
Abstract
There is a long-standing debate in cognitive science surrounding the source of commonalities among languages of the world. Indeed, there are many potential explanations for such commonalities—accidents of history, common processes of language change, memory limitations, constraints on linguistic representations, and so on. Recent research has used psycholinguistic experiments to provide empirical evidence linking common linguistic patterns to specific features of human cognition, but these experiments tend to use English speakers, who in many cases have direct experience with the common patterns of interest. Here we highlight the importance of testing populations whose languages go against cross-linguistic trends. We investigate whether adult monolingual speakers of Kîîtharaka, which has an unusual way of ordering words, mirror the word-order preferences of English speakers. We find that they do, supporting the hypothesis that universal cognitive representations play a role in shaping word order.
Keywords
Introduction
Human languages vary dramatically, but also have certain properties in common. For example, languages tend to form complex words by adding suffixes to the ends of words—e.g., “cat-s”—rather than adding prefixes to the beginnings—e.g., “un-happy.” Languages also tend to place adjectives (e.g., “red”) closer to the nouns they modify than demonstratives (e.g., “that”).
These kinds of commonalities, called cross-linguistic generalizations, are extensively studied in the language sciences, but what explains them is a source of ongoing debate (Bybee, 2008; Chomsky, 1995; Evans & Levinson, 2009; Prince & Smolensky, 1993/2004; Rooryck et al., 2010). One possibility is that they reflect universal cognitive preferences or biases. However, commonalities between languages also reflect things such as patterns that emerged during the origins of human language (Gell-Mann & Ruhlen, 2011), accidents of history in the spread and death of languages (Dunn et al., 2011), and processes of language change that are independent of cognition (Bybee, 2008). Whether a particular cross-linguistic generalization provides evidence for a universal cognitive bias is not trivial to establish (Chomsky, 2013; Culbertson, 2023; Evans & Levinson, 2009; Ladd et al., 2014; Piantadosi & Gibson, 2014). Recent evidence has come from experiments using artificial languages (Culbertson, 2023), which show that people more readily learn, generalize, or perceive cross-linguistically common patterns (e.g., Culbertson & Adger, 2014; Fedzechkina et al., 2012; Martin & White, 2021).
For example, the cross-linguistic generalization that suffixing is more common than prefixing has been argued to reflect a universal cognitive principle: Speakers attend more to word beginnings and prefer to put lexical content there (e.g., cat), and grammatical content (e.g., -s), at the end (Hawkins & Cutler, 1988; Pycha, 2015). In line with this, artificial-language experiments suggest that people treat novel words that differ in the presence of a suffix as more similar to one another than novel words that differ in the presence of a prefix (Bruening et al., 2012; Hupp et al., 2009). For instance, given a novel word “tate,” participants judge “tatebo” as more similar to it than “botate.”
In a similar vein, the cross-linguistic trend for placing adjectives closer to nouns than demonstratives is also recapitulated in artificial-language experiments. Participants taught nouns (like “cup”) and modifiers (like “red” or “that”) assume, without explicit evidence, that adjectives are ordered closer to nouns than demonstratives (e.g., “that red cup” or “cup red that”; Culbertson & Adger, 2014; Martin et al., 2019, 2020). It has been argued that this phenomenon supports a potential universal cognitive bias favoring such orders.
Importantly, however, these and most other such experiments target a small subset of speaker populations, typically speakers of English and related languages. In addition to concerns about the lack of cultural variety in experimental work (Henrich et al., 2010), the range of linguistic variety here is not sufficient to test the relevant hypotheses effectively (Blasi et al., 2022). Experiments on suffixing test English speakers, yet English is itself a predominantly suffixing language. Finding that English speakers treat suffixed words as more similar to each other than prefixed words could simply reflect their extensive experience with a language which happens to adhere to the cross-linguistic generalization. Similarly, research on the order of noun modifiers tests speakers of English and Thai, which both conform to the relevant cross-linguistic generalization.
What is needed is evidence from populations whose experience diverges from the cross-linguistic trends in question—speakers of a prefixing language, or a language with demonstratives closer to nouns than adjectives. By definition, languages that violate cross-linguistic generalizations are relatively rare, and sometimes extremely rare, and thus accessing participant populations can be challenging. However, Majid (2023) highlighted the importance of theory-based sampling of this kind, arguing that claims of cognitive or psychological universality require experimentalists to test participants from cultures predicted to differ (or not) on the basis of existing theories. Though large-scale comparative study may be the ideal, Majid (2023, p. 200) argued that when resources are limited (e.g., when relevant populations cannot be accessed, or are very difficult to access), “a critical test of universality can come from only two cultures—if those cultures are maximally distinct for the research question at hand.” In the case of a hypothesized suffixing bias, comparing a pair of populations in this way has in fact revealed distinct preferences, not universality.
Statement of Relevance
Claims of universality are commonly made in cognitive science, and they abound when it comes to language. For example, linguists appeal to universality to explain why certain word-ordering patterns are found much more often than others across languages. Yet experimental evidence for universal representations or preferences tends to come exclusively from speakers whose languages follow cross-linguistic trends. These speakers are often from WEIRD (Western, Educated, Industrialized, Rich, Democratic) populations that are more accessible to researchers. But there is no guarantee that evidence from WEIRD populations will generalize to other populations. Indeed, there is good reason to suspect that speakers of languages that do not follow cross-linguistic trends will behave very differently from speakers of languages that do. Here, we compare two such adult populations to test a hypothesized universal cognitive bias that has been proposed to explain the distribution of word orders across languages. We find, perhaps surprisingly, that both populations behave similarly, providing strong support for this particular claim of cognitive universality.
Martin and Culbertson (2020) compared English-speaking participants to speakers of Kîîtharaka, a Bantu language spoken in Kenya. In contrast to many of the world’s languages, Kîîtharaka forms most complex words using prefixes. Whereas English speakers treat words that differed in a suffix as more similar, Kîîtharaka speakers treat words that differed in a prefix as more similar. This suggests that speakers’ preferences are driven not by a universal cognitive bias but by experience with their native language.
In the remainder of this article, we report a new study, using this same theoretically motivated sampling method to study the cognitive universal proposed to account for the order of noun modifiers. We again compare speakers of English, a language that follows the cross-linguistic generalization, with speakers of Kîîtharaka, a language that goes against it. In this case, we find evidence supporting a universal cognitive bias.
A hypothesized universal cognitive bias shaping word order
Complex noun phrases, like “those two beautiful kittens,” involve a noun combined with three types of modifiers (demonstratives, numerals, adjectives). There are 24 potential ordering patterns, but some are much more frequent than others (Cinque, 2005; Dryer, 2018; Greenberg, 1963; see Fig. 1a). An influential theory claims that noun-phrase structure across languages involves a common hierarchical representation reflecting how human beings organize meaning in the conceptual domain of entities (Rijkhoff, 2004). In this hierarchy, adjectives are most closely connected to nouns, whereas demonstratives are least closely connected (Abels & Neeleman, 2012; Cinque, 2005; see Culbertson et al., 2020, for a discussion of the origins of the hierarchy, and Adger, 2003, and Alexiadou et al., 2007, for syntactic evidence from various languages that supports it). Some ways of linearly ordering elements in a noun phrase transparently reflect this hierarchy, and others do not. For example, the two most common orders, noun–adjective–numeral–demonstrative (as in Thai), and demonstrative–numeral–adjective–noun (as in English), reflect the hierarchy perfectly—adjectives are linearly closest to nouns and demonstratives the furthest away. But there are six additional orders that involve a transparent mapping from the hierarchy to linear order—that is, they are homomorphic to the hierarchy (Fig. 1b)—which are also highly frequent. Together, over 80% of the world’s languages have one of the eight homomorphic noun-phrase word orders. A universal cognitive bias favoring homomorphism to the underlying hierarchy is thus one hypothesized explanation for the skewed distribution.
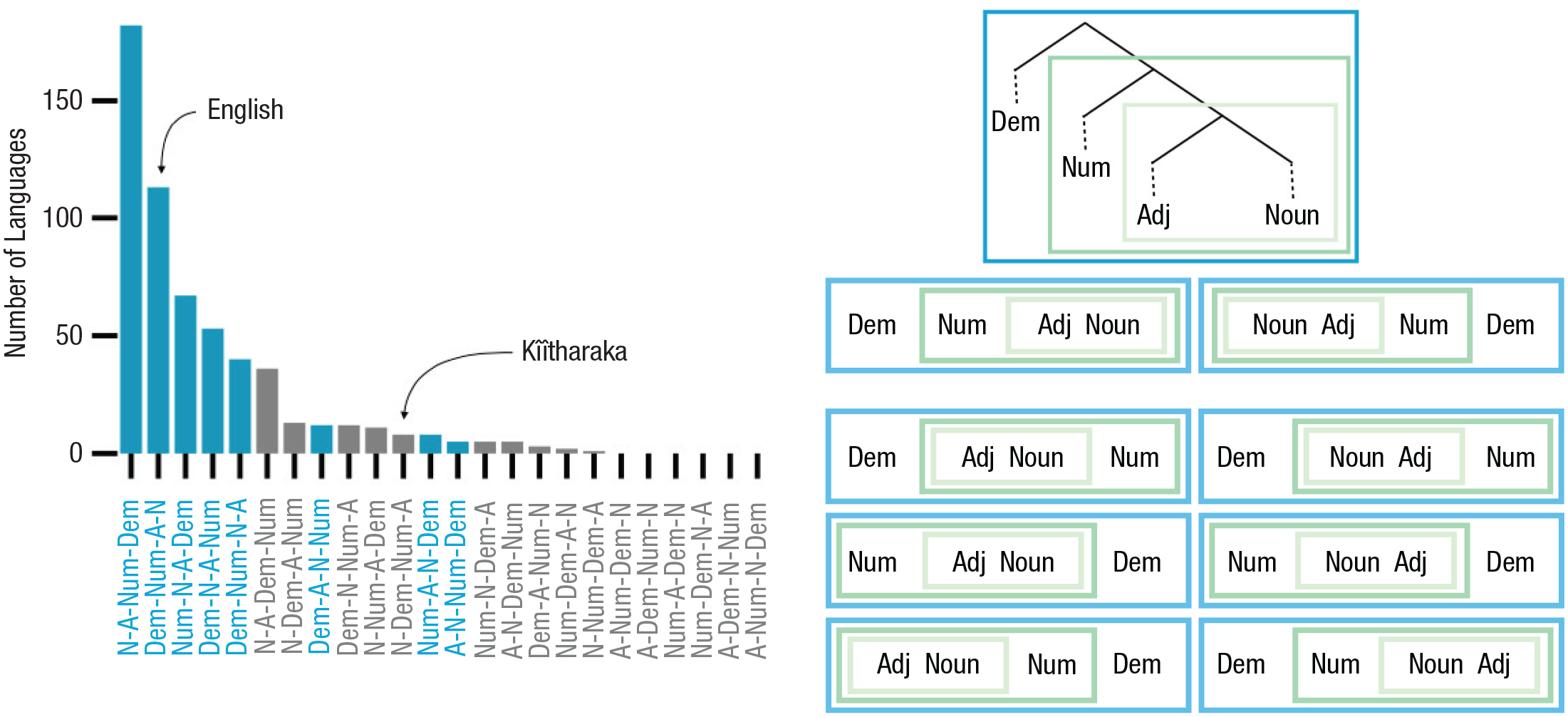
Distribution of noun-phrase word orders across languages (a); blue patterns are homomorphic; data taken from Dryer, 2018). In (b), the hypothesized underlying hierarchy is illustrated. Nouns form a unit with adjectives, this unit combines with numerals, and this larger unit combines with demonstratives. Boxes immediately underneath the tree structure show the two linear orders (the most common ones) that perfectly reflect the hierarchy; below that are the six other homomorphic orders. Dem = demonstrative; Num = numeral; A or Adj = adjective; N = noun.
Culbertson and Adger (2014) and Martin et al. (2020) found that English speakers who were taught miniature artificial languages favored orders that were linearly different from English but homomorphic, like noun-adjective-demonstrative, over nonhomomorphic orders like noun-demonstrative-adjective, which maintain the same linear order of modifiers found in English (i.e., demonstrative preceding adjective). Martin et al. (2019) replicated this for Thai speakers, who also ignored the linear order of modifiers in their native language in favor of an order that is homomorphic to the hierarchy. These results point to the primacy of hierarchical representations over surface ones: Structural distance was more important than linear order for participants in these studies (Culbertson & Adger, 2014). However, these results do not provide strong support for a universal cognitive bias favoring homomorphism; because English and Thai are themselves homomorphic, they already provide structural evidence that adjectives should be closer to nouns and demonstratives further away. Evidence for universality must come from speakers of one of the rare languages whose noun-phrase word order is not homomorphic. For these speakers, the hierarchy might look completely different: For example, demonstratives could be grouped with nouns more closely than adjectives.
Monolingual Kîîtharaka speakers
We therefore tested Kîîtharaka speakers. In addition to being predominantly prefixing, Kîîtharaka is also unusual in having the demonstrative, rather than the adjective, closest to the noun (noun–demonstrative–numeral–adjective; e.g., tûbaka tûtû twîrî tûthongi, or literally “kittens those two beautiful”). Crucially, unlike Martin and Culbertson (2020), here we test monolingual Kîîtharaka speakers living in rural Tharaka-Nithi County (see Fig. 2a) who have no experience with other languages, like English, that could influence their use (or not) of a homomorphic order. We trained these monolingual Kîîtharaka speakers on an artificial language consisting of nouns, adjectives, and demonstratives (see the Method section). Participants learned how to form simple phrases involving a single modifier that preceded the noun, unlike the structure in their own language. They heard phrases like taka iti (“red cup,” describing a neutrally positioned red cup), or himi iti (“this cup,” describing a gray cup, spatially close to the speaker; see Fig. 2b).
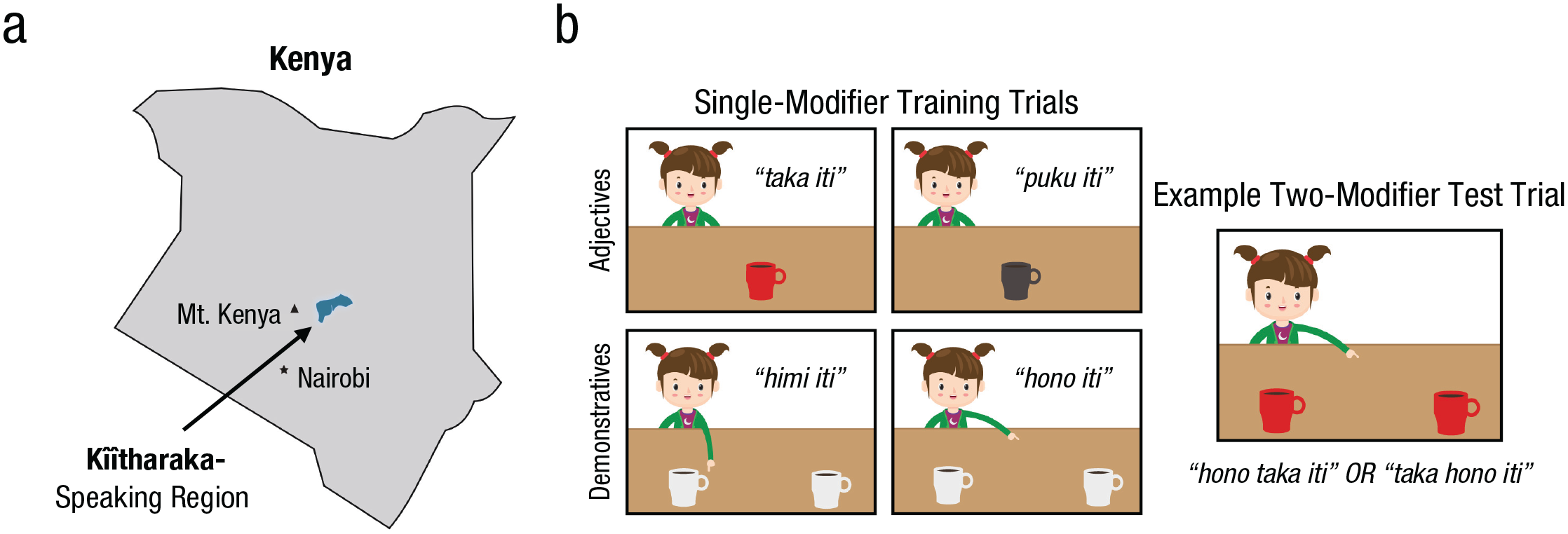
The Kîîtharaka-speaking region in Kenya (a). In (b) we illustrate single-modifier training stimuli (adjective and demonstrative) and an example two-modifier test trial (adjective and demonstrative); the target means “that red cup.”
Then we asked participants to describe new images that required using both an adjective and a demonstrative (e.g., a red cup close to the speaker, or a black cup far from the speaker; see example test trial in Fig. 2b). Because participants were given no information about how the two types of modifiers should be ordered relative to one another, they had to guess. If there is a universal cognitive bias, then Kîîtharaka speakers, like English and Thai speakers, should guess a homomorphic order, with adjectives closest to the noun and demonstratives furthest away. If there is no universal cognitive bias and if instead the structural distance between nouns and modifiers in participants’ native language determines their inferred order, then Kîîtharaka speakers should follow the structural closeness pattern in their own language and guess that the demonstrative comes closest to the noun.
There is a third possibility: that Kîîtharaka speakers will follow the linear order of modifiers in their language. This would lead them to produce demonstrative-adjective-noun—superficially a homomorphic order, but one that is potentially generated by simply following the surface modifier order of Kîîtharaka. We can confidently rule out this possibility through exactly the comparison we target—a homomorphic language like English and a nonhomomorphic language like Kîîtharaka. English speakers (and Thai speakers) have been consistently shown to ignore the linear order of modifiers in their native language in this task (Culbertson & Adger, 2014; Martin et al., 2019, 2020). In order to produce the homomorphic order they do, these speakers necessarily have to ignore linear order—they must invert the order of demonstrative-adjective-(noun) to get (noun)-adjective-demonstrative. Thus we have good reason to believe that what drives behavior in this task is not linear order, but structural order of modifiers. If the structural order English speakers used came from their native language, then we would expect Kîîtharaka speakers to produce a nonhomomorphic order. If they produce a homomorphic order, then the most parsimonious explanation is that both populations are ignoring linear order and accessing a shared universal cognitive bias for orders homomorphic to the hierarchy.
Method
Open practices statement
All stimulus materials and anonymized coded data, along with the full data cooking and analysis notebook and extended method description, can be found with supporting information on the Open Science Framework at the following link: https://osf.io/xavb7/.
Materials
The artificial language included three nouns (eyey, “feather”; uhu, “ball”; and iti, “cup”), two adjectives (taka, “red”; puku, “black”), and two demonstratives (himi, “this”; hono, “that”). Words were individually recorded by a phonetically trained speaker. The visual stimuli consisted of cartoon images depicting different objects on a table in front of a cartoon girl (see Fig. 2b).
Procedure
The procedure followed Martin et al. (2020) but was adapted for this population by spreading the training and testing over 2 days. All participant recruitment and testing was done in Kîîtharaka by a local team member. On the first day, participants were trained on the nouns as well as on combinations of a noun and a single modifier (adjective or demonstrative). Training consisted of passive exposure, picture matching (where two images appeared, a word or phrase in the language was played, and participants had to point to the corresponding image), and production (with feedback); see extended methodology for details. On the second day, participants went through the training again and then completed the critical testing block. Participants were told that they would have to describe images that they had not seen, using three words. They were shown an image depicting an object that was either red or black and was either in a proximal or distal position relative to a cartoon girl. There were 16 such trials. The noun was always “cup” (in order to ease the burden of lexical access). If participants had trouble remembering any lexical items, the experimenter could assist them with only one of them on a given trial.
Participants
Ninety-one participants were recruited from the Kîîtharaka-speaking region of Tharaka-Nithi County in Kenya between September 2019 and August 2022. In order to avoid any meaningful exposure to English, we recruited participants from rural areas who had little or no formal education. Our participants were thus older than those tested in typical artificial-language-learning experiments: The median age was 48 years, and the maximum age was 79 years. We used strict inclusion criteria in order to analyze data only from participants who were verifiably functionally monolingual. We excluded data from participants who self-reported more than minimal English knowledge or who were able to describe the two-modifier images using English words (N = 25). Data from participants who failed to produce at least 10 on-task responses (i.e., demonstrative-adjective-noun or adjective-demonstrative-noun) in the two-modifier phase (N = 32), or who were provided with more than one lexical item by the experimenter on any trial, were also excluded (N = 14). We therefore analyzed data from 20 monolingual participants. Our recruitment, testing, and data-processing procedures were approved by the ethics committee of the School of Philosophy, Psychology and Language Sciences of The University of Edinburgh.
Results
Focusing on the critical trials described above, we measured how often participants in our task produced a homomorphic order (1) and how often they produced a nonhomomorphic order (0). Results are displayed in Figure 3. We conducted our statistical analysis using logistic mixed-effects models implemented using the lme4 package (Bates, 2010) in R (R Core Team, 2020). We designed a full model with homomorphic as the the binary dependent variable along with by-participant random intercepts. We then used a likelihood ratio test to compare this model to a null model with no intercept term to test if, on average, participants chose homomorphic orders above the 50% chance level. We found a statistically significant difference between the full and null models, β = 2.94, SE = 1.3, χ2(1) = 7.01, p < .01, indicating an above-chance preference for homomorphic orders. We also compared the preferences of our Kîîtharaka-speaking participants with those of the English-speaking participants from Martin et al. (2020). We designed a full model with homomorphic as the binary dependent variable along with population as a deviation-coded factor and by-participant random intercepts; we then compared this model to a simpler model excluding the population factor. We found no significant difference between the two models, χ2(1) < 1, and thus no statistical evidence of a difference in preferences between the English- and Kîîtharaka-speaking samples. Given that there is no reason to assume Kîîtharaka speakers are different from English and Thai speakers in using structure rather than linear order to make inferences about a new language, this result supports the presence of a universal cognitive bias toward homomorphic orders in speakers of a language that goes against that bias.
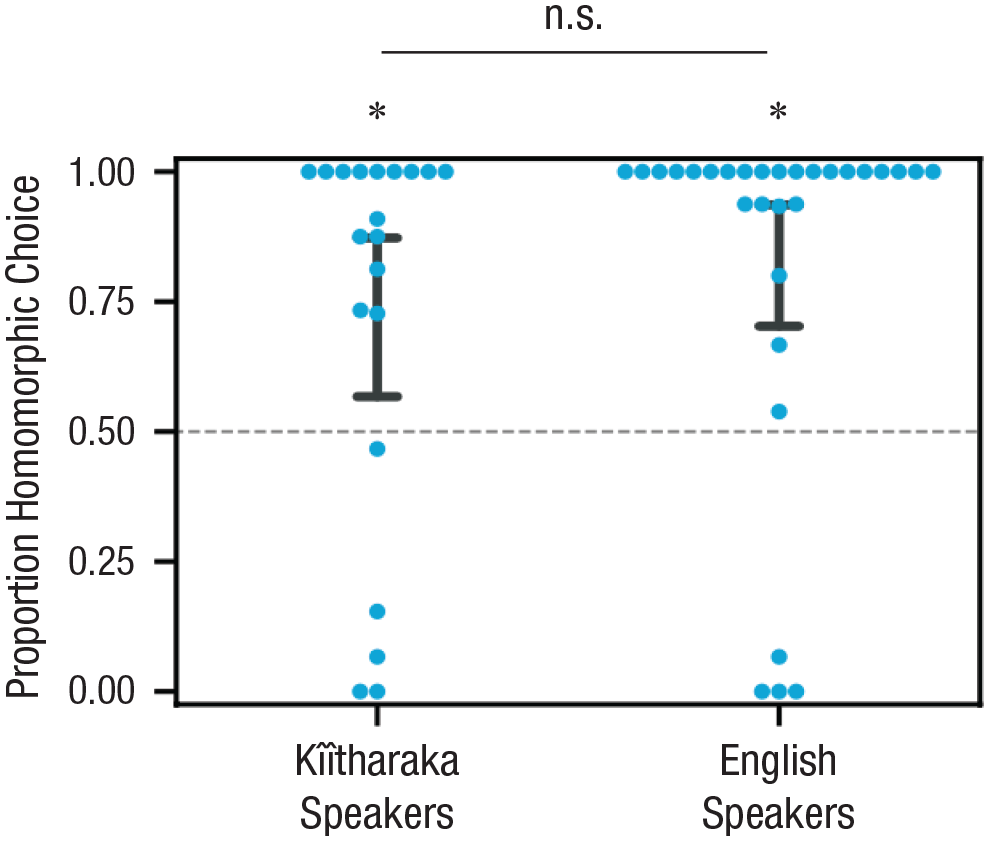
Experimental results showing consistent homomorphism preference across the two-speaker populations (English results reproduced from Experiment 3 of Martin et al., 2020). The dashed line represents chance. Error bars represent 95% confidence intervals around the group mean. Asterisks represent significant above-chance performance.
Discussion
Whether cross-linguistic generalizations reflect universal features of cognition has been a source of long-standing debate in cognitive science. Although evidence from artificial-language experiments has sometimes supported this link, participants in such studies, like participants in most psychological research, tend to come from a narrow sample of the world’s cultures and are overwhelmingly English-speaking. Although English undoubtedly exhibits some unusual linguistic features (Blasi et al., 2022), it conforms in many cases to cross-linguistic generalizations, raising the possibility that at least some previous results reflect biases specific to speakers of English, not universal ones. Here, we compared English and Kîîtharaka speakers in order to revisit a hypothesized explanation for a cross-linguistic generalization about word order in complex noun phrases. These two populations differ in a crucial way: English conforms to the generalization, and Kîîtharaka violates it. These two populations thus allow us to adjudicate between two different types of hypotheses for the cross-linguistic generalization in question: a universal cognitive bias, or cognition-external forces (like accidents of history, processes of change, etc.).
We found that despite differences in surface word order, the preferences of these two populations aligned: Both English and Kîîtharaka speakers prefer orders in which the adjective comes closest to the noun and the demonstrative furthest away. This is by far the most common type of pattern found across languages, but not in Kîîtharaka. That this population nevertheless prefers this kind of order when learning a new language is striking. It contrasts clearly with previous results showing that Kîîtharaka speakers’ preferences do not align with English speakers’ preferences in other domains of language (Martin & Culbertson, 2020). Our results therefore suggest that a universal cognitive bias drives noun-phrase word-order patterns across languages. This universal bias reflects a common hierarchical structure—a representation shared across speakers, regardless of their native language. The origin of this shared representation remains an open question; it may be innate (Adger, 2003; Cinque, 2005), or it may reflect conceptual knowledge about the world (Culbertson et al., 2020) or about which linguistic categories are more informative about each other (Hahn et al., 2021). Regardless of how the hierarchy comes to be represented in speakers’ minds, our findings suggest that the explanation must appeal to common cognitive mechanisms or experiences. Of course we have presented data from only one population whose language goes against the cross-linguistic generalization, and evidence from other populations would strengthen the generalizability of our findings. The nature of our testing procedure, requiring participants to learn new linguistic material, meant that many in our target population were unable to complete our task, and further methodological refinements might improve the scalability of this kind of research.
Nonetheless, our findings highlight the importance of evaluating explanations for common linguistic patterns using theory-based sampling and including populations whose languages go against the trend. Without evidence from diverse groups of learners whose experience differs in critical ways, it is impossible to make progress on fundamental questions about variation and universality in our species.
Supplemental Material
sj-pdf-1-pss-10.1177_09567976231222836 – Supplemental material for A Universal Cognitive Bias in Word Order: Evidence From Speakers Whose Language Goes Against It
Supplemental material, sj-pdf-1-pss-10.1177_09567976231222836 for A Universal Cognitive Bias in Word Order: Evidence From Speakers Whose Language Goes Against It by Alexander Martin, David Adger, Klaus Abels, Patrick Kanampiu and Jennifer Culbertson in Psychological Science
Footnotes
Acknowledgements
We would like to thank Tarsila Gatonga, Grace Kaindi, and Charity Karunga for help in participant recruitment.
Transparency
Action Editor: Sachiko Kinoshita
Editor: Patricia J. Bauer
Author Contributions
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.