
Abstract
To navigate complex physical environments, animals keep track of the spatial relations among objects using various reference frames, both body-based (e.g., left/right) and environment-based (e.g., east/west), but how these spatial representations interact remains unresolved. Whereas neuroscientific findings show habitual integration across reference frames, psycholinguistic accounts suggest humans use one reference frame at a time, as in speech. This article examines whether people spontaneously use two reference frames in the same action. When placing a single object in a two-dimensional array, adult participants (N = 110) routinely used an environment-based frame to determine the object’s left–right position while using a body-based frame to determine its front–back position at the same time. Such hybrid responses were prevalent among both Indigenous Tsimane’ and educated U.S. participants, suggesting that people across cultures habitually construct compound cognitive maps to represent the multidimensional spatial relations that compose natural settings.
Spatial cognition is central to human behavior (Descartes, 1983; James, 1890): It allows us to navigate across vast forests, mountain ranges, and oceans (Davis & Cashdan, 2019; Fernandez-Velasco & Spiers, 2024); perform complex bodily actions from crochet to karate; distinguish tiny differences in size and shape (Yau et al., 2016); and remember the spatial structure of our surroundings in exquisite detail, even without vision (Teng et al., 2012; Tversky, 2019). Performing such behaviors requires representing an enormous variety of spatial relations, which people do using various spatial reference frames. Whereas egocentric frames are defined by one’s own body (e.g., my left and right), allocentric frames are defined by the features of the surrounding environment (e.g., east–west; uphill–downhill).
The reference frame people prefer (at a given scale) varies dramatically across cultures, contexts, and age groups, as revealed by simple behavioral tasks (e.g., Acredolo, 1978; Haun et al., 2006; Levinson, 1996; Pederson et al., 1998; Shusterman & Li, 2016; Wassmann & Dasen, 1998). For example, when asked to reconstruct a tabletop array of objects in a new location from memory, some people preserve the egocentric spatial relations of the original array (e.g., maintaining objects’ left–right positions), whereas others violate them to preserve the allocentric relations (e.g., window side–door side; Pederson et al., 1998). In other tasks, this distinction between egocentric and allocentric space also determines the way people describe simple scenes (Levinson, 1996; Majid et al., 2004), learn new dance routines (Haun & Rapold, 2009; Pitt et al., 2023), remember the location of hidden objects (Haun et al., 2006), track pathways through a maze (Brown & Levinson, 1993), and gesture about spatial events (Kita et al., 2001; Marghetis et al., 2020).
Despite their preferences, however, people show remarkable flexibility in adopting alternative reference frames, even when these frames are atypical or culturally dispreferred. For example, although children often show preferences for allocentric frames (Shusterman & Li, 2016), they can quickly learn to search for hidden targets using an egocentric rule, even before they have mastered egocentric spatial words such as “left” and “right” (Li & Abarbanell, 2019; as can bonobos and rats: Rosati, 2015; White & McDonald, 2002). Infants and adults across cultures show similar flexibility in spatial memory, alternating between egocentric and allocentric frames depending on the salience of spatial cues in context (Acredolo, 1978, 1979; Li & Abarbanell, 2018; Li & Gleitman, 2002; Li et al., 2011; Pitt et al., 2022, 2023).
Although it is clear that people maintain multiple reference frames for encoding spatial relations, it remains unclear whether and how these “multiple spatial maps” interact with each other in real time in the minds of individual people (Burgess, 2006; Colby, 1998). On some accounts, different reference frames represent “competing conceptual coding systems” (Brown & Levinson, 1993) with “incommensurable” coordinate systems (Levinson, 2003; see also Shusterman & Spelke, 2005), leading each language group to converge on a single predominant reference frame (Bohnemeyer & Levinson, 2011; Haun & Rapold, 2009; Haun et al., 2006, 2011; Levinson, 1996; Levinson et al., 2002; Majid et al., 2004; Pederson et al., 1998; Wassmann & Dasen, 1998). Competition among reference frames is most apparent in language, in which speakers must select one word at a time—and therefore one reference frame at a time—to describe a given spatial relation (e.g., “The fork is right/north of the plate”; Carlson, 1999). As a consequence, people “may have no choice but to fixate predominantly on just one frame of reference” (Levinson, 1996, p. 12) at a time.
However, findings in neuroscience show that many animals do much more than simply alternate between mental maps but rather integrate across them to guide behavior (Behrmann & Tipper, 1999; Bottini & Doeller, 2020; Burgess, 2006; Draschkow et al., 2022; Fiehler et al., 2014; Shelton & McNamara, 2001). Rats, bats, primates, and other animals represent a variety of egocentric and allocentric spatial relations, including their position and heading in the environment, the locations of local and distal landmarks, the orientation of their head and eyes, and the shape of their desired path (Andersen & Buneo, 2002; O’Keefe & Nadel, 1978; Wang et al., 2020). One study, for example, recorded the brain activity of rats as they ran through a variety of zig-zag paths and found that the same population of neurons coded spatial information across three reference frames, including the location of the path in the larger space, the animal’s position on the path, and the direction of the turns (i.e., left or right; Alexander & Nitz, 2015). This integration across disparate reference frames is thought to be powered by dedicated neural machinery (perhaps in the retrosplenial cortex; Alexander & Nitz, 2015; Andrej & Burgess, 2018; B. J. Clark et al., 2018) and, on some accounts, is not optional: Given that sensorimotor experience is inherently egocentric (Kant, 1992), planning and performing coherent actions in the environment may require integrating egocentric and allocentric representations from early in life (Colby, 1998; Gofman et al., 2019; LaChance et al., 2019; Lu et al., 2022; Nitz, 2009).
Does human memory for object location behave like language, privileging one reference frame over others at a given moment, or like animal navigation, with habitual integration across cognitive maps (Tolman, 1948)? This article addressed this question in U.S. university students and in the Tsimane’, members of a small-scale Indigenous culture in Bolivia. Living in small villages in the Amazon basin, the Tsimane’ rely primarily on hunting, gathering, fishing, and farming for subsistence (see Fig. 1; Gurven et al., 2017; Huanca, 1999). Many Tsimane’ adults have little or no formal schooling and do not read, write, or use math (Piantadosi et al., 2014) but are skilled in craftsmanship, ethnobotanical remedies, and spatial navigation (Reyes-García et al., 2016; Schniter et al., 2015). Starting in childhood, they traverse large swaths of the forest on foot and canoe and can use dead reckoning to locate distant villages (Davis & Cashdan, 2019; Pitt et al., 2022; Trumble et al., 2016).

The Tsimane’ context. An indigenous group of farmer–foragers, the Tsimane’ live in thatch-roof huts along the Maniqui River in the Amazon basin of Bolivia.
Unlike many industrialized groups, the Tsimane’ do not show a strong preference for one reference frame over another in either spatial language or memory (Pitt et al., 2022). Rather, in a recent study, they used different reference frames in different trials, depending on which spatial axis was relevant. Specifically, they preferred allocentric frames when asked to reconstruct lateral (i.e., left–right) arrays of objects but preferred egocentric frames to reconstruct sagittal (i.e., front-back) arrays (Pitt et al., 2022). This cross-axis pattern may reflect the unique difficulty of left–right spatial distinctions: People habitually conflate shapes with their left–right mirror image (e.g., b vs. d), and this mirror invariance is especially pronounced among illiterate populations (Brown & Levinson, 1993; Kolinsky et al., 2011; Li & Abarbanell, 2019; Marghetis et al., 2020; Pederson, 1993; Pitt et al., 2022, 2023; Shapero, 2017; Shusterman & Li, 2016). Whatever its causes, the observed dissociation in spatial memory within individual Tsimane’ adults affords an opportunity to test whether people spontaneously combine reference frames in the same action, using different frames on different spatial axes simultaneously to compose compound cognitive maps (see Fig. 2). In principle, such mixing of egocentric and allocentric frames—if it occurs at all—could be found only among people who habitually use both frames, such as Tsimane’ adults. In this way, the comparison group of U.S. adults can address whether any effects in the Tsimane’ generalize to dramatically different cultures, even those with a dominant frame (i.e., egocentric; Majid et al., 2004).
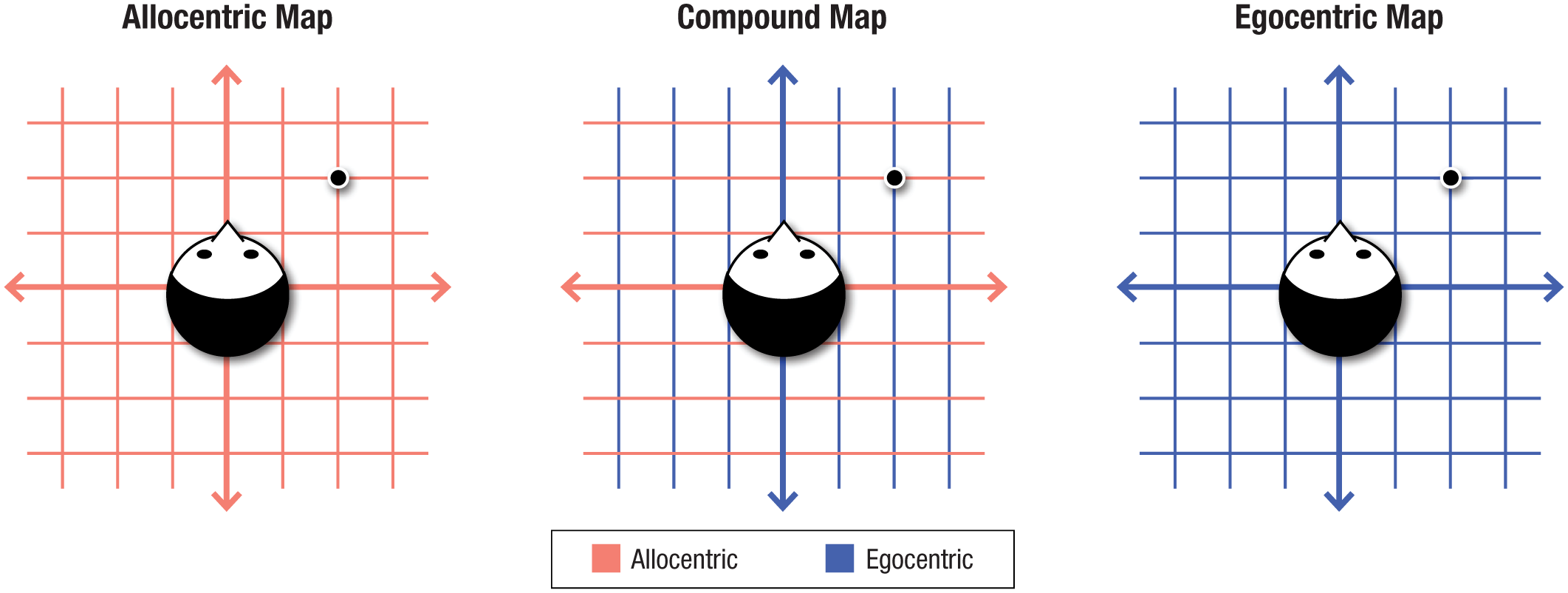
Three hypothetical maps of object location: purely egocentric, purely allocentric, and compound.
Participants performed a novel two-dimensional test of their spatial memory called the 4Quads task (see Fig. 3). In each trial, participants retrieved an object from one of 16 critical cups (arranged in four groups of four), turned around 180° to face an identical array of cups, and were asked to place the object in the corresponding cup. As with other tests of spatial memory (e.g., Brown & Levinson, 1993; Haun et al., 2006; Shusterman & Li, 2016), participants’ actions after rotation revealed whether they used an egocentric or allocentric reference frame to remember the target location. Critically, whereas previous tasks have typically presented participants with a single row of objects, the two-dimensional configuration used here required that participants respond on both the lateral and sagittal axis at once.
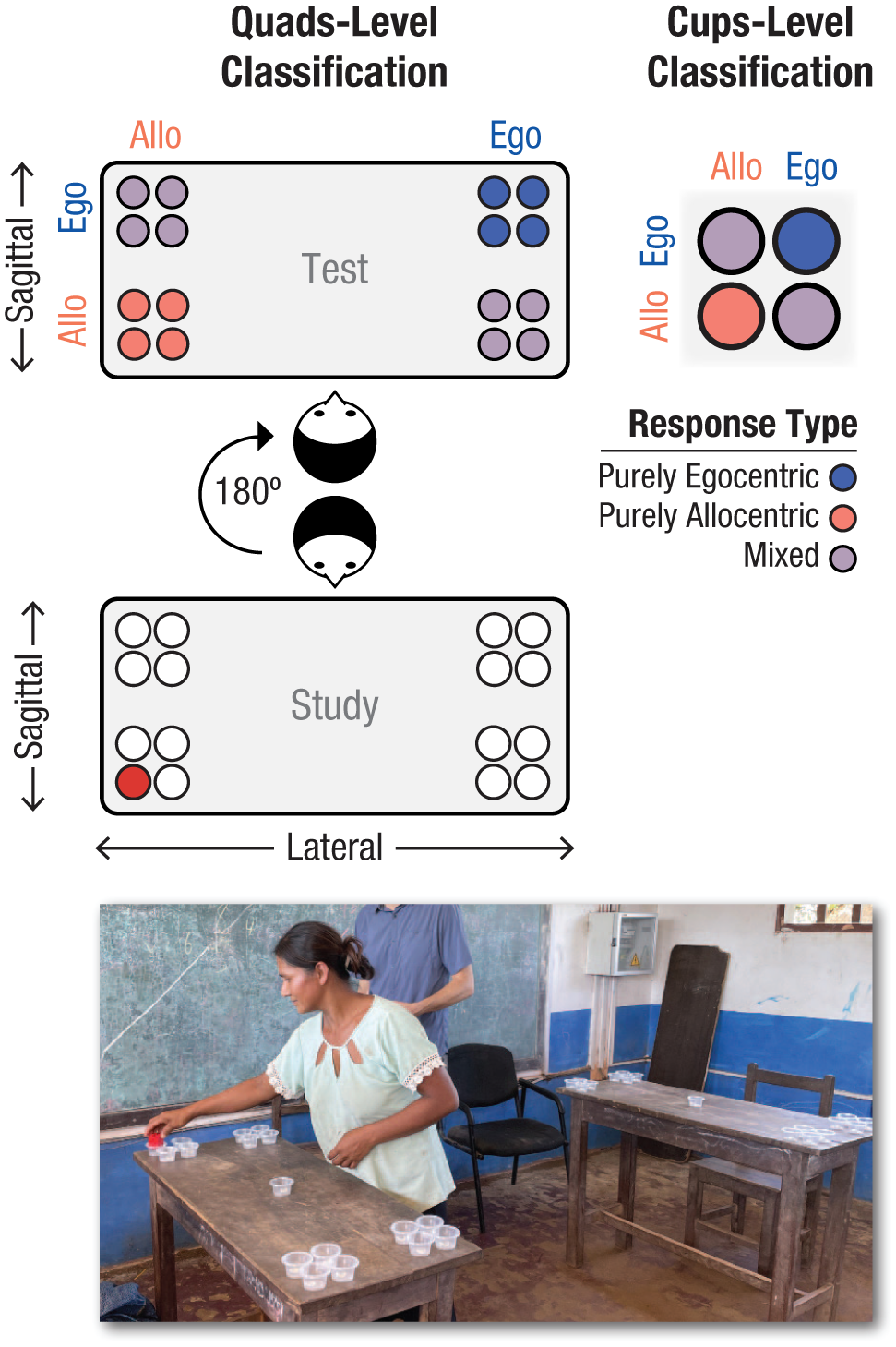
The 4Quads task. Participants viewed an object in one of 16 cups at the study table and were asked to place it in the same cup on the test table after turning 180°. The reference frame of each response was classified on each axis (i.e., lateral and sagittal) at the level of the four quads (top left) and at the level of the individual cup within a quad (top right). Colors show response types for an example trial. The bottom photograph shows a Tsimane’ woman performing the task.
This design has two primary benefits. First, it better reflects the memory demands presented by the natural environment, in which neat rows of objects are rare. In everyday experience, people keep track of complex, hierarchical spatial relations across multiple dimensions at once (e.g., as they navigate a horizontal landscape) such as those in the 4Quads task. Second, this design permits testing whether people habitually use multiple reference frames to represent the location of an individual object, arguably the smallest unit of spatial memory. If they do, then participants should not only switch from one reference frame to another—they should also mix maps together, making individual responses that are allocentric on the lateral axis and egocentric on the sagittal axis for the same object: one action, two reference frames (see Fig. 2).
Any such cross-axis effect should be clearest among the Tsimane’, who preferred different reference frames on these two axes when each axis was tested separately (Pitt et al., 2022). U.S. Americans provide a stricter test case of map-mixing, which permits evaluating whether people combine reference frames across disparate cultures, including cultures in which one frame predominates. Alternatively, integrating multiple reference frames into the same action could be cognitively taxing for any group, potentially creating conflict with any culturally preferred reference frame (Levinson, 1996). In this case, participants in each culture should use a single reference frame to guide individual actions on one object, even if their preferences vary across trials, individuals, or groups.
Research Transparency Statement
General disclosures
Study disclosures
Method
Participants
Forty-two Tsimane’ adults (mean age = 40 years, range = 22–89 years) participated in exchange for household goods. Two other participants were excluded from the analysis, one because of visual impairment and another because of excessive inattention. No other data were excluded because every participant completed every trial and every trial yielded a codable response (i.e., there were no incorrect responses). The research team in Bolivia included U.S. Americans, Bolivian academics, and native Tsimane’ experimenters. Villages were selected according to their accessibility from San Borja in consultation with Centro Boliviano de Investigación y Desarrollo Socio Integral, a nongovernmental organization based in Bolivia that specializes in the study of Tsimane’ health and behavior and that also consulted on task design and implementation. Tsimane’ participants consisted of volunteers presenting themselves at the village schoolhouse. A Tsimane’ researcher explained aloud to potential volunteers the purpose, risks, benefits, duration, and voluntary nature of the study, as well as the request to store and use images and anonymized behavioral data. Because many Tsimane’ adults do not read or write, all consent procedures and instructions were conducted orally in Tsimane’, and consent was documented by the research team.
Sixty-eight U.S. adults (mean age = 21.5 years, range = 19–28 years) participated in exchange for university course credit in the Department of Psychology at the University of California, Berkeley. The target range for the samples sizes was established a priori on the basis of previous findings (Pitt et al., 2022), and the final samples were determined by the duration of the fieldwork in Bolivia (for Tsimane’ participants) and the duration of the academic term at the University of California, Berkeley (for U.S. participants).
All protocols (in both groups) were approved by the Institutional Review Board at the University of California, Berkeley, and Tsimane’ protocols were also approved by Gran Consejo Tsimane’ (Tsimane’ Grand Council), which oversees research in Tsimane’ communities.
Apparatus and procedure
In the 4Quads task, participants stood facing the study table, where they saw an array of 17 identical plastic cups: four sets of four cups (i.e., four quads) in each corner of the table plus one cup in the center (see Fig. 3). The task includes four quads, rather than just four cups, because this design (a) provides 16 unique critical trials, (b) discourages linguistic coding of the stimuli (e.g., “far right”), (c) makes distance information relevant not just on the sagittal axis (i.e., near vs. far cups) but also on the lateral axis (creating near-right, far-right, near-left, and far-left cups), and (d) better reflects the hierarchical structure of spatial relations in the natural environment. Participants were told the task was designed to test their spatial memory.
In each trial, the experimenter placed an object into the target cup on the study table and asked the participant to pick up the object from that cup, turn around 180° to face the test table, which had an identical array of cups, and place it in the “same” cup on the test table. This phrasing was intentionally ambiguous in both languages with respect to the reference frame: The position could be the same egocentrically or allocentrically. Experimenters with native-language abilities gave instructions in English to U.S. participants and in Tsimane’ to Tsimane’ participants and demonstrated the mechanics of the task once using the central cup (i.e., without choosing a side or reference frame). Throughout testing, experimenters carefully avoided providing any verbal or gestural suggestions about which reference frame to use (e.g., referring to “this” and “that” side, not the “left” and “right” side; for verbatim instructions, see the Supplemental Material).
To get accustomed to the task, participants first performed a practice trial using the center cup as the target cup, in which the response was the same using either an egocentric or allocentric frame. After successfully completing this practice trial, participants performed 16 critical trials (i.e., one in each of the 16 critical cups) in one of two predetermined orders, one the reverse of the other; participants completed all four cups in each quad before switching to another quad. To maintain a shared perspective, the experimenter stood beside or behind the participant, facing the same direction during both the study and the test, rotating in place as the participant turned from the study table to the test table. Tsimane’ participants were tested in their local schoolhouses, with limited visibility of external landmarks; U.S. participants were tested in a testing room at the University of California, Berkeley. Participants’ geocentric headings were varied across testing sessions (even within the same testing room across subjects) to counterbalance any incidental alignment of salient landmarks (e.g., walls, windows, furniture) with the spatial axes of interest.
Analyses
By design, each response in the 4Quads task preserved the target object’s egocentric or allocentric position on each axis at each of the two levels. At the quads level, participants’ responses were classified according to the position of the chosen quad on the table, regardless of the position of the chosen cup in the quad (see “quads-level classification” in Fig. 3). At this level, one quad preserved the egocentric position on both axes; another quad preserved the allocentric position on both axes; and the other two quads were mixed, preserving the egocentric position on the lateral axis and allocentric position on the sagittal axis (i.e., EgoLat + AlloSag) or vice versa (i.e., AlloLat + EgoSag). At the cups level, the same responses were classified according to the position of the chosen cup in its quad, regardless of the position of the quad on the table (see “cups-level classification” in Fig. 3). At this level, within a given quad, one cup preserved the egocentric position on both axes; another cup preserved the allocentric position on both axes; and the two other cups were mixed, preserving the egocentric position on one axis and the allocentric position on the other axis, as on the quads level. Therefore, in this hierarchical and multidimensional design, each action (i.e., selection of a cup) yielded four data points (i.e., 2 axes × 2 levels), which were pooled for analysis.
All statistical tests used the lme4 package (Bates et al., 2015) in R (Version 4.1; R Core Team, 2023) to run generalized mixed-effects logistic regression models of responses with sum-coded contrasts and the bobyqa optimizer. To test the use of reference frames across axes for each group, reference frame was predicted by axis with random subject slopes and intercepts and random intercepts for trial:level, where “level” is cups or quads—model structure: reference frame ~ axis + (1 + axis|id) + (1 | trial:level). An analogous model was used to compare effects across groups—i.e., reference frame ~ group × axis + (1 + axis|id) + (1 | trial:level). Axis-specific effects were computed using the emmeans package. To compare rates of mixed response types (i.e., EgoLat + AlloSag vs. AlloLat + EgoSag; see purple quadrants of Fig. 5) to chance, a generalized mixed-effects logistic regression with random intercepts was used for subjects and trial:level—i.e., response type ~ 1 + (1 + axis|id) + (1 | trial:level). All models can be run using the publicly available data and analysis scripts (https://osf.io/67ckx).
Results
Different reference frames in the same person
Patterns of spatial memory were first compared across axes and groups. Tsimane’ participants showed no preference for one reference frame over the other overall (48% egocentric): b = –0.12, 95% confidence
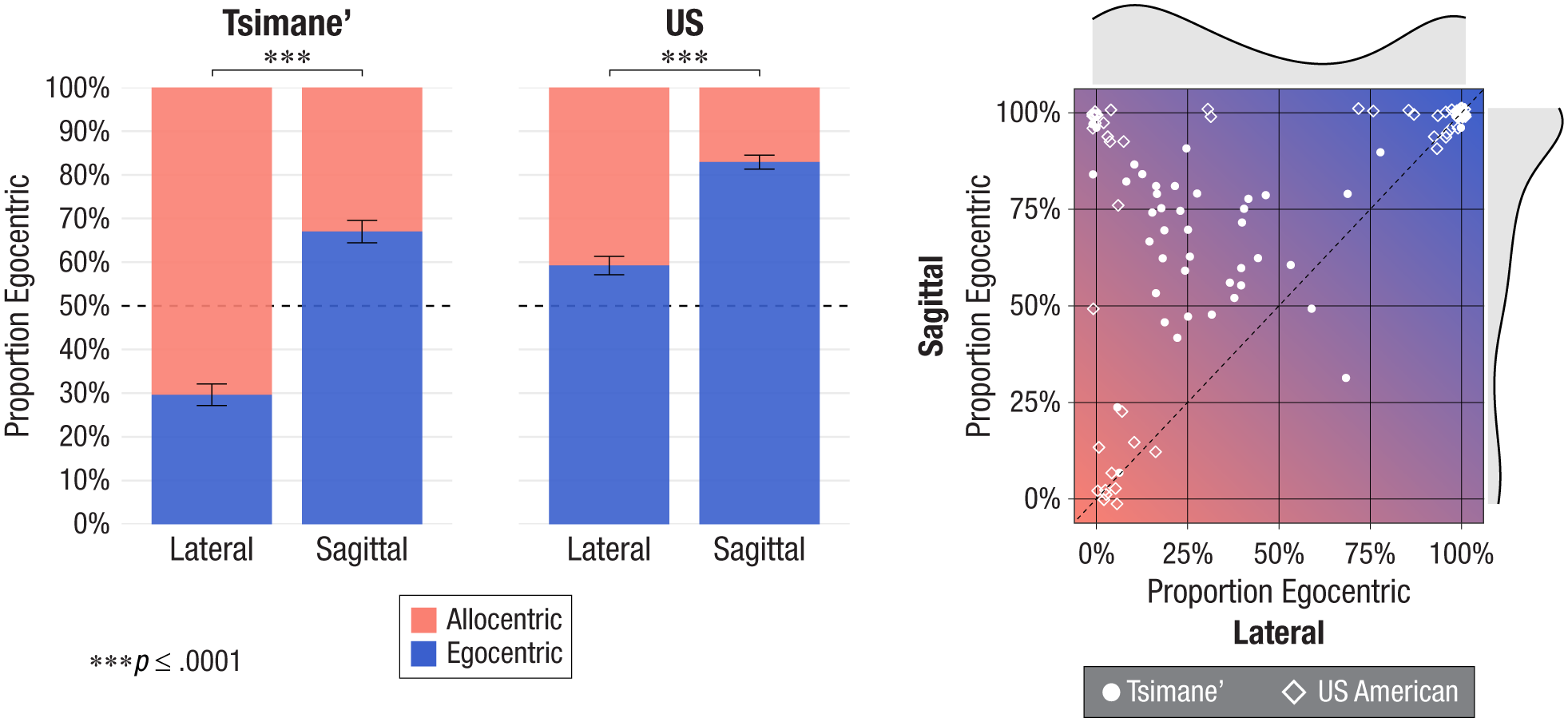
Group-level and individual-level patterns of spatial memory on each axis. The bar plots (left) show the rates of egocentric and allocentric responding on each axis in each group. The dashed line shows chance, and the error bars show binomial 95% confidence intervals. The scatter plot (right) shows participants’ patterns of responding on each axis (position jittered). Bluer regions index more egocentric responding, warmer-colored regions index more allocentric responding, and purple regions index mixed responding. Points above the diagonal line represent participants who responded more egocentrically on the sagittal than lateral axis. Gray curves show marginal density distributions.
By contrast, U.S. participants generally preferred egocentric reference frames more than chance (71%),
Interestingly, responses varied more across trials among Tsimane’ participants than among U.S. participants. As shown in Figure 4 (right), U.S. participants (diamonds) tended toward the extremes of the scales, indicating that responses were highly consistent across trials, even as they varied across participants and axes. For example, points in the top left (0, 100) reflect participants whose responses were always allocentric on the lateral axis and egocentric on the sagittal axis. By contrast, many Tsimane’ participants occupy intermediate regions of the plot, reflecting within-subjects variability in the reference frame individuals preferred on a given axis. This inconsistency could reflect the absence of a dominant reference frame among Tsimane’ participants (Bohnemeyer, 2011; Pitt et al., 2022) or lapses in their attention or memory, a potential source of noise. Nevertheless, the predicted cross-axis pattern was found across all trials in both groups (see the Supplemental Material).
In summary, although U.S. participants were overall more egocentric than Tsimane’ participants, both groups were more egocentric on the sagittal than lateral axis. This effect of axis was not significantly different across groups,
Different reference frames in the same action
Importantly, here participants chose both the lateral and sagittal position at once, which allowed spatial memory to be compared not just in each group and participant but also in each response (i.e., placement of the object in a cup). There were four types of responses, examples of which are depicted in Figure 3. Tsimane’ participants made roughly equal numbers of purely egocentric responses (19%) and purely allocentric responses (22%)—responses in which they used the same reference frame on the lateral and sagittal axes. Critically, however, most of their responses (59%) were mixed, reflecting different reference frames on different axes at once, as shown in Figure 5 (left). Specifically, the most common response in this group—accounting for nearly half (48%) of all responses—was allocentric on the lateral axis and egocentric on the sagittal axis (see Fig. 2, center). For example, for this pattern, participants who retrieved the object from their far-left cup at the study table would place it in their far-right cup at the test table (see Fig. 3). The opposite pattern was the least common: Only 11% of Tsimane’ responses maintained the egocentric position on the lateral axis and allocentric position on the sagittal axis. These two types of mixed responses occurred at significantly different rates, b = –1.84, 95% CI = [−2.35, −1.33],
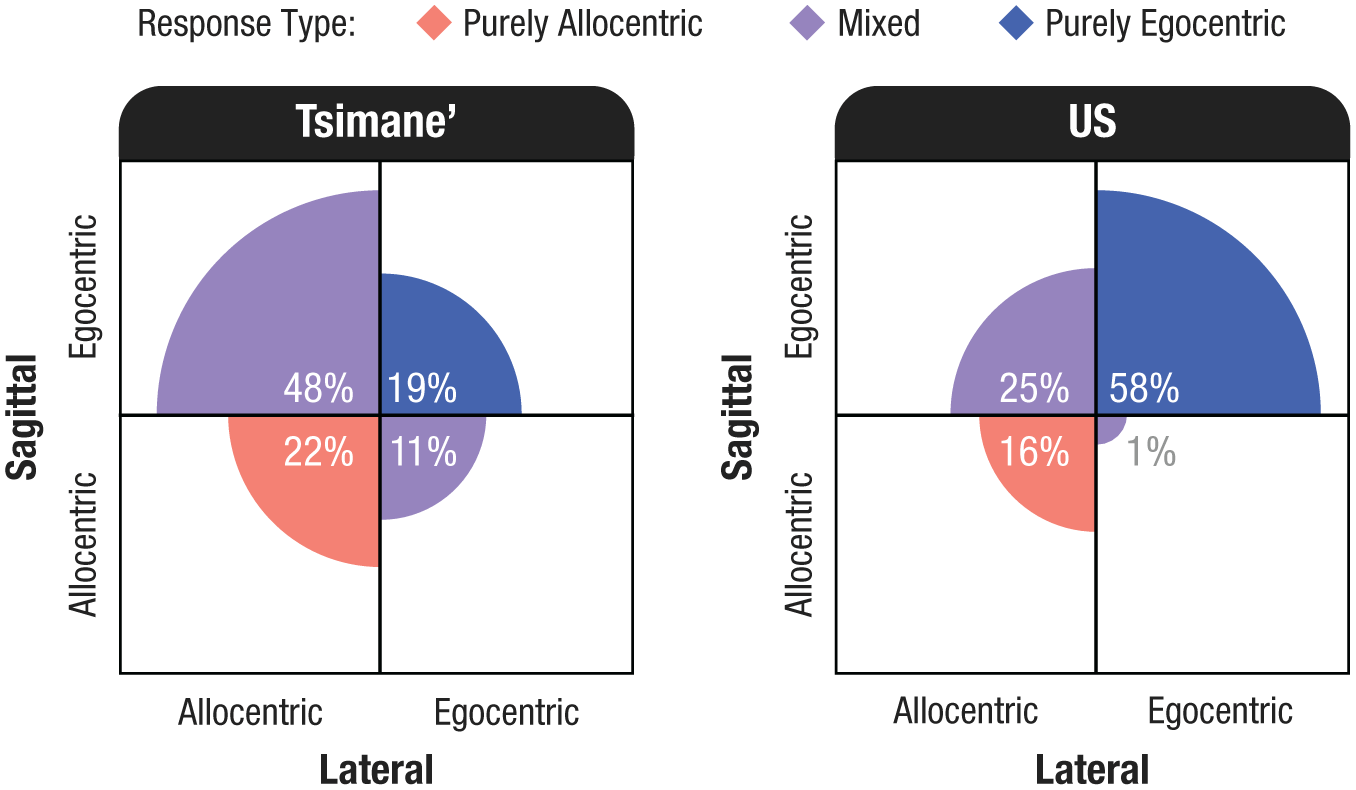
Multidimensional response types. The area of the colored sections is proportional to the number of responses of that type in each group.
U.S. adults also gave many mixed responses, as shown in Figure 5 (right). Although the most common response in this group was purely egocentric (58%), the second most common—accounting for one of every four responses—was the same response that predominated among Tsimane’: egocentric on the sagittal axis and allocentric on the lateral axis. The opposite pattern was again the least frequent (1%), significantly less frequent than the other mixed response type, b = –8.63, 95% CI = [−13.84, −3.42],
Discussion
Studies of spatial cognition have often asked which reference frame is used in a given context, leading scholars to classify individuals, age groups, cultures, and even species as primarily egocentric or allocentric. These classifications have largely been based on tests of linear (i.e., lateral) spatial arrays, but real spatial scenes rarely vary on only one axis at a time. Rather, in more naturalistic settings—such as navigating through a forest, planting a seed, or finding one’s keys—people must remember multidimensional (and often hierarchical) spatial relations among many objects (Uttal et al., 2006). Previous findings have shown that individuals switch rapidly between reference frames depending on which spatial axis is most relevant, challenging the idea that individuals in a given physical context can be classified as egocentric or allocentric (e.g., Li & Abarbanell, 2019; Marghetis et al., 2020; Pitt et al., 2022). Using a multidimensional test of spatial memory, the present study shows that even individual actions are likewise unclassifiable. When placing a single object in a two-dimensional tabletop array, participants regularly mixed reference frames, using egocentric coordinates to determine the object’s sagittal position while simultaneously using allocentric coordinates to determine its lateral position. These hybrid responses were prevalent among both Indigenous Tsimane’ and educated U.S. adults, suggesting that when encoding the complex spatial relations of naturalistic scenes, people across cultures are not limited to one spatial reference frame at a time, even for the same object. Rather, they may habitually draw on multiple reference frames at once, constructing compound cognitive maps of object location (see Fig. 2).
This pattern is especially noteworthy among U.S. adults, whose language and culture emphasize egocentric space, for example, in practices such as reading and writing, driving and biking, using faucets, and setting the dinner table. Given the prevalence of these egocentric cultural practices, we might expect U.S. adults to be overwhelmingly egocentric in their spatial memory, especially in the specific testing conditions used in this study (i.e., an unfamiliar testing room without windows), which lacked salient geocentric cues (Li & Gleitman, 2002). Yet these participants used allocentric frames in nearly a third of their responses, often combining them with egocentric frames in the same way as Tsimane’ adults. In this way, these results show that although egocentric cultural practices may increase the use of egocentric reference frames overall, they do not eliminate allocentric responding, even at small spatial scales, or prevent people from preferentially blending egocentric and allocentric reference frames together.
These results inform theoretical accounts of spatial cognition and its variation. If spatial memory were shaped primarily by spatial language, as some scholars have long argued, then participants should have been limited to one reference frame at a time, as they are in speech and writing, largely preferring the reference frame that predominates in their language (e.g., allocentric among Tsimane’ and egocentric among U.S. participants; Brown & Levinson, 1993; Levinson et al., 2002; Majid et al., 2004). Even without strong influences of language, egocentric and allocentric reference frames could be difficult to integrate or perhaps even “incommensurable” (Levinson, 2003). In that case, participants would have been forced to choose one reference frame in which to encode each individual action (i.e., purely egocentric or purely allocentric on both axes), even if their preferences differed across trials, individuals, or groups. Alternatively, participants could have performed the spatial memory task by simply performing the same motor movements twice, once when retrieving the target object from the study table and again when placing it on the test table after turning around. This process of blind repetition would have resulted in purely egocentric responses, consistent with the accounts of Kant (Kant, 1991), Piaget (Piaget & Inhelder, 1956), and other prominent scholars (Jammer, 1954; Miller & Johnson-Laird, 1976; Poincaré, 1913) who have argued that egocentric space is primary. The results showed none of these patterns. Instead, participants mixed multiple coordinate systems in the same action, consistent with neuroscientific findings showing that animals routinely integrate information from distinct reference frames to navigate complex environments (Burgess, 2006; Fiehler et al., 2014; Shelton & McNamara, 2001; Wang et al., 2020). In this way, these findings suggest a potential continuity in memory systems across species, cultures, and spatial scales in which the cognitive processes animals use to represent landmarks during large-scale spatial navigation may extend to human memory for object location in peripersonal space (Chan et al., 2012; Manns & Eichenbaum, 2009).
Why do people mix reference frames, when using one would do? The specific response pattern observed here suggests one potential answer. The overwhelming majority of hybrid responses followed a canonical pattern, preserving an allocentric position on the lateral axis and egocentric position on the sagittal axis; the opposite combination was rare. This pattern has been observed in previous cross-axis comparisons (Brown & Levinson, 1993; Li & Abarbanell, 2019; Marghetis et al., 2020; Pederson, 1993; Pitt et al., 2022, 2023; Shapero, 2017; Shusterman & Li, 2016) and corresponds to a known difference in the discriminability of egocentric spatial axes: In a phenomenon sometimes called “mirror invariance,” people habitually conflate objects, characters, and geometric shapes with their left–right mirror images (e.g., b vs. d), even when viewing them simultaneously, but rarely conflate up–down mirror images (e.g., b vs. p) or other spatial transformations (Blackburne et al., 2014; Bornstein et al., 1978; Fernandes et al., 2016; Gregory et al., 2011; Pegado et al., 2011), perhaps because of inherent differences in bodily symmetry (Clark, 1973). The relative difficulty of the lateral axis can explain why people prefer different reference frames on different axes, whether tested simultaneously or sequentially (Pitt et al., 2022). On this account, people across cultures prefer egocentric space on the sagittal axis in part because front–back discriminations are relatively easy and disprefer it on the lateral axis because the egocentric distinctions on that axis (i.e., left–right) are often more challenging than the allocentric alternatives (e.g., door side–window side). The same reasoning can also help to explain differences across cultures and age groups. Mirror invariance is typically most pronounced in illiterate groups, such as young children and some Indigenous communities, who need not reliably distinguish mirror-image characters (such as b and d) or use interfaces that rely on left–right spatial distinctions, such as faucets, books, and cars (Blackburne et al., 2014; Brown & Levinson, 1992; Cox & Richardson, 1985; Danziger & Pederson, 1998; Kolinsky et al., 2011; Pederson, 2003; Pegado et al., 2014). Differences in left–right spatial discrimination may explain in part why adults with extensive schooling tend to be more egocentric than unschooled adults and preschoolers, at least when tested on the lateral axis: Without sufficient cultural training in left–right discrimination, people often abandon that egocentric continuum in favor of more discriminable, allocentric spatial continua to structure their spatial memory (Brown & Levinson, 1993; Li & Abarbanell, 2019; Pitt et al., 2023). In this way, people may combine reference frames in a single action for the same reason they switch between them across contexts and differentially prefer them across groups: To mentally represent the multidimensional spatial relations that compose naturalistic environments, people combine the set of spatial continua they can best discriminate in a given context, whether those continua are defined by the body or the environment (Pitt et al., 2022).
Supplemental Material
sj-pdf-1-pss-10.1177_09567976251391172 – Supplemental material for One Action, Two Reference Frames: Compound Cognitive Maps of Object Location
Supplemental material, sj-pdf-1-pss-10.1177_09567976251391172 for One Action, Two Reference Frames: Compound Cognitive Maps of Object Location by Benjamin Pitt in Psychological Science
Footnotes
Acknowledgements
I would like to thank Manuel Roca, Robin Nate, Elías Hiza, Tomás Huanca, Esther Conde, and Saima Malik Moraleda for their help with the fieldwork; Alison Gopnik and Steven Piantadosi for their advice; and Alaina Heeren, Julian Michael Shea, Samuel Gingrich, Erica Luu, Tiffy Brailow, and Maggie Debelak for their help with the U.S. data collection.
Transparency
Action Editor: Louis J. Moses
Editor: Simine Vazire
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.