
Abstract
Everyday face recognition presents a difficult challenge because faces vary naturally in appearance as a result of changes in lighting, expression, viewing angle, and hairstyle. We know little about how humans develop the ability to learn faces despite natural facial variability. In the current study, we provide the first examination of attentional mechanisms underlying adults’ and infants’ learning of naturally varying faces. Adults (n = 48) and 6- to 12-month-old infants (n = 48) viewed videos of models reading a storybook; the facial appearance of these models was either high or low in variability. Participants then viewed the learned face paired with a novel face. Infants showed adultlike prioritization of face over nonface regions; both age groups fixated the face region more in the high- than low-variability condition. Overall, however, infants showed less ability to resist contextual distractions during learning, which potentially contributed to their lack of discrimination between the learned and novel faces. Mechanisms underlying face learning across natural variability are discussed.
Keywords
On a daily basis, humans rely on the ability to process information from faces to effectively navigate their social world. Accurate face recognition provides an entry point into human social interactions and lays a foundation for subsequent complex cognition, such as trait perception, impression formation, discrimination, and prejudice. Successful face recognition involves two aspects: (a) Telling faces apart (i.e., detecting differences between identities) requires sensitivity to between-person variability (Pascalis et al., 2002), and (b) “telling faces together” (i.e., recognizing different images as the same person despite natural variations in the person’s appearance) requires formation of a generalizable representation of that person (Burton, 2013).
Most studies investigating how people discriminate between faces use a limited number of highly controlled images to represent an individual’s appearance. These studies greatly underestimate the real challenge of face identification. This is because faces viewed in the real world vary naturally in appearance as a result of changes in lighting, expression, viewing angle, hairstyle, and makeup; the pictorial cues (e.g., shadow on a face image) that participants rely on for face recognition in laboratory tests are no longer reliable in daily life. This oversight of within-person variability in the face-recognition literature leaves a significant gap in knowledge about exactly how we recognize faces in the real world (Jenkins & Burton, 2011; Laurence et al., 2016).
It is only recently that the challenge of recognizing faces despite within-person variability has emerged at the forefront of face-recognition research. Within-person variability, including both changes in the face itself (e.g., age, expression, makeup, stress level, fatigue) and changes in the capture conditions (e.g., lighting, filming distance, surrounding context), influences the apparent facial configuration, attractiveness, age, and distinctiveness of a given identity, making accurate face identification difficult (Burton, 2013; Jenkins et al., 2011; Mileva et al., 2020). It has been proposed that tolerance of within-person variability is a key difference between familiar and unfamiliar face recognition: Whereas familiar face recognition is robust across changes in images, unfamiliar face recognition is fragile and can be easily disrupted by superficial changes in appearance (Johnston & Edmonds, 2009; Young & Burton, 2018). When a face contains idiosyncratic variability in appearance, different photographs of the same person are often perceived as different people, unless that person is familiar to perceivers (Jenkins et al., 2011; Zhou & Mondloch, 2016). Thus, understanding perception of within-person variability is thought to be key to understanding how unfamiliar faces become familiar, a ubiquitous task that guides humans’ social interactions. Exposure to how faces vary enhances people’s subsequent perceptual matching of the faces (Andrews et al., 2015; Dowsett et al., 2016) and later recall of the faces from memory (Baker et al., 2017; Hayward et al., 2017; Ritchie & Burton, 2017; Zhou et al., 2018). Researchers therefore argue that multiple exposures to within-person variability of a given face allow perceivers to separate transient changeable facial variations from the stable characteristics of the face, leading to reliable learning of that face, consistent with Bruce’s (1994) idea of “stability from variation.”
Despite the important role of within-person variability in face recognition and learning, our current understanding is primarily based on behavioral tasks in adults (Jenkins et al., 2011). Few developmental studies have investigated how within-person variability affects identity perception in children. Laurence and colleagues found that whereas children older than 6 years can recognize familiar faces despite within-person facial variability, their recognition of unfamiliar faces continues to develop between 4 and 12 years of age (Laurence & Mondloch, 2016). Matthews et al. (2018) found that exposure to how faces vary facilitates children’s perceptual matching of previously seen faces. Baker et al. (2017) found that 6- to 13-year-old children require exposure to more within-person variability than adults to learn a newly encountered face. Therefore, children are less efficient than adults at learning faces from variability, although it is unclear why.
To our knowledge, no studies have examined how infants perceive faces when faces incorporate a wide range of natural variations in appearance. Most infants develop within a rich visual environment that requires them to cope with face variability to successfully recognize important faces (e.g., caregivers), yet it remains unclear how this ability develops. Using single face images, or images that vary across a single dimension (e.g., viewpoint or facial expression), past studies revealed that within days of birth, infants are able to recognize their mother’s face (Bushnell, 2001) and can recognize unfamiliar faces after short familiarization periods (Pascalis & de Schonen, 1994). However, early identity recognition is fragile: Newborns do not recognize their mother’s face when the hair is masked (Pascalis et al., 1995), young infants’ face recognition is disrupted by the addition of paraphernalia (Bulf et al., 2013), and there is mixed evidence about whether young infants can recognize an unfamiliar face across transformation in viewpoint (Cohen & Strauss, 1979; Turati et al., 2008). In general, researchers agree that the ability to recognize faces across single transformations (e.g., in viewpoint or facial expression) becomes increasingly robust by 6 to 7 months of age (Bornstein & Arterberry, 2003; Kobayashi et al., 2014). Thus, infants show some limited capability to cope with variability in appearance. However, no studies have investigated identity recognition in infancy using face stimuli that approximate what infants see in daily life (i.e., faces that vary across multiple dimensions concurrently, including expressions, lighting, pose, hairstyle, and background context).
Statement of Relevance
Face recognition in the real world is challenging. Faces vary naturally in appearance because of changes in the face itself (e.g., expression) and changes in the surrounding context (e.g., lighting). We know little about how humans develop the ability to learn faces despite naturalistic facial variability. The current study was the first examination of attentional mechanisms underlying adults’ and infants’ naturalistic face learning. Participants viewed dynamic videos of faces that varied in appearance. Using eye tracking and a novel facial-tracking program, we performed spatial and temporal analyses of participants’ face scanning. Infants showed adultlike prioritization of face over nonface regions, yet overall, they showed less ability to resist environmental distractions. These results highlight that attentional mechanisms critical for successful face recognition in the real world continue to develop beyond the first year. The innovative facial-tracking program introduced here shows significant promise for future research.
In the present study, we intentionally introduced a wide range of naturalistic within-person variability in facial appearance and conducted the first examination of the attentional mechanisms underlying adults’ and infants’ naturalistic face learning using eye tracking. We familiarized adults and 6- to 12-month-old infants with naturalistic videos of models reading a storybook for 1 min; the videos captured either high or low variability in models’ appearance. Later, participants viewed the learned model paired with a novel model to test recognition. To process large-scale video eye-tracking data (containing millions of data points), we developed a novel Python-based dynamic facial-tracking program. This program allowed us to automatically place dynamic areas of interest (AOIs) on models’ facial features along with models’ frame-by-frame movement in the video and to perform temporal analysis of adults’ and infants’ eye movements during dynamic face learning with extremely high efficiency. Applying this novel program in combination with eye tracking, we specifically asked how internal (i.e., eyes, nose, mouth) and external (i.e., hair, neck, background information) visual cues attracted visual attention during naturalistic face learning and whether this affected learning of faces differently in infants and adults.
Method
Participants
Forty-eight young adults (44 female; age: M = 21.55 years, SD = 4.90, range = 17–42) and forty-eight 6- to 12-month-old infants (20 female; age: M = 261.17 days, SD = 51.85, range = 180–363) were recruited from the Ryerson Psychology Research Pool and from the Ryerson Infant and Child Database, respectively. All adult participants had normal or corrected-to-normal vision. The adult sample comprised White (n = 16), East Asian (n = 11), South and Southeast Asian (n = 11), Black (n = 8), and mixed race (n = 2) participants. Data from eight infant participants were excluded from analysis because of fussiness (n = 2), failure to find the pupil (n = 2), calibration failure (n = 3), or experimental error (n = 1). The final infant sample comprised White (n = 24), East Asian (n = 5), South and Southeast Asian (n = 2), Black (n = 1), and mixed race (n = 8) participants. All infants were born between 37 and 42 weeks’ gestational age. Parents reported that none of the infants had been diagnosed with any visual impairments or developmental delays.
An a priori power analysis indicated that our experimental design required 54 participants to uncover an effect size (f) of .25 (similar to the effect size found by Xiao et al., 2015, who showed developmental changes in eye tracking of dynamic faces across infancy) in a 2 (within subjects) × 2 (between subjects) analysis of variance (ANOVA) given an α of .05 and 95% power (correlation among repeated measures = .5, no nonsphericity correction). We purposely oversampled with a goal of testing 48 participants per age group, anticipating that some participants would not be included in the final analysis, and data collection continued until this goal was reached. Our final sample size (N = 88), after we excluded data from participants as described above, exceeded the sample size required as indicated by the a priori power analysis.
Apparatus
The EyeLink 1000 Plus (SR Research, Mississauga, Ontario, Canada), sampling at a rate of 500 Hz (16-mm lens), was used to track adults’ and infants’ monocular eye movements using a remote-desktop configuration. Under optimal conditions, the EyeLink has an accuracy of 0.5° and a tracking range of 32° × 25° (horizontal × vertical). Remote tracking allows head movements within a 22 cm × 18 cm × 20 cm (horizontal × vertical × depth) space without compromising accuracy. The tracker camera and infrared illuminator box were mounted on an adjustable arm below an attached 23-in. display monitor. A target sticker was placed on the participant’s forehead to track head distance, position, and movement. A Dell monitor, with a screen resolution of 1,920 pixels × 1,200 pixels and a refresh rate of 60 Hz, was used to present the task.
Stimuli
Video stimuli for familiarization
We made two dynamic videos of each of eight White female models reading the storybook Where the Wild Things Are (Sendak, 1963): one low-variability video and one high-variability video, each 1 min long. We chose 1 min for the length of the familiarization video because previous studies examining infants’ processing of moving faces used comparable familiarization times (Bahrick et al., 2002; Coulon et al., 2011; Xiao et al., 2015). Additionally, previous studies examining face learning across variability demonstrated that adults show efficient face learning after 1 min of exposure to videos similar to those used in the current study (Baker et al., 2017; Zhou et al., 2018). Models were filmed with a Sony α NEX-5 camera with an 18-mm to 55-mm lens. Each model was filmed in three separate scenes that were used for both low-variability and high-variability conditions (see Fig. 1). In each of the filming scenes, we systematically manipulated the filming distance, viewing angle, lighting conditions, models’ hairstyle, and makeup intensity (see Table 1). For Scene 1, models were filmed from a moderately close low angle (i.e., from below) in soft lamplight with the light source out of the video frame. Models had their hair down and behind their shoulders and wore no makeup. Scene 2 was filmed at a straight angle, farther away from the model. A central overhead white light was used as a light source. Models tied their hair back loosely and wore a moderate amount of makeup (eye liner, light lipstick only). Scene 3 was filmed from a top angle at a medium distance from the model. The models were filmed in front of an image of a public park; a bright white light was directed from the front of the model and some natural light came from the window of the filming room. Models wore a high ponytail and heavy makeup, including liquid foundation, blush, eyebrow fillers, eye shadow, face highlighter, and heavy lipstick. For consistency, one research assistant applied makeup to all of the models for Scenes 2 and 3, and all models were draped with a black cloth around their shoulders and filmed for 1 min in each of the three scenes. For all of the scenes, the book was not included in the frame to ensure that the models would make eye contact with the camera.

Screenshots demonstrating the appearance of two models in low-variability (left) and high-variability (right) videos in the familiarization phase (top) and in the accompanying static photos used in the testing phase (bottom), in which the learned model was paired with a novel model. Note that each participant learned two models, but each model was learned in only one type of variability (e.g., Model 1 was learned in a low-variability video and then Model 1 was tested against a novel identity; Model 2 was learned in a high-variability video and then Model 2 was tested against a novel identity). For illustration purposes, both high- and low-variability versions are shown for both models.
Parameters Manipulated During Filming of Models to Create Low-Variability and High-Variability Videos
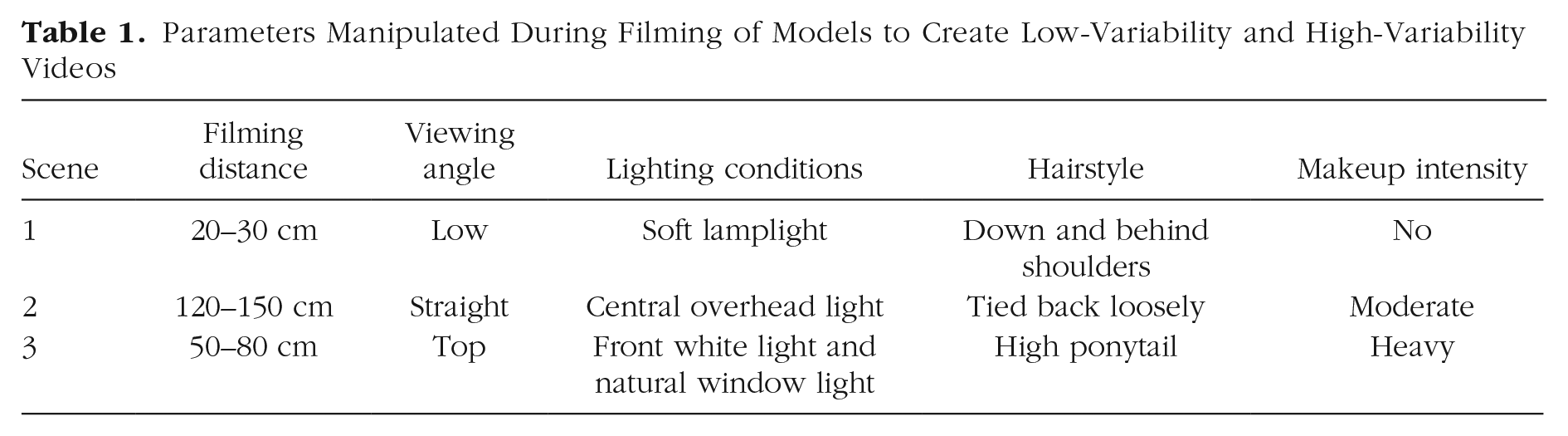
To create the high-variability video, for each model, we cut 20 s from each of the three scenes and combined them into one video that was approximately 1 min in length. The order of the three scenes was the same for all high-variability videos. The high-variability videos captured extensive variability in background and in the models’ appearance associated with factors related to the models themselves (e.g., makeup) as well as external factors (e.g., lighting, distance). A soft 40-ms fade between cuts was applied to simulate a natural transition between sections. To make the low-variability videos, for each model, we spliced the entire Scene 1 video into three 20-s sections and then combined them. Therefore, each low-variability video was also 1 min in length and contained fade transitions between sections but captured only minor changes in models’ appearance (e.g., expression, head movement). The other factors, including filming distance, angle, lighting, hairstyle, and makeup, remained constant. To eliminate the effect of speakers’ voice on identity perception, we muted the sound in all videos.
Static stimuli for testing
The testing stimuli were pairs of static face images (see Fig. 1), one of which was the learned face and the other a novel face that matched on physical similarities. The novel face was one of the eight models who was not seen in the familiarization phase (see the Supplemental Material available online). All models wore no makeup and made a neutral expression in photographs that were taken in our laboratory. The face images were then cropped into an oval (10.62 cm × 12.7 cm) so that the upper neck, ears, and a portion of the upper hairline were the only visible external features around the face. The two face images in each pair were separated by 20 cm and were presented on a black background (67.73 cm × 42.33 cm). The brightness of the two faces was adjusted to approximately the same level.
Procedure
This study received clearance from the Ryerson University Research Ethics Board. Testing of each participant started with a 3-point calibration procedure to guarantee eye-tracking accuracy (Farroni et al., 2007). During the calibration, a colorful and animated cartoon character was presented with sound on the screen. Calibration was achieved when participants successfully fixated at three locations (top center, left, and right corner). If any validation points resulted in an error value greater than 1.0°, participants were recalibrated. Following successful calibration and validation, the task was immediately initiated.
The task was divided into two trials, each of which included a familiarization phase and a testing phase. The eight models were paired, and each participant was randomly assigned to one of the four learning-model pairs: Models 1 and 2, Models 3 and 4, Models 5 and 6, and Models 7 and 8. The pair to which a participant was assigned determined which models served as the familiarization stimuli. In each of the model pairs, the low-variability video was presented for one, and the high-variability video was presented for the other (e.g., Model 1 in low-variability video, Model 2 in high-variability video). In each particular pair, the model who served as the high-variability model was randomized across participants. Therefore, each participant was familiarized with both high-variability and low-variability videos (with different models), and the presentation order (high-variability video first vs. low-variability video first) was counterbalanced across participants. This resulted in a total of eight different conditions, and each participant was randomly assigned to one of the eight conditions, which determined model pair and variability order (see the Supplemental Material).
Following familiarization, a test phase displayed the static faces of the familiarized model and a novel model. The left/right position of the learned and the novel models in each face pair was randomized on the first test trial, and then their left/right position was reversed on the second test trial. As in numerous previous studies of infant face recognition, each trial was presented for 10 s, resulting in a total of 20 s for the testing phase. Five- to 10-s test trials are commonly used in studies of infant face perception (e.g., Heron-Delaney et al., 2011; Kelly et al., 2007; Quinn et al., 2020). The images were displayed in the vertical center of the screen, aligned to the left and right sides. An attention getter was displayed between test trials to orient the participants’ attention to the center of the screen.
The task was presented in a dimly lit room with a screen brightness level of 60%. After providing consent, participants sat (infants were seated on their caregiver’s lap) at a distance of approximately 50 cm from the display monitor so that each static image subtended 25.3° × 32.0° (width × height) of visual angle at the sides of the screen. After the task, adults filled out a demographic questionnaire, and infants’ parents filled out an additional questionnaire assessing infants’ daily exposure to facial within-person variability (see the Supplemental Material).
Data analysis
Following many past infant eye-tracking studies using the EyeLink 1000 Plus, we used the fixation events that were determined by the host software. Specifically, the EyeLink online-parsing program computes fixation events by using a saccade-picking algorithm that designates fixations as different from saccades and blinks on the basis of acceleration, instantaneous velocity, and gaze-motion thresholds. Saccades were defined as eye movements that exceeded 0.2° motion, 40°-per-second velocity, and 8,000°-per-second2 acceleration. Blinks were defined as the time at which the pupil in the eye-tracking camera was missing for a minimum of three consecutive samples. Fixations were defined as times between saccades not containing blinks. These saccadic thresholds are preset for a typical eye-tracking task and are commonly used for remote or head-free tracking with the EyeLink 1000 Plus system (for online-parsing details, see EyeLink 1000 Plus User Manual; SR Research, 2013). Fixation events with durations less than 80 ms were considered contaminated with noise and were removed (Holmqvist et al., 2011).
Dynamic AOIs for learning faces
Traditional manual placements of AOIs used in past eye-tracking studies primarily apply to static image stimuli. However, placing AOIs manually for the dynamic stimuli in the current study would have been a highly time-consuming procedure requiring enormous work and trained eye-tracking experts (i.e., 6 AOIs × 1,800 video frames × 2 models × 88 participants) and yet would have suffered from inevitable human errors (e.g., fatigue, lack of concentration). To overcome these limitations, we developed an automatic Python-based dynamic facial-tracking program to process large-scale video eye-tracking data applying a widely used facial-detection-and-mapping technique (Sagonas et al., 2013, 2016). Crucially, this program can automatically place dynamic AOIs on models’ facial features along with models’ frame-by-frame movements in the learning videos and perform time-series analysis of the fixations that fall into specific AOIs regardless of the changes in models’ appearance. Specifically, for each video frame, a facial-landmark detector was used to produce 68 (x, y) coordinates (reference points) that map to specific facial structures of learning models (Ranjan, 2017). These 68 reference-point mappings were generated by training a shape predictor on the labeled 300-W data set (designed by the Intelligent Behavior Understanding Group [iBUG] at Imperial College London; Sagonas et al., 2013, 2016).
The iBUG 300-W data set was chosen because it consists of a large number of naturalistic face images (more than 3,000 images for training set and 2 × 300 images for testing set) that were captured in totally unconstrained real-world settings (both indoor and outdoor scenes, such as at a party, a conference, and protests), and these in-the-wild face images show a variety of naturalistic facial variations such as different poses, spontaneous expressions, illumination, background, occlusion, and image quality. Critically, the annotation of the 68 reference facial landmarks used in the iBUG 300-W has been shown to be highly accurate despite the highly variable nature of the training face images, making the iBUG 300-W one of the most widely used data sets in the face-detection domain (Sagonas et al., 2016).
The generation of 68 reference points and the face-mapping process were automatically repeated for each of the 1,800 video frames (1 min) for both high- and low-variability videos and for each of the eight learning models. This process enabled the dynamic facial-tracking program to automatically extract facial features, estimate head pose, and detect expressions and eyeblinks, making the processing of the large-scale video eye-tracking data set (containing millions of data points) highly efficient. Indeed, as shown in the demonstration video (see Fig. 2 for link to video), the facial-landmark detection of the dynamic facial-tracking program is highly accurate. In addition, we compared the performance of the dynamic facial-tracking program and performance of manual AOI placement on three randomly selected face images; the mean overlapping areas between automatic and manual AOIs were all greater than 97.37%, indicating that the dynamic facial-tracking program performed reliably. An illustration of our dynamic AOIs using 68 reference-points mapping is shown in Figure 2. Python codes for the facial-tracking program are freely available from the Corresponding Author, X. Zhou.
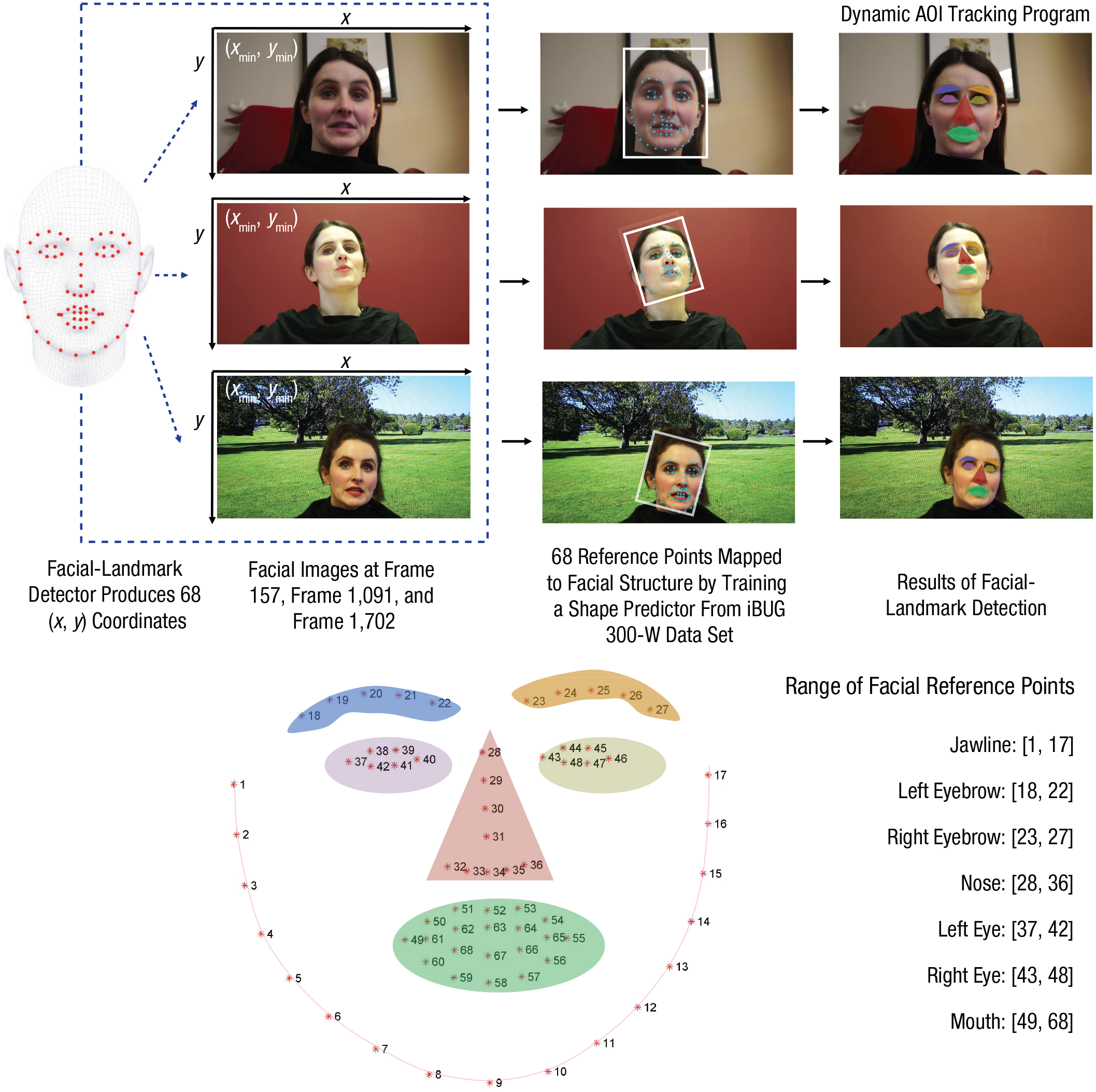
Procedure for mapping facial reference points (top) and dynamic areas of interest (AOIs; bottom) used in the familiarization phase. Sixty-eight facial reference points were mapped to each model’s face at Video Frames 157 (from Scene 1), 1,091 (Scene 2), and 1,702 (Scene 3) using the dynamic facial-tracking program. The dynamic areas of interest (AOIs) generated via the mapping of the 68 reference points is shown at the bottom. An MP4 video showing the final facial-landmark-detection results can be accessed at https://osf.io/fwypd/. iBUG = Intelligent Behavior Understanding Group.
Static AOIs for testing faces
For each model, we created six separate AOIs for the (a) entire head, (b) entire face (approximately 72.89% of the head), (c) left eye (3.09%), (d) right eye (3.09%), (e) nose (4.66%), and (f) mouth (5.07%; see Fig. 3). Fixations on the left and right eyes were combined as fixation on the eyes region for data analysis. The size of the AOIs was adjusted across models to best fit the model’s facial configuration. Each AOI was slightly bigger than the corresponding facial features to allow for the sampling variations in eye-tracking precision.
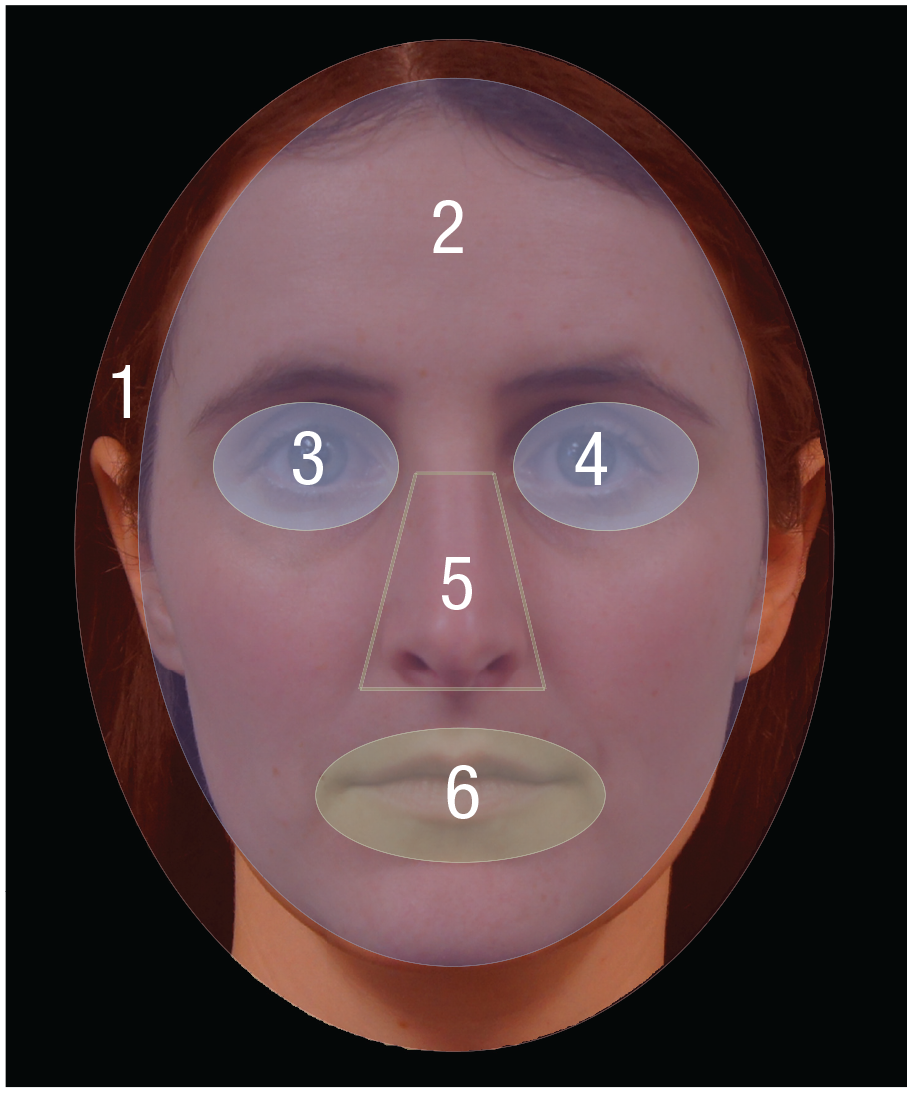
Illustration of the areas of interest (AOIs) used in the testing phase. AOIs were created for the (1) entire head region, (2) face region, (3) left eye, (4) right eye, (5) nose, and (6) mouth.
Results
The average calibration accuracy across the adult and infant samples was 0.42° and 0.61° of error, respectively. Precise calibration values were unavailable for two infants; however, the task was never initiated if an infant had poor calibration.
Familiarization phase (dynamic video)
First, we examined how much time infants and adults directed toward the screen during the familiarization phase as a measure of attentiveness during learning. On average, infants spent 63.79% of their time (M = 38.27 s, SE = 1.90) and adults spent 88.4% of their time (M = 53.05 s, SE = 1.63) looking at the video during the familiarization phase. This was true for both low-variability videos (75.93% of time on screen; M = 45.56 s, SE = 1.19, across age groups) and high-variability videos (76.27% of time on screen; M = 45.76 s, SE = 1.84, across age groups). Although there was a significant difference in infants’ and adults’ attention during familiarization (p < .001), both age groups were attentive during learning.
Next, we examined fixation to various aspects of the familiarization stimuli. The relative areas of facial features, the face, and the nonface region changed dynamically across videos because of models’ facial movements; if participants directed their fixations randomly across stimuli, areas of the stimulus that are larger (e.g., nonface region) would receive more fixations than areas of the stimulus that are smaller (e.g., face region) by chance alone (Carter & Luke, 2020). Thus, to reveal true patterns of visual attention, it is critically important to adjust fixation counts within AOIs by weighting them relative to the area of the screen. Considering this, we calculated the fixation counts within an AOI on the basis of its weighted area. For example, if a participant had 10 fixations to each of the face and nonface regions, and the sizes of the face and nonface regions in that specific video frame were 20% and 80% of the whole screen, respectively, then the fixation counts in that video frame were transformed by dividing the fixation count by the percentage area, resulting in area-weighted fixation counts of 50 (10/20%) and 12.5 (10/80%) for the face and nonface regions, respectively. Averages of area-weighted fixation counts across 1,800 video frames were then calculated for each AOI, each variability condition, and each model. Except where specified, all of the values that we report below reflect area-weighted fixations.
Preliminary analyses revealed no effect of model pair, F(3, 75) = 0.72, p = .544, η p 2 = .03, or learning order (high variability first or low variability first), F(3, 75) = 0.01, p = .957, η p 2 = .01, on the mean area-weighted fixations for high-variability and low-variability videos; therefore, data were collapsed across testing orders and model pairs for further analyses.
Face versus nonface area
To examine whether variability type influenced participants’ attention to the face versus nonface regions (i.e., ears, neck, hair, and background area), we conducted a mixed ANOVA with AOI (face vs. nonface) and variability (high variability vs. low variability) as within-subjects factors and age (adults vs. infants) as a between-subjects factor. Significant effects were followed up with Bonferroni-corrected pairwise comparisons. We found significant main effects of AOI, F(1, 81) = 671.33, p < .001, η p 2 = .89; variability, F(1, 81) = 37.14, p < .001, η p 2 = .31; and age, F(1, 81) = 94.61, p < .001, η p 2 = .54. Participants allocated more area-weighted fixations to the face region (M = 580.59, SE = 21.14) than the nonface region (M = 19.59, SE = 1.90) and more area-weighted fixations in high-variability videos (M = 342.40, SE = 14.59) than low-variability videos (M = 257.78, SE = 9.98). Adults (M = 401.22, SE = 13.50) made more area-weighted fixations than infants (M = 198.96, SE = 15.81). Notably, we found a significant interaction between AOI and variability, F(1, 81) = 38.04, p < .001, η p 2 = .32.
Although the AOI × Variability × Age interaction was significant, F(1, 81) = 6.53, p = .012, η p 2 = .08, follow-up tests confirmed a similar effect in both age groups, whereby variability type influenced participants’ fixations on the face region (ps < .001) but not on the nonface region (ps > .900). Specifically, area-weighted fixations were greater for faces in high-variability videos (M = 703.20, SE = 39.24) than low-variability videos (M = 523.20, SE = 27.30), t(82) = 6.43, p < .001, Cohen’s d = 0.71. However, fixations on the nonface region did not significantly differ for high-variability videos (M = 18.71, SE = 2.29) and low-variability videos (M = 18.61, SE = 2.40), t(82) = 0.04, p = .968, Cohen’s d = 0.01, a pattern consistent across age groups (see Fig. 4a). This suggests that, like adults, infants between 6 and 12 months of age were capable of directing their attention to highly variable faces despite the presence of increased variability in the background context in the high-variability condition. There was also a significant interaction between AOI and age, F(1, 81) = 97.84, p < .001, η p 2 = .55. Adults (M = 788.80, SE = 32.85) fixated the face region significantly more than infants (M = 372.38, SE = 20.43), t(81) = 9.85, p < .001, Cohen’s d = 2.19, and infants (M = 25.55, SE = 2.98) fixated the nonface region significantly more than adults (M = 13.63, SE = 2.41), t(81) = −3.13, p = .002, Cohen’s d = 0.70. Nevertheless, both adults and infants demonstrated a clear face over nonface scanning pattern during face learning (ps < .001), and this pattern was similar for high-variability and low-variability videos.
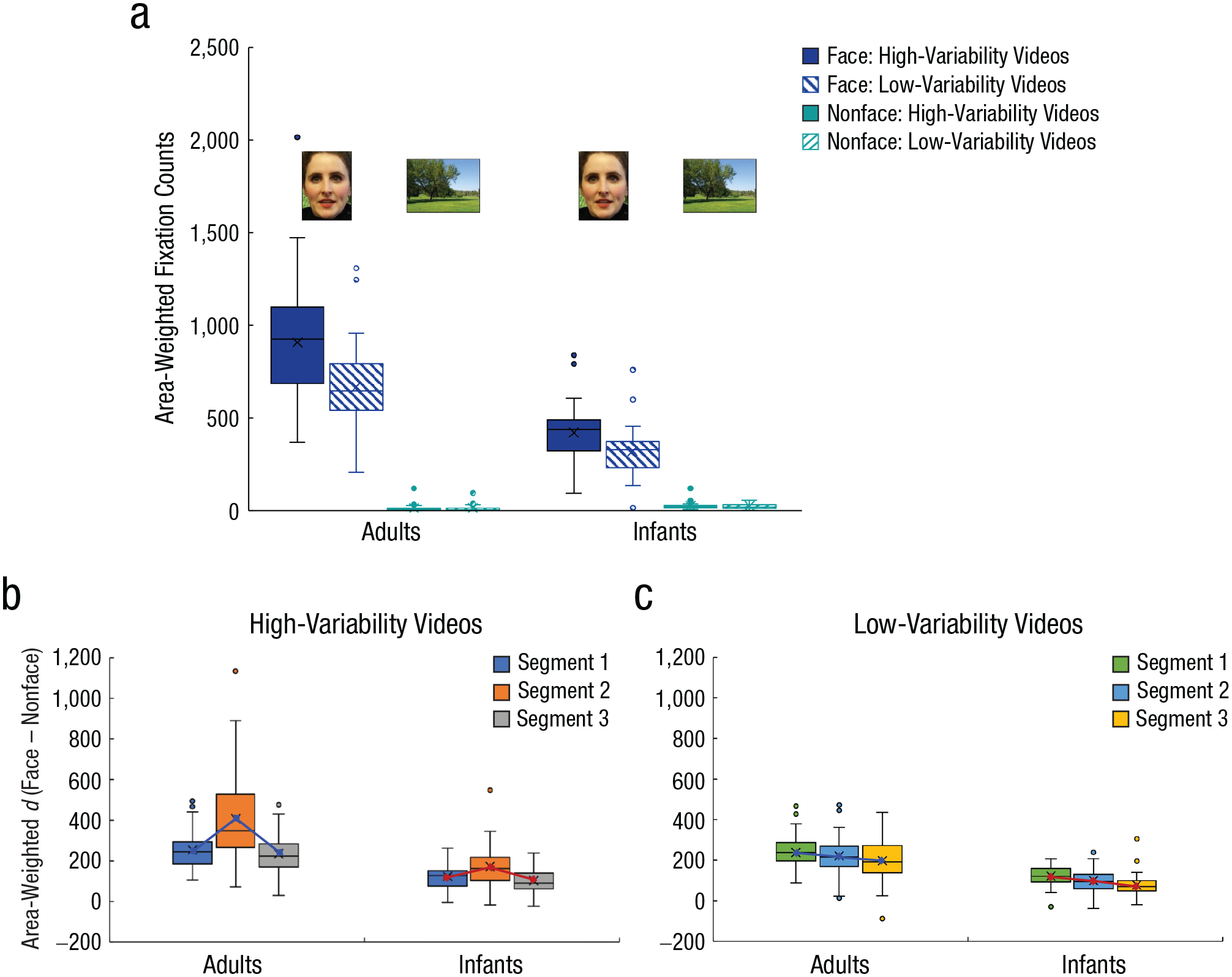
Area-weighted fixation counts and differences in fixation counts for the face and nonface regions. Adults’ and infants’ area-weighted fixation counts (a) are shown separately for face and nonface regions in high-variability videos (solid bars) and low-variability videos (patterned bars) during face learning. Adults’ and infants’ differences in fixation counts (ds) between the face and nonface regions during the first 20 s (Segment 1), second 20 s (Segment 2), and last 20 s (Segment 3) of learning are shown separately for high-variability videos (b) and low-variability videos (c). In all panels, the midline and X in each box represent the median and mean, respectively. The bottom and top of each box respectively indicate the first and third quartiles. Points displayed beyond the end of each whisker are outliers. Note that in (a) we use one of the background pictures (a park) as a demonstration of the nonface region. However, the nonface regions defined in our learning videos included both variations in models’ external features (hair, neck, shoulders) and variations in the background.
Because the 1-min familiarization videos consisted of three segments, each lasting for 20 s, we explored whether the pattern of increased fixation on the face over nonface region in both age groups changes over time and whether it was affected by variability type. To do so, we calculated the difference score (d) between area-weighted fixations on face and nonface regions for each participant by subtracting fixations on nonfaces from fixations on faces. A greater d indicates a greater number of fixations on the face area and a decreased number of fixations on the nonface area, adjusting for the area of each region, reflecting increased attention to the face over the nonface region. We then conducted a mixed ANOVA with the video segment (first 20 s, second 20 s, third 20 s) and variability type as within-subjects factors and age as a between-subjects factor. All of the main effects were significant (ps < .001). There was a significant Age × Segment interaction, F(2, 162) = 6.39, p = .002, η p 2 = .07, and a significant Segment × Variability interaction, F(2, 162) = 24.89, p < .001, η p 2 = .24. These effects were qualified by the significant Age × Segment × Variability interaction, F(2, 162) = 5.11, p = .007, η p 2 = .06. Follow-up tests revealed that the effect of segment and variability differed for infants and adults (ps < .013). Specifically, when infants learned faces from high-variability videos, d was greater for Segment 2 than both Segments 1 and 3 (ps < .021), and there was no difference between Segments 1 and 3 (p = .150); but when they learned faces from low-variability videos, there was a linear decrease of d from Segment 1 to Segment 3, and there were significant differences among the three segments (ps < .013). For adults, patterns were similar to those in infants for high-variability videos: d was greater for Segment 2 than both Segments 1 and 3 (ps < .001), and there was no difference between Segments 1 and 3 (p = .190); but when adults learned faces from low-variability videos, there was no decrease of d from Segment 1 to Segment 2 (p = .121) or from Segment 2 to Segment 3 (p = .076) but a decrease of d from Segment 1 to Segment 3 (p = .006).
Together, these results suggest that adults’ and infants’ increased attention to face over nonface regions remained relatively consistent throughout the learning phase when participants learned faces from high-variability videos (i.e., no decrease of d throughout the three segments; see Fig. 4b). However, when participants learned faces from low-variability videos, where the facial features and background information remain relatively unchanged, infants demonstrated a clear decrease in their fixations on the face over the nonface region across time (i.e., significant decrease of d across the three segments). This pattern was less clear in adults (see Fig. 4c). To better visualize how adults’ and infants’ visual attention evolved over time for high-variability and low-variability videos, we plotted adults’ and infants’ gaze changes to the face versus nonface regions frame by frame during the entire 1-min learning period (see Fig. 5).
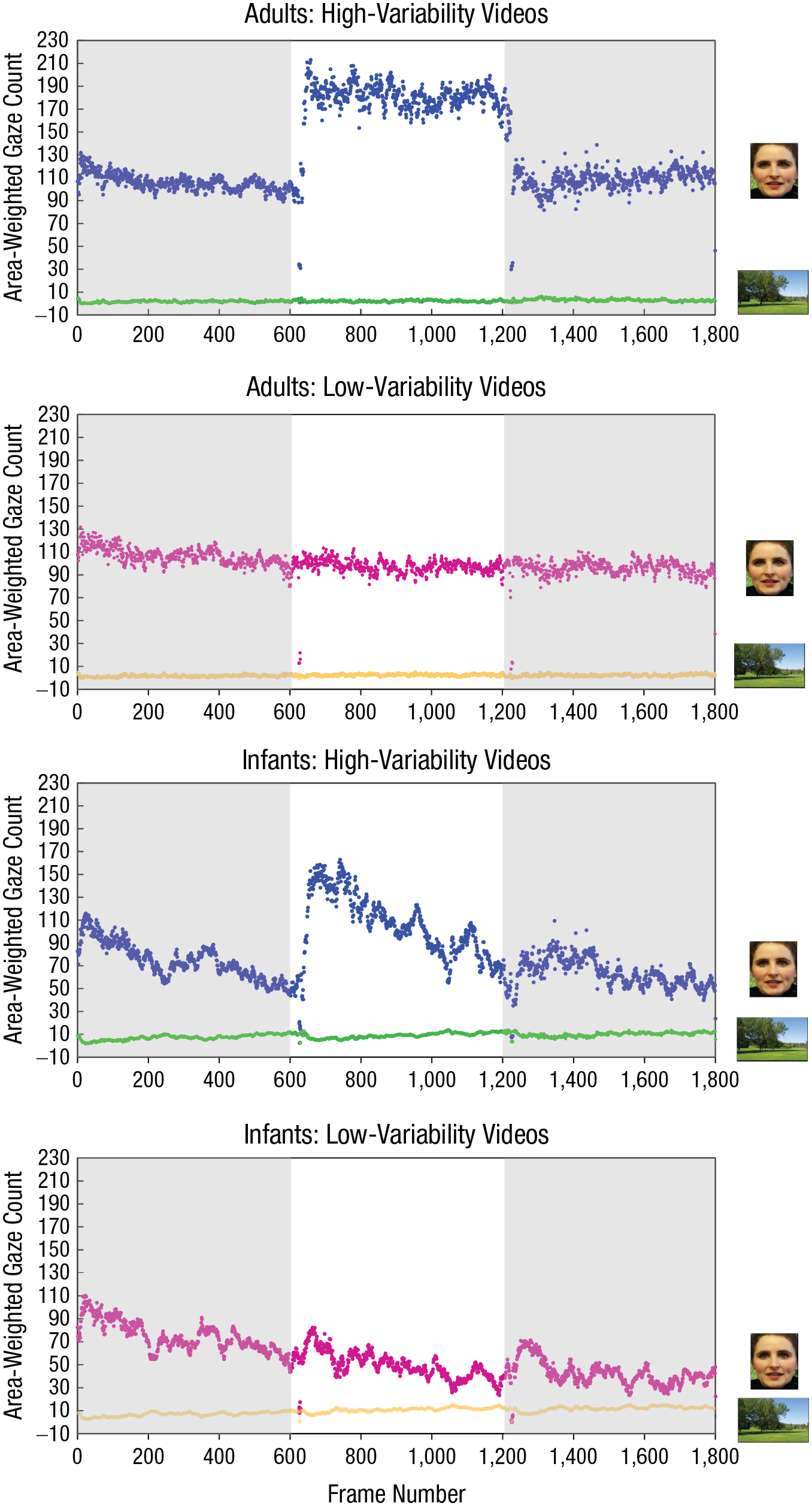
Individual frame-by-frame gaze changes to the face region and the nonface region across the 1-min familiarization phase in adults and infants. Each dot represents an area-weighted gaze count for a specific video frame, and results are shown separately for adults’ and infants’ gazes for the high- and low-variability videos. There were 30 frames per second, resulting in a total of 1,800 video frames in each 1-min learning video. Shading indicates the three 20-s segments of the video: The first segment is from 0 to 600 frames, the middle is from 601 to 1,200 frames, and the last is from 1,201 to 1,800 frames.
Facial features: eyes versus nose versus mouth
We next examined whether the spatial distribution of area-weighted fixations on facial features (eyes vs. nose vs. mouth) differed for high-variability and low-variability videos in adults and infants. We found significant main effects of AOI, F(1, 81) = 24.99, p < .001, η p 2 = .24; variability type, F(1, 81) = 13.60, p < .001, η p 2 = .14; and age group, F(1, 81) = 36.18, p < .001, η p 2 = .31. Participants allocated more area-weighted fixations to the eye region (M = 5,943.88, SE = 853.27) and nose region (M = 5,690.79, SE = 465.17) than the mouth region (M = 1,210.98, SE = 120.56; there was no difference between eyes and nose, p = .761). Fixation counts were greater in high-variability videos (M = 4,810.89, SE = 447.68) than low-variability videos (M = 3,752.88, SE = 319.07) and in adults (M = 6,455.24, SE = 469.25) than in infants (M = 2,108.53, SE = 549.52). Importantly, we found a significant AOI × Variability interaction, F(2, 160) = 4.57, p = .012, η p 2 = .05; a significant AOI × Age interaction, F(2, 160) = 6.72, p = .002, η p 2 = .08; and a significant AOI × Variability × Age interaction, F(2, 160) = 5.22, p = .006, η p 2 = .06. Follow-up tests revealed that the AOI × Variability interaction was significant for adults, F(2, 94) = 8.10, p = .001, η p 2 = .15, but not for infants, F(2, 68) = 0.34, p = .710, η p 2 = .01. Specifically, adults’ area-weighted fixation counts on the eyes and nose were greater in high-variability than low-variability videos (ps < .003), but their fixation counts on the mouth were similar in high-variability and low-variability videos (p = .944). In contrast, infants’ area-weighted fixation counts on all facial features were similar for high-variability and low-variability videos (ps > .190).
Testing phase (static face pairs)
The proportion of fixation durations within each AOI for each condition was analyzed for the testing phase. Analyses of fixation counts yielded identical results and therefore are not reported here. Here, we report analyses of fixation duration without adjusting for area because the familiar and novel stimuli were identical in size. A preliminary examination of the fixation duration to the learned and novel faces suggested increased looking to the familiar face overall. Therefore, we calculated a familiarity-preference score by dividing looking time to the learned face by total looking time to the learned and novel faces. There were no effects of testing order or learning models (ps > .558). In addition to common frequentist statistics, Bayesian statistics were used in follow-up tests to help interpret the current pattern of results. An advantage of Bayesian statistics over standard null-hypothesis significance testing is that we are able to evaluate the evidence in favor of both the alternative hypothesis and the null hypothesis in terms of Bayes factors (BF10s).
In a 2 (age) × 2 (variability) mixed ANOVA, we found a significant main effect of age, F(1, 86) = 9.60, p = .003, η p 2 = .10, but no effect of variability or interactions with this factor (ps > .457). Adults showed a significantly greater familiarity preference (M = .58, SE = .02) than infants (M = .49, SE = .01), t(86) = 3.11, p = .003, Cohen’s d = 0.67, BF10 = 13.77. 1 Follow-up tests were run to compare the familiarization-preference score with chance level (.5) in each age group. 2 Adults demonstrated a significant familiarity preference, t(47) = 3.32, p = .002, BF10 = 17.49, whereas infants did not, t(39) = −0.72, p = .475, BF10 = 0.22 (see Fig. 6). In line with commonly used standards for evidence (van Doorn et al., 2021), our Bayesian results reveal strong evidence for a familiarity preference in adults, moderate evidence for no preference in infants, and strong evidence for a difference in familiarity preference between adults and infants.

Heat maps showing an example of two adults’ (top) and two infants’ (bottom) fixations on novel faces and faces that were learned from either high-variability (left column) or low-variability (right column) videos.
Another metric of preference we compared was the length of the first fixations for the learned and novel models. Although overall, infants had longer first fixations than adults (p = .020), infants’ first fixations to the learned and novel models did not differ in length (p = .142), which is consistent with their lack of preference across the entire trial.
We next examined whether adults’ and infants’ looking duration to specific facial features (eye, nose, and mouth) during the testing phase changed as a function of variability type. Participants spent a greater proportion of time looking at the eyes (M = .17, SE = .01) than both the nose (M = .06, SE = .01) and mouth (M = .05, SE = .01), a greater proportion of time looking at facial features of the learned face (M = .10, SE = .01) than the novel face (M = .08, SE = .01, p = .031), and a greater time looking at facial features of high-variability models (M = .09, SE = .01) than of low-variability models (M = .09, SE = .01, p = .031). A significant Novelty × Age interaction, F(1, 86) = 8.20, p = .005, η p 2 = .09, suggests that whereas adults fixated longer on facial features of the learned model (M = .72, SE = .04) than of the novel model (M = .53, SE = .03), t(47) = 3.01, p = .004, Cohen’s d = 0.43, infants demonstrated a similar fixation duration for facial features of the learned model (M = .45, SE = .03) and novel model (M = .48, SE = .03), t(39) = −0.79, p = .433, Cohen’s d = 0.13. All other interactions were found to be nonsignificant (ps > .164).
Age-related change in infancy
To test whether infants’ face learning across within-person variability changes with age, we ran multiple linear regressions to predict their area-weighted fixation counts in the familiarization phase and their familiarity-preference score in the testing phase on the basis of their age in days. The analyses revealed that infants’ age in days did not predict their area-weighted fixation counts for faces learned in the high-variability videos, β = −0.51, t(33) = −1.03, p = .311, or low-variability videos, β = −0.07, t(33) = −0.15, p = .878, nor did it predict their familiarity preference in the testing phase for faces learned in the high-variability videos, β = 0.01, t(33) = 0.17, p = .854, or in the low-variability videos (see Fig. 7), β = 0.01, t(33) = −1.51, p = .142. These results suggest that there was no age-related change in face learning from naturalistic variability in 6- to 12-month-old infants in the current study.
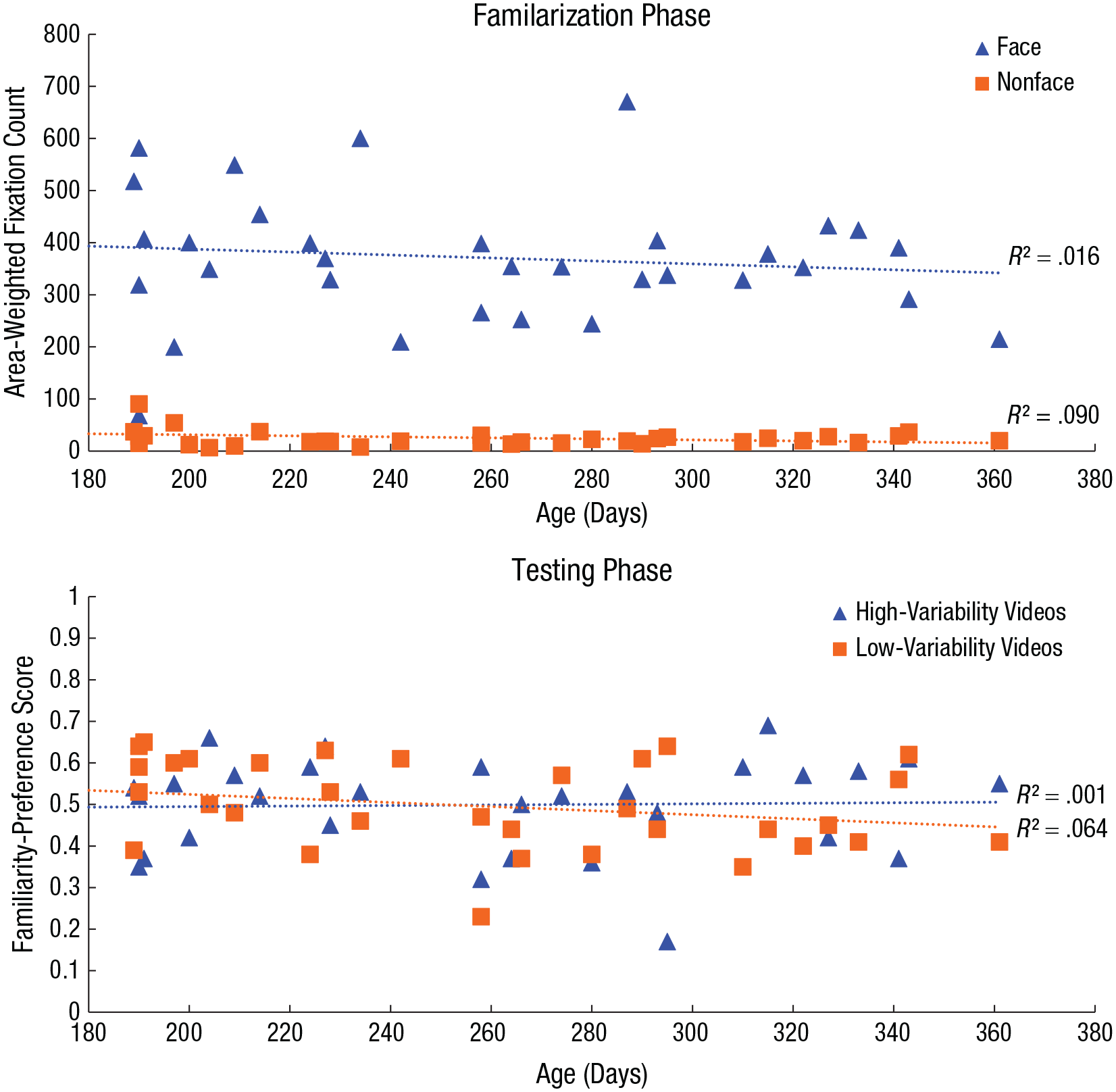
Scatterplot (with best-fitting regression lines) showing the relation between infants’ age and visual behavior. For the familiarization phase, visual behavior is indexed by the number of area-weighted fixations toward faces and nonfaces (top), whereas for the testing phase, visual behavior is indexed by the familiarity-preference score for high- and low-variability videos (bottom).
Additional analyses found that there were no effects of participant race or gender on participants’ visual behavior during either the familiarization or testing phase. Detailed results are reported in the Supplemental Material.
Discussion
Applying eye tracking in combination with the dynamic facial-tracking program, the present study provided the first examination of how naturalistic within-person variability influences adults’ and infants’ visual attention during face learning. To our knowledge, this is the first explicit investigation of face learning across naturalistic within-person variability reported in an infant population.
Within-person variability affected adults’ and infants’ visual attention to faces during learning. Faces learned in the high-variability condition attracted significantly more attention than faces learned in the low-variability condition in both adults and infants. This finding dovetails with the results of recent behavioral studies showing that adults’ and children’s face learning benefits from high variability in facial appearance (Andrews et al., 2015; Baker et al., 2017). Our study provided the first evidence that, like adults, infants between 6 and 12 months of age are capable of directing visual attention to highly variable faces, despite the presence of increased variability in the background context. Like adults, infants demonstrated a face-over-nonface scanning pattern during face learning. However, their visual attention was not fully adultlike. Overall, infants fixated on the videos less than adults; they also fixated more than adults on the nonface region but less than adults on the face region. These findings together suggest that infants’ visual attention is more likely to be attracted by variations in external features and environmental context than adults’ visual attention during face learning. This might lead to inefficient learning of newly encountered faces, thereby causing the observed lack of discrimination between the learned and novel faces in the testing phase, a point we will return to below.
Crucially, our time-course analyses provide further evidence that the extent to which external and environmental information attracts visual attention changes across learning in high-variability compared with low-variability learning conditions and in adults compared with infants. Although adults showed higher difference scores than infants overall for fixations on faces relative to nonfaces, both age groups in the high-variability condition maintained relatively consistent attention on face over nonface regions across the three segments, despite extensive variability in external and environmental information. This was not true in the low-variability condition, where difference scores decreased significantly across the three segments in infants and, to a lesser extent, in adults. This finding is somewhat counterintuitive: In a context of increased background variability, both infants and adults maintain more consistent attention on the to-be-learned face. This suggests that the context in which a face is learned influences how both adults and infants direct their visual attention toward the face in potentially surprising ways. However, it is important to note that the order of the three segments in the high-variability condition was not randomized; thus, we cannot be certain that the pattern of looking in this condition would remain the same if the segments were presented in a different order. It is also unclear whether the maintained focus on the face in the high-variability condition is driven by increased variability in the face itself or whether the increased variability in the background serves to increase attention to the face. Future studies that vary the extent of variability in the face and background independently would help to disentangle these possibilities.
During the test phase, we found a clear familiarity preference in adults, but we found no preference in infants, suggesting that infants were unable to discriminate the learned face from the novel face despite being attentive during the learning phase. This finding is consistent with a small number of past studies showing that infants demonstrate no preference between newly learned and novel faces after being familiarized to moving faces (Bahrick et al., 2002; Coulon et al., 2011; Xiao et al., 2015). It is also broadly consistent with research demonstrating that young children show difficulty recognizing even familiar faces because of the various factors that can alter a person’s appearance (Laurence & Mondloch, 2016), and learning faces from variability is significantly less efficient in children than adults (Baker et al., 2017). Researchers generally agree that infant looking preferences following familiarization reflect the amount of familiarity and are influenced by task difficulty and stimulus complexity (Hunter & Ames, 1988; Pascalis & de Haan, 2003). Given that our face stimuli incorporated significant natural variability, and we tested infants’ recognition using novel images of the learned face, a task more difficult than recognizing familiar images of learned faces, it is perhaps not surprising that we found no preference in infants. This lack of discrimination suggests that 1 min of learning was not sufficient for infants to build a robust face representation, potentially because of less efficient use of internal and external facial cues. This finding is important, especially when considered in light of the existing literature on face perception in infancy. Much of the traditional face-perception research in infancy uses static faces that minimize real-world variability; our results suggest that this approach may underestimate the true challenge of face recognition for infants in their daily life. It would be valuable for future studies to investigate how much exposure to dynamic, naturally varying faces is needed for infants to form a generalizable face representation by systematically manipulating the length of the familiarization period (e.g., 1 min vs. 3 min vs. 10 min).
Addressing exactly how facial variability facilitates face learning is beyond the scope of the current study. However, our study suggests that holding a stable focus on facial features and resisting distractions from the surrounding context are critical for efficient face learning. We argue that when face information and contextual information compete for attention, prioritizing the processing of faces while ignoring contextual distractions might particularly facilitate two aspects of face recognition. First, it might help the visual system to filter what information is critical for identification and what is not so as to enhance the accurate abstraction of an average face representation across the various factors that can alter a person’s appearance (i.e., ensemble coding; Burton et al., 2005; Davis et al., 2021; Kramer et al., 2015), consistent with Bruce’s notion of learning “stability from variation” (Bruce, 1994; Young & Burton, 2018). However, how ensemble coding is related to the use of internal and external cues requires further investigation. Second, given that visual attention orienting is linked to visual memory and learning (de Haan, 2007), it might help guide individuals to build facial representations from exemplar instances and update these instances in visual memory. Because the integration of attention and memory continues to develop between 6 and 15 months of age, as a result of the maturation of frontal circuitry (Colombo & Cheatham, 2006), we would expect an improvement in consolidating faces into stable representations in memory as infants age. However, how such ability develops calls for future investigation.
In summary, our study was the first examination of the attentional mechanisms underlying adults’ and infants’ face learning across the extensive factors that can alter a person’s appearance. It reveals that facial variability is an important factor shaping both adults’ and infants’ visual attention during face learning but that infants are overall less efficient than adults in maintaining attention on a face in naturalistic face-learning contexts, which may influence their ability to build a stable representation. Our study calls for the use of face stimuli that incorporate naturalistic within-person variability in future face-recognition research to understand how face recognition occurs in infants’ daily life.
Supplemental Material
sj-docx-1-pss-10.1177_09567976211030630 – Supplemental material for Naturalistic Face Learning in Infants and Adults
Supplemental material, sj-docx-1-pss-10.1177_09567976211030630 for Naturalistic Face Learning in Infants and Adults by Xiaomei Zhou, Shruti Vyas, Jinbiao Ning and Margaret C. Moulson in Psychological Science
Footnotes
Acknowledgements
We thank our anonymous reviewers for their comments, Marlene Ma and Eunice Kim for their assistance in data collection, and our models for contributing to video filming.
Transparency
Action Editor: Leah Somerville
Editor: Patricia J. Bauer
Author Contributions
X. Zhou developed the study concept. All the authors contributed to the study design. X. Zhou and S. Vyas conducted testing, data collection, and analyses of behavioral and eye-tracking data. X. Zhou and J. Ning developed the Python-based facial-tracking program and analyzed and interpreted the data under the supervision of M. C. Moulson. X. Zhou drafted the manuscript, and S. Vyas and M. C. Moulson provided critical revisions. All the authors approved the final manuscript for submission.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.