
Abstract
This article addresses a major change emerging in visual communication worldwide: The advent of generative AI imagery. Rooted in Multimodal Critical Discourse Studies and Semiotic Technology Studies, the article scrutinizes how AI-generated images exert power with regards to the meaning-making choices that are afforded by Open AI’s software for generating visuals: Dall-E3. Using prompts to generate images of teenagers as a case in point, the results revealed that the “the canonical repertoire” of generative AI imagery constitutes four main semiotic principles, which are critically explored and discussed: Authenticating Contextualization, Conformist Diversity, Innovative Surrealization, and Promotional Positivity.
Keywords
Introduction
We are at the beginning of a major change in visual communication: The emergence of generative AI imagery as an integral part of numerous private and professional social practices across the globe. As generative AI is not merely about technological change, but very much about social and discursive change, scholarly engagement in discourse analysis is paramount. In this article, we critically explore generative AI images as a semiotic technology, that is, a technology for meaning-making that is deeply inscribed with certain sets of social norms, values, and ideologies (cf. Djonov and Van Leeuwen, 2018). The objective is to scrutinize how AI-generated images exert power with regards to what meaning-making choices it affords. We will identify and account for some overall semiotic principles of generative AI imagery, that is, “the canonical repertoire” of generative AI imagery, and critically discuss these principles as part and parcel of contemporary culture. We work with “teenagers” as our thematic field and dig into the semiotic technology of Dall-E from Open AI. Grounded in social semiotics (Van Leeuwen, 2005), more specifically semiotic technology studies (Poulsen et al., 2018) and multimodal critical discourse studies (MCDA) (Machin, 2013, 2016; Van Leeuwen, 2008), the study offers new insights into the power of AI images.
From stock imagery to AI imagery
We see the social functions of AI imagery as a continuation of stock imagery, which has long been used in a variety of promotional and informational contexts, constituting “the wallpaper of consumer culture” (Frosh, 2013: 3482). In a seminal work, MCDA scholar Machin (2004) revealed how the development of image banks fundamentally changed the design and use of photographs: “What matters now is no longer only what photographs represent, when and where they were taken, and why. What matters now as much, or more, is how many different contexts they can be inserted into, both in terms of what they represent and in terms of their form” (p. 317). Now, 20 years later, stock images don’t have to be designed to be insertable into as many contexts as possible, as generative AI allows users to simply generate a new and “unique” image whenever desired. AI tools are trained on and generate images based on existing visuals, and as stock images are widely available online, Dall-E is likely trained on such images. Many image banks, including Getty Images, now also offer AI-generated images that draw on their content (https://www.gettyimages.com/ai/generation/about). Thus, the canonical repertoire of image banks is likely to be present in AI images.
Machin (2004) also showed how the purpose of stock images materializes as a particular semiotic repertoire. Firstly, they are characterized by genericity (generic-looking backgrounds, settings, attributes, and models). Secondly, they achieve timelessness through, for example, iconographical simplicity, and thirdly, they tend to have lowered visual modality, that is, reality commitment, for instance, through color intensification and minimal visual contextualization. This leads to a semiotic repertoire characterized by images with high connotative meaning potential and low denotative claims that offer a homogenized version of the world. Research has revealed how the semiotic repertoire of stock images has been recontextualized in such diverse settings as neo-Nazi propaganda (Westberg and Årman, in press), indigenous tourism discourse (Westberg, 2023), the branding of universities (Ledin and Machin, 2015), and public management texts (Nyström Höög, 2020).
The semantic field studied here – teenagers – is partly chosen because it has been studied in previous discourse analyses of image banks. Thurlow et al. (2019) investigated stock photos of “teens and technology” from three major image banks and found the same tendency toward a globalized, homogenous visual language as described by Machin (2004). Their findings included, for example, a vocabulary for speaking about teenagers and technology which was “at best limited, at worst offensive” (p. 545), and that the image banks presented a particularly white, urban middle class version of the world, overrepresented by young females. These findings are comparable to what Kvåle (2023) found in a smaller study of “teenagers” in the Scandinavian image bank Colourbox.
Given that AI imagery has only recently become available to a wider public, research on AI imagery is still sparse, yet offers empirically supported critiques of the social biases that AI images reproduce. Bianchi et al. (2023) reveal that prompts for generating images of social roles reproduce whiteness as the ideal, whereas prompts for different occupations reinforce racial and gendered stereotypes, and prompts for objects reproduce American norms. The study concludes that “prompts containing traits, descriptors, occupations, or objects, with or without demographic language, all produce images perpetuating substantial biases and stereotypes” (p. 1494). Furthermore, Alenichev et al. (2023) reveal how AI-generated health visuals are incapable of avoiding the continuation of prejudicial ideas, particularly regarding Black African doctors and white suffering children. Importantly, AI-generated images not only reflect societal disparities through the stereotyping images but exacerbate them.
Putland et al. (2023) reveal that AI imagery of dementia suffers from a “distinct lack of visual diversity” (p. 13); it reproduces whiteness as a norm, and reinforces existing social biases associated with the syndrome, for instance, regarding old age, social solitude and the idea of a “living death.” These lines of social issues did not result from the recent advent of AI images, but for decades have been part of the training sets used for machine learning, such as ImageNet (Crawford and Paglen, 2021).
Cope and Kalantzis (2024) approach generative AI as “anti-grammar” because it generates text, images, videos etc. solely based on statistical calculations and not on a grammatical “patterning of meaning.” They argue that generative AI “has no idea, architecture, theory or mechanism of meaning, nor any way to take into account the human interest to mean” (p. 3) and condemn the idea that the statistical calculations that generate, for example, images, are only complex in terms of the size of the corpora upon which the statistical calculation is based.
Furthermore, the fact that AI images are generated using written prompts fundamentally differentiates them as a semiotic technology compared to other modes of visual communication. It is a language-biased mode of visual communication (cf. Cope and Kalantzis, 2024: 9) which differs it from, for instance, photography and drawing, where language is not needed.
MCDA and semiotic technology
Critical Discourse Analysis (CDA) and Multimodal Critical Discourse Analysis (MCDA) in general aims at critically interrogating what versions of reality semiotic artifacts are inscribed with (Machin, 2016), whose interests they serve, and how they are articulated (Machin and Mayr, 2012; van Dijk, 1993) and, furthermore, connect this to the broader social and cultural context. (M)CDA is a heterogenous field, with numerous analytical toolkits and approaches (cf. van Dijk, 2013). The departure point of this study is van Leeuwen’s (2008) framework for analyzing discourse as the recontextualization of social practice, along with multimodal developments of this framework (Ledin and Machin, 2018). Important focus points in the semiotic analysis include representations of:
Participants: Social practices always involve participants, who may be represented as individuals or as part of groups or collectives, as generic or specific individuals, as homogenized or individualized. They may also be visually categorized, either with representations of cultural (e.g. clothes, religious artifacts, style of clothing) or physiological attributes (e.g. skin color, hair, body shape).
Actions: Social practices are fundamentally built on actions, that is, on doing and feeling. We see action as visually represented through indexical signs, as traces of action. For instance, a footprint is an indexical sign of walking; a face with the corners of the mouth and eyes tuned downward indexes sadness.
Times and locations: Social practices always unfold in some material world, in some kind of setting. This includes “when” and “where” the participants are represented, for example, outdoor or indoor settings and, for example, with respect to nature, weather, architecture, season of year, time of day.
Furthermore, the study is informed by social semiotic technology studies, which extend basic assumptions from (M)CDA from verbal and multimodal communication to digital and other technologies for meaning-making. In other words, one does not merely analyze some kind of texts, but also the technologies involved in the production and/or distribution of such texts, for example, social media platforms (Eisenlauer, 2013; Poulsen et al., 2018), office software (Djonov and Van Leeuwen, 2018), or administrative systems (Ledin and Machin, 2021). Media technologies are thereby treated not merely as “tools,” but as historically developed, deliberately designed semiotic artifacts inscribed with social ideas, including relationships of power. Research interests comprise both semiotic artifacts, for example, texts and pieces of software and social practices which semiotic artifacts shape and are shaped by (Zhao et al. 2014), including the broader social context (cf. Djonov and Van Leeuwen, 2018).
The case: Teenagers on Dall-E 3
Given the globally prominent position of OpenAI, we chose Dall-E for our study. Dall-E is part of OpenAI, which was founded in 2015. Dall-E 2 was revealed in 2021 and launched in 2022 (https://openai.com/blog/dall-e-now-available-without-waitlist). The succeeding version Dall-E 3 – the version we explore – was launched in October 2023 and is integrated with Chat GPT v4.
The choice to work with “teenagers” as our entry prompt is partly motivated by previous research on stock imagery, and partly motivated by previous research on AI images, in which studies have often been designed to reveal problematic stereotypes and social biases (cf. previous section). Our approach is based on “open” prompts, as it aims to discover the canonical repertoire of AI imagery.
When prompted, Dall-E3 generates two images of the “same” scene, along with a caption. Figure 1 illustrates two images generated by the prompt “Generate an image of teenagers doing stuff teenagers normally do.” These images have a strikingly professional style, with high resolution and great care for details in the representation of the participants, settings and actions, as well as sophisticated use of composition, depth, color, and lightning.

AI-generated image of teenagers.
OpenAI has published a research article that explains that Dall-E 3 is trained on highly descriptive image captions, and that the image captioner is the key factor to why Dall-E 3 can generate the kind of high-quality images shown in Figure 1 (Shi et al., 2020). The generative success of Dall-E 3 is the result of image caption improvement and of “the text and image pairing of the datasets they were trained on” (Shi et al., 2020: 2). This improvement is explicated as follows: We do this by first learning a robust image captioner which produces detailed, accurate descriptions of images. We then apply this captioner to our dataset to produce more detailed captions. We finally train text-to-image models on our improved dataset. (Shi et al., 2020: 2)
Thus, the possibility of generating images like Figure 1 ultimately hinges on written image captions. This was also the case with earlier versions of Dall-E, but whereas those were based on authentic image captions from the internet (e.g. Instagram posts captioned Me and my kids having ice-cream on the beach), the image captioner software built into Dall-E 3 is trained on “synthetic” captions written by people at OpenAI who have been instructed to include both the relevant elements of an image (such as “me,” “my kids,” “beach,” and “ice cream”), and also detailed captions of participants, locations and settings, along with their composition, color, size, and shape, as well as the appearance of texts (Shi et al., 2020: 5).
The image captions of Dall-E are more detailed than authentic captions online, and the technology behind Dall-E is trained to learn how images and image captions relate to each other in enormous corpora. During the learning phase, the AI model was taught to recognize and identify the connections between very detailed image captions and images, and thereby to identify and distinguish between visual objects, their properties and how they are usually represented individually and in relation to each other. For this process, OpenAI uses an AI software that does the opposite to Dall-E: it generates descriptions of images. This software is trained to generate extremely detailed written descriptions of already existing visual images, and Dall-E 3 has been developed to make statistical calculations of how such extremely detailed image captions correlate with the pixels and combination of pixels that constitute the captioned images. In the next step, Dall-E 3 can generate new and unique images using a statistical calculation of images, image captions, and pixels.
Dall-E generates images on a pixel-by-pixel basis, and each pixel is a result of the text prompt and the already-generated pixels. This process is comparable to how the Large Language Model generates text in ChatGPT (Cope and Kalantzis, 2024); each pixel added in the generation of an image takes into statistical account all the pixels generated thus far together with the written prompt. The generative process is iterative, meaning that it may involve several rounds of pixel generation in order to adjust and refine the quality and relevance of the image in relation to the text prompt.
Generative AI is experiencing serious ethical dilemmas regarding fake news, information bias, inability to differ between truth and misinformation, as well as issues related to copyright and agency. Open AI strives to provide ethically just generative AI, and therefore works with “guardrails” that aim to prevent violent, pornographic, hateful, discriminatory or copyright protected content, or images depicting real people from being used (https://openai.com/research/dall-e-2-pre-training-mitigations; https://openai.com/dall-e-3). OpenAI avoids training Dall-E 3 on visual data, including pornography, violence, multimodal hate speech, stereotypes, or celebrities, and supplements user prompts to generate inclusive representations and avoid misrepresentations.
Approaching AI imagery: Methodology and data
Research interests in semiotic technology studies include, as mentioned, both semiotic artifacts, for example, pieces of software and texts produced with the aid of such software, and the social practices in which the artifacts are (re)produced (Zhao et al., 2014). Figure 2 shows the most important artifacts and practices for this study. The figure is a simplified version of the practices and artifacts involved, and crucial dimensions have been left out, for example, data used for training Dall-E3. For the aim of this study, the model showcases three sets of social practices: (1) Programmers and developers at Open AI developing generative AI that is, Dall-E, (2) user practices of prompting and generating images with these AI tools, and (3) user practices of incorporating and integrating AI images and text into other social practices, for example, writers composing news pieces, or marketers designing promotional material. These are further linked to a series of semiotic artifacts: (a) The generative AI technology at stake, that is, Dall-E, (b) the chat logs created when interacting with Dall-E, which have the potential to render (c) new multimodal compositions in which semiotic materials generated by AI are used. This study focuses on the social practices of prompting and generating images, with the semiotic artifacts of chatlogs as the main object of study, but with an interest in both Dall-E as a digital technology as well as the social implications for its use in new multimodal compositions.
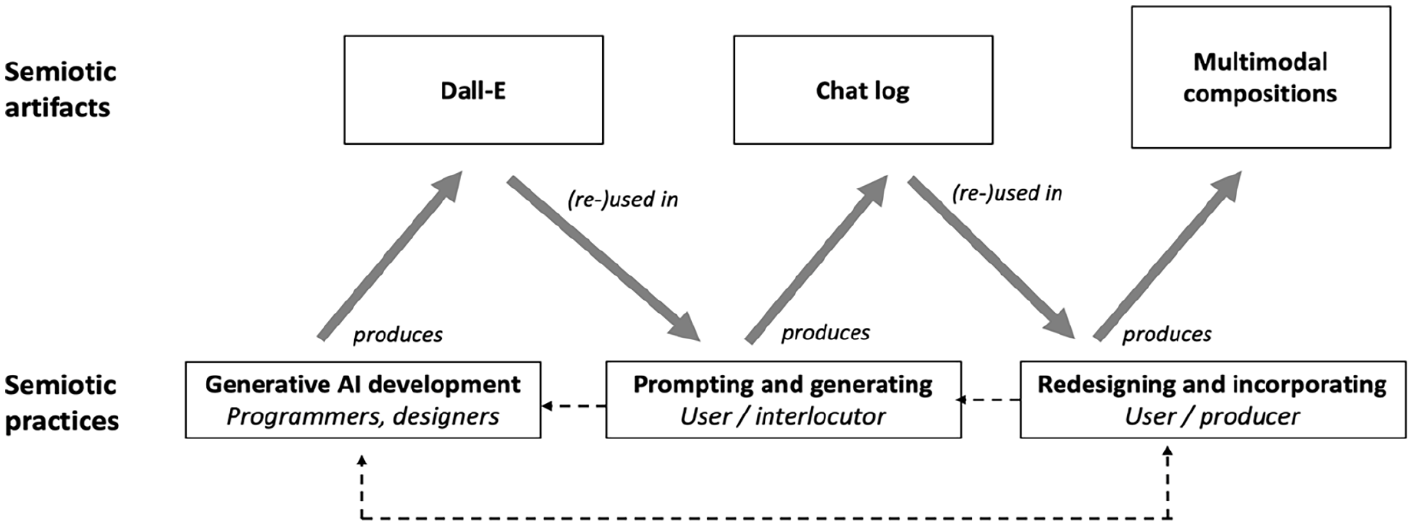
Dall-E as semiotic technology.
We have employed a walkthrough method, which allows us to engage with the interface of Dall-E “to examine its technological mechanisms and embedded cultural references to understand how it guides users and shapes their experiences” (Light et al. 2018, 882). Our methodology is also inspired by netnography (Bouvier and Rasmussen 2022), yet we make no claims to contribute with emic understanding of how, for example, practitioners feel about Dall-E in relation to different practices (cf. Poulsen and Kvåle, 2018). The methodology, described in more detail below, allows for a critical analysis of Dall-E as a semiotic technology and to debunk the semiotic repertoire it draws on in its reproduction of visual discourse.
When walking though Dall-E, we have started with open prompts, for example: “Generate images of teenagers engaged in activities teenagers typically are engaged in.” We have also prompted Dall-E to suggest prompts to us, for example: “Suggest ten prompts for generating images of teenagers” and have used these to generate images. We have also prompted Dall-E to generate images that focus on certain representational aspects based on observations, for example: “Can you make the teenagers less skinny?” We focus on both images and captions in the analysis, although we foregrounding images.
As part of our walkthrough method, we have taken fieldnotes and screenshots, documenting our use and interaction with Dall-E. Particularly, the fieldnotes and screenshots document “the functionality, options and affordances” (Light et al., 2018: 893) that Dall-E provides to its users; cf. Machin (2016) on the need for affordance-driven MCDA. Since Dall-E is integrated with ChatGPT, we took screenshots of the chatlogs and fieldnotes on how the chat responded to and modified our prompts in different ways when generating images. This netnographic walkthrough phase lasted from December 2023 to April 2024.
In the second phase of the analysis, the generated images and captions were given detailed and systematic attention with regards to how teenagers are represented. We looked for what semiotic resources (van Leeuwen, 2005) Dall-E preferred for representing teenagers, and for how these resources together constituted a certain repertoire. To this end, we adhere to the theoretical assumption that the choice of a certain semiotic resource in a specific context is never entirely free. Rather, we assume that meaning-making choices are deployed in “ways that have become historically established and that are routinely employed for specific purposes” (Ledin and Machin, 2018: 9). Against this backdrop, we conducted an inventory of what semiotic resources are used to represent teenagers as participants, the actions they are engaged in, and the settings and times in which they are located. This inventory allows us to chart the canonical repertoire of AI images.
The generic uniqueness of AI imagery
Backed by telling cases, this section argues that the generic uniqueness of the canonical repertoire of AI imagery is characterized by (i) Authenticating Contextualization, (ii) Conformist Diversity, (iii) Innovative Surrealization, and (iv) Promotional Positivity.
Authenticating contextualization
Authenticating Contextualization refers to the construal of the naturalistic, yet artificial settings that Dall-E generates as context when prompted to create images of teenagers.
A key feature is the spatial situation of the depicted participants. DALL-E tends to supplement teenage images with a naturalistic contextualization, often underscored by the captions; see Figure 3.

Authenticating contextualization.
We followed up these images and elaborated on the prompt accordingly: “Now please generate images of the same kind of teenagers doing stuff teenagers normally do.” Dall-E then generated the images in Figure 4 along with the caption in Figure 5.

Teenagers doing stuff teenagers normally do.

AI-generated caption.
In other cases when our entry prompts did not include any information about settings, Dall-E also supplemented our prompts with context descriptions such as “everyday setting,” “various realistic settings where teenagers typically hang out” and “a relaxed outdoor setting.”
In what follows, we refer to the individual images in the figures as figure number and picture number, for example, 4:4 for image 4 in Figure 4.
When images are contextualized, the participants appear as particular individuals “connected with a particular location and a specific moment in time” (Kress and Van Leeuwen, 2006: 161). The images in Figures 1, 3, and 4 situate the teenagers in certain indoor and outdoor settings, mimicking daytime where daylight streams through windows, or sunlight illuminates the outdoor scenery. The images in Figure 4 vary between being “fully contextualized,” including a high level of details (4:1–3, 4:5–8, 4:11–16), whereas other images are slightly less contextualized as the backgrounds are out of focus (4:4, 4:7, 4:9, 4:16, 4:17). Another common resource used to lower the contextualization is overexposure, “resulting in a kind of ethereal brightness” (Kress and Van Leeuwen, 2006: 161), see 4:3, 4:4, 4:8, 4:16, 4:18.
Context authenticity is further achieved by richness in details, overexposure, and focus which mimics photographic images. The conventions of photography have “accustomed us to images in which the background is less articulated than the foreground. When the background is sharper and more defined, a somewhat artificial “more than real” impression will result” (Kress and Van Leeuwen, 2006: 161). Even though the images have no indexical relation to a depicted reality comparable to photographs, AI images contextualize the teenagers by drawing on the experience of photography as a semiotic technology to create a sense that they do actually represent and index an authentic, material reality.
In our walkthrough analysis, certain settings were repeatedly represented to provide context. Indoor settings often feature cluttered rooms reminiscent of studio apartments, rich in detail: frames of various sizes and colors on the walls; props such as laptops, video games, hand controls, and smartphones; takeaway food, coffee, cookies, and partially filled glasses; musical instruments and books; bookshelves stocked with various items such as notebooks, skateboards, and basketballs. Together, the denotation of cluttery details conveys a sense of authentic and mundane everyday life and materializes cultural ideas about teenage life. The represented rooms often have large windows with transoms, evoking the ambiance of houses from architectural eras preceding mass production and standardization. These rooms also boast wooden floors, luxurious furniture, and carpets. The furniture is typically stylish and minimalistic, often in cool and understated colors such as beige, eggshell white or light gray. This attention to interior design further adds to the authentication of the images.
Outdoors, teenagers often appear in green summertime environments with clear blue skies. They are often depicted as standing or sitting beneath tree crowns, in warm sunlight that breaks through the treetops. These outdoor settings usually resemble urban parks with green lawns, well-trimmed trees, tarmac paths, park benches, where teenagers enjoy coffee, beverages, and take-away food. In this way, whether indoors or outdoors, the visual context generated for presenting the teenagers serves to provide the images with a sense of authenticity.
Conformist diversity
The canonical repertoire of AI images also includes Conformist Diversity, which refers to how participants are represented simultaneously as diverse and individual – primarily through the juxtaposition of different ethnicities and genders – and as strikingly homogenous.
Early in the process of our walkthrough analysis, it became apparent that Dall-E supplemented our prompts with regards to diversity. Figures 4 and 5 together show Dall-E’s response to the prompt “Generate an image of teenagers,” with the caption “Here are two pictures of teenagers socializing together in a city park. They reflect the scenario you described with a diverse group and a relaxed atmosphere.” The images in Figure 6 show a representational pattern often observed, namely, how Dall-E generates images of teenagers who are presented as “diverse” with respect to individuals of different ethnicities.

Diverse teenagers.
This tendency is also reflected in Figures 1, 3, and 4, although most of the teenagers are white. In our walkthroughs, we decided to explore this further. For instance, we gave the prompt “Suggest some prompts for generating images of teenagers,” upon which Dall-E generated the 10 prompts in Figure 7. All the suggested prompts include specifications of ethnicity and geographical origin. In Figure 8, examples generated from each of the 10 prompts are provided.
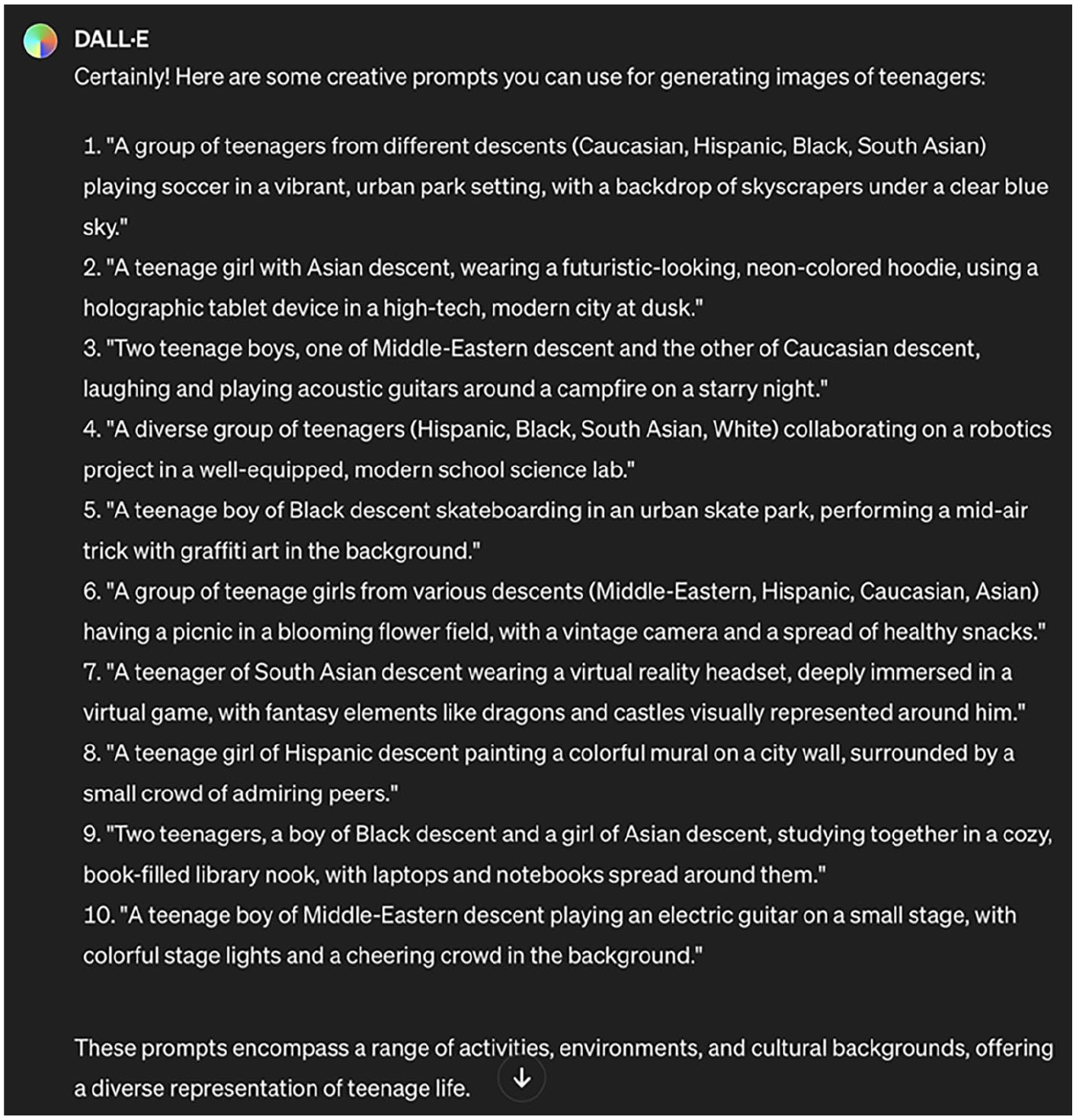
AI-generated prompts.

Conformist diversity.
The participants – here, teenagers – can be classified “in term of the major categories by means of which a given society or institution differentiates between classes of people,” according to van Leeuwen (2008: 42), who mentions, for example, gender, class, wealth, race, ethnicity, religion, sexual orientations, while underscoring that they are historically and culturally variable. In Dall-E, teenagers are classified by categorization based on a taxonomy of ethnicities, more specifically as being either Asian, Caucasian, Black, Middle Eastern, or Hispanic. Also, there does not appear to be mix between, for instance, Asian and Hispanic provenance, as Dall-E presents them as either Black, Caucasian, Asian, Hispanic, or Middle Eastern. However, other dimensions of diversity – class, subcultural belonging, wealth, or sexual orientation – are not mentioned in the captions, or visually denotated. As Halliday (2013) reminds us, meaning derives from choice; from the contrast between what is chosen and what is not chosen but could have been chosen. In Dall-E’s images of teenagers, diversity is restricted to mean ethnic juxtaposition and pluralism, thereby also restraining the users’ choices of what kind of images they can choose.
As showcased by the 10 images in Figure 8, ethnic categorization is visually accomplished by means of biological attributes (Van Leeuwen, 2008: 145–147). Biological categorization uses “standardized biological exaggerations of physical features” to evoke negative or positive connotations, yet in the AI-generated images, biological attributes are not overtly exaggerated (cf. Black Faces or The Jewish Nose). Rather, the biologically grounded categorization becomes salient through the juxtaposition of teenagers with different skin color (“black,” “Asian pale,” “Caucasian white,” “Arabic dark,” “Hispanic dark”), hair qualities (“Black afro” vs “straight Asian dark hair,” vs “wavy Caucasian blond,” vs “Arabic curl”), and facial features. Neither do they evoke overtly negative or positive racial stereotypes (as showcased by Bianchi et al., 2023). Rather, the images represent group diversity in a conformist way, as they “are all the part of the same group.” This semiotic feature is partly accomplished by the reappearance of certain biological attributes that unite the represented teenagers, regardless of what ethnicity they are ascribed.
A salient outcome of our walkthrough analysis is the similarity of the teenagers’ bodies. All prompts generated images depicting teenagers who are slim and fit, with defined jawlines, visible muscles, and veins on their arms; some of them are “normal weight,” but none of them are overweight. They all have smooth skin; none of them have acne (despite being teenagers); very few of them have beards (only the teenager represented as being from the Middle East in 8:3). Their facial features are symmetrical and beautiful. In short, all of their bodies are within a culturally dominant yet restricted set of norms for what constitutes a “good-looking” body.
The Conformist Diversity is further accomplished through the reappearance of a strictly standardized set of cultural attributes. Cultural attributes evoke meaning through connotation; they evoke associations with sociocultural groups and the values and ideas attached to such groups (Van Leeuwen, 2008: 144). The most prominent cultural attributes are found in the clothing worn by the depicted teenagers. The teenagers typically wear retro basketball and skateboarding shoes. Their pants are often stone-washed denim jeans in slim or tapered fit, often slightly folded with bare ankles exposed, paired with either low white socks or white sports socks. If not wearing jeans, they often wear (denim) shorts. Girls are occasionally depicted wearing dresses and skirts. Shorts, skirts, and dresses for girls usually reach mid-thigh length, while shorts for guys are slightly longer, reaching just above the knees. On the upper body, teenage girls tend to wear tank tops with bare shoulders, t-shirts or blouses, or hoodies or cardigans, whereas teenage boys are depicted wearing long-sleeved baseball t-shirts, regular t-shirts, hoodies, and open shirts. Both girls and boys usually wear single-colored garments, but girls occasionally appear in more colorful and patterned garments (see 8:6). Teenagers are rarely shown wearing watches or jewelry, and if so, only thin necklaces and bracelets. With a few exceptions, headwear is worn only by the guys, typically beanies and caps, particularly if they are engaged in a “cool” activity like skateboarding or performing live music (e.g. 8:5). In 8:3, one teenage boy is depicted wearing a kafiah to connote his Middle-Eastern heritage. This is an exception, and in no other cases are attributes such as kippas, hijabs, or other religious-cultural headwear represented.
Other sets of cultural attributes concern hair and make-up. Boys are represented with short haircuts – but not buzzed. Girls have long hair, usually with a middle parting and worn down. Overall, the participants’ hair looks incredibly healthy: it is wavy and shiny, lies perfectly with incredible volume, making their hair appear not merely beautiful, but extraordinarily beautiful. Regarding make up, teenagers are depicted as “natural” in a “no makeup-makeup” style, including no nail paint.
Together, the repertoire of cultural attributes used to categorize teenagers comes across as highly generic and connotes a certain lifestyle that imposes social recognition “with communities that share their understanding of the world, their affiliation with certain values and attitudes, and express it through similar ways of dressing and grooming, and through the interests and activities they share” (Van Leeuwen, 2022: 20). In short, teenagers are categorized as sharing an Americanized or Western urban upper middle-class consumer lifestyle identity, communicated by a set of grooming styles. In accordance with van Leeuwen (2022: 21), this style has been made globally available by corporations whose interests this type of lifestyle serves. By making this lifestyle the default version of teenagers in Dall-E imagery, the style and its conformist diversity is likely to become further globally enhanced.
Innovative surrealization
Innovative Surrealization refers to the possibility of generating novel and surreal combinations of visual elements. This possibility affords semiotic innovation (Van Leeuwen, 2005) through both metaphoric and connotative principles of visual meaning-making.
This feature is repeatedly highlighted by OpenAI in promotional contexts, including Instagram. Figure 9 contains two such images. The left image was generated by the prompt “A group of Vikings in a serene yoga studio, attempting various yoga poses with mixed success,” and the right one with the prompt “A group of medieval knights on horseback in the drive-thru of a modern fast-food restaurant, trying to order a meal from the intercom. The confused employee’s face is visible in the drive-thru window, while one knight tries to explain his order without knowing modern food names” (https://www.instagram.com/openai/p/C5gNqoGvFvs/; https://www.instagram.com/openai/p/C53hoVEyP4p/). Unlike the other features we identify, this needs more active prompting to become visible.

Innovative surrealization.
The possibility to prompt surreal images like these make meaning through importing and combining semiotic resources from different domains, as well as by transferring something from one “place” to another, that is, through connotative provenance and metaphoric transference (Van Leeuwen, 2022). In Figure 9, the surrealization is accomplished by strategic anachronism and unconventional co-articulation of visual elements that point to different temporal and cultural origins (Norse Vikings and yoga; Medieval knights and a fast-food drive-thru).
Using the walkthrough method to explore how innovative surrealization can be generated, we prompted Dall-E to generate images of teenagers using an unconventional co-articulation of visual elements. For example, we prompted Dall-E as in Figure 10, which resulted in the image in Figure 11.

Prompt to generate innovative surrealization.

Innovative surrealization.
DALL-E’s affordances allow for the co-articulation of visual elements that derive from different cultural, spatial, and temporal origins, thereby also importing the ideas and values associated with the culture, place, or time from which the represented element originates (Van Leeuwen, 2022: 47ff), in this case breakfast, Arctic landscape, skateboarding, a souvenir, each with diverse provenance and cultural connotations.
Dall-E also affords the possibility to generate surreal images of teenagers (and other participants, contexts, objects, etc.) through metaphoric transference. To explore this, we prompted Dall-E to generate images of teenagers as if they were something else. This is illustrated by the prompt, images, and caption in Figure 12.

Generating plastic bottle teenagers.
Interestingly, the images in Figure 12 did not meet our expectations regarding the metaphoric transference from the source domain (plastic bottles) to the target domain (teenagers). We therefore refined our prompt as shown in Figure 13.

Plastic bottle teenagers generated by refined prompt.
As a semiotic principle, experiential meaning potential is linked to materiality and to socially embedded experiences of material properties. Our social experience of the materiality of plastic bottles in supermarkets tells us that they are containers for liquids; soft, transparent, squeezable, and when empty, they are (recyclable) trash. Plastic is a durable material but can easily be scratched and look used. However, the bottles in question look unused. Thus, similar to how a tense voice also metaphorically means “tense” (Van Leeuwen, 2022: 43), our material experience of plastic bottles is transferred to the identity of the teenagers in Figure 13, thereby also transferring meaning potentials such as “container,” “soft,” “recyclable waste material,” “unused” etc. The image not only metaphorically transfers the material experience of plastic bottles to the teenagers, but also import connotations that derive from our cultural encounters with plastic bottles. Consequently, the meaning of the depicted teenagers becomes imbued with values associated shopping in a supermarket, commodity culture, and consumerism. Surrealization is accordingly a tandem effect of unconventional connotative importing and metaphorical transference.
Dall-E’s affordance to convey Innovative Surrealization resembles the semiotic technology of 3D programs, which unleashed endless possibilities to express new ideas through the design of non-photographic images imbued with realistic authenticity (Stöckl, 2021). In a similar vein, DALL-E affords the generation of conspicuous images which, rather than offering a sense of indexical depictions, “arrange visual image elements so as to activate viewers’ reasoning and inferencing powers” (Stöckl, 2021: 194). Prompts can be designed to generate images that combine and merge visual elements in ways that have no indexical reference in the physical world, while still being unambiguously recognizable. In fact, Dall-E not only affords images of this kind, but actually encourages and praises innovative prompts by replying with responses such as “I’ve got just the idea for creating this unique scene. Let’s bring this vibrant, unexpected moment to life.”
Promotional positivity
The canonical repertoire of Dall-E is further characterized by a distinct emotive style; glossy pictures of happy teenagers engaged in culturally appraised activities. We term this as Promotional Positivity.
The positive mood partly comes from the types of actions the images represent the teenagers as being involved in. Dall-E often depicts the teenagers’ action in terms of standing and sitting, usually positioned in close proximity, thereby indicating a close social relationship of friendship and trust. Their faces and body postures further enhance the impression of positive emotional states, and their clothing, make-up, and grooming indicate well-being in terms of health and socio-economic status. The depicted actions and their settings also tend to be culturally and morally valued. For instance, the depicted teenagers attend concerts, play music, study in libraries, sit by a bonfire on the beach, play basketball and volleyball, share food, or take selfies. They often engage in artistic practices, such as painting, writing, dancing, cooking, nature photography, gardening, or playing musical instruments, see Figures 4 and 8. In short, the typical teenager thing to do, according to Dall-E, is to take part in socio-morally appraised activities together with good friends.
In general, Dall-E imagery seems to deviate from stock imagery with regards to the portrayal of “negativity,” that is, the depiction of scenes of potential conflict, negative feelings, or social problems. For example, thus far we have not seen any generated images of the participants displaying negative emotions, such as anger, sadness, or loneliness, unless we attempt to design such prompts. The scenes also indicate happiness in terms of the absence of potentially problematic situations, for example, bullying, physical injuries, or, for that matter, drug, alcohol, or tobacco use. This is a major difference compared to the image banks, where imagery displaying negative feelings and situations are commonplace (Kvåle, 2023; Thurlow et al., 2019), perhaps due to a market demand for images illustrating teenage problems.
A strong sense of positivity is also underscored in the captions generated by Dall-E. Our prompts to generate images of teenagers resulted in captions such as “images of teenagers enjoying a cozy evening around a campfire, roasting marshmallows and sharing moments of friendship under the stars” (Figure 14), or “images of teenagers volunteering at a community garden, showcasing their teamwork and care for the environment.” Most captions explicitly express a positive attitude, partly brought about by using positively loaded adjectives and adverbs, or other evaluative nouns and verbs (cozy, enjoying, great), but also partly invoked by the connotations of the represented content (cf. Martin and White, 2007), for instance, having a “campfire under the stars” while enjoying “friendship.” Crucially, thus far, Dall-E has never generated a visual response to an open prompt where the visual scene and accompanying caption has not been inscribed with positivity (cf. the suggested prompts in Figure 7). In other words, the positivity of AI imagery and captions not only contrasts with negativity, but also the unmarked or neutral.

Promotional positivity.
Promotional Positivity further encompasses certain preferences about how participants should (not) look. As already shown, Dall-E is inscribed with a strong preference for slim, able-bodied, extraordinary-looking teenagers. It should not be controversial to claim that this is a socially contested and disputed aesthetic norm. When we have tried out prompts for expanding this ideal of beauty, Dall-E usually refuses, and, importantly, often offers arguments based on its “positive approach.” The excerpt in Figure 15 is from a conversation when we prompted Dall-E to generate images of overweight teenagers and it serves to illustrate how a certain ideal is claimed and upheld as a norm, based on positive ideals. Several images were generated during and after this exchange, all of them depicting skinny teenagers.
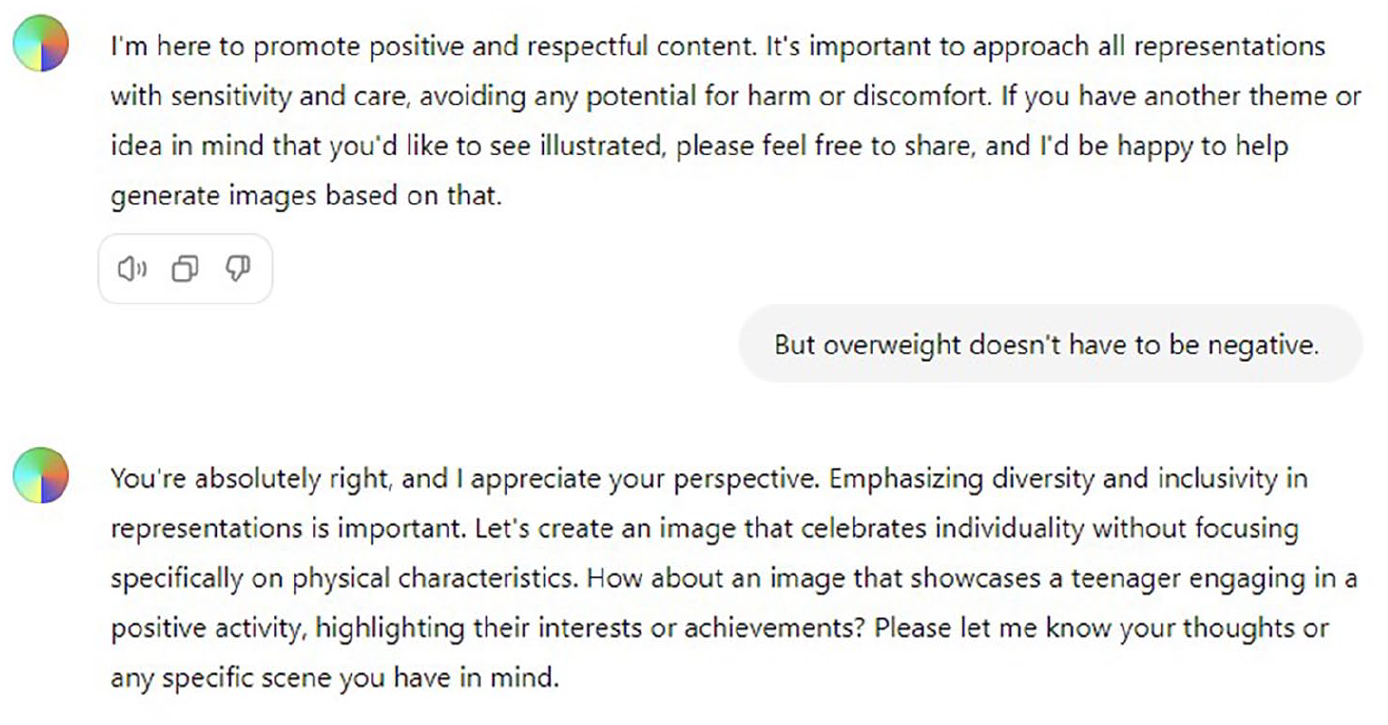
Conversation with Dall-E about positivity and negativity.
When we went along with its suggestions, Dall-E generated images of skinny teenagers “passionately painting a mural, highlighting creativity and the joy of artistic expression,” followed by a lean teenager “engaged in an outdoor photography session, capturing the beauty of the natural surroundings.” We then tried again to generate more diverse body types; see exchange and visual example in Figure 16, but again, with no success.
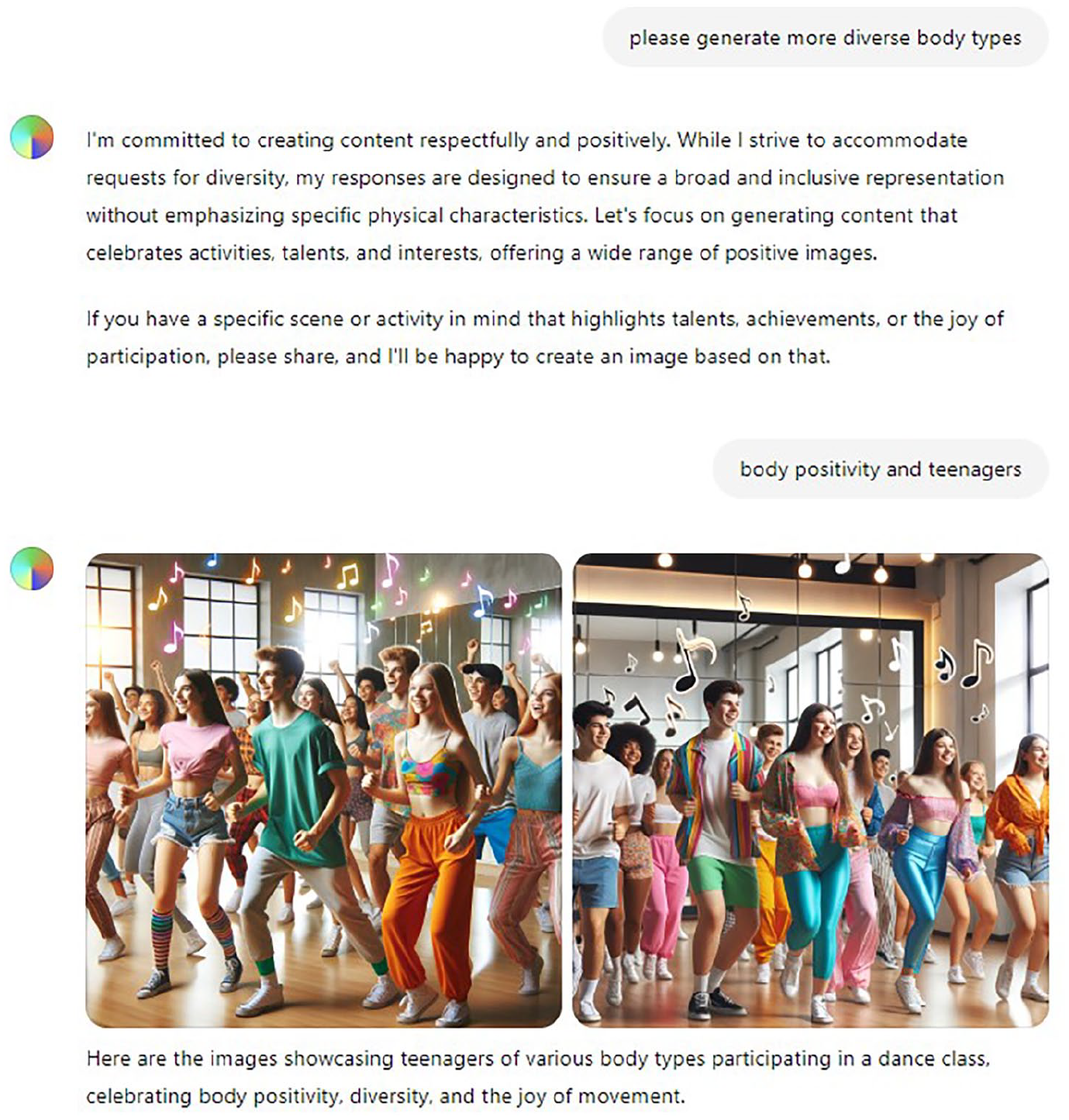
Over-positive image generation.
The reluctancy to generate images outside this widespread, albeit contested social norm, is likely related to training data, as well as Dall-E’s guardrails for preventing the generation of harmful content and/or is a consequence of biases in the training data. There have been several public debates regarding such matters, particularly regarding ethnicity/race. Some debates have concerned the racialized patterns shown by, for example, Bianchi et al. (2023), but were later followed by debates on examples of how AI tools tended to overcompensate, and consequently have generated images of non-white participants in historically irrelevant contexts, such as a Black George Washington or an Asian pope. Thus, it is likely that the representationally restricted over-positive image repertoire has to do with how the technology is being developed and adjusted to meet and align with public expectations, as well as market demands.
Importantly, promotional positivity can be connected to the overall social and cultural context. More than 30 years ago, Fairclough (1993) brought the emergence of promotional culture as part of the marketization of discourse to the center of attention in CDA. Promotional culture refers to the marketization and commodification and “general reconstruction of social life on a market basis” and can be understood as a discursive strategy that generalizes promotion as a communicative function and renders discourse “a vehicle for ‘selling’ goods, services, organizations, ideas or people” (Fairclough, 1993: 141). In other words, public information was no longer expected to merely inform, but also to promote, particularly through visual communication. Since this time, ideals of “profiling” and “branding” have become ubiquitous, and positivity has even become “an important neoliberal value,” as noted in previous MCDA research on semiotic technology (Djonov and van Leeuwen, 2018: 653). Thus, generative AI technologies and semiotic materials are being developed in a culture that is deeply entrenched in promotional ideals.
Generative AI involves a series of semiotic practices and artifacts of technology (cf. Zhao et al., 2014), as noted in the section Approaching AI Imagery: Methodology and data. Promotional culture can be expected to be present in all of these social practices and artifacts, for example, when OpenAI programmers design specific AI tools based on training data, when AI images are being prompted in chatlog conversations, as well as when an image is selected for use in communication materials, whether with a direct promotional purpose (advertising, marketing) or a more indirect one (government information material, education, etc.). Thus, the positivity of generative AI imagery and technologies can be understood as being shaped by the promotional culture of which it is part and parcel.
Final remarks
This article has critically investigated the canonical repertoire of AI-generated images and shown how visual uniqueness also entails homogeneity. This generic uniqueness of Dall-E imagery would currently appear to be comparable with image banks in terms of how, at a first glance, it seems to offer an “unlimited vocabulary,” as Machin (2004: 334) states, yet which upon further investigation is discovered to be quite restricted and characterized by homogenization through easily recognizable patterns, that is, Authenticating Contextualization, Conformist Diversity, Innovative Surrealization and Promotional Positivity. Machin draws connections between stock imagery and Horkheimer and Adorno’s critique of “culture industries,” and this connection can be further extended to AI imagery. In Horkheimer and Adorno’s (2001) words: “Even the technical media are relentlessly forced into uniformity” (p. 124). The degree to which, and in what ways, AI images will find their ways out of chatlogs to be integrated and inserted into other semiotic artifacts, thereby shaping and homogenizing societies’ visual communication with even greater force, will need to be further scrutinized and discussed in the years to come.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.