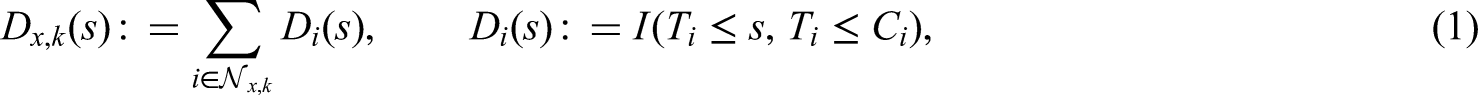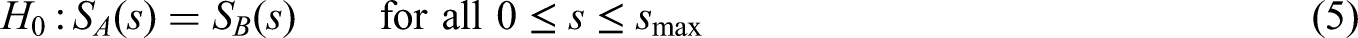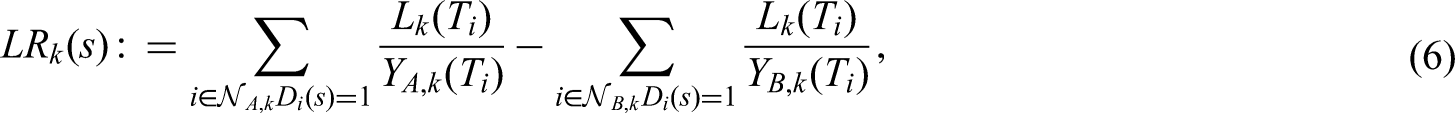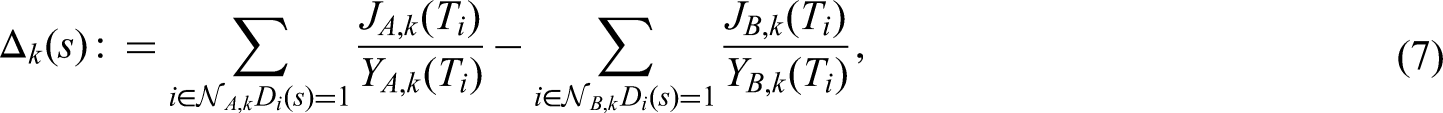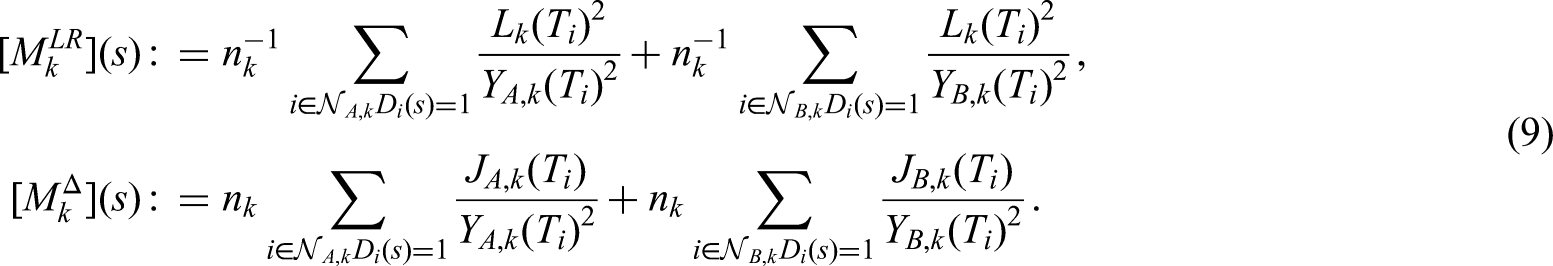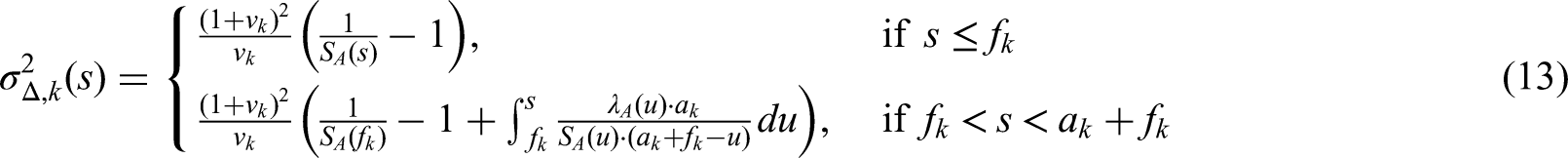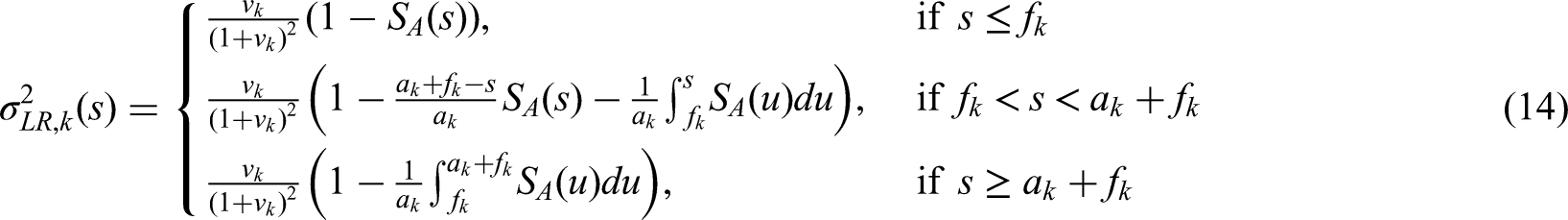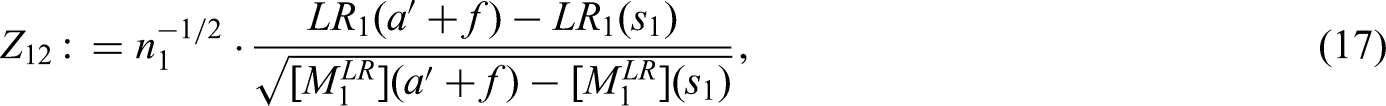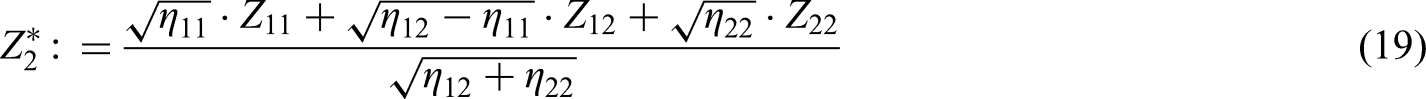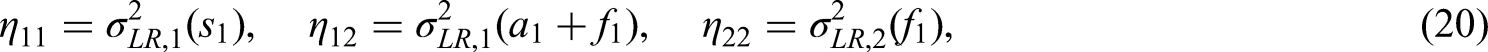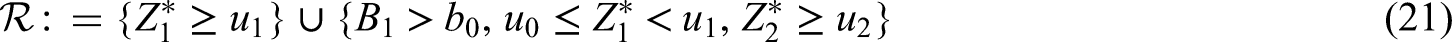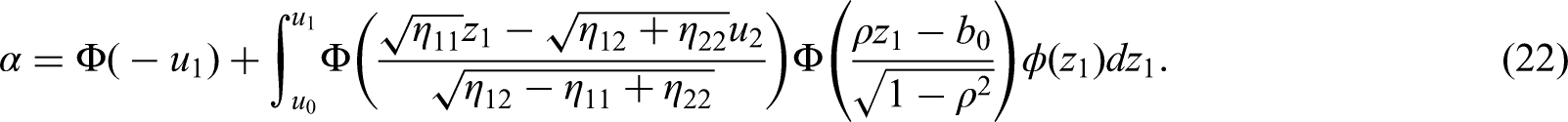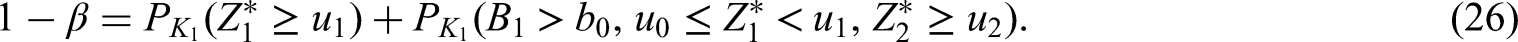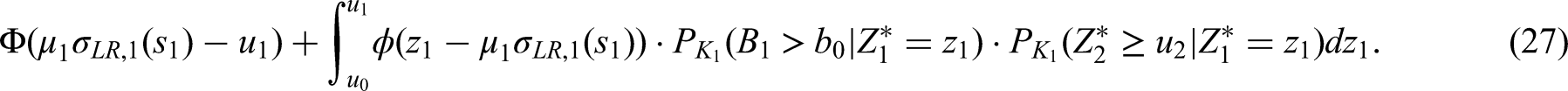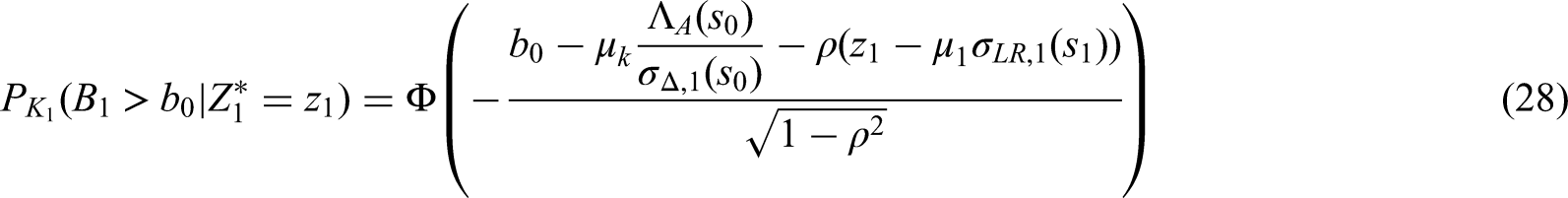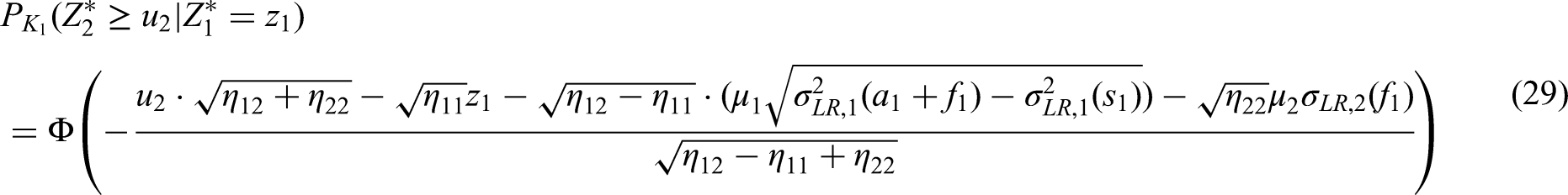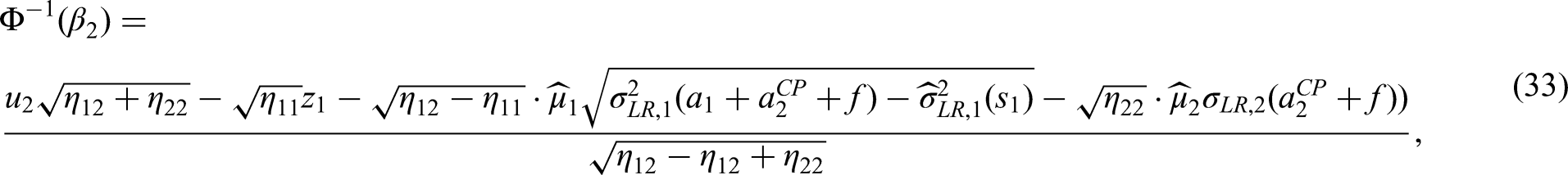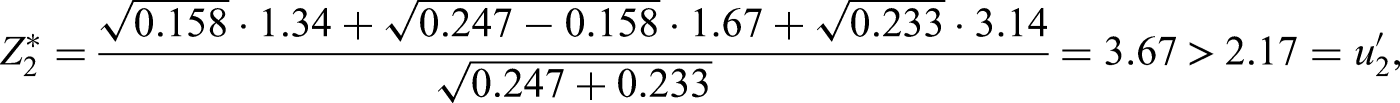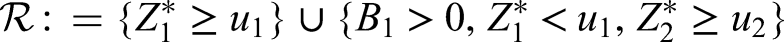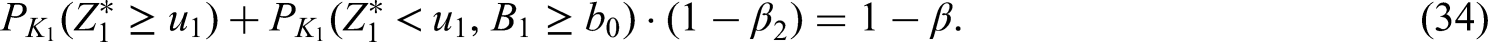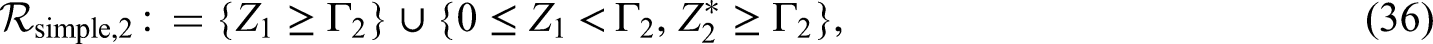Whereas the theory of confirmatory adaptive designs is well understood for uncensored data, implementation of adaptive designs in the context of survival trials remains challenging. Commonly used adaptive survival tests are based on the independent increments structure of the log-rank statistic. This implies some relevant limitations: On the one hand, essentially only the interim log-rank statistic may be used for design modifications (such as data-dependent sample size recalculation). Furthermore, the treatment arm allocation ratio in these classical methods is assumed to be constant throughout the trial period. Here, we propose an extension of the independent increments approach to adaptive survival tests that addresses some of these limitations. We present a confirmatory adaptive two-sample log-rank test that allows rejection regions and sample size recalculation rules to be based not only on the interim log-rank statistic, but also on point-wise survival rate estimates, simultaneously. In addition, the possibility is opened to adapt the treatment arm allocation ratio after each interim analysis in a data-dependent way. The ability to include point-wise survival rate estimators in the rejection region of a test for comparing survival curves might be attractive, e.g., for seamless phase II/III designs. Data-dependent adaptation of the allocation ratio could be helpful in multi-arm trials in order to successively steer recruitment into the study arms with the greatest chances of success. The methodology is motivated by the LOGGIC Europe Trial from pediatric oncology. Distributional properties are derived using martingale techniques in the large sample limit. Small sample properties are studied by simulation.
The log-rank test1 is presently the gold standard method for analysing differences in survival data in randomised clinical trials. For this reason adaptive survival tests are commonly based upon the log-rank test statistic and its independent increments structure.2,3 However, these designs suffer from some limitations we want to address. One limitation is that effectively only the interim log-rank statistic may be used for design modifications (such as data-dependent sample size recalculation).4 Moreover, the treatment arm allocation ratio in these classical methods is assumed to be constant throughout the whole trial period. However, in the context of seamless phase II/III designs or early phase trials it may be desirable to include point-wise survival rates (e.g. 1 year survival rates) in the decision making, since survival rates at a given time-point of interest are chosen as a primary endpoint regularly in such trials. Likewise, data-dependent adaptations of the treatment arm allocation ratio could be helpful in multi-arm trials in order to successively steer recruitment into the study arms with the greatest chances of success. Therefore we propose an extension of the independent increments approach to adaptive survival tests, which can rely on both: (i) the pointwise Neelson Aalen type survival rates estimator and (ii) the log rank test statistic. More specifically our approach extends the commonly used methodology by Wassmer,3 which neither supports the use of point-wise survival rate estimates nor foresees data-dependent adaptations of the treatment arm allocation ratio. In doing so, our approach avoids those difficulties associated with alternative methods based on the patient-wise separation principle, which have the common disadvantage that the test procedure may either neglect part of the observed survival data or tend to be conservative. We will show by simulation that our extended methodology maintains the performance of the current standard methodology while offering various new design possibilities.
The methodology presented here is motivated by the LOGGIC Europe trial (Eudra-CT: 2018-000636-10). LOGGIC Europe is a randomized, international multicentre phase III therapy optimization trial for children and adolescents with low–grade glioma. Primary endpoints of the trial are the progression-free survival (PFS) and the disease control rate (DCR). PFS addresses long–term efficacy of treatment and is defined as time from randomization up to progression of disease or death for all reasons whatever occurs first. DCR addresses short–term efficacy of treatment redand is essentially defined as the PFS-rate at some early timepoint.
The paper is organized as follows. We start by settling notation and stochastic assumptions. Section ‘Joint martingale representation of the log–rank statistic and cumulative hazard difference’ presents briefly the bivariate representation of the two test statistics and its distributional properties. The design algorithm and corresponding planning methodology is presented in section ‘Adaptive log–rank test with simultaneous use of interim log–rank statistic and cumulative hazard rate difference’. In section ‘Example: A two–step log–rank test with futility criterion based on short–term survival rate’ we present some example use-case in order to illustrate practical implementation of our method. Small sample properties are studied by simulation in section ‘Simulation’. We conclude with a discussion of our findings and prospects for future research. Mathematical proofs are shifted to the supplemental material.
Notation and stochastic assumptions
Let denote the probability space upon which all random variables are defined. Unless otherwise specified, random variables are denoted by capital Latin letters, whereas realizations of random variables are denoted by the corresponding lower case Latin letters. We set whenever formal division of zero by zero occurs in sequel.
We consider the problem of testing the equality of survival distributions for two treatments and , say, based on accumulating survival data across several stages of a sequential design. After each stage a confirmatory (interim) analysis is performed with the possibility for interim decisions (e.g. binding futility stop or sample size recalculation) based on (i) the observed interim log–rank statistic and (ii) interim estimates of -years survival rate differences for some prefixed time-point .
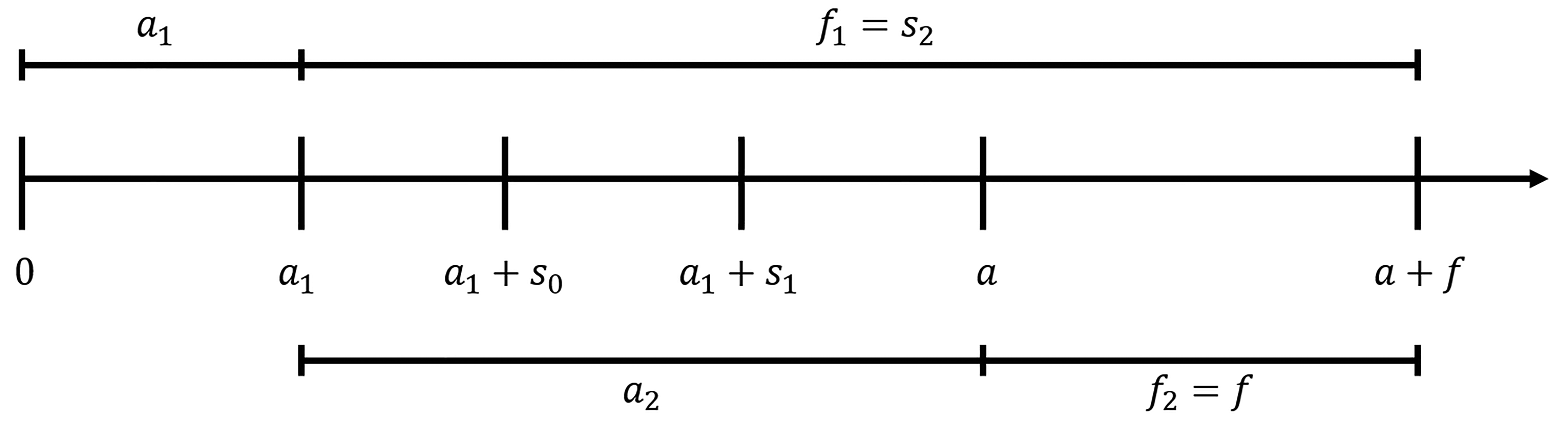
In this context we will assume an initial trial design with stages. The stages will recruit patients successively, i.e. patients from stage are recruited between calendar times and where are the recruitment period lengths of the stages. We set as the overall recruitment period length. The final analysis will be performed at calender time . Patients from stage will therefore have at least a follow-up period length of . An example timeline for stages is given in Figure 1. The planned annual recruitment rate is denoted with .
Initial time schedule. At time of the final analysis, first stage patients would have a minimum follow-up of years under the initial time schedule. Second stage patients would have a minimum follow-up of at time of the final analysis.
For this purpose, let denote the set of patients from treatment group , who entered the trial at stage (i.e. between calendar time and ), and let denote the number of such patients. Let denote the set of all patients from stage pooled over both treatment groups, and the overall set of trial patients. Let and . The parameter will index the arrival process and asymptotic results will be derived in the limit . Accordingly, we assume that group sizes grow uniformly as total sample size increases, i.e. we assume there exist constants such that and in probability as . Thus the constants are the asymptotic, stagewise allocation ratio between the treatment groups. We furthermore assume that the stages also grow uniformly as total sample size increases, i.e. in probability as .
To patient is associated a random triplet . is the entry time into the study, the possibly infinite random variable is the time of censoring after entry, and is the survival time after entry. Our stochastic assumptions are as follows: (1) , and are mutually independent for fixed , and (2) data from different patients are independent and identical distributed within treatment groups.
Based on the observed data, we will calculate the number of events in stage from treatment group up to study time as
and the number at risk by study time in stage and treatment group as
Finally, let and the log-rank weight factor
For each , let be the –algebra generated by
for . We consider , , , as stochastic process in study time , adapted to the filtration . The filtration comprises the information that is observed in the study. Whenever we want to emphasize the dependence of above processes on , we will index them additionally by e.g. instead of .
As usual, we let denote the hazard of a patient from treatment group . We denote by and the corresponding cumulative hazard and survival functions for treatment group , respectively.
In this context, we consider testing the two–sided null hypothesis
that the survival functions in the two treatment arms coincide within some prefixed interval .
We proceed as follows to test . Using martingale techniques, we will first derive the joint distribution of (i) the stage–wise log–rank test statistics and (ii) the stage–wise difference in the Nelsen–Aalen estimates between the two treatment arms evaluated at some prefixed study time . On this basis, we provide a confirmatory adaptive two–sample log–rank test where provision is made for interim decision making and design modifications based on both (i) the interim log–rank statistic and (ii) interim estimates of the cumulative hazard rate differences at timepoint . With a view to practical application, sample size recalculation is one of the most common design modifications. Therefore, sample size recalculation based on conditional power will be elaborated and studied in detail, analytically and by simulation.
Joint martingale representation of the log–rank statistic and cumulative hazard difference
The weighted two–sample log–rank statistic in stage is defined as
where is the weight from equation (3). The difference of the group–wise Nelson–Aalen estimates in stage is given as
which are both –adapted processes. It follows from theorem A2, that under mild regularity assumptions and the proportional hazards assumption for some , the following distributional approximation holds:
where and are some deterministic functions (see equations (14) and (13) below) and
The left hand side of (8) has also approximately independent, bivariate normal distributed increments as stated in theorem A2.
For given we set
In practice the time-dependant correlation parameter on the right hand side of (8) is unknown. However, for a fixed time point it can be consistently estimated at time of the interim analysis (see (24)). Under further planing assumptions it is possible to deduce closed formulas for the functions and . Assuming (in addition to above mentioned mild regularity conditions of theorem A2):
No loss to follow-up:
Uniform recruitment:
the following two equations hold (see appendix for proofs):
Adaptive log–rank test with simultaneous use of interim log–rank statistic and cumulative hazard rate difference
The design algorithm
For the sake of notational simplicity we will focus on two-step designs in the sequel (i.e. ). The two–step adaptive design will proceed as follows: Assume an initial design with accrual of patients between calender time and years, and a final analysis at calender time (corresponding to minimum follow–up period of years). We assume that the value of is prefixed by clinical consideration. Choice of will be detailed in section ‘Initial sample size calculation’ based on power arguments. Patients recruited prior to calender time define the set of first stage patients , and patients recruited between calendar time and define the set of second stage patients . The interim analysis will take place at time for some and will include the patients of stage one with their first years of follow-up.
At the interim analysis the log–rank statistic in stage 1 patients based on information up to study time
and the standardized cumulative hazard rate difference at some prefixed (early) study time
will be calculated. is an interim estimate of the difference in short–term response. More specifically, is an interim estimate of . The design algorithm is as follows: The design stops at the interim analysis with rejection of if the observed value for exceeds some critical value . The design stops for futility if either falls below some futility bound or if the observed value for drops below some prefixed boundary . Otherwise, if and , the design continues to stage two. At this time, the recruitment period length of stage two can be data–dependent recalculated. The recalculated recruitment period length of stage two is chosen in dependence of the observed values for and subject to the constraint . Here, denotes a maximum trial recruitment period length that is fixed in advance in order to avoid unrealistic or unfeasible trial duration. We set and .
The final analysis will take place at calendar time and will include both, patients of stage one with their full follow-up data of at least years and the set of second stage patients with their follow-up time of at least years. At the time of the final analysis, the increment of the log–rank statistic in stage one patients beyond study time will be calculated
as well as the log–rank statistic of stage two patients
Notice that and are conditionally independent given and .
The null hypothesis will be rejected at the final analysis if the second stage test statistic
exceeds some critical value , where the prefixed weight factors
amount to the expected variance of the log–rank statistics under some initial planning alternative (see section ‘Calculation of the critical bounds’). Their values are given in (13) and (14). The weights have to be fixed in advance and remain unchanged while the trial is ongoing.
The rejection region
The design algorithm described in section 4.1 corresponds to the rejection region
of the null hypothesis . It is crucial that the design parameters , , , and as well as the critical bounds , are prefixed and remain unchanged during the trial. Note that the critical bound will be calculated at the interim analysis according to formula 22 when the correlation of and can be estimated to obtain a rejection region which exhausts the full significance level. The calculation of the critical bounds , , , is elaborated next.
Calculation of the critical bounds
The rejection region defines a level test of the null hypothesis if the critical bounds , , , are chosen according to the proviso that , i.e. such that
Notice that the critical bounds depend on the nuisance parameter
which is in fact unknown during the trial if one does not know the true hazard function . However, it may be estimated consistently at time of the interim analysis via
Nevertheless there are infinite parameter combinations of the critical bounds which satisfy equation (22). It is therefore crucial, that one parameter constellation is chosen in advance and remains unchanged during the trial. The critical bound will then be calculated at the interim analysis as the unique solution to (22) with plugged in for .
Initial sample size calculation
Initial sample size calculation is performed under the planning alternative hypothesis
and under the assumption, that no sample size recalculation is performed i.e. . For the initial sample size calculation we need to fix the proportion of accrual to stage 1. Note that the weights are fixed in advance and must not be changed while the trial is ongoing. In fact they have to be calculated simultaneously with the sample size. For given weight factors , the condition to reject null hypothesis with probability under planning alternative is . Using the distribution approximation (8) this proviso is tantamount to
Notice that and are independent given . Thus the right hand side of (26) equals
Using again the distribution approximation (8) we get the identities
and
Using the identities (28) and (29), formulas (13) and (14) for and and the identity in equation (26), one can solve (26) and (22) numerically to obtain the critical bound and the needed recruitment period lengths and . We provide R syntax in the supplemental material to do so.
At the interim analysis, and thus may be modified in a data–dependent way to keep up adequate power performance of the trial, as will be detailed in the next section.
Data–dependent sample size recalculation at the interim analysis based on conditional power
At the interim analysis, we are free to revise the length of the stage two accrual period in the light of (interim log–rank statistic) and (observed difference in short–term response) without compromising type I error rate control. This is a consequence of the independent increments structure of the bivariate process given by the left hand side of (8). For this purpose, we will first calculate the required length of the accrual period to achieve a desired conditional power. To avoid unrealistic large trial duration, the revised length of the accrual period will finally be chosen as
Recall that is the calendar time of the interim analysis and is a prefixed maximum trial recruitment period length.
Likewise, we are free to revise the allocation ratio between treatment groups in the light of and . Let denote the revised allocation ratio of stage two patients to treatment group B as referred to treatment group A. Furthermore we may use an updated recruitment rate to adjust for new experience.
To calculate , we estimate the true hazard ratio via
Notice that and are observed at the interim analysis. We can also estimate consistently at the interim analysis through the estimator . Sample size recalculation will be performed under the revised planning alternative
suggested by the observed interim estimate of the true hazard ratio. The condition to achieve a conditional power of under the revised planning alternative is equivalent to
where is the estimated drift. Plugging in the identities and the formulas for and given by (14) with updated values and , we can solve above equation (33) to obtain . Note that the equation can not be solved if holds. In this case we define .
The revised length of accrual is finally chosen according to (30). We will provide R syntax to do so in the supplementary material.
Example: A two–step log–rank test with futility criterion based on short–term survival rate
In this section, we illustrate application of our methodology using the example of a two-step log-rank test with binding futility criterion based on a short-term survival rates and sample size recalculation based on conditional power. Recall that the underlying null hypothesis is for all for some prefixed . The underlying physical units of s will be ”years”.
In general, our two-step test of depends on a set of design parameters that have to be fixed in advance:
(a) parameters , , , defining the rejection region acc. to (22),
(b) parameters and steering the amount of follow-up included into interim decision making,
(c) parameters , , defining the initially planned lengths of stage one accrual, stage two accrual, and follow-up period
(d) parameters , , defining the initial accrual rate, and stage-wise treatment arm allocation ratios
(e) weights , and of the stage-wise log-rank increments acc. to (20) and (14).
More specifically, let us assume that we aim for a two-step, Pocock-type log-rank test of with binding stopping for futility if the observed months survival rate in the experimental arm is worse than in the standard arm. This futility condition is realized by choosing , , and . The Pocock condition means choosing .5 Note that an uncountable number of alternative functional relationships between and could have been chosen. The difference - is the interval between the time when the short-term endpoint becomes known and the date of the interim analysis. For practical reasons, should not be chosen too large. On the other hand, should be sufficiently large such that the interim log-rank statistic is informative. In our exemplary setting, we consider as sensible choice. The parameters and are determined by the clinical frame conditions. Let us assume a desired follow-up period of years, and an annual overall accrual rate of . Also assume that we aim for equal randomization to both arm (i.e. ) as well as an interim analysis after half of the planned overall accrual period, i.e. . Finally, assume that we set a significance level of , that we aim for a power of if the true hazard ratio equals (planning alternative hypothesis), and that there are exponentially distributed survival times with scale parameter of to a good approximation in the standard therapy arm.
With these specifications, the parameters and remain as the only unknown from the parameters listed under a)-d). Whereas the weight is also fixed by above specifications, the weights and remain as functions in acc. to equation (20), since , , . We are now in a position to determine the rejection region (see Section ‘The rejection region’) and to perform the initial sample-size calculation (see Section ‘Calculation of the critical bounds’). Using , , and acc to (8) the equations (22) and (26) may be solved simultaneously for the two remaining free parameters and . Doing so, yields a stage-one recruitment period length of years (corresponding to patients), together with a stage-one critical boundary . On this basis, the weights may be calculated as , , using (20) and (14). To ensure that the rejection region does not depend on our initial planning assumptions regarding , the value of the critical bound will be updated and ultimately fixed as described below at the time of the interim analysis, when an estimate of becomes available.
After years, instead of can be evaluated. Assume that we find a value of instead of , which concludes that the trial can continue (no stopping for futility). After years, the interim log-rank statistic becomes known and the interim analysis has to be performed. Let us assume that a test statistic of is observed as well as an estimated hazard ratio of . In this case the trial continuous to stage two and the sample-size can be adapted in the light of this new information.
In a first step we now estimate the covariance parameter according to (24) in the light of the interim data. Assume that we find an estimated value of . With this estimate we calculate the final value of the stage–two critical boundary by solving (25) with our estimate plugged in as , and all remaining parameters as specified as above. Doing so yields in the value and ensures that the rejection region does not depend on our initial planing assumptions regarding .
Having determined the final rejection region, let us now recalculate the sample-size such that a conditional power of is achieved, say, under the constraint that the overall accrual period is at least years, but must not exceed years. Notice that it is principally possible to adapt the recruitment rate or the allocation ratio depending on or at time of the interim analysis. For simplicity, we here assume that neither accrual rate nor allocation ratio shall be adapted, i.e. we choose and . In order to carry out sample size recalculation according to these specification, we first calculate the required length of the second stage accrual period to realize the desired conditional power of . This can be done by solving equation (33) for the only remaining indeterminate , which in our case yields . To implement the constraint on the minimum and maximum length of accrual, the revised length of the second stage accrual period is finally chosen according to (30). With , , equation (30) yields , corresponding to patients in stage two.
Finally after years after start of the trial, the final analysis is due. At this time the test statistics and become known. Assuming that and are observed, we finally obtain the final test statistic according to (19)
which concludes a successful trial with rejection of after stage two.
We will present an example design for a seamless phase II/III trial in detail in the supplemental material.
Simulation
Design of the main scenario
We consider testing the hypothesis formulated in equation (5) for all using the two-step adaptive design presented in section 4.1.
In the context of the LOGGIC Europe trial, it was of interest to show a positive effect on the short term PFS-rate at an interim analysis to obtain the preliminary conditional marketing authorisation. Only with this conditional marketing authorization it was desired to continue recruitment of patients and to additionally test the effect on the long-term progression free survival.
More specifically, a design with rejection region of the form
would have been of interest. Notice that we set the critical boundaries and . We set , and . This corresponds to a two–step log–rank test with binding futility criterion based on the 18-months response rate.
The following frame conditions were chosen as the main scenario for this simulation study: Patients are allocated equally to both treatment arms (allocation ratio ). Survival times are Weibull distributed with scale parameter of and shape parameter , which corresponds to a scaled exponential distribution with median survival of 1 year. To study the performance of our algorithm we ran also simulations with shape parameters and . Planing was done under the planing alternative , where . We also ran simulations with . We let the true hazard ratio range between 0.5 and 1 in steps of . The one sided type 1 error rate was set to and the desired power was set to . We set the conditional power parameter such that it satisfies the equation
This choice tries to stabilize the power of the whole trial despite the adaptation. The recruitment rate was set to . The maximal trial duration was set as times the duration of a corresponding single–step two–sample log–rank test.1 In some of our scenarios (Figure 2) we let the parameter vary in the set as a fine-tuning parameter.
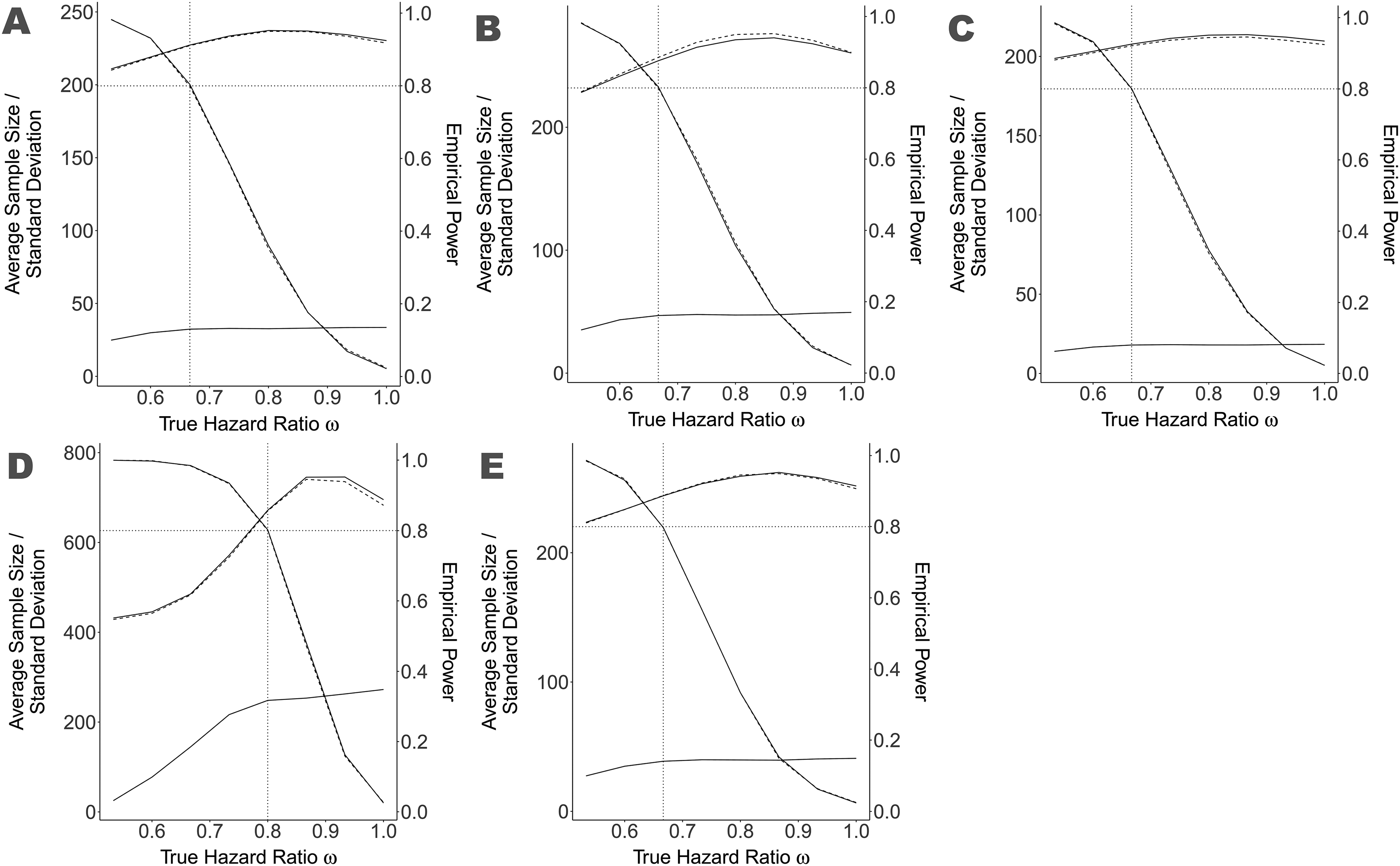
Average sample size, standard deviation of sample size and empirical power of the main scenario and some variations true hazard ratio ranging between 0.5 and 1.0, compared to a standard adaptive design with stop for futility. The solid lines represent our new methodology and the dashed lines the standard methodology, where the monotone decreasing lines starting at nearly 1 and ending by 0.025 represent the empirical power. The remaining upper lines show the average sample size and the lower lines the standard deviation of the sample size. Notice that the latter lines overlap considerably and are therefore difficult to distinguish. The vertical dotted line represents the value for used as planing alternative. The dotted, horizontal line represents the aimed power of 80. Figure A is the main scenario, Figure B the variation with , Figure C the variation with , Figure D the variation with and Figure E is the variation Pocock boundaries. The value of the fine-tune parameter is presented in the table on the bottom right for each scenario variation.
No loss to follow–up was assumed as well as block-randomization and uniform recruitment assumptions as required by theorem A2.
For each simulation the required recruitment period lengths of stage one and stage two were calculated according to section ‘Initial sample size calculation’. In our simulations we additionally distinguished between (i) a Pocock-type design with and (ii) a design without early stopping where . Note that the critical bounds and have to be fixed in advance, whereas the value for is calculated according to equation (22) at the interim analysis, when the estimator for becomes available. Thus the theoretical equality ”” in the Pocock setting is effectively only realized approximately.
With above values for , , and , the weights , , were calculated according to equations (20).
Then patients were simulated as first stage patients, with preliminary censoring at study time , which represents the data we are allowed to use at the interim analysis. Based on this simulated data the interim statistics , , , and were calculated.
The test statistics and were then compared to the prefixed critical bounds and to determine whether early successful stopping or stopping for futility has occurred.
In the case of an ongoing trial, i.e. and , the critical bound is obtained by solving equation (22) with the estimator plugged in. Additionally, the required recruitment period length of stage two was calculated such that a conditional power of is achieved under the revised planing alternative hypothesis corresponding to the observed hazard ratio . The actual recruitment period length of stage two patients was then updated as stated in (30), to stipulate the boundary conditions.
We then proceeded (i) to simulate patients of stage two and (ii) to update the censoring date of stage one patients to calendar time .
Finally the test-statistic was calculated according to (19) and compared to the critical bound derived at the interim analysis to obtain the final test decision.
The above presented simulation algorithm was run 10,000 times for each scenario.
Results
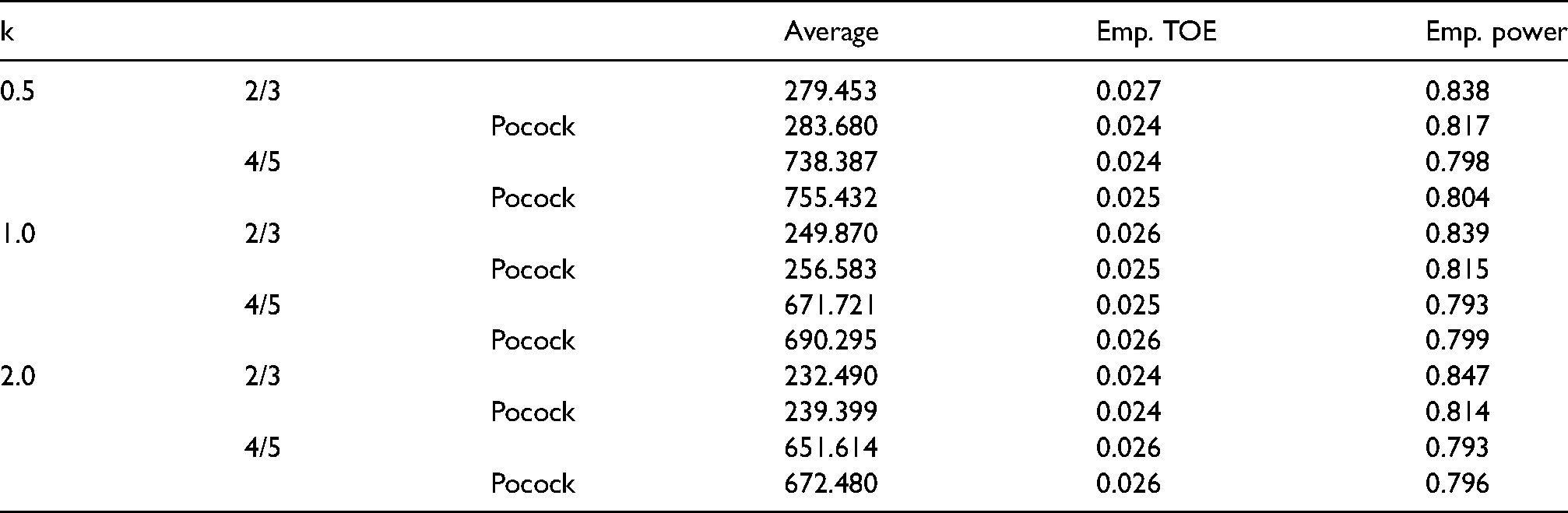
The simulation results are presented briefly in Table 1. Reassuringly the designs hold the aimed significance level of , even in the small sample size case. Note that with 10,000 simulations per scenario the estimated accuracy of our type one error rate estimator given through -confidence intervals is . Accordingly in no scenario the empirical type I error rate exceeded the aimed significance level of in a statistically noticeable way.
Empirical type I error rate and power in the simulation scenarios. Empirical type I error rate (TOE) was obtained from simulations where the true hazard ratio . Empirical power was obtained by simulations where the true hazard ratio equals the planing hazard ratio . For further simulation details see section 6.
k
Average
Emp. TOE
Emp. power
0.5
2/3
279.453
0.027
0.838
Pocock
283.680
0.024
0.817
4/5
738.387
0.024
0.798
Pocock
755.432
0.025
0.804
1.0
2/3
249.870
0.026
0.839
Pocock
256.583
0.025
0.815
4/5
671.721
0.025
0.793
Pocock
690.295
0.026
0.799
2.0
2/3
232.490
0.024
0.847
Pocock
239.399
0.024
0.814
4/5
651.614
0.026
0.793
Pocock
672.480
0.026
0.796
The empirical power however shows a little more variation. This is due to the fact, that the initial sample size calculation does not factor in the randomness introduced by , which effects the sample size recalculation based on conditional power. This is a well-known effect of such adaptive designs.
Main simulation scenario. The strength of adaptive designs is undoubtedly the possibility for correction when the initial planning assumptions seem to be wrong. When the treatment effect is small one can stop for futility or increase the sample size to hold on the desired power. Conversely when the treatment effect is larger than expected one can decrease the sample size while still holding the desired power.
We simulated our main scenario ( with some variations. We used the parameter as a fine-tuning parameter to level out the variation introduced by and to match the aimed power quite exactly. The choice of these fine-tuning parameter is presented in the table within Figure 2.
We compare our test algorithm with a standard adaptive design based on the standard methodology by Wassmer.3 To assure comparability we implemented a futility stop, when the short term log-rank test based on the first half of patients shows a negative result. More specifically in the non Pocock designs, we compared our design to an adaptive design with rejection region
where is chosen such that . In the Pocock scenario we compared our design to a design with rejection region
where is chosen such that . These are rejection regions, which can be used within the methodology of Wassmer and are included in our methodology.
We set the required sample size such that the standard design also holds the desired power of under the planing hypothesis .
The operating characteristic of our test algorithm in the main simulation scenario is presented in Figure 2 together with some variations of the scenario.
Across all scenario variations, the power and sample-size performance of our test statistic fits the performance of the standard methodology quite well.
In the main scenario the mean sample-size difference between the standard methodology and our new methodology is 0.74 at maximum. Under the planing hypothesis the maximal increase of the mean sample-size across all scenario variations was 0.5, while in some cases the new design reduced the mean sample-size about .
This suggests the use of easily interpretable survival rate differences as an interesting option for interim decision making in survival trials.
By using various Weibull shape parameters, planning hypothesis and design types we assured that the performance consistency is not dependant on our specific scenario assumptions.
Discussion
The confirmatory adaptive two–step log–rank test proposed here extends the one proposed by Wassmer.3 Whereas the test proposed by Wassmer essentially only allows the use of the interim log–rank statistic for data–dependent design modifications, our approach allows simultaneous use of the interim log–rank statistic and observed differences in cumulative hazard rates at time for interim decision making, while avoiding those problems arising with methods based on patient wise separation.6–8 Next to an adaptation of sample size, our approach also allows modification of the allocation ratio between the treatment arms or the recruitment rate, which neither has been described by Wassmer3 nor Jenkins.6 This is of importance when thinking about application of our methodology in a multiarm, multistage setting. Even though the focus of this paper was on a trial design with two treatment arms and two analyses, the generalization to more than two arms and more than two analyses is straightforward using the methodology described by Hommel et al.9
Our adaptive two–step log–rank test exploits the independent increments structure of the limiting Gaussian process of the joint bivariate process defined by the log–rank statistic and the Nelson–Aalen difference at some time . Therefore, we emphasize that the full use of arbitrary interim data for design modifications is still not admissible here.4 However, our approach makes provision for the simultaneous use of (i) the interim log–rank statistic and (ii) differences in cumulative hazard rates at an arbitrary time .
The calculation of rejection regions and sample size formulas were based on distributional approximation of the bivariate test statistic in the large sample limit. Our methodology used mild regularity assumptions as well as the proportional hazards assumption. It is well known, that the log–rank test is less efficient and its distribution depends on the distribution of censoring times, when the proportional hazards assumption is violated.10 This is likely to be inherited by our method. The small sample properties were studied by simulations. The validity of the proposed design does not depend on specific model assumptions underlying these simulations such as exponentially distributed survival times. In view of the flexibility offered by our approach, however, applicants are recommended to assess different choices of design parameters in order to identify those parameter constellations with best operating characteristics as compared to a standard single–step two–sample log–rank test. For this purpose, we provide an R program in the supplemental material that enables easy assessment of operating characteristics and thus optimal calibration of the design parameters in a specific trial setting. The R program also underlies our simulation.
Supplemental Material
sj-R-1-smm-10.1177_09622802211043262 - Supplemental material for Adaptive group sequential survival comparisons based on log-rank and pointwise test statistics
Supplemental material, sj-R-1-smm-10.1177_09622802211043262 for Adaptive group sequential survival comparisons based on log-rank and pointwise test statistics by Jannik Feld, Andreas Faldum and Rene Schmidt in Statistical Methods in Medical Research
Supplemental Material
sj-R-2-smm-10.1177_09622802211043262 - Supplemental material for Adaptive group sequential survival comparisons based on log-rank and pointwise test statistics
Supplemental material, sj-R-2-smm-10.1177_09622802211043262 for Adaptive group sequential survival comparisons based on log-rank and pointwise test statistics by Jannik Feld, Andreas Faldum and Rene Schmidt in Statistical Methods in Medical Research
Supplemental Material
sj-R-3-smm-10.1177_09622802211043262 - Supplemental material for Adaptive group sequential survival comparisons based on log-rank and pointwise test statistics
Supplemental material, sj-R-3-smm-10.1177_09622802211043262 for Adaptive group sequential survival comparisons based on log-rank and pointwise test statistics by Jannik Feld, Andreas Faldum and Rene Schmidt in Statistical Methods in Medical Research
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
ORCID iDs
Jannik Feld
Andreas Faldum
Supplemental material
Supplemental material for this article is available online.
Appendix A
We will now deduce the distributional approximation presented in (8). The proofs presented here are formulated for a single-step design. However, the extension to a multi-step design is straight forward using the independent increments structure. We therefore drop the stage indices for notational simplicity.
It is well known that for a patient from treatment group ,
is an –martingale.11 In particular, with and for any –adapted left–continuous process ,
is an –martingale with optional and predictable covariation process12
We aim for the joint distribution of the weighted two–sample log–rank statistic, which has the integral representation
and the difference of the group–wise Nelsen–Aalen estimates
as –adapted processes, i.e. we aim for the distribution of the bivariate process
is a bivariate mean–zero –martingale. Since and , the optional covariation matrix of has components
Since and , the predictable covariation matrix of has components
Above equations are easily checked (see Aalen et al.13 Sec. 2.2.5). On this basis we may deduce the distributional properties of the bivariate process in the large sample limit, as stated in the following theorems. The proofs of the theorems A1, A2 and equations (13) and (14) are presented after some additional results, which we need.
A seamless phase II/III design
In this section we elaborate application of our design algorithm in the context of a two–armed randomized seamless phase II/III survival trial. In the phase II part, we assume that the two treatments are compared regarding the short–term endpoint survival rate at time . I.e. as phase II part, we consider a local level test of the confirmatory null hypothesis on the survival rates using the rejection region
realizes a single step test of . Only in the case of rejection of (i.e. ), we continue the trial in order to compare the two treatments also regarding long–term survival. I.e. as phase III part, we consider a local level test of the confirmatory null hypothesis for all for some prefixed using the rejection region
realizes a two-step test of . It makes sense to synchronize the analysis of with the interim analysis of . Notice that, we may choose if we wish to refrain from testing already at the interim analysis and that adjustment to multiple testing is done by hierarchical testing in the order followed by , i.e. we reject to the multiple level if and only if and are both rejected by their local level tests. can be rejected to the multiple level if is rejected locally.
At the interim analysis, we are free to perform a data–dependent sample size recalculation based on the observed interim log–rank statistic and the observed difference in the short term response .
For a sample size calculation algorithm we have to apply the methodology presented in section ‘Initial sample size calculation’ to the rejection region
with power defined by the probability under some planing alternative .
References
1.
PetoRPetoJ. Asymptotically efficient rank invariant test procedures. J R Statist Soc A1972; 135: 185–207.
2.
SchäferHMüllerHH. Modification of the sample size and the schedule of interim analyses in survival trials based on data inspections. Stat Med2001; 20: 3741–3751.
3.
WassmerG. Planning and analyzing adaptive group sequential survival trials. Biom J2006; 48: 714–729.
4.
BauerPPoschM. Letter to the editor: modification of the sample size and the schedule of interim analyses in survival trials based on data inspections. Stat Med2004; 23: 1333–1335.
5.
PocockS. Group sequential methods in the design and analysis of clinical trials. Biometrika1977; 64: 191–199.
6.
JenkinsMStoneAJennisonC. An adaptive seamless phase II/III design for oncology trials with subpopulation selection using correlated survival endpoints. Pharm Stat2011; 10: 347–356.
7.
IrleSSchäferHH. Interim design modifications in time-to-event studies. J Am Stat Assoc2012; 107: 341–348.
8.
MagirrDJakiTKoenigF, et al. Sample size reassessment and hypothesis testing in adaptive survival trials. PLoS ONE2016; 11: e0146465.
9.
HommelG. Adaptive modifications of hypotheses after an interim analysis. Biom J2001; 43: 581–589.
10.
BruecknerMBrannathW. Sequential tests for non-proportional hazards data. Lifetime Data Anal2017; 23: 339–352.
11.
SellkeTSiegmundS. Sequential analysis of the proportional hazards model. Biometrika1982; 70: 315–326.
12.
AndersenPKBorganOGillRD, et al. Statistical Models Based on Counting Processes. New York: Springer, 1993.
13.
AalenO. Borgan O and Gjessing H. Survival and Event History Analysis. New York: Springer, 2008.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.