
Abstract
Many discussions on serendipitous research discovery stress its unfortunate immeasurability. This unobservability may be due to paradoxes that arise out of the usual conceptualizations of serendipity, such as “accidental” versus “goal-oriented” discovery, or “useful” versus “useless” finds. Departing from a different distinction drawn from information theory—bibliometric redundancy and bibliometric variety—this paper argues otherwise: Serendipity is measurable, namely with the help of altmetrics, but only if the condition of highest bibliometric variety, or randomness, obtains. Randomness means that the publication is recommended without any biases of citation counts, journal impact, publication year, author reputation, semantic proximity, etc. Thus, serendipity must be at play in a measurable way if a paper is recommended randomly, and if users react to that recommendation (observable via altmetrics). A possible design for a serendipity-measuring device would be a Twitter bot that regularly recommends a random scientific publication from a huge corpus to capture the user interactions via altmetrics. Other than its implications for the concept of serendipity, this paper also contributes to a better understanding of altmetrics’ use cases: not only do altmetrics serve the measurement of impact, the facilitation of impact, and the facilitation of serendipity, but also the measurement of serendipity.
Introduction
In the context of research discovery, measuring serendipity seems problematic. Serendipity is often defined in situational-subjective terms (Liu et al., 2022: 447) denoting it as an “accidental” or “unexpected” encounter with “useful” scientific publications, as opposed to “purposeful” and “expected” or “useless.” But how can one ascertain that a user found a “useful” research publication “accidentally” (Erdelez, 1997: 412) rather than through a goal-oriented search? Analyses of interviews, diary entries or participant observations (Björneborn, 2008; Makri et al., 2015; Rubin et al., 2011) may pinpoint serendipitous happenings, but these methods are intrusive, hardly scalable, and susceptible to biases typical for self-reported narratives.
There are also attempts to conceptualize serendipity in methodically less intrusive ways. For instance, automated analyses of social network patterns (Grange et al., 2019; Hoffmann et al., 2016), or the tracing of web-based interactions such as clicks, likes, reposts (Jiang et al., 2019), or search log queries (Sakai and Nogami, 2009; Yi et al., 2017) have been suggested as possible venues for detecting serendipity. These indicators may seem “objective” in the sense that they do no longer rely on self-reported intentions; but despite their seeming objectivity, such suggestions usually still premise a definition of serendipity as a subjectively constituted phenomenon. For instance, algorithms of paper recommenders try to ensure some kind of “unexpectedness” and “accidentality” by drawing from a user’s existing corpus of research papers, and by recommending a publication not only through semantic proximity or through co-citational patterns, but also through a certain distancing: instead of suggesting papers that reference to the user’s existing corpus directly, they list papers that reference to those publications that, in turn, cite the papers in the user’s possession (for a similar application, see Janssens et al., 2020). A related example recommends documents that are “liked” by other people in a given user’s network of friends (Grange et al., 2019). Such second-order approaches still cannot conceptualize clearly how “accidentality” is to be defined in opposition to a “goal-oriented” search—a paper recommendation might seem objectively “useless” (because the paper is cited by multiple works in the user’s corpus) but subjectively “useful” (because the user was not aware of it), it might be “expected” in information-theoretical terms, but “unexpected” in the momentary mind of a given individual. Many suggestions for serendipity-measuring devices thus inhere the paradox of a purposeful accidentality, of an expected unexpectedness, of a useful uselessness, of a non-serendipitous serendipity (cf. McBirnie, 2008). It is due to this indeterminacy why, so far, serendipity has been repeatedly found “extremely difficult to study” (Kotkov et al., 2016: 180; see also Kaminskas and Bridge, 2017: 2; Reviglio, 2019: 161; Yaqub, 2018: 176–178).
This paper suggests another approach to measure serendipity, one that is not intrusive, with data that should be easily accessible—namely, altmetrics—but only under the condition that a paper was discovered through randomness. To flesh out this conceptual link, this paper proceeds with an overview of altmetrics and its relation to serendipitous research discovery. Thereafter, the paper draws not from the (situational-subjective) concepts of usefulness/uselessness or accidentality/goal-oriented, but rather from the (information-theoretical, objective) distinction between bibliometric redundancy/variety. In its core, the paper argues that the measurement of serendipity through altmetrics should ascertain that a publication was encountered by a user not through the venue of bibliometric redundancy (i.e. not through a query-based keyword search and not through patterns of co-citations), but rather through the venue of bibliometric variety (i.e. through browsing, or, even better, through randomness). It is only then that a rise in an altmetric score can be undoubtfully attributed to what is called an “accidental” information encountering, that is, to serendipity, and not to a goal-oriented search behavior. In other words, under the condition of high bibliometric variety or randomness, the manifest variable of altmetrics allows one to infer the latent variable of serendipity. A possible device for such a serendipity-measuring machine—namely a random paper bot on Twitter—will also be outlined. While merely offering a simple thought experiment, the paper concludes with reflections on how the scientific system may witness aggregate changes in bibliometric patterns if altmetrics were designed primarily for the purpose of serendipitous research discovery (Holbrook, 2019: 6).
Key concepts to be combined: Altmetrics and serendipity
Three use cases of altmetrics
Altmetrics allow observations on “how people interact with a given scholarly work” other than through citations in scientific publications (Williams, 2017: 311). For example, they quantify the number of times a scholarly publication was downloaded, bookmarked, “liked,” or mentioned in non-scientific contexts, be it on social media, policy documents, popular encyclopedia articles, news outlets, or blogs. Providers of altmetrics may simply list these interactions (as CrossRef Event Data does), or they may offer a composite index calculating a single altmetric score attributed to the publication (as Altmetric does). Whatever relation is enacted to a paper, as long as it is not a science-internal citation, it can be captured with non-scientific—that is, “alternative,” or “alt-”—metrics. (Note: it is in this general sense that the term “altmetrics” is used in this paper; references to the popular implementation called Altmetric will be written with a capitalized “A”).
Based on this capacity, the literature has underlined three major functions of altmetrics: The measurement of impact, the facilitation of impact, and the facilitation of serendipity—what has been missing is the measurement of serendipity. 1
The first and most prominent use pertains to the measurement of a scholarly publication’s societal impact. Altmetrics enables research assessment on the article-level by quantifying the publication’s reception in web-based and other online communities (Tunger et al., 2018: 123). The measurement of scholarly impact was indeed stated as the original intent behind the launch of altmetrics (Piwowar, 2013; Priem et al., 2012), and this task is made particularly conspicuous through the wide-used implementation called Altmetric (with a capital “A”). This implementation accompanies each paper with colorful visualizations harboring a numerical score (Altmetric, 2015): if a work was mentioned in seven Tweets, two blog posts, and one news article, the paper obtains an approximate Altmetric Attention Score of 25 (the score is weighted by source, 7 × 1 + 2 × 5 + 1 × 8). The visualization comes in form of a badge or so-called “donut” in which proportions of the respective sources obtain different colors (e.g. Twitter is light blue, blog posts are yellow, and news sources are red). With journals and other science-related websites listing these Altmetric donuts in an optically appealing manner, and with university reports honoring high Altmetric Attention Scores as proxies of impact, researchers have become incentivized to enact a certain “gaming” behavior so as to strategically attain higher scores (Roemer and Borchardt, 2015).
In other words, altmetrics not only measure a publication’s societal impact, but they also motivate and thus facilitate their attainment. The colors and scores are so conspicuous, so salient visually that they attract they eye of scientists and other relevant stakeholders. Rankings of altmetric scores allow publics to quickly find the most discussed-about research findings, to distribute them across media channels, and thus to further heighten their visibility. Dedicated websites have sprung up to list those colorful badges with the highest Altmetric Attention Scores in certain disciplines (cf. Figure 1). They incite researchers to actively promote their publications so as to attain even greater scores and wider alleged impact.
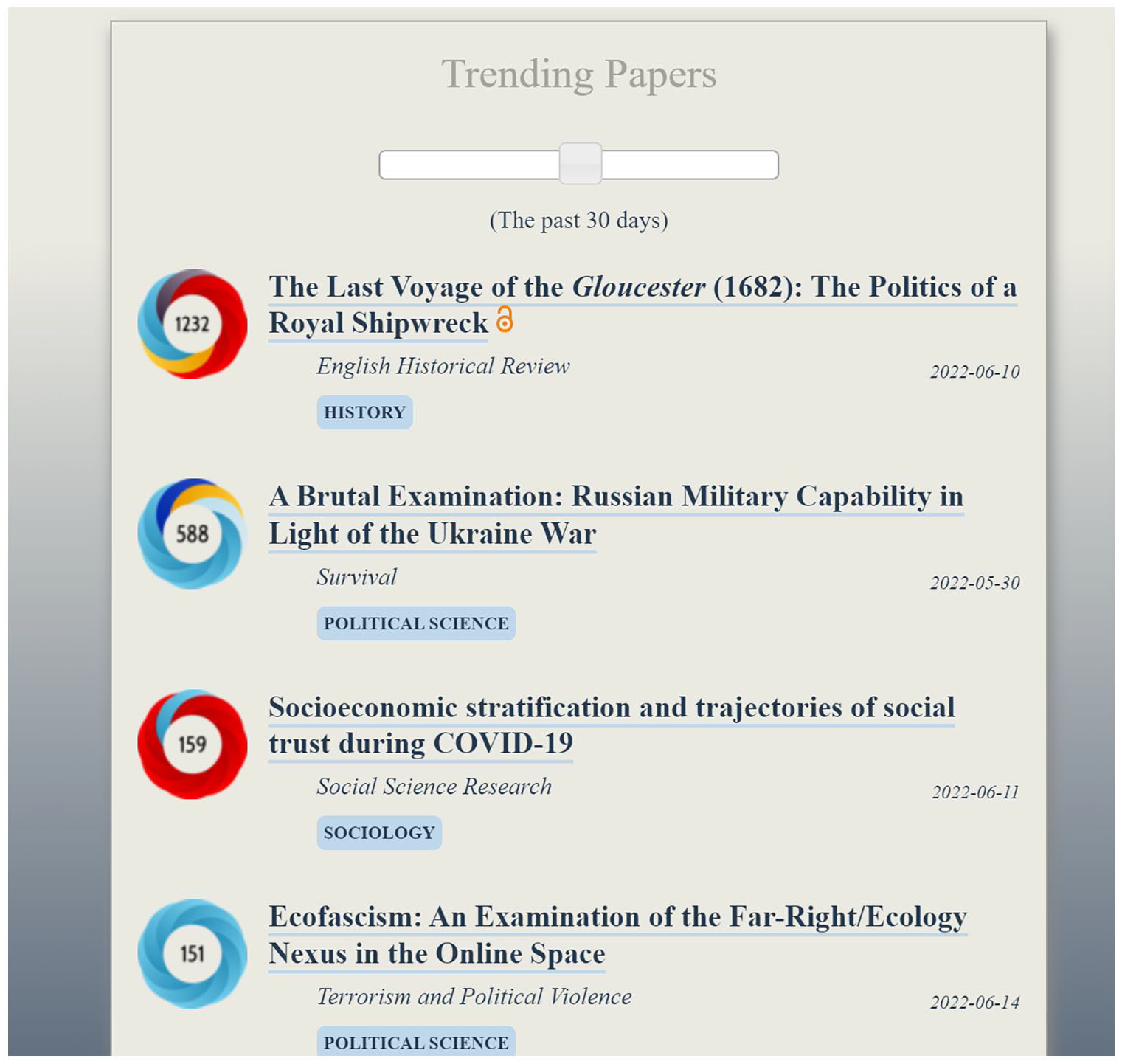
A list of top “trending” papers across some social science disciplines, as of 21 June 2022, a screenshot of the website Observatory of International Research (https://ooir.org). The colorful badges harboring the Altmetric Attention Scores are visually appealing, and they incentivize researchers to obtain higher scores, thus higher ranks, thereby facilitating researchers to obtain societal impact.
It is based on these two functions of altmetrics—the measurement of impact and the facilitation of it—that shortcomings regarding their implementation are regularly criticized. On the one hand, altmetrics have been touted as “democratizers of the scientific reward system” (Haustein, 2016: 413). On the other hand, however, researchers call attention, on various weaknesses—such as on the non-comparability between various altmetric providers, on the untransparent data processed by opaque algorithms, on the heterogeneity of events that influence a single index, or on the distorting gaming behavior driven by altmetrics (Bar-Ilan et al., 2019; Ortega, 2018; Robinson-Garcia et al., 2017; Thelwall, 2020; Zhang et al., 2019). Such discussions may even doubt whether altmetrics really are indicative of societal impact at all (cf. Banshal et al., 2021), ultimately concluding that altmetrics “cannot actually be seen as alternatives to citations; at most, they may function as complements to other type of indicators” (Haustein, 2016: 1). Altmetrics, such reflections infer, “might mainly reflect the public interest and discussion of scholarly works rather than their societal impact” (Tahamtan and Bornmann, 2020: 1; cf. also Nicholas et al., 2020: 269; Regan and Henchion, 2019: 485). They seem to be designed mainly “for research managers to judge whether the researchers have had satisfactory broader impacts” (Holbrook, 2019: 6; cf. also Martin, 2011). And if research administrators start to mandate a certain (now measurable) degree of societal reception, this may “breed resentment [against altmetrics] by forcing compliance” (Holbrook, 2019: 4). 2
A third use case of altmetrics thus soon emerged. It centers around the idea of facilitating serendipity, or gainful encounters with other research and researchers (cf. Kapidzic, 2020; Muscanell and Utz, 2017). The central suggestion here is that instead of highlighting “hits,” altmetrics band together “networks” (Robinson-Garcia et al., 2018). For altmetrics offer a gateway for researchers to stumble upon like-minded people who participate in online communities to proactively distribute scientific findings (Tunger et al., 2018: 129). As these “communities of attention” (Araujo, 2020) are “networked environments” (Williams, 2017: 312) accessible via altmetric dashboards, one can quickly tap into these publics to consort with scholars of similar interests, to spark new discussions, to exchange ideas, to obtain feedback (Penfield et al., 2014: 31) and to find potential collaborators for further research (Jünger and Fähnrich, 2020; Sugimoto et al., 2017: 2039). One may even put forth the idea of designing altmetrics primarily, and not secondarily, “as a tool for serendipity,” that is, as “a tool that empowers researchers to identify and reach out to people who are interested in (perhaps even concerned about) their research” (Holbrook, 2019: 6). Without altmetrics, chancing across such opportunities may seem improbable, but once a well-designed altmetric device is in place—such as the Altmetric or PlumX dashboards—one can sagaciously invest efforts into systematically seizing such opportunities. Examples of studies that show how tweeting about articles reliably increases community attention (Dehdarirad and Didegah, 2020; Fraser et al., 2020; Wang et al., 2020) attests to altmetrics’ suitability in enabling a high degree of serendipitous research discovery. And indeed, this function does align with the main reasons behind the academics’ presence on social media (cf. Jester, 2022): “Connecting with other researchers (for community building or collaboration), disseminating research, and following the research output of others are primary motivations for scholarly use of social networking sites” (Sugimoto et al., 2017: 2039).
Thus, the literature on altmetrics has so far discussed three main functions extensively—the measurement of research impact, the facilitation of impact, and the facilitating of serendipitous encounters with other scholars and publications. This paper will suggest a fourth function below, namely the measurement of serendipity—a function that seems vexed because usual definitions of serendipity draw from a paradoxical semantics requiring one to encounter “useful” information in an “unexpected” and “accidental” way without clearly distinguishing these terms from “expected” and “goal-oriented” approaches (e.g. Adamopoulos and Tuzhilin, 2015; Copeland, 2019). As a consequence of this conceptual indeterminacy, serendipity has been repeatedly said to be almost impossible to measure. One possible path out of this paradox is to dispense with distinctions like useful/useless or accidental/unaccidental altogether, and to instead find a different definition to depart from. This is where we head to the next section.
Toward bibliometric randomness
Another common variable behind all research discovery and “information encountering” (Erdelez and Makri, 2020) could aid in highlighting the conditions for measuring serendipity. For this purpose, one may draw from a typology of research discovery tools according to the information theoretical concepts of (bibliometric) redundancy and variety (Luhmann, 1992: 436–449; Nishikawa-Pacher, 2021). In brief, bibliometric redundancy reproduces extant co-citation patterns, while bibliometric variety generates novel links between publications. Research discovery services reproduce bibliometric redundancy if they draw from semantic similarities or from citational couplings (Leydesdorff et al., 2018; Ma, 2020). Query-based academic search engines and many paper recommender systems are thus redundancy-reproducing research discovery tools (e.g. Kudlow et al., 2021; Qin et al., 2022). They are based on probabilistic models that calculate the informational relevance of a suggested publication (Amati and Van Rijsbergen, 2002). On the other side of the typology are those discovery tools that enhance bibliometric variety. They do not draw from extant (semantic or citational) similarities between a given corpus of papers and a newly recommended publication, but they rather present research outputs either through a user’s browsing behavior (e.g. in a journal’s table of contents) or through a large degree of randomness. 3 In short, while query-based and citation-based research discovery services reproduce bibliometric redundancy, browsing-based, and randomness-based devices engender bibliometric variety.
Such a typology based on the common variable redundancy/variety allows for a clearer positioning of serendipity: The “accidental” and “unexpected” encountering of “useful” research—that is, serendipity—is located at the variety-end of the dimension.
It follows that the measurement of serendipity requires that a publication was found either through a browsing behavior or through randomness. But variety/redundancy are not opposites; both may occur simultaneously (Nishikawa-Pacher, 2021: 3). This becomes obvious in the case of browsing-based research discovery: while browsing spawns greater bibliometric variety than query-based or citation-based tools, it cannot rule out redundancy-reproducing effects depending on the unit of analysis. For instance, browsing a journal’s table of contents may reproduce that journal’s intra-citation patterns, and browsing articles within a specific research field may reproduce that research field’s intra-citation links. As a consequence, a truly variety-enhancing and thus serendipitous research discovery must reside on the randomness end of the typology (Luhmann, 1992: 467). While the other (i.e. query-based, citation-based, and browsing-based) approaches do not preclude serendipity, they cannot guarantee it sufficiently. The unambiguous measurement of serendipity thrives on the condition of randomness.
Note that this distinction of bibliometric redundancy/variety abstracts away all psychic occurrences as exogenous. It is irrelevant to this distinction whether one subjectively reaches a sense of information-seeking “deadlock” (Solomon and Bronstein, 2022: 60) in redundancy-reproducing venues, or whether one indulges in the “joy of serendipity” (Casselden and Pears, 2020: 616); it is irrelevant whether the specific users’ personality traits exhibit a high “openness to experience” measurable with psychological tests (Qin et al., 2022: 5); and, likewise, it is irrelevant whether the encounter with the publication occurred during the “active” performance of an information-acquisition task, or while resting in a “passive” mode of attention (Erdelez and Makri, 2020: 733–734). The conceptualization is thus blind to the concrete trigger of an information encountering. Instead, it simply indicates the (“objective”) information structure, the aggregate pattern of bibliometric links behind an instance of research discovery.
Result: Measuring serendipity with altmetrics and randomness
As the former section demonstrated, randomness links altmetrics and serendipity conceptually together. Altmetrics capture interactions with research outputs other than through scientific citations. Serendipity is undoubtedly present only in cases when a research publication was recommended in a random fashion. It follows that the measurement of serendipity through altmetrics requires randomness at play. The user interaction captured by altmetrics must relate to publications that appear through algorithms of randomness, and not through, say, algorithms of co-citational or semantic proximities. It is only then that the research discovery and the publication encounter is without doubt to be attributed to serendipity, and not to a redundancy-reproducing search. And it is only then that serendipity can be measured with the help of altmetrics.
To offer an idea how of a practical implementation of a serendipity-measuring device with altmetrics may look like, one could suggest a bot designed in the following manner (cf. Figure 2 for an illustration):
Collect a huge corpus of scientific papers from as many disciplines and as many publication years as possible, comprising tens and hundreds of millions of publications from a host of research fields published across several centuries.
Create a Twitter bot and accrue a sufficiently large following for that bot.
In a regular time interval (say, every 6 hours), let the bot pick one random paper from the huge corpus. The bot extracts the paper’s title and DOI (Digital Object Identifier), and links to it in a Tweet. Every single paper has the equal probability (or improbability) 4 of being picked; there is no bias in terms of citation counts, impact, journal outlet, scientific discipline, year of publication, or sociodemographic parameters of the author(s) at play.
Measure user interactions with each Tweet in the form of altmetrics, for example, the clicks on the DOI, the retweets and “likes,” and continue observing interactions with the linked paper over time. (The premise is that every single count of an interaction with that paper measures an instance of serendipity because the paper recommendation cannot be but “unexpected” due to its randomness.)
Make these numbers about the interactions publicly available as open data.
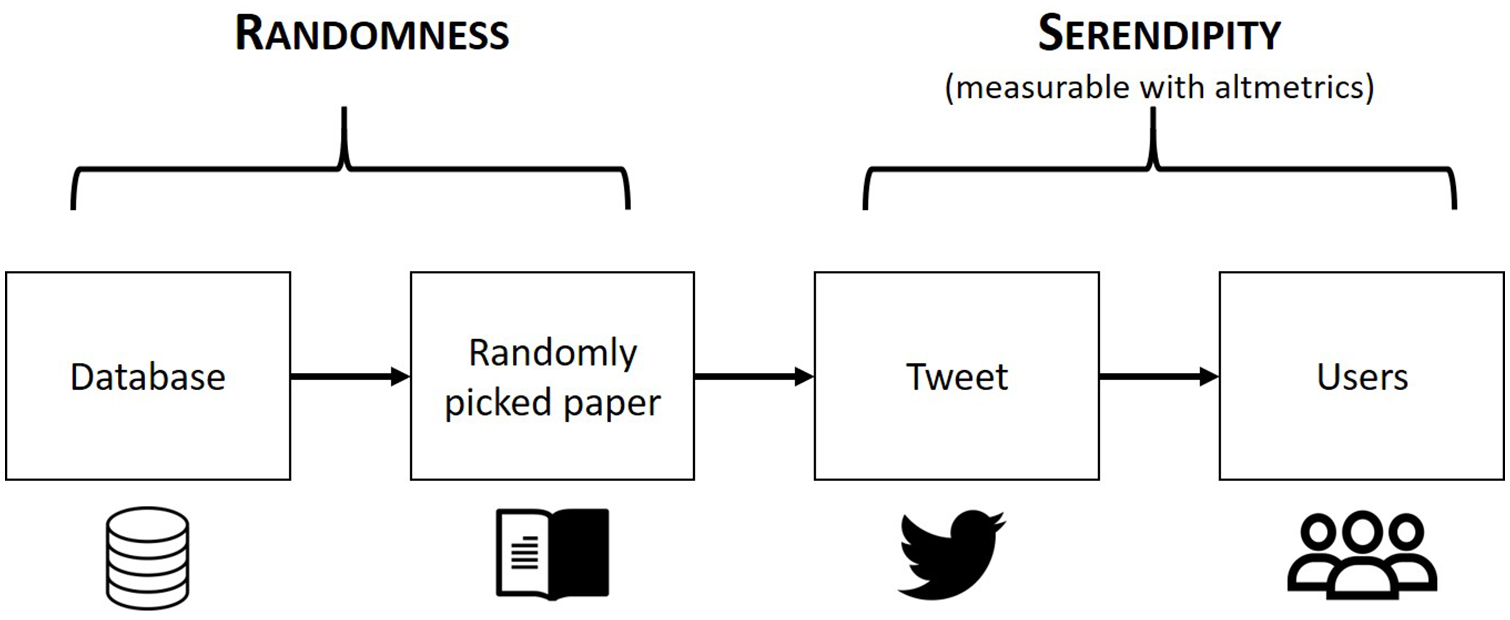
An illustration of the random paper bot that enables and measures serendipitous research discovery. The icons whose licenses kindly permit the present re-use were designed by phatplus at flaticon.com (the database at the very left), by Mike Ashley at creativecommons.com/website-icons (the book), by Pixel perfect at flaticon.com (the Twitter bird), and by Freepik at flaticon.com (the audience at the very right).
Every interaction with the tweeted publication, every single “like” and link click and retweet indicates an objectified instance of serendipity, an (inherently “unexpected”) happening of randomness that nevertheless captured someone’s attention (and thus must have been “useful”). All these interactions are “post-activities (e.g. exploring, sharing, using or storing) [occurring] after encountering unexpected information” (Liu et al., 2022: 452). The interaction itself is captured numerically in the form of altmetrics so that no recourse to psychic motifs, to subjective sentiments, to situational accidents, or to contextual circumstances is necessary. 5 It suffices that there was randomness at play to know that the paper recommendation must have been unexpected in both an information theoretical-objective and situational-subjective way.
Such a machine does not seem to exist yet; an informal and cursory survey of Twitter profiles that regularly link to research publications attests to this lack. While there are indeed similar machines and profiles that approximate the ideal device, none of them fulfill the pure randomness condition. For instance, seeming “opinion leaders” whose Tweets regularly lead to a considerable increase in altmetric scores of the publications they mention cannot be deemed to operate through randomness. They are, instead, humans who curate their own Twitter feed by selecting what research they tweet about according to their own and their audience’s interests (cf. Marcella-Hood and Marcella, 2022). 6 If one drew from our redundancy/variety-based definition of serendipity, then a user interested in political science cannot undoubtedly call an encounter with a political science paper serendipitous simply because one of the central nodes in the academic Twitter network happened to mention that paper; the user may have encountered that paper anyway through other means (through paths of co-citations, semantic searches, networking at conferences, or mere browsing in journals) because paths to that paper are made redundant. Other Twitter accounts draw from algorithms to tweet about “trending” papers with high altmetric scores. For instance, the account Hot Computer Science monitors “the most discussed computer science papers” of each day—again a case of redundancy-reproduction. 7 Or, the Twitter account of the Observatory of International Research (OOIR) 8 regularly tweets a ranking of trending papers in social science disciplines based on Altmetric Attention Scores. However, they too cannot guarantee serendipity without doubt. There are always possible biases behind altmetric scores that can indirectly reproduce bibliometric redundancy—such as the observation that high-impact journals tend to enjoy higher altmetric scores than low-impact outlets (cf. Banshal et al., 2022; Loach and Evans, 2015; Nuredini, 2021). The tweets that draw from altmetric algorithms thus do not provide “random” papers, but rather reproduce systemic redundancy.
In sum, only a bot that draws from a random (and not potentially biased) corpus of scientific publications could ensure the presence of serendipity which, in turn, would be quantifiable with the help of altmetrics.
Discussion
Serendipity is a measurable phenomenon: It is measurable with the help of altmetrics if a certain condition, namely the condition of randomness, obtains. In other words, the latent variable of serendipity becomes manifest through altmetrics under the condition of a research discovery based on high bibliometric variety. If users encounter a publication and induce a rise in its altmetric score, it cannot undoubtedly imply an “accidental” information encountering with useful publications (i.e. serendipity) unless there was randomness at play. In other settings, the users may have encountered that publication by typing in queries in an academic search engine or by using a paper recommender service that draws from extant citational links. In that case, the “accidentality” is in doubt. If the publication was recommended through randomness, and if the user then decides to click on it, to download the paper, to read it, to retweet it, to bookmark it, to recommend it, to “like” it—then, and only then, do we know that serendipity, and not a goal-oriented search and not a systemically biased paper suggestion, must have been at play.
This finding is in contrast to a frequent statement in the literature on serendipity according to which serendipity is a phenomenon difficult, if not impossible, to measure. The main reason for this resigned attitude is an indeterminate distinction between the “accidental” and the “goal-oriented,” the “useful” and the “useless,” the “expected” and the “unexpected” behind common definitions of serendipity. Once different foundational distinctions are used—such as the concepts of bibliometric redundancy/variety—then one may obtain a clearer focus on how serendipity can be observed empirically without oscillating between paradox semantics. And one way to empirically measure serendipity is by combining altmetrics with randomness.
A key limitation of this paper is that it remains on a purely conceptual side. It awaits an implementation in order to validate whether and how the thought experiment works in practice. Technical difficulties can be expected—for instance, the random paper bot outlined above needs a sufficiently large following in order to work well. But how can one accrue, say, thousands of researcher-followers on Twitter for a bot which has not even started its operation yet, and even if one achieved this feat, how would the issue of a potential self-selection undermine the generalizability of the experiment? More importantly, would the conceptual bot even work as intended? Could it be that opaque Twitter algorithms will interfere with the intended mechanisms, disturbing the machine such that the bot’s postings reach different audiences based on user-targeted algorithms unbeknownst to the public (cf. Gillespie, 2014; Savolainen and Ruckenstein, 2022: 13)?
One can expect further disturbances acting upon the latent variable of serendipity in the form of redundancy-induced (rather than randomness-induced) altmetrics. A user may, to name one example, search for specific keywords (say, “Medieval Bulgarian ceramics”) on Twitter to find that our Twitter bot had recommended a publication on that topic randomly. The user will stumble upon the Tweet, perhaps “like” it, click the link and download the paper, thus influencing an observer’s perception of the manifest variable of randomness-induced altmetrics. And since the situational context of that specific user remains in a conceptual blind spot, no observer will be able to distinguish between randomness-induced and redundancy-induced altmetrics. To hedge against the risk of such measurement errors, the practical implementation should ensure that—perhaps unrealistically—interventions by Twitter algorithms and search functions are minimized: set up the users’ Twitter feeds of postings in a purely chronological manner, and render the Tweets impossible to be seen other than through that chronological Twitter timeline (i.e. “likes” in one’s network of friends should not heighten the Tweets’ visibility). While a laboratory experiment (similar to Bornmann et al., 2022) might establish these ideal parameters, the actual dynamics behind social media platforms may likely deviate from that setting. What is more, there are other, more subtle structural biases at play whose relationships to serendipity or bibliometric redundancy are not yet well-understood—such as the observation that specific syntactic properties of article titles serve as attractors and thus correlate with higher citation counts (Guo et al., 2018; Nair and Gibbert, 2016). The fundamental problem behind all these potential measurement errors is that “information will, on average, decrease randomness” (Hickey, 1982: 230). A final practical issue to be mentioned is that not all interactions can be captured by altmetrics (yet), such as when users take screenshots of Tweets, or when they write down a paper title found through the bot in a handwritten notebook. Such instances remain to be best captured by methodically intrusive analyses like diary entries and other self-reported narratives. All these randomness-decreasing difficulties—distortions though self-selection, algorithms, linguistic attributes, and unobservable events—pose intricacies that need to be considered if the thought experiment was to become a practical one.
But once these hurdles are overcome, the measurement of serendipity may engender broad bibliometric implications. One could observe how scientific citation patterns change in effect of such a Twitter bot. For instance, was a randomly recommended paper with the publication year 1958 that has not been referenced for decades suddenly cited a few months after the Tweet? Does it perhaps inspire further research afterward and enjoy a revival similar to what scientometricians call a “sleeping beauty” (van Raan, 2004)? If that is so, then the serendipity-inducing Twitter bot may aid in reducing research waste, in supporting the dissemination of forgotten papers, in recovering lost works, in enabling greater variety and thus the innovative cross-pollination of ideas across time and discipline. One can then expect the scientific system to diversify its citation patterns away from structural biases toward greater bibliometric and intellectual variety, perhaps even with other subsequent gains for society at large (cf. Heitz et al., 2022)—and all that will occur in numbers that will be empirically observable with the help of altmetrics and randomness.
Footnotes
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Open Access funding provided by University of Vienna.