
Abstract
People overaccept information that supports their identity and underaccept information that opposes their identity—a phenomenon known as partisan bias. Although partisan-bias effects in judgments of misinformation are robust and pervasive, there is ongoing debate about whether partisan-bias effects arise from identity-protective motivated reasoning or differential knowledge of identity-congenial versus identity-uncongenial information. Prior empirical work has been unable to differentiate the two accounts because of a reliance on groups with pre-existing differences in knowledge (e.g., Democrats and Republicans). The current research addresses this issue by using randomly assigned rather than pre-existing identities. Across two experiments (Ntotal = 1,411), adult U.S. Prolific workers showed lower thresholds for accepting information that is congenial versus uncongenial to a randomly assigned identity, despite having no differences in prior knowledge. These results support theories that emphasize identity protection as a factor underlying partisan bias in the acceptance of misinformation, with important practical implications for misinformation interventions.
Keywords
Introduction
Given the vast amount of misinformation on the Internet and other media, people are commonly tasked with deciding what is true and what is false. Although people are quite good at discerning true from false information (Gawronski et al., 2025; Pennycook & Rand, 2021a; Pfänder & Altay, 2025), they do make systematic errors. In particular, people tend to accept information that is congenial to their personal beliefs and to reject information that is uncongenial to their personal beliefs, which can lead them to mistakenly judge false information as true if it supports their views and identities, and to mistakenly judge true information as false if it opposes their views and identities (Gawronski et al., 2025). This tendency—which we refer to as partisan bias—is one of the most robust and pervasive factors in judgments of misinformation (Batailler et al., 2022; Gawronski et al., 2023; Nahon et al., 2024).
Although the existence of partisan bias in judgments and information processing is supported by a large body of evidence, the mechanisms underlying partisan bias are subject to ongoing debate (Ditto et al., 2025). Some have argued that partisan bias is driven in part by motivated reasoning (Celniker & Ditto, 2024; Ditto et al., 2025; Kahan, 2016; Peterson & Iyengar, 2021; Van Bavel et al., 2024). Yet others have pointed out that partisan bias can be explained in purely cognitive terms as the product of differential knowledge (Baron & Jost, 2019; Druckman & McGrath, 2019; Pennycook & Rand, 2021b; Tappin et al., 2020). The current research aims to advance this debate by testing whether people show partisan bias in judgments of true and false information even without differences in prior knowledge.
Identity protection versus differential knowledge
At the heart of the debate about the underpinnings of partisan bias is the concept of motivated reasoning, or the tendency to arrive at conclusions one wants to arrive at (Kunda, 1990). Although there are many motivations that might influence judgments (Briñol & Petty, 2005), one particularly relevant motivation is the need for identity protection. According to theories emphasizing identity protection, partisans overaccept information that supports their side and underaccept information that opposes their side because they are motivated to support and protect their partisan identity (Van Bavel et al., 2024).
At first glance, partisan bias in truth judgments may appear to be a clear case of identity-protective motivated reasoning. However, some researchers have pointed out that partisan bias can also be explained in purely cognitive terms (Baron & Jost, 2019; Druckman & McGrath, 2019; Pennycook & Rand, 2021b; Tappin et al., 2020). According to this purely cognitive account, partisan bias occurs because people typically have more knowledge of information that supports their partisan identity compared with information that opposes their partisan identity (Pennycook & Rand, 2021b). Such knowledge differences are often rooted in selective exposure, in that people tend to seek out information that is congenial to their views and to avoid information that is uncongenial to their views (Hart et al., 2009; Stroud, 2010). Because information is more likely judged to be true if it is consistent rather than inconsistent with one’s prior knowledge (Brashier & Marsh, 2020; Gawronski, 2012), greater knowledge of identity-congenial than identity-uncongenial information should increase the likelihood that new information is judged as true when it supports, rather than opposes, one’s partisan identity.
Given the strong empirical support for differential knowledge across partisan groups, it is worth noting that proponents of the identity-protection account do not deny the role of knowledge-driven effects. Rather, the critical question under debate concerns the presumed role of identity-protective motivated reasoning as a factor underlying partisan bias (Ditto et al., 2025).
Empirically testing identity protection
Providing evidence for identity-protective motivated reasoning that cannot be explained in terms of differential knowledge has proven notoriously challenging (Ditto, 2010; Druckman & McGrath, 2019; Tetlock & Levi, 1982). One line of research that has attempted to provide evidence for identity-protective motivated reasoning has used matched-information paradigms (see Ditto et al., 2025). In matched-information paradigms, partisans are asked to judge information that differs only in terms of its slant. Despite the information being otherwise identical, participants tend to judge identity-congenial information more favorably than identity-uncongenial information (e.g., Cohen, 2003; Lord et al., 1979).
Although results of matched-information studies are often interpreted as evidence for motivated reasoning, closer causal analysis demonstrates that these studies are incapable of differentiating between motivated reasoning and differential knowledge (Ditto et al., 2025; Tappin et al., 2020). This ambiguity is rooted in the fact that any findings involving pre-existing groups (e.g., Democrats and Republicans) can be explained by systematic differences in prior knowledge between these groups. Thus, addressing the debate requires alternative methods that convincingly rule out knowledge differences as a driving force. Some studies have attempted to address the problem by statistically controlling for prior knowledge (Celniker & Ditto, 2024), but no prior research has ruled out differential knowledge by experimentally manipulating group membership.
The current research
The current research aims to provide a more compelling test of identity protection as a factor underlying partisan bias in judgments of true and false information by using randomly assigned instead of pre-existing identities. In two experiments, we randomly assigned participants to one of two teams (experimental conditions) or to no team (control condition) and asked them to judge the veracity of true and false information that favored one team over the other. By using random assignment to groups, we eliminated the possibility of pre-existing knowledge differences, thereby isolating identity protection as a potential driver of partisan bias. Although the identity-protection account predicts that participants should be more likely to accept information that favors their randomly assigned in-group compared with information that favors their randomly assigned out-group, the differential-knowledge account does not predict partisan bias for randomly assigned groups.
Research Transparency Statement
General disclosures
Experiment 1 disclosures
Experiment 2 disclosures
Experiment 1
Method
Participants and design
Experiment 1 utilized a 3 (Group Assignment: Team United Kingdom [UK] vs. Team France vs. No Team) × 2 (Statement Accuracy: true vs. false) × 2 (Statement Slant: pro-UK vs. pro-France) mixed design with the first factor varying between subjects and the other two factors varying within subjects. We aimed to recruit a total of 600 participants. Sensitivity analyses using G*Power (Version 3.1.9.6; Faul et al., 2007) demonstrated that a sample of 600 provides 80% power to detect a small effect of f = 0.075 for the predicted interaction between group assignment and statement slant, assuming a correlation (r = .30) between measures and using a nonsphericity correction of ∊ = 1.
Participants were recruited on Prolific Academic. Participation was restricted to Prolific workers who are (a) U.S. citizens currently residing in the United States, (b) are fluent in English, (c) have completed at least 100 previous assignments, and (d) had an approval rating of 95% or higher on previous submissions. The study took approximately 15 min to complete, and participants were compensated with USD$3. This experiment was approved by the Institutional Review Board of the University of Texas at Austin (Protocol No. 00000822).
A total of 601 participants completed the study (one participant completed the study but did not request compensation). Following our preregistered exclusion criteria, participants were excluded if they failed an instructional attention check (nTeam UK = 9, nTeam France = 14, nNo Team = 15; Oppenheimer et al., 2009). Exclusions did not significantly differ across conditions, χ2(2) = 1.65, p = .438. After applying this exclusion criterion, our final sample consisted of 563 participants (190 Team UK; 185 Team France; 188 no team). Demographic information is provided in Table 1.
Participant Demographics in Experiments 1 and 2

Procedure
Participants from the United States were randomly assigned to either a Team UK condition or a Team France condition (experimental conditions) or to a no-team condition (control condition). The UK and France were used for the two teams given that the two countries are relatively similar, have a history of conflict, and are well known to U.S. participants. To bolster the effectiveness of the group manipulation, all participants were informed that the study concerned “differences between people from countries that have experienced conflict,” and they were provided with a brief description of the UK and France as being in conflict with one another, along with images of the British flag and the French flag. The position of the two flags (left vs. right) was counterbalanced across participants. For the assignment to the two teams, participants completed a bogus personality assessment (i.e., a short version of the Big Five; Soto & John, 2017), ostensibly aimed at determining with which country their personality was most closely aligned. Previous work within the minimal-groups literature has found this procedure to be an effective method for inducing identification with a novel group (Pinter & Greenwald, 2011). After completing the bogus personality assessment, participants in the experimental conditions were shown a loading screen, followed by their team assignment which stated: “Based on the results of your personality test, you are on . . . [Team UK/Team France].” For participants in the control condition, the study proceeded to the next part after the personality test without bogus feedback linking them to one of the two countries.
Following the bogus personality test, all participants completed a series of demographic questions asking them about their gender, age, ethnicity, race, and education. Next, all participants completed a series of questions assessing their identification with the United Kingdom and France (Pinter & Greenwald, 2011). These items included three questions per country (six total) asking about their identification with each country (“I identify with [the UK/France]”), attachment to each country (“I feel attached to [the UK/France] ”), and attitude toward each country (“I like [the UK/France]”). Responses were measured with 7-point rating scales (1 = strongly disagree; 7 = strongly agree). The three questions were blocked by country and presented in the same fixed order for each country. The order of the two countries (UK first vs. France first) was counterbalanced across participants.
For the truth-judgment task, participants read a total of 60 statements and responded either true or false to the question: “To the best of your knowledge, is the claim in this statement true or false?” The statements varied in terms of their veracity (true vs. false) and slant (pro-UK vs. pro-France). Examples of the statements used include: “In terms of GDP, the UK has a stronger economy than France” (pro-UK true) and “France ranked higher than the UK on a measure of political stability in 2022” (pro-France false). Statements were pilot tested to ensure that the slant of each statement matched the respective condition and that the average slant was of equal strength across conditions. 1 Statements were also balanced for valence such that all statement conditions contained an equal number of positive statements (e.g., pro-France in the pro-France statement condition), negative statements (e.g., anti-UK in the pro-France statement condition), and comparative statements (e.g., France better than the UK in the pro-France statement condition). For further details on the selection and pilot testing of statements, see the Supplemental Material available online.
Data-analytic approach
Following prior research on partisan bias in judgments of misinformation (e.g., Batailler et al., 2022; Gawronski et al., 2023), we used signal-detection theory (SDT; Green & Swets, 1966) to calculate indices for truth sensitivity and acceptance threshold. SDT’s index for truth sensitivity, d′, captures the extent to which participants accurately distinguish between true and false information. High truth-sensitivity scores indicate a higher likelihood of responding “true” to true statements (hits) and “false” to false statements (correct rejections). Conversely, low truth-sensitivity scores indicate a higher likelihood of responding “false” to true statements (misses) and “true” to false statements (false alarms). SDT’s index for acceptance threshold, c, captures participants’ general tendency to respond “false” (vs. “true”) irrespective of whether the statements are true or false. High acceptance-threshold scores indicate a higher likelihood of responding “false” to both false statements (correct rejections) and true statements (misses). Conversely, low acceptance-threshold scores indicate a higher likelihood of responding “true” to both false statements (false alarms) and true statements (hits).
Following our preregistered data-aggregation plan, hit and false-alarm rates were first calculated for pro-UK and pro-France statements. Hit rates (H) were calculated as the proportion of true statements judged as true. False-alarm rates (FA) were calculated as the proportion of false statements judged as true. Following recommendations by Macmillan and Creelman (2004), we converted values of 0 to
Partisan bias is reflected in lower acceptance thresholds for identity-congenial compared with identity-uncongenial statements (Batailler et al., 2022; Gawronski et al., 2023; see also Ditto et al., 2025). The central question of the current study was whether partisan bias emerges for randomly assigned groups, in that participants show a lower acceptance threshold for statements that favor their randomly assigned in-group compared with statements that favor their randomly assigned out-group. Specifically, we tested the preregistered hypotheses that acceptance thresholds in judgments of pro-UK and pro-France information will differ as a function of group assignment, such that participants assigned to Team UK will show a lower threshold for pro-UK information than for pro-France information and participants assigned to Team France will show a lower threshold for pro-France information than for pro-UK information. Acceptance thresholds in the no-team condition should not differ for pro-UK and pro-France information.
Although some have argued that partisan bias should lead to lower truth discernment (or truth sensitivity) for identity-congenial compared with identity-uncongenial information (e.g., Pennycook & Rand, 2021b), a tendency to accept identity-congenial and to reject identity-uncongenial information should be reflected in differential acceptance thresholds, and identity effects on acceptance thresholds may not necessarily affect truth sensitivity (see Gawronski, 2021; Gawronski et al., 2025). For identity-congenial information, partisan bias involves not only a higher likelihood that false information is judged as true (i.e., increased false-alarm rate), but also a higher likelihood that true information is judged as true (i.e., increased hit rate), which should lead to an overall null effect on truth sensitivity. Conversely, for identity-uncongenial information, partisan bias involves not only a higher likelihood that true information is judged as false (i.e., reduced hit rate), but also a higher likelihood that false information is judged as false (i.e., reduced false-alarm rate), which should lead to an overall null effect on truth sensitivity. On the basis of these considerations, we further tested the preregistered hypotheses that group assignment will not affect truth sensitivity overall or differentially for pro-UK and pro-France information.
Results
Means and 95% confidence intervals (CIs) for the number of statements accepted as true per condition are reported in Table 2.
Means and 95% Confidence Intervals (CIs) of the Number of Statements Accepted as True as a Function of Group Assignment in Experiment 1
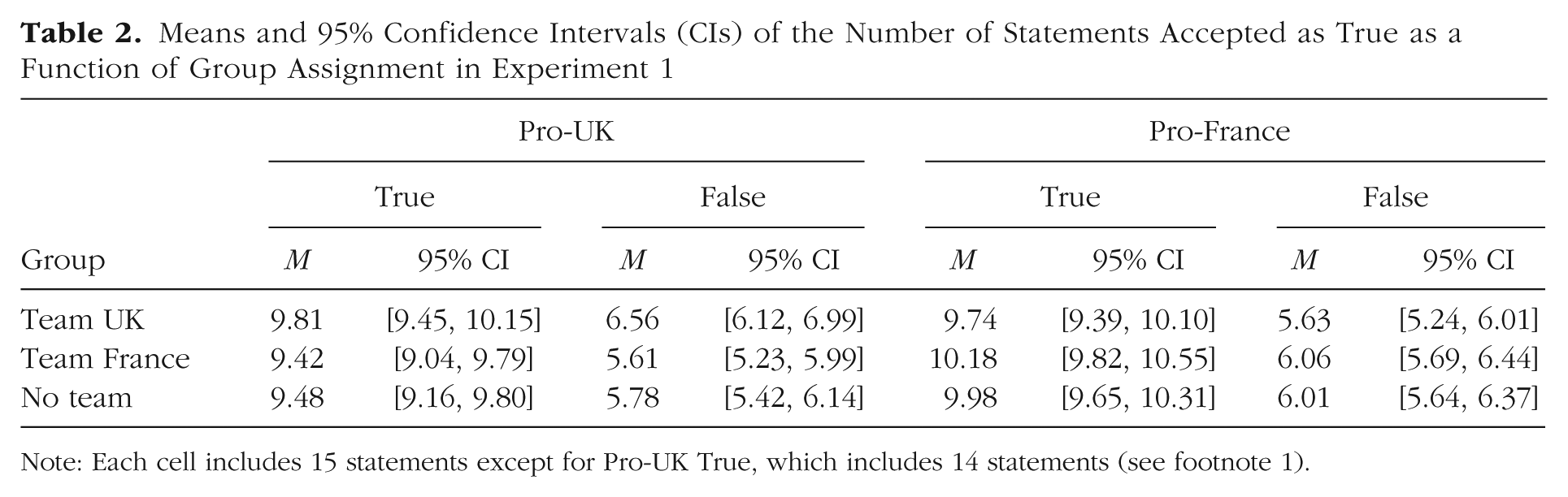
Note: Each cell includes 15 statements except for Pro-UK True, which includes 14 statements (see footnote 1).
Manipulation check
To confirm the effectiveness of the group assignment, we calculated group-identification scores on the basis of participants’ responses to the six identification items. Following our preregistered data-aggregation plan, group-identification scores were calculated by averaging responses to the three items for each country and then subtracting the mean identification scores for France from the mean identification scores for the United Kingdom. Thus, positive scores on this index indicate stronger relative identification with France, whereas negative scores indicate stronger relative identification with the United Kingdom. A preregistered one-way analysis of variance (ANOVA) comparing group-identification scores across group-assignment conditions (Team UK vs. Team France vs. No Team) revealed a significant difference across conditions (MTeam UK = −1.20 vs. MTeam France = 0.25 vs. MNo Team = −0.41), F(2, 560) = 41.86, p < .001, η p 2 = .13, 95% CI = [.08, .18]. Preregistered post hoc t tests confirmed the effectiveness of the group assignment, supporting all preregistered hypotheses. Specifically, relative identification with France versus the United Kingdom was significantly stronger in the Team France condition compared with the Team UK condition, t(373) = 8.00, p < .001, d = 0.83, 95% CI = [0.62, 1.04], and the no-team condition, t(371) = 4.45, p < .001, d = 0. 46, 95% CI = [0.25, 0.67]. In addition, relative identification with France versus the United Kingdom was significantly stronger in the no-team condition compared with the Team UK condition, t(376) = 5.48, p < .001, d = 0.56, 95% CI = [0.36, 0.77].
Acceptance thresholds
In our primary analysis concerning partisan bias, we submitted acceptance-threshold scores to a preregistered 3 (Group Assignment: Team UK vs. Team France vs. No Team) × 2 (Statement Slant: pro-UK vs. pro-France) mixed ANOVA with the first factor varying between subjects and the second factor varying within subjects. The main effects of group assignment, F(2, 560) = 0.28, p = .756, η p 2 < .01, 95% CI = [.00, .01] and statement slant, F(1, 560) = 2.91, p = .088, η p 2 = .01, 95% CI = [.00, .02] were not significant. However, as predicted, there was a significant interaction between group assignment and statement slant, F(2, 560) = 8.79, p < .001, η p 2 = .03, 95% CI = [.01, .06] (see Fig. 1). Following our preregistered analysis plan, we conducted follow-up t tests for dependent means to examine this interaction. As predicted, acceptance thresholds in the Team UK condition were significantly lower for pro-UK statements compared with pro-France statements, t(189) = −4.02, p < .001, d = −0.38, 95% CI = [−0.57, −0.19]. Although acceptance thresholds in the Team France condition were descriptively lower for pro-France statements compared with pro-UK statements, the observed difference did not reach statistical significance, t(184) = −1.35, p = .179, d = −0.12, 95% CI = [−0.30, 0.06]. Finally, as predicted, acceptance thresholds in the no-team condition did not significantly differ for pro-UK statements and pro-France statements, t(187) = −0.01, p = .991, d < 0.01, 95% CI = [−0.18, 0.18].
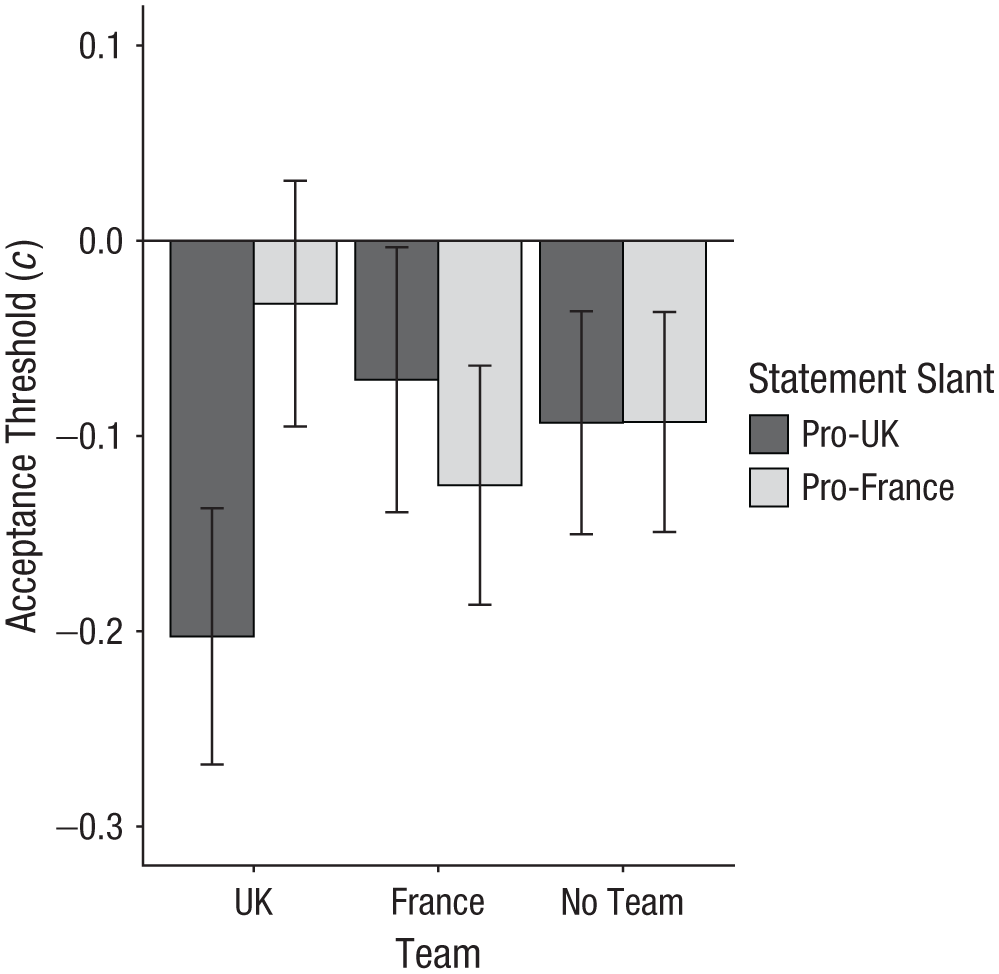
Acceptance threshold as a function of group assignment and statement slant in Experiment 1. Acceptance threshold scores (c) were calculated using signal-detection theory. Lower scores reflect a stronger tendency to accept information. Error bars represent 95% confidence intervals.
Nonpreregistered follow-up t tests comparing acceptance thresholds in the control versus experimental conditions separately by statement type (pro-UK vs. pro-France) revealed a significant difference between the Team UK and the no-team conditions for pro-UK statements, t(376) = −2.48, p = .014, d = −0.26, 95% CI = [−0.46, −0.05]. All other comparisons for pro-UK statements, t(371) = 0.49, p = .624, and pro-France statements, all ts < 1.42, all ps ≥ .158, were not significant. We also conducted nonpreregistered follow-up t tests to compare partisan bias in the Team UK and Team France conditions, respectively, to the no-team condition. To do so, we calculated partisan-bias scores by subtracting acceptance thresholds for pro-France statements from acceptance thresholds for pro-UK statements (
Truth sensitivity
Because truth sensitivity and partisan bias are independent (Gawronski 2021; Gawronski et al., 2025), we predicted that truth-sensitivity scores would be unaffected by the group-assignment manipulation. To test this hypothesis, we submitted truth-sensitivity scores to a preregistered 3 (Group Assignment: Team UK vs. Team France vs. No Team) × 2 (Statement Slant: pro-UK vs. pro-France) mixed ANOVA with the first factor varying between subjects and the second factor varying within subjects. Results supported all preregistered hypotheses, in that the main effect of group assignment was not significant, F(2, 560) = 0.71, p = .495, η p 2 < .01, 95% CI = [.00, .01], nor was the interaction between group assignment and statement slant, F(2, 560) = 0.88, p = .417, η p 2 < .01, 95% CI = [.00, .02] (see Fig. 2). Furthermore, across conditions, truth-sensitivity scores were significantly greater than zero, t(562) = 40.13, p < .001, d = 1.69, 95% CI = [1.56, 1.82], and comparable in size to truth-sensitivity scores found in research on political misinformation (e.g., Gawronski et al., 2023), indicating that participants did not randomly guess the truth or falsity of the presented statements.
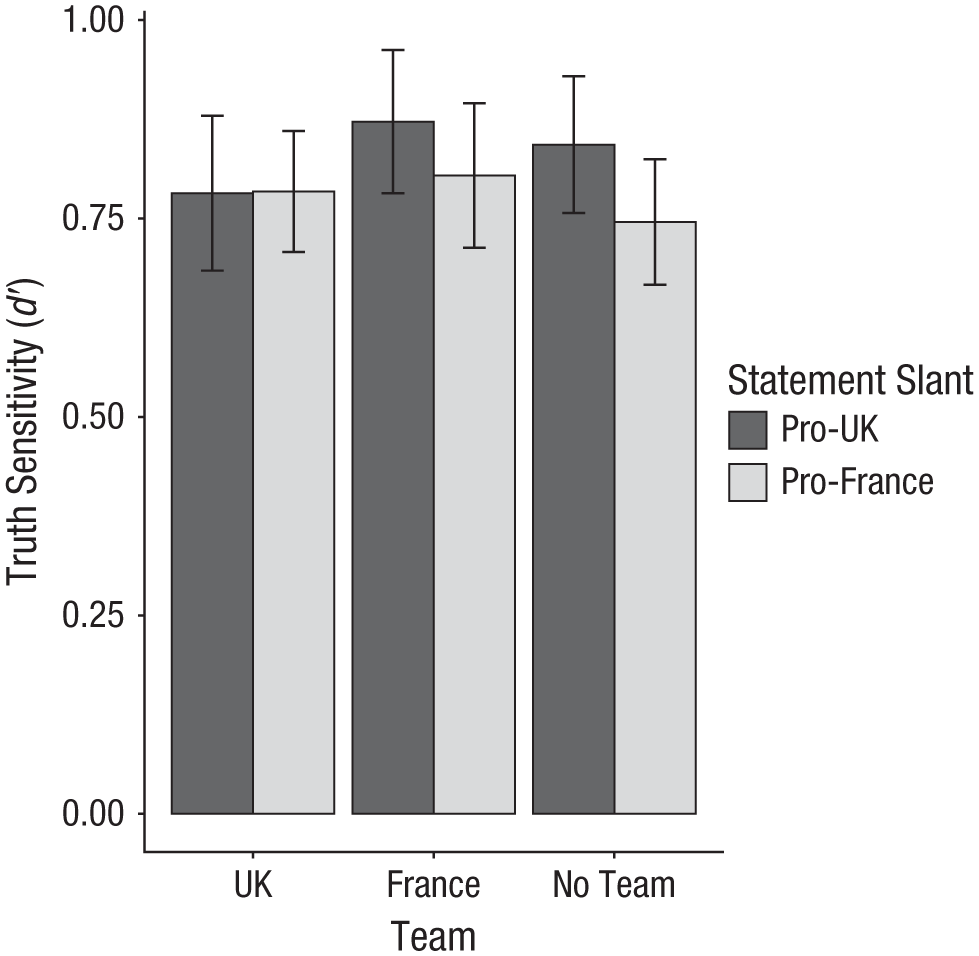
Truth sensitivity as a function of group assignment and statement slant in Experiment 1. Truth sensitivity scores (d′) were calculated using signal-detection theory. Higher scores reflect greater accuracy in discerning true from false information. Error bars represent 95% confidence intervals.
Discussion
Experiment 1 provides initial evidence that partisan bias in judgments of true and false information can emerge for randomly assigned identities without differences in prior knowledge. However, whereas participants in the Team UK condition showed a significant partisan-bias effect, the predicted partisan-bias effect in the Team France condition was not statistically significant. Upon further inspection, this asymmetry may have been due to an unexpected baseline preference for the United Kingdom over France, as reflected in the finding that participants in the no-team condition showed a significantly stronger identification with the United Kingdom compared with France. 2 This baseline asymmetry may have suppressed the induced identification with France in the Team France condition, reducing the strength of the predicted partisan-bias effect. 3 Expanding on these considerations, the two goals of Experiment 2 were (a) to replicate the main findings of Experiment 1 with a larger sample and (b) to resolve the identified asymmetry by using countries that showed equal baseline identification scores in a pilot study (i.e., Spain vs. Greece).
Experiment 2
Method
Participants and design
Experiment 2 utilized a 3 (Group Assignment: Team Spain vs. Team Greece vs. No Team) × 2 (Statement Accuracy: true vs. false) × 2 (Statement Slant: pro-Spain vs. pro-Greece) mixed design with the first factor varying between subjects and the other two factors varying within subjects. We aimed to recruit a total of 900 participants. Sensitivity analyses using G*Power (Version 3.1.9.6; Faul et al., 2007) demonstrated that a sample of 900 provides 80% power to detect a small effect ( f = 0.061) for the predicted interaction between group assignment and statement slant, assuming a correlation (of r = .30) between measures and using a nonsphericity correction (∊ = 1).
Participants were recruited via Prolific Academic. Participation was restricted to Prolific workers who (a) are U.S. citizens currently residing in the United States, (b) are fluent in English, (c) have completed at least 100 previous assignments, (d) had an approval rating of 95% or higher on previous submissions, and (e) did not participate in Experiment 1. Completion of the study took approximately 15 min, and participants were compensated with USD$3. This experiment was approved by the Institutional Review Board of the University of Texas at Austin (Protocol No. 00000822).
A total of 907 participants completed the study (7 participants completed the study but did not request compensation). After excluding participants who failed the preregistered attention check (nTeam Spain = 18, nTeam Greece = 19, nNo Team = 22; Oppenheimer et al., 2009), our final sample consisted of 848 participants (283 Team Spain; 284 Team Greece; 281 no team). Exclusions did not significantly differ across conditions, χ2(2) = 0.45, p = .799. Demographic information is provided in Table 1.
Procedure
Experiment 2 used the same procedure as Experiment 1, the only difference being that we used Spain and Greece as countries for the group-assignment manipulation. We also slightly modified the instructions for the group assignment to better align them with the relation between the two countries. Spain and Greece were selected on the basis of pilot testing, which revealed equal identification with the two countries among U.S. participants (for more details, see the Supplemental Material). Participants judged the truth of 60 statements that varied in terms of their veracity (true vs. false) and slant (pro-Spain vs. pro-Greece). Examples of the statements used include “Spain has produced more Nobel Prize winners than Greece” (pro-Spain true) and “Greece was ranked as a more charitable country than Spain” (pro-Greece false). Statements were pilot-tested to ensure that the slant of the statements matched the respective condition and that the average slant was of equal strength across conditions. For further details on the selection and pilot testing of statements, see the Supplemental Material. Data were analyzed using signal-detection theory following the procedures in Experiment 1.
Results
Means and 95% confidence intervals for the number of statements accepted as true per condition are reported in Table 3.
Means and 95% Confidence Intervals (CIs) of the Number of Statements Accepted as True as a Function of Group Assignment in Experiment 2
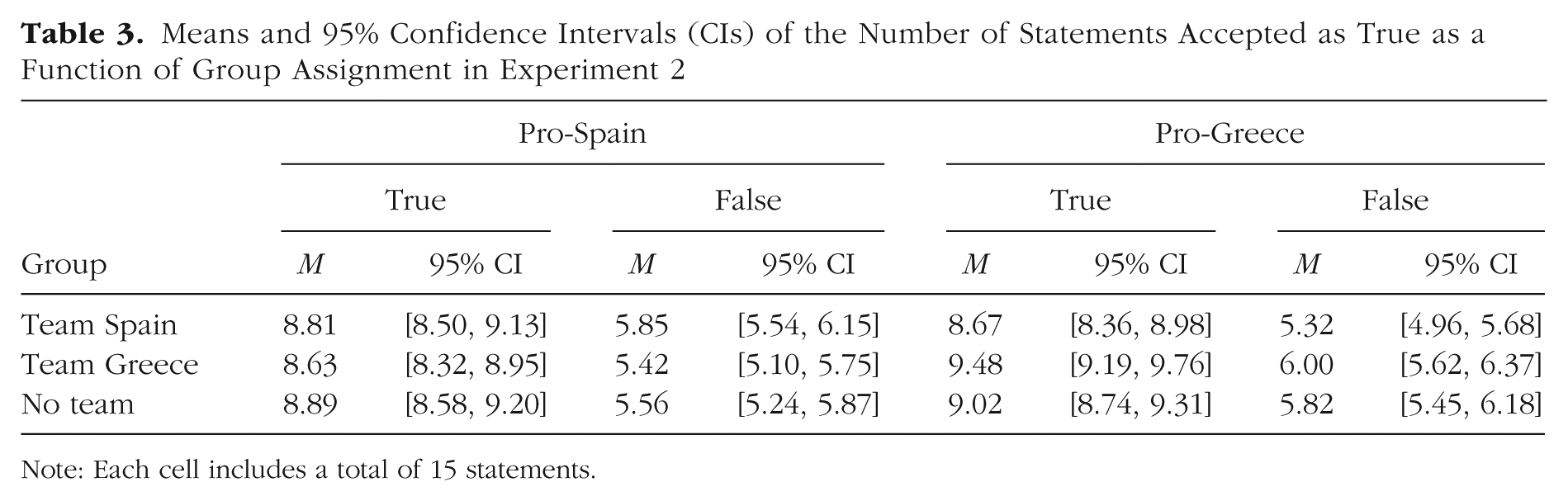
Note: Each cell includes a total of 15 statements.
Manipulation check
Group-identification scores were calculated following the procedures in Experiment 1: Higher scores represent stronger identification with Greece compared with Spain. A preregistered one-way ANOVA comparing group-identification scores across group-assignment conditions (Team Spain vs. Team Greece vs. No Team) revealed a significant difference across conditions (MTeam Spain = −0.81 vs. MTeam Greece = 0.98 vs. MNo Team = −0.02), F(2, 845) = 100.21, p < .001, η p 2 = .19, 95% CI = [.15, .24]. Preregistered post-hoc t-tests confirmed the effectiveness of the group assignment, supporting all preregistered hypotheses. Specifically, relative identification with Greece vs. Spain was significantly stronger in the Team Greece condition compared with the Team Spain condition, t(565) = 12.44, p < .001, d = 1.04, 95% CI = [0.87, 1.22], and the no-team condition, t(563) = 8.47, p < .001, d = 0.71, 95% CI = [0.54, 0.88]. Moreover, relative identification with Greece vs. Spain was significantly stronger in the no-team condition compared with the Team Spain condition, t(562) = 6.75, p < .001, d = 0.57, 95% CI = [0.40. 0.74]. Further confirming the effectiveness of the group-assignment manipulation, nonpreregistered t tests for dependent means revealed that participants in the Team Spain condition identified more strongly with Spain than Greece, t(282) = 8.05, p < .001, d = 0.66, 95% CI = [0.48, 0.84]; participants in the Team Greece condition identified more strongly with Greece than Spain, t(283) = 9.53, p < .001, d = 0.79, 95% CI = [0.60, 0.97]; and participants in the no-team condition did not significantly differ in their identification with Spain and Greece, t(280) = 0.39, p = .699, d = 0.02, 95% CI = [−0.09, 0.13].
Acceptance thresholds
In our primary analysis concerning partisan bias, we submitted acceptance-threshold scores to a preregistered 3 (Group Assignment: Team Spain vs. Team Greece vs. No Team) × 2 (Statement Slant: pro-Spain vs. pro-Greece) mixed ANOVA, with the first factor varying between subjects and the second factor varying within subjects. The main effects of group assignment, F(2, 845) = 1.01, p = .364, η p 2 < .01, 95% CI = [.00, .01], and statement slant, F(1, 845) = 2.26, p = .133, η p 2 < .01, 95% CI = [.00, .01], were not significant. However, as predicted, there was a significant interaction between group assignment and statement slant, F(2, 845) = 10.80, p < .001, η p 2 = .02, 95% CI = [.01, .05] (see Fig. 3). Following our preregistered analysis plan, we conducted follow-up t tests to examine this interaction. All preregistered hypotheses were supported. Specifically, acceptance thresholds in the Team Spain condition were significantly lower for pro-Spain statements compared with pro-Greece statements, t(282) = −2.46, p = .015, d = −0.17, 95% CI = [−0.30, −0.03]. Acceptance thresholds in the Team Greece condition were significantly lower for pro-Greece compared with pro-Spain statements, t(283) = −3.71, p < .001, d = −0.26, 95% CI = [−0.40, −0.12]. Finally, acceptance thresholds in the no-team condition did not differ significantly for pro-Spain versus pro-Greece statements, t(280) = 1.17, p = .242, d = 0.07, 95% CI = [−0.05, 0.19].
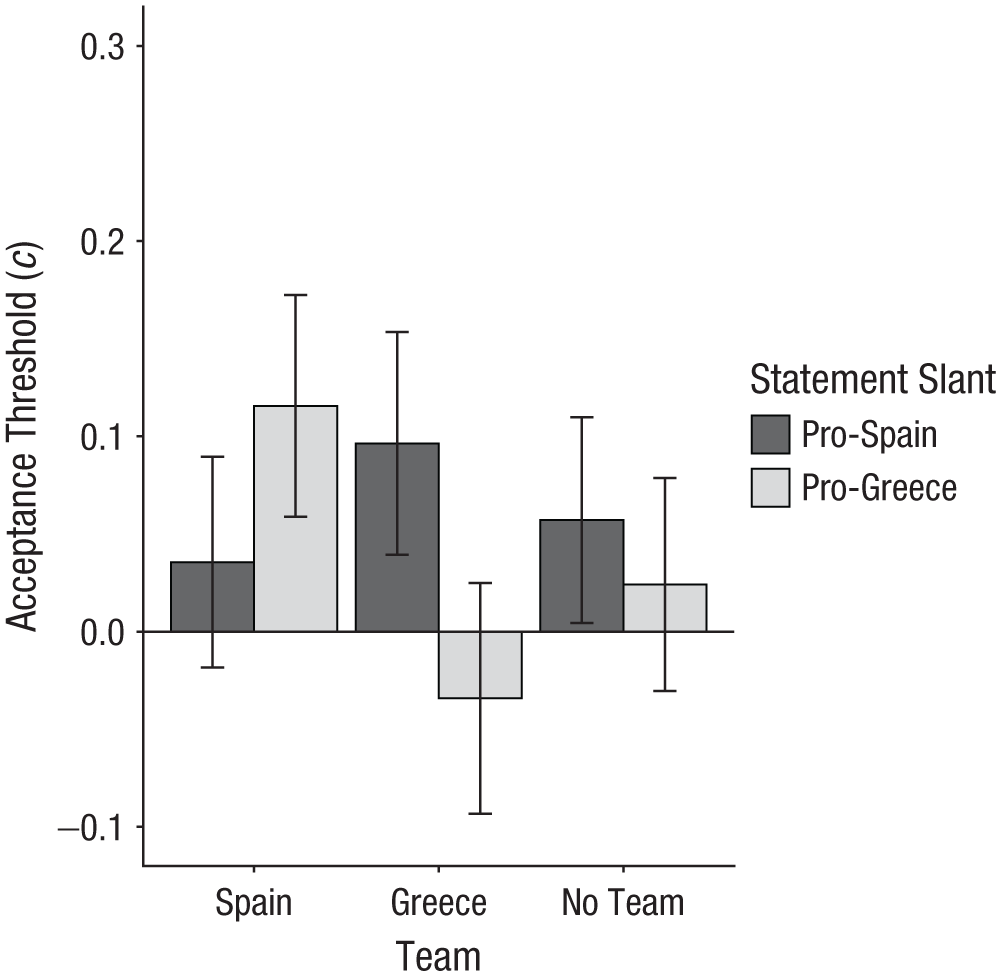
Acceptance threshold as a function of group assignment and statement slant in Experiment 2. Acceptance threshold scores (c) were calculated using signal-detection theory. Lower scores reflect a stronger tendency to accept information. Error bars represent 95% confidence intervals.
Nonpreregistered follow-up t tests comparing acceptance thresholds in the control versus experimental conditions separately by statement type (pro-Spain vs. pro-Greece) revealed a significant difference between the Team Spain and the no-team conditions for pro-Greece statements, t(562) = 2.29, p = .023, d = 0.19, 95% CI = [0.03, 0.36]. All other comparisons for pro-Spain statements, all ts < 1.00, all ps > .31, and pro-Greece statements, t(563) = −1.43, p = .154, were not significant. We also conducted nonpreregistered follow-up t tests to compare partisan bias in the Team Spain and Team Greece conditions, respectively, to the no-team condition. To do so, we calculated partisan-bias scores by subtracting acceptance thresholds for pro-Greece statements from acceptance thresholds for pro-Spain statements (
Truth sensitivity
As in Experiment 1, we predicted that truth-sensitivity scores would be unaffected by the group-assignment manipulation. To test this hypothesis, we conducted a preregistered 3 (Group Assignment: Team Spain vs. Team Greece vs. No Team) × 2 (Statement Slant: pro-Spain vs. pro-Greece) mixed ANOVA with the first factor varying between subjects and the second factor varying within subjects. Results supported all preregistered hypotheses, in that neither the main effect of group assignment, F(2, 845) = 0.31, p = .733, η p 2 < .01, 95% CI = [.00, .01], nor the interaction between group assignment and statement slant, F(2, 845) = 1.84, p = .160, η p 2 < .01, 95% CI = [.00, .02], were statistically significant (see Fig. 4). Across conditions, truth-sensitivity scores were significantly greater than zero, t(847) = 40.41, p < .001, d = 1.39, 95% CI = [1.29, 1.48], and again comparable in size to truth-sensitivity scores found in research on political misinformation (e.g., Gawronski et al., 2023), indicating that participants did not randomly guess the truth or falsity of the presented statements.
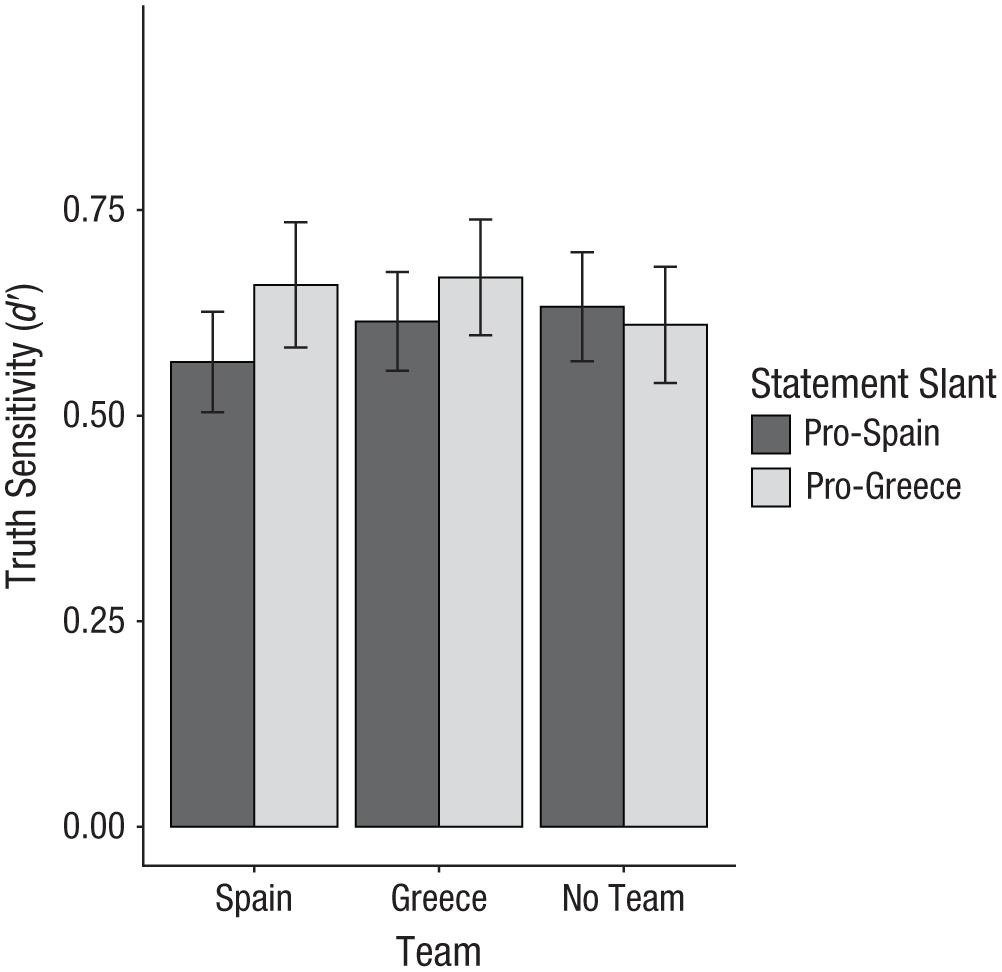
Truth sensitivity as a function of group assignment and statement slant in Experiment 2. Truth sensitivity scores (d′) were calculated using signal-detection theory. Higher scores reflect greater accuracy in discerning true from false information. Error bars represent 95% confidence intervals.
General Discussion
Across two experiments, we found that participants were more accepting of information that was congenial versus uncongenial to a randomly assigned identity. Crucially, because assignment to the groups was random, the observed partisan-bias effect could not be driven by differential knowledge of identity-congenial versus identity-uncongenial information. Hence, the current findings support the hypothesized role of identity protection as a factor underlying partisan bias in judgments of true and false information (see Van Bavel et al., 2024).
Although the use of randomly assigned groups allowed us to more cleanly rule out effects of differential knowledge, a natural next question is, how much does identity-protection contribute to partisan bias relative to knowledge-based effects? The effect sizes for partisan bias in the current experiments were relatively small (η p 2s = .03), but they plausibly represent lower bounds on the effects of identity protection, given that motivational effects of randomly assigned identities are likely much weaker compared with those of existing identities with personal significance (e.g., Democrat vs. Republican). By modeling the effects of preferences and prior expectations, Celniker and Ditto (2024) provided evidence that effects of motivated reasoning and differential knowledge are similar in size. However, future research may quantify the relative contribution of identity protection and differential knowledge in judgments of misinformation.
Another important question concerns the mechanisms underlying the obtained effects. Research on motivated reasoning often pits “hot” against “cold” processes. However, randomly assigning participants to national teams seems unlikely to evoke strong affective responses, raising questions about alternative mechanisms. Critics might argue that, in the absence of relevant knowledge, participants may have used their assigned group identity as a default heuristic to guide their judgments. However, participants in the current studies did have relevant knowledge. Effect sizes for truth sensitivity were quite large, with Cohen’s ds of 1.7 (Experiment 1) and 1.4 (Experiment 2), indicating that participants had substantial knowledge. Hence, it seems unlikely that participants were merely relying on their assigned groups as a default heuristic to compensate for a lack of relevant knowledge. Future studies are needed to investigate the mechanisms underlying identity-protection effects on judgments of true and false information.
The current work supports the role of identity-protective motivated reasoning in the acceptance of misinformation, but it is based on a conceptualization of motivated reasoning as the tendency to arrive at desired conclusions (Kunda, 1990). The findings do not speak to an alternative conceptualization of motivated reasoning as enhanced partisan bias resulting from cognitive elaboration (the motivated-system-2 hypothesis; see Kahan, 2013; Pennycook & Rand, 2021a). In terms of the latter conceptualization, the difference in acceptance thresholds for identity-congenial versus identity-uncongenial information should increase with greater cognitive elaboration (see Batailler et al., 2022). Future research may measure or manipulate cognitive elaboration to test the validity of the motivated-system-2 hypothesis (for related evidence, see Sultan et al., 2024). Furthermore, it should be noted that the generalizability of these findings is potentially limited to Prolific workers in the United States.
Overall, the current findings have important implications for addressing partisan bias in the acceptance of misinformation (Gawronski et al., 2024). Although it is often implied that acceptance of misinformation is due to the other side not “having the facts,” our results demonstrate that this is not the full story. Even if partisans have identical knowledge about the relevant facts, they may still come to opposing conclusions. Thus, although it remains important to reduce knowledge differences arising from echo chambers and selective exposure, the current research highlights the fact that an exclusive focus on knowledge-based effects will be insufficient to eliminate partisan bias. Instead, future interventions aimed at reducing partisan bias must be designed to also target people’s underlying motivations (Hornsey & Fielding, 2017).
Conclusion
The current experiments provide a novel test addressing the debate between identity-protection and differential-knowledge accounts of partisan bias in judgments of misinformation. By utilizing randomly assigned identities, as opposed to groups with pre-existing differences in prior knowledge, we showed that partisan bias occurs even in the absence of differential knowledge. These findings demonstrate that misinformation susceptibility is not merely due to differences in knowledge, but also to underlying motivations. Thus, to prevent the acceptance of misinformation, interventions must be designed to consider the motivations underlying partisan bias in judgments of true and false information.
Supplemental Material
sj-docx-1-pss-10.1177_09567976251404040 – Supplemental material for Understanding Partisan Bias in Judgments of Misinformation: Identity Protection Versus Differential Knowledge
Supplemental material, sj-docx-1-pss-10.1177_09567976251404040 for Understanding Partisan Bias in Judgments of Misinformation: Identity Protection Versus Differential Knowledge by Tyler J. Hubeny, Lea S. Nahon and Bertram Gawronski in Psychological Science
Footnotes
Transparency
Action Editor: Yoel Inbar
Editor: Simine Vazire
Author Contributions
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.