
Abstract
SEnSOR (Smart Energy Speed Optimizer Rail) is a direct method based optimization algorithm developed at DLR for determining minimum energy speed trajectories for railway vehicles. This paper aims to reduce model error and improve this algorithm for any alternative powertrain architecture. Model simplifications such as projecting the efficiency maps of different train components onto one-dimensional space can lead to inaccuracies and non-optimalities in reality. In this work, 2D section-wise Chua functional representation was used to capture the complete behavior of efficiency maps and discuss its benefits. For this purpose, a new smoothing method was developed. It was observed that there is an average of 6% error in the energy calculation when both, 1D and 2D, models are compared against each other. Previously, solving for different powertrain architectures was time consuming with the requirement of manual modifications to the optimization problem. With a modular approach, the algorithm was modified to flexibly adapt the problem formulation to automatically take into account any changes in powertrain architectures with minimum user input. The benefit is demonstrated by performing optimization on a bi-mode train with three different power sources as developed within the EU-project FCH2RAIL. The advanced algorithm is now capable to adapt to such complex architectures and provide feasible optimization results within a reasonable time.
Keywords
Introduction
Compared to diesel engines, electric motors are more efficient, require less maintenance and allow for more environmental-friendly operation of railway. Thus, diesel-powered trains which previously covered non-electrified railway sections are more and more replaced by electric solutions. If overhead line electrification is not an option due to economic or technical constraints, train architectures with onboard energy storage are required. Currently, different topologies are being developed, for example consisting of batteries, fuel cells, capacitors and sometimes additional overhead line power supply. 1
Even with electrified operation, there is still a need to reduce energy demand and corresponding costs, as the transformation to sustainable power supply requires heavily increased amounts of renewable electricity and green hydrogen in all sectors. 2 Thus, to reduce energy demand in railway transport, Scheepmaker et al. 3 highlight four main approaches: minimum energy train control, energy-efficient timetabling, efficient components and demand analysis. Focusing on optimal control, they found Pontryagin’s Maximum Principle (PMP) to be intensively applied to determine energy-efficient train operation regimes. The optimal switching points between these regimes and hence the optimal trajectory are then usually obtained by other numerical algorithms such as Gradient Search, Dynamic Programming (DP) or Genetic Algorithms. The application of Direct Methods (DM) to such problems is still rare in the literature.
Macian et al.
4
found that using DM for combined energy management and trajectory optimization on a diesel-electric train yields similar results in comparison to that obtained by DP and PMP, while requiring heavily reduced computational time and memory. This motivated the development of SEnSOR (
The following paper poses the question if SEnSOR is able to handle any kind of electric power train architecture in a flexible and straight-forward manner. At the same time, it aims to demonstrate that utilizing the possibility of DM to include high-complexity constraints enables us to reduce model inaccuracies significantly. It is expected that the gains in flexibility and model accuracy will increase the overall computational time taken by the algorithm. However, this paper shows that the benefits may outweigh this aspect.
The first section provides a brief overview of the current algorithm and its implementation objectives. Afterwards the models and implementation methods are described in detail, including the derivation of our 2D efficiency map smoothing method. The subsequent section illustrates and discusses example results, concluding with the most significant findings.
Background - The SEnSOR algorithm
SEnSOR is a DM-based optimization algorithm for calculating minimum energy trajectory for various railway vehicles, implemented in MATLAB. In particular, it optimizes speed profile and energy management simultaneously to guarantee a tailored solution for a given train type. It automatically transforms a standardized input of vehicle and track parameters into objective functions, nonlinear constraints and boundary conditions of the optimization. To find the mathematical optimum, SEnSOR uses an interface for IPOPT (
With its current capabilities, 6 SEnSOR still faces challenges to account for all realistic features. Most importantly, it uses simplified 1D load-dependent efficiency characteristics for all components. For some of them however, the efficiency has a significant dependency on more than power throughput, for example speed. This simplification can cause inaccuracies. An optimized control obtained by this model can be non-optimal in reality, if used directly. Shifting to a multidimensional model may prove computationally expensive. In this study, we will try to answer what is the benefit of transitioning to such a more realistic model by performing simulations on a test track.
Secondly, SEnSOR shall be flexible to account for any changes in components or the entire train architecture. Currently, each time a change is to be made, the optimal control problem (OCP) has to be manually reformulated. This can be very time consuming and sometimes lead to model and human-induced errors. For this study, we will remove the requirement of hard-coding the optimization problem by the user, introduce additional modularity into SEnSOR’s implementation and analyze its benefits. To demonstrate the adaptability to different train architectures, we will then optimize the energy management control of a complex bi-mode powertrain architecture. This is part of the FCH2RAIL project, 8 in which this novel train type is developed and tested. One of the goals within the project is to optimize the energy management strategy of the bi-mode train to reduce energy consumption, both electric and hydrogen. In this paper, this was done by running simulations using a generic train model on a long real world track.
Models and methods
Two-Dimensional modeling of efficiency maps
The objective function and constraints of the OCP in SEnSOR comprises of functions that use the efficiency maps of different train components. These maps are often available in the form of two-dimensional numerical tables, that is, values of efficiency at discrete values of wheel speeds and power control settings. In SEnSOR, this map was to be modified to compute the power loss of the component by taking the normalized power p and the speed of the train v as input arguments to directly give the normalized power as output. It is now a choice how one chooses to handle the discrete data. One natural idea would be to use them by interpolation. However, IPOPT requires that the objective functions and constraints are at least twice continuously differentiable to guarantee the local optimality of the solution. In order to incorporate them into the objective function and constraints and solve the problem using IPOPT, these maps were to be represented by an explicit analytical function,
For simplification, the task was previously reduced to finding an approximation of f (p, v),
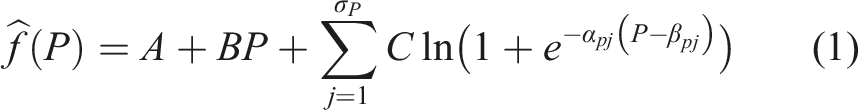
Where β pj ’s and α pj ’s are the breakpoints and the smoothing parameters that control the level of smoothing at each breakpoint in the P-direction, σ p is the total number of breakpoints, A, B and C are data-dependent model coefficients. Thus, the objective function and constraints of the OCP were effectively reduced to be only dependent on the train power control setting.
While this procedure simplifies the problem and results in a robust solution, it introduces a significant model error in the energy transmission between different train components. The effect of averaging of efficiencies may under/over-estimate the power losses depending on the available data and thus cause inaccuracies in the final solution. An optimal control solution using such a simplified model can be non-optimal with realistic energy transmission. Thus, it may be crucial to consider the multidimensional dependence of efficiencies. We will analyze and discuss the benefits and drawbacks of shifting to a more realistic implementation. For this, an explicit 2D function f is required as detailed above.
Chua and Kang 9 developed a section-wise piecewise-linear models to also fit multi-dimensional data. In this case, 1D canonical piecewise-linear representation were used in each dimension by fixing the other dimensions. This is mathematically equivalent to a bilinear interpolation in 2D with the additional benefit of having a compact analytical representation of the given 2D data. However, unlike the 1D case, there exists no formal smoothing procedure for such a model. In this study, we extend the work of Jimenez-Fernandez et al. 10 by deriving a transformation formula for smoothing 2D section-wise piecewise-linear functions.
Smoothing method for functional 2D-Representations
The section-wise piecewise-linear representation of a given 2D dataset is obtained by using a 1D chua piecewise linear representation in one dimension, while holding the other dimension fixed.
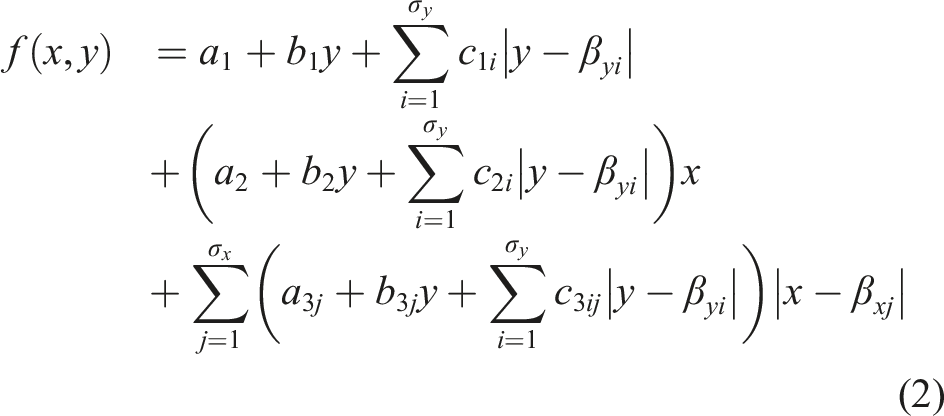
Twice continuous differentiability of this function is ensured by applying a smooth approximation of the absolute value terms.
10
For the detailed derivation of the transformation formula, see the Supplementary Material. For clarity, the final transformation formula is re-written:
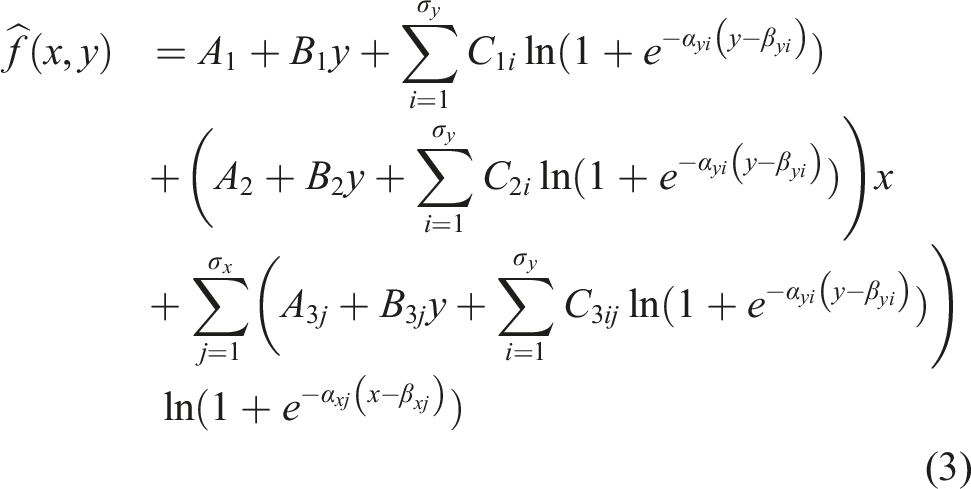
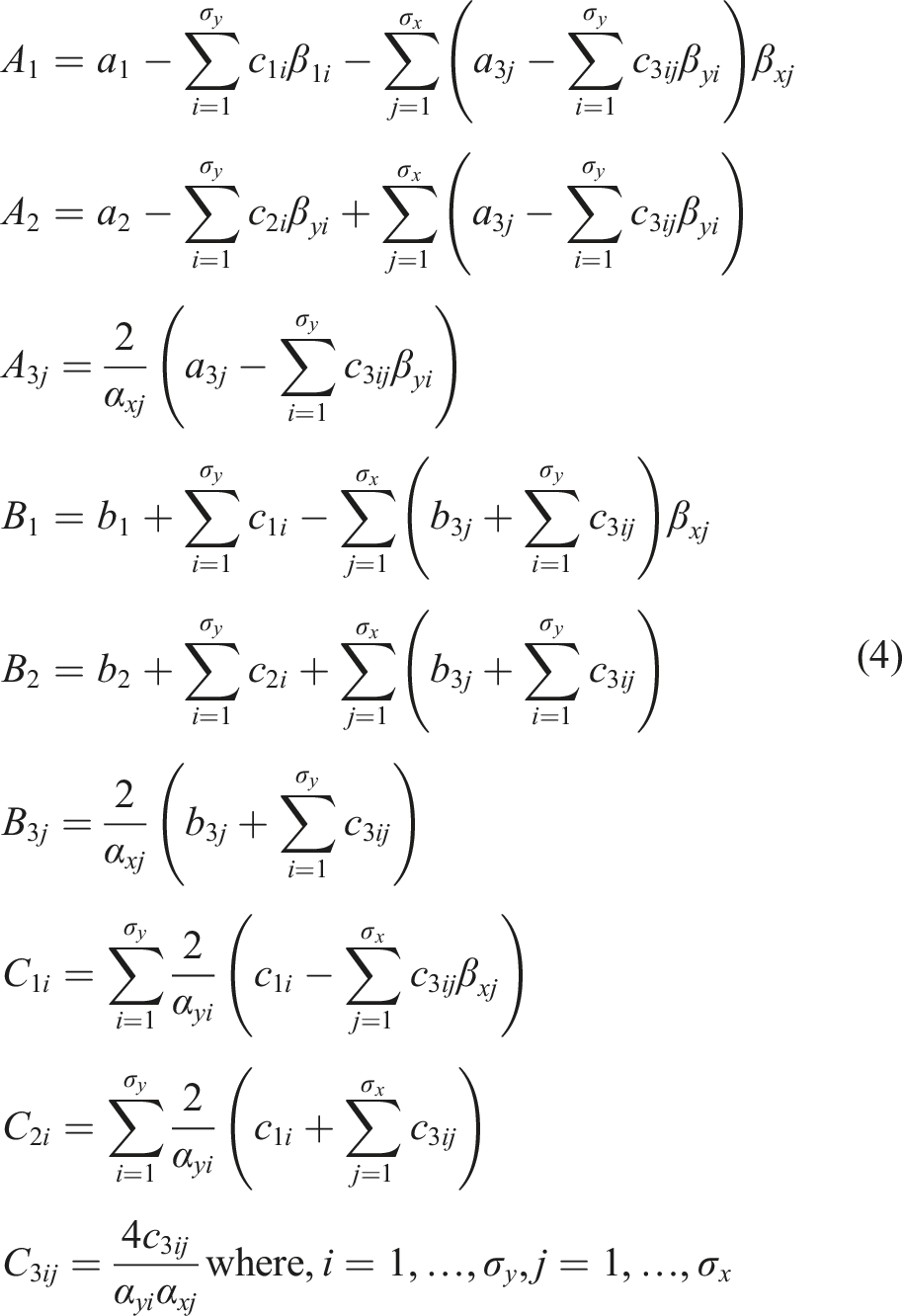
The parameters α control the smoothness of the function at breakpoints, that is how much the function deviates from the specified breakpoint. More formally, like in the 1D case, 10 we can state the following theorem:
Any two-dimensional canonical section-wise piecewise linear function that is characterized by σ
x
and σ
y
breakpoints, respectively in each direction, can be transformed into a section-wise linear smooth-piecewise function expressed as in eq. (3), where the set of (σ
x
σ
y
+ 2σ
x
+ 2σ
y
+ 4) parameters can be determined with eqns. (4) and the (σ
y
+ σ
x
) parameters {α
xj
, α
yi
} for i ∈ [σ
y
] and j ∈ [σ
x
] can be used to preserve a smoothness at any breakpoint location. As the values of α approach ∞, eq. (3) approaches eq. (2).
For a detailed proof of this theorem, see the Supplemental Material provided. In the next subsection, we discuss how a suitable smoothing parameter was choosen to construct these smoothed functions for our objective functions and constraints.
Implementation

The fourth step of the algorithm can be efficiently done by identifying the terms inside the different summations in equation (3), whose second derivatives are unbounded or are not defined. The value of α i are chosen in such a way that these derivative terms remain well-defined and bounded at any given point. The choice of α i depends on the distance between the point of interest and the breakpoints. Since the terms to approximate each piecewise-linear sections of the whole functions are either monotonously in- or decreasing, the critical values are on the boundary of the domain. Hence, it is most efficient to check only at boundaries if the derivative terms are defined and lower the respective α if they are not.
Modular, flexible power train architecture
Following the approach to a more realistic representation of the system, the next step after modeling the efficiencies in a 2D-manner is to depict all components more realistically. The previous implementation 6 represented the train architectures in a hard-coded way within the constraints and objective functions. As long as the power train architecture is exactly the same as in this representation, no model error will occur. However, if the train architecture or the type of some of the components changes, either the model has to be adapted within the code or a simplified approximation to fit the current model has to be made which introduces an additional model error. To avoid this, the tool was revised to account for a flexible and modular approach in the power train architecture. First we will show the details and capabilities of the new implementation, afterwards we demonstrate that the tool is able to optimize any train’s energy consumption in a straightforward way by applying it to a complex powertrain architecture.
Implementation
The idea behind making the tool adaptable to different powertrain architectures was to minimize the time required in building the objective functions and constraints, and the probability of occurrence of human-induced errors associated with it. This task was particular complex, since the automated generation of Jacobian and Hessian for faster optimization requires an additional symbolic representation. 11
A more efficient way to achieve this is to allow the user to define the architecture once before running the simulation and let the tool automatically construct the OCP. In order to achieve this level of automatization, different components of the train are now grouped together and defined as modular branches based on their functions. As an example, Figure 1 shows the division of the powertrain architecture we use into different branches. Inside each of these branches, one can flexibly add or remove components as needed. Then, the tool automatically uses the components defined in the overall architecture to construct the required OCP. This automation of constructing the OCP was done by recognizing patterns within the problem formulation. We found that there were two inherent patterns in the formulation that could be taken advantage of: 1. Nested Functions (N-Branch). Total power transmission of some branches are computed by a series of function composition operations. Each component within the branch transmits its power to the next component in the branch taking into account its efficiency (calculated from efficiency models discussed in previous section). 2. Addition of contributions (A-Branch). The total power transmission of some branches are computed by summation of the power passed through individual components or different N-Branches. Schematic representation of N-Branches and A-Branches. The total power transmission across an N-Branch is calculated by a nested composition of the individual power loss functions of the components inside the branch. The arrows represent the direction of power transmission at any moment of time during the train’s journey. On the other hand, the total power transmission across an A-Branch is the sum of power transmitted by the components or branches defined inside it.
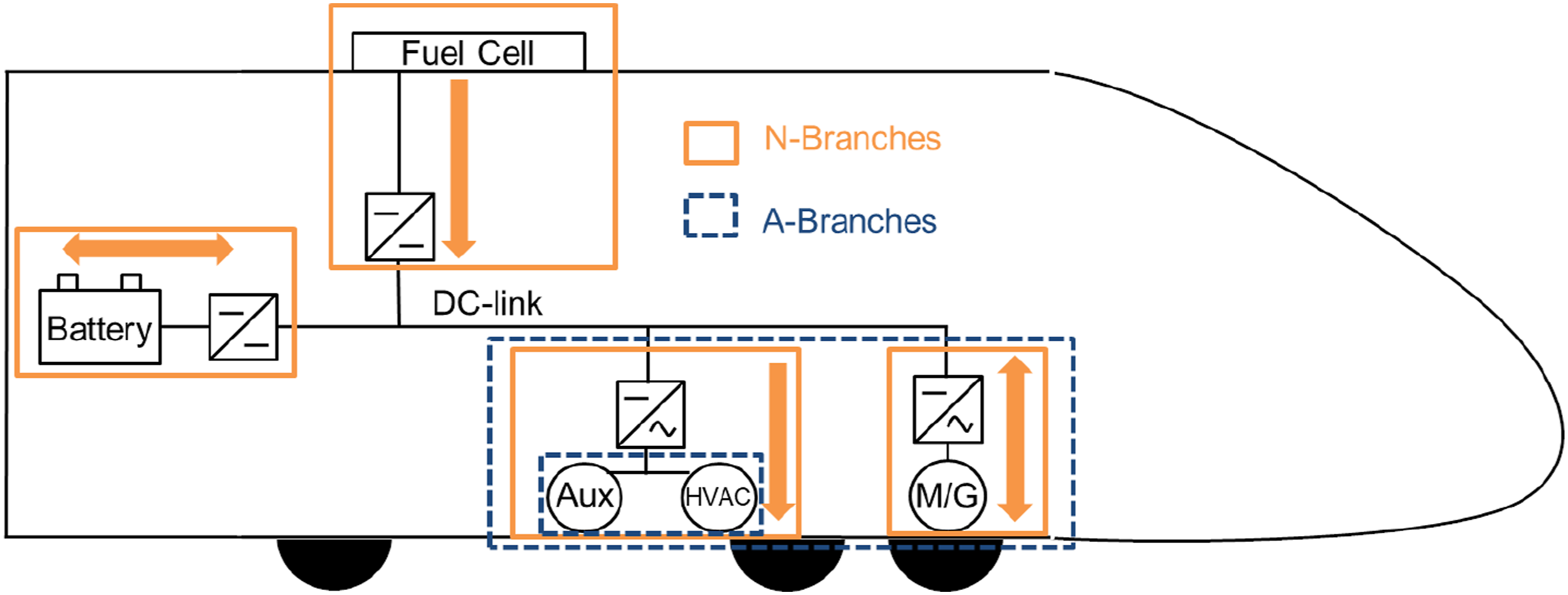
Through combinations of these two branch types, the construction of the symbolic representation of objective functions and constraints can be fully automated. After automatically generating symbolic derivative matrices in form of the Jacobian and Hessian for faster optimization, all symbolic representations are then transformed into MATLAB function handles. This eliminates all human effort required to manually calculate and define them.
Example: Powertrain with Bi-Modal operation
To demonstrate the capabilities of the new implementation, a complex powertrain architecture was chosen for optimization. Bi-mode trains as developed for example within the FCH2Rail EU-project
8
pose a particular challenge in modeling and optimization due to the combination of three power sources, that is hydrogen fuel cell, a battery and overhead power supply via pantograph (see Figure 2). For these trains, optimization is of high interest as an efficient energy management strategy is complex to determine and thus energy consumption may be unnecessarily high with an unsuitable control. Schematics of bi-mode train architecture, consisting of fuel cell, battery and overhead line power sources.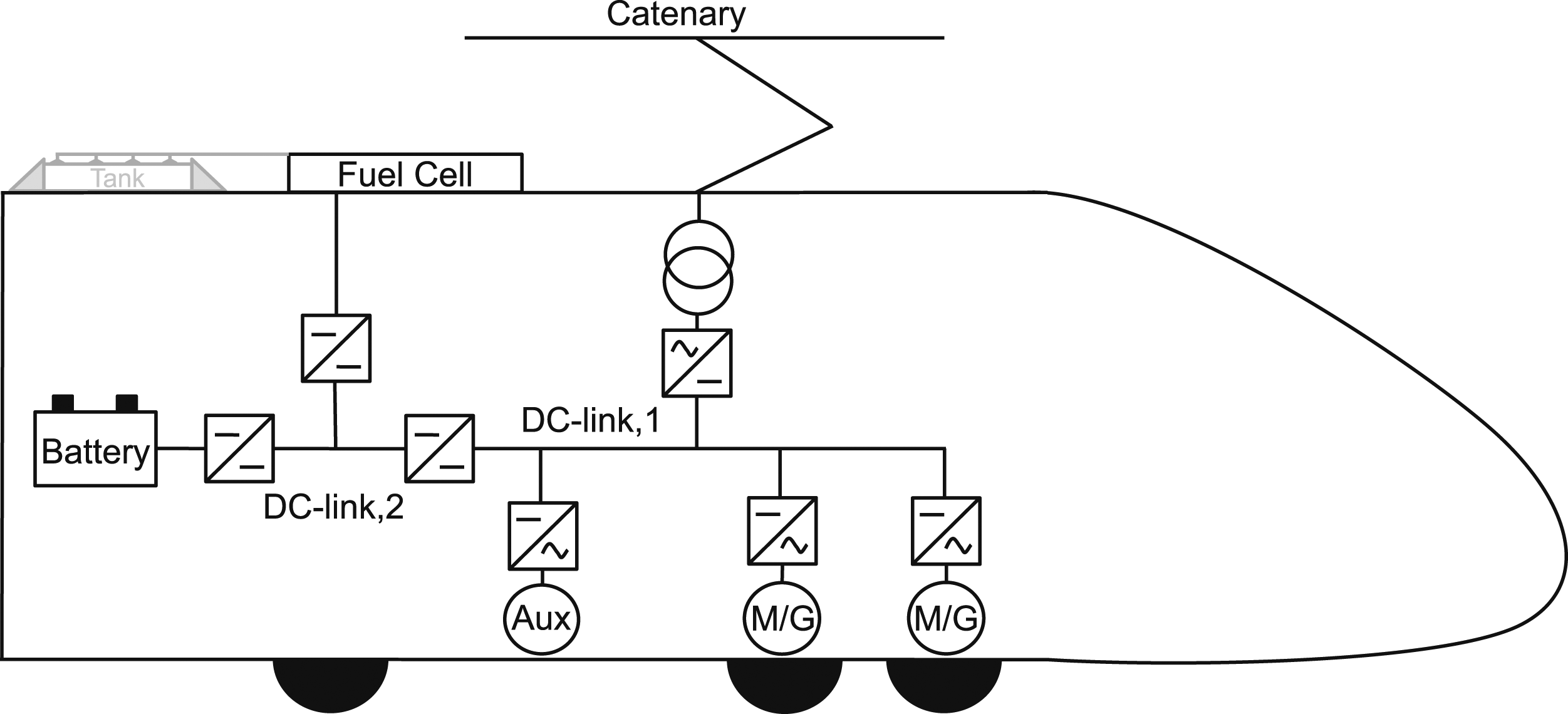
In order to optimize the energy consumption of a bi-mode train, there is a distinction from the objective functions used for Battery Electric Multiple Units (BEMUs) or Fuel Cell Electric Multiple Units (FCEMUs), as power drawn from two external sources has to be reduced in parallel. Thus, the objective function has to account for both catenary (Pcat) and fuel cell consumption (PFC,chem):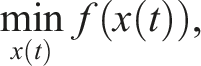
All power drawn over the system boundary is summed up, which in the case of the overhead line is electrical energy and in case of the fuel cell chemical energy, both in kWh, with w being a weighting factor between the two energy sources. A w > 1 indicates that that the hydrogen energy is ”more valuable” as it is limited in the onboard storage and leads to a more flexible operation, since higher range is enabled when utilizing more power from the overhead line. Because the optimization does not consider detailed costs for now, a w of two was chosen. The energy drawn from the battery is optimized implicitly, because a charge-sustaining operation is enforced through boundary conditions. This means the initial state of charge has to be met in the end of the simulation, forcing the battery to be recharged by either power source which are part of the sum in the objective function.
Furthermore, the power balance has to be fundamentally adapted in order to represent the power distribution on the DC-link according to the more complex structure of the bi-mode power train. In comparison to previous implementations,5,6 the blending factors θ and ϵ have been removed and replaced by a more efficient power balance constraint on the DC-link, considering all consumers PDC−link,i on the DC-link.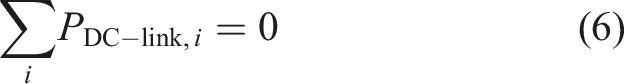
For the bi-mode train, the equation has to be slightly adapted due to the existence of two separate DC-links: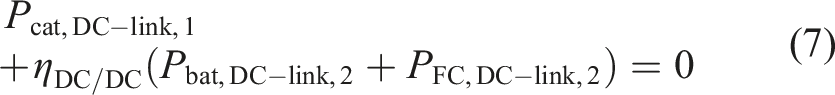
Use and test case parameters
For all analyses, a generic regional vehicle is used as a basis. To analyze the overall performance of 2D efficiency model on SEnSOR, different train types were considered: • a generic Electric Multiple Unit ( • a Battery Electric Multiple Unit ( • and a Fuel Cell Electric Multiple Unit (
Vehicle and track parameters.

For the performance of the efficiency representation, a short 20 km test route with five stops as developed in 5 is used, to generate multiple results quickly. In this case relative comparison is of higher interest than absolute consumption values. The main optimization use case with the bi-mode train is then run on a hilly regional track between Plattling - Bayrisch Eisentsein - Plattling in Germany. Except for the assumption of additional electrification, this route is adopted from Kühlkamp. 6 Additional electrification was placed in the form of charging points at the junctions in Gotteszell (33 km) and Zwiesel (58 km), as well as a 3 km long section at the turning point in Bayerisch Eisenstein. The key characterists of this long track are given in Table 1 as well.
Results and discussion
Modeling and approximation error estimates
In the beginning of the paper, we postulated that the 1D approximation assuming a uniform behavior across all speed levels creates a significant model error and thus a more detailed representation in for of the 2D approximation is required. We verify this hypothesis using validated, generic component model data from the EU project FINE-1
12
(relevant components: motor and traction inverter). The upper part of Table 2 summarizes the error of the 1D functions in approximating the original 2D data points. The quality of fit of the analytic functions to the given data points were estimated using set of metrics: • Root mean square error (Δ
RSME
) between the values at the given discrete 2D data points and the function evaluated at these points • L1 error (ΔL1) as normalized integrated difference between the constructed function and multi-linear interpolated function over whole 2D domain Upper part: Approximation errors of the 1D power loss function when compared to the original 2D data points. Lower part: Errors of the 2D section-wise linear Chua functions in approximating the 2D data points and the contribution of error arising due to the smoothing procedure.

A more detailed definition of these metrics can be found in the Supplementary Material provided. One can see that the averaging effect of the efficiency introduce significant errors of almost 5% in the L1 error over the whole domain.
As expected, the errors of the 2D model are well below these numbers, as shown in the lower of Table 2. The modeling error in the first line indicates the approximation error of the 2D functions in fitting the 2D data points. Here, the 2D section-wise Chua functions reaches a similar quality of fit than it was possible with the previous 1D model. This highlights the power of the Chua functional representation in approximating given data points. With the L1 error, one can see that the major part of the error stems from smoothing. However, even after smoothing, the error between MATLAB’s non-smooth interpolated functions and the constructed smoothed section-wise Chua functions are lower than 0.01%. This is because the smoothing procedure only introduces errors very close to the sharp corners. Figure 3 shows the effect of smoothing procedure at non-smooth regions of a section-wise linear Chua function. Despite introducing errors at non-smooth region, it captures the overall structure of the data very well. The smoothed 2D section-wise linear Chua function fitted onto 2D power loss data of induction motor. The upper right hand corner shows the zoomed-in part of the smoothed function at a location that has sharp step change (marked region). This same location is shown without smoothing in the lower left corner.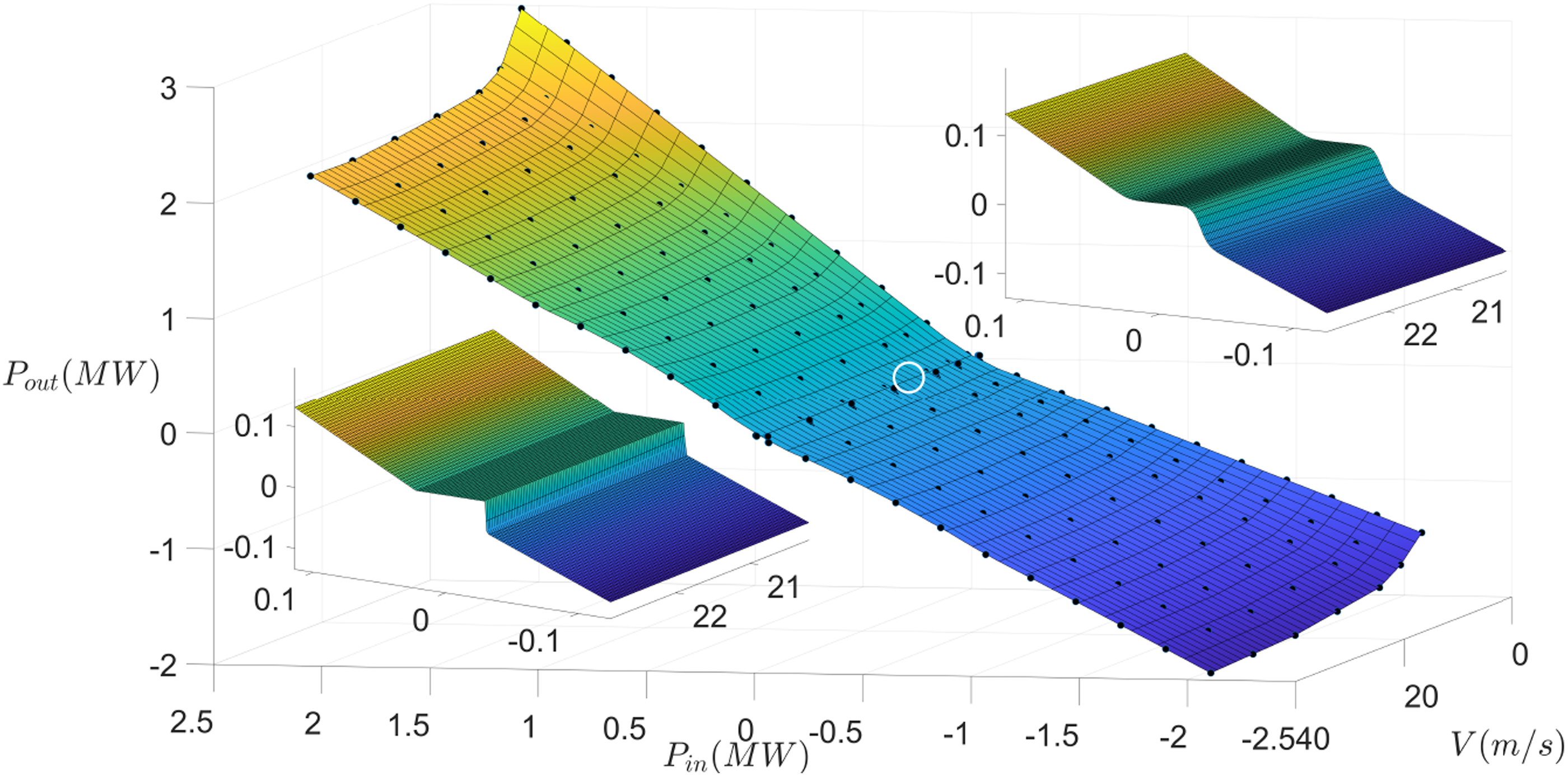
Effect of 2D efficiency model implementation on optimization results
Energy consumption per km for different train types for 1D and 2D efficiency model, as well as the calculation difference caused by the application of the different models.

The difference in the optimization result indicates various inaccuracies caused by the simplification of using a 1D model. The analysis in the previous section showed that the 2D model results are more accurate with regard to the specified component efficiencies. The model error of the 1D model thus causes two issues in the optimization, which are of main interest: Non-optimality of the solution as a result of the simplification, and under-/overestimation of the total energy consumption even in case of optimal controls.
Detailed comparison of the solution variables shows that both issues are present: The 1D solution variables yield a non-optimal result if plugged into the 2D efficiency calculation and the 1D model overestimates the energy consumption, when applied on the 2D solution variables. The overall difference including both of these inaccuracies shows higher energy consumption for all train types when using the simplified 1D efficiency model. The difference increases from just below 5% for the EMU to over 7% for the FCEMU, thus with complexity of the powertrain architecture. The differences between the train types may be due to the fact that in BEMU and FCEMU there is additional power transfers within the train back and forth from the onboard energy storage. Due to the additional power losses, inaccuracies in the model are propagated and multiplied. With increasing complexity (e.g. number of components), this issue is amplified. Therefore, the new implementation shows greater benefit in BEMU and FCEMU than in EMU.
Time taken by SEnSOR to achieve the optimal controls for a given train type and compute the resulting energy consumption.

Results of the modular, flexible powertrain implementation: Bi-Mode train
As described in the implementation section, the bi-mode powertrain is chosen to demonstrate the capabilities of the new implementation. This, in particular, was done by running the simulation on a real route between the Plattling - Bayrisch Eisentsein - Plattling in Germany. We were able to implement the complex powertrain architecture in a straight-forward way and gain converging optimization results. With a computational time of around 16 min, the model results in an energy demand of roughly 315 kWh at the catenary and 10.8 kg hydrogen for this specific scenario and the combination of the chosen track and vehicle.
Figure 4 shows the results of the optimization. In the upper graphic, the speed and power control setting (throttle demand) are shown. The lower one illustrates the power split on the main DC-link. Both are for a specific uphill segment of the track. During the acceleration and cruising phase (approx. between minute 17 and 24), the fuel cell is running around maximum power to provide the base load, while the battery follows the remaining power request. Where possible, the fuel cell also slightly reduces its power to operate in a more efficient operating point. In the coasting section without traction demand (minute 24 to 26), the auxiliaries are covered directly by the fuel cell and the batteries are not used. Then, during braking and standstill phase (minute 26 to 30), which is partly under catenary, the fuel cell operates in idle mode. First, the battery stores the recuperative energy from the electro-dynamic brakes (just after minute 26). Afterwards, it is recharged at maximum power by the overhead line, which also supplies the auxiliaries required in standstill. Finally, the catenary supports the acceleration process of the next section, before the behavior repeats again in the non-electrified part of the section. The power split fulfills the given physical constraints and follows a logical behavior, thus giving the expected results. Results of bi-mode train optimization: power demand at the DC-link and split between the different power sources in MW for a specific section between minute 16 and 34 of the track.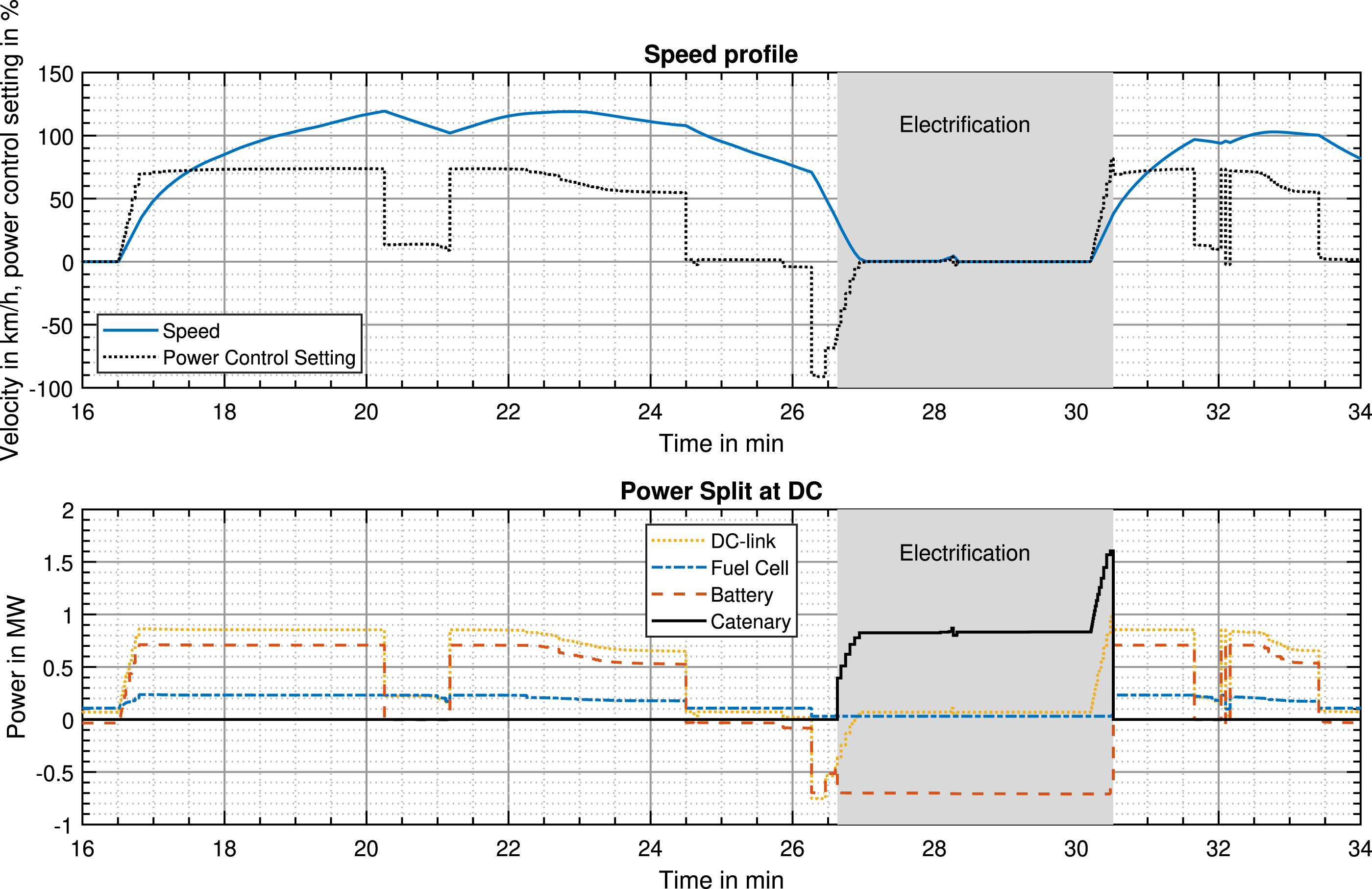
Figure 5 shows the cumulative energy demand over time. For the battery, the energy fluctuates around zero due to recharging processes on the route, with a maximum discharge of around 100 kWh. The final value settles at 0 kWh, since charge-sustaining operation is enforced. Thus, the total energy consumption consists of electric power from the catenary and hydrogen energy. Naturally, the energy drawn from catenary only grows in the electrified sections of the track and otherwise stays constant, while the hydrogen consumed by the fuel cell has a steady increase. Both reach final values of between 300 and 400 kWh, with slightly higher value for hydrogen. Energy consumption profile over the course of the complete track in kWh for each power source of the bi-mode train.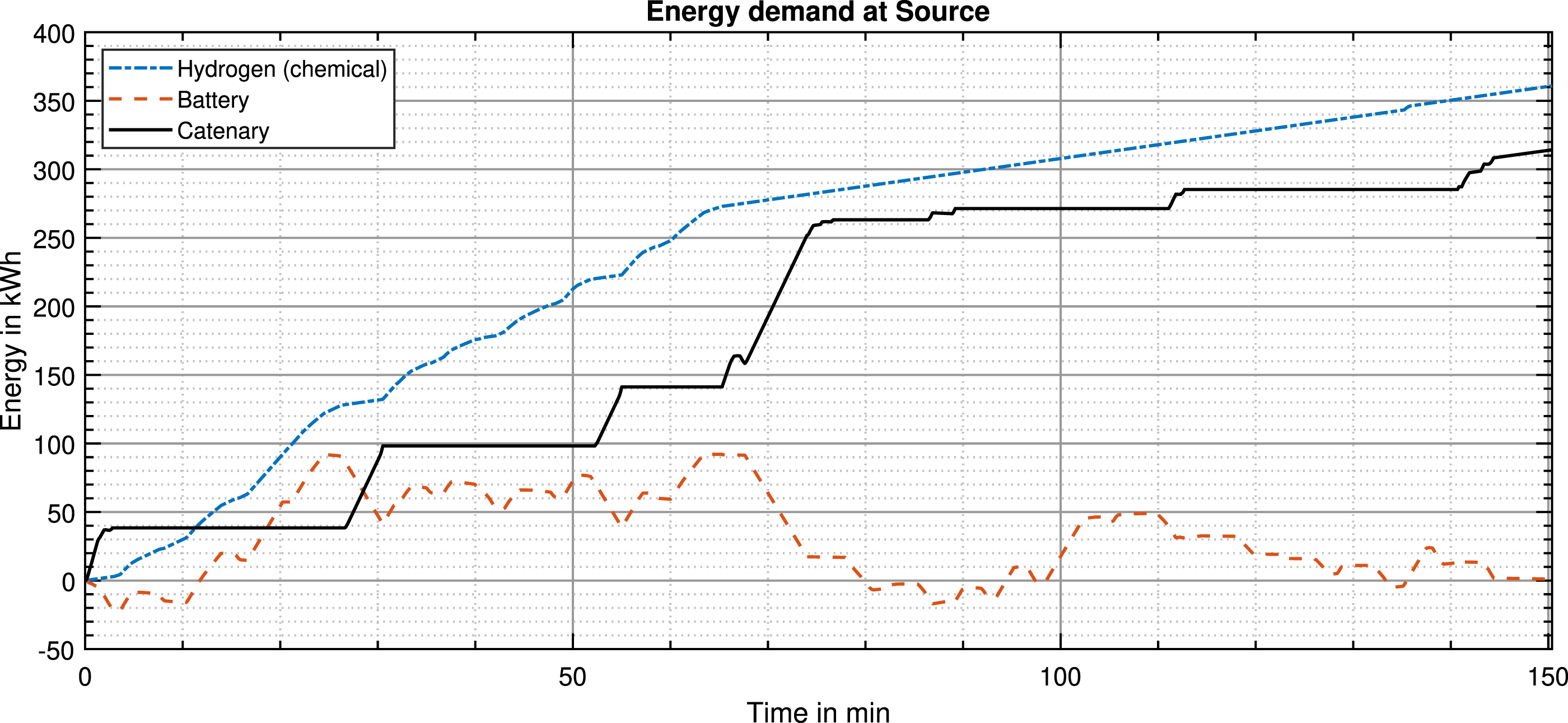
The total runtime remains almost the same with the new modular implementation. This comparison does not include the amount of manual pre-processing and debugging time required that goes into changing the OCP formulation with each change in the powertrain architecture. Therefore, the benefits are not objectively quantifiable, but noticeable in terms of effort required to optimize a new powertrain architecture.
Conclusions and future scope
The use and test cases demonstrate that the main goals achieved and the research question could be answered positively: integrating high-complexity constraints to reduce model errors and enabling highly modular flexibility to represent any powertrain architecture in the DM optimization algorithm SEnSOR. The first goal was analyzed with the implementation of two dimensional efficiency maps. Chua’s functional representation is computationally efficient and accurate in terms of approximating given data points. The availability of an analytic representation allows to easily perform mathematical operations on the represented data. Furthermore, the representation can be made smooth without significant information loss of the given data points (less than 0.01%). Sufficient smoothness is usually favorable to guarantee optimality of solutions obtained using higher order optimization procedure. Hence, this makes it a suitable choice in modeling OCPs. An enduring limitation is assumption of section-wise linearity between the data points. This strong assumption about efficiency maps may introduce significant model errors if the data set is coarse. For future works, it would be interesting to explore further approximations such as B-splines to study the robustness of the solutions to such changes.
The overall effect of approximation of the original data points onto lower dimensional space on the quality of solution is clearly evident from the results. The results suggest that the 1D approach overestimates the overall energy consumption and also yiels non-optimal results, especially in BEMU and FCEMU trains, with differences between 4 and 7%. With almost 45% average increase in computational time, the computational performance of the 2D-approach is lower than for the 1D-approximation as expected in the hypothesis. However, the decrease in model error is sufficiently high to justify the change in the model. Based on the modeling goal, one could choose to either use the 1D-approach for a quickly converging estimation. For all train types but the EMU, if accuracy is of higher importance, it is suggested to use the more complex model.
The second overarching goal of a modular, flexible algorithm structure to be able to handle a wide range of powertrain architectures and application cases was demonstrated with the successful optimization of the speed profile and energy management for a bi-mode train. The power distribution between three sources was implemented in a straight-forward way into SEnSOR. The results show convergence of a real world railway route within 16 min, minimizing hydrogen and overhead line electricity consumption at the same time. The power split between all power sources follows a reasonable behavior, with the battery covering peak loads and utilizing regenerative braking energy, as well as the catenary continuously recharging the battery and primarily covering traction demand. The fuel cell is used to cover base load and otherwise hold steady in a high-efficiency operating point. For optimization of operation, energy from overhead line and hydrogen could also be weight differently, if one of the power sources is preferential, for example with a cost model.
We showed the potential of DM optimization algorithms in offline railway simulation to reduce energy demand. Highly complex powertrain architecture are integrated easily and optimized within reasonable computational time. Future activities will focus primarily on further improving computational performance and thus potential applicability into real-time train control to offer optimized driving advice and energy management on the train.
Supplemental Material
Supplemental Material - Optimization algorithm for minimizing railway energy consumption in hybrid powertrain architectures: A direct method approach using a novel two-dimensional efficiency map approximation
Supplemental Material for Optimization algorithm for minimizing railway energy consumption in hybrid powertrain architectures: A direct method approach using a novel two-dimensional efficiency map approximation by Rahul Radhakrishnan and Moritz Schenker in Part F: Journal of Rail and Rapid Transit
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the FCH2Rail project has received funding from the Clean Hydrogen Partnership under Grant Agreement No 101006633. This Joint Undertaking receives support from the European Union’s Horizon 2020 Research and Innovation program, Hydrogen Europe and Hydrogen Europe Research.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.