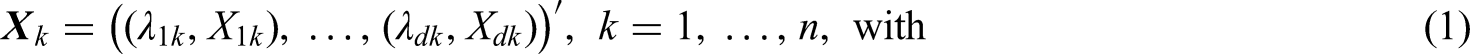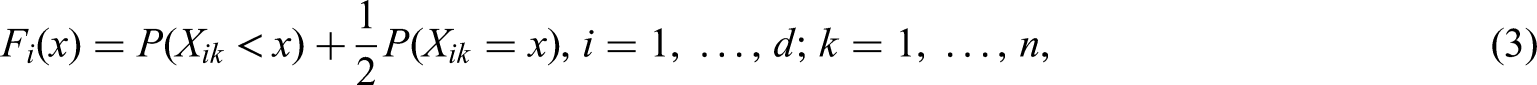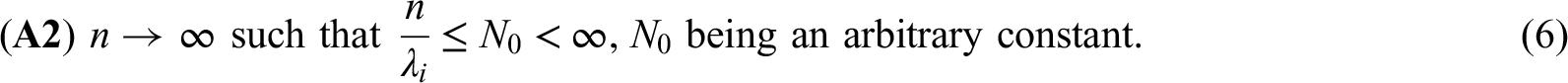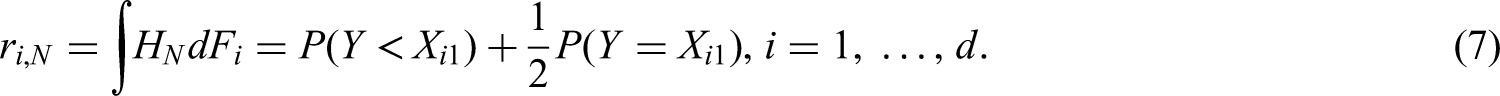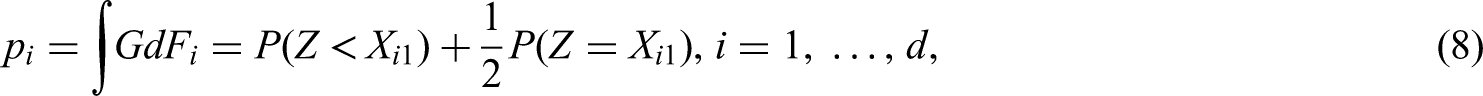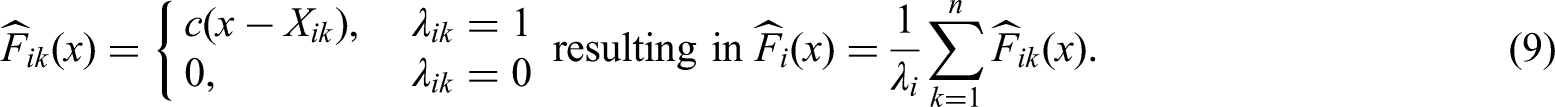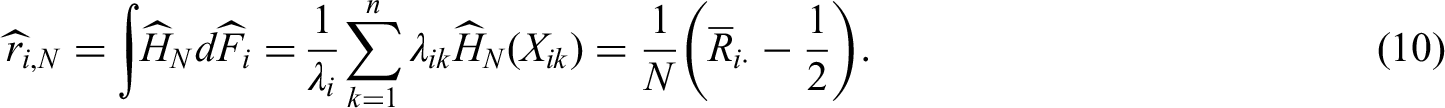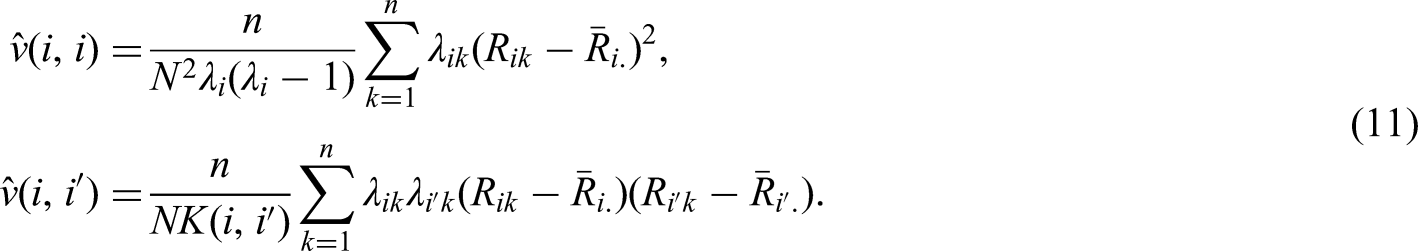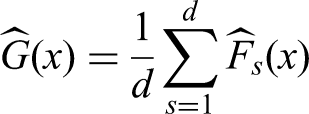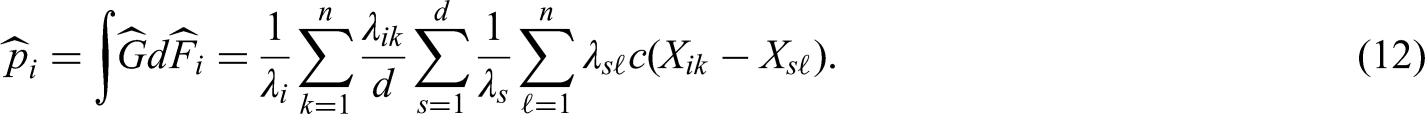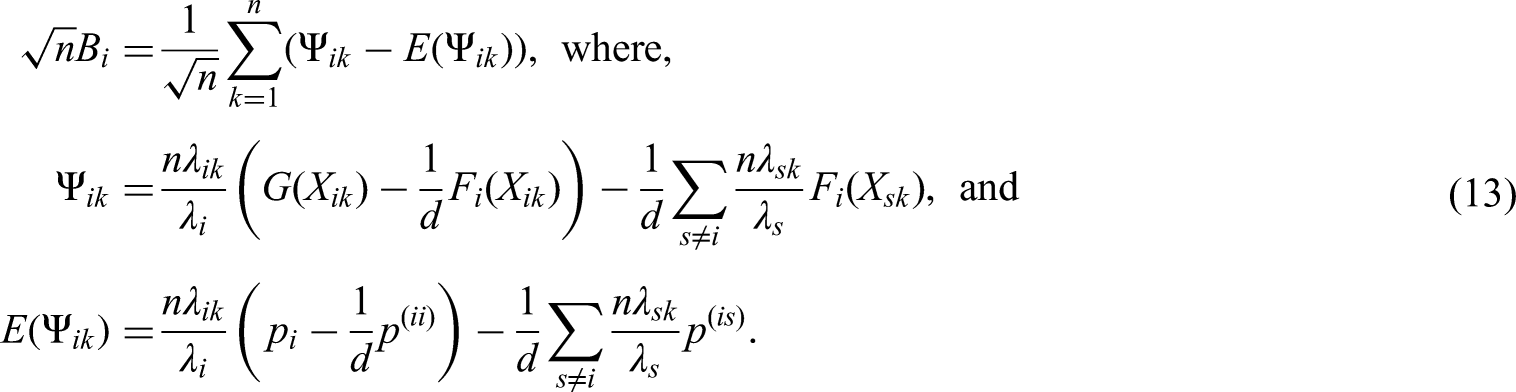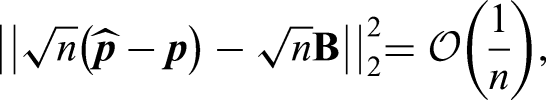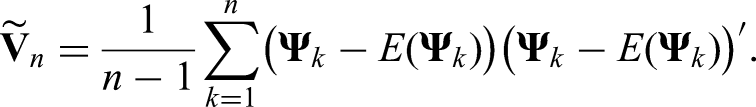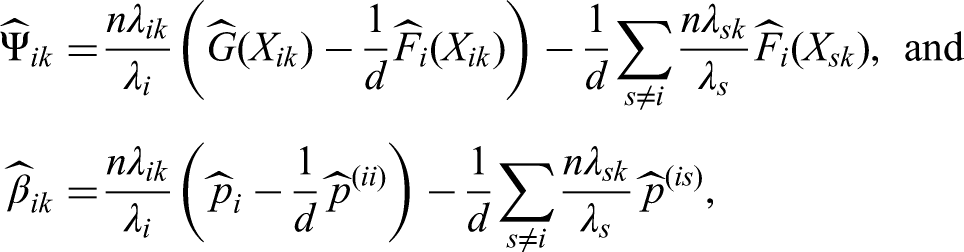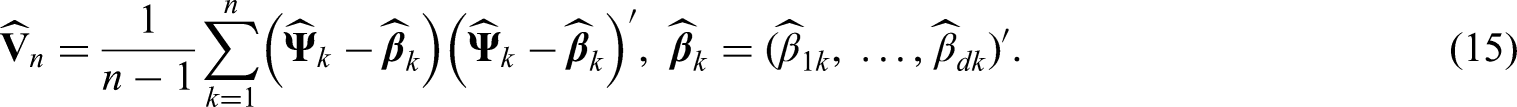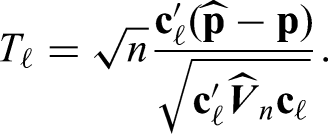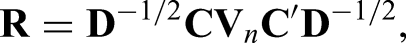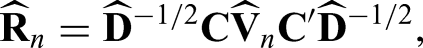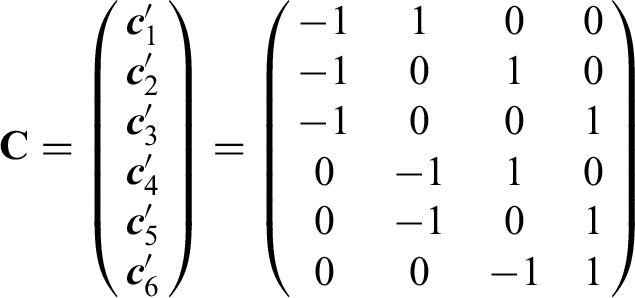We develop purely nonparametric methods for the analysis of repeated measures designs with missing values. Hypotheses are formulated in terms of purely nonparametric treatment effects. In particular, data can have different shapes even under the null hypothesis and therefore, a solution to the nonparametric Behrens-Fisher problem in repeated measures designs will be presented. Moreover, global testing and multiple contrast test procedures as well as simultaneous confidence intervals for the treatment effects of interest will be developed. All methods can be applied for the analysis of metric, discrete, ordinal, and even binary data in a unified way. Extensive simulation studies indicate a satisfactory control of the nominal type-I error rate, even for small sample sizes and a high amount of missing data (up to 30%). We apply the newly developed methodology to a real data set, demonstrating its application and interpretation.
Repeated measures (RM) designs are commonly used in various research areas and especially in biomedicine. In such layouts, subjects (e.g. patients) are observed under different time points or experimental conditions allowing for statistical inference within a longitudinal framework. A special example is given by a paired design in which each subject is observed twice. Even though RM designs might be more efficient and a cost saving alternative to general factorial designs involving independent units only, missing values might occur, which aggravate both the statistical modeling and evaluation tremendously. Besides determining the missing value mechanism (missing completely at random (MCAR), missing at random (MAR) or missing not at random), estimation of treatment effects along with testing hypotheses of interest becomes a challenging part. Up to now, many powerful parametric (mean-based) as well as purely nonparametric (rank-based) statistical methods exist for data evaluations. To name a few, RM analysis of variance (RM-ANOVA), linear mixed models, or generalized estimation equations are well-established parametric tools that can be used to analyze RM with missing data (assuming normality and specific covariance matrices). For a detailed overview we refer to Little and Rubin1. Brunner et al.2 and Domhof et al.3 propose purely nonparametric rank-based methods, which do not rely on any distributional assumption and can be used for analyzing metric, discrete or even ordinal data in a unified way. While these ranking methods assume MCAR data, Akritas et al.4 propose a generalized approach for bivariate data that is valid under a mixture of MCAR and MAR observations. The methods are known to be powerful and robust (with respect to data distributional shapes) and, in particular, they are invariant under any monotone transformation of the data. Therefore, ranking procedures are often preferred for making statistical inference in ordinal data, in general. In RM designs with missing values, however, the application of existing ranking methods has some disadvantages, which are all motivated from a practical point of view:
The procedures can only be used to test global null hypotheses formulated in terms of the distribution functions (i.e. all distributions are identical). Thus, they do not allow for variance heteroscedasticity under the null hypothesis. But, allowing for different variances makes the statistical method more flexible and robust to model mis-specifications.
Testing the global null hypothesis usually does not answer the main research question of the practitioners; inferring linear contrasts in means of the effects of interest to detect local and specific differences is of practical importance (controlling the family wise error rate in the strong sense).
The methods cannot be inverted into confidence intervals for the treatment effects. Confidence intervals, however, are used to display variability in the data and shall complement any decent statistical analysis. In particular, international regulatory authorities (e.g. international conference on harmonization ICH) require the computation of confidence intervals (see ICH E9 for clinical trials).
The procedures proposed by Domhof et al.3 might not even be computable, because the estimator of the proposed variance-covariance matrix is not necessarily positive semidefinite3.
The present paper aims to improve upon these points and thus foster the applicability of nonparametric methods. As a specific example, we propose a solution to the nonparametric Behrens-Fisher problem in RM designs with missing data. All of the proposed methods use all-available data and are valid under the MCAR mechanism. In particular, to tackle point 4, the paper proposes a positive-semidefinite estimator of the variance-covariance matrix of the rank means, that is consistent under arbitrary (but fixed) alternatives. The estimation of the covariance matrix as proposed by Konietschke et al.5 cannot be easily transferred to the case of incomplete data. Thus, this estimation problem along with the development of statistical methods is the main focus of this paper. As a side note, we also introduce a new approximation of the distribution of the ANOVA-type statistic of Konietschke et al.5 via the Greenhouse-Gaisser method, first introduced by Box6. The remainder of the paper is organized as follows. A motivating example with real data is given in section “Motivating example”. In the next section “Nonparametric statistical model and effects”, the statistical model is introduced. Existing ranking methods and their limitations are discussed in section “Existing rank methods and their limitations”. Point estimators along with their asymptotic distributions are exemplified in section “Estimators and their asymptotic distribution” followed by positive semidefinite estimation of the variance covariance matrix in section “Estimation of the covariance matrix”. Test procedures and confidence intervals are provided in Section “Test statistics”. Results of extensive simulation studies are presented in Section “Simulation study”, where we exemplify the behavior of the methods in case of MCAR and MAR scenarios. It turns out that the methods are also applicable in MAR scenarios. The paper closes with the evaluation of the illustrative example in section “Analysis of the example” and a discussion about the findings in section “Discussion and conclusions”. Technical proofs and additional results of the simulation study can be found in the supplementary material.
Motivating example
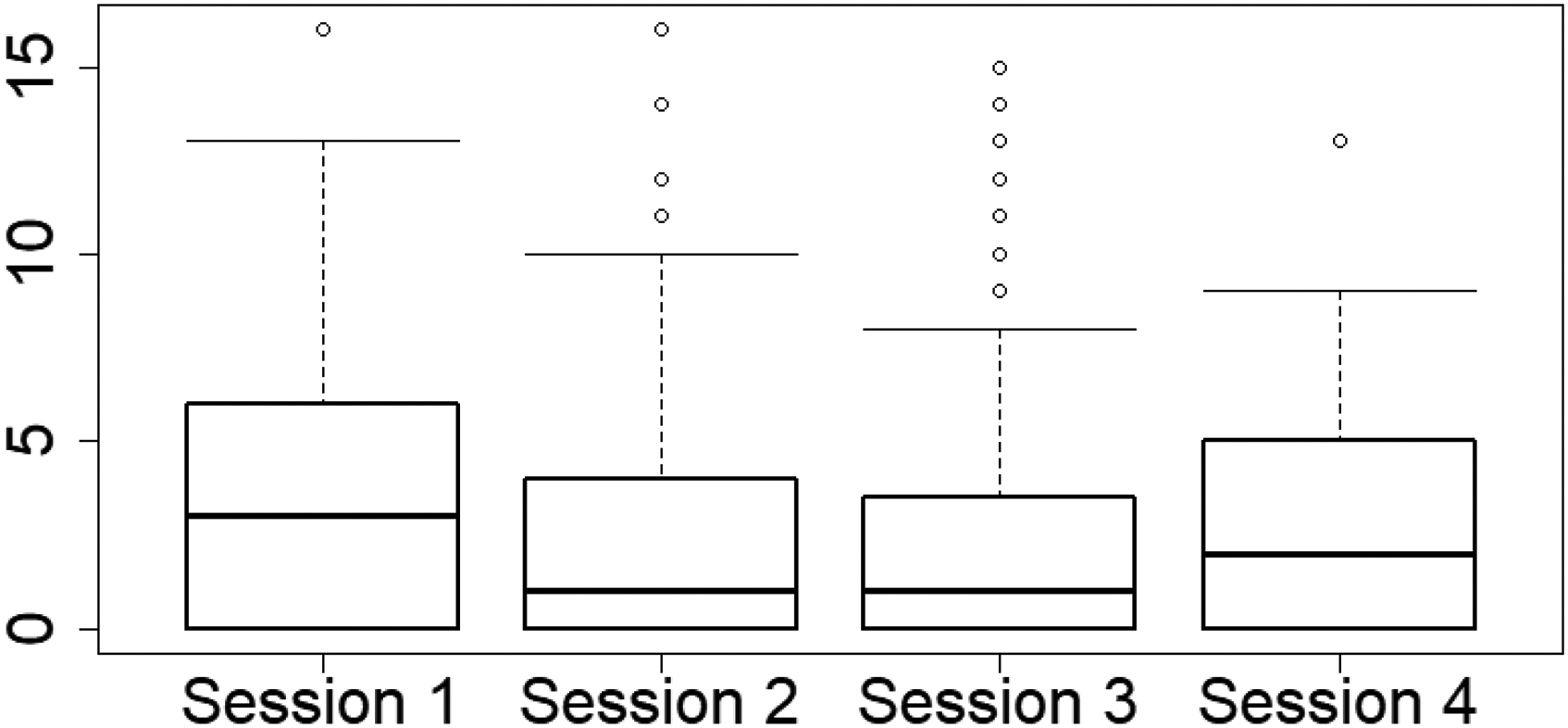
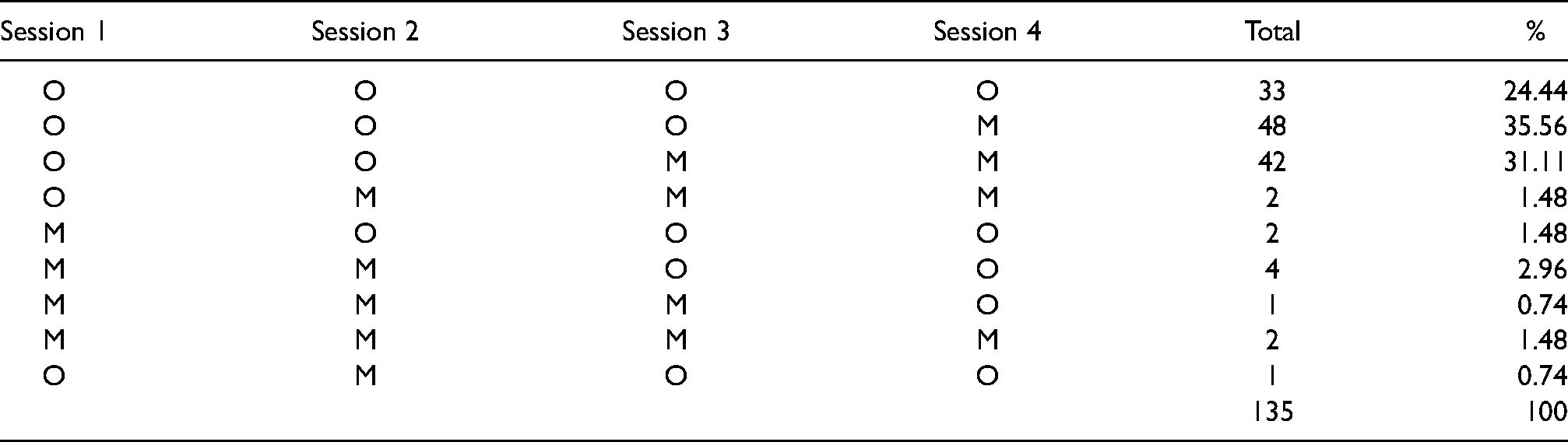
As a motivating example we consider a migraine trial data set, which has already been investigated by Kostecki-Dillon et al.7, Gao8, and Konietschke et al.9. In total 135 patients were enrolled in a non-drug headache program, which consisted of four consecutive sessions. In each session, the headache severity level was measured on an ordinal scale ranging from 0 to 20. The lower the score, the better the clinical outcome. The objective of this study is to investigate whether the scores change during the four consecutive sessions. Boxplots of the scores are displayed in Figure 1. It can be readily seen that scores decrease (on median) until session 3 and slightly increase in the last session. However, the data set contains a large amount of missing values, out of the 135 patients, only 33 could be observed in each of the four sessions. Table 1 displays the exact missing pattern. Gao8 performed correlation analyses of the missing proportions versus the headache severity level and concluded that assuming MCAR mechanism is reasonable for the study. Note that the data is measured on an ordinal scale and is highly skewed. Therefore, calculating means and applying mean-based inference methods for analyzing this data set is inappropriate. As a remedy, a purely nonparametric statistical model will be introduced in the next section.
Boxplots of the migraine severity level for all four sessions—all available cases.
Missing pattern in migraine trial, O = observed, M = missing.
Session 1
Session 2
Session 3
Session 4
Total
%
O
O
O
O
33
24.44
O
O
O
M
48
35.56
O
O
M
M
42
31.11
O
M
M
M
2
1.48
M
O
O
O
2
1.48
M
M
O
O
4
2.96
M
M
M
O
1
0.74
M
M
M
M
2
1.48
O
M
O
O
1
0.74
135
100
Nonparametric Statistical Model and Effects
The data example from Section “Motivating example” can be described by independent and identically distributed -dimensional random vectors
and marginal distributions . The indicators are known constants and used for convenient notation. In order to account for metric, discrete, ordered categorical, and even dichotomous data in a unified way, we use the normalized version of the distribution function
which is the average of the left- and the right continuous versions and of the distribution function, respectively. The normalized version of the distribution function was first mentioned by Ruymgaart10 and was later used by several authors developing rank statistics in the case of ties. A detailed overview is provided by Brunner et al.11.
In model (1), the numbers of non-missing observations under condition and in total are given by
respectively. In order to derive asymptotic results, we consider the following general framework:
These assumptions imply that asymptotic results hold even when the numbers of missing values are bounded, which is the most realistic case. Beyond that, other assumptions as, e.g. specific pattern of missing values, are not required. Model (3), however, does not contain any parameters which could be used to define an appropriate treatment effect. To accomplish this, Domhof et al.3 propose to use the marginal distributions within the weightedrelative marginal effects
Here, denotes a weighted mean distribution function and . Since depends on the amount of missing data, is not a model constant and cannot be used to quantify causal differences between the distributions a priori. Testing hypotheses formulated in terms of the weighted relative effects as well as computing confidence intervals for them would be dubious. Following Konietschke et al.12 and Brunner et al.13 for the complete case setting, we therefore propose to use unweighted relative effects
see also Umlauft et al.14. Here, denotes the unweighted mean distribution function and , independent of . Thus, relates the distribution relatively to the mean distribution and models whether observations coming from tend to result in larger values than those from . If , then data coming from tend to be smaller than those coming from . If , then none of the observations tend to be smaller or larger. No treatment effect is therefore indicated as , where denotes an appropriate contrast matrix and denotes the vector of all relative marginal effects. Note that the null hypothesis implies , whereas the reverse does not hold in general, as can be easily seen in normal distribution models. Therefore, testing is known as the nonparametric Behrens-Fisher problem15. We note that Domhof16 develops univariate confidence intervals for the effects , which, however, might result in paradox conclusions, for example, non-transitive relative effects and we therefore do not follow this approach further. The asymptotic results however, are similar. First, existing rank methods for testing the null hypothesis will be discussed.
Existing rank methods and their limitations
It has been shown in (7) that the weighted relative marginal effect is a summary measure of the marginal distribution functions and . A consistent estimator of is now obtained by replacing each marginal distribution function and with their empirical counterpart within the integral representation of in (7). In order to account for possibly missing values, we define the empirical distribution function of the data under condition as the average of the all-available data by
Here, , according as , denotes the normalized version of the count function. Furthermore, let denote the empirical counterpart of and note that is the mid-rank of among all observed values. If and thus is missing, , for convenience. Plugging-in and into (7) leads to a rank estimator of as
Here, denotes the mean of the ranks under condition . For convenient representation of asymptotic results, the point estimators are collected in the vector .
Akritas and Brunner17 have shown that follows, asymptotically, as , a multivariate normal distribution with expectation and covariance matrix under the special null hypothesis , where . The asymptotic distribution of the estimators under (any) alternative has not yet been developed. Moreover, since is unknown in practical applications and must be estimated from the data, Domhof et al.3 propose to use with
Here with , see Brunner et al.18 and Domhof et al.3. The estimator , however, is not necessarily positive semidefinite in case of missing values and thus might result in a negative variance estimator of a linear combination of the estimators . In addition, since the distribution of the estimators is only known under the null hypothesis , confidence intervals for the effects of interest—even without missing values—cannot be computed. In the next section, consistent estimators of the unweighted relative effects along with a positive semidefinite estimator of its variance-covariance matrix will be proposed. The estimator is even consistent under general alternatives formulated in terms of .
Estimators and their asymptotic distribution
Following the above ideas, a point estimator for in (8) is readily available by replacing each of the unknown distribution functions and with their empirical counterparts in the integral representation of . Plugging-in the empirical counterpart
In general, the estimator cannot be computed using ranks of the data; instead it is a sum of indicators (values of the count functions) and therefore its numerical computation is slightly more involved than that of . If no missing values are apparent, then . First its asymptotic properties will be studied in the following proposition.
The estimator is asymptotically unbiased and strongly consistent under (A1) in (5), i.e.
.
Next, the asymptotic distribution of the statistic will be derived. The following Theorem 1 shows that has, asymptotically, under (A1) and (A2), the same distribution as the random vector , whose components are sums of independent random variables:
Here, and denote pairwise defined relative marginal effects between time points and and and , respectively.
Let be the vector of the random variables , as defined in (13). If such that (A1) and (A2) in (5) and (6) hold, then,
with denoting the -norm.
It follows from Theorem 1, that the asymptotic covariance matrix of the linear rank statistic is given by
The asymptotic multivariate normality of the linear rank statistic is given in the next Theorem.
Under the assumptions (A1) and (A2), the statistic follows asymptotically, as , a multivariate normal distribution with expectation and covariance matrix .
The covariance matrix , however, is unknown in practical applications and must be estimated from the data for making statistical inferences. We will derive a consistent and positive-semidefinite estimator in the next section.
Estimation of the covariance matrix
If the random variables in (13) were observable, then an estimator of would be given by
Note that in the definition of each vector is centered with its own specific expectation and therefore, is not the empirical covariance matrix of the vectors . However, the variables are not observable and thus, cannot be computed in practical applications. Therefore, we replace them with observable random variables, which are ‘close enough’ to in an appropriate norm. Define the vectors , the components of which are the empirical counterparts
In this section, we introduce different test procedures (global and multiple) to test the null hypothesis . First, quadratic test procedures will be explained and a linear multiple contrast test procedure (MCTP) will be introduced afterwards. One advantage of the MCTP over the quadratic test procedures is, that it can be used for testing multiple hypotheses as well as for constructing simultaneous confidence intervals for the relative marginal effects and linear combinations thereof. In particular, the adjusted p-values and the corresponding confidence intervals are compatible, that is, it is not possible that the null hypothesis is rejected by the multiple comparison procedure, but the corresponding confidence interval includes - the hypothetical value of no treatment under .
Quadratic tests
Domhof et al.3 introduce two different types of test statistics to infer the global null hypothesis formulated in terms of the distribution functions. Since both of the methods only depend on the vector of point estimators, their estimated variance-covariance and hypothesis (contrast) matrices, they can be generalized to test using the newly developed estimators. Consider the Wald-type statistic (WTS)
which is a quadratic form in the point estimators . Under , the distribution of can be approximated by a distribution with degrees of freedom. Here, denotes the Moore-Penrose inverse of a matrix. Simulation studies indicate, however, that the test upon behaves liberal and highly over-rejects the null hypothesis when sample sizes are small. Therefore, Domhof et al.3 propose to approximate its distribution by an F-distribution resulting in the so-called ANOVA-type statistic. Let be a projection matrix and let be a generalized inverse of . Then, the null hypotheses and are equivalent. It holds under that the distribution of the ATS
can be approximated by a distribution with
degrees of freedom. Here, denotes the trace of the matrix . However, simulation studies indicate a liberal behavior of the ATS in some settings5. We therefore propose to apply the Greenhouse-Gaisser method introduced by Box6 resulting in
which can be approximated by an distribution with
degrees of freedom. Note that we will refer to (17) as the first version of the ATS or ATS (1) and to (19) as the second version of the ATS or ATS (2) for convenience. Next, MCTPs along with simultaneous confidence intervals will be introduced.
Multiple contrast test procedure
As already outlined above, the quadratic test procedures can only be used to test the global null hypothesis of no effect. Therefore, Konietschke et al.5 propose a MCTP for making local statistical inference. In order to test the individual null hypothesis , consider the test statistic
Here, denotes the th row vector of . Even though the exact distribution of for finite sample size remains unknown, it is asymptotically standard normal. Furthermore, the test statistics and are not necessarily independent due to the chosen contrasts and () and/or the RM data. In order to take the correlations across the test statistics within the multiplicity adjustment into account, we collect them in the vector
It follows from Theorem 2 and Slutzky’s Theorem, that follows, asymptotically, a multivariate normal distribution with expectation and correlation matrix
where is a diagonal matrix of the diagonal elements of . For large sample sizes, the individual null hypothesis will be rejected at multiple level , that is, the procedure controls the familywise type-I error rate, if
where denotes the two-sided -equicoordinate quantile of the distribution12. The two-sided -equicoordinate quantile satisfies the condition for . Compatible -simultaneous confidence intervals for the effects are given by
We refer to Bretz et al.19 for the numerical derivation of the equicoordinate quantile. Finally, for large sample sizes, the global null hypothesis will be rejected at two-sided multiple level , if
The correlation matrix, however, is unknown in practical applications. We recommend to replace with its consistent estimator
in (21), (22), and (23), respectively. Here, denotes the diagonal matrix obtained from the diagonal elements of . For small sample sizes, we follow Konietschke et al.5, who proposed in the case of complete observations to approximate the distribution of by a multivariate central distribution. It follows from sections “Estimators and their asymptotic distribution” and “Estimation of the covariance matrix” that both choices lead to asymptotic correct multiple contrast tests.
Simulation study
All of the procedures developed in the previous sections are of asymptotic nature and thus, investigating their finite sample behavior with respect to their control of the type-I error rate (at nominal level) and power to detect alternatives within extensive simulation studies is mandatory. We considered all introduced tests, namely
the WTS in (16) with a critical value from a distribution,
the ATS (1) in (17) with the proposed -approximation,
the ATS (2) in (19) with the proposed -approximation,
the WTS and ATS for testing as proposed by Domhof et al.3
in different homo- and heteroscedastic RM designs with different rates of missing values. Even though Domhof et al.3 reported a liberal behavior of the WTS (for testing ), we added the method as a competing procedure for completeness. We thus also investigated their robustness to variance heteroscedasticity. Since all of the methods above use all-available data, we additionally compared them with two MCTP-based approaches: a complete case analysis and a naive imputation approach, in which we either
deleted the whole observation vector of subject if any was missing (), or
if was missing (), we calculated , and assigned it to and set .
Data have been generated using discretized, by rounding to integers, normal and log-normal distributions with varying numbers of time points , sample sizes , amount of missing values , and six different types of covariance matrices
The covariance matrices were chosen to model a broad selection of dependency patterns, including homoscedastic ( and ) as well as heteroscedastic marginals. Note that holds only under and . We furthermore investigated the methods’ sensitivity to both MCAR and MAR data to cover realistic scenarios. In order to generate the former, we multiplied the observations with randomly chosen indicators , with a zero entry being interpreted as a missing observation, whereas we followed Santos et. al.20 for the latter. Hereby we defined pairs of observations , where determines the probability that was actually observed. For instance, in case of we defined the pairs and . Following the idea of Amro et al.21, we investigated two different types of MAR scenarios, MAR (1) and MAR (2). First, for the MAR (1) scenario, we divided into three groups: (1) , (2) , and (3) , where is the variance of . Then, we assigned a missing rate of to the first and third group and a missing rate of to the second group. Second, in the MAR (2) scenario, data was divided into two groups using the median, following the idea of Zhu et al22. Specifically, we defined (1) and (2) . Here, we assigned a missing rate of to the first group and a missing rate of to the second group.
For each design, simulation runs were performed using the software package of statistical computing, version R 3.6.423. The complete simulation code is available on https://github.com/KerstinRubarth/RM_Miss.
First, we will discuss simulation results when holds and data is MCAR (Table S. 1). It appears that the ATS for testing tends to be slightly liberal when samples are rather small (). Otherwise, it exhibits an almost accurate type-I error control. In fact, the amount of missing values impact its behavior only by slightly increasing or decreasing the type-I error rate. A similar behavior of the newly developed ATS (1) for testing can be detected. The ATS (2) for testing controls the type-I error even more accurate while sometimes being slightly conservative. Moreover, the new MCTP tends to be quite accurate in most settings and gets slightly liberal if the probability of missingness increases. Contrary, both WTS methods are too liberal for all settings and cannot be recommended. Overall, the simulations for indicate that both versions of the ATS and the MCTP for testing control the type-I error rate quite accurately when .
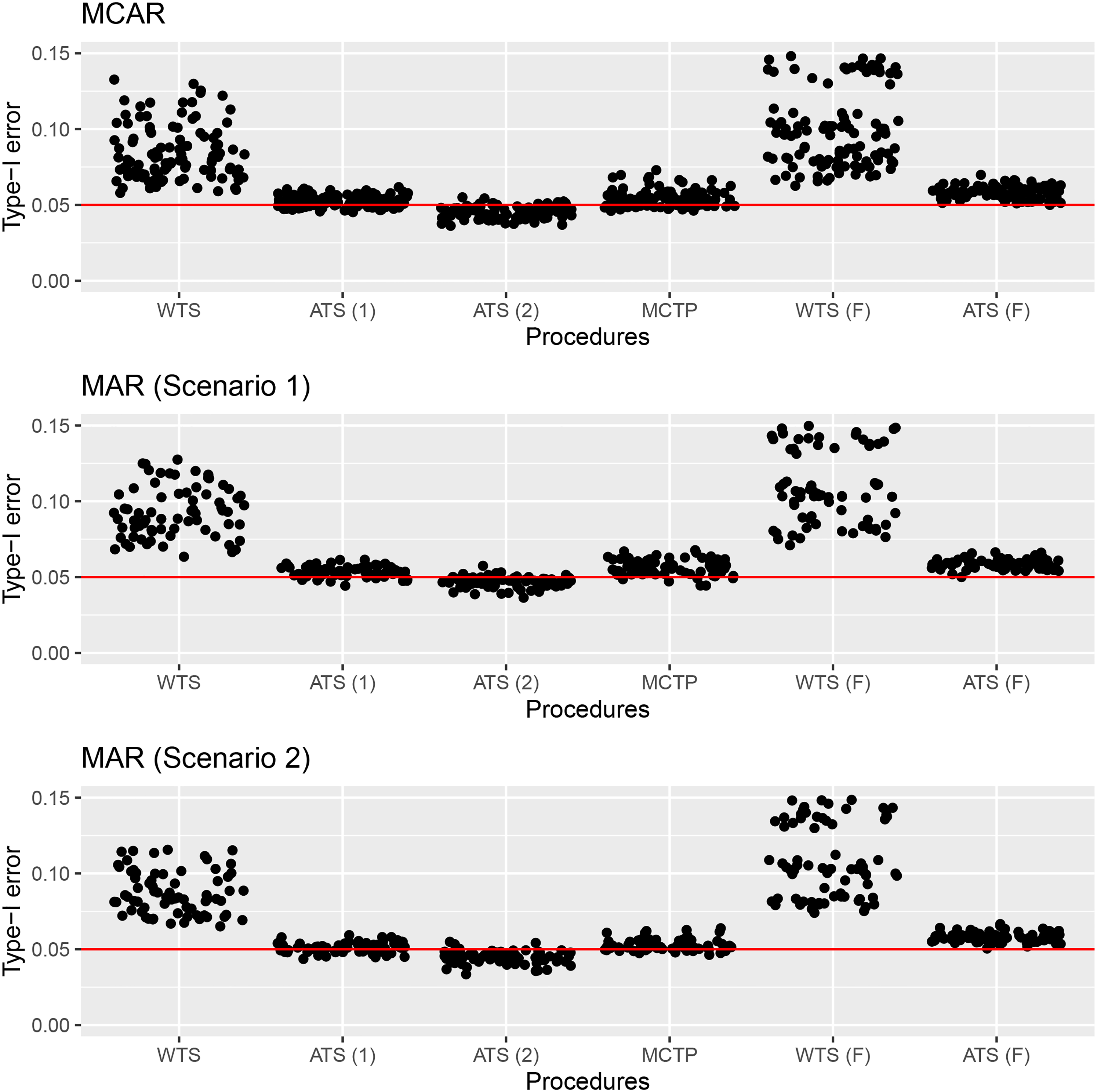
Next, we will explore the methods’ behavior under variance heteroscedasticity (Table S. 2 and Table S. 3). It turns out that the methods tend to be quite accurate in most scenarios and tend to over-reject the null hypothesis when samples are small and missing probabilities are high. However, some scenarios also indicate a fairly robust behavior of the methods for testing . Overall, the methods seem not be too sensitive towards variance heteroscedasticity. In general, the procedures work equally well in case of normally and log-normally distributed data. However, in most scenarios, both versions of the ATS for testing control the type-I error more accurate than the ATS for testing . As already pointed out, both WTS procedures do not control the type-I-error rate in case of smaller sample sizes. Again, for small sample sizes, e.g. , the ATS (2) under performs better than the MCTP. However, all test statistics show a conservative behavior in case of high correlations and small sample sizes. This was already mentioned in Konietschke et al.5 and Friedrich et al.24 for the RM design without missing data and Munzel25 as well as Harrar et al.26 and Amro et al.27 for the paired two sample case. Overall, the simulation studies indicate that the newly developed methods based upon the ATS, especially the second version, and (to some extend) the MCTP control the type-I error well when . Next, we compare the results of the type-I error simulation for data under MCAR and MAR mechanisms. A graphical overview of the type-I error rates of the procedures for testing and in various settings can be found in Figure 2. Since the missing rates in the MCAR and MAR scenarios in these simulations were similiar and no difference in terms of the type-I error rates is apparent, the procedures seem to be fairly robust to the missing value mechanism, though the theory was developed under the MCAR assumption.
Type-I error rates of the newly proposed Wald- (WTS), ANOVA-type (ATS (1) and ATS (2)) and MCT procedures and the procedures of Domhof et al.3 under the three different missing mechanisms MCAR, MAR (1) and MAR (2). MCT: multiple contrast test; MCAR: missing completely at random; MAR: missing at random.
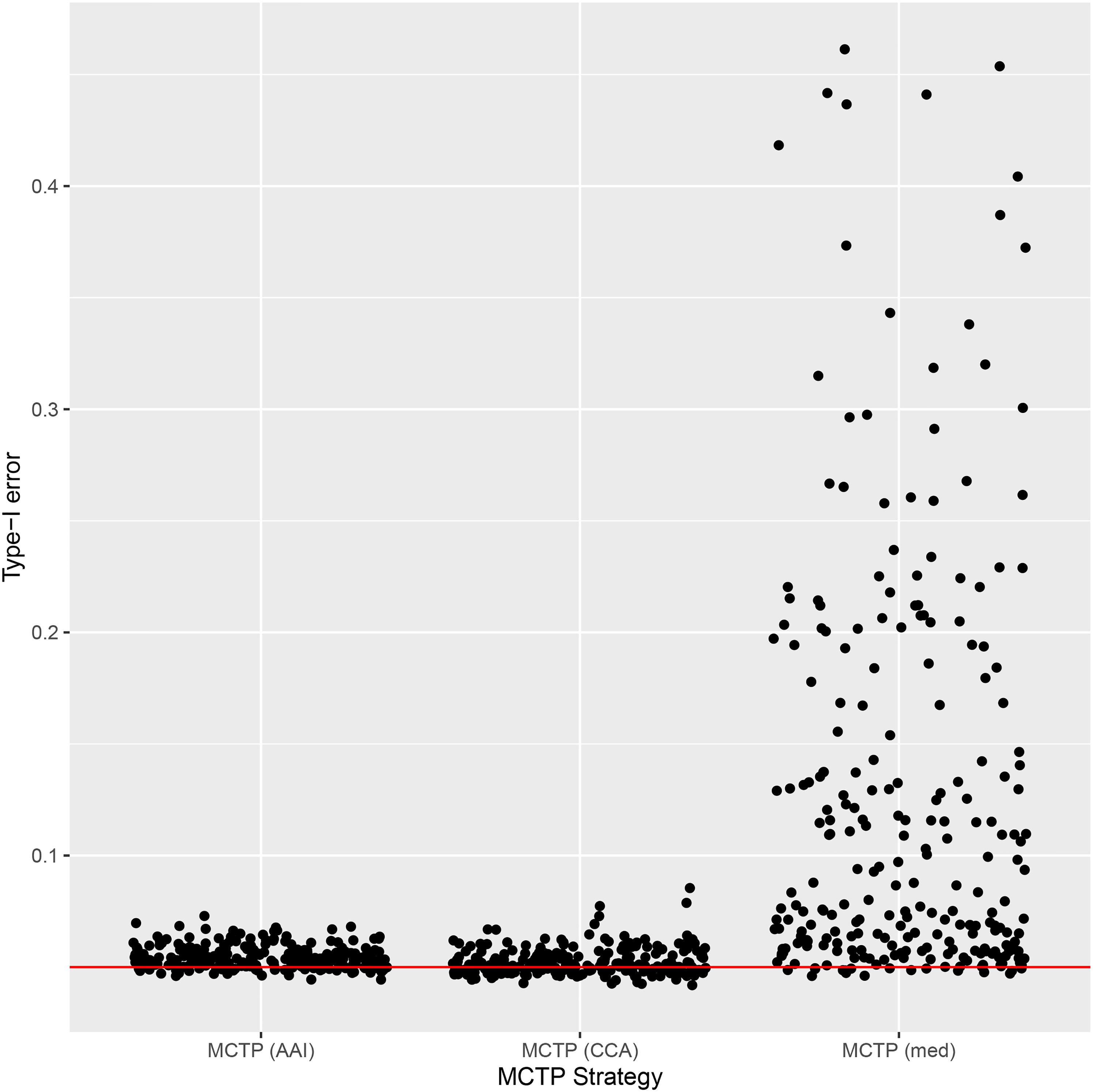
Since we advocate to use the MCTP as it additionally allows the simultaneous testing of the corresponding single contrast hypotheses, we want to compare its behavior in terms of type-I-error rates in comparison to two “naive” procedures for handling missing data: median imputation and complete case analysis. A graphical presentation of the results can be found in Figure 3. The results for the newly proposed MCTP which uses all-available information and the MCTP using only complete cases are comparable. As expected (van Buuren28, Ramosaj et al.29), the simple median imputation yields in some scenarios with many missings extremly inflated type-I error rates and is therefore not recommend. Note that data has been generated under MCAR and MAR assumptions for this comparison.
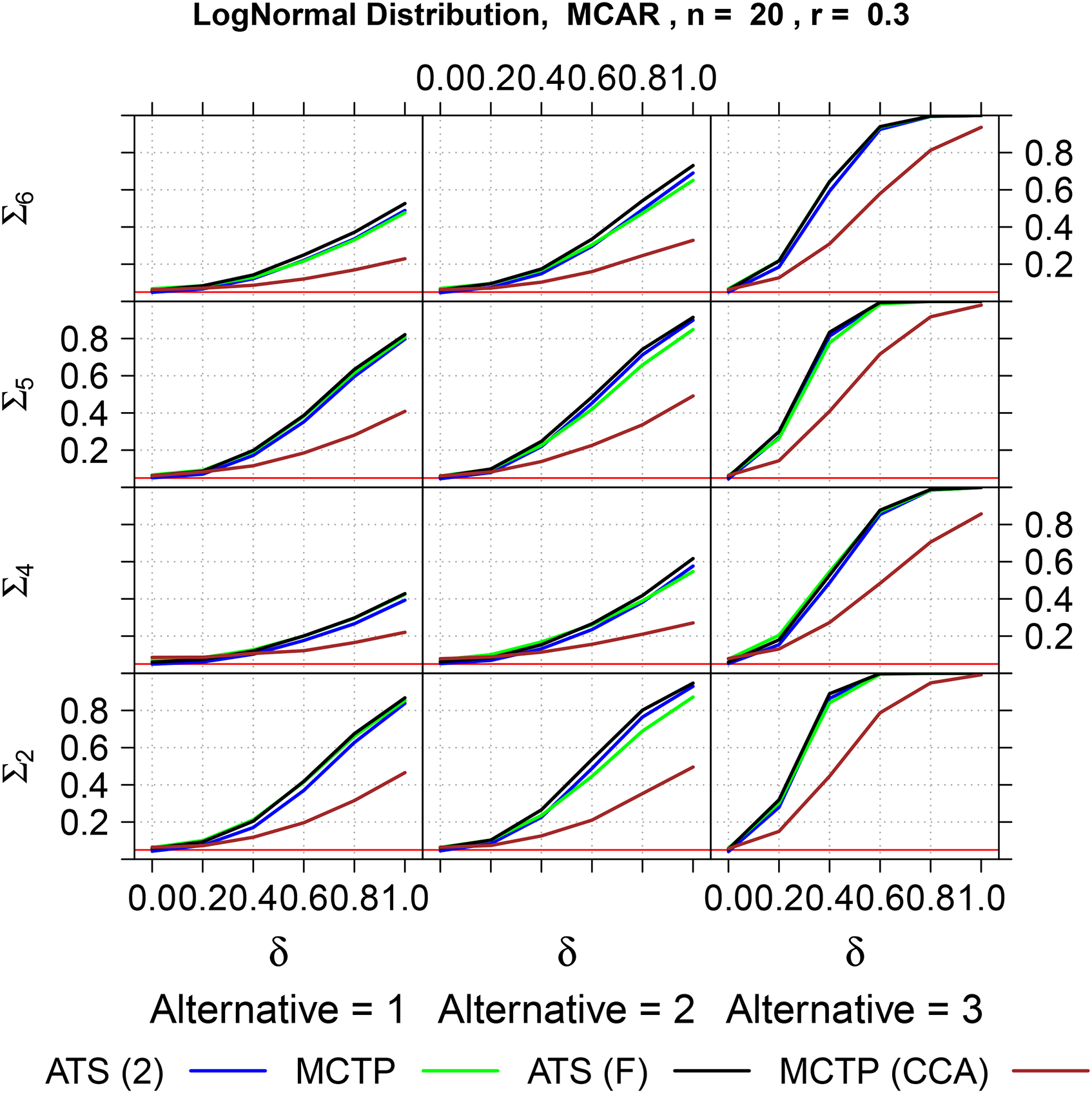
In order to investigate the power of the procedures, a simulation study was conducted using four-dimensional normal and log-normal distributions with and covariance matrices . In particular, three different types of shift-alternatives were considered
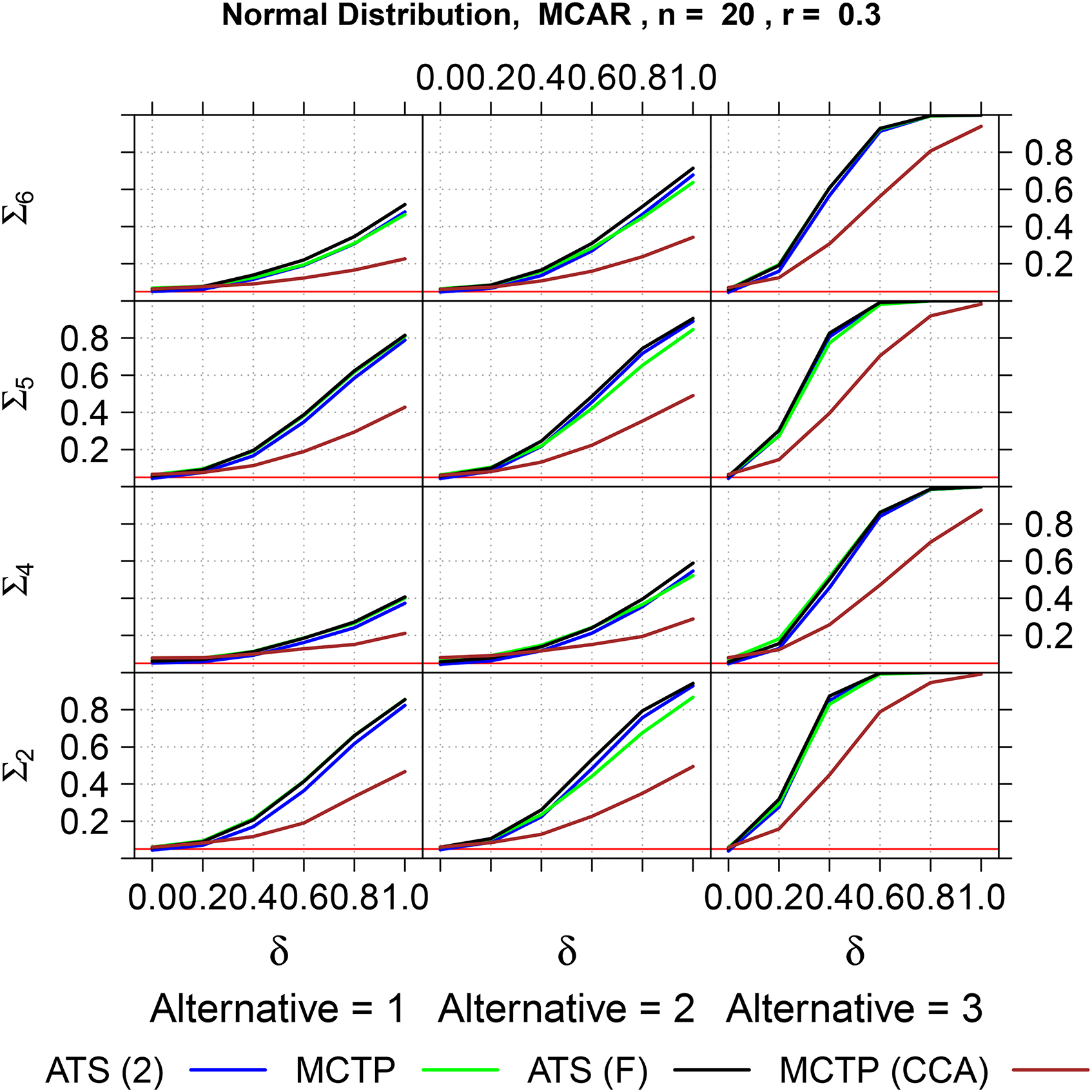
with ranging and different amount of missing values. As the WTS turned out to be inappropriate for small sample sizes, it was not included into the power analysis. Moreover, since the second version of the ATS for testing showed a more accurate behavior than the first version, we only present results for the second version. The results for covariance matrix and under the MCAR assumption are displayed in Table S. 4 (normal distribution) and S. 5 (log-normal distribution). A graphical overview for under the MCAR assumption is presented in Figures 4 (normal distribution) and 5 (log-normal distribution) for and . Additionally, we investigated the power of the MCTP using only complete cases, which has a low power compared to the approaches using all-available information due to the decreased sample size. It follows that none of the procedures which use all-availble information is superior in terms of their powers to detect alternatives. However, the MCTP using all available information, provides more information by local test decisions, simultaneous confidence intervals and adjusted p-values and is therefore recommended for practical applications despite beeing slightly liberal in some cases.
Type-I error rates of the MCTP, either using AAI, only complete cases and an imputed data set, using the median for each repeated measurement. MCTP: multiple contrast test procedure; AAI: all-available information; CCA: Complete Case Analysis; med: median.
Power simulation of the second version of the ATS and the MCTP for testing , the ATS for testing and the MCTP for testing using only complete cases, data is MCAR. MCTP: multiple contrast test procedure; MCAR: missing completely at random; ATS: ANOVA-type statistic.
Power simulation of the second version of the ATS and the MCTP for testing , the ATS for testing and the MCTP for testing using only complete cases, data is MCAR. MCTP: multiple contrast test procedure; MCAR: missing completely at random; ATS: ANOVA-type statistic.
Next, we investigate the power of the procedures under both MAR scenarios. The results can be found in Figures S. 2 to S. 5. Similar to the results under MCAR, none of the procedures which use all-available information is superior. However, the MCTP using only complete cases exhibits a comparable power in the second MAR scenario compared to the competing procedures using all-available information. To summarize, we still recommend the novel MCTP for testing using all-availabe information if data is MAR.
Analysis of the example
The headache severity level migraine trial presented in Section “Motivating example” was analyzed using the MCTP, since this procedure can be used not only for testing the global hypothesis of no effect over all time points but also for testing pairwise comparisons. Thus, we chose a Tukey-type contrast matrix
for testing the null hypotheses . The estimated unweighted relative effects are given by , which indicate that the scores obtained under session 3 are smallest, followed by sessions 2 and 4, whereas the scores obtained under session 1 are the largest. These computations match the visual impression attained by the boxplots in Figure 1. As the direction of the trend was unknown, we calculated two-sided simultaneous confidence intervals (22) at 95% confidence level. The results along with the values of test statistics and p-values are displayed in Table 2. Note, that no multiplicity adjustment was necessary as we used the critical value obtained from the MCTP in each comparison.
It follows from Table 2 that the data provides the evidence to reject the global null hypothesis (p-val. = ), indicating that the treatment has an effect on the migraine of the patients over the course of time. However, session 4 does not indicate an improvement upon the first session. Applying the ANOVA-type procedure yields a higher global p-value of (first version of the ATS) and (second version of the ATS), respectively.
Point estimators, simultaneous confidence intervals, t-values, and p-values for Tukey-type contrasts in relative effects in the migraine trial.
Comparison
Estimator
95 %- Confidence interval
t-value
p-value
[, ]
2.867
0.023
[, ]
2.882
0.022
[, 0.080]
0.610
0.927
[, 0.058]
0.522
0.952
0.058
[ 0.168]
1.241
0.594
0.075
[, 0.187]
1.566
0.393
Discussion and conclusions
Missing values appear naturally in RM designs. Beyond proper statistical modeling, estimation problems of (model) parameters exist and typically complicate the analysis. In this paper, we discussed purely nonparametric methods and their limitations. In particular, we extended the methods proposed by Konietschke et al.5 to allow for missing data. The simulation study demonstrates that the proposed methodology controls the type-I-error satisfactorily even for small sample sizes and a high missing rate. The already existing method for RM data with missing values from Domhof et al.3 can only be used for testing the null hypothesis with regard to the marginal distribution functions, which is difficult to interpret and does not allow for calculating confidence intervals. The newly proposed method can be used for testing the less strict hypothesis and for calculating confidence intervals. Note, that the procedures are not limited to metric data; even ordered categorical data and binary data can be examined in a unified way. All results achieved in this paper are valid under the MCAR mechanism and the results of our simulation study indicate that all proposed methods are not sensitive to MAR scenarios. Further simulation studies indicated that in “extreme” scenarios, for example, smaller sample sizes, high missing probabilities, heteroscedasticity, and high correlations, the MCTP tends to be liberal. Therefore, we plan to explore resampling techniques for making the MCTP more accurate in these scenarios. Moreover, extensions to split plot designs and clustered data will be part of future research.
Supplemental Material
sj-pdf-2-smm-10.1177_09622802211046389 - Supplemental material for Ranking procedures for repeated measures designs with missing data: Estimation, testing and asymptotic
theory
Supplemental material, sj-pdf-2-smm-10.1177_09622802211046389 for Ranking procedures for repeated measures designs with missing data: Estimation, testing and asymptotic
theory by Kerstin Rubarth, Markus Pauly and Frank Konietschke in Statistical Methods in Medical Research
Footnotes
Acknowledgments
The authors are grateful to the Associate Editor and the two anonymous referees for helpful comments which considerably improved the paper.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work of Kerstin Rubarth and Frank Konietschke was funded by Deutsche Forschungsgemeinschaft, Grant/Award Number: DFG KO 4680/3-2. The work of Markus Pauly was funded by Deutsche Forschungsgemeinschaft, Grant/Award Number: DFG PA 2409/3-2.
ORCID iDs
Kerstin Rubarth
Frank Konietschke
Supplemental Material
Supplementary material for this article is available online.
References
1.
LittleRRubinD. Statistical analysis with missing data. 2nd edn. hoboken. NJ: John Wiley & Sons, Inc2002; 4.
2.
BrunnerEDomhofSLangerF. Nonparametric Analysis of Longitudinal Data in Factorial Experiments. 2002.
3.
DomhofSBrunnerEOsgoodDW. Rank procedures for repeated measures with missing values. Sociol Methods Res2002; 30: 367–393.
4.
AkritasMAntoniouEKuhaJ. Nonparametric analysis of factorial designs with random missingness: Bivariate data. J Am Stat Assoc2006; 101: 1513–1526.
5.
KonietschkeFBathkeAHothornL, et al. Testing and estimation of purely nonparametric effects in repeated measures designs. Comput Stat Data Anal2010; 54: 1895–1905.
6.
BoxGEP. Some theorems on quadratic forms applied in the study of analysis of variance problems, I. Effect of inequality of variance in the one-way classification. Ann Math Stat1954; 25: 290–302.
7.
Kostecki-DillonTMonetteGWongP. Pine trees, comas and migraines. Newsletter York University Institute for Social Research1999, 14.
8.
GaoX. A nonparametric procedure for the two-factor mixed model with missing data. Biometrical J Biometrische Zeitschrift2007; 49: 774–788.
9.
KonietschkeFHarrarSLangeK, et al. Ranking procedures for matched pairs with missing data – asymptotic theory and a small sample approximation. Comput Stat Data Anal2012; 56: 1090–1102. Second Issue for COMPUTATIONAL STATISTICS FOR CLINICAL RESEARCH.
10.
RuymgaartF. A unified approach to the asymptotic distribution theory of certain midrank statistics, volume 821. ISBN 978-3-540-10239-7, 2006. pp. 1–18.
11.
BrunnerEBathkeAKonietschkeF. Rank and Pseudo-Rank Procedures for Independent Observations in Factorial Designs: Using R and SAS. 2018. ISBN 978-3-030-02912-8.
12.
KonietschkeFHothornLBrunnerE. Rank-based multiple test procedures and simultaneous confidence intervals. Electron J Stat2012; 6: 738–759.
13.
BrunnerEKonietschkeFPaulyM, et al. Rank-based procedures in factorial designs: Hypotheses about nonparametric treatment effects. J R Stat Soc, Series B (Stat Methodol)2016; 79: 1463–1485.
14.
UmlauftMPlaczekMKonietschkeF, et al. Wild bootstrapping rank-based procedures: Multiple testing in nonparametric factorial repeated measures designs. J Multivar Anal2019; 171: 176–192.
15.
BrunnerEMunzelU. The nonparametric behrens-fisher problem: Asymptotic theory and a small-sample approximation. Biom J2000; 42: 17–25.
AkritasMGBrunnerE. A unified approach to rank tests for mixed models. J Stat Plan Inference1997; 61: 249–277.
18.
BrunnerEMunzelUPuriML. Rank-score tests in factorial designs with repeated measures. J Multivar Anal1999; 70: 286–317.
19.
BretzFGenzAA HothornL. On the numerical availability of multiple comparison procedures. Biom J2001; 43: 645–656.
20.
SantosMSPereiraRCCostaAF, et al. Generating synthetic missing data: A review by missing mechanism. IEEE Access2019; 7: 11651–11667.
21.
AmroLKonietschkeFPaulyM. Incompletely observed nonparametric factorial designs with repeated measurements: A wild bootstrap approach, 2021. 2102.02871.
22.
ZhuBHeCLiatsisP. A robust missing value imputation method for noisy data. Appl Intell2012; 36: 61–74.
23.
R Core Team. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria, 2013. http://www.R-project.org/.
24.
FriedrichSKonietschkeFPaulyM. A wild bootstrap approach for nonparametric repeated measurements. Comput Stat Data Anal2017; 113: 38–52.
25.
MunzelU. Nonparametric methods for paired samples. Stat Neerl1999; 53: 277–286.
26.
HarrarSWFeyasaMBWenchekoE. Nonparametric procedures for partially paired data in two groups. Comput Stat Data Anal2020; 144: 106903.
27.
AmroLKonietschkeFPaulyM. Multiplication-combination tests for incomplete paired data. Stat Med2018; 38: 3243–3255.
28.
Van BuurenS. Flexible imputation of missing data. Boca Raton: CRC press,2018.
29.
RamosajBAmroLPaulyM. A cautionary tale on using imputation methods for inference in matched pairs design. Bioinformatics (Oxford, England)2020, 36: 3099–3106. doi: 10.1093/bioinformatics/btaa082.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.