
Abstract
The multi-objective buffer allocation problem of production lines is a non-deterministic-polynomial-hard problem. Many metaheuristic algorithms have been proposed to solve this problem. However, further investigation of new algorithms is still required because metaheuristic algorithms highly depend on the problem types. Furthermore, the balance between the solution quality and computational efficiency requires further improvement. Therefore, a data-driven algorithm consisting of the black widow optimizer and simulated annealing algorithm is proposed to maximize throughput and minimize energy consumption in production lines. Numerical examples demonstrate that the proposed algorithm achieves better solution quality than other state-of-the-art algorithms without losing computational efficiency. This study contributes to multi-objective optimization of resource scheduling in production lines.
Keywords
Introduction
The multi-objective buffer allocation problem (MBAP) in production lines is a non-deterministic-polynomial-hard problem. A production line consists of machines and buffers between the machines, which are typically sequentially arranged in a line. Because buffers can decrease the blocking phenomenon and keep machines working smoothly, it is vital to allocate buffers reasonably to improve the system performance and optimize the system energy consumption.1,2
The MBAP can be solved by integrating evaluative algorithms with optimization algorithms.3,4 Optimization algorithms search for candidate solutions, whereas evaluative algorithms select optimal solutions among candidate solutions. This process continues until a predefined objective is satisfied.
Evaluative algorithms consist of exact, approximation, simulation, and data-driven methods. Exact methods and simulation methods typically obtain results close to actual values 5 ; however, long computational times limit their application in MBAP, in which many evaluations are required. Approximation methods are widely used because of their higher computational efficiency than exact methods and simulation methods.6–8 However, in MBAPs that require a large number of evaluations, a certain amount of computational time is required for approximation methods. Data-driven methods utilize machine learning algorithms to analyze the data obtained by mathematical models or industrial data and build performance prediction models.9,10 Despite their high computational efficiency, their predictive accuracy remains a major challenge. To achieve a balance between predictive accuracy and computational efficiency, approximation methods are being combined with data-driven methods.
Optimization algorithms include enumeration algorithms (EAs), dynamic programing, search algorithms, and metaheuristics. Both enumeration algorithms and dynamic programing are typically used to obtain global-optimal solutions for production lines on a small scale owing to their long computational time.11,12 Search algorithms can obtain the near-optimal solution quickly by using guidance information to update the candidate solutions.13,14 However, the effectiveness of the guidance information is difficult to determine, which directly affects solution quality. Metaheuristics are widely used to solve resource scheduling problems, such as MBAP.15–17 Yelkenci Kose and Kilincci 18 proposed a simulated annealing (SA) based nondominated sorting genetic algorithm II (NSGA-II) to maximize the average system throughput and minimize the total buffer size. Xi et al. 19 developed a decomposition coordination method to minimize the total cost investment by allocating buffers and machines and selecting machine types. Despite the rich number of previous studies on metaheuristics, the performance of a meta-heuristic algorithm highly depends on the problem being handled. 20 Therefore, it is necessary to investigate new optimization algorithms against classical algorithms. Furthermore, the balance between solution quality and computational efficiency requires further improvement to satisfy increasing industrial application requirements.
This study proposes a data-driven ensemble algorithm (DDEA) of the black widow optimizer algorithm (BWOA) and SA to maximize the throughput and minimize the energy consumption of production lines subject to the total buffer capacity. In the proposed algorithm, the BWOA is improved for global search, whereas SA is used to intensify local search and detect promising regions. The nondominated-sorting-II method is used to efficiently sort the Pareto optimal solutions. Furthermore, an evaluative algorithm is utilized to calculate the throughput and energy consumption. Simultaneously, a gradient boosting regression tree (GBRT) is used to build surrogate models using a database, improving the evaluative efficiency of the local search.
This study proposes a novel DDEA to solve the MBAP of production lines, significantly improving solution quality without losing computational efficiency. This can help engineers design and optimize resource scheduling in production and logistics systems.
The remainder of this study is organized as follows. Section 2 describes the problem. Section 3 presents the solution methodology. Section 4 compares the proposed algorithm with other state-of-the-art algorithms to demonstrate its effectiveness. Finally, conclusions and future research are summarized in Section 5.
Problem statement
Assumption
The assumptions in this study are as follows.
There are
The first machine is never starved, and the final machine is never blocked.
Each machine had an identical failure rate, repair rate, and energy consumption for different operations, and their values were predefined.
First come first serve 21 is used to describe the processing sequences for the parts in front of the machines.
Blocking after service 21 is used to describe the blocking behavior of the parts between the buffers and machines.
The transfer time between machines is assumed to be zero.
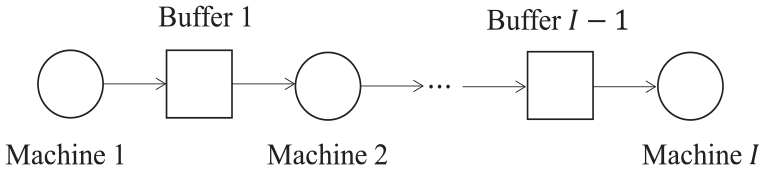
Model of a production line.
Notation
Table 1 presents the notations used in this study.
Notations in this study.

Multi-objective optimization problem of buffer allocation
The MBAP in this study is aimed at maximizing the throughput and minimizing the energy consumption of production lines subject to the total buffer capacity. This problem can be expressed as follows:
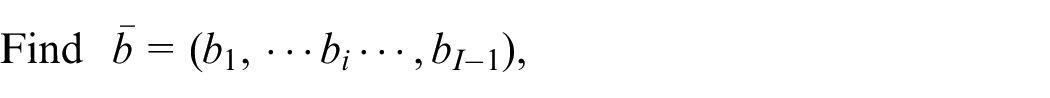
to maximize the
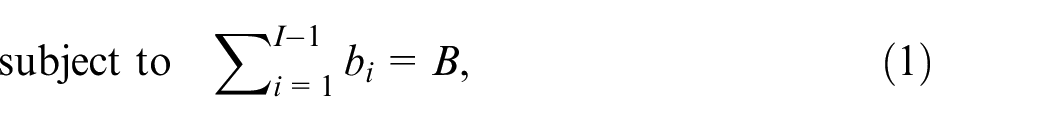

where equation (1) regulates the decision variables
In the case where the sub-objective of
Pareto dominance
A solution
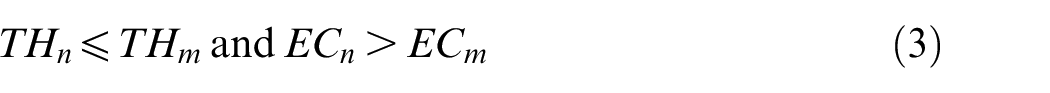
or
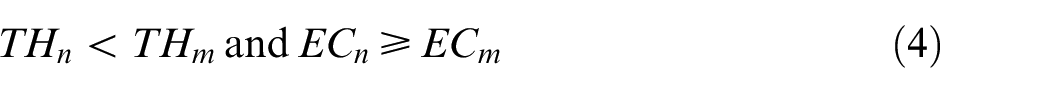
Pareto optimality and Pareto optimal front
A given solution
Solution methodology
In this study, the DDEA was integrated with the economic and energetic performance evaluation method (EEPEM) 24 to solve the MBAP. In the DDEA, the BOWA 25 is improved for a global search to exploit candidate solutions, whereas the SA is used for a local search to explore more promising regions. Surrogate models are constructed based on a database that stores the historical data of candidate solutions to reduce the computational time of the local search.

The EEPEM
EEPEM calculates the throughput and energy consumption of a production line based on discrete Markov chain formulations. 24 First, it calculates the steady-state probabilities of the buffers and approximates the effective service rate of each machine based on these steady-state probabilities. The throughput of the production line is the lowest effective service rate among the machines. Furthermore, EEPEM computes the energy consumption of each machine based on failure rates, machine repair rates, steady-state probabilities of buffers, and energy consumption of various machine operations. The sum of all the machine energy consumption is the system energy consumption. Readers can refer to the literature 24 for details on EEPEM.
The DDEA
Coding and initialization operator
Individuals denote candidate solutions, and coding represents the solution expression. The coding of an individual is defined as:

Furthermore,
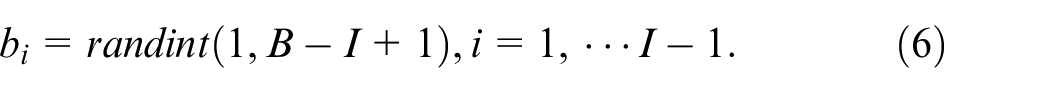

Surrogate model and
The GBRT, which is effective in prediction research, was used to construct surrogate models.
26
The surrogate models were trained using the sklearn library (version 0.24.2) in Python (version 3.6). For more details on GBRT, readers can refer to the literature.
26
The SA in the DDEA
Move representation and neighborhood structure
The SA has satisfactory local search ability,
18
and its move representation determines the neighborhood individuals of the current optimal individuals. The move representation is defined in this study as changing a certain number of capacities between two buffers and a certain service rate between the two machines of each individual in
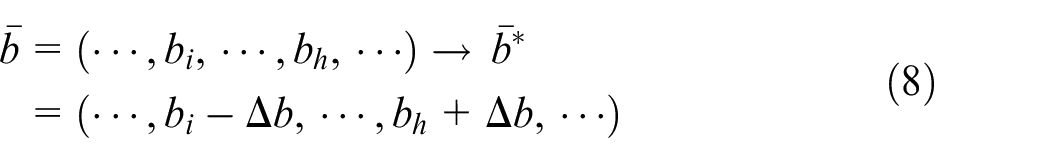

subject to
The neighborhood structure is a subset of all feasible neighborhood individuals considering the computational efficiency. Each individual in
Temperature settings
Acceptance and stopping criteria for SA
The acceptance criterion is defined using the Metropolis criterion and Pareto optimality. If an individual is dominated by its neighborhood individual, the neighborhood individual is accepted; otherwise, if equation (10) is satisfied, the neighborhood individual is also accepted.
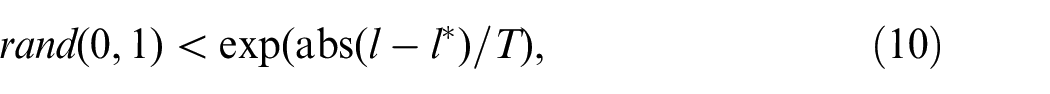
where
The stopping criterion for SA is defined as the maximum number of iterations (
Genetic operator
The BWOA has a satisfactory global search ability 25 inspired by the movement and pheromones of black widows. In this study, the BWOA was extended to solve the MBAP. By imitating the linear and spiral movements of black widows, each individual’s buffer capacity can be expressed as follows:

where
The pheromone of the
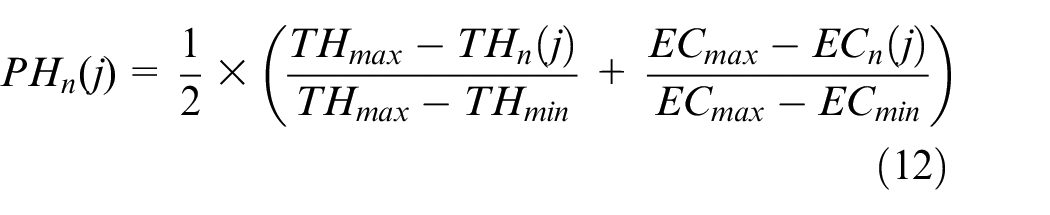
where
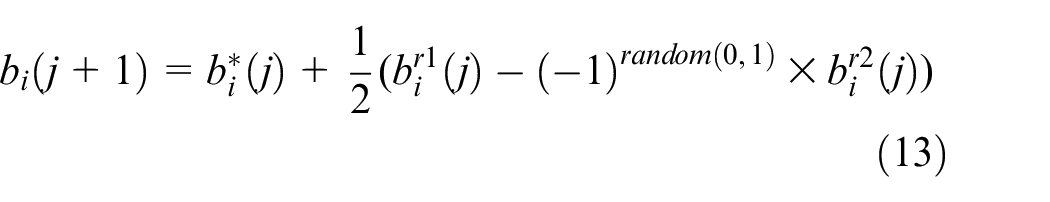
where
To avoid the buffer capacity from being lower than the lower limit, the reflection operator is expressed as

where
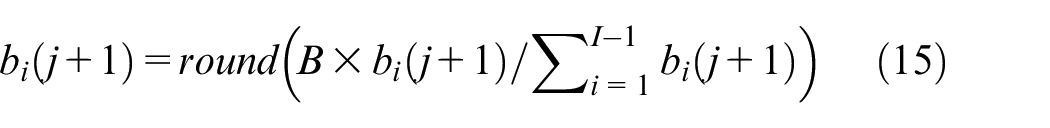
Stopping criterion
The stopping criterion for either DDEA was defined as the maximum number of iterations (
Numerical example
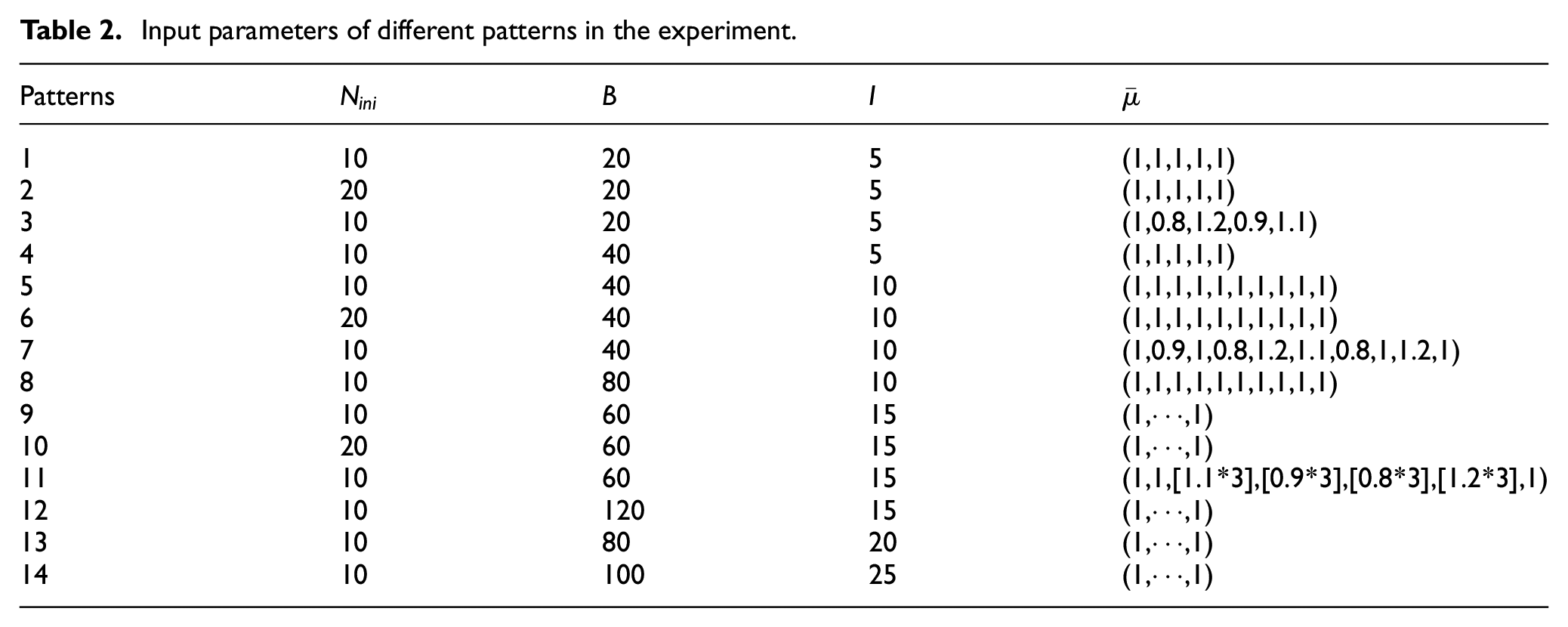
The proposed DDEA was tested in production lines involving 5, 10, 15, 20, and 25 machines. To test its sensitivity, the effects of the total buffer capacity, initial individual size, and service rate allocation were considered in the numerical examples. The experimental settings are presented in Table 2.
Input parameters of different patterns in the experiment.
The proposed DDEA was compared with the NSGA-II, SA, and BWOA. The settings of the four algorithms are listed in Table 3. In addition, an EA was used to demonstrate the absolute solution quality of small-scale problems, including Patterns 1–4.
The proposed DDEA, NSGA-II, SA, and BOWA were written in Python 3.6, and executed for all experiments on a laptop computer with a 2.5 GHz Intel Core 2 Duo CPU.
Comparison criteria
The number of Pareto optimal solutions (
Experiment
Setting
Production lines with different total buffer capacities (
Parameter settings of comparison algorithms.
Results and discussion
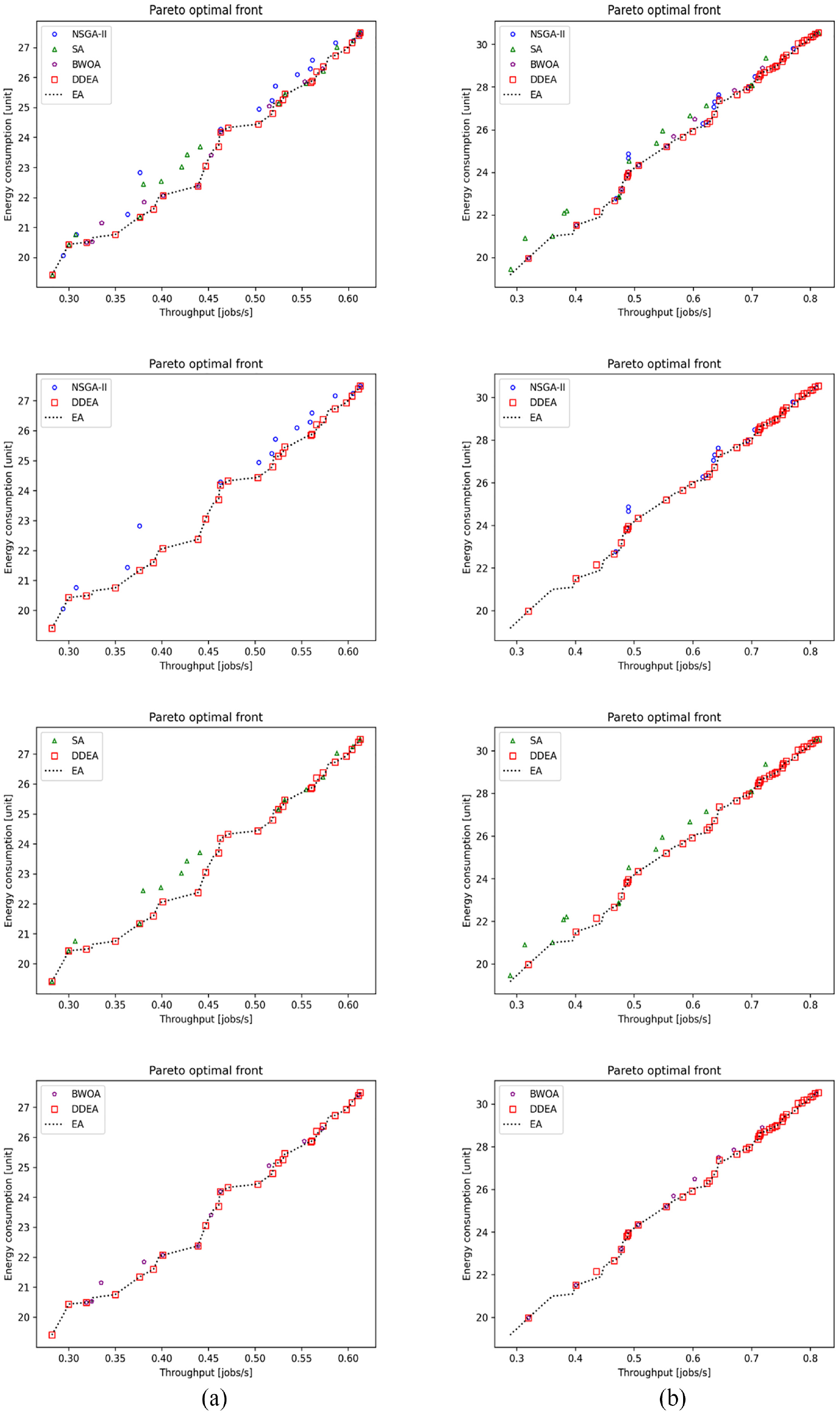
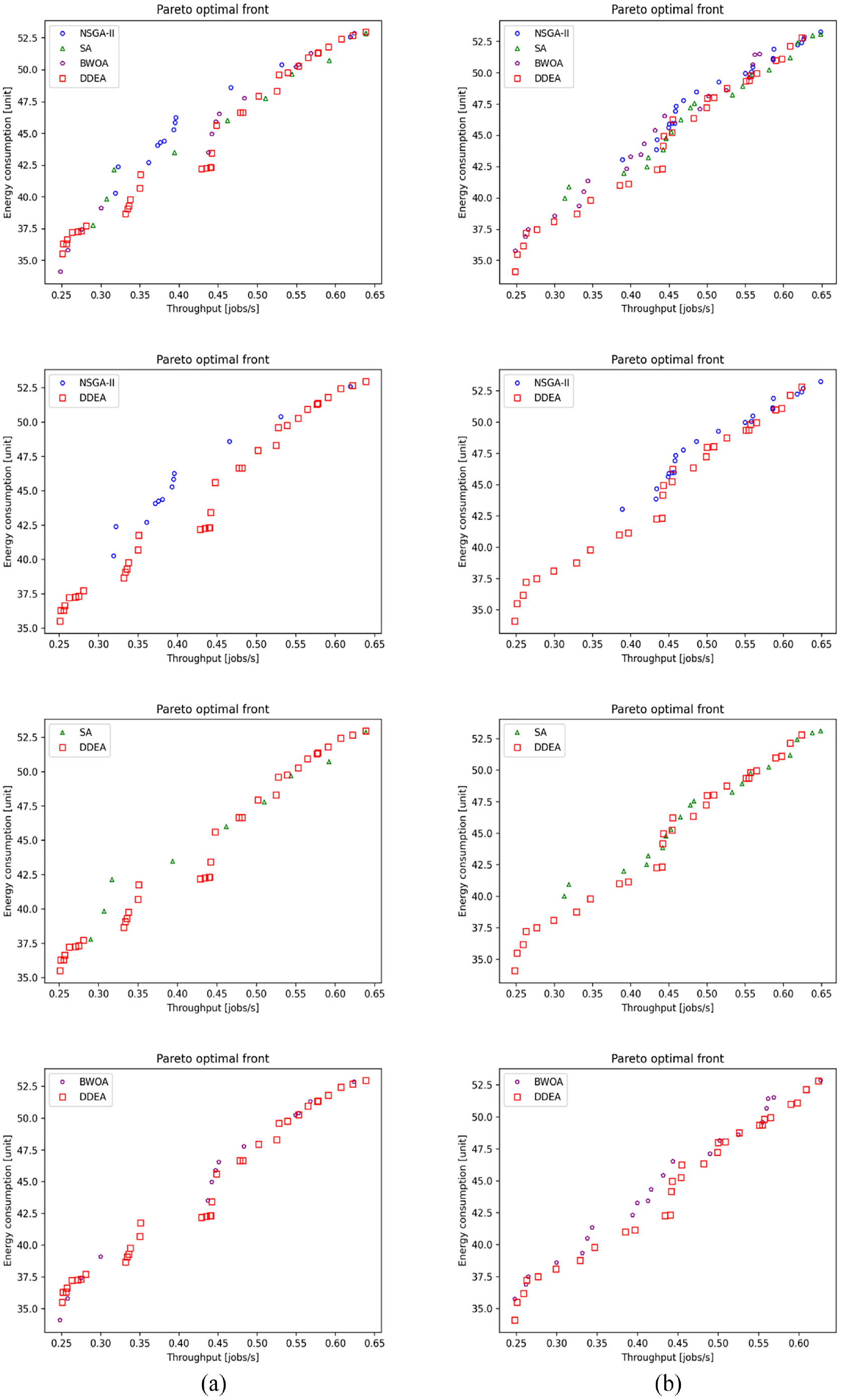
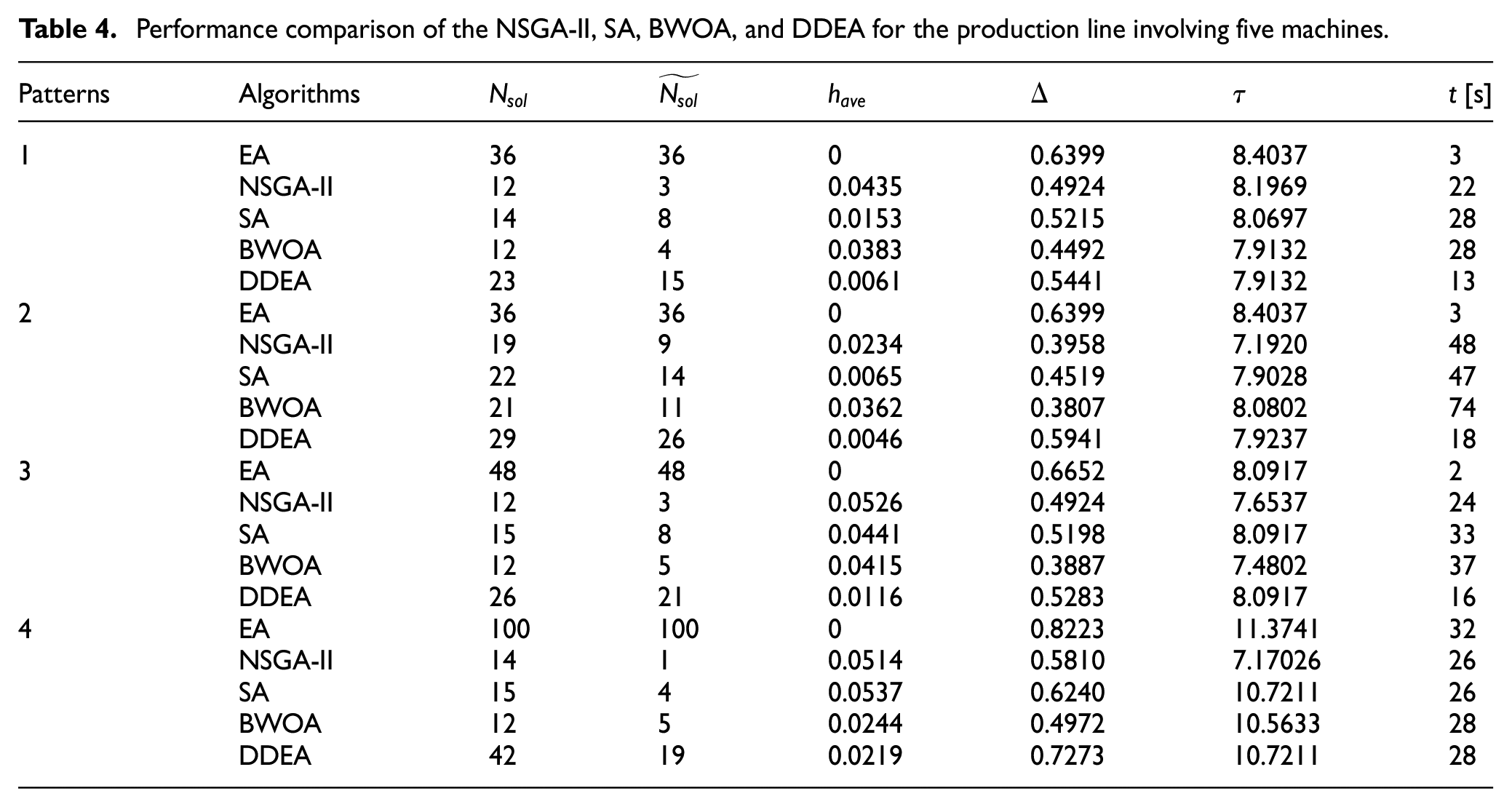
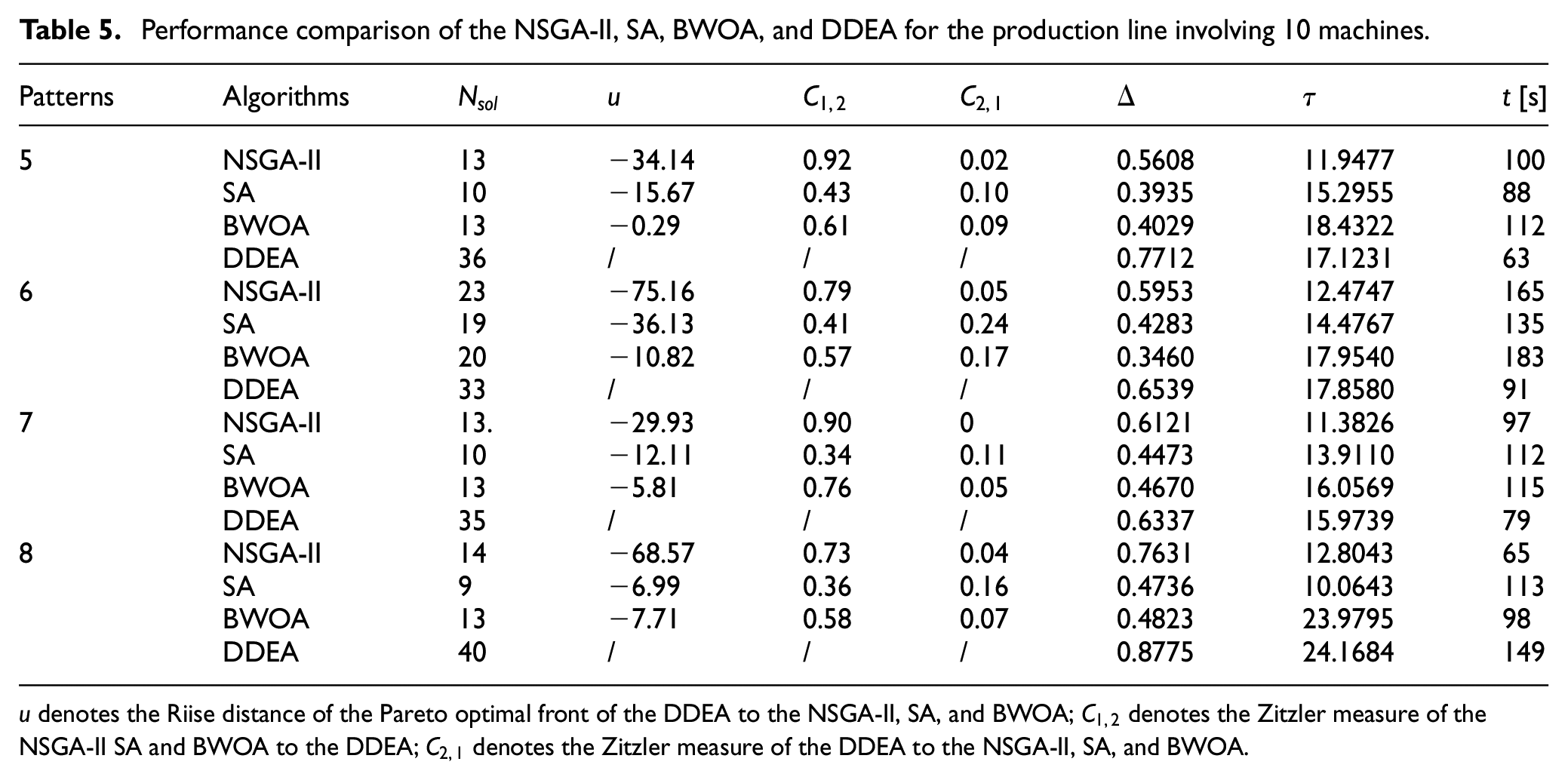
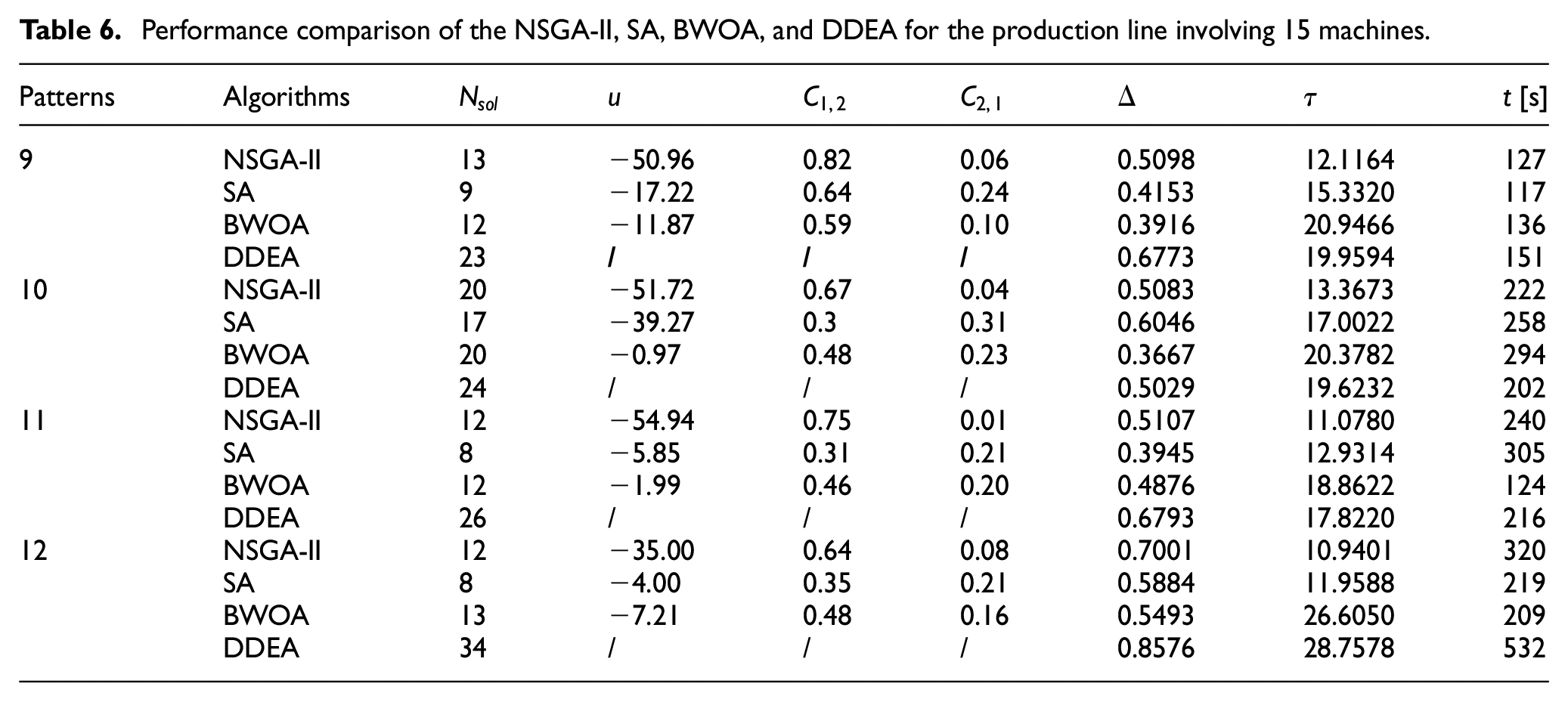
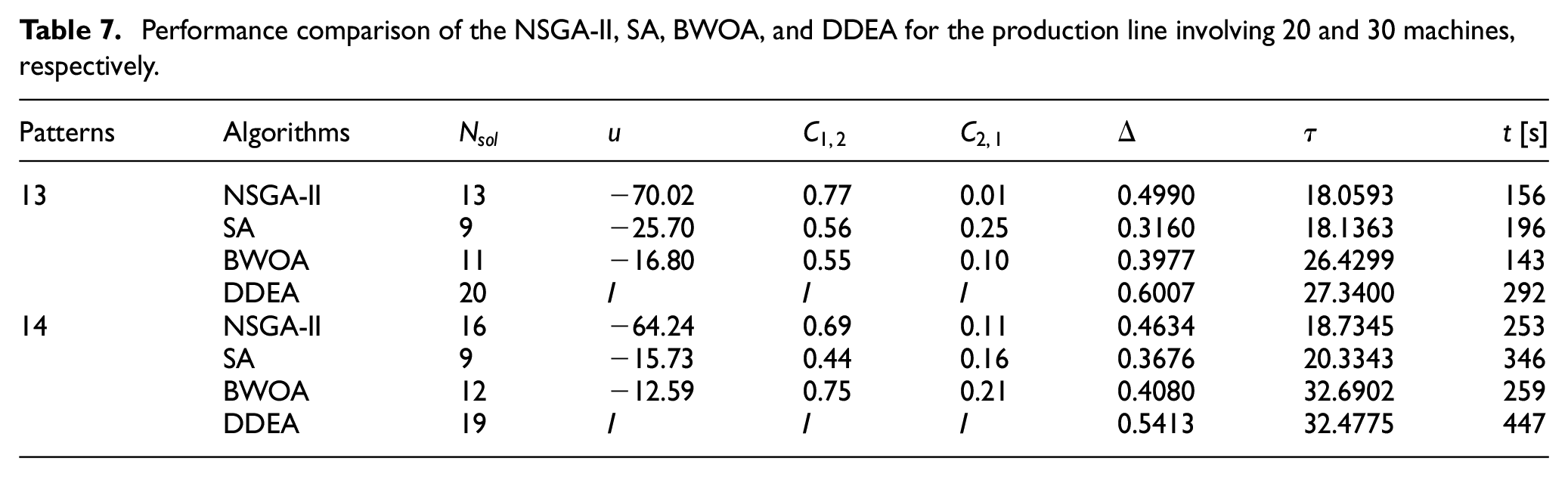
Figures 2 to 8 show the performance comparison of the NSGA-II, SA, BWOA, and DDEA. In Patterns 1–4, the Pareto optimal front obtained by the DDEA is closer to the Pareto front obtained by the EA than the NSGA-II, SA, and BWOA, indicating better performance of the DDEA. In Patterns 5–14, the Pareto optimal front obtained by the DDEA is under those obtained by the NSGA-II, SA, and BWOA. Consequently, DDEA still performs better, although the total buffer capacity and machine size increase. The following conclusions were drawn based on Tables 4 to 7.
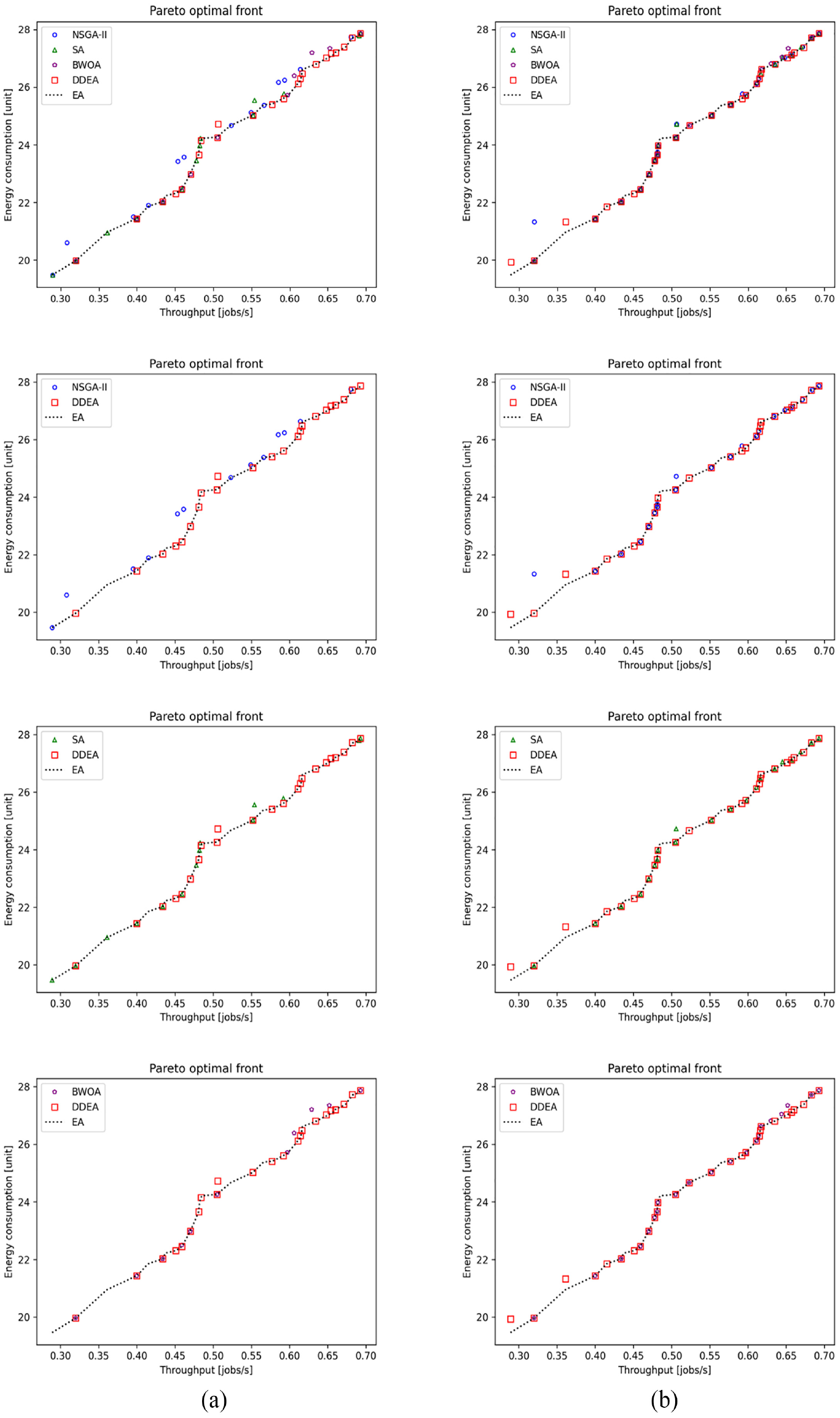
Performance comparison of the NSGA-II, SA, BWOA, and DDEA in Patterns (a) 1 and (b) 2 for the production line involving five machines.
Performance comparison of the NSGA-II, SA, BWOA, and DDEA in Patterns (a) 3 and (b) 4 for the production line involving five machines.
Performance comparison of the NSGA-II, SA, BWOA, and DDEA in Patterns (a) 5 and (b) 6 for the production line involving 10 machines.
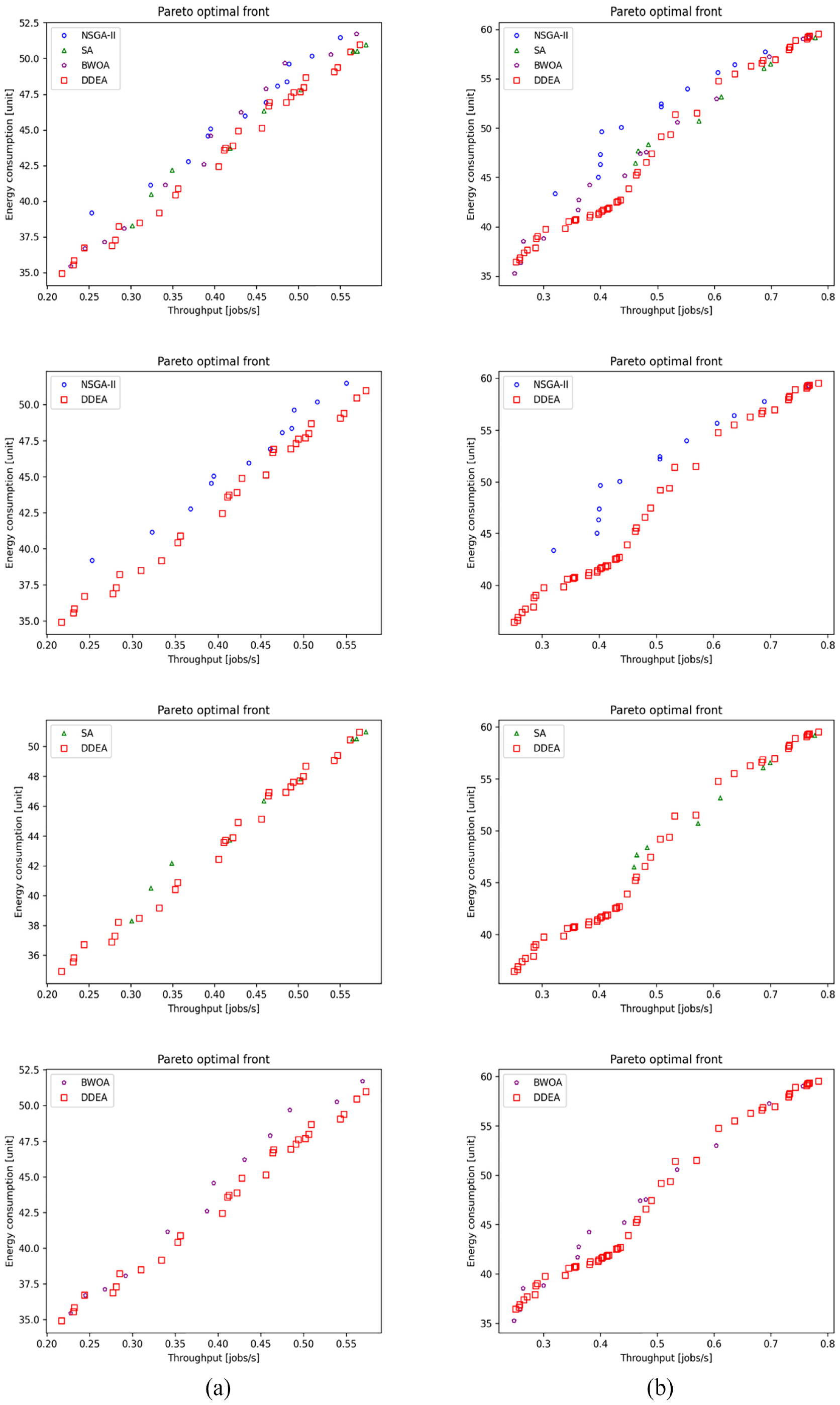
Performance comparison of the NSGA-II, SA, BWOA, and DDEA in Patterns (a) 7 and (b) 8 for the production line involving 10 machines.
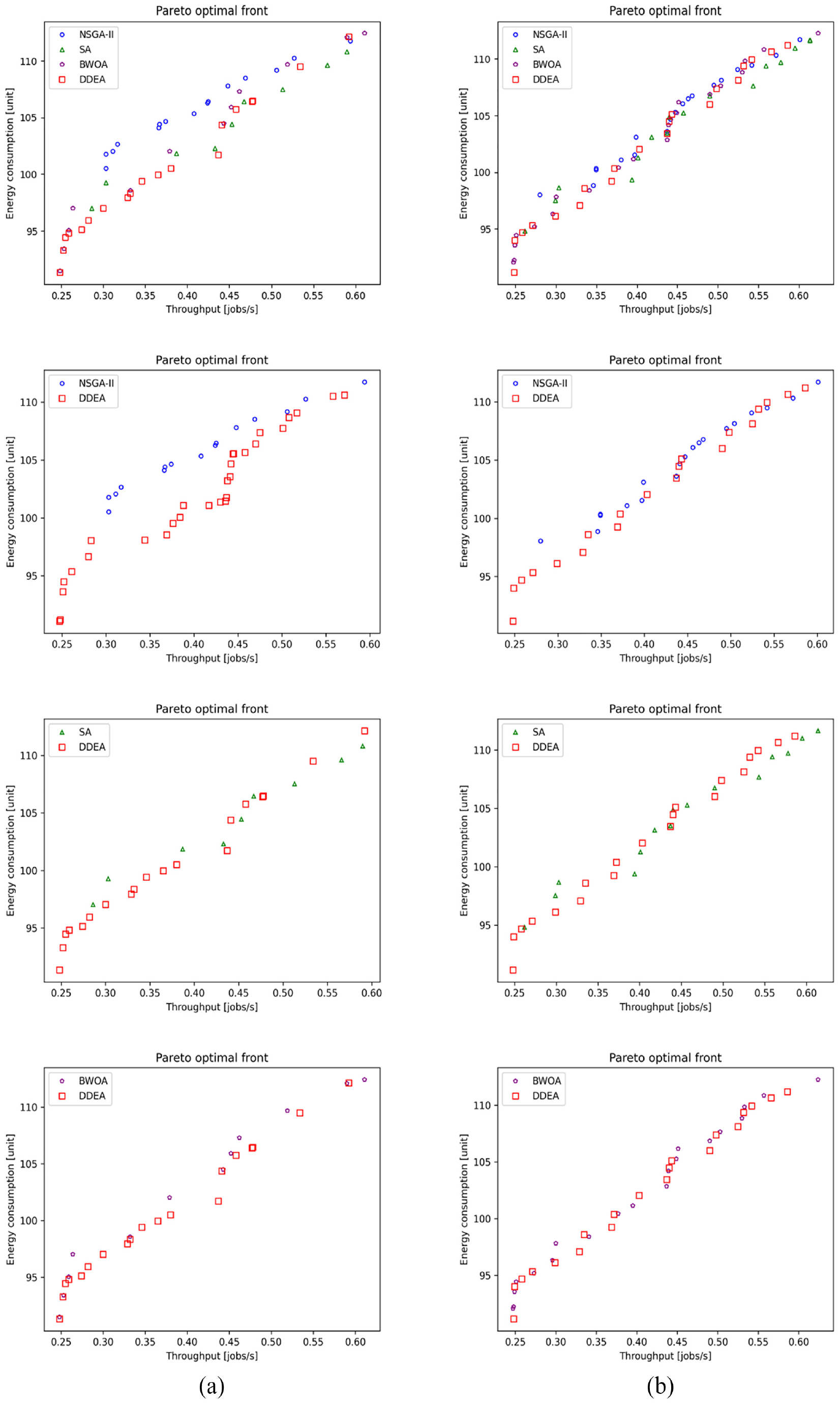
Performance comparison of the NSGA-II, SA, BWOA, and DDEA in Patterns (a) 9 and (b) 10 for the production line involving 15 machines.
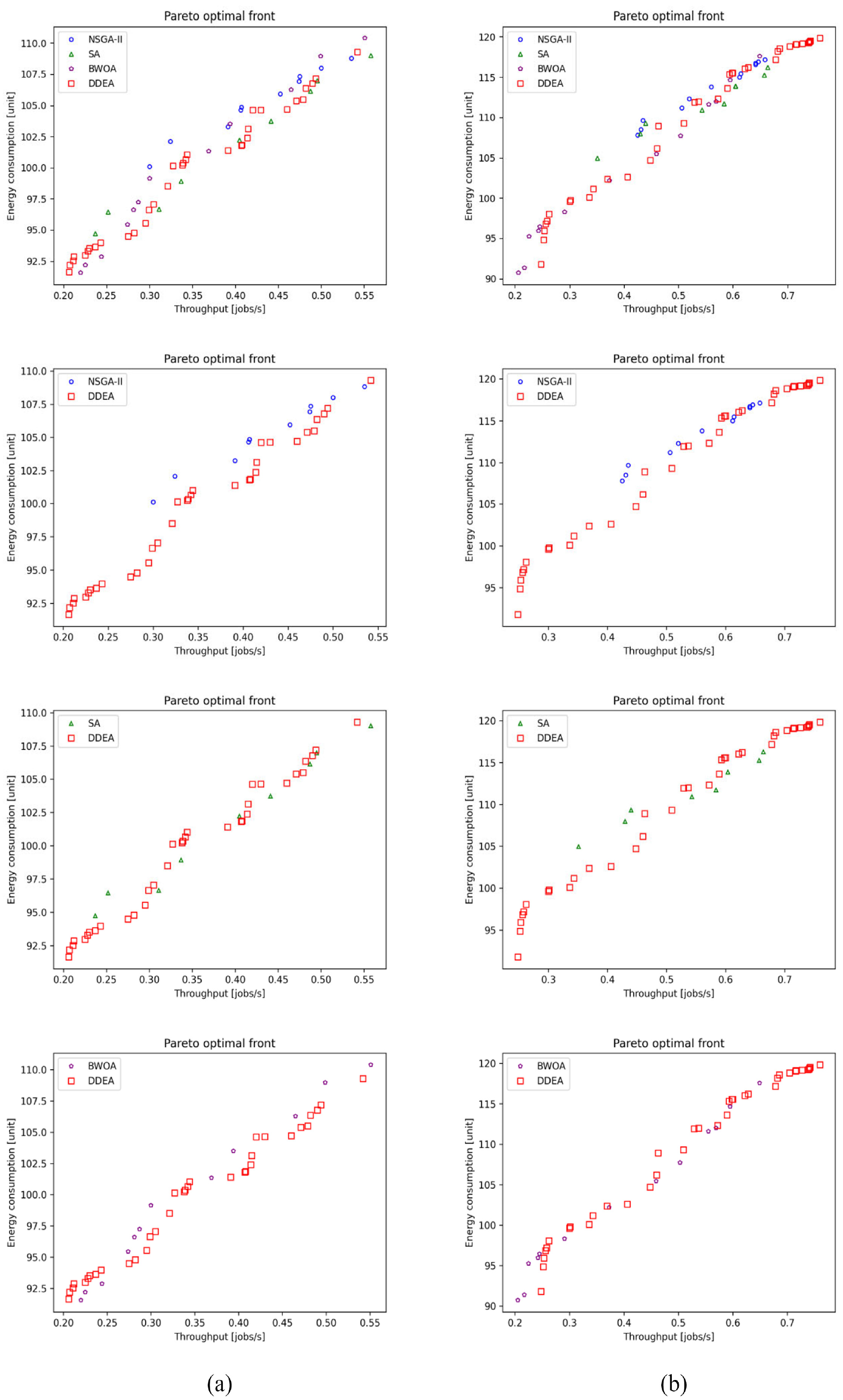
Performance comparison of the NSGA-II, SA, BWOA, and DDEA in Patterns (a) 11 and (b) 12 for the production line involving 15 machines.
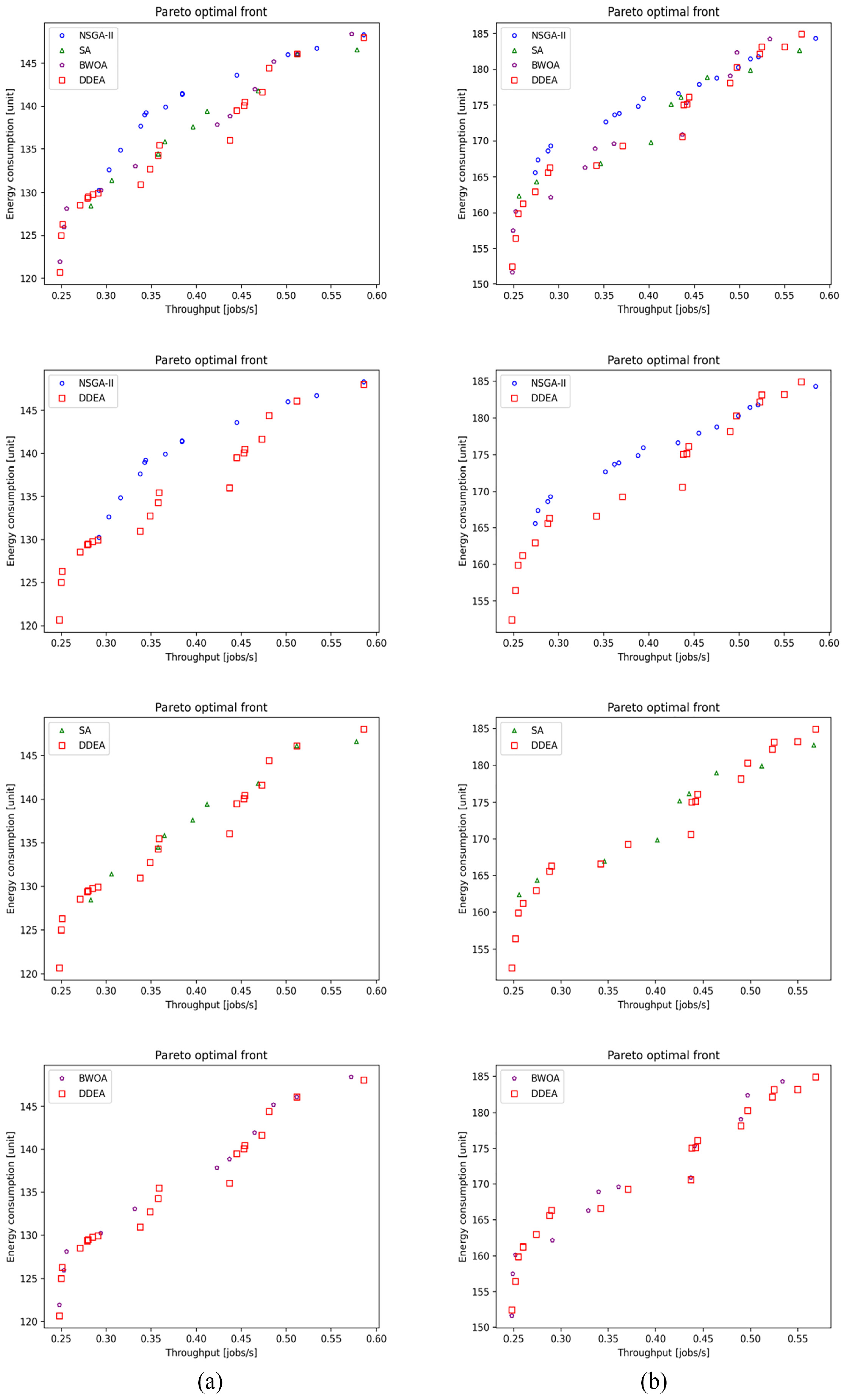
Performance comparison of the NSGA-II, SA, BWOA, and DDEA in Patterns (a) 13 and (b) 14 for the production line involving 20 and 25 machines, respectively.
Performance comparison of the NSGA-II, SA, BWOA, and DDEA for the production line involving five machines.
Performance comparison of the NSGA-II, SA, BWOA, and DDEA for the production line involving 10 machines.
Performance comparison of the NSGA-II, SA, BWOA, and DDEA for the production line involving 15 machines.
Performance comparison of the NSGA-II, SA, BWOA, and DDEA for the production line involving 20 and 30 machines, respectively.
Convergence analysis
In Pattern 1–4, the DDEA obtained the highest
Diversity analysis
Computational time analysis
In Patterns 1–7, the search scope was small because of the low total buffer capacity and small machine size. The computation time of the DDEA was the shortest among the four algorithms, indicating its high computational efficiency. With increasing problem scale and extending the search scope, the computational time of the DDEA increased more significantly than that of the other three comparison algorithms because the SA searched for more promising regions and the BWOA tested more candidate solutions. However, the maximum computational time is less than 10 min. Considering the convergence improvement of DDEA, its computational efficiency is still satisfactory.
Sensitivity analysis
The changes in the total buffer capacity, machine size, and service rate allocation hardly affected the efficacy of the DDEA, demonstrating its stability. However, the unbalanced service rate allocation in Patterns 3, 7, and 11 increased the difficulty of MBAP in production lines. Consequently, the computational time of DDEA increased.
Overall, the proposed DDEA can balance exploration and exploitation, generating better convergence without losing diversity. Furthermore, the computational efficiency is satisfactory. This proves the feasibility of integrating different optimization and machine learning algorithms to solve the MBAP in production lines.
Conclusions and future work
This study presented a DDEA of the BWOA and SA to maximize throughput and minimize energy consumption subject to the total buffer capacity in production lines. The proposed algorithm was compared to NSGA-II, SA, and BWOA using numerical examples to test its performance. The experimental results showed that the proposed algorithm achieved better convergence and computational efficiency than the compared algorithms without losing much diversity for small- and medium-scale problems. In large-scale problems, the computational efficiency of DDEA decreases.
This study integrates a data-driven surrogate into optimization algorithms to decrease computational efficiency and extend the solution methods of the MBAP. This can assist engineers design and optimize the layout of production lines in the industry more efficiently.
The accuracy of the surrogate model in the DDEA may fluctuate in large-scale problems. Therefore, one future direction is to study surrogates with higher and more stable predictive accuracy. Furthermore, the MBAP sorting method requires further investigation in order to reduce the effects of local searches and improve the diversity of the DDEA.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was fully supported by the National Natural Science Foundation of China (Grant No. 61873283 and 52072412) and the International Postdoctoral Exchange Fellowship Program (Talent-Introduction Program, No. YJ20210201).