
Abstract
With the development of Industry 4.0 and requirement of smart factory, cellular manufacturing system (CMS) has been widely concerned in recent years, which may leads to reducing production cost and wip inventory due to its flexibility production with groups. Intercellular transportation consumption, sequence-dependent setup times, and batch issue in CMS are taken into consideration simultaneously in this paper. Afterwards, a multi-objective flexible job-shop cell scheduling problem (FJSCP) optimization model is established to minimize makespan, total energy consumption, and total costs. Additionally, an improved non-dominated sorting genetic algorithm is adopted to solve the problem. Meanwhile, for improving local search ability, hybrid variable neighborhood (HVNS) is adopted in selection, crossover, and mutation operations to further improve algorithm performance. Finally, the validity of proposed algorithm is demonstrated by datasets of benchmark scheduling instances from literature. The statistical result illustrates that improved method has a better or an equivalent performance when compared with some heuristic algorithms with similar types of instances. Besides, it is also compared with one type scalarization method, the proposed algorithm exhibits better performance based on hypervolume analysis under different instances.
Keywords
Introduction
With the globalization of market, the increased level of competition puts forward higher requirement for manufacturing systems, how to quicker and accurate response to customers’ desiring to purchase multiple varieties of high-quality and low-cost products is an urgent problem. Consequently, production mode of multi-variety and small-batch in manufacture has received widespread attention recently by most manufacturing firms. Meanwhile, flexible manufacturing1,2 is developed to meet such challenges. As an application of group technology, cellular manufacturing system (CMS)3,4 can handle production control in each cell independently, which outperforms traditional system in reducing production cost, production time, and wip inventory,5–7 especially in the semiconductor industry.8,9 Temporarily, lot-splitting process in CMS can respond rapidly to requirement of production mode of multi-variety and small-batch. Besides, manufacturing industry is facing challenges of energy conservation and emission reduction currently. Therefore, CMS considering lot-splitting process and energy consumption is most effective production way to ward multi-variety and small-batch energy-saving production.
In CMS, different machines and jobs are aggregated into one cell, which possesses the capability of processing the production of part families. However, in contrary to original intention of CMS, assigning all machines and parts in the same cell, it is difficult to achieve in practice, that is, some exception parts (EP), are permitted to be machined in more than one cell for reducing number of dedicated machines. For example, in wafer pretreatment of semiconductor manufacturing, some successive operations of wafer need to be processed between expensive and fixed machines among different cells, which leads to intercellular transportation and prolongs makespan of cell parts scheduling (CPS), which plays a crucial role in the operation of CMS. Hence, parts inter-cell processing is beneficial for enterprises to reduce machine costs. But it brings task for CPS, of which the goal is to determine a part sequence and minimize some effectiveness measures, such as makespan and total transportation cost.10–13
Furthermore, with the rapid development of green manufacturing technology, energy saving, and emission reduction has become an unavoidable consideration for enterprises. In recent years, more scholars have paid attention to energy consumption of semiconductor industry. Hu et al. 14 proposed energy savings approaches for high-tech manufacturing factories for a semiconductor manufacturing wafer fab. Wang et al. 15 proposed a fuzzy nonlinear programing approach for planning energy-efficient wafer fabrication factories, thereinto, the total power consumption is obtained by summing the power consumptions of all the products in wafer fab. Lin et al. 16 investigated a flow shop scheduling problem with low carbon emission into consideration. For specific scheduling problems, Li et al. 17 studied a multi-objective energy-saving scheduling in a permutation flow line shop. Iqbal et al. 18 developed a mathematical model to minimize the idle energy based on job sequence in a cellular manufacturing system. However, energy consumption is seldom attempted in FJCSP. Besides, due to the inevitable intercellular transportation in CMS, energy consumption is becoming more complicated in modern manufacturing system. Therefore, in this study, energy consumption is calculated as an objective, so as to acquire a scheduling scheme which can provide a better energy saving and emission reduction scheduling scheme.
Besides, jobs are usually grouped into different part families, which generates setup times between two different families on machines in CMS. Li et al. 19 assumed setup time is sequence-independent and included it in the processing time of CMS minimized the makespan and balance the total workload in CMS with consideration sequence-independent setup times, machine sharing, and flexible routes to solve a CPS problem. However, in practical production, setup times between different parts tend to be related to the sequence of them. Sequence-dependent setup times (SDST) are widely studied especially in traditional manufacturing system. Costa et al. 20 developed a hybrid genetic algorithm to minimize the makespan with SDST in a flow-line shop. Abdelmaguid 21 and Shen et al. 22 taken SDST into consideration to solve flexible job shop scheduling problem (FJSP). It can be inferred from the above literature most studies focus on sequence-independent in CMS, sequence-dependent in traditional FJSP, and flowline cell scheduling. Few references can be found to combine SDST with FJCSP. Considering SDST adds complexity to CMS, but it is more suitable for actual production, such as semiconductor wafers process. 9 Meanwhile, in some real production process, job needs to be split into several batches. For instance, production unit in semiconductor manufacturing is called a wafer but the process comprises the concurrent processing of several wafers, where one lot contains at most 25 wafers. 23 Investigation shows that batch processing can lead to the reduction of makespan, which is better than overall processing of part families. 24 Xu 25 studied the quality control of multi-variety mixed in production shopfloor. Huang and Yu 26 mentioned that applications of lot-splitting in manufacturing processes may increase complexity of scheduling but are rewarding for efficiency and flexibility of scheduling results under some manufacturing circumstances, such as printing, paints, or chemical production. Defersha and Bayat Movahed 27 developed a linear programing model with lot streamlining in flexible job shop. Vaez et al. 28 proposed a mathematical model with consideration lot-sizing in scheduling problem, which aimed to minimize CO2 emissions while maximize the total profit. However, batch issue is only widely attempted in traditional shop scheduling and few researches about batch can be found in FJCSP. Accordingly, to fill up above gaps, SDST and job batch are considered in this paper.
Due to global searching capability, genetic algorithm (GA) is an effective tool to solve single objective optimization problem in mechanical engineering and production process. 29 Furthermore, nondominated sorting genetic algorithm (NSGA-II) is served as a multi-objective optimization algorithm to seek for a Pareto-optimal set in shop scheduling and mechanical manufacturing (e.g. mechanical cooling tower).30–34 However, pure dominance-based multi-objective evolutionary algorithm (MOEA) such as NSGA-II usually have the deficiency of solution diversity. 35 In previous studies, local search techniques were designed to improve the quality of local area individuals and they were incorporated into the MOEA to improve the solution diversity. 36 More researchers embedded local search into heuristic algorithms to improve performance of algorithm. For instance, Wu and Che 37 investigated an adaptive multi-objective VNS to deal with flow shop scheduling problem and verified performance of proposed algorithm was better than NSGA-II. An et al. 38 adopted hybrid VNS into improved biogeography-based optimization (BBO) algorithm to amend local search ability in a hybrid multi-objective FJSP. Therefore, in this study, a hybrid variable neighborhood search (HVNS) is utilized to enhance the local searching capability of NSGA-II to deal with the multi-objective optimization problem.
Based on aforesaid discussion, previous work generally considered classical objectives (e.g. makespan, cost) in flowline cell scheduling, or cogitated setup times and batch but neglect energy consumption in FJCSP. Simultaneous consideration of intercellular transportation consumption, sequence-dependent setup times, and batch sizes in flexible job-shop cell scheduling has not yet done. Meanwhile, since FJSP is a more complicated NP-hard problem than job shop scheduling, this brings new challenge to FJCSP optimization. 39 The main contribution of this paper can be summarized as: (1) to better react to green manufacturing and requirement of production mode, a novel mathematical model is proposed for FJCSP by taking makespan, total cost, and total energy consumption into consideration; (2) to enhance local search ability of NSGA-II for solving complex FJCSP, a HVNS is designed to amend performance of algorithm; (3) to verify the validity of proposed algorithm, comparisons with six heuristic methods based on benchmark instances and another kind of method from literature is analyzed.
The rest of this paper is arranged as follows. Section 2 provides the basic elements of FJCSP. In Section 3, HVNS, elite storage strategy (ESS), and improved algorithm framework is introduced in detail. Section 4 analyzes the effectiveness of improved algorithm by comparisons with seven algorithms. Section 5 presents the conclusions and future directions.
Problem description and formulation
In this section, the problem is descripted at first. After that, some basic assumptions are provided, as well as the related notations are utilized in this study. Next, the formulas about total energy consumption and total costs are displayed to show the computation of each component. Finally, a multi-objective optimization model is established.
Problem description
In FJCSP, there exist two sets, that is, a set includes
Assumptions and notations
To concentrate the study of FJSP in CMS, the model is based on following assumptions.
(a) The number of cells, part families, and layout of cell is known.
(b) Machine fault is ignored.
(c) All jobs are not interrupted once are proceed.
(d) All jobs have the same priority.
(e) The buffer of input and output is not limited.
(f) Each operation can be distributed to one of available machines.
(g) The processing time of operations for each part family on machines is known.
(h) The machines and jobs are available at time 0.
(i) The intracellular transportation time is 0.
(j) Each machine can process at most one operation.
The symbols, parameters, and variables are listed, as shown in Table 1.
The variables and parameters involved in the model.

Objective function
In this paper, the objective function of the optimization model is to minimize makespan, total energy consumption, and total costs.
Makespan
The first objective makespan
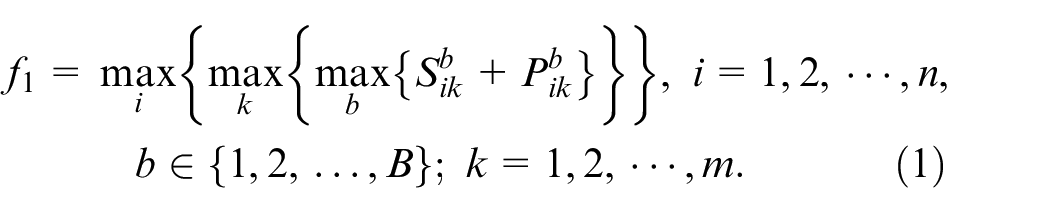
Total energy consumption
The second objective total energy consumption

where
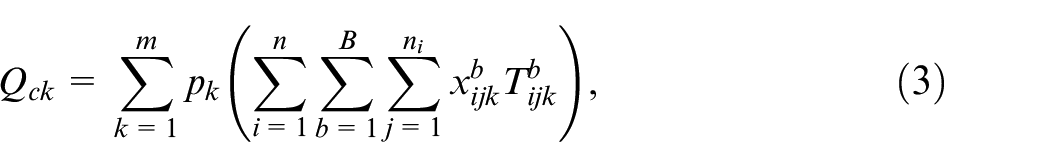
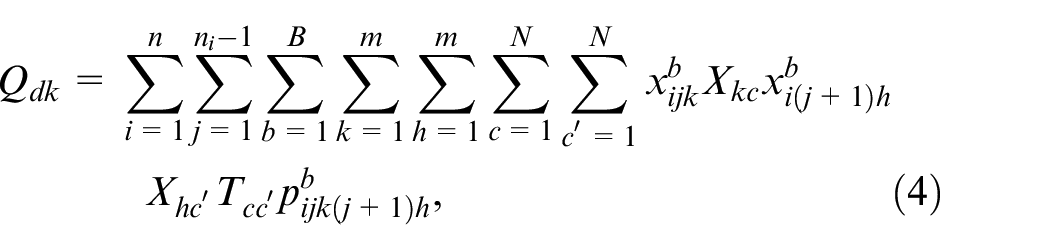
Total cost
The total costs

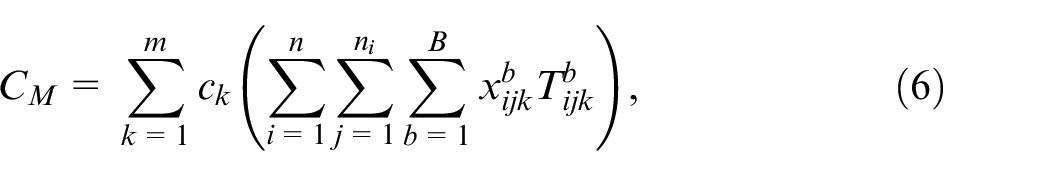
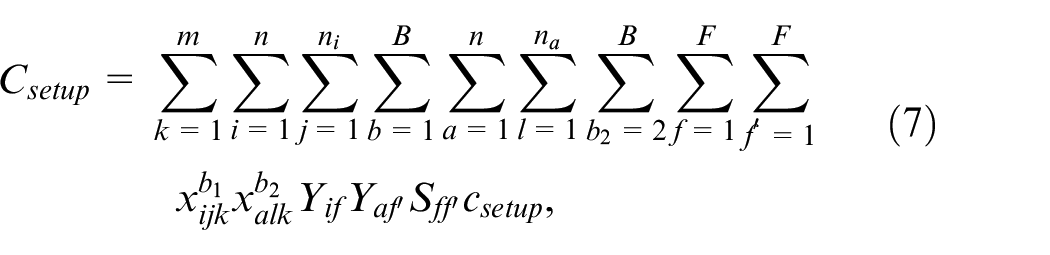

Constraints
Optimization model include batch constraints, sequence constraints, and time constraints, which are shown in equations (9)–(15).



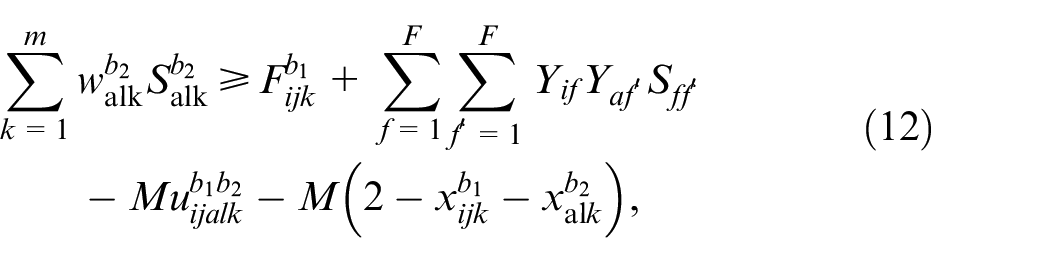
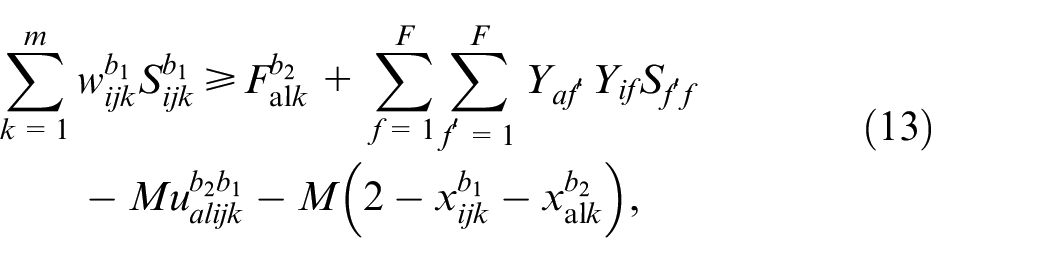
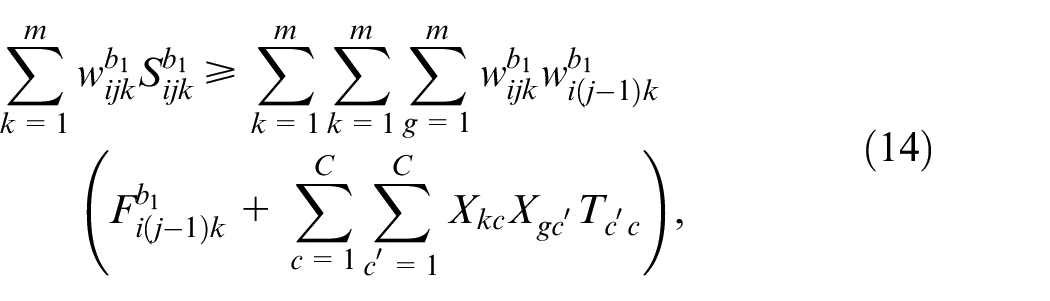

In the model, equation (9) indicates that the batch size is same for each job. Equation (10) indicates that only one machine can be selected for
Illustrative example
To better understand the model, we combine with one 4/2/4/2 instance from literature
13
to illustrate. Thereinto, there are four parts, two part families, four types of machines, and two cells independently, which is shown in Table 2. The two part families are presented as: [
The data of 4/2/4/2 instance.

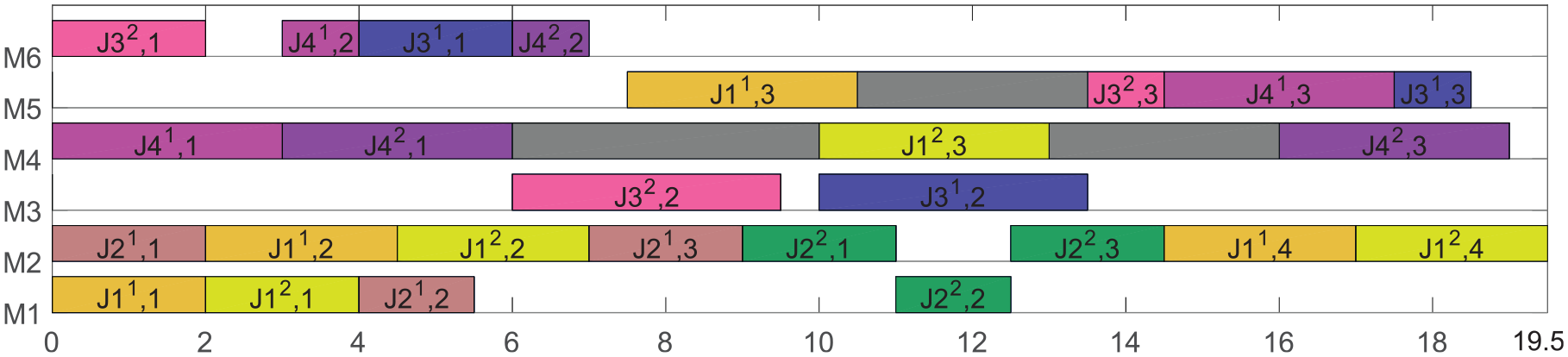
The first solution of 4/2/4/2 instance (
Method and algorithm
In this section, a brief description of the standard NSGA-II and improvement motivation are introduced at first. Then, a hybrid variable neighborhood search is provided. Last, the overall process of proposed HVNS-NSGA-II with specific improvements is summarized.
NSGA-II and improvement motivations
NSGA-II 40 is served as a multi-objective optimization algorithm to seek for a Pareto-optimal set. In the whole process of NSGA-II, the most core operations owe to the calculation of fast non-dominated sorting and crowding distance. The former one, that is, fast non-dominated sorting, ensures the convergence of the solutions. When the solution is closer to the Pareto-optimal front, it shows a better quality. The latter one, that is, crowding distance, keeps diversity of population.
Hybrid variable neighborhood search (HVNS)
Variable neighborhood search (VNS) is presented by Mladenović and Hansen 41 firstly, which was used to avoid poor local optimization by changing neighborhood systematically and had been rapidly and successfully adopted in various fields. Recently, VNS has been widely studied in shop scheduling problems, 42 such as job-shop scheduling problem (JSP).
There are several neighborhood structures in VNS.
43
Thereinto, machine-oriented idle time neighborhood, N5 neighborhood, random whole neighborhood (RWN) are adopted into NSGA-II. Compared with other neighborhood structures, the first structure is more complex and efficient. Figures 2 and 3 illustrate the operation movement of the same machine and cross-machine by a Gantt chart, respectively. In Figure 2, transferring operation
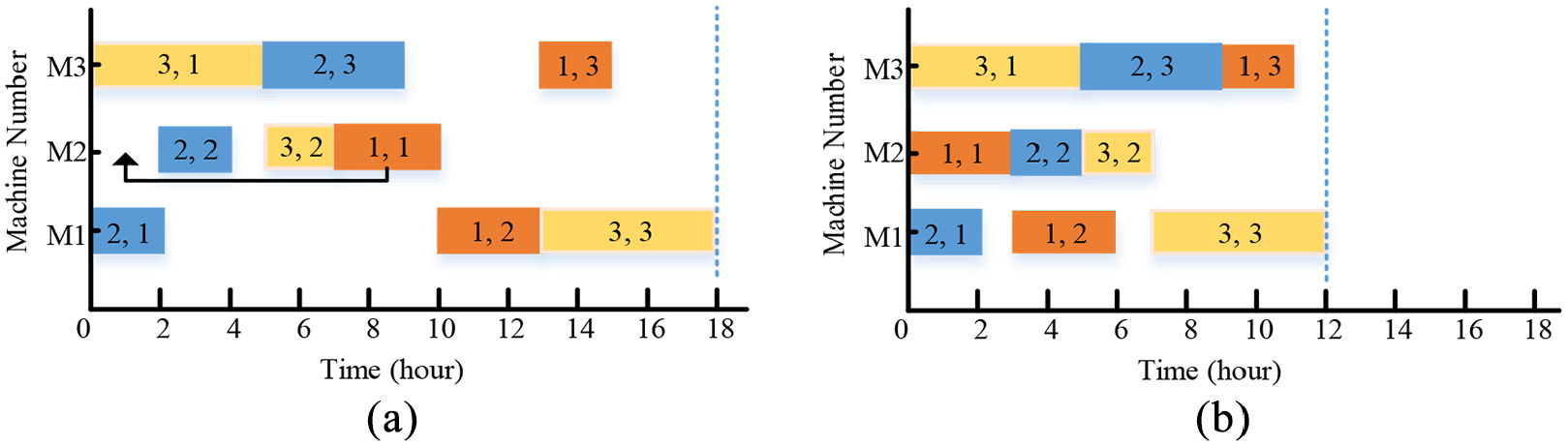
Operation movement on the same machine: (a) original Gantt chart and (b) changed Gantt chart.
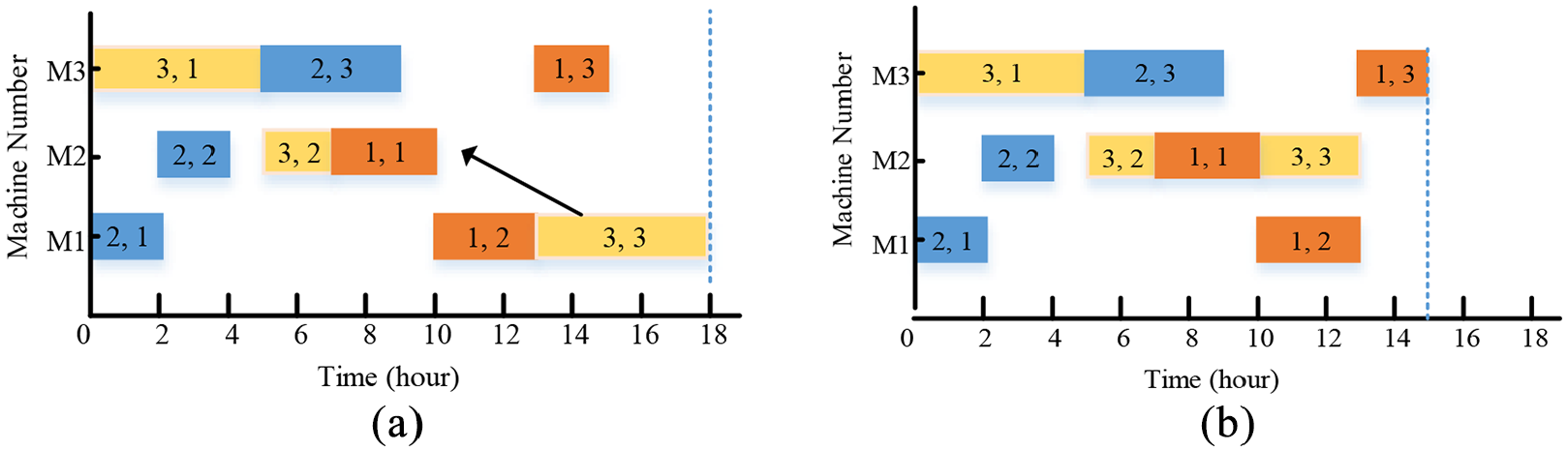
Operation movement across machines: (a) original Gantt chart and (b) changed Gantt chart.
The proposed HVNS-NSGA-II
Encoding and decoding
In general, chromosomes are encoded according to real operations and machines in FJSP. OS of the chromosome is encoded by number of job. For example, the second “3” in OS [3 1 2 2 1 3] stands for the second operation of job
The production data of an instance.
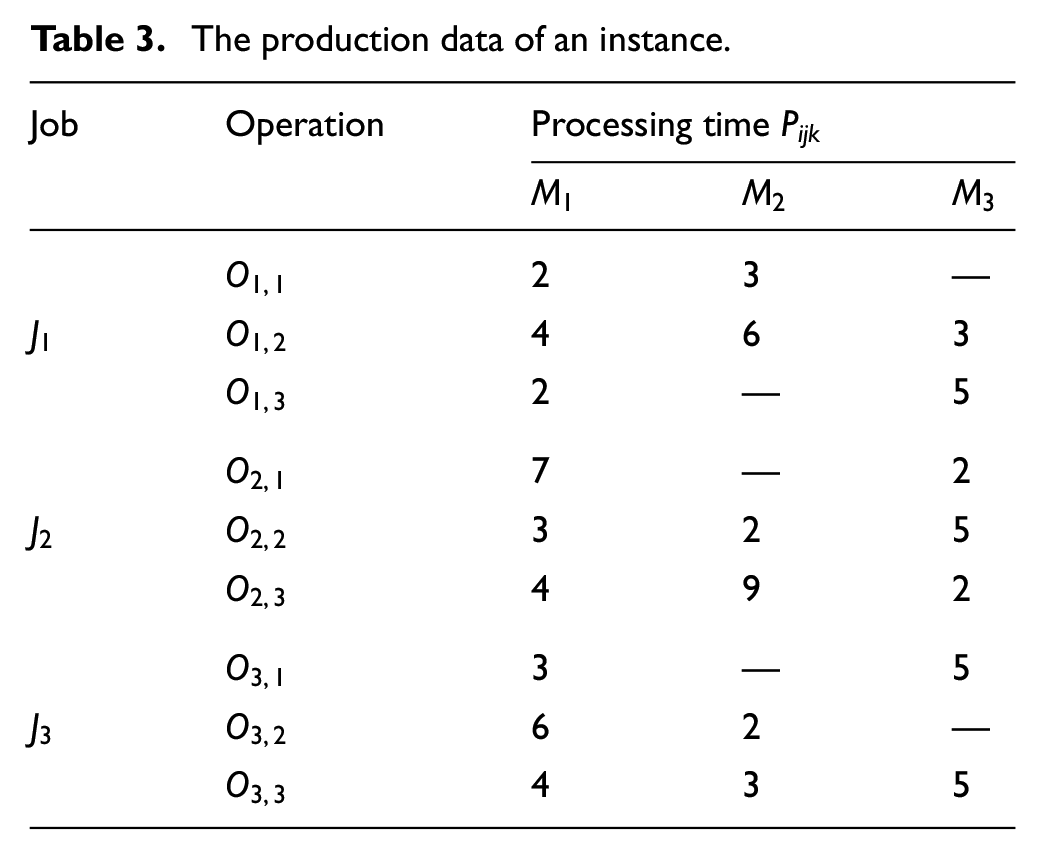

Encoding process of chromosome for instance.
Selection
In traditional NSGA-II, non-dominated sorting and crowding distance are utilized to sort objectives. Especially, if there are multiple Pareto frontier solutions, crowding distance combined with roulette wheel selection strategy is used for individual selection. However, in multi-objective optimization, most of crowding distance is infinite, which brings much difficulty to maintain the diversity of population solutions. Fortunately, Niche technology exhibits good performance on ensuring the diversity of individuals in cross pool to some extent, in which Hamming distance and Euclidean distance is used to evaluate similarity of multiple Pareto frontier solutions and then calculating the shared fitness value of individuals. Meanwhile, roulette wheel is used to select the Pareto front individuals to enter cross pool. The specific operation process is shown in Figure 5.
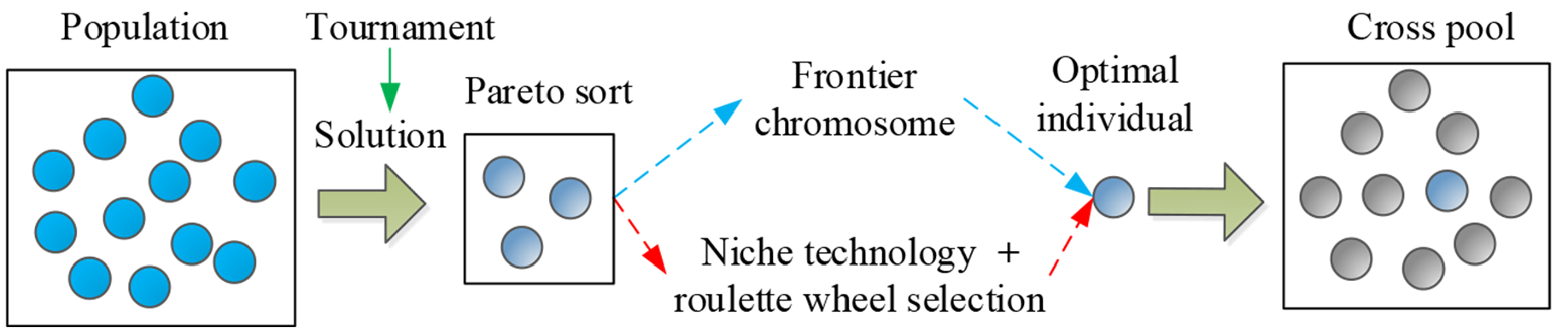
Tournament selection diagram.
Crossover
Crossover of processing sequence in chromosomes adopts generalized precedence operation crossover (POX) operation 44 and uniform crossover operation 45 strategies. Multi-point preservative crossover (MPX)46,47 is adopted for the crossover of machines with chromosome processing allocation. These two type crossover operations are described in detail below.
Precedence operation crossover (POX)
POX operation is implemented in this study, which depicts in Figure 6, and detailed operation process is shown as follows. Parent 1 and Parent 2 generate two offsprings after crossover. The process of crossover consists of three steps. Firstly, all jobs need to be divided into two sets, that is,
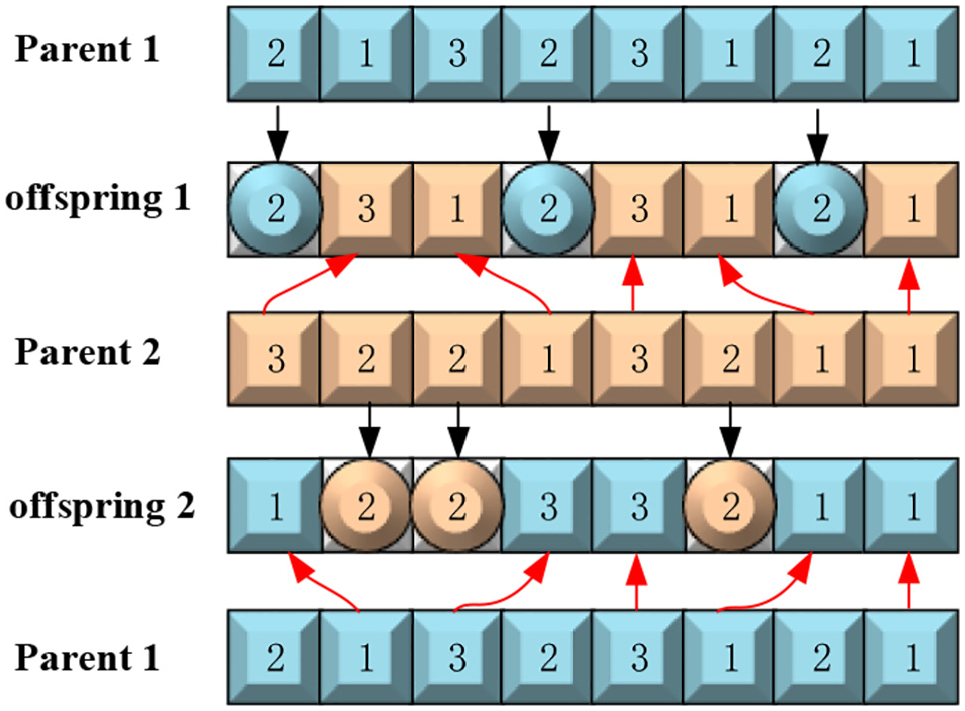
POX operation (
Uniform crossover
The operation of uniform crossover can be seen in Figure 7. Firstly, a set of number called Alpha is generated randomly by 0 or 1 with same length of chromosome. Parent 1 is swapped to Parent 2 corresponding to the position that equals 0 can be used as offspring 1. Parent 1 is swapped to Parent 2 corresponding to the position that equals 1 can be used as offspring 2. Eventually, two offspring are formed.
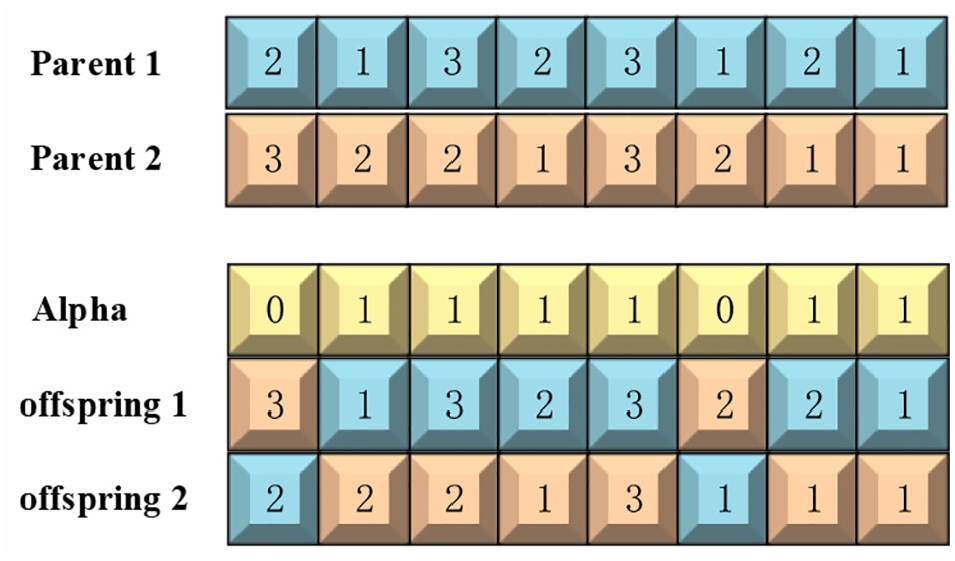
Uniform crossover operation.
Multi-point preservative crossover (MPX)
Multi-point preservative crossover (MPX) only cross selected machine in paternal chromosome, operation sequence of offspring is same with parents. The process of MPX can be seen in Figure 8. Firstly, a set of number called
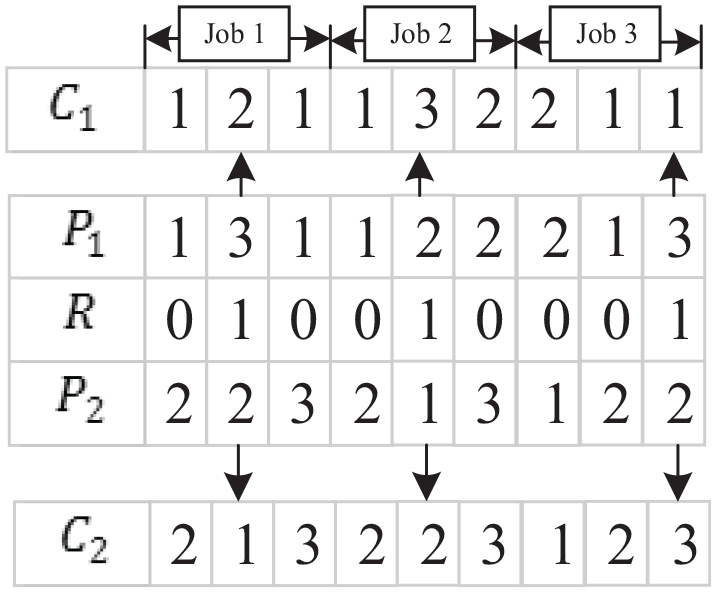
MPX crossover operation based on machine.
Based on the above consideration, the details of crossover operation are depicted by pseudo-code presented in Algorithm 1.

Mutation
Mutation is an effective technique to improve population diversity, two mutation operations are adopted in this paper. One is RWN for processing sequence, which choose rearranged position arbitrarily and rearrange them. It can be seen from Figure 9. Another mutation is for machine selection, machine with the shortest processing time is selected to replace genes, as can be seen in Figure 10.
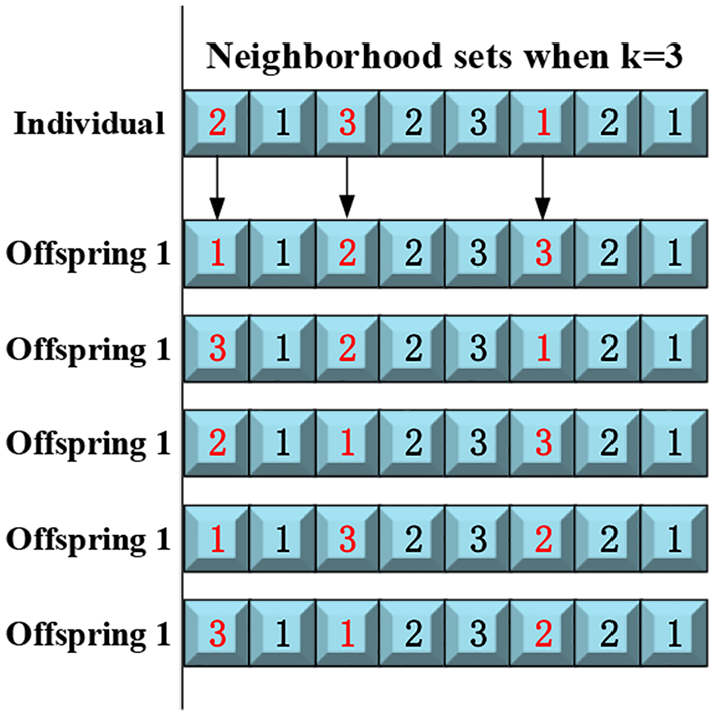
Random whole neighborhood.
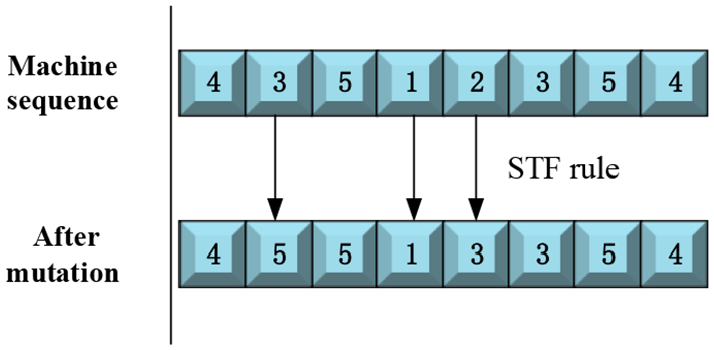
Machine chain mutation operation diagram.
Based on the above consideration, the details of mutation operation are depicted by pseudo-code presented in Algorithm 2.

Elite storage strategy (ESS)
After crossover, mutation and local search, Pareto non-dominant sorting and crowding distance are used to stratify the population, and a new population is generated. To prevent the optimal solution lost in iteration process, the elite memory bank
The framework of proposed HVNS-NSGA-II algorithm
Based on the above consideration, the details of HVNS-NSGA-II are depicted by pseudo-code presented in Algorithm 3.

Results and comparative analysis
In this section, multiple experiments are designed and make comparisons with seven algorithms to verify effectiveness of proposed HVNS-NSGA-II method. Two types of metrics are adopted to evaluate quality and diversity of the obtained non-dominated solutions through proposed algorithm. Effectiveness and superiority of the presented algorithm is verified by comparison with some other commonly used heuristic algorithms. Besides, comparison with one conic scalarization method (CSM) 13 further demonstrates the performance of proposed algorithm.
Design of experiments
In this subsection, environment setting, data source, and performance metrics are separately introduced.
Environment setting
All of the experiments and algorithms are written and implemented in MATLAB 2018a, with Intel® CoreTM i5-760Qm CPU @ 2.80 GHz and 8.00 GB RAM.
Data Source
To verify the performance of proposed method, dataset from literature
13
is utilized, which includes twelve instances. Taking p/m/l/k to represent the general representation of each instance. Thereinto,
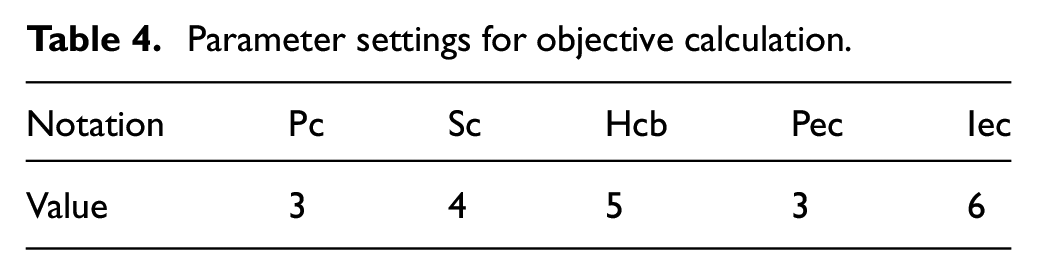
In this paper, the value of processing cost (Pc) on machine
Parameter settings for objective calculation.
Performance metrics
Non-dominated solutions metrics
To evaluate performance of obtained solutions, three metrics are adopted, namely the number of obtained non-dominated solutions
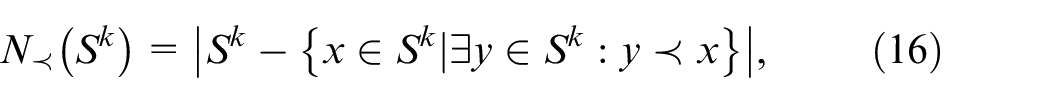

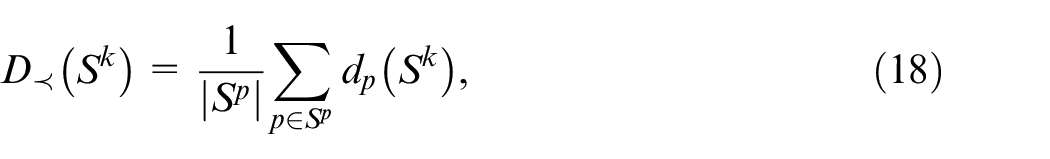
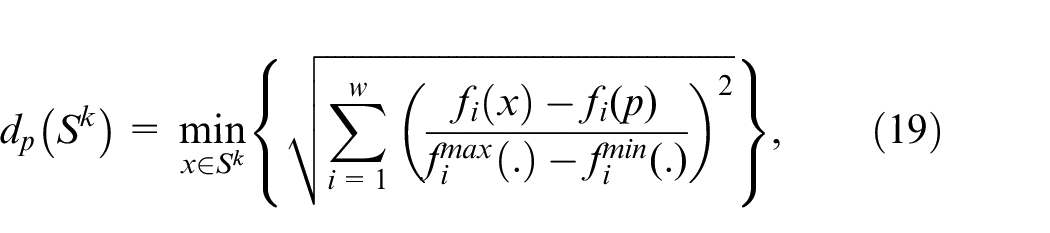
where
From above formulas,
Hypervolume
Hypervolume (HV) is an outstanding and widely used indicator to evaluate the comprehensive performance of different algorithms, which characterizes the magnitude of the volume dominated by Pareto front sets rather than reference point
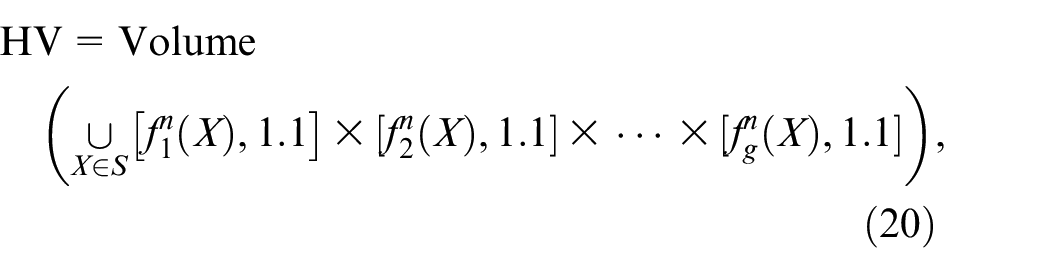
where
Indicator of makespan
It is worth noting that comparison of one objective function result can verify the efficiency between signal objective and multi-objective optimization algorithm.
48
In this paper, we compare makespan

where
Parameter setting
In this paper, parameters, such as number of individuals and interactions of proposed algorithm are listed in Table 5.
Parameter settings for proposed algorithm.

Comparisons with heuristic algorithms
In order to assess the validity and superiority of proposed HVNS-NSGA-II algorithm, computational results are discussed in this section with some other commonly used heuristic algorithms. In this Section, three objectives
48
in classical multi-objective optimization models for FJSP are compared, which are makespan
Comparisons of four Kacem instances
To exhibit the performance of proposed algorithm, four algorithms including PSO + TS, 52 HTSA, 53 and P-DABC 54 are employed and compared through four Kacem et al. 55 instances (4 × 5, 8 × 8, 10 × 7, and 10 × 10 instances).
Table 6 exhibits computational results of different algorithms, it finds that HVNS-NSGA-II has a higher efficiency than other methods when deal with four Kacem instances. In comparison with PSO + TS, the proposed HVNS-NSGA-II algorithm not only can acquire superior solutions but also obtain richer optimal solutions. Similarly, the proposed algorithm obtains much richer optimal solutions than PSO + TS, especially for 10 × 10 instance. When compared with HTSA, the proposed algorithm again obtains much richer optimal solutions than HTSA algorithm for 4 × 5 and 8 × 8 instance. For the medium and large scale instance 10 × 7 and 10 × 10, the solutions obtained by proposed algorithm have the same quality and quantity. In comparison with P-DABC, the proposed algorithm gets much richer optimal solutions for 4 × 5 instance. The solutions of other three instances show the same performance between the proposed algorithm and P-DABC.
Comparison of results on the four Kacem instances.
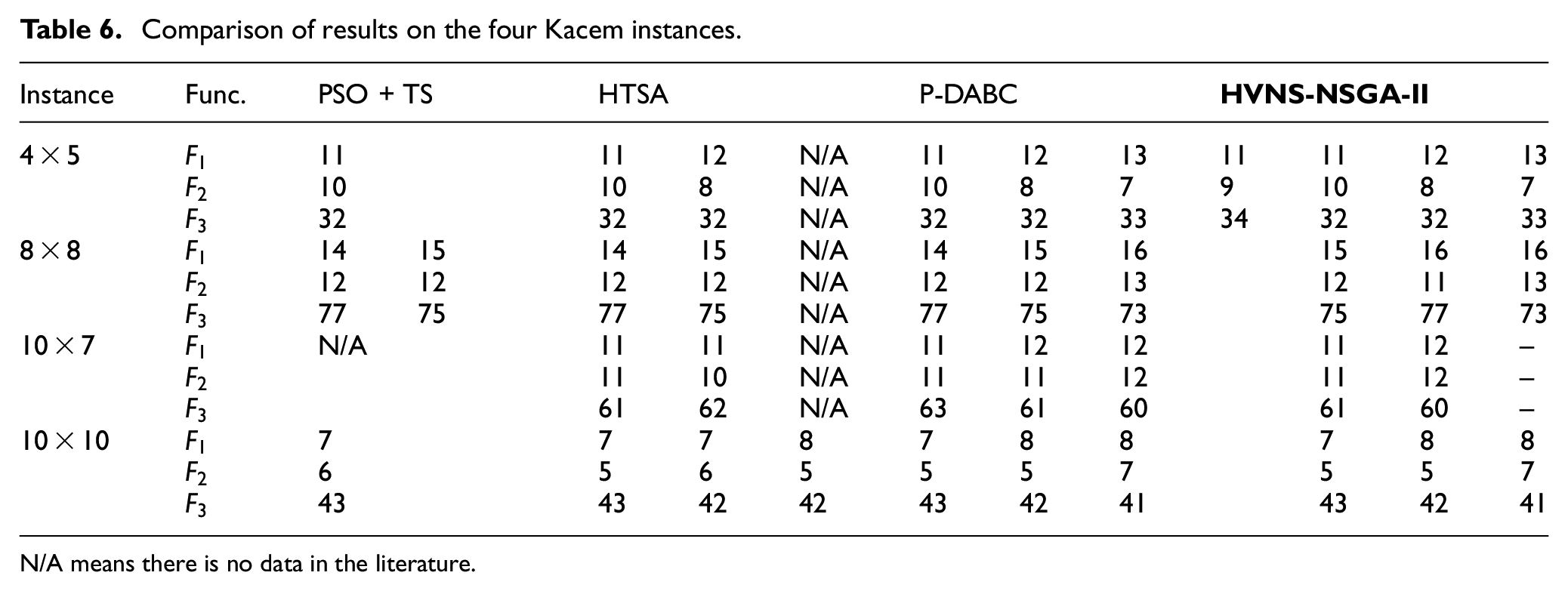
N/A means there is no data in the literature.
Comparisons of four BRdata instances
In this subsection, comparisons are made among some heuristic algorithms from literature on four BRdata instances (Mk01, Mk03, Mk05, Mk08). 56 Three heuristic algorithms are selected to compare, that is, MOGA algorithm by Wang et al., 57 BEG-NSGA-II algorithm by Deng et al., 44 and PSO + RRHC by Kato et al. 58 The comparative results are presented in Table 7.
Comparison of results on four BRdata instances.
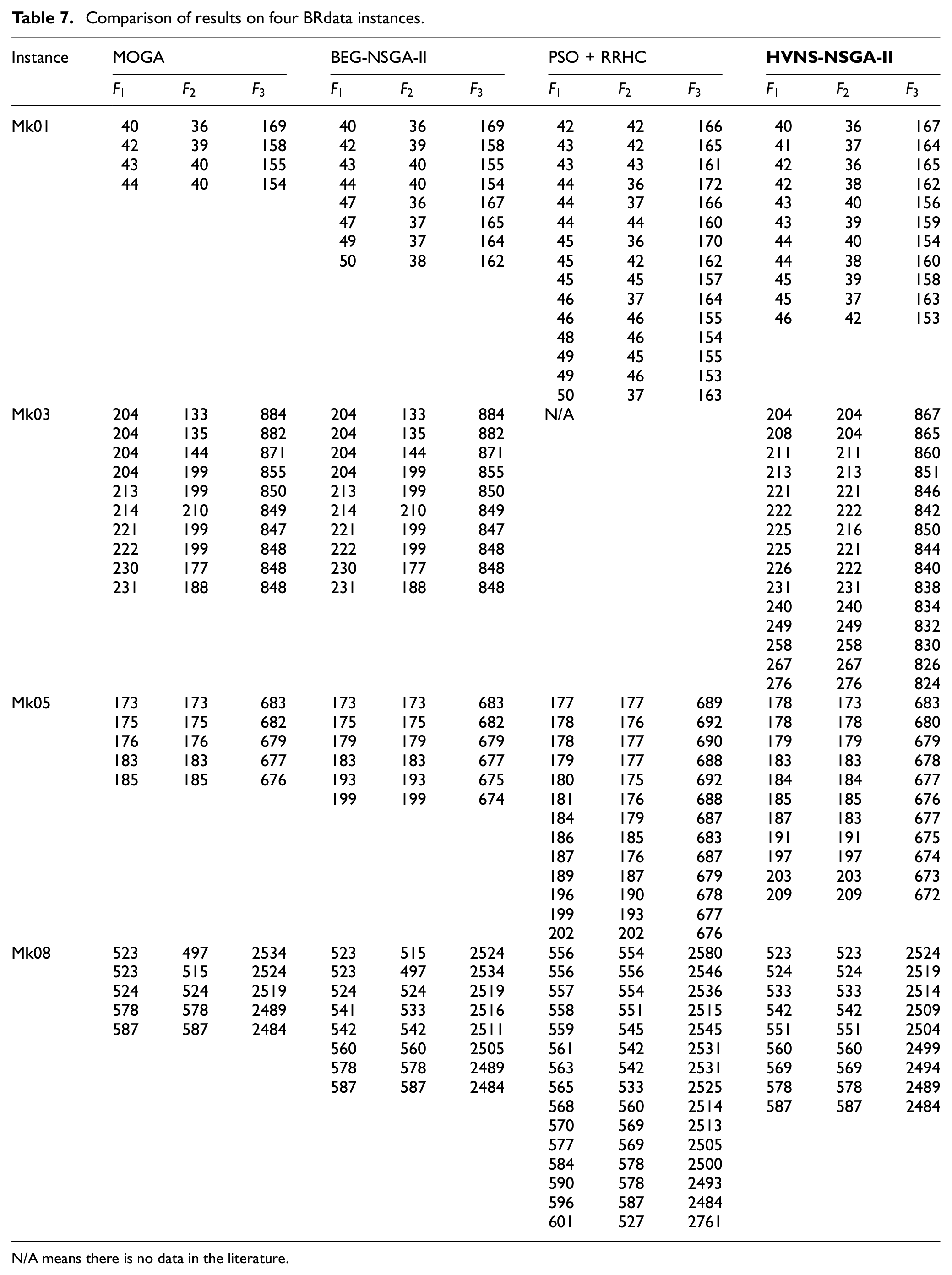
N/A means there is no data in the literature.
In comparison with MOGA, the proposed algorithm obtains superior and richer optimal solutions for each instance. When compared with BEG-NSGA-II, for Mk01 and Mk05 instance, the proposed algorithm has superior and richer optimal solutions. For Mk03 and MK08 instance, solution proposed algorithm obtains solutions with the same quality and quantity. In comparison with PSO + RRHC, all instances have obtained either same or richer solutions. Taking Mk08 instance as an example, the Gantt chart of the proposed method is shown in Figure 11. It is worth noting that there is a little difference from the Gantt chart explanation in Section 2.5, the mark
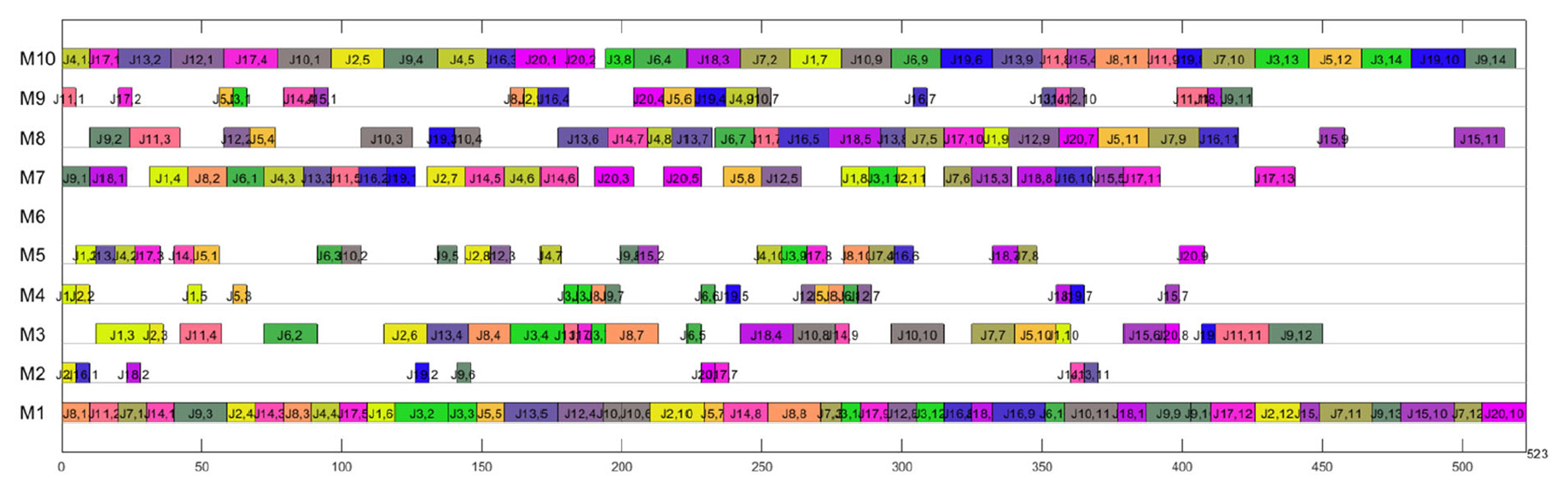
The first solution of MK08 (
Performance analysis
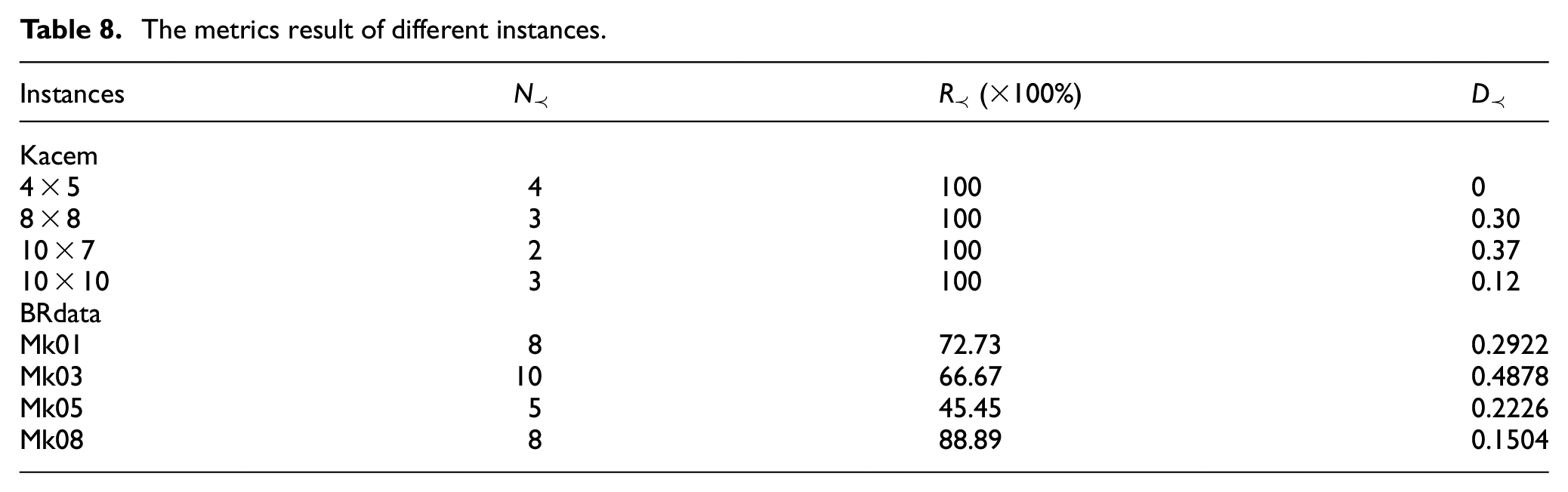
Based on mentioned three metrics in Section 4.1.3, the performance of the proposed HVNS-NSGA-II is shown in Table 8. It can be seen that the value
The metrics result of different instances.
To further compare the overall performance of proposed algorithm, the quality of normalized solution sets of each instance is evaluated by hypervolume (the bigger the better), and the results of Kacem and BRdata instances are shown in Tables 9 and 10 seperately. For the sake of comparison the ability of different algorithms to solve Kacem set problem, the Friedmantest
59
is used to assess whether there are significant differences in the effectiveness of HVNS-NSGA-II and other methods based on HV values, in which the significance level
Hypervolumes of different algorithms for four Kacem instances.
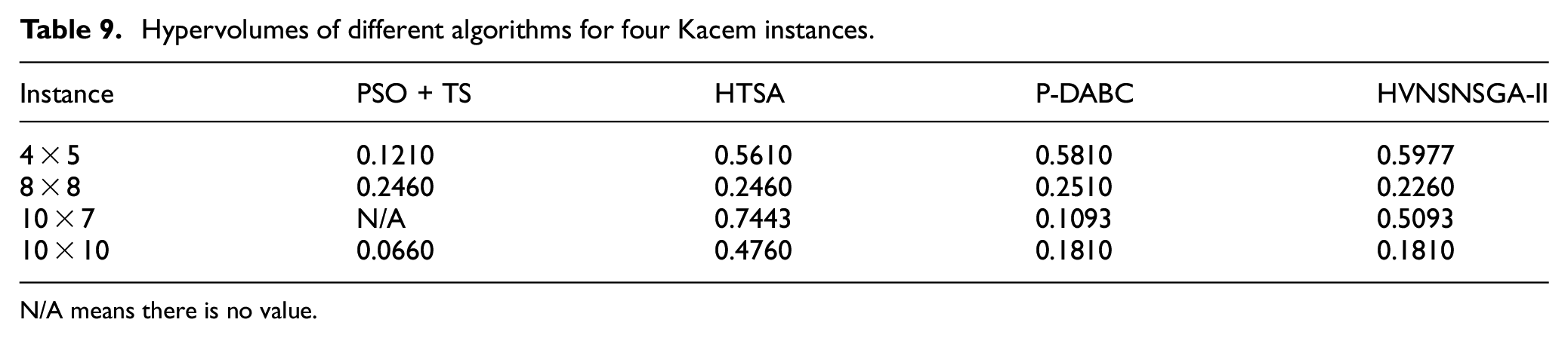
N/A means there is no value.
Hypervolumes of different algorithms for four BRdata instances.

N/A means there is no value.
Comparisons with scalarization method
Based on the definition of makespan indicator in Section 4.1.3, comparison results of makespan
Comparison of makespan
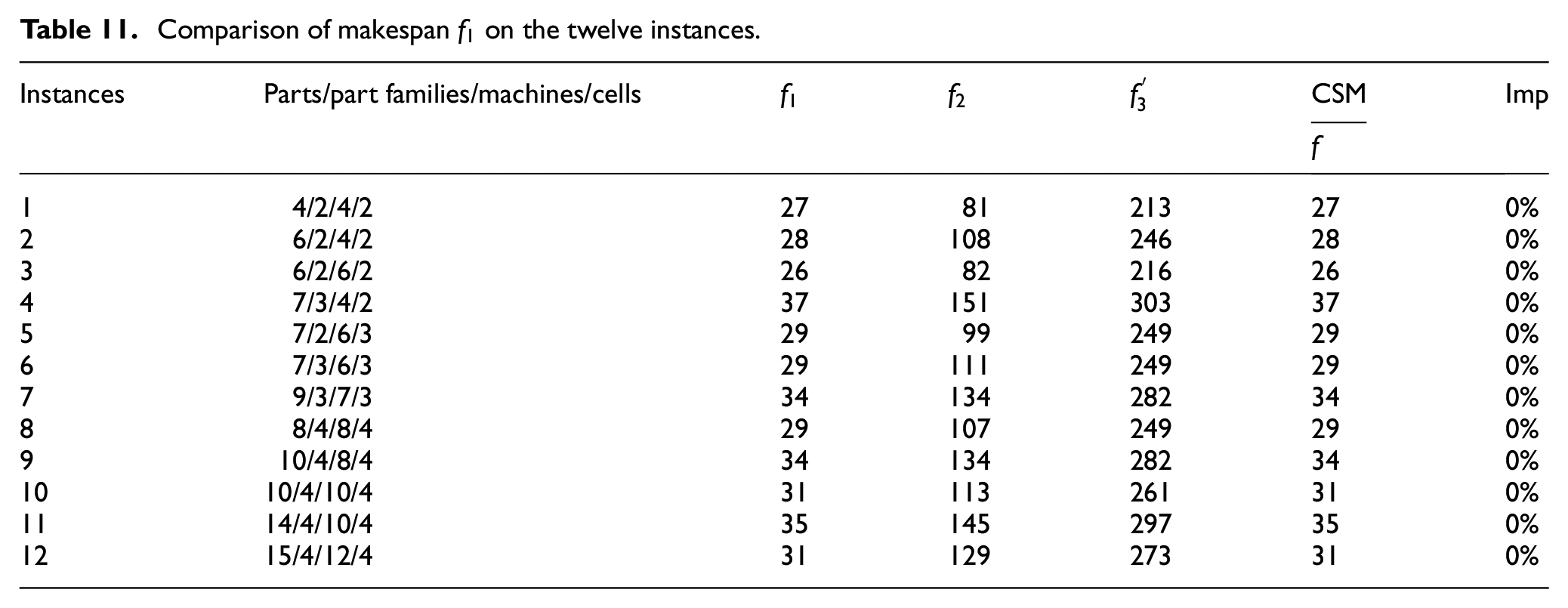
The first solution for 7/3/4/2 instance (
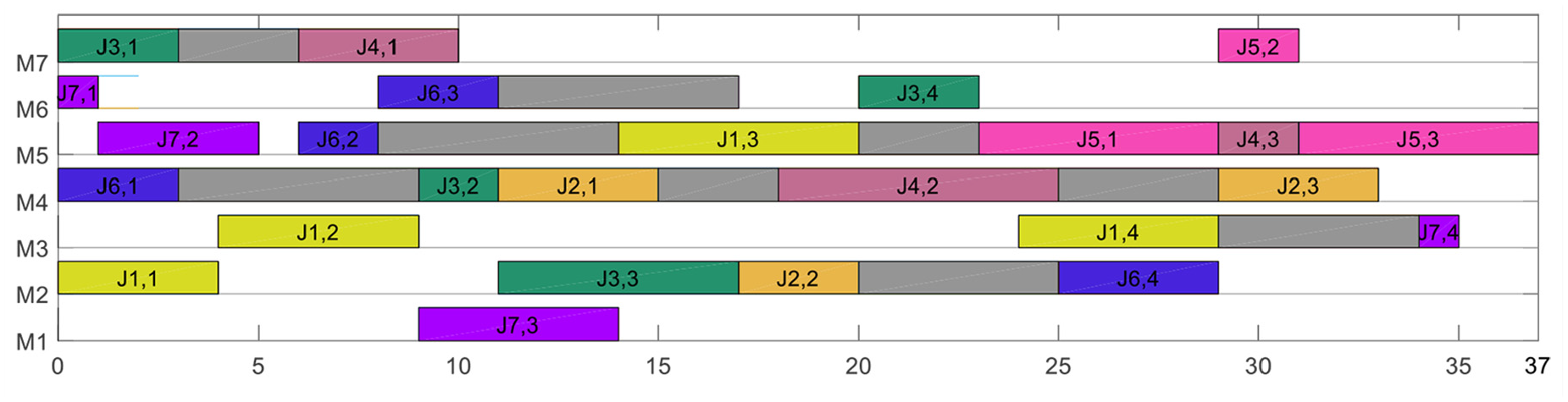
The first solution of 10/4/10/4 instance (
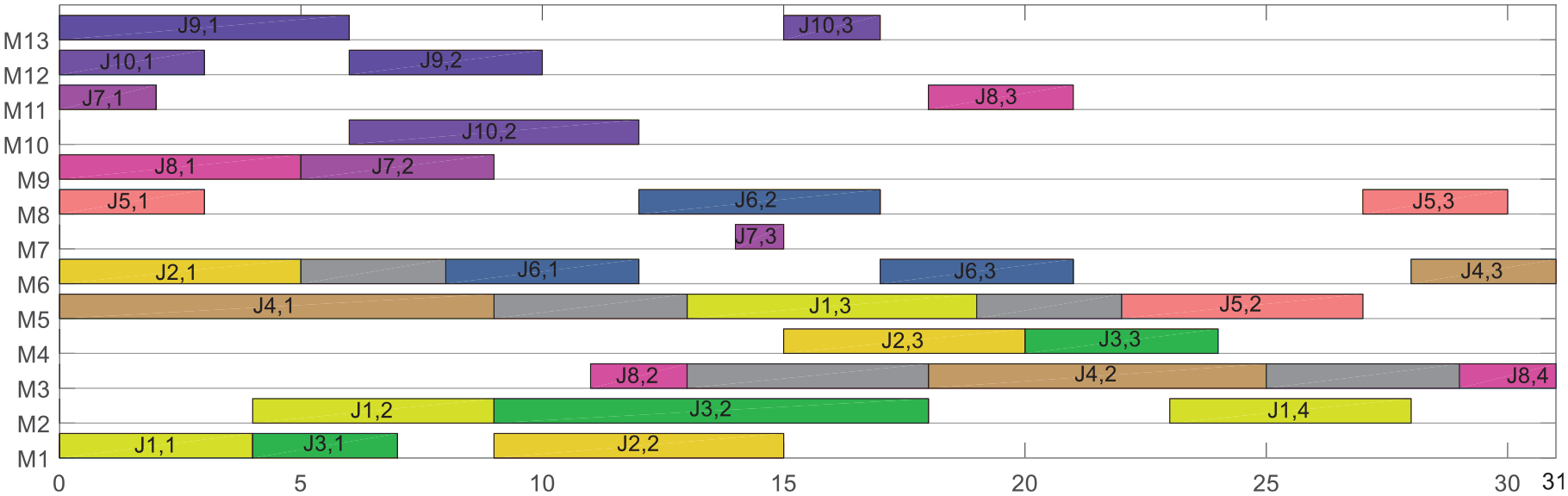
With the purpose of testing convergence of above solutions obtained in Table 11, we calculate HV indicators for all generations of each instance, which is shown in Figure 14. It can be seen from the figure all instances except Instance 1 converge in the second generation. This substantiates that proposed algorithm converges fast for problems with different cells and part families.
The hyper volume indicator of twelve instances of CSM.
Conclusions and future studies
This study focuses on a multi-objective FJCSP. An improved non-dominated sorting genetic algorithm, namely HVNS-NSGA-II, is proposed to solve the FJCSP. The main contribution and findings of this study can be summarized as follows: (1) intercellular transportation, energy consumption, sequence-dependent family setup times, and batch sizes are taken into consideration simultaneously in the FJCSP; (2) a hybrid variable neighborhood search, composed of three types of structures, has been embedded into NSGA-II to improve the local exploitation capability of original NSGA-II for obtaining more optimal solutions in multi-objective FJCSP; (3) based on different case studies, comparisons with other heuristic algorithms from literature on two types of benchmark instances have been confirmed the higher effectiveness of HVNS-NSGA-II. Besides, the efficiency of proposed algorithm has been verified by comparison of makespan with one scalarization method.
In future research, the influence of maintenance on scheduling will be considered with many real-life constraints. In parallel, the local search capacity will be improved to obtain more optimal solutions and speed up the convergence of algorithm.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Graduate Scientific Research and Innovation Foundation of Chongqing, China (CYB19008), and Fundamental Research Funds for the Central Universities (2019CDCGJX214).