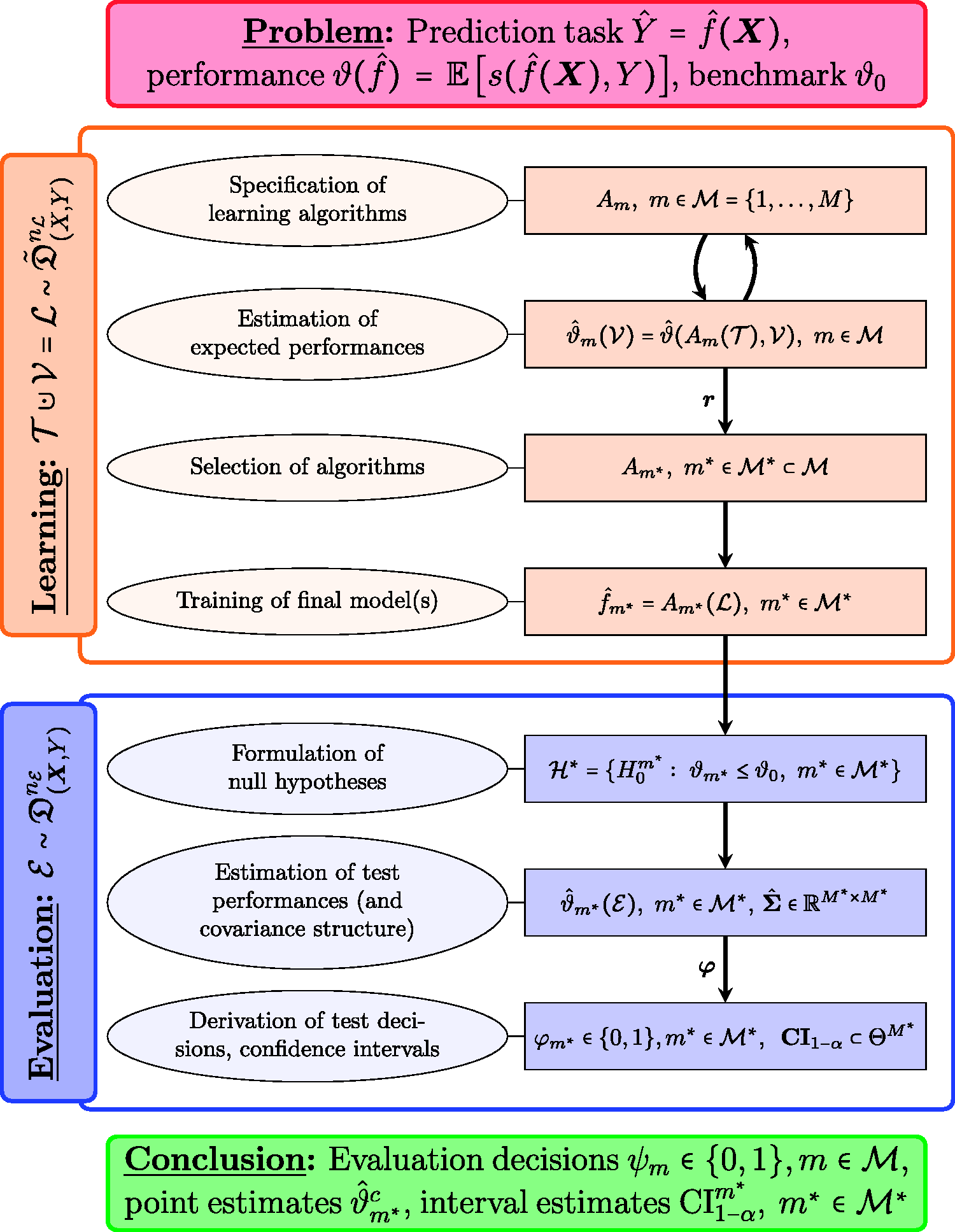
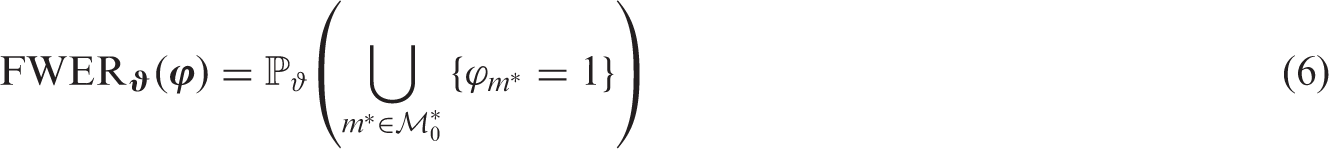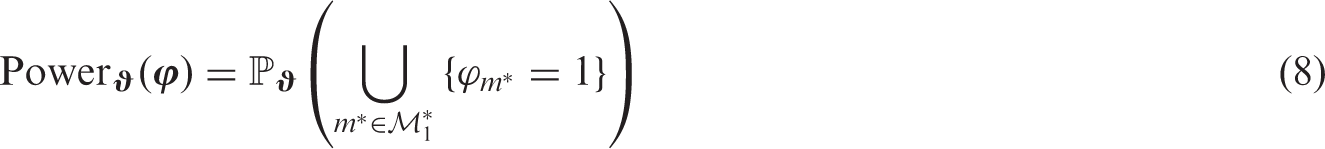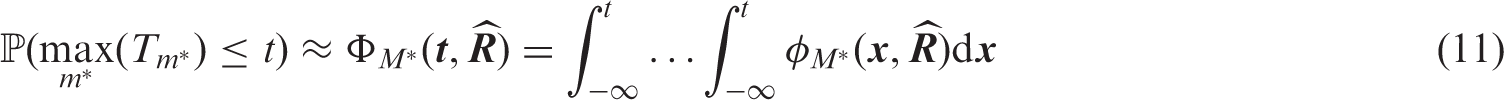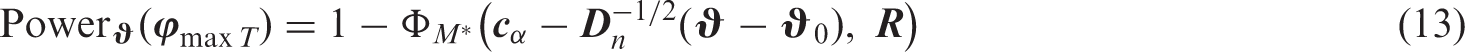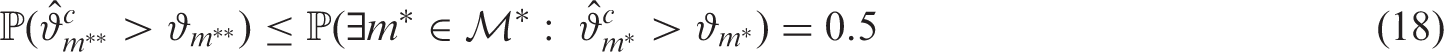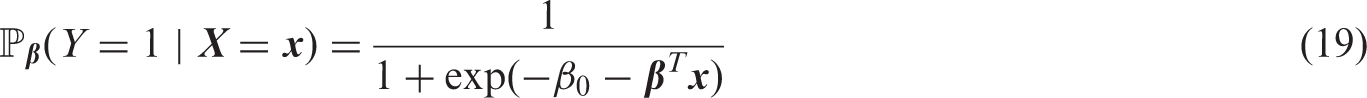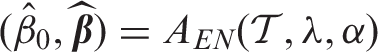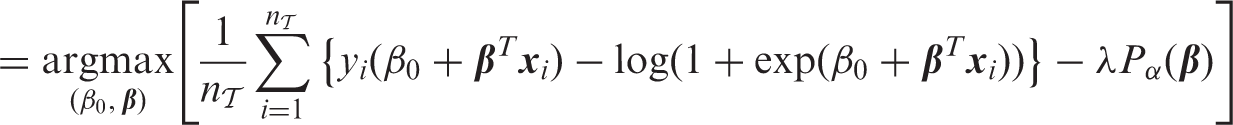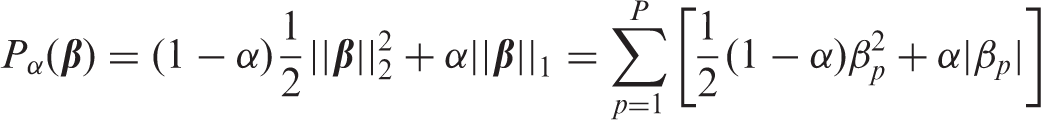Model selection and performance assessment for prediction models are important tasks in machine learning, e.g. for the development of medical diagnosis or prognosis rules based on complex data. A common approach is to select the best model via cross-validation and to evaluate this final model on an independent dataset. In this work, we propose to instead evaluate several models simultaneously. These may result from varied hyperparameters or completely different learning algorithms. Our main goal is to increase the probability to correctly identify a model that performs sufficiently well. In this case, adjusting for multiplicity is necessary in the evaluation stage to avoid an inflation of the family wise error rate. We apply the so-called maxT-approach which is based on the joint distribution of test statistics and suitable to (approximately) control the family-wise error rate for a wide variety of performance measures. We conclude that evaluating only a single final model is suboptimal. Instead, several promising models should be evaluated simultaneously, e.g. all models within one standard error of the best validation model. This strategy has proven to increase the probability to correctly identify a good model as well as the final model performance in extensive simulation studies.
Accurate and reliable diagnosis and prognosis are of utmost importance in clinical practice. New technologies rapidly add a vast variety of data sources that may be used as potential predictors. More often than not, these data are complex and high dimensional. As a result, many efforts are made to provide trustworthy diagnostic tools in the form of prediction models obtained via machine learning techniques.1–4 A recent example is the application of deep learning for tumor classification based on imaging mass spectrometry data.5 A major challenge in this process is the selection of a good model and a reliable assessment of its predictive performance. In this work, we address both questions with particular focus on increasing statistical power for model evaluation while avoiding overoptimistic claims regarding the final model performance.
In the following, we consider the problem of predicting a target variable Y (dependent variable) from a set of features (independent variables). In supervised machine learning, this is achieved by learning a deterministic function which provides a prediction based on the observed features . In practice, this is accomplished by a learning algorithm A which learns from the training data , that is to say . We assume that the observations are sampled i.i.d. from the unknown joint probability distribution from and Y or for short. A typical example is medical diagnosis, e.g. prediction if a patient has a certain disease (Y = 1) or not (Y = 0) based on a collection of clinical measurements , where denotes the number of features. In contrast to this (binary) classification task, the case of is referred to as a regression problem. We refer to standard references for a throughout introduction to fundamental machine learning concepts.6,7
Once a prediction model has been learned from , we consider it as a given, deterministic function. An important task is then the evaluation of its predictive performance. The (generalization) performance of is defined as , where is a deterministic, real-valued function which measures the similarity of prediction and truth y. In some cases, one rather defines a dissimilarity measure (loss) and accordingly the (generalization) error . Typical examples for a similarity and dissimilarity measure are , defining classification accuracy, and , defining the mean squared error (MSE) for a regression problem. In the following, we only refer to ϑ as performance. The question on how to choose s for a specific application is not covered in this work and we refer to the existing literature for a comparison of different (dis)similarity measures.8–12
A natural estimator for ϑ is the empirical performance on a dataset . It is well known that estimation of ϑ on the training data may lead to overly optimistic (upward biased) performance estimates, if the learning algorithm overfits the training data. The usual recommendation is therefore to estimate ϑ on validation data that is independent of .
In practice, usually not only a single but rather multiple learning algorithms Am, , are considered. The algorithms Am may be completely different, e.g. a logistic regression versus a tree-based model, or just differ regarding the choice of a hyperparameter like the strength of a penalty term. Two important aspects of machine learning are how to select a model and estimate its performance . The naive approach of estimating for all models, on the same dataset and then choosing the empirically best model has the severe downside that the estimate for is usually biased upward. This is often referred to as selection-induced bias which is particularly important in case statistical inference regarding the unknown parameter is the ultimate goal, e.g. deciding if for a performance threshold . Statistical inference for model performance in form of test decisions or interval estimates may not always be needed in machine learning applications, but it certainly is in regulated environments like evaluation of diagnostic or prognostic devices and procedures in medical research.13,14
The predominant recommendation in the literature concerning model selection and evaluation is to sample learning data and evaluation data and perform the following steps6,8,15–17
Learning: The learning data is split into training set and validation set . The random splitting may be repeated multiple times leading to techniques like (repeated) K-fold-cross-validation and different bootstrap versions, cf.18 and references therein. In this case, the resulting estimates are averaged to estimate the expected performance of each algorithms Am. The algorithm which yields the highest estimated (expected) performance is selected and used to learn the final model on the whole learning data .
Evaluation: The performance of the final model is assessed on the independent evaluation set . It is frequently emphasized that only a single model shall be evaluated on to enable an unbiased performance estimation. A statistical test may be used to decide if the null hypothesis can be rejected in favor of alternative .
In the machine learning literature, is commonly referred to as the test set. Unfortunately, is also sometimes referred to as validation data. To avoid confusion, we will only use the term evaluation data for and validation data for in the following.
The default learning-evaluation-strategy described above has several advantages. Mainly, it limits the danger of overfitting to the training data and it allows to obtain an unbiased estimate of , the performance of the final model . Furthermore, it is usually not difficult to derive a statistical test for the (one-sided) null hypothesis . The threshold needs to be defined prior to the evaluation study and should reflect the minimal required performance for the application at hand. For diagnostic devices in medical applications, expresses the sacrifice in accuracy one is willing to make compared to the reference standard due to other advantages of the new procedure (e.g. lower invasiveness or costs). It is also possible to estimate of an established comparator on the same evaluation data for a direct comparison. For simplicity, we will however assume that is known in the remainder of the work. Requiring that the null hypothesis needs to be rejected before implementing a new diagnostic tool in clinical practice expresses that we would rather err on the side of caution. That is to say, we would rather not implement a good model (type 2 error) than falsely implementing a bad model (type 1 error). This is in particular true in critical applications where life threatening decisions may be based on the diagnostic results. This approach is established in particular in phase 4 or phase 3 diagnostic accuracy studies, depending on the taxonomy.9,19 Furthermore, several works highlight that (external) evaluation studies for the final model are important but rarely conducted in practice.13,14,20,21
However, it might also be disadvantageous to select only one model for final evaluation, namely if the selected model is far worse than one of its competitors . This is a relevant threat in practice when validation performance estimates are highly variable, e.g. in case of few validation observations. Another obstacle might be non-representative learning samples, i.e. when the data used for model development strongly deviates from the target population in key characteristics. In our experience, this is not unlikely in medical research when the learning data is collected retrospectively from a wide variety of data sources. For instance, the learning data might differ strongly from the target population regarding relevant features like age, sex or comorbidities. The prospective evaluation study, however, is conducted in a cohort fulfilling rigorous inclusion criteria leading to charasteristics closer to the target population. Performance estimates during learning and evaluation phase might hence differ substantially. A similar effect might originate from ongoing advances of sample preparation procedures and biomarker assays over time, i.e. from (past) to (future). Such developments are certainly positive in general, but may nonetheless lower the chances to correctly identify a truly good model with regards to samples from the target distribution based on the non-representative learning data.
As a result, we may thus be in danger to conduct correct inference for an underperforming model. A potential remedy is to evaluate multiple models on the evaluation data with the goal to increase the probability to correctly identify at least one model which is able to outperform the benchmark . This problem can be stated as a multiple test problem specified by the following system of null hypotheses
Inference regarding may be conducted via a multiple test, i.e. a mapping whereby implies that hypothesis is rejected. is expected to control the family wise error rate (FWER), a generalization of the type 1 error for multiple hypothesis tests. In addition, we consider the disjunctive power as an important characteristic of , which is defined as the probability to correctly reject at least one false null hypothesis. When rejecting a single null hypothesis from , we also reject the global null hypothesis
Multiple hypothesis testing is not commonly employed in model evaluation practice although different approaches have been showcased and compared in this context.22 This might stem from the fact that the omnipresent recommendation to completely seperate model selection and evaluation results in a valid and easy-to-use strategy to avoid an overoptimistic performance assessment. To avoid the beforementioned downsides associated with this strategy when the uncertainty regarding model selection is high, we will investigate a particular multiple test in this work. The so-called maxT-approach is based on the joint distribution of the test statistics and assumes (approximate) normality. Technical details are provided in the next section. We note that, even if the validation ranking is correct, we might benefit from evaluating multiple models in terms of statistical power.
In this context it should also be noted that in the usual framework, the properties of the multiple test for , i.e. FWER control and maximization of power, are assessed conditional on the previously conducted model selection. Formally, we assume that this selection is based on a selection rule which is a mapping . That is to say, a subset of models is selected for evaluation based on the learning data, in particular the validation estimates . In order to link model selection and performance assessment, we propose to extend a given selection rule and a multiple test for to a multiple test for the initial hypothesis system
by setting
This means that we evaluate all models negatively, i.e. do not reject the according null hypothesis. With definition (4) we formalize what is implicitly done in practice, namely to ‘spend’ all of the significance level α on the evaluation of the selected model(s) and neglect all other models. We perceive the global null
associated with as much more relevant in practice than associated to . That is, it is more natural to ask if any of the candidate models considered in the first place () outperforms the performance benchmark rather than asking the same question restricted to the few (or single) models which were chosen to be evaluated. This approach enables us to assess the quality of model selection and evaluation together.
Our main research questions can be stated as follows: (1) In which situations is it beneficial to evaluate more than one model? (2) How do different model selection rules perform relative to each other regarding FWER control, statistical power and estimation bias? The remainder of this work is structured as follows: In the second section, a few important concepts from multiple testing theory are defined. In addition, we show that our approach is applicable for a wide variety of performance measures, namely if the empirical performance estimate (sample average) is used. In the third section, we will present the results from numerical experiments we conducted to compare several heuristic model selection rules in conjunction with the maxT-approach with regards to FWER, power and estimation bias. In the fourth section, our evaluation strategy is applied to two real datasets. Finally, in the last section, we will discuss our findings and propose possible extensions to our work.
2 Statistical model and theoretical aspects
We will assume the following scenario: Given a prediction task , a similarity measure s and learning data , the goal is to provide empirical evidence that at least one of the candidate models , can outperform the benchmark . The evaluation is conducted via a selection rule , an evaluation sample and a multiple test . We are interested in properties of the multiple test introduced via equation (4) in terms FWER and power and the bias of the performance estimate(s). As the traditional assumption may be violated in practice, we will also consider the case were is sampled from an altered distribution . Our perception of the learning-evaluation process is depicted in Figure 1, whereby some aspects will be derived in the following. Note that the learning phase may be iterative which is indicated by the double arrow between training and validation. In contrast, the hypotheses and hence the prediction models in the evaluation phase cannot be changed after the data has been observed when the goal is strict control of the type 1 error.
Schematic representation of the machine learning and evaluation process.
2.1 Multiple testing in model evaluation
In the following we introduce some important definitions, mainly adopted from Dickhaus.23 The system of null hypothesis is defined in equation (1). A (non-randomized) multiple test for is a mapping . For the null hypothesis gets rejected if . The family-wise error rate of is defined as
where is defined as the set of indexes such that is true which depends on the true parameter vector ϑ. This probability to make any false positive claim shall be bounded by the significance level . Formally, ϕ is said to control the FWER strongly if
whereby is the parameter space. This is a very important property, as without FWER control or another way of limiting false positive test decision any multiple test is essentially pointless. Regarding type 2 errors (false negative test decisions), the disjunctive (or 1-minimal) power is defined as
whereby . A usual way to choose between different multiple tests for the same problem is to seek maximum power given control of the FWER at a specific significance level, e.g. . There are other power concepts in multiple testing, aiming at the simultaneous rejection of several false hypotheses, which are not considered in this work.24
2.2 The maxT-approach
We will consider one particular multiple test for in this work, namely the so-called maxT-approach which is also called projection method in the literature.23,25
Let be the vector of estimates for the unknown parameter . By we denote the evaluation set size. Let furthermore be an estimate of the covariance matrix with where an is a nondecreasing sequence. In addition, we assume that follows asymptotically a multivariate normal distribution, i.e. . We condense these two assumptions to
to describe the approximate distribution of . We define the test statistics or in vectorized form, whereby . Assumption (9) entails
where is the estimated correlation matrix of . From this, the approximate distribution of the maximum test statistic can be derived as
where is the density function of the -dimensional multivariate normal distribution with mean and covariance matrix . From this we can calculate the simultaneous critical value by solving numerically for . This defines a multiple test for by rejecting if and only if . Calibrating under the global null yields weak control of the FWER. In this case, even strong FWER-control is warranted because the subset pivotality condition (SPC) is met.23 (p.48). One might also construct approximate simultaneous (e.g. lower) confidence intervals with confidence level via
The maxT-approach is a simultaneous test procedure (STP), meaning that all test statistics are compared to the same critical value. Taking into account the correlation between the performance estimates results in an increased rejection rate compared to simpler procedures when the correlations are positive. For instance, the critical value is less than or equal to which corresponds to a Šidák correction with equality in case the test statistics are uncorrelated23 (p.55).
One might ask the question, in which situations it is more efficient to test multiple hypothesis instead of just one. By efficiency we refer to distjunctive power as defined in equation (8). If ϑ and are assumed to be known, can be calculated explicitly. For the power is given as one minus the probability that all observed test statistics are smaller than , i.e.
In case not all null hypotheses are false, the quantities and in equation (13) need to be restricted to the index set of false null hypothesis. This may be used for an approximation of when assuming certain and evaluation sample size . Conversely, the sample size n to achieve a specific power may also be calculated. However, since equation (13) ignores the fact that needs to be estimated, simulations may yield a more precise power estimate.
2.3 Performance estimation
We will now restrict our attention to binary classification, i.e. , as this case is most important for medical diagnosis and consider overall accuracy as the performance measure defined through . From the observed evaluation data the actual relevant similarity matrix
is derived by applying all selected models to the observed feature data . Note that this step is deterministic, given that all prediction rules are deterministic.
The true performances can be estimated as the sample proportions of correct predictions , the column means of . A consistent estimate for the covariance matrix of ϑ is given by , the sample covariance matrix of (divided by n). The entries of can be written as
where is the estimated proportion of common correct predictions of model and . Due to the multivariate central limit theorem,26 the joint distribution of is asymptotically multivariate normal
This result can be generalized to arbitrary similarity functions s as long as the estimator is employed. This justifies assumption (9) and hence the use of the maxT-approach when the empirical performance estimator is used.
2.4 Model selection based on the evaluation data
Since we are no longer limited to evaluate only one model on , the final model selection now needs to be conducted based on the evaluation data. When using the maxT-approach, the most obvious choice is . For classification accuracy, this is equivalent to choosing because is a strictly increasing function. Of course, (non-)rejection of is equivalent to (non-)rejection of the global null hypothesis .
We expect that conducting the final model selection based on the evaluation data will again introduce an upward bias of the estimate . One elegant way to correct for this bias is to calculate the lower bound of a one-sided simultaneous 50% confidence interval as an estimator for . More explicitly, for every selected model we define a corrected point estimate for as
where satisfies . Under the assumption of normality and a known covariance matrix we have
as the event implies . The estimator is therefore (approximately) median-conservative. Equality in equation (18), which corresponds to median-unbiasedness of , follows in the case when all selected models have the same true performance as in this case E1 = E2.
2.5 Transition from to
As stated before, in the context of model selection and evaluation we perceive the hypothesis system as much more relevant than . We thus define a multiple test for by combining a selection rule with a multiple test for to a multiple test for as given in equation (4). Due to this construction, controls the FWER strongly for if strongly controls the FWER for for all . This is given (approximately) in our framework as pointed out in the statistical model section.
In summary, in the presented framework, we obtain corrected point estimates (17), a simultaneous confidence region (12) and test decisions , for the selected models after having conducted the evaluation phase. Additionally, for all models which have not been selected we conclude , i.e. not to reject the null hypothesis , compare Figure 1.
3 Simulation study: model evaluation in practice
The purpose of our numerical experiments is to simulate the complete learning-evaluation process as illustrated in Figure 1 and compare different evaluation strategies which differ with regards to the employed selection rules based on the validation data. The simulation was conducted with R (version 3.4.4) and the batchtools package (version 0.9.8).27,28 The maxT-approach was implemented with help of the mvtnorm package which allows the calculation of the critical value as indicated in equation (11).29 The R code used to conduct the simulation study can be accessed via a public GitHub repository.a In the following, essential characteristics of the simulations are described.
3.1 Setup
First, the joint distribution is specified by means of the general product rule via and . For all simulations, we consider P = 50 features with joint multivariate normal distribution, i.e. where is a equicorrelation matrix with correlation . The conditional distribution of Y given the features is specified by the logit model
defined by the coefficient vector . The intercept β0 is set to zero in all simulations which corresponds to a prevalence of 50% for the event Y = 1 at the mean of the covariates. We mainly considered two different coefficient models for the entries βp of the P-by-1 vector :
a sparse model with only nonzero coefficients ,
a dense model where .
In our numerical experiments, we considered different μ1, μ2, ρ and to adjust the difficulty of the prediction task. In total, different scenarios were implemented, defined by and .
As a variation, the learning data was also sampled from an altered data distribution for the sparse coefficient model. Here, we assumed that but defined through may differ from defined through . For example, we consider the case where some of the active coefficients from are multiplied by a factor in . This way we emulated the relevant scenario that covariate effects are damped or amplified in the learning data compared to the target population.
For the learning phase, we considered penalized logistic regression models from the elastic net (EN) class with varying L1 and L2 penalties.30,31 Training and cross-validation was carried out using the glmnet package (version 2.0–13), which allowed for fast computations.31 The EN algorithm maximizes the penalized conditional log-likelihood
where are tuning parameters and the penalty term is given by
Predictions are obtained by thresholding the predicted probability for the event Y = 1 at 0.5.
For every learning data set , we train M = 100 models by considering and for each α, 20 equidistant values for λ in the interval . Hereby λmin is close to zero and λmax, for which depends on the training data. Details are provided in the glmnet documentation.32 Expected performance estimates for all algorithms Am are obtained via 10-fold cross-validation.
In the following, different heuristic selection rules based on the (cross-)validation performance estimates are defined.
default: evaluate only the best validation model
within 1 SE: evaluate all models with validation performance within one standard error of the best validation model
best 10%: evaluate the top 10% of models based on the validation ranking
no selection: evaluate all initial candidate models
Besides these four rules, we also consider the oracle selection rule defined as the (truly) best model. This rule can of course not be employed in practice but may serve as a benchmark. As the final simulation step, evaluation data is generated and the selected models are evaluated with the maxT-approach. We considered different evaluation sample sizes .
All results given in the following are averaged over all of Nsim = 5000 performed simulation runs per scenario . For estimated proportions (FWER, Power) this implies a standard error of at most . We performed a paired comparison, meaning that evaluation strategies are applied to the same 5000 combinations of learning and evaluation datasets per scenario. For all trained prediction models, the true model performance is ‘calculated’ on a large population data set of size with negligible numerical error.
3.2 Results
3.2.1 Prediction tasks
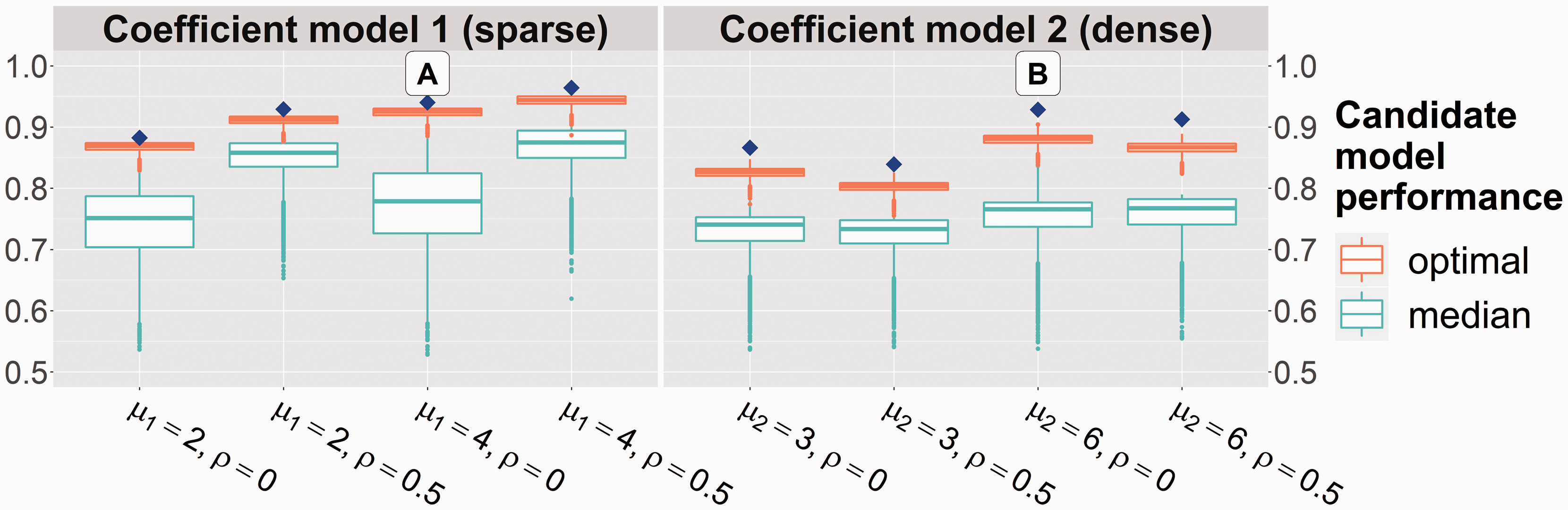
For , Figure 2 visualizes the empirical distribution (over the 5000 simulations) of the optimal performance and the ‘median’ performance , defined as the empirical median of . Additionally, the accuracy of the true (data generating) model is indicated. This can be seen as an illustration of how well the prediction tasks can be learned by the considered elastic net algorithm class for each of the eight learning tasks.
Illustration of the optimal and median performance of the M = 100 candidate models over Nsim = 5000 simulation runs for stratified by prediction task. The diamond symbols indicate the performance of the data generating model.
As expected, performances are increasing in the effect sizes controlled by μ1 and μ2. In the following, we will only present our findings for scenario A and B in detail as highlighted in Figure 2. For the mean optimal performances (over all simulations) are 92.4% and 88.0% for scenario A and B, respectively. Besides a slightly increased mean optimal performance (A: 93.4%, B: 89.6%) when training the models on instead of 200 observations, model selection quality should also be superior in this case, since more validation data is available. Learning a good model for task A is easier with the considered class of algorithms in the sense that the optimal candidate model performance is on average closer to the theoretically achievable performance (A: 94.0%, B: 92.9%).
Note that only the within 1 SE rule selects a varying number of models while is constant for all other selection rules tested. The overall median over all scenarios is 8 with an interquartile range (IQR) of 9. For , the median was 9 () for scenario A and 6 () for scenario B. As is on average close to 10, the results of the within 1 SE and the best 10% rules are quite similar in our simulation study. Consequently, we will only show the results for the within 1 SE rule to streamline the presentation.
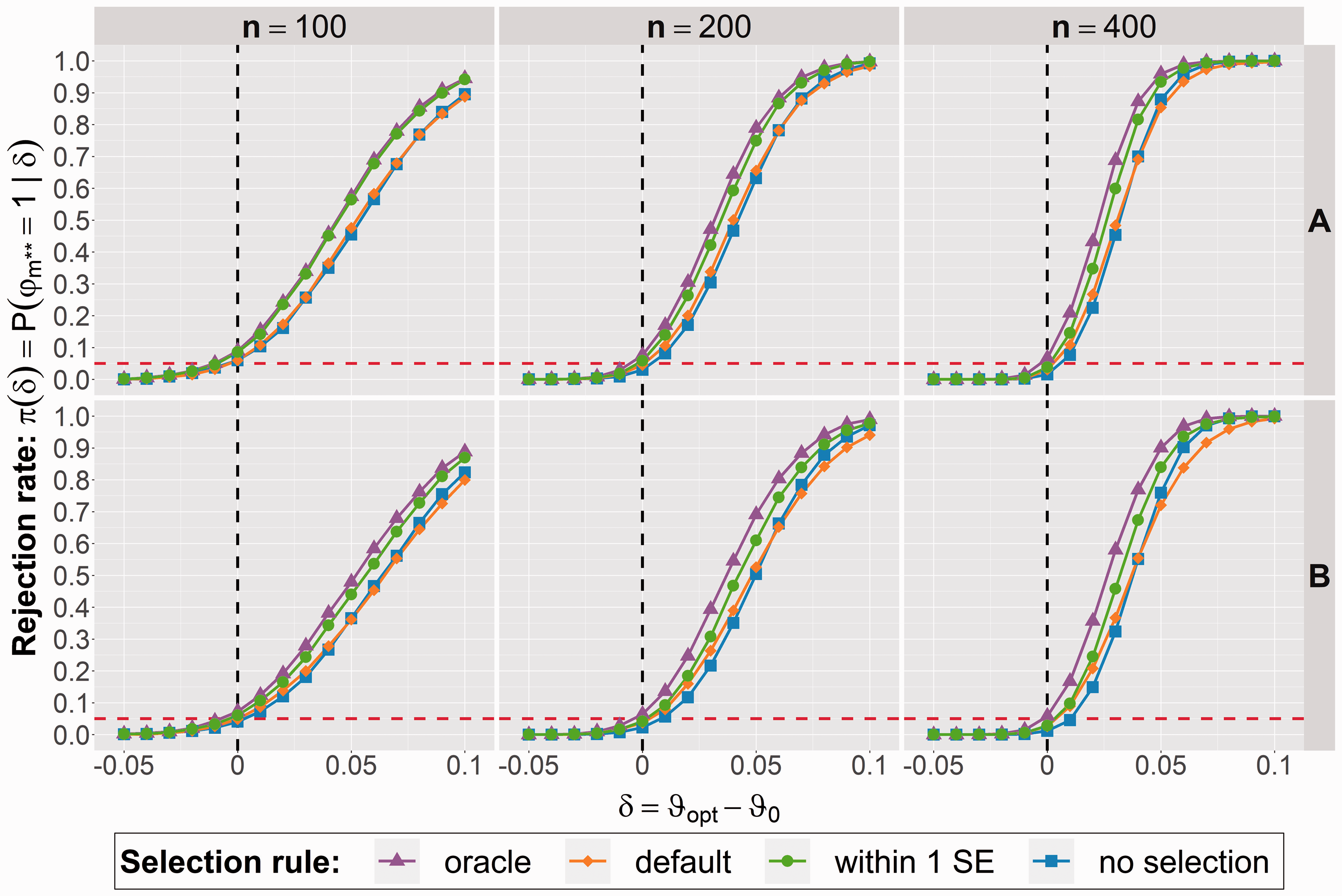
3.2.2 Rejection rate
Figure 3 compares the different evaluation strategies regarding their overall rejection rate, i.e. the probability of a successful evaluation study. Here, the black vertical line represents the scenario , the maximum value of such that all null hypothesis , are still true. As pointed out above, the mean is 92.4% for scenario A and 88.0% for scenario B. The value describes if the global null G is true () or false ().
Rejection rate for the null hypothesis of the final model stratified by scenario (top: A, bottom: B) and evaluation sample size (from left to right: ).
As described earlier we will select as our final model based on the evaluation data. We consider , the rejection rate for , as most important. In practice, the evaluation study is declared successful if and only if . For , a rejection of is always wrong and π coincides with the FWER. The situation is more complex: a rejection of is not automatically correct as we might have for another . We found in separate analyses that the probability for a false rejection is maximal for δ = 0 and monotone decreasing in , as expected. Altogether should be increasing in δ while being bounded by for .
It can be observed that the within 1 SE selection rule uniformly outperforms the default strategy where only the best model from the evaluation stage is selected. The gain in terms of rejection rate is up to 10% in specific situations (depending on and δ). On the other hand, when the candidate model set is not reduced at all based on the validation data (no selection), the rejection rate is commonly lower compared to the default approach. We confirmed through separate analyses that the increased rejection rate is not inflated by false-positive test decisions but rather represents a real power increase.
For lower samples sizes , we observe an increased FWER up to 10% for δ = 0. Note that the default approach can also not control the type 1 error exactly, but the problem is less severe here.
3.2.3 Estimation bias
The price to pay for the increased power is the upward bias of the point estimate of the final model . This can be seen in the upper part of Figure 4, which shows the distribution of the relative deviation stratified by selection method for scenario B. This finding is not surprising, as one of the reasons to evaluate only one model (default approach) was to obtain an unbiased performance estimate for that model. Besides the regular point estimate we also consider the alternative point estimate defined in equation (17). The lower part of Figure 4 shows that the upward bias vanishes indeed due to this correction. On the other hand, when more (all) models are evaluated, we now rather observe a downward bias of the corrected estimate, which is also in line with our expectations as the corrected estimator is median-conservative.
Relative deviation of the naive (top) and corrected (bottom) point estimate compared to the true value of the final model performance for scenario B and different evaluation sample sizes . The diamond symbols indicate the sample means.
3.2.4 Final model performance
We also investigate the true performance of the final chosen model relative to the optimal performance , which is depicted for scenario B in Figure 5. Here the relative performance is shown stratified for selection rule, learning sample size and evaluation sample size . As stated above, the true performance in our simulations is calculated as the sample average over a large population dataset with 100,000 observations.
Distribution of final model performance relative to the optimal performance for learning task B. Results are stratified by evaluation sample size (columns) and learning sample size (rows).
We first note that all selection rules work well in the sense that the relative final performance is close to 100% on average. Interestingly, the expected final model performance when multiple models are evaluated is slightly higher. When more than a single model is evaluated, the expected model performance increases in the number of evaluation observations. This is plausible because the final model is selected based on these observations. When all models are evaluated (no selection rule), the performance is lower compared to the within 1 SE rule.
3.2.5 Learning from non-representative data
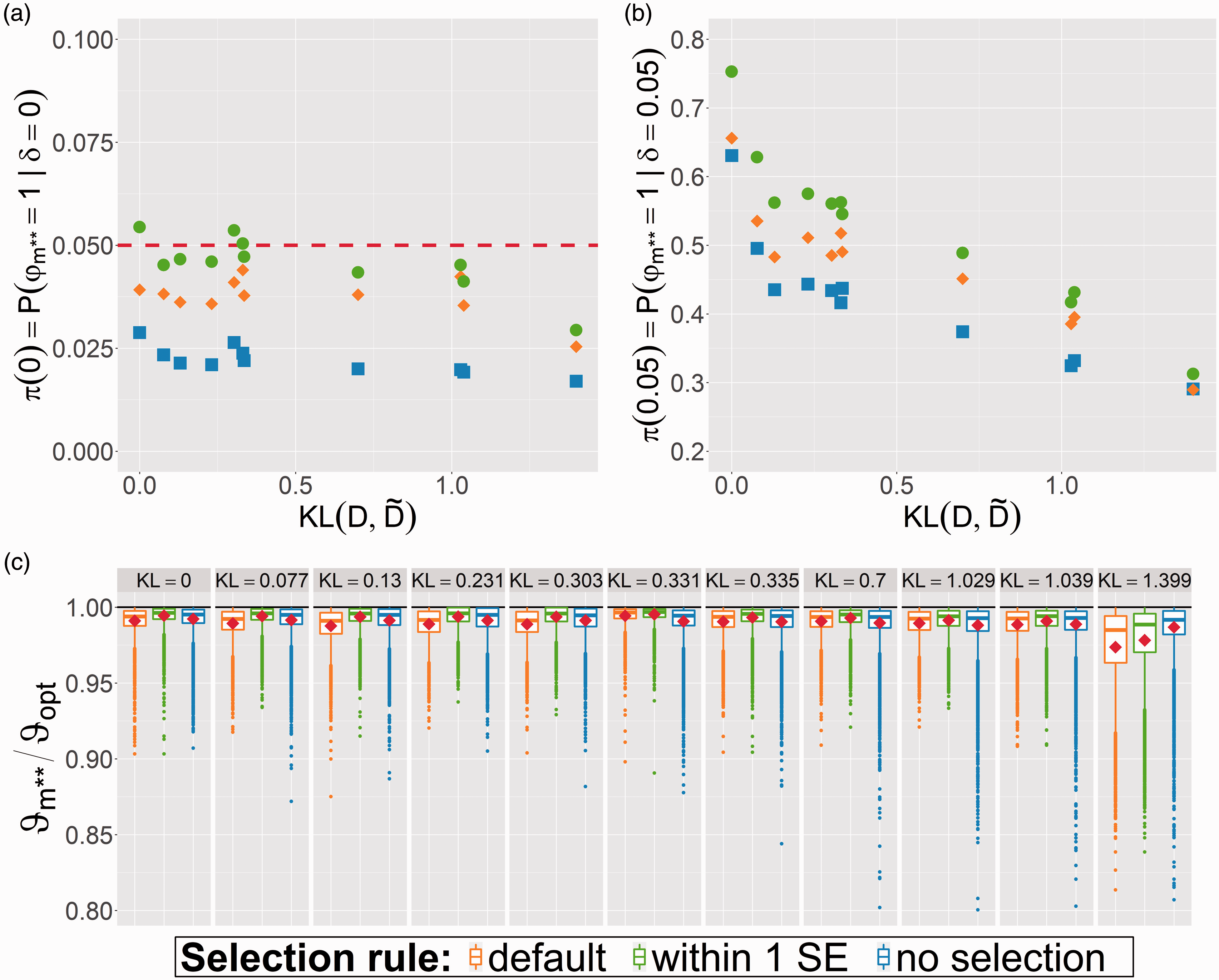
Finally, we consider the case when the learning data is sampled from an altered distribution compared to the target distribution for scenario A (). Figure 6 shows the rejection rate under the global null (Figure 6(a): ) and under the alternative (Figure 6(b): ) where the likelihood to obtain an non-representative sample is measured as , the Kullback-Leibler (KL) divergence from to .26 (p.329). We observe that all evaluation strategies perform worse the larger becomes. Just as in the optimal case the within 1 SE rule clearly outperforms the default approach as well as the no selection strategy. Figure 6(c) shows the distribution of the final model performance. For all cases, except the one with the highest disturbance, the within 1 SE approach yields the highest expected performance .
Properties of selection rules when learning and evaluation population differ (measured via KL divergence from learning distribution to evaluation distribution ) for prediction task A. (a) Rejection rate under global null (). (b) Rejection rate under alternative (). (c) Relative final model performance .
3.2.6 Sensitivity analyses
The results for all other simulated prediction tasks (Figure 2) were similar to the presented results. In particular, the default approach was always outperformed by the within 1 SE selection rule with regards to rejection rate and final model performance. In addition, we repeated our analysis with 5-fold CV instead of 10-fold CV as a basis for the model selection in the learning stage (Nsim = 2000). Despite the slightly higher bias of in this case, results were very similar to the results obtained when employing 10-fold CV.
3.2.7 Different learning algorithms
In our main simulation, all prediction models arise from the same learning algorithm, the elastic net, by variation of two hyperparameters. Another case of practical interest involves the comparison of several different learning algorithms on the same task. To mimic this case, we implemented the following additional simulation.
Instead of 100 elastic net models, 20 models were trained from each of the following five learning algorithms: elastic net, random forests, decision trees, support vector machines and extreme gradient boosting. We used existing implementations of these algorithms from the caret package (and according dependencies), by setting the training method to glmnet, ranger, rpartCost, svmLinearWeights2 and xgbTree, respectively.33 Additional details are provided in the web-based help for the caret package.b
These algorithms depend on two to seven hyperparameters which were sampled randomly according to the default caret implementation in this simulation. We limited this analysis to learning tasks A and B (compare Figure 2) due to the increased computational demand for training algorithms other than the elastic net. In addition, we used a simple hold-out validation rather than cross-validation to further reduce the computatinal burden of this study. Apart from these changes, the setup was exactly as described earlier for the main simulation. Overall, this simulation includes 5000 instances of the learning-evaluation pipeline per scenario .
In summary, the results concerning this sensitivity analysis qualitatively match the main results. The power when employing the within 1 SE rule is strictly greater than for the default approach. This is true for all sample sizes and both learning tasks resulting in graphs highly similar to Figure 3. On the other hand, the type 1 error rate is also slightly increased. In contrast to the main simulation, the type 1 error was controlled at the nominal level α in all cases for both selection rules, even for the smaller evaluation sample sizes. Concerning estimation bias and the expected final model performance, the results were again very similar to those reported in Figures 4 and 5, respectively.
4 Application to real data
Finally, we illustrate our simultaneous model evaluation strategy on real data. For this purpose, we use the Breast Cancer Wisconsin (Diagnostic) Data Setc and the Cardiotocography Data Setd which are both freely accessible at the UCI Machine Learning Repository.34 Details regarding these datasets are given by Street et al.35 and Ayres-de Campos et al.,36 respectively. Both our analyses are briefly described in the following and are fully reproducible as the corresponding R code is publicly accessible.a Our primary goal here is not to come up with a superb prediction model, but rather illustrate how multiple models can be evaluated simultaneously and results shall be interpreted. Similar to our simulation study, we consider M = 100 penalized logistic regression candidate models from the elastic net class for each learning task.30,31 We will employ the within 1 SE selection rule.
4.1 Diagnosis of breast cancer
This dataset contains of 569 observations of 30 numerical features which “are computed from a digitized image of a fine needle aspirate (FNA) of a breast mass. They describe characteristics of the cell nuclei present in the image.”3 Features describe texture, area and spatial structure, among others. Our learning task is to predict breast cancer, which is the given label for 212 out of the 569 available instances. We randomly split the dataset into observations for learning and samples for evaluation.
In the learning phase, the 100 candidate models are compared by means of 10-fold CV. The best model is one with zero L1 penalty and hence all 30 model coefficients (not counting the intercept) are nonzero. It achieves a CV accuracy of 97.2%. Two further models with only 13 and 8 nonzero coefficients fall within one standard error of the best model. Hence we obtain a total of selected models for the evaluation phase.
In the evaluation study, we observe uncorrected performance estimates of for two of the models and 95.8% for the last model. As our usual strategy to simply pick the best model leads to a tie, we decide to favor the more parsimonious model (eight nonzero coefficients) over the saturated model (30 nonzero coefficients). For this final model, we obtain a corrected performance estimate of 95.8% and a lower 95% confidence limit of 93.4% via the maxT-approach; compare equations (17) and (12). If our goal was to reject the null hypothesis of a performance less or equal to 90% with a FWER of 5%, we should do so based on this evidence.
4.2 Prediction of abnormal fetal state
The second dataset contains 2126 fetal cardiotocograms (CTGs). “They were automatically processed and the respective diagnostic features measured. The CTGs were also classified by three expert obstetricians and a consensus classification label assigned to each of them.”4 Our learning task is to predict a suspect or pathologic fetal state (295 + 176 instances) versus a normal state (1655 instances). The 24 features include diverse properties of the fetal heart rate histogram. As with the breast cancer data we employ a 3:1 ratio for the splitting into learning and evaluation data. However, since each observation has an associated measurement date, we learn on the first and evaluate on the last instances, mimicking the real life condition of time delay between the two phases. The date attribute was not used for model devolopment.
In the learning phase, the best cross-validation performance is 93.5% obtained by a rather sparse model with eight nonzero coefficients. In this case, seven additional models with 6 to 23 nonzero coefficients are within one standard error of the best model and hence selected for evaluation. Based on these intermediate results, one may seek to obtain a final model with an accuracy greater than .
In the evaluation study, empirical performances of the selected models range between 72.9% and 79.5%. The performances dropped significantly from learning to evaluation phase, hinting at systematic differences due to the different sampling time periods. Interestingly, the best validation model performs worst among the selected models on the evaluation data. For the best evaluation model, which also has eight nonzero coefficients, we obtain a corrected accuracy estimate of 78.7% and a lower confidence limit of 75.9%. Hence, the null hypothesis cannot be rejected. This example clearly illustrates the advantage of the proposed within 1 SE strategy although unlike in our simulations the ground truth is not known: If we would have used the default selection approach and thus decided on the final model based only on the validation data, the final estimated performance would have been only 72.9%. The lower confidence limit would have been .
5 Discussion
5.1 Conclusions
This work shows that the simultaneous evaluation of multiple predictions is feasible and false positive claims regarding model performances can be controlled. This is achieved via a multiple test that (asymptotically) controls the family wise error rate, i.e. the probability to make at least one false positive test decision. In this work, we applied the maxT-approach as one possibility of such a multiple test. Its main advantage is to explicitly take into account the similarity of models in terms of the correlation between performance estimates. This reduces the necessary adjustment for multiplicity compared to simpler methods like the Šidák correction if the evaluated models give similar predictions. The maxT-approach is applicable in a wide context, most importantly when the empirical performance estimate (sample average) is used. This also applies to performance measures for regression tasks. Other measures may also be used as long their estimators approximately follow a multivariate normal distribution, as it is for instance the case for the (nonparametric) area under the curve (AUC) estimator.37 As we have only conducted simulations regarding classification accuarcy, the operating characteristics of the multiple testing approach (FWER, power, estimation bias) may deviate from our results for other performance measures.
One major advantage of selecting multiple models for evaluation is the higher power, i.e. the increased probability to correctly identify a model that performs sufficiently well. Employing this approach will therefore lead to evaluation studies that are more likely to be successful or, equivalently, need less observations per study to achieve the same power. This is relevant when the sample sizes cannot be too large due to cost constraints or ethical considerations, which is often the case in medical research. Luckily, the main drawback of the procedure, namely the overoptimistic estimation of the final model performance, can be negated by means of a corrected point estimator. This is another major benefit of the maxT-approach and not easily possible for simpler methods like the Šidák correction.
Based on our results, we recommend to select all models for evaluation which are close to the best model based on the validation estimates, e.g. within one standard error. As seen in our numerical experiments, this strategy outperforms the default approach regarding power and also slightly improved the final model performance. This conclusion is still valid in the suboptimal but realistic case when learning and evaluation distributions are not identical but rather differ systematically. Although we could not yet derive precise conditions under which our approach is superior, our results can intuitively be explained as follows. First, any selection rule can be seen as a compromise between the default approach (evaluate only best validation model) and the no selection approach (evaluate all models). In these two extreme cases model, selection is conducted completely in either the validation phase or the evaluation phase. However, when a subset of models is (pre-)selected based on the validation ranking and the final model is selected based on the evaluation data, effectively more data is used for the model selection.
Apart from the power increase, the performance of the final model also improves when employing the within 1 SE selection rule compared to the default approach. Albeit the magnitude of this effect was rather small in our simulations, this performance improvement comes with no additional cost in the sense that the FWER can still be controlled (asymptotically). In this regard, our evaluation strategy can be seen as a way to improve model selection by incorporating the evaluation data without introducing over-optimism.
5.2 Limitations
Our simulation results are meaningful but strictly speaking limited to the considered (true) model performances ϑ and the correlation structure between performance estimates. However, these might also occur when other candidate model types than the elastic net class is considered. The results remained qualitatively the same when considering a more diverse collection of learning algorithms to train the prediction models. The according simulation study was, however, smaller in scope. We plan to extend our numerical experiments regarding several aspects such as the prediction tasks and employed learning algorithms even further in the future.
The only true limitation of the maxT-approach is the loss of exact FWER control for lower evaluation sample sizes due to the asymptotic nature of this procedure. We observed an increased FWER of up to 10% (instead of the targeted ) for low evaluation samples sizes around . The same problem, however, also applies to the default approach where only one model was selected, due to the used normal approximation of the binomial distribution of θhat. This can be seen when comparing the default with the oracle selection rule (Figure 3): the default approach is only closer to the target level because of imperfect model selection. A simple approach to alleviate this problem is to apply a transformation to the performance estimates, e.g. the logit transform and to apply the (multivariate) delta method. This reduced the FWER slightly (by around 2%) in ancillary simulations not shown here in detail. If strict FWER for low evaluation sample sizes is needed, we suggest to replace the maxT-approach by an exact (non-asymptotic) multiple test which is appropriate for the considered performance measure.
We remark that under least favorable parameter configurations, i.e. when all evaluated models have the same true performance equal to the benchmark , the control of the type 1 error will get worse when more models are included. This is, however, also an increasingly unlikely scenario. For the most extreme case when all initial candidtate models are evaluated (no selection rule), we observed a rejection rate below the nominal level (Figure 3) due to considerably different true parameter values (Figure 2).
5.3 Outlook
Although the simultaneous evaluation of multiple prediction models worked great in our simulations, there is no theoretical guarantee to obtain a certain power increase, with the selection rules we employed. This leads to the question of optimal selection rules. For instance, one could explicitly take estimates for performance and correlation structure from the validation data into consideration in order to maximize the expected power. We encourage further research in this direction.
In practice, it may of course be necessary to also consider other factors besides raw predictive performance. In this regard, an appropriate strategy would be to formulate and check suitable side conditions before the evaluation study. For instance, an implausible or overcomplex model might not be considered for evaluation even if the empirical validation performance is high.
A common approach in machine learning is to combine different models into a single ensemble model. Different techniques exist in this regard, e.g. bagging or boosting.6 As they can also be seen as the output of a learning algorithm, ensemble models are technically already covered in our multiple testing framework. Our smaller ancillary simulation also covers boosted trees as an example of such an ensemble technique. An interesting question for future work would be to compare the efficieny in terms of statistical power (and final model performance) of (a) the selection of multiple promising models for evaluation and (b) averaging (weighting) these models to get a single ensemble model which will then be evaluated.
Our work sheds new light on the question how to optimally allocate observations to the training, validation and evaluation datasets. This issue has received some attention in the past.38 The statistical power of the evaluation study was, however, not considered as an important property of the machine learning and evaluation pipeline. As a general guideline, we recommend that a power estimation should precede any evaluation study, see equation (13). In the best case, the evaluation study is conducted prospectively and hence it can be decided (within certain bounds) how many observations need to be acquired. In case the estimated power is low even under ideal conditions (maximum acquirable sample size, optimistic assumptions regarding true performance(s)), we would refrain from conducting a formal evaluation study and consequently from making strong claims about the predictive performance.
For classification tasks, accuracy is seldom used alone as a single performance measure. Instead, at least in medical diagnostic accuracy studies, sensitivity and specificity are defined to be co-primary endpoints. In this case, the statistical inference problem is more complex and there are more options for model selection during validation and evaluation phase which will be compared systematically in the future.
Footnotes
Acknowledgements
We are grateful for the helpful comments provided by the two referees. In addition, we acknowledge the provision of the Breast Cancer Wisconsin (Diagnostic) Data Setc and the Cardiotocography Data Setd at the UCI Machine Learning Repository.34
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This project was funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) – Project number 281474342/GRK2224/1.
Notes
References
1.
SajdaP. Machine learning for detection and diagnosis of disease. Annu Rev Biomed Eng2006; 8: 537–565.
2.
WernickMNYangYBrankovJG, et al.Machine learning in medical imaging. IEEE Signal Process Magazine2010; 27: 25–38.
3.
WangSSummersRM. Machine learning and radiology. Med Image Analys2012; 16: 933–951.
4.
KourouKExarchosTPExarchosKP, et al.Machine learning applications in cancer prognosis and prediction. Computat Struct Biotechnol J2015; 13: 8–17.
5.
BehrmannJEtmannCBoskampT, et al.Deep learning for tumor classification in imaging mass spectrometry. Bioinformatics2017; 34: 1215–1223.
6.
FriedmanJHastieTTibshiraniR. The elements of statistical learning2009; Vol 2New York, NY: Springer series in statistics.
7.
Shalev-ShwartzSBen-DavidS. Understanding machine learning: from theory to algorithms, Cambridge: Cambridge University Press, 2014.
8.
JapkowiczNShahM. Evaluating learning algorithms: a classification perspective, Cambridge: Cambridge University Press, 2011.
9.
PepeMS. The statistical evaluation of medical tests for classification and prediction, Medicine, 2003. Oxford: Oxford University Press, 2004.
10.
SokolovaMLapalmeG. A systematic analysis of performance measures for classification tasks. Inform Process Manage2009; 45: 427–437.
11.
Buja A, Stuetzle W and Shen Y. Loss functions for binary class probability estimation and classification: Structure and applications. Working draft 2005.
12.
FerriCHernández-OralloJModroiuR. An experimental comparison of performance measures for classification. Pattern Recognition Lett2009; 30: 27–38.
13.
BossuytPMReitsmaJBBrunsDE, et al.Stard 2015: an updated list of essential items for reporting diagnostic accuracy studies. BMJ2015; 351: h5527.
14.
CollinsGSReitsmaJBAltmanDG, et al.Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (tripod): the tripod statement. BMC Med2015; 13: 1.
15.
ZhengA. Evaluating machine learning models – a beginner's guide to key concepts and pitfalls, Sebastopol, CA: O'Reilly Media, 2015.
16.
GoodfellowIBengioYCourvilleA, et al.Deep learning2016; Vol 1Cambridge: MIT Press.
17.
GéronA. Hands-on machine learning with Scikit-Learn and TensorFlow: concepts, tools, and techniques to build intelligent systems, Sebastopol, CA: O'Reilly Media, Inc., 2017.
18.
BorraSDi CiaccioA. Measuring the prediction error. a comparison of cross-validation, bootstrap and covariance penalty methods. Computat Stat Data Analys2010; 54: 2976–2989.
19.
KnottnerusJABuntinxF. The evidence base of clinical diagnosis-theory and methods of diagnostic research, Oxford: Blackwell Publishing Ltd, 2008.
20.
AltmanDGVergouweYRoystonP, et al.Prognosis and prognostic research: validating a prognostic model. BMJ2009; 338: b605.
21.
SiontisGCTzoulakiICastaldiPJ, et al.External validation of new risk prediction models is infrequent and reveals worse prognostic discrimination. J Clin Epidemiol2015; 68: 25–34.
22.
Raschka S. Model evaluation, model selection, and algorithm selection in machine learning. arXiv preprint arXiv:1811.12808. 2018 Nov 13.
23.
DickhausT. Simultaneous statistical inference, New York, NY: Springer, 2014.
24.
Porter KE. Statistical power in evaluations that investigate effects on multiple outcomes: A guide for researchers. Journal of Research on Educational Effectiveness 2018; 11: 267--295.
25.
HothornTBretzFWestfallP. Simultaneous inference in general parametric models. Biometric J2008; 50: 346–363.
26.
HeldLBovéDS. Applied statistical inference: likelihood and Bayes, New York, NY: Springer Science & Business Media, 2013.
27.
R Core Team. R: a language and environment for statistical computing, Vienna, Austria: R Foundation for Statistical Computing, 2013.
28.
LangMBischlBSurmannD. batchtools: Tools for r to work on batch systems. J Open Source Software2017, pp. 2: 135.
ZouHHastieT. Regularization and variable selection via the elastic net. J Royal Stat Soc: Ser B (Stat Methodol)2005; 67: 301–320.
31.
FriedmanJHastieTTibshiraniR. Regularization paths for generalized linear models via coordinate descent. J Stat Software2010; 33: 1.
32.
Friedman J, Hastie T and Tibshirani R. Regularization Paths for Generalized Linear Models via Coordinate Descent. Journal of Statistical Software 2009; 33: 1--22.
Dheeru D and Karra Taniskidou E. UCI machine learning repository, http://archive.ics.uci.edu/ml (accessed 31 May 2019).
35.
StreetWNWolbergWHMangasarianOLNuclear feature extraction for breast tumor diagnosis. In: Raj SAcharyaDmitry BGoldgof (eds). Biomedical image processing and biomedical visualization1905; Vol 1905Bellingham, Washington: International Society for Optics and Photonics, pp. 861–871.
36.
Ayres-de CamposDBernardesJGarridoA, et al.Sisporto 2.0: a program for automated analysis of cardiotocograms. J Matern-Fetal Med2000; 9: 311–318.
37.
DeLongERDeLongDMClarke-PearsonDL. Comparing the areas under two or more correlated receiver operating characteristic curves: a nonparametric approach. Biometrics1988; 44: 837–845. .
38.
Crowther PS and Cox RJ. A method for optimal division of data sets for use in neural networks. In: International conference on knowledge-based and intelligent information and engineering systems, Melbourne, VIC, Australia, 14--16 September 2005, pp.1–7.