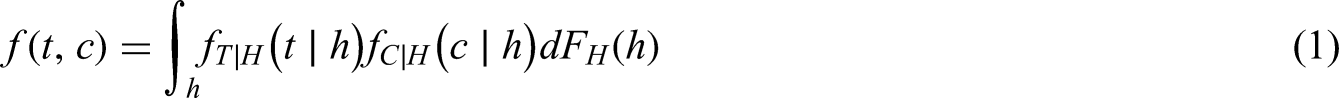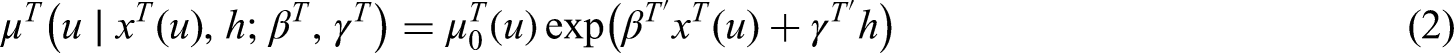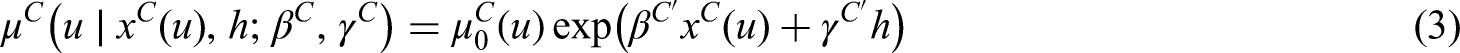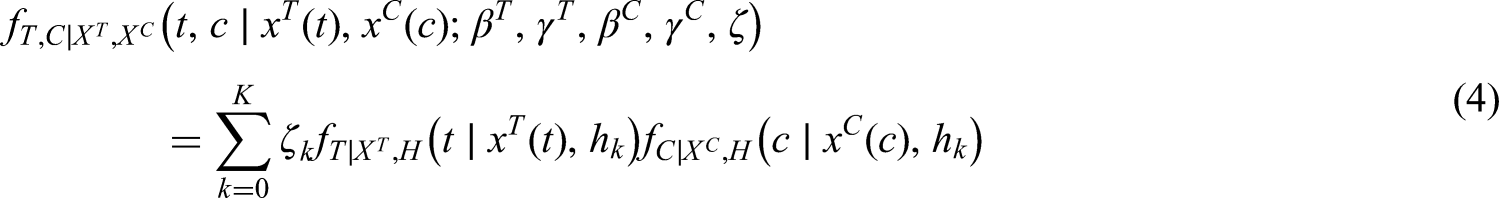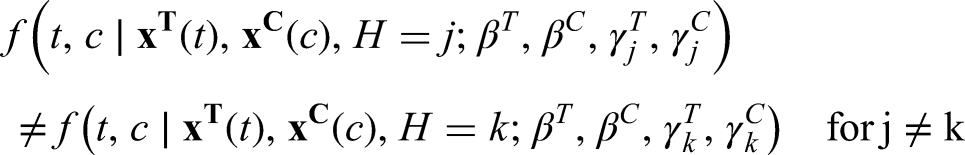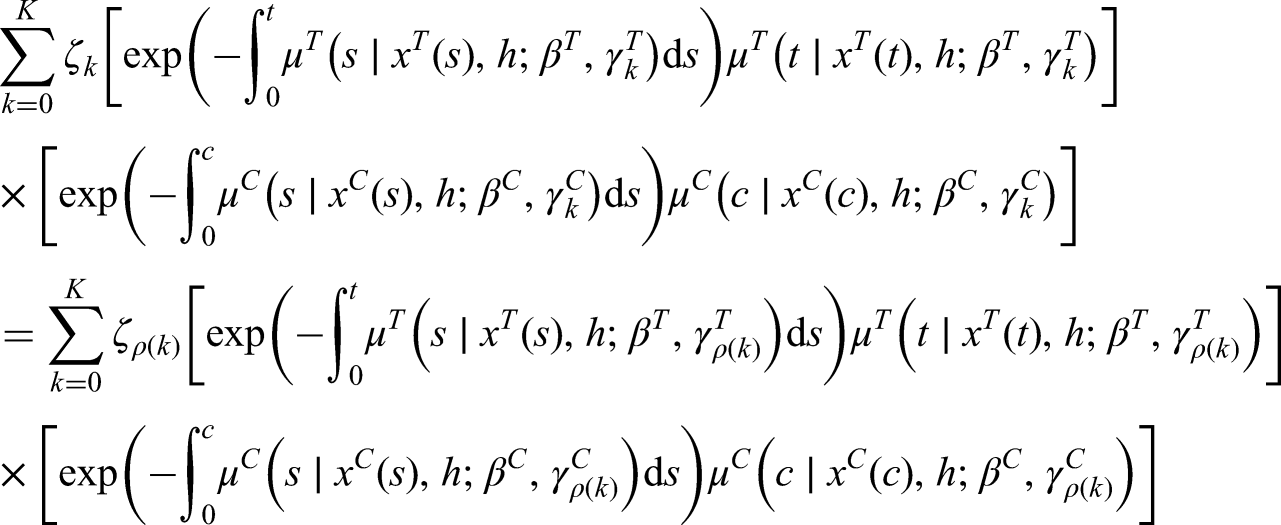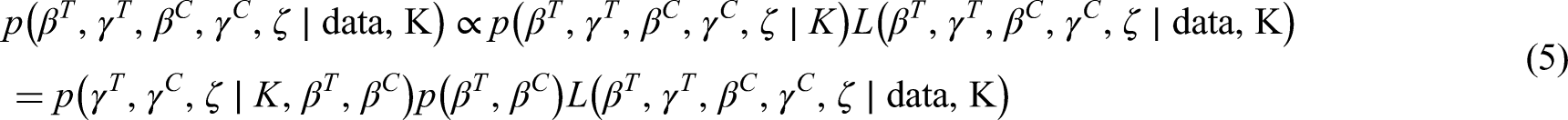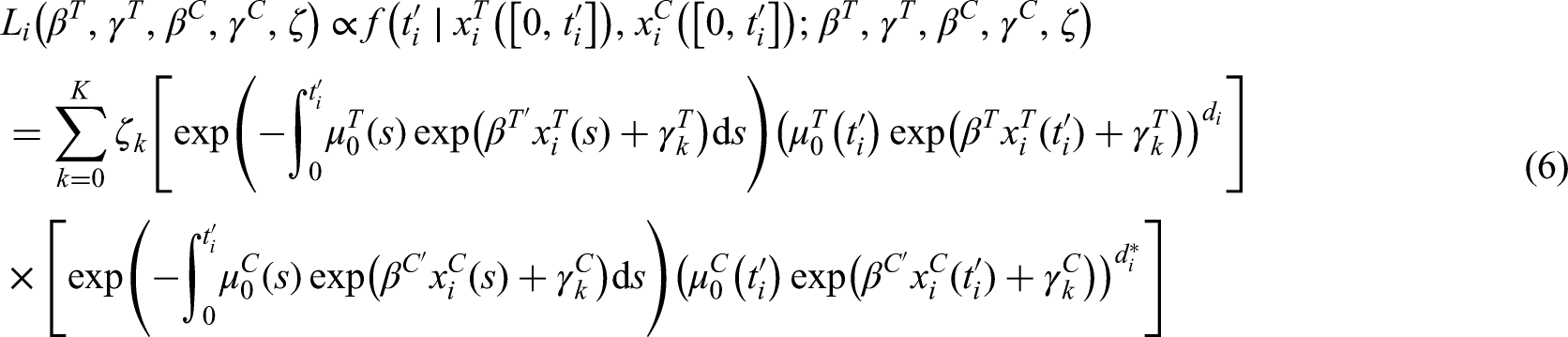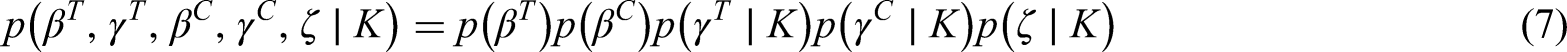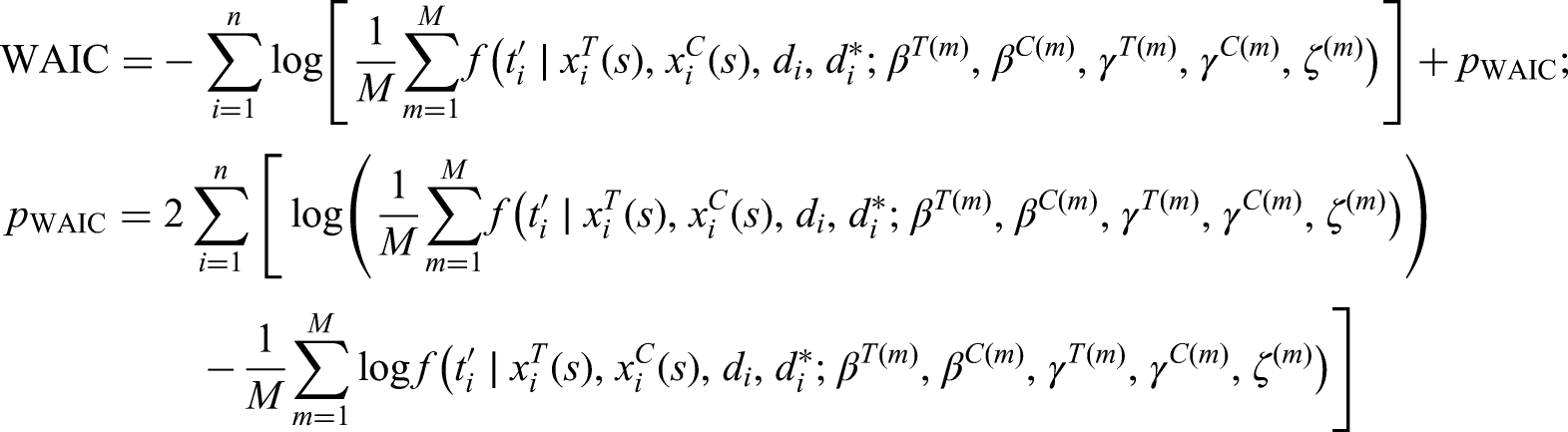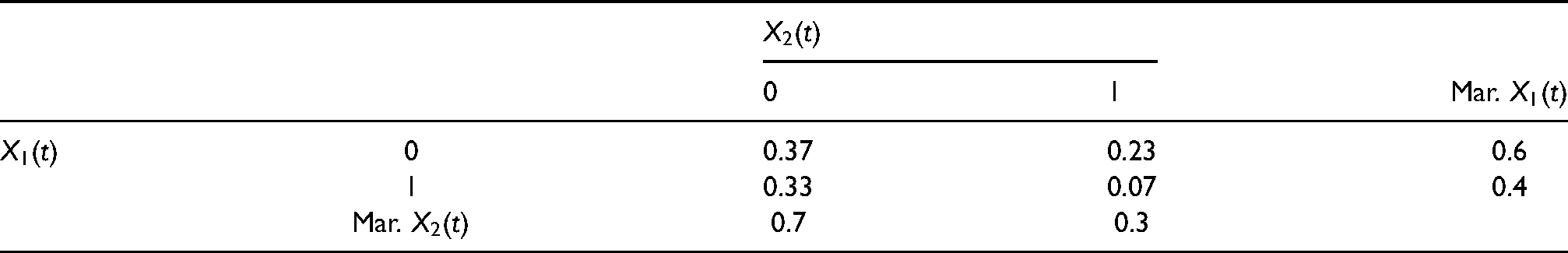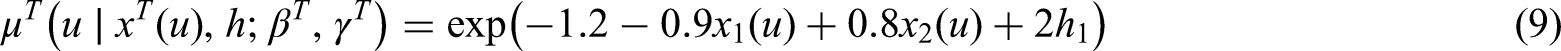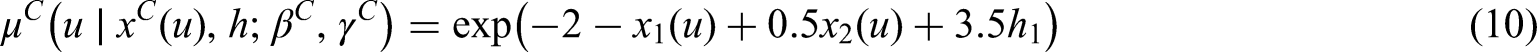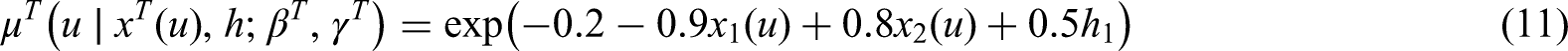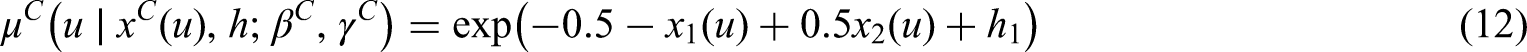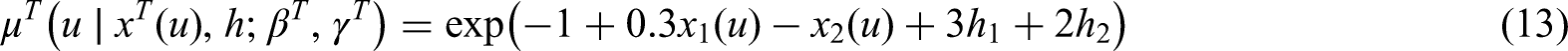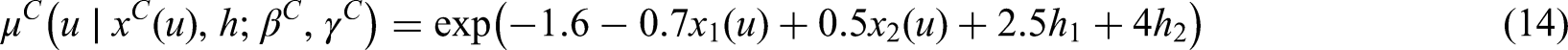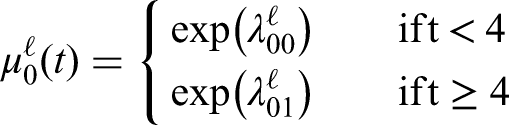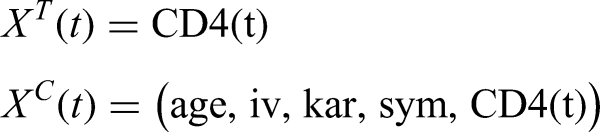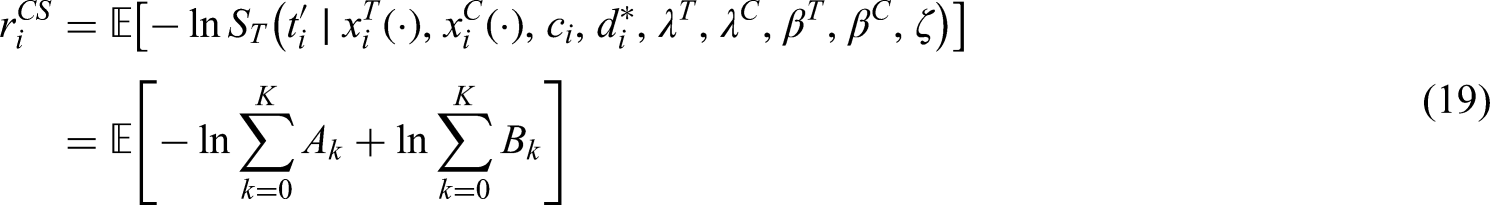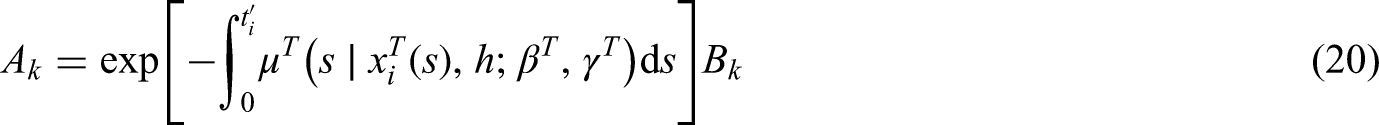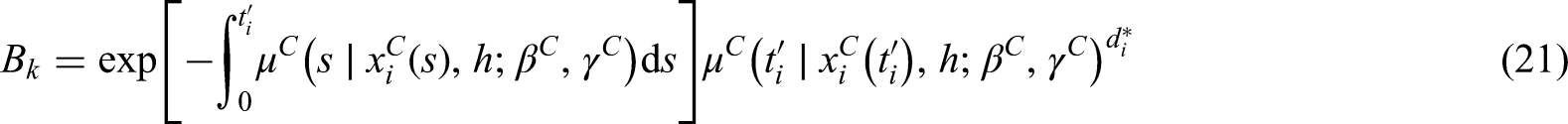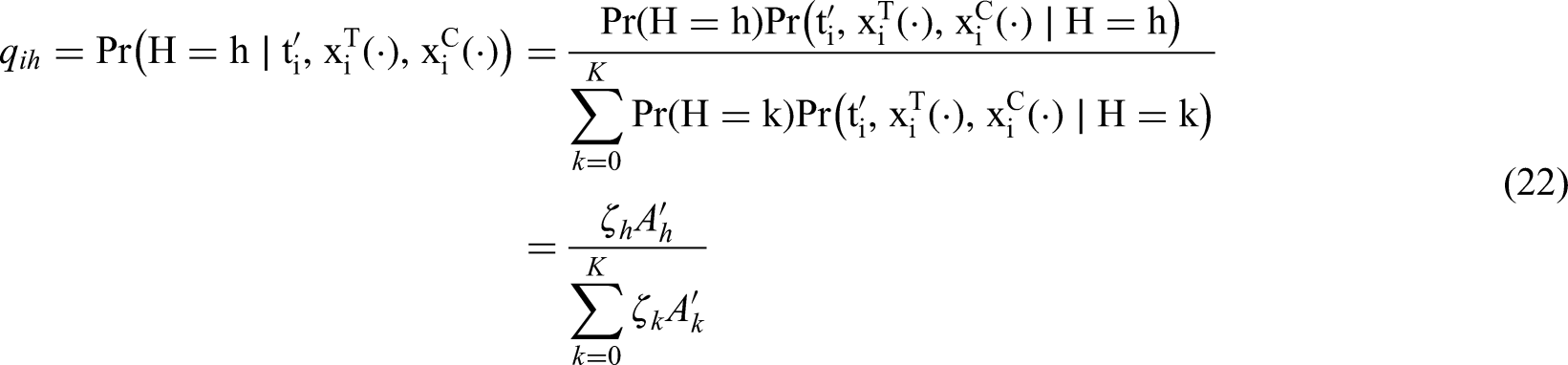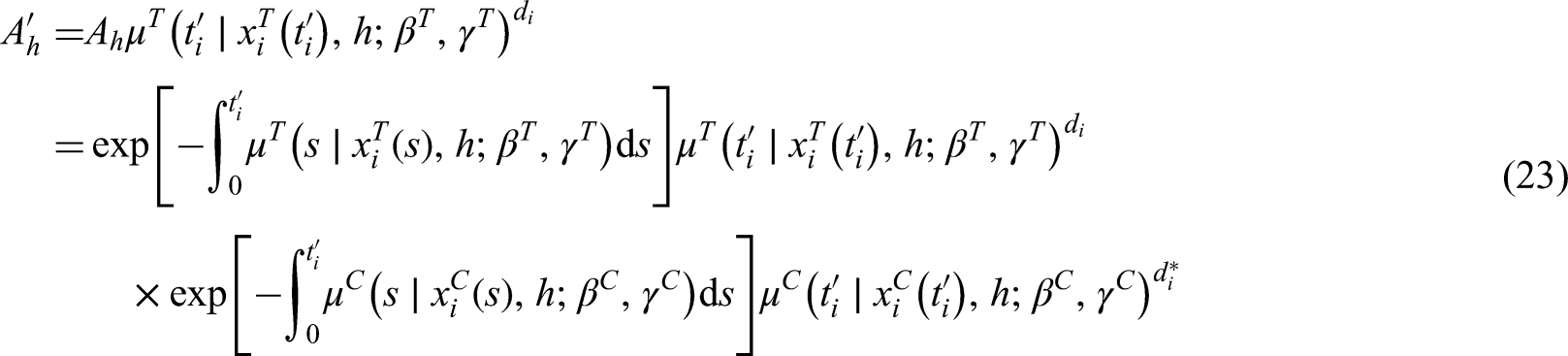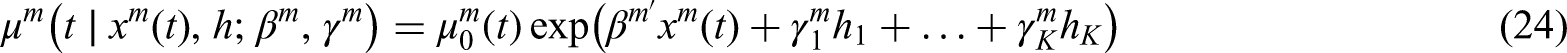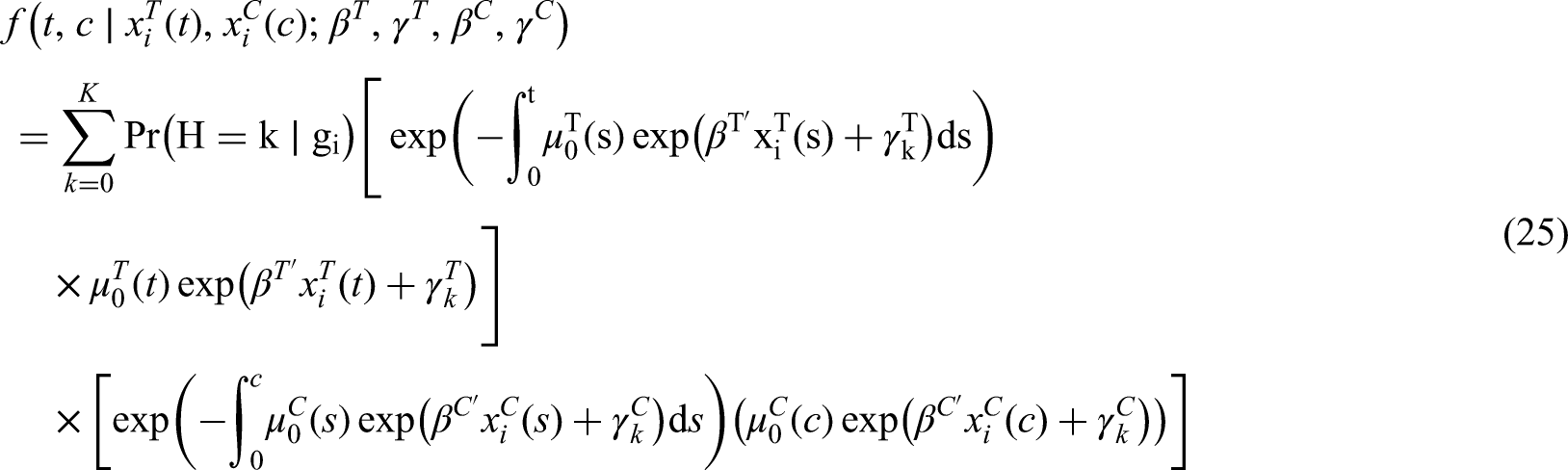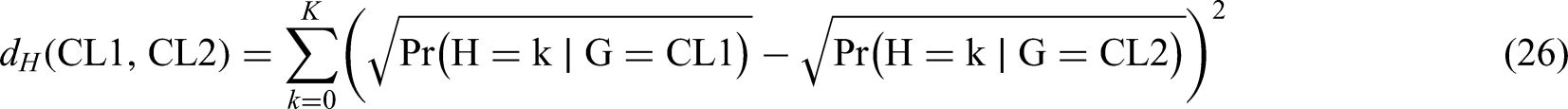This work discusses the problem of informative censoring in survival studies. A joint model for the time to event and the time to censoring is presented. Their hazard functions include a latent factor in order to identify this joint model without sacrificing the flexibility of the parametric specification. Furthermore, a fully Bayesian formulation with a semi-parametric proportional hazard function is provided. Similar latent variable models have been described in literature, but here the emphasis is on the performance of the inferential task of the resulting mixture model with unknown number of components. The posterior distribution of the parameters is estimated using Hamiltonian Monte Carlo methods implemented in Stan. Simulation studies are provided to study its performance and the methodology is implemented for the analysis of the ACTG175 clinical trial dataset yielding a better fit. The results are also compared to the non-informative censoring case to show that ignoring informative censoring may lead to serious biases.
Right-censored survival times are very common in event time studies. Right-censoring is non-informative if the censoring times do not depend on the event of interest. For instance, units whose event of interest has not occurred by the end of the clinical study (type I censoring). Conversely, units may drop out from the study for reasons which depend on the event of interest. For example, in a clinical study on the efficacy of a new treatment, a patient may withdraw due to the worsening of their medical conditions.
In case of informative censoring, we need to consider a model for the joint distribution of the censoring time and the time to event . Not addressing this dependency between and may result in a biased estimation of the distribution of . However, this joint distribution is not identifiable given the data, since we only observe the minimum between and (see1,2 and3 for a more detailed account of this issue). Thus, we have to make untestable assumptions if we wish to study the joint distribution of and .
Some examples from the literature are the works of4, who proposed and analysed the use of a bivariate Weibull model for , and the work of5 who analyse the consistency of the estimator of the marginal survival function of and based on a copula model with known dependence parameters. These parametric models are typically used to investigate sensitivity with respect to the dependency parameter.
Scharfstein and Robins6 consider a hazard function specification for the censoring time which has a multiplicative relationship with a function of , while7 specify a semi-parametric hazard function (8) for , which has a step-change associated with the censoring event. In this way, they avoid modeling the marginal distribution of . The limitation of these approaches is their need to fix the parameter which calibrates the degree of dependence between and , since it cannot be estimated on the basis of available data.
Huang and Wolfe9 proposed the use of a latent variable to account for the dependency between and . Given this latent variable, then and are independently distributed. They assume that this latent variable is normally distributed with mean zero and unknown variance. This latent variable operates on a cluster level (e.g., clinics with patients) where each cluster has its own frailty, which is shared by all units in the cluster. The limitation of this approach is that the parametric class of distributions for the latent variable must be known.
Rowley et al.10 extended the work of9 by considering a latent factor with a finite but unknown number of possible outcomes. The resulting joint distribution of and turns out to be a mixture distribution with an unknown number of components. The authors suggested to estimate this joint distribution with the Maximum-a-Posteriori (MAP) estimator and they recommended to determine the number of levels with the Bayesian Information Criterion (BIC).
Among all options of modeling the joint distribution of T and C, the latent variable approach seems to be the most promising, since it has the least limitations compared to alternative parametric hazard function specifications.
However, statistical models including latent factors, such as those proposed in10, contain singularities in their parameter space, which means that there is not a one-to-one mapping from the parameter space to a probability distribution. As a consequence, the Fisher Information Matrix may not be invertible (see11 and12). Thus, estimators like maximum likelihood (ML) and MAP do not have asymptotic normal distributions and may yield divergent parameter estimates when applied to real datasets. The asymptotic distribution of the parameter estimators deviates from being Gaussian in ill-posed models, particularly when the estimator reaches the boundary of the parameter space (13). When dealing with mixture distributions this problem occurs when the mixture weight is close to zero, when two mixture components are very close to one another, or more generally when a mixture in components can be equivalently obtained as a mixture in components, with .
The problem of model selection between distributions with different number of mixture components turns out to be extremely critical in this context. Classical information criteria such as the AIC (14) and the BIC (15) cannot be used (see16 for further details).
Another criticism towards the use of ML and MAP estimators is that for a mixture model with components the likelihood function is most likely multimodal. Fitting a -component mixture model on observations, results in a likelihood function of the form of a sum of terms, each corresponding to the likelihood function obtainable under the possible realizations of the latent factor. Thus, there may exist multiple roots, and the observed solution can be affected by the choice of the starting values. Finally, the numerical optimization can require high computational time, due to the large number of parameters and the complexity of the objective function, and there would not be any guarantee that all roots will be found.
This work focuses on a joint model for and , where they are independently distributed conditional on a latent class or factor , similar as in10. A point-identifying assumption for this distribution is specified, without sacrificing the flexibility of the parametric model.
We propose the use of a fully Bayesian analysis, where instead of focusing on a point estimate, we try to estimate the posterior distribution of the parameters. The contribution of this work is thus to address the inferential challenges posed by these mixture models for addressing informative censoring in survival models. We will discuss identifiability, the Bayesian inference for this model, including prior specification and parametrization of the mixture model, and the model selection problem for mixture distributions with unknown number of components.
Section 2 will discuss these model formulations, while Section 3 addresses the estimation problem within the Bayesian inferential paradigm. Section 4 contains a simulation study to assess the performance of the inferential strategy described in Section 3. As an illustrative example the ACTG175 clinical trial (17) is analysed, and the results are illustrated in Section 5. Extension of the use of joint models with latent factors are discussed in Section 6. Finally, Section 7 provides a summary and a discussion.
Modeling non-informative censoring with latent factors
In our model we assume that the event time and the censoring time are conditionally independent given latent factor . Thus the joint density of is given by:
where denotes the density function while denotes the distribution function. We refer to the latent factor as the frailty.
Furthermore, we allow that the distribution of and may depend on a vector of time varying covariates at time , denoted by and respectively. In this work, we include covariates by means of the Cox proportional hazard model (8). We assume that the distribution of is independent of and .
Model
We assume that the latent factor is a discrete variable which takes possible values, denoted for simplicity by the set of integers . is considered to be fixed but unknown. We set as the baseline level, and write , such that .
The following models for the hazard function of and are considered:
where is the vector of regression coefficients capturing the effect of the covariates , and is the baseline hazard function. The unknown parameters capture the proportional effect of each outcome of on the the hazard (). We assume that .
As result, now the frailty component has a discrete distribution with sample space , for .
10 also allow for the possibility of regression parameters which depend on , and the distribution of may depend on . An even more structured model, would allow to be time-varying.
The latent factor can be interpreted as an underlying health state or situation of a (group of) patient(s). For example, whether a patient used zidovudine for HIV Type I infection. In this case, the number of levels for latent factor is known and equal to two.
The resulting joint distribution of and still corresponds to the integral of equation (1), where the frailty component is dominated by the counting measure, hence the density can be rewritten as follows:
where and . Equation (4) is in fact a mixture distribution with components induced by the presence of a latent factor . can be considered as the non-parametric distribution of (see18,19,20).
The mixture formulation also accounts for non-informative censoring, which occurs when either one or both conditions hold:
i) ;
ii) ;
In particular, in situation i) we obtain the Cox proportional hazards model without heterogeneity between patients in hazard for the time to event , while in ii) the hazard function for is still characterized by sources of heterogeneity which are not explained by the censoring mechanism.
Identifiability
General conditions for the identifiability of this modelling approach have been analysed in21,22 and23.
Nevertheless, given the finite mixture nature of our approach, two additional conditions are needed to ensure its global identifiability1 (see also25 and26):
For every value of , different values of should result into different p.d.f.s:
and thus two different hazard functions for or two different hazard function for given their conditional independence;
for . This condition is needed because if for any we have , then and can take any value without affecting the mixture distribution.
However, the joint probability distribution of outlined so far is not locally identifiable: by permuting the labels of , we obtain exactly the same joint p.d.f.:
where represents any permutation of the indexing given by , and .
This problem can be easily overcome by restricting the parameter space of the hazard function. In Section 3.2 we address this issue in the perspective of improving the efficiency of the Hamiltonian Monte Carlo sampler.
Inference
For the reasons described in Section 1, in this work we carry out our inferential exercise using Bayesian techniques. Let denote the -dependent prior distribution of the parameter vector . The learning object is thus given by the following posterior distribution of the vector :
where denotes the likelihood as a function of the parameters, given the data and . In order to avoid the use of a cumbersome notation will denote the density function of the parameters.
In equation (5) we remarked the dependence of the posterior distribution on , since it determines the dimension of the parameter space, particularly for , and .
Likelihood function
Let us first distinguish from , where the former denotes the time to informative censoring, and the latter denotes the time to non-informative censoring (e.g. administrative censoring). Let , and . Thus, if a time to event is subject to non-informative censoring, then .
The latent factor is never observed, hence the th individual likelihood contribution must be marginalized with respect to :
where and for is the set of covariates value at time .
In equation (6) the covariates are assumed as continuously observed throughout the whole time span . In practice, covariates are observed at discrete time points, and several assumptions can be made for their value at intermediate time points. For example, in the simulation study (Section 4) and in the empirical analysis (Section 5) the covariates are assumed constant between two observation times, and equal to the previously observed value.
The resulting likelihood function of the parameters, given the data is the sum of terms, each corresponding to a realization of the latent factor for each unit in the sample.
Prior specification and model reparametrization
In general, the Bayesian analysis of a mixture model is particularly challenging. For this reason, the prior should be chosen accurately, and the model needs to be parametrized in a way that makes the sampling process efficient.
First of all, we assume for convenience that the vectors , , , and are pairwise independently distributed, that is:
where each density depends on some hyperparameters.
The specification of the prior distribution for the regression coefficient parameters and does not represent a problem, hence it is possible to specify a non-informative prior in order to reduce the extent of subjective assumptions on the inference.
The prior distribution of , and must be specified with more care. The use of prior distributions which are at least weakly informative is appropriate, in order to enhance the efficiency of the sampler.
For example, with the use of an exchangeable prior on , and of a uniform prior on 2, then their posterior distribution will maintain the permutation invariance induced by the mixture likelihood (27 and28).
This multimodality hinders the efficiency of the sampler, because it would take a large number of iterations to fully explore the posterior distribution. Indeed, the sampler is likely to get stuck in an area of the parameter space corresponding to one mode of the posterior distribution (see29).
In Bayesian inference the identifiability of a mixture distribution turns out to be more crucial. In Section 2.2 we mentioned how a constraint allows for a model to be identifiable. In our case we also need to follow a strategy which allows for an efficient sampling for the posterior distribution.
For the joint distribution of equation (4), we need to place an ordering constraint on the set , which can be done by ordering either or . For example, we can set:
where we take into account also the component corresponding to . An account of the geometric interpretation of this constraint can be found in28. This constraint also turns exchangeable priors into nonexchangeable ones due to the restriction of the parameter space into its subset, singling out one mode of the posterior distribution, as induced by the label permutation. Conversely, the exchangeability in the prior distribution will be inherited also by the posterior distribution.
However, when the mixture components are not well separated (i.e. these are very close to one another in value), then also the posterior distribution will be affected by the imposed constraint. For example, suppose we set an ordering as in equation (8), and there is a nonnegative probability that (all else being equal, which is more likely if is very close to ), then the true posterior distribution cannot be captured by the posterior distribution satisfying such constraint.
In the extreme case where the mixture components overlap, then the posterior distribution will be more difficult to explore (28), as may occur when the value of is larger than actually needed to explain the heterogeneity among the units. In this case the components in excess will collapse into those which are necessary and have been already included in the model.
This justifies our inferential strategy of analyzing increasingly complex models in terms of needed mixture components, as we describe in Section 3.3.
Choice of the number of mixture components
The value of is inferred by solving a model selection problem, where models with different values of are separately fitted and then compared to one another using appropriate information criteria. Algebraic geometry tools have been proven useful in order to understand the asymptotic behavior of the posterior distribution of the parameters when dealing with singular statistical models. For example,11 proposes the Widely Applicable Information Criterion (WAIC), which generalizes the AIC to the analysis of singular models.
The WAIC is computed as follows (notation simplified for ease of exposition):
where is the number of sampled values from the posterior distribution of the parameters, and is a penalization term which can be interpreted as the effective number of parameters, and measures the fluctuation of the posterior distribution (see16).
Our strategy is to first analyze the model with ( and independently distributed given and ) and then we fit models with increasing until the WAIC does not decrease, as we aim at its minimization.
Similar information criterion have been proposed to generalize the BIC, such as the singular BIC of12 and the Widely Applicable Bayesian Information Criterion (WBIC) of30. The former is of harder implementation in practice, while we found in a simulation study (not discussed here) that the WBIC shows a slightly better performance than the WAIC in selecting the true model, particularly when the mixture components are well separated. The WAIC is hereby preferred over the BIC generalization for two practical reasons: i) it provides a measure of model dimension through ; ii) it turns out to be more practical since it allows to use the same output from the posterior sampling process.
Estimation
For the estimation of the posterior distribution of equation (5) we use the Hamiltonian Monte Carlo (HMC) sampler (see31). This algorithm belongs to the general Metropolis-Hastings family. HMC uses Hamiltonian dynamics which allow for a faster exploration of the parameter space. It turns out to be more efficient than more traditional Gibbs and random-walk Metropolis samplers for posterior distributions showing high correlations among the parameters, as it occurs for mixture distributions.
The HMC sampler is implemented by using the Stan software package (32) and its R interface (33), by means of the package rstan. In its default implementation Stan uses the No-U-Turn sampler of34 which allows for an automatic tuning of the sampler. Furthermore, the rstan can automatically initialize the sampling process.
Simulation study
Set up
Simulation studies are carried out to assess the performance of the methodology outlined in this work. We focus on the posterior distribution of the parameters , , and , and thus on whether the WAIC allows to chose the true model. We look at whether the 95% credible intervals of the posterior distribution include the true value of the parameters, and we analyse whether the posterior mean can be considered as an unbiased point estimate of the parameters.
We compare these results with the parameter estimates and the 95% coverage intervals obtainable from the Cox proportional hazards model. This gives us the opportunity to quantify the need for our method in certain settings.
For each simulation run, we generate samples of 500 potentially censored lifetimes.
For each patient we assume the vector of time-varying binary covariates (for example treatment and disease) with the probability distribution shown in Table 1.
Joint probability distribution of .
0
1
Mar.
0
0.37
0.23
0.6
1
0.33
0.07
0.4
Mar.
0.7
0.3
The binary covariate variables are independent throughout time.
We consider an observational period of 8 years, and a follow up period of 4 years for simplicity such that the researcher observes for . In medical practice, these values can change at very high frequency over time, for example whether a patient has a high or low blood pressure, or the time-dependent treatment, although applied statistical analyses contain simplifications to overcome the issue. In this simulation study we assume that is constant between one observation and the other.
For each unit, is generated from a distribution.
For we consider two scenarios: the case of well separated mixture components (WS), and the case of poorly separated mixture components (PS).
In the WS scenario and are generated under the following hazard functions:
Conversely, in case of poorly separated mixture components, we specify:
For the case of two mixture components we set and is chosen in order to keep a stochastic ordering in the hazard function of the censoring time due to higher values of .
When , then and are generated according to the following hazard functions:
and . In this case, we consider only the case of well separated mixture components due to the smaller sample size.
The analysis of models with more than three mixture components requires ideally larger samples than those analysed in this work, while the case can be more efficiently fitted with a Cox proportional hazard model. For each value of we generate 100 datasets. In all cases we ensure that the datasets have around 40% censored units and a negligible percentage of type I censoring cases.
Drawing a value for (T,U)
A general property of survival models is that the integrated hazard function is a random variable with distribution.
Therefore, conditional on a standard uniform random variable , a set of covariates and a factor , a sampled value of , denoted by , is given by the solution of the following equation:
Given the set-up described in Section 4.1 and the hazard function specification of equations (9)-(14), then equation (15) has a closed form solution. In the same way we can sample a value for the censoring time .
Then, once and are obtained, a value for the triplet is calculated as follows:
Implementation
We use weakly informative prior distributions for each parameter, instead of fully non-informative ones in order to foster the convergence of the sampler. In this way, the posterior distribution will not be strongly affected by prior assumptions. Indeed, with enough observations, the effect of the prior should be negligible (16).
Furthermore, we assume that parameters are a priori independently distributed.
We model the baseline hazard function of and using a piecewise constant hazard function as follows:
where , in order to ease the representation, considering a time span divided into two sub-periods of 4 years.
The posterior modeling involves , since in this way we do not need to constrain the parameter space, and the sampler works more efficiently.
The piecewise constant baseline hazard function represents a useful yet flexible specification, mainly if the number of knots (or intervals) increases. Alternative models can be given for example by a Gamma Process for the integrated baseline hazard function (see35), or the use of splines (36). Further alternatives are discussed in the book of37.
For the prior distribution we assume that , , and are vectors of pairwise independent and normally distributed variables with mean 0 and variance equal to 10. When fitting a model with we assume that , truncated at the lower bound of 0 and . When , the prior of and are as before, while , truncated at the lower bound of and . In a similar fashion, when fitting a model with we assume , truncated at the lower bound of and . In all cases, when choosing the Dirichlet distribution parameters, we kept a prior sample size (the sum of the Dirichlet distribution parameters) of 50.
The HMC sampler is run for 5,000 iterations and the first half draws are discarded in order to allow for burn-in and fine-tune the No-U-Turn sampler. Indeed, given our simulation settings, 5,000 iterations are sufficient to allow for the chains to mix and obtain a stationary posterior distribution, which ensures convergence of the sampler.
Results
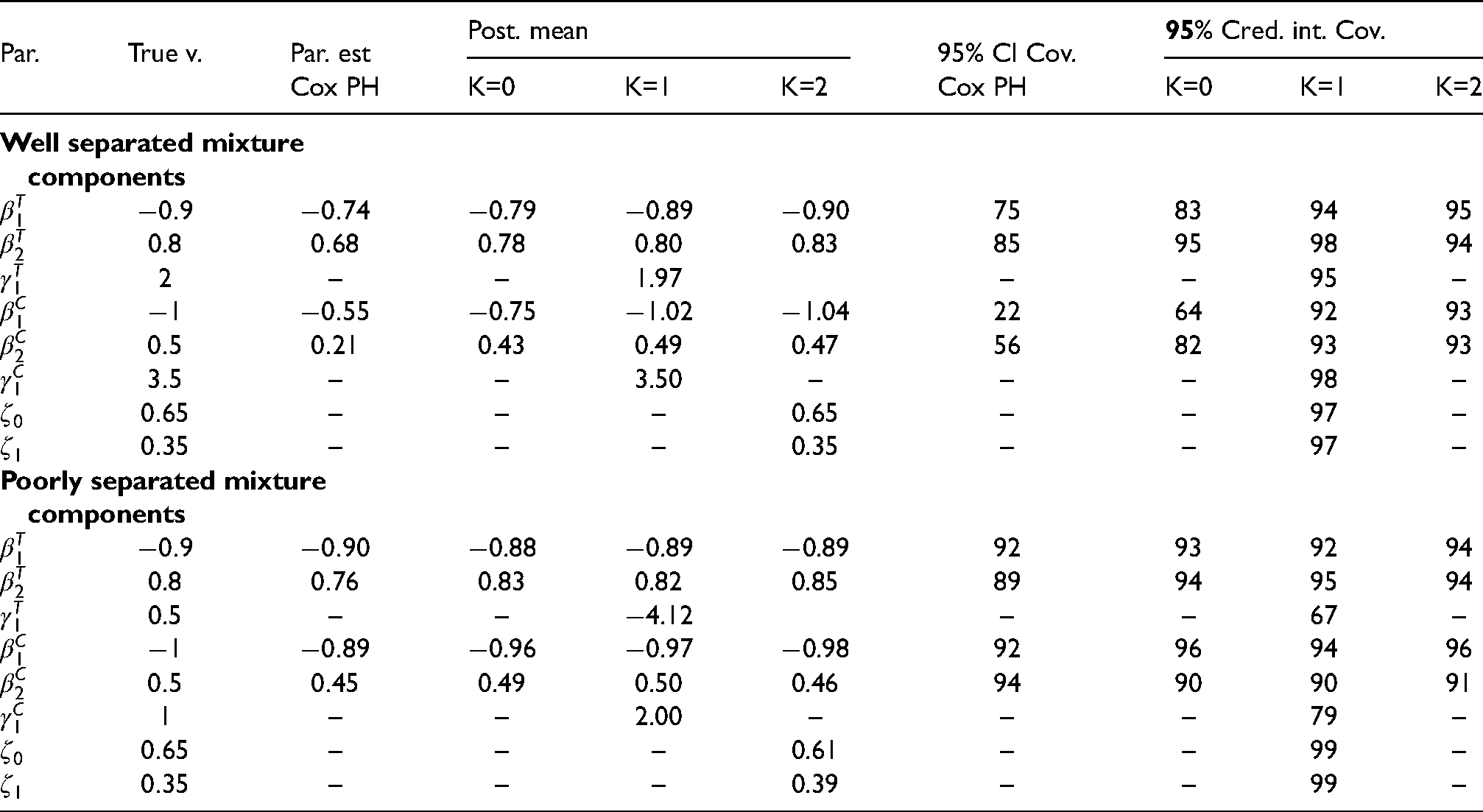
The results in Table 2 for show that the 95% credible intervals from the posterior distribution of the parameters include their true value with a coverage close to normal when fitting the true model and the mixture components are well separated. In case of lesser separated mixture components, the 95% credible intervals still show a coverage larger than 90% for , and . However, the coverage sensibly decreases for and , whose posterior mean turns out to be divergent from their true values.
Parameter estimates with the Cox proportional hazard model (Cox PH), posterior mean estimate for the models with , coverage of the 95% confidence interval (for the Cox model) and coverage of the 95% credible intervals.
Par.
True v.
Par. est
Post. mean
95% CI Cov.
Cred. int. Cov.
Cox PH
K=0
K=1
K=2
Cox PH
K=0
K=1
K=2
Well separated mixture components
0.79
0.89
0.90
75
83
94
95
0.8
0.78
0.80
0.83
85
95
98
94
–
–
1.97
–
–
95
–
0.75
1.02
1.04
22
64
92
93
0.43
0.49
0.47
56
82
93
93
–
–
3.50
–
–
–
98
–
–
–
–
0.65
–
–
97
–
–
–
–
0.35
–
–
97
–
Poorly separated mixture components
0.88
0.89
0.89
92
93
92
94
0.8
0.83
0.82
0.85
89
94
95
94
0.5
–
–
4.12
–
–
67
–
0.96
0.97
0.98
92
96
94
96
0.49
0.50
0.46
94
90
90
91
1
–
–
2.00
–
–
–
79
–
–
–
–
0.61
–
–
99
–
–
–
–
0.39
–
–
99
–
When the mixture components are well separated, the 95% credible intervals have a coverage below nominal for almost all parameters when fitting the model assuming that and are independently distributed (K=0): and have a coverage of 83% and 95% respectively, and and are included in the credible intervals with 64% and 82% probability respectively. As expected, in case of poorly separated mixture components, without a very large sample size, the model with tends to show a coverage close to nominal for the parameters and . Indeed, the true model tends to be closer to the model with .
The results for the posterior mean follow from those of the credible intervals. We see that the regression parameters and are in line with respect to their true value when and the mixture components are well separated. Same applies for the baseline hazard (not shown) when fitting the true model with , as well as for , and .
Analogous results are obtained for the model with as shown in Table A1 in Appendix A.1. For this particular case, with a sample of 500 units we note that the posterior mean of is different compared to its true value, despite the credible intervals show a coverage of 92%. A closer inspection of this result showed that this is the consequence of the small number of events for those units with (around 5% of the observations), which causes to be estimated with larger uncertainty.
Table 3 shows that when the mixture components are well separated in all cases the WAIC excludes the lack of heterogeneity, ruling out the model with . In 90 cases out of 100 it selects the model with K=1, while in 10 cases it selects the model with . In this latter case, the WAIC for the model is never higher than 2 compared to the model with . This means that if we chose the more parsimonious model with , we do not lose much information. Clearly, these results depend on the values of and , which we purposely chose in order to ensure that the mixture components are well separated. Conversely, when the mixture components are poorly separated, in case of smaller sample sizes the models with tend to behave similarly. Indeed, when the WAIC picks the model with , then it is never larger than 1, compared to the true model with . Similarly, when the WAIC picks the model with , the difference with the WAIC for the true model is never larger than 3.2.
Number of times out of 100 the WAIC selects the true model based on .
True
Sample
Mixture
Fitted models
model (K)
size
sep.
K=0
K=1
K=2
K=3
500
PS
41
40
0
500
WS
0
10
0
500
WS
0
54
7
1,000
WS
0
18
22
5,000
WS
0
7
10
Given our choice of the parameters in equations (13)–(14) related to the case we could see that the WAIC chooses the true model in 39 cases, while in 54 cases it chose the model with and in 7 cases the model with . The model with is always ruled out. When the model with is chosen the difference in WAIC is never higher than 1.79, and thus we reach the same conclusions as the previous cases.
These results do not necessarily mean that our approach to model selection has a poor performance as the true increases: the more complex the model, the larger the sample size should be in order to capture the heterogeneity in the units. Indeed when using a sample size of 1,000 and of 5,000 units, then the true model is selected in 60 and 83 cases out of 100 respectively. In addition, as aforementioned, also the true values of the parameter and play a fundamental role to capture heterogeneity among the units.
This simulation study showed how the model is always capable to spot the heterogeneity in the distribution of induced by informative censoring. Another key point is that failing to account for this heterogeneity yields a bias in the estimation of the regression coefficients, as shown by their smaller coverage. The probability of selecting the true model increases with sample size, as we can expect in highly parametrized models as analysed in this work. Parsimony is also preserved, since even when fitting a larger model which shows a better performance in terms of WAIC, then selecting a smaller model does not result in a great loss of information. Compared to the use of the Cox proportional hazard model, the results of this work are even more robust if we consider that in our model we needed to specify a baseline hazard function.
Analysis of ACTG 175 dataset
The AIDS Clinical Trial Group (ACTG) 175 study (17) is a double-blind randomised clinical trial where a total of 2,467 adults infected with HIV type I and CD4 cell counts between 200 and 500/mm are randomly assigned to four different treatments: i) zidovudine, ii) didandosine, iii) zidovudine plus didandosine and iv) zidovudine plus zalcitabine.
Enrolment run from December 1991 until October 1992, while patients were scheduled to stay under analysis until November 1994. In particular, they are examined at weeks 2, 4, 8 and every 12 weeks afterwards.
For each patient we could observe baseline covariates, such as age, gender, ethnicity, CD4 count, Karnofsky score, prior use of antiretroviral therapy, haemophilia and whether the HIV was symptomatic or not; as well as some other information like the primary endpoint, and the reason for drop out from the study3 . CD4 cell counts are checked at the initial visit and then from week 8 onwards.
The primary endpoints (the time to the event of interest we want to model in this work) of the study were a 50% decrease in CD4 cell counts with respect to the baseline, AIDS or death. At the end date of the observational study there are some patients whose primary end point did not occur, hence these can be considered as non-informatively type 1 censored.
However, some other patients can drop out from the study earlier than the end date without reaching the primary endpoint for some reasons, such as toxicity of the therapy, request of the patients themselves or of the investigator, while some others just do not show up at the next planned visit (loss to follow up). In these cases it is reasonable to assume that these drop out causes are related to the primary endpoint, since for example a patient may ask to discontinue a therapy because she feels better, therefore the death event is less likely to occur (other things being equal). In this case, the Kaplan-Meier estimate of the survival function (which considers censoring as non informative) is likely to be pessimistic about patient survival.
Similar to the work of6 and39 we focus on the analysis of those patients treated with zidovudine only. We thus have 614 patients of which 195 experienced the primary endpoint (151 had 50% CD4 reduction, 14 died and 30 developed AIDS).
Hence, of the remaining 419 patients, 183 are Type I censored and 236 are considered as subject to informative censoring.
Furthermore,17 observed that throughout the study ”younger patients, those reporting injection-drug use and those with lower CD4 cell counts, lower Karnofsky score and symptoms of HIV infection at enrollment are more likely to discontinue the treatment before the study ends”.
For illustration we consider the following covariates vector for and :
We chose based on the WAIC, while is chosen on the basis of the aforementioned considerations of17. is the same vector of covariates chosen in6 and39.
In particular, age denotes the age of the patient at time of randomization, iv is an indicator of intravenous drug use, kar indicates the Karnofsky score, sym is a binary variable indicating the presence of symptoms of HIV infection and CD4 indicates the CD4 cells count at each visit . We assume for simplicity that the CD4 cell count is constant between one visit and the other.
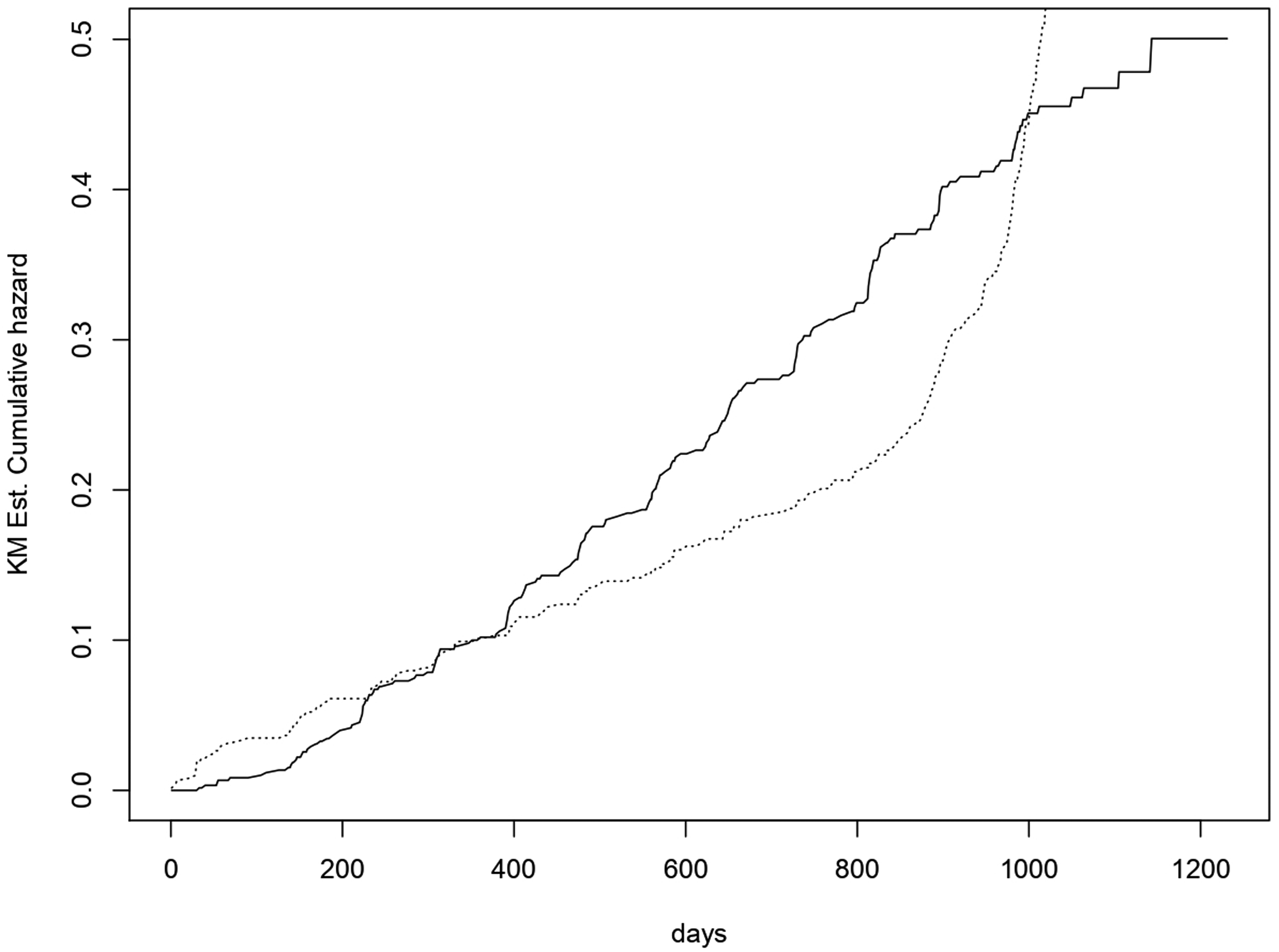
From a look at the Kaplan-Meier curve of the integrated hazard function, shown in Figure 1 we could have a rough idea about the shape of the baseline hazard function which seems approximately piecewise linear for both and . For this reason we specify a piecewise constant baseline hazard function for and with two breakpoints. As stated in Section 4.3 other specifications for the non-parametric baseline hazard function can be possible. For this dataset we noted that the use of a Gamma process would rather slower the HMC sampler without returning better results.
Kaplan Meier estimate of the cumulative hazard function for T (solid line) and for the censoring (dotted line).
The breakpoints have been chosen by fitting a piecewise linear function with two breakpoints where the cumulative hazard function obtained from the Kaplan-Meier estimator is regressed against the time to event using the package segmented (40). The breakpoint vector for is , while the vector for is .
In a similar fashion with respect to the simulation study we chose weakly informative prior distributions. Hence, we assume that , , and are vectors of independent and normal random variables with mean 0 and standatd deviation equal to 10. and are chosen in the same way as in the simulation study, while assuming a prior sample size for equal to 25 for all fitted models. For different prior distribution have been specified for . This does not exclude the possibility for the researcher to use expert judgement when specifying the prior distribution. The choice of the best model is again based on the WAIC.
For each value of we run 4 parallel chains, each for 20,000 iterations (10,000 used as warm-up).
In addition, we compare these results with those obtainable from fitting a Cox proportional hazard model, which assumes independence between and .
Results
We observe that for the analysed models the HMC sampler converged towards the posterior distribution, as we can see for example from the traceplots of Figure A1, where we showed only the first two chains in Section A.2.1, and the statistic of41 for all parameters which is always equal to 1. The marginal posterior density of each parameter is nearly symmetric, except for due to the chosen local identifiability constraint (Figure A2).
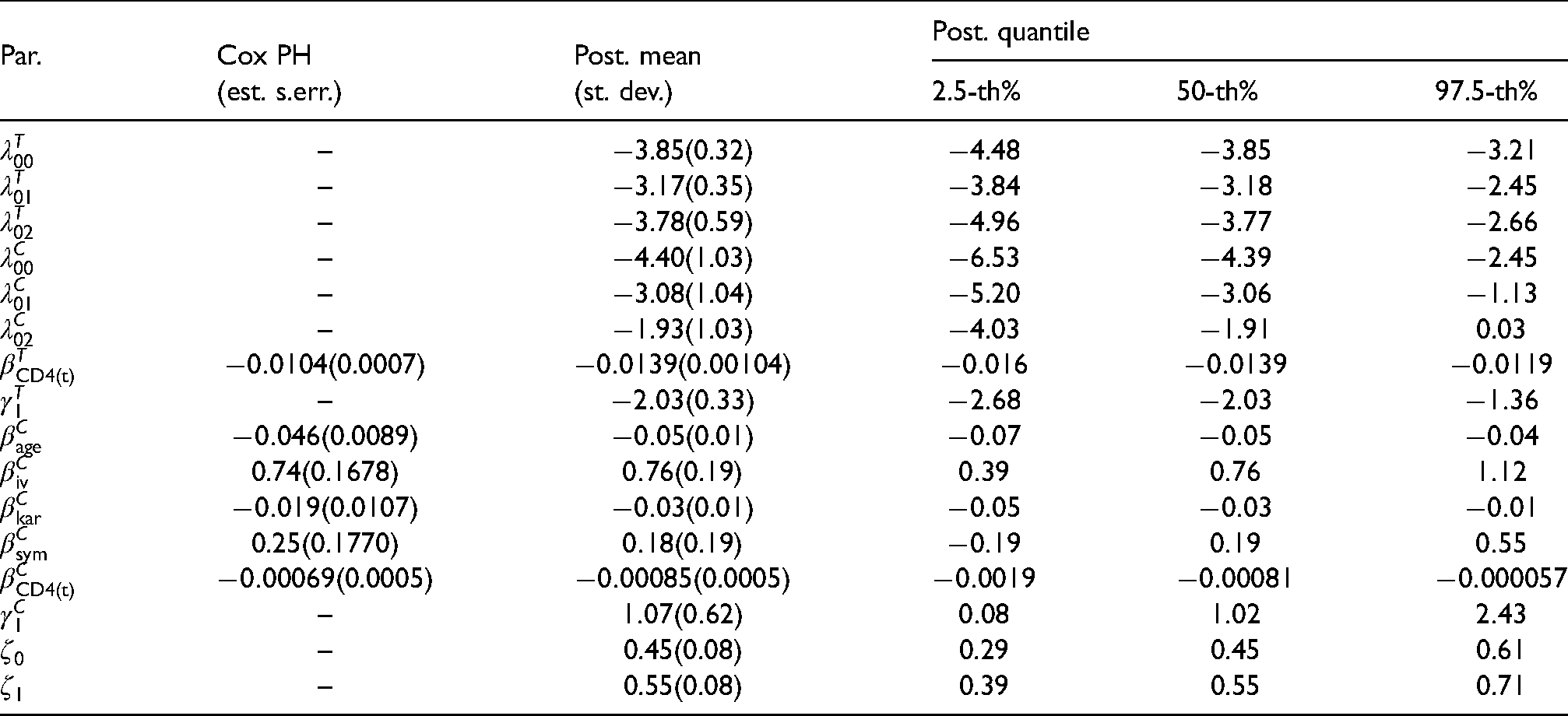
The WAIC leads to the choice of the model with (Table 5), whose results are shown in Table 4. As emphasized in the simulation study of Section 4 the true value of may be higher than 1 due to the relatively small sample size, although we did not have a great loss of information. As we can see, the WAIC progressively increase with after hitting its lowest point at the value of 1.
Cox proportional hazard model estimate of the parameters (Cox PH) and summary of the posterior distribution of the parameters for the model with .
Par.
Cox PH
Post. mean
Post. quantile
(est. s.err.)
(st. dev.)
2.5-th%
50-th%
97.5-th%
–
3.85(0.32)
4.48
3.85
3.21
–
3.17(0.35)
3.84
2.45
–
3.78(0.59)
4.96
3.77
2.66
–
4.40(1.03)
6.53
4.39
2.45
–
3.08(1.04)
5.20
3.06
1.13
–
1.93(1.03)
4.03
1.91
0.03
(0.0007)
–
(0.0089)
(0.01)
0.74(0.1678)
(0.19)
(0.0107)
(0.01)
0.25(0.1770)
(0.19)
(0.0005)
(0.0005)
–
–
0.45(0.08)
0.29
0.45
0.61
–
0.55(0.08)
0.39
0.55
0.71
WAIC and effective number of parameters () for the models with .
K=0
K=1
K=2
K=3
WAIC
3,462.76
3,457.34
3,458.13
12.30
13.83
14.90
15.48
For all values of we see that lower time to primary endpoints are associated with lower CD4 cell counts, coherently to our expectations. This is because it is an indicator of progression of the HIV and of immunologic health.
Again, when analysing the time to censoring, we can see that our results are consistent with the observations of17 mentioned in the previous section, hence with the evidences obtained by6.
The standard errors of the parameter estimates obtained with the Cox PH model are smaller than the standard deviations of the posterior distribution of the parameters from our Bayesian modelling approach. This is presumably due to the fact that the Cox model tends to yield lower uncertainty about parameter estimates than the joint model developed in this work since the latter has more parameters, as we specify a baseline hazard and include a latent factor.
The covariates intravenous drug use and the presence of symptoms do not show statistical significance, which may be explained by the role of CD4 cell counts. For example,42 in the analysis of the progression of the HIV between hard drug users and other subjects in the Women’s Interagency HIV Study, noted that hard drug users tend to drop out from the study earlier, and that those subjects have lower mean of CD4 cell counts. Thus the effect of intravenous drug use may be mediated by CD4 cell count. Additionally, the CD4 count may be a confounder for the effect of symptoms and the direct effect of symptoms is relatively small when corrected for CD4 cell count.
For this particular dataset the summaries of the posterior distribution of and from the model with are very close to those for the models with , as we can see in Tables A2–A4 in Appendix A.2.2, although we can see some major differences with reference to the baseline hazard functions (from 16 to 40% in absolute value), (25% higher than the same parameter for the model with ) and (34% lower). As we could see also from the simulation study, the assumption of independence may lead to considerable risk of wrong parameter estimates following model misspecification. When comparing the results of the latent factor model with with the Cox proportional hazard model which leaves the baseline hazard function unspecified (Table 4), once again we see that the heterogeneity may have a considerable effect on the value of parameter estimates which may be biased if this further heterogeneity is not taken into account. For example, the Cox model underestimates the effect of the CD4 cell counts.
The parameter , has a marginal posterior distribution such that values around zero are very unlikely. This means that there is further heterogeneity in which may be captured from other factors. When coupled with the distribution of (Figure A2) we can see that this heterogeneity may be due to the presence of informative censoring (posterior mean equal to 1.07). A further sign of convergence is that large probability mass lies far from the boundary of the sample space, as determined by the constraint.
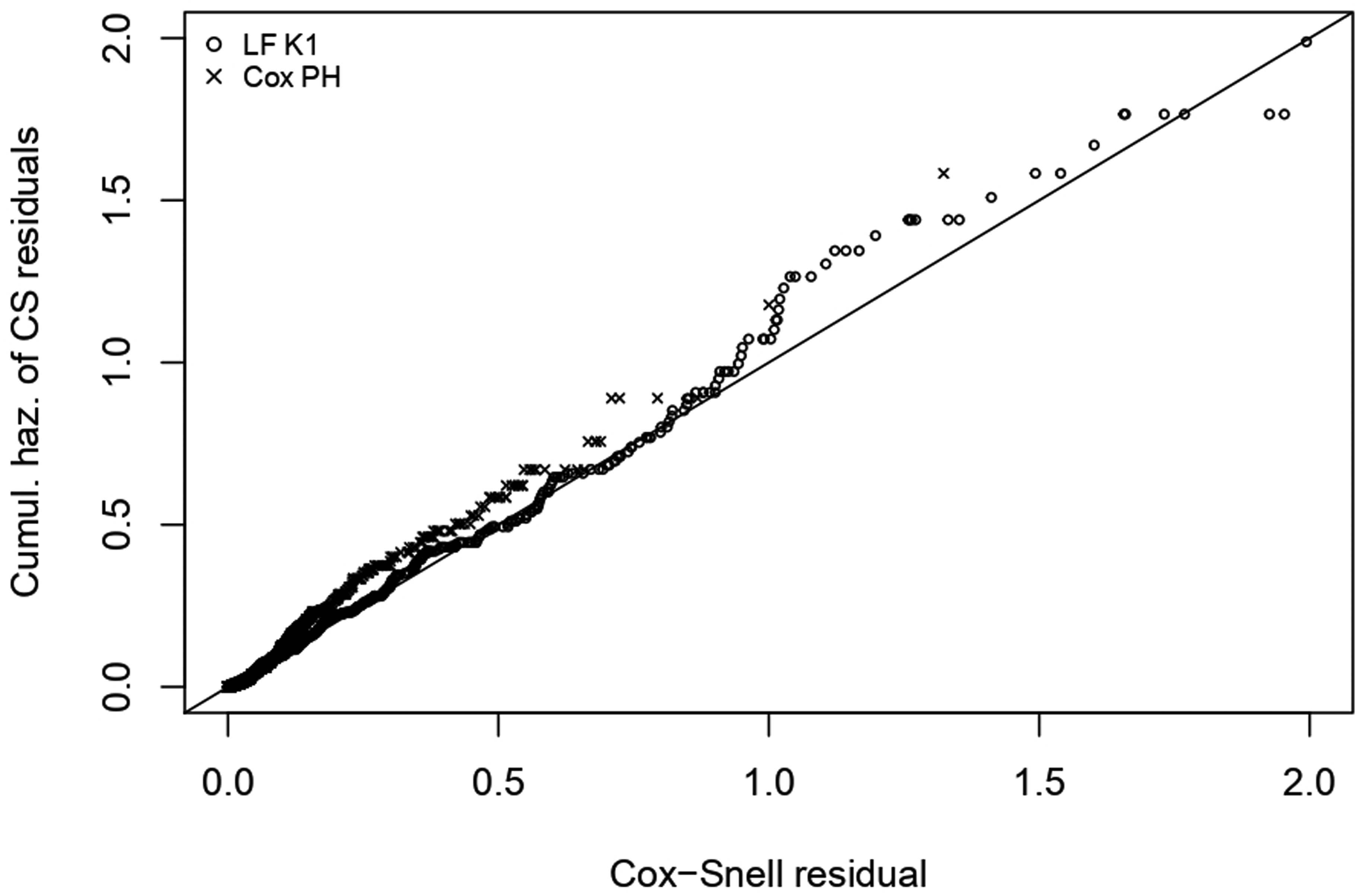
In addition, we compare these two models in terms of goodness of fit, which can help in the choice between these two models. At this purpose we look at the Cox-Snell residuals, (43), defined as the integrated hazard function. A well known result in mathematical statistics states that these residuals have an Exp(1) distribution if the model has been properly specified.
For the Cox PH model, these can be derived as a by product of the estimation process by using the package survival (44), while for the latent factor model of this work, is calculated as follows:
where
In other words, unlike the Cox PH model where we have a point estimate for the integrated hazard function, we average the integrated hazard function for the latent factor model over the draws from the posterior distribution. In addition, since we jointly model the time to event and the censoring time, we need to consider the probability distribution of conditional on the censoring time (other than the covariates).
In order to check whether has Exp(1) distribution, we then calculate the Kaplan-Meier estimate of such residuals, and we plot against their Kaplan-Meier estimate of the integrated hazard function, as shown in Figure 2.
Cox-Snell residuals for the latent factor model with (LF K1, o) and for the Cox PH model (x) plotted against their cumulative (or integrated) hazard function.
We see that the Cox-Snell residuals of the latent factor approach of this work follows more closely the 45-degrees straight line, compared to the Cox PH model, meaning that the former returns a better fit for the distribution of the time to event .
A by-product of this analysis is the possibility to analyse the profile of the two subgroups (since K=1) arising from this modelling approach. Using Bayes’ theorem we can calculate the posterior distribution of for each patient :
where
The patient can be hard-assigned to each group by using the Bayes’ rule: let denote to which group the patient has been assigned. According to this rule we obtain that if for , that is, the patient is assigned to the group for which is highest.
For this dataset we could observe for example that 234 out of 236 censored patients are classified as corresponding to the group with , which is characterized by a lower hazard function for the primary event (since ) and (obviously) a higher hazard for the censoring event. In addition, patients with lower baseline CD4 cell count are more likely to be classified in the group with (mean 345.64 against a mean of 365.28 for ). Further analysis with other covariates are likewise possible. We hereby take into account the CD4 as it is part of the hazard function specification for and .
Extensions
Analysis of competing risks
We can extend the approach described so far to the analysis of the joint distribution of where is the time to event for the th cause of decrement (). Within a competing risks framework only can be observed.
Suppose that conditional on the latent factor , is a vector of pairwise independently distributed times to event, whose distribution is characterized by the following hazard function:
for
In this way, we can also account for further independence assumptions: for example, if , then is independently distributed with respect to the vector .
More generally, instead of having one common latent factor for all competing risks, we can have (), such that the statistical association among time to events is characterized by the joint distribution of .
Clustered units
Suppose we deal with units divided into clusters, such as patients in different clinics, each corresponding to a level of the categorical variable , whose value is known for each patient.
It is possible to account for the specific cluster either by including as a factor in the hazard function, or by letting to explain the heterogeneity in the distribution of for each unit.
In the latter case, we can reasonably assume that is independently distributed with respect to and conditional on , and . Then, the joint distribution of for the th individual becomes:
This modelling framework allows also to compare clusters. One possibility is the use of the Hellinger distance, which is used for example in topic models to qualitatively compare the topical content of two documents (45). Let and be any two different known clusters for the units in the sample: the Hellinger distance is
When Bayesian techniques are used for inference, as we do in the present work, then the Hellinger distance is given by the expectation of with respect to the posterior distribution of the parameters.
Conclusions
This work illustrated the potential of the use of latent factors to accomodate for the possibility of informative censoring in survival analysis. We rejoined existing literature, and described how we can generalize the specification of the heterogeneity component of the hazard function. We also emphasized how this methodology can be extended to the analysis of competing risks (Section 6.1) and of data from different known clusters (Section 6.2).
The inferential challenges of this type of ill-posed models have been addressed by means of a fully Bayesian approach and we described how modern computational tools such as Hamiltonian Monte Carlo methods are strongly recommended in these circumstances.
We applied those methodologies to the analysis of the ACTG175 clinical trial and we found that modelling the heterogeneity and the presence of informative censoring turns out to improve the model fit in terms of information criterion when compared with standard approaches such as the assumption of non-informative censoring.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
ORCID iD
Francesco Ungolo
Notes
Appendix
References
1.
TsiatisA. A nonidentifiability aspect of the problem of competing risks. Proc Natl Acad Sci U.S.A1975; 72: 20–22.
2.
CrowderM. On assessing independence of competing risks when failure times are discrete. Lifetime Data Anal1996; 2: 195–209.
3.
CrowderM. A test for independence of competing risks with discrete failure times. Lifetime Data Anal1997; 3: 215.
4.
EmotoSEMatthewsPC. A weibull model for dependent censoring. Ann Statist1990; 18: 1556–1577.
5.
ZhengMKleinJP. Estimates of marginal survival for dependent competing risks based on an assumed copula. Biometrika1995; 82: 127–138.
6.
ScharfsteinDORobinsJM. Estimation of the failure time distribution in the presence of informative censoring. Biometrika2002; 89: 617–634.
7.
JacksonDWhiteIRSeamanS, et al. Relaxing the independent censoring assumption in the cox proportional hazards model using multiple imputation. Stat Med2014; 33: 4681–4694.
8.
CoxDR. Regression models and life-tables. Journal of the Royal Statistical Society Series B (Methodological)1972; 34: 187–220.
9.
HuangXWolfeRA. A frailty model for informative censoring. Biometrics2002; 58: 510–520.
10.
RowleyMGarmoHVan HemelrijckM, et al. A latent class model for competing risks. Stat Med2017; 36: 2100–2119.
11.
WatanabeS. Asymptotic equivalence of Bayes cross validation and widely applicable information criterion in singular learning theory. J Mach Learn Res2010; 11: 3571–3594.
12.
DrtonMPlummerM. A Bayesian information criterion for singular models. Journal of the Royal Statistical Society: Series B (Statistical Methodology)2017; 79: 323–380.
AkaikeH. A new look at the statistical model identification. IEEE Trans Automat Contr1974; 19: 716–723.
15.
SchwarzG. Estimating the dimension of a model. Ann Statist1978; 6: 461–464.
16.
GelmanACarlinJBSternHS, et al. Bayesian Data Analysis, Third Edition. Chapman & Hall/CRC Texts in Statistical Science. Taylor & Francis, 2013.
17.
HammerSMKatzensteinDAHughesMD, et al. A trial comparing nucleoside monotherapy with combination therapy in HIV-infected adults with CD4 cell counts from 200 to 500 per cubic millimeter. N Engl J Med1996; 335: 1081–1090.
18.
LindsayBG. Properties of the Maximum Likelihood Estimator of a Mixing Distribution. Dordrecht: Springer Netherlands, 1981. ISBN 978-94-009-8552-0, 1981. pp. 95109. DOI: 10.1007/978-94-009-8552-0 8.
19.
LindsayBG. The geometry of mixture likelihoods: A general theory. Ann Statist1983a; 11: 86–94.
20.
LindsayBG. the geometry of mixture likelihoods, part II: The exponential family. Ann Statist1983b; 11: 783–792.
21.
HeckmanJSingerB. A method for minimizing the impact of distributional assumptions in econometric models for duration data. Econometrica1984; 52: 271–320.
22.
HeckmanJJHonorèBE. The identifiability of the competing risks model. Biometrika1989; 76: 325–330.
23.
AbbringJHVan Den BergGJ. The identifiability of the mixed proportional hazards competing risks model. Journal of the Royal Statistical Society: Series B (Statistical Methodology)2003; 65: 701–710.
McLachlanGJPeelD. Finite mixture models. Wiley Series in Probability and Statistics, New York, 2000.
26.
TitteringtonDMSmithAFMMakovUE. Statistical Analysis of Finite Mixture Distributions. Wiley, New York, 1985.
27.
MarinJ-MMengersenKLRobertC. Bayesian modelling and inference on mixtures of distributions. In Dey, D. and Rao, C., editors, Handbook of Statistics: Volume 25. Elsevier, 2005.
Stan Development Team, Stan reference manual. http://mc-stan.org/, version 2.18, 2018.
30.
WatanabeS. A widely applicable Bayesian information criterion. J Mach Learn Res2013; 14: 867–897.
31.
NealRM. MCMC using hamiltonian dynamics. Handbook of Markov Chain Monte Carlo2010; 54: 113–162.
32.
Stan Development Team. RStan: the R interface to Stan. R package version 2.17.3, http://mc-stan.org/, 2018.
33.
R Core Team. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria. http://www.R-project.org/, 2013.
34.
HoffmanMDGelmanA. The no-U-turn sampler: Adaptively setting path lengths in Hamiltonian monte carlo. J Mach Learn Res2014; 15: 1593–1623.
35.
KalbfleischJD. Non-parametric Bayesian analysis of survival time data. Journal of the Royal Statistical Society Series B (Methodological)1978; 40: 214–221.
IbrahimJGChenMHSinhaD. Bayesian Survival Analysis, Berlin, Heidelberg, New York, London, Paris, Tokyo, Hong Kong: Springer Verlag, 2001, pp. 479, ISBN: 0-387-95277-2, 2001.
38.
ElashoffRLiGLiN. Joint Modeling of Longitudinal and Time-to-Event Data. Chapman and Hall/CRC, DOI:10.1201/9781315374871, 2016.
39.
RotnitzkyAFarallABergesioA, et al. Analysis of failure time data under competing censoring mechanisms. Journal of the Royal Statistical Society: Series B (Statistical Methodology)2007; 69: 307–327. DOI: 10.1111/j.1467-9868.2007.00590.x.
40.
MuggeoVM. segmented: an R package to fit regression models with broken-line relationships. R News2008; 8: 20–25. https://cran.r-project.org/doc/Rnews/.
41.
GelmanARubinDB. Inference from iterative simulation using multiple sequences. Statist Sci1992; 7: 457–472. DOI: DOI:10.1214/ss/1177011136.
42.
MooreCMCarlsonNEMaWhinneyS, et al. A dirichlet process mixture model for non-ignorable dropout. Bayesian Analysis2020; 15: 1139–1167. DOI: 10.1214/19-BA1181.
43.
CoxDRSnellEJ. A general definition of residuals. Journal of the Royal Statistical Society Series B (Methodological)1968; 30: 248–275.