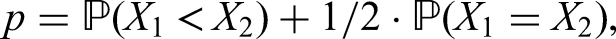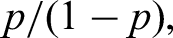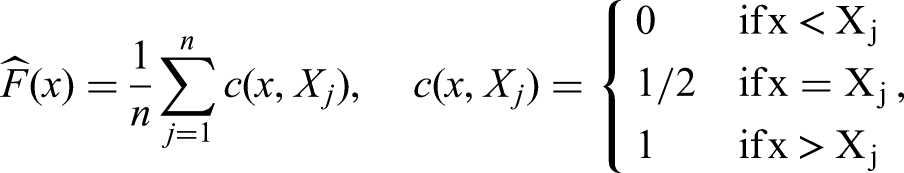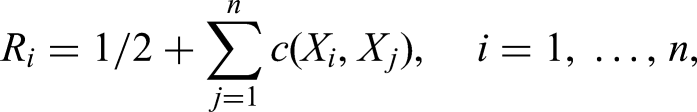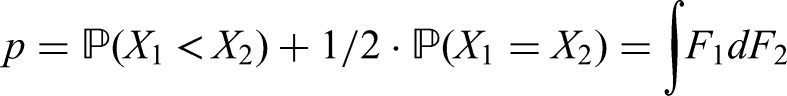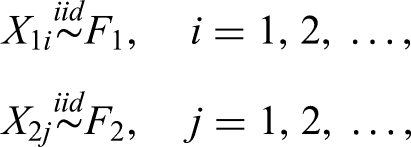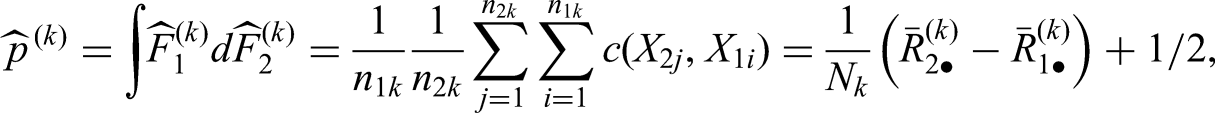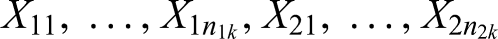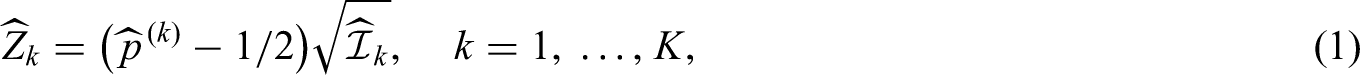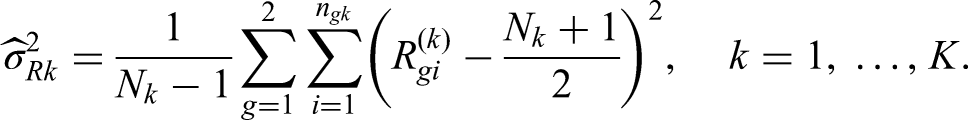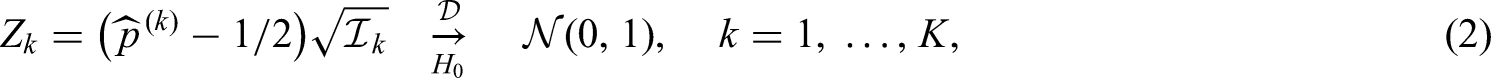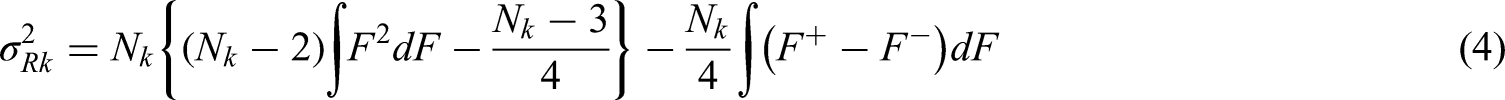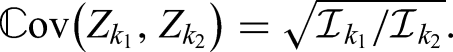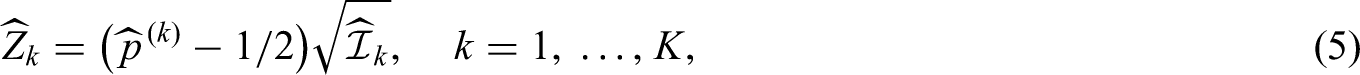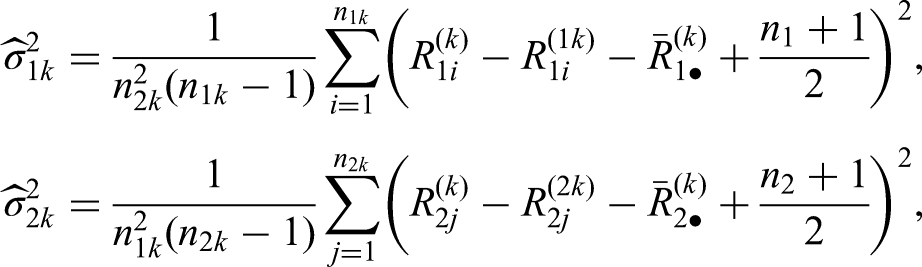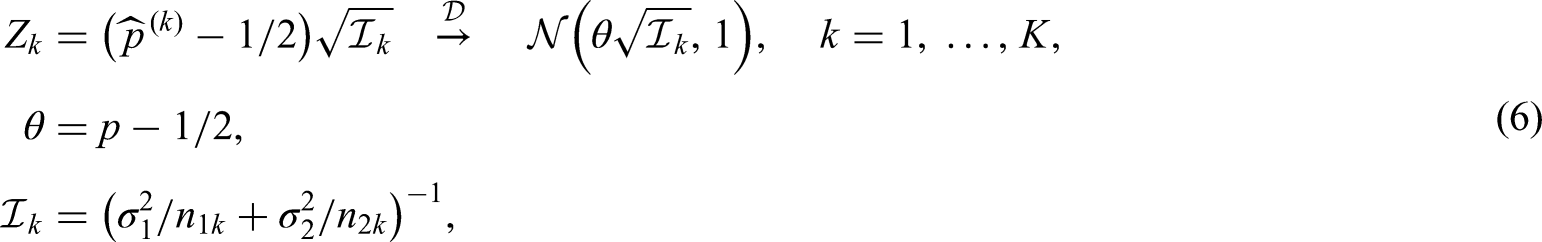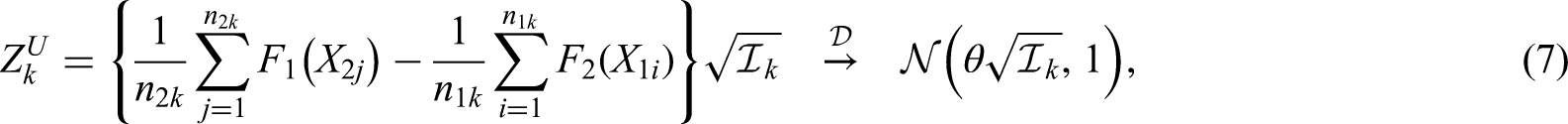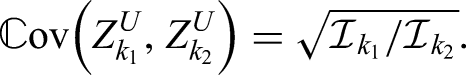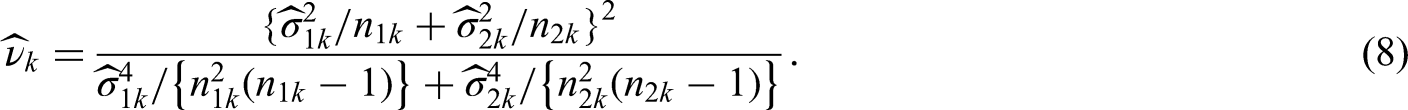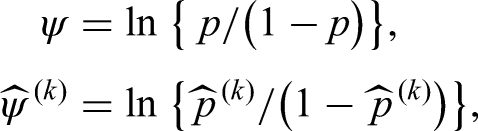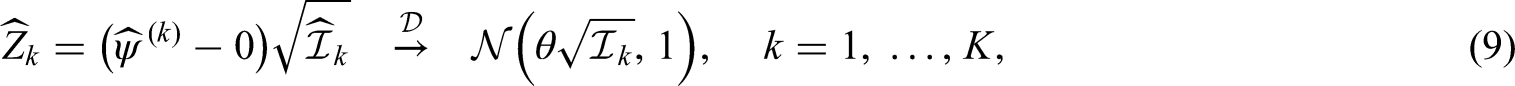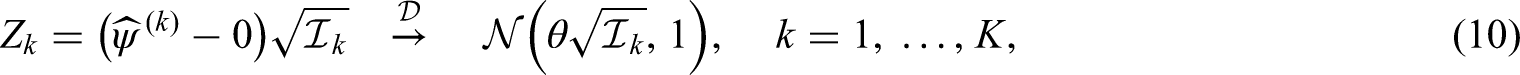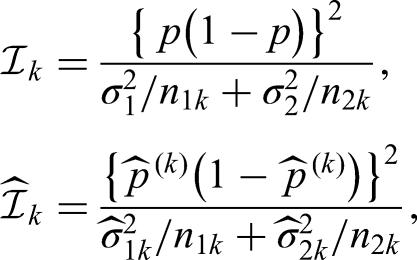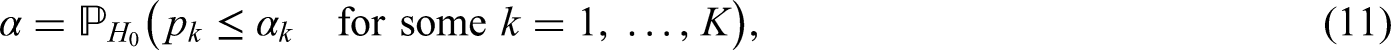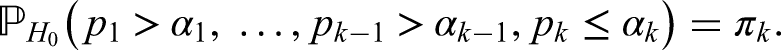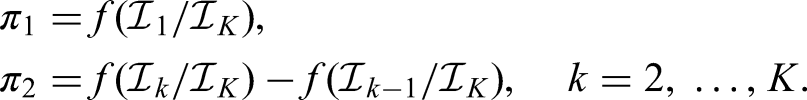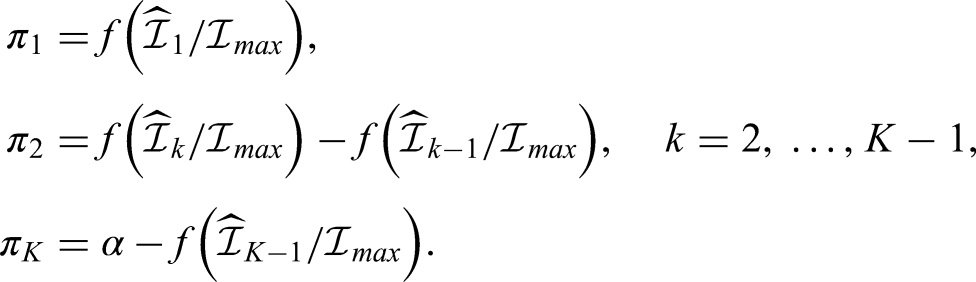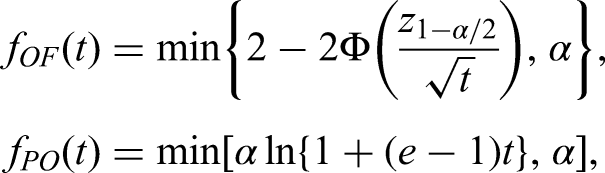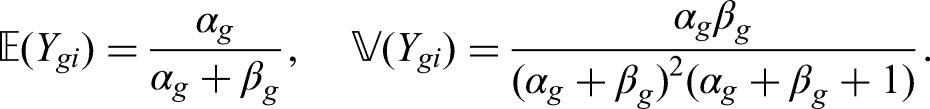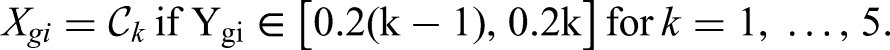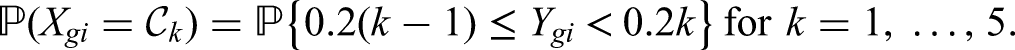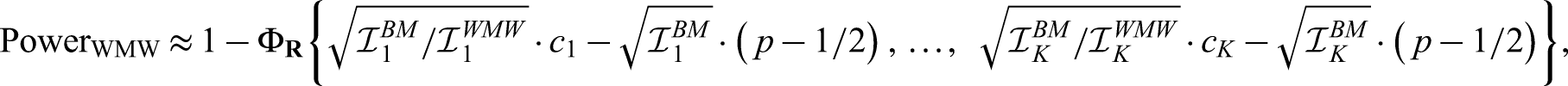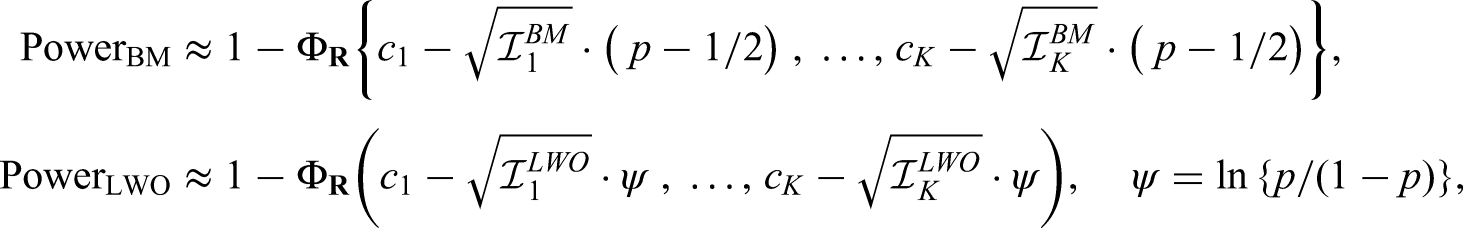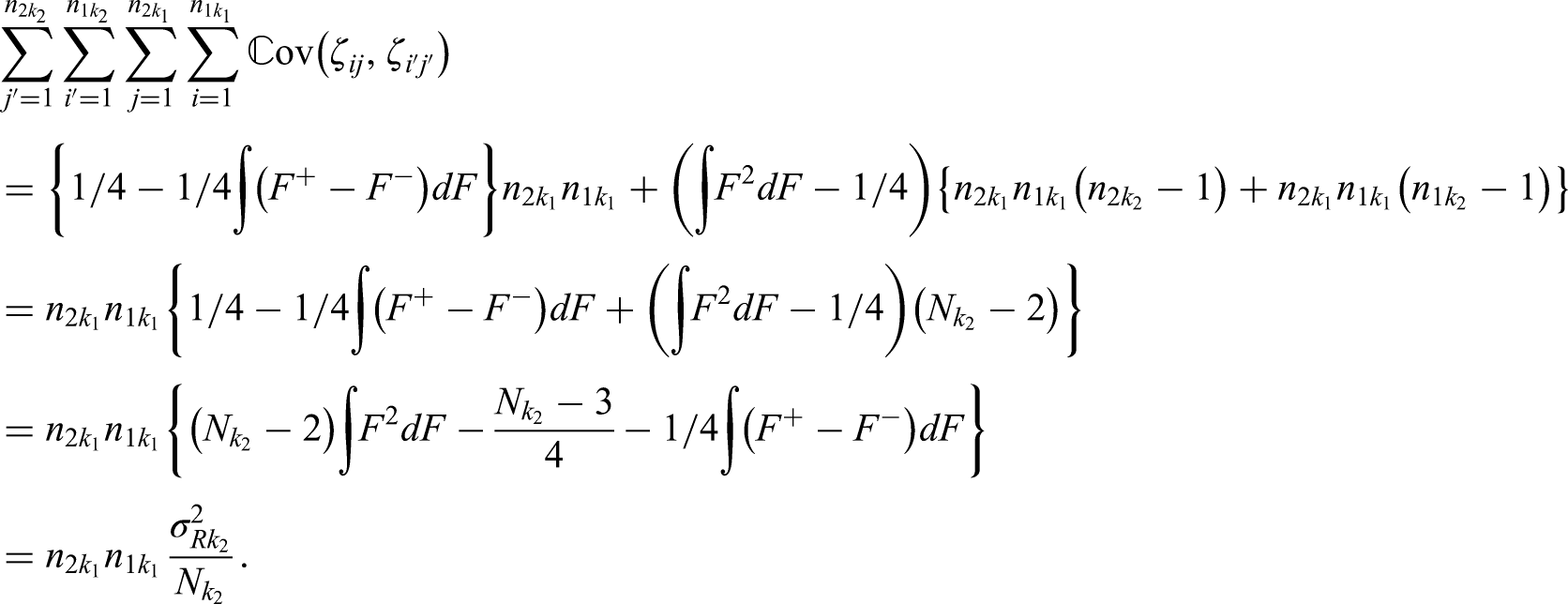Late phase clinical trials are occasionally planned with one or more interim analyses to allow for early termination or adaptation of the study. While extensive theory has been developed for the analysis of ordered categorical data in terms of the Wilcoxon-Mann-Whitney test, there has been comparatively little discussion in the group sequential literature on how to provide repeated confidence intervals and simple power formulas to ease sample size determination. Dealing more broadly with the nonparametric Behrens-Fisher problem, we focus on the comparison of two parallel treatment arms and show that the Wilcoxon-Mann-Whitney test, the Brunner-Munzel test, as well as a test procedure based on the log win odds, a modification of the win ratio, asymptotically follow the canonical joint distribution. In addition to developing power formulas based on these results, simulations confirm the adequacy of the proposed methods for a range of scenarios. Lastly, we apply our methodology to the FREEDOMS clinical trial (ClinicalTrials.gov Identifier: NCT00289978) in patients with relapse-remitting multiple sclerosis.
Since it is not uncommon for phase III clinical trials to run for a number of years, there is much interest in being able to assess safety and efficacy while the trial is still ongoing. Unsurprisingly, regulatory authorities (EMA,1 FDA2) point out the need to adequately address multiplicity issues and give practical guidance on group sequential methods, which allow for repeated significance testing on accumulating data without inflating the nominal overall type I error rate.
While standard textbooks such as Jennison and Turnbull3, Proschan,4 or Wassmer and Brannath5 primarily discuss continuous, binary and survival endpoints, the Wilcoxon-Mann-Whitney test6–8 has also been extended to group sequential settings.9–11 In our view, the estimand most naturally associated with the Wilcoxon-Mann-Whitney test is the probability
where and denote two independent random variables. The quantity is called nonparametric relative effect of with respect to , probabilistic index or Mann-Whitney parameter.12–15 Dividing by its complement produces
the so-called win odds.16 Adding half of the probability of equal outcomes to neatly aligns with Putter’s generalisation17 of the Wilcoxon-Mann-Whitney test to the case of ties. By the same token, Brunner et al.16 regard the win odds to be a tie corrected version of the win ratio , which has recently attracted attention in the context of time-to-event data,18 continuous endpoints,19 and stratification.20 Of course, if tied values cannot occur almost surely, that is, if , then equals and the win odds coincide with the win ratio.
To illustrate the interpretation of the nonparametric relative effect , let us assume that and refer to outcomes from treatment arms 1 and 2, respectively, and that lower values point to a more favourable outcome. Then is nothing but the probability that patients on arm 1 will fare better than those on arm 2, including times the probability of equal outcomes. Perhaps a little easier to interpret are the win odds. For instance, if , then the odds that a patient on arm 1 will fare better than one on arm 2 are , with the possibility of equal outcomes equally allocated to the ‘fare better’ and ‘fare worse’ scenarios.
However, asymptotic results of the Wilcoxon-Mann-Whitney test as commonly employed are only valid if both distributions coincide, that is, if . Hence the null hypothesis is usually formulated in terms of the distribution functions as well, that is, and not the Mann-Whitney parameter as such. While implies , the reverse does not hold. For instance, any two symmetric distributions with the same centre of symmetry, such as two normal distributions and , would imply . In essence, the nonparametric Behrens-Fisher problem addresses the testing problem , while making no further assumptions on and , which is precisely the scenario that the Brunner-Munzel test12 was developed to deal with. In that regard, unlike the Wilcoxon-Mann-Whitney test, the limiting distribution of the Brunner-Munzel test is normal with unit variance under both the null and the alternative hypotheses, thus allowing for test inversion and computation of confidence intervals for , which in turn facilitates the derivation of simple power approximations in the group sequential setting.
A key tool in group sequential theory which we will also rely on here is the so-called canonical joint distribution.3–5,21 More precisely, a sequence of test statistics with information levels for a single parameter are said to follow the canonical joint distribution if
follows a multivariate normal distribution,
,
As might be expected, group sequential versions of the nonparametric tests just discussed follow the canonical joint distribution only asymptotically, which is why we will check its applicability for finite sample sizes by way of extensive simulations.
This paper is organised as follows. Section 2 introduces notation and group sequential methods for hypothesis tests based on the nonparametric relative effect , with derivations concerning the covariance structure of the corresponding group sequential statistics referred to the appendix. Following a discussion on error spending in Section 3, we set out results from simulation studies in Section 4 to assess type I error rates for finite sample sizes. Section 5 deals with the retrospective application of our proposed methodology to a completed clinical trial, whereas Section 6 outlines how to plan a group sequential trial with the aid of simple approximate power formulas. More detailed results and technical considerations regarding the simulations are provided in the Supplemental Material.
2 Nonparametric group sequential models
We start with notation from nonparametric theory necessary to develop group sequential models for the Wilcoxon-Mann-Whitney test, the Brunner-Munzel test and a logit transformed version of the latter, which we refer to as the log win odds test. With the asymptotic normality of the test statistics at issue already established for the fixed sample size scenario, a vector of such statistics based on accumulating groups of data is asymptotically multivariate normal by the Crámer-Wold theorem.22 Thus, in order to obtain the asymptotic joint distribution, it remains to properly define the information levels and derive the expectation and covariance matrix of .
2.1 Notation
Let be a univariate random variable representing real-valued or ordered categorical data, defined on the probability space . Adopting common notation, we denote by
version of the cumulative distribution function of .23,24,12
Now suppose we have a sample of observations . Then we call
the normalised version of the empirical cumulative distribution function. Moreover,
denotes the mid-rank of among the observations .
For two independent random variables and , the probability
is called nonparametric relative effect of with respect to (or of with respect to ). We say that
tends to smaller values than if ,
tends to larger values than if ,
and are stochastically comparable if .
For a more comprehensive discussion on nonparametric theory we refer to Brunner et al.13
Throughout the remainder of this paper we will focus on a parallel two-arm clinical trial and consider accumulating responses
from treatment arms 1 and 2, respectively. Apart from assuming that and that there exists no such that or , which excludes the degenerate cases of completely separated samples and one-point distributions, and are otherwise arbitrary.
With and denoting the cumulative number of observations available at analysis for the respective treatments, , we can estimate the nonparametric relative effect by
with , where is the mid-rank of among all observations
available at analysis ; ; .
For asymptotic results, we let both sample sizes tend to infinity such that neither vanishes, that is, for both and , .
2.2 Wilcoxon-Mann-Whitney test allowing for ties
To test the hypothesis against , we employ at each interim analysis the same test statistic as in the fixed design, namely
with estimated information , where
It is well known that each converges in distribution to a standard normal random variate, provided the null hypothesis is true.13
To derive the asymptotic joint distribution of we need to compute its covariance matrix. Proceeding in accord with Jennison and Turnbull,3 we first replace the estimated information with its population version, resulting in
where we assume the variance
and therefore the true distribution to be known.13 If is continuous, the information simplifies to .
Since are consistent estimators of , , the vector of Wilcoxon-Mann-Whitney test statistics has the same limiting distribution as its counterpart with the true population information. The limiting distribution being multivariate normal, it remains to establish the covariances of the components of .
To test the null hypothesis against , we now compute, analogous to before, for each interim analysis the Brunner-Munzel test statistic
with estimated information , where
and denotes the mid-rank of among the observations of the th treatment group available at analysis ; ; .
For the derivation of the asymptotic covariance, we take an approach similar to before. Once again, we substitute the estimated information with the true one
where and . However, since the definition of the variance components and is actually based on an asymptotically equivalent version of the s, that is to say,
we compute the covariance accordingly. This result is given in the following proposition.
Thus, consistently estimating , , the sequence of Brunner-Munzel test statistics asymptotically follow the canonical joint distribution. In the nonsequential scenario, the test has been shown to be too liberal for small sample sizes when using standard normal quantiles.12 Analogous to the parametric Behrens-Fisher problem, they propose a Satterthwaite-Smith-Welch -approximation25–27 with degrees of freedom estimated by
Another way is to employ a variance stabilising transformation, such as the logit function, producing the logarithmised win odds, which we will explore in the next subsection.
2.4 Log win odds test
To address the liberal behaviour of the Brunner-Munzel test, we now consider
at stage . Consequently, straightforward application of the delta method yields
with effect and information levels
which is nothing but times, or times, the information for the corresponding effect from the Brunner-Munzel test as in Section 2.3. Moreover, Proposition 2 together with the information obtained by the delta method directly imply that the log win odds test statistics asymptotically follow the canonical joint distribution.
To recapitulate, in all three cases under the respective assumptions, the standardised test statistics with information for the parameter asymptotically follow the canonical joint distribution. The difference between the Wilcoxon-Mann-Whitney and Brunner-Munzel tests arises solely from the way in which we define the information, both distributions and needing to coincide for the former but not the latter. The log win odds test is nothing but a Brunner-Munzel test based on the logit transformed nonparametric relative effect .
Before we investigate the adequacy of the proposed methods by means of simulations, we turn our discussion to error spending to explain in more detail the manner in which we wish to reject the null hypothesis.
3 Error spending
Initially, group sequential methods required the number of interim looks to be specified in advance and equally spaced: Pocock28 considered standard normal test statistics and derived local significance levels (‘stage levels’) which are identical across all stages, while O’Brien and Fleming29 stage levels are extremely low at the first interim and increase with each stage in such a way that the final stage level is quite close to the nominal overall significance level . To avoid having to specify the time or number of interim looks in advance, Lan and DeMets30 suggested the use of error spending functions, which we will employ in the simulations.
With statistics and information levels , , , , , given as in the previous section, a right-sided group sequential test for efficacy maintains the nominal significance level if the stage levels are chosen such that
where we regard the repeated -values , , to be random variables, denoting the cumulative distribution function of the standard normal distribution. The null hypothesis is rejected at stage if and the trial is consequently stopped. We do not, however, set up futility bounds.
To obtain specific stage levels, we split the global into positive parts (‘ spent at stage ’), , such that and
To compute the stage levels , we make use of the underlying limiting canonical joint distribution of the statistics and estimate the covariance of and by , , where is the prespecified information that we believe would be available if the total maximum sample size of the trial were observed under the respective treatment allocation scheme.
The error spending function prescribes precisely how the global is to be spent across the stages. More formally, an error spending function is defined as a nondecreasing function such that and for all . Then the amount of allocated to stages is given by
However, the true information levels are not known in advance. Therefore, we use instead of and replace the other information levels by their estimates,
As might turn out to be lower than , the last equation ensures that the full amount of still available is spent at the last stage. Moreover, it is important to bear in mind that the information levels are estimated at stage and remain unchanged thereafter.
4 Simulations
As the methods developed in Section 2 are of asymptotic nature, we explore their applicability for finite sample sizes in a range of scenarios. To this end, we simulate the group sequential Wilcoxon-Mann-Whitney, Brunner-Munzel, and log win odds tests given as in (1), (5), and (9), respectively. Assuming that lower values correspond to more favourable outcomes, we want to show that treatment 1 is superior to treatment 2, yielding a one-sided efficacy test with against and a nominal overall significance level of . In that regard, it is perhaps more natural to view the Wilcoxon-Mann-Whitney test as a means to test the null hypothesis as well, with constituting a model assumption under the null.
To gauge the type I error rate of our proposed methods, we perform 100,000 simulation runs for each scenario, giving rise to a Monte Carlo error of about based on a 95%-precision interval for a global . Altogether, we present the results of 120 scenarios for each data generating process, that is all combinations of
total maximum sample sizes
allocation ratios or (twice as many patients on treatment arm 1),
two, three, or four stages, and
two error spending functions.
More specifically, we consider O’Brien and Fleming29 as well as Pocock28 type error spending functions
using the information fractions , to determine the amount of to be spent since we know the true maximum information . For the subsequent computation of the stage levels, we make use of the command from the package .31 In addition to using standard normal quantiles for the Wilcoxon-Mann-Whitney, Brunner-Munzel, and log win odds tests, we compute rejection rates based on the Satterthwaite-Smith-Welch -approximation for the Brunner-Munzel test. As is suggested by Jennison and Turnbull3 and Wassmer and Brannath5 to provide satisfactorily accurate results for the two sample -test, we use the same stage levels for the -approximation and change the computation of the repeated -values only, namely , where denotes the cumulative distribution function of the -distribution with degrees of freedom as in (8).
It might occur that our methods break down, for instance the variance estimate of the Brunner-Munzel test might be zero in finite samples or the estimated information could actually decrease in a subsequent stage. Since this happened very rarely and has virtually no influence on the results presented in the main paper, we relegate the discussion on exception handling to the supplementary material. Moreover, we only report the overall type I error rate here, that is, the relative frequency of simulation runs, where the null hypothesis could be rejected at some stage. Readers interested in a more detailed presentation of the results such as cumulative rejection rates for each stage are again referred to the supplementary material.
4.1 Normal distribution
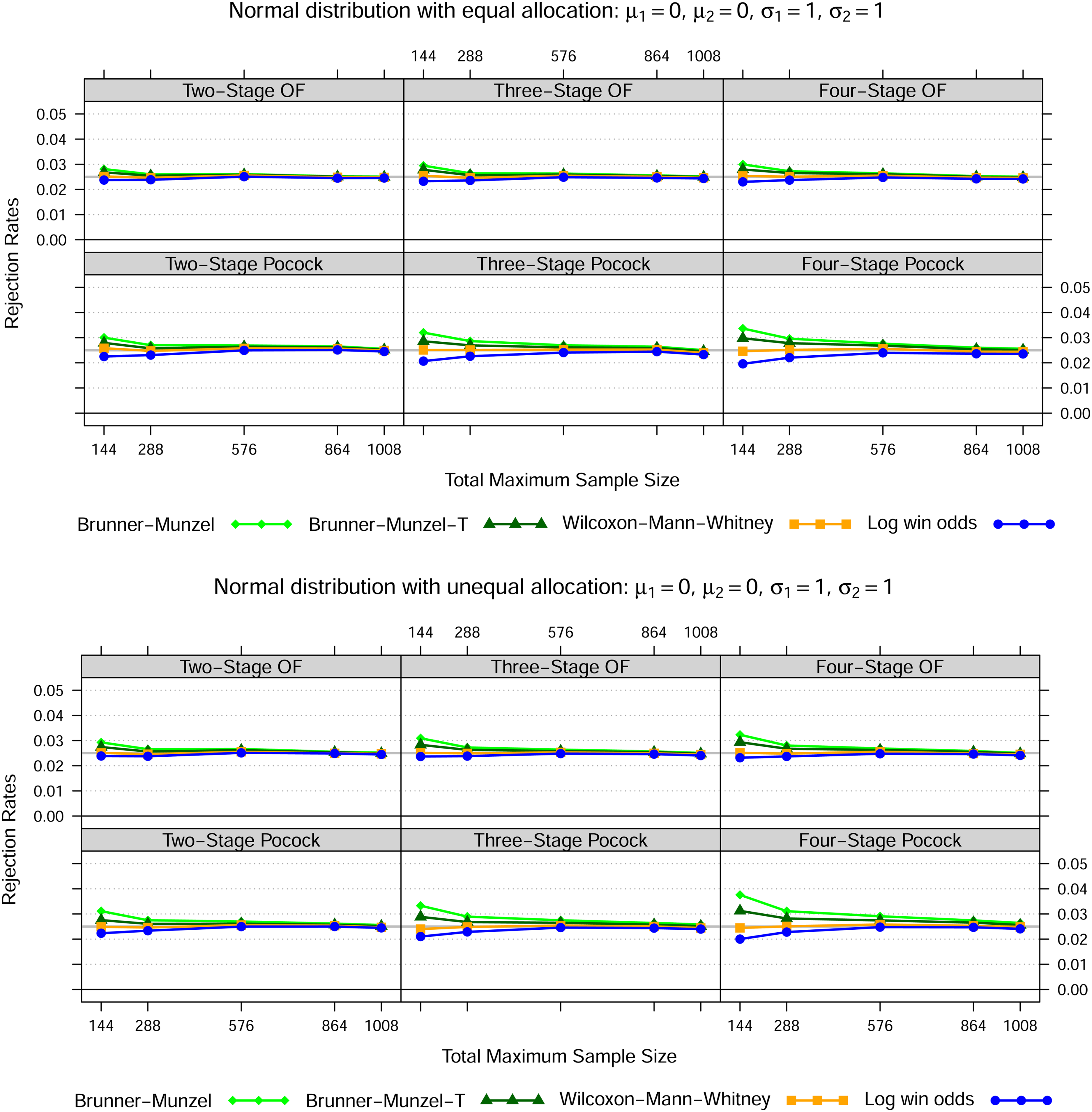
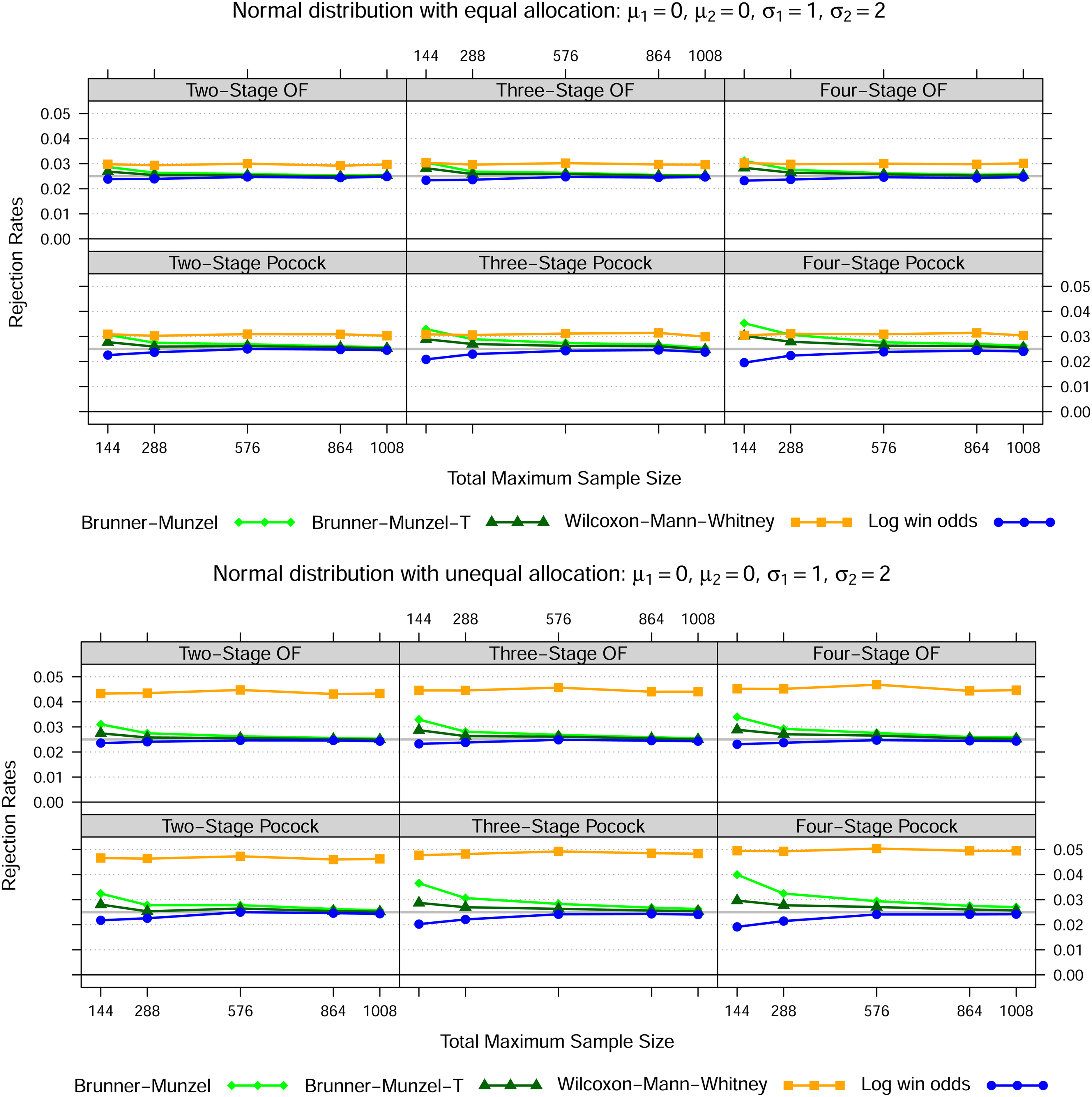
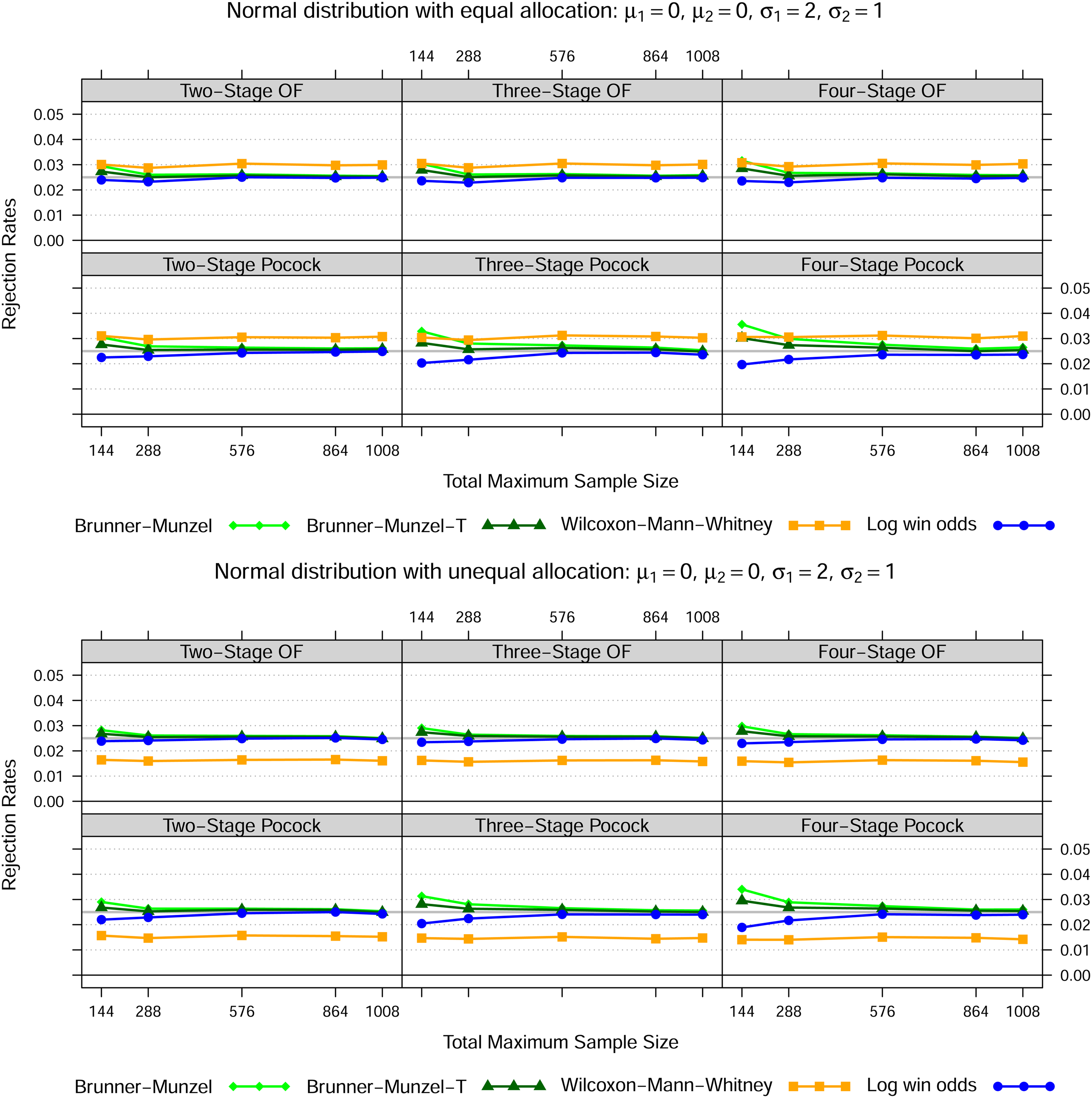
First we generated data from normal distributions, namely , , , for three different settings as set out in Figures 1 to 3. In case of equal variances, the Wilcoxon-Mann-Whitney test best maintains the nominal type I error rate for all total maximum sample sizes, whereas the Brunner-Munzel test with or without -approximation tends to be too liberal and the log win odds test too conservative for smaller samples sizes. In both heteroskedastic settings, that is settings 2 and 3, the Wilcoxon-Mann-Whitney test exceeds the nominal significance level across all sample sizes if the allocation ratio is 1:1. However, if twice as many patients receive treatment 1, then the Wilcoxon-Mann-Whitney test is far too liberal if the data in treatment 1 is less dispersed than in treatment 2 and far too conservative conversely. Again, this behaviour is not affected by sample size.
Normal distribution—Setting 1
Notes: The lines show the relative frequency of the 100000 simulation runs, where the null hypothesis could be rejected at some stage based on the Brunner-Munzel test (with t-approximation) as in (5), the Wilcoxon-Mann-Whitney test as in (1) and the log win odds test as in (9) for five different total maximum sample sizes, two error spending functions, up to four stages in total as well as two different allocation ratios.
Normal distribution—Setting 2
Notes: The lines show the relative frequency of the 100000 simulation runs, where the null hypothesis could be rejected at some stage based on the Brunner-Munzel test (with t-approximation) as in (5), the Wilcoxon-Mann-Whitney test as in (1) and the log win odds test as in (9) for five different total maximum sample sizes, two error spending functions, up to four stages in total as well as two different allocation ratios.
Normal distribution—Setting 3
Notes: The lines show the relative frequency of the 100000 simulation runs, where the null hypothesis could be rejected at some stage based on the Brunner-Munzel test (with t-approximation) as in (5), the Wilcoxon-Mann-Whitney test as in (1) and the log win odds test as in (9) for five different total maximum sample sizes, two error spending functions, up to four stages in total as well as two different allocation ratios.
In line with the simulation results of Brunner and Munzel12 for the fixed sample size scenario, the rejection rates pattern of the other tests are not affected by heteroskedasticity or different allocation schemes.
4.2 Ordinal data
Now we consider ordinal data divided into five categories , with a smaller index pointing to a more favourable outcome. As in Brunner et al.,16 the probabilities of each category occurring are derived through a latent Beta distribution: Let , , , denote a Beta distributed random variable with shape parameters , such that the expectation and variance of are given by
Then, the random variable , , , is defined by
Consequently, the probability mass function of is nothing but
We specify three different parameter settings to mimic the homo-/heteroskedasticity pattern for the normal scenarios in Section 4.1. The results exhibit virtually the same behaviour as the normally distributed responses shown previously and are therefore included in the online supplementary material.
5 FREEDOMS clinical trial
The FREEDOMS clincial trial (ClinicalTrials.gov Identifier: NCT00289978) was a placebo-controlled phase III study running from January 2006 to July 2009 to analyse the efficacy and safety of fingolimod in patients with relapsing-remitting multiple sclerosis.32 The primary efficacy endpoint was the annualised relapse rate at 24 months after baseline evaluation. The definition of a relapse was based on the Expanded Disability Status Scale (EDSS),33 with values ranging from 0 (normal status) to 10 (death due to multiple sclerosis) and a step size of 0.5, although a value of is not possible. Thus, a higher score on the EDSS indicates more severe disability.
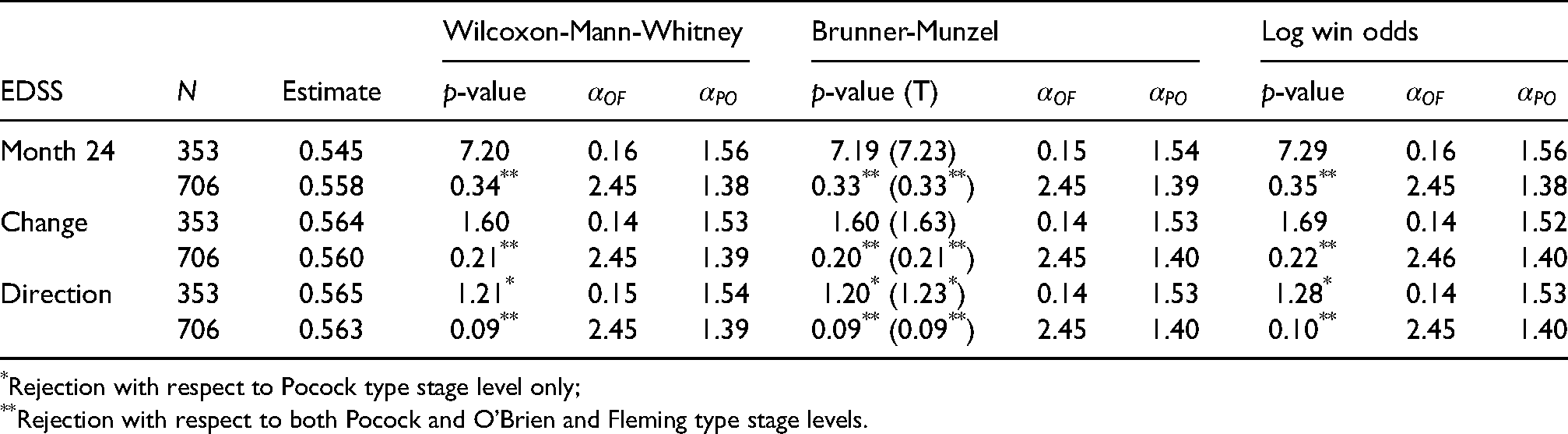
In this paper, we focus on the EDSS score at 24 months, its change compared to the baseline (post minus prae), and its direction of change, that is, whether the EDSS score at 24 month decreased (), stayed the same (), or increased () with respect to the baseline value. To simplify the presentation of the results, we only considered the complete cases data set, that is, patients where the EDSS score was observed both at baseline and 24 months thereafter. Summary descriptive statistics depicted in Table 1 reveal in all three cases that, at the end of the trial, the mean EDSS outcome of patients on the placebo arm is higher and therefore less favourable than for those on the fingolimod 0.5 mg treatment.
While the original design of the FREEDOMS trial did not provide for interim looks, we now retrospectively analyse the data as though there were two equally spaced stages. More specifically, the first 353 patients on either arm who completed the 24 month evaluation form the basis of the first stage analysis, while all 706 patients are taken into account at the second and therefore last stage. As we did in the simulation section, we consider the Wilcoxon-Mann-Whitney test, the Brunner-Munzel test (with -approximation) as well as the log win odds test and employ O’Brien and Fleming as well as Pocock type error spending functions. Since we do this analysis retrospectively, we can choose . In all scenarios the estimated information fractions are close to , essentially coinciding with the sample size fraction .
Summary descriptive statistics for EDSS data at month 24, month 24 minus baseline (change), and direction of change from the FREEDOMS clinical trial.
EDSS
Treatment
Mean
SD
Min
Median
Max
Month 24
Fingolimod 0.5 mg
374
2.269
1.442
0
2
6.5
Placebo
332
2.545
1.507
0
2
7.0
Change
Fingolimod 0.5 mg
374
0.004
0.878
0
3.5
Placebo
332
0.131
0.936
0
3.5
Direction
Fingolimod 0.5 mg
374
0.734
0
1
Placebo
332
0.099
0.769
0
1
Analogous to the simulation section, we aim to reject at a global significance level of . As Tables 2 to 4 demonstrate, we can reject the null hypothesis at some stage in any scenario and conclude that fingolimod treatment is efficacious. Only the direction of change endpoint leads to early rejection, that is, when using Pocock type stage levels. Even if the trial could not have been stopped at the interim, second stage -values in the region of would have resulted in rejection eventually. Consistent with the results from the simulations, the -values and confidence intervals from different tests are fairly close.
Repeated effect estimates, -values in % based on standard normal and approximation (T), O’Brien and Fleming () and Pocock type () error spending stage levels in %.
Rejection with respect to Pocock type stage level only;
Rejection with respect to both Pocock and O’Brien and Fleming type stage levels.
Repeated 95%-confidence intervals based on Pocock type alpha spending function.
EDSS
Estimate
Brunner-Munzel
Brunner-Munzel (T)
Log win odds
Month 24
353
0.545
0.479
0.610
0.479
0.610
0.478
0.609
706
0.558
0.511
0.606
0.511
0.606
0.511
0.605
Change
353
0.564
0.499
0.628
0.499
0.628
0.499
0.626
706
0.560
0.514
0.605
0.514
0.605
0.514
0.605
Direction
353
0.565
0.503
0.628
0.503
0.628
0.502
0.626
706
0.563
0.519
0.608
0.519
0.608
0.518
0.607
Repeated 95%-confidence intervals based on O’Brien and Fleming type alpha spending function.
EDSS
Estimate
Brunner-Munzel
Brunner-Munzel (T)
Log win odds
Month 24
353
0.545
0.454
0.635
0.453
0.636
0.454
0.633
706
0.558
0.516
0.601
0.516
0.601
0.516
0.600
Change
353
0.564
0.475
0.652
0.474
0.653
0.474
0.649
706
0.560
0.519
0.601
0.519
0.601
0.518
0.600
Direction
353
0.565
0.479
0.651
0.478
0.652
0.478
0.649
706
0.563
0.524
0.603
0.523
0.603
0.523
0.603
6 Planning and sample size considerations
In planning a clinical trial, a careful examination of the power of different scenarios under the alternative appears to be advisable at any rate. With the nonparametric relative effect chosen as the efficacy estimand of the primary endpoint, we now extend and slightly modify the approach to sample size planning for the fixed scenario proposed by Happ et al.34 to the group sequential setting.
As before, we consider the hypothesis pair and with a nominal overall significance level of . To determine the power of a particular alternative, it is convenient to specify the distributions and as well as a constant sample size ratio for all stages such that is the distribution of the whole data ignoring the group structure, which appears in the variance formula (4) of the Wilcoxon-Mann-Whitney test. If we then choose the sample sizes for the particular stages , we immediately get the true information , , as given in (3), (6) and (10), respectively. Approximate power formulas for the group sequential Wilcoxon-Mann-Whitney, Brunner-Munzel and log win odds tests then take the form as provided in the following two propositions.
Let denote the critical values computed from a -variate normal distribution with mean vector , covariance matrix , , and error spending function of choice. Then the approximate power of the group sequential Wilcoxon-Mann-Whitney test for is given by
where denotes the cumulative distribution function of a -variate normal distribution with mean vector and covariance matrix , .
Let denote the critical values computed from a -variate normal distribution with mean vector , covariance matrix , , and error spending function of choice. Then the approximate power of the group sequential Brunner-Munzel and log win odds tests for is given by
respectively, where denotes the cumulative distribution function of a -variate normal distribution with mean vector and covariance matrix as given above.
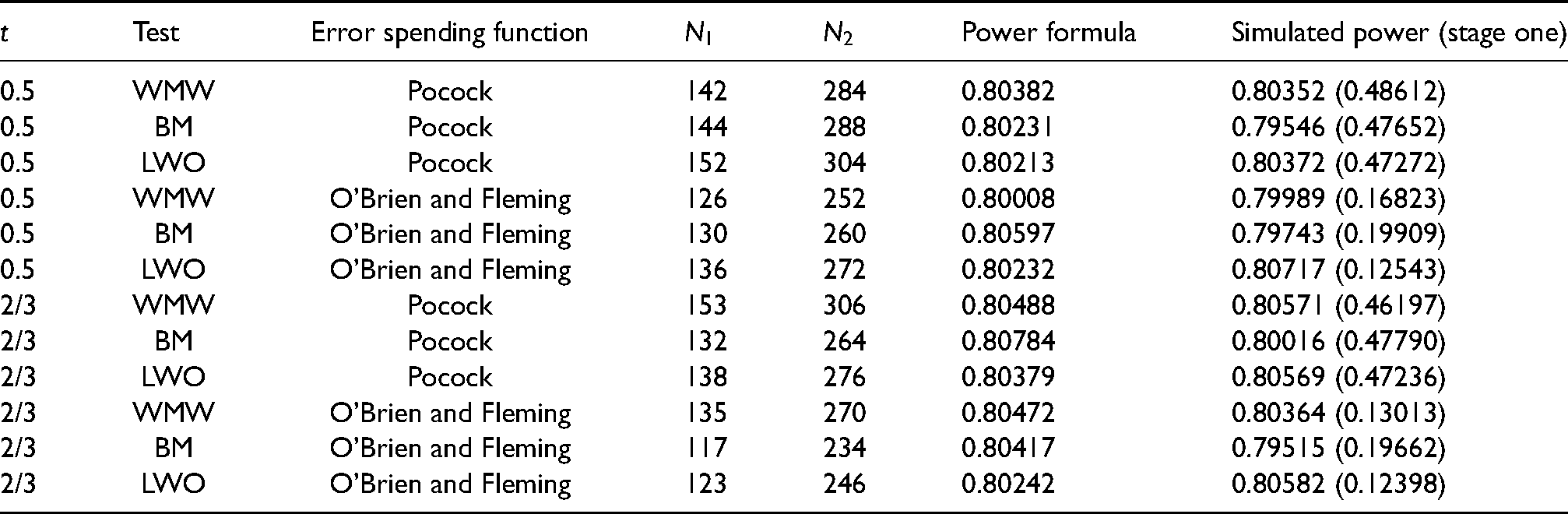
The critical values as well as can be easily obtained from the commands getDesignGroupSequential and pmvnorm of the respective R packages rpact31 and mvtnorm.35 To demonstrate the adequacy of the formulas just presented, the results of a small simulation study with 100,000 replications based on the ordinal distribution defined as in Section 4.2 are depicted in Table 5.
Power of the Wilcoxon-Mann-Whitney (WMW), Brunner-Munzel (BM), and log win odds (LWO) tests for an equally spaced two stage trial with ordinal data as in Section 4.2, , , , , .
Test
Error spending function
Power formula
Simulated power (stage one)
0.5
WMW
Pocock
142
284
0.80382
0.80352 (0.48612)
0.5
BM
Pocock
144
288
0.80231
0.79546 (0.47652)
0.5
LWO
Pocock
152
304
0.80213
0.80372 (0.47272)
0.5
WMW
O’Brien and Fleming
126
252
0.80008
0.79989 (0.16823)
0.5
BM
O’Brien and Fleming
130
260
0.80597
0.79743 (0.19909)
0.5
LWO
O’Brien and Fleming
136
272
0.80232
0.80717 (0.12543)
2/3
WMW
Pocock
153
306
0.80488
0.80571 (0.46197)
2/3
BM
Pocock
132
264
0.80784
0.80016 (0.47790)
2/3
LWO
Pocock
138
276
0.80379
0.80569 (0.47236)
2/3
WMW
O’Brien and Fleming
135
270
0.80472
0.80364 (0.13013)
2/3
BM
O’Brien and Fleming
117
234
0.80417
0.79515 (0.19662)
2/3
LWO
O’Brien and Fleming
123
246
0.80242
0.80582 (0.12398)
7 Discussion
In this paper, we derived group sequential methodology for the Wilcoxon-Mann-Whitney, the Brunner-Munzel, and the log win odds tests, establishing their convergence in distribution to the canonical joint distribution, with simulation studies lending further support to the validity of our approach.
If one is willing both to assume the distributions to be equal under the null and to dispense with confidence intervals, the group sequential Wilcoxon-Mann-Whitney test best maintains the nominal significance level, particularly if sample sizes are small.
In the presence of heteroskedasticity, the Wilcoxon-Mann-Whitney test is either too liberal or too conservative depending on the heteroskedasticity pattern and the sample size allocation ratio. On the other hand, the log win odds test never exceeds the nominal significance level but does have a somewhat conservative tendency in certain scenarios. Nonetheless, the log win odds test allows for test inversion to compute confidence limits for the log win odds, which can readily be converted to the win odds or nonparametric relative effect scales. While the Brunner-Munzel test, with or without -approximation, can be inverted in the same manner, it tends to be too liberal, especially in case of small sample sizes. In light of the fact that the Brunner-Munzel test gives rise to liberal test decisions for nominal significance levels smaller than 0.05 in the nonsequential setting in small samples, this result is hardly surprising.
In the randomised clinical trial setting, there appears little reason to conclude that distributions under the null are not identical. Still, if the treatment arms produce heteroskedastic outcomes in the alternative, one may well be led to infer from the simulation results that the Wilcoxon-Mann-Whitney test might actually turn out to be less powerful than the log win odds test in certain cases. However, as our case study in Section 5 suggests, the different behaviours of the tests are presumably negligible when sample sizes are reasonably large.
Care should be taken when adopting our methods for multi-arm trials. While Dunnet-type36 many-to-one comparisons should not pose particular difficulties, Tukey-type37 all-pairwise comparisons might lead to Efron’s paradox,38–40 that is, the nonparametric relative effect as defined in this paper may point to nontransitive conclusions. If treatment 1 is more beneficial than treatment 2 and treatment 2 is more beneficial than treatment 3, then it does not necessarily follow that treatment 1 is more beneficial than treatment 3.
Since the variance estimators require the endpoint at issue to induce a rank representation and therefore all pairwise comparisons to be transitive, the methodology presented here does not cover hierarchical composite and possibly censored endpoints in general terms as discussed in Buyse,41 Cantagallo et al.,42 Péron et al.,43 or Buyse and Péron.44 However, the idea of linking group sequential theory with generalised -statistics45,46 might prove fruitful in extending our approach in this direction.
Supplemental Material
sj-pdf-1-smm-10.1177_09622802221107103 - Supplemental material for Group sequential methods for the
Mann-Whitney parameter
Supplemental material, sj-pdf-1-smm-10.1177_09622802221107103 for Group sequential methods for the
Mann-Whitney parameter by Claus P Nowak, Tobias Mütze and Frank Konietschke in Statistical Methods in Medical Research
Supplemental Material
sj-R-2-smm-10.1177_09622802221107103 - Supplemental material for Group sequential methods for the
Mann-Whitney parameter
Supplemental material, sj-R-2-smm-10.1177_09622802221107103 for Group sequential methods for the
Mann-Whitney parameter by Claus P Nowak, Tobias Mütze and Frank Konietschke in Statistical Methods in Medical Research
Supplemental Material
sj-R-3-smm-10.1177_09622802221107103 - Supplemental material for Group sequential methods for the
Mann-Whitney parameter
Supplemental material, sj-R-3-smm-10.1177_09622802221107103 for Group sequential methods for the
Mann-Whitney parameter by Claus P Nowak, Tobias Mütze and Frank Konietschke in Statistical Methods in Medical Research
Footnotes
Declaration of conflicting interests
The author(s) declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: Claus P. Nowak and Tobias Mütze are employees of Novartis Pharma AG.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research is supported by the German Science Foundation awards number DFG KO 4680/4-1.
ORCID iDs
Tobias Mütze
Frank Konietschke
Supplemental materials
The supplemental material as regards the simulations can be found online.
Proofs
Proof of Proposition 1. We begin with the derivation of the covariance for the group sequential Wilcoxon-Mann-Whitney test statistics assuming and allowing for ties. Setting , we have for
First, we observe that . Now, with and , there are four cases to distinguish, that is
and by similar arguments, .
Altogether, there are
terms with index combination and ,
terms with and ,
terms with and ,
terms with and .
Thus, if but not necessarily continuous, the quadruple sum reduces to
Putting everything together, we obtain
In case of no ties, three of the four cases discussed above further simplify to and , producing the desired result. Proof of Proposition 2. As for the Brunner-Munzel test, it holds for ,
which concludes the proof. Proof of Proposition 3. As for the Wilcoxon-Mann-Whitney test, we first consider the fixed design, that is, , under . Adopting the notation from Sections 2 and 6 we have
since is approximately standard normal under . Setting for all immediately gives
yielding . The formula for general follows directly from the canonical joint distribution. Proof of Proposition 4. The arguments are completely analogous to the ones given for Proposition 3 and are therefore omitted.
US Food and Drug Administration. Adaptive Designs for Clinical Trials of Drugs and Biologics: Guidance for Industry, 2019. https://www.fda.gov/media/78495/download (Accessed November 9, 2020).
3.
JennisonCTurnbullBW. Group Sequential Methods with Applications to Clinicial Trials. Boca Raton: Chapman & Hall/CRC, 2000.
4.
ProschanMALanKKGWittesJ. Statistical Monitoring of Clinical Trials: A Unified Approach. MA, New York: Springer, 2006.
5.
WassmerGBrannathW. Group Sequential and Confirmatory Adaptive Designs in Clinical Trials. Springer International Publishing, 2016.
6.
MannHBWhitneyDR. On a test of whether one of two random variables is stochastically larger than the other. Ann Math Stat1947; 18: 50–60.
7.
WilcoxonF. Individual comparisons by ranking methods. Biometric Bull1945; 1: 80–83.
8.
WilcoxonF. Probability tables for individual comparisons by ranking methods. Biometrics1947; 3: 119–122.
9.
AllingDW. Early decision in the Wilcoxon two-sample test. J Am Stat Assoc1963; 58: 713–720.
10.
PhatarfodRMSudburyA. A simple sequential Wilcoxon test. Aust J Stat1988; 30: 93–106.
11.
ShusterJJChangMNTianL. Design of group sequential clinical trials with ordinal categorical data based on the Mann–Whitney–Wilcoxon test. Seq Anal2004; 23: 413–426.
12.
BrunnerEMunzelU. The nonparametric Behrens-Fisher problem: Asymptotic theory and a small-sample approximation. Biom J2000; 42: 17–25.
13.
BrunnerEBathkeACKonietschkeF. Rank and Pseudo-Rank Procedures for Independent Observations in Factorial Designs. Springer International Publishing, 2018.
14.
ThasODe NeveJClementLet al. Probabilistic index models. J R Stat Soc B (Statistical Methodology)2012; 74: 623–671.
15.
FayMPBrittainEHShihJHet al. Causal estimands and confidence intervals associated with Wilcoxon-Mann-Whitney tests in randomized experiments. Stat Med2018; 37: 2923–2937.
16.
BrunnerEVandemeulebroeckeMMützeT. Win odds: An adaptation of the win ratio to include ties. Stat Med2021; 40: 3367–3384.
17.
PutterJ. The treatment of ties in some nonparametric tests. Ann Math Stat1955; 26: 368–386.
18.
PocockSJAritiCACollierTJet al. The win ratio: A new approach to the analysis of composite endpoints in clinical trials based on clinical priorities. Eur Heart J2011; 33: 176–182.
19.
WangDPocockS. A win ratio approach to comparing continuous non-normal outcomes in clinical trials. Pharm Stat2016; 15: 238–245.
20.
GasparyanSBFolkvaljonFBengtssonOet al. Adjusted win ratio with stratification: Calculation methods and interpretation. Stat Methods Med Res2020; 0: 1–32.
21.
ScharfsteinDOTsiatisAARobinsJM. Semiparametric efficiency and its implication on the design and analysis of group-sequential studies. J Am Stat Assoc1997; 92: 1342–1350.
22.
CramérHWoldH. Some theorems on distribution functions. J Lond Math Soc1936; s1-11: 290–294.
23.
LévyP. Calcul des probabilités, volume 9. Paris: Gauthier-Villars Paris, 1925.
24.
Ruymgaart FH (1980) A unified approach to the asymptotic distribution theory of certain midrank statistics. In Raoult JP (eds.) Statistique non Paramétrique Asymptotique. Lecture Notes in Mathematics, Vol 821. Springer, Berlin: Heidelberg. https://doi.org/10.1007/BFb0097422
25.
SatterthwaiteFE. An approximate distribution of estimates of variance components. Biometrics Bull1946; 2: 110–114.
26.
SmithHF. The problem of comparing the results of two experiments with unequal errors. J Council Sci Ind Res1936; 9: 211–212.
27.
WelchBL. The significance of the difference between two means when the population variances are unequal. Biometrika1937; 29: 350–362.
28.
PocockSJ. Group sequential methods in the design and analysis of clinical trials. Biometrika1977; 64: 191–199.
29.
O’BrienPCFlemingTR. A multiple testing procedure for clinical trials. Biometrics1979; 35: 549–556.
30.
LanKKGDeMetsDL. Discrete sequential boundaries for clinical trials. Biometrika1983; 70: 659–663.
DunnettCW. A multiple comparison procedure for comparing several treatments with a control. J Am Stat Assoc1955; 50: 1096–1121.
37.
TukeyJ. Comparing individual means in the analysis of variance. Biometrics1949; 5: 99–114.
38.
GardnerM. The paradox of the nontransitive dice and the elusive principle of indifference. Sci Am: Math Games Column1970; 223: 110–114.
39.
SavageRP. The paradox of nontransitive dice. Am Math Mon1994; 101: 429–436.
40.
ThangeveluKBrunnerE. Wilcoxon-Mann-Whitney test for stratified samples and Efron’s paradox dice. J Stat Plan Inference2007; 137: 720–737.
41.
BuyseM. Generalized pairwise comparisons of prioritized outcomes in the two-sample problem. Stat Med2010; 29: 3245–3257.
42.
CantagalloEDe BackerMKicinskiMet al. A new measure of treatment effect in clinical trials involving competing risks based on generalized pairwise comparisons. Biom J2021; 63: 272–288.
43.
PéronJBuyseMOzenneBet al. An extension of generalized pairwise comparisons for prioritized outcomes in the presence of censoring. Stat Methods Med Res2018; 27: 1230–1239.
44.
BuyseMPeronJ. Generalized pairwise comparisons for prioritized outcomes. In Piantadosi S and Meinert CL (eds.) Principles and Practice of Clinical Trials. Cham: Springer, 2020. pp. 1–25.
45.
HoeffdingW. A class of statistics with asymptotically normal distributions. Ann Stat1948; 19: 293–325.
46.
LeeAJ. U-Statistics: Theory and Practice. New York: Marcel Dekker, 1990.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.