
Abstract
In several areas of clinical research, it is common for trials to assign different sites of the participants’ bodies to different interventions. For example, a randomized controlled trial comparing surgical techniques for correcting myopia may randomize each eye of a participant to a different operation. Under such bilateral (‘split-body’) interventions, the observations from each participant are correlated. It is challenging to account for these correlations at the meta-analysis level, especially when the outcome is rare. Here, we present a meta-analysis model based on the bivariate binomial distribution. Our model can synthesize studies on patients who received one intervention at one body site, patients who received two interventions at different sites or a mixture of these two groups. The model can analyse studies with zero events in one or both treatment arms and can handle the case of incomplete data reporting. We use simulations to assess the performance of our model and to compare it with the bivariate beta-binomial model. In the case of bilateral interventions, our model performed well and outperformed the bivariate beta-binomial model in all scenarios explored. We illustrate our methods using two previously published meta-analyses from the fields of orthopaedics and ophthalmology. We conclude that our model constitutes a useful new tool for the meta-analysis of binary outcomes in the presence of split-body interventions.
1 Introduction
Correlated outcome data can occur in trials when multiple related outcomes are measured, when a single outcome is measured at multiple time-points or when patients receive more than one intervention. Typical examples of the latter category are the cross-over trials and the within-person randomized trials. 1 For example, outcomes from patients receiving different surgical operations for myopia in each of their eyes or different carpal-tunnel release methods in each of their arms are correlated. We will refer to this kind of interventions as ‘split-body’ or ‘bilateral’ interventions. At the meta-analysis level, disregarding the correlation induced by bilateral interventions and analysing observations as if they belong to different patients may affect the precision of the pooled estimates.2–6
For the case of binary outcomes, if studies with bilateral interventions report the full, ‘cross-classified’ information (number of events by patients and treatments) one can readily account for the correlations. This cross-classified information is, however, usually unavailable to the meta-analysts. If not available, an assumed value of the correlation between the arm-specific effects (e.g. the log-odds) can be imputed and the data can be synthesized using a bivariate normal likelihood.
While this approach might be reasonable for efficacy outcomes, it is problematic for safety outcomes. Safety outcomes are often rare and in this case, the normal approximation performs poorly while the estimation of the between-study variance (heterogeneity) becomes challenging. 7 Moreover, the normal approximation of the log-odds or log risks cannot be readily used in the presence of studies with zero events in one (‘single-zero’ studies) or both arms (‘double-zero’ studies). Such studies are frequently encountered in meta-analyses: in a sample of 500 Cochrane reviews, 30% included at least one single-zero, while 34% of these reviews included at least one meta-analysis with a double-zero study.8,9 In such cases, researchers usually resort to performing a ‘continuity correction’ i.e. they add a factor in each cell of the corresponding two-by-two table. The choice of the factor, however, may heavily affect the meta-analysis estimates10,11 and might lead to paradoxical results. 12 Double-zero studies are typically excluded from meta-analysis. 8
Alternative meta-analysis models that do not require a continuity correction and do not exclude studies have been suggested. These include generalized linear mixed models, 13 using the arcsine difference, 14 a Poisson-Normal model, 15 a zero-inflation model, 16 a Poisson-Gamma model, 17 Firth's logistic regression model 18 and a bivariate beta-binomial model19–21 (sometimes called Sarmanov beta-binomial model). Kuss 8 reviewed and compared 10 different methods for meta-analysing rare events in a simulation study and recommended the use of the beta-binomial model for the meta-analysis of rare events. None of the aforementioned methods, however, can account for correlations induced by bilateral interventions.
Although there are methods available for meta-analysing correlated binary outcomes, it is not clear whether they are appropriate when the outcome is rare and when reporting is incomplete. In this paper, we propose a new model fitted within a Bayesian framework that can be used to meta-analyse studies of unilateral design (each patient received one intervention in one body part), bilateral design (all patients received two interventions in different body parts) or a mixed design (where some patients received one intervention and some patients both). Our model uses a bivariate binomial likelihood that explicitly accounts for the correlations induced by the presence of bilateral interventions without employing the normal approximation. Our model can accommodate a meta-analysis in the presence of rare events, without excluding single- or double-zero studies from the dataset and can handle the case of incomplete reporting in the original studies, i.e. when cross-classified information is not provided.
The paper is structured as follows. In section 2, we describe the datasets from orthopaedics and ophthalmology we use to exemplify our methods. We chose these particular examples because they include studies of different designs and they cover both the case of rare and common outcomes. In section 3, we present our model and discuss how it can be applied for the case of studies of different designs. In section 4, we present results from simulations that we conducted in order to assess the performance of our model and to compare it with the previously recommended beta-binomial model. In section 5, we present results from the examples. Finally, in section 6, we highlight our main findings, summarize the strengths and weaknesses of our approach and discuss possible extensions.
2 Example datasets
2.1 Two surgical treatments for carpal tunnel syndrome
Our first example comes from a Cochrane review
22
that compared the endoscopic release vs. any other open surgical intervention for carpal tunnel syndrome (CTS). CTS is a painful compression of a nerve at the root of the hand. One of the safety outcomes was the occurrence of minor complications (such as numbness around the incision or superficial infection) reported in 24 studies. Minor complications were rare: five out of 24 studies were single-zero and four were double-zero. In section 1.1. of the online Appendix, we provide a detailed description of the data. We categorize the 24 studies in four different types, depending on their design and reporting:
Unilateral design (studies 1–12): patients received one intervention in one of their arms. Studies report number of patients and number of events per intervention group. Bilateral design (studies 13–15): each patient received both interventions in different arms. In the CTS example, these studies reported number of patients and number of events per intervention group. They did not report cross-classified information (e.g. number of patients with events in both of their arms, with events in none of their arms, with events in one of their arms). Mixed design (studies 16–22): some patients received one intervention in one of their arms, and some patients received both in different arms. In the CTS example, these studies reported the corresponding number of patients in each group (or we calculated them from the reported data). No cross-classified information was reported. Unknown design (studies 23–24): these studies only report number of events and number of treated arms, per intervention group. They do not provide information on how many patients (if any) received both interventions in both of their arms.
2.2 Two surgical techniques for correcting myopia
Summary of the type of data available for the CTS and myopia examples. a

CTS: carpal tunnel syndrome.
rA (rB) denotes the number of events and NA (NB) the number of patients who received intervention A (B). With N, we denote the total number of patients included in each study.
3 Methods
In this section, we present our random effects meta-analysis model that can be fit within a Bayesian framework. Methods for estimating and summarizing treatment effects from studies of unilateral and bilateral design are established and we start by revising them. However, the number of events per patient and intervention (the cross-classified information) is required for a proper analysis of studies of bilateral design. Such information is often not available. We introduce a model that bypasses this problem, and then we extend it for the analysis of studies of mixed and unknown design. In section 3.6, we discuss approaches for formulating prior distributions for all model parameters. We only consider the case of a binary outcome, i.e. each patient can only have up to one event per intervention.
3.1 Unilateral design
Let's assume that a study i compared interventions A and B, and that it applied only unilateral interventions. Let us assume
Alternatively, we can do the meta-analysis in a single step using a hierarchical model. A one-step model can be written as follows
The advantage of model (equation (2)) is that in the case of rare events, it facilitates the estimation of the parameters by ‘borrowing strength’ for the average risk across studies. The price to pay is that the model makes an additional assumption, i.e. the exchangeability of average risk across studies. Note that one can write alternative one-stage models, e.g. by assigning a prior to
3.2 Bilateral design: studies providing cross-classified information
‘Contingency’ table for a study of bilateral design with N patients, providing the full cross-classified information. a

A+(A−) denotes events (non-events) in intervention A; likewise for treatment B. n1 denotes the number of patients with events for both interventions. n2 is the number of patients with an event for A and a non-event for B, the opposite is n3. n4 denotes the number of patients with no events in any intervention.
From this table, we can estimate the probability of an event in each treatment. E.g. by maximizing the likelihood, we estimate 
This covariance term can be written as a function of Pearson's ϕ coefficient,
25
which is a measure of the correlation between two binary variables of a 
If we ignore the cross-classifications (
In order to correctly account for this covariance, we need to use the full information and to employ a multinomial likelihood
We can then estimate
For this analysis, one would need to have the cross-classified information of Table 2. Alternatively, if the study has performed an appropriate analysis, one could use the reported results (e.g. standard error or p value) to reverse-engineer equation (3) so as to calculate the entries of Table 2 and then use the correct multinomial distribution of equation (5). To our experience, published studies rarely report the information needed for such back-calculations. To make matters worse, some of the studies may include a mixture of unilateral and bilateral interventions, often without reporting the corresponding numbers. In the following sections, we show how to correctly analyse the data in such circumstances. We start by the simplest cases of data availability and move on to more complex situations.
3.3 Bilateral design: studies that do not provide cross-classified information
Let us assume a bilateral study where only the margins of Table 2 are reported (i.e. 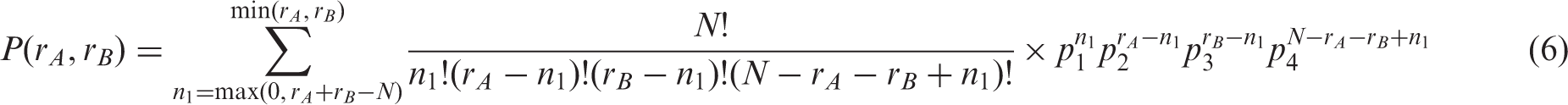
Equation (6) runs through the total number of different set-ups of the contingency table that gives rise to the same margins
However, this approach would result to an average of all possible values for this correlation. It might be the case, however, that having an event in A is highly correlated with having an event in B. This could happen when for instance events are induced by the presence of a certain characteristic in the patient, irrespective of intervention received. In the CTS example, it might be the case that patients with manual labour professions are more prone to having a minor complication in both arms. In such cases, there would be a strong underlying correlation, which would not show in this approach. A hypothetical example to clarify this point is presented in Figure 1, where a study of 100 bilateral interventions reports 60 events in intervention A and 70 in B, but no information on the cross-classification. The likelihood of equation (6) sums across all possible contingency tables: from those that correspond to a high correlation, like the one with Three possible configurations of the 2 × 2 table of a study of 100 bilateral interventions reporting only the margins of the contingency table. The first configuration corresponds to a large positive correlation (φ = 0.80), the second to no correlation (φ = 0), the third to a large negative correlation (φ = –0.53).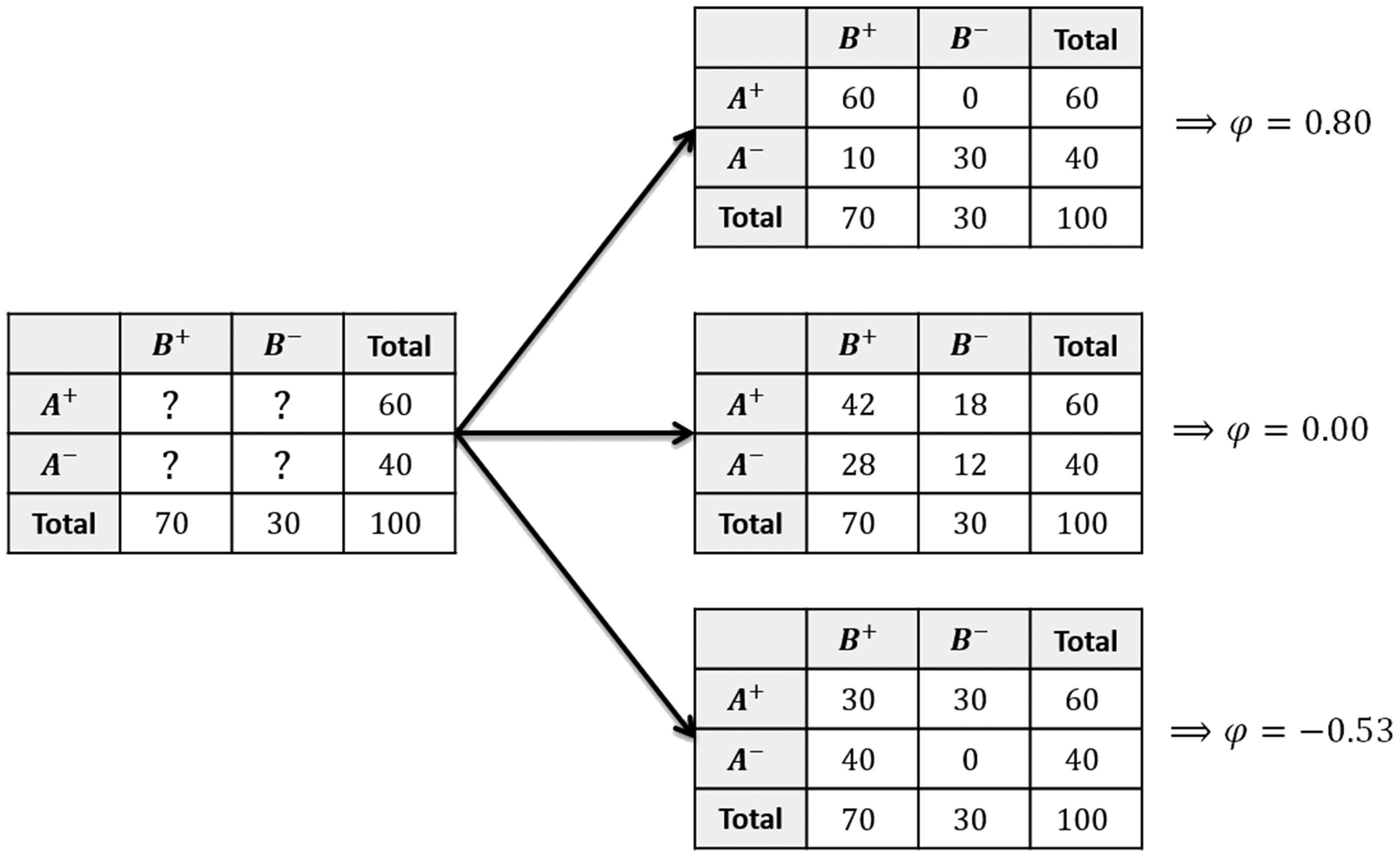
In order to use an informed account of the correlations while employing the correct likelihood of the data described in equation (6), we instead utilize external information for ϕ. In section 3.6, we discuss how to formulate prior distributions for this quantity based on external data or expert opinion. Given
An alternative method for reconstructing the 2 × 2 table uses the odds-ratios of the cross-classified information instead of ϕ. The advantage of this method is that it does not require any truncation. The disadvantage is that it is less easy to formulate clinically meaningful priors for the parameters. Details on this alternative approach are presented in section 3 of the online Appendix.
3.4 Mixed design
We now move on to the situation where a study includes a mixture of bilateral and unilateral interventions (mixed-design studies). For including this type of studies in the analysis, we will make one extra assumption. We will assume that in each such study, the probability of having an event when receiving a specific intervention is the same in patients receiving unilateral interventions (patients receiving only that intervention) and bilateral interventions (patients receiving both interventions):
In what follows, we suppress the study index. Let us start by assuming that such a study provides all relative information, i.e. the number of patients who only received intervention A, the number of patients who only received B, as well as the number of patients who received both A and B; also, the number of events for each of these three patients groups, and the full cross-classifications for the bilateral interventions. We can estimate relative effects from such a study by employing the methods described in the previous sections, namely two independent binomial likelihoods for the unilateral interventions in A and B, and a multinomial likelihood as in equation (5) for the bilateral ones. If no information on the cross-classifications is available, likelihood (equation (6)) needs to be used instead, together with some external information on the correlation coefficient. According to our assumptions, these three groups inform only two probability parameters,
Let us now focus on an even more complicated scenario, which also corresponds to the seven mixed-design studies in the CTS example. More precisely, let us assume that such a study provides information on the events on each intervention (
We first need to calculate the number of patients who received unilateral and bilateral interventions, using the reported data. Let us keep in mind that each patient can have a maximum of one event per intervention. Let us denote
We do not have information on how the
We also do not know how the Graphical analysis of the different ways in which the observed events can be distributed among different categories of patients in a mixed-design study. x, y and n1 are not reported.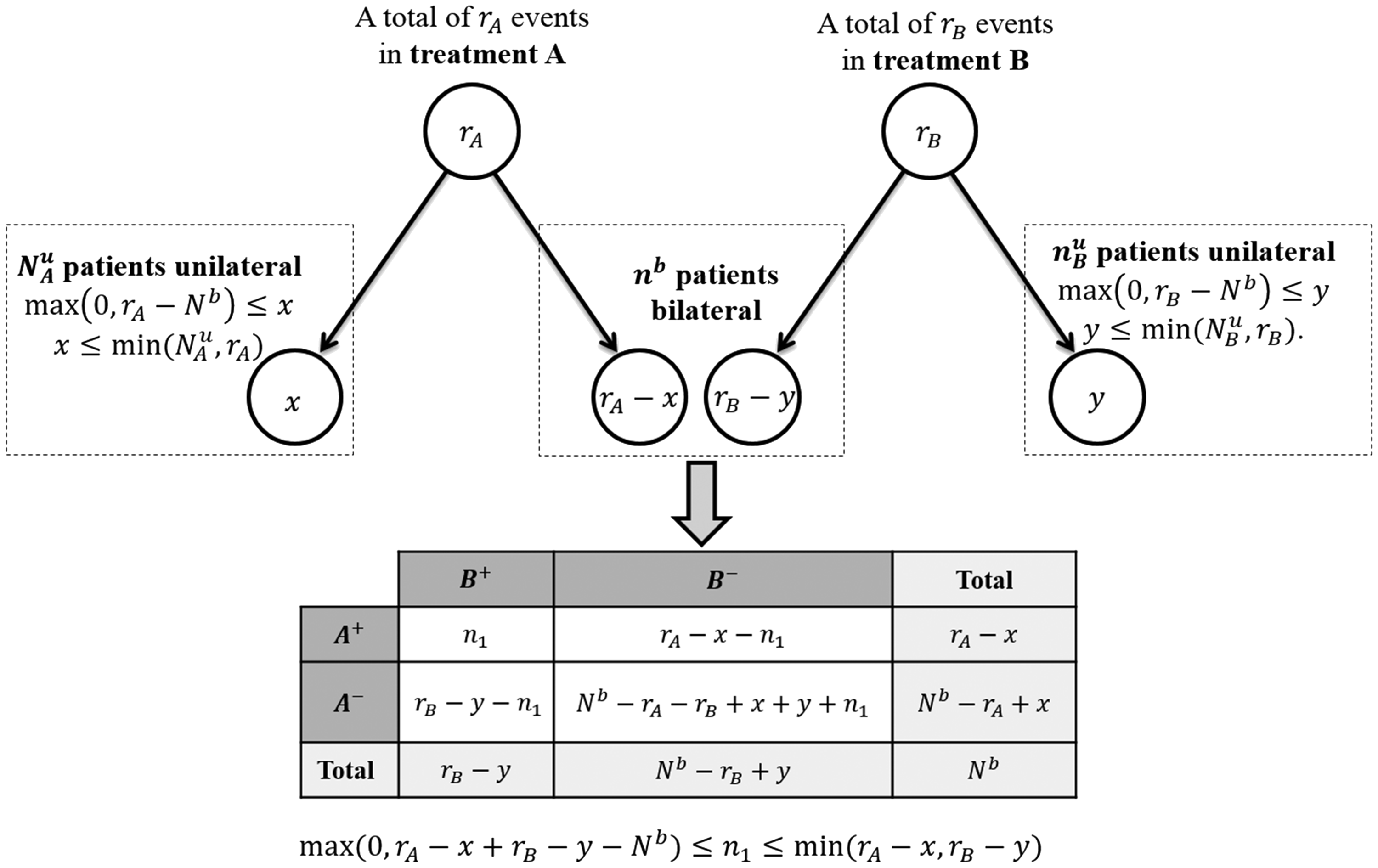
Quantities 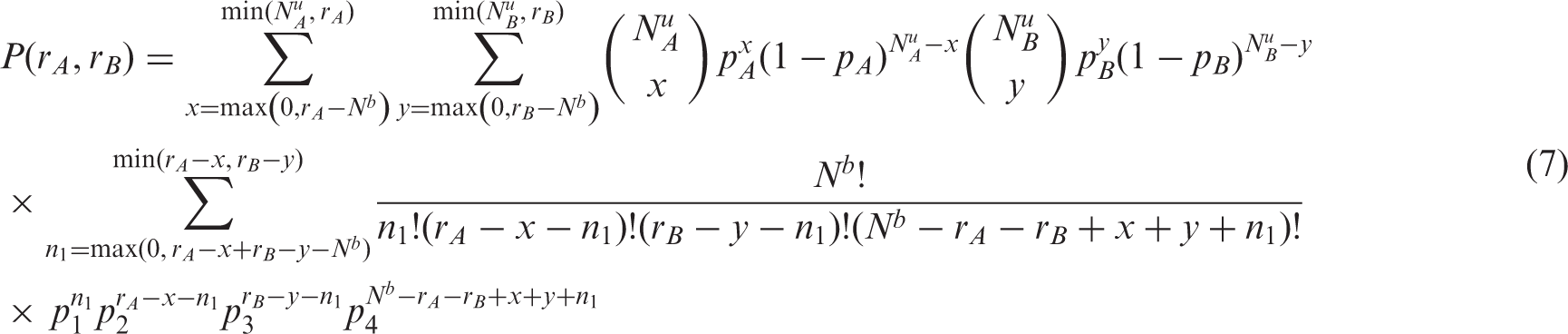
This likelihood is a generalization of the cases described in sections 3.1 (unilateral interventions only) and 3.3 (bilateral interventions only). It is easy to see that this likelihood decomposes into a simple product of two independent binomials if we set
The joint posterior distribution for
3.5 Unknown design
A study of this type reports
The lack of more information from these studies means that researchers cannot use the methods described in the previous sections to take into account correlations in the estimation of relative intervention effects, unless some strong assumption is employed, i.e. on the percent of bilateral interventions in the study. The simplest approach for the analysis is to assume two independent binomials. As we discussed, this may lead to over- or under-precision in the estimated relative intervention effects if the correlation is non-zero.
The two extreme cases for such a study are (1) there are no bilateral interventions and (2) there are a maximum number of bilateral interventions (
In section 5 of the online Appendix, we provide a summary table of how to choose the likelihood for each study, depending on its design and on the information it provides.
3.6 Formulating informative prior distributions
In what follows, we discuss how meta-analysts can augment the information included in the studies using external information in the form of informative prior distributions for the model parameters. We focus on one-step meta-analysis models. We discuss the following parameters: the heterogeneity variance, the mean and variance of the average risk and the correlation (ϕ coefficient).
3.6.1 Heterogeneity
In a recent meta-epidemiological study by Turner et al.,
32
the authors re-analysed data from around 15,000 binary outcome meta-analyses from the Cochrane Database of Systematic Reviews. Results were used to create informative predictive distributions for
3.6.2 Average risk
The optimal source of information for this parameter would be to use eligible randomized controlled trials that were excluded from the original meta-analysis due e.g. to inadequate reporting of effect sizes. This would allow researchers to obtain a realistic estimate of the mean and variance of the (logit-transformed) average risk in order to formulate priors that can be included in the model. Alternatively, one could use observational studies (such as registries or large cohort studies). Note, however, that in order to formulate a prior distribution for the variance (parameter
3.6.3 Correlation
If some of the studies report full, cross-classified information (as described in section 3.2), then the corresponding estimates of the correlation coefficients can be used to formulate an informative prior distribution for the analysis of the rest of the studies. Alternatively, one can formulate priors by eliciting information from expert clinicians. In a previous work, we describe how to elicit information on correlation indirectly, using a conditional probability.
25
Here, we propose a more straightforward method. As shown empirically by Clemen et al.,
35
directly asking for the correlations is a reasonable approach, often more accurate than indirect methods. More detail on how to synthesize information from multiple experts in order to construct a prior distribution for ϕ can be found in section 7 of the online Appendix. The method uses the Fisher transformation to synthesize information,
It is unclear whether the choice of the prior distribution for the different parameters of our model is equally important, and whether researchers should focus on obtaining informative priors for some of the parameters rather than others. It is also unclear what would be the impact of using misspecified prior distributions to our model estimates. Lambert et al. 36 showed that in general the choice of scale parameters (such as standard deviations) is more important than the choice of location parameters in Bayesian analyses with sparse data. As we will see in the next section, this agrees with the findings of our simulations. There we discuss that heterogeneity is the most influential parameter in our model. Using an informative prior for heterogeneity can greatly increase precision and enhance the power of the model. As we will also see, using minimally informative (or even misspecified) priors for the rest of the parameters may have a smaller impact on the model's performance.
4 Simulations
4.1 Data generation procedure and description of the scenarios
We performed a small-scale simulation study to assess the performance of the model we proposed in this paper. We limited the simulations to the case of studies with bilateral design where only the marginal numbers of events are reported, and among which there is variability (heterogeneity). We explored a range of different scenarios. For each scenario, we simulated 100 datasets, with each dataset corresponding to an independent meta-analysis.
Scenarios 1–20 aimed to compare our model with the bivariate beta-binomial model. This model has been previously recommended for meta-analysing rare events. 8 For these scenarios, we simulated 20 studies for each meta-analysis. Two additional scenarios (21 and 22) aimed to explore the importance of specifying informative priors for the parameters of our bivariate binomial model. For these scenarios, we simulated 10 studies for each meta-analysis, aiming to increase the impact of the prior distributions.
To generate data, for each scenario, we first defined the true relative treatment effect on the log-OR scale (μ), the log-odds of the average risk of event and its standard deviation
Using
We explored scenarios using the following values for the simulation parameters:
We generated all data in R, 37 code is provided in the online Appendix, section 8.
4.2 Analyses of the simulated datasets
The simulated datasets were analysed using the bivariate binomial model discussed in section 3.2. The model is also presented in more detail in section 2 of the online Appendix. We performed our analyses in OpenBUGS,38,39 the code is available in section 9 of the online Appendix. For each analysis, we simulated a single chain of 20,000 samples, and we discarded the first 5,000 samples. This was deemed to be sufficient based on some initial runs and also after visually inspecting the posterior distributions. 40
Results from analysing scenarios 21 and 22, for different choices of priors for the model parameters. a
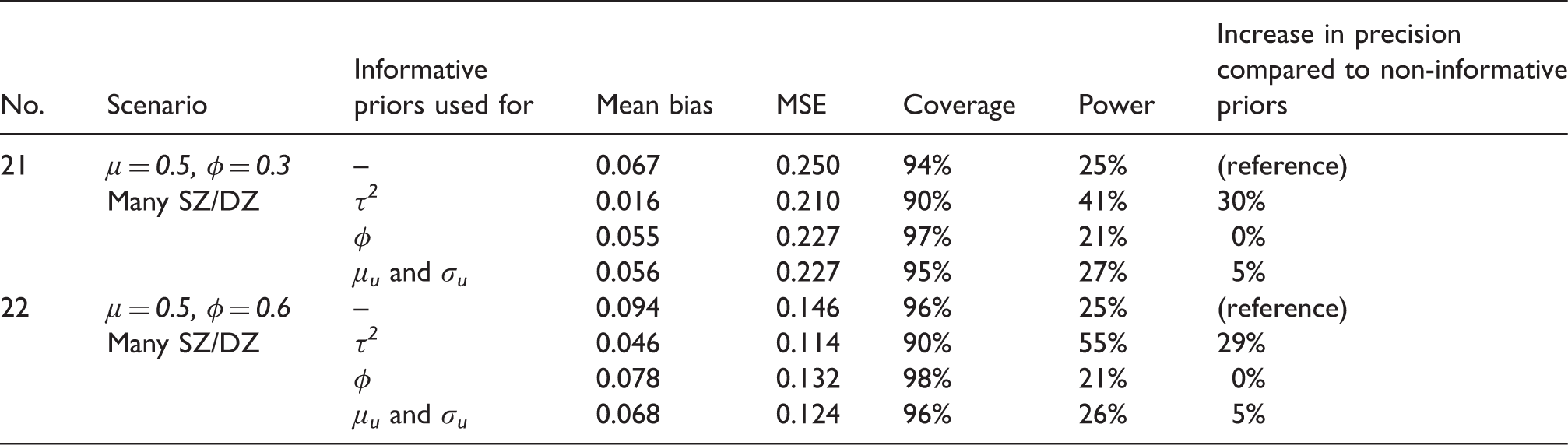
MSE: mean squared error.
μ denotes the log-odds ratio and φ the correlation. μ u and σ u denote the mean and standard deviation of the average risk.
4.3 Results from the simulations
Results from 20 scenarios, comparing the proposed bivariate binomial model to the bivariate beta-binomial model. a
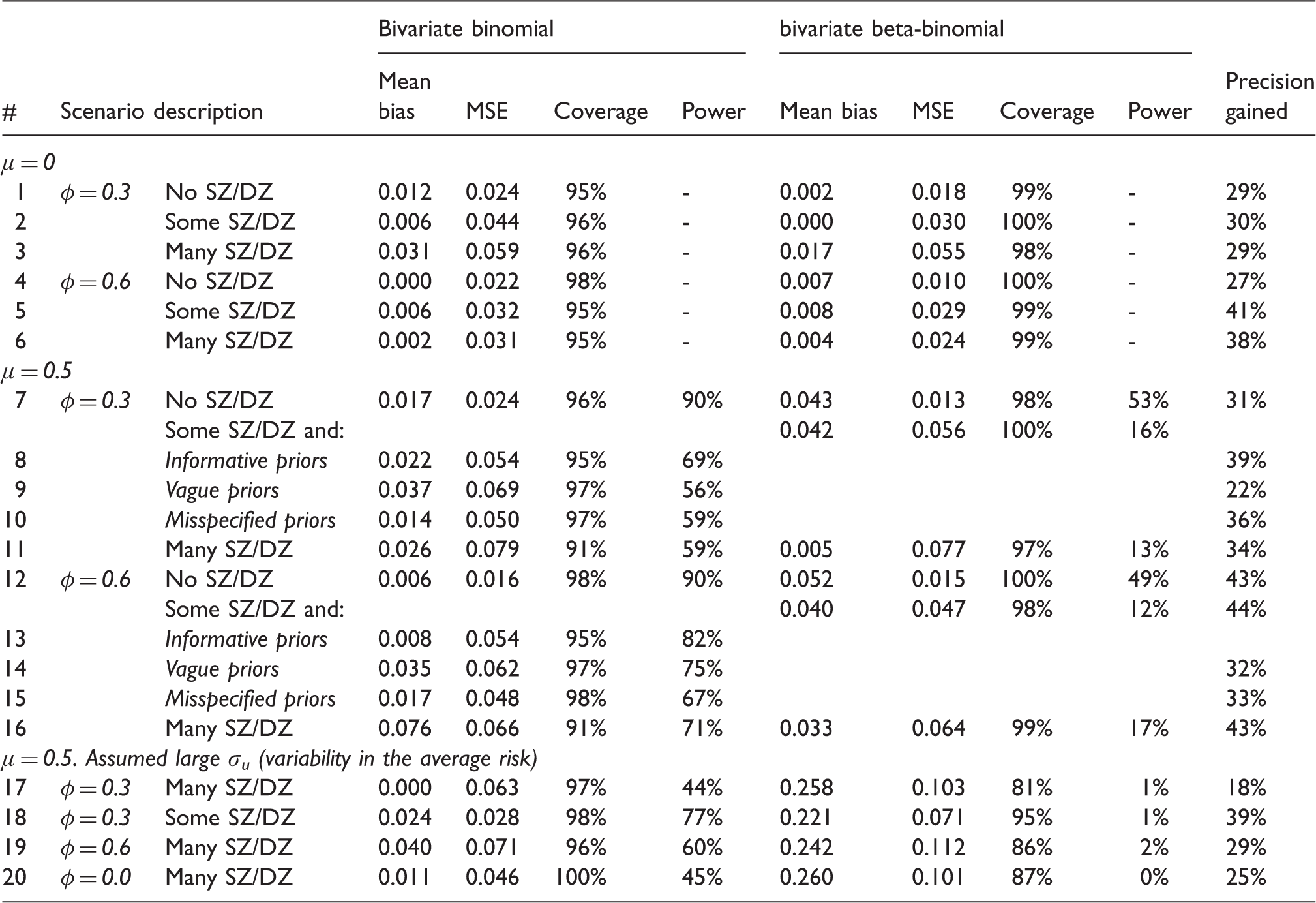
CrI: credible interval; MSE: mean squared error.
All scenarios are analysed using informative priors on φ for the bivariate binomial model, except otherwise noted. SZ (DZ): single (double)-zero studies. ‘Some SZ/DZ’ denotes scenarios with 0–30% SZ/DZ studies. ‘Many SZ/DZ’ denotes scenarios with >30%. μ denotes the true log-odds ratio, φ the true correlation in each scenario and σ u the standard deviation of the log-odds of the average risk. Large heterogeneity in average risk corresponds to σu > 2. Gain in precision corresponds to the percentage reduction in the width of the 95% CrI of our model vs. the beta-binomial.
Simulations showed that our model performs markedly better than the beta-binomial model in most scenarios we explored. In almost all cases, our approach led to smaller mean bias and similar MSE. Coverage probability was closer to the nominal 95% in our approach for most scenarios. Our model led to an increased precision of the estimates. This increase in precision, quantified as the percentage reduction of the width of the 95% CrI, ranged from 29 to 44% in all scenarios. Our approach performed much better in scenarios with many single- and double-zero studies, when we assumed non-zero log-ORs. In these settings, the beta-binomial model had very low power to detect a relative treatment effect. Our simulations showed that in the presence of bilateral interventions, even when the prior distributions are only mildly informative or misspecified, the bivariate binomial model performs better than the bivariate beta-binomial (Scenarios 13–16).
Another interesting finding in our simulations was that for the case of non-zero relative treatment effects and large heterogeneity in the average risk (Scenarios 17–20), the beta-binomial model was very inefficient. In these scenarios, this model showed excessive bias, and in all cases, the bias was towards zero treatment effects. Moreover, there was large MSE, insufficient coverage and minimal power. This was the case even under zero correlation scenario, i.e. for the usual unilateral design (Scenario 20). This finding comes in contrast with the recommendations by Kuss, 8 i.e. to use the beta-binomial model for all meta-analyses of rare events. But, in his simulations, 8 Kuss did not explore the scenario of large heterogeneity in the average risk of an event. In a somewhat different context (meta-analysis of proportions, not relative effects), Ma et al. showed that the beta-binomial model performs worse when the event rates are relatively large (e.g. >5%). 42
In Table 4, we present the results from the analysis of data simulated under scenarios 21 and 22, using different priors for the model's parameters. Results suggested that the most influential prior is the one for heterogeneity. Using an informative prior distribution for
5 Applications
In this section, we show results from applying our methods to the two examples presented in section 2. We used the following models for the analysis:
Univariate fixed-effects meta-analysis, i.e. we used model in equation (2), but omitting the random effects distribution. This analysis ignores the correlations due to bilateral interventions. We fitted this model in a Bayesian as well as a frequentist setting, using maximum likelihood estimation (MLE). Univariate random effects meta-analysis (UNI-RE), using the model in equation (2). This analysis ignores the correlations due to bilateral interventions. We fitted this model in a Bayesian as well as a frequentist setting, using MLE. Bivariate binomial, fixed-effects meta-analysis: we used the model described in this paper accounting for the correlations due to bilateral interventions, as discussed in sections 3.3 and 3.4. We omitted random effects. Bivariate binomial, random effects meta-analysis (BB-RE): the same as in model 3, but also including random effects The bivariate beta-binomial model. Note that this is by definition a random effects model.
We provide the OpenBUGS code in section 11 of the online Appendix. In section 12 of the online Appendix, we provide codes for fitting the model in R using the R2WinBUGS package, 43 and for fitting the model of equation (2) in a frequentist setting. We performed 20,000 iterations, and we discarded the first 5000 samples. We fitted the bivariate beta-binomial model in R. 21 We fitted all models using a conventional laptop computer. The run-time required for fitting our bivariate binomial model was around 23 min for the CTS example and less than a minute for the myopia example.
5.1 Surgical operations for CTS
Two studies in this dataset had unclear design. We analysed these studies as if they were of unilateral design following the arguments presented in section 3.5 as we expect a positive correlation between complications in two arms of the same patient.
For models 1 to 4, we assume a vague prior Meta-analysis for minor events, endoscopic vs. open surgical operation for CTS, using a range of alternative models: UNI-FE (B/F): univariate fixed-effect (Bayesian/Frequentist), UNI-RE (B/F): univariate random effects (Bayesian/Frequentist), BB-FE: bivariate binomial fixed-effect (Bayesian), BB-RE: bivariate binomial random effects (Bayesian). For all Bayesian models, we present the median of the posterior distribution.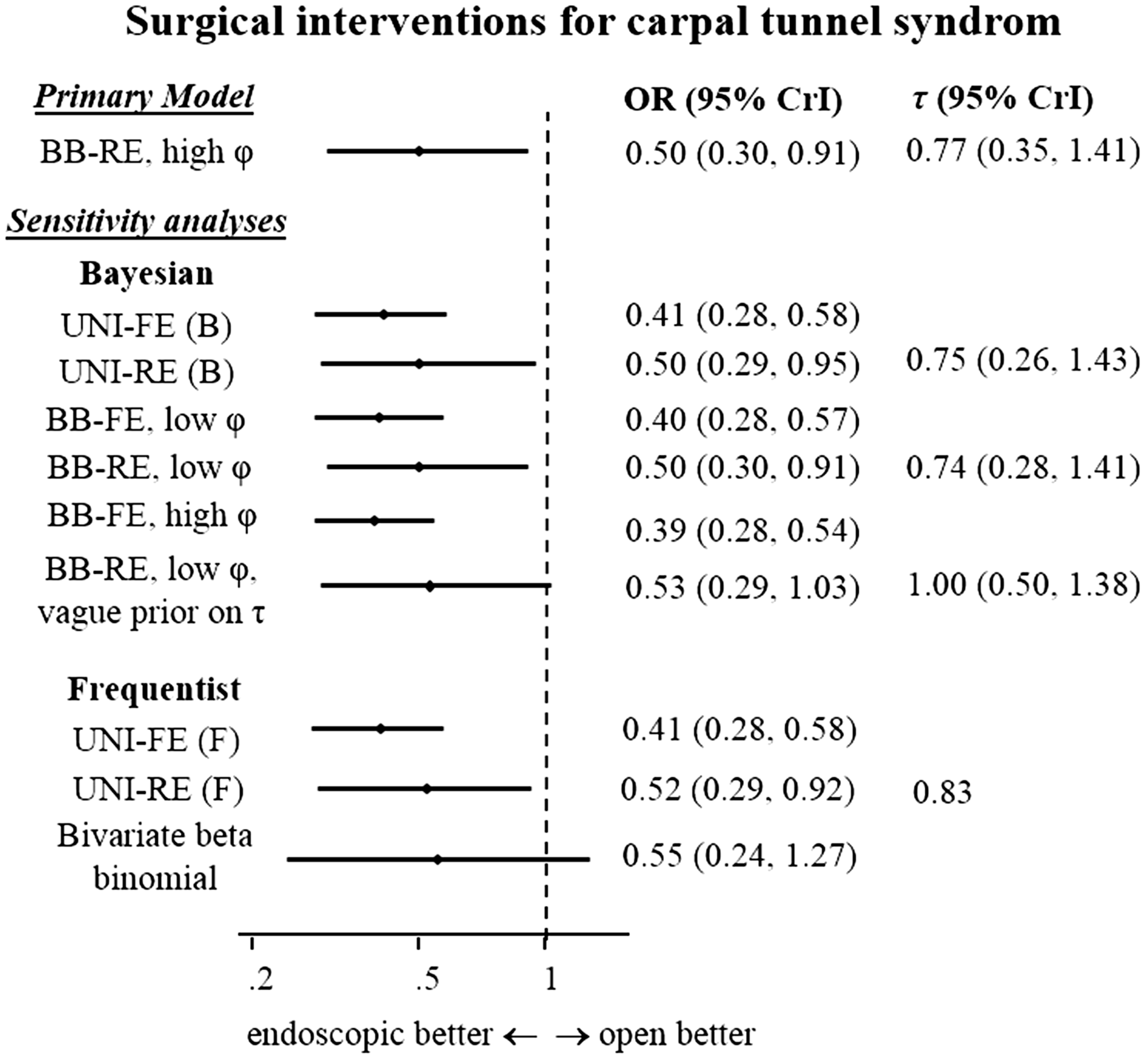
The endoscopic surgical operation was found to be more safe than the open in all analyses. When switching from the univariate to the bivariate model, the increase in precision was rather small, especially when a low correlation was assumed. This should come as no surprise, as only 13% of the patients in this meta-analysis received bilateral interventions. One interesting observation was that when we increase the assumed correlation in the BB-RE scenario, the estimate and CrI for the OR remained unchanged. This is because the increased precision in study-estimates is accompanied by an increase in the estimated heterogeneity. All implementations of the bivariate binomial model were more precise than the beta-binomial model. Comparing the Bayesian and frequentist implementations of the UNI-RE model, we see some differences, which reflect the impact of the prior distributions. E.g. the MLE estimate for τ in the UNI-RE (F) model was 0.83, while for UNI-RE (B), the median of the posterior median for τ was 0.75. This difference was due to the impact of the informative prior distribution, which has median 0.48, thus pulling the MLE estimate towards lower values. The estimate for the ORs was also slightly different (0.50 for the Bayesian implementation vs. 0.52 for the frequentist). This difference can be attributed to the prior used for logOR, which was centred at 0, thus pulling the MLE estimate to lower values.
In order to assess the impact of the prior distributions in our results, we did a sensitivity analysis for model 4 (BB-RE) with low correlation. Assuming vague priors for μ,
Finally, as we argued in section 3.3, the only information the data carries for the correlation coefficient ζ is the range of the allowed values within each study determined by the marginal total counts (as also depicted in Figure 1). As a result, the posterior estimates for ζ are entirely determined by their prior distributions.
5.2 Surgical techniques for correcting myopia
Two studies in this dataset had unclear design. We analysed these studies as if they were of unilateral design. We used the following prior distributions for the model parameters: Meta-analysis for uncorrected visual acuity (UCVA) of 20/20 or better, at six months after treatment, LASIK vs. PRK for myopia. Model abbreviations as per Figure 3.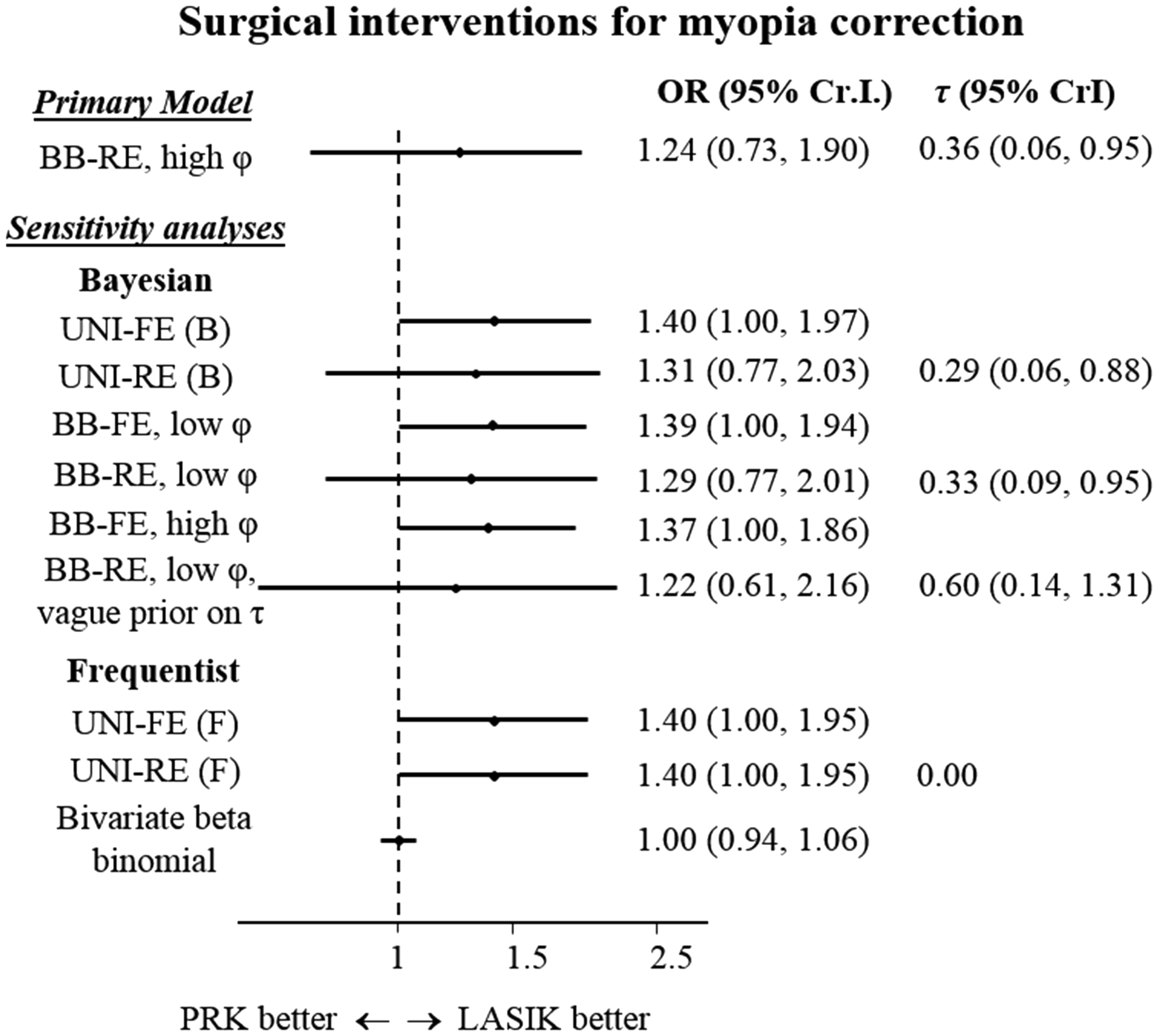
Accounting for correlations using our approach led to an increase in precision of the pooled estimates. For the case of random effects model, some of the increase in precision was again counterbalanced by an increase in the estimates for
The OR estimated from the beta-binomial model was 1.00 (0.94, 1.06). This finding was markedly different to the results from all bivariate binomial models. It was also in disagreement with the frequentist analysis performed in the original publication; the authors performed a Mantel-Hanszel fixed-effects meta-analysis resulting into OR = 1.40 (1.00, 2.00), which is in broad agreement with bivariate binomial models.
One explanation for this important discrepancy between beta-binomial and the other approaches lies in the distribution of the average risk in the included studies. The average event risk ranged from 8 to 97% in the included studies, despite the fact that the relative treatment effect was not very heterogeneous (see online Appendix, section 1.2). In such situations, the bivariate beta-binomial model may be heavily biased towards zero, as shown in the simulations (section 4, scenarios 17–20). Additionally, the bivariate beta-binomial model was shown to perform well when the event rate is small; here it is on average 70%. 42
6 Discussion
In this paper, we have presented a Bayesian meta-analysis model for synthesizing binary data obtained from collection studies of different designs: studies of the usual parallel design, studies of a bilateral (split-body) design and studies including a mixture of unilateral and bilateral interventions. Our model uses a bivariate binomial distribution that accounts for the correlations induced due to bilateral operations and has several distinct advantages. It uses the exact likelihood of the data; it does not employ the normal approximation; it respects the randomization of the studies; it includes in the analysis data coming from studies with zero events in one or even both interventions, without a need for imputation. Our model has similarities with the bivariate beta-binomial (Sarmanov) model for meta-analysis (e.g. as described by Chen et al. 21 ). The two models differ, however, in the model parametrisation and the assumption of random effects. The bivariate beta-binomial model assumes random effects for the arm-specific event probabilities while the mean log-OR is not a parameter of the model. In our approach, random effects are assumed for study-specific log-ORs, and the mean log-OR is a parameter directly estimated in the model. This feature allows us to assume an informative prior distribution for the log-OR, based on available empirical distributions.
The bivariate beta-binomial model has been previously suggested as the optimal approach for meta-analysing rare events. 8 Our simulations showed that our model may lead to significant increase in precision, coverage and power, and a decrease in bias, as compared to the bivariate beta-binomial model. Moreover, according to our simulations, the bivariate beta-binomial model was found to perform very badly when the baseline risk was very variable in the included studies, even when no correlation was assumed. This was also demonstrated in one of the two real data-sets we used to illustrate our methods. The increase of precision in our model is more pronounced in fixed-effects meta-analyses. In the random effects regime, increasing the precision of the study estimates by accounting for correlations can be partly counterbalanced by an increase in the estimate for heterogeneity.
We set our model in a Bayesian framework. This allows the inclusion of external information for the model parameters. However, for the case of rare events, inferences from Bayesian meta-analyses may heavily depend on the choice of prior distribution for the parameters – even when these are thought to be uninformative. 36 Due to this fact, the use of frequentist approaches instead of Bayesian approaches is sometimes advocated. We understand the reasoning behind this view; in this paper, however, we argue in favour of a Bayesian approach. We think that the scarcity of information due to the rarity of events should not be seen as an argument against the use of Bayesian methods. On the contrary, we think that meta-analysts should opt for using Bayesian methods when they have the opportunity to include high quality, trustworthy external evidence in the analysis.
The major limitation of our model lies on its complexity. The software code we provide might be computationally heavy when studies have very large sample sizes. This may be especially true if there are large, mixed-design studies in the dataset. Moreover, embarking into this complicated modelling will only make a difference in the estimates if the corresponding correlation is large. If the correlation is expected to be small (e.g.
In our model, we assumed exchangeability on the average risk. This might be a very strong assumption to make, e.g. if there are large differences in the randomization ratio across studies. Alternatively, researchers can assume exchangeability in the probability of having an event in one of the interventions,
One additional limitation of our model is that it cannot correctly account for correlations induced by patients that received the same intervention in multiple sites of their bodies i.e. a classical cluster design (e.g. the same intervention in both hands, both eyes, multiple teeth, multiple people in a household, etc.). This situation requires an extension of the approach described in this paper. Other possible extensions of our bivariate binomial meta-analysis model relate to the case of two correlated outcomes (for studies of the usual, parallel design) and for the meta-analysis of twin studies. Also, our model can be extended for the meta-analysis of the accuracy of multiple diagnostic tests. Finally, it would be interesting to explore the use of the non-central hypergeometric distribution15,44 for bilateral interventions, and compare it with the bivariate binomial approach described in this paper.
Dimou et al. 45 discuss an alternative method that can be used to fill the (unknown) cross-classified information in the contingency tables of studies that do not report it. Their method uses information from studies that report the full tables. When no studies report the full tables, the authors suggest the use of the iterative proportional fitting algorithm, 46 which is, however, based on strong assumptions. Both these methods do not account for uncertainty in the (unobserved) missing values of the contingency tables. Moreover, the methods described in that paper are not suitable to use in the case of rare events.
A different approach to synthesizing data from studies with bilateral design is to only use information on the number of discordant pairs, 2 i.e. the number of patients with an event in A but not in B, and the number of patients with an event in B but not in A. This approach, however, could not be used for the case where some studies in the meta-analysis are of a unilateral design, and/or some studies are of a mixed design. E.g. this approach could not have been used in the examples presented in this paper.
To summarize, we think that the model we presented constitutes the best available method for meta-analysing binary outcomes in the presence of bilateral (split-body) interventions, and that its implementation is in practice straightforward.
Footnotes
Acknowledgements
We would like to thank Nikolaos Pandis and Haris Vasileiadis for their help in choosing and interpreting the clinical examples we used.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: OE was supported by the Swiss National Science Foundation (grant title: ‘Enhancing methods for evaluating the comparative safety of medical interventions’). GR was funded by the German Research Foundation (DFG) (grant RU 1747/1-2). GS is a Marie Skłodowska-Curie Fellow (MSCA-IF-703254).
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.