
Abstract
Familiar faces can be confidently recognized despite sometimes radical changes in their appearance. Exposure to within-person variability—differences in facial characteristics over successive encounters—contributes to face familiarization. Research also suggests that viewers create mental averages of the different views of faces they encounter while learning them. Averaging over within-person variability is thus a promising mechanism for face familiarization. In Experiment 1, 153 Canadian undergraduates (88 female; age: M = 21 years, SD = 5.24) learned six target identities from eight different photos of each target interspersed among 32 distractor identities. Face-matching accuracy improved similarly irrespective of awareness of the target’s identity, confirming that target faces presented among distractors can be learned incidentally. In Experiment 2, 170 Canadian undergraduates (125 female; age: M = 22.6 years, SD = 6.02) were tested using a novel indirect measure of learning. The results show that viewers update a mental average of a person’s face as it becomes learned. Our findings are the first to show how averaging within-person variability over time leads to face familiarization.
Keywords
It has long been known that the visual system treats unfamiliar and familiar faces differently. For example, matching a low-quality image of a person captured from CCTV to a high-quality photograph of them is easier when the person is familiar (Burton et al., 1999). What makes this task difficult for unfamiliar faces is that faces vary in unique ways depending on factors such as lighting, viewing angle, and aging. When a face is unfamiliar, this within-person variability has not been experienced, so different photos depicting the same person are mistaken as photos of different people (i.e., telling people “together” as opposed to telling people apart; Andrews et al., 2015). When a face is familiar, this variability is easily tolerated and recognition is successful. Exposure to within-person variability improves recognition (Jenkins et al., 2011; Ritchie & Burton, 2017), suggesting that experiencing within-person variability may be important for face learning.
Bruce (1994) explained that exposure to within-person variability leads to stability in the memorial representation of a face by allowing viewers to learn how faces change from one encounter to the next. The representation of the face is thus refined with experience. Burton et al. (2005) suggested that one candidate process underlying the formation of this stable representation is ensemble coding, a domain-general ability of the visual system to average across encounters of visually similar items such as the average diameter of a set of circles of varying sizes (Ariely, 2001) or the average orientation of a set of tilted lines (Robitaille & Harris, 2011). Accordingly, as one gains more experience with a person’s idiosyncratic variability, the representation of their face in memory is updated through averaging, increasing the likelihood that subsequent encounters with the face will lead to recognition.
Kramer et al. (2015) provided evidence that such prototypes are computed for images depicting different photos of a person’s face (see also Neumann et al., 2018; Rhodes et al., 2018; Roberts et al., 2019). In their experiment, subjects were asked whether a probe was present in a set of four photos of one individual seen a few moments prior. Subjects were as likely to indicate that they saw a composite probe made by averaging the photos in the set as they were to identify a photo that was actually in the set. This false recollection can be explained by assuming that viewers compared the composite with a mental average of the previously seen photos, finding a good match between the composite and the mental representations of both the individual photos presented in the set and their average. Interestingly, subjects were somewhat more likely to misremember a composite of unseen photos of the target face than unseen individual photos. This can be explained by assuming that a composite consisting of four unseen photos of a person will be a better match to the computed average of the seen photos than any one previously unseen photo of the individual.
Although compelling, these studies do not provide direct evidence that refinement of a mental average over time contributes to learning because familiarity is tested only once. Moreover, any plausible model of face learning must account for the fact that people sometimes learn to recognize people without conscious intent and that people will encounter nontarget identities between exposures to the target identity. However, there is evidence that averages can be created across exposures to different identities (de Fockert & Wolfenstein, 2009; Neumann et al., 2013). Similar to the work by Kramer et al. (2015), subjects were asked to indicate whether a probe face was present in a previously viewed set of faces depicting different unfamiliar (de Fockert & Wolfenstein, 2009) or familiar (Neumann et al., 2013) faces. Both found that subjects mistakenly recognized the set average as having appeared in the previous set more frequently than an unseen set’s average. Importantly, Neumann et al. (2013) showed that this was the case for both when subjects were asked to recognize the probe image, or the identity depicted in the probe image, demonstrating an ability to average across not only images but also identities. If averaging is indeed an underlying mechanism of face learning, the automatic extraction of the set average across different identities should not interfere with the automatic extraction of the average of different encounters with a target. However, it is unclear whether an average of a target’s face would emerge when distractor identities intervene.
Statement of Relevance
A familiar face can be recognized in photos in which the person is young or old, talking or laughing, wearing makeup, or sporting a beard. How do faces achieve this level of familiarity? One idea is that every time we encounter a person’s face, we update a mental average of it. Eventually, this average represents only those aspects that do not change from one encounter to the next. However, whether face familiarization results from updating a mental average, as has been suggested, is unknown. We show that people can learn to recognize a face from multiple photos of the same person interspersed among photos of other people, even unintentionally. We also show that people refine mental face averages as they become increasingly familiar. A better understanding of the mechanisms of face recognition will be important for improving forensic and security procedures that require successful face recognition, in addition to advancing theory.
Additionally, existing findings can be explained without invoking averaging at all. For example, the finding that subjects misidentify composites of seen target images as having been previously presented more often than composite probes of unseen target images (Kramer et al., 2015) would be expected even in the absence of averaging because composites of seen photos should be more effective retrieval cues for the photos averaged together to create them than composites of unseen photos. Care must be taken to ensure that improvements in performance actually reflect greater learning of the target rather than better use of retrieval cues. This is especially important when using composites as probes because as more photos are seen during training, the likelihood that at least one of them shares similarity with the probe increases.
In the present study, we wished to provide direct evidence that as people become better at recognizing a target, they build an increasingly refined mental average of the target’s face. In Experiment 1, we show that people can learn to recognize a target identity despite exposure to nontarget faces and without intention. In Experiment 2, we show that exposure to within-person variability refines a stored average of a target face over time. Most importantly, we introduce an indirect measure of face learning that is uncontaminated by the similarity between the mental representation of a face and the probe used to test for it.
Experiment 1
Any plausible mechanism of face learning must operate without intention. Recent research suggests that intention enhances spatial (Miyawaki, 2012) and word (Popov & Dames, 2022) learning by allowing observers to use strategies that facilitate selective encoding. However, no previous study has directly examined whether similar benefits are observed for faces. In previous face-learning studies, subjects knew that their memory would be tested; thus, it is unclear whether a face can be learned comparably well when subjects do not know which face they will be tested on or that there is a target face to be learned at all. Additionally, this target face ought to be interspersed among different identities to mirror how faces are naturally encountered. However, in previous studies, different photos of the target’s face were viewed either simultaneously or sequentially, with all photos of the target presented in an uninterrupted sequence (Kramer et al., 2015; Neumann et al., 2015, 2018). In Experiment 1, we aimed to demonstrate empirically whether face learning can be achieved incidentally (i.e., without conscious and deliberate intent) and despite intervening encounters with distractors before directly testing for averaging as a plausible mechanism in Experiment 2.
Method
Participants
We required 159 participants on the basis of a power analysis conducted using G*Power (Faul et al., 2009) to detect a medium effect (Cohen’s f = .25) in a between-subjects one-way analysis of variance (ANOVA) with three levels. We recruited 164 University of Regina undergraduate students with normal or corrected-to-normal vision. All procedures were carried out in accordance with the Canadian Tri-Council Policy Statement on the ethical treatment of research participants and were approved by the University of Regina Research Ethics Board. All participants signed a consent form prior to their participation, and they received 1% bonus credit toward a psychology course as compensation. During debriefing, it was determined that 11 participants were familiar with at least one of the faces, so data from these participants were discarded from the analysis, leaving data from 153 participants for analysis (88 female, 65 male; age: M = 21 years, SD = 5.24).
Materials and stimuli
Photos of 191 different identities were downloaded from the Internet to be used as intervening distractors, along with an additional 10 to 15 photos for each of the six (three female) target identities. The identities used in the study were Turkish celebrities, chosen to be unfamiliar to the Canadian participants. Ambient images in which viewing conditions (i.e., lighting, angle, expression, background, and so on) are not controlled were used as stimuli because they have been consistently shown to facilitate face learning (Andrews et al., 2017; Burton, 2013; Jenkins et al., 2011; Kramer, Jenkins, Young, & Burton, 2017; Ritchie & Burton, 2017). All images were cropped and resized to be 600 × 800 pixels. The experiment was initially programmed and conducted using MATLAB’s (The MathWorks, Natick, MA) Psychophysics Toolbox extension (Brainard, 1997; Kleiner et al., 2007; Pelli & Vision, 1997); however, because of technical limitations, the same experiment was reprogrammed using PsychoPy3 (Peirce, 2007). Ninety-four of the participants were run with the MATLAB version and the remaining 62 participants were run with the Python version. This computer program was used to perform all stimulus presentation and timing operations. The data were collected in person. All materials used in the experiment can be found at https://osf.io/fyvbh/.
Procedure
Each participant was randomly assigned to one of three conditions: incidental learning, active learning, or baseline. Whereas the participants in the learning conditions (i.e., incidental learning and active learning) were given a 40-trial training sequence for each of the six targets, the participants in the baseline condition were given only the matching task (Clutterbuck & Johnston, 2004), which was also given in the learning conditions at the end of each training sequence to measure participants’ learning of the targets. Participants in the learning conditions underwent the same procedure except for the experimental instructions and whether the first trial of each block depicted a target face. Participants in both conditions were instructed to rate the attractiveness of each face as it was presented, using a slider placed at the bottom of the screen. The attractiveness ratings served as a cover story for the participants in the incidental learning condition and encouraged participants to attend to the faces. No data were collected from the attractiveness ratings in Experiment 1. Participants in the active learning condition were additionally informed that the first face that appeared after the instructions screen belonged to the target to be learned. The participants in the incidental learning condition were blind to the face-learning aspect of the study, and whether the first trial depicted the target was randomized to decrease the saliency of the target for this condition.
An example illustration of the procedure can be found in Figure 1. Participants in the learning conditions completed six blocks of training followed by testing (i.e., the matching task). Each of the six target identities was randomly assigned to a block, and the instructions were repeated at the beginning of each block as the target identity changed. Each block consisted of 40 trials of training, and eight trials that depicted different photos of the target were randomly interspersed among the remaining 32 trials, each depicting a unique distractor identity. Distractor identities varied in gender to emulate natural conditions of learning a face, where people of different genders are seen between encounters with a target. This may make it easier to ignore distractors whose gender differs from the target’s gender. However, this would be true only for the active learning condition, where the target identity is revealed to the participants; thus, we expected this to confer an advantage for participants in that group over those in the incidental learning condition.
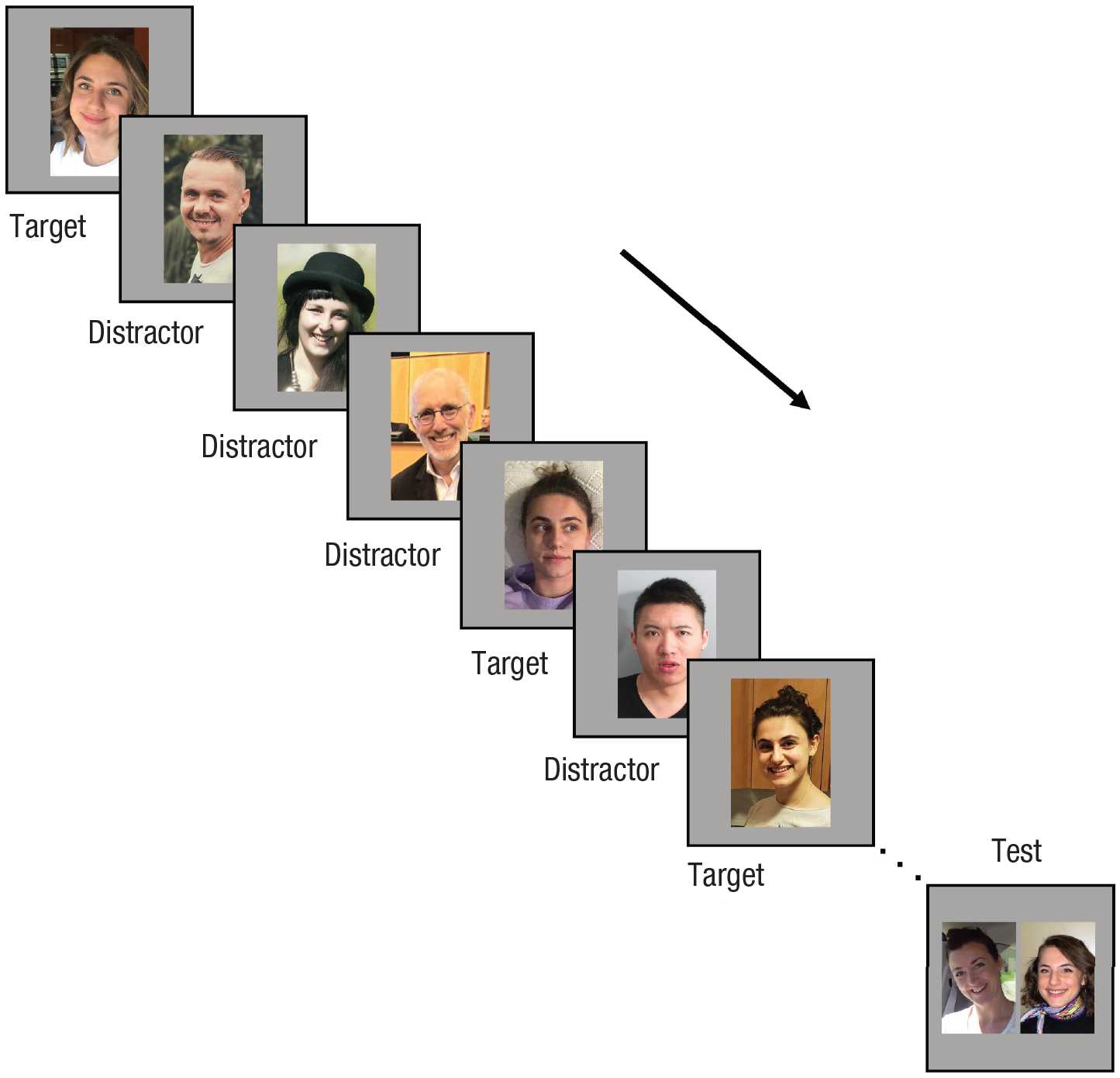
An example sequence of trials within a block. Note that the prompts shown to participants (e.g., the slider) have been omitted from the figure.
Upon completing one training sequence, the participants were given a matching task to measure learning. The matching task included a new photo of the target paired with either another new photo of the target or a new foil identity who resembled the target. Participants were instructed to indicate using a key press whether these two photos belonged to the same person. Accuracy in the matching task was recorded as the dependent variable. Participants in the baseline condition performed the matching task in isolation for six consecutive trials (i.e., one trial for each target) without completing the training sequences. A manipulation check was implemented at the end of the experiment to ensure that the participants were unfamiliar with the faces used in the study prior to the experiment.
Results
All analyses for this experiment can be found at https://osf.io/fyvbh/. Data from 153 observers were analyzed using both classic and Bayesian ANOVAs. Accuracy for each observer was analyzed in a mixed-model ANOVA with the between-subjects factor of learning condition (active learning, incidental learning, baseline) and the within-subjects factor of test type (match, mismatch) using JASP (Version 0.14.1; JASP Team, 2020); a complementary analysis of sensitivity using A′ is reported in the Supplemental Material available online. Bayes factors (BFs) were computed for each effect in the design using the default priors provided by JASP. Following Lee and Wagenmakers’ (2013) recommendations for interpreting BFs, we interpreted BF01 and BF10 values greater than 3 as moderate evidence for and against the null hypothesis, respectively. Results revealed a significant interaction between learning condition and test type, F(2, 150) = 6.35, mean square error (MSE) = 0.057, p = .002, η p 2 = .08, BF10 = 11.83 (Fig. 2). A separate analysis of match trials revealed that accuracy increased from the baseline condition to the experimental conditions, leading to a significant simple main effect of learning condition, F(2, 151) = 12.10, p < .001, BF10 = 1468.34. A Tukey’s honestly significant difference test with an alpha of .05 revealed a significant difference between the active learning (M = .80, SD = .23) and baseline (M = .56, SD = .27) conditions (95% confidence interval, or CI, for the difference = [.10, .39], p < .001, BF10 = 5333.33) and a significant difference between the incidental learning (M = .73, SD = .29) and baseline conditions (p = .006, 95% CI = [.03, .33], BF10 = 21.74). Importantly, there was no significant difference between the active learning and incidental learning conditions (p = .78); however, the Bayesian analysis did not provide evidence for or against this effect (BF01 = 2.30). No difference in performance was observed in the mismatch condition, F(2, 151) = 1.00, p = .37, 95% CI = [−.08, .22], BF01 = 6.63.
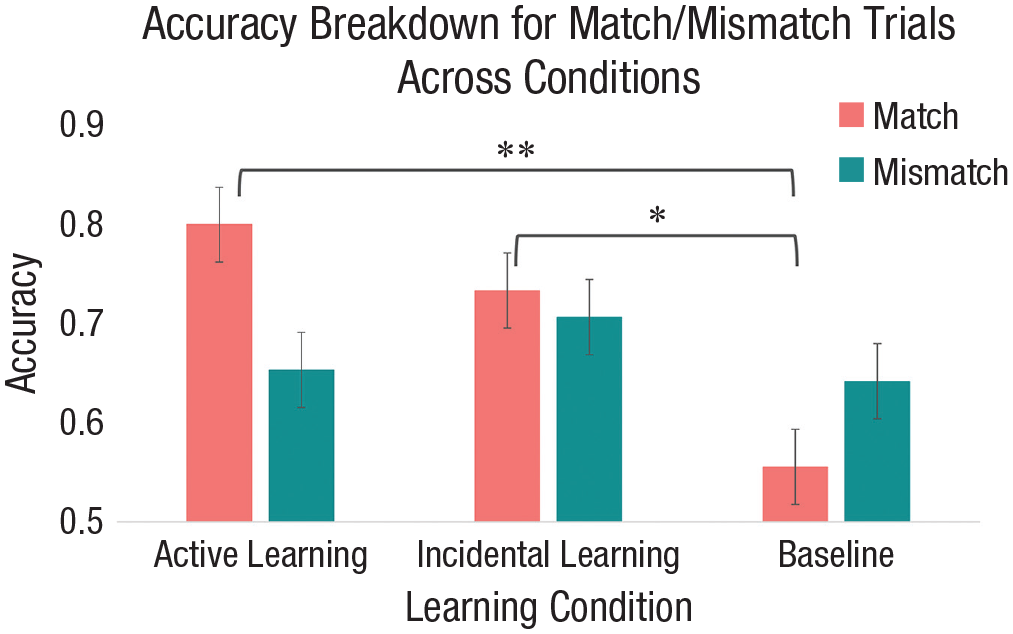
The Learning Condition × Test Type interaction. Error bars represent 95% confidence intervals. *p < .01, **p < .001.
Experiment 2
Experiment 1 confirmed that a target can be learned when the observer is unaware of the target’s identity and in the presence of intervening identities. In Experiment 2, we tested whether this was accomplished by computing and refining averages of the target images. To do so, we had observers view four sequences of photos containing different images of a single target presented among distractors as in Experiment 1. However, at the end of each sequence, rather than judging whether two photos depicted the same person, participants were instead shown a new photo of the target and a previously unseen distractor and asked to report which of the two people was shown in the previous sequence. Each target photo was a composite of either four photos that appeared in the sequence (member average) or four new photos of the target (nonmember average). We hypothesized that recognition accuracy would be higher for member average probes than nonmember average probes for Time 1 but that as participants learned the target, recognition would be less dependent on the specific images seen. Thus, the difference in accuracy was expected to continuously decrease from Time 1 to Time 4.
Because attractiveness is a relatively stable property of familiar individuals (Mileva et al., 2019), attractiveness ratings were expected to become less variable over time. As the target is learned, participants should be less likely to evaluate the attractiveness of the photo (i.e., a property that will vary with factors such as lighting, pose, makeup, and hairstyle) and more likely to evaluate the inherent attractiveness of the person shown. To determine whether this was the case, we computed the standard deviation of attractiveness ratings at each time point to obtain an implicit measure of person-specific learning that is independent of the ambient characteristics of the images themselves.
Method
Participants
To determine the desired effect size, we assumed a maximum effect size (Cohen’s f) at Time 1 of .48 as reported for Kramer et al.’s (2015) Experiment 2, which we expected would be reduced to 0 by Time 4. Thus, in the study, we assumed an average effect size ( f) of .48/4 = .12. A power analysis conducted using G*Power (Faul et al., 2009) indicated that 140 participants would be required to detect the expected two-way interaction with 80% power for a factorial ANOVA with four groups and four measurements on the repeated factor. After we excluded nine participants who were familiar with the faces shown in the study and an additional 13 participants who did not finish the study, data from 170 participants were available for analysis (125 female, 44 male, 1 nonbinary; age: M = 22.6 years, SD = 6.02). All procedures were carried out in accordance with the Canadian Tri-Council Policy Statement on the ethical treatment of research participants and were approved by the University of Regina Research Ethics Board.
Materials and stimuli
More than 800 Turkish celebrity images were gathered using Google Images. As in Experiment 1, all collected images were in color and were taken from various angles in various settings to maximize the natural variability present in the images. Because images in profile and images with objects obscuring the face cannot be averaged together, none of the images depicted the target in profile and the faces were not obscured with glasses, hands, or other accessories. The images were edited using InterFace (Kramer, Jenkins, & Burton, 2017), a software used for landmarking and averaging faces, which also crops the photos such that only the internal features of the face are shown in the resulting image.
Six identities (three female) were chosen to be targets on the basis of the number of eligible photographs available on the Internet because there needed to be 32 unique photos gathered for each target. These photos were then randomly divided into eight sets; additional details are included in the Supplemental Material. Each set contained four photos, and those photos were averaged to create eight averages per target. Furthermore, for every target, 10 foil identities that resemble the target were identified by the researcher and her assistant, who are both familiar with Turkish celebrities. Four photos were gathered for each foil identity and were also averaged using InterFace. The averages, unlike the exemplar images, were made grayscale to limit the possibility of participants using color cues (e.g., eye color) to base their judgment, as was done in Murphy et al. (2015). The resulting averages for foils were narrowed down to the best resembling four foil identities per target with a pilot study described in the Supplemental Material. Therefore, multiple photos were gathered for targets and foils. An additional 384 distractor photos were gathered for the experiment, with each photo belonging to a unique identity. The experiment was programmed using jsPsych 6.1.0 (De Leeuw, 2015), a JavaScript library for creating behavioral experiments, and was run on pavlovia.org, an online platform for running behavioral experiments. Therefore, the experiment was completed on the participants’ personal computers. All materials used in the experiment can be found at https://osf.io/fyvbh/.
Procedure
For an example illustration of the overall procedure, see Figure 3. In Experiment 2, there were six blocks for six targets. One block contained four sequences of training, each followed by testing. During training, the participants rated the attractiveness of the faces on the screen using a slider at the bottom of the screen. During testing, the participants indicated which one of the two people on the screen they had seen in the previous set. Accuracy was the dependent variable. The independent variables were (a) learning type (incidental learning, active learning), (b) image type (member average, nonmember average), and (c) time point (Time 1, Time 2, Time 3, Time 4). Crossing learning type and image type yielded four between-subjects conditions to which each participant was randomly assigned: (a) active learning–member average, (b) active learning–nonmember average, (c) incidental learning–member average, and (d) incidental learning–nonmember average. Time point, which corresponded to the four times at which participants were tested for each target, was manipulated within subjects.
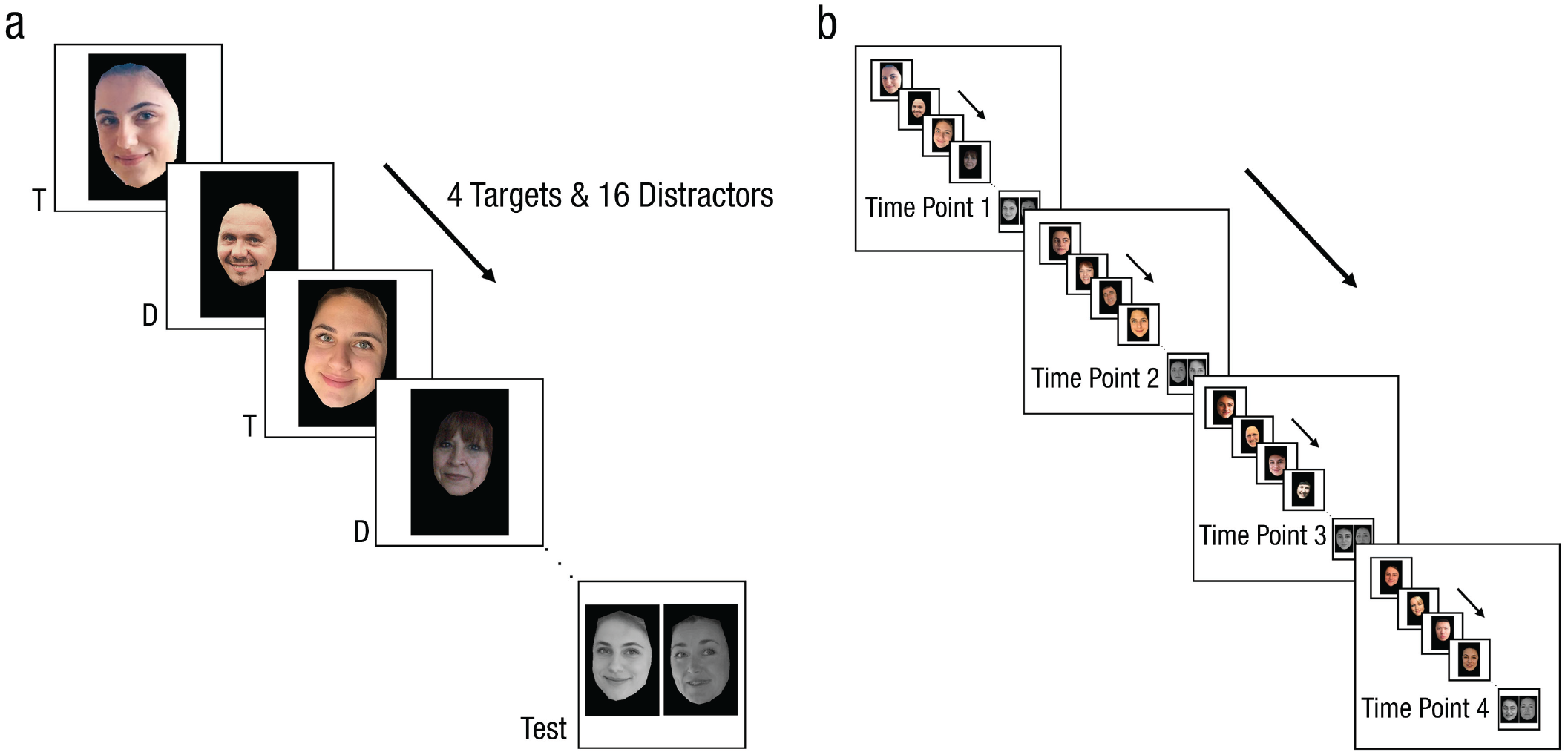
An illustration for the experimental procedure for Experiment 2. (a) An example sequence of training followed by testing. Note that the experimental prompts shown to participants, such as the slider, are not included in the illustration. T = target; D = distractor. (b) An example block made of four sequences for one target. Each sequence corresponds to a time point. The experiment was blocked by target identity; therefore, when a block was completed, a new target identity was assigned to the following block.
As in Experiment 1, participants in the active learning groups were informed that each sequence would start with a target identity that is to be memorized, whereas participants in the incidental learning groups were kept blind to the face-learning aspect of the study. Furthermore, for participants in the member average groups, learning with each target was tested using an average of the four target photos shown during training, whereas participants in the nonmember average groups were shown an average of four unseen target images at testing.
The overall procedure closely followed that of Experiment 1. However, instead of completing one training sequence and one testing trial for each target, the participants completed four consecutive training sequences, each followed by a test trial. The four sequences were blocked by target identity in a randomized order. One training sequence contained 20 trials, with four of them depicting different photos of the target randomly interspersed among 16 unique randomly chosen distractors, except for the first trial, which always depicted the target. 1 The test trial that followed each sequence asked the participants to indicate which one of the two people on the screen was seen in the previous sequence. The test trial consisted of an average target image (a member or a nonmember average) paired with an average image of a novel foil (selected with a pilot study), ensuring that participants were always asked to choose between two average images. Note that because the foils were always unseen identities, the correct response was always the target. Because the participants were tested on the same target four times, the change in accuracy across the four time points was of interest. At the end of the experiment, a manipulation check was implemented to ensure that the participants had no prior familiarity with the faces used in the experiment.
In Experiment 2, we collected data from the attractiveness ratings provided during training by using a 100-point slider (0 = not attractive at all, 100 = very attractive). Because the participants completed four training sessions for each target, with four target appearances within a sequence, we were able to compute the standard deviation of the attractiveness ratings for the targets within each sequence as a separate dependent variable. For comparison, a random subset of four distractor attractiveness ratings (i.e., ratings of four unique individuals) was pulled from each sequence, and their standard deviations were also computed. Further details of the procedure can be found in the Supplemental Material.
Results
All analyses for this experiment can be found at https://osf.io/fyvbh/. To interpret the results of Experiment 2, we considered two potential approaches that participants could take to this task. In the first, viewers might compare each probe image with their memory of previously seen target images. Presumably, member average probes consisting of four seen images of the target will serve as better retrieval cues for the target’s photos than nonmember average probes, leading to better recognition accuracy for the member average group than the nonmember average group. To succeed on this forced-choice task, however, participants needed to find only one target photo in memory that was a good match with the probe photo. Because the probe in the member average condition always comprised the four photos that were seen in the preceding sequence, and the probe in the nonmember average condition always comprised four new photos, the most straightforward prediction was that accuracy should be constant over time in each condition; we refer to this account of behavior as the match-to-recent model. However, it is also possible that as more target photos are seen, the likelihood of a good match to some photo in memory increases simply because a greater number of photos will capture more within-person variability. We refer to this as the match-to-all model to emphasize that both models assume that participants compare the probes with stored exemplars in memory without computing an average; the predictions of these models are depicted in Figure 4.
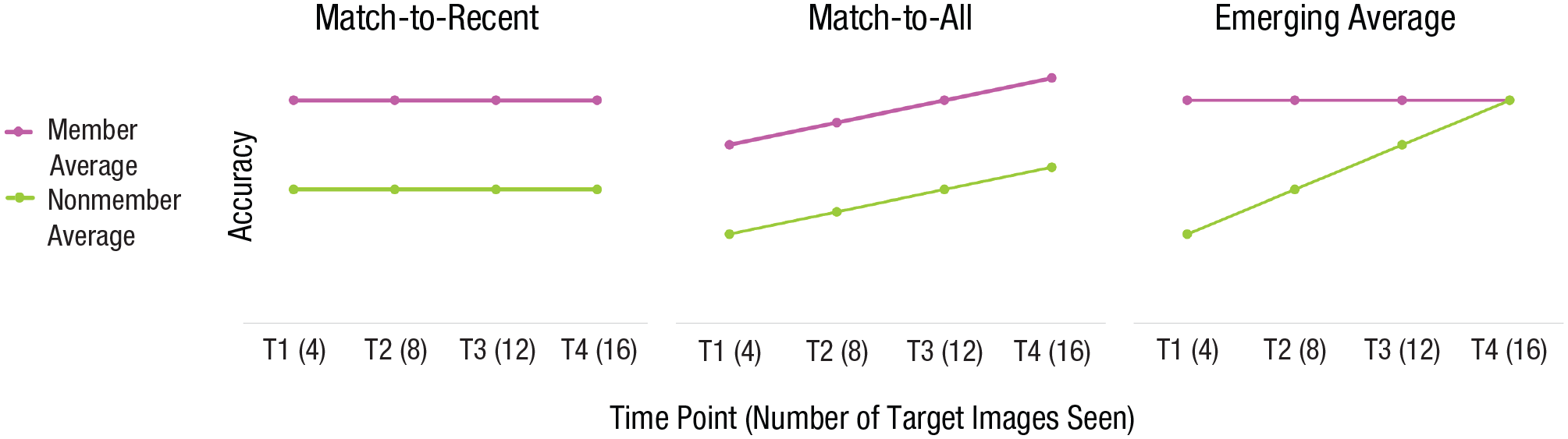
Predicted patterns of results assuming use of three different strategies. The match-to-recent and match-to-all models represent the predicted results if viewers are comparing probes with instances of targets instead of averaging them. If viewers compare the probe with the last four retained exemplars to recognize the target, performance would be constant across both conditions because the similarity of the probe to any of the four retained instances will not change over time (match-to-recent). If viewers compare the probe with all seen exemplars, performance would be expected to get better for both conditions as more targets are seen over time (match-to-all). The emerging average model represents the predicted results if viewers are updating a mental average of the targets. In that case, performance for the member average condition is not expected to improve to a great extent because the member average probe will be a good match to the emerging average representation in memory at all time points, whereas performance would improve for the nonmember average condition as the average representation is refined. T1 = Time 1; T2 = Time 2; T3 = Time 3; T4 = Time 4.
A different pattern of results is expected if observers are updating and refining an average representation of the target over time. After Sequence 1, the member average probe will presumably correspond very well with the four target photos seen in Sequence 1. However, incorporating four more target images into the mental average will likely yield a mental representation that is quite similar to the representation formed after viewing the first four images (Fig. 5, top row); adding an additional four would do little to refine this representation further. This is not the case for the nonmember average probe. Because the initial mental representation formed after viewing the first four target photos is not a particularly good match for the composite probe, incorporating an additional four images into the mental representation would likely substantially improve the correspondence between the nonmember probe and mental representation (Fig. 5, bottom row). Incorporating additional images would be expected to lead to further improvement; however, the addition of new images will yield diminishing returns, and eventually the representation emerging in the nonmember average condition should approach that formed over time in the member average condition. We refer to this model as the emerging average model; Figure 5 presents a comparison of the three models under consideration.
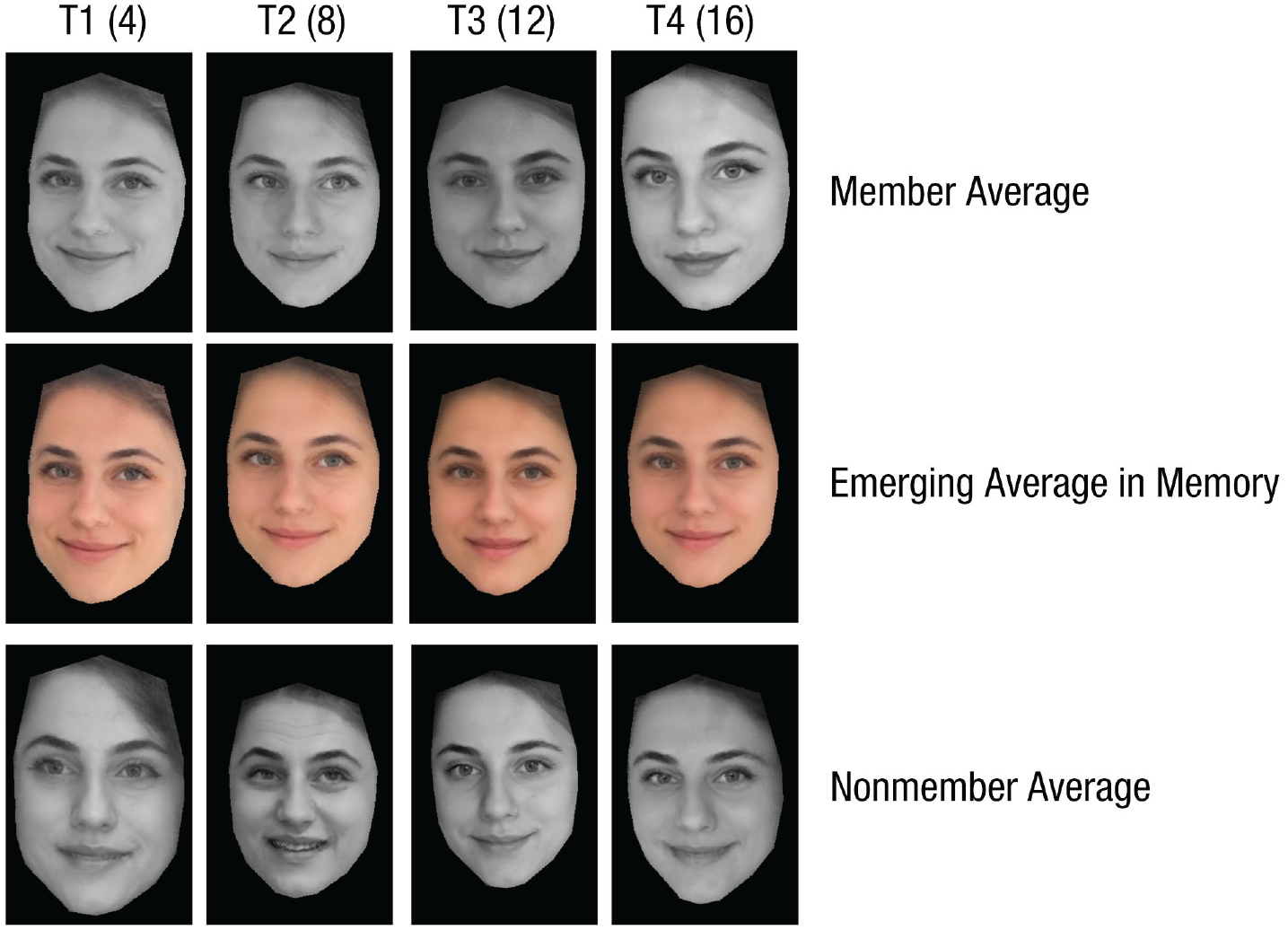
An example set of probe images used in the study. Examples of member average probes are shown at each time point (top row). Examples of nonmember average probes are shown at each time point (bottom row). Hypothesized emerging average representations in memory are shown at each time point (middle row). The memory average depicted at each time point is assumed to be an unweighted average of all items seen up to that point in time. Thus, after the first sequence, the memory average and the member average probe are assumed to be identical. The nonmember average probe, in contrast, consists of unseen images. Therefore, the emerging average in memory is initially more similar to the member average probe than to the nonmember average probe. As more images are seen, the emerging average captures invariant properties of the face, yielding a representation that corresponds increasingly well with both probe types. T1 = Time 1; T2 = Time 2; T3 = Time 3; T4 = Time 4. The number of images seen up to each time point is given in parentheses.
To determine which of the models described above corresponds best to participants’ performance, we analyzed accuracy using a 2 (learning type: incidental learning, active learning) × 2 (image type: member average, nonmember average) × 4 (time point: 1, 2, 3, 4) mixed-model ANOVA (Bayesian and classic). There was a main effect of learning type; participants in the active learning condition (M = 73%) had slightly higher overall accuracy than participants in the incidental learning condition (M = 68%), F(1, 166) = 4.12, MSE = 0.075, p = .04, η p 2 = .02, but note that the Bayesian analysis found no substantial evidence for or against such an effect of learning type (BF10 = .38). There was also a main effect of image type, F(1, 166) = 56.3, MSE = 0.075, p < .001, η p 2 = .25, BF10 > 100, resulting from significantly higher accuracy overall for the member average condition (M = 78%) than for the nonmember average condition (M = 62%). Moreover, there was a main effect of time point, F(3, 498) = 3.75, MSE = 0.032, p = .01, η p 2 = .02, BF10 = 5.69.
Importantly, there was a significant interaction between image type and time point, F(3, 498) = 4.66, MSE = 0.032, p = .003, η p 2 = .03, BF10 = 10.3. To explore this effect further, we computed a linear contrast that revealed a significant linear trend in the interaction between image type and time point, F(1, 166) = 11.74, p = .001, η p 2 = .06, indicating that the effect of image type decreased in a linear fashion over time. Independent-samples t tests corrected with the Welch correction for heterogeneity of variance and the Bonferroni correction (α = .0125 for four tests) for multiple comparisons confirmed that the effect of image type was significant at all time points. The difference was 24% at Time 1, t(166.78) = 7.83, p < .001; 17% at Time 2, t(166.78) = 5.44, p < .001; 14% at Time 3, t(167.46) = 4.26, p < .001; and 9% at Time 4, t(166.31) = 2.76, p = .006. There was no significant three-way Learning Type × Image Type × Time Point interaction, F(3, 498) = 0.50, MSE = 0.032, p = .68, η p 2 = .003, and extremely strong evidence against this possibility from the Bayesian analysis (BF01 = 394.243), suggesting that participants in both learning groups demonstrated the same pattern of learning (Fig. 6).
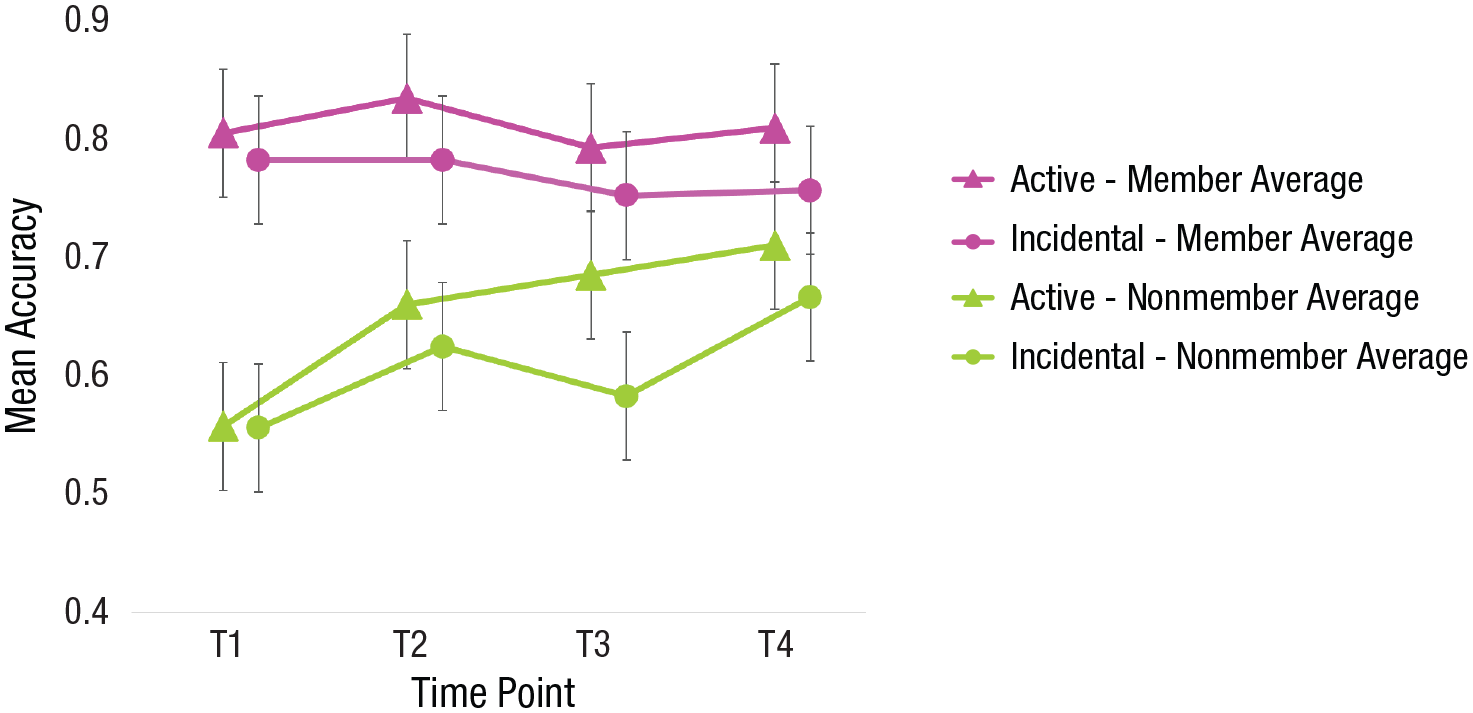
The Image Type × Time Point interaction grouped by learning type (incidental, active). Error bars represent 95% confidence intervals. T1 = Time 1; T2 = Time 2; T3 = Time 3; T4 = Time 4.
The pattern of means suggests that time point influenced accuracy on nonmember average trials but not on member average trials. Simple effects tests confirmed that the effect of time point was not significant in the member average condition, F(3, 231) = 0.80, MSE = 0.02, p = .50, η p 2 = .01, BF01 = 36.654, but was significant in the nonmember average condition, F(3, 267) = 6.75, MSE = 0.04, p < .001, η p 2 = .07, BF10 = 77.309. For the nonmember average condition, there was a significant difference between Time 1 (M = 55%) and Time 2 (M = 64%; p = .02), between Time 1 and Time 3 (M = 62%; p = .04), and between Time 1 and Time 4 (M = 68%; p < .001).
For each participant, the standard deviation in attractiveness ratings for the target and a random selection of four distractors in each sequence was computed as a function of learning type (active, incidental). A 2 (learning type: active, incidental) × 2 (identity: target, distractor) × 4 (sequence: 1, 2, 3, 4) mixed ANOVA was conducted using JASP. The analysis revealed a significant main effect of identity, F(1, 168) = 502.248, p < .001, MSE = 40.144, η p 2 = .75, BF10 = 4.636 × 10201, with a higher standard deviation for distractors (M = 20.4) than for targets (M = 12.7). There was also a main effect of sequence, F(3, 504) = 3.868, p = .009, MSE = 9.18, η p 2 = .02, BF10 = .01. Importantly, the results revealed a significant interaction between identity and sequence, F(3, 504) = 8.765, MSE = 9.77, p < .001, η p 2 = .05, BF10 = 2.669; group means are displayed in Figure 7. Post hoc comparisons using Bonferroni correction (all reported p values are adjusted) confirmed that the standard deviation of the ratings decreased over time only for the target identities, with significant differences between Sequence 1 (M = 13.8) and Sequence 2 (M = 12.8; p = .03), between Sequence 1 and Sequence 3 (M = 12.2; p < .001), and between Sequence 1 and Sequence 4 (M = 11.9; p < .001). On the other hand, no significant pairwise differences between sequences were observed for the distractors. The results also revealed a significant three-way interaction among identity, sequence, and training condition, F(3, 504) = 2.94, MSE = 9.77, p = .03, η p 2 = .02. However, the interaction was not meaningful, and the Bayesian analysis provided strong evidence for the absence of this interaction (BF01 = 402.422). A graph for this interaction can be found at https://osf.io/fyvbh/. There were no other main effects or interactions. Further analyses of attractiveness ratings are provided in Figure S2 in the Supplemental Material.
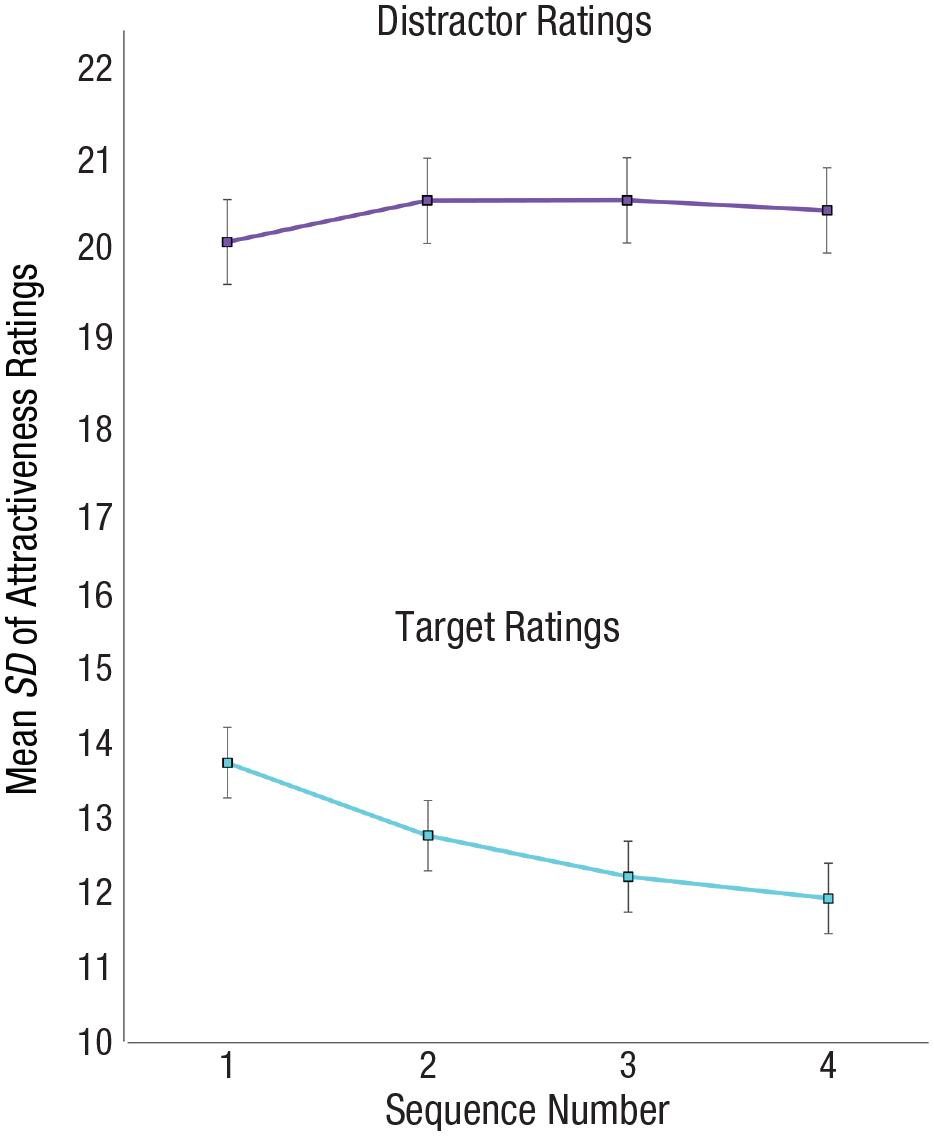
Mean standard deviation of the attractiveness ratings for targets (left) and four randomly selected distractors (right) within each sequence. Error bars represent 95% confidence intervals.
Discussion
Can identities be learned incidentally?
The results from Experiment 1 demonstrated that prior exposure to targets facilitated matching task performance. Importantly, performance was similar in participants who learned the faces actively versus incidentally, despite not knowing the target’s identity. We acknowledge the possibility that participants may have become aware that one face was repeated in each sequence in Experiment 1 and then deliberately tried to memorize this face. However, we think that it is unlikely that participants would expend the extra effort required to try to figure out which face was the target because they were not asked to recall the target during the matching task that they were given at the end of the training sequence. Participants’ memory for the target was tested in Experiment 2, so it is more likely that they would have tried to guess the target’s identity in this experiment. Here, though, participants would need to keep track of each face as it was shown and watch for repetitions (assuming that they came to realize that the face they were tested on was always shown multiple times in each sequence). The ability to detect repetitions is contingent on learning to recognize that two different photos depict the same person, something that researchers have repeatedly pointed out poses great difficulty for observers (e.g., Jenkins et al., 2011; Kramer, Manesi et al., 2018). Indeed, in our own Experiment 1, matching accuracy was near chance in the baseline condition when two different photos of the same individual were shown side by side (Fig. 2). Thus, it seems unlikely that observers would have been able to notice repetitions of an identity in Experiment 2 where at least one nontarget identity—and often more—intervened between successive presentations of the target, but the present findings do not allow us to rule this out.
There was some suggestion that performance was better in the active condition versus the incidental condition in Experiment 2. This may simply reflect the advantage of knowing the target’s identity in anticipation of the recognition memory test in that experiment. Regardless, the critical finding is that both groups demonstrated the same pattern of learning, showing that viewers can incidentally learn a target face from photos of the target interspersed among distractors.
Is identity learning mediated by averaging?
At the outset of this experiment, we considered three possible outcomes as depicted in Figure 4. The results of Experiment 2 revealed better recognition when learning was tested using a composite of the previously seen photos versus the unseen photos. Critically, this discrepancy diminished as the targets became increasingly familiar. Therefore, the emerging average model would appear to provide the most parsimonious account of the results. Initially, there is a clear advantage of testing memory with member average probes because these probes comprise the same images used to build the representation of the target. Over time, the average representation gets updated and refined; because averages composed of different images will become indistinguishable as more images are incorporated (Burton et al., 2015; Kramer et al., 2015), the advantage of testing with a composite of recently seen images disappears. Thus, successful recognition of the targets becomes less reliant on the particular images shown and is instead mediated by a robust, abstract representation that captures what is invariant across different encounters with the target face (Fig. 5).
A combination of the match-to-recent and match-to-all models could account for the findings if different strategies are used when evaluating member average probes versus nonmember average probes. Specifically, if observers compare the probe with only the four most recently seen images of the target (match-to-recent), performance would be constant over time; this was observed in the member average condition but not in the nonmember average condition. If observers compare the probe with all target items seen up to that point in the experiment (match-to-all), performance should improve; this was observed in the nonmember average condition but not in the member average condition. Thus, explaining the full pattern of results requires the additional assumption that observers are approaching the task differently across the two conditions. Alternatively, the match-to-all model could account for the full pattern of results, assuming that performance in the member average condition is constrained by a ceiling effect. We regard this as unlikely, however, because accuracy in Experiment 2 was approximately 78%, but previous research has demonstrated that participants can achieve almost perfect performance for highly familiar targets (Jenkins et al., 2011; Kramer, Young et al., 2018). Nevertheless, accuracy was generally high even for the first sequence of the member average condition (ranging from 67% to 89%; see Table S1, Supplemental Material), so it will be important in future studies to identify stimuli that are initially low in memorability to rule out this possibility. We note, however, that the superior performance in this condition is not due to the faces themselves, because testing for the same faces using nonmember average probes yields much lower accuracy (ranging from 52% to 69%; see Table S1).
Can person-centered ratings be used as an index of face learning?
Attractiveness ratings became more consistent over time for targets but not for distractors, as was expected if learning to recognize the targets causes viewers to shift from rating pictures to rating the person in them. This finding cannot be explained in terms of similarity between the images shown and the probe because the attractiveness of the probes was not rated and because viewers were not asked to compare their current rating of a person’s attractiveness with their previous ratings. In fact, they may not even have been aware that the person depicted in the photos had been seen previously (particularly in the incidental learning condition). Examining changes in consistency of person-centered ratings over time provides a powerful—and, we believe, novel—tool for evaluating changes in face learning with experience, decoupled from the similarity between the images used to train and test for familiarization.
Limitations and future directions
Although we have argued that the present results are best accounted for by assuming refinement of an average representation of the target, the experiment does not address whether familiar faces are also represented as exemplars. Previous literature on perceptual averaging mechanisms has consistently shown poor memory for exemplars (see Ariely, 2001). However, Kramer et al. (2015) found that memory was as good for exemplars as for averages when participants were presented with a set of faces that belong to the same individual. If participants are consulting a representation in memory that corresponds to an average of the photos shown in the set, any one photo from that set is likely to be a good match to that mental average. Thus, observing similar performance when exemplars and averages are used as probes does not necessitate that the individual exemplars are actually retained in memory. Moreover, if exemplars are stored, it is unclear what additional value would be gained by also storing an average. Future research should aim to clarify whether and when exemplars and averages are computed and retained.
Another limitation of the present study is that because the experiments took less than an hour, all photos of a given target were experienced within minutes of one another. In the real world, variability is encountered over a much longer time frame. Thus, future research should introduce delays between target encounters and between training and testing to increase the ecological validity of this paradigm. There are also potential limits to the generalizability of our findings because our participants consisted of undergraduate students from Canada. Future research should aim to replicate our work with a more representative sample of the population.
There was a strong suggestion in the results of Experiment 1 that training improved matching performance when the same person was depicted in the photos to be compared but not when different people were shown. 2 Thus, it may be the case that prior exposure to within-person variability facilitated the ability to tell people “together” but had no impact on their ability to tell people apart. The fact that the representation of a face can be refined in a way that allows observers to tolerate within-person variability without necessarily improving their ability to distinguish the target from other similar individuals is intriguing and deserving of further exploration.
Concluding remarks
Using a novel training paradigm that measures changes in learning over time, we provide the first direct evidence that averaging is a plausible underlying mechanism for face familiarization. This new training paradigm closely resembles our real-world interactions with faces because we seldom make an active effort to learn faces, and we see other people in the process. Most importantly, we introduced an implicit measure of learning decoupled from the probes used to test for recognition. The findings highlight the ubiquitous nature of perceptual averaging (Whitney & Yamanashi Leib, 2018) and its role in visual learning more generally (Dubé, 2019; Im et al., 2021). We believe that coupling indirect measures of learning with explicit tests of recognition yields compelling evidence that exposure to within-person variability helps viewers recognize not just the photos they have seen, but the people in them.
Supplemental Material
sj-docx-1-pss-10.1177_09567976221131520 – Supplemental material for From Pictures to the People in Them: Averaging Within-Person Variability Leads to Face Familiarization
Supplemental material, sj-docx-1-pss-10.1177_09567976221131520 for From Pictures to the People in Them: Averaging Within-Person Variability Leads to Face Familiarization by Yaren Koca and Chris Oriet in Psychological Science
Footnotes
Acknowledgements
We thank Suhana Patel and Caitlyn Winand for technical assistance.
Transparency
Action Editor: M. Natasha Rajah
Editor: Patricia J. Bauer
Author Contribution(s)
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.