
Abstract
Within paediatric populations, there may be distinct age groups characterised by different exposure–response relationships. Several regulatory guidance documents have suggested general age groupings. However, it is not clear whether these categorisations will be suitable for all new medicines and in all disease areas. We consider two model-based approaches to quantify how exposure–response model parameters vary over a continuum of ages: Bayesian penalised B-splines and model-based recursive partitioning. We propose an approach for deriving an optimal dosing rule given an estimate of how exposure–response model parameters vary with age. Methods are initially developed for a linear exposure–response model. We perform a simulation study to systematically evaluate how well the various approaches estimate linear exposure–response model parameters and the accuracy of recommended dosing rules. Simulation scenarios are motivated by an application to epilepsy drug development. Results suggest that both bootstrapped model-based recursive partitioning and Bayesian penalised B-splines can estimate underlying changes in linear exposure–response model parameters as well as (and in many scenarios, better than) a comparator linear model adjusting for a categorical age covariate with levels following International Conference on Harmonisation E11 groupings. Furthermore, the Bayesian penalised B-splines approach consistently estimates the intercept and slope more accurately than the bootstrapped model-based recursive partitioning. Finally, approaches are extended to estimate Emax exposure–response models and are illustrated with an example motivated by an in vitro study of cyclosporine.
Keywords
1 Introduction
Children of different ages given a new medicine may be characterised by different dose–exposure and exposure–response (E–R) relationships due to age-related differences in growth, development and physiological differences. 1 Several regulatory guidance documents have suggested general age groupings, such as the International Conference on Harmonisation (ICH) E11 document, 1 which suggests one possible categorisation: preterm newborn infants; term newborn infants (0–27 days); infants and toddlers (28 days to 23 months); children (2–11 years); and adolescents (12 to 16–18 years, depending on region). The National Institute of Child Health and Human Development (NICHD) guideline, suggests similar age groups, but with extra splits at 1 and 6 years. This paper aims to estimate the E–R relationship in children and to identify age groupings which define practical and effective dosing rules.
An understanding of how the E–R relationship of a drug varies with age will inform whether and how we leverage adult data to support drug development in children. Hampson et al. 2 reviewed paediatric investigation plans (PIPs) and found that it was common to plan to identify paediatric doses by matching target adult exposures. This is an appropriate dose-finding strategy if E–R relationships are similar in adults and children. This assumption might be justified for some paediatric subgroups but not others. For example, Takahashi et al. 3 concluded that whilst pubertal (12–18 years) and adult patients had similar PD responses to long-term warfarin therapy, there were differences between pre-pubertal (1–11 years) patients versus pubertal and adult patients. If E–R relationships can be assumed to be similar across age groups, it may be appropriate to make a complete extrapolation of efficacy data from one age group to another, so that only dose–exposure data are needed in the unstudied age group to identify doses producing exposures known to be efficacious in the studied age group.2,4 However, if E–R relationships cannot be considered similar, a partial extrapolation approach 4 may be considered, where dose–exposure and E–R data may be accrued in specified age groups to confirm differences in E–R relationships and confirm dosing.
One common approach to modelling nonlinear E–R relationships is the Emax model. 5 Thomas et al. 6 show that the Emax model provides good fit to the dose–response relationship of almost all compounds and diseases in the time window they studied. Parkinson et al. 7 developed a sigmoid Emax model for the relationship between dapagliflozin exposure and urinary glucose excretion for adult and paediatric patients with type 2 diabetes mellitus. After accounting for significant covariates (e.g. sex, race, baseline fasting plasma glucose), further covariates were included for paediatric patients which failed to improve model fit. The authors took this as evidence that adult and paediatric patients had similar E–R relationships. Earp et al. 8 used E–R modelling and exposure matching analyses to estimate paediatric doses for esomeprazole for the treatment of gastroesophageal reflux disease. The authors modelled E–R relationships of intragastric pH for adults and children separately and concluded similarity of E–R based on a visual inspection of fitted E–R relationships. In this paper, a more quantitative approach to evaluating differences between E–R relationships is taken using sophisticated modelling approaches.
Age groups characterised by different E–R relationships can be considered as distinct subgroups. Lipkovich et al. 9 reviewed methods for the identification and analysis of subgroups in clinical trials. Ondra et al. 10 reviewed methods for designing and analysing clinical trials that aim to investigate differences in treatment effects across subgroups. In this paper, we consider two model-based approaches to quantifying how E–R model parameters vary over a continuous age range: Bayesian penalised B-splines, 11 and model-based recursive partitioning (MOB)12,13 which is used to fit model-based trees to bootstrapped samples of the E–R data. Based on estimates of how E–R model parameters vary with age, we propose an approach to identify the age groups and exposure levels that define a dosing rule which is optimal for targeting a certain level of response; definition of the dosing rule is then completed by using the exposure levels and estimated dose–exposure relationship to make dosing recommendations for each age group. The estimated dose–exposure relationship is not considered in this paper.
Thomas et al. 14 use MOB to estimate patient subgroups with different dose–response curves, and apply this method to data from a dose-finding trial. In this paper, we focus on estimating age groups with different E–R relationships since in practice, when seeking to relate dose to response, a two-step process relating dose to exposure then exposure to response is often adopted. For example, the ICH E4 guidance 15 states that E–R information can help to identify a range of concentrations likely to lead to a satisfactory response, which can in turn inform dose selection. While parameters of the dose–exposure relationship are expected to depend on age, for some medicines, parameters of the E–R relationship are expected to remain stable across age groups. In such cases, the two-step modelling process can be advantageous because it enables separate modelling of the dose–exposure and E–R relationships, which allows for changes due to age to be captured in each relationship separately. In a simulation study to compare the performance of the two-step and single-stage approaches to dose finding, Berges and Chen 16 found that the two-step approach resulted in more precise E–R model parameter estimation and more accurate dose selection, although gains depend on properties of the drug, trial design features and the target response.
Pharmacokinetics (PK) is the study of the time course of drug levels in the body and the mathematical modelling of such data. 17 Population-PK models are an extension of PK modelling, studying PK at the population level and modelling data from all individuals simultaneously. 18 Hsu 19 found that in scenarios with increased intrinsic PK variability, E–R modelling has advantages for dose selection over dose–response modelling, provided measurement error for exposures is small. As an example of a two-stage approach to selecting a dosing rule, Schoemaker et al. 20 developed a population PK model to describe the relationship between brivaracetam dose and plasma concentration in adults with partial onset seizures, and a population PK-pharmacodynamic model to describe the relationship between brivaracetam plasma concentration and daily seizure counts. The authors then simulated from these models to estimate the relationship between dose and response, enabling them to identify a dose range producing the maximum response.
This paper proceeds as follows. Section 2 gives a motivating example while Section 3 defines two E–R models. In Section 4, we introduce the methods that will be used to estimate parameters of E–R relationships. Section 5 proposes an approach for using fitted E–R models to identify practical dosing rules for children. We use simulation to evaluate the performance of E–R modelling approaches and the operating characteristics of the dosing rule algorithm. The design of the simulation study is described in Section 6, and the results are presented in Section 7. An example illustrating how the E–R modelling approaches can be applied to non-linear models is given in Section 8. The paper concludes with a discussion in Section 9.
2 Motivating example
We motivate the work that follows by considering the development of epilepsy medicines for paediatric patients with partial onset seizures. Girgis et al.
21
study both monotherapy and adjunctive therapy with the anti-epileptic drug topiramate, whilst Nedelman et al.
22
consider adjunctive therapy with oxcarbazepine. For adjunctive therapy, Girgis et al.
21
and Nedelman et al.
22
take response,
3 Exposure–response models
We start by considering a linear model for the E–R relationship. Suppose E–R data are available from a single study which recruited children aged 0 to 18 years and let Yi represent the response of subject i, for
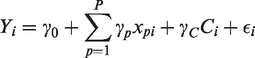
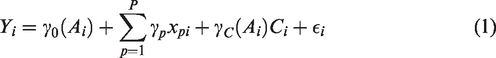
In Section 4 we will consider different approaches for parameterising
Non-linear Emax models are often used to represent the E–R relationship.
23
For example, it could be modelled by a sigmoid Emax model:
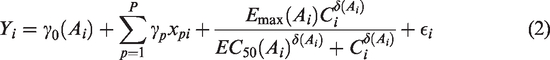
4 Estimating the exposure–response relationship
In this section, we describe three E–R modelling approaches that can be applied when we assume the E–R relationship follows model (1) with age-dependent intercept and slope. These methods are linear regression with categorical covariates for age groups; MOB and partially additive linear model (PALM) trees; and Bayesian penalised B-splines. We highlight where methods can be applied more generally with non-linear E–R models. A worked example illustrating how each method can be applied to fit a linear E–R model is given in Supplementary Appendix A.
4.1 Linear model fit with categorical age covariates
If we knew that the age groups defined by different E–R relationships were
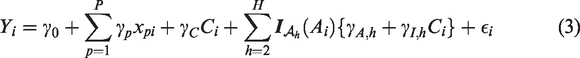
4.2 MOB and PALM trees
Building on model (3), MOB allows data to be split into groups based on partitioning variables, with each subgroup characterised by its own parametric model. 13 We implement MOB using age as the only partitioning variable. The MOB algorithm we use comprises the following steps 13 : Fit a parametric model to the data set, finding parameter estimates by minimising an objective function; test whether the model parameters significantly change with age using a generalized M-fluctuation test13,24 which assesses whether the scores of the model systematically deviate from 0 with age; partition the model into two subgroups with respect to age by finding the value of age which minimises an objective function segmented at this split point; repeat the fitting, testing and splitting procedure in each identified age group until no significant changes are found in the model parameters over age within each group. In our subsequent examples, the parametric model will be taken to be a linear model, where the parameters of interest are the intercept and slope. The MOB algorithm13 can be implemented using the ‘mob’ function found in the ‘partykit’ package13,25 in R. 26 As MOB allows subgroups defined by any parametric model, non-linear models (such as Emax models) are possible.
PALM trees are a variation of MOB, allowing for global parameters which remain constant across subgroups. However, PALM trees are restricted to generalised linear models (GLM).
12
For our linear model example with outcome Yi and partitioning age variable Ai, PALM trees can contain globally fixed linear effects
We implement MOB and PALM tree approaches using bootstrap aggregating 27 to improve the accuracy and precision of age-specific E–R model parameter estimates and reduce overfitting. The E–R data are bootstrapped and each bootstrap sample is used to fit a MOB or PALM tree. From each bootstrap tree fit, estimates of age-specific model parameters (intercept and slope) can be evaluated for a grid of ages covering the interval [0, 18] years. For each grid point in turn, we then aggregate across the bootstrap samples and, applying linear interpolation to the average age-specific parameter estimates, can thus obtain an estimate of the E–R intercept or slope for any given age. The important aspect to note here is that no parametric assumptions are made about the form of the relationship between each model parameter and age. One disadvantage of this is that these relationships cannot then be easily recorded in a closed form for future reference.
We fit linear E–R models using PALM trees in Section 6 because we also consider the case of having an additional global covariate whose effect is independent of age, which we present in Supplementary Appendix B. In Section 8, we fit non-linear E–R models using MOB.
4.3 Bayesian penalised B-splines
Splines define flexible regression models by joining smooth curves (differentiable at every point) together at knot points.
28
An E–R model parameter that can be written as a smooth function of A, f(A), can be modelled as a spline. Here, we will consider the penalised B-splines developed by Eilers and Marx.
11
B-splines can be written as a linear combination of B-spline basis functions of degree d, that is,

A B-spline basis function of degree d consists of d + 1 polynomial curves of degree d, each joined in sequence.
11
The degree of the B-spline basis controls how differentiable the spline is and can influence the smoothness of the spline. We implement B-splines of degree 2 as in the examples we have considered we gain little in terms of smoothness for the added complexity of using degree 3 B-splines. We therefore fit linear E–R models defining the intercept and slope as B-splines of degree 2
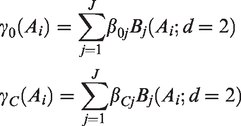
We set J = 26 given our choice of degree and number of knots: five equally spaced knots within each of the four ICH E11 age groups (not including pre-term newborn infants), knots at each age group boundary, along with two external knots below age zero and two above 18 years. We use the function ‘splineDesign’ in the R package ‘splines’ 26 to construct our 26 B-spline basis functions. Further details of how the B-spline basis functions are constructed can be found in Bowman and Evers. 28 Note that for penalised B-splines, Eilers and Marx 11 recommend using equidistant knots and suggest that there are no gains to be made from using unequally spaced knots, as the penalty smooths any sparse areas. However, we specify knots using the prior information on potential age groupings that is contained in the ICH E11 guidance document. 1 By specifying an equal number of knot points across each ICH E11 age group, knots are more densely spread across age ranges where model parameters are expected to change most rapidly with age. A sensitivity analysis to explore the impact of knot placement would be appropriate in many cases.
For penalised B-splines, a roughness penalty is used to control the smoothness of the estimated spline, rather than the choice of knot location and number.
11
In a Bayesian context, penalised B-splines are implemented placing random walk priors on the B-spline coefficients.28,29 For example, to penalise differences between adjacent B-spline coefficients, first-order random walk priors are used
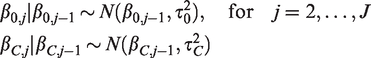
We fit the Bayesian penalised B-splines model using Hamiltonian Monte Carlo, calling Stan 31 from R 26 using the RStan package, 32 and running three chains with a default thinning rate of one for 3000 iterations, 1500 of which are discarded as burn-in samples. Following equation (4), the posterior means of the B-spline coefficients are multiplied by the B-spline basis functions to estimate the B-spline for the respective E–R model parameter.
Bayesian penalised B-splines are a very flexible modelling approach, with the capacity to be used to represent the parameters of any parametric E–R model. The ability to write the relationship between E–R parameters and age in a simple form, as in equation (4), means it is easy to record and communicate the estimated relationship. However, Bayesian penalised B-spline models can comprise many parameters which can make them computationally expensive to fit.
5 Dosing recommendations
5.1 Optimisation criterion
We could use the modelling approaches described in Section 4 to derive personalised dosing recommendations tailored to a patient’s exact age and baseline covariates. However, for practical reasons, we seek to identify dosing rules based on wider age subgroups. As outlined in Section 1, we focus on identifying age groups and exposure levels targeting a certain level of response, assuming that in a second step we could use a PK model to link each target exposure to dose. Therefore, we use ‘dosing rule’ as a short-hand to refer to a set of age groupings and corresponding target exposures. First, we derive target exposure levels for up to K age groups of children. For practical reasons, K would likely be small, e.g. K = 5 in the ICH E11 guideline.
1
When defining the target exposure for each age group, we would like to minimise the difference between the expected response and a target response denoted by
We derive dosing rules assuming the E–R model and parameter estimates (maximum likelihood for the frequentist approaches, posterior means for the Bayesian penalised B-splines) are identical to the true model and parameter values. Given a proposed age grouping, let Ck denote the target exposure for the kth age group
5.2 Identifying an optimal number of age groups in our dosing rule
Define Begin with K = 1 age group; For K age groups, search over configurations of Λ
K
to find the dosing rule minimising GK; Save Repeat steps (2) and (3), successively increasing K by one until
The minima
6 Design of the simulation study
We performed a simulation study to explore the performance of the modelling approaches described in Section 4 and the approach of Section 5 for defining dosing rules. We consider a range of data generation scenarios for the linear model described in Section 3. For the categorical age covariates model, we follow the ICH E11 age groups to fix the age intervals as
We simulate studies enrolling 25 subjects into each of four ICH E11 age groups,
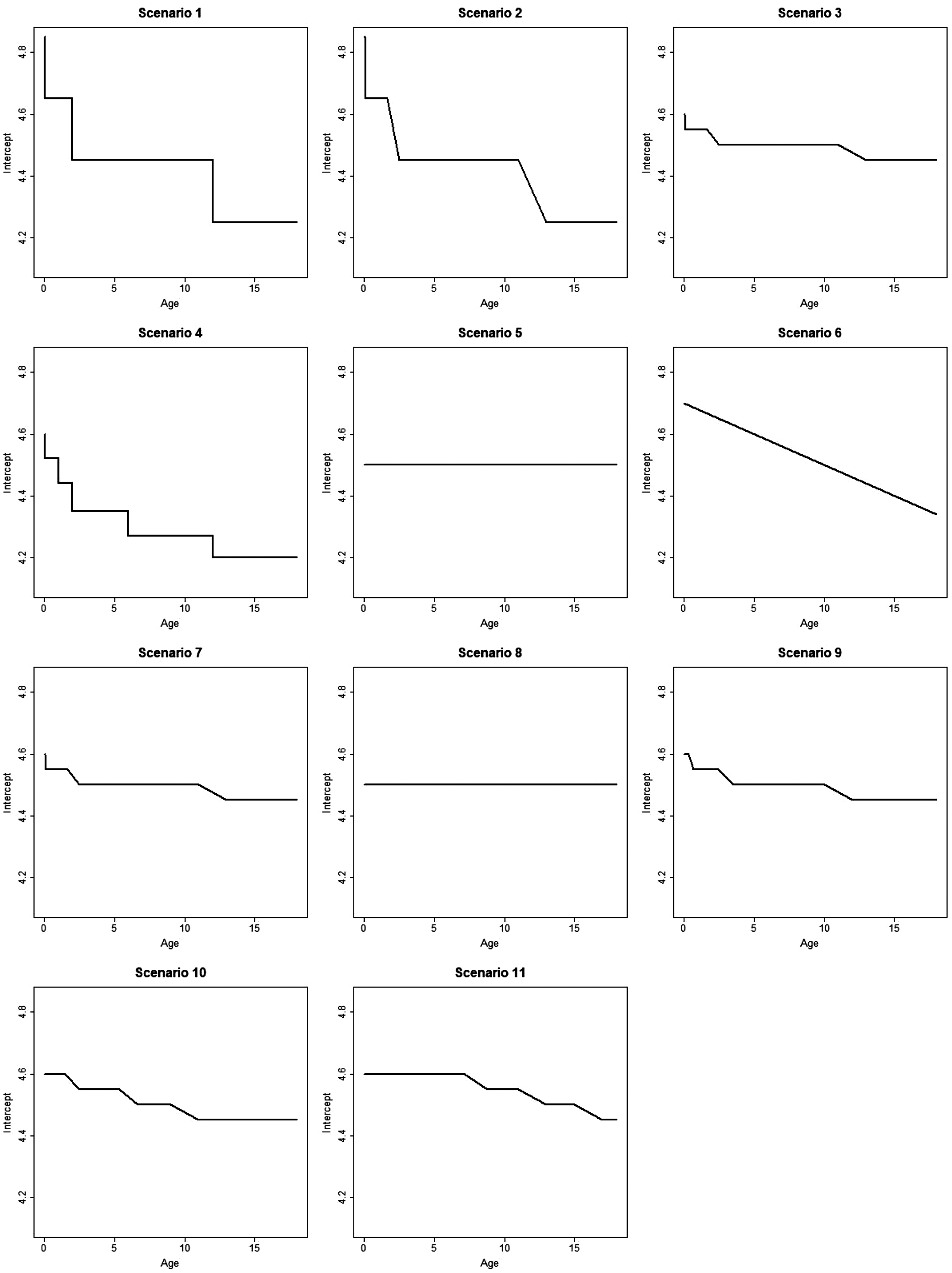
Plot showing how the intercept of the E–R model changes with age in simulation scenarios 1–11.
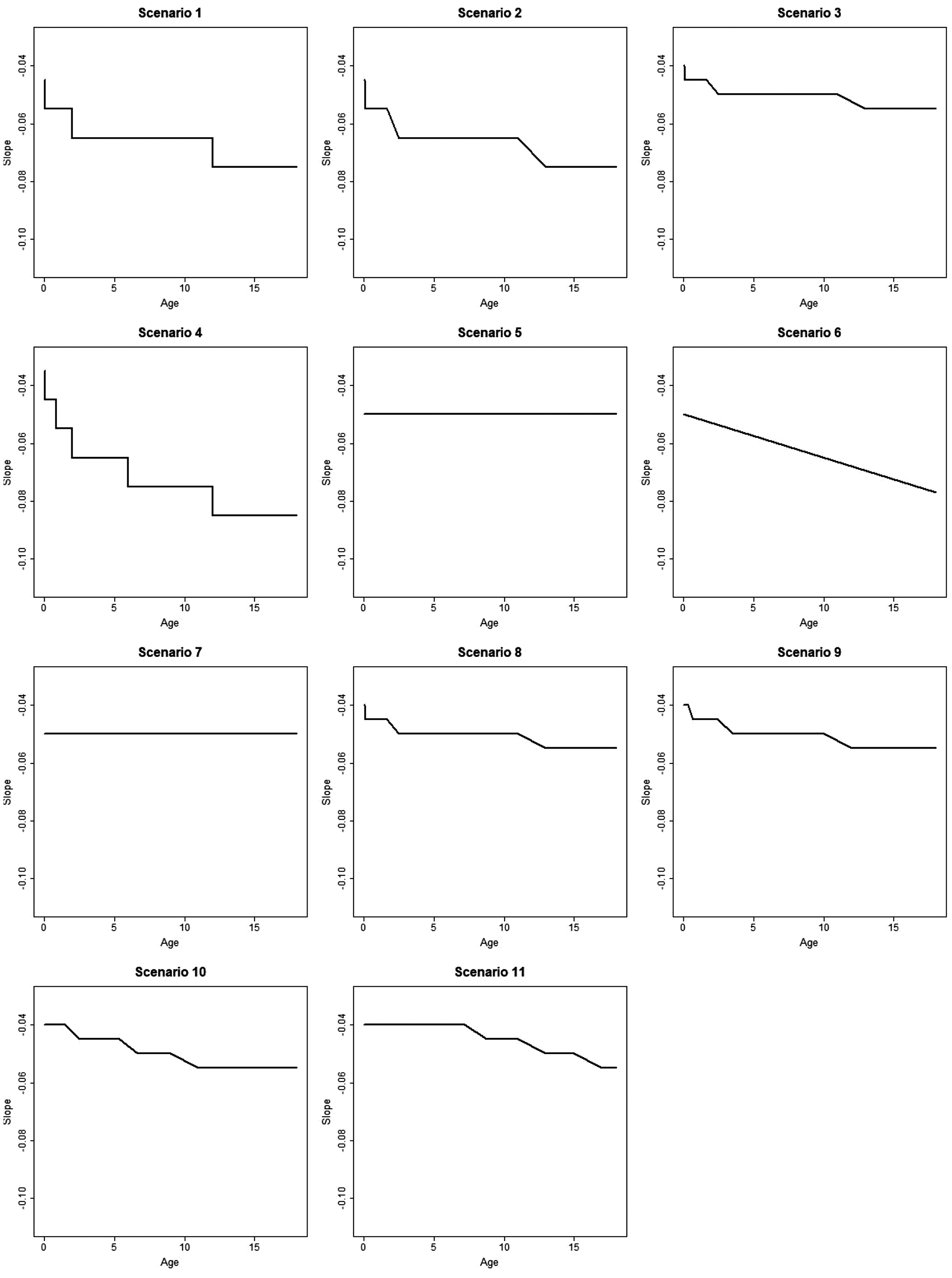
Plot showing how the slope of E–R model changes with age in simulation scenarios 1–11.
We measure exposure by Cmin. Following Wadsworth et al.,
34
we sample
6.1 Evaluating different approaches to modelling the E–R relationship
We use the following measures to compare the modelling approaches. Define
Let
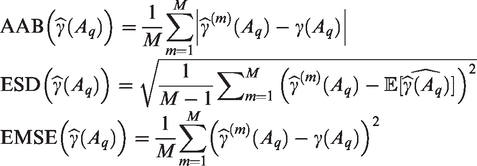
Similarly, let Yqj denote the response at age, Aq, and exposure,
Let
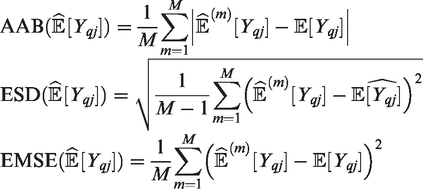
These evaluations produce Q × J matrices of values for AAB, ESD and EMSE. For each Cj, for
6.2 Measuring the accuracy of dosing rules
Following the algorithm of Section 5, we find dosing rules comprising
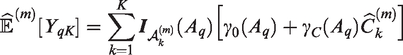
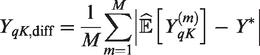
This measure can be interpreted as the accuracy of the K-group optimal dosing rule at age Aq. As with Section 6.1, we calculate the integral of
7 Results
Figures 3 to 5 plot the integrated absolute bias and integrated empirical SD of E–R model parameter estimators for each modelling approach in each simulation scenario. For estimates obtained fitting Bayesian penalised B-splines, bootstrapped PALM trees, a single PALM tree and the linear model with categorical age covariate, Supplementary Tables S2 to S5, in Supplementary Appendix C, present the integrated AAB, empirical SD (as shown in Figures 3 to 5) and empirical MSE (not included in the paper) of the estimated intercepts, slopes and expected response.
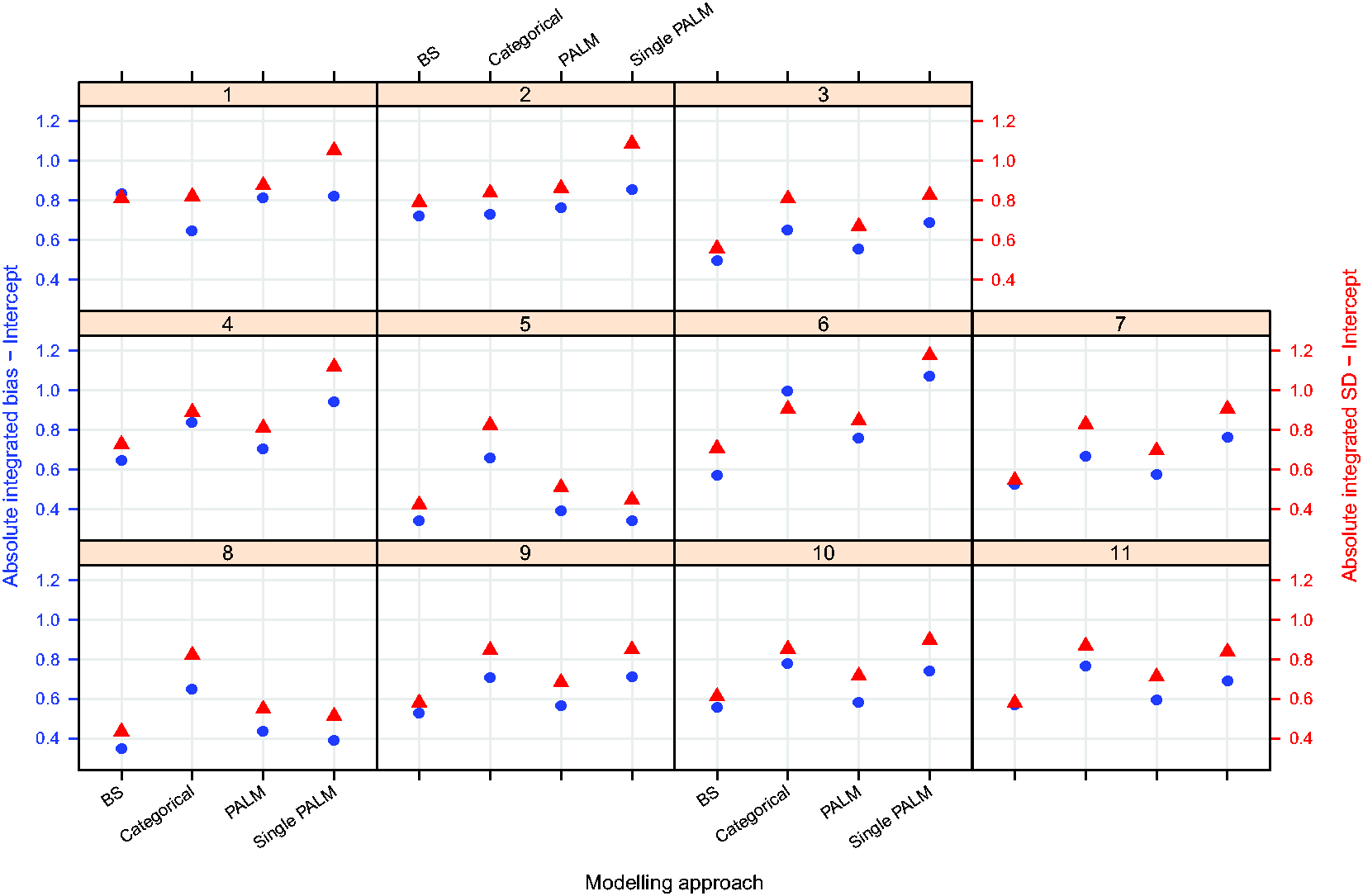
Integrated absolute bias (blue circles) and integrated empirical SD (red triangles) for the E–R model intercept. On the horizontal axis, ‘BS’ refers to the Bayesian penalised B-splines approach, ‘Categorical’ the linear model adjusted for a categorical age covariate, and ‘PALM’ and ‘singlePALM’ label the bootstrapped PALM tree approach and single PALM tree, respectively.
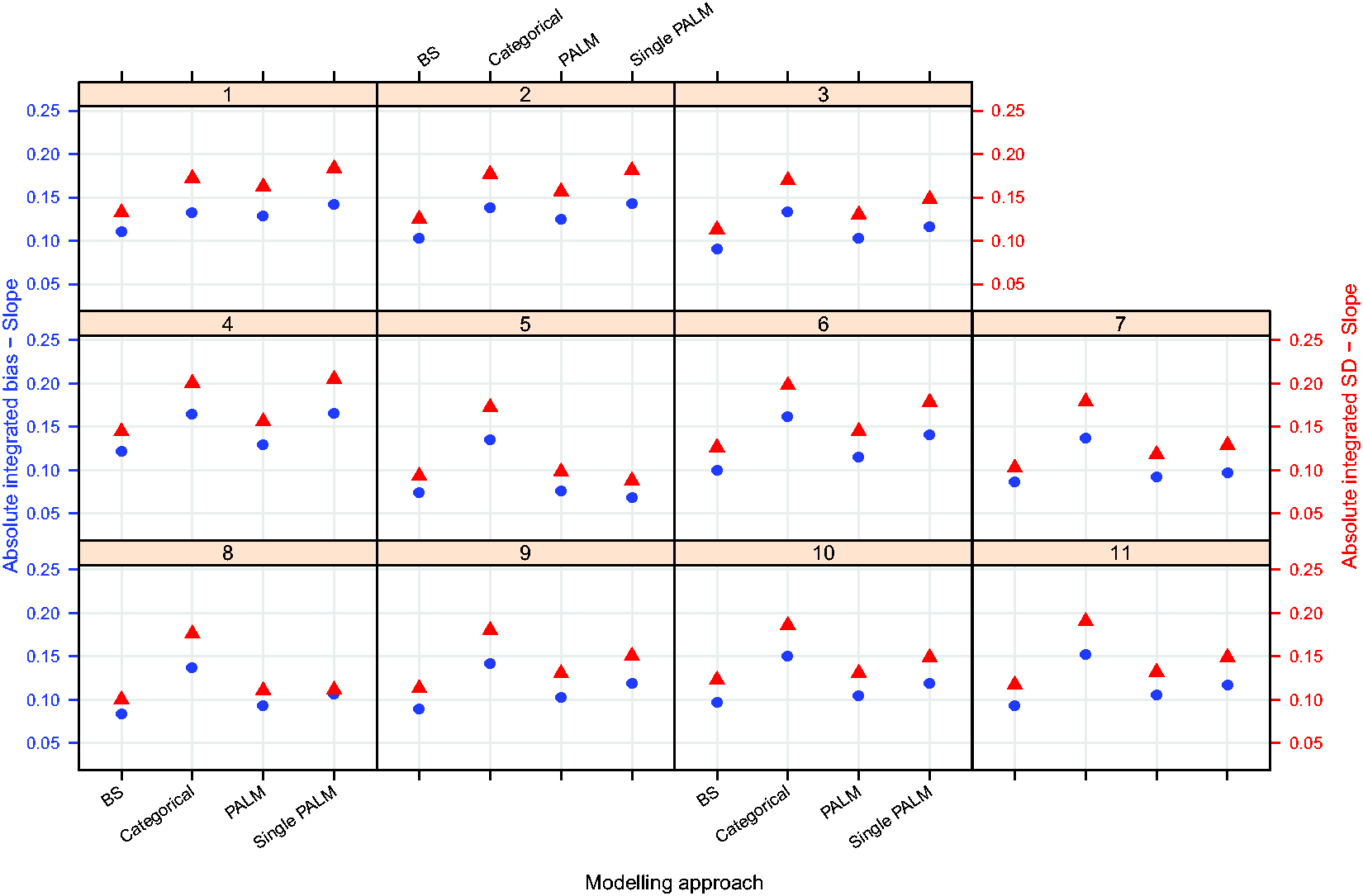
Integrated absolute bias (blue circles) and integrated empirical SD (red triangles) for the slope of the E–R model. On the horizontal axis, ‘BS’ refers to the Bayesian penalised B-splines approach, ‘Categorical’ the linear model adjusting for a categorical age covariate, and ‘PALM’ and ‘singlePALM’ label the bootstrapped PALM tree approach and single PALM tree, respectively.
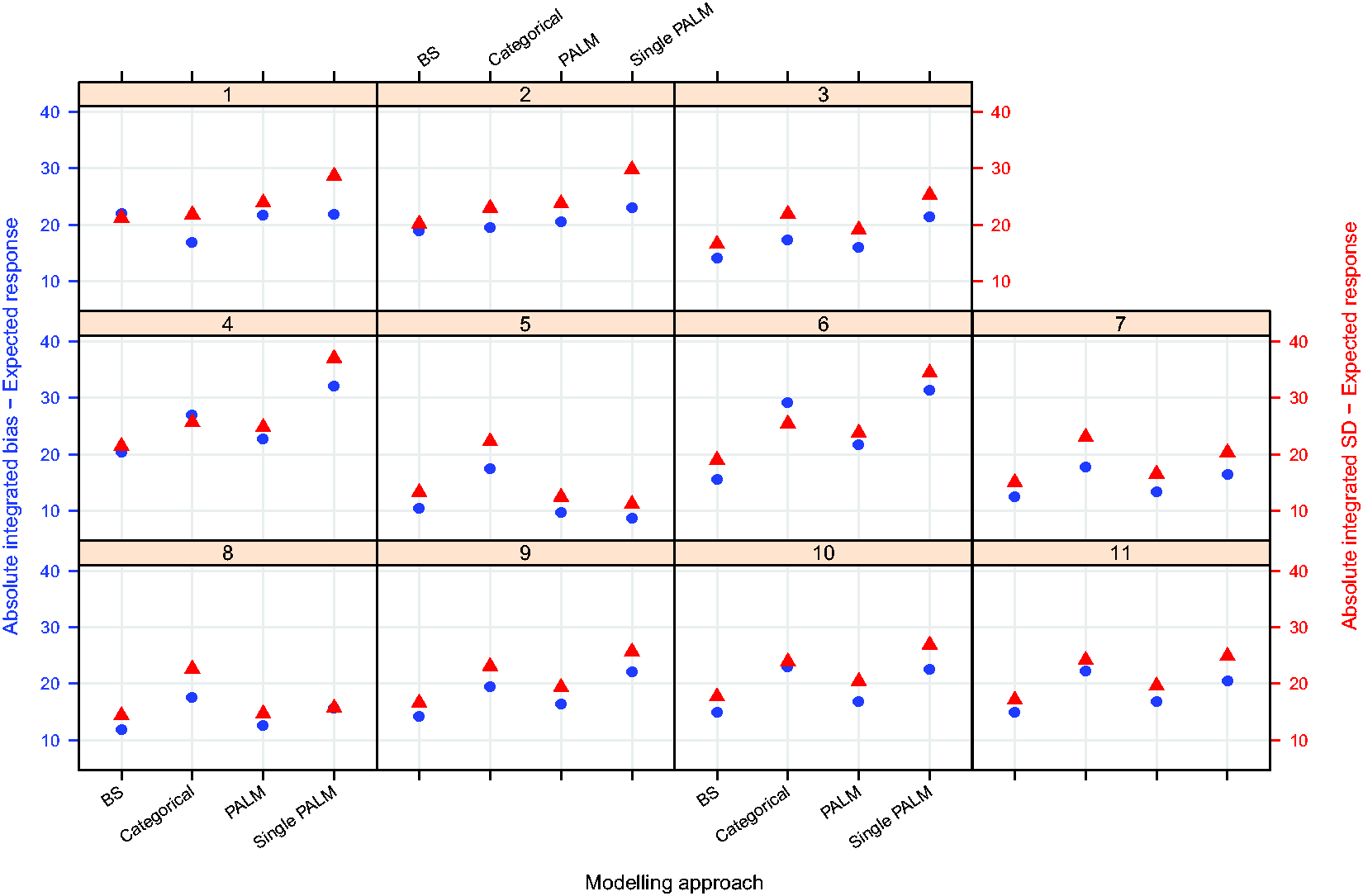
Integrated absolute bias (blue circles) and integrated empirical SD (red triangles) for the expected response. On the horizontal axis, ‘BS’ refers to the Bayesian penalised B-splines approach, ‘Categorical’ the linear model adjusting for a categorical age covariate, and ‘PALM’ and ‘singlePALM’ label the bootstrapped PALM tree approach and single PALM tree, respectively.
Comparing different modelling approaches within a scenario, Figures 3 to 5 suggest that, in general, estimates of the functional relationship between the E–R model intercept and slope parameters obtained via Bayesian penalised B-splines are more accurate than estimates obtained using bootstrapped PALM trees. The single PALM tree fit is outperformed by the bootstrapped PALM tree approach in terms of both integrated absolute bias and empirical SD across most scenarios and both parameters, suggesting that bootstrapping is a refinement to the single PALM tree approach. As would be expected, the categorical covariate fit performs best in terms of accuracy and precision in scenario 1, where age groups are most distinct and follow the categories suggested by the ICH E11 guidance, excluding pre-term newborns.
Figure 6 compares the performance of dosing rules minimising GK under different values of K, derived from E–R models fitted using different modelling approaches. As the linear model adjusting for a categorical age covariate has fixed age groups and the single PALM tree approach estimates specific age groupings, results for optimised dosing rules are only presented for the Bayesian penalised B-splines and bootstrapped PALM tree approaches. Figure 6 shows that overall both Bayesian penalised B-splines and bootstrapped PALM trees define K-group dosing rules with a similar performance in terms of getting the expected response close to the target response under the simulation model. In most scenarios, there comes a point at which there is little to be gained in terms of accuracy by refining the dosing rule further by allowing for additional age groups. As K increases, typically either the true expected response (under the simulation model and implied by the estimated dosing rule) better matches the target response or differences between the performances of the K-group dosing rules for ether modelling approach diminish.
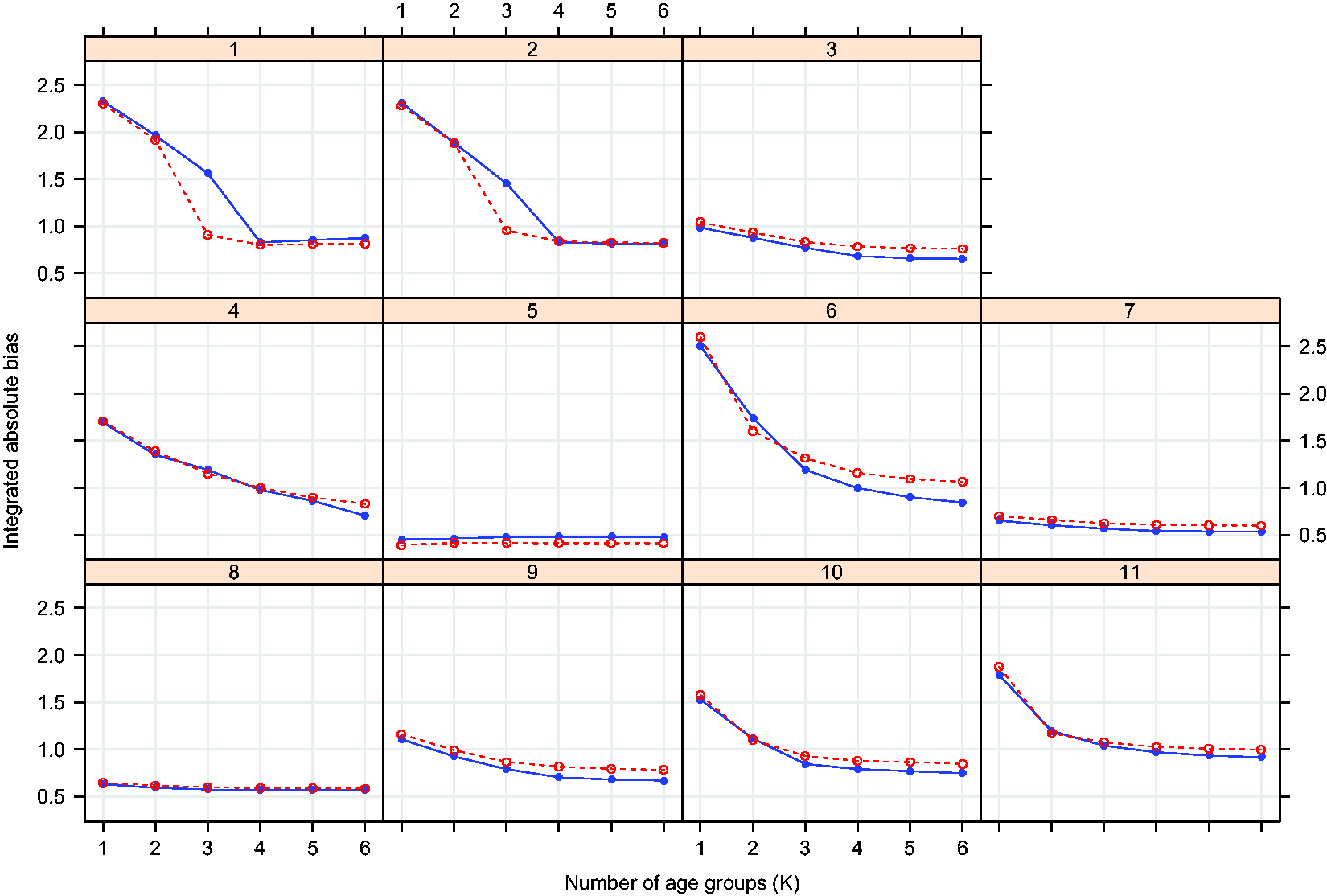
Integrated absolute difference between the target response and true expected response when children are dosed according to the K group optimal dosing rule. Results are shown for dosing rules obtained modelling the E–R relationship using Bayesian penalised B-splines (solid blue line) and bootstrapped PALM trees (dashed red line).
Figure 7 shows the percentage of simulations where the global optimum dosing rule comprises
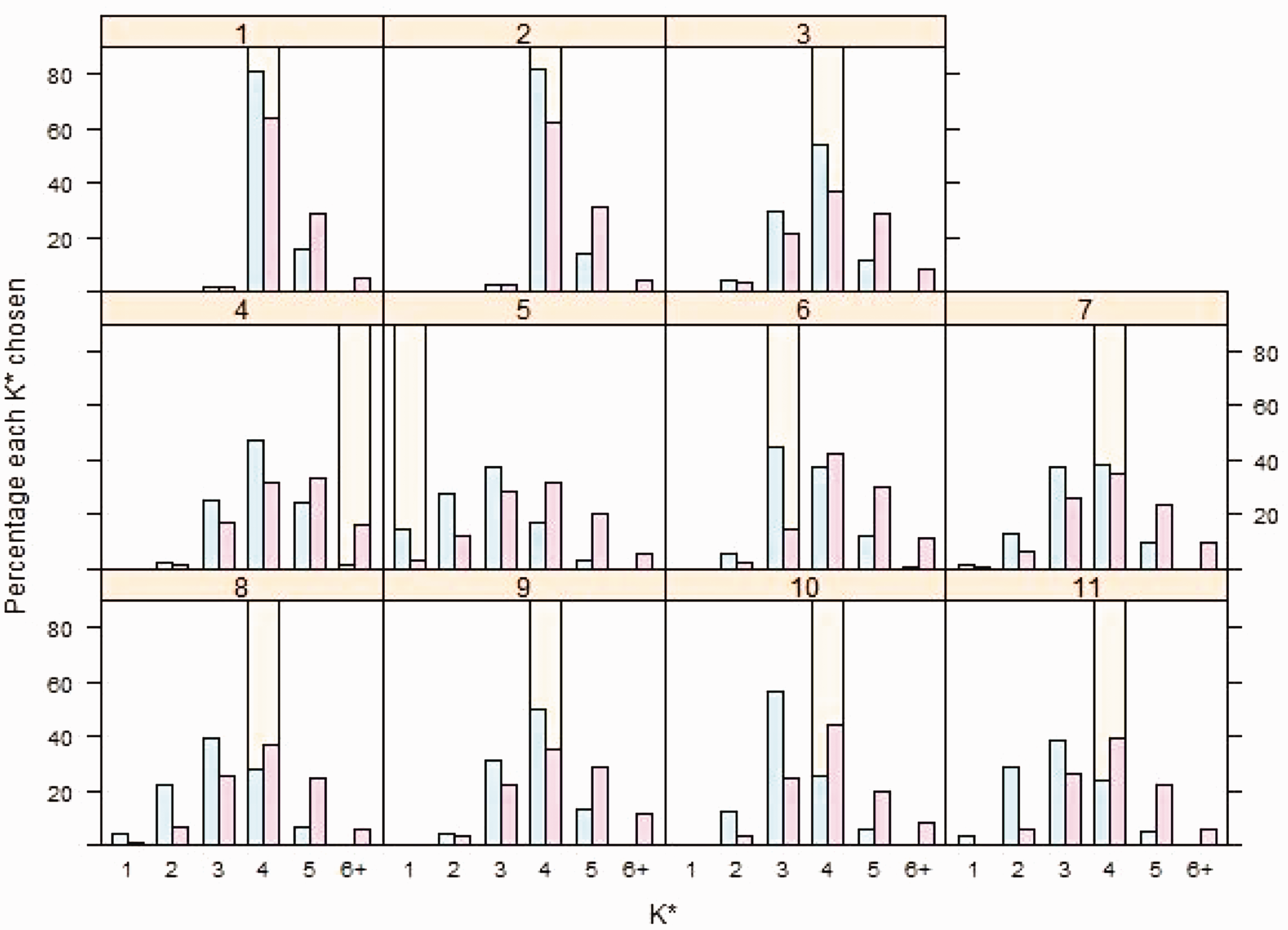
Percentage of 1000 simulations in which
Focusing on Bayesian penalised B-splines, we see from Figure 7 that in scenario 1, where larger differences are present in the underlying E–R model parameters, the large majority (81.6%) of simulated data sets would lead to the investigator selecting a global optimum dosing rule with
Similar patterns are seen for the bootstrapped PALM trees approach in Figure 7. It seems that both bootstrapped PALM trees and the Bayesian penalised B-splines approach are capable of identification of dosing rules with multiple age groups when differences in the underlying E–R relationships across age groups are large, but fewer are identified as differences diminish. For the single PALM tree fit, for scenarios where larger differences are present in the underlying E–R model parameters, as in scenarios 1 and 2, a single PALM tree often identifies dosing rules with four groups; 96.9% and 94.6% would choose four groups, respectively. In not one scenario did a single PALM tree select a dosing rule with
8 Extension to Emax model
We consider a simulated example informed by the data presented in Marshall and Kearns,
37
who modelled the relationship between cyclosporine concentration and in vitro inhibitory effect on peripheral blood monocyte (PBM) proliferation as a sigmoid Emax curve (2). We simulate responses for 41 subjects assigned to one of four age groups: 10 infants (0-1 year); 12 children (1-4 years); 9 pre-adolescents (4-12 years); and 10 adults (12-18 years). Data are generated such that for each of the following concentrations of cyclosporine (6.25; 12.5; 25; 50; 100; 250; 500; 1000 and 5000 ng/mL) a patient was recruited from each age group and the remaining patients in each age group (one infant; three children; one adult) were randomly assigned a concentration from this set. Within an age group, patients’ ages are assumed to follow a uniform distribution. In a deviation from Marshall and Kearns,
37
patient responses are simulated according to a hyperbolic Emax model (setting
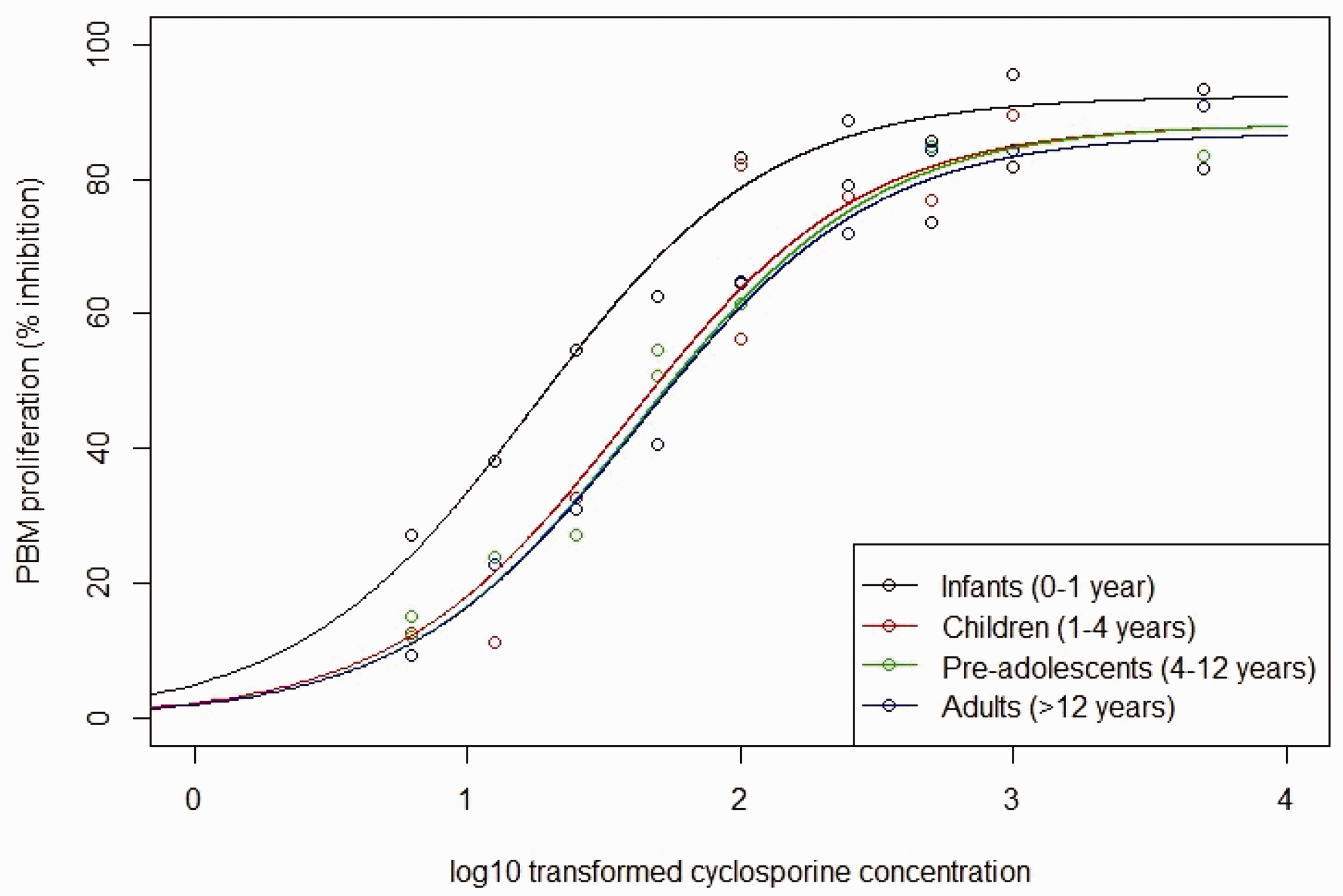
Fitted curves of the relationship between log base-10 transformed cyclosporine concentrations and PBM proliferation based on frequentist two-parameter Emax model fit for each of the four age groups considered. Fitted curves are the solid lines and the points are simulated data. (a) Emax. (b) EC50.
8.1 Bayesian penalised B-splines
We implement the Bayesian penalised B-splines model by running three Markov chains using a thinning rate of 3 and 9000 iterations, 4500 of which are discarded as burn-in samples. We adopt the first-order random walk prior defined in Section 4.3 for the penalisation. We found a great deal of sensitivity, in terms of convergence, to the choice of prior for the standard deviation parameters of the random walk priors on the B-spline coefficients of the Emax and EC50 parameters. This sensitivity was found when using the Inverse-Gamma priors as used in Section 6. We would advise caution and appropriate checks to ensure posterior results are reliable. One should check a priori the plausible range of values for these standard deviations, which would depend on the magnitude of the Emax and EC50 parameters. Gamma
Figure 9 shows the fitted Bayesian penalised B-spline for the Emax and EC50 parameters over age, showing the median, 2.5th and 97.5th quantiles. The fitted B-splines for both the EC50 and Emax parameters seem to follow closely to the true underlying parameter values and, as can be seen from Figure 10(a), the underlying E–R relationships are accurately estimated. Figure 10(a) plots fitted expected response against concentration in each of the four age groups. The fitted expected response is calculated by setting the Emax and EC50 to values obtained by evaluating the Emax and EC50 fitted B-splines at the mid-points of each age group.
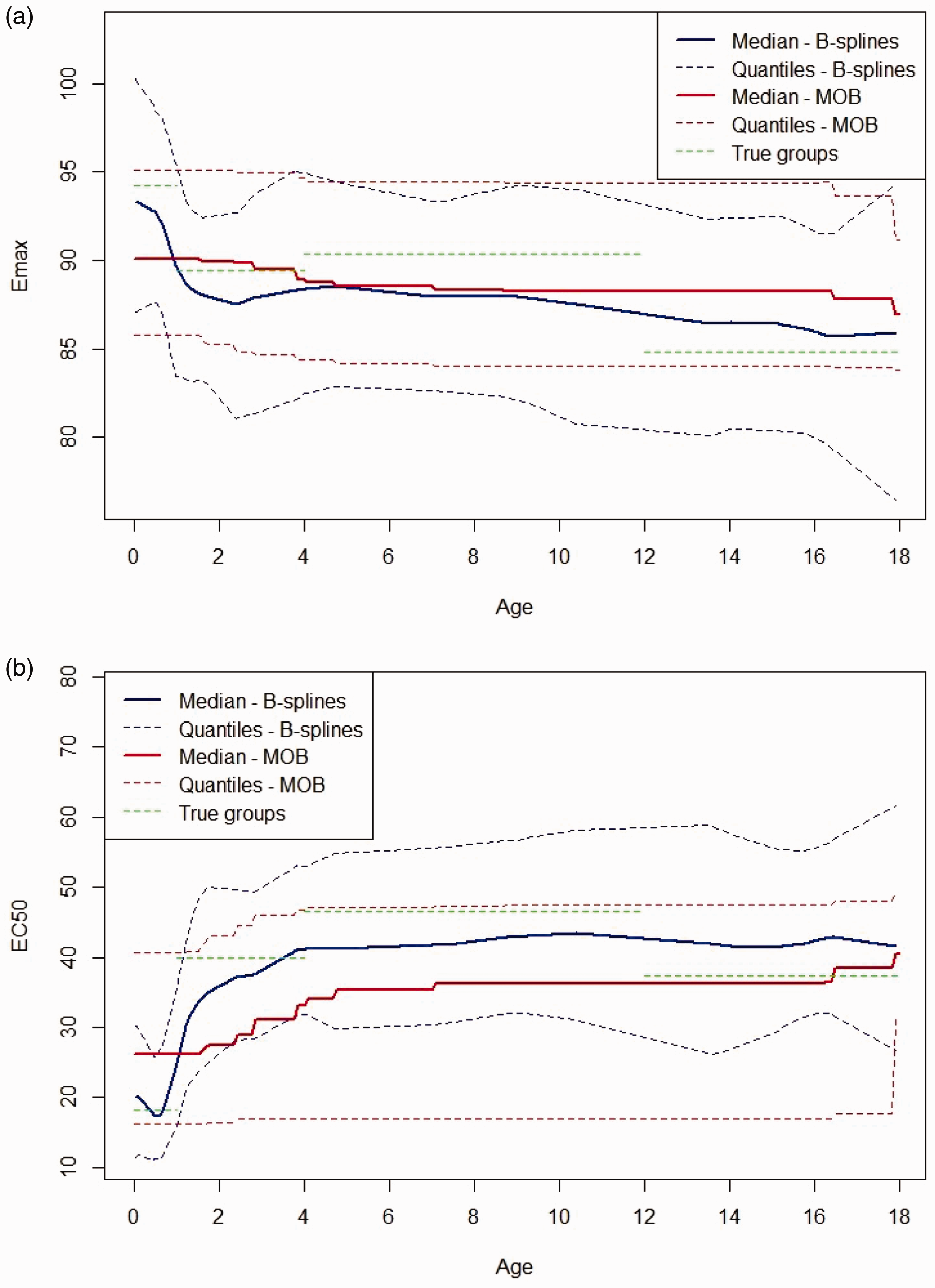
Plots of the Bayesian penalised B-spline and bootstrapped MOB fits of (a) the Emax parameter and (b) the EC50 parameter. The median of each parameter, with 2.5th and 97.5th quantiles, over the 1000 simulated bootstrap samples and true parameter values reported by Marshall and Kearns 37 given by the green dotted lines are also shown. (a) B-splines. (b) MOB. MOB: model-based recursive partitioning.
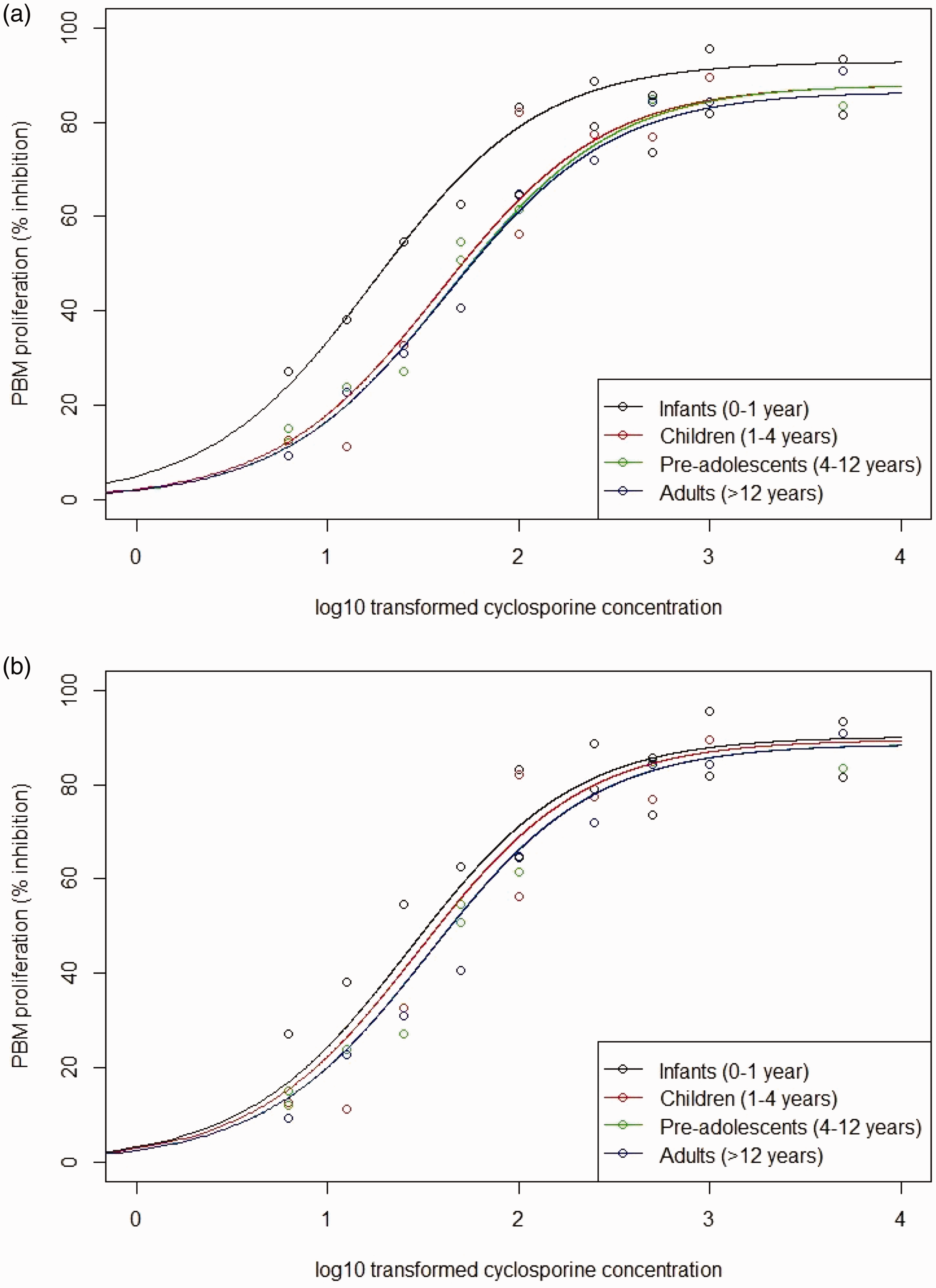
Fitted relationships between log base-10 transformed cyclosporine concentrations and PBM proliferation based on parameter estimates for the four age groups obtained with (a) the Bayesian penalised B-spline approach and (b) the bootstrapped MOB approach.
8.2 Bootstrapped MOB
To implement the bootstrapped MOB approach, we used the ‘mob’ function in R with a two-parameter Emax model. Otherwise, the approach proceeds exactly as the bootstrapped PALM trees approach described in Section 4.2. To incorporate a two-parameter Emax model in the ‘mob’ function, we built on code provided by Thomas et al., 14 using the ‘nls’ function in R 26 to specify the two-parameter Emax model.
Figure 9 shows the fitted bootstrapped MOB for the Emax and EC50 parameters over age, showing the median, 2.5th and 97.5th quantiles over the bootstrapped samples. The fitted Emax and EC50 parameters do change with age. However, they are both quite far from the true underlying values. When looking at Figure 10(b), we see that the model still fits fairly well to the general shape of the data. However, Figure 10(b) highlights that there is worse separation between the fitted E–R curves for different age groups across the whole concentration range when using the bootstrapped MOB approach as compared with the Bayesian penalised B-splines.
8.3 Deriving dosing rules
Following the procedure to derive optimal dosing rules described in Section 5, Figure 11 provides a plot of the objective function values for rules based on both the Bayesian penalised B-splines and bootstrapped MOB approaches. Overall, the bootstrapped MOB approach achieves lower objective function values. For both approaches, two age groups would almost certainly be recommended by visual inspection.
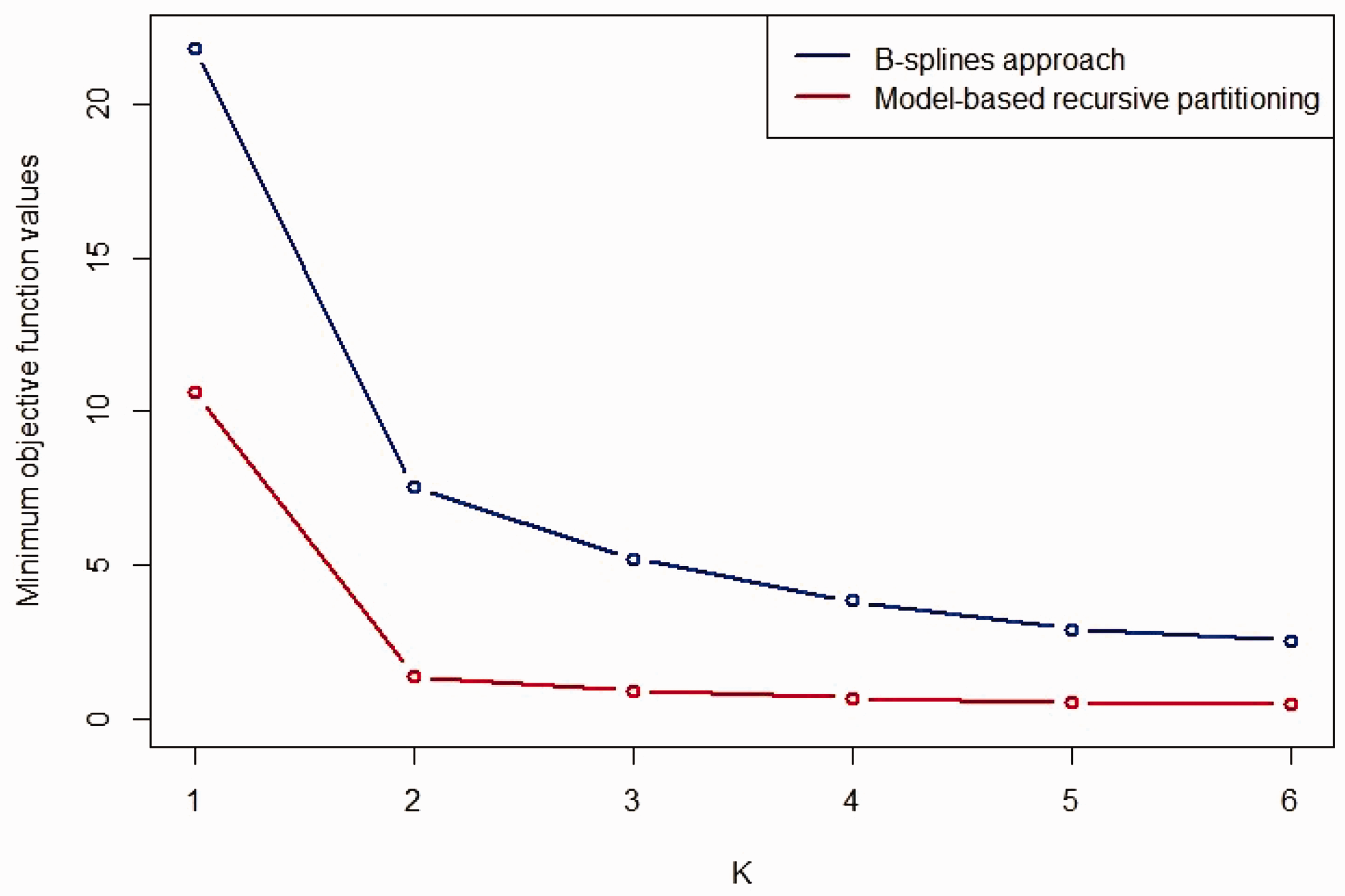
Plot of the objective function values from the optimisation procedure used to identify age groups for the Bayesian penalised B-splines approach (blue line) and bootstrapped MOB (red line).
For two age groups, the optimal age groups defining the bootstrapped MOB dosing rule would be 0 to 3.33 years and 3.33 to 18 years, with target exposures of 191.95 and 294.87, respectively. The optimal age groups defining the Bayesian penalised B-splines dosing rule would be 0 to 0.84 years and 0.84 to 18 years, with target exposures of 110.36 and 446.04, respectively. It is interesting to note how different the dosing rules are for these two methods: the bootstrapped MOB rule stipulates a wider youngest age group, with larger target exposure levels than the Bayesian penalised B-splines rule. However, overall the bootstrapped MOB dosing rule has a lower maximum target exposure than the Bayesian penalised B-splines dosing rule. This seems to be indicative of the larger differences between the age group-specific E–R relationships found using the Bayesian penalised B-splines approach.
9 Discussion
In this paper, we have considered several approaches to estimating if and how E–R model parameters change with age in order to determine practical dosing rules for distinct paediatric age groups. Our approaches concentrate on the relationship between exposure and response, deriving target exposures for age groups. These target exposures can then be used to identify dosing rules based on a separate relationship between dose and exposure. We do not develop PK models relating dose and exposure in this paper, although many methods exist to do this. 40 In other therapeutic areas, non-monotonic changes in E–R model parameters over some age intervals may be plausible. Evaluating the performance of our methods in these scenarios is outside the scope of this paper, but is something that could be investigated in future research.
We derive the target exposures for each age group by taking the age group mid-point and finding the exposure level at which the expected response would be equal to the target response. In reality, this may not actually be the optimal exposure level over the whole age group. Rather than using the exposure appropriate for the age group midpoint, an alternative approach for deriving a more accurate target exposure would be the following: within an age group, target the single exposure level which minimises the total absolute difference between the expected response associated with the target exposure and the target response, integrating over the age group. This approach is computationally more demanding making it unsuitable for use in our simulation study, but can be quickly implemented for one data set in practice.
Results of our simulations with linear E–R models suggest that the Bayesian penalised B-splines and bootstrapped PALM tree approaches perform similarly in terms of estimating changes in E–R model parameters over age, though the integrated absolute bias and empirical SD is consistently lower in the Bayesian penalised B-splines approach. Plots of the absolute difference between the true expected response implied by proposed target exposures and the target response also suggest that for most scenarios both approaches perform similarly, though in some scenarios Bayesian penalised B-splines perform better than bootstrapped PALM trees, and vice versa. In fact, the Bayesian penalised B-splines approach appears to outperform all other approaches in most scenarios; only the approach using categorical covariates sometimes has lower integrated absolute bias, and even then, only in scenarios where the true underlying E–R models contain four age groups matching ICH E11 guidance (as is assumed in the categorical covariates approach).
Supplemental Material
SMM903751 Supplemental Material1 - Supplemental material for Exposure–response modelling approaches for determining optimal dosing rules in children
Supplemental material, SMM903751 Supplemental Material1 for Exposure–response modelling approaches for determining optimal dosing rules in children by Ian Wadsworth, Lisa V Hampson, Björn Bornkamp and Thomas Jaki in Statistical Methods in Medical Research
Footnotes
Acknowledgements
The authors are grateful to Dr. Graeme Sills of the University of Liverpool for his advice on realistic simulation scenarios and target responses, and to Marius Thomas for sharing R code to fit MOB with more complex models.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: IW and LVH are grateful to acknowledge funding from the UK Medical Research Council (MR/M013510/1). This work is independent research and Professor Jaki's contribution to it was funded by his Senior Research Fellowship (NIHR-SRF-2015-08-001) supported by the National Institute for Health Research. The views expressed in this publication are those of the authors and not necessarily those of the UK Medical Research Council or the National Institute for Health Research.
Supplemental Material
Supplemental material for this article is available online.
Appendix 1: Simulation scenarios in detail
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.