
Abstract
Successful adaptive behavior requires efficient attentional and locomotive systems. Previous research has thoroughly investigated how we achieve this efficiency during natural behavior by exploiting prior knowledge related to targets of our actions (e.g., attending to metallic targets when looking for a pot) and to the environmental context (e.g., looking for the pot in the kitchen). Less is known about whether and how individual nontarget components of the environment support natural behavior. In our immersive virtual reality task, 24 adult participants searched for objects in naturalistic scenes in which we manipulated the presence and arrangement of large, static objects that anchor predictions about targets (e.g., the sink provides a prediction for the location of the soap). Our results show that gaze and body movements in this naturalistic setting are strongly guided by these anchors. These findings demonstrate that objects auxiliary to the target are incorporated into the representations guiding attention and locomotion.
Keywords
Investigating what guides attention and action in real-world settings is essential to understanding natural human behaviors (Ballard et al., 1995; Draschkow et al., 2021; Foulsham et al., 2011; Hayhoe & Ballard, 2005; Á. Kristjánsson & Draschkow, 2021; Tatler et al., 2011). Past research has extensively studied how behavior is guided by (a) the properties of the targets of our goals (Wolfe, 2020, 2021; Wolfe & Horowitz, 2017) and (b) the global environmental context (Hutchinson & Turk-Browne, 2012; Neider & Zelinsky, 2006; Torralba et al., 2006; Wolfe, Võ, et al., 2011). For example, the color yellow is a key target feature in the process of searching for both bananas and tennis balls, yet we are much more likely to identify a yellow object in a kitchen as a banana (Bar, 2004; Davenport & Potter, 2004; Lauer et al., 2018, 2021).
It remains unclear whether and how aspects of our environment that are neither properties of the target itself nor low-level global contextual cues (such as summary statistics; Brady et al., 2017; Greene & Oliva, 2009) influence behavioral guidance. After all, our surroundings are not random compositions of arbitrary parts but comprise a multitude of stand-alone objects that are connected by high-level environmental regularities (Greene, 2013; Mack & Eckstein, 2011), making our environment both comprehensible and functional (Võ, 2021; Võ et al., 2019). Are individual objects from the environment that are not the target of our actions incorporated into the representations we use to guide attention?
A promising candidate category of objects that might be used for behavioral guidance is anchor objects (Boettcher et al., 2018; Draschkow & Võ, 2017; Võ, 2021; Võ et al., 2019). These objects are hypothesized to structure the spatial predictions in our surroundings by providing a hierarchy of object information that supports priors (i.e., predictions) about the presence and location of other nearby local objects. For example, a sink predicts not only that the soap is nearby but also specifically that it will be somewhere on top of it; a reading lamp is often next to rather than on top of the bed. In this way, anchors can act as a bridge between target objects and their global scene context (Võ, 2021; Võ et al., 2019).
A commonly used approach to demonstrate how global contextual information affects target-related processes, such as object recognition, visual search, memorization, or action, is to violate regularities within scenes (e.g., by placing the tennis ball in the refrigerator). This subversion of our scene-related expectations can lead to changes in behavior, gaze dynamics, and electrophysiological correlates (Biederman et al., 1982; Davenport & Potter, 2004; Draschkow & Võ, 2017; Ganis & Kutas, 2003; Henderson et al., 1999; Hollingworth & Henderson, 1998; Lauer & Võ, 2022; Võ & Henderson, 2011; Võ & Wolfe, 2013a, 2013b). This approach has been used to investigate how the relationship between targets and global scene context influences cognition, but it can also be utilized to investigate how other objects in the environment guide behavior (Mack & Eckstein, 2011).
In the present study, we observed search in realistic 3D virtual reality environments and independently manipulated (a) the local availability of anchor objects (by replacing them by size-matching gray cuboids) as well as (b) the consistency of the high-level global scene context (by rearranging all objects against expectations, essentially shuffling object locations). This allowed us to investigate whether search behavior is guided by the anchor objects’ semantic identity (what specific anchor object it is) and by the spatial arrangement of anchor objects (how they provide a rough spatial layout for local objects, i.e., a syntax of sorts; Võ et al., 2019). To increase ecological validity, we used a repeated-search design in which participants completed a large number of searches in one scene multiple times (Hout & Goldinger, 2010; Võ & Wolfe, 2012, 2013b; Wolfe, Alvarez, et al., 2011). Furthermore, these repetitions in our design allowed us to control for a variety of design-related variables that are known to contribute to learning in repeated search (Li et al., 2016; Võ & Wolfe, 2015). Combining virtual reality with eye and motion tracking allowed us to capture eye movements and body locomotion simultaneously. Given how indicative eye movements are of top-down control processes in everyday tasks (Land & Hayhoe, 2001), our study provided us with optimal measures to investigate how auxiliary anchor-object information guides attention and locomotion in natural behavior.
Statement of Relevance
Everyday tasks, such as finding a teakettle, often appear effortless despite requiring us to move our entire body through space. We waste little attentional and locomotive effort in this search because we can use knowledge about what we are looking for (the teakettle is blue) and its likely surroundings (the teakettle is in the kitchen). It is less clear whether objects that are not the target (e.g., the stove) are also incorporated in the representations that guide our behavior. Using realistic but highly controlled virtual reality environments in combination with eye and motion tracking, we demonstrated that meaningful nontarget information facilitates attentional allocation, speeds object recognition, and minimizes costly body movements. These findings highlight the important realization that the representations we use to make us efficient actors in natural search behavior can contain entire bound objects that are not the target of our actions.
We hypothesized that when people search for objects in scenes, both the semantic identity of anchor objects and their spatial arrangement guide search behavior and, thus, facilitate the localization and recognition of objects. This guidance should be apparent in eye-tracking measures related to (a) how efficiently targets are located (time to first target fixation, number of fixations per trial, scan-path length) and (b) how quickly objects are recognized (the time between first target fixation and the participants’ response; decision time) as well as (c) motion-tracking parameters capturing how much participants move (length and spatial extent of movement before finding the target). Specifically, we hypothesized that the semantic identity of anchor objects and their spatial arrangement interact in their guidance: Finding the target should be most efficient in consistent scenes with intact anchors; removing anchor information in spatially consistent scenes or scrambling object locations in scenes where anchor information is available should interfere with the representations guiding search behavior, making it harder to find the target. However, search in inconsistently arranged scenes without anchor information should result in more efficient object localization than search in inconsistently arranged scenes with anchor information, because the anchors’ semantic identity cannot be used to guide attention meaningfully in the absence of regular spatial relations between objects. Therefore, in spatially inconsistent scenes, we expected anchors to interfere with search guidance.
Method
Participants
We recruited 24 participants (a convenience sample acquired through on-campus and social media advertising in the summer of 2019; age: M = 23.5 years, range = 18–37 years; 18 women and 6 men; 22 right-handed and 2 left-handed; height: M = 170.1 cm, range = 155–183 cm) at Goethe University Frankfurt. Sample size was set to be larger (Brysbaert, 2019) than in a similar study (Boettcher et al., 2018) in which three experiments revealed robust results with 12 participants. Here, we set the sample size to 24 to enable counterbalancing. Participants were fluent German speakers, had normal or corrected-to-normal visual acuity (at least 20/25 vision) and normal color vision as assessed by the Ishihara test, and reported no neurological diseases. All participants were volunteers, gave informed consent, and were compensated with either course credit or €24. Participants were naive to the purpose of the experiment.
The research protocol was approved by the local ethics committee of the Faculty of Psychology and Sport Sciences at Goethe University Frankfurt.
Apparatus
To implement our virtual reality eye-tracking paradigm, we used a Tobii Pro VR Integration unit (Tobii Pro, Danderyd, Sweden), which is a retrofitted version of the HTC Vive head-mounted display (HTC Corporation, Taoyuan City, Taiwan). The Tobii Pro VR Integration unit has a built-in binocular dark-pupil eye tracker that streams eye movements at a sampling rate of 90 Hz (the refresh rate of the head-mounted display) with a declared spatial accuracy of approximately 0.5° and a 100° (horizontally) × 110° (vertically) trackable field of view (full field of the head-mounted display). Past assessments of the eye tracker’s practically achievable accuracy have yielded a precision below 1.1° within a 20° window centered in the view ports and a worst-case maximal latency below 30 ms (David et al., 2020, 2021). The head-mounted display uses two organic light-emitting diode (OLED) screens with a resolution of 1,080 × 1,200 pixels. Two base stations (Lighthouse tracking system) emit 60 infrared pulses per second, which are detected by 37 infrared sensors in the head-mounted display; this enables location tracking to a fraction of a millimeter. Tracking is further optimized by an accelerometer and a gyroscope in the head-mounted display. Participants held an HTC Vive controller in their writing hand. The trigger at the back of this wireless controller, which participants were instructed to pull with their index finger, was used for response collection.
The experiment was programmed and run in Unity (Version 2017.3.0; Unity Technologies, 2017) using SteamVR (Version 1.6.10; Valve Corporation, 2019) on a computer equipped with Microsoft Windows 10.
Environments
Sixteen virtual indoor scenes were created (three living rooms, three bedrooms, three bathrooms, three kitchens, and four offices; Fig. 1a). They were all of equal size, approximately 380 cm (length) × 350 cm (width) × 260 cm (height). Textures for wall coverings, flooring materials, and ceilings were tailored to the room category (e.g., tiles in the bathrooms). In every scene, there were 36 category-appropriate objects. All of them were singletons, meaning that no object (or a different exemplar from the same object category) was present more than once in the same scene. In every scene, one object was the door of the room. Of the remaining objects, there were seven that we considered the anchors of the scene and 28 local objects. Anchors were large, static objects (e.g., couch, stove, shower, desk), whereas local objects were smaller and movable items (e.g., pillow, frying pan, shampoo bottle, pencil) that people typically interact with when performing actions in a scene. In addition to these experimental scenes, there was a practice room with objects that would not be expected in any of the other presented scene categories (e.g., traffic light, diving helmet, triceratops) to avoid any memory interference with the experimental scenes. The 3D models used for the scenes were a mixture of purchased assets from CGAxis and free resources taken from several online repositories (Archive 3D, CGTrader, Free3D, TurboSquid, and the Unity Asset Store).
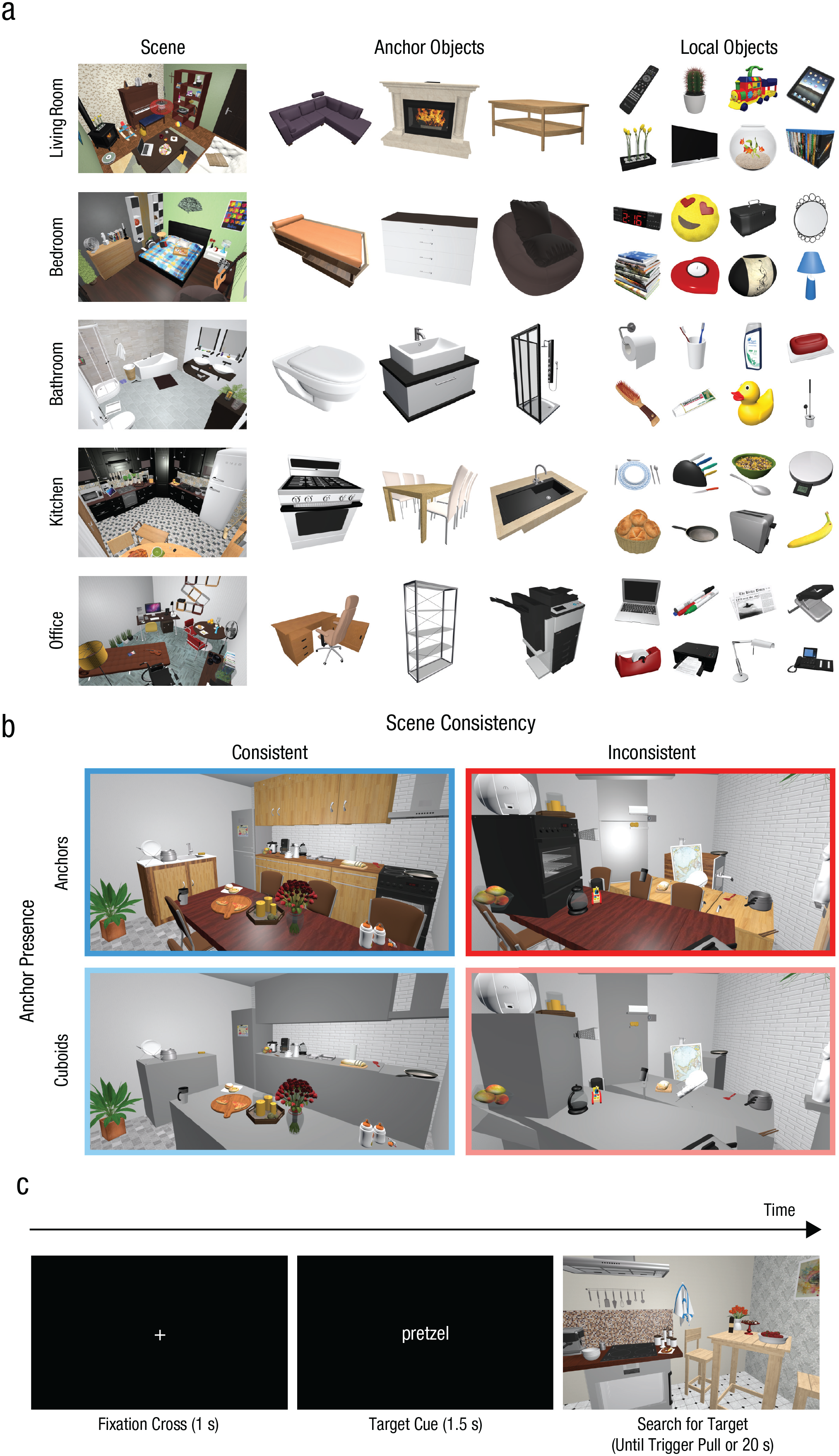
Experimental stimuli, conditions, and trial sequence. Example scenes, anchor objects, and local objects from each of the five room categories are shown in (a). The four scene-manipulation conditions are shown in (b): These consisted of consistently or inconsistently arranged scenes in which anchor objects were either intact or replaced by cuboids. The procedure of a single search trial is shown in (c). Note that the target cue is presented here in English for display purposes (it was presented in German in the experiment).
Using a 2 × 2 design (Scene Consistency × Anchor Presence), we created four different versions of every scene (Fig. 1b). In the syntactically consistent version with intact anchors, the scene was entirely in keeping with expectations about its components and their arrangement. Manipulating scene consistency entailed repositioning all objects (anchors and local objects independently) to locations in which they would not be expected, hence creating an inconsistent scene in which the spatial link between anchors and their local objects was broken (Draschkow & Võ, 2017; Võ & Wolfe, 2013a, 2013b). In inconsistently arranged scenes, objects did, however, adhere to the laws of physics (e.g., did not float or intersect with one another) and were not placed in a way that occluded them significantly compared to their location in consistent scenes. The inconsistent object arrangement was prepared by the experimenters beforehand and was the same for all participants (i.e., if the inconsistent location of a coffee mug in a bedroom was chosen to be on a pillow, all participants visiting this scene in the inconsistent condition would find the mug in this location). The manipulation of anchor presence consisted of replacing anchor objects (and the door) by formations of gray cuboids, the sizes of which matched those of the anchors. Therefore, besides (a) the regular scenes (consistently arranged with intact anchors), there were also (b) consistently arranged scenes with cuboids for anchors, (c) inconsistently arranged scenes with intact anchors, and (d) inconsistently arranged scenes with cuboids for anchors.
Images showing overviews of all scenes in all conditions of the experiment are provided in the Supplemental Material available online.
Procedure
After arriving at the lab, participants were familiarized with the virtual reality apparatus and lab space as well as the calibration procedure of the eye tracker. Once equipped with the head-mounted display and controller, they were instructed to search for the cued objects in the scene on every trial and to pull the trigger on the controller while looking at the target once they had located it. They were informed that they could move freely within the virtual rooms, that the targets were always present exactly once in the scene, and that there was a time-out after 20 s. There were 10 practice trials in the practice room before the actual experimental trials started.
A video demonstration of example trials is available at https://osf.io/5xhet/. In every trial, participants were first presented with a fixation cross for 1 s. Then, a verbal cue in German was presented for 1.5 s, indicating the search target of the trial. Both the cue and a plus sign that was used as the fixation cross were presented in white 64-point sans-serif font at a viewing distance of about 80 cm in the center of the display (and would move along with participants’ movements to remain there). The visual surroundings were completely black during the fixation cross and the presentation of the target cue. Once the target cue disappeared, the scene became visible, and participants could search in it until they either pulled the trigger or the search time-out of 20 s was reached (Fig. 1c).
There were 25 consecutive trials in each scene and 16 different scenes per participant (four in each condition). Between scenes, the environment changed into an empty room with gray walls in which participants had to move to a small blue square on the floor and could then initiate the next scene’s search trials. This was done to ensure that (a) when starting search trials in a new scene, participants would not stand inside of objects and (b) all participants started from roughly the same point with all objects equally visible. A 5-point calibration of the eye tracker was carried out after every fourth scene. Once search trials in all scenes were completed, participants revisited every scene and performed the same search task again with the same trials (second episode) and then one more time (third episode). There were 10-min breaks between episodes. The entire experimental session, including instructions and breaks, took between 2.5 hr and 3 hr.
The assignment of scenes to conditions (scene consistency, anchor presence) was different for every participant: Scenes were randomly assigned to the four conditions with the constraint that there could not be more than one scene of the same category in any condition. Given the number of scenes in each room category (see the Environments section), this meant that there was one office in each of the four conditions, whereas each of the other room categories (living room, bedroom, kitchen, bathroom) was missing from one condition, as there were just three exemplars of each. The order of scenes was also balanced with respect to the conditions: Every second scene had cuboids in place of anchor objects (the state of the first scene alternated with every participant), and consistency was varied in an ABBA–BAAB–ABBA–BAAB pattern. For each scene, there was a fixed set of 25 targets (out of the 28 local objects). The experimenters selected the targets on the basis of the objects’ nameability (i.e., objects for which it was hard to find a conventional official name were avoided as targets because the cuing procedure was achieved by means of verbal labels). The order of the 25 trials in a scene was random in every episode.
Data analysis
Data exclusion
Analyses were performed only on trials in which participants responded accurately, that is, trials in which the target was found (hits; 97.1%). A trial was considered accurate when gaze was detected on the bounding box of the target object (the smallest possible cuboid around the convex hull of the 3D object mesh) at the moment the trigger was pulled. Additionally, all non–time-out trials in which this was not the case were rewatched after data collection to check whether the participant had actually misidentified the object or whether gaze was just not on the target because of imprecisions of eye tracking or because the participant prematurely pulled the trigger a moment before their gaze would have hit the target. Trials in which the participant had most likely been right about the target were coded as accurate. Of all hits, gaze was on the target at the trigger pull on 92.9%. About half of the inaccurate trials were time-outs (47.1%).
Eye-tracking measures
Eye-movement samples (gaze points) were recorded at 90 Hz. For fixation filtering, we used a velocity-based algorithm (Salvucci & Goldberg, 2000; velocity-threshold identification [I-VT]) with a velocity threshold of 100° per second (Tobii Pro, 2018) and an additional minimum fixation duration of 100 ms. To account for small, bridgeable tracking interruptions, we allowed for gaps of up to 75 ms between two consecutive gaze points for both to be considered part of the same fixation (Komogortsev et al., 2010). Time to first fixation was calculated as the time that elapsed between search onset and the beginning of the first fixation on the target object of the trial. This measure was computed only on trials in which the target was fixated at least once and the first target fixation did not start at search onset (84.5% of hits). Decision time was obtained by subtracting the time to first fixation from the trial’s response time (i.e., elapsed time between search onset and the point in time at which the trigger was pulled). The number of fixations is a simple trial-based fixation count (on all trials with a target fixation; 92.8% of hits). Scan-path length was computed as the sum of euclidian distances of consecutive fixations’ centroids. Naturally, this measure was obtainable only on trials with more than one fixation (80.6% of hits). We used the time to first fixation, number of fixations, and scan-path length as measures of how efficiently overt attention was guided in a search trial. We interpreted decision time as a measure of how quickly targets were identified once fixated (object recognition).
Locomotion data
The position of the head-mounted display in 3D space was sampled at 90 Hz as well. From this, we calculated two measures of how much participants had moved on a trial. The length of movement was computed as the sum of euclidian distances of the horizontal-plane coordinates of consecutive position samples. The spatial extent of movement was approximated by calculating the surface area of the convex hull of all position samples’ horizontal-plane coordinates. We considered both of these trial-based measures of how efficiently participants moved in a search trial.
Statistical model and software
Data preprocessing and analyses were carried out in the R statistical programming language (Version 3.6.2; R Core Team, 2019) using RStudio (Version 1.2.5033; RStudio Team, 2019). Linear mixed-effects models (LMMs) and generalized linear mixed-effects models (GLMMs), run with the lme4 package (Version 1.1-21; Bates et al., 2015), were used to analyze the effects in our data. We chose to use LMMs and GLMMs because they allowed us to control for between-subject and between-stimulus variance simultaneously and, thus, yielded advantages over traditional general-linear-model approaches, such as F1/F2 analyses of variance (Baayen et al., 2008; Kliegl et al., 2011). The lmer_alt() wrapper from the afex package (Version 1.0-1; Singmann et al., 2021) was used to correctly remove correlations between random effects. The final models’ architecture is specified as follows for all dependent variables:
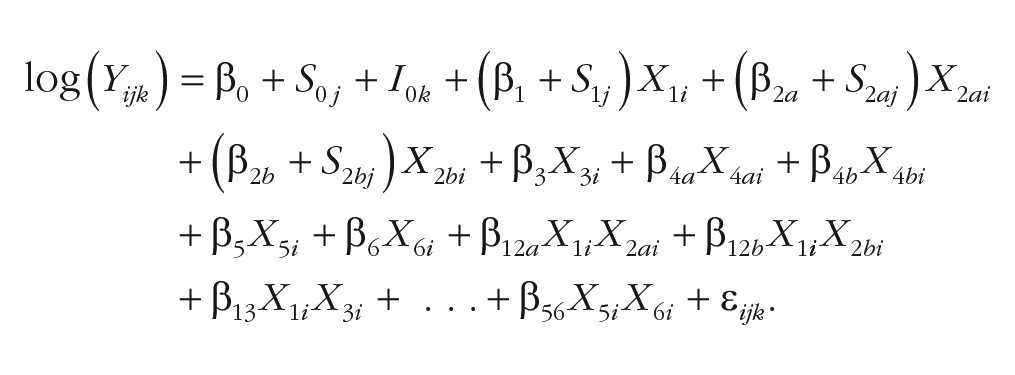
In this equation, Yijk represents the dependent variable outcome i of subject j with search target (item) k, β0 is the fixed intercept, S0j is the random intercept of subject j, I0k is the random intercept of item k, βl is the fixed-effect parameter of Xl (double-index βlm indicates two-way interactions Xl Xm), Xli is the predictor l of outcome i (l: 1 = scene consistency, 2 = anchor presence, 3 = trial number, 4 = episode number, 5 = incidental gaze duration, 6 = target angle), Slj is the random Xl slope of subject j, and εijk represents the residual of outcome i (subject j, item k). Note that (a) for predictors and their fixed-effects parameters, when one factor is coded into two variables for contrasts (Scene Consistency × Anchor Presence, episode transitions), this is indicated by subscript letters a and b behind the variable index l; (b) in case of the number of fixations, we did not log-transform the fixation count but instead used a Poisson link function (GLMM); and (c) that for the scan-path-length model only, the random by-participant slopes for anchor presence, S2.j, were restricted to zero.
All models were fitted with the restricted-maximum-likelihood criterion. For each model, we report unstandardized regression coefficients with the t statistic (or z statistic in case of the fixation-count GLMM) and the results of a two-tailed test corresponding to a 5% error criterion for significance. To obtain p values for LMMs, we used an implementation of Satterthwaite’s degrees-of-freedom method from the lmerTest package (Version 3.1-1; Kuznetsova et al., 2017); GLMM p values were based on asymptotic Wald tests from lme4. Further details about the model structure and the model-selection procedure are outlined in the Supplemental Material.
Dependent variables
To investigate the impact of our scene manipulations on the search process, we used the time to first fixation, decision time, number of fixations, scan-path length, length of movement, and spatial extent of movement as dependent measures. Of these, we interpreted the time to first fixation, number of fixations, and scan-path length as measures of how efficiently objects were localized, and we used decision time as indicative of how rapidly the objects’ identity was verified (object recognition/identification). With the two movement measures, we aimed to identify differences in how much participants moved through the scenes in the different conditions. After inspecting all dependent variables’ distributions, linear model residuals, and power coefficients (λ) of the Box–Cox procedure (Box & Cox, 1964), which was run with the MASS package (Version 7.3-51.5; Venables & Ripley, 2002), we log-transformed these values to approximate a normal distribution more closely and meet LMM assumptions. The only exception to this was the fixation count, which was not log-transformed (O’Hara & Kotze, 2010); instead, we used a Poisson GLMM to predict the number of fixations.
Results
We found that overt attention (as assessed by eye movements indicative of efficient target localization) and locomotion were supported by auxiliary anchor-object information across all dependent variables. Below, we break these effects down in more detail. Effects related to the interaction of scene consistency and anchor semantics, which are central to our research question, are described in the following three sections sorted by topic (overt attention, object recognition, body locomotion). All other significant effects are outlined in the Supplemental Material: They largely replicate well-known effects from the visual-search and scene-perception literature (Draschkow & Võ, 2017; Lauer & Võ, 2022; Võ & Wolfe, 2013b, 2015; Wolfe, 2020). All eye- and motion-tracking measures’ LMM or GLMM parameter estimates, with their t/z statistic and corresponding p values, are given in Table S1 in the Supplemental Material.
Auxiliary scene information guides overt attention
In consistent scenes with intact anchors, the target was fixated numerically more quickly than in consistent scenes in which cuboids replaced those anchors (Fig. 2a); however, this effect was not significant, b = 0.04, t = 2.03, p = .05. The time to the first target fixation was faster for cuboids than for intact anchors in inconsistent scenes, b = −0.09, t = −3.39, p = .002. Further, there were fewer fixations on trials in consistent scenes with intact anchors than in consistent scenes with cuboids, b = 0.05, t = 3.56, p < .001 (Fig. 2b). In inconsistent scenes, this effect was again reversed: More fixations were made when anchors were present than when cuboids were present, b = −0.08, t = −6.66, p < .001. Finally, in consistent scenes, scan paths were longer when anchors were replaced by cuboids, b = 0.08, t = 3.17, p = .002 (Fig. 2c). For inconsistent scenes, scan-path length was shorter in scenes with cuboids than in those with anchors, b = −0.05, t = −2.26, p = .02. In short, in consistent scenes, the presence of anchors facilitated search, whereas it disrupted attentional guidance in inconsistent scenes (causing less efficient search).
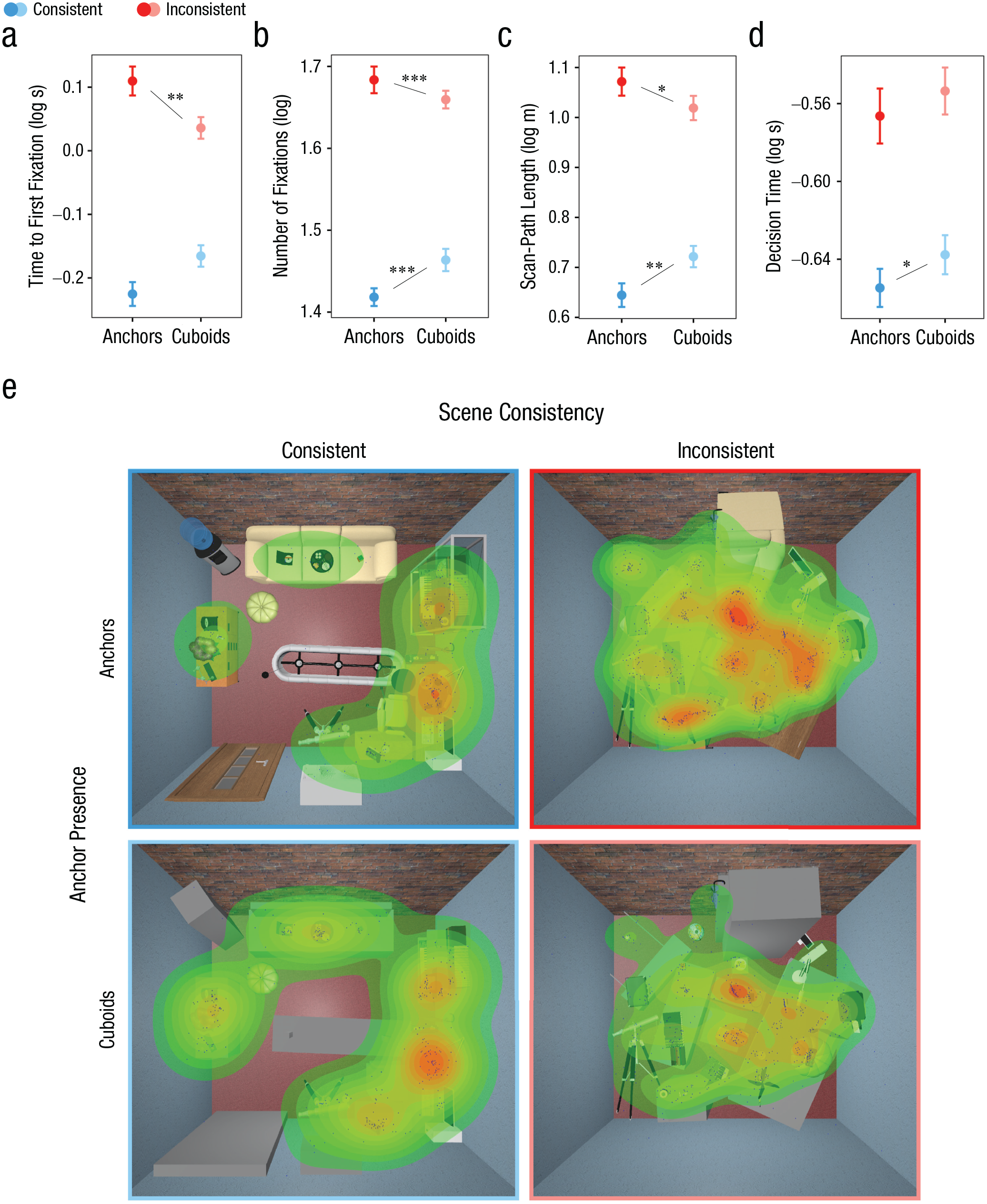
Eye-movement results. The graphs show the effect of anchor presence (anchors vs. cuboids) and scene-consistency manipulation (consistent vs. inconsistent) on time to first fixation (a), number of fixations (b), scan-path length (c), and decision time (d). Asterisks indicate significant differences between anchor-presence conditions (*p < .05, **p < .01, ***p < .001). Error bars represent standard errors of the mean. The distribution of fixations in space (e) is shown for the first five search trials of all participants in the four different conditions of an office scene. Each blue dot represents a fixation, and the color gradient reflects the density of fixations with the length of individual fixations taken into account.
The successful attentional guidance by the anchor objects is further illustrated in the example spatial distribution of fixations in Figure 2e. The auxiliary anchor objects provided useful guidance in consistently arranged scenes but became distracting visual clutter in inconsistent scenes, highlighting the interplay of the anchors’ identity and arrangement in guiding attention.
Auxiliary scene information aids object recognition
Decision time was calculated as the time between the participants’ first target fixation and their response. It is indicative of how rapidly the target identity is verified and functions as a proxy for object recognition/identification. In consistent scenes with intact anchors, decision time was significantly faster than in consistent scenes with cuboids, b = 0.03, t = 2.59, p = .01 (Fig. 2d). For inconsistent scenes, there was no significant difference in decision time between the anchor and cuboid conditions, b = 0.01, t = 0.37, p = .72. These patterns indicate that anchor objects facilitate the identification of nearby local objects in intact scenes, which is in line with classic consistency effects in object recognition (Bar, 2004; Biederman et al., 1982; Davenport & Potter, 2004; Lauer et al., 2018; Sauvé et al., 2017) and recent evidence that scene context helps us to disambiguate bottom-up object information (Wischnewski & Peelen, 2021).
Auxiliary scene information supports efficient locomotion
The pattern of locomotion results resembled that of the eye-tracking measures. In consistent scenes, the length of movement was shorter when anchors were present than when replaced by cuboids, b = 0.07, t = 3.09, p = .005, whereas in inconsistent scenes, it was shorter for cuboids than for anchors, b = −0.08, t = −2.97, p = .007 (Fig. 3a). Likewise, movement in space was more limited in consistent scenes with anchors than in consistent scenes with cuboids, b = 0.15, t = 3.31, p = .001, but was again more extensive in inconsistent scenes with anchors than in inconsistent scenes with cuboids, b = −0.14, t = −2.45, p = .02 (Fig. 3b). These patterns demonstrate that auxiliary scene information not only shapes attentional allocation but also guides body movements in realistic interactions within immersive virtual reality. These effects are also evident in the example movement paths depicted in Figure 3c.
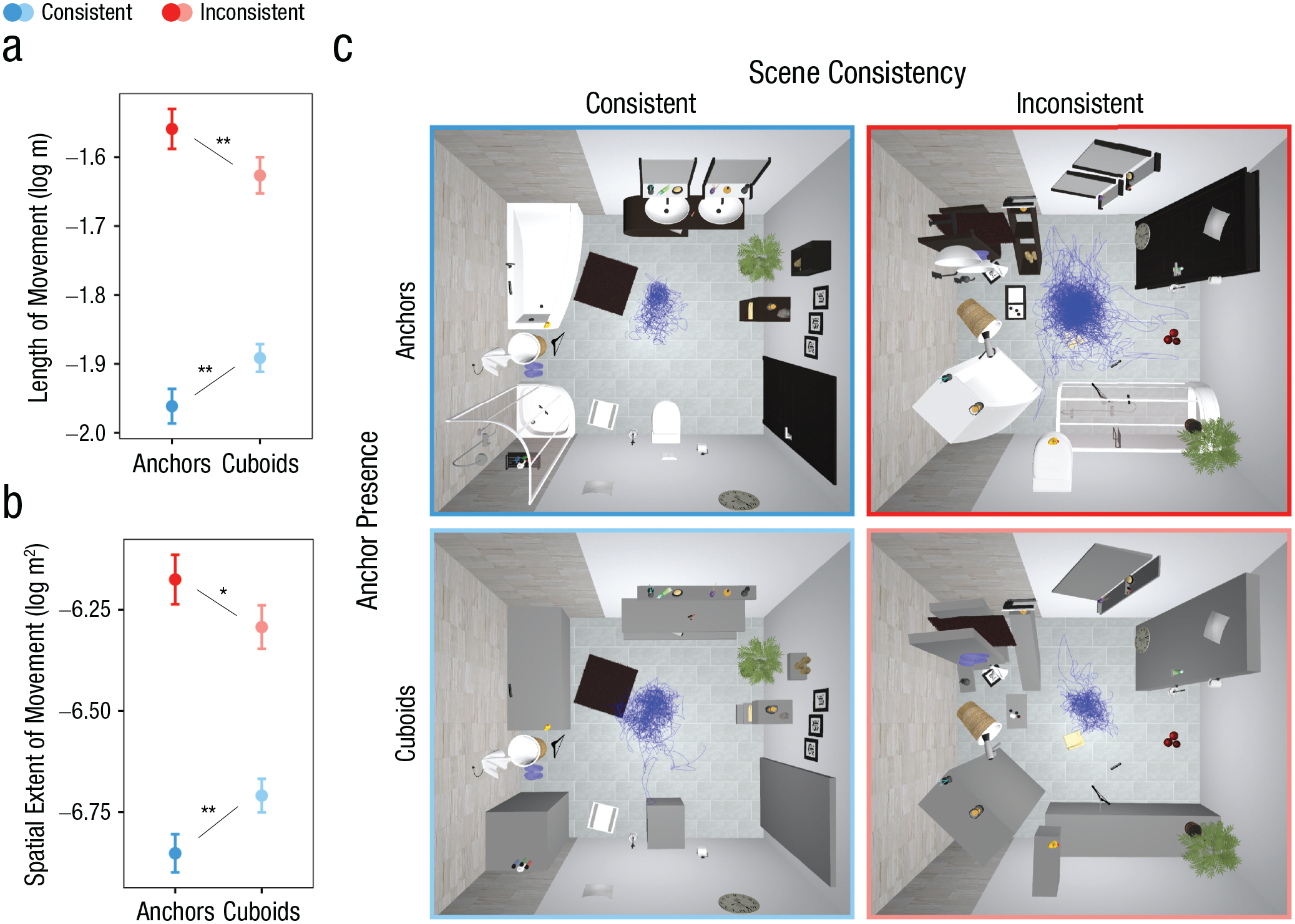
Body-locomotion results. The graphs show the effect of anchor presence (anchors vs. cuboids) and scene-consistency manipulation (consistent vs. inconsistent) on length of movement (a) and spatial extent of movement (b). Asterisks indicate significant differences between anchor-presence conditions (*p < .05, **p < .01). Error bars represent standard errors of the mean. Movement paths from all trials of all participants are shown in the four different conditions of a bathroom scene (c). Paths are represented by blue lines.
Discussion
Our results show that efficiently locating objects in immersive environments, with respect to both eye and body movements, relies on auxiliary nontarget information provided by a class of stand-alone objects known as anchor objects (Boettcher et al., 2018; Draschkow & Võ, 2017; Võ, 2021; Võ et al., 2019). Efficient attentional guidance and locomotion rely on a combination of (a) the consistent composition of the environments’ building blocks and—once this intact spatial layout is provided—(b) the semantic identity of anchor objects. These findings reveal that individual objects from the environment that are not the target of our actions can be incorporated into the representations we use to guide attention and locomotion.
In our study, we showed that auxiliary anchor objects can play an important part in guiding behavior. These objects have been proposed to structure the spatial predictions in natural surroundings by providing a hierarchy of object information that supports priors about the presence and location of nearby potential target objects (Boettcher et al., 2018; Draschkow & Võ, 2017; Võ, 2021; Võ et al., 2019). The conceptualization of these objects stems from approaches designed to describe similarities between the structure of language and the structure of scenes (Biederman, 1972; Biederman et al., 1973, 1982; Võ et al., 2019). In these approaches, scenes can be regarded as “grammatical” compositions of sub-scenelike phrases (e.g., a sink phrase), each of which is arranged around a central anchor object (sink) that supports predictions of the presence and location of the nearby local objects (toothbrush, soap, etc.). The efficiency of searching for objects in real-world environments stems from the ability to exclude whole phrases (e.g., the toilet or shower phrase) from the search area when looking for a toothbrush. Our results highlight the behavioral relevance of this phrasal structure within scenes: On an intraphrase level (i.e., when the object arrangement within a phrase is intact), the identity of the anchor object is necessary auxiliary information to improve performance. On an interphrase level (i.e., spatially consistent arrangement vs. inconsistent arrangement), we found that attentional guidance relies on intact phraselike clusters of objects, as breaking these up decreased search performance (or, in other words, increased search effort).
More global expectations related to what belongs in a scene (scene semantics; object identities; e.g., the pot goes in the kitchen) are typically distinguished from rules about where objects are located (scene syntax; the pot often rests on a stovetop; Draschkow & Võ, 2017; Võ, 2021; Võ et al., 2019; Võ & Wolfe, 2013a). In addition to this approach being a useful metaphor for describing scene regularities and their violations, there is evidence for commonalities between the processing of language and scenes, as they share similarities in their organization (Draschkow & Võ, 2017; Võ, 2021; Võ et al., 2019; Võ & Wolfe, 2013a) and development (Maffongelli et al., 2020; Öhlschläger & Võ, 2020). In the context of our study, scene semantics and syntax can also be applied to describe our two manipulations. Replacing anchors by cuboids can be considered a manipulation that primarily operates on a semantic level, because the spatial layout (syntax) of other objects in the scene remains intact. The consistency manipulation, on the other hand, can be described as a violation of scene syntax, because the natural spatial layout is distorted. Thus, our results highlight how the interplay of semantic and syntactic scene information can increase the efficiency of attention, locomotion, and object recognition. We want to stress the universality and flexibility of this efficiency because it is not limited to well-known environments—hence the term “grammar.” That is, just as we can understand sentences we have never heard before because we know the meaning of the words and the rules of how they need to be arranged to form meaning, we can understand new scenes by knowing the identities of objects and the rules that govern their spatial layout (scene grammar; Võ et al., 2019).
This study and previous work have identified anchor objects as building blocks of a hierarchical scene organization, which is of unique importance to how we form predictions of object locations (Boettcher et al., 2018; Draschkow & Võ, 2017; Võ et al., 2019). In future studies, it will be important to investigate these predictions in a more fine-grained manner. Here, we selected larger static objects as anchors and observed how they shaped predictions for the remaining objects as targets. In reality, it is likely that the hierarchy of objects predicting each other in space is more profound than that. For example, many of the objects we selected as local objects are probably anchoring predictions themselves: A large computer monitor on a desk likely predicts the keyboard and mouse resting below. In many cases, these predictions could be multidirectional (e.g., a glass of milk and a plate of cookies side by side, predicting each other). Therefore, more complex object networks, in which weighted links between objects indicate the extent to which they predict each other, will most likely provide us with better models of how spatial priors are formed during natural behavior. Analyzing large databases of scenes to extract regularities of objects’ frequencies, co-occurrences, and spatial relations to each other will be key in this endeavor (Boettcher et al., 2018; Greene, 2013; Võ et al., 2019; Yang et al., 2019). Furthermore, it will be important to look more closely at eye movements during the search process when anchors guide attention: Although we have shown that these are indicative of increased efficiency of the search process when anchor objects and the scene’s structure are intact, more research in even more standardized environments is needed to understand precisely how fixations are related to anchor guidance. What role do fixations on anchors play in guiding search? How are saccades between anchors and local objects guided by scene grammar? When do we not fixate (i.e., skip) the anchor before fixating the target?
It is worth noting that we included repetitions in our trial-by-trial design because we believe that repeatedly searching through the same, unchanging environment reflects what we experience daily (rather than jumping from one scene to another, we tend to look for several items within the same scene, e.g., when preparing dinner in a kitchen; Hout & Goldinger, 2010; Võ & Wolfe, 2012; Wolfe, Alvarez, et al., 2011). We accounted for these repetitions in our statistical models, but nevertheless, using different research designs with altered trial structures (e.g., comparing repeated search in changing and unchanging scenes or looking only at initial search trials in a larger number of scenes) will be important when aiming to more precisely disentangle the differential roles of semantic knowledge (general assumptions about scenes, such as those provided by anchor objects) and episodic memory (knowing specific scenes and their unique regularities; Võ & Wolfe, 2013b).
Methodologically, our study joins the rapidly growing list of efforts to investigate search in realistic virtual reality scenes (Beitner et al., 2021; Bennett et al., 2021; David et al., 2020, 2021; Draschkow & Võ, 2017; Enders et al., 2021; Figueroa et al., 2017; Hadnett-Hunter et al., 2019; Helbing et al., 2020; Kit et al., 2014; T. Kristjánsson et al., 2022; Li et al., 2016, 2018; Lukashova-Sanz & Wahl, 2021; Olk et al., 2018). Studies such as these enable us to probe search flexibly while ensuring both unprecedented ecological validity (realistic environments, navigable space, and behaviorally relevant task settings) and a high degree of experimental control (precise timing, eye and motion tracking, and full control over the field of view). We believe that this approach is essential in order to replicate, scrutinize, and extend findings from decades of screen-based experimentation on scene perception and visual search. Only when behavior is studied in these naturalistic settings can we get a functional perspective of underlying cognitive processes (Foulsham et al., 2011; Á. Kristjánsson & Draschkow, 2021; Malcolm et al., 2016; Tatler et al., 2011, 2013). To increase the generalizability of our findings to other settings (Yarkoni, 2022), it will be relevant to investigate search in large-scale virtual environments with multiple connected scenes (e.g., apartments, office spaces, train stations), because our representations of these complex multiscene spaces may carry with them unexplored possibilities for auxiliary guidance by contextual information. Further, to increase the generalizability of our findings beyond groups conveniently proximate to the research site (often undergraduate students who might not represent the target population; Henrich et al., 2010), it will be important to sample larger and more representative populations. This large-scale and more diverse sampling can be enabled by remote online experimentation using virtual reality, as the market for consumer virtual reality systems is growing (Draschkow, 2022).
The unparalleled efficiency of natural adaptive behavior in real-world environments is an impressive property of human cognition. Broadly, our findings demonstrate that this efficiency is supported by spatial priors generated by auxiliary information that is not a direct property of the targets of our actions. More precisely, our findings reveal that target representations used for guiding natural behavior can include stand-alone objects that anchor people’s hierarchical representations of scenes and the objects within them.
Supplemental Material
sj-pdf-1-pss-10.1177_09567976221091838 – Supplemental material for Auxiliary Scene-Context Information Provided by Anchor Objects Guides Attention and Locomotion in Natural Search Behavior
Supplemental material, sj-pdf-1-pss-10.1177_09567976221091838 for Auxiliary Scene-Context Information Provided by Anchor Objects Guides Attention and Locomotion in Natural Search Behavior by Jason Helbing, Dejan Draschkow and Melissa L.-H. Võ in Psychological Science
Supplemental Material
sj-pdf-2-pss-10.1177_09567976221091838 – Supplemental material for Auxiliary Scene-Context Information Provided by Anchor Objects Guides Attention and Locomotion in Natural Search Behavior
Supplemental material, sj-pdf-2-pss-10.1177_09567976221091838 for Auxiliary Scene-Context Information Provided by Anchor Objects Guides Attention and Locomotion in Natural Search Behavior by Jason Helbing, Dejan Draschkow and Melissa L.-H. Võ in Psychological Science
Footnotes
Acknowledgements
We thank Jenny Helbing and Rieke Löffler for their valuable help with the stimulus material and data collection as well as Julia Beitner and Erwan David for helpful conversations about the work presented here.
Transparency
Action Editor: Sachiko Kinoshita
Editor: Patricia Bauer
Author Contributions
D. Draschkow and M. L.-H. Võ contributed equally to this work. All authors conceptualized the experimental design and methodology. J. Helbing programmed the experiment and collected the data. J. Helbing and D. Draschkow analyzed the data and created visualizations. J. Helbing wrote the original draft of the manuscript. D. Draschkow and M. L.-H. Võ reviewed and edited the manuscript. D. Draschkow and M. L.-H. Võ supervised the project. All the authors approved the final version of the manuscript for submission.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.