
Abstract
The aim of the paper is to define Artificial Intelligence (AI) for librarians by examining general definitions of AI, analysing the umbrella of technologies that make up AI, defining types of use case by area of library operation, and then reflecting on the implications for the profession, including from an equality, diversity and inclusion perspective. The paper is a conceptual piece based on an exploratory literature review, targeting librarians interested in AI from a strategic rather than a technical perspective. Five distinct types of use cases of AI are identified for libraries, each with its own underlying drivers and barriers, and skills demands. They are applications in library back-end processes, in library services, through the creation of communities of data scientists, in data and AI literacy and in user management. Each of the different applications has its own drivers and barriers. It is hard to anticipate the impact on professional work but as information environment becomes more complex it is likely that librarians will continue to have a very important role, especially given AI’s dependence on data. However, there could be some negative impacts on equality, diversity and inclusion if AI skills are not spread widely.
Keywords
Introduction
Many technologies pass through a ‘hypecycle’ of hope and disillusion before they may come accepted into common use, but the current wave of excitement (and anxiety) around Artificial Intelligence (AI) is remarkably strong. In the UK, for example, there is a national strategy for AI, but many other institutions, such as the National Health Service, have their own. UKRI the main research funding body has an AI strategy; as does JISC the national body supporting digital solutions for UK higher and further education and research. The same is true for many other countries: at the time of writing the OECD AI policy observatory lists over 700 policy initiatives from 60 countries (54 from the UK alone) (https://oecd.ai/en/). Equally, globally, there are dozens of statements on the ethics of AI from international bodies, governments, tech companies and civil society groups (Jobin et al., 2019).
The power of these narratives reflects a number of things. AI is not one technology but a bundle of technologies with general applications across many sectors of activity. Significantly, the current wave of AI is also part of a long running story that has entered the popular imagination. Unlike many other technologies there are rich cultural meanings attached to the idea of AI such as those projected through science and speculative fiction in books and movies. For example, according to a listing on wikipedia there have been at least 150 movies featuring robots and AI, since the first, Metropolis, in 1927 (https://en.wikipedia.org/wiki/List_of_artificial_intelligence_films). Different cultures have different versions of such stories (http://lcfi.ac.uk/projects/ai-narratives-and-justice/global-ai-narratives/). These stories are probably more often dystopian than utopian. Reflecting specifically on the emergence of AI based virtual assistants (VA), Moran comments that ‘The advent of AI VA is drenched with fantasy’ (Moran, 2021: 31). But as she goes on to argue there are deep biases in these fantasies that reinforce social inequalities. We could sidestep some of this debate by restricting the discussion to a less storied term such as ‘machine learning’. Yet arguably we need, even within library work, to acknowledge the hope and fear attached to the idea of AI. The questions AI raises about the nature of humanity in the context of automation relate to library work too.
At the same time the use of AI in library work is very much in its infancy (Cox et al., 2019; Hervieux and Wheatley, 2021). There is immense potential for it to increase access to knowledge in fundamental ways, for example through improved search and recommendation, through description of digital materials at scale, through transcription, and through automated translation. Equally, the use of AI in libraries poses a number of ethical issues (Cox, 2022) and there is a recurrent fear that AI may in some way replace human librarians’ work. There could be impacts on equality, diversity and inclusion (EDI) in the profession because AI is usually represented as white and male (Cave and Dihal, 2020) and as a trend it emphasises the IT aspect of library work where men are over-represented. In this context, the purpose of this paper is to build up a definition of AI from a librarian’s perspective. It draws selectively on the literature to offer an early description of what AI might mean in the library context. It is pitched at an audience of readers who think AI could be a strategic priority, rather than at a technical level. The approach is descriptive and in parts speculative, but this is justified because it is an emergent area of practice. Our approach is fourfold:
○ To analyse formal definitions of AI
○ To define some key technologies and explain how they might relate to library work
○ To identify key AI use cases in libraries
○ To reflect on the potential implications for professional work and particularly equality, diversity and inclusion within it
The paper is based on an exploratory literature review. Although systematic searches of Scopus, LISA and Google scholar were undertaken, the emergent nature of the literature prevented following a systematic SLR methodology. Firstly, there are ambiguities in the terminology about what counts as AI and many of the issues raised by previous trends are relevant, such as those around data, text and data mining and even learning analytics. Secondly, as an area of professional practice many of the most valuable resources are non-peer reviewed items, that are not visible within bibliographic databases. Thirdly, the wider technical literature is vast and hard to relate to the library context, so can only be referenced selectively.
Formal definitions of AI
An obvious starting point to help clarify what AI is for librarians would be to examine some formal definitions. There have been so many reports and strategy documents exploring AI since at least 2018 with most containing their own explicit definition of AI (but also acknowledging the disagreement about its definition). Box 1 includes just a few of these.
Definitions of artificial intelligence.

Examining these definitions, some common patterns emerge. One is that many are rooted in the idea that AI has the ‘ability to perform tasks’ that humans normally do (A, B, C, F, G). The exact list of sensory or cognitive processes varies (emotion is not mentioned) but these tend to imply quite high order activities. Definition A seems to link to specific classes of technologies. Definition B stresses the idea of computers learning and I gives more detail on how this might work. H in contrast uses the word ‘imitate’ to stress the difference between actual human intelligence and AI and imply the latter’s inferiority. ‘D’ stresses that humans control the whole process. Definition E is a bit different placing stress on an infrastructure of data, algorithms and computing power, usefully emphasising the importance of data to AI. But certainly an implicit concern in nearly all the definitions is to relate AI to human capabilities. The list in F (from a UK research funding body) is perhaps the most expansive, acknowledging ways it might surpass human capabilities or perform tasks, such as creativity, often seen as beyond computers. However, there is relatively less consideration across the definitions of the way AI might do things humans do not or could not do, or doing things in usefully non-human ways (bias is very human!). What is apparent is that the definitions are quite abstract and open ended. They tend not to specify technologies, reinforcing that AI is an idea, and one that is evolving and also suffused with cultural meaning and significance that even in its most professional applications cannot be ignored.
Evidently, AI is something to do with technologies that either perform or at least imitate human sensory or cognitive processes. Just as importantly, it is an evolving idea with rich cultural meanings attached to it. Yet such definitions only take us a small way to understanding their relevance to libraries. If abstract definitions of AI only offer a broad picture of what it is, perhaps we can turn to an analysis of underlying technologies to understand how library work might be affected by them.
AI technologies
AI is a broad term that encapsulates a range of approaches, machine learning being one of the most important of them (Hu et al., 2019). Machine learning is the use of statistical techniques to derive models from data without the need to program parameters of the model (Valiant, 1984). In contrast to machine learning, traditional computer programmes are developed by programmers who define the rules and parameters for the models, drawing upon their experience, understanding and analysis of the data. This involves the process of discovering relationships between predictor and response variables using statistical methods (Hastie et al., 2009; Witten and Frank, 2002). A generic Machine Learning approach requires completion of this set of tasks: collection and preparation of data, selection of appropriate features (e.g. which variables are relevant), choice of machine learning algorithm, selection of models and parameters, training and performance evaluation (Alzubi et al., 2018). In machine learning, this process is automated to enable the machine to discover patterns, set rules and parameters of models by studying the data. Machine learning thus involves developing models that have been influenced by the data that has been fed-in and therefore, the role of data is critical.
Critical to machine learning is allowing the computer to discover, ‘train’ it to develop a model within data. The process of training involves the machine using historical data as inputs and learning patterns from them to fine-tune model parameters in an iterative manner to ensure a reasonable (pre-defined) level of accuracy in estimating an output for an unknown input. For example, a machine learning model might use historical data on visitors to a library together with weather and events information as an input dataset in order to develop a model to predict how many visitors could be expected in a given day. This is an example of a supervised machine learning task, where a training dataset is used to train the model, and then to predict outputs for an unknown dataset. Where the machine learning model does not require previous examples to learn from, unsupervised machine learning methods are used. An example of this could be a clustering task where a large number of visitors regularly attend a library, seeking different services and there is a need to automatically segment the visitors into different categories. Semi-supervised learning is another type of machine learning that is used when sufficient training examples do not exist or are difficult to create. In cases such as these, a few manually labelled examples (from a larger collection) can be used to train a model, which is then used to predict outputs for a large number of unknown examples. The original labelled dataset can then be combined with the outputs that have the highest confidence to create a larger training dataset to improve the model. For example, in a use case of categorising millions of large documents into different genres or categories, it is difficult to create a large enough sample of examples to learn from. In this scenario, a fewer number of hand-created examples could be sufficient to develop a larger training dataset. Another type of machine learning involves reinforcement learning, which does not require training data but the model learns through a system of rewards for positive responses and corrections where responses suggest a mismatch. For example, a real-time recommendation system could train itself based on user interactions to identify which types of content they are likely to engage with and which ones they would reject.
While we have explored the different AI approaches in terms of how they function/are designed, it might also be interesting to explore the possible application contexts based on the data itself. For example, employing Natural Language Processing (Olsson, 2009) to quickly analyse large volumes of unstructured text from unknown datasets could offer an insight into the content, sentiment and genre of the text. Topic modelling (where a model uses statistically significant keywords) can help explain how the different topics in the collection have evolved over time. Using speech recognition, oral history recordings could be converted to digital text, which then can be indexed, for future retrieval or analysed for understanding topics of discussions, or identifying specific mentions of names, places or events (using named entity recognition). Handwritten manuscripts, through a process of optical character recognition could be digitised into text, which could be further indexed or analysed to determine topics of interest or entities. Images (photographs or collections) could be analysed to identify specific objects and entities to support more accurate retrieval. This could be done by training existing manually annotated images as training data for deep neural networks to identify known objects in large image collections. Such automated processes can sift through a large number of documents and offer recommendations on the most appropriate descriptors or keywords for cataloging. The range of applications of AI can be wide-ranging, for example, in classification of books (using Natural Language Processing), managing repositories and library resource usage analysis, metadata services and citation analytics (text data mining), preservation and archival of imagery and video library databases (image processing) and so on (Ali et al., 2020).
A slightly more holistic application of AI systems is the example of digital assistants in consumer devices such as Amazon Alexa or Google Assistant, where a system interacts with a user to simulate a conversation or at least respond to questions and offer guidance on a collection (Aghav-Palwe and Gunjal, 2021; Seeger et al., 2021). Such systems combine a range of AI technologies such as speech recognition, recommender systems, natural language processing to deliver an enriched experience for users. Other systems that combine multiple AI technologies could also focus on a specific aspect of the library system such as the search engine, for example, the CiteSeerX system using AI to extract metadata, de-duplicating documents, author disambiguation and table extraction (Wu et al., 2015). The possibilities, therefore, of libraries engaging with AI technologies, although yet to become mainstream are immense. Furthermore, most of the examples given so far refer to applications of AI to data from libraries themselves. In reality, the library role may be more general. Services such as to discover and license non library data may be more likely services that libraries will provide in the context of AI. Here it is the data stewardship and governance functions of libraries that will be central. As well as coming to see library collections as themselves data; what is in the collection may be expanded to include data, with library notions of collecting therefore shifting. They can also manage data through the whole lifecycle from creation through to preservation.
Robots are physical machines that are programmed to carry out a series of actions in an autonomous way. Often these are simply repeated without learning, but AI can be combined with robotics. For example, a robot picking items in a warehouse might use an algorithm to select the best path to navigate around the warehouse or to learn to place items in different places based on their attributes. In this paper, because we are trying to think inclusively about the AI field, we have included some examples of robots in a library context.
This section has established in a general way how AI techniques may touch library work. But it does only begins to hint at how libraries and library work might change in practice. The next section examines practical examples of application organised by the area of library operation.
Library applications
This section examines more closely the range of specific AI applications that seem to be emerging as relevant to libraries today. It builds and extends a few other attempts to define the range of AI applications in libraries, such as in Cox (2021), Hervieux and Wheatley (2022) and Huang (2022). The approach taken here is to adopt an expansive and inclusive definition, as a way to help the reader navigate the breadth of what is a rather complex scene. In particular library sectors some applications may feel much more relevant, for example knowledge discovery applications in research libraries and archives. Public libraries are arguably more likely to be centrally concerned with the links between AI and information literacy. Our purpose is to paint the widest picture so we can gain an understanding of change across the sectors.
We suggest here that there could be five conceptually different use cases of AI in libraries. Table 1 summarises these, with some indication of the skills and knowledge required (column C), key drivers (column D) and barriers (column E). Our taxonomy is organised not by differing technologies but more by which aspect of library work is impacted (column B).
Use cases of AI in libraries.
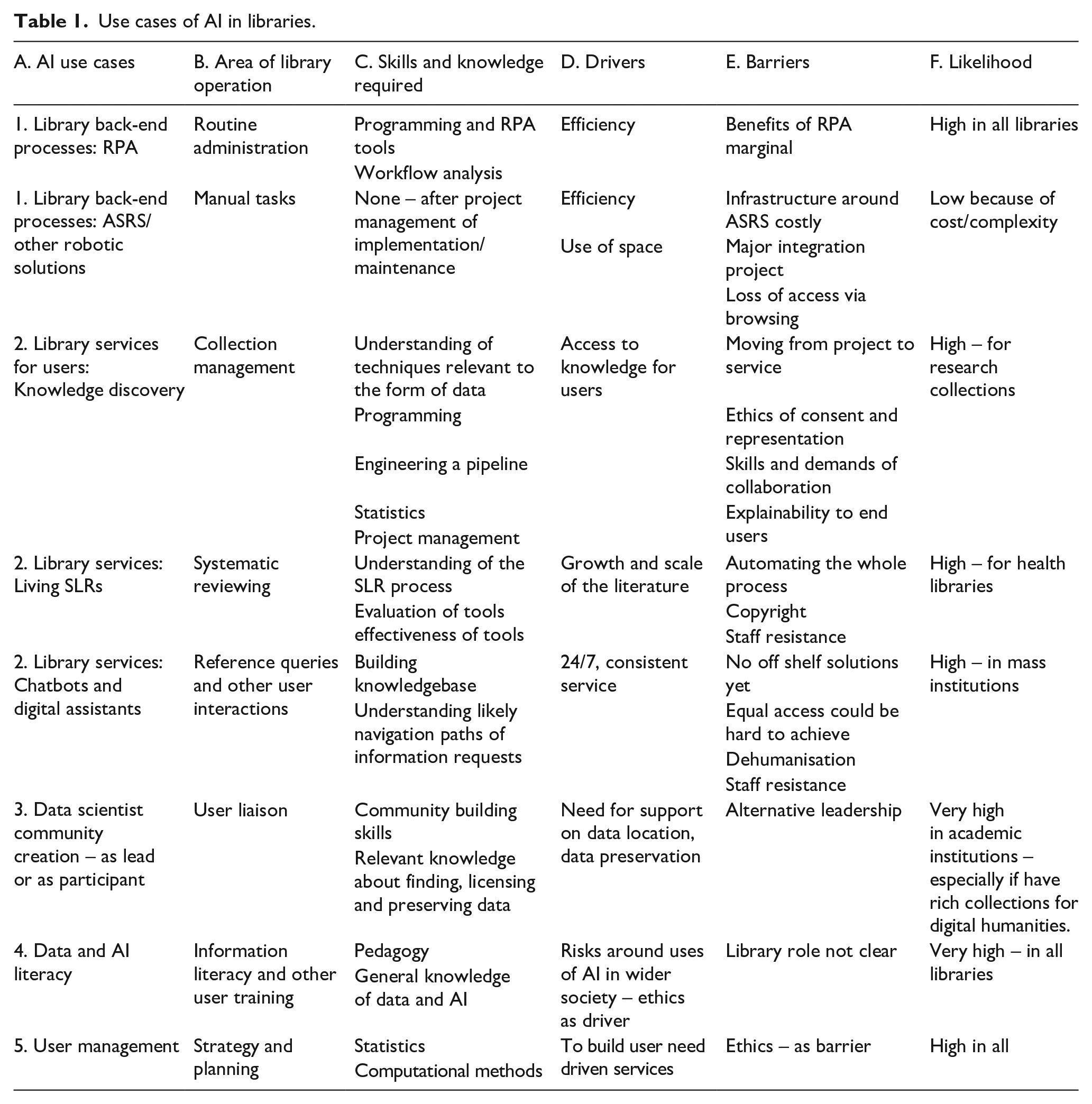
Use case 1: Application of AI to backend library operations
This is where AI is applied to routine clerical and manual tasks. Two contrasting examples can be identified: one is the use of Robotic Process Automation (RPA) in automating often repeated clerical tasks (Lin et al., 2022; Milholland and Maddalena, 2022). RPA allows one to get a computer to perform tasks usually performed manually which involve a set of repetitive steps where limited human judgement is required to manipulate text or other data, such as to take data from a number of sources, process it in some way and record the output. Such applications are highly relevant to all libraries in automating workflows such as processing inputs from forms, migrating data from one system to another or reconciling inputs from a number of sources (Lin et al., 2022). Lin et al. (2022) offer a case study of such uses. Skills required include knowledge of how to analyse workflows and technical knowledge to use RPA tools.
The second example is the use of robotics in the manual tasks around sorting returned books or checking shelves for out of sequence books (Tella, 2020; Vlachos et al., 2020). We could also see the spread of use of generic robots, such as robot cleaners. The most striking use of robot power in a library context is Automated Storage and Retrieval Systems (AS/RS) or ‘bookbots’ where books are stored in mass storage and retrieved on demand for use (McCaffrey, 2021; Sproles and Kuehn, 2014). Pioneer libraries began using such systems around 2005. A key driver of this is to free up space from bookshelves for other uses. But introducing such systems is only likely to be undertaken as part of a major rebuilding project and has fundamental impacts on systems and the organisation, as the McCaffrey (2021) case study makes clear. Free standing robotics are likely to be more widely used.
Both these types of use are driven by efficiency and appear to be less controversial because generally they seem to be relieving humans of mundane tasks.
Use case 2: Application of AI to library services to users
This is where AI is applied directly to library services for users. Two main examples are the application to knowledge discovery and chatbots.
The use of AI in knowledge discovery involves applying AI techniques to describe library collections, usually special collections of unique archival material, such as found in research libraries (Cordell, 2020; EuropeanaTech, 2021). But equally it could be applied to legal texts and knowhow in a law library. This would often be driven by the scale involved, where the amount of material defies human creation of metadata for discovery. Automatically created descriptive data could also add a new dimension to discovery where it created new ways to navigate content (Coleman et al., 2022). AI techniques could be applied to a wide range of types of collections, including texts, handwritten manuscripts, sound files or images. This type of work has a fairly long tradition, though it has not always been called AI. Here AI relates to the central library role of collection management.
One of the main barriers is that algorithms trained on modern handwriting or images will be less effective with historic script or images. This implies the need to create costly training data for unique collections. There may be limited ability to reuse such training data. Currently there are limited off the shelf solutions, so there are significant technical development costs and many libraries would probably not have the resources to undertake them. Further, even big institutions with significant resources and a long history of developing such solutions acknowledge the challenge of turning projects to services at scale (EuropeanaTech, 2021). Hence much of the relevant literature cites projects working on particular collections, often in digital humanities contexts.
There are a number of ethical concerns here too (Padilla, 2019). Such developments of AI arise at a time when the provenance of collections is being increasingly closely questioned: particularly those that were gathered about indigenous peoples during the time of colonialism, which reflect collecting practices that are far removed from contemporary notions of consent and represent indigenous people in ways that they have not agreed to. AI may in some ways entrench or exacerbate these problems. There is also an issue around how to make outputs intelligible to scholars and other users not expert in the technology (Terras, 2022). It is also important to mention that there are sustainability issues around some machine learning (Brevini, 2020).
What could be considered a variation on this application, is the use of AI techniques to create living systematic literature reviews (SLRs) (Grbin et al., 2022; Jonnalagadda et al., 2015). Given the scale and velocity of publication the ability of researchers to keep up with the literature by manual methods is under threat. A living systematic review would employ automated techniques in part of the SLR process. This is particularly critical in the health context, where SLRs are relied on as the basis for advice on evidence-based healthcare interventions. For example, new publications could be sifted for material relevant to an SLR and some filtering occur for non-relevant material.This is typically a librarian role because of their knowledge of bibliographic databases and precise search techniques. Here AI is being applied to texts but published texts rather than rare or unique collections as in the previous application. Some element of automation, but likely that librarians continue to have a role such as in choosing databases, training tools and interpreting licence agreements (Grbin et al., 2022). Grbin et al. (2022) offer a case study of library involvement in building such an SLR system.
A rather different application of AI for use within library services for users are chatbots and digital assistants. The potential merits of chatbots have been forwarded for some time, based on their 24/7 availability to respond to user enquiries and ability to deal with scale (McNeal and Newyear, 2013; Vincze, 2017). The benefits would appear to apply across the library sectors and relate to library roles in interacting with users. Not all chatbots are based on AI, but AI can help produce more adaptive responses and move away from very programmed interactions. There does seem to be some evidence that the technology is maturing so that chatbots can be created without programming skills; although there are still limited off the shelf solutions for libraries. Chatbots have a wide range of potential uses in libraries: the most obvious being to respond to routine information requests or even handle the early stages of complex reference enquiries. Digital assistants, such as Alexa, can also be customised to answer user queries, to explain collections or offer guided tours (Williams, 2019). Chatbots and digital assistants could also be used to gather routine information from users, such as students or support performance of certain tasks (such as requesting an ILL). Chat interfaces to search may come. Chatbots that are buddies or offer emotional support are also being trialed in educational contexts. It seems that people can develop quite rich complex relations with chatbots (Skjuve et al., 2021). Such applications do raise a number of ethical issues, such as about how to ensure an unbiased response to all users and, if user data is collected to make the service adaptive, how consent is obtained for this and privacy protected.
To date the take up of chatbots and voice agents seems limited (though the authors are not aware of a systematic study of the spread of use of chatbots in libraries), perhaps because the cost of development is seen to outweigh the value of the benefits in the context of the complexity of user enquiries. Reference interview theory emphasises the way that a presenting question is not the ‘real’ question that the user has and that the interview process is a complex interaction to elicit the true information need. If that is the case chatbots are unlikely to be fully effective. But it seems that they could address many routine information requests that libraries receive and refer others to a human.
These types of applications of AI are central in many cases to how AI might change the way libraries are experienced, at least in the long run. As such they are likely to all be met with some resistance in terms of how they seem to change professional work and replace professional skill with automation. Change management will be critical to success.
Use case 3: Supporting communities of data scientists
Our third major application of AI in libraries is where the library supports data scientist communities, drawing on their expertise in stewardship of information. Libraries have a number of capabilities that could be highly relevant to data scientists in an organisation, such as:
Data search as an extension of support to searching for literature
Data licensing as an extension of their licensing of other types of content
Copyright advice, as an extension of their expertise in IPR
Data management as an extension of collecting activities
Data preservation, for example providing a repository for derived data and for code, as an extension of their preservation function within collection management
Open methods, as an extension of the wider commitment of many libraries to openness, for example open science.
In this context the library is one among a number of service providers which could support data science communities. The library’s role is particularly plausible where it is a research collection based in the library around which numbers of scholars are working. This would most typically be researchers in the digital humanities where library collections are often a primary source. Libraries might well play a leadership role in creating such communities, though the focus here might be outward facing to scholars from any institution interested in a particular collection. But many institutions, especially universities also have within them growing communities of data scientists or researchers using some data science techniques across all the disciplines, to whom the library could offer expertise. These types of community are perhaps more likely to be led by computer scientists or even platform vendors, but one can see an important role for the library, especially in trying to expand interest in data science beyond engineers. It could act as a neutral space for interdisciplinary working. AI labs or collaboratories hosted in libraries have begun to emerge to do this and offer case studies of what might be involved (Dekker et al., 2022; Wang et al., 2022). The activities in such units could include organising training programmes and reading groups. Libraries might support data science teaching programmes with data management teaching, which tends to get neglected in curricula (Shao et al., 2021).
Use case 4: Data and AI literacy as a dimension of information literacy
The previous examples mostly relate to using AI in some way directly in library work. But with the pervasive use of AI in wider society, adding a dimension of data and AI literacy to citizen literacies becomes a key issue. Citizens need some data and AI literacy because AI is being used in decision making in many sectors of life, both by the state and commercial companies (Ridley and Pawlick-Potts, 2021). More directly in the realm of information seeking and use, search and recommendation tools that most of us encounter every day, such as google and amazon, are based on AI. Furthermore, other applications of AI are encountered increasingly in daily knowledge work such as transcription of online meetings, translation of texts and the widening array of writing tools, from auto-suggest and auto-correct, grammar and style checking to content writers, which will compose text based on a short prompt. The availability of these tools is exciting for access and creation of knowledge, but they need to be used appropriately, based on some understanding of how they work. AI is also used in creating false information such as deepfakes. Citizens need some understanding of this too. These issues point to the need for information literacy training to encompass some basic understanding of data and AI (Long and Magerko, 2020). In developing this role an important driver is the need to protect freedom of expression and to search, and so core ethical values of librarianship (IFLA, 2019). Hence Toane et al. (2022) describe a case study of a library using a Finnish created Open Educational Resource on AI to educate their user base about what AI is. More specifically libraries may be involved in initiatives to inform users about particular classes of AI relevant to their activities, such as teaching international students to better understand how to use translation tools appropriately (Bowker et al., 2022). Incorporating data and AI literacy into IL and other user training, implies some basic knowledge of AI combined with librarians already increasing understanding of pedagogy. Ridley and Pawlick-Potts (2021) identify a further role in helping to make AI explainable in general.
Use case 5: Use of data to analyse, predict and influence user behaviour
AI is about using data to identify patterns. Libraries have collections that can be treated as data, but they also have many forms of data about users. AI techniques are highly relevant to analysing user data (Litsey and Mauldin, 2018). This could be to predict or perhaps even influence user behaviour. A simple example is the use of sentiment analysis to investigate positive or negative feelings towards the organisation. Predictive modelling would seek to anticipate levels of use of the library at certain times of year or to predict book circulation: Iqbal et al. (2020) offer a case study of doing this. If the driver for use 4 is ethical, the main challenges of use 6 are themselves ethical. Clearly it is a legitimate activity, indeed a key strategy and planning requirement for libraries to study users to design better services. Applying AI to data about users is simply an extension of this. It is generally accepted that data science is a combination of domain knowledge, statistical analysis and computational methods (Shao et al., 2021). Librarians have the first. They would need the other two types of skills. But there are risks in this type of use.
Given that this is all about using data, it is useful to reflect on some of the failings in how libraries have used data in another, related context: learning analytics. This is the movement to use all sorts of data about student learners to inform them and their teachers about their learning. What critics of library use of learning analytics have uncovered is a number of ethical failings (at least in the US) in how this data has typically been used (Jones et al., 2020). Students often had not given consent to these uses and had no awareness that their data was being used in such ways. Projects had not undergone ethical review and few libraries had responsible data use statements. There were clearly privacy issues about how such data had been employed and a potential for a chilling effect on free thought and expression. Ultimately it often seemed quite unclear whether students benefited from the use of their data or whether it was institutions that were the main beneficiaries. There is also evidence that the statistical analyses applied to learning analytics by libraries is often flawed (Robertshaw and Asher, 2019). Applying AI to collections as data is clearly problematic ethically at some level, but this appears to be much more true this is of personal data about users and their behaviour. In Europe GDPR may also place legal limits on how data about users can be analysed.
Discussion: How will AI impact employment and equality, diversity and inclusion in libraries?
Because it is a complex picture, concerns about the impact on the work and jobs of librarians cannot easily be answered. Global Partnership on Artificial Intelligence (2020) elaborate the wide range of potential impacts of AI on employment: whereby jobs can replaced or reduced (automation destroys jobs), divided (some benefit, others are deskilled and so workforce divisions deepened), complemented and supplemented (where AI adds to what the professional is able to do) or even rehumanised (where jobs are enriched by having routine elements removed). All these are likely to happen to some degree and we do not yet know the balance of effects will play out. The skills required for the different types of application of AI seem different (Table 1 column C). At least we can be pretty sure librarians will still be needed, because we are entering a more complex information landscape than ever before so information mediating roles will shift but not disappear. Given the reliance of AI on good quality, well managed data, the fact that librarians have good quality data in their collections will become important. Librarians’ understanding of things like data structures puts them in a good position to play future roles. Probably they need to do more work to translate their existing skills in finding, managing and preserving information to apply specifically to data, and talk more about data.
But we should also think about the potential impact of these uses of AI on equality, diversity and inclusion within a profession which has a female majority but still has persistent gender pay gap (Hall et al., 2016; Howard et al., 2020). AI should not be seen simplistically as a neutral technology. AI symbolically privileges white male identity, not because of some essentialist link between IT and gender and race, but because there is a deep-seated link between cultural notions of (information) technology as rational and neutral, and cultural constructions of masculinity. AI itself – as currently conceived and represented in Western thought – is masculine (Adam, 2006) and white (Cave and Dihal, 2020), it has been argued. More directly, IT is stereotypically a male profession, and specifically in AI workforces, especially in technical roles, white males are over-represented (Gehlhaus and Mutis, 2021). Furthermore, AI is often today being developed by very powerful, global tech companies which are embedded within the capitalist system with its historical links to patriarchy, colonialism and neo-liberalism (Crawford, 2021; Jimenez et al., 2022). The manifestations of AI produced within these technological systems are likely to perpetuate sexist and racist assumptions. This is relevant to wider developments of AI in society, but also touches on how AI might manifest itself in the library world.
Thus there is a widely recognised problem of under-representation of women in the design of AI systems. This applies not just to roles in IT, but groups such as librarians and other information professionals who have both some role in the direct creation and development of AI, but also in maintaining and managing AI systems (Collett et al., 2022). Unchallenged AI might well reinforce inequalities within the information profession because men are over-represented in technical roles, which are seen as driving automation, and in more senior roles, which are less vulnerable to automation.
At a symbolic level, the treatment of technology in LIS/librarianship has often been solutionist, portraying technology as an almost magical solution to complex societal problems (Morozov, 2013). This reinforces aspects of LIS which also portray libraries as neutral objective rational spaces (Mirza and Seale, 2017). For example, when the US information professional body represents future trends (including AI) it emphasises individualistic entrepreneurialism, while ‘Emotion and care work, reproductive labor, service, maintenance work, and manual labor are disproportionately seen as feminised labor and “non-skilled” service labor’. (Mirza and Seale, 2017: 178). Future trends are described by the professional body without acknowledgement of the precarious ghost work on which it is actually based and without acknowledging its environmental impact. Such discourses around future technologies like AI play an important role in defining what is important in the work of a profession but do so in ways that entrench inequality by emphasising forms of work in which white males are over-represented (Mirza and Seale, 2017). Fortunately, this does not mean that inequalities are pre-determined. They can be challenged especially by initiatives to expand access to learning the relevant skills (Collett et al., 2022).
Conclusion
This paper has sought to help librarians to navigate the potentially widening impact of AI on libraries. The general definitions in part one assist the reader in understanding the scope of AI and point to the underlying concern about the relation between machines and humans, but also reveal it as an evolving idea. Part two offers some insights into the technology itself with library-based examples. Part three zooms in to identify how AI can be applied in different areas of library operation. This reveals the potential of AI to raise the efficiency of library operations; improve user services such as through enhanced knowledge discovery, dynamic SLRs and user interaction through chatbots; create new roles around supporting communities; add a new dimension to information literacy; and support understanding and control over user behaviour. There remain significant barriers such as ethical and legal issues, lack of off the shelf solutions, cost and implementation challenges, skill gaps, collaboration challenges and simply the pull of other priorities and innovations. The discussion turns to consider the potential impact of AI on library work and particularly the implications for equality, diversity and inclusion within the profession.
Having been through this process of analysis it is easier to understand the wider picture of the pervasive but also uneven impact of AI. AI developments are quite well developed in some library sectors, at least in some institutions within them. Equally there are some applications that have been proposed on good grounds for many years but seemingly not yet materialised at scale. Some of these potential applications may not, in the end, have significant impact on services at all. So, there is a sense here of possibility not inevitability. We feel it is an important message to say that everything we have written about are possibilities that we can shape not an inevitable ‘wave of the future’.
We may be able to say something about what use cases of AI are most likely in most contexts. It is reasonable to expect the applications closest to what libraries already do and that have the lowest resource implications to be most quickly and widely adopted. This would make it likely that work around AI literacy will develop faster than anywhere else. Applications to the collection for knowledge discovery are developing in libraries with rich unique collections and large resources. Yet as in relation to most technologies, it seems likely that libraries will turn to third party commercial vendors to supply pre-packaged solutions, for example easy to customise chatbots. So it remains unanswered how AI will start being applied by library system vendors, bibliographic service providers and other Tech companies in the library space.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.