
Abstract
The serial interval of an infectious disease, commonly interpreted as the time between the onset of symptoms in sequentially infected individuals within a chain of transmission, is a key epidemiological quantity involved in estimating the reproduction number. The serial interval is closely related to other key quantities, including the incubation period, the generation interval (the time between sequential infections), and time delays between infection and the observations associated with monitoring an outbreak such as confirmed cases, hospital admissions, and deaths. Estimates of these quantities are often based on small data sets from early contact tracing and are subject to considerable uncertainty, which is especially true for early coronavirus disease 2019 data. In this paper, we estimate these key quantities in the context of coronavirus disease 2019 for the UK, including a meta-analysis of early estimates of the serial interval. We estimate distributions for the serial interval with a mean of 5.9 (95% CI 5.2; 6.7) and SD 4.1 (95% CI 3.8; 4.7) days (empirical distribution), the generation interval with a mean of 4.9 (95% CI 4.2; 5.5) and SD 2.0 (95% CI 0.5; 3.2) days (fitted gamma distribution), and the incubation period with a mean 5.2 (95% CI 4.9; 5.5) and SD 5.5 (95% CI 5.1; 5.9) days (fitted log-normal distribution). We quantify the impact of the uncertainty surrounding the serial interval, generation interval, incubation period, and time delays, on the subsequent estimation of the reproduction number, when pragmatic and more formal approaches are taken. These estimates place empirical bounds on the estimates of most relevant model parameters and are expected to contribute to modeling coronavirus disease 2019 transmission.
Keywords
Introduction
The purpose of this paper is to determine the best estimates for the parameters we need to calculate the effective reproduction number (Rt) for the UK, and in particular the key quantities of the serial interval and generation interval. The calculation of Rt can be made pragmatically using simplifying assumptions, or in a more formal manner, for which other key parameters are also required, in particular the delay between infection and diagnosis. Given that these parameters are all associated with uncertainty we investigate how this uncertainty may affect our estimates of the reproduction number, and we qualitatively compare the pragmatic approach compared to the more formal approach.
Since the end of 2019, the novel strain of coronavirus, Severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) has caused a global pandemic of disease. The speed with which the virus spreads is dependent on biological determinants that enable viral replication within individuals and onward transmission to others. The minimal set of parameters required for understanding the dynamics of any novel infectious disease pathogen include the potential for transmission, the duration of infectiousness (often captured in models as a recovery rate), and the generational interval: the time between two subsequent cases in a chain of infection.
Estimating the generation interval is particularly challenging due to the fundamentally hidden nature of transmission events. In Figure 1, we summarize the timeline of key events for two adjacent infected individuals (infector and infectee) in a chain of transmission.
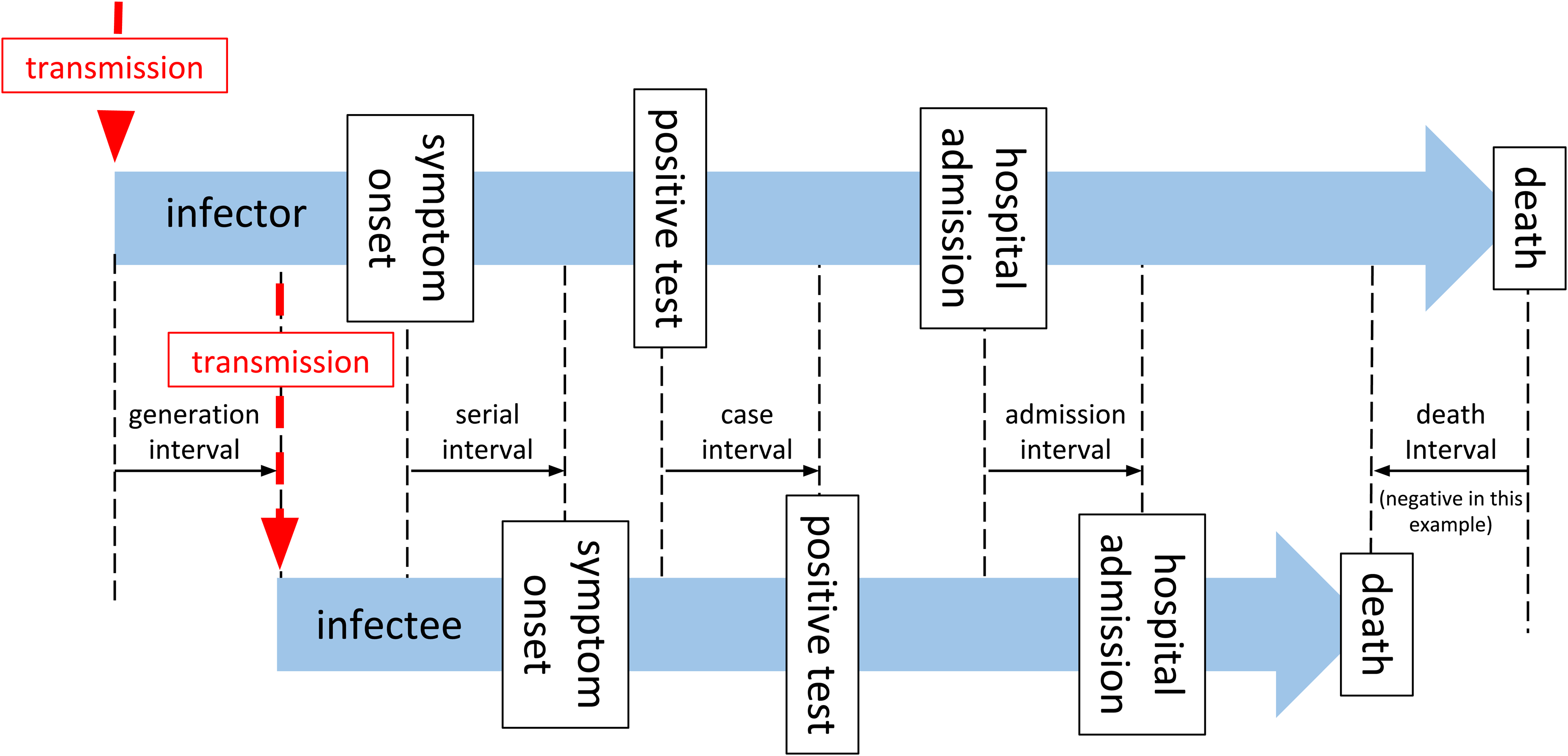
A timeline of events associated with a single infector–infectee pair in a transmission chain.
As described by Svensson, 1 the generation interval is defined as the time between the infection of an infector and infectee, and in practice is not easy to observe, as infection goes through some latent period, during which it is undetectable, 2 and a pre-symptomatic phase during which an individual may be infectious, but possibly detectable through screening, before the disease manifests with clinical symptoms. The latent period and pre-symptomatic phase are together usually referred to as the incubation period (Tincubation). From the onset of symptoms, the diagnosis will be confirmed by some canonical test after some time delay (Tonset→test), later the patient may require admission to hospital (Tonset→admission), or may die (Tonset→death). These subsequent events clearly may not happen in that order, and even diagnosis may occur after death. The time between these key events (onset of symptoms, test confirmation of case, hospital admission, and death) for two sequentially infected people in a chain of transmission are described as serial intervals, 1 although in general usage, and in the rest of this paper, the term “serial interval” is taken to mean the interval between onset of symptoms (SIonset). In Figure 1 and the rest of this paper, we use the terms “case interval” (SIcase), “admission interval” (SIadmission), and “death interval” (SIdeath) to differentiate the other intervals. The generation interval is by definition a non-negative quantity, but all the other measures may be negative if the variation of the delay from the event of infection from person to person exceeds the period between infections. This is more likely for death interval than for serial interval, and for diseases with long pre-symptomatic periods, for example, HIV. 3 The generation interval is defined for all transmission pairs, but the other intervals may or may not be, if for example one of the infector, or infectee is asymptomatic, or does not go to hospital, or does not die, in which case the related intervals are not defined for this pair.
The effective reproduction number (Rt) is a key measure of the state of the epidemic. In its simplest form, for a given population, the effective reproduction number is the number of secondary infections that are expected to arise from one primary infection, at any given instant, and depends on the biological properties of the virus, the immune status, and the behavior of that population. Estimation of the effective reproduction number can either be done forward in time, where we estimate the number of infections that arose from cases detected on a given day (case or cohort reproduction number 4 ), or backward in time where we estimate the number of cases that caused the infections observed on a given day (instantaneous reproduction number 5 ).
Estimation of the instantaneous reproduction number is implemented in the “renewal equation” method for estimating Rt, and depends on a time series of infections, and on the “infectivity profile”—a measure of the probability that a secondary infection occurred on a specific day after the primary case, given that a secondary infection occurred.6,7 A Bayesian framework is then used to update a prior probabilistic estimate of Rt on any given day with both information gained from the time series of infections and the infectivity profile to produce a posterior estimate of Rt. From this point, we refer to Rt to specifically describe the instantaneous reproduction number estimated using the renewal equation method.
The infectivity profile in the renewal equation method is the probability a secondary infection occurred on a particular day after the primary infection, given a secondary infection occurred. This is the same as the probability density function of the generation interval distribution over all transmission pairs. However, in both the original 5 and revised 7 implementations of this method, the authors acknowledge the pragmatic use of the serial interval distribution, as a proxy measure for the infectivity profile, and the incidence of symptom onset or case identification as a proxy for the incidence of infection, with the caveat that these introduce a time lag into the estimates of Rt. It has been noted by various authors that the use of the serial interval distribution as a proxy for infectivity profiles is a pragmatic choice5,7 but can introduce a bias into estimates of Rt.8,9
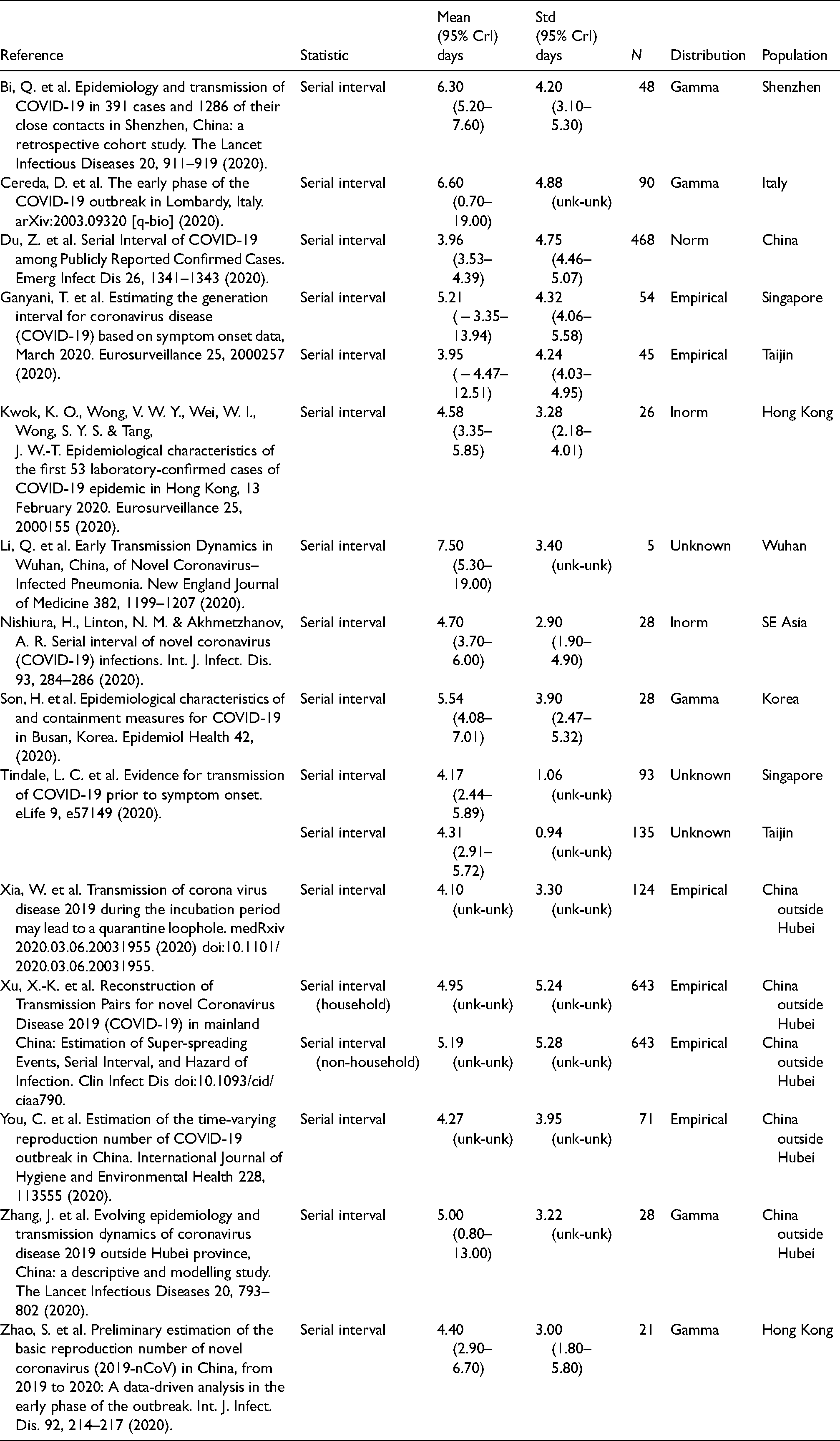
In the COVID-19 outbreak, a limited number of estimates of the serial interval distribution are available from studies of travelers from infected areas, and early contact tracing studies (detailed in Table 2). The infectivity profile is comprised of non-negative values by definition. The serial interval, on the other hand, can be measured as negative for several reasons. For example, if the incubation period of the infector is at the short end of the distribution and that of the infectee is at the tail, a negative serial interval would be observed. Negative values have been noted as a feature in at least one estimate of the serial interval of SARS-CoV-2 to date, 10 but cannot be used in renewal equation-based estimates of Rt.
Sources of serial interval estimates from a literature search.
Direct measurement of the serial interval distribution is further complicated by the fact that symptom onset is often not observed due to the scale of the outbreak and that infection may be asymptomatic.11,12 The data available during an epidemic are a time series of counts of observations, such as confirmed cases (test results confirming diagnosis), hospital admissions, and deaths. As depicted in Figure 1 these events occur after infection, following a period of time. Therefore the observed time series of observed cases is a result of the unobserved time series of infections governed by the serial interval, convolved by the distribution of the time delay from infection to case identification.
Since renewal equation-based estimates of Rt are predicated on infections a “formal” approach to estimation is to infer the unobserved incidence of infection from the observations we have using backpropagation or de-convolution,3,9 using the generation interval as the infectivity profile. However, this requires knowledge of the temporal relationship between unobserved infections and observed cases, admissions or deaths.
A pragmatic alternative 9 is to simply calculate Rt using a serial interval as the infectivity profile, and un-adjusted case numbers with a simple correction for the time delay between infection and cases by shifting our Rt estimates backward in time. As the renewal equation methods assume that the time between two infections cannot be negative, the serial interval distribution must be truncated at zero in this pragmatic approach.
Both formal and pragmatic approaches need estimates of the generation interval or serial interval, and the time delays between infection and symptom onset (incubation period), infection and case identification (test), infection and admission, and between infection and death. The formal method also needs an understanding of the shape of the distribution of these delays. In the rest of this paper, we estimate these key quantities and investigate the impact that uncertainty in these quantities has on an estimation of Rt (Table 1).
Comparison of two approaches for estimating the reproduction number and parameters needed to support each approach.

Methods
Serial interval estimation
Firstly, we conducted a literature review for studies that describe serial interval estimates using PubMed and the search terms “(SARS-CoV-2 or COVID-19) and ‘Serial interval’” and reviewed the abstracts of relevant original research papers. These were compared to papers reported on the MIDAS Online Portal for COVID-19 Modeling Research, 13 and with existing meta-analyses. 14 From these papers, serial interval mean and standard deviation estimates were extracted, along with information about assumed statistical distributions, and the sample size of the study. A random-effect meta-analysis was conducted 15 on the subset of papers that reported confidence intervals. The assumption of normal distribution underpinning the meta-analysis16–18 is reasonable for the mean of the serial interval, given the central limit theorem, however, we cannot extend this to the standard deviation of the serial interval distribution and hence cannot assess the overall shape of the serial interval distribution. To address this and combine parameterized distribution estimates from multiple studies into a single distribution we undertook a re-sampling exercise, as described below, the goal of which was to reconstruct a data set of serial intervals that accurately reflect the distributions reported in each of the studies above, so that they could be combined and analyzed together.
Most studies reported a central estimate of a probability distribution for the serial interval, specified in terms of the mean and standard deviation of a given serial interval distribution. They also reported uncertainty on these mean and standard deviations as confidence or credible intervals. For these studies, we randomly selected one hundred probability distributions consistent with the central estimates and confidence intervals reported in each paper (further details are available in Supplemental table 1). From this family of probability distributions, we drew random samples based on the original sample size.19,20 This gives us a set of samples that are consistent with the shape and uncertainty of the distributions reported by the source studies and which represent their sample size in a comparable way. Other studies reported empirical distributions and for these, we obtained original serial interval data were available and made 100 random bootstrap sub-samples with replacement, to a relative size determined by the original sample size of the study.
The 100 empirical and 100 probability distribution-based serial interval samples were combined into 100 groups, with each group containing serial intervals representative of each source article with numbers proportional to the size of the original study. This allows us to calculate 100 empirical probability distribution estimates from which we can derive summary statistics with confidence intervals (from here on referred to as the “re-sampled serial interval estimate”).
As much of the data is captured at the resolution of a single day, serial intervals appear as an integer number of days in the data. The discrete nature of the data was estimated using continuous distributions by replacing integer values, x, with interval-censored ranges spanning from the value
As a comparison, we also used data collected under the “First Few Hundred” (FF100) case protocols by Public Health England23,24 which provides a limited number of linked cases of proven transmission, mostly within households, and interval-censored symptom onset dates. To this data, we fitted normal, gamma, and Weibull distributions using the same methodology as above.
In both cases, when fitting gamma and Weibull distributions we truncated the interval-censored data at zero, to prevent negative values, and for the gamma distributions we required that the shape parameter had a lower bound of 1, which enforces that the distribution density is zero at time zero. This however makes goodness of fit statistics not comparable between the normal distribution fit and the two other distributions.
Incubation period estimation
The incubation period has been previously estimated by Lauer et al. 25 and Sanche et al. 26 for China in the early phase of the epidemic. The FF100 data contains interval-censored exposure data coupled to symptom onset; using this we derived a UK-specific estimate to assess if it was consistent. Furthermore, the Open COVID-19 Data Working Group27,28 provides a large international data set that includes some travel history and symptom onset data.
Compared to data on which earlier estimates of the incubation period were made25,26 where travel principally originated from Wuhan, the travel cases in the Open COVID-19 data set include travelers between a far wider set of destinations, and in a later stage of the epidemic, which we believe reduces selection bias. 29 As we are performing this analysis retrospectively we also benefit from fewer issues due to the right censoring of the data.
For both data sets, we use random samples with replacement and fit 100 of each of gamma, Weibull and logn-ormal probability distributions to the interval between putative exposure and symptom onset, accounting for censoring were present, to estimate the incubation period distribution and uncertainty associated with its parameters. We remove from the data records where the time from exposure to symptom onset is negative or when it is longer than 21 days (on the basis of biological implausibility).
For subsequent phases of the analysis, we retain the 100 parameterized distributions of the distribution with the best overall fit to the data from the Open COVID-19 Data Working Group data set. From these, we can generate a parameterized bootstrap sample representative of the Open COVID-19 Data Working Group data set but without censoring.
Generation interval estimation
The generation interval is the fundamental variable for modeling transmission. Under the assumption that the generation interval follows a gamma distribution we can infer its parameters using the bootstrap samples from the re-sampled serial interval data set, and the bootstrap samples from the incubation period data set from earlier stages, and the constraint that the generation interval is a non-negative quantity. We combined random samples from a parameterized gamma distribution for the generation interval with two of the bootstrap samples from the incubation period to satisfy the following relationship, thus simulating the serial interval: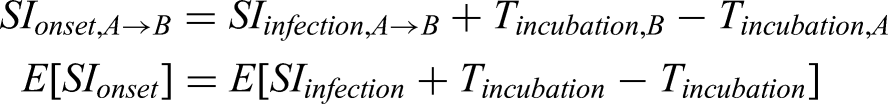
Impact of using the serial interval on an estimation of Rt
With various estimates of serial interval and generation interval, we wished to understand the qualitative impact this variation might have on our estimates of Rt. To investigate this we used the forward equation approach implemented in the R library EpiEstim.5–7 We estimate values of Rt for 4 time points in the first wave of the COVID-19 pandemic in England representative of the ascending phase, the peak, the early descending phase, and the late descending phase. We used data retrieved from the Public Health England API30,31 representing cases with positive test results, hospital admissions, and deaths within 28 days of a positive test, in the first wave of the outbreak in England. For this analysis we assume the infectivity profile can be represented using a parameterized gamma distribution, and estimate Rt for a wide range of combinations of mean and standard deviation, using a fixed calculation window of 7 days, at each of our 4 time points. The resulting relationship between Rt, mean infectivity profile, and standard deviation of infectivity profile were compared visually to qualitatively examine how the serial interval estimates influence the estimates of Rt.
Time delays from infection to case identification, admission, and death
Estimation of the time interval between the onset of symptoms and the observations of the positive test result, hospital admission, and death was performed (Tonset→test, Tonset→admission, and Tonset→death) using the CHESS data set. 32 The CHS data set is hospital-based, and was initially limited to intensive care admissions, but a subset of hospitals have reported all admissions, and this is what we focused on (see Supplemental table 2). Within the CHESS data set there are a set of patients who have symptom onset dates recorded, dates that a specimen was taken that subsequently was tested positive, hospital admission date, and date of death, if the patient died. We restricted cases to those in which a positive test was found no more than 14 days before and 28 days after symptom onset on the grounds of biological implausibility. Because we conducted this analysis at the end of the first wave of COVID-19 in the UK when patient numbers in hospitals had fallen to a low level there was minimal right censoring present in the data and this was not accounted for.
The time delay from infection to observation was obtained by combining our estimate of the incubation period distribution from the Open COVID-19 Data Working Group data set27,28 with onset to observation delays from the CHESS data set
32
using the following relationship:
The resulting time delays from infection to the different observations of the positive test result, hospital admission, or death were calculated and fitted to probability distributions using the same maximum likelihood estimation methods implemented in R 22 as described above.
Impact of deconvolution
In the final piece of our analysis, we sought to qualitatively compare estimates of Rt based on data for England from the Public Health England API,30,31 in each of the following two scenarios.
Firstly, following the “pragmatic” course outlined in the introduction, we based Rt estimates on observational data (cases, admissions, deaths) as a proxy for infection events, and used a truncated empirical serial interval distribution derived from our re-sampling procedure as a proxy for infectivity profile. In line with the pragmatic approach, simple to the dates of these Rt estimates was made to align the estimate to date of infection rather than the date of observation.
Secondly, the more formal approach was employed: using the time delay distributions from the previous stage, we used de-convolution to infer a set of time series of infections from the same observational data and used our estimate of the generation interval as a proxy for the infectivity profile. This second approach has been recommended by Gostic et al. 9 To do this, we applied a non-parametric back-projection algorithm from the surveillance R package, 33 based on work by Becker et al. 3 and Yip et al., 34 to infer three putative infection time series from observed cases, admissions or deaths. The inferred time series were then used to estimate Rt through EpiEstim using the parametric gamma-distributed estimate of the generation interval from above. In applying the de-convolution we discovered it requires a full-time series beginning with zero cases for sensible results and this required we impute the early part of the hospital admission time series, which we did by assuming an early constant exponential growth phase.
In both cases, we used the renewal equation method with a 14-day sliding window to estimate a continuous time series of Rt. The resulting Rt time series were compared qualitatively.
Results
Serial interval estimation
Our PubMed search retrieved 62 search hits of which 14 were original research articles containing estimates of serial intervals.10,35–48 The mean and standard deviation of parameterized distributions were extracted and are presented in Table 2. The estimates of the mean range from 3.95 to 7.5 days. The majority of studies provided their results as gamma distributions defined by mean and standard deviation. Some studies, particularly Xu et al. 10 noted that the serial interval was not infrequently negative.
The random-effects meta-analysis on the subset of studies that reported modeled distributions, resulted in an overall estimate of the mean of the serial interval of 4.83 (95% CI 3.93–5.70) (for more details see Supplemental figure 1). This estimate is limited in its value by the fact that it only covers the subset of the studies in the table above, and does not represent the distributional nature of the serial interval.
In Figure 2 panel A, we present the results of the re-sampled serial interval estimate. The histogram shows the empirical distribution of the combination of all the studies, reinforcing the finding of a substantial proportion of the serial interval being negative. For the gamma and Weibull distribution fit the data is truncated at zero, and the full data is used for the normal distribution, resulting in mean values of 5.72 (gamma), 4.87 (norm), or 5.70 (Weibull) days. Full detail of the parameterization of this is available in Supplemental table 3.
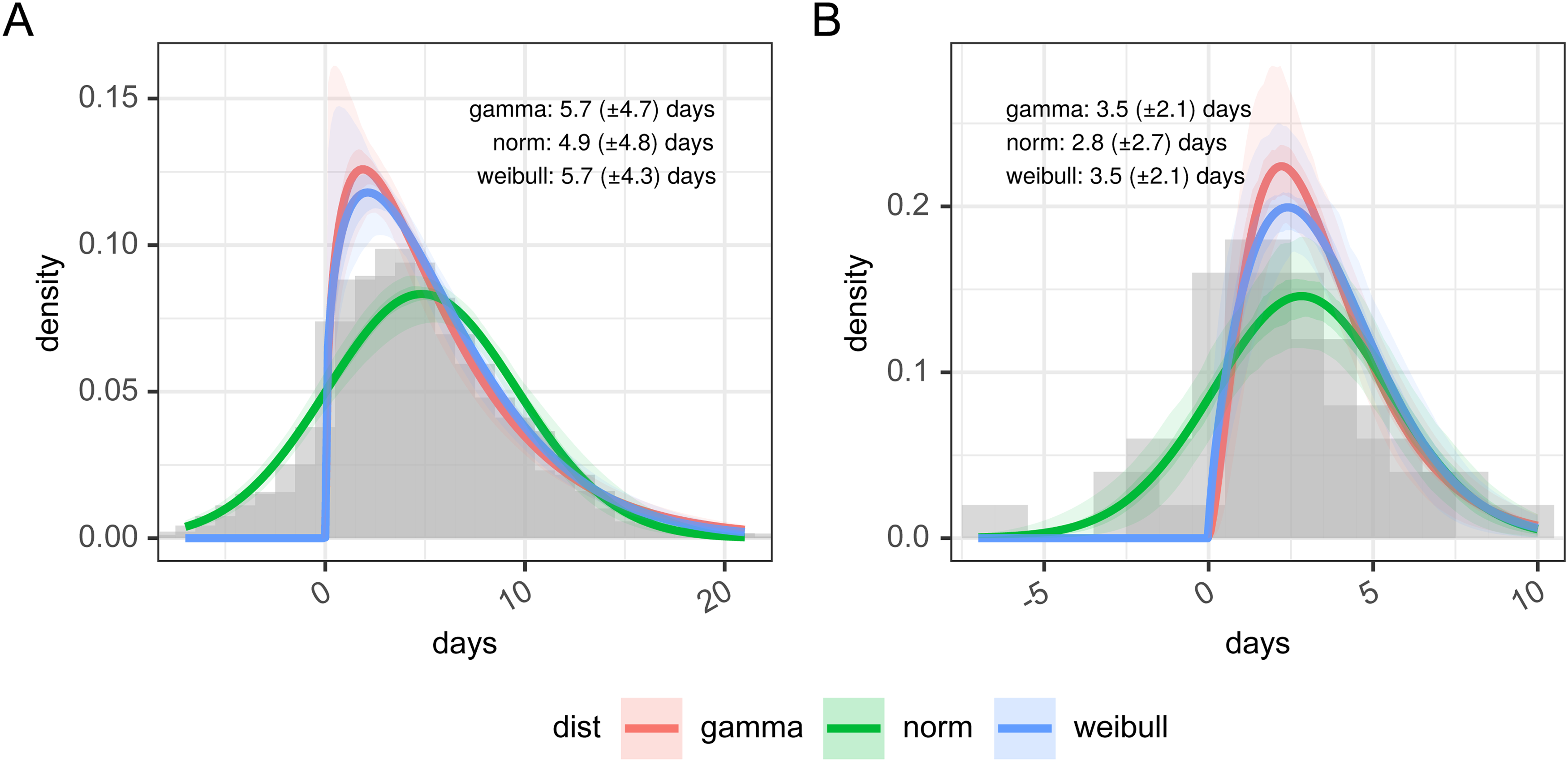
Panel A: days between infected infectee disease onset based on resampling of published estimates from the literature and panel B: estimates of the serial interval from FF100 data. The histogram in panel A shows the combined density of all sets of samples within the original research.
In Figure 2 panel B, we present the distribution of the 50 linked cases in the FF100 data set for which onset dates are available for both infector and infectee. As with the re-sampled data the parameterized versions of this are based on truncated data for Weibull and gamma distributions, and hence show a poorer fit against the whole distribution (full detail of the parameterization of this is available in Supplemental table 4). Supporting the observations of Xu et al., 10 the FF100 data shows evidence of negative serial intervals. The mean of the serial interval from FF100 data was 3.50 (gamma) or 3.52 (Weibull) when data was truncated to exclude negative serial intervals and 2.81 (norm) with no truncation. This is on the lower end of the values reported in the literature.
As noted in the methods, the re-sampling process allows us to estimate the serial interval as an empirical distribution. Within EpiEstim, our chosen framework for estimating Rt however the use of negative serial intervals is not supported as a proxy for the infectivity profile. In the pragmatic approach to estimating Rt, we truncate the empirical distribution at zero to support this. Once truncated the resulting estimate, therefore, has a mode of 3.86 days, shorter than the normal distribution parameterization and is a truncated empirical distribution, with a mean plus 95% confidence interval of 5.88 days (5.22; 6.70), and a standard deviation of 4.12 days (3.79; 4.72), which is more in line with the gamma distribution parameterization.
Incubation period estimation
Figure 3 and Table 3 show the results of estimating a parametric probability distribution to data from FF100 and data from the Open COVID-19 Data Working Group. Histograms of the data are not shown as it is interval-censored, which is not straightforward to represent graphically. There are only a small number of records from the FF100 data which suggest the mean of the incubation period is between 1.82 and 1.94 days. The data from the Open COVID-19 Data Working Group suggests the incubation period is longer with a mean of 5.19 days with best fitting distribution, and this agrees better with other estimates in the literature.14,25,26 The best fit to the Open COVID-19 data is obtained with a log-normal distribution as shown in Table 3, with the lowest Akaike information criterion, Bayesian Information Criterion (both representing least information lost), and the largest value for the log-likelihood. (Full details of the fitting parameters and graphical assessment of the quality of fit are in Supplemental table 5 and Supplemental figure 2).
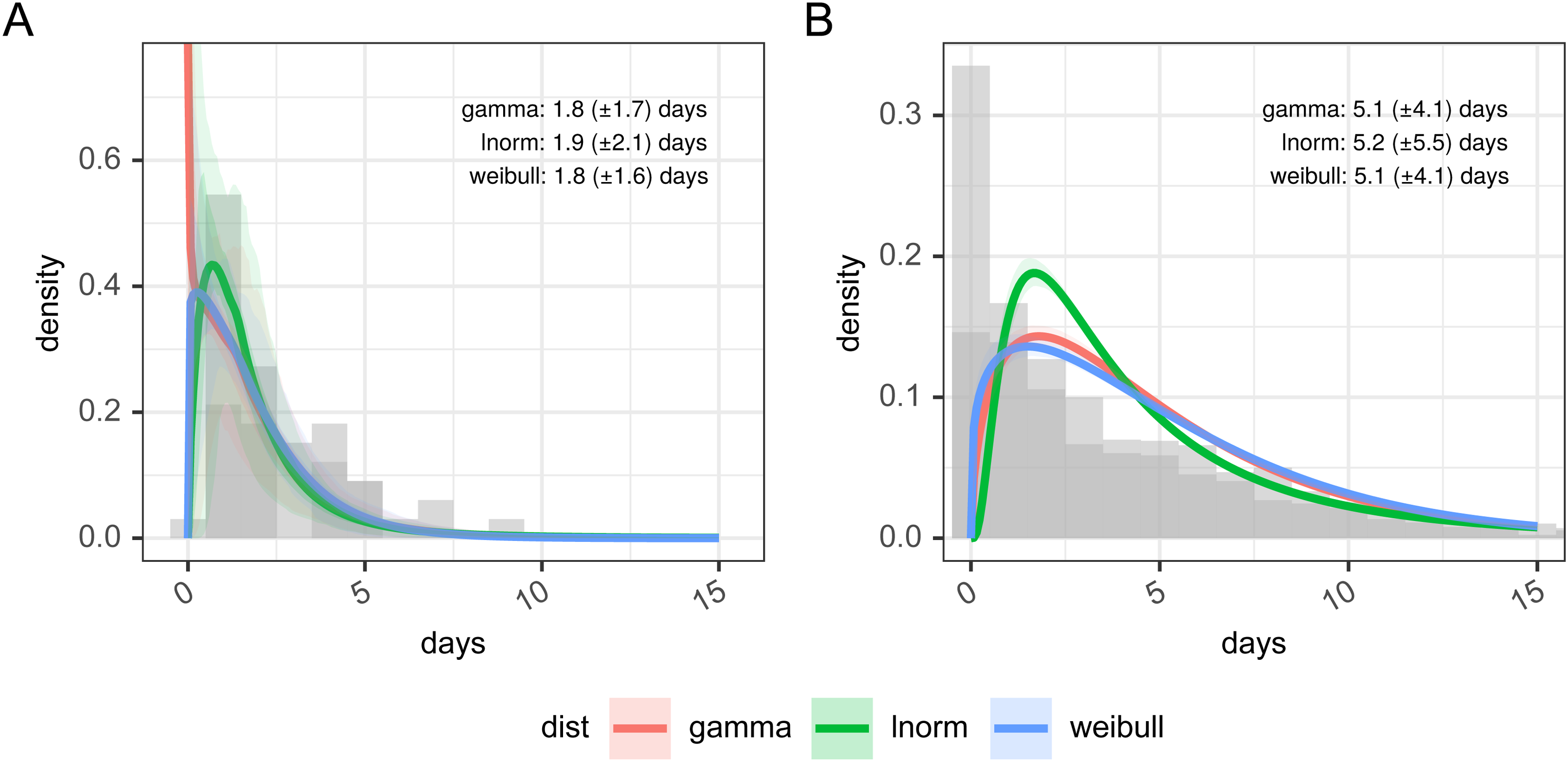
Incubation period distributions were reconstructed from the Open COVID-19 Data Working Group and from FF100 data. Histogram data is approximate due to interval censoring.
Goodness of fit statistics for incubation period distributions reconstructed from open COVID-19 data working group and from FF100 data.

Generation interval estimation
The generation interval is then inferred from the incubation period and empirical serial interval distribution prior to truncation. Our best estimate for this is a gamma distribution, with a mean plus 95% confidence interval of 4.87 days (4.24; 5.51), and a standard deviation of 1.98 days (0.53; 3.19), as shown in Figure 4. The mean of 4.87 days is identical to that of the empirical serial interval distribution prior to truncation in panel B, Figure 2 as a result of the constraints imposed during fitting. The standard deviation of our generation interval estimate is 1.98. This is within the confidence limits of estimates from the literature from both China (0.74–2.97) and Singapore (0.91–3.93). 49 The mean and standard deviation of these distributions are not independent, and this is explored further in Supplemental figure 3.
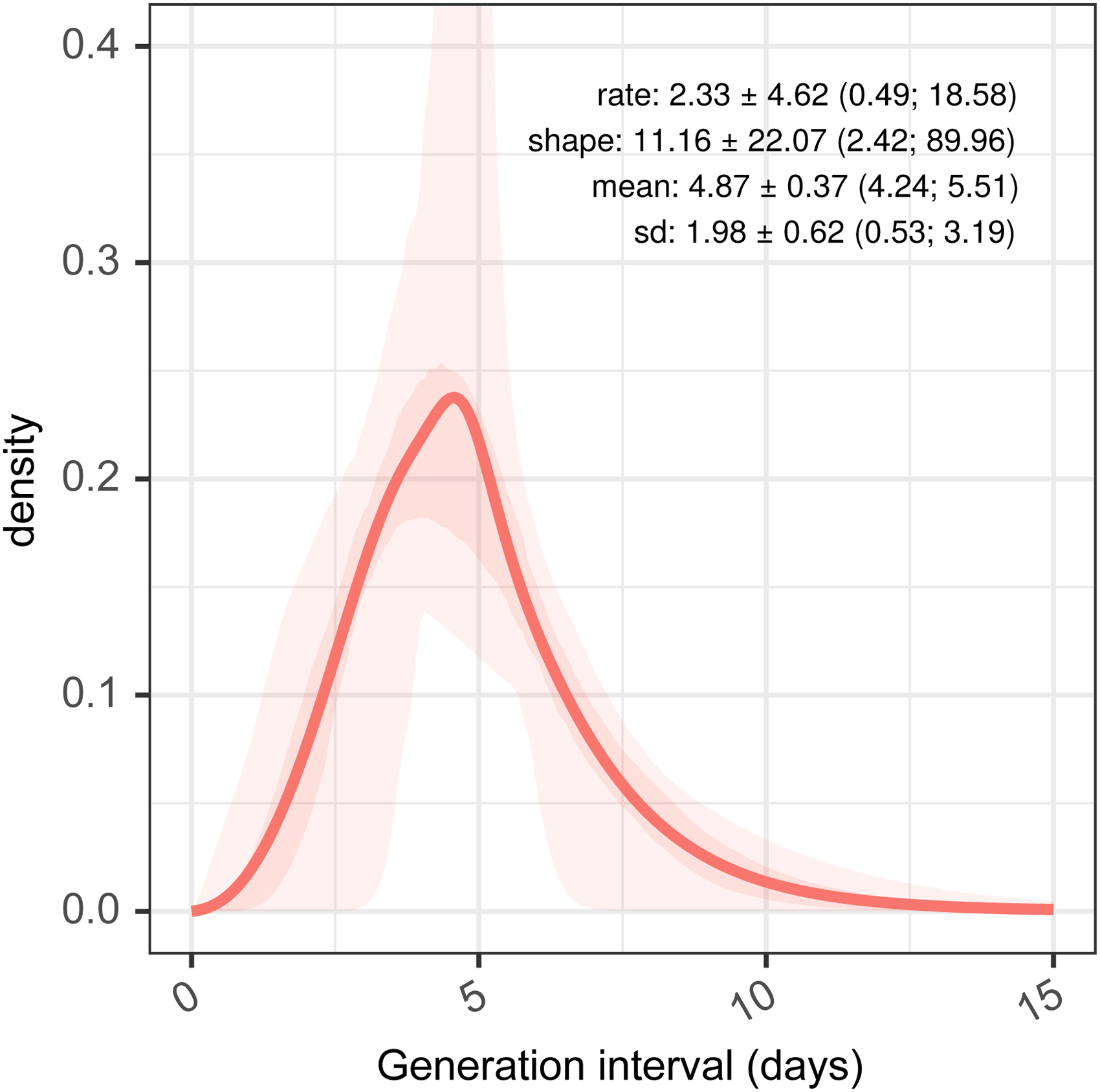
Estimated generation interval distributions, from resampled serial intervals as a predictor, and estimated serial intervals from incubation period combined with samples from a generation interval assumed as a gamma-distributed quantity.
Impact of using the serial interval on an estimation of Rt
With our three estimates of the serial interval and one generation interval and observed COVID-19 case counts, we investigate the impact on the estimates of Rt, of using these estimates as a proxy for the infectivity profile. This uses data at 4 time points on an epidemic curve from the first wave of the COVID-19 outbreak in England, as shown in Figure 5, which are 19 March, 12 April, 12 May, and 23 June, corresponding to the ascending, peak, early descending, and late descending phases, respectively.
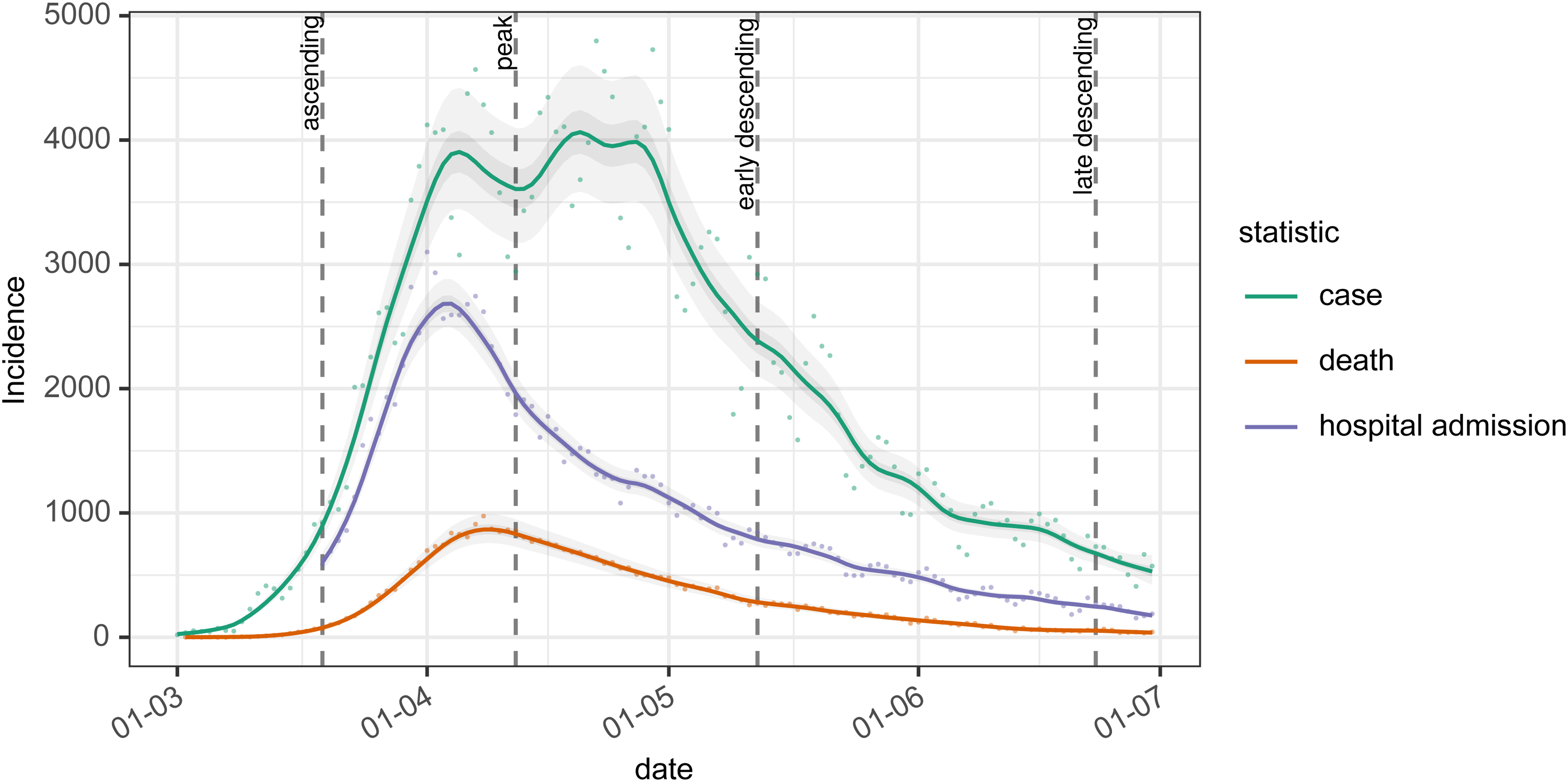
The epidemic curve for cases, deaths, and hospital admissions are used for analysis in this paper. Dashed vertical lines show dates at which we conduct our analysis, chosen to represent the ascending, peak, early, and late descending phases of cases during the first wave in the UK.
At each of these 4 time points, Figure 6 shows the estimated Rt under the range of different assumptions about the mean and standard deviation of the infectivity profile, modeled as a gamma distribution. In the top left, bottom left and bottom right panels the effect of increasing the mean of the infectivity profile is to push the resulting estimate of Rt away from the critical value of 1 at which the epidemic is growing. In the top right panel, at the peak, the mean of the infectivity profile has a less clear-cut effect. The impact of changes to standard deviation is likewise varied. In the top left, bottom left and bottom right panels during ascending and descending phases there is relatively little impact of changing the standard deviation of the infectivity profile on the estimates of Rt, and any small changes that do occur depend on the shape of the preceding epidemic curve. At the peak, however, in the top right panel, the wider the standard deviation the more historical information influences the estimation of Rt and this acts to delay the estimated transition from positive to negative growth. The overall result of this is that estimates of the infectivity profile with a high standard deviation will predict Rt crossing 1 later than estimates based on an infectivity profile with a low standard deviation, but the point of crossing 1 is relatively insensitive to the value of the mean of the infectivity profile.
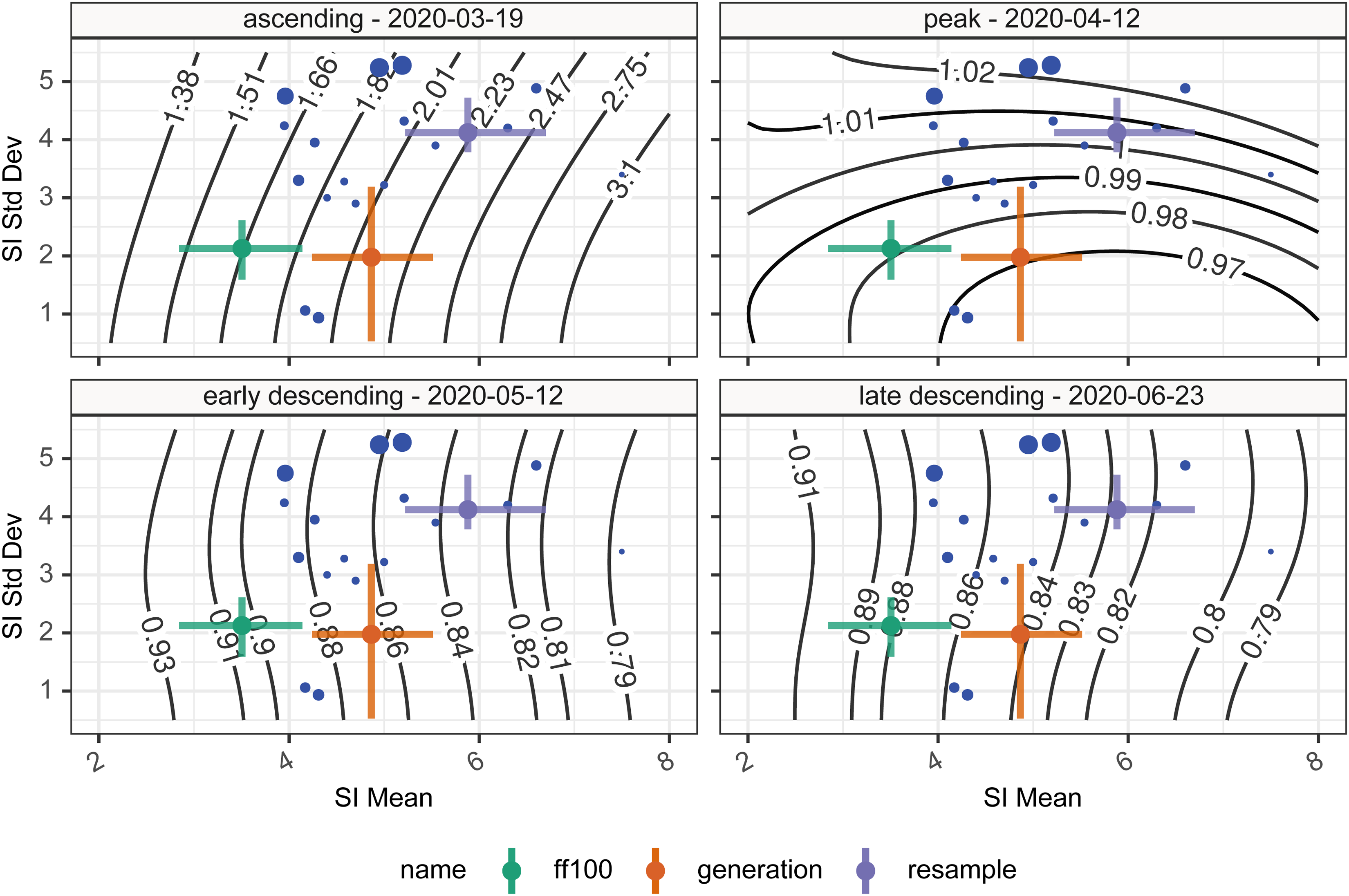
Time-varying reproduction numbers given various assumptions on the serial interval mean and standard deviation. The blue points show the central estimate of serial intervals from the literature, whereas the colored error bars show the mean and standard deviation of the two serial intervals (green, violet) and one generation interval (orange) estimates presented in this paper. Contours show the Rt estimate for that combination of mean and standard deviation serial interval. The four panels represent the four different time points investigated.
When we consider using the various estimates of the serial interval or generation interval, as a proxy for the infectivity profile, on the resulting estimates of Rt we can see from the colored crosses in Figure 6 representing the different estimates of serial or generation interval, that in the situations of dynamic change such as the ascending phase the variability may have quite a large impact on subsequent estimates of Rt but at other times the impact is much smaller [ascending—28% variation (Rt: 1.66–2.20); peak—3% variation (Rt: 0.97–1.00); early descending—8% variation (Rt: 0.83–0.90); late descending—6% variation (Rt: 0.83–0.88)].
Time delays from infection to case identification, admission, and death
There are 9902 patients in the subset of the CHESS database we examined of which 82.3% had a symptom onset date. In Figure 7, we show probability distributions fitted to data from the CHESS data set which define times from symptom onset (Panel A) to case identification (Tonset→case), admission (Tonset→admission), or death (Tonset→death). Symptom onset to test (case identification) can be a negative quantity if a swab is taken during disease screening and the patient is pre-symptomatic. In this data the time point that defines the time of test is the date when the specimen is taken, which will subsequently be tested positive for SARS-CoV-2, so does not include sample processing delays. However, in this hospital-based data source of admitted patients, the onset data were collected retrospectively. We also note peaks at 1 day, 1 week, 2 weeks, and so on which suggests approximation on data entry, and there may well be biases in the data collection.
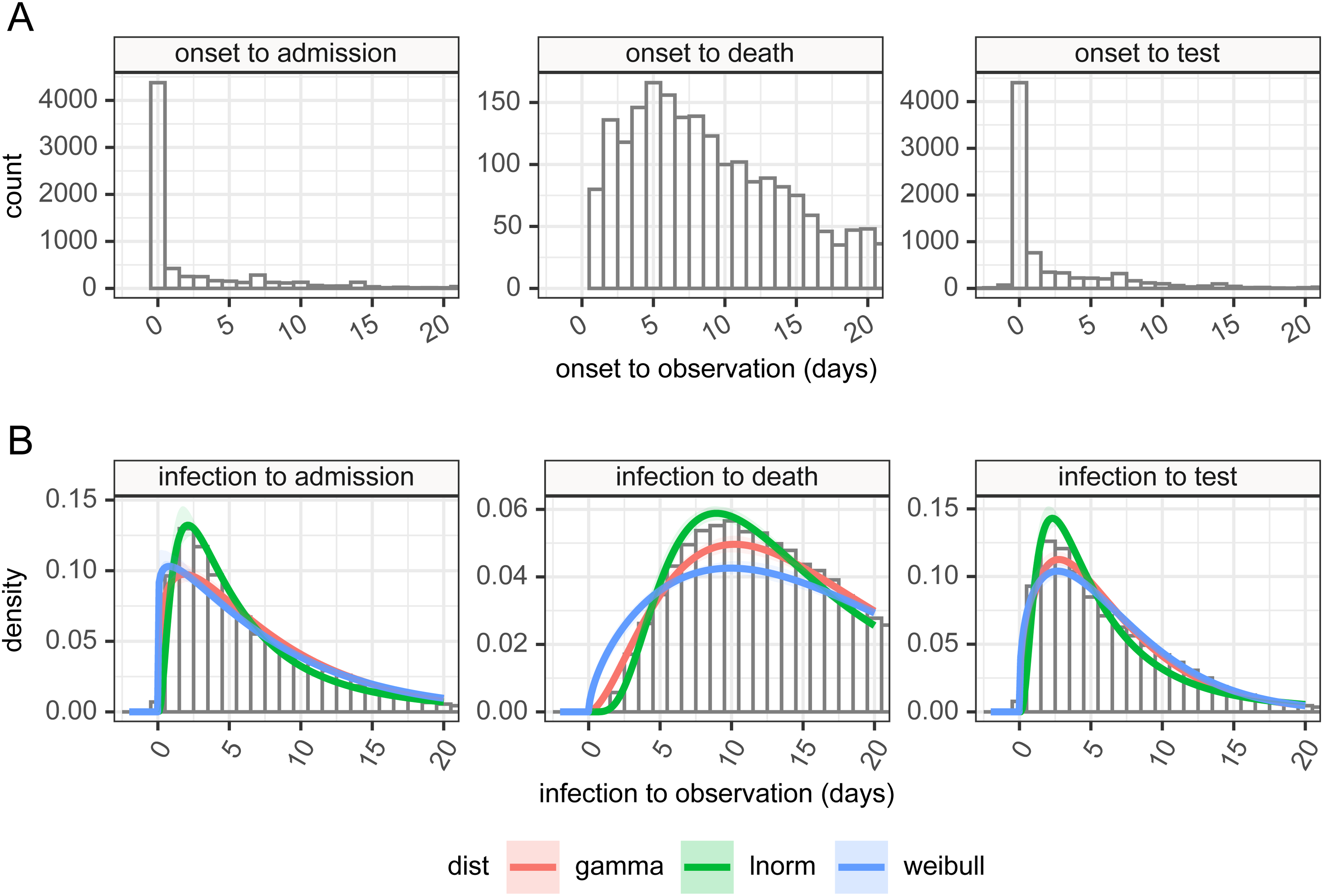
Panel A: time delay distributions from symptom onset to test (diagnosis or case identification), admission or death, estimated from CHESS data set, plus in panel B estimated delays from infection to observation, and can be negative in certain cases, based on the incubation period and observation delay. These can be used for deconvolution.
It is more obvious from the clinical course of COVID-19 that admission should occur after disease onset. In the data, a large number of cases are reported to have symptom onset on the day of admission. This is potentially a reporting artifact as in the absence of certain knowledge about the onset, it is possible that the day of admission may have been captured instead, and we again see the peaks at 1 week, 2 weeks, and so on, suggesting approximations in data entry.
The time between the onset of symptoms and death can also be assumed as a positive quantity given this is based on an in-hospital cohort. This distribution shows a large tail, and some patients in that tail were noted to be admitted many months before the appearance of COVID-19. These patients likely represent hospital-acquired cases in chronically unwell patients. The extreme outlying values (with delay from admission to death greater than 100 days, or with admission before 1 January 2020) were removed as they prevented sensible estimation of the rest of the distribution.
By combining the incubation period distribution in panel B in Figure 3 with the time delay distributions in panel A of Figure 7, we can obtain probability distributions from infection to observation, and these are shown in panel B for the three observations of test (case identification), admission, and death. These distributions provide us with a means of estimating a time series of infection from observed case counts, admissions, and deaths. As above full details of their parameterizations are available in Supplemental table 6. The mean time from infection to the various time points described in the timeline in Figure 1 is presented in Table 4. The infection to onset is the incubation period, with a mean of 4.2 days. On average 6.4 days pass from infection to diagnosis, a subsequent 1.2 days until admission, and a further 8.3 days until death, however, it also shows considerable variation in these delays, exemplified by the 95% quantiles for the time from infection to death estimated as ranging from 3.6 to 42.9 days.
Estimated time delays between infection and various observations over the course of an infection, based on the combination of incubation period and symptom onset to observation delay.

Estimation of Rt
With the estimates of a delay from infection to observation, we are able to use a non-parametric back-propagation as described in the methods to estimate a time series of infections as recommended by Gostic et al. 9 when using EpiEstim. The results of the back-propagation are shown in Figure 8, panel A which depicts the resulting point and smoothed infection curves associated with observation curves from England. The back-projection results in a sharper and narrower epidemic curve than the observation it is derived from and indicates additional structures (such as more pronounced fluctuations) which are not obvious from the underlying observations. Estimates of Rt are shown in panel B based on de-convolved time series plus generation interval, versus raw observation counts, re-sampled serial interval estimates, with time adjustment on the resulting Rt estimates to align Rt estimate date to putative date of infection. We have not calculated confidence intervals for the estimates of Rt. The estimates of Rt differ from their mean (using symmetric mean absolute percentage error, sMAPE) by between 3.33% and 6.51% [case: sMAPE 3.44% (IQR 1.86%; 5.17%); death: sMAPE 6.51% (IQR 2.62%; 12.24%); hospital admission: sMAPE 3.33% (IQR 1.46%; 5.60%)].
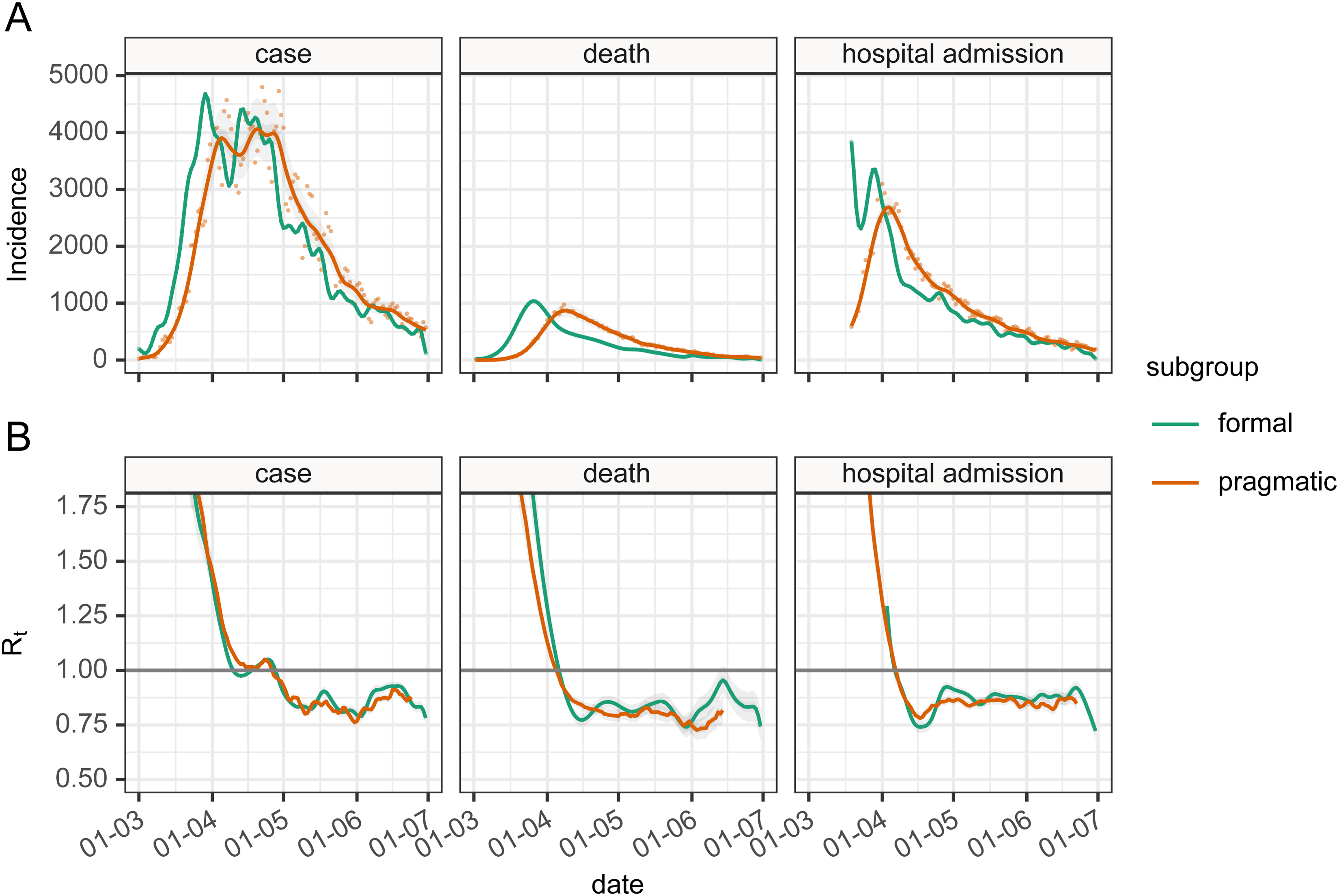
Panel A: The epidemic incidence curves in England for different observations (orange—formal) and inferred estimates of infection rates (green—pragmatic) based on deconvolution of the time delay distributions. Panel B: the resulting Rt values were calculated either using infection rate estimates and generation interval (formal subgroup) or unadjusted incidence of observation and serial interval (pragmatic). The Rt estimated directly from observed incidence curves (pragmatic) have their dates adjusted by the mean delay estimate.
Discussion
Our estimate of the serial interval from the FF100 UK data was found to be short, compared to international estimates. The FF100 data was collected in the early stage of the epidemic and is based mainly on household contacts of international travelers which may impart bias. As the participants in the study were put into self-isolation upon discovery observations the contact period tends to be shortened, leading to shorter serial interval estimates, and because of this, we do not believe the estimate from the FF100 study to be specific to the UK but rather that the data set is not broadly representative of the UK population.
In contrast, our literature search allowed us to estimate the serial interval from a much larger pooled sample drawn from multiple studies. Random effects and re-sampling meta-analyses produced comparable results (random effects: mean 4.83 (95% CI 3.93–5.70) days and re-sampling: mean 5.9 (95% CI 5.2; 6.7) and SD 4.1 (95% CI 3.8; 4.7) days), but our re-sampling study more clearly showed the potential for the serial interval to be negative, due to the relatively long and variable incubation period of SARS-CoV-2. This is seen in the unsatisfactory fits of parameterized probability distributions in Figure 2, and we choose not to use these in our pragmatic estimation of Rt. instead of which we rely on the set of empirical distributions resulting from our sampling analysis. Even so, the negative values of the serial interval within these are theoretically problematic for their use as a proxy for the infectivity profile of SARS-CoV-2 in transmission modeling, which requires the infectee is infected after the infector. As a way around this, we truncate the re-sampled serial interval at zero and use this as the infectivity profile, but as seen here this truncation increases the mean of the resulting serial interval distribution from 4.87 to 5.88 days.
An alternative to this is to use the generation interval as a proxy for the infectivity profile, but there are limited estimates of this quantity available in the literature. 49 Derivation of the generation interval from the serial interval is possible using knowledge of the incubation period. We again looked at the FF100 data for estimates of the incubation period and again found that the UK data suggests a value that is shorter than international estimates, for the same reasons as mentioned above.25,45,50–52 We cross-referenced this with a second estimate derived from the Open COVID-19 Data Working Group data set,27,28 which is based on a large international data set of people who tested positive for SAR-CoV-2 after traveling from areas with outbreaks. The resulting estimates of the mean incubation period of 5.5 days (log-normally distributed) are much closer to previous estimates, and we expect to be less influenced by right censoring. Again, we regard the short incubation period calculated from the FF100 data set to be a feature of the data set rather than a UK-specific finding. In fact, the estimate based on the Open COVID-19 Data may in itself be an under-estimate as the majority of travel histories only include the return date of the visit in question and not the start date.
With incubation period and serial interval estimates, we derived an estimate for generation interval, assuming a gamma distribution. This was comparable to previous estimates in that although it is based on a different serial interval, and hence has a different mean, the standard deviation of our estimate is in accordance with that estimated by Ganyani et al. 49 Although the confidence intervals for the mean and standard deviation of the generation interval are comparable, the variation in the shape and rate parameters of the underlying gamma distribution are quite large. Care should be taken when generating bootstrap samples from the generation interval when it is specified as an uncertain gamma distribution parameterized with mean and standard deviation, as it is possible that some combinations of parameters produce unrealistic distributions, particularly when the standard deviation is small and the mean is large, which could, in theory, result in posterior estimates for Rt being largely determined by the reciprocal of just a small number of observations.
Using estimates of the serial interval distribution and generation interval distribution as a proxy for infectivity profile, we investigated the resulting variation in the estimation of Rt using incident cases in England and the forward equation approach. We found the bias between the smallest and largest of our estimates to be as high as 20–25% of the central estimate of Rt when Rt was high, but somewhat smaller when Rt values were 1 or lower. Distributions with lower values of the mean tended to result in estimates of Rt that were closer to one. This suggests that biases introduced by the use of different serial interval distributions should not influence the answer to the key question, “is Rt greater or less than 1?” which defines whether the epidemic is expanding or contracting in size. It is also to be expected that the nature of change of Rt over time is not affected by this bias, so an increasing value of Rt will be increasing regardless of the infectivity profile that is used to estimate it.
Estimating Rt is based on knowledge of the incidence of infections. This is not a quantity that is readily observed in the SARS-CoV-2 epidemic, and pragmatically use of observations including symptom onset, case identification, admission, and death are expected to be used as proxy measures for infection.5,7 However, as pointed out elsewhere 9 the variable time between infection and such observations causes the signal to be both delayed and blurred. By combining our estimates of the incubation period with data from hospital admissions in the CHESS data set we were able to make estimates of the distribution of the delay from infection to observation for the UK. There are several caveats to this part of our analysis that must be kept in mind. The CHESS data set relies on a retrospective report of onset of symptoms, and this field is not recorded for all patients. We select only those patients who have reported an onset date and it may be the case that these patients represent a subgroup of patients whose symptom onset is significantly different from the average patient. The data collection around these dates as noted above to show patterns suggestive of rounding or approximation and this could also introduce some bias. The delay distributions are also unlikely to remain fixed during the outbreak, as we would hope to see the time from infection to case identification shorten during the epidemic, and the time from infection to death lengthen as treatment improves, and as the cohort of susceptible individuals changes. Our confidence in these distributions is therefore somewhat low, although we note acceptable agreement between our estimates produced using a mixture of international and UK data, and previously published estimates from different countries, most notably China52–55 which cite an onset to an admission of 2.7–5.9 days26,44,52 and onset to death delay of 16.1–17.8 days.26,52 Given our estimate of the incubation period is log-normally distributed, it is unsurprising that the combination of incubation period and delay from onset to observation is also best described by log-normal distributions (Figure 7 panel B), and with these, we can apply non-parametric back-propagation to infer a time series of putative infections from the delayed observations we have available.
In Figure 8, we bring all the different parts of the analysis together and compare the two approaches of formal estimation of Rt using the generation interval and back-propagation of case, admission or death counts to putative infection, versus a pragmatic estimation using the truncated re-sampled serial interval, and direct use of observation numbers, combined with the simple-but-incorrect adjustment to the resulting Rt time series, shifting the date backward by the mean of the delay distribution. 9
In comparing formal versus pragmatic methods, given the number of moving parts in this comparison it is encouraging to see the level of agreement between the Rt estimates from the two methods (Figure 8 panel B) in the early phase of the epidemic, and also to see that there is some similar structure of the Rt time series in the later parts. This is particularly the case for estimates based on cases and admissions, but less so for deaths where the de-convolution time series shows additional features that are not obvious from the data. We have no gold standard in comparing the Rt estimates for England, so we are limited in what we can conclude, but we do observe that Rt estimates based on our attempt at de-convolution have more variability than ones from un-adjusted observations, and de-convolved estimates have additional features not present in the un-adjusted estimates. The de-convolved estimates of infection are also noted to run to the end of the time series, which is somewhat surprising as estimates of infection rates at the end of the time series should depend on data that has not yet been observed. This is a feature of the back-propagation algorithm which needs to be used with caution as the resulting estimates of Rt based on de-convolution for the latter part of the time series appear inconsistent with each other.
Limitations
We did not fully quantify uncertainty in our analysis and estimation of Rt. The informal approach to estimating Rt has uncertainty arising from the serial interval distribution, and stochastic noise in the value of the observation in question. The formal approach involves uncertainty in the initial estimation of the serial interval, uncertainty in the incubation period, resulting in uncertainty in the generation interval, the back- propagation itself is a source of uncertainty and involves uncertain time-delay distributions which are in turn based on uncertain incubation period, and finally the stochastic noise in the observation under consideration. Accurately tracking the uncertainty of all these components into a final estimate remains a challenge. One of the key reasons we choose to make simplifying assumptions in our use of the pragmatic approach in estimating Rt is that it makes comparatively transparent assumptions that can be backed up by experimental data, and for which the resulting biases are best understood.
Our estimates are based on the best available information at the present stage of the epidemic. However, the serial interval is not a fixed quantity and may be affected by behavioral changes such as case isolation, or social distancing. The assumption is constant is questionable although we have very little hard evidence about how it may vary over time. Similarly time distributions from infection to case identification, admission, and death are expected to be highly variable over the course of an outbreak. This has implications for their use in de-convolution, as changing time distributions will have a significant effect on the shape of inferred infection incidence curves, and the complexity of the de-convolution.
There are implicit selection biases in all the data sources we use. A large proportion of SARS-CoV-2 cases are asymptomatic.12,56,57 It is highly likely that these people participate in transmission chains, and they may do so with a very different infectivity profile to those that are symptomatic, however, we have no information about these people in the data sets, and hence all the estimates presented here could be quite different when asymptomatic cases are taken into consideration.
The data used to assess delays to death rely on hospital-based data as this was the best UK-specific data we had. However, this means that delays to deaths are only assessed for the subset of patients that die in hospital, and we are forced to generalize this to the whole population.
Our approach in estimating key parameters has been to combine different data sets, which come from different international sources, and which have potentially different biases. In combining data sets we assume that time delays are independent of one another, and can be combined randomly, as we have no other evidence to the contrary. This assumption is questionable, as physiologically we can imagine that patients with a long incubation period, for example, may well have a longer period from symptom onset to admission. This could have unpredictable effects on our estimates of time delays but the most likely is that our estimated variance is too small as a result.
Conclusions
We argue that our estimates for the statistical distributions of these key parameters or serial interval, incubation period, generation interval, for the UK, along with their uncertainty represent the best available estimates for the UK, at the time of writing (September 2020), given the current state of knowledge.
As there is a wide range of candidate values for these quantities, we have assessed the bias that the variation in choice of parameters introduces to Rt estimation, when using the forward equation method. Whilst these introduce significant variation in the worst-case scenario, we find that even large differences in infectivity profile can have only small impacts on estimates of Rt when Rt is close to 1. Larger values for the mean of the infectivity profile appear to result in Rt estimates that are further away from 1. This is a relatively reassuring finding in that the answer to the key question “is the epidemic under control?” is insensitive to the mean of the infectivity profile.
Using more formal methods for estimating Rt by back-propagation inference of infection rate and estimates of the generation interval, produces Rt estimates that are more variable when compared to the more pragmatic direct use of case counts as a proxy for infection. Both methods agree on when the epidemic crossed the Rt threshold of 1. However there is considerable uncertainty in the quantities needed to perform the back-propagation, and we are not able to ensure that all this uncertainty could be faithfully quantified in our resulting Rt estimates. We did not set out to assess whether one method is better than another, and this would be a natural extension to this work, however, we note that new methods for combining back-propagation with an estimation of Rt are under active development58,59 and may very well address such further questions.
Supplemental Material
sj-pdf-1-smm-10.1177_09622802211065159 - Supplemental material for Meta-analysis of the severe acute respiratory syndrome coronavirus 2 serial intervals and the impact of parameter uncertainty on the coronavirus disease 2019 reproduction number
Supplemental material, sj-pdf-1-smm-10.1177_09622802211065159 for Meta-analysis of the severe acute respiratory syndrome coronavirus 2 serial intervals and the impact of parameter uncertainty on the coronavirus disease 2019 reproduction number by Robert Challen, Ellen Brooks-Pollock, Krasimira Tsaneva-Atanasova and Leon Danon in Statistical Methods in Medical Research
Supplemental Material
sj-pdf-2-smm-10.1177_09622802211065159 - Supplemental material for Meta-analysis of the severe acute respiratory syndrome coronavirus 2 serial intervals and the impact of parameter uncertainty on the coronavirus disease 2019 reproduction number
Supplemental material, sj-pdf-2-smm-10.1177_09622802211065159 for Meta-analysis of the severe acute respiratory syndrome coronavirus 2 serial intervals and the impact of parameter uncertainty on the coronavirus disease 2019 reproduction number by Robert Challen, Ellen Brooks-Pollock, Krasimira Tsaneva-Atanasova and Leon Danon in Statistical Methods in Medical Research
Footnotes
Authors contributions
All authors discussed the concept of the article and RC wrote the initial draft. KTA, EB-P, and LD commented and made revisions. All authors read and approved the final manuscript. RC is the guarantor. The views presented here are those of the authors and should not be attributed to TSFT or the GDE.
Declaration of conflicting interests
Support for RC and KTA’s research is provided by the EPSRC via grant EP/N014391/1, RC is also funded by TSFT as part of the NHS Global Digital Exemplar program (GDE); no financial relationships with any organizations that might have an interest in the submitted work in the previous three years, no other relationships or activities that could appear to have influenced the submitted work.
Funding
RC and KTA gratefully acknowledge the financial support of the EPSRC via grant EP/N014391/1 and NHS England, Global Digital Exemplar program. LD and KTA gratefully acknowledge the financial support of The Alan Turing Institute under the EPSRC grant EP/N510129/1. LD and EBP are supported by Medical Research Council (MRC) (MC/PC/19067). EBP was partly supported by the NIHR Health Protection Research Unit in Behavioural Science and Evaluation at the University of Bristol, in partnership with Public Health England (PHE).
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.