
Abstract
Recent minimum sample size formula (Riley et al.) for developing clinical prediction models help ensure that development datasets are of sufficient size to minimise overfitting. While these criteria are known to avoid excessive overfitting on average, the extent of variability in overfitting at recommended sample sizes is unknown. We investigated this through a simulation study and empirical example to develop logistic regression clinical prediction models using unpenalised maximum likelihood estimation, and various post-estimation shrinkage or penalisation methods. While the mean calibration slope was close to the ideal value of one for all methods, penalisation further reduced the level of overfitting, on average, compared to unpenalised methods. This came at the cost of higher variability in predictive performance for penalisation methods in external data. We recommend that penalisation methods are used in data that meet, or surpass, minimum sample size requirements to further mitigate overfitting, and that the variability in predictive performance and any tuning parameters should always be examined as part of the model development process, since this provides additional information over average (optimism-adjusted) performance alone. Lower variability would give reassurance that the developed clinical prediction model will perform well in new individuals from the same population as was used for model development.
Background
Clinical prediction models (CPMs) aim to predict the risk of an event-of-interest occurring given an individual's set of predictor variables.1,2 CPMs have many practical uses in healthcare such as aiding in treatment planning, underpinning decision-support, or facilitating audit and benchmarking. To support such uses, the process of CPM development requires careful consideration, and has correspondingly received large attention in both the statistical and medical literature.3–6
A primary concern in prediction modelling is to ensure that the developed CPM remains accurate in new (unseen) observations. However, predictive accuracy of a CPM often drops between development and validation.7,8 Using data that have insufficient observations (i.e. small sample size) for CPM development often contributes to this reduction in predictive performance, and leads to models that are overfitted. Overfitting results in predicted risks that, on average, are too extreme in new individuals and thereby the model may not perform well at the time of model validation or implementation.
Sample size justification for CPM development studies was historically based on having an events per predictor parameter (EPP, also known as events per variable) of 10 or more.9–11 This rule-of-thumb has been shown to be overly simplistic and has weak evidence to support its use, 12 with formal sample size formula recently proposed by Riley et al.13–15 Appealingly, the criteria outlined in these sample size formulae aim to reduce the potential for a developed CPM to be overfitted to the development data set.
Correspondingly, the use of penalisation methods, which reduce variance but introduce bias into parameter estimation through shrinking parameter estimates towards zero, have previously been recommended to develop CPMs in smaller sample sizes.11,16–18 Such techniques include LASSO regression, ridge regression and Firth's correction.19–21 Compared with unpenalised estimation methods (such as traditional maximum likelihood estimation, MLE), several studies have found that predictive performance can be improved through penalisation methods, especially when the EPP is small.12,16,17,22 Nevertheless, such methods do not themselves justify developing CPMs in data of insufficient size. 23 Recent work by Van Calster et al. 24 and Riley et al. 23 found that while parameter shrinkage improved prediction accuracy on average, the between-sample variability of predictive performance metrics was high, especially in small EPP. Additionally, these studies found a negative correlation between the estimated shrinkage and the ‘true’ shrinkage, meaning that the level of penalisation was lower in scenarios where it was most needed; this finding supported earlier work by van Houwelingen. 25
However, it remains uncertain whether the previously observed between-sample variability of predictive performance metrics persists in data that meet, or surpass, the recently proposed Riley et al. criteria.13–15 If such variability does persist, then examining this as part of the model development processes would be crucial; we aimed to investigate this concept here. In particular, it seems prudent to use penalisation methods to derive a CPM, but only in data that meet minimum sample size requirements.13–15 Theoretically, such a combined approach would expose the CPM to the benefits of penalisation, while avoiding development on insufficient data. For example, penalisation methods such as LASSO can aid in variable selection, 19 while penalisation through a Bayesian perspective 26 would allow the modeller to incorporate prior knowledge directly into the CPM derivation (e.g. from expert opinion or existing CPMs). 27
Therefore, the aim of this study is two-fold. First, to examine the characteristics of CPM performance metrics, upon validation, of models developed using a range of penalisation methods compared with unpenalised maximum likelihood estimation, in derivation data that satisfy formal sample size criteria. Second, to explore the importance of quantifying variability in predictive performance as part of the model development processes, for example through bootstrap internal validation. We investigate these aims through a simulation study and real-world clinical example of critical care data. Note, we are interested in variability in overall performance, rather than stability of individual risks as studied recently. 28
The remainder of the paper is structured as follows: section ‘Shrinkage and penalisation methods to developing prediction models’ describes the common approaches to develop CPMs using penalisation; section ‘Riley et al. sample size criteria’ gives a brief overview of the Riley et al. sample size criteria; section ‘Simulation study’ describes the methods and results of our simulation study; while section ‘Empirical study’ reports the results from the real-world critical care example. Finally, concluding remarks are given in section the ‘Discussion’ section.
Shrinkage and penalisation methods to developing prediction models
Throughout, we consider the development of a CPM to estimate the probability of a binary outcome, Y, conditional on a set of P predictors, which we denote
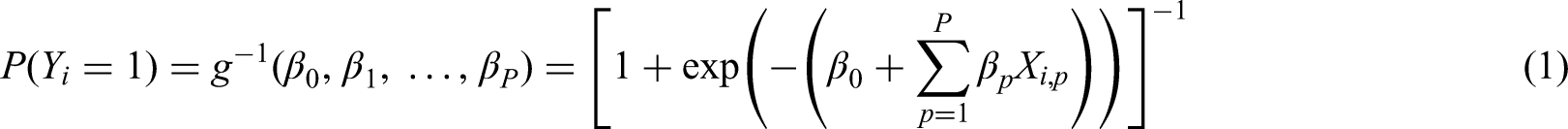
Unpenalised maximum likelihood estimation (MLE)
This is the standard unpenalised approach to developing a logistic regression CPM, whereby the regression coefficients are estimated by maximising the following log-likelihood (LL) function:
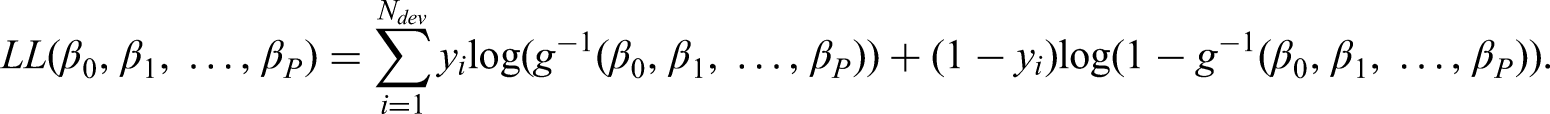
Closed-form uniform shrinkage
This approach applies a post-estimation uniform shrinkage factor to all the coefficients estimated using the unpenalised MLE approach, where the shrinkage factor is calculated based on the likelihood ratio statistic.13,14,29 The shrinkage factor (S) is calculated as
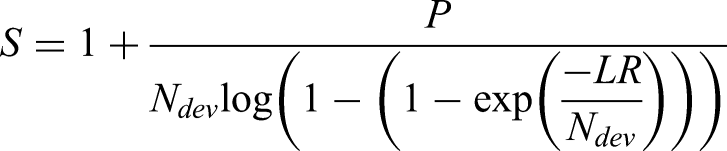
Uniform bootstrap shrinkage
This is similar to the closed-form uniform shrinkage, except that the shrinkage factor is calculated through the following steps: (i) take bootstrap samples from the development data, (ii) fit a (MLE) model in this bootstrap sample replicating all modelling steps, (iii) calculate the linear predictor of this model on each observation in the original development data and (iv) fit a logistic model to the observed outcomes with the linear predictor from step (iii) as the only covariate. In this study, we repeated this process 500 times and took the shrinkage factor to be the average of the corresponding coefficient from step (iv). In essence, this shrinkage factor is an estimate of the in-sample optimism of the calibration slope, as calculated using a bootstrap internal validation.6,29
Firth's correction
Here, we implement bias-reduced penalised logistic regression, as proposed by Firth.
21
This approach is equivalent to penalising the LL by a Jeffrey's prior of a logistic regression model. In particular, if we denote
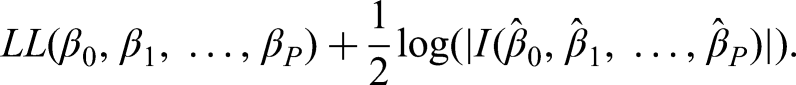
Penalised logistic regression using LASSO
LASSO penalises the (log-)likelihood of the logistic regression model, such that the coefficients are shrunk towards zero and some coefficients might be shrunk to exactly zero (thereby performing variable selection).
19
Explicitly, LASSO maximises a penalised LL of the form:
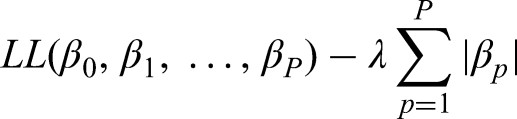
Penalised logistic regression using ridge
This approach is similar to LASSO, except that coefficients are shrunk towards zero but none will be exactly zero.
20
Explicitly we maximise the penalized LL
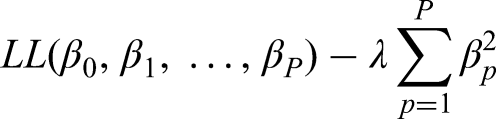
Riley et al. sample size criteria
In this section, we give an overview of the sample size criteria proposed by Riley et al.13–15 However, we refer readers to previous publications13–15 for a detailed explanation and example illustrations for how to calculate these criteria.
The Riley et al. criteria
13
for calculating minimum sample sizes for logistic regression CPMs are based on satisfying all of the following criteria: (i) a uniform shrinkage factor of >0.9, (ii) ensuring a small absolute difference in the apparent and adjusted Cox-Snell R-squared,
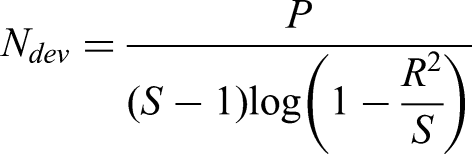
Mathematical details for criteria (ii) and (iii) are given in Riley et al. 13 The minimum required sample size is then taken as the maximum required to meet criteria (i)–(iii). In this study, we used the ‘pmsampsize’ 31 R package to estimate the minimum required sample size.
Simulation study
We now describe the design and results of our simulation study, which aimed to investigate the predictive performance of CPMs developed using MLE, post-estimation shrinkage (closed-form uniform shrinkage and uniform bootstrap shrinkage) and penalised regression (Firth's, LASSO and ridge) approaches (section ‘Shrinkage and penalisation methods to developing prediction models’), on data that meet minimum sample size requirements.13–15 We designed the simulation following best practice guidelines. 32
Data-generating mechanism and simulation scenarios
Throughout all simulations, we begin by generating a large (N = 1,000,000 observations) population-level dataset, which aims to mimic an overarching population that one subsequently obtains random samples from to develop a CPM. We generated
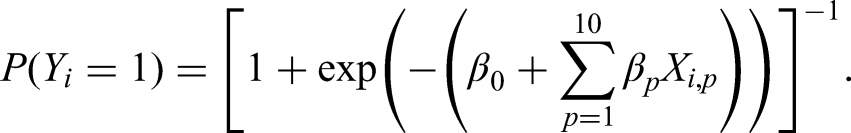
Following generation of this population-level data, we randomly sampled (without replacement) a development cohort of size
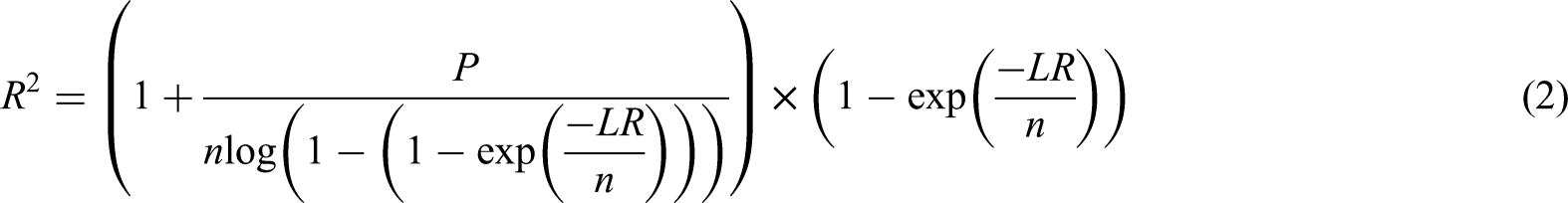
Secondly, given that in practice such information might not be available a priori, we also considered the recommendation of Riley et al.
15
to calculate

The above data-generating processes were implemented across all combinations of
Overview of each simulation scenario.

Methods considered
Within each sampled development cohort (of size
Performance measures
We quantified the predictive performance of each analysis model using calibration (agreement between the observed and expected outcome proportions, across the full risk range) and discrimination (ability of the model to separate those who have the outcome from those that do not have the outcome) within an independent validation set. This validation set was formed in each simulation iteration by including all observations from each simulated population-level dataset that were not sampled into the development cohort. This represents extremely large-sample independent validation (i.e. N = 1,000,000 minus
In each of the samples from the validation set, calibration was quantified with the calibration-in-the-large and calibration slope. Calibration slope was estimated by fitting a logistic regression model to the observed outcomes in the validation data with the linear predictor of each analytic method as the only covariate, alongside an intercept. Calibration-in-the-large was obtained by the intercept estimate when fitting the same model but with the slope fixed at unity. A calibration-in-the-large less than 0 implies the model overestimates the overall outcome proportion in the validation data, while a calibration slope less than 1 implies model overfitting. Discrimination was quantified using the area under the receiver operating characteristic curve (AUC). Additionally, we estimated the Cox-Snell
Alongside investigating the distribution of the estimated calibration-in-the-large, calibration slope, AUC, Cox-Snell
Software
R version 4.0.2 was used for all simulations,
33
along with the packages ‘tidyverse’,
34
‘pROC’,
35
‘glmnet’,
36
‘logistf’
37
and ‘pmsampsize’.
31
The ‘glmnet’ package was used to fit the LASSO and Ridge models (using the default cross-validation selection procedure for
Simulation results
Minimum required sample size
The minimum required sample sizes across simulation iterations are summarised in Supplemental Table 1, for all simulation scenarios (i.e. Table 1). For each of the simulation scenarios where the sample size calculation was based on equation (3) – that is, based on 15% of maximum Cox-Snell
Supplemental Figure 1 shows the scatter of the Cox-Snell
Average performance upon validation
Table 2 shows the median (taken across the 500 iterations for each scenario) of the calibration slope, where we find that the median calibration slopes were close to 1 for all methods, but in absolute terms the median calibration slope was closer to 1 for uniform closed-form shrinkage, uniform bootstrap shrinkage, Firths correction, LASSO, and Ridge compared with unpenalised MLE. As expected, the calibration slope of the unpenalised MLE was >0.9, on average, for the scenarios where the pre-specified Cox-Snell
The median (2.5% and 97.5% quantile) of the calibration slope for each analytical method, upon validation, across the 500 iterations for each simulation scenario. See Table 1 for the numbering of each simulation scenario.

The median (across the 500 iterations for each simulation scenario) of the AUC and Cox-Snell
Distribution of estimated performance upon validation
Figure 1 depicts the distribution of the calibration slope, upon validation, across iterations. The median interquartile range for calibration slope (across iterations and methods) was approximately 0.12 (with this varying slightly by simulation scenario). The degree of variability in calibration slope (across all methods) was slightly higher in simulation scenarios where the model development sample size calculation was based on the population
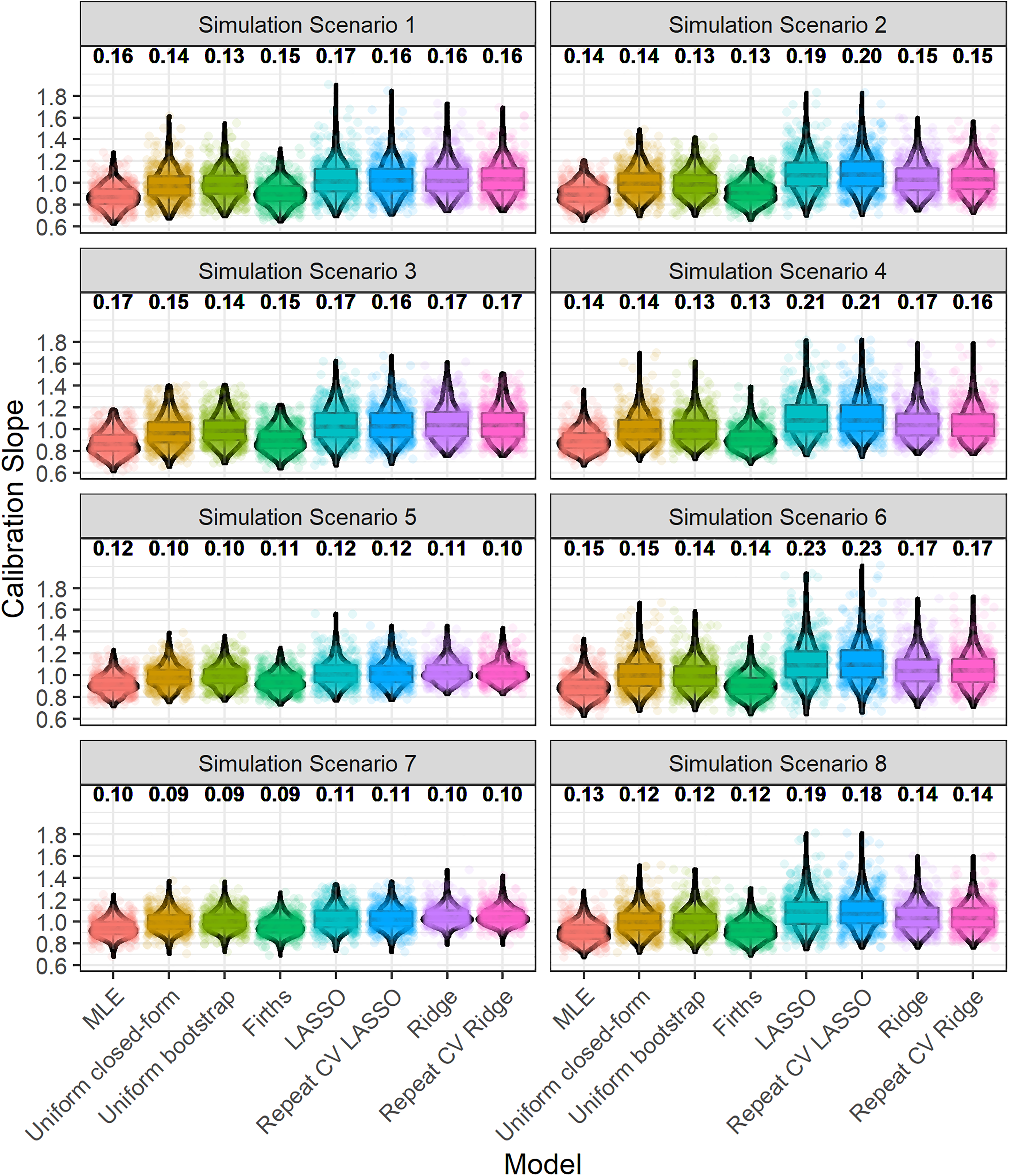
Boxplot and violin plot showing the distribution, across iterations, of the calibration slope, upon validation. The numbers above each plot show the root-mean-square deviation of the calibration slope. Random jitter has been applied to each point to aid visual clarity. The numbering of simulation scenarios is given in Table 1.
As discussed above, the penalisation/shrinkage methods further mitigate the risks of overfitting on average (e.g. Table 2) compared with maximum likelihood. However, by also examining variability in predictive performance, we see from Figure 1 that this comes at the cost of slightly higher variability in predictive performance, upon validation, for LASSO and Ridge compared with maximum likelihood. Specifically, the root-mean-square deviation in calibration slope for the LASSO or Ridge regression was usually slightly higher than (or in some situations equal to) that of maximum likelihood. This is due to the added uncertainty in the underlying shrinkage factor/penalisation estimate (Figure 2). Interestingly, the root-mean-square deviation (variability) in calibration slope for uniform bootstrap shrinkage was consistently lower than that for maximum likelihood, likely because the variability in the estimated shrinkage factor of this method was generally quite low (Figure 2).
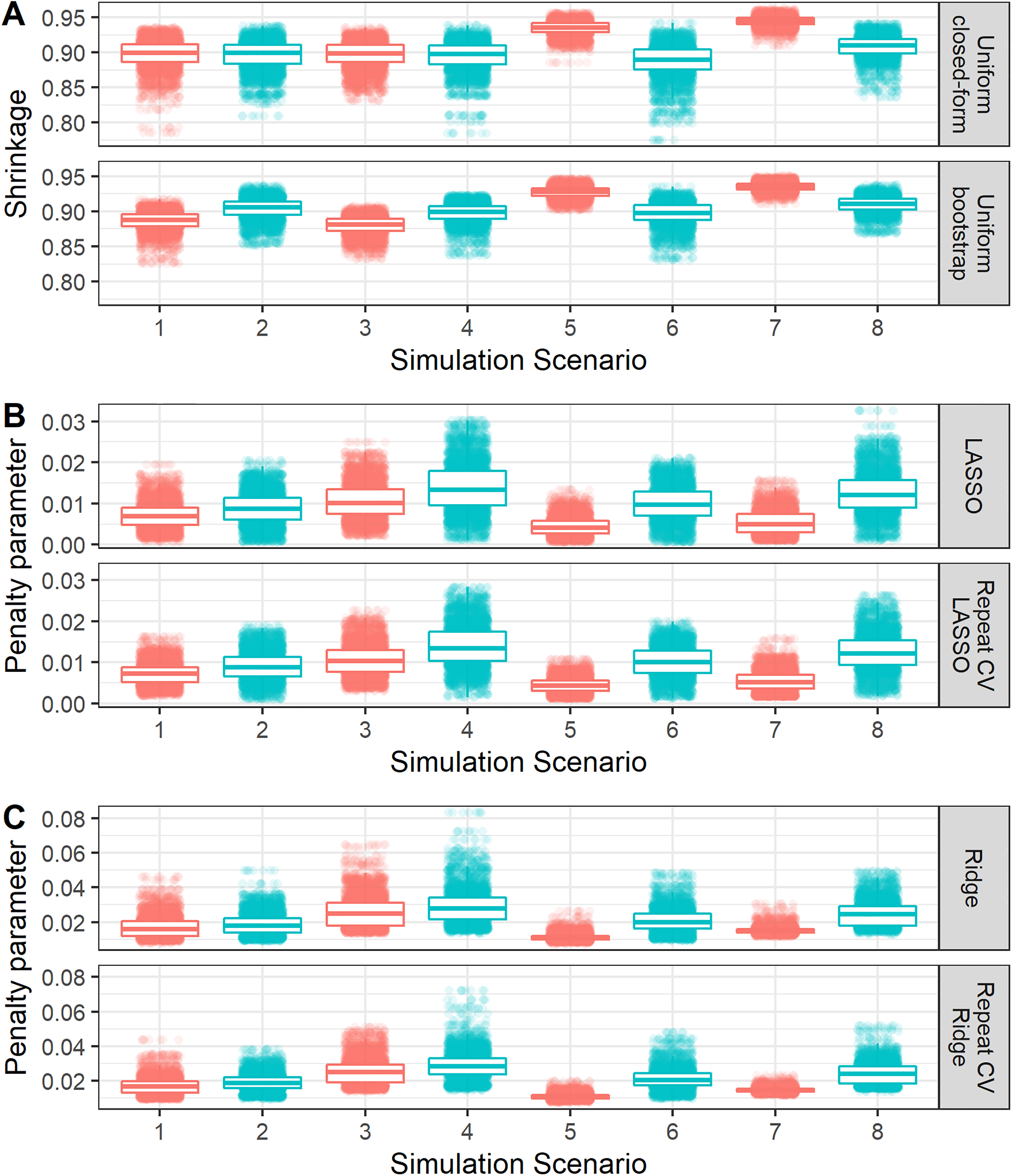
Boxplot and violin plot showing the distribution, across iterations of each simulation scenario, of the shrinkage factor or penalisation terms. Random jitter has been applied to each point to aid visual clarity. The numbering of simulation scenarios is given in Table 1. The colouring on the plot differentiates simulation scenarios where all 10 variables where true predictors (red) or where only 5 of them where true predictors (blue).
These results show the added information that is supplied by exploring variability in performance (and tuning parameters) over just examining average performance. The results suggest that if there is larger uncertainty in the estimates of shrinkage factors or penalisation terms then this corresponds to a higher chance that the model will be miscalibrated, upon independent validation. Therefore, even in data that meet minimum sample size requirements, in practice it will be important to examine the potential uncertainty of penalisation, and therefore predictive performance when developing a CPM (e.g. using bootstrapping; see section ‘Empirical study’). Presenting boxplots as illustrated in this paper would be an informative way of reporting such variability.
Similarly, there was some variability in other performance metrics (calibration-in-the-large, AUC, Cox-Snell
Comparisons in variability of shrinkage and penalisation estimates across methods
As discussed above, investigating the variability across iterations (or, in practice, across bootstrap samples – see section ‘Empirical study’) in the estimates of shrinkage factors or penalisation terms (tuning parameters) is important. Figure 2 shows how the variability compares between methods to conduct each type of shrinkage/penalisation method. Specifically, Figure 2, Panel A shows that the uniform bootstrap method generally resulted in lower variability in the shrinkage factor than the uniform closed-form approach. Figure 2, Panel B compares approaches to undertaking LASSO regression, where the use of repeated 10-fold cross-validation reduced the variability in the penalisation term
Across all methods, variability was generally lower when all 10 predictor terms ‘truly’ associated with the outcome or when the sample size calculation was based on maximum
Empirical study
In this section, we apply the estimation methods to a real-world critical care example and use bootstrap internal validation to illustrate how one should obtain an indication of variability (uncertainty) in predictive performance in practice, by repeating each modelling step including estimation of the tuning parameters (where relevant).
Data source, study population and outcomes
De-identified critical care data were obtained from the Medical Information Mart for Intensive Care III (MIMIC-III) database. 38 MIMIC-III contains information from the Beth Israel Deaconess Medical Center in Boston, Massachusetts, between 2001 and 2012. For this case study, we considered the development of a prediction model for in-hospital mortality after admission to an intensive care unit (ICU). Note the aim was not to develop a CPM for clinical use in this setting, but to illustrate the estimation methods on a real-world dataset, and how one should obtain an indication of variability (uncertainty) in predictive performance in practice.
We defined an ICU admission to be any admission that lasted at least 24 h, and we took the end of day 1 on ICU as the time point at which a prediction is made. We extracted a cohort of patients over 18 years of age, who were admitted to ICU for any cause for at least 24 h. We excluded any ICU admission of less than 24 h. For simplicity, we only included a patient's first ICU admission and first recorded hospitalisation within MIMIC-III.
For the included patients, we extracted information on their age, gender, ethnicity, type of admission, and mean of the lab tests recorded over the first 24 h. Lab tests included measures of the following: bicarbonate, creatinine, chloride, haemoglobin, platelet count, potassium, partial thromboplastin time, international normalized ratio, prothrombin time, blood urea nitrogen and white blood count.
The SQL code to extract the data from the MIMIC-III database is available at https://github.com/GlenMartin31/Penalised-CPMs-In-Minimum-Sample-Sizes.
Model development and bootstrap internal validation
We developed CPMs for the binary outcome of in-hospital mortality using each of the methods outlined in section ‘Shrinkage and penalisation methods to developing prediction models’. We did not consider predictor selection (with the exception of LASSO, where this is implicit in the method), and all of the models included the following candidate predictors: age (categories of 10-year increments available in MIMIC-III), sex (male vs female), admission type (elective vs non-elective), ethnicity (categorical), and the 24h mean of each of the aforementioned lab tests (all continuous). We considered a total of 23 predictor parameter (accounting for multiple factor levels, where applicable). We undertook a complete case analysis to develop the models; while in practice one should consider alternative approaches to handle missing data, we consider complete case here for illustrative simplicity and computational ease.
We calculated the minimum required sample size to develop a logistic regression model for in-hospital mortality, using the Riley et al. criteria.
13
The pre-specification of the Cox-Snell
We undertook two analyses: first, developing each of the CPMs in the whole MIMIC-III cohort; second, developing each of the CPMs in a random subset of the MIMIC-III cohort with size equal to the minimum required sample size according to the Riley et al. criteria. 13 Here, the second analysis (hereto called the sub-analysis) is mimicking a situation where the available data exactly matches minimum requirements. In both cases, we applied bootstrap internal validation to assess adjusted calibration and discrimination. Specifically, we took 100 bootstrap samples (with replacement) of the development dataset (either the full cohort or the sub-analysis), applied the exact same modelling steps in each bootstrap sample, and calculated the optimism for each performance statistic: that is, the difference between the predictive performance of the models within each bootstrap sample and the predictive performance of each bootstrap CPM applied to the original development data. We then subtracted each of the 100 optimism estimates from the apparent performance (performance of the models developed on MIMIC-III, within the MIMIC-III data) to give 100 optimism-adjusted performance estimates. From these, we summarised both the mean optimism-adjusted performance and visualized the distribution across the 100 bootstraps (to investigate variability, mimicking the simulation above). Bootstrap corrected 95% confidence intervals for each optimism-adjusted performance metric were calculated as the 2.5th and 97.5th percentiles (across the 100 optimism-adjusted performance estimates); an alternative (computationally expensive) approach has been described previously. 39
Empirical study results
After applying the inclusion and exclusion criteria, our extracted cohort included 28,859 patients, of which 3316 (11.5%) died in-hospital. Using this observed outcome proportion and 15% of the maximum
Table 3 shows the mean (taken across the 100 bootstrap samples) optimism-adjusted performance results for each modelling approach, for both the main analysis and the sub-analysis. As expected, each of the models are well calibrated, with the exception of ridge regression which is slightly over-shrunk (calibration slope slightly higher than 1); importantly, the mean calibration slope of the unpenalised MLE model was
The mean (95% bootstrap confidence interval) of the optimism-adjusted performance results in the MIMIC-III example for each estimation method. Main study corresponds to model fitting on the whole MIMIC-III dataset, while subset corresponds to the sub-analysis on the minimum required sample size.
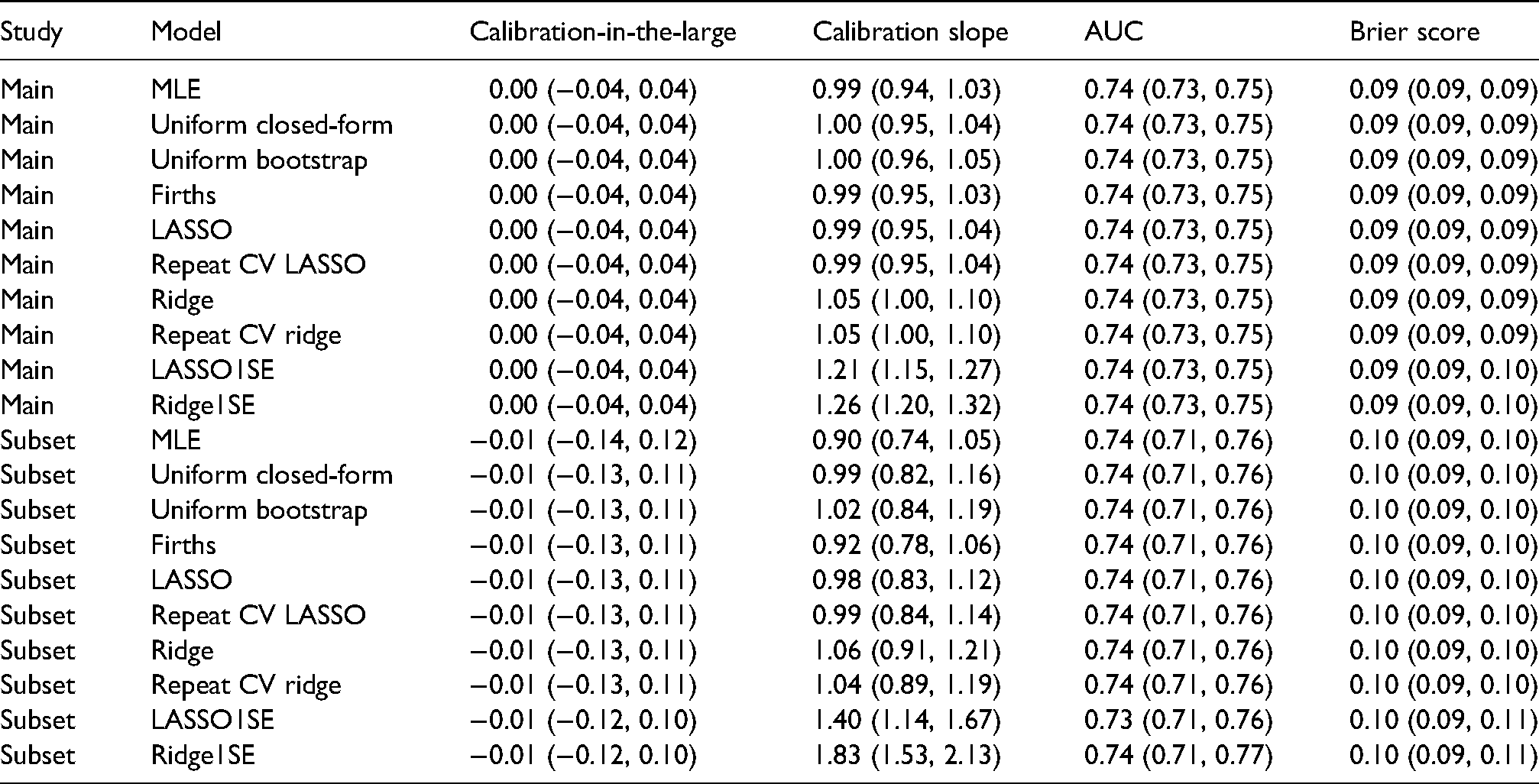
Figure 3 shows the distribution of the estimated shrinkage factors/penalisation terms (tuning parameters) across bootstrap samples. We found that there was larger variability in the shrinkage factors/penalisation terms for the subset analysis than the main analysis (due to the smaller sample size in the former). 23 Larger variability in the shrinkage factors/penalisation terms resulted in corresponding larger variability in the calibration slope of these methods (Figure 4). For this empirical study, we considered choosing the penalisation term based on the 1-standard-error method for LASSO and Ridge; we found that this generally resulted in larger variability and also lead to underfitting (Figure 4). The width of the 95% bootstrap confidence intervals of each performance metric was larger for the sub-analysis compared with the main analysis (Table 3), caused by larger variability in the distribution of the apparent performance minus optimism across the 100 bootstrap samples (Figure 4). For the main analysis, we found very low levels of variability across bootstrap samples, which is because of the large sample size for model development (relative to the minimum required sample size based on the Riley et al. criteria). For example, in the main analysis, the majority of (adjusted) calibration slope estimates for unpenalised MLE were between 0.95 and 1.05; this gives strong reassurance that the developed CPM will perform well when applied to new individuals from the same population as was used for model development. In contrast, the majority of (adjusted) calibration slope estimates for unpenalised MLE were between 0.8 and 1.1 in the sub-analysis, demonstrating wider variability and hence less reassurance that the developed CPM will perform well when applied to new individuals from the same population as was used for model development.
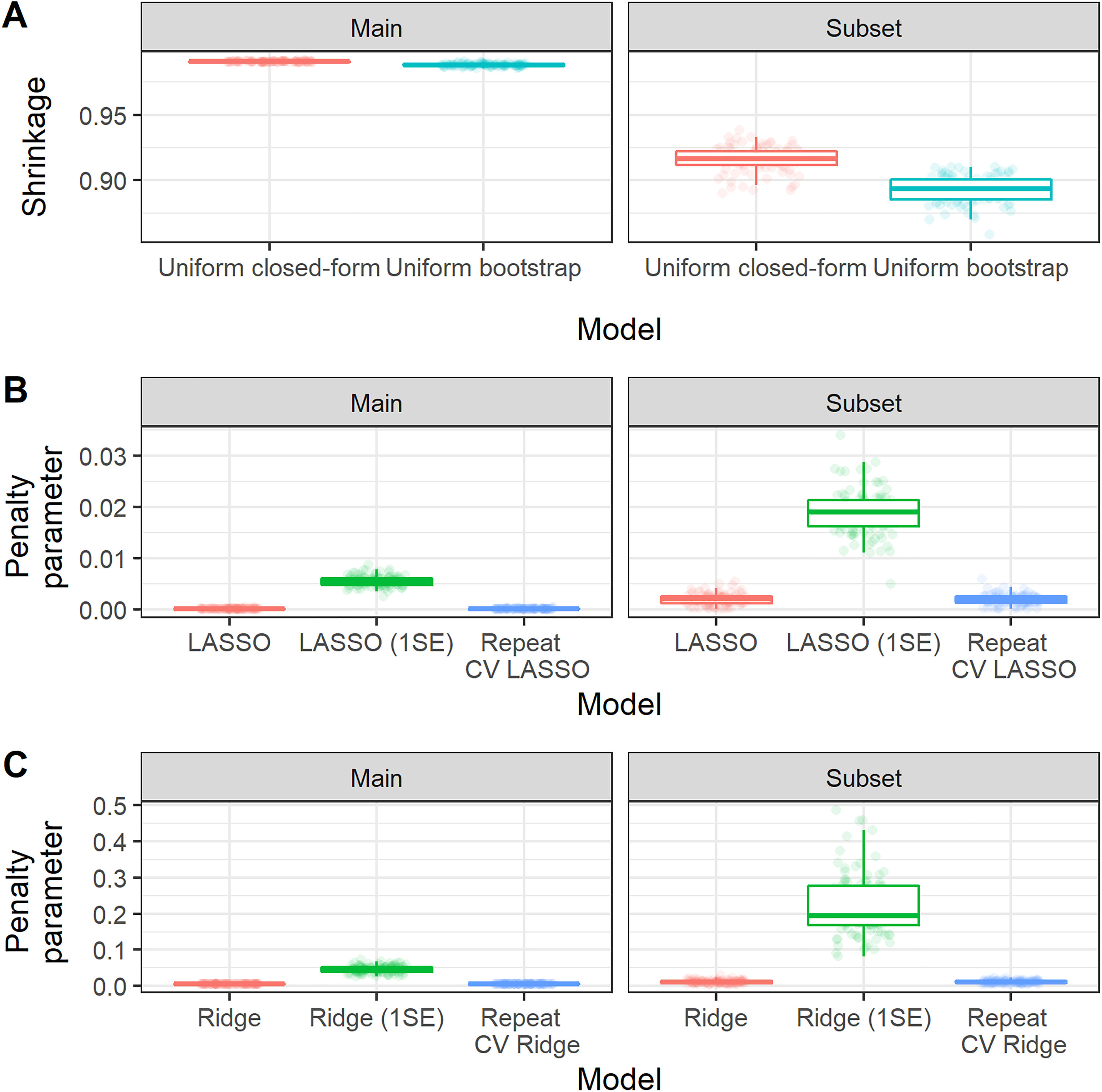
Boxplot showing the distribution, across bootstrap iterations of the MIMIC-III analysis, of the estimated shrinkage factor or penalisation terms. Random jitter has been applied to each point to aid visual clarity. Main study corresponds to model fitting on the whole MIMIC-III dataset, while subset corresponds to the sub-analysis on the minimum required sample size.
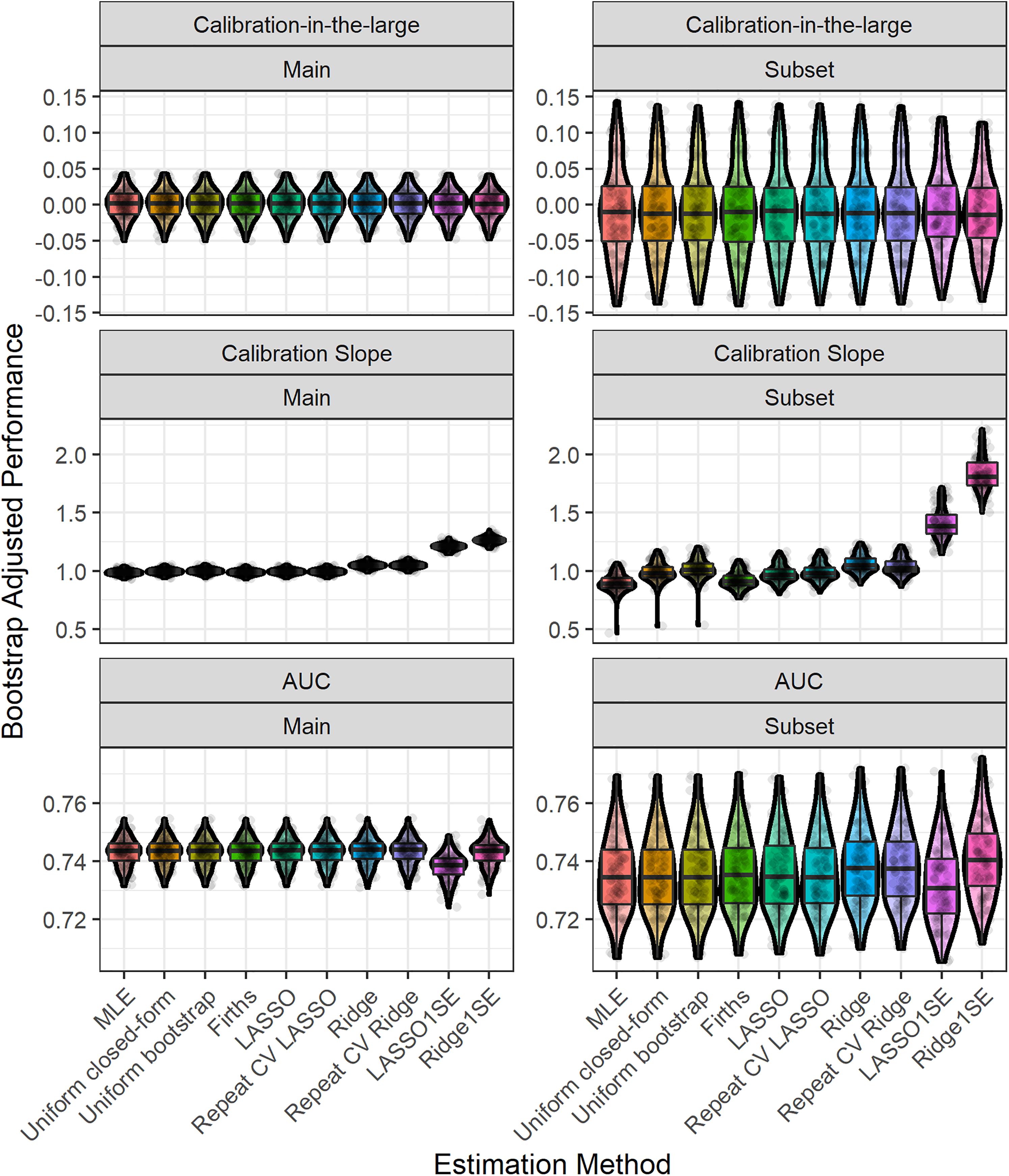
Boxplot and violin plot showing the distribution, across bootstrap iterations, of the (bootstrap) optimism-adjusted performance results in the MIMIC-III example for each estimation method. Random jitter has been applied to each point to aid visual clarity. Main study corresponds to model fitting on the whole MIMIC-III dataset, while subset corresponds to the sub-analysis on the minimum required sample size.
Discussion
This study has investigated the predictive performance of CPMs developed in sample sizes that adhere to minimum requirements. We found that, on average, all of the methods resulted in well-calibrated CPMs within an independent dataset, with penalisation/shrinkage further reducing the level of overfitting compared to unpenalised methods. However, this benefit of the penalisation methods came at the cost of slightly increased variability in the performance metrics across simulated/bootstrap datasets; this was often marginal but may still be important in practice. Models that exhibit less variability (uncertainty) in their predictive performance (and their estimated penalty and shrinkage factors) are more likely to correspond to robust CPMs when applied in new individuals. Given these findings, we recommend the use of penalisation/shrinkage methods to develop a CPM within data that (at least) meet minimum sample size criteria,13–15 to further help mitigate overfitting, while also examining/reporting the variability in predictive performance (and tuning parameters) as part of the model development process, to help gauge the model's stability, and thus its reliability in new data. This can be achieved by deriving confidence intervals via bootstrap internal validation 39 and/or plotting the distribution of predictive performance (and tuning parameters) in a similar way to shown in this study.
This study builds upon, and supplements, previous work in this area.12,16,17,22–24 Most of the previous literature has focused on the effect of penalisation methods to develop CPMs in terms of varying EPP values. However, following the publication of formal sample size requirements for CPMs,13–15 investigating the effect of penalisation methods in data that meet such minimum requirements is crucial. Indeed, contrary to common beliefs, penalisation approaches are not a solution to insufficient sample sizes (or low EPP), especially given the high variability in the effect of penalisation in low sample size settings.23,24 This study is the first to investigate variability of performance in data that meet (or surpass) formal minimum sample size requirements.
Some of the findings of this study are, perhaps, unsurprising. Given that we focused on the case of development data that (at least) adhered to minimum sample size requirements, it is unsurprising that MLE resulted in CPMs that were reasonably well calibrated, on average. For example, our use of the Riley et al. sample size criteria targeted a shrinkage of 0.9, so we would naturally expect the mean calibration slope to be
We found that the level of variability in performance metrics was lower than in previous work,23,24 but was still relatively high in some situations. For example, we found that variability was higher in the simulation scenarios where only 5 of the 10 simulated predictor variables where ‘truly’ associated with the outcome (i.e. simulation scenarios 2, 4, 6 and 8), likely caused by the increase ‘noise’ within the dataset. This was particularly apparent for LASSO compared with the other methods we considered, which might be explained by the fact that this is the only method (out of those considered) that incorporates variable selection into the estimation process. We also observed more variability in performance results in the situations where we used the ‘true’ (population-level) Cox-Snell
In this paper, we have illustrated how one can use bootstrap internal validation to understand the likely variability in performance metrics, within the given population. Specifically, each modelling step is repeated during bootstrap internal validation process, including estimation of the tuning parameters (where relevant). When bootstrap internal validation is implemented (as recommended6,29), it is common for the point estimates of predictive accuracy to be adjusted by the bootstrap-based optimism estimate, but confidence intervals are not usually corrected.
39
We recommend that future CPM studies should show the distribution of ‘apparent performance minus each bootstrap optimism estimate’ alongside average (optimism-adjusted) performance. To do so, one can create boxplots of the distribution of adjusted predictive performance (and shrinkage factors/penalisation terms, as relevant) across the bootstrap samples, similar to the graphics presented in this paper. If such plots show that the developed CPM exhibits ‘large’ variability/scatter in calibration (across bootstrap samples), then this would indicate caution about using the CPM within the given population, and flag the need for additional validation (and potential model updating or recalibration), even if average (optimism-corrected) performance is deemed satisfactory in the bootstrap process. What is considered to be ‘large’ variability in predictive performance will be context specific, but (for example) if one finds that average (optimism adjusted) calibration slope is approximately 1 (e.g. using penalisation methods within data that meet minimum requirements), but the (adjusted) calibration slope estimates across bootstrap samples are commonly outside of 0.9–1.1, then this would indicate caution. Moreover, the number of bootstrap samples will affect the amount of variability; hence, we recommend that bootstrap internal validation is undertaken with a large number of samples (e.g. 500, and certainly
Our simulation study and the sub-analysis of the empirical study considered development data that met, but did not surpass, minimum sample sizes, while our main empirical study illustrated a case where the size of the development data clearly surpassed minimum requirements. We note that usually one would strive for larger samples than a minimum threshold. In the main empirical study, the larger sample sizes (relative to minimum requirements) reduced the variability in tuning parameters and in predictive performance compared with the simulation and empirical sub-analysis. Thus, if one wished to strive for narrower variability, then larger-than-minimum sample sizes would be required, or one would need to calculate the sample size formula under more stringent criteria (e.g. increase the shrinkage factor from 0.9 to 0.9513,14). Similarly, the findings from our simulation study where we used the ‘true’ (population-level) Cox-Snell
A number of limitations should be considered when interpreting the findings of this study. First, while our empirical data illustrated situations where development data met or surpassed minimum requirements, the generalisability of the empirical findings needs to be considered. Second, we did not consider choices that modellers might need to make when developing a CPM (e.g. variable selection, missing data imputation or consideration of interaction terms), which might increase the level of variability in performance within independent data. This practical point adds further emphasis for the need for those developing CPMs to report/show the variability in performance. Third, we only considered CPMs developed using logistic regression, and continuous or time-to-event outcomes were not explored; however, we would not expect the results to differ substantially. Finally, all of the models in our simulation and empirical analyses had AUC values between 0.7 and 0.8. In practice, CPMs might have AUC values lower than this. We note, however, that if the ‘true’ AUC was lower than those considered in the study, then this would effectively mean the ‘true’ R2 was lower (e.g. see Riley et al. 40 ), which in turn would increase the minimum required sample size. Despite this being sample size being larger in absolute terms, it would still be the minimum required for that particular situation, so there will still be variability; again, reporting this variability will directly show this, irrespective of the (average) performance of the CPM.
In conclusion, the use of penalisation methods can further mitigate risks of overfitting even within datasets that adhere to, or surpass, minimum suggested sample sizes. However, although this might resolve overfitting on average, in a particular dataset it may still not be perfect, and indeed because of the need to estimate tuning parameters (that define shrinkage), it comes at the costs of slightly higher variability in predictive performance. Thus, we recommend the use of penalisation/ shrinkage methods to develop a CPM within data that (at least) meet minimum sample size criteria,13–15 to further help mitigate overfitting, while also investigating (and reporting) variability in predictive performance through robust bootstrap internal validation, including accounting for the uncertainty in estimating shrinkage/tuning parameters. Those models that exhibit less variability (uncertainty) in their predictive performance (and their estimated tuning parameters/shrinkage factors) are more likely to correspond to robust CPMs when applied in new individuals.
Supplemental Material
sj-pdf-1-smm-10.1177_09622802211046388 - Supplemental material for Developing clinical prediction models when adhering to minimum sample size recommendations: The importance of quantifying bootstrap variability in tuning parameters and predictive performance
Supplemental material, sj-pdf-1-smm-10.1177_09622802211046388 for Developing clinical prediction models when adhering to minimum sample size recommendations: The importance of quantifying bootstrap variability in tuning parameters and predictive performance by Glen P Martin, Richard D Riley, Gary S Collins and Matthew Sperrin in Statistical Methods in Medical Research
Footnotes
Acknowledgements
We wish to thank two anonymous reviewers and the Editors for their constructive comments which helped improve the article upon revision.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by funding from the MRC-NIHR Methodology Research Programme (grant number: MR/T025085/1). GSC was supported by the NIHR Biomedical Research Centre, Oxford, and Cancer Research UK (programme grant: C49297/A27294).
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.