intervals30,31 rather than pointwise confidence intervals so that every estimate of overall risk will simultaneously be within the pre-defined margin of error. This will require a larger sample size than considering pointwise confidence intervals and is therefore conservative.
It is important to mention that we are primarily interested in a precise estimate of the mean risk of each outcome category across all individuals in the population after adjustment for predictors. However, the mean risk of each outcome category across all individuals will often be similar to the outcome proportions observed from a null model with no predictors (which we are working with above). The variability of these two quantities will therefore also be similar, and we can approximate the variability of the mean risk of each outcome category in the population using the above formula.
A summary of our proposed sample size criteria for a multinomial logistic regression model is given in Table 2.
Summary of the proposed minimum sample size criteria for multinomial logistic regression CPMs
Step 1: Choose number of predictor parametersconsidered for inclusion in each sub-model at model development
Recognise that one predictor may require > 1 predictor parameter; for example, categorical predictor with > 2 categories, a continuous predictor with nonlinear terms, and interaction terms.
Step 2: Choose sensible values forand, the proportion of individuals in the cohort with outcomes in categorykand {k, r}andfor the multinomial model, andof each distinct logistic regression model
Ideally, this will be based on previously published models in the same setting with similar outcome definition, a variety of ways to estimate these from various reported statistics are given in the ‘Practical recommendations for implementing criteria in practice (estimating and dealing with large required sample sizes)’ section. If no previous information is available to estimate , use values which correspond to an in each sub-model.
Step 3: Criterion (i)
1. Calculate the minimum sample size () for each distinct logistic regression model , where, using equation (4) based on a pre-specified level of shrinkage (for example, targeting shrinkage factors of ) and an estimate of .
2. Calculate the total number of individuals needed to achieve the required number in each distinct logistic regression model , by dividing by
3. Take the minimum sample size for criterion (i) to be , which will target all the multinomial sub-model specific shrinkage factors to be greater-than-or-equal to the pre-specified threshold.
Step 4: Criterion (ii)
Use equation (21) to calculate a sample size to target the difference between the apparent and optimism adjusted to be , using estimates of and . Previously has been recommended.14
Step 5: Criterion (iii)
Use equation (23) to calculate a sample size to target the simultaneous 95% confidence intervals of the estimates of overall risk for each category to be , using estimates of . We recommend .
Step 6: Final sample size
The required minimum sample size is the maximum value from steps 3 to 5, to ensure criteria (i), (ii) and (iii) are met.
Practical recommendations for implementing criteria in practice (estimating and dealing with large required sample sizes)
To perform our proposed sample size calculations, an estimate of needs to be pre-specified. As with earlier work11,12,14 we recommend that this is based on similar, previously developed or validated prediction models. When calculating criterion (i), estimates of are required for each distinct logistic regression model , corresponding to the sub-models of the multinomial logistic model. When calculating criterion (ii) an estimate of is required for the multinomial logistic regression model. We discuss how to estimate these using the published data below. We also urge researchers to report the metrics discussed below when publishing future CPM development papers based on multinomial logistic regressions, to aid the sample size calculations of others. Finally, we make recommendations on what to do if the calculated required sample size is unfeasibly high.
Recommendations for deriving of distinct logistic regression models
To calculate criterion (i) estimates of are required. If the appropriate ‘one-vs-one’6 distinct logistic regression models have been fitted in a published study and estimates of have been reported, these can be used directly. If other pseudo- statistics have been reported (for each distinct logistic), there are a variety of ways to derive from these; see Riley et al.12 Alternatively, if the C-statistics of each distinct logistic regression model are available, then can be estimated using a simulation approach.15
However, it is highly likely that each distinct logistic regressions will not have been fitted alongside any previously developed multinomial logistic regression model. In this case, the pairwise C-statistics32 (using the conditional risk method) of the multinomial logistic regression might have been reported. Here, since these pairwise C-statistics provide an estimate of the C-statistic for each distinct logistic regression model, they can be used to estimate using the simulation approach of Riley et al.15 We illustrate this approach in our worked example in the ‘A worked example of calculating sample size criteria for a multinomial logistic regression model’ section.
If neither pseudo- or (pairwise) C-statistics are available a priori, we suggest calculating the minimum sample size following the approach suggested by Riley et al.,14 for when information on is not available. Specifically, under a conservative assumption of optimism adjusted of (15%), equation (5) can be modified to give for each distinct logistic regression model. Here, can be estimated for each model using equation (6):
where can be calculated for each distinct logistic regression model using:
where and are the number of outcome events in the category k and r, respectively. Alternatively (and equally), for each distinct logistic regression model can be calculated as:
where , is the outcome proportion in the category k relative to the reference category r. If a multinomial model had been published, then this information would be available for each distinct logistic regression model assuming the number of events in each category had been reported.
Recommendations for deriving of multinomial logistic regression models
To calculate criterion (ii) a pre-specified estimate of the overall is required. As previous, this would ideally be based on information from a previous multinomial logistic regression model. Similarly to binary logistic regression, if other pseudo- statistics have been reported, there are a variety of ways to derive from these, as outlined in Riley et al.12
Alternatively, one could again take a conservative approach to setting (corresponding to an of ). There are two ways to calculate for multinomial logistic regression. The first is to use equation (6), where can be calculated for a multinomial logistic regression as:
with denoting the number of events in outcome category k. Alternatively, can be expressed as:
where is the observed frequency of category k, as defined in the ‘Extending criterion (iii) to multinomial logistic regression’ section. This expression follows naturally from equations (6) and (27), and details of its derivation are given in Appendix S1. Some implications of basing the estimate of on the assumption are also given in Appendix S1.
Recommendations if required sample size is too high
We propose three strategies if the required sample size is completely unfeasible to recruit. It is worth reiterating, that the estimated sample size is required to build the proposed model with the specified levels of overfitting, optimism and precision. In order to reduce the sample size, the model must either be simplified, or you must be willing to accept overfitting, optimism and precision below the desired level.
Merge outcome categories. We believe the first consideration could be to merge some of the outcome categories that are driving the high sample size; looking at each pairwise criterion (i) will indicate which categories are driving the sample size. This should only be done if it makes sense from a clinical point of view, and knowing the risks of the merged categories would be of clinical interest.
A second suggestion is to reduce the number of candidate predictor parameters considered for inclusion in the model, which is inline with previous suggestions.11,12,14 However, we have only looked at scenarios where there are a fixed number of predictor parameters considered for each sub-model. This means when reducing the number of predictor parameters, one would be doing so across all sub-models. An alternative to this is to only reduce the number of predictor parameters considered for inclusion in the sub-model(s) with the highest level of overfitting. This is an enticing approach, as one does not want to reduce the number of predictor parameters in sub-models that are not suffering from overfitting. However, the implications of such an approach are not yet clear and would require further research before this could be recommended.
Reduce the acceptable level of overfitting between specific pairs of outcomes. Rather than having the acceptable level of shrinkage at 0.9, it could be reduced (e.g. to 0.8), specifically for the pair of outcomes that are driving the high sample size. This is somewhat undesirable as criterion (i) is in place to minimise overfitting. However, at least the targeted level of overfitting would be explicitly stated and the limitations of the model would therefore be well quantified.
A worked example of calculating sample size criteria for a multinomial logistic regression model
Hypothetical scenario and information available in literature
In this section, we present a worked example to illustrate how our proposed sample size criteria could be implemented in practice. The code that was used to do this is available on GitHub.33 Our example aims to calculate the minimum sample size required to develop a multinomial logistic regression prediction model to predict the tumour type (benign, borderline, stage I invasive, stage II-IV invasive, or metastatic) when presented with an ovarian mass. This is an important preoperative diagnosis, as dependent on the type of tumour, different clinical action may be taken.
Van Calster et al.8 considered the development of such a model using the International Ovarian Tumor Analysis Group34 dataset. The following information is available from that work. The model was developed on a dataset of 3506 tumours, of which 2557 were benign, 186 were borderline, 176 were stage I invasive, 467 were stage II–IV invasive, and 120 were metastatic. The following pairwise C-statistics32 were reported for every combination of outcome comparisons: 0.85 (benign vs borderline), 0.92 (benign vs stage I invasive), 0.99 (benign vs stage II–IV invasive), and 0.95 (benign vs metastatic), 0.75 (borderline vs stage I invasive), 0.95 (borderline vs stage II–IV invasive), 0.87 (borderline vs metastatic), 0.87 (stage I invasive vs stage II–IV invasive), 0.71 (stage I invasive vs metastatic) and 0.82 (stage II–IV invasive vs metastatic). These pairwise C-statistics are reported from a temporal validation and are free from in-sample optimism concerns, therefore we can use these to estimate directly with no adjustment for optimism required. There were 17 candidate predictor parameters considered for inclusion in the model including all the fractional polynomials of continuous variables (each extra fractional polynomial term counts as an additional predictor parameter). We will assume we will consider the same set of variables for inclusion before applying variable selection techniques. We now illustrate the use of the aforementioned information to perform our sample size calculation.
Steps 1 and 2: Identifying values for , , , , and
and r take the values (benign), (borderline), (stage I invasive), (stage II–IV invasive), and (metastatic).
Calculating
Assuming we consider the same set of variables for variable selection that were used in the work by Van Calster et al.,8 this would mean .
Calculating and
is the proportion of individuals that have outcome category , is the proportion of individuals that have outcome category where . To estimate these values, we use the prevalence of each outcome category as reported in the ‘Hypothetical scenario and information available in literature’ section: , , , , , , , , , , , , , , .
Calculating
We calculated using equation (28), and the prevalence of each outcome category :
Calculating
Given the of the overall multinomial model had not been reported, we based our estimate of on assuming . Using the estimate of in equation (5) gave an estimate of:
Calculating
No data was available on the in the work of Van Calster et al.,8 therefore we had to estimate them indirectly using the simulation approach of Riley et al.15 This method utilisises the pairwise C-statistics, on which data was available.8 Estimates of the pairwise outcome proportions of category k relative to the reference category r are also required to implement the simulation approach. These were estimated using the number of tumours in each category: , , , , , , , , , . The simulation approach was followed for each sub-model to give estimates of: , , , , , , , , , . Code for this simulation approach is provided at the GitHub repsitory,33 as well as more general code on how to implement this simulation approach in the original work.15
Step 3: Criterion (i)
Following the process in the ‘Final proposal for criterion (i)’ section, first, each was calculated using equation (4) and the estimates of from the ‘Calculating ’ section. Then the total number of individuals required to target a multinomial sub-model specific shrinkage factor of for sub-model , , was calculated by dividing by :
The minimum required sample size was taken as the maximum of these, and therefore , approximately 9527 benign tumours, 693 borderline, 656 stage I invasive, 1740 stage II–IV invasive and 447 metastatic (assuming same outcome proportions as in Van Calster et al.8).
Step 4: Criterion (ii)
Criterion (ii) aims to calculate a sample size required to ensure a difference of 0.05 between the apparent and adjusted , which holds if equation (21) is satisfied (‘Extending criterion (ii) to multinomial logistic regression’ section). Plugging in the estimates of and into equation (21) gives:
So 1477 individuals are required to meet criterion (ii), approximately 1077 benign tumours, 78 borderline, 74 stage I invasive, 197 stage II–IV invasive, and 51 metastatic.
Step 5: Criterion (iii)
Criterion (iii) is to ensure a precise estimate of risk in the overall population. Following the steps outlined in the ‘Extending criterion (iii) to multinomial logistic regression’ section, for a 95% confidence interval (, using the estimated values for with and an absolute margin of error of , then the required sample size for each outcome is (equation (23)):
Leaving the sample size for criterion (iii) to be approximately 382 benign tumours, 28 borderline, 26 stage I invasive, 70 stage II–IV invasive, and 18 metastatic.
Step 6: Final sample size
The final sample size is taken as the maximum of the sample sizes required to satisfy each criterion (i)–(iii), which was 13,063 (i), 1476 (ii) and 524 (iii) respectively. Hence, the minimum required sample size would be , approximately 9527 benign tumours, 693 borderline, 656 stage I invasive, 1740 stage II–IV invasive and 447 metastatic (assuming same outcome proportions as in Van Calster et al.8). For contrast, using the definition of events per variable (EPVm) from De Jong et al.,16 an EPVm of would result in a sample size of , and an EPVm of would result in a sample size of .
Suggestions for dealing with high sample size
The required sample size is high and is being driven by outcome categories 3 (stage I invasive) and 5 (metastatic). If the proposed model was developed with a sample size smaller than 13,063, the level of overfitting between these two outcomes would not be targeted at the pre-specified level of . Following the suggestions in the ‘Recommendations if required sample size is too high’ section, the first solution would be to merge categories 3 and 4 (stage I invasive with stage II–IV invasive). With such a combination the model would retain clinical interpretation. If it was essential to keep these outcome categories separate, fewer predictor parameters could be considered instead. The value of incorporates fractional polynomial terms and interactions which could be removed, or one of the predictors could be removed altogether. A final possible option is to reduce the targeted level of overfitting for pair . Plugging a value of into the ‘Step 3: Criterion (i)’ section would give , and the final sample size would be driven by . While this is slightly undesirable, the targeted level of overfitting for all other outcome pairs would still be at , and one could report that overfitting may be more likely for outcome pair .
Discussion
We have presented sample size criteria for the development of prediction models for multiple-category outcomes using multinomial logistic regression. This builds upon recent developments in this space for continuous, binary and time-to-event outcomes.11,12 Criterion (ii) and (iii) both had a natural extension into a multinomial framework. Criterion (i) did not and therefore we tested the properties of our proposed approach in a simulation (Appendix S1), finding that the sample size resulted in the desired level of overfitting. Our approach to criterion (i) may lead to high sample sizes if some of the outcome categories are rare, or have a low pairwise , however this is necessary if you want to ensure overfitting is minimised in prediction between all pairs of outcome categories. If the required sample size cannot be achieved, we have made some recommendations on how the model could be adjusted to lower the number required.
The biggest practical challenge with implementing these recommendations in practice is the availability of information on past , given multinomial logistic regression CPMs are not (yet) very common. The proposed criteria will be most effective in achieving their aim when an accurate estimate of the is available for both the multinomial model () and each distinct logistic regression model (). We have given advice on how to pre-specify these, but also want to urge researchers to report the relevant information when developing a multinomial logistic regression to enable this process. Currently, there is no way to estimate for the multinomial model from metrics which are not pseudo- (for example there is no way to estimate it from the PDI35), meaning reporting is very important. Estimates of can be obtained from a variety of metrics from previously published ‘one-to-one’ distinct logistic regression models.12,15 However, when fitting a multinomial logistic regression, it is important to (at least) report the pairwise C-statistics using the conditional risk method32 when fitting a multinomial logistic regression model. This is an informative performance metric that should be reported anyway, and it will allow future researchers to estimate (as was done in our worked example). In theory, the conditional risk method could also be used to report directly, although we are not aware of any instances of people doing this is in the literature.
There are five important areas of future work. First, to establish a relationship between the PDI,35 a commonly reported statistic for discrimination of a multinomial logistic regression model, and the distribution of the linear predictors of the sub-models. This relationship has been established for the C-statistic and logistic regression36–39 allowing to be estimated when only the C-statistic is available.15 Secondly, the simulation (Appendix S1) found that there was poor agreement between the heuristic shrinkage factors and the sub-model-specific shrinkage factors when covariate effects were large and sample sizes were small (Table S3). This resulted in not having the desired level of shrinkage in the developed models. This finding extends to binary logistic regression, but it is not clear whether similar results would be found for continuous or time-to-event outcomes. Given the proposed criterion (i) for every outcome type11,12 targets the heuristic shrinkage factor to be at the chosen threshold, it's important to establish in which scenarios where this may be a poor predictor of the sub-model specific shrinkage factors. Third, to extend the criteria of van Smeden et al.,13 to multinomial logistic regression. Their work acts as a fourth criterion,14 to target the mean absolute prediction error (MAPE) of a binary logistic regression model to be below a pre-specified threshold. This helps ensure precise predictions across the spectrum of predicted values. The formula is derived from a detailed simulation, in which a variety of binary logistic regression models are simulated and the MAPE assessed when the model is applied to new individuals from the target population. The first step to extending this criteria to multinomial logistic regression would be to define an extension of the MAPE for multinomial outcomes, which would then need to be followed by a similar simulation as the one used to derive the formula for binary logistic regression. The fourth is to develop sample size formula for the prediction of ordinal outcomes. The sample size formula proposed in this study are for a multinomial logistic regression, which can be fit to either nominal or ordinal outcomes. However if wanting to predict an ordinal outcome, an ordinal model could be fitted which would likely require a smaller sample size since they require less parameters to be estimated (for example if a proportional odds assumption is made). While the sample size criteria proposed in this paper would be valid for the prediction of an ordinal outcome using multinomial logistic regression, it is a conservative estimate. Future work could develop less conservative sample size criteria developed specifically for ordinal regression modelling techniques. In clinical trials for ordinal outcomes the proportional odds assumption has been shown to impact the required sample size,40 and this would be no different for CPMs. The fifth is to explore the idea of reducing the number of candidate predictor parameters in specific sub-models of the multinomial logistic regression as a way to reduce the required sample size, as discussed in the ‘Recommendations if required sample size is too high’ section.
These sample size criteria will be embedded into existing software (pmsampsize in R41 and Stata42) so they can be widely implemented in practice.
Supplemental Material
sj-docx-1-smm-10.1177_09622802231151220 - Supplemental material for Minimum sample size for developing a multivariable prediction model using multinomial logistic regression
Supplemental material, sj-docx-1-smm-10.1177_09622802231151220 for Minimum sample size for developing a multivariable prediction model using multinomial logistic regression by Alexander Pate, Richard D Riley, Gary S Collins, Maarten van Smeden, Ben Van Calster, Joie Ensor and Glen P Martin in Statistical Methods in Medical Research
Footnotes
Acknowledgements
The authors wish to thank anonymous reviewers and the Editors for their constructive comments which helped improve the article upon revision.
Author contributions
AP, GM and RR conceived and designed the study. AP conducted the analysis and interpreted the results in discussion with GM and RR. AP wrote the initial draft of the manuscript with support from GM, which was then critically reviewed for important intellectual content by GM, RR, GSC, MVS, JE and BVC. JE will embed the methods into R and Stata software. All authors have approved the final version of the paper.
Availability of data and materials
Full reusable code for running the simulation and worked example are provided at the referenced GitHub repoistory.33
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by funding from the MRC-NIHR Methodology Research Programme [grant number: MR/T025085/1]. GSC was supported by the NIHR Biomedical Research Centre, Oxford, and Cancer Research UK (programme grant: C49297/A27294).
ORCID iDs
Alexander Pate
Gary S Collins
Ben Van Calster
Joie Ensor
Glen P Martin
Supplemental material
Supplemental material for this article is available online.
Appendix
References
1.
CollinsGSReitsmaJBAltmanDG, et al.Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): the TRIPOD statement. Ann Intern Med2015; 162: 55–63.
2.
van SmedenMReitsmaJBRileyRD, et al.Clinical prediction models: diagnosis versus prognosis. J Clin Epidemiol2021; 132: 142–145.
3.
WijesinhaABeggCBFunkensteinHH, et al.Methodology for the differential diagnosis of a complex data set. Med Decis Mak 1983; 3: 133–154.
4.
SchuitEKweeAWesterhuisM, et al.A clinical prediction model to assess the risk of operative delivery. BJOG An Int J Obstet Gynaecol2012; 119: 915–923.
5.
BarnesDEMehtaKMBoscardinWJ, et al.Prediction of recovery, dependence or death in elders who become disabled during hospitalization. J Gen Intern Med2013; 28: 261–268.
6.
Van CalsterBValentinLVan HolsbekeC, et al.Polytomous diagnosis of ovarian tumors as benign, borderline, primary invasive or metastatic: development and validation of standard and kernel-based risk prediction models. BMC Med Res Methodol 2010; 10: 96.
7.
RoukemaJVan LeonhoutRBSteyerbergEW, et al.Polytomous regression did not outperform dichotomous logistic regression in diagnosing serious bacterial infections in febrile children. J Clin Epidemiol2008; 61: 135–141.
8.
Van CalsterBVan HoordeKValentinL, et al.Evaluating the risk of ovarian cancer before surgery using the ADNEX model to differentiate between benign, borderline, early and advanced stage invasive, and secondary metastatic tumours: prospective multicentre diagnostic study. Br Med J2014; 349: 1–14.
9.
BiesheuvelCJVergouweYSteyerbergEW, et al.Polytomous logistic regression analysis could be applied more often in diagnostic research. J Clin Epidemiol2008; 61: 125–134.
10.
MartinGPRileyRDSperrinM, et al.Clinical prediction models to predict the risk of multiple binary outcomes : a comparison of approaches. Stat Med 2020; 40: 498–517.
11.
RileyRDSnellKIEEnsorJ, et al.Minimum sample size for developing a multivariable prediction model: part I – continuous outcomes. Stat Med2019; 38: 1262–1275.
12.
RileyRDSnellKIEEnsorJ, et al.Minimum sample size for developing a multivariable prediction model: part II - binary and time-to-event outcomes. Stat Med2019; 38: 1276–1296.
13.
SmedenMVMoonsKGMGrootJAHD, et al.Sample size for binary logistic prediction models: beyond events per variable criteria. Stat Methods Med Res2019; 28: 2455–2474.
14.
RileyRDEnsorJSnellKIE. Calculating the sample size required for developing a clinical prediction model. Br Med J2020; 368: m441.
15.
RileyRDVan CalsterBCollinsGS. A note on estimating the Cox-Snell R(2) from a reported C statistic (AUROC) to inform sample size calculations for developing a prediction model with a binary outcome. Stat Med2021; 40: 859–864.
16.
De JongVMTEijkemansMJCVan CalsterB, et al.Sample size considerations and predictive performance of multinomial logistic prediction models. Stat Med2019; 38: 1601–1619.
17.
Van SmedenMDe GrootJAHMoonsKGM, et al.No rationale for 1 variable per 10 events criterion for binary logistic regression analysis. BMC Med Res Methodol2016; 16: 1–12.
18.
NagelkerkeNJD. A note on a general definition of the coefficient of determination. Biometrika1991; 78: 691–692.
Van HouwelingenJLe CessieS. Predictive value of statistical models. Stat Med1990; 9: 1303–1325.
21.
CalsterBVSmedenMVCockBD, et al.Regression shrinkage methods for clinical prediction models do not guarantee improved performance: simulation study. Stat Methods Med Res2020; 29: 3166–3178.
22.
RileyRDSnellKIEMartinGP, et al.Penalization and shrinkage methods produced unreliable clinical prediction models especially when sample size was small. J Clin Epidemiol2021; 132: 88–96.
23.
CoxDRSnellEJ. Analysis of binary data. 2 ed. London: Chapman and Hall/CRC, 1989.
24.
AgrestiA. Categorical data analysis. USA: Wiley Series, 2002.
25.
HoordeKVVergouweYTimmermanD, et al.Assessing calibration of multinomial risk prediction models. Stat Med2014; 33: 2585–2596.
26.
SteyerbergEWVickersAJCookNR, et al.Assessing the performance of prediction models: a framework for traditional and novel measures. Epidemiology2010; 21: 128–138.
27.
SteyerbergEW. Clinical prediction models - a practical approach to development, validation, and updating(2nd ed). Cham: Springer, 2019.
28.
SteyerbergEWVergouweY. Towards better clinical prediction models: seven steps for development and an ABCD for validation. Eur Heart J2014; 35: 1925–1931.
29.
BeggCBGrayR. Calculation of polychotomous logistic regression parameters using individualized regressions. Biometrika1984; 71: 11–18.
30.
QuesenberryCPHurstDC. Large sample simultaneous confidence intervals for multinomial proportions. Technometrics1964; 6: 191–195.
31.
GoodmanLA. On simultaneous confidence intervals for multinomial proportions. Technometrics1965; 7: 247–254.
32.
Van CalsterBVergouweYLoomanCWN, et al.Assessing the discriminative ability of risk models for more than two outcome categories. Eur J Epidemiol2012; 27: 761–770.
TimmermanDTestaACBourneT, et al. Logistic regression model to distinguish between the benign and malignant adnexal mass before surgery: a multicenter study by the International Ovarian Tumor Analysis Group. J Clin2005; 23: 8794–8801. Epub ahead of print 2005. DOI: 10.1200/JCO.2005.01.7632.
35.
Van CalsterBVan BelleVVergouweY, et al.Extending the c-statistic to nominal polytomous outcomes: the Polytomous Discrimination Index. Stat Med2012; 31: 2610–2626.
36.
AustinPCSteyerbergEW. Interpreting the concordance statistic of a logistic regression model: relation to the variance and odds ratio of a continuous explanatory variable. BMC Med Res Methodol2012; 12. Epub ahead of print 2012. DOI: 10.1186/1471-2288-12-82.
37.
PencinaMJAgostinoRBDMassaroJM. Understanding increments in model performance metrics. Lifetime Data Anal2013; 19: 202–218.
38.
SuJQLiuJS. Linear combinations of multiple diagnostic markers linear combinations of multiple diagnostic markers. J Am Stat Assoc1993; 88: 1350–1355.
39.
ZelenMSeveroNC. Probability function. Washington, DC: National Bureau of Standards Applied Mathematics, 1964.
40.
WhiteheadJ. Sampe size calculations for ordered categorical data. Stat Med1993; 12: 2257–2271.
EnsorJ. PMSAMPSIZE: stata module to calculate the minimum sample size required for deveoping a multivariable prediction model.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.