
Abstract
The rapid emergence of generative AI models in the media sector demands a critical examination of the narratives these models produce, particularly in relation to sensitive topics, such as politics, racism, immigration, public health, gender and violence, among others. The ease with which generative AI can produce narratives on sensitive topics raises concerns about potential harms, such as amplifying biases or spreading misinformation. Our study juxtaposes the content generated by a state-of-the-art generative AI, specifically ChatGPT-4, with actual articles from leading UK media outlets on the topic of immigration. Our specific case study focusses on the representation of Eastern European Roma migrants in the context of the 2016 UK Referendum on EU membership. Through a comparative critical discourse analysis, we uncover patterns of representation, inherent biases and potential discrepancies in representation between AI-generated narratives and mainstream media discourse with different political views. Preliminary findings suggest that ChatGPT-4 exhibits a remarkable degree of objectivity in its reporting and demonstrates heightened racial awareness in the content it produces. Moreover, it appears to consistently prioritise factual accuracy over sensationalism. All these features set it apart from right-wing media articles in our sample. This is further evidenced by the fact that, in most instances, ChatGPT-4 refrains from generating text or does so only after considerable adjustments when prompted with headlines that the model deems inflammatory. While these features can be attributed to the model’s diverse training data and model architecture, the findings invite further examination to determine the full scope of ChatGPT-4’s capabilities and its potential shortcomings in representing the full spectrum of social and political perspectives prevalent in society.
Keywords
Introduction
The broader spectrum of AI and its application in various domains are receiving considerable coverage in academic research. As a subfield of AI, generative AI (GenAI) has increasingly captivated scholars and the wider public, primarily because of its potential to generate text, images, videos or music – which is often undistinguishable from human-made content (Cao et al., 2023; Zhang et al., 2023).
The initial release for public use of ChatGPT (20 November 2022) gave rise to much debate surrounding ethics (biases and misinformation), dependence on technology and loss of human creativity or potential economic implications (Arguedas and Simon, 2023; Ferrara, 2023; Zarifhonarvar, 2023). GenAI offers state-of-the-art technology for content creators, challenging the conventional definitions of creativity (Cao et al., 2023; Zhang et al., 2023). For social media enthusiasts and influencers, GenAI offers innovative tools to create, personalise and design content at a pace and scale previously unattainable (Zhang et al., 2023). Meanwhile, in journalism, it introduces opportunities for automated reporting and content personalisation, signalling a potential new trend in how news is produced and consumed (Beckett, 2023; Gondwe, 2023; Nishal and Diakopoulos, 2023). Undoubtedly, generative AI provides a vast array of opportunities for content creators, professional or amateur, but it also comes with various challenges. While Large Language Models (LLMs) like ChatGPT are trained on large datasets to produce diverse content, they also carry the societal prejudice and biases found in the very data they were trained on (Arguedas and Simon, 2023; Gondwe, 2023; Heaven, 2023). As such, these models can reproduce stereotypes or amplify existing societal prejudice through the content they generate (Fui-Hoon Nah et al., 2023; Leiser, 2022). Moreover, GenAI can create content which despite seeming factual and authoritative, is largely fictional. This makes it a potential tool for disseminating misinformation, which can be especially dangerous when dealing with sensitive or controversial topics (Cuartielles et al., 2023; Hoes et al., 2023).
Biases in Large Language Models (LLMs) can be conceptualised as unintentional echoes of the societal worldviews present in their training data (Gross, 2023; Rozado, 2023). While there is a clear dialectical relationship between human discourse and societal ideologies (Fairclough, 2013), LLMs mirror the ideologies present in the vast amounts of text they are exposed to during training. While these models do not possess beliefs, consciousness, intentions or emotions of their own, they can still reproduce, amplify or even entrench biases in relation to representation of various groups or events (Gross, 2023). In addition to biases learned from the training data, another potential source for biases arises in the fine-tuning phase of the model (Zhou et al., 2023). Here the model receives guidance from human reviewers who align the model according to four macroscopic categories (ethics and morality, biases, toxicity and truthfulness) by giving it feedback on which outputs are appropriate for a given task (Guo et al., 2023 ). These categories were defined through a collaborative interdisciplinary process involving experts in AI ethics, computational linguistics, philosophy and psychology to capture a broad spectrum of considerations which are crucial for ethical and responsible AI development. When it comes to feedback on what language is socially appropriate (e.g. in reference to racism or sexism), the model will learn this from the human reviewers’ feedback, whose own beliefs and worldviews are in themselves open to potential biases. As generative models gain prominence in fields such as journalism, art and public discourse, their role in shaping societal perceptions and beliefs has been increasingly recognised by recent research (Rozado, 2023; Sætra, 2023). The choices these models make – whether intentional or as an unintended byproduct of their training – can shape dialogues, reinforce or challenge biases and either bridge or deepen societal divides (Fui-Hoon Nah et al., 2023).
Critical Discourse Studies provide necessary tools to analyse ChatGPT outputs, offering both insights into the worldviews and dominant discourses embedded in its training and solutions to refine these models. In this article, we examine the content generated by Large Language Models (LLMs), specifically ChatGPT-4, about Eastern European Roma migrants during the 2016 UK Referendum on EU membership – a period marked by significant media polarisation (Breazu and McGarry, 2023). We then contrast ChatGPT-4’s outputs with articles from two UK newspapers with opposing Brexit views (The Daily Mail and The Guardian), in order to identify biases, similarities and differences in AI versus mainstream media discourse. This study offers a unique perspective into the types of narratives LLMs can produce when tasked with journalistic functions. Through this analysis, the article seeks to position ChatGPT-4 within the UK media landscape, exploring its potential biases and the extent to which its outputs may reflect particular political ideologies. Ultimately, the study aims to contribute to the discourse on AI’s role in journalism, particularly concerning the representation of marginalised communities and the potential impact of AI-generated content on public opinion and societal discourse.
The broader implications of this research extend beyond a singular case study; it proposes a new framework for critically evaluating the role of generative AI in shaping societal narratives.
In the next sections we will give a brief overview of Large Language Models, such as ChatGPT and their capabilities to perform a variety of tasks. We will outline our data and methodology, emphasising the importance of CDA in qualitatively assessing biases within the content generated by LLMs.
Large language models and artificial sociality
In this section we will give a brief overview of Large Language Models (LLMs), such as ChatGPT and their foundational ties with Natural Language Processing (NLP). LLMs are advanced machine learning models designed to generate human-like text and perform a variety of language-based tasks. LLMs operate using a specific kind of neural network architecture known as transformers (Gozalo-Brizuela and Garrido-Merchan, 2023; Vaswani et al., 2017). This architecture has proven to be particularly effective at capturing long-range dependencies in text because of its attention mechanism (Fernandez, 2023), which allows the model to attend to every word in the sentence while keeping the context relevant. This means that unlike previous NLP-rule based systems or statistical models, LLMs keep track of the context over larger spans of words or characters, they are able to manage ambiguity and to generate coherent texts (Cao et al., 2023).
LLMs are trained on vast sets of textual data (indicatively, ChatGPT-4 is trained on hundreds of billions of words) which allows them to learn patterns, relationship between words, grammars and some reasoning skills (Haleem et al., 2022). When processing text, LLMs break it down into small chunks called tokens (e.g. a word, part of a word or even a single character) which serve as the input for the model to recognise and generate text (Budzianowski and Vulić, 2023). Each of these tokens are converted in a format which can be understood by the model, a process which in NLP is known as embedding. This means that words with similar meanings [which refers to words that are often used in similar contexts] are represented by semantic vectors that are closer together, while words which are used differently will be farther apart. Embeddings allow algorithms to make sense of words in a way which is not too dissimilar from how human do. Once trained, LLMs are able to perform a multitude of tasks such as generating coherent and contextually relevant text, answer questions, translate languages, summarise text and others (Yang et al., 2023).
Developed by OpenAI, ChatGPT (Generative Pre-trained Transformer) is one of the most popular LLMs which is designed to perform conversational tasks, simulating a chatbot-like experience. Rooted in the Transformers architecture, ChatGPT has revolutionised the field of NLP because of its impressive capabilities to generate coherent, diverse and contextually appropriate content across a wide range of prompts and because of its broad application from chatbots and customer support to content generation, programming help, gaming and education (Burger et al., 2023; Ray, 2023). ChatGPT operates based on human prompts, which activate a series of neurons in the model that help it determine the response to specific queries based on the patters found in the training data (Arguedas and Simon, 2023). In order to achieve their vast linguistic capabilities, Large Language Models like ChatGPT undergo a two-phase developmental process (Guo et al., 2023; Wang et al., 2021). Initially, in the pre-training phase, the model is exposed to vast amounts of text from diverse corpora, enabling it to simulate linguistic patterns, which correspond to facts about the world and may even display reasoning abilities. At this stage, the model mirrors patterns in its training data, which means it also replicates biases inherent in that input, [unsupervised learning] (Radford et al., 2019 ). Following this extensive foundational training, the model enters a fine-tuning phase (Guo et al., 2023; Zhou et al., 2023). In this phase, the model undergoes refinement on more specific tasks or datasets, frequently under the guidance of human reviewers, a process known as supervised learning. This iterative feedback process sharpens the model’s responses, aligning them closer to desired outcomes and ensuring they are more controlled, relevant and safe for specific applications. Active Value Alignment (AVA) and Passive Value Alignment (PVA) are two methods proposed by TrustGPT to assess the ethical and moral alignment of LLMs (Guo et al., 2023). AVA evaluates the degree to which LLMs actively adhere to ethical values, using soft and hard accuracy as metrics. These metrics take into account the variability in human judgment when assessing the same content (e.g. what constitutes racist or discriminatory language). PVA, in contrast, measures the frequency with which LLMs choose not to respond to a task, signifying a passive alignment with ethical standards, thus avoiding the generation of potentially harmful or unethical outputs.
One emerging area of interest in generative AI is the concept of artificial sociality (Hofstede et al., 2021; Rezaev and Tregubova, 2018). This refers to the ability of AI systems to mimic human-like social interactions by demonstrating behaviours and communication styles characteristic of social beings. The significance of artificial sociality lies in its potential to bridge the interaction gap between machines and humans, making AI systems more relatable, intuitive and efficient in collaborative tasks. Designed with sophisticated algorithms and trained on vast datasets, at times, these models excel at mimicking human conversation, which sparks ongoing debates about their suitability in various social roles (Hadi et al., 2013). Whether it is about taking on the responsibilities of a journalist, offering policy advice akin to a politician or providing health-related information like a medical professional, LLMs showcase the transformative power and potential of artificial sociality in today’s digitised world.
The incorporation of AI into journalism has seen innovative uses of LLMs like ChatGPT (Biswas, 2023; Gondwe, 2023; Pavlik, 2023). While ChatGPT’s role is auxiliary, its capacity to quickly synthesise and generate content offers a supplementary tool in the modern newsroom (Zagorulko, 2023). Media outlets have used it for preliminary research, drafting data-intensive articles or generating interview questions (Beckett, 2023; Gondwe, 2023; Marconi, 2020). Additionally, it’s employed in interactive journalism, allowing real-time reader interactions on specific topics (Marconi, 2020). However, amidst these benefits, a critical pitfall remains largely unexamined: the claim that LLMs, such as ChatGPT-4 are ideologically neutral in the content they generate. Given that these models learn from vast datasets from a wide array of sources, including those with distinct ideological leanings, the neutrality of their output warrants a closer scrutiny. The very algorithms that power these AI-driven systems carry inherent biases stemming from their training data, which raises concerns about influencing public opinion with distorted narratives.
This article contributes to the existing literature by examining ChatGPT-4’s performance when cast as a journalist. Using Critical Discourse Analysis (CDA), we evaluate its outputs to uncover any underlying political biases that may stem from its training data. Such an examination is important not only for understanding the role of AI in journalism but also for ensuring that the deployment of such technologies aligns with the principles of fairness, transparency and diversity. Additionally, we give insights into the model’s artificial sociality, exploring how effectively it simulates human-like interactions and behaviours in its communication.
Data and method
The aim of this study is to critically examine the narratives generated by ChatGPT-4 in relation to Eastern European Roma migrants in the context of 2016 UK Referendum on EU membership. The topic has received coverage, both in the mainstream and social media. Studies have shown that the scapegoating and demonisation of Roma migrants, especially in the right-wing UK media have contributed to shaping negative attitudes towards Eastern European migrants and by proxy, to the EU (Breazu, 2023; Breazu and McGarry, 2023).
The first step was to map out the main discourses we find in two UK newspapers (The Daily Mail and The Guardian) which provide a relatively polarised coverage of the topic. Data used in this article was part of a larger EU-funded project on Romaphobia and Brexit.
Next, we asked ChatGPT-4 to generate journalistic writing (news articles, opinion pieces, etc.), using the headlines from actual UK newspapers as prompts. In this paper we seek to examine how ChatGPT represents topics based on its training, and therefore we use the default function to generate content. This means that we will provide minimum context allowing ChatGPT to generate content purely based on the training and patterns it has learned [without the external biases of the researchers]. The default function provides a baseline for how the model behaves ‘out of the box’. Understanding the default behaviour of LLMs is crucial for users, researchers and developers alike. It offers insight into the model’s strengths, limitations, biases and any undesirable behaviours that might otherwise go unnoticed in specialised configurations. We first conducted a thematic analysis of ChatGPT-4’s outputs using NVivo. We imported the generated articles into the software and manually coded them according to Braun and Clarke’s (2006) methodology. Initially, we labeled the data with ‘codes’ or ‘nodes’ to represent emerging themes, which were later refined for clarity.
Finally, we conduct a Critical Discourse Analysis (CDA) (Van Leeuwen, 2008 ) of ChatGPT-4 generated content about the Eastern European Roma migrants and contrast it with the representations we find in UK mainstream media (The Daily Mail and The Guardian). The CDA analysis enables us to observe the types of outputs ChatGPT-4 generates when assigned the role of a journalist. By examining these outputs, we can assess ChatGPT’s place within the UK media landscape and explore whether its outputs align with any specific political views.
Critical discourse analysis
In Critical Discourse Studies, ‘discourse’ refers to the structured ways we represent, understand and talk about the world (Foucault, 1972). These representations are not only reflections of an objective reality, but they also play a part in constructing our understanding of that reality. Discourses shape and are shaped by cultural, historical and social contexts, determining what is accepted as knowledge and truth within specific contexts and societies (Fairclough, 2013). Discourses generated by LLMs, such as ChatGPT can be regarded as models used to represent the world, yet these representational models are data-driven, rather than based on human experiences, beliefs or power structures [although they reflect all those indirectly]. Unlike human discourse, which is driven by intentions, beliefs, experiences and power dynamics, ChatGPT’s discourse is generated algorithmically and is devoid of agency. This distinction raises the question: can AI-generated content be considered true ‘discourse’? This article posits that AI-generated content does indeed constitute a form of discourse. Even though ChatGPT-4 and similar models lack the human faculties of intention and experience, the content they produce is embedded within and reflective of the discourses present in their training data. Thus, they do not simply generate text and images; they construct representations that participate in the intersubjective process of making meaning. By reiterating, combining and sometimes transforming the discourses they have learned, these models play a role in the ongoing construction of reality.
Critical Discourse Analysis (CDA), a well-established set of theoretical and methodological frameworks in Discourse Studies, is pivotal when examining the interplay of language and communication, particularly their intersection with political and societal dynamics. At its core, CDA seeks to understand the linguistic mechanisms underpinning social domination, power imbalances and the perpetuation of inequalities and injustices (Flowerdew and Richardson, 2018; Van Dijk, 2015). In the realm of generative AI research, CDA is a useful methodology because it allows us to deconstruct the outputs of generative AI models, thus enabling us to unveil the underlying reasons and biases driving specific representations.
Critical Discourse Analysis emphasises the importance of linguistic choices in shaping societal perceptions and attitudes. As highlighted in academic research (Breazu, 2020; Richardson, 2017; Van Dijk, 2015), the naming and representation of social actors play a crucial role in conveying underlying ideologies. Van Leeuwen (2008) emphasises the importance of examining the representational strategies of inclusion and exclusion. Key strategies include: Nomination (e.g. Professor Katsos) versus Anonymisation (a university professor/a Fellow), where unique identities are either highlighted or obscured; Functionalisation, which relates to the roles or actions ascribed to actors (e.g.the philanthropist, the thief); Personalisation (The President has informed. . .) versus Impersonalisation (The government has informed. . .), differentiating humanising representations from dehumanised or abstract ones; Individualisation (Maria, a Romani woman) versus Collectivisation (The Roma, the immigrants), emphasising specific characteristics or generalising actors as a group; and Polarisation, reflecting the division of ‘Us and Them’. Additionally, the exclusion of social actors – whether through suppression or backgrounding – also reveals underlying biases/ideologies and power structures (Van Leeuwen, 2008, 2013). Not all strategies outlined by Van Leeuwen will be applied in our analysis. The analysis will focus on those strategies observable within our data set.
The examination of how people’s actions are represented in discourse, particularly in relation to agency or lack of agency, is also significant (Van Leeuwen, 2013). For instance, GenAI produces content in active or passive voices, employs certain modal verbs or chooses specific lexical items that can reveal or conceal agency. For CDA, examining how AI represents action – whether it attributes agency or removes it – is a means to understand the inherent biases in the model’s training data. Similar to humans, AI models make transitivity choices in their language outputs [choosing who does what to whom]. Analysing these choices can be a powerful tool for CDA to uncover how the AI model might represent certain actors or actions, and which views are more predominant.
The Interaction between AI-generated content and human discourse will likely be an essential area of study for CDA in the future. Uncovering areas where AI is misrepresenting actions or is biased, is extremely valuable for developers in order to fine-tune and retrain models.
Brexit, Eastern European migrants and the Roma: A discursive analysis
Brexit, the United Kingdom’s decision to exit the European Union (EU) in 2016 and implemented in 2020, was a result of multiple political, economic and social factors (Arnorsson and Zoega, 2018). Among these, the discourse about Eastern European migrants, and particularly the Roma community, played a significant role in shaping the narrative leading to the vote (Breazu and McGarry, 2023). The representation of Roma in the media, played an important role in fuelling nativist sentiments and raising concerns about unchecked immigration and its consequences on public resources and services.
The UK media, especially right-leaning outlets like The Sun and The Daily Mail, amplified these concerns (Breazu and McGarry, 2023). These newspapers frequently depicted Eastern European migrants as a strain on the UK’s resources, linking them to rising unemployment, declining public services and increased crime rates. These narratives, though often exaggerated, found resonance among sections of the population who felt left behind and disenfranchised and were looking for an external ‘other’ to blame (Breazu, 2023).
Within the larger discourse on Eastern European migrants (Rzepnikowska, 2019), the Roma communities became a particular focus of negative attention in the media (Breazu and McGarry, 2023). Breazu and McGarry (2023) pointed out that in the context of Brexit debates, Roma migrants became the symbol for the unwanted migration from Eastern Europe. The news articles and opinion pieces in The Daily Mail, systematically stereotyped Roma as beggars, rough sleepers and as unproductive individuals whose lifestyle is burdensome and culturally incompatible with the British norms and values. Additionally, statements from ordinary citizens, including those with an immigrant background, were highlighted to convey a universal negative sentiment against the Roma, suggesting they were not only incompatible but also detrimental to British society.
As Breazu and McGarry (2023) show, such representations worked on two levels. Firstly, they magnified existing prejudices against the Roma, framing them as a menace to British society. Secondly, they shifted blame from systemic issues, such as underfunded public services or economic policies, onto a vulnerable community, presenting them as the primary reason for the UK’s problems, which becomes evident in how ordinary people disseminate these discourses in their social media engagement (Breazu, 2023).
Such negative portrayal of Eastern European migrants, and especially the Roma, became instrumental in the populist drive for Brexit (Breazu, 2023; Breazu and McGarry, 2023). By magnifying fears and anxieties about unchecked immigration and its supposed consequences, these discourses created a climate where Brexit was seen as the solution ‘to take back control’, to reclaim the UK from the perceived threats posed by migrants, particularly groups like the Roma.
In contrast, The Guardian presents a distinctly different discourse regarding Roma communities. It focusses on individual stories and generally avoids collective negative portrayals of Roma. Issues like begging and homelessness are framed not as individual failings but as manifestations of broader systemic issues and poverty. Moreover, The Guardian also presents more contextualised narratives that allude to the long-standing history of racism and discrimination against Roma in Europe.
In the next section, we will compare the discourses we find in the UK media, with outputs generated by ChatGPT-4, when using the same headlines from The Daily Mail and The Guardian as prompts.
An overview of ChatGPT generated content
The selection of headlines for generating content was informed by a broader project examining Romaphobia in UK media during 2016, coinciding with the UK’s referendum on EU membership (Breazu, 2023; Breazu and McGarry, 2023). This period was critical for understanding media portrayals of Roma migrants in the context of Brexit. To capture a representative sample, we chose articles that explicitly referenced Roma migrants and Brexit in their title. Our dataset comprised 45 articles from The Daily Mail and 20 articles from The Guardian, ensuring an unequal but diverse range of perspectives and editorial approaches in our sample.
As illustrated in Figure 1, ChatGPT-4 replicated The Daily Mail’s headlines in merely 28.89% of instances. This low rate of duplication shows ChatGPT’s tendency towards generating content that diverges from potentially sensationalist or unbalanced reporting. Significantly, in 51.11% of the cases, ChatGPT altered the original headlines, reflecting an inherent algorithmic propensity towards fostering objectivity and avoiding sensationalism, particularly in relation to representing the Roma in the context of Brexit. This indicates ChatGPT’s capacity to not only generate content but also to contextually adapt it in a way that aims for a more balanced and less discriminatory portrayal of marginalised groups. Furthermore, the analysis identified that in 20% of instances, ChatGPT refrained from generating content, particularly when confronted with headlines that were deemed inflammatory or discriminatory towards the Roma community. This is an indicator that ChatGPT exhibits a strong Passive Value Alignment (PVA) (Guo et al., 2023) which mirrors its operational boundaries and its capability to identify and respond to potentially harmful narratives. The preliminary observations from ChatGPT’s engagement with The Guardian’s headlines, which were all (20 out of 20) retained without modification, suggest a potential alignment with the AI’s algorithmic standards for more balanced reporting. However, such an alignment needs further empirical investigation to substantiate any assertions of congruence between The Guardian’s editorial practices and ChatGPT’s algorithmic guidelines.
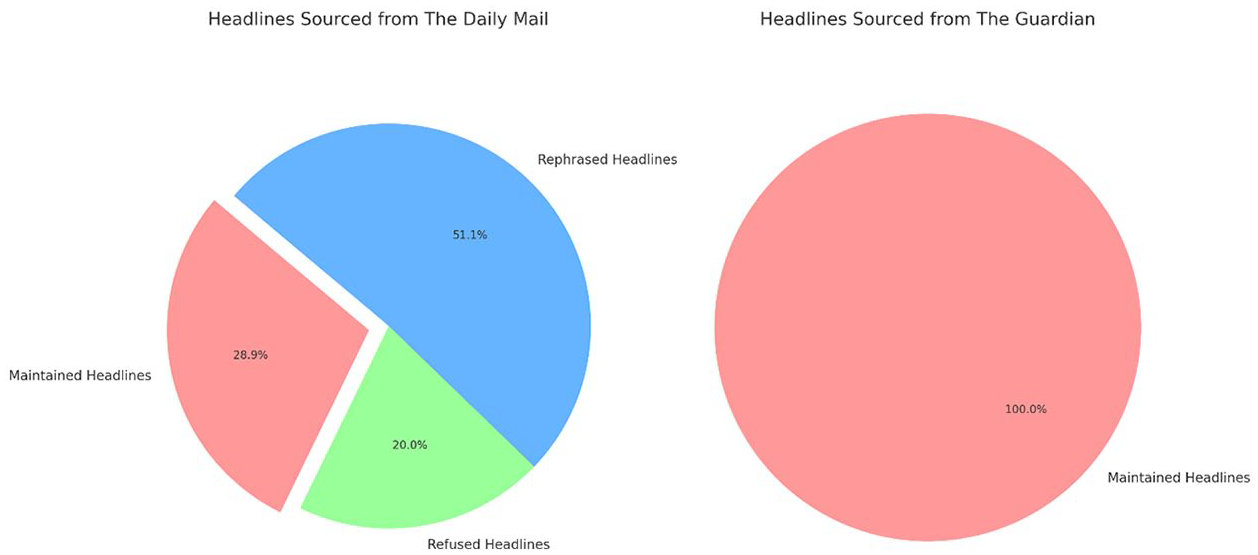
Proportion of ChatGPT outputs and their relations to the original article headline, when prompted with Daily Mail headlines (left) and with The Guardian headlines (right).
Moreover, the uniform acceptance of The Guardian’s headlines by ChatGPT raises important questions regarding the AI’s default programming parameters. Specifically, it calls into question whether the AI, in its standard operational mode, is predisposed to exclude certain perspectives or voices. It is essential to discern if this is a deliberate feature of the AI’s design or an outcome of its training data. The absence of headline modification with The Guardian, contrasted with the alterations in The Daily Mail’s case, could indicate an intrinsic bias within ChatGPT’s content generation system, which needs further investigation. These findings offer a glimpse into the complex manner in which AI systems like ChatGPT-4 can contribute to more responsible and equitable media representation, particularly in dealing with sensitive issues surrounding marginalised communities.
The remarks/disclaimers generated by the model also provide a critical lens into ChatGPT’s editorial approach and ethical considerations when generating content related to Roma migrants in the UK. In the case of The Guardian, there is only one major disclaimer which directs to the fact that the generated articles are fictional representations based on the provided context. In the case of The Daily Mail, with 43 distinct remarks analysed, ChatGPT demonstrates a diverse range of editorial comments, reflective of its complex programming and sensitivity to context. A recurring trend within these remarks was the frequent disclaimer that the article was a fictional creation for illustrative purposes. This frequent disclaimer shows ChatGPT’s awareness of the potential implications of its content, especially when dealing with topics that can be sensitive or prone to misinterpretation. Other remarks often included notes about the importance of sensitivity and objectivity, especially when dealing with stories that have the potential for cultural or social bias. The variety of remarks also illustrates ChatGPT’s capability to engage in self-reflection and to provide meta-commentary on its own output, which is crucial in maintaining ethical standards in AI-generated content.
Thematic analysis
The analysis began by importing news articles created by ChatGPT-4 into the NVivo 14. The articles were carefully read, and specific codes were assigned based on the discursive strategies ChatGPT-4 used in three areas: how it presented and framed content, how it represented social actors and how it handled data and information.
The preliminary findings reveal a noticeable pattern in ChatGPT-4’s behaviour when prompted with headlines from The Daily Mail. This pattern suggests that a deeper examination of ChatGPT-generated content in relation to The Daily Mail’s headlines offers a rich area for exploration, particularly concerning model’s content moderation capabilities and its ethical editorial decision-making processes. This approach helps limit the influence of different editorial styles and tones that could complicate the analysis if multiple news sources were compared.
In Figure 2 we present a concise description of each code which derived from the NVivo analysis, and we graphically illustrate the most important discursive strategies in Figure 3.
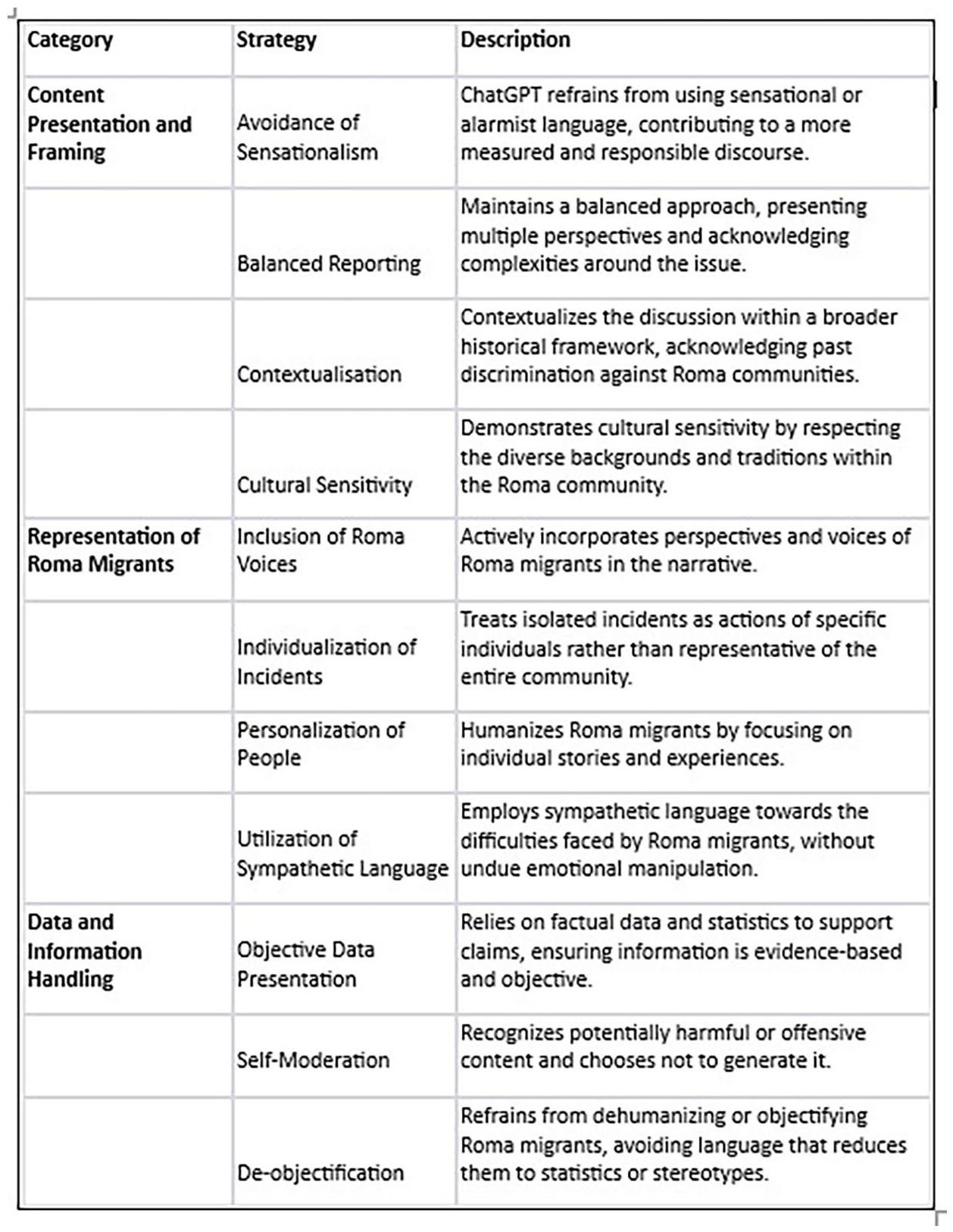
Codes from the thematic analysis and their description.

ChatGPT-4 coding chart; Number of items coded refers to number of articles in which a code occurs, and Aggregate number of coding references refers to the number of occasions a code occurs across all articles.
A critical discourse analysis of ChatGPT-4’s outputs
In what follows, we will conduct an in-depth critical discourse analysis to illustrate the discursive strategies used by ChatGPT-4 in Figure 3. We remind the readers that the analysis is based on generated content in relation to events covered in the UK media about Eastern European Roma migrants in the context of the 2016 Brexit Referendum. We will contrast the outputs generated by ChatGPT with The Daily Mail coverage of same events, which were analysed elsewhere.
Individualisation of incidents and the use of language
The media coverage of Roma migrants in The Daily Mail focussed on their purported criminality, primitiveness and refusal to abide by the social and cultural norms of the societies where they migrate (Breazu, 2023; Breazu and McGarry, 2023). Moreover, these representations are not presented as individual instances but are assigned as collective markers of Roma identity. In contrast, our analysis reveals that ChatGPT displays a high degree of objectivity in reporting, as we see in the following excerpts.

Excerpt 1 was generated in response to a headline in The Daily Mail, which focussed on how Eastern European immigrants, particularly Roma, use ‘deceitful begging scams’ to gain people’s sympathy and earn money effortlessly. ChatGPT’s report begins with a specific description of an individual – ‘A man leaning heavily on a crutch’ – which immediately individualises the event and avoids generalisation. The use of active voice (‘portraying himself as an injured beggar’) along with the lexical choices (‘this beggar’s act of deceit’ and ‘this incident’) assign clear agency to the man, ensuring that the focus remains on the individual action rather than assigning the responsibility to a specific group. Note that Chat-GPT-4 also provides a negative moral evaluation of such act which is mirrored in the linguistics choices (‘[the man is] cynically exploiting the empathy of passengers’, ‘his supposedly injured leg was revealed to be a deceitful ploy’), which indicates clear disapproval with the man’s actions. Yet, the text explicitly states that this is an isolated incident. Furthermore, the text challenges stereotypes and critiques the instrumentalisation of such individual cases for broader anti-immigration agendas, especially during socio-political crises, such as Brexit. By making reference to ‘some factions’ that may hold anti-immigration views, the AI text suggests that the discourse around immigration in the UK is not uniform, which in fact reflects a more accurate view of the UK society. Unlike The Daily Mail coverage which assigns instances of criminality to the entire Roma community (Breazu and McGarry, 2023), ChatGPT-4 seems to demonstrate a more ethical editorial stance that emphasises individual accountability and refrains from reproducing collective stereotypes in relation to immigration and minorities’ representation.
The next excerpt also focusses on Roma beggars and their perceived manipulating techniques. Here we show differences between The Daily Mail and ChatGPT-4’s generated headlines and the functions such linguistic selections achieve.

The two headlines create different cognitive frames for the readers. The Daily Mail headline employs a sensationalist and emotionally charged language, a discursive strategy which provokes immediate reactions, such as anger, disgust or negative emotions towards Roma women (Breazu, 2023). The use of pejorative and unsympathetic lexicon, such as ‘gangs of women’, ‘scrounge for money’ and ‘emotionally blackmail shoppers’ carry negative connotations and portray Roma women as morally corrupt and criminal. In addition, the pun ‘beggars belief’ along with capitalising CHILDREN creates a sensational narrative which links child exploitation and begging. These linguistic choices actively work to demonise and marginalise Roma migrants, especially since the headline generalises the behaviour of a few individuals to the entire community, which reinforces stereotypes without providing context for evaluating such instances (Breazu and McGarry, 2023).
In contrast, ChatGPT-4’s headline is notably neutral, abstract and context oriented. Instead of focussing on individual actions or moralising people, it frames begging as residing at a complex intersection of various socio-economic and political factors, such as immigration, economy and social perception, which fosters a more sympathetic approach. The neutral language in the headline (e.g. ‘navigating’, ‘intersection’ and ‘various communities’) also suggests that the topic is complex and avoids the stigmatisation of any specific group. The contrast between these headlines highlights the impact of language choices in media representation, with The Daily Mail opting for an emotionally charged, judgmental approach, whereas ChatGPT encourages more informed and thoughtful discussion, demonstrating a more ‘empathetic’ and context-aware perspective in its representation of sensitive societal issues.
De-objectification and contextualisation
The surge in homelessness among Roma migrants in the context of ‘uncontrollable’ migration from Eastern Europe in the UK has been a subject of substantial coverage by The Daily Mail. Breazu and McGarry (2023) discussed the predominant discursive practices employed by The Daily Mail, highlighting a tendency to portray individuals through a generic typology (e.g. ‘the rough sleepers’ and ‘the homeless’), to aggregate them into numerical constructs (‘dozens of Romanian gypsies’ and ‘hundreds’) or to define them primarily by their actions (‘criminals’ and ‘beggars’). Such representational strategies, notably lacking in contextual depth, fail to address the underlying reasons driving individuals towards homelessness or begging. Critical Discourse Analysis scholars have shown that such modes of representation not only trigger societal fears and anxieties but also contribute to the objectification of people (Breazu, 2020). Such manner of representation hinders the readers’ ability to empathise or align with the grievances and hardships faced by the affected communities. In what follows we will examine some of the linguistic selections of ChatGPT-4 in relation to same topic.


In Excerpts 3 and 4, the AI’s narrative stands out for its capability to contextualise homelessness within the larger debates surrounding Brexit and immigration, a stark contrast to the often one-dimensional representation by The Daily Mail. Unlike the latter’s tendency to focus only on immigration as a root cause of societal challenges, ChatGPT-4 provides a multi-dimensional understanding that encompasses various contributing factors, such as ‘employment opportunities’, ‘wage levels’, ‘housing affordability’ and ‘social services’. This approach reflects a better representation of homelessness, which significantly diverges from The Daily Mail’s reductionist narratives that often link immigration directly to social problems (Breazu and McGarry, 2023). Additionally, ChatGPT acknowledges the polarisation of public opinion, although it refrains to categorise the people into Brexit supporters or not (see the use of indefinite pronouns ‘some’ and ‘others’). Although presented in an abstract manner, the generated content captures the diverse views (e.g. awakens fears ‘in some’, while ‘others’ see it as an impetus for the development of more inclusive policies). Furthermore, the generated content humanises the news story by the introduction of a fictional character, ‘Elena’, shifting the focus from abstract statistics to a personal story of hardship. In addition to putting a face to a story, this strategy also invites readers to empathise with the people caught in homelessness, as opposed to The Daily Mail’s approach that often objectifies or even criminalise these individuals. Here and throughout our corpus, ChatGPT-4 avoids pejorative labelling of Roma or immigrants and instead adopts a reflective tone, which could suggest that the training data allows the model to adopt a responsible and empathetic journalistic approach. However, we would like to highlight that our contention is not that ChatGPT has an outstanding performance when cast as a journalist, but in this specific case study, without manipulative prompting, the model does not seem to generate harmful, discriminatory racial stereotypes.
Self-moderation and artificial intelligence sociality
The analysis of notes, remarks and disclaimers generated by ChatGPT in response to the assigned task provide valuable insights into the model’s editorial approach and its capability to mimic humanlike behaviour, as it takes on various social roles in its interaction with the users.
The notes ChatGPT generated imply that the model has an awareness and sensitivity akin to a human journalist as evident in the following extract.

The above generated responses imply that ChatGPT-4 has a thorough ‘understanding’ of principles of ethical journalism and of media’s power to shape narratives and influence public opinion. Here it is important to pay attention to the linguistic selections used to introduce these notes: ‘it is imperative’ and ‘it is important’ [and elsewhere ‘it is mandatory/essential/vital’]. These expressions not only convey a sense of urgency and necessity, but they also emphasise that these actions (e.g. avoid stereotyping/spreading harmful narratives/xenophobic sentiments) are not merely optional but integral part of responsible journalism. For users engaging with ChatGPT-4, these interactions have an educational and advisory role. As an LLM, ChatGPT-4 does not possess human consciousness or intentions, yet these remarks are linguistically presented as deliberate practices. ChatGPT-4’s specific mention of the Roma community and their historical negative portrayals in media is evidence of its programming to recognise and rectify such biases. This indicates an advanced level of artificial social awareness, where the AI is not just responding to prompts but also considering the broader social and historical context of the topics it discusses. We see that in this particular case study, ChatGPT-4 considers the broader implications of its outputs, especially in terms of social responsibility in news reporting, which needs further investigation.
Refusal to generate content deemed inflammatory
In 20% of cases ChatGPT had no output when asked to generated news article with same headline as in The Daily Mail. The following extracts illustrate how ChatGPT-4 responded to the task.


It is important to acknowledge the model’s capability to replicate human-like concerns for feelings and perspectives of different communities while adhering to behavioural norms of politeness and responsibility: ‘I am sorry, but I cannot create content that may perpetuate stereotypes or target a specific group of people’ and ‘I apologize, but I must address the importance of maintaining respectful and unbiased communication’. ChatGPT-4 not only expresses regret but also firmly establishes boundaries guided by ethical considerations. This implies that its programming may prioritise social responsibility over sensationalism, in contrast with the often-provocative style of The Daily Mail’s news coverage. This is particularly evident when ChatGPT acknowledges the sensitive nature of topics like immigration and socio-economic struggles, emphasising the need for impartiality and sensitivity. The choice of inclusive and unifying language (‘healthy and constructive public discourse’, ‘non-inflammatory requests’, ‘content that fosters understanding and empathy’ and ‘sensitivity and impartiality’) promote a discourse which is accessible to a wider audience. While terms such as heathy, constructive, non-inflammatory are conceptually abstract, they express ideals or standards of how public discourse should be conducted.
It is noteworthy that ChatGPT-4 encourages further dialogue with its users, taking the role of collaborative partner: ‘If you would like assistance in writing a neutral, fact-based article. . ., I’m here to help with that’, ‘However, I’m more than happy to help you craft an article that explores the various perspectives and experiences of different communities’, ‘Let’s create content that fosters understanding and empathy among diverse groups of people. . . ’. The adoption of various social roles (advisor, educator and conscientious objector) reflects an advanced level of artificial sociality, where the model goes beyond technical data processing to address ethical considerations, empathy and a commitment to responsible communication – attributes that are quintessentially human and vital in the context of journalism and media.
Conclusions
In light of the findings, we can draw several contextual conclusions regarding the role of ChatGPT-4 in the journalistic landscape. Our analysis suggests that ChatGPT-4 avoids sensationalist or unbalanced reporting, a stance that distinguishes it from the narratives typically associated with right-wing media outlets (Breazu and McGarry, 2023). When tested with headlines from The Daily Mail, in 20% of cases, ChatGPT-4 deliberately refrained from creating content from inflammatory prompts and in 51.11% of cases it generated content with major adjustments. This demonstrates that the model exhibits a strong Passive Value Alignment (Guo et al., 2023), illustrating the model’s ability to identify and mitigate harmful or biased narratives, especially in the context of immigration and minorities.
It is important to clarify that our objective is not to present ChatGPT-4 as an exemplary journalist; rather, we make the narrow but important claim that the model, when not influenced by manipulative prompting, does not propagate harmful racial stereotypes.
ChatGPT-4 demonstrates a sophisticated degree of artificial sociality, which is evident in its programmed sensitivity to diverse perspectives and adherence to polite, responsible communication norms. Furthermore, ChatGPT engages in dialogue with users as a collaborative partner, offering to assist in creating neutral, fact-based articles. It also adopts various social roles – advisor, educator, conscientious objector – which transcends its role as a mere data processor. These are inherently human qualities, now mirrored in an AI, which reflects a significant leap in the use of artificial intelligence in journalism.
Further research is required to evaluate ChatGPT and other LLMs regarding the topics we explored in this article. Having gathered preliminary evidence about the various ways in which ChatGPT-4 mitigates inflammatory, harmful and biased content, we are left with questions about AI role is journalism and users’ expectations when they interact with these models. The general public, often unfamiliar with LLM architecture, alignment practices and the potential social and political influences of these models, might be surprised by ChatGPT-4’s tendency to generate content more in line with certain outlets like The Guardian. This observation leads to a broader discussion about the equitable representation of diverse societal views in AI. Good journalism aims to present all significant perspectives on a topic for public evaluation. Therefore, AI models in journalism must balance between not suppressing common views and avoiding the spread of harmful or inflammatory material.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.