
Abstract
Reinforcement Learning (RL) has been considered a promising method to enable the automation of contact-rich manipulation tasks, which can increase capabilities for industrial automation. RL facilitates autonomous agents’ learning to solve environments with complex dynamics with little human intervention, making it easier to implement control strategies for contact-rich tasks compared to traditional control approaches. Further, RL-based robotic control has the potential to transfer policies between task variations, significantly improving scalability compared to existing methods. However, RL is currently inviable for wider adoption due to its relatively high implementation costs and safety issues, so current research has been focused on addressing these issues. This paper comprehensively reviewed recently developed techniques to improve cost and safety for RL in contact-rich robotic manipulation. Techniques were organized by their approach, and their impact was analysed. It was found that current research efforts have significantly improved the cost and safety of RL-based control for contact-rich tasks, but further improvements can be made by progressing research towards improving knowledge transfer between tasks, improving inter-robot policy transfer and facilitating real-world and continual RL. The identified directions for further research set the stage for future developments in more versatile and cost-effective RL-based control for contact-rich robotic manipulation in future industrial automation applications.
Keywords
Introduction
As Kroemer et al. 1 state, ‘robot manipulation is central to achieving the promise of robotics’. Endowing robots with the ability to alter their environment, with flexibility and reliability that match humans, would unlock novel and exciting capabilities for industrial automation, leading to significant societal impact. For instance, robots could be deployed to improve the flexibility of manufacturing2,3 and improve the efficiency of the circular economy via remanufacturing. 4 Contemporary robots, however, are rigidly programmed and only able to complete specific manipulation tasks within highly controlled environments, which limits their applicability. Improving their flexibility has been an important research topic.1,5,6
A critical sub-problem within robotic manipulation is performing contact-rich tasks. Contact-rich tasks involve frequent physical contact between the robot and the environment, encompassing most day-to-day activities that robots are expected to execute in some scenarios, such as assembly. These tasks involve multiple contact interactions with the environment and require suitable control schemes to react to these interactions safely. Due to the complex, non-linear, and discontinuous dynamics involved in contact interactions, traditional control approaches7,8 that model the environment to analyse contact states and design manoeuvres to react to these states are time-consuming to produce. They are also unscalable, as control strategies developed with traditional control approaches are sensitive to variations in task configurations, which can lead to failure and thus require re-implementation.
Reinforcement Learning (RL) has recently become a trending Machine Learning (ML) approach due to its ability to learn to solve complex problems from experience without human supervision. RL removes the laborious process of handcrafting controllers for challenging environments, making it promising for contact-rich robotic manipulation. RL initially found success in only simple problems9,10 due to limitations in computing power and the inability of early algorithms to handle continuous state and action spaces. With the increased accessibility of powerful hardware and the incorporation of deep learning, the capability of RL has improved and gained success in many research domains. Recent works show the success of RL-trained deep Artificial Neural Networks (ANNs) applied to many other areas, such as playing games11–14 autonomous ground15,16 and air navigation,17,18 robotic manipulation19–22 and recommender systems. 23 Despite RL’s potential, it is still far from being an off-the-shelf solution for robotics, 19 so there is an active research effort to develop techniques to improve its practicality.
This paper comprehensively reviews the recent research to improve RL for contact-rich robotic manipulation. It highlights the current techniques developed, their motivation, and the existing gaps to offer directions for future research. To aid in understanding the current research directions, techniques are grouped based on their underlying approach, where an approach is a general outlook of a problem that motivates the development of a technique and a technique is a specific solution implementing the approach. The techniques developed within each approach are discussed in isolation and followed by a holistic analysis of the current state of research.
Works similar to this review exist that analyse the research on RL for robotic manipulation. Kober et al. 19 provided an early review of RL in robotic manipulation. However, their review in 2013 covered the state-of-the-art before a decade of rapid progress and did not focus specifically on contact-rich manipulation. Kroemer et al. 1 provided a more recent review on robotic manipulation but did not focus specifically on contact-rich tasks or RL. Suomalainen et al. 24 surveyed contact-rich robotic manipulation techniques but did not focus on RL-related techniques. The most recent and relevant review was conducted by Elguea-Aguinaco et al., 25 who analysed RL for contact-rich robotic manipulation. Their review focused on applying RL-based robotic control to contact-rich task types that have been studied extensively and present techniques as made to improve the performance for those specific tasks. In contrast, this review frames techniques as task-agnostic, meaning they can improve RL-based robotic control across different contact-rich task types, even those not previously studied. This perspective sets the stage for the application of RL-based control for novel contact-rich task types, which is important to consider improving the wider adoption of RL-based control in future industrial automation. The main contributions of the present review can be summarized as follows:
It identifies the key challenges in RL for contact-rich robotic manipulation that the current research aimed to address.
It highlights the techniques developed from 2015 to 2025 that improve RL for contact-rich robotic manipulation regarding the key challenges identified.
It organizes the techniques into groups, known as approaches, to understand the main themes of the existing body of work.
It highlights trends and gaps in the literature and offers a perspective on future directions for research.
The review is organized as follows. Section 2 introduces core concepts for RL and contact-rich robotic manipulation. Section 3 summarizes the literature and themes. Section 4 organizes the relevant works into approaches and presents the key techniques for each approach. Section 5 contains a holistic analysis of trends and gaps within the literature. Section 6 provides concluding remarks about the contents covered in the previous sections.
Core concepts
Contact-rich robotic manipulation
Contact-rich robotic manipulation refers to manipulation tasks requiring the robot’s End Effector (EEF) or grasped tools and objects to interact with the environment. In contact-rich tasks, contact is required for task completion and cannot be avoided. Therefore, the robot must react to contact accordingly to progress towards task completion while acting safely to prevent damage to the robot or environment. Due to the natural world’s non-linear contact dynamics, precisely anticipating the required control inputs for task completion is challenging and time-consuming, which may cause conventional control methods to be impractical for addressing contact-rich tasks.
The contact-rich tasks studied in the reviewed literature can be grouped into five task types, where tasks belonging to the same task type require semantically similar skills to accomplish. Contact-rich task types include, but are not limited to, insertion, non-prehensile manipulation, surface tracking and object extraction. These task types are depicted in Figures 1 and 4(a) show the proportion of reviewed works focused on addressing each task. By grouping tasks into task types, one can leverage techniques applied on a task to new tasks belonging to the same task type, reducing implementation costs.

Below are descriptions of each task type, examples of tasks belonging to that task type, the expected contact interactions and appropriate robot reactions to them and the challenges presented in such tasks which motivate the use RL for them.
Insertion
Insertion involves inserting an object into hole with corresponding geometry. Examples of insertion task include the classic peg-in-hole task, assembly, key insertion and the initial phase of unscrewing.
In an ideal scenario, the position and orientation of the hole are perfectly known, allowing a robot to execute a simple yet precise motion to perform insertion. In reality, only inaccurate approximations of the hole’s position and orientation can be given. A naïve control strategy that does not account for this inaccuracies may miss the hole if hole’s position estimate is inaccurate, or cause jamming or wedging during insertion, which can result in material damage to the object and hole, if the hole’s orientation estimate is inaccurate.
An appropriate control strategy can account for discrepancies by performing a multi-stage approach that exploits contact interactions, involving a searching process to find the hole and a dynamic object re-alignment process during insertion. In the initial stage of search, the object attached to the robot makes an impact contact with the hole’s surface and must limit this contact force. During the search, the robot glides the object across the surface of the hole until the object is positioned within the hole. Searching requires the robot to apply enough tangential force to overcome friction and also apply enough normal force keep the object in contact with the surface it without causing the material damage. Using force measurements, the robot can determine if the hole has been found and then proceed to the insertion operation. During insertion, misalignment between the hole and object may cause further sliding, jamming or wedging contacts that resist the insertion motion. In these cases, the robot must dynamically re-align the object in response to such contacts to complete insertion whilst minimizing contact forces.
Analytical methods that characterize the contact states during insertion, using sensory observations and designing manoeuvres to react to them can be time-consuming. This is especially true as the complexity of the hole and object geometry increases. Furthermore re-implementation may be required depending as the geometry and material properties of the object and hole changes. 29 Analytical methods are thus considered unscalable when considering a wide variety of insertion tasks.
Non-prehensile manipulation
Non-prehensile manipulation tasks are a class of tasks that involve moving an object without grasping it. Such tasks involve pushing, pulling or tilting an object a desired position or orientation.
Contact interactions in non-prehensile motion include normal pushing contact to adjust position and tangential pushing/pulling contact, that utilizes friction, to adjust an object’s pose. Using conventional control methods, one can analytically design a control strategy that pre-determines the sequence of contact interactions assuming that effect of the contact interactions on the object’s pose are perfectly known. However, due to uncertainty in environment dynamics (e.g. friction, mass), the true trajectory of the object may deviate from the assumed trajectory, causing later actions in an analytical method to fail. For instance, during a normal pushing interaction, unexpected sliding between the robot and an object can occur, causing unintended rotation. Following actions that expect the object to be in a specific orientation may then fail as result.
A successful non-prehensile manipulation strategy should be robust to uncertainty in the environment by being reactive to deviations in the object’s trajectory. Designing robust control strategies analytically can be time-consuming and requires significant re-implementation for changes in the environment, thus is unscalable.
Surface tracking
Surface tracking tasks require the robot to maintain sustained contact with a surface and move the robot’s EEF tangentially to perform some given task. Tasks belonging to this task type include wiping, polishing and grinding.
In surface tracking, the primary contact interaction is sliding, which involves applying enough normal force to maintain contact with the surface without material damage and enough tangential force to overcome friction.
For flat surfaces, maintaining contact whilst moving tangentially can be already be achieved by using conventional force controllers. However, surfaces with curves may require extra effort to programme a robot to track safely and will need to be re-implemented for different surface geometries, making conventional methods unscalable.
Furthermore, depending on the objective task, the robot may need to re-visit certain regions of the surface, rather traversing through a pre-determined route in a single pass. For instance, in polishing or wiping, the surface condition (surface finish or cleanliness) may not meet the requirements after the first pass. In these cases, a reactive robot controller is required to be able to monitor the surface conditions and decide if certain surface regions need re-visiting.
Door opening
Door opening involves interacting with door-like objects that possess constrained degrees of freedom, typically limited to rotational or translational motion about fixed hinges or sliding tracks. They involve grasping a handle and moving it along the permissible degrees of freedom until the door is opened. Tasks in this task type included opening hinged doors and drawers.
In door opening, the primary contact interaction is a frictional contact between the robot gripper and the handle. The robot must then follow the permissible degree of freedom of the door. Should the robot not follow the correct trajectory, the door may be damaged or the robot loses grip with the handle, ultimately failing the task.
With conventional control methods, one can deduce the permissible trajectory of robot that is grasping the handle, given a perfect model of the door object and the robot’s relative pose from it a priori. The robot can then, in principle, execute this trajectory to perform the task. However, the true permissible trajectory may differ from the one assumed due to uncertainties in the hinge or track’s pose relative to the handle, and the pose of the robot relative to the door. Therefore, executing the assumed trajectory may result in failure of the task.
It is unfeasible to predict the parameters of a door opening task a priori for all possible instances of this task. Therefore, analytical methods that rely on perfect a priori knowledge are impractical in addressing a variety of door opening tasks. A robust and scalable control method is thus needed to react to unexpected variability in door opening.
Object extraction
Object extraction can be considered the inverse of insertion and usually includes tasks associated with disassembly. It involves grasping an object, that is part of an assembly, and performing the reverse assembly motion to extract the object. For example, peg-hole extraction and gear disassembly.
Object extraction can be attempted using conventional control methods by assuming perfect knowledge of the extraction trajectory and programming a robot to follow that pre-defined path. However, assumed trajectories can be inaccurate due to variability in the condition or geometry of the assembly. Executing assumed trajectories can result in unintentional sliding, jamming or wedging of the object against its surroundings, which may result in material damage.
To deal with this uncertainty, the robot must identify contact interactions between the object and the assembly and manoeuvre in way that minimizes contact forces. As mentioned in insertion tasks, characterizing contact states with sensory observations and analytically designing reaction manoeuvres is time-consuming and unscalable.
Reinforcement learning
RL is a data-driven framework for sequential decision-making. It involves the learner and decision maker (the agent) acting within an environment with a specified goal. At every timestep, the agent selects actions based on the state of the environment, and the environment changes to a new state in the next time step. The environment administers rewards for certain states and actions, regulated by a reward function, that specifies the desired behaviour. Through continual interaction with the environment, the agent gathers experience about it and learns how rewards are obtained. Then, the agent adjusts its actions to maximize the rewards. 30
RL assumes that the environment can be modelled as a Markov Decision Process (MDP), 31 a general mathematical formalism for sequential decision-making problems. In MDPs, actions influence immediate rewards, subsequent states, and hence future rewards. Therefore, a solution to an MDP must trade-off between immediate and delayed rewards. MDPs also model stochastic state transitions, making it possible to model uncertain environments.
This review uses the notational standard MDPNv1
32
whereby MDPs are defined by the tuple
Let
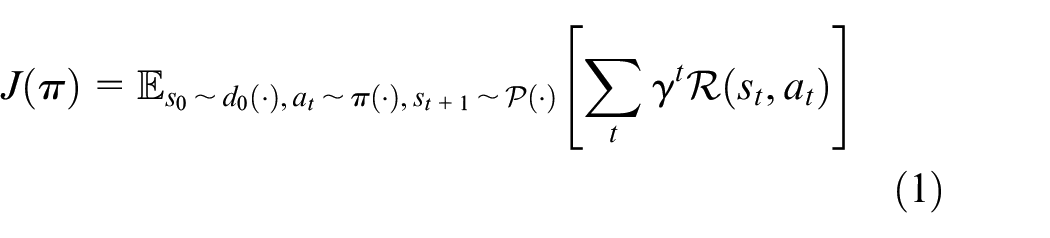
The optimal policy,

Different RL algorithms that solve MDPs in varied manners have been proposed, and each algorithm presents trade-offs concerning one another. This review does not focus on RL algorithms, but instead the techniques applied alongside the algorithms to improve cost and safety. As such, the reader is referred to30,33–35 for a comprehensive understanding of RL algorithm types. For a more focused discussion on RL algorithms specific to the context of robotic control, the reader is referred to.19,22,36
It should be noted that this sub-section presents the most fundamental problem formulation for RL. This formulation is extended for techniques described in the latter sections to facilitate additional functionality unavailable with the basic formulation. However, these extended formulations remain consistent with the basic formulation so that the basic formulation provides a suitable foundation for further extensions. Where appropriate, the notation for the extended formulation will be introduced in later sections when certain techniques are discussed.
RL-based robotic control
A generic RL-based robotic control architecture schematic is presented in Figure 2, which helps one understand the effects of proposed techniques and opportunities for combining them to compound their effects.
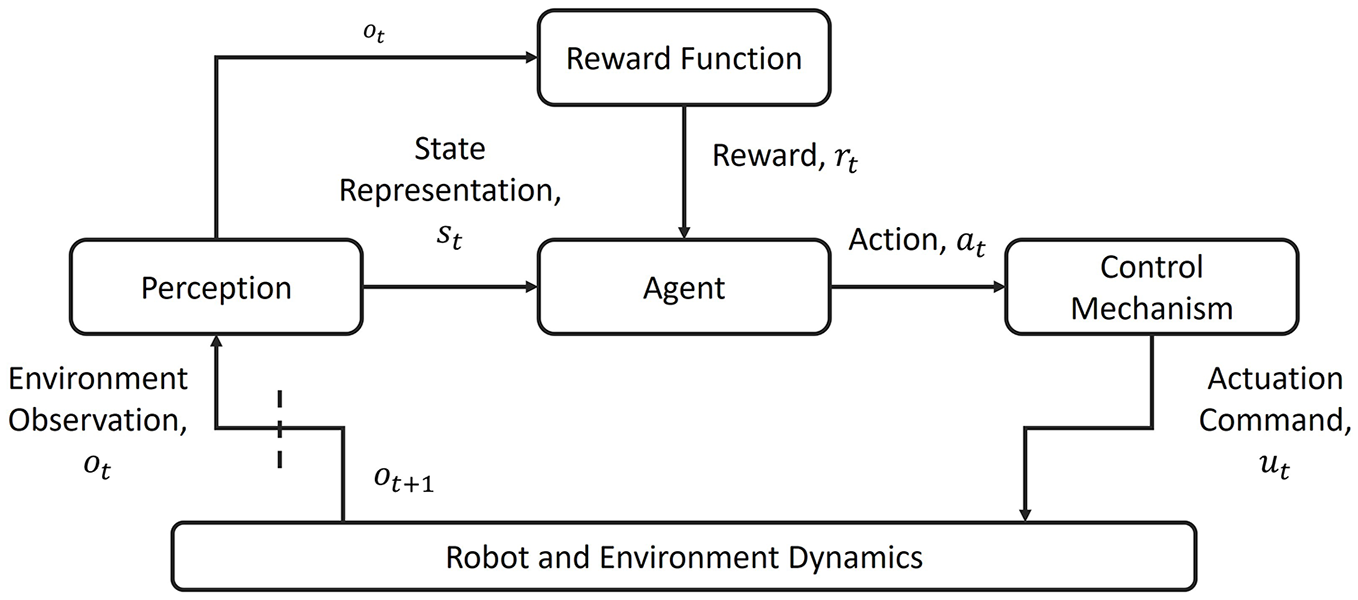
Schematic representation of a generic RL-based robotic control architecture. This diagram has been inspired by Sutton and Barto 30 but has been adapted to emphasize the components tailored for robotic control.
RL-based robotic control consists of an RL agent at the core, a control mechanism serving as the interface between policy and the environment, a perception module comprised of sensors to collect high-dimensional observations and an inference mechanism to reduce observations to low-dimensional state information and a user-specified reward function that specifies the task’s objective. Figure 2 depicts the relationship between the components and the feedback loop, enabling the RL agent to learn. The proposed architecture extends the notation to facilitate the introduction of robot-specific components
Firstly, the state
Secondly, a control mechanism interfacing the agent’s actions and the environment is added rather than the agent directly acting on the environment. The control mechanism
Literature overview
Trends were observed after conducting a thorough literature review related to RL for contact-rich robotic manipulation. The trends consisted of the challenges the research addressed regarding RL in robotic manipulation, the approaches to addressing such challenges and the types of contact-rich tasks studied.
Key challenges in RL for contact-rich robotic manipulation
Despite RL’s potential to reduce the manual effort in developing robotic control strategies to address diverse and complex robotic manipulation problems more easily, RL-based robotic control has yet to gain mainstream traction due to challenges in cost and safety.22,25,38,39 As such, traditional control approaches remain the dominant approach for industrial robotic control. 40 Addressing these challenges has become the focus of the current literature to improve the practicality of RL-based control and its future adoption by practitioners.
Cost
Cost is the most significant barrier to the mainstream adoption of RL-based robotic control.19,36 RL is a data-driven control approach that requires numerous data samples to learn effective control policies, which can be expensive and time-consuming. In comparison, traditional control approaches do not involve such expensive training as they rely direct programming based on expert knowledge, making it a more feasible control approach over RL-based robotic control.
Researchers have focused on improving sample efficiency and generalizability to alleviate the high costs of RL-based robotic control. These aspects, in the context of RL, and how they affect implementation costs are explained below:
Safety
Ensuring RL-controlled robots behave safely is essential to consider in protecting nearby humans from injuries and mitigating material damage caused by uncontrolled collisions between the robot and its environment.38,43 RL-based robotic control introduces unique safety challenges as practitioners do not directly control the robot’s behaviour, unlike traditional control approaches, as its behaviour emerges from autonomous learning. The main risks in RL-based robotic control arise during training when the policy executes exploratory actions, which can cause unexpected collisions. RL-based control also risks acting hazardously in environment configurations unseen during training. For example, a policy trained in an environment without obstacles may be unsafe when deployed to a similar environment as the policy was not trained to avoid obstacles. Therefore, safety must be ensured during all stages (training and deployment) of the policy’s lifecycle. 39
Summary of literature
From analysing the techniques proposed in the reviewed papers, nine approaches were identified, which are presented in Figure 3. Each approach corresponds to a particular outlook on the challenges of RL-based robotic control, motivating the development of techniques. Identifying these approaches, we can understand the critical areas of research in this field and gain a broad overview of the general progress to address the challenges in cost and safety for RL-based robotic control.
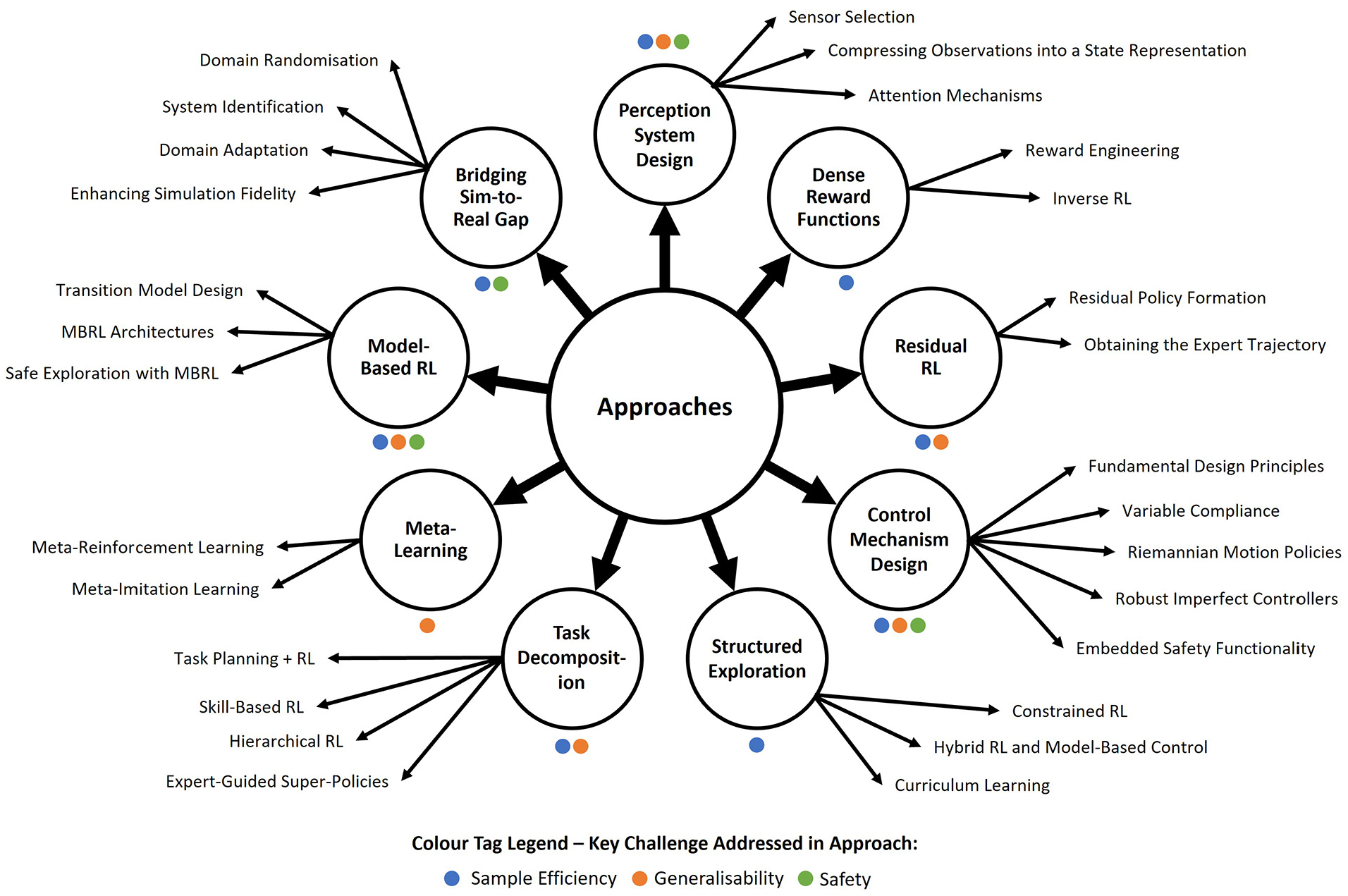
A mind map providing an overview of the literature reviewed. Intermediate nodes indicate the main approaches identified to address the key challenges of RL in robotic control. Leaf nodes denote the notable techniques or sub-approaches under each approach. Colour tags accompany intermediate nodes to indicate the challenges addressed by each approach.
Table 1 summarizes the reviewed literature. It shows all the papers considered in the review, the approach they belong to, the task type studied in the paper and the challenge that each paper’s proposed technique aimed to address. Figures 4 and 5 summarize Table 1 to highlight notable trends observed in the reviewed literature.
An overview of the literature reviewed in tabular format.
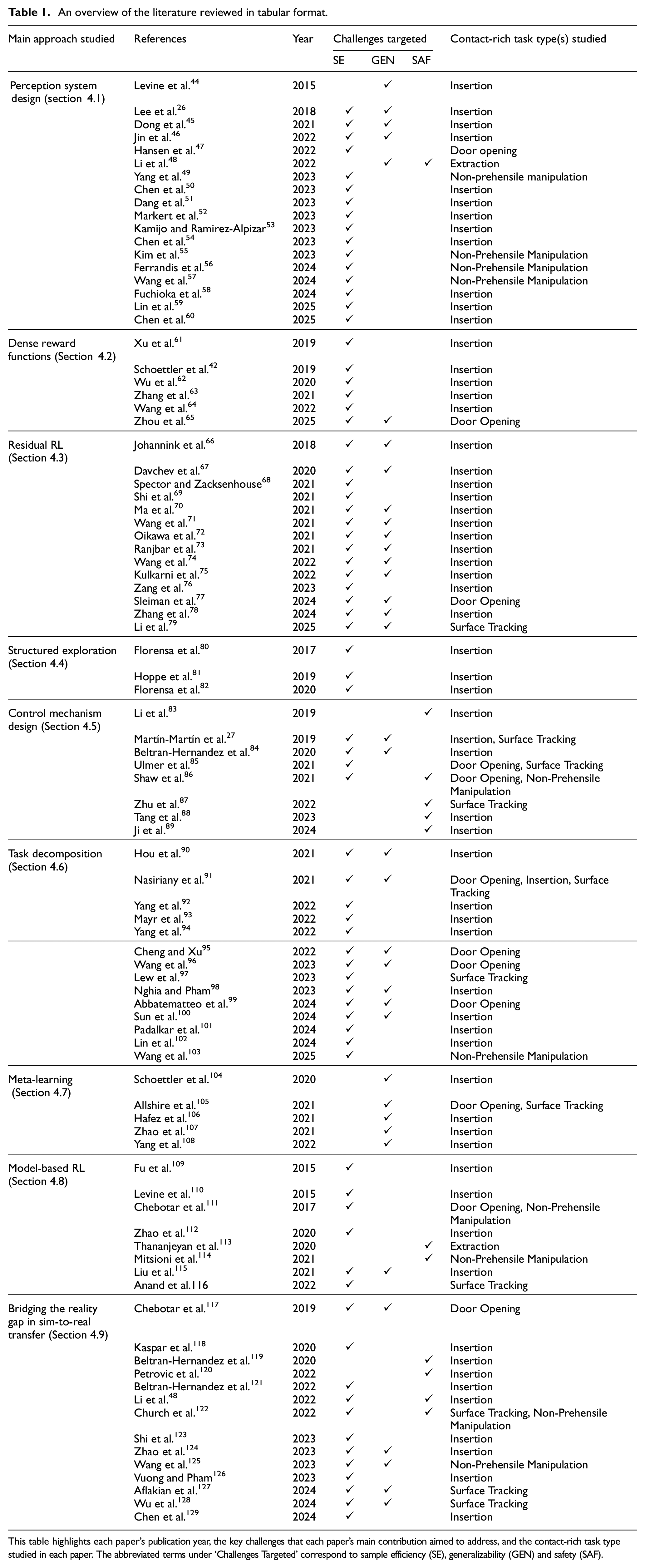
This table highlights each paper’s publication year, the key challenges that each paper’s main contribution aimed to address, and the contact-rich task type studied in each paper. The abbreviated terms under ‘Challenges Targeted’ correspond to sample efficiency (SE), generalizability (GEN) and safety (SAF).
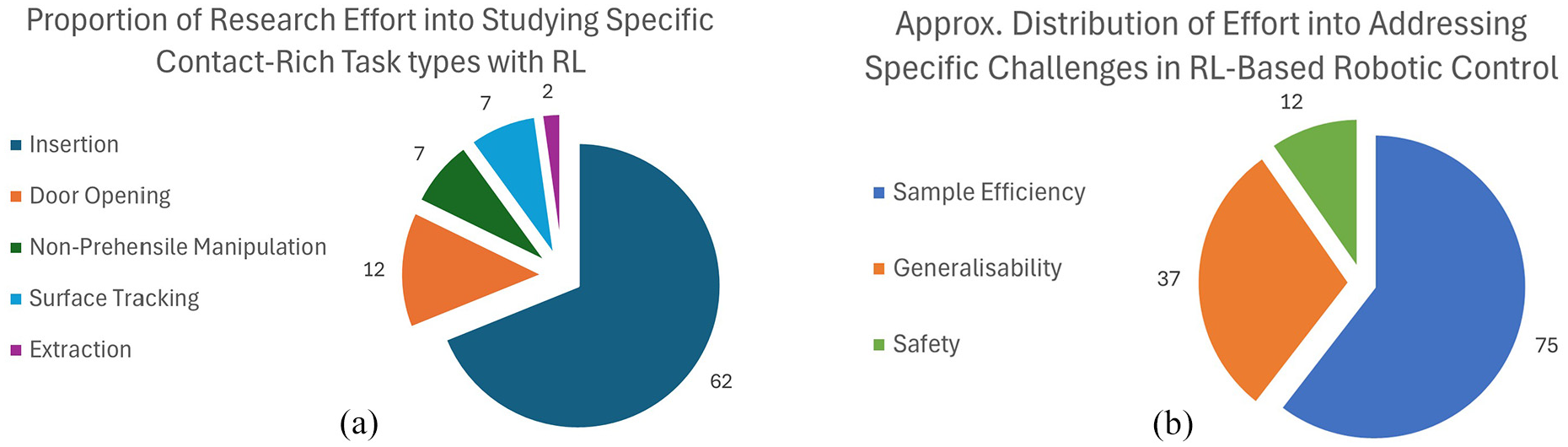
Pie charts showing (a) the proportion of research effort aimed at studying specific contact-rich task types and (b) the approximate distribution of research efforts in addressing the key challenges identified across the reviewed literature.
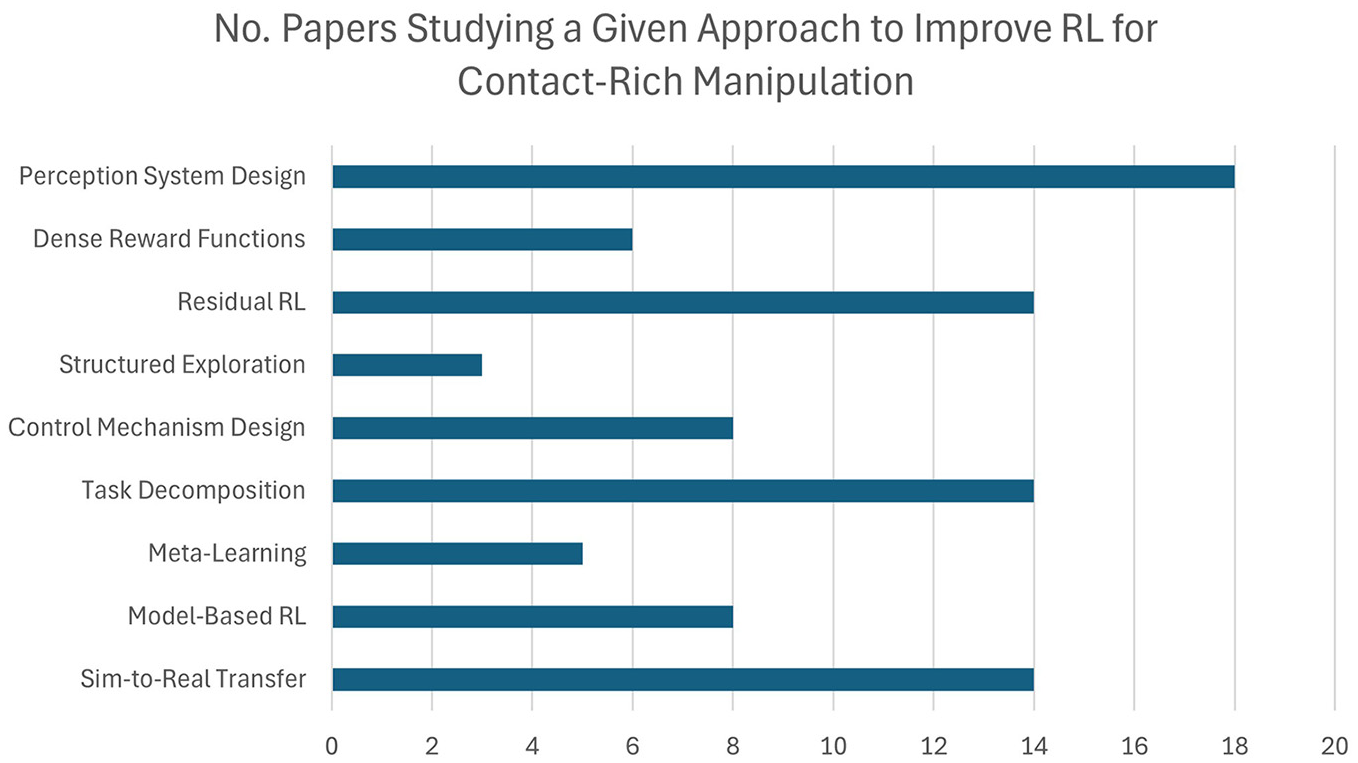
A bar chart showing how many studies were reviewed for each of the approaches identified.
Approaches to improve RL-based contact-rich robotic manipulation
Perception system design
Perception plays a crucial role in RL-based control, directly impacting the agent’s ability to make informed decisions and learn tasks efficiently and safely. Thus, researchers have investigated improving perception system design to improve RL for contact-rich robotic manipulation. The perception system encapsulates sensor selection and sensory data processing, and these two components’ design considerations are discussed.
Sensor selection
Most reviewed works use haptic and proprioceptive feedback as the sensor composition for contact-rich tasks.25,52 Proprioception informs the robot of its pose and motion relative to the environment. Haptic feedback, via Force/Torque (F/T) sensors, enables the robot to measure external forces from the environment, enabling the robot to detect contact and enable the RL agent to learn safe safely react to contact interactions. With this combination, an agent can determine the location of expected contact points in an environment and react accordingly to complete the task. Even without visual feedback, this minimal sensor composition has proven sufficient to learn a range of contact-rich tasks. 25 Further, this composition facilitates the most sample-efficient learning as low dimensional input minimizes the policy network’s size and the training required. However, this minimal sensor composition gives the agent a limited understanding of the environment’s state, which can cause the policy to fail in completing variants of the original task. 26 Additional sensing modalities can be added to the policy to enable a richer understanding of the environment’s state and improve policy generalizability.
Visual feedback (e.g. RGB, RGB-D) can be added as direct feedback to the agent (i.e. visuomotor learning).26,42,44,46,48,57 Visual feedback can give the agent real-time spatial awareness of its environment, enabling it to sense possible contacts without physical interaction, thus improving safety. More concretely, an agent with visual input can learn to associate the intersection of visual features with unsafe contact interactions and can use this insight to prevent certain unsafe interactions from occurring, which may not be possible without it. For example, Elguea-Aguinaco et al. 130 train an object extraction policy with vision and include the objective of avoiding human contact in training to result in a policy that dynamically avoids human contact during deployment. Further, visual feedback helps improve generalizability, as environment variations can be immediately observed and adapted to. For example, in insertion tasks with no accurate estimation of the hole position or varying geometries, the agent can learn a single insertion policy that can address all these uncertainties and variations by using vision to guide decision making.26,46,48,50 In wiping, a policy with visual input can learn wipe a surface with a variety of surface contaminant positions. 97 However, adding these high-dimensional sensing modalities increases the size of the policy network, which increases the training required before an optimal policy is learned.
Tactile sensors observe the deformation of a skin-like membrane at the robot gripper’s fingertips to monitor normal and shear stress on the membrane. By monitoring forces in this way, tactile sensor can be used in the same capacity as F/T sensors to indirectly measure external contact forces with the environment. For instance, Dong et al. 45 substitute F/T sensors with tactile sensors for insertion tasks. Their work also report an improvement in the generalizability of the insertion policy using tactile sensor compared to one using F/T sensors. The physical imprint of an object’s geometric features when in contact with a tactile sensor may also be observed. This property can be utilized to determine the pose of objects in contact with the sensor, which has been exploited in learning insertion, door opening and non-prehensile manipulation tasks.47,49,56
Compressing observations into a state representation
Converting raw sensory data,
State Representation Learning (
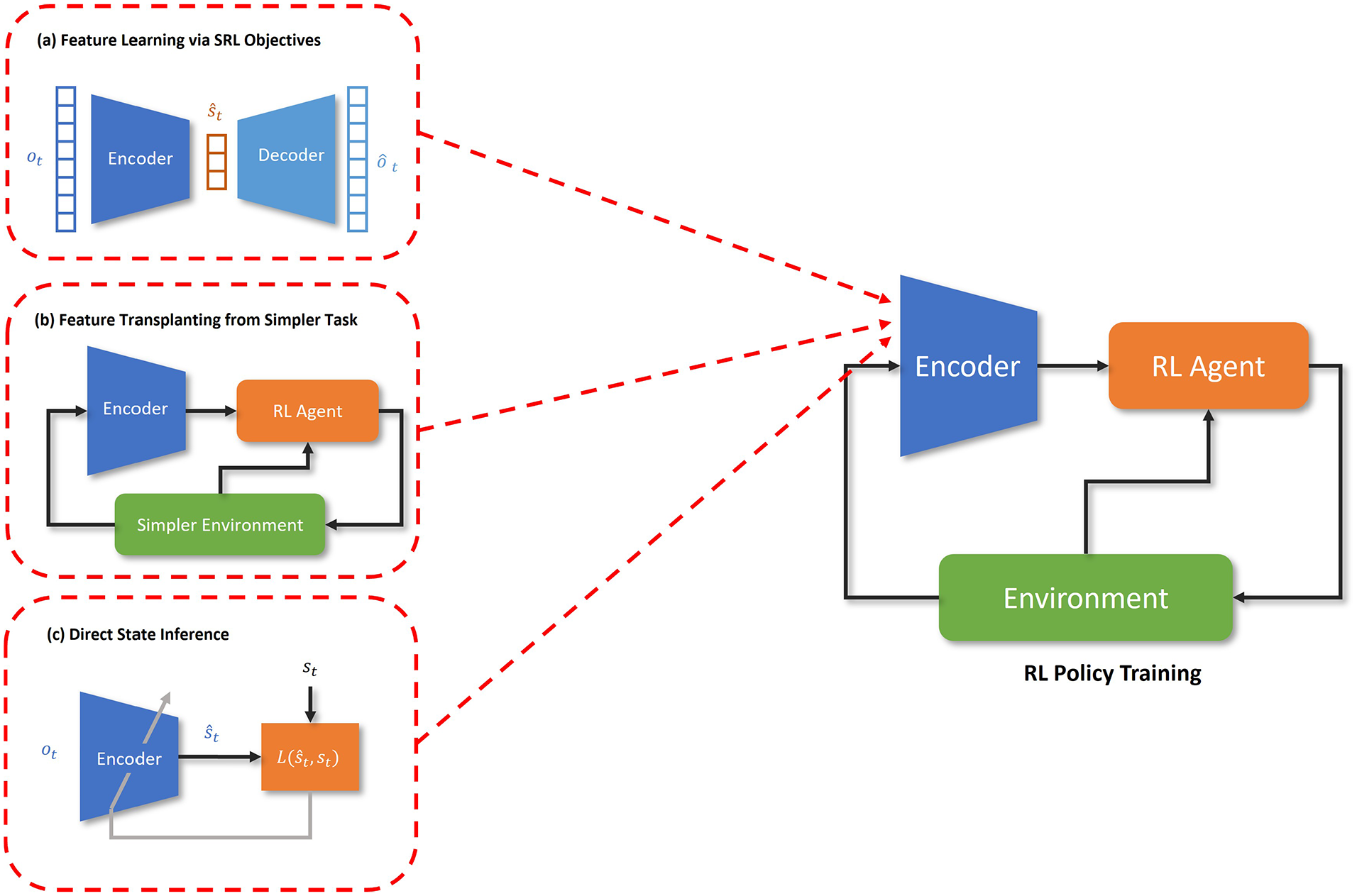
Schematic diagram illustrating the difference between (a) state representation learning, (b) feature transplanting and (c) supervised learning techniques for acquiring a state representation.
Jin et al. 46 proposed a simpler and more cost-effective technique to learn an abstract state representation (Figure 6(b)). It involved training a policy with visual inputs on a simple source task and then transplanting the lower layers, corresponding to the visual encoder, to another policy network trained on a complex target task related to the source task. The simple task was designed to be easy to learn to minimize training time. Sample efficiency was enhanced when learning the complex task as relevant state features were transferred from the simple task, leading to shorter retraining. However, manual effort is required to define the source and target tasks, which can limit scalability.
Another set of techniques aim to explicitly infer a concrete state representation (i.e. state parameters directly that map to measurable variables in the environment) from the high-dimensional observations (Figure 6(c)). This inference model is typically obtained by collecting privileged state information from simulation and simulated observation data and training the model to correctly infer the privileged state information. Yang et al. 49 train a Convolutional Neural Network (CNN) with supervised learning to infer the pose of an object using tactile sensor observations for an object non-prehensile manipulation policy. Kamijo and Ramirez-Alpizar et al. 53 train an ANN to infer the relative orientation of a grasped peg from on-finger tactile sensory data for an insertion to enable sample efficient learning of that task. Chen et al. 54 train an ANN to infer a categorical contact state between a peg and hole to learn the insertion task in a sample efficient manner. Chen et al. 54 train a key point detector to detect key points of an object to directly infer its pose to quickly learn a non-prehensile manipulation skill. To improve robustness to sensor noise and partially observability, the use of probabilistic state inference models were also investigated. Ferrandis et al. 56 trained a probabilistic ANN also to infer the position of an object for an object non-prehensile manipulation policy from occluded visual feedback and feedback from a tactile sensor. Chen et al. 60 uses a Gaussian Mixture Model (GMM) to probabilistically infer the relative position of grasped nut from a nut to quickly learn nut insertion using only F/T observations. Dang et al. 51 used a mechanism based on a template matching 77 to extract the relative position of an elastic peg from the hole and its deformation. Using this technique, elastic insertion was learned in a sample efficient manner. Whilst these techniques increase the interpretability of how the RL agent perceives the environment and makes decisions, they require a specific implementation for the specific task and thus is not as scalable as techniques that build abstract representations from scratch using data.
Attention mechanisms for perception systems
Attention is a mechanism in deep learning that selectively focuses on the most relevant parts of the input, filtering out less important information. By assigning different levels of importance to various input features, attention enhances the model’s ability to learn complex patterns efficiently. Typically, attention mechanisms are integrated into the learning process by computing weighted combinations of input features, where the weights indicate each feature’s relevance to the task. These weights are dynamically learned during training, enabling the model to adjust its focus based on the task objectives.
Attention is widely used in tasks such as natural language processing Chaudhari et al. 137 and computer vision Guo et al., 138 and enables state-of-the-art performance in these domains. Some works also investigated attention with RL139,140,141 on RL benchmark tasks. However, results do not suggest a definitive improvement in performance and sample efficiency resulting from this addition.
In RL for contact-rich robotic manipulation, researchers have used simpler attention mechanisms that do not require the agent to autonomously learn to assign attention. Ferrandis et al. 56 introduces a tactile gating mechanism, which dynamically blocks flow of tactile sensor information through the policy network when the no contact is made on the tactile sensor. Tactile gating was shown to improve the agent’s exploitation of tactile signals in decision making, which reportedly increased sample efficiency in door opening tasks. Lin et al. 59 used a prompt-guided image segmentation technique to filter out task-irrelevant image features to increase the sample efficiency of learning insertion tasks.
Dense reward functions
During training, rewards regulate the predicted (state or state-action) values and guide exploration towards more promising states and actions to accelerate training. Sparse reward functions are the most straightforward, with a reward issued upon task completion. However, predicted values remain uninformative until the reward is encountered, which delays the exploration of promising actions and prolongs training. This is worsened in large state-action spaces where reaching a goal state under a semi-exploratory policy can take longer. Therefore, dense reward functions are typically implemented in robotic manipulation.
Regardless of task completion, dense reward functions issue continuous rewards to the agent, the magnitude of which is inversely proportional to the agent’s proximity to its goal. It should be noted that in contact-rich tasks, the measure of proximity is not only limited to physical proximity but can include proximity between measured and desired values of other sensory inputs such as force. With dense rewards, predicted value updates are more informative much sooner, resulting in more efficient exploration and improved sample efficiency. 142
Reward shaping
The most common implementation technique for dense reward functions is reward shaping, which is a process where practitioners manually define equations, 90 a set of rules, 26 or use fuzzy logic61,64,70 to express the dense reward function. Reward shaping enables the relatively simple implementation of dense rewards. It also allows practitioners to explicitly define auxiliary objectives to produce policies that conform to specific user preferences. For instance, terms in the reward function can be added to train policies that apply a target contact force to the environment71,74 or to minimise energy consumption 27 . Further, dense rewards can improve safety by penalising the entry of unsafe states, such as states where contact forces exceed a threshold 84 . However, safe behaviour is guaranteed only after training, as the unsafe states must first be encountered during training before the agent learns not to revisit such states.
Reward shaping has effectively improved sample efficiency across various contact-rich tasks. However, the cost of reward shaping and the policy’s quality mainly depends on the practitioner’s experience. Further, the reward shaping process must be repeated for new tasks, making this technique unscalable and impractical for settings where robots are required to complete varied tasks.
Inverse reinforcement learning
Inverse Reinforcement Learning (IRL) 143 is a technique in which a dense reward function is inferred through expert demonstrations, addressing scalability and policy quality limitations in reward shaping.
Zhang et al. 63 employed Adversarial IRL (AIRL) 144 to infer a reward function and quickly train a policy for peg insertion and cup placement. Zhou et al. 65 also used AIRL to quickly learn the insertion task. AIRL is an adversarial learning-based IRL technique which enables reward functions to be inferred in environments with large and continuous state-action spaces, making it suitable for robotic manipulation. However, adversarial techniques require numerous demonstrations to infer a reward function, making it costly to train and can experience training instabilities. 144
An alternative technique was proposed by Wu et al., 62 which required only a single demonstration, involved less training and was not susceptible to training instabilities. Their technique involved learning a latent measure of task progress from a single demonstration to act as the reward function. Their study demonstrated accelerated learning of a peg insertion policy.
Residual RL
Residual RL involves an expert policy,
Residual RL enhances sample efficiency as the initial policy directly steers the agent towards goal states, reducing the exploration required to encounter rewards, which enables the exploration of more promising actions sooner. Constrained exploration around
Residual RL has gained traction within the contact-rich robotic manipulation domain, particularly in the area of peg insertion,66,71,73,74 assembly69,70,72,75,76,78 and grinding. 79 Since its introduction by Johannink et al., 66 many variations of residual RL have spawned primarily differing by the formulation of the residual policy and the incorporation of imitation learning.
Residual policy action formulation
The original implementation by Johannink et al.,
66
Residual Policy Learning (RPL),
Oikawa et al. 72 presented a unique residual policy formulation that used a discrete action space. Their residual policy learned to change the force controller’s stiffness matrix discretely by selecting from a pre-defined set of matrices. The stiffness matrices were non-diagonal, facilitating smooth local exploration around the expert trajectory when the robot was in contact with the environment. Due to the discrete action space, sample efficiency was significantly improved. However, the set of matrices must be manually selected, increasing implementation difficulty as choosing a set of non-diagonal matrices may involve trial and error. Spector and Zacksenhouse 68 proposed a similar technique, but allowed the policy to set any real value for select elements of the stiffness matrix, which reduced manual effort at the expense of sample efficiency.
Obtaining the expert trajectory
The original residual RL implementation relies on a trajectory generated from interpolating between the start point to a goal position and thus tend to be simple straight-line trajectories. For tasks such as door opening 105 or L-shaped insertion, 71 complex curved trajectories may be needed. Using the conventional robot programming methods, these trajectories may be implemented by composing spline and circular motion commands. However, such an approach requires significant time to implement and thus is unscalable.
Rather than manually defining trajectories, an robot can learn to imitate expert demonstrations, known as imitation learning, 145 to form the desired initial trajectory and implement residual RL for complex tasks in a more time- and cost-efficient manner. The variations of this technique differ by the imitation learning frameworks used to learn the demonstrations. Ma et al. 70 used GMMs, which enable robust imitation of an insertion trajectory within four demonstrations. However, their technique only allowed the imitation of the EEF translation and not rotation. Davchev et al. 67 used Dynamical Movement Primitives (DMPs) 146 to imitate insertion demonstrations. This technique enabled EEF translation and rotation to be imitated and required only one demonstration for successful imitation. Wang et al. 71 proposed a novel imitation learning to imitate an expert insertion trajectory robustly. Their imitation learning framework required more computation and demonstrations than Davchev et al. 67 and Ma et al. 70 but guaranteed more robust imitation.
Another technique for generating the expert trajectory is to use trajectory optimisation 147 , which can generate arbitrarily complex trajectories. This is achieved by treating trajectory planning as optimization problem that optimizes a given performance metric and is bound by a given set of constraints. Sleiman et al. 77 uses trajectory optimization to obtain an initial trajectory for door opening and uses RL to refine the motion to account for environmental uncertainties. The limitation of this approach is the necessity of an environment model that the trajectory optimization model can use for planning, which may be difficult to implement for varied environments.
Structured exploration
Structured exploration is an approach that aims to achieve enhanced sample efficiency by strategically restricting the agent’s exploration. Regions of the state-action space deemed unpromising can be avoided, focussing on exploring more promising actions and states. Different techniques have been developed to realize this approach.
Curriculum learning
Curriculum learning is a training strategy used in RL to help agents learn more effectively by gradually increasing the complexity of the tasks they must solve. 148 This learning scheme is inspired by how humans and animals learn, where they gradually progress from simple to more challenging tasks.
The technique developed by Florensa et al. 80 involved training the agent near the goal state in early training episodes and gradually moving the starting position further away in later episodes. Starting close to the goal increases the probability of reaching the goal and receiving a reward, accelerating the acquisition of informative value function updates and improving exploration efficiency, even in sparse reward settings. Moving the start point gradually further from the goal, the agent quickly learned to perform the tasks from any starting state.
Hybrid RL and model-based control
Another strategy is to use model-based controllers to steer agents towards promising regions of the state space and resume RL from those regions. Hoppe et al. 81 combined trajectory optimization controller with model-free RL. The RL component explores and collects data as usual. Using the data collected, the trajectory optimization controller places the agent in promising state regions and resumes RL to accelerate learning. Florensa et al. 82 proposed Guided Uncertainty Aware Policy Optimization (GUAPO), which involved a perception system that divided the EEF space into free and uncertain spaces. Uncertain space encompassed regions where contact interactions with objects are expected, which is the space where the RL policy acts. The free space was the remaining region where point-to-point control was applied to redirect the EEF back to the uncertain space to return to using the RL policy.
Control mechanism design
The control mechanism is the interface that connects the agent to the robot’s actions within its environment. As mentioned in Section 2.3, design choices concerning the control mechanism have been shown to significantly impact the sample efficiency, generalizability and safety of RL for robotic control.
Fundamental design principles
Current control mechanism designs for contact-rich tasks follow common principles prescribed by prior seminal works.
Peng and Panne
149
prescribed RL with policies that learn how to operate a basic feedback controller, that converts agent actions to torques (i.e.
Bellegarda and Byl
150
prescribed using EEF space control over joint space control for the downstream controller. EEF and joint space control differ in how the RL agent expresses actions before converting them to actuator torques. Joint space control requires the agent to express actions in joint space and is mapped to actuator torques, that is,
Another fundamental design principle is using compliant control schemes for the downstream controller. Compliant controllers allow the robot to comply to external contact with the environment instead of rigidly resisting it, enabling safer interactions and improved adaptability in uncertain or dynamic environments. In principle, an RL agent using a rigid position controller and access to force information can learn to regulate contact forces by learning to position itself in a way that limits contact forces. However, its effectiveness in regulating contact is limited by the RL agent’s sampling frequency and adds to the learning burden, decreasing sample efficiency. Compliant control schemes also allow the robot to adapt well to environmental uncertainties when in contact, enhancing the policy’s generalizability. The control schemes most relevant to the literature are impedance, 153 admittance154,155 and hybrid motion-force control. 156 The review by Elguea-Aguinaco et al. 25 found that compliant control schemes can be used interchangeably for the same task when using RL-based control. Most works used impedance control due to the relative ease of implementation compared to admittance and hybrid motion-force control, which rely on more complicated control systems with reliable F/T sensor(s). 157 However, impedance control is only suitable for torque-controlled robots. The most widely used robots are position-controlled, so admittance and hybrid motion-force control are used in these circumstances. 84
Variable compliance control
Variable compliance control involves online adaptation of controller compliance, achieved by adding dimensions of variable compliance to the agent’s action space. This concept was introduced by Buchli et al. 158 and was later enhanced by Martín-Martín et al. 27 by combining variable compliance control with the EEF-space impedance control. Beltran-Hernandez et al. 84 proposed a similar control mechanism, but their mechanism was based on admittance control, which enabled variable compliance control for rigid position-controlled robots.
Variable compliance control improves the policy’s safety, execution time and energy consumption, given that the reward function specifies these preferences. Safety was enhanced as the policy can learn to increase compliance in states where contact is expected. Execution time is minimized as the policy can learn to reduce compliance when no contact is expected, which increases movement speed. Finally, energy consumption is minimized as the policy can learn to increase compliance, reducing maximum actuator torque when required. Another benefit is that it circumvents manually tuning the controller gains, which can be time-consuming. As such, it has become an essential aspect of current controller mechanisms designed for contact-rich robotic manipulation. Such tasks include peg insertion, assembly, disassembly, door opening and surface tracking.66,86,92 Works employing variable compliance control typically allow the RL agent to modulate only the diagonal terms of the gain matrices. However, some works allow control over all terms in gain matrices,68,89 facilitating local exploration on surfaces that the robot is in contact with.
Ulmer et al. 85 proposed an alternative implementation of variable compliance control. Their control mechanism modulates compliance within the inner control loop instead of being modulated by the upstream policy (i.e. adaptive control 159 ), reducing the agent’s action space. As a result, using Ulmer et al.’s control mechanism results in improved sample efficiency relative to Martín-Martín et al. 27 and Beltran-Hernandez et al. 84 as the exploration required by the agent was reduced.
Riemannian motion policies
Ratliff et al. 160 introduced the Riemannian Motion Policy (RMP) framework, which is based on differential geometry. This framework facilitates the modular combination of motion policies for robotic control. A common use for the RMP framework is to enhance a primary motion policy by combining it modularly with auxiliary policies that satisfy other objectives. Typically, these auxiliary policies include collision avoidance (at the EEF and intermediate joints) and joint-limit avoidance, which steer the robot away from these unsafe states, improving safety. This modularity simplifies the controller mechanism design process as the complexity of tasks and robot embodiments increases.
Shaw et al. 86 investigated using RMPs to enhance the control mechanism for RL in contact-rich robotic manipulation and demonstrated improved sample efficiency and safety for surface tracking and door-opening. Sample efficiency was enhanced by the joint limit and collision avoidance auxiliary policies, which prevented episode-terminating collision and joint-limit violations, allowing the agent to learn the task in far fewer episodes. The collision avoidance policies improved safety and were most impactful in the earlier episodes where the agent typically explores more dangerous actions. Whilst promising, the obstacle avoidance policies require real-time knowledge of surrounding obstacles, which require advanced perception mechanisms that may be difficult to implement for varied environments.
Improving robustness of imperfect controllers
Torque-based control methods, such as impedance control, are highly sensitive to inaccuracies in the controller’s assumed robot dynamics model, which include inertial and friction parameters. These inaccuracies cause deviations in motions intended by an RL agent, as real-world conditions differ from the idealised simulation. Position control relies on high gains and integration to mitigate uncertainties, ensuring a precise trajectory. These techniques are unviable for impedance control as it removes its compliant properties.
Tang et al. 88 proposed a policy-level action integrator mechanism that acts similarly integration terms in classical PID control. This technique rejects unmodelled disturbances, which results in much closer behaviour of the robot between simulation and reality, eliminating the need for retraining in real environments, thus increasing sample efficiency. This mechanism also limits the accumulated efforts from the integrator to retain the compliant characteristics of the impedance controller.
Embedding safety functionality
Modern control mechanisms for contact-rich robotic manipulation have embedded safety functionality to protect the robot and its environment and maintain safe conditions during operation. Safety can be ensured with relatively simple techniques consisting of handcrafted mechanisms. For instance, the control mechanism can limit maximum joint torque 123 or velocity. 83 If unintended contact occurs, these measures limit the damage inflicted on the robot or environment. Another simple technique is triggering a pre-defined recovery procedure if a particular sensor measurement reaches undesirable values. For example, EEF position or F/T measurements outside a desired range may trigger the termination of training.61,104
Zhu et al. 87 proposed a more sophisticated technique. It involved a contact detector for intermediate robot joints and a novel controller that performs null space operation, reconfiguring the manipulator without displacing the EEF. This technique enables the robot to comply with disturbances at intermediate joints without disturbing the task execution, which enhances safety.
Task decomposition
A promising approach is to consider RL problems modularly, decomposing tasks into smaller, more manageable subtasks. With this view, the policy
This modular approach allows agents to think and act at higher temporal resolutions, considering longer action sequences and higher-level plans rather than making decisions at each timestep. This improves sample efficiency as temporally extended actions result in quicker exploration of states far from the starting point, accelerating the exploration of promising actions and enhancing the agent’s ability to learn long-horizon tasks. 161 Long-horizon tasks require agents to make decisions over an extended period, involving numerous actions before task completion and reward acquisition, which are more challenging to learn with basic RL. 161 Additionally, task decomposition facilitates sub-policy reuse across different tasks, that is, knowledge transfer, further improving sample efficiency when learning new tasks. Generalizability is also enhanced by transferring super-policies between task or environment variation, which reduces the required fine-tuning in policy transfer as policies are retrained at the sub-policy level, each addressing smaller portions of a task.
Four sub-approaches have been identified in the literature that adopt the task decomposition approach for contact-rich robotic manipulation: namely, Task Planning with RL, Skill-Based RL, Hierarchical RL, techniques using an expert-guided super-policy. These sub-approaches, which are illustrated in Figure 7 and the techniques proposed under each sub-approach are discussed in this section.
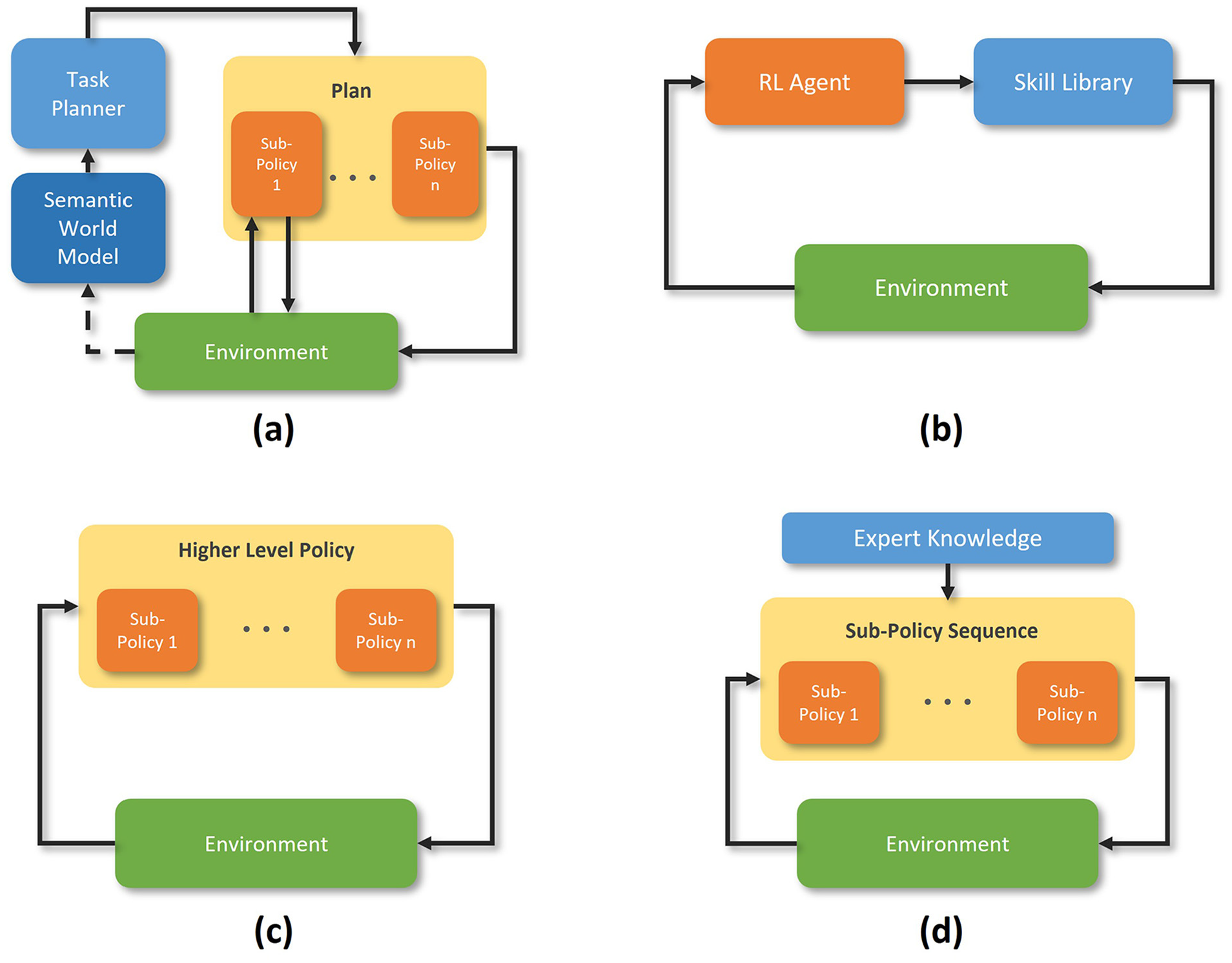
Task planning with RL
Task planning162–164 is a robotics technique using a semantic environment model and planner to execute long-horizon tasks. It involves a symbolic planner assessing the state of the environment and producing a sequence of actions that fulfil a user’s desired goal(s). Actions are typically selected from an action library shared between task plans to simplify the planning process. Finally, the action sequence is passed to an execution module to implement the plan. The main strength of task planning is its generalisability potential, as it can, in principle, immediately facilitate the completion of any task in any given environment, given a suitable semantic environment model and action library. However, the actions are typically unsuitable for contact-rich tasks as actions are not well suited to complex and uncertain contact interactions, which can fail. As such, researchers have combined task planning and RL to produce actions that are robust to environmental uncertainties. This is accomplished by using the planner
Mayr et al. 93 proposed using a planner that generated an action sequence from a library of tuneable action primitives, and later, RL was used to fine-tune the action primitives. Cheng and Xu 95 used a planner that identified the relevant sub-goals for a task and learned the actions from scratch with RL. The main bottleneck in these techniques is the reliance on semantic world models. Semantic world models are challenging to produce due to the limitations of current perception and semantic environment model generation algorithms which limit scalability. Therefore, applying task planning with RL in uncertain and novel environments is limited.
Skill-based RL
Skill-based RL involves training a model-free RL agent with an augmented action space, where actions represent a sequence of low-level actions
The skill-based RL techniques applied to contact-rich robotic manipulation differ primarily by the method for defining the skill space. Lew et al.
97
proposed a technique where the RL agent learns to command a downstream trajectory optimization module, which takes a goal pose and executes an to optimal trajectory to the goal. This technique was applied to learn a surface tracking task. Nasiriany et al.
91
defined the skill space as a finite set of hand-crafted skills. These skills were also parametrized with skill parameters
As the agent is model-free, skill-based RL circumvents the need for prior knowledge of the environment, which increases its applicability compared to task planning with RL. However, a skill-based RL agent’s performance is limited by the skill space’s quality, as a sub-optimal skill space can harm learning efficiency. 167 Skill spaces require human input, so the implementation may be time-consuming depending on the implementer’s skill level, which can limit skill-based RL’s scalability and effectiveness.
Hierarchical RL
Unlike other task decomposition sub-approaches, Hierarchical RL (HRL)161,168 involves learning both the super- and sub-policies from scratch without assistance from injected expert knowledge. HRL techniques involve autonomous segmentation of tasks into sub-tasks to learn the super-policy and autonomous learning of each sub-policy for their respective sub-task. As a result, HRL involves less manual effort than other task decomposition sub-approaches and eliminates sub-optimality introduced by human input, which can be useful if the given task’s structure is challenging to decompose, or the required sub-policies are unknown or difficult to produce. However, these benefits trade-off with reduced sample efficiency as more environment interactions are needed to learn the task decomposition and set of suitable sub-policies from scratch. Hou et al. 90 is the only work using HRL techniques for contact-rich robotic manipulation where it was used to learn multi-peg insertion.
Expert-guided super-policy
Rather than learning the
More sophisticated techniques construct
Meta-learning
Meta-learning
171
is an ML approach that focuses on algorithms and techniques enabling models to learn how to learn. It involves a meta-training process where a meta-model is trained on a distribution of domains (tasks or datasets),
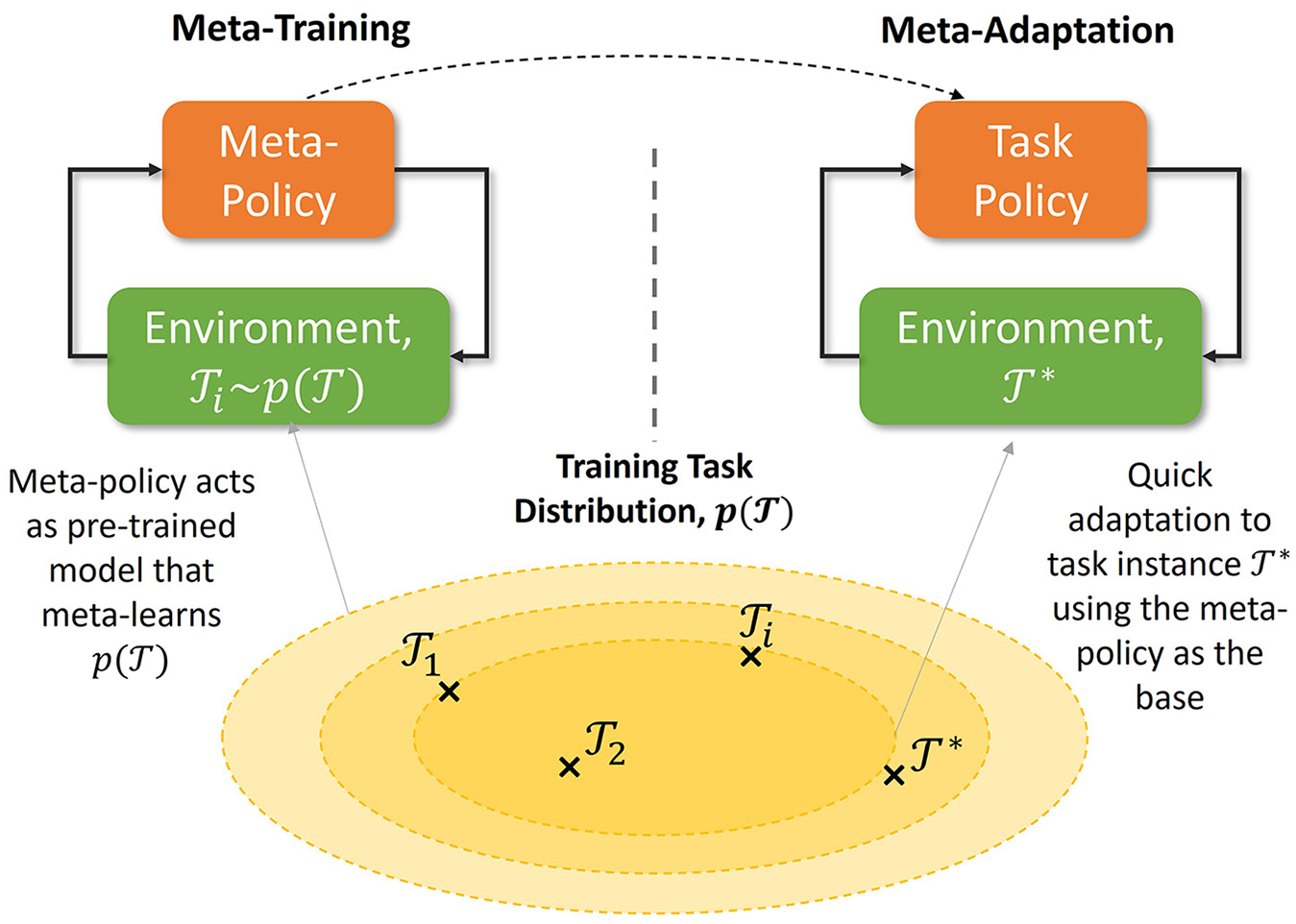
Illustration of the central concept behind meta-RL.
Meta-learning is similar to transfer learning, 172 as both techniques facilitate knowledge transfer between domains to minimize additional training. However, transfer learning only facilitates transfer between a single source and target domain due to its naïve approach, which involves fine-tuning a pre-trained model on a new domain without knowledge of the variance between domains. Instead, meta-learning models first learn the variance between domains in a training domain distribution, which enables it to adapt to any domain within the training domain distribution, not just one. Meta-adaptation is also much quicker than naïve transfer learning, with some works completing successful meta-adaptation with little or no further training, referred to as few- or zero-shot transfer, respectively. 173
Meta-learning techniques produce generalized models that can quickly adapt to changes in different domains. This is especially beneficial for contact-rich manipulation tasks, where robust and adaptable policies are needed to operate efficiently in uncertain environments with minimal retraining.
Meta-reinforcement learning
Meta-Reinforcement Learning (Meta-RL) applies meta-learning concepts to sequential decision-making.
153
It involves meta-training a meta-policy on a task distribution,
Many Meta-RL techniques have been proposed, such as Recurrent Neural Network (RNN) based174,175 and variational inference-based approaches, 176 which formalize the problem as a Partially Observable MDP. 177 Other techniques adopt a gradient-based approach. 178 The variational inference-based technique, Probabilistic Embeddings for Actor-Critic RL (PEARL), 176 is the only Meta-RL technique adopted in contact-rich robotic manipulation as it decouples task inference from task completion, which can enhance sample efficiency by facilitating off-policy learning. 179
Schoettler et al. 104 and Hafez et al. 106 used PEARL to train a meta-policy in simulated insertion tasks with domain randomization. The randomized simulation emulated meta-training on a distribution of varied insertion tasks. More specifically, their task distribution randomized hole position estimates, peg-hole clearances, and position controller step size to emulate uncertainties in the real world not captured in the simulation. The experiments found that the meta-policy adapted to real insertion tasks much quicker than a basic policy trained on a single simulated environment.
The application of Meta-RL in these works only meta-train on relatively narrow task distributions with minor variations between task instances, limiting the generalizability potential of the final meta-policy. In principle, meta-training can be performed on broader task distributions to attain higher generalizability potential, such as a meta-policy that can insert cables or assemble objects, not just variations of the basic peg and hole problem. However, attaining high generalizability potential significantly increases meta-training time and cost, 107 which offsets its advantage over more straightforward transfer learning techniques. Furthermore, successful meta-adaptation requires careful task distribution design to ensure the target task falls in this distribution, increasing implementation difficulty as the task distribution’s scope grows as designing each task requires considerable manual effort.
Meta imitation learning
To address the challenges of Meta-RL’s high cost, researchers combined imitation learning
145
with Meta-RL, which we refer to as Meta-Imitation Learning (Meta-IL). Meta-IL leverages demonstrations to learn each task from
Meta-IL has typically been achieved by training a VAE
136
to reconstruct policies learned from demonstration for tasks from
Model-based reinforcement learning
Model-Based RL (MBRL) 180 is an approach to RL centred around the use of a virtual environment transition model for training as a supplement or substitute to training in a real environment. By using such a model for training, data required for training can be generated using this virtual model rather than sampling data from the environment. As such, is can be much quicker and cheaper than the more Model-Free RL (MFRL), effectively increasing sample efficiency.
Transition model design
Despite MBRL’s strengths, MFRL has gained more traction in contact-rich manipulation. MFRL typically achieves greater maximum reward than MBRL because contact dynamics are challenging to model accurately, leading to inaccurate transition models. Policies then overfit to this inaccurate model, resulting in degraded asymptotic policy performance, and is known as model bias. 181 To realise MBRL’s potential in contact-rich manipulation, researchers have focused on improving transition model design to minimise model bias.
MBRL research for contact-rich robotic manipulation exclusively adopts learned over analytic transition models as learned models are more straightforward and less time-consuming to implement than analytic models, offering a more practical solution for MBRL. Learned models only require feeding an appropriate amount of labelled data collected from the real environment to an ML algorithm to model the dynamics. In contrast, analytic models require more effort, involving precise modelling of the environment and physical phenomena to obtain an accurate dynamics model. Further, analytical models present an unfavourable trade-off between accuracy and latency182,183 as analytic models require expensive calculations to model non-linear contact dynamics that become more expensive as the model’s fidelity increases, resulting in time-intensive model queries. Learned models achieve this by fitting a non-linear function to the acquired data, which makes it quicker to query 184 and the query latency does not scale directly with the model’s fidelity. Some researchers182,183 have investigated hybrid learned-analytic models and shown promising results. However, proposed models have not yet been studied in more complex robotic manipulation environments or in conjunction with RL.
Transition models within the reviewed works are also probabilistic, meaning that a state transition distribution is predicted rather than a single transition. 180 This is because state transition prediction is subject to epistemic and aleatoric uncertainty. 185 Epistemic uncertainty arises from insufficient amounts of data to make accurate predictions. It can be reduced by providing training models with more data but is seldom eliminated due to the associated costs. Aleatoric uncertainty arises from measurement noise, environment variability, non-linear dynamics and partial observability of the environment state. It is irreducible as it is caused by inherent environment stochasticity. Attempting to predict state transition deterministically will result in inaccurate predictions and degraded policy performance. Using probabilistic transition models, an agent can consider multiple likely outcomes for its actions during training, reducing model bias, significantly improving the maximum reward attainable by an MBRL agent.181,186,187
Given that learned probabilistic transition models are most suitable, three prominent ML frameworks have been adopted to represent the transition model in the MBRL works reviewed. Namely, probabilistic ANNs, 188 Gaussian Processes (GPs) 189 and Gaussian Mixture Models (GMMs) 190 due to their ability to model non-linear functions. Using these ML frameworks as transition models with MBRL algorithms (e.g.,177–183) resulted in contact-rich tasks being learned successfully. For instance, insertion,110,112 door opening 111 and surface tracking. 116 In these cases, sample efficiency was improved compared to MFRL, and the maximum reward obtained was comparable to that obtained by an MFRL policy.
Transition model transferability
The drawback of learned transition models is that they are specific to the training environment and require further training for a new environment, reducing the scalability of MBRL. As such, researchers have investigated transition model transferability to accelerate learning in new environments to improve MBRL’s scalability. Only ANN transition models have been used to investigate transition model transferability, as ANNs are widely studied in the context of transfer learning.191,192
Fu et al. 109 fine-tuned an ANN transition model learned from a prior insertion task to quickly learn a variant of the insertion task. The technique proposed by Tanaka et al. 193 involved training an ANN to aggregate a transition model ensemble from previous assembly environments to learn a new assembly environment’s dynamics quickly. Nagabandi et al. 194 proposed a meta-learning technique to transition model learning and was applied by Liu et al. 115 to learn variations of insertion tasks with MBRL in a sample-efficient manner.
These techniques require pre-trained transition models from prior environments similar to the target environment for quick transfer, which is suitable for addressing a set of similar environments. However, when addressing novel environments that differ too much from previously seen environments, transition models must be learned from scratch, as prior transition models cannot utilize current transfer techniques to accelerate training. Therefore, current techniques only partially address the scalability issue of MBRL. To address the scalability issues of MBRL completely, future research should focus on knowledge transfer techniques that enable quick learning of novel environments by reducing the reliance on access to prior transition models from environments similar to a target environment.
Safe exploration with MBRL
Some researchers focused on exploiting the foresight afforded by the transition model to facilitate significantly safer exploration during training.
Mitsioni et al. 114 developed a technique involving pre-training a classifier that segregated the state space into safe and unsafe sets. During training, actions likely to reach unsafe states were filtered out of the viable actions set during policy deployment in the real world, resulting in safer operation. Thananjeyan et al. 113 proposed using a pre-trained safety critic that predicted the probability of visiting unsafe states in the future given the current action and state. The safety critic was trained offline with a dataset of example trajectories where the agent reached the state. This cost critic was then used as a function for the agent to minimize when learning with MBRL, resulting in safe and sample-efficient learning in an object extraction task.
Bridging the reality gap in sim-to-real transfer
An essential approach for improving the practicality of RL for robotic control is sim-to-real transfer, referring to pre-training a policy in simulation and then fine-tuning it in the real environment. Simulation training enables training episodes to be executed faster than wall clock time, reducing training time and cost. Safety is also improved as the most hazardous early training phase, where actions are random, is conducted in a simulation with no consequences for unsafe exploration. The physics simulators typically used for RL in contact-rich robotic manipulation are MuJoCo, Gazebo, Bullet and Isaac.
There is a mismatch between simulation and reality, referred to as the reality gap. 195 The reality gap is caused by three factors described below. The effects of these factors are also discussed.
The more significant the reality gap, the more fine-tuning is required to complete sim-to-real transfer, reducing the time, cost and safety benefits of sim-to-real transfer. Therefore, techniques have proposed to close the reality gap to enable efficient transfer of simulation-trained policies to real environments. The techniques are discussed in this subs-section are grouped into sub-approaches use data-driven methods to overcome the reality gap, namely Domain Randomization (DR), System identification (SI) and Domain Adaptation (DA), which are illustrated in Figure 9. Another sub-approach is discussed that aims to close the reality gap by enhancing simulation fidelity.
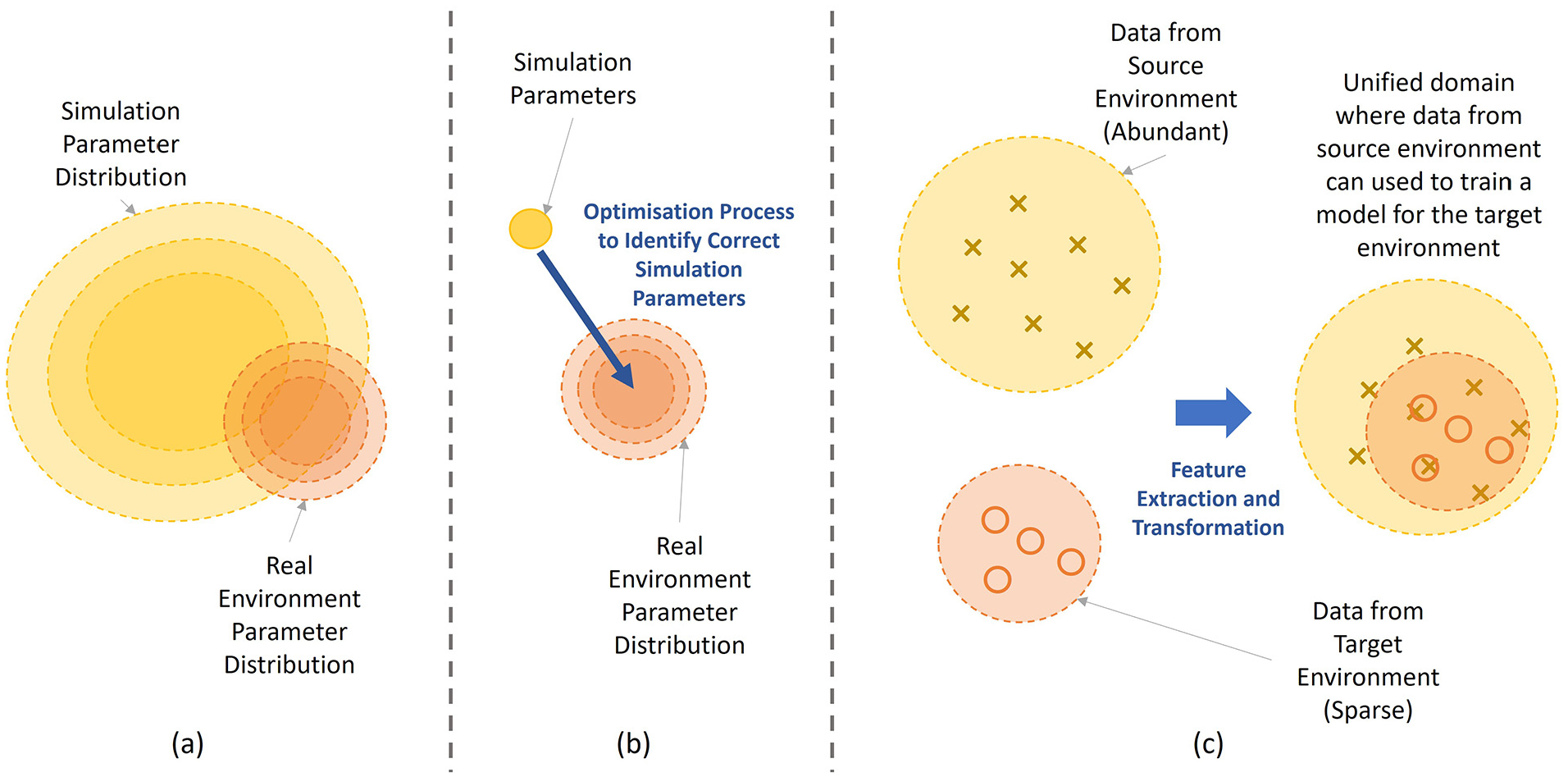
Visualisations illustrating the intuition behind the three data-driven sub-approaches in closing the reality gap for sim-to-real transfer. (a) domain randomisation, (b) system identification, (c) domain adaptation.
Domain randomization
DR195,197 involves randomising select simulation parameters during in-simulation training and training the agent on the distribution of environments. By training a policy to be successful in a distribution of environments, the policy can be transferred to the real environment with little fine-tuning, as it can be considered as an instance within the environment distribution already seen in training. DR has been the most commonly applied sim-to-real transfer technique within the contact-rich manipulation literature27,48,68,119,120,125 due to its simplicity and effectiveness. Typically, parameters such as joint damping, geometry, friction, surface appearance and stiffness are randomised to facilitate successful sim-to-real transfer for contact-rich tasks. This technique can be seen as a way to compensate for reality gaps caused by all factors discussed.
The optimal use of DR relies on carefully designing the parameter sampling distribution. The parameter sampling distribution’s mean should be placed near the real environment’s expected parameter values to minimize the required fine-tuning. Also, the distribution’s variance should be large enough to account for environmental uncertainty and compensate for the physics engine’s low fidelity and inaccurate environment reconstruction. However, the variance should be limited as too much produces an overly conservative policy with sub-optimal performance 198 and unnecessarily worsens sample efficiency. These design considerations can make it challenging to implement DR successfully, so researchers have proposed extensions to DR that streamline implementation to achieve optimal results quickly.
Chebotar et al. 117 proposed a technique that iteratively updates the sampling distribution of environment variants towards around the real environment parameters. The optimization process was facilitated with a closed-loop system that updated the simulation using data from the real environment. This technique was used enable successful sim-to-real transfer of a door opening policy. Beltran-Hernandez et al. 121 proposed combining curriculum learning with DR for insertion, which involved adapting the parameter sampling distribution’s variance with the average reward obtained during training – the larger the average reward, the larger the variance grew. The adaptive variance enabled the agent to learn broad parameter sampling distributions quicker than with a static variance, as the adaptive variance scheme presented the agent with tasks of progressive difficulty, which were easier to learn. Aflakian et al. 127 also employ this technique for a surface tracking task. Another extension of DR is to combine it with Meta-RL (Section 4.7).104,106 In basic DR, the RL algorithm assumes the environment variations are a single environment, so the agent will learn an average optimal policy across all variations rather than addressing each variant optimally. This results in overly conservative policies for broad task distributions and will require more fine-tuning to transfer well to the real environment. In Meta-RL, the meta-policy instead considers the environment variations as distinct tasks. The meta-policy learns the common features or representations across environmental variations to facilitate fast adaptation to other potential environmental variations. This alternative approach reduces the fine-tuning required when transferring the real environment.
System identification
SI aims to identify the real environment’s dynamic parameter values directly and use these values to improve simulation accuracy. It aims to partially address the reality gap associated with inaccurate reconstructions of the real environment. With a more accurate simulation, sim-to-real transfer requires less fine-tuning when transferring to the real environment, which improves sample efficiency. As accurate environment parameter values are difficult to obtain manually, SI techniques infer parameter values in a data-driven manner. The technique developed by Kaspar et al. 118 involved executing a handcrafted controller in the real and simulated environment and iteratively optimizing the simulation parameters until the robot trajectory in each environment matched.
Domain adaptation
DA 199 is an ML technique enabling model transfer to a target domain even when the available data from the target domain is too scarce to facilitate transfer via regular fine-tuning. DA is achieved by unifying the source (simulation) and target (real) domain data in the same feature space, allowing knowledge obtained in the source domain to improve the model’s performance in the target domain. It is often used to address the reality gap associated with inaccurate synthetic sensor data generation in simulation. DA can be promising for sim-to-real transfer as this can reduce the amount of real environment fine-tuning for successful sim-to-real transfer, which improves sample efficiency.
DA techniques typically centre around the use of Generative Adversarial Networks (GANs). 200 GANs are trained in an unsupervised manner to generate ability to realistic samples that imitate a relatively scarce dataset. In the context of RL for contact-rich robotic manipulation, GANs will be trained on a scarce dataset of sensor data from reality. After training a GAN, the underlying distribution of real data is captured in a low-dimensional latent space. The latent spaces of data captured in the real environment and the simulated environment can then be aligned, creating a mapping from the source environment. Then, a policy trained in simulation can directly be transferred to reality without further re-training using the mapping of sensory observations between the source and target domains.
Shi et al. 123 used CycleGAN 201 to learn a function to transform image observations from the real environment to equivalent observations in simulation. This enabled the simulation-trained visuomotor policy for insertion to transfer to the real environment with little fine-tuning. Zhao et al. 124 also used CycleGAN to transfer an insertion policy using tactile data from simulation to reality. Church et al. 122 use the pix2pix framework, 201 also based on GANs, to map real tactile sensor data to sensor data used for learning in simulation to enable efficient transfer of a surface tracking and non-prehensile manipulation policy from simulation to reality. Wu et al. 128 use a GAN-VAE framework to enable the sim-to-real transfer of a surface tracking policy using tactile sensory observations.
Enhancing simulation fidelity
Some works aim to close the reality gap by enhancing simulations to better simulate the physical phenomena in the real world. These techniques intend to address reality gaps caused by low-fidelity physics simulations and inaccurate synthetic sensor data generation.
Vuong and Pham 126 propose a technique that reduces the number of contact points used to compute contact forces when objects are in contact bounding the stiffness of each contact point. With these modifications, the speed, accuracy and stability of the contact simulation was shown to have improved. The authors demonstrate in simple studies the improved accuracy of contact simulation with their technique and demonstrate an insertion policy successfully being transferred from simulation to reality with their modified simulation. However, extensive validation studies are required to further validate the effectiveness of this technique.
Chen et al. 129 use a more expensive Finite Element Method (FEM) simulator to obtain more accurate simulation of the deformation of an on-finger tactile sensor when in contact with an object. They then showed successful transfer of an insertion policy with tactile sensory input that was trained in the FEM simulation to a real environment. They also compared the performance of a policies trained in a FEM and rigid body simulator and showed the improved transferability with their policy.
Discussion
Assessing the current state of the key challenges
We revisit the key challenges presented in Section 3.1 and analyse their present status given the recently developed techniques. We also identify gaps where further improvement may be necessary.
Cost
Recent techniques have reduced the cost of implementing RL-based robotic control by improving sample efficiency and generalizability. Improving sample efficiency reduces the time required to learn an effective policy from scratch when learning a new environment. Enhancing generalizability also reduces training time, but when a policy for an environment similar to the target environment is available for re-use, in other words, when re-using policies between tasks belonging to the same task type. We discuss the works improving these aspects of RL below and their impact on cost.
Sample efficiency
Various approaches have been utilised to enhance sample efficiency, as highlighted in Section 4. These approaches rely on expert knowledge injection, auxiliary knowledge being learned, or knowledge transfer between task types to accelerate the exploration of promising states and actions, resulting in convergence to an optimal policy within fewer environment interactions. The findings in the literature demonstrate that employing these approaches results in improved sample efficiency compared to basic RL, potentially reducing the associated training times and costs. Table 2 summarises the approaches targeting improved sample efficiency.
A table showing an analysis of the approaches that aim to improve sample efficiency.
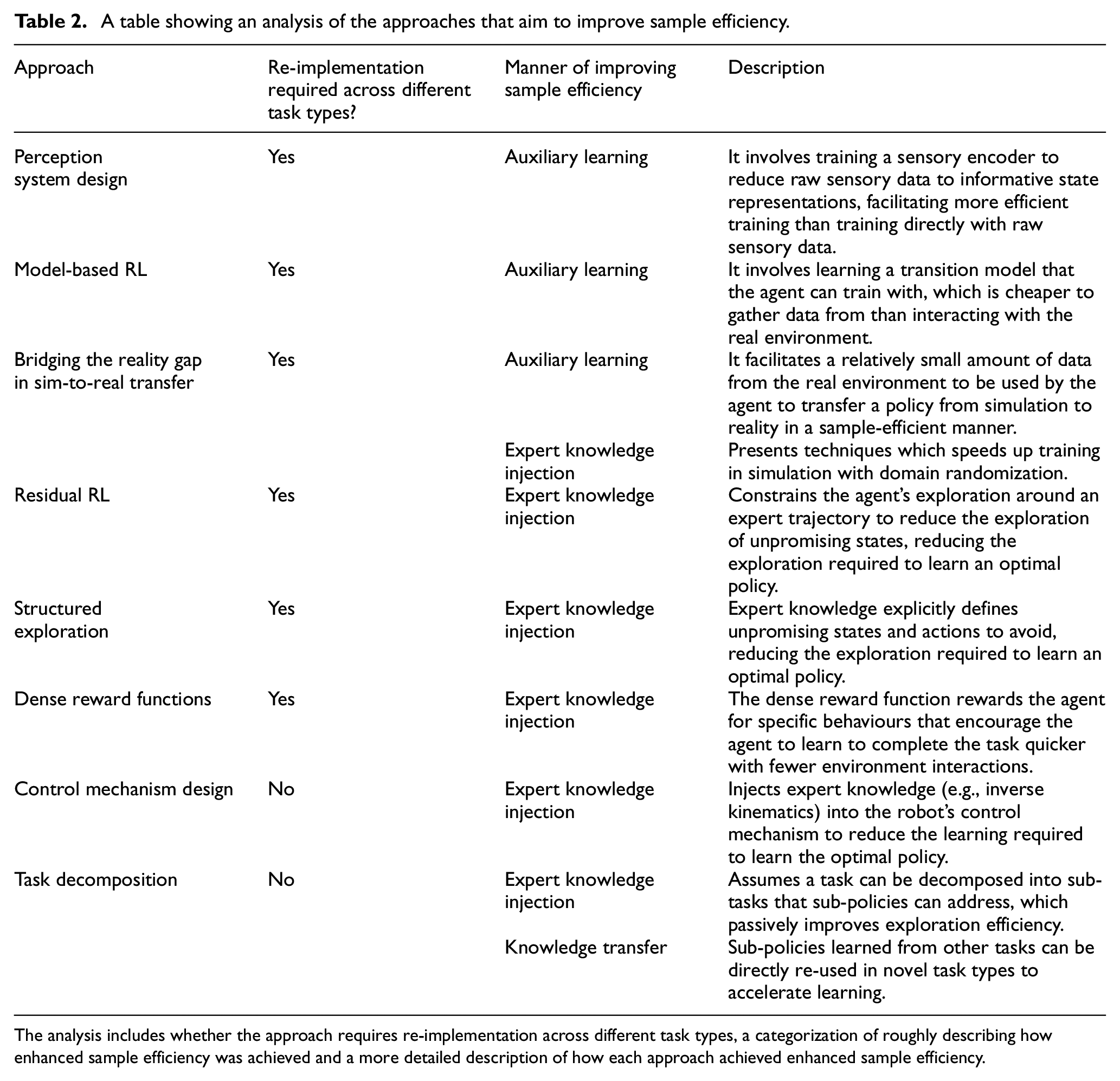
The analysis includes whether the approach requires re-implementation across different task types, a categorization of roughly describing how enhanced sample efficiency was achieved and a more detailed description of how each approach achieved enhanced sample efficiency.
Most approaches enhance sample efficiency using injected expert knowledge or learned auxiliary knowledge specific to the task type. In these cases, the task-specific knowledge is used to directly guide the agent towards the goal, significantly accelerating reward acquisition and quickly converging to an optimal policy. Despite significantly improving sample efficiency, these approaches must be re-implemented when learning new task types, as the underlying knowledge used may not be applicable for accelerating the learning of a novel task type. For example, dense reward functions are specific to a task type and only apply to the task type it was designed for, so a new dense reward function must be designed for a new environment. Re-implementing these techniques across task types offsets the cost-savings from enhancing sample efficiency when practitioners must consider a diverse set of task types, which is not ideal.
A minority of approaches do not require re-implementation across different task types due to the universal nature of the knowledge used to improve sample efficiency. For example, inverse kinematics is used in control mechanism design to improve sample efficiency, and re-implementation is not required for a new environment to achieve the same effect. However, these approaches result in a less significant sample efficiency enhancement as the knowledge used does not directly guide the agent towards the desired goal and only passively improves learning.
As a result, approaches that require re-implementation have been more prominently studied. To minimize their re-implementation costs, techniques have been developed to streamline the implementation of these approaches by reducing manual effort and reliance on specialized knowledge. For instance, self-supervised SRL 26 in perception system design, IRL62,63 for dense reward functions, the integration of imitation learning with residual RL67,70,71 and transition model transferability109,115,193 in MBRL.
A promising solution is directly transferring knowledge between policies from previously learned task types to new task types. In the current literature, the only approach to facilitate knowledge transfer is task decomposition by enabling the reuse of modular sub-policies between task types. Studies90–95 have shown accelerated and successful learning of a set of varied task types using a fixed set of sub-policies. Task decomposition approaches could potentially be scaled up to learn a broader range of novel task types quicker with RL-based robotic control, but this scalability requires further development.
161
The main benefit of knowledge transfer is that learning different task types can be achieved sample efficiently without re-implementation between task types, significantly reducing the cost of RL-based robotic control.
Generalizability
The current research addresses generalizability at various scopes. In increasing order of scope, the scopes of generalizability considered were robustness to environment uncertainty, generalizability between tasks belonging to the same task type, and policy reuse between different robots.
Residual RL and control mechanism design approaches have addressed policy robustness to environment uncertainty. Residual RL uses a residual policy to consider environmental uncertainty not considered by the expert trajectory to enhance the expert trajectory’s robustness to different environmental uncertainties.66,67,70–74,105,145 Control mechanism design principles prescribe compliant control schemes, which enable robots to adapt to environmental uncertainty by allowing the robot to adjust its behaviour in response to unexpected external forces.27,84,85
Approaches such as perception system design, meta-learning and task decomposition improve the generalizability of policies regarding tasks belonging to the same task type as well handling environmental uncertainty. Perception system design focuses on capturing state features independent of task variations through richer sensor modalities like visual feedback, creating a policy adaptable to different task variants. Meta-learning explicitly trains a meta-policy on a distribution of similar environments, resulting in environments captured by the task distribution to be quickly learned using the meta-policy.104–108 Task decomposition modularizes the policy, facilitating faster transfer to tasks sharing similar structures as adaptation occurs at the sub-policy level, requiring less fine-tuning than a monolithic policy.90,95
Finally, policy re-use between robots has been addressed by control mechanisms design by suggesting using EEF space control to make policies independent of robot kinematics. 27 However, successful inter-robot policy transfer still requires extensive fine-tuning due to the unaccounted variability of dynamics between robots, which may be costly. Future work should be directed at developing techniques that account for robot dynamics variability to reduce the cost of inter-robot policy transfer. 204
Safety
Different approaches have been utilised to enhance safety across RL agent lifecycle phases. Combining techniques from these approaches can improve safety across the RL agent’s lifecycle. The different phases of the RL agent’s lifecycle are listed and summarised below:
During early training, sim-to-real transfer and residual RL ensure safety by bypassing the early training phase and beginning training with a mature policy that makes it less prone to behaving dangerously. Sim-to-real transfer conducts the early training phase in simulation and transfers the policy to reality, which starts training in reality with a mature policy. A policy in residual RL only explores locally around an expert trajectory, which mimics a mature policy being fine-tuned. These approaches are the most commonly adopted as they are simple to implement but may be limited by scalability. Sim-to-real transfer requires an accurate reconstruction of the task in simulation, which can be time-consuming and expensive to produce. Residual RL may need different expert trajectories to be implemented across various tasks, which can be time-consuming and costly.
In the late training phase, exploration is less random, but there is still a risk of acting hazardously during fine-tuning. As a fallback, control mechanism features such as compliant control schemes and limiting actuator torque or velocity can minimize damage in the event of contact during the final stages of training.61,83,104,123 Dense reward terms can encourage safer policy behaviour and further enhance the safety of the final policy.71,74,84
MBRL has been used to improve safety during the early and late phases of training. This was achieved by predicting future state transitions, pre-defining unsafe states for the agent to avoid during exploration and preventing the execution of actions that will lead to unsafe states. 114 As MBRL involves learned transition models, managing implementation costs across varied environments is a concern due to sample efficiency and implementation complexity. However, using learned transition models opens the possibility of transferability of the learned knowledge to enhance safety across different environments whilst minimizing re-implementation costs. Therefore, building on MBRL may be a promising direction for future research in improving safety. 39
During deployment, the robot may be vulnerable to unsafe novel scenarios as it has not learned how to behave safely in such scenarios during training. Since learning is suspended during deployment, non-ML-based techniques, such as RMPs86,160 and facilitating null space transformations, 87 have been developed to enhance safety in novel scenarios. However, the scope of scenarios for which these techniques can maintain safe operation is undetermined, and more non-ML-based techniques may be required to cover more unsafe scenarios. Developing more of these non-learning techniques may be a direction in future research.
Promising directions for future research
The following directions for future research are proposed based on the gaps identified in Section 5.1.
Knowledge transfer across diverse tasks
The long-term ambition for robotic control is to develop systems capable of performing a wide range of tasks without task-specific adjustments or fine-tuning. Achieving this would require robots to leverage experiences from diverse tasks to determine appropriate actions for new tasks in a zero-shot manner, similar to how large language models have demonstrated impressive generalisation capabilities in the natural language processing domain.
Current research in robotic control is predominantly focused on single-task settings, with limited emphasis on leveraging knowledge gained from different tasks. Existing approaches are often require task-specific implementation, lacking mechanisms for transferring or generalizing knowledge across varying objectives and environments. While meta-learning techniques have been explored, their application has been largely confined to related tasks within narrow domains.
Expanding the scope of research to encompass broader task distributions and more effective knowledge transfer mechanisms could significantly enhance the generalization capabilities of robotic systems. Developing architectures that can consolidate knowledge from diverse experiences and apply it to novel tasks remains a critical challenge. Future efforts should focus on designing frameworks that facilitate scalable knowledge transfer, allowing robots to continually expand their skill-sets through interaction with varied environments without extensive retraining.
Enabling cross-platform generalization through inter-robot policy transfer
One of the most significant barriers to widespread deployment of RL-based control systems is their lack of generalisability across different robotic platforms. The current reliance on training in EEF space addresses kinematic differences but neglects the complexities introduced by diverse dynamics, particularly during contact interactions. 204
Achieving true inter-robot policy transfer requires developing methods that are invariant to both kinematic and dynamic discrepancies between platforms. Such advances would pave the way for universally applicable policies that can be seamlessly deployed across various robots, drastically reducing the cost and time associated with re-training.
Future research could explore embedding dynamic awareness into policies, leveraging techniques like meta-learning. Breakthroughs in this area could enable plug-and-play robotic controllers applicable to a multitude of platforms, thus accelerating the mainstream adoption of RL-based robotic control.
Beyond controlled environments: real-world RL and continual learning
In the current implementation of RL, agents are trained to maximise rewards in controlled training environments. Controlled environments are simulated or real-world environments where the environment’s state can be precisely monitored to administer rewards accurately, and the environment can be easily reset between training episodes. The policy is continuously updated during this training based on the experiences gathered during environmental interactions.
Once a desired agent behaviour has been obtained, training is suspended, and the best version of the policy is deployed in the operating environment, which is not controlled. Training is suspended as precisely monitoring the operating environment’s state is not guaranteed, so computed rewards may not be useful for updating the policy. 205 Further, resetting the environment in the real world across many attempts may be impractically time-consuming if the agent requires many training episodes to adapt to the operating environment. During deployment, the policy is no longer updated based on new experiences gathered, and decisions are made based solely on what was considered optimal for the controlled environments seen during training. This may result in the policy failing in an unseen variation of the intended environment and may even act unsafely.
Current research using meta-learning104–108 aimed to address this problem by training the agent in varied environments and so that the agent performed well across those variations, thus being robust to variations in the operating environment. However, this can be very costly due to the significantly longer training times, and the agent can still fail if the variations in the operating environment are not represented by the environment presented during training. 173
A potential path forward is to enable continuous policy updates through the agent’s interactions within the operating environment by addressing the issues with reward assignments and environment resetting. This is currently being investigated for other applications of RL and is known as real-world RL.205–207 Another component required for this is continual or lifelong learning,208,209 which is an advanced ML paradigm, enabling an agent to incrementally learn continuously from a stream of incoming data rather than in one instance on a static set of past experiences without forgetting past learnings. Incorporating these components into RL for contact-rich robotic manipulation could enable agents to learn to deal with unseen task variations and avoid novel unsafe scenarios without needing to return the agent to a controlled environment for a formal training process.
Conclusion
RL-based robotic control is a promising approach for addressing contact-rich robotic manipulation tasks due to its ability to solve complex environments with minimal human supervision. It was identified that the current research was motivated by the need to improve the cost (through improving sample efficiency and generalizability) and safety of RL-based control, which were considered to be bottlenecks in its wider adoption.
To improve cost and safety, researchers developed techniques to address these challenges. To organize the literature, the review organized the techniques into approaches corresponding to a specific perspective on the problems of RL-based robotic control that motivates the development of a given technique. The approaches and the associated techniques were presented in an organized manner to provide a structured overview of the current state of research.
The approaches were then holistically analysed based on their cost and safety impact. It was found that cost and safety had improved significantly due to the recent developments, making RL-based robotic control more viable for wider adoption for future industrial automation. To further enhance RL-based robotic control, it was suggested that improving knowledge transfer between different task types, improving inter-robot policy transfer and implementing real-world RL and continual learning, were promising research directions.
Footnotes
Correction (November 2025):
In the published version of the article, the textual errors “MDPNv132” and “two-dimensional” on page 5, have been corrected to “MDPNv132” and “low-dimensional”. The citation “Aflakian et al.127” on page 23 has been corrected to “Chen et al.129” and lastly, the sentence “RL Manchin et al.,139 Fernandes et al.,140 Sorokin et al.141 on RL benchmark tasks” on page 12 has been revised to “RL139,140,141 on RL benchmark tasks.” The online version of the article has been updated to reflect the changes.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Engineering and Physical Sciences Research Council (EPSRC) under Grant EP/W00206X/1.