
Abstract
No single study has collected data over individuals’ entire lifespans. To understand changes over the entire life course, it is necessary to combine data from various studies that cover the whole life course. Such combination may be methodologically challenging due to potential differences in study protocols, information available and instruments used to measure the outcome of interest. Motivated by our interest in modelling blood pressure changes over the life course, we propose the use of Bayesian adaptive splines within a hierarchical setting to combine data from several UK-based longitudinal studies where blood pressure measures were taken in different stages of life. Our method allowed us to obtain a realistic estimate of the mean life course trajectory, quantify the variability both within and between studies, and examine overall and study specific effects of relevant risk factors on life course blood pressure changes.
Keywords
1 Introduction
Most evidence about changes over the lifespan in markers of physical function has been produced either by comparison of cross sectional data at different points in time or by longitudinal studies with limited follow-up. The comparison of cross sectional data can produce misleading results as samples compared over time may differ due to differential dropout, study design, cohort effects and eventual changes in measuring instruments. Although some of these are factors that also affect longitudinal studies, longitudinal data offer the opportunity of investigating population and person level changes in the outcome of interest. Yet, most longitudinal studies conducted so far have limited follow-up. Although studies exist (1946 British birth cohort, 1958 British birth cohort) where individuals have been followed since birth, study participants have not yet reached old age. Therefore, to describe changes over the entire lifespan, it is necessary to combine data from studies where individuals have been assessed during different stages of life.
The combination of data from longitudinal studies, as of cross sectional studies, is methodologically challenging. As mentioned before, studies will be likely to differ in their design and these differences will need to be taken into account in the models. For example, some samples may be age homogeneous at study entry, whilst other samples may be conformed by an age heterogeneous group; some samples may be population representative whilst others may be selected samples; and some studies may be gender specific whilst other studies may include both men and women. It is likely that in some situations, studies may have employed different instruments to measure the same variable of interest. Furthermore, these differences may be present within the same study when instruments were changed in the different data collection waves. For instance, as more technologically advanced devices became available, a switch in the measuring device used to measure blood pressure occurred between the 1982 and 1989 assessments in the NSHD 1946.
Longitudinal data are often modelled using parametric random effects models, 1 as these models permit the description of mean change whilst informing about variability across individuals about that mean change. However, standard parametric formulations of random effects models may be inappropriate for the description of change of some biological markers as most of these parametric formulations produce unrealistic trajectory shapes.2–4 Non-parametric formulations of random effects models are a more flexible alternative for the description of change of biological markers. In particular, splines 5 are an appealing and computationally efficient alternative that can be used to smooth noisy data. Initially an approach where a spline with a fixed and predetermined number of knots could be used to model the data; however, the choice and location of these knots may influence the estimation of the smoothed line. For example, a large number of knots would produce a very detailed line whilst a small number of knots may not capture the pattern of change sufficiently well.
To overcome these difficulties, DiMatteo et al. 6 proposed the use of Bayesian adaptive splines to fit curves with free knots to data drawn from an exponential family. In DiMatteo’s proposed method, reversible jump Markov chain Monte Carlo (RJMCMC 7 ) allows the number of knots, as well as their locations, to be estimated as model parameters; hence the spline’s level of detail adapts to the information present in the data. A prior distribution is required for the number of knots, their locations, the corresponding spline coefficients and the residual standard deviation. DiMatteo et al.’s chosen prior allowed the joint marginal posterior distribution for the number and location of knots to be obtained analytically (by integrating out the other parameters), allowing for efficient exploration of that marginal posterior by the RJMCMC method. Note that RJMCMC can be difficult to implement and often relies on the model being mathematically tractable in some way. DiMatteo et al. applied their approach to single studies, but it is not applicable in hierarchical settings, as are discussed in this paper.
In this paper, motivated by our interest in understanding changes in BP across the life course, we extend DiMatteo et al.’s method by incorporating a hierarchical structure to combine data from multiple longitudinal studies thus covering the entire life course. To the best of our knowledge, ours is the first attempt to model trajectories of a biomarker over the entire life course. Previously, Wills et al. 8 modelled blood pressure measures of a set of longitudinal studies that include the studies used in our work independently using splines. In this publication, random effects models that described change using cubic and quadratic polynomials were fitted to blood pressure measures and the effect of several risk factors was examined. This paper produced relevant information about study-specific blood pressure changes and the effect of risk factors on each of these studies, but did not combine the different studies. This limited the ability of researchers to examine information such as variability across the different studies and of estimating a life course trajectory.
The paper is organised as follows. In Section 2, we describe the data sets used. Then, we describe the model structure in Section 3 and present results in Section 4. We discuss results in Section 5 and provide the WinBUGS code used for the analyses conducted in Appendix 1.
2 Data
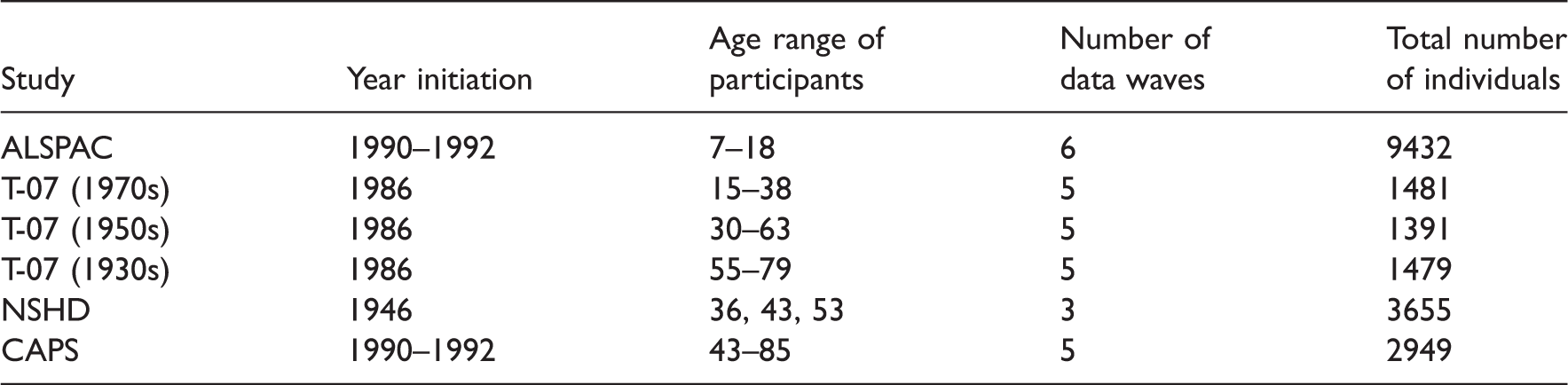
Blood pressure measures from four studies were analysed here. These studies are part of the FALCon collaboration and were selected on the basis of being funded by the UK Medical Research Council and covering different but overlapping periods of the life course with at least two measures of blood pressure. Studies included in the analysis are: (1) the Avon Longitudinal Study of Parents And Children (ALSPAC), relating to children born in Avon in the 1990s; 9 (2) the Medical Research Council (MRC) National Survey of Health and Development (NSHD) 10 of individuals born in England, Scotland or Wales in 1946; (3) the Caerphilly Prospective Study (CAPS), 11 which includes only men initially recruited in and (4) the Twenty-07 study (T-07), 12 undertaken in the west of Scotland and started in 1986. The T-07 study is formed by three age defined subcohorts of individuals born in 1970s, 1950s and 1930s that were regarded as independent studies.
Blood pressure measures were taken by trained nurses in all studies except for CAPS, where measures were taken by physicians in the first four data collection waves and by a trained field worker in the fifth wave. In most studies at least two measurements were taken at each assessment. Instead, in CAPS one single blood pressure measure was taken in all collection waves except the second when two measures were taken. At the time of taking the measures, participants were seated and allowed at least 2 min rest prior to measurement. Different devices were used over time and in the different studies to take blood pressure reading. In ALSPAC and late waves of CAPS, NSHD and T-07 an automated oscillometric (AO) device was used to take the readings, whilst a manual random zero sphygmomanometer (MRZ) was used in earlier waves of the CAPS, NSHD and T-07 studies. Specifically, in CAPS, an MRZ machine was used in the first four waves and an AO machine in the last wave. In NSHD, an MRZ machine was used in the first two waves and an AO in the third one, whilst T-07 switched from an MRZ to an AO in the third wave, when both machines were used.
Age range of individuals and number of waves within each cohort.
We derived a set of variables to account for factors known to be associated with hypertension. First, using information about social class, we derived an indicator of manual occupation at study entry. Body mass index (BMI) was calculated as
Where information about medication intake was available, blood pressure readings were corrected for medication intake using published methods 15 that assume that blood pressure from medicated individuals is higher than the observed measure. This correction was conducted by adding 15% of its value to the observed measure.
To correct for possible differences in the blood pressure measures taken in the first and second reading, we calculated the average of the two readings. Given the differences observed in blood pressure trajectories within the different studies, data from men and women were analysed separately.
3 Methods
Suppose we wish to model life course trajectories using splines in some way. As we will invariably have data on many individuals, we might consider fitting a separate spline to each individual and then characterising the population distribution of spline parameters in some way. However, this would require that all individuals share the same set of parameters, albeit with different values, which is impractical when individuals are observed over different stages of life, not least because each individual spline would have to be extrapolated into the unobserved age ranges. As an alternative, we propose using a single spline to define the population mean life course, with individuals’ departures from that mean behaviour accounted for by adding random effects to the spline rather than its parameters. We also add random effects to account for differences between cohorts/studies that are due to unmeasured covariates. A principal advantage of this approach is that the spline may be adaptive, with an a priori unknown number of knots. Individual-specific adaptive splines would have different numbers of parameters with different meanings, in general, which would preclude overall inferences.
3.1 Model description
Let 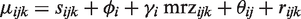
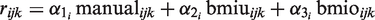
The spline sijk is a piecewise polynomial given by
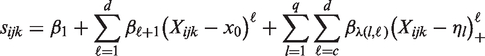
Possible differences in the variability of measurements by device were accounted for by modelling the residual standard deviation 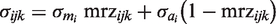
3.2 Model estimation
The model was estimated within a Bayesian framework. Analyses were performed using WinBUGS16,17 with ‘Jump’ interface installed. 18 As described by Lunn et al., 18 the reversible jump algorithm is implemented in WinBUGS16,17 to draw samples from the joint full conditional distribution of the coefficients β, knots η and number of knots q, whilst standard Gibbs/Metropolis steps are used to update the remaining model parameters. As the value of q changes during the Markov chain Monte Carlo (MCMC) simulation, so do the dimensions of β and η. One of the main challenges in such ‘variable dimension’ analyses is choosing sensible values for the spline coefficients when attempting a dimension-changing move. This is because the change of dimension necessitates a change of parameter space, which may have been visited previously (in the MCMC simulation) only rarely, if ever. Hence the MCMC sampler will have had little opportunity to learn about appropriate parameter values in the new space. This problem can be alleviated if we can derive the full conditional distribution for the coefficients in closed form, since appropriate coefficients can then be generated instantly for any set of proposed knots. A multivariate normal prior for the coefficients β combines with the normal likelihood to give a multivariate normal full conditional, which is straightforward to derive. In our analyses the prior mean and variance for each coefficient are 0 and 1002, respectively.
As the age range was scaled to the interval (0,1), we chose a Unif(0,1) distribution as a prior distribution for the location of each knot. The RJMCMC algorithm considered here increased the model flexibility with regard to the number of knots of the model. However, it requires a prior distribution for the number of knots q. We chose a Poisson prior with mean 3 as this distribution represents our a priori expectation that, after increasing throughout childhood and adolescence, blood pressure may begin to level off in early adulthood; it may then begin to increase again in middle age, with a possible further change in later life. The shape of the Poisson distribution then penalises large numbers of knots, which encourages parsimony.
The individual- and study-level random effects (or their logarithms) were assumed to arise from normal population distributions. For 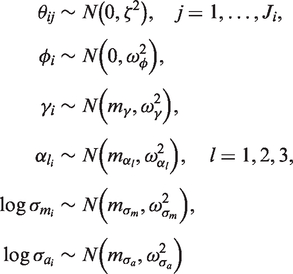
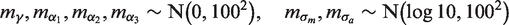
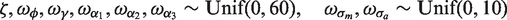
The code can be found in Appendix 1, and a graphical representation of the model is presented in Figure 1. For each analysis, two MCMC chains were simulated from different initial states. Convergence was assessed via visual inspection of the trace plots and by the Brooks–Gelman–Rubin method.19,20 The Monte Carlo standard error (MCSE) for all parameters of interest was examined periodically to ensure accurate inferences. The rule of thumb of requiring an MCSE less than 5%
21
(p. 277) was fully satisfied in our analysis, with Directed acyclic graph (DAG) corresponding to blood pressure life course model. ‘Nodes’ represent variables in the model and are joined together by arrows to show direct dependence between variables. Solid arrows denote stochastic dependence whereas ‘dashed’ arrows denote logical dependence (deterministic functions). Rectangular nodes represent covariates that have been included in the model. The rectangular ‘containers’ labelled 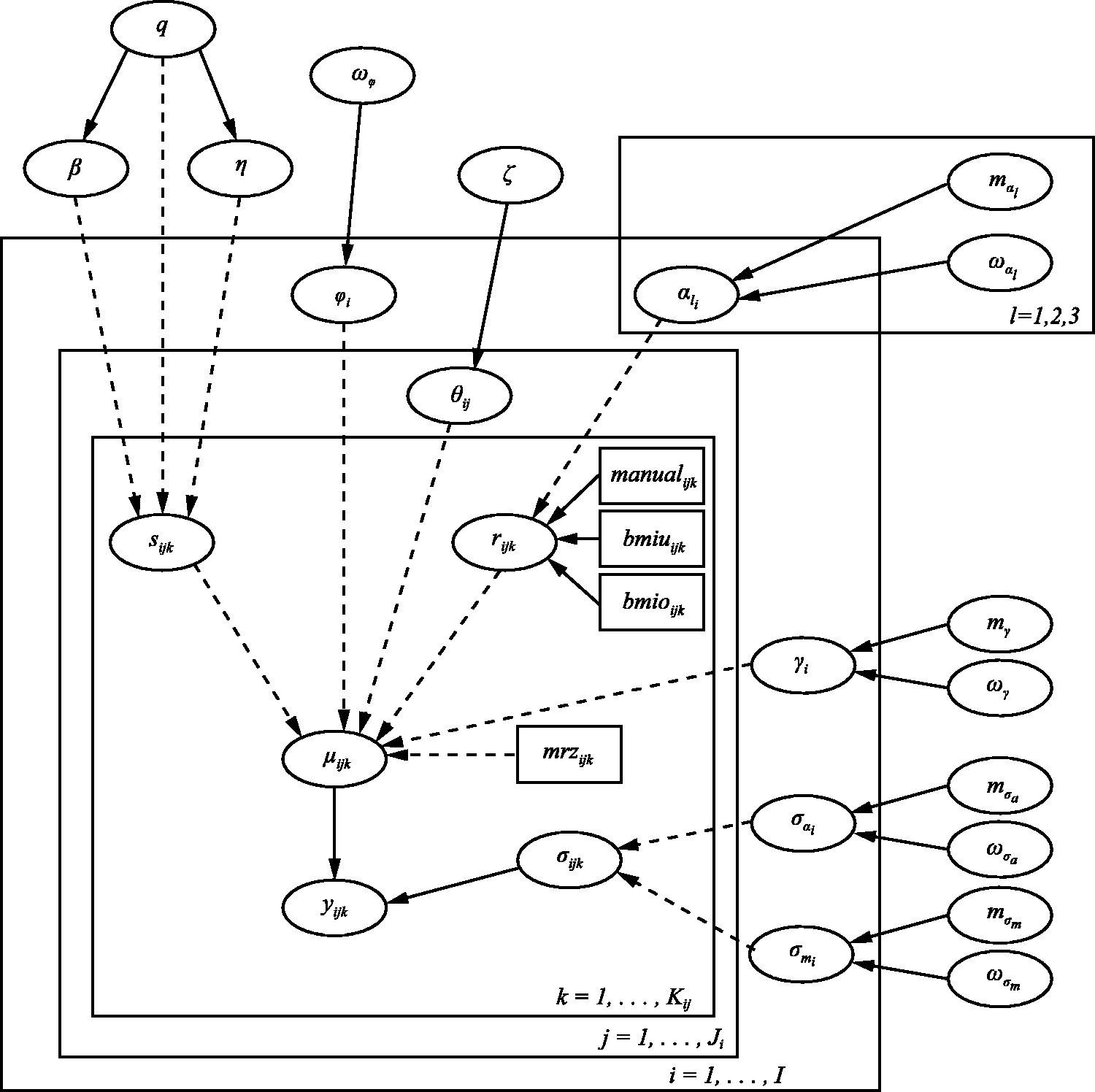
4 Results
Our results indicate that blood pressure increases with age as illustrated in Figure 2. The figure shows, for both genders, a rapid increase in blood pressure coinciding with peak adolescent growth, followed by a gentle increase in early adulthood, a midlife acceleration beginning in the fifth decade of life and a final period of deceleration in late adulthood. Following the rapid acceleration during adolescence, women typically have lower blood pressure than men (by up to around 10 mmHg), until their late 60s.
Overall systolic blood pressure trajectories, with 95% credible bands, for males (dark grey) and females (light grey).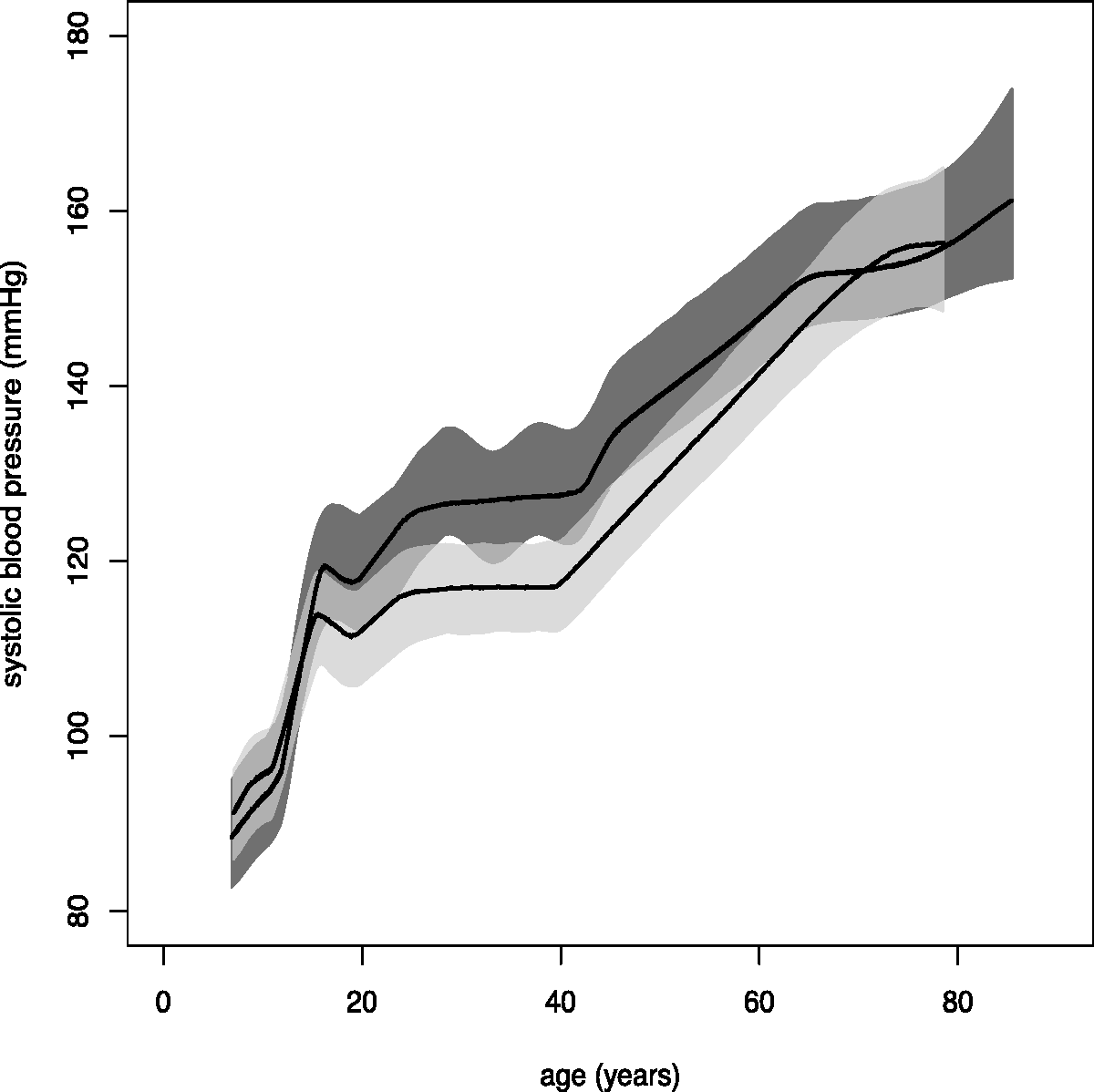
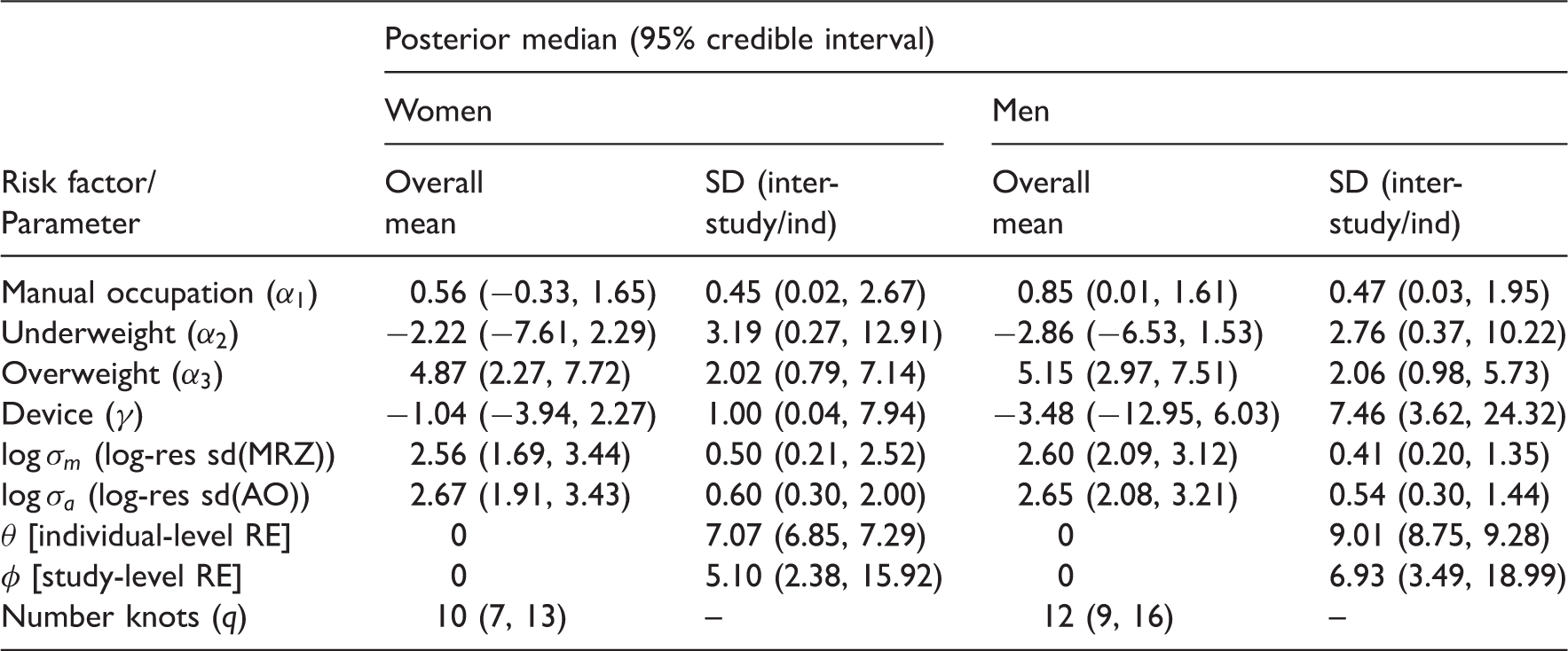
Posterior median estimates (with 95% credible intervals in parentheses) for overall parameters and inter-study/inter-individual standard deviations.
Posterior mean estimates, standard deviations and 95% credible intervals of study-specific parameters.
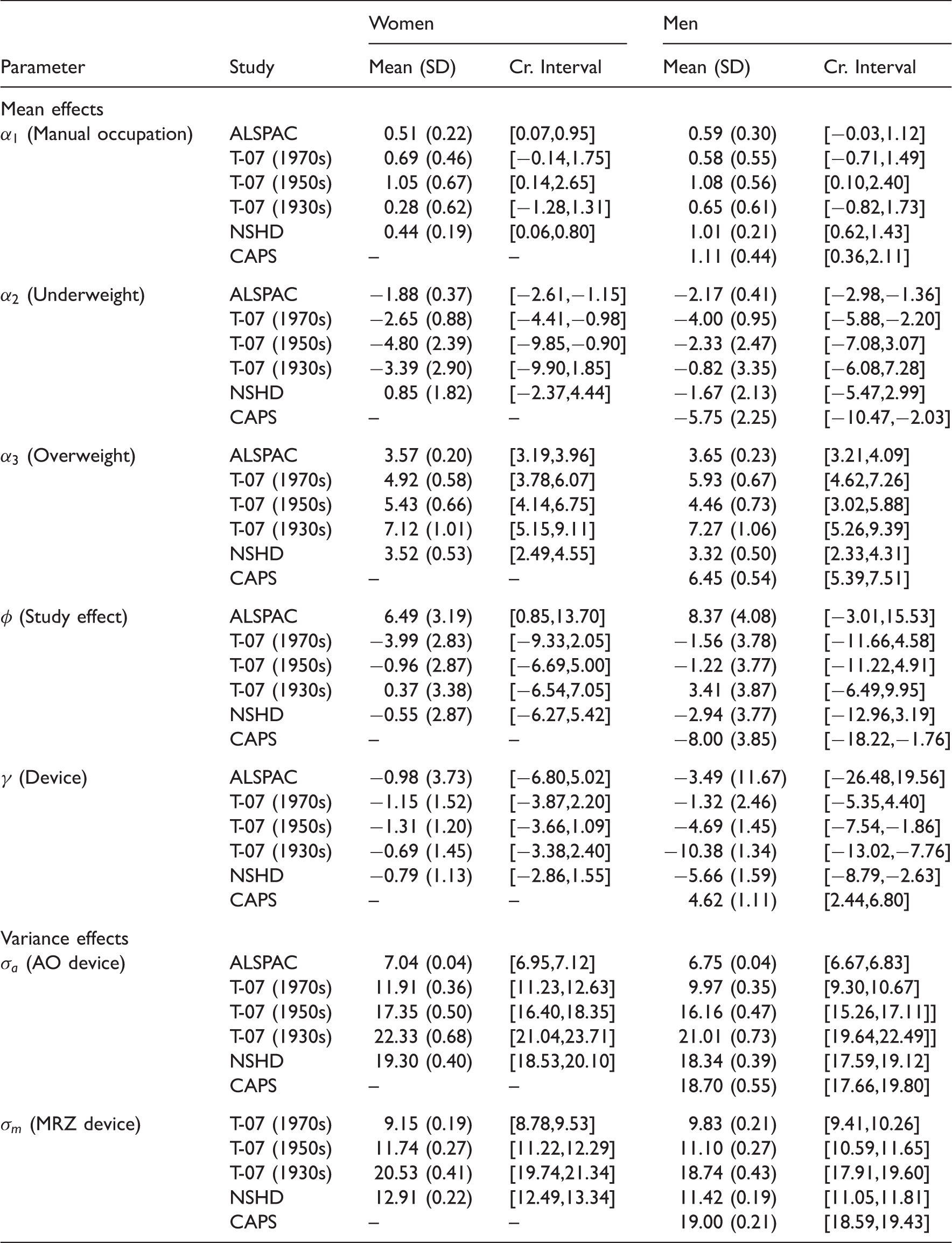
It is interesting to note that the direction of estimated study-level random effects (
Previous to the work reported here, we conducted a series of sensitivity analyses on each of the independent datasets to examine robustness of results to the method of adjustment for medication intake and to examine whether results varied if the first or second measure was modelled instead of their average. In both cases, results were robust.
Results reported here were obtained adjusting blood pressure measure for medication intake by adding 15% to the registered measure. To examine robustness of results to this method, we varied the percentage added (5, 10, 15, 20, 25%) and also added fixed constants (5, 10, 15 mmHg). Results obtained remained robust.
5 Discussion
In this paper, we propose a method to combine data from longitudinal studies of individuals in different stages of life to produce a life course trajectory. The method has been illustrated using blood pressure measures from four UK-based longitudinal studies. Our results elucidate the nature of the life course and provide scope for targeting public health interventions at specific age groups. They are also in general agreement with those reported by Wills et al., who found a rapid increase in blood pressure coinciding with peak adolescent growth, gentle increase in early adulthood, midlife acceleration beginning in the fifth decade of life and a final period of deceleration in late adulthood. In addition, they reported differences in blood pressure trajectories by gender, with a similar blood pressure level by the seventh decade. Our results show that following rapid acceleration during adolescence, women typically have lower blood pressure than men (by up to around 10 mmHg), until their late 60s. The local maxima occurring in the late teens for both genders are likely an artefact of the model rather than true maxima, as discussed below. Males with a manual occupation have higher blood pressures, as do overweight individuals from both genders. Although some cohort effects may exist on the risk factors that were not optimally considered when we opted for using cut-off points for the definition of BMI categories, our results suggest other interesting effects, such as underweight individuals having lower blood pressure and a trend between residual (unexplained) variation and age, but these have not been shown to be statistically significant.
Modelling life course trajectories is severely complicated by the fact that individuals are invariably only monitored over some fraction of their life course. In attempting to draw overall inferences about the population of interest, we might naturally wish to fit a parametric model to each individual’s data and characterise the population distribution of model parameters. However, unless the appropriate model is well established, this seems unrealistic, since in order to obtain a complete overall/population trajectory, each individual’s fitted trajectory must cover the whole life course, with much ‘borrowing of strength’ required to extrapolate into the (extensive) unobserved periods. If the parametric model is linear in the parameters, such as a spline, then one way around this might be to integrate out the individual-level parameters. However, this would require a bespoke MCMC algorithm, particularly if the number of knots is unknown, as here, rather than the more general modelling framework offered by BUGS, say. This might exploit some aspects of DiMatteo et al.’s RJMCMC approach, but would be substantially more complex due to the hierarchical structure of our model. (Note that we would have to assume a common set of knots for all individuals.) A very basic alternative might be to simply average the observed data in each of a series of short ‘age bins’, but this would preclude the possibility of controlling for covariates, say. Instead, our approach has been to start with the population life course trajectory and account for departures away from this ‘overall’ behaviour, due to variability between cohorts and individuals within cohorts, say, by adding random effects. Such an approach is limited, however, by the additive nature of the random effects. For example, excepting the effects of covariates, an individual can only deviate from his/her cohort’s overall trajectory, and that cohort can only deviate from the ‘global’ trajectory, by a constant amount (not changing with age). We could explore the inclusion of multiplicative random effects also, but the model’s flexibility would still be limited.
A principal objective of this work has been to avoid the need for strong parametric assumptions regarding the shape of the fitted trajectory whilst accommodating possible risk factors. By assuming the number and location of the spline knots to be unknown, the spline’s ‘smoothness’ is not pre-determined and it can adapt itself to the information in the data; estimation is thus largely data driven. As a consequence, the methodology is applicable to much smaller data sets than those considered herein, although the level of detail in the fitted curve will be reduced accordingly. We chose to use a linear adaptive spline, as opposed to a quadratic or cubic spline, say, because then the knots correspond directly to change points in the fitted trajectory, whereas higher order splines can change direction away from the knots (the change points also tend to be more ‘visible’ with a linear spline). This aids in the specification of a prior distribution for the number of knots and in the interpretation of the fitted trajectory. We note, however, that extensions to higher order splines are straightforward. In our work, a larger than initially expected number of knots was estimated (12 for men and 10 for women). This may be a consequence of the large amount of data included in the analysis, which allows even small variations in the data to be tracked inexpensively by the spline.
In our analyses, the estimation of study-level random effects (
The introduced methodology assumes that missing information on blood pressure measurements is modelled as missing at random. Although a missing at random missing data assumption is likely to be plausible in the younger cohorts, it may not be realistic in the older cohorts as individuals with higher blood pressure are more likely to dropout of the studies. Extensions to the proposed method are under consideration to account for informative missing data.
Footnotes
Acknowledgements
The FALCon researchers are: Avan Aihie Sayer,Yoav Ben-Shlomo, Michaela Benzeval, Rachel Cooper, Rebecca Hardy, Diana Kuh, Debbie Lawlor and Andrew Wills. We are grateful to all of the participants in the Study and to the survey staff and research nurses who carried it out. The data are employed here with the permission of the Twenty-07 Steering Group. The Hertfordshire Ageing Study acknowledges the National Centre for Social Research and University College London (Department of Epidemiology and Public Health) as the principal investigators and original creators of the HSE 2005 dataset, and the depositors of this dataset with the UK Data Archive, University of Essex, Colchester. We are also grateful to two referees, whose comments helped us improve on an earlier version of this paper.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by a UK Medical Research Council Population Health Sciences Research Network (PHSRN) grant. The West of Scotland Twenty-07 Study is funded by the UK Medical Research Council (WBS U.1300.80.001.00001) and the data were originally collected by the MRC Social and Public Health Sciences Unit. The Caerphilly study is funded by the Medical Research Council Epidemiology Unit and in Speed well by the district health authorities. The ALSPAC study has the financial support of the Medical Research Council, the Wellcome Trust, UK government departments, medical charities and others. The NSHD study is funded by the Medical Research Council. The Information Centre for Health and Social care was the original source of funding for the HSE 2005. All authors are supported by the UK Medical Research Council: E. Bakra, G. Muniz-Terrera, F. E. Matthews (U105292687) and D. J. Lunn (U105260557).