
Abstract
Changes in cognitive function over time are of interest in ageing research. A joint model is constructed to investigate. Generally, cognitive function is measured through more than one test, and the test scores are integers. The aim is to investigate two test scores and use an extension of a bivariate binomial distribution to define a new joint model. This bivariate distribution model the correlation between the two test scores. To deal with attrition due to death, the Weibull hazard model and the Gompertz hazard model are used. A shared random-effects model is constructed, and the random effects are assumed to follow a bivariate normal distribution. It is shown how to incorporate random effects that link the bivariate longitudinal model and the survival model. The joint model is applied to the English Longitudinal Study of Ageing data.
Keywords
Introduction
In ageing research, data from various tests of cognitive functioning are often collected as longitudinal data, i.e. the same sample is tracked at different points in time. Generally, longitudinal data on ageing research are multi-dimensional data that contain observations for multiple phenomena obtained over multiple time periods for the same individual. 1 For instance, the English Longitudinal Study of Ageing (ELSA) contains several cognitive tests relating to literacy, numeracy, memory and information processing. 2 Individuals are tested every few years and the test scores are recorded; these test scores are in the form of non-negative integers. An important research topic in ageing research is the change in cognitive function over time. In our model, we present an extension of the binomial model to measure the change in non-negative cognitive test scores.
Cognitive function, also known as cognitive ability, is the individual’s ability to process information, mainly with regard to learning and problem-solving. Researchers are committed to obtaining scores that reflect the level of cognitive function of individuals through different tests.
In ageing research, it is important to investigate the changes in the individual’s cognitive function. The relationship between changes in cognitive function and the risk of death is also of interest. 3 Researchers provide advice on whether the elderly need care by analyzing the relationship between cognitive function decline and ageing. 4 For example, an individual whose cognitive function drops suddenly during a period might suffer from a disease such as Alzheimer’s disease that affects cognitive abilities or even threatens life, and he/she needs professional medical care. The work in Laird and Ware, 5 Cox 6 and Van Den Hout and Muniz-Terrera 7 model longitudinal data and time-to-event data separately, however, if the two response processes are correlated this may lead to biased effect size estimates. 8 Therefore, it is reasonable to use a joint model to measure both processes simultaneously. The use of joint models is not limited to the ageing research. Previous research has shown that joint modelling can improve the efficiency of statistical inference and reduce bias, and it can provide significant benefits when designing experiments.9,10
Research into the joint modelling of longitudinal and time-to-event data has received considerable attention over the past three decades.3,11 Faucett and Thomas, and Wulfsohn and Tsiatis wrote seminal articles in this field in 1996 and 1997 respectively, and after that extensions to joint models have been proposed in the literature. 12 In the early stages of research on joint models, research on joint models has focused on single longitudinal responses and single time-event responses, i.e. univariate joint model. This approach has been widely used in clinical research 13 and there are a number of mainstream software packages available for calculating related problems.14–16 However, as we mentioned above, longitudinal and time-to-event data, especially the longitudinal part, are usually multidimensional and contain observations of multiple phenomena obtained by the same person over multiple time periods. While univariate joint models allow us to determine the relationship between a survival outcome and a single longitudinal outcome, more frequently, multiple biomarkers are associated with the event of interest. 12 Multivariate joint models allow us to consider more information simultaneously, thus enabling us to better understand the dynamic complexity of changes in disease or biological indicators. In recent years, a number of researchers have devoted their research to the multivariate joint model. For example17–19 are multivariate joint model investigations with continuous response variables. There are also many articles focusing on other data types, e.g. article 20 considers multivariate binary data, the model in Rizopoulos and Ghosh 21 combines continuous response variables with binary counterparts and article by Wang et al. 22 uses ordinal data. Rue et al. 23 build a joint multivariate model related to discrete data. Although the responses in Rue et al. 23 are discrete variables, the longitudinal data model in the article still uses the normal distribution model and the beta model. Many software packages also provide relevant functionality for multivariate joint models. Examples include merlin in Stata 24 and the JMbayes package in R. 25 In this paper, we construct a bivariate discrete joint model to address the potential estimation bias caused by separate modelling and to avoid the lack of information caused by dropping longitudinal responses when using a univariate joint model. This joint model can take into account discrete data.
A joint model for longitudinal responses describes the change of responses using a model for longitudinal data and describes the risk of the event using a survival model. 26 The principle of joint models is to link these two models using a common latent variable. This common latent variable captures the association between the processes. Based on this principle, two joint models have been proposed: the shared random effects model 11 and the latent class model. 27 Articles Rouanet et al., 28 Proust-Lima et al. 26 and Proust-Lima et al. 29 used latent class models to construct multivariate joint models. The limitation of the latent class model is that the classification may not be interpretable because we do not know what the different classes represent; moreover, we can only calculate the probability that an individual belongs to a certain class and cannot assign him or her to a specific class with certainty. To avoid these limitations, we model the latent variable as a random effect. Conditional on random effects we assume that the longitudinal outcome is independent of the time-to-event outcome. 14 Also, we assume that the repeated measurements in the longitudinal outcome are independent of each other given the random effects.
A multivariate shared random effects model was introduced by Rizopoulos in Rizopoulos. 14 In this model, the association between longitudinal variables is captured by the random effects. Our bivariate joint model uses an extended bivariate binomial distribution 30 in the longitudinal part of the model. This distribution includes a parameter that represents the correlation coefficient between the two longitudinal outcomes. The model allows us to avoid using random effects to capture all the correlations of the joint model.
In this paper, we will investigate the bivariate responses changing over time, in which the responses are different measurements representing cognitive function for individuals. The shared random effects can take into account unobservable individual-specific characteristics. 14 Since the cognitive function is usually measured by non-negative integers, the bivariate extension of the binomial distribution proposed by Altham and Hankin 30 is used for the longitudinal model. This model not only measures whether the model is over- or underdispersed compared to the standard binomial distribution but also measures the association between the two longitudinal outcomes. For the survival part, the Weibull hazard model and the Gompertz hazard model are used. In univariate joint models, the link functions which contains in both the longitudinal model and the survival model are well defined. 31 However, for the bivariate joint model, we do not know beforehand which link will provide the best result. We will therefore discuss several different link functions.
We apply the models to analyze the ELSA data. There are two non-negative longitudinal outcomes in the ELSA data, and they are related to verbal learning and recall. Individuals were asked to learn ten words and recall them at two different time points (immediate and later), but in the same interview; see Van den Hout and Muniz-Terrera. 7 In the ELSA data, the event time for the joint model is the time of death.
The ‘Models section provides a brief overview of the models in this paper: the extension of the bivariate binomial distribution proposed by Altham and Hankin, the Weibull hazard model and the Gompertz survival model. The link between the longitudinal model and the survival model is also discussed in this part. The ‘Maximum likelihood function given left truncation section constructs the marginal log-likelihood function for the joint model, discusses the left truncation and proposes the method for computation. In the ‘Simulation section, we use a simulation study to validate the accuracy of the joint model parameter estimates. We analyze the ELSA data through fitting the shared random-effects model in the ‘Application section. The conclusion of this paper and possible extensions options for the joint model are discussed in the ‘Conclusion section.
Models
The joint model is given by
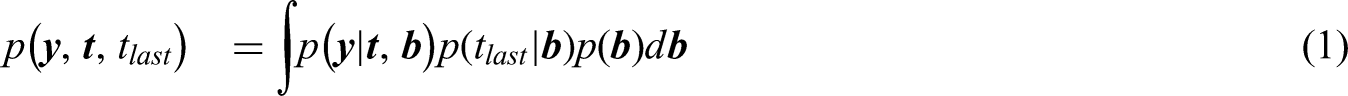
The first part of this section introduces the bivariate binomial distribution used for the longitudinal model. The second part proposes the hazard survival model. The third part defines the link between the longitudinal model and the survival model, which consists of parameters common to both models and the random effects. For what follows, assume that the random effects are given by vector
Generally, the scores for cognitive function are discrete non-negative integers. For example, the Mini-Mental State Examination (MMSE) test is a 30-point questionnaire, widely used extensively in clinical and research settings to measure cognitive impairment. A higher score represents better cognitive function. We model the probability of success (answering the question correctly and earning one point). For the MMSE, this would imply the assumption that the 30 questions are independent of each other and that the distribution of the total-score follows the binomial distribution. It is worth to notice that even if the probability of success is different, the total-score distribution still follows the binomial distribution. 32
Let
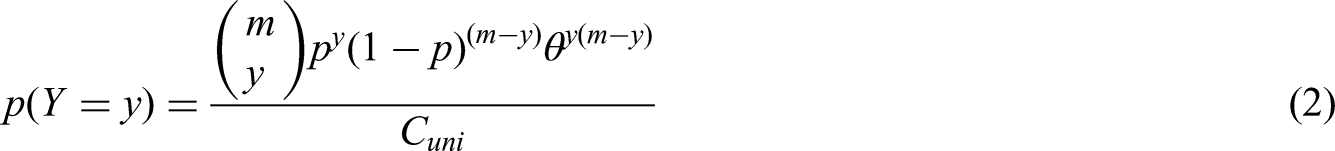
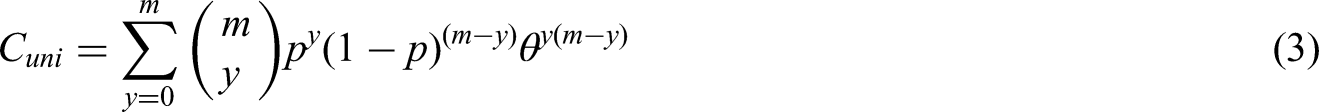
In this paper, we use the bivariate extension of (2)
30
to analyze the longitudinal data. Let
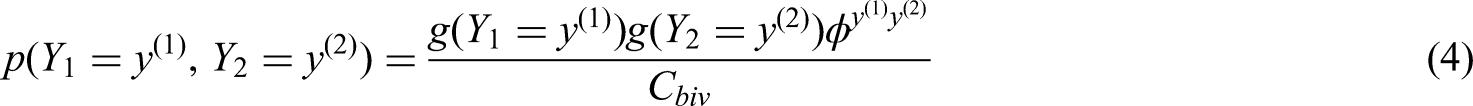
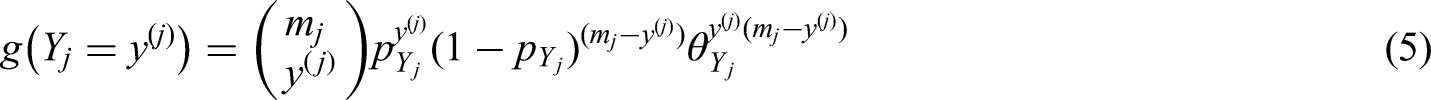
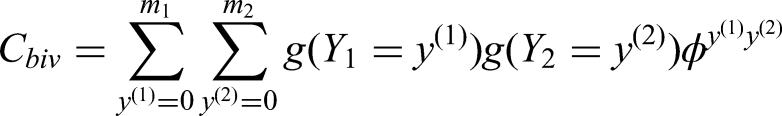
Assume that the random variable
To investigate the relationship between time and the response variables, we use the random-effects logistic regression model:
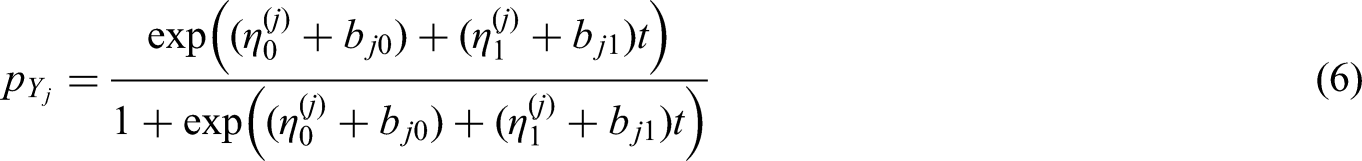
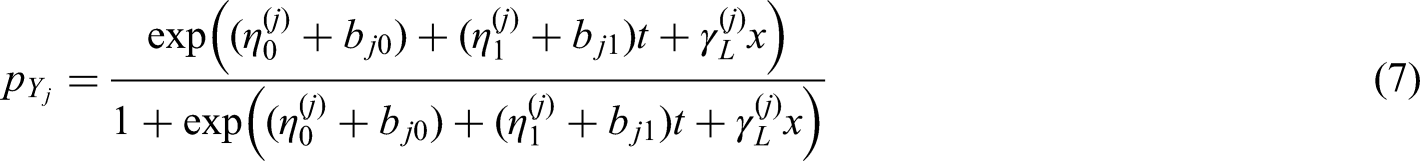
In this paper, we will investigate restricted models. We will explain the reasons for using restricted models in the later section. The restricted models are defined by restrictions on random effects, for example:

We can also set


The reason for choosing this bivariate binominal distribution is that the formula of the probability density function is relatively simple, and it belongs to the exponential family.
30
Moreover, this distribution allows
We define the hazard models and the corresponding survivor models for analyzing the time-to-event data. The hazard model is a parametric regression model given by

There are many widely used parametric hazard models in survival analysis, such as the exponential hazard model, the Weibull hazard model, the Gompertz hazard model, and the log-logistic distribution. In this paper we use two commonly adopted models to construct the survival part of the joint model: the Weibull hazard model and the Gompertz hazard model.
The Weibull model is a survival model with two positive parameters and it is a generalization of the exponential model. We denote the Weibull model
We have the following baseline hazard models:

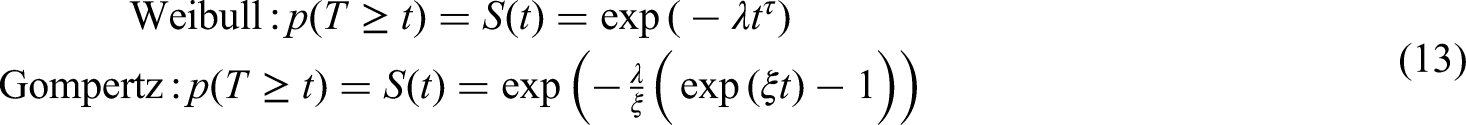
The definition for the range of

In this part, we introduce the link function
The hazard model (11) allows for several specializations. In joint models,




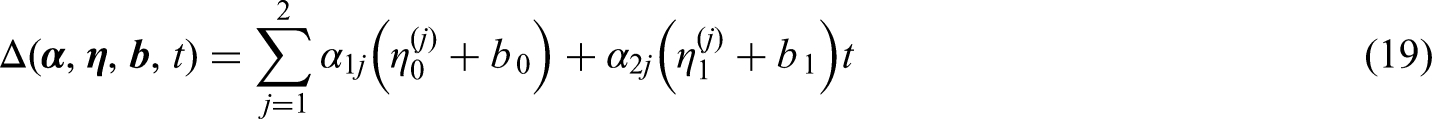
In addition to the link functions above, there are many other common forms of link functions. For example, in many joint models which use a linear mixed model as their longitudinal model, the linear predictor is the conditional expectation of the response variables. Such models make it possible to use the expectation in constructing the link function:
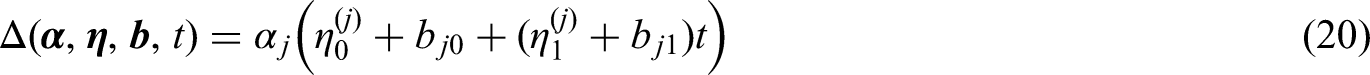
When substituting the above
For the Weibull hazard, when the expression of




For the Gompertz hazard, we have:


As we mentioned at the beginning of the ‘Models section, we use
Maximum likelihood function given left truncation
Left truncation, also called delayed entry, occurs when individuals have been at risk before entering the study. 37 For example, when the event of interest is death, individuals who died before the study started will not be included in the study. In ageing research, the main timescale is age. Since the event of interest is death, individuals can be included in the data only if they have not experienced the event before they enter the study. If we do not deal with the left truncation, the estimation is based on the assumption that individuals were not at risk of dying before the start of the study. Therefore, the left truncation needs to be taken into account in the model estimation.
For individual
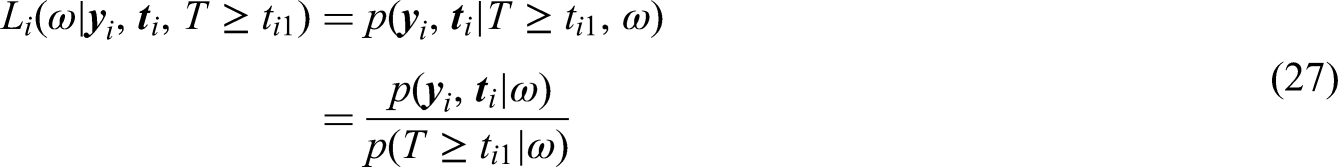
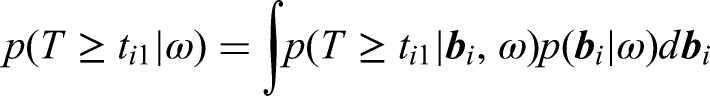
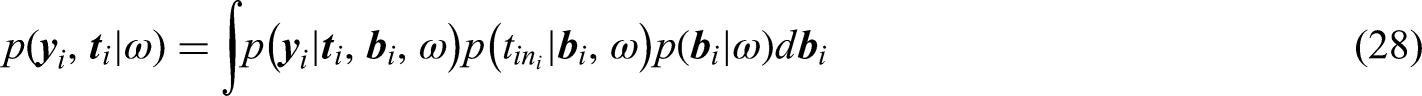
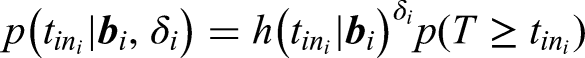
This model offers a flexible way to model the correlation between the value change of responses and the risk of event. 39 The advantage of using the normal distribution is that it is one of the most common distributional choices in linear mixed-effects models and that it enables using Gauss-Hermite quadrature in the numerical optimization of the marginal likelihood. However, even if we can use the Gauss-Hermite integration, this model is still computationally intensive due to the numerical integration.
We code the marginal log-likelihood function in the R software.
40
The corresponding parameters are estimated using the ucminf function in package ucminf.
41
For the shared random-effects model (28), where the random effect
It is worth mentioning that the bivariate Gauss-Hermite quadrature can be undertaken by using two univariate normal distributions (see, e.g. Van Den Hout
39
). The bivariate normal distribution

We conduct a small simulation study to investigate the parameter estimation for the joint model. We used the ADEMP structure to plan the simulation study. 42 The ADEMP structure includes Aims, Data-generating mechanisms, Methods, Estimands, Performance measures.
The main Aims of our simulation study are to check the estimation method and to investigate the performance of joint model given various sample sizes.
Date-generating mechanism: We use the joint model with the best results in the ‘Application section as the model for the ‘Simulation section. The mechanism is based on the extension of the bivariate binomial distribution (4) and the Gompertz hazard model (13). As Morris et al.
42
mentioned, varying the sample size of the simulation dataset is a common approach when changing the data generation mechanism since the performance tends to vary with the sample size. We also refer to the article by Van den Hout and Muniz-Terrera,
4
which designed a small simulation study in a similar setting. Therefore, to investigate the small sample bias, for the joint model we set the sample size
For the joint model, the logistic regression model is defined by (6) with
The true values of the parameters, i.e. the values used when generating the data, are listed as ‘Value’ in Table 1. It is worth noting that we set
Simulation study for the first joint model.The follow-up interval is 3.
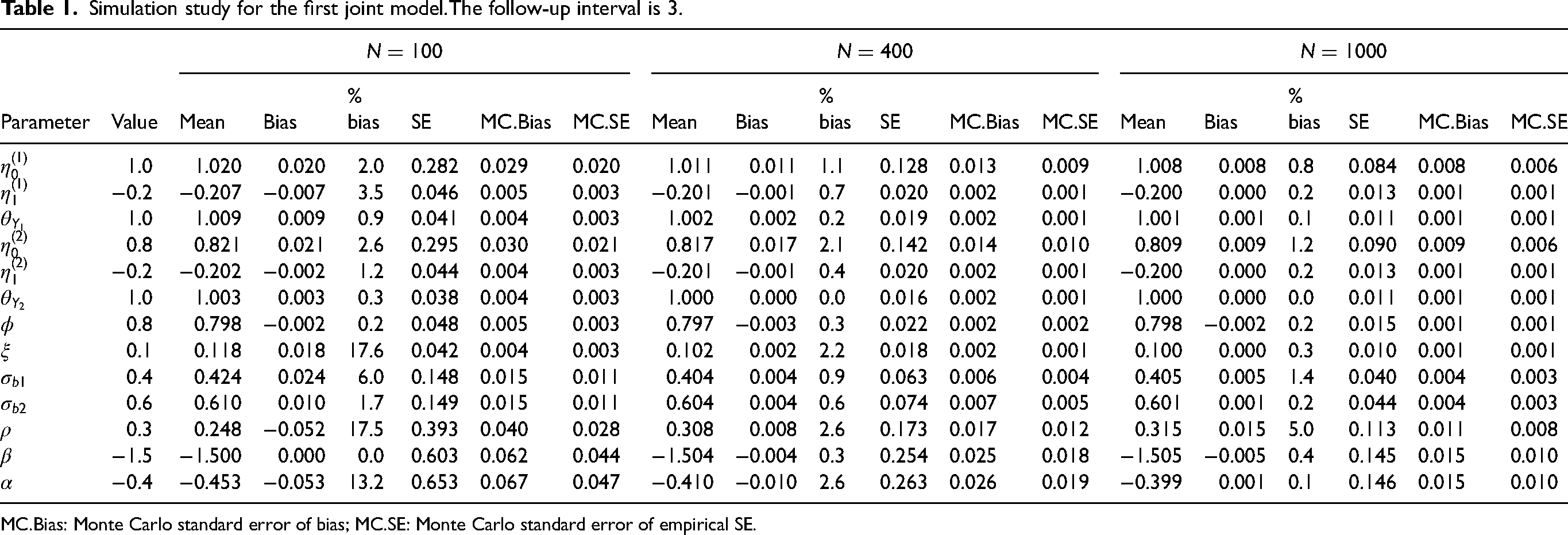
Simulation study for the first joint model.The follow-up interval is 3.
MC.Bias: Monte Carlo standard error of bias; MC.SE: Monte Carlo standard error of empirical SE.
Estimands: In this simulation study, the estimands of interest are the model parameters over the
Methods: In the simulation study, to eliminate the effect of left truncation, we set the observation time for all individuals beginning at time zero. If an individual does not drop out, the follow-up ends at 24 years. Follow-up intervals are set to three years to ensure that we have enough information about changes in response variables over time. When the follow-up interval was fixed at once every three years, it means that there are 9 observations for individuals who do not drop out at the end of the experiment.
Given the specified parameters and follow-up intervals, the data for an individual is firstly simulated by drawing random effects. Based on these effects, the bivariate longitudinal trajectories were simulated using the Metropolis-Hastings algorithm. Afterwards, random effects are used again to define the Gompertz parameter
Performance measures: In this section, we will calculate the means of estimated parameters over the
Table 1 shows the simulation results for the choices
Based on the bias values and the corresponding MC.Bias values in Table 1, we plot the Figure 1. From this figure, we can observe that for most of the parameters, 0 is included in the 95% confidence interval. From the left to the right of the figure, i.e. from
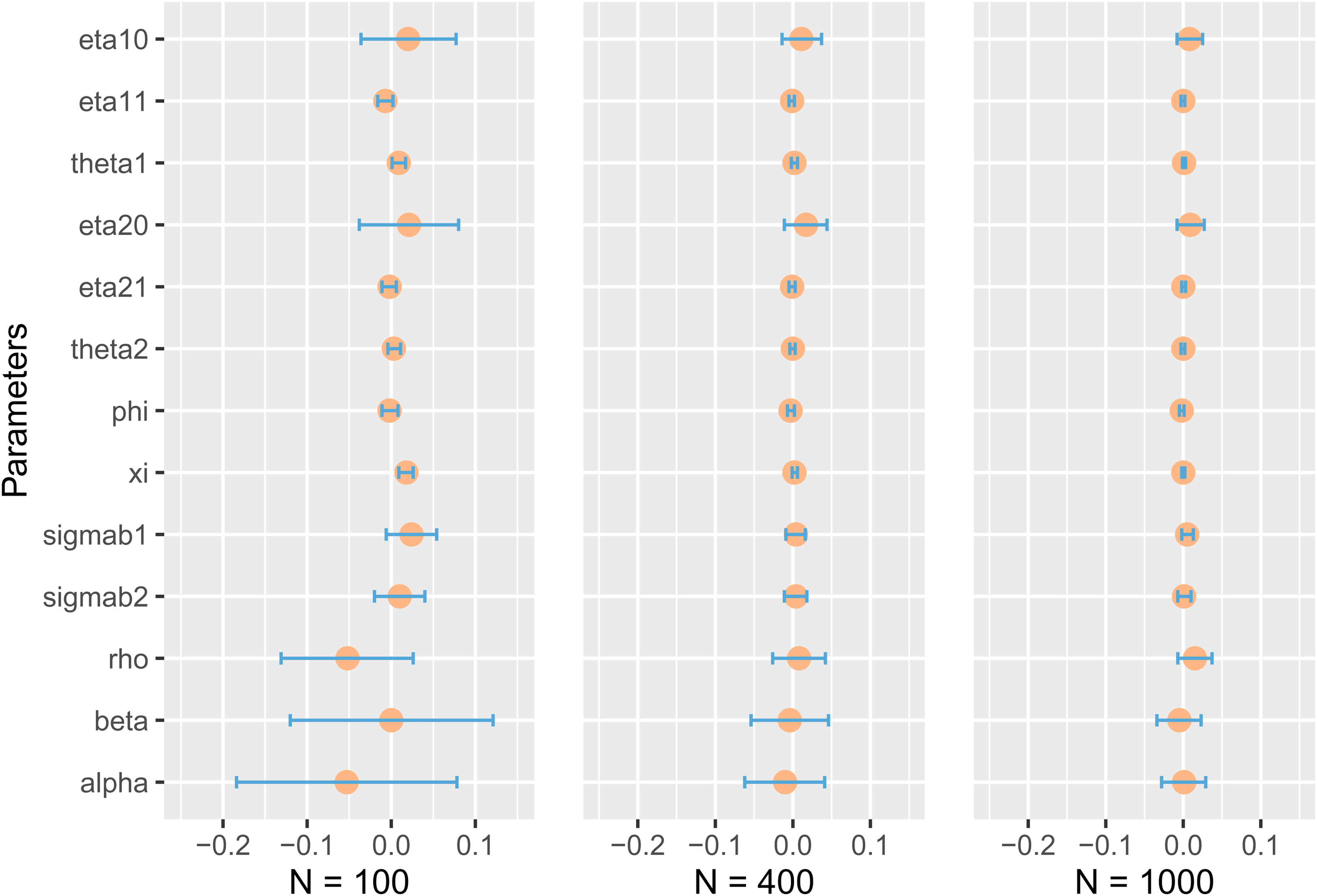
Bias and corresponding Monte Carlo 95% confidence interval. Circles represent biases, and geometry bars represent Monte Carlo 95% confidence interval.
This simulation also shows that
The estimation by marginal likelihood can reproduce the parameters that were used to generate the data. The function ucminf combined with the Gauss-Hermite method gives accurate estimates. The settings of the arguments in this paper are reasonable, e.g. in the Gauss-Hermite method the node is set to 7 and in the simulation the number of iterations is set to 100. It is worth noting that while in this paper we have justified setting the number of nodes to 7 through simulation, in other cases, such as when there is considerable heterogeneity between subjects, we may need more nodes when using the Gauss-Hermite method. The bias of the parameter estimates decreases significantly when the sample size increases. In particular, when the sample size is
The ELSA is a rich resource of information on the dynamics of health, social, wellbeing and economic circumstances in the English population aged 50 and older. Established in 2002, the original sample was drawn from households that had previously responded to the Health Survey for England between 1998 and 2001. The same group of respondents have been interviewed at two-yearly interviews, known as ‘waves’, to measure changes in their health, economic and social circumstances. Younger age groups are replaced or refreshed to retain the panel. Data from the ELSA can be obtained via the Economic and Social Data Service (www.esds.ac.uk). The information collected provides data on household and individual demographics, health, social care, work and pensions, income and assets, housing, cognitive function, social participation, effort and reward, expectations, walking speed and weight for individuals.
In this paper, we focus on a test with two responses in the ELSA data. 43 This test asks individuals to remember 10 words in the same interview. The first response in the test, representing the individual’s short-term memory ability to some extent, is the number of words the individual recalls immediately (immediate recall). An individual’s long-term memory ability is indicated by recording the number of words he/she can remember after five minutes (delayed recall).
The number of immediate-recall words is represented by
In the ELSA data, there are 11,932 individuals interviewed. In this section, we analyze the ELSA data which were also used in Van den Hout and Muniz-Terrera’s paper. 4 Van den Hout and Muniz-Terrera processed the data via the following four aspects: remove individuals who were interviewed only once with missing data on the number of words; remove individuals without information on the year of birth; remove individuals who were younger than 50 years old at baseline wave 1 and remove individuals with censored age at baseline.
In this paper, the main purpose of this paper is to illustrate the methodology rather than a study of ELSA data. Therefore, we use a subset of the data above.
7
The subset has Individuals are younger than 90 years at baseline and do not have censored age during follow-up. Each individual has at least two records. These two records can either include two observations or an observation and a time of death.
The age in this dataset is rescaled by subtracting 49. The number of deaths is 195, where the attrition rate is close to the full data. The ratio of women to men in the data is 540: 460, which is also close to that ratio for the full data. The average of first recorded immediate-recall words for all individuals is
Figure 2 shows the frequency distribution of recalled words at baseline interview. Compared with the distribution of immediate recall words, the distribution of delayed-recall words is concentrated on the left. It can also reflect that individual’s short-term memory is better than long-term memory. In Figure 3, we select 30 individuals and plot the trajectories of their responses. We can see from the picture that an individual’s ability to remember words (cognitive ability) is fluctuating and overall the number of words that people remember decreases over time.
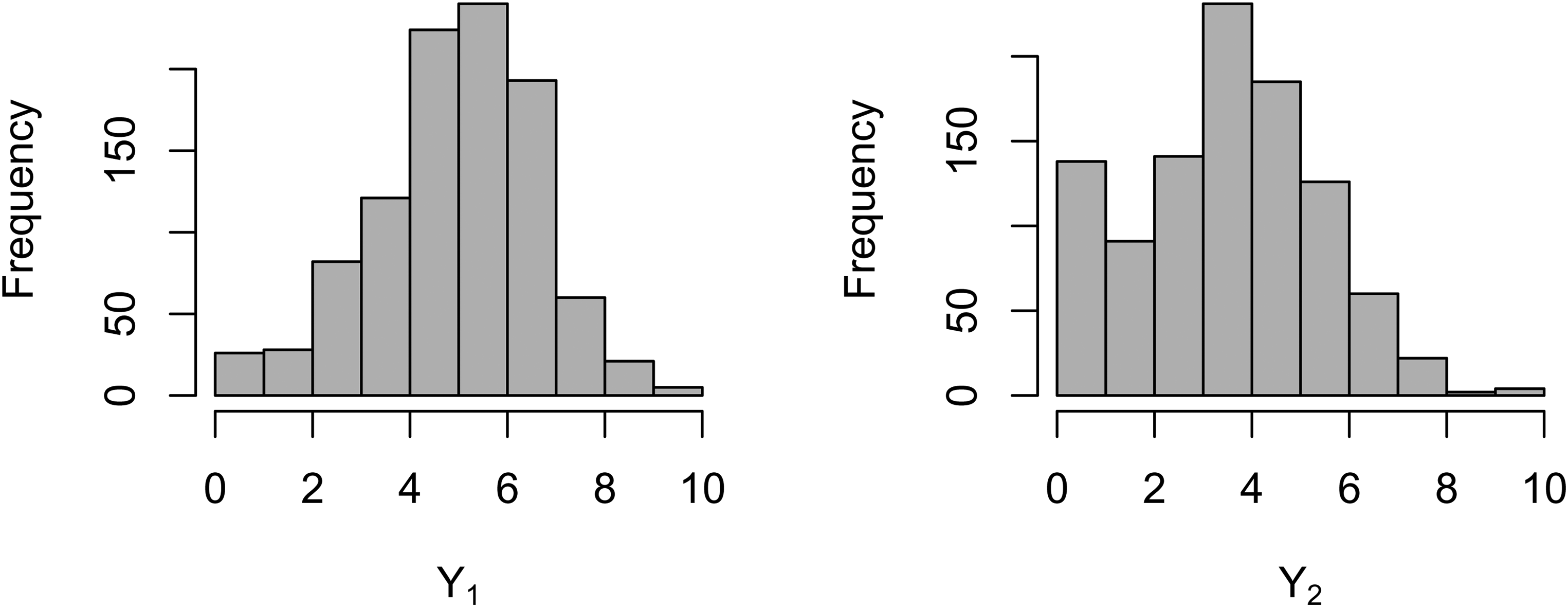
Frequency distribution of recalled words at baseline interview.
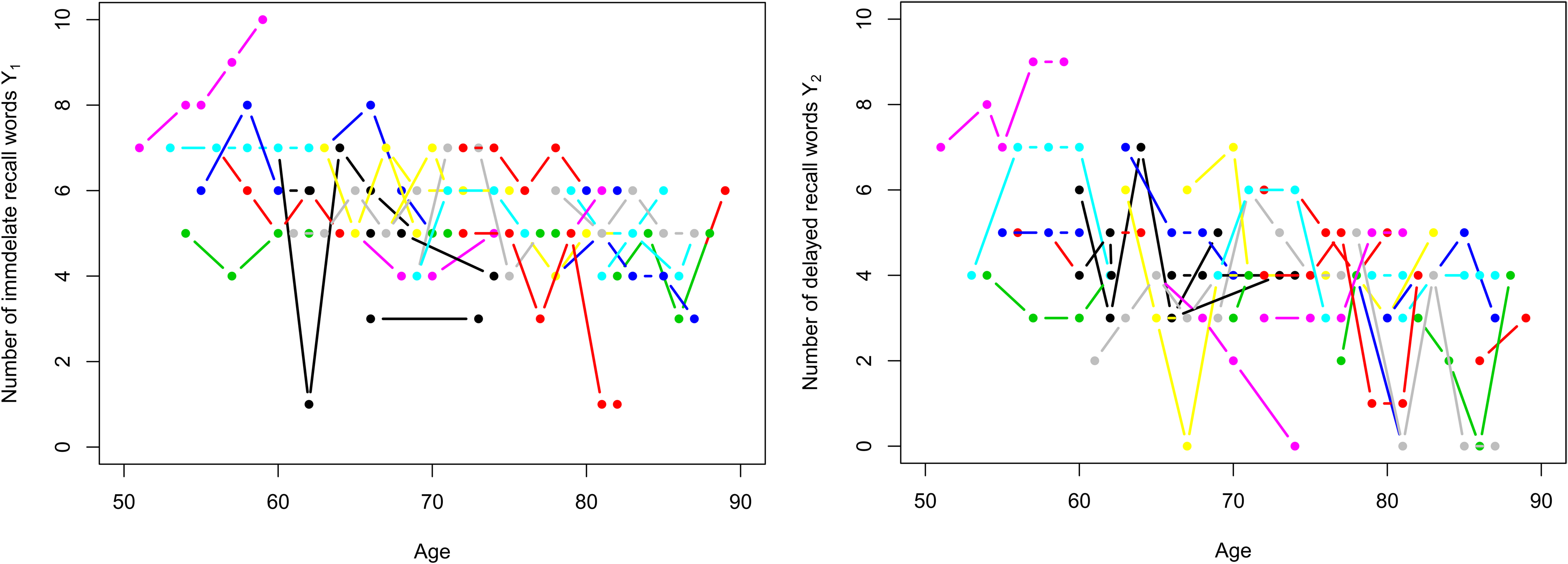
Recalled words trajectories. Left-hand side: immediate-recall words
The joint model in this subsection uses the extension of bivariate binomial distribution mentioned in the the ‘Longitudinal model section; the Gompertz hazard model and the Weibull hazard model mentioned in the the ‘Hazard models section. The longitudinal model and the survival model are joined together given the normally distributed bivariate random effects. The joint model mentioned in this section is divided into two main parts: the first part is a bivariate extension model based on the univariate model proposed in Van den Hout and Muniz-Terrera’s paper 4 ; the second part contains joint models constructed based on the link functions we discussed in the ‘Link between the models section.
Van den Hout and Muniz-Terrera constructed a univariate shared random-effect joint model with binomial distribution and beta-binomial distribution. 4 Here, we would like to use a similar method, i.e. a shared random-effect method, to construct bivariate joint models. Although we use different distributions and have different numbers of responses, because the same shared random-effect method is applied, we think it is still worthwhile to construct a bivariate model with a similar structure based on this univariate model in Van Den Hout and Muniz-Terrera. 4 We use the same structure with random intercept and random slope as in Van Den Hout and Muniz-Terrera 4 for one of the responses, and the other response is modelled with fixed effects.
For the univariate joint model in Van Den Hout and Muniz-Terrera
4
, the estimation of 
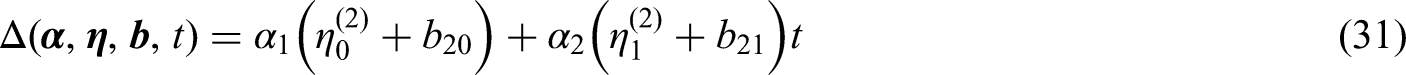
ELSA: Parameter estimates for the bivariate extension of the joint model in paper. 4 The values in parentheses are the standard errors of the corresponding parameters.

The
The probability of remembering a word at baseline age (
We will now construct the joint model based on the link function mentioned in the ‘Link between the models section. Our joint model consists of the bivariate extension binomial distribution as the longitudinal model and the Gompertz hazard or the Weibull hazard as the survival model. Gender is added to the model as a covariate (0 for women, 1 for men). The corresponding logistic regression model and link function is given by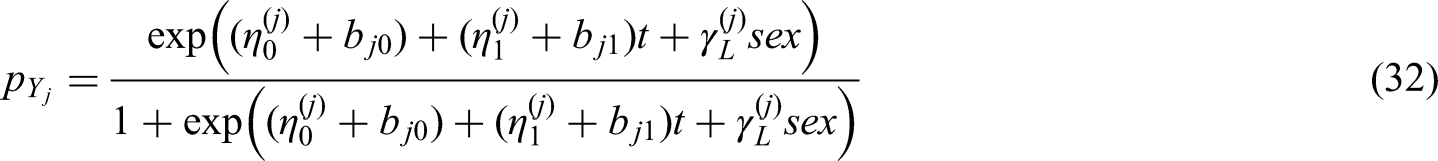
We also add gender to the link function 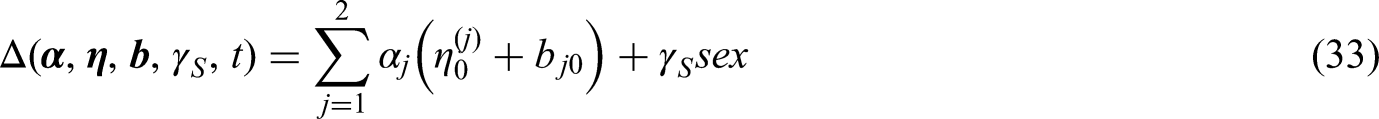
We use
The Akaike information criterion (AIC) values and the corresponding parameters of link function
ELSA: AIC and estimated
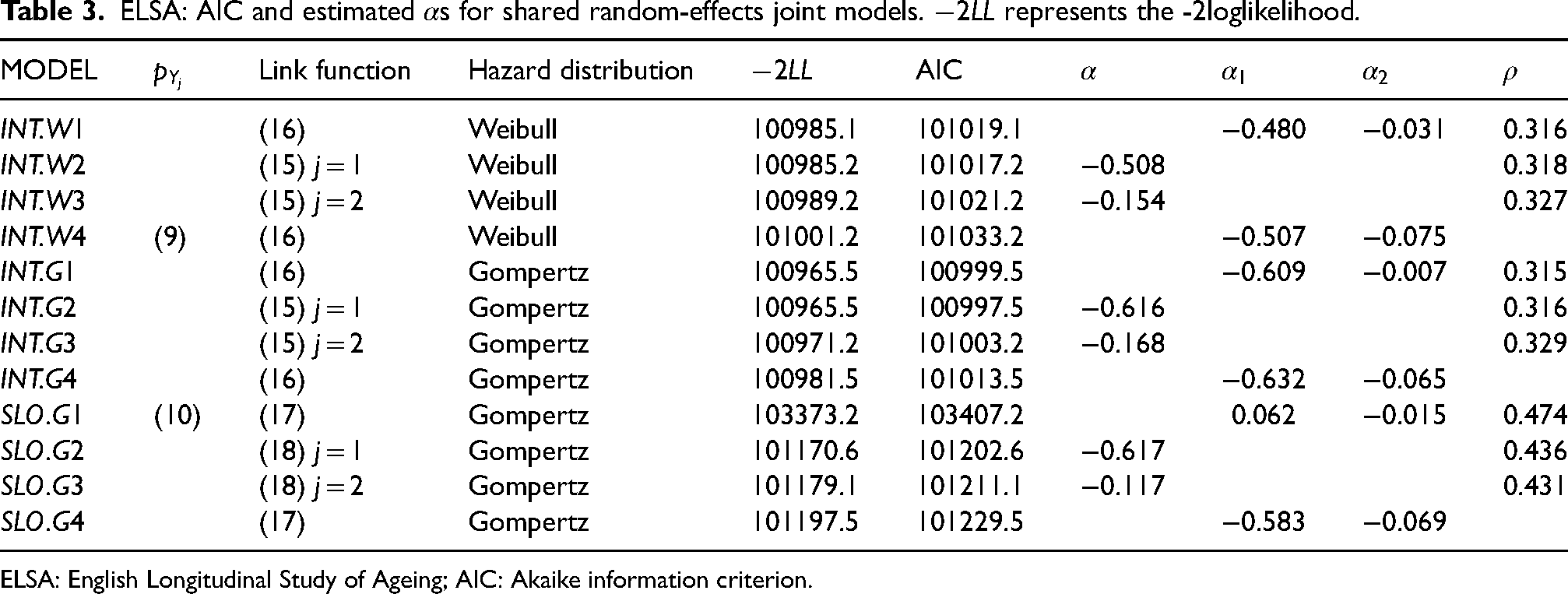
ELSA: English Longitudinal Study of Ageing; AIC: Akaike information criterion.
We expect the risk of death to be relatively lower when individuals have a good cognitive function at baseline age or the downward trajectory over time of cognitive function is slow. For all models except Model
When the link function has random slopes for both responses (17), the model’s estimate of
In general, the AIC value for the model with random intercept (e.g. Model INT.W2) is smaller than that for the corresponding model with random slope (e.g. Model
The joint Model INT.G2, using the Gompertz survival model with link function (15) for In Table 4, we have
Compare with the probability of remembering a word ( For the Gompertz hazard model, we rewrite the hazard model based on (25): In Model In Table 3, we have
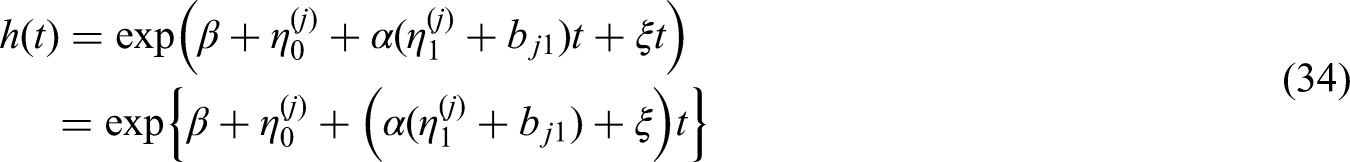

ELSA: Parameter estimates for Model INT.G2 with (15) j = 1. The values in parentheses are the standard errors of the corresponding parameters.
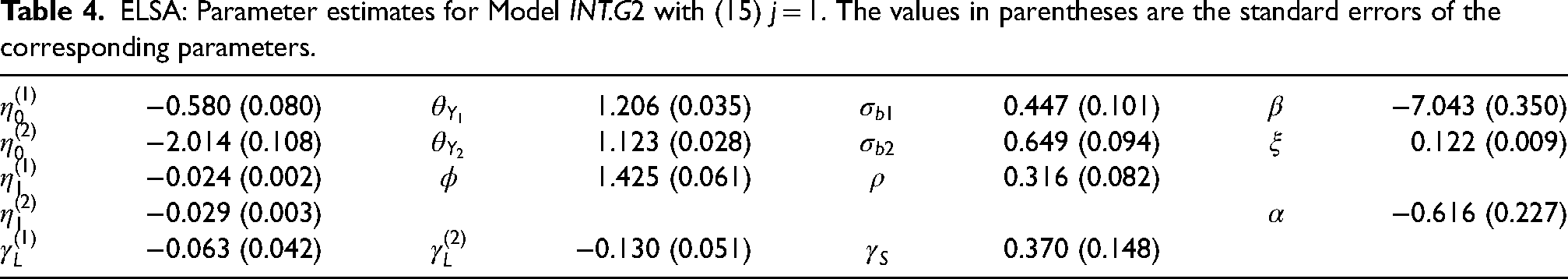
In order to investigate model fit, in this section we will first calculate the corresponding individual-specific random effects and then plot the fitted distribution based on the mean of random effects. After that we will discuss the accuracy of model predictions by comparing the predicted survival curves with the observed survival curves.
Denote the responses for individual 
We draw the three-dimensional plot Figure 4 of the bivariate binomial distribution based on the result in Table 2 with random effect
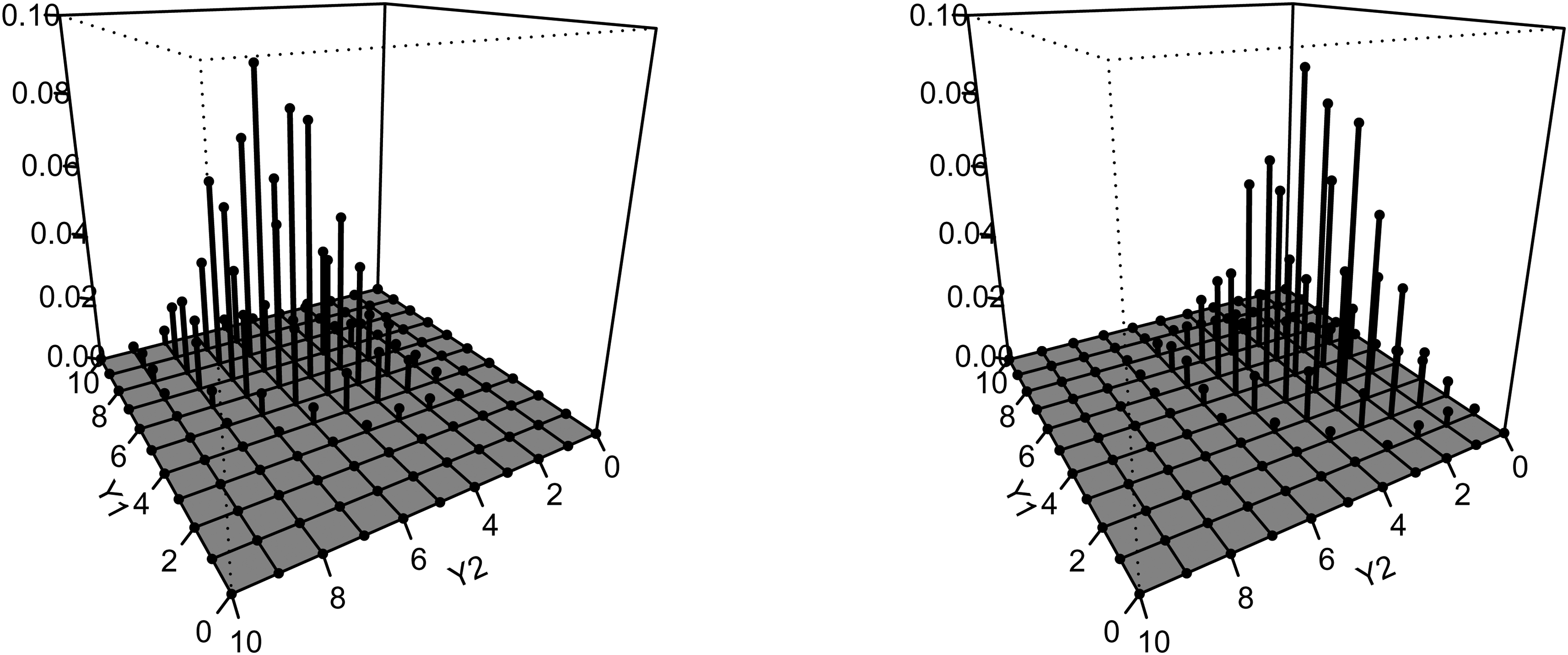
Fitted bivariate binomial distribution for immediate recall (
Given the observed age and corresponding responses, we expect that our joint model can predict the risk of death. To prove this, we plot predicted survival curves based on the calculated random effects and compared these curves to the observed survival curve (i.e. the K-M curve). Figure 5 shows the comparison of Kaplan–Meier survival curves and predicted model survival curves based on Model INT.G2 with (15)
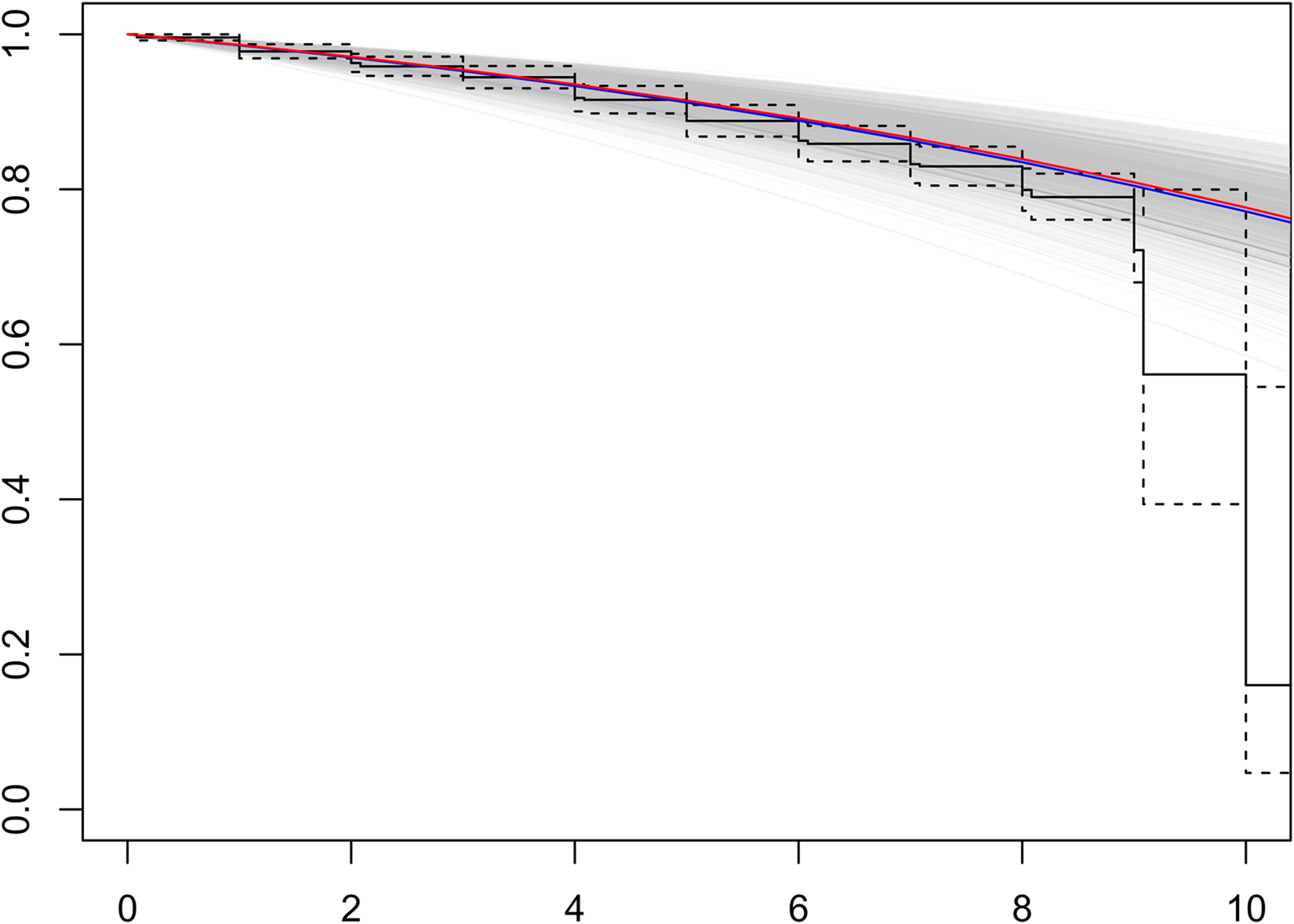
Comparison of K-M survival curves: predicted survival curves (grey lines), the mean of those survival curves (blue line) and the median of survival curves (red line).
Joint models are constructed to analyze longitudinal and time-to-event data in ageing research. Since the tests used in the application are based on discrete values, and we are interested in two tests, the bivariate extension of the binomial distribution with mixed-effects regression is specified to model the longitudinal data. The bivariate extension of the binomial distribution allows modelling for correlation between the responses. The Gompertz hazard model and the Weibull hazard model are explored for the time-to-event data. The two models are joined together via the link function
The joint model is used to analyze the ELSA data. Model comparison is undertaken by applying the Akaike information criterion. The AIC of the joint model with random intercept link function is smaller than the joint model using random slope link function, based on the same expression. When the link function equals to random slope for both responses, we got unexpected results: the slowly decline of the cognitive function over time is correlated with the high risk of death or dementia. The cause of this phenomenon needs further investigation.
We used the shared random-effects model to construct joint models in this paper. This model offers a flexible way to measure the correlation between the responses and the risk of event, i.e. the random effect follows a distribution instead of being equated to a fixed value. Instead of using random effects to capture correlation between responses, the joint model in this paper uses a separate parameter to model the correlation between responses. This allows us to more clearly identify the relationship between two responses.
Our modelling framework has some disadvantages. Firstly, it is computationally intensive since we need to calculate the double integral. Secondly, the distribution of random effects is set in advance. For example, we use the bivariate normal distribution in this paper. The multivariate normal distribution is the standard modelling choice for random effects in longitudinal submodels. 3 Pantazis and Touloumi 45 investigated the misspecification of the random effects distributions. They conclude that the fixed effects parameter estimates are fairly robust, except for the parameter estimates in the time-to-event sub-model. However, the SEs may be underestimated for severely skewed distribution. If the actual distribution is different from the normal distribution, it may lead to biased estimates.
There are still some aspects that can be used as starting points for further research. Firstly, we use linear predictors and logistic regression to model the probability in the bivariate binomial distribution. In further research, the linear effect of age in the logistic regression can be modelled more flexibly by using B-splines or other semi-parametric methods. Secondly, there are restrictions imposed by the shared random-effects model, which we have discussed earlier in this paper. Thirdly, in this paper, we construct a bivariate joint model whereas in longitudinal data there may be more than two responses. It is possible to construct the corresponding multivariate extended binomial distribution based on Altham and Hankin, 30 and use this distribution in our joint model. However, this will imply a computational challenge with respect to integrating out the random effects. An alternative might be to use a Bayesian approach; for a recent development in this area see the JMbayes package. 25 Lastly, as we mentioned in the ‘Models section, our framework is flexible in its choice of parametric hazard models, i.e. it is easy to replace the Gompertz hazard model and the Weibull hazard model by other parametric hazard models. Joint models using other parametric hazard models are worth being investigated.
To conclude, in this paper we construct a bivariate joint model to investigate the change in cognitive function. This bivariate joint model is general and can be used in a wide range of bivariate discrete-valued tests in ageing research. We discussed the shared part which is contained in both the longitudinal model and survival model. We hope our discussion will provide ideas for constructing other bivariate joint models in ageing research.
Footnotes
Acknowledgements
The authors really appreciate researchers in the University College London, NatCen Social Research, and the Institute for Fiscal Studies, who collect the ELSA data and make it available to PhD students and researchers. The ELSA was developed by a team of researchers based at the University College London, NatCen Social Research, and the Institute for Fiscal Studies. The data were collected by NatCen Social Research. The funding is currently provided by the National Institute of Aging (R01AG017644), and a consortium of UK government departments coordinated by the National Institute for Health Research.
The authors would like to thank the reviewers for their comments on our manuscript. We have learned a great deal from their feedback, which has enabled us to improve the manuscript considerably and allowed us to take note of relevant issues in our future research work.
Availability of data and materials
The authors do
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.