
Abstract
Risk prediction models have been developed in many contexts to classify individuals according to a single outcome, such as risk of a disease. Emerging “-omic” biomarkers provide panels of features that can simultaneously predict multiple outcomes from a single biological sample, creating issues of multiplicity reminiscent of exploratory hypothesis testing. Here I propose definitions of some basic criteria for evaluating prediction models of multiple outcomes. I define calibration in the multivariate setting and then distinguish between outcome-wise and individual-wise prediction, and within the latter between joint and panel-wise prediction. I give examples such as screening and early detection in which different senses of prediction may be more appropriate. In each case I propose definitions of sensitivity, specificity, concordance, positive and negative predictive value and relative utility. I link the definitions through a multivariate probit model, showing that the accuracy of a multivariate prediction model can be summarised by its covariance with a liability vector. I illustrate the concepts on a biomarker panel for early detection of eight cancers, and on polygenic risk scores for six common diseases.
1 Introduction
Risk prediction is important in many medical contexts in which prediction models can guide decision making. 1 Examples include primary prevention, such as cholesterol reduction in subjects at risk of cardiovascular disease 2 ; secondary prevention, such as the targeted enrolment of individuals into screening programmes 3 ; allocation of treatment according to prognosis 4 ; and differential diagnosis. 5 In general, models are constructed with the prediction of a single discrete outcome in mind. Thus models for identifying individuals at risk of, for example, breast cancer, 6 cardiovascular disease 7 and diabetes 8 have been developed by separate research communities with different study cohorts, although the models may share some variables and identify some of the same individuals as at risk. Consequently, evaluation of prediction models is also done according to single outcomes.
The emergence of “-omic” and other molecular biomarkers has raised the prospect of panels of features that can simultaneously predict multiple outcomes from a single biological sample. For example, a blood test called CancerSEEK has been proposed for early detection of eight cancers from circulating proteins and tumour DNA mutations. 9 Genome-wide association studies have garnered particular attention as many diseases are heritable and the DNA sequence is fixed throughout life. Because many diseases are influenced by numerous variants across the entire genome, genetic risk can be efficiently measured with a generic micro-array, 10 and in principle could be calculated for multiple conditions at any point in life. Epigenetic variation may also provide useful risk stratification and has been advocated for the early detection of several cancers. 11 Furthermore, the emergence of large, broadly phenotyped cohorts such as UK Biobank 12 provides useful resources for developing and evaluating such models.
Apart from the practical efficiencies of conducting several assessments in parallel, simultaneous prediction has other potentially useful applications. Individuals may be more concerned about their risk across a range of conditions rather than of one in particular, a demand increasingly targeted by direct-to-consumer genetic testing companies. 13 Furthermore, some interventions may be effective for several conditions, and identification of individuals at increased risk of any of them may lead to greater impact of such interventions. As a simple example, body mass index is associated with several diseases with otherwise distinct causes, including coronary heart disease, type-2 diabetes, breast cancer and depression. 14 A weight loss intervention might be more effective when targeted to those at increased risk of any of those conditions. Similarly, evidence that aspirin usage could reduce the risk of various cancers 15 as well as of cardiovascular disease suggests that risk prediction for a set of diseases could be of benefit. More speculatively, forensic applications could utilise simultaneous prediction of phenotypes from anonymous DNA samples.16,17
Prediction of this nature is already done informally using recurrent risk factors such as age, gender, smoking and blood pressure. For example, in the UK the NHS Health Check is offered to individuals aged between 40 and 74 on account of the strong association of age with risk of stroke, kidney disease, heart disease, type 2 diabetes and dementia. For such risk factors, their strength of association and ease of measurement obviate any need for formal evaluation over many outcomes. But for emerging risk factors it is less clear whether their utility is enhanced by their potential to predict multiple outcomes. There are problems of multiplicity reminiscent of those in exploratory hypothesis testing, but a framework is lacking for addressing these issues in the context of risk prediction.
Prediction of multiple outcomes can be distinguished from prediction of a single composite outcome. Composite outcomes have been used to group related conditions, such as cardiovascular disease, 18 and to define outcomes of specific interest such as frailty and all-cause mortality. 19 Prediction of such outcomes may be viewed as a crude form of multiple outcome prediction: here I consider the composite evaluation of multiple predictions, rather than the evaluation of a single composite prediction. Composite evaluation may offer improved accuracy over a composite outcome; pragmatically it can use predictors developed individually for each outcome without the need to develop a specific predictor for their composite.
Several authors have studied the statistical modelling of a multivariate response, using methods such as partial least squares 20 and multivariate linear regression. 21 –23 While it is recognised that prediction can be improved by exploiting correlation among responses, the literature has emphasised methods to improve model fitting, with accuracy typically measured by squared error metrics for each response marginally22,24 or in total across responses. 21 This may be adequate in applications such as chemometrics and genetic selection where the responses are quantitative, but is less satisfying for prediction of discrete outcomes. Here I am not concerned with model fitting per se but in evaluating models, however estimated, in the context of their joint risk predictions. There is some work on mutually exclusive events, such as polytomous outcomes 25 and competing risks, 26 but general vectors of dichotomous outcomes have not been studied.
Here I propose definitions of some basic criteria for evaluating risk prediction models of multiple outcomes. The evaluation of single outcome models, while not a settled question, has at least a standard set of core criteria that serve as a basis for more nuanced assessment. 27 The present aim is to propose a similar set of core criteria as a starting point for the development of more refined approaches. I do not aim to give a complete account of multiple outcome prediction, but to identify and open discourse around some basic issues in this emerging area.
In section 2, I identify four senses in which multiple predictions can be evaluated, termed outcome-wise, joint, and weak and strong panel-wise. Examples are given in which each sense of prediction may be appropriate. I define sensitivity, specificity, concordance, and relative utility in each of these senses. In section 3, I develop analytical expressions for each of these quantities from a multivariate probit model. These show that the accuracy of a multivariate prediction model can be summarised by its covariance with a liability vector, and from this covariance matrix all the proposed criteria can be derived. Section 4 applies the results to some examples of current applications, and uses the model of section 3 to project their future performance as improved predictors are developed. Section 5 provides some discussion.
2 Definitions
2.1 Preliminaries
For individual
As for single outcome prediction, calibration is a desirable property of a risk predictor, and it will be generally useful for the predictor to be calibrated for all outcomes. Informally, calibration requires that predicted risks equal actual risks, but a distinction can be made between the risk among individuals with given predictors The risk prediction model Calibration is usually assessed by plots or goodness-of-fit tests.
29
–31
While these approaches could generalise to a multivariate setting, the following component-wise definition is sufficient for application to marginal prediction models, and can be assessed by applying univariate methods to each component of The risk prediction model Calibration implies component-wise calibration, but the converse need not hold. In the rest of the paper I assume that Let Definition 1
Definition 2
2.2 Outcome-wise criteria
A straightforward approach is to treat outcomes, rather than individuals, as the sampling units and then apply standard criteria to the vectorised outcomes. Such a view might be appropriate when the consequences of predicting or developing the outcomes are independent. This approach has been used in evaluating carrier screening panels for Mendelian disorders.
32
Another example might be in molecular screening for allergies.
33
Outcome-wise sensitivity is the probability of a positive prediction for an outcome that did occur. Over the joint sample space of The first term in the summand is the classical sensitivity for outcome Weights may be used to attach greater importance to the prediction of some outcomes. This may be done by generalising the outcome-wise sensitivity to
Outcome-wise specificity is the probability of a negative prediction for an outcome that did not occur.
Similarly to the sensitivity, the outcome-wise specificity is the weighted sum of the individual outcome specificities, with the weights as the relative probabilities of the complementary outcomes. General weights may be introduced as for the sensitivity. A standard, if often criticised
34
–36
summary of sensitivity and specificity is the area under the receiver operating characteristic (ROC) curve, which for a single outcome is constructed by plotting sensitivity against 1-specificity over the range of The C-index for a single outcome is the probability that, given one individual with the outcome and one without, the prediction is higher for the former, i.e. A more satisfactory approach is to compare a prediction for an outcome that did occur to a prediction for the same outcome when it did not occur. This just yields the C-index for that outcome, so the expected C-index for multiple outcomes is the weighted sum of individual outcome C-indices. For outcome
Outcome-wise C-index is the weighted sum of individual outcome C-indices.
One criticism of the ROC curve is that it treats sensitivity and specificity equally when they may entail different benefits and costs. The relative utility curve has been proposed to address this issue,38,39 and is especially useful for comparing different risk prediction models. Here I summarise its derivation for one outcome before developing an outcome-wise extension. Let It follows that if the risk predictor is weakly calibrated, the net benefit is positive if Therefore, use of the threshold The relative utility is the ratio of this expectation to its theoretical maximum when sensitivity and specificity are both 1, thus
The net benefit is understood as resulting from taking action on a prediction, and so is relative to the result of taking no action. If the default, in the absence of risk prediction, is to take no action, then that is equivalent to a risk predictor with sensitivity 0 and specificity 1 at all thresholds. Conversely, if the default were always to take action then the sensitivity is 1 and the specificity is 0. A default of no action is rational when its relative utility is greater than under the default of always taking action. The definition of These expressions assume negligible cost of evaluating If the risk predictor is weakly component-wise calibrated, then
Therefore, the use of threshold vector Under additive benefits and costs, the expected net benefit over the population is
Outcome-wise relative utility for threshold vector
As before, a diagonal weight matrix Definition 3
Definition 4
Definition 5
Definition 6
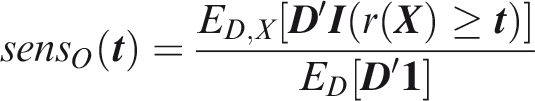
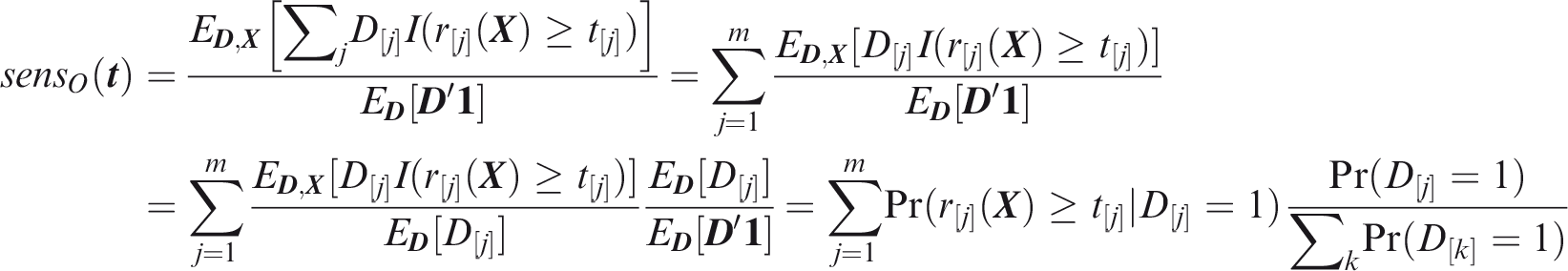
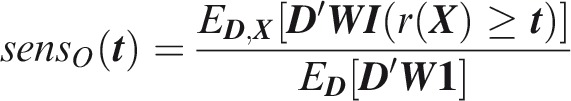
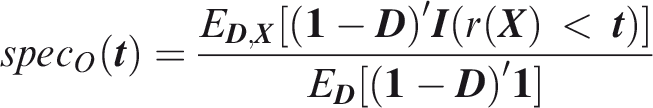
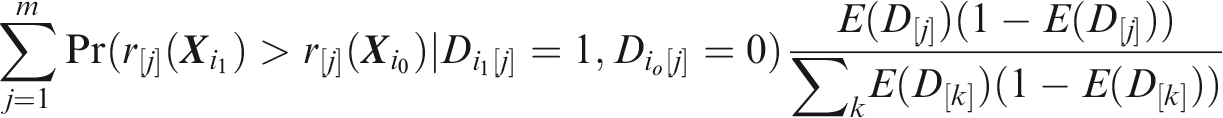
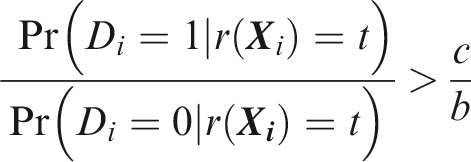
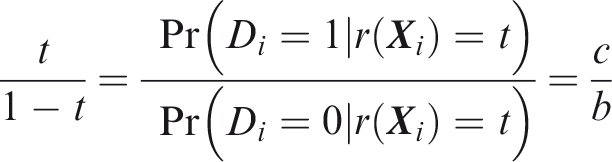
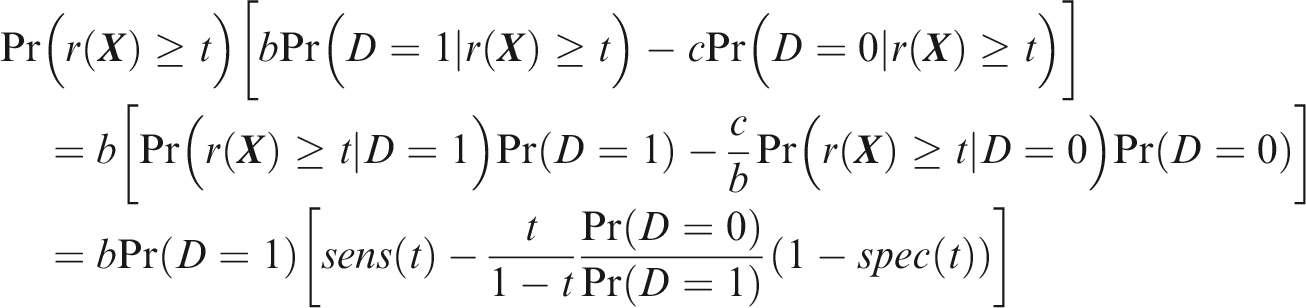
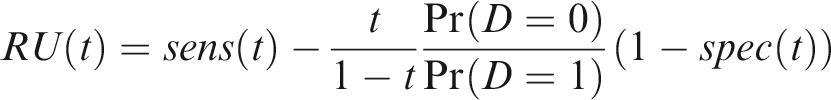
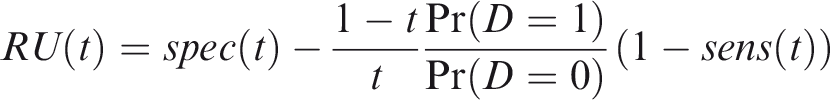
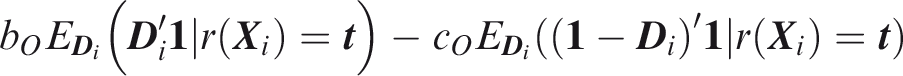
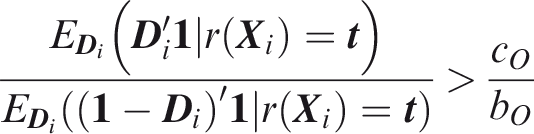
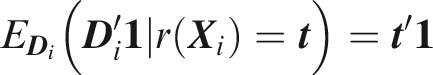
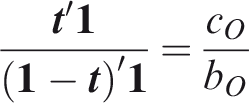
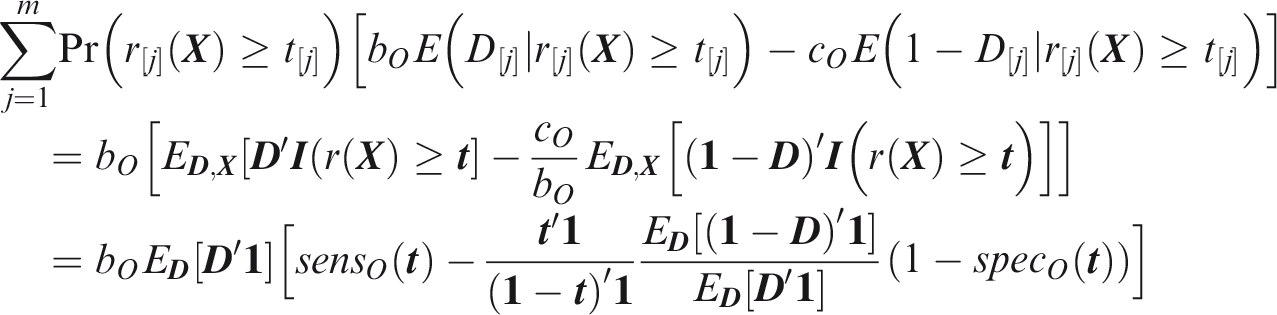
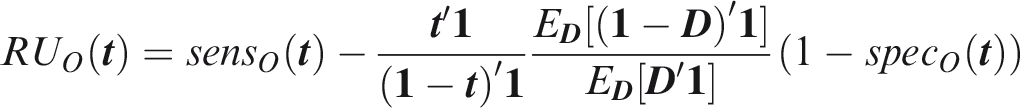
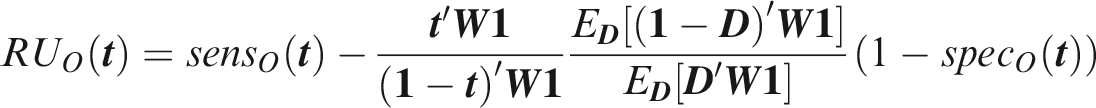
2.3 Joint criteria
An issue with outcome-wise measures is that actions are applied to individuals rather than outcomes. In many contexts, it is more appropriate to summarise risk predictions for each individual before taking action. To this end I now define individual-wise measures, which vary according to the definition of a true positive prediction. For joint measures, the aim is to predict the joint occurrence of all outcomes in an individual. An example might be in forensic identification from an anonymous DNA sample, where a profile could be constructed from several traits such as hair colour,
40
height
16
and weight,
41
each discretised into broad categories.
Joint sensitivity is the probability of predicting all outcomes to occur, in an individual for which all outcomes did occur.
If the elements of In this case, the joint sensitivity is the product of individual outcome sensitivities. However, in the general case of dependence between elements of
Joint specificity is the probability of predicting at least one outcome not to occur, in an individual for which at least one outcome did not occur.
Note that this may depend on the distribution of To define joint concordance, note that Joint C-index is the probability that, given one individual in which all outcomes did occur and one individual in which at least one outcome did not occur, the minimum risk prediction is higher in the former individual.
To define relative utility, let bJ be the benefit of predicting all outcomes to occur when all outcomes did occur, and Therefore, use of the threshold vector
Joint relative utility for threshold
In general The relevant region is Definition 7
Definition 8
Definition 9
Definition 10
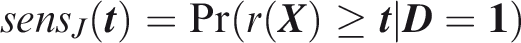
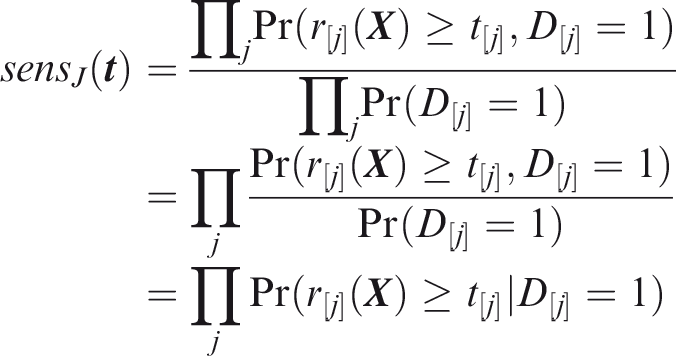
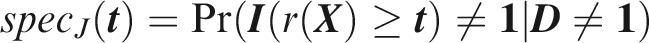
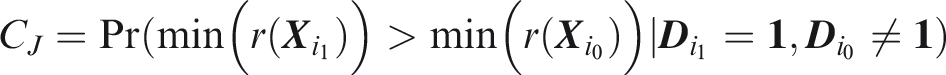
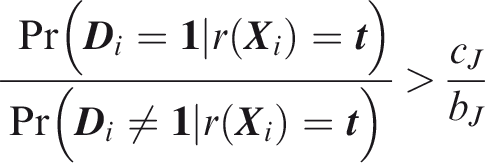
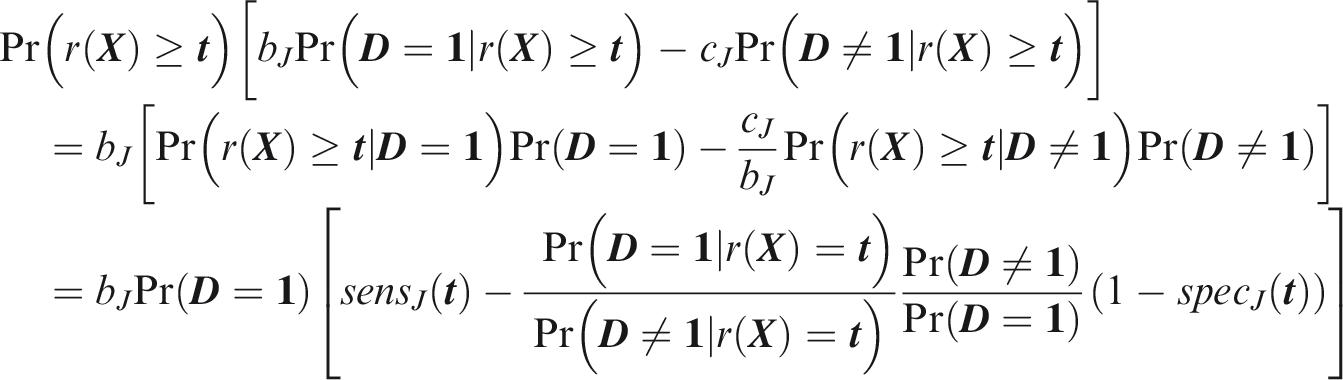
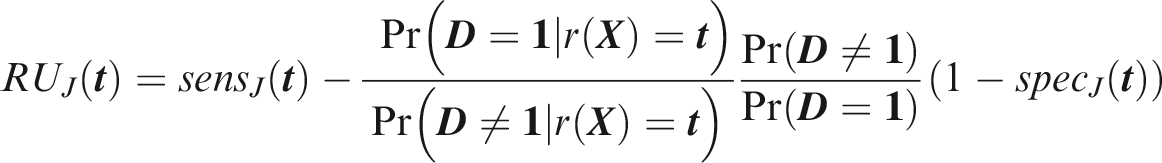
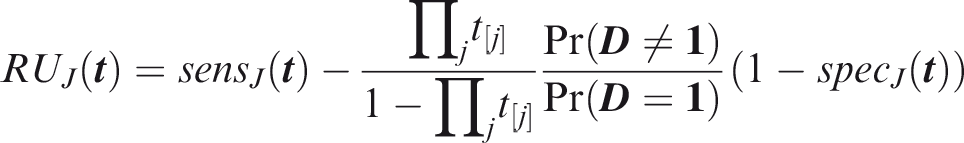
2.4 Panel-wise criteria
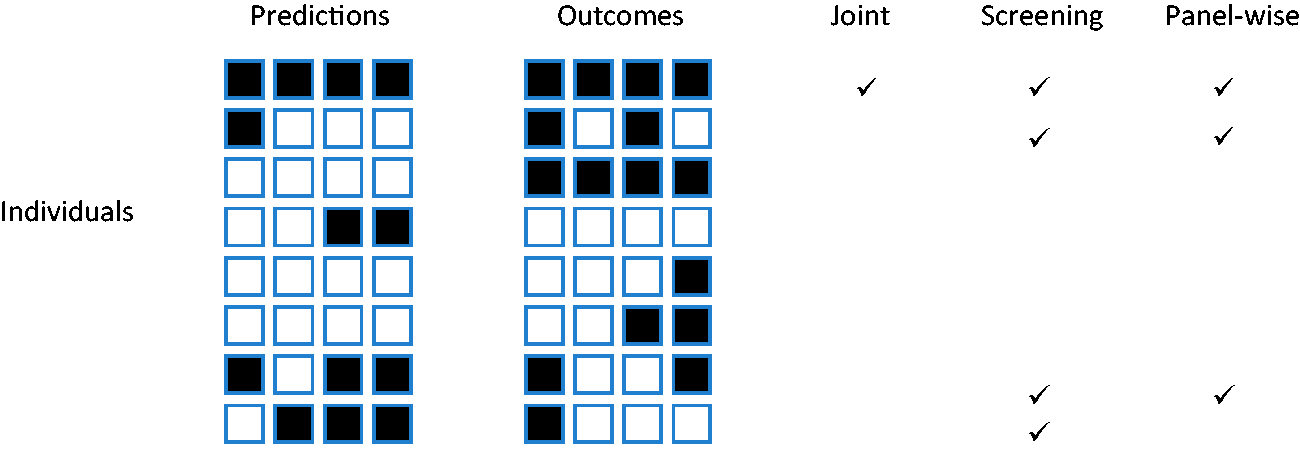
For panel-wise criteria the aim is to predict the occurrence of at least one outcome in an individual. A correct prediction may, however, be defined in different ways according to whether the predicted outcomes are the same as those that did occur. Here I propose two senses of panel-wise prediction, called the weak and strong senses by analogy to family-wise errors in hypothesis testing. Weak panel-wise sensitivity is the probability of predicting at least one outcome to occur, in an individual for which at least one outcome did occur.
The subscript Weak panel-wise specificity is the probability of predicting no outcomes to occur, in an individual for which no outcomes did occur.
Definitions 11 and 12 are complementary to the joint sensitivity and specificity, and similarly the weak panel-wise specificity is the product of the component-wise specificities in the case that risk predictions and outcomes both are jointly independent. The complement of weak panel-wise specificity is analogous to the weak sense of family-wise type-1 error rate in hypothesis testing. Similar arguments to the joint criteria give the following definitions of concordance and relative utility. Weak panel-wise C-index is the probability that, given one individual in which at least one outcome did occur and one individual in which no outcomes did occur, the maximum risk prediction is higher in the former individual.
Weak panel-wise relative utility for threshold vector
If risk predictions and outcomes both are jointly independent, and the risk predictor is weakly component-wise calibrated, then
The relevant region is Turning to the strong sense definitions, the key difference is that the predicted and actual outcomes must coincide for at least one outcome that did occur. Strong panel-wise sensitivity is the probability that at least one outcome is correctly predicted to occur in an individual for which at least one outcome did occur.
Estimates of Strong panel-wise specificity is the probability that all outcomes that did not occur are predicted not to occur in an individual for which at least one outcome did not occur.
Definitions 15 and 16 complement each other in a different way to the weak sense definitions 15 and 16. The complement of strong panel-wise specificity is analogous to the strong sense of family-wise type-1 error in hypothesis testing. Note that an individual may count towards both sensitivity and specificity, a property shared with the outcome-wise measures. Strong panel-wise C-index is the probability that, given one individual in which at least one outcome did occur and one individual in which at least one outcome did not occur, the maximum risk prediction is greater among the outcomes that did occur in the former individual than among the outcomes that did not occur in the latter.
Note that under this definition an individual may appear on both sides of the inequality (i.e. Relative utility cannot be developed in the same manner as Strong panel-wise relative utility for threshold vector If risk predictions and outcomes both are jointly independent, and the risk predictor is weakly component-wise calibrated, then
Which of the weak or strong measures is more appropriate will depend on the application. For example, if the same action would be performed for all outcomes, it is less important to predict specific outcomes. That might be the case when screening for a range of conditions with a common intervention, as is done say when measuring blood pressure with a view to prescribing anti-hypertensives. For this reason I suggest screening, with subscript Figure 1
Example outcomes in eight individuals. Outcomes predicted to occur are shown in black on the left panel. Outcomes that did occur are shown in black on the right panel. Ticks show individuals counting in the numerator for each sense of sensitivity. Here the sample joint sensitivity is 1/2, the screening sensitivity is 4/7, and the panel-wise sensitivity is 3/7. The outcome-wise sensitivity is 7/16.Definition 11
Definition 12
Definition 13
Definition 14
Definition 15
Definition 16
Definition 17
Definition 18
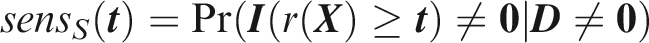
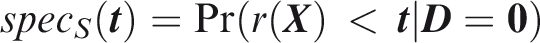
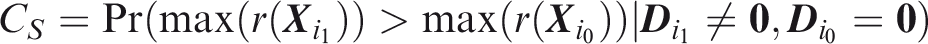
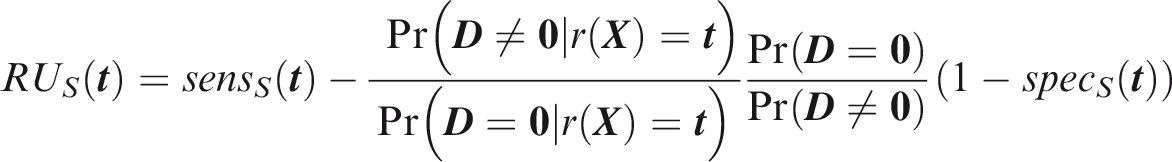
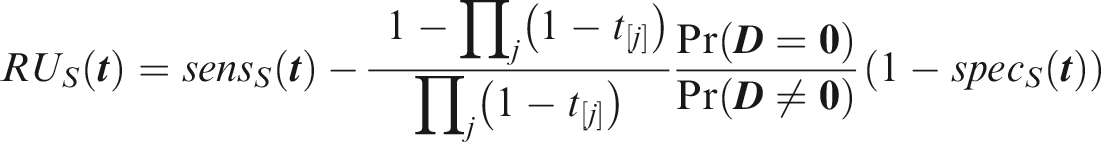
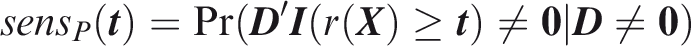
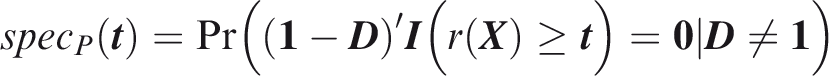
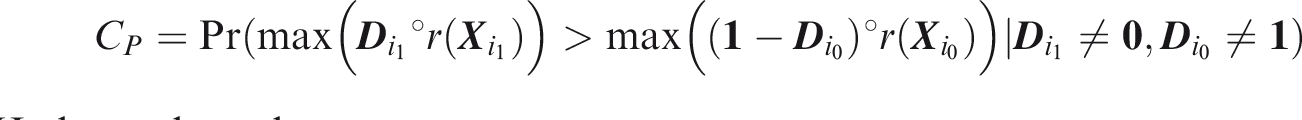
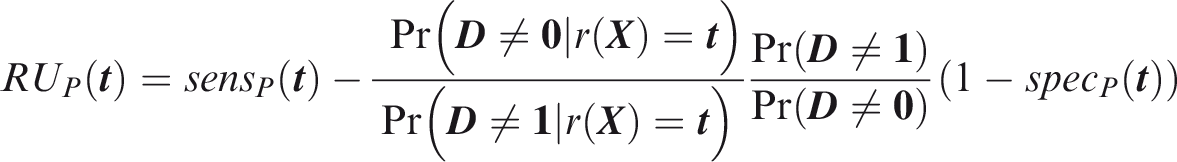
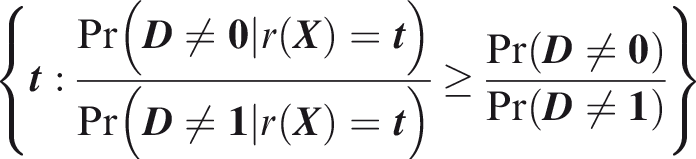
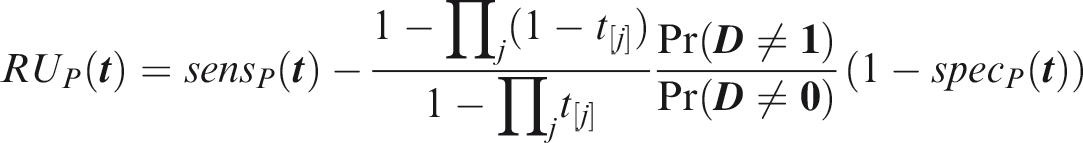
3 Multivariate probit model
For a single outcome, many measures of predictive accuracy can be expressed in terms of variance explained by the risk predictor, assuming a probit model for the outcome. 42 This allows any of the measures to be derived from reported values of any others, and argues for the use of variance explained as a fundamental measure of prediction accuracy without the caveats associated with, for example, ROC curves. Here this framework is extended to the prediction of multiple traits using a multivariate probit model for outcomes. 43
Assume that individual
Assume that each outcome has a single normally distributed predictor, so that the predictor vector
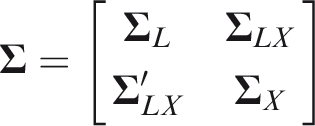
The following expressions will be useful. If each element of

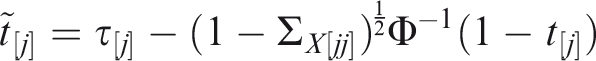
Given outcomes

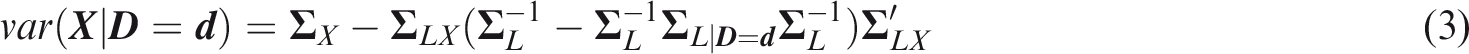
Assume that conditional on
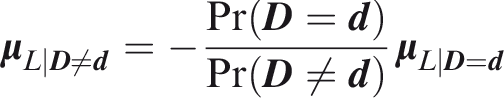
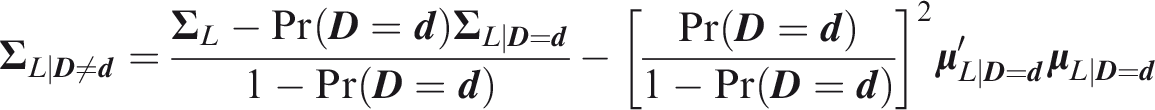
Finally assume that conditional on a prediction


The outcome-wise criteria can be expressed in terms of single outcome criteria, which are special cases of the joint criteria below and are therefore omitted for brevity.
3.1 Joint criteria
From Definition 7
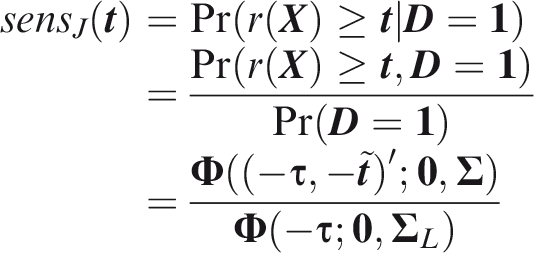
From Definition 8
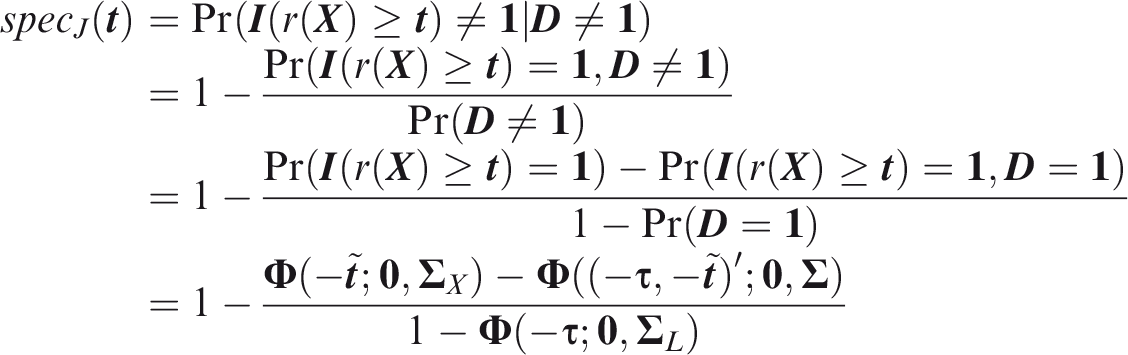
Calculating joint concordance requires the distribution of the maximum element of the multivariate risk predictor. This has recently been derived analytically
47
but can be approximated by simulation
From Definition 10, the joint relative utility is
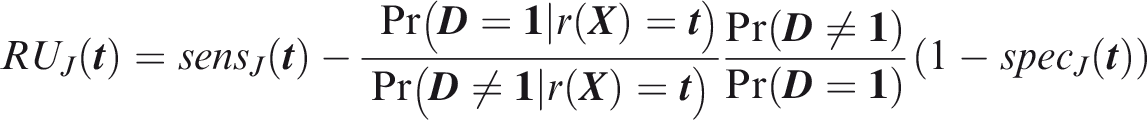
3.2 Screening criteria
Following analogous steps to the joint measures, from Definition 11
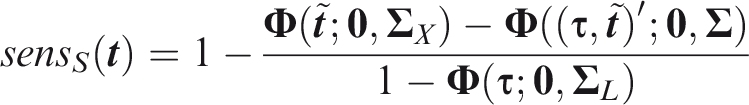
From Definition 12
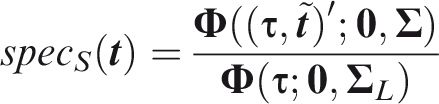
To estimate screening concordance, first simulate a predictor from the multivariate normal distribution conditional on
From definition 14, the screening relative utility is
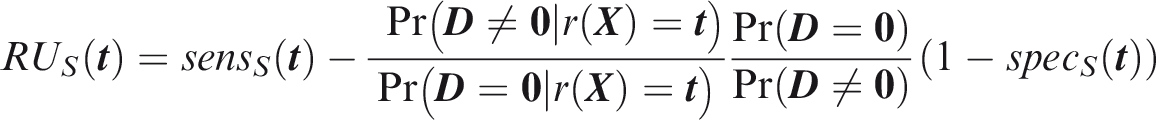
3.3 Panel-wise criteria
Panel-wise measures can be evaluated by summing over outcome vectors
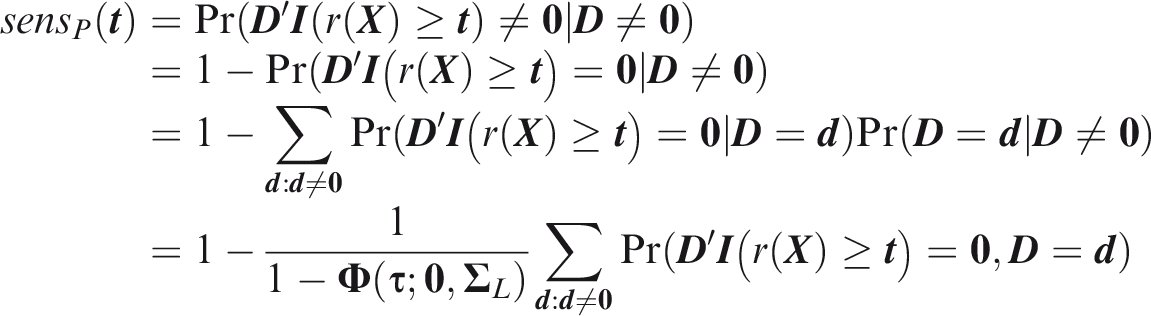
The probability in the summand is an integral of the multivariate normal density with mean vector
From definition 16 the panel-wise specificity is
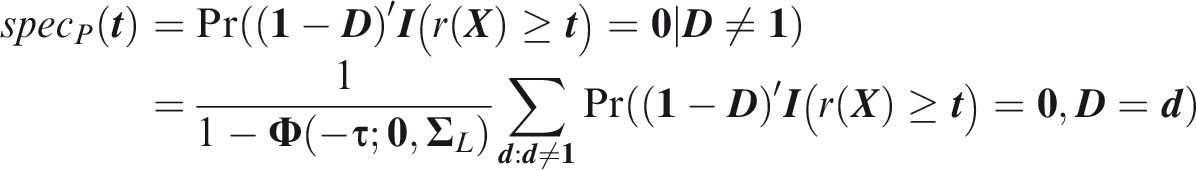
For components
To estimate panel-wise concordance, simulate liabilities
The panel-wise relative utility can be calculated from Definition 18 using expressions given above.
All the criteria are now expressed in terms of the marginal outcome probabilities
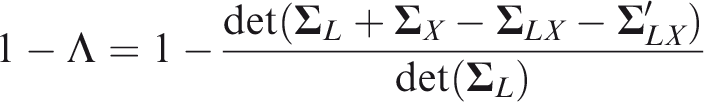
This is the proportion of variance of
4 Examples
4.1 CancerSEEK
CancerSEEK is a blood-based test of circulating proteins and tumour DNA mutations that are associated with the presence of cancer. 9 It has been proposed for early detection of cancers of the ovary, liver, stomach, pancreas, esophagus, colorectum, lung, or breast. A single test is applied, from which a positive result suggests the presence of one of these cancers. Given a positive test, a secondary algorithm identifies the likely site of the cancer.
CancerSEEK tests a composite outcome, and as such the standard univariate criteria correspond to screening criteria. However, the authors reported sensitivities for each cancer individually, at a risk threshold of 0.893, and reported their incidence-weighted average as 55%. This average corresponds to outcome-wise sensitivity (Definition 3), but it is also a screening sensitivity if at most one cancer is present in each subject. The screening specificity was reported as over 99%.
The in-sample screening sensitivity at this risk threshold was 62.2% and the area under the ROC curve (AUC) was 91% (Figure 2a in Cohen et al. 9 ). However, as noted in Definition 11 these estimates are subject to ascertainment bias, in particular the under-sampling of breast cancers relative to other cancer cases, explaining the discrepancy between the in-sample and incidence-weighted sensitivities. I randomly resampled cases from each cancer (their Table S4) in proportion to their incidence rates (L. Danilova, personal communication). The in-sample screening sensitivity was now 55%, equal to the outcome-wise sensitivity, and the screening concordance reduced to 89%. This is the concordance that would be expected in a population screening context.
4.2 Polygenic risk scores
A polygenic risk score (PRS) is an aggregation of genetic risk,
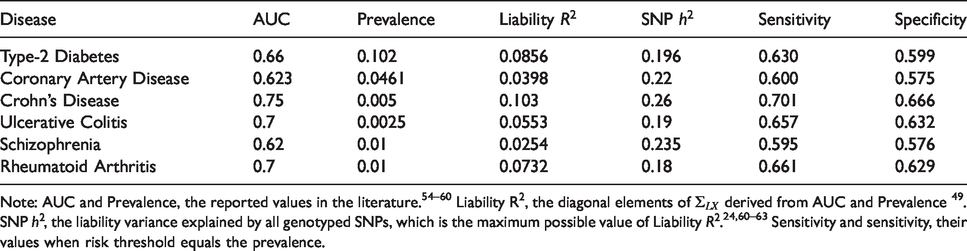
Properties of fitted PRS for six common diseases.
Note: AUC and Prevalence, the reported values in the literature.
54
–60
Liability
Variance–covariance matrix
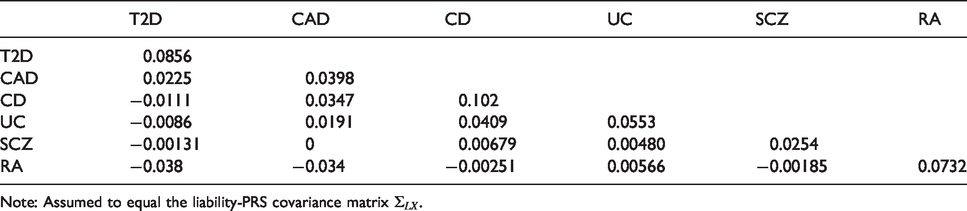
Note: Assumed to equal the liability-PRS covariance matrix
Genetic correlations between the six diseases of Table 1.
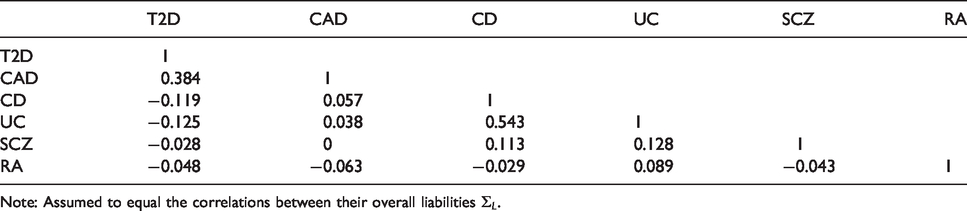
Note: Assumed to equal the correlations between their overall liabilities
Under the model developed in section 3, the event-wise concordance is 0.653, the screening concordance is 0.607, which is lower than all individual AUCs, and the joint concordance is 0.749. The panel-wise concordance is 0.49, compared to a value of 0.37 obtained when the correlation matrices are the same but all individual AUCs are set to 0.5.
For illustration, consider a screening application to identify, early in life, those at elevated risk of at least one of these diseases. Suppose the risk threshold vector is set equal to the prevalence, so that the predictor identifies individuals with above-average predicted risk for at least one disease. The screening sensitivity is 0.955, which is considerably higher that the individual sensitivities (Table 1). However, the screening specificity is much lower at 0.074. Similarly to multiple hypothesis testing, the prediction of multiple outcomes increases both the true-positive and false-positive rate at a given threshold vector, but the thresholds that reflect the cost–benefit ratio are different in the multiple prediction context than for the single predictions. The screening concordance of 0.607 suggests that, across all thresholds regarded equally, the sensitivity-specificity trade-off is not as good as for any disease individually. The screening relative utility is −0.004, suggesting that these PRS provide no benefit in a multiple screening application. The liability variance explained is
In principle, PRS could be developed that explain greater proportions of liability
48
up to the so-called SNP heritability (Table 1). Under this scenario the liability variance explained increases to
5 Discussion
Standard concepts of sensitivity and specificity generalise naturally to the multivariate setting. Positive and negative predictive values generalise similarly, and for completeness their definitions are provided in the supplementary text. Although the ROC curve does not extend so easily, the related concept of concordance does so. However, in contrast to the single outcome setting, concordance is sensitive to the outcome probabilities, negating one perceived advantage of that criterion. In the strong panel-wise sense the concordance is unsatisfying because an individual can be regarded as being discordant with itself, and there is no natural interpretation in terms of discrimination. The range of panel-wise concordance depends upon the number of outcomes and the covariance of predictors and outcomes, and may fall below 0.5. In practice its minimum value can be estimated by simulation or theory, as in section 4.2, by setting the predictors to be independent of the outcomes while maintaining the correlation among predictors and among outcomes. Strong panel-wise measures have an intermediate position between outcome-wise and screening measures, in that prediction is evaluated at the individual level but the predictions of specific outcomes are taken into account. The proposed definitions are motivated by possible applications in early detection of disease, and have convenient analogies with family-wise error in hypothesis testing, but other approaches may be possible.
Relative utility, which is a useful summary of sensitivity and specificity when predicting a single outcome, presents some difficulties when predicting multiple outcomes. I propose definitions assuming common benefits and costs for all outcomes, which allow analogous development to that for a single outcome, but may lead to sub-optimal assessment of utility when the benefits and costs vary across outcomes. When outcomes are correlated, accurate calculation of relative utility may be difficult, so approximations are provided assuming independent predictors and outcomes. It remains to be seen how useful these definitions prove in practice, given their assumptions of common additive benefits and costs, and independent predictors and outcomes.
Some examples of screening have been discussed, but examples of outcome-wise or joint accuracy can also be envisaged. CancerSEEK is a recent example of molecular technology applied to early detection of multiple cancers. Its performance was reported in the screening sense, but the proposed definitions clarify that all quantities can be affected by ascertainment bias. The present criteria are more sensitive to incidence and sampling rates than the corresponding univariate measures.
I have only considered the accuracy of a given predictor, and have not considered how such predictors are constructed. Multivariate predictors could be constructed simply by concatenating univariate predictors. The example of PRS shows that this is feasible and pragmatic given that such scores are currently constructed from case/control studies of individual diseases. In future, given the increasing availability of extensive phenotyping in large cohorts, it will be possible to build prediction models with the optimisation of multiple outcome prediction as the direct objective. Methodology for such model building is a fertile area for future work.
Prediction models are often evaluated for their improvement over existing models. Evaluation of incremental performance remains a controversial subject when predicting a single trait. Among several proposed measures the net reclassification index has attained a default status among practitioners yet has received strong criticism.51,52 Such issues are likely to be magnified when predicting multiple traits.
Given predictors for a set of outcomes, a natural question is whether there is some subset of outcomes for which risk prediction is most effective. Naïve comparison of, say, relative utilities for different groups of outcomes would be inappropriate without consideration of the relative benefits of predicting each group. Thus, the finding that the screening concordance of PRS is lower over six diseases than for each disease individually should not in itself argue against a screening application, because the benefits and costs of screening six diseases are different from those of screening one disease. Many authors have argued for decision-theoretic treatments of risk prediction.28,53 Such approaches can also be developed for the multiple outcome setting and would put the comparison of predictors for different groups of outcomes on a more coherent footing.
Competing risks present a problem for mutually exclusive outcomes, such as diseases of later life. There is a distinction between accounting for competing risks in model building, and in model evaluation. The emphasis here is on evaluation, for which the proposed criteria could be adapted to account for competing risks. However, the explicit consideration of multiple outcomes may encourage more careful consideration of competing risks at the model building stage and lead to improved prediction in general.
An R library to calculate these criteria from empirical data, and to evaluate the multivariate probit formulae of section 3, is available from https://github.com/DudbridgeLab/multipred.
Supplemental Material
sj-pdf-1-smm-10.1177_0962280220929039 - Supplemental material for Criteria for evaluating risk prediction of multiple outcomes
Supplemental material, sj-pdf-1-smm-10.1177_0962280220929039 for Criteria for evaluating risk prediction of multiple outcomes by Frank Dudbridge in Statistical Methods in Medical Research
Footnotes
Acknowledgement
I am grateful to Paul Newcombe for reading the manuscript, and to Richard Morris, Alex Sutton and Angelica Ronald for their helpful suggestions.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.