
Abstract
The integration of process planning and scheduling is important for an efficient utilization of manufacturing resources. However, the focus of existing works is mainly on deterministic constraints of jobs. This article proposes a novel memetic algorithm for the integrated process planning and scheduling problem with processing time uncertainty based on processing time scenarios. First, a mathematical model for the stochastic integrated process planning and scheduling problem based on the network graph is established. Due to the nonlinearity in the model and the complexity of the problem, a memetic algorithm is then suggested for this problem. A novel local search (variable neighborhood search) algorithm is incorporated into the memetic algorithm. Two effective neighborhood structures are employed in the variable neighborhood search algorithm to improve the overall performance of the population. Furthermore, for the uncertainty in processing times, a set of scenarios have been generated to evaluate each individual. Finally, two performance measures—the expected performance measure and the worst-case deviation measure—are introduced and compared. In the experimental studies, the proposed memetic algorithm is tested on typical benchmark instances. Computational results show that the expected makespan measure performs better than the worst-case deviation measure and the proposed method exhibits high performance especially for large-scale instances. In addition, the results obtained by the proposed memetic algorithm are more satisfactory than those obtained by the algorithm that considers deterministic processing times only.
Introduction
Process planning and scheduling are two important functions in a manufacturing system.1,2 In tradition, the two functions are split each other: the scheduling procedure is performed after the process plan of each job is determined. This is a simple paradigm of many real production processes. However, this paradigm ignores the inherent relationship between process planning and scheduling. The integration of the two functions can truly bring significant improvements in reducing scheduling conflicts, lead time, human intervention, and so on. 3
Three approaches are mainly adopted in addressing the integrated process planning and scheduling (IPPS) problem: the mixed integer linear programming (MILP)-based approach, the meta-heuristic-based approach, and the agent-based method. Existing MILP models investigated by some researchers are based on the assumption that all the available process plans are prepared in advance. A successful model is suggested 4 among a variety of research articles. However, as revealed in that article, their model is efficient for small-scale instances only, and the quality of the algorithm deteriorates in solving medium- or large-scale instances. Similar models can also be found in existing literatures.3,5 The meta-heuristic-based approaches have garnered tremendous attention and have been adopted widely for the IPPS problem. For instance, Shao et al. 6 developed a modified genetic algorithm to address the problem. A novel imperialist competitive algorithm 7 was considered to address the IPPS problem. In addition, the agent-based method, a kind of artificial intelligence, is also a practical method to deal with the IPPS problem and a representative research 8 has been presented. Moreover, the rescheduling strategy considering machine breakdown was also studied. 9
In literatures mentioned above, processing times are deterministic. However, a manufacturing system in the real world is often subject to many sources of uncertainty. One source of uncertainty lies in the processing time of an operation which may fluctuate within a certain range. Therefore, a predefined schedule may usually be affected 10 and subsequent processing programs may also be put off because scheduling decision makers are exposed to the risk that an optimal schedule with respect to a deterministic model will perform poorly when evaluated relative to actual processing times. 11 Chance-constrained programming approaches have been considered in some research articles regarding uncertain processing times.12–14 For instance, Elyasi and Salmasi 14 give detailed descriptions on applying the chance-constrained programming method in solving stochastic scheduling problems. On the other hand, some articles consider fuzzy processing times within a meta-heuristic framework;15–17 applications of meta-heuristic algorithms bring convenience to solve uncertain constraint problems. Besides, Horng et al. 18 recommended an evolutionary algorithm called evolutionary strategy in ordinal optimization, (ESOO) for solving the stochastic job shop scheduling problem (SJSSP); they show that their method can obtain promising results. Artificial intelligence-based methods have also been covered. For example, Azadeh et al. 19 suggested an artificial neural network (ANN)-based method where the ANN is adopted to select the optimal dispatching rule for each machine in a job shop with stochastic processing times. Recently, Wang and Choi 20 presented a novel decomposition-based holonic approach (DBHA) for minimizing the makespan of a flexible flow shop with stochastic processing times.
To our knowledge, there are two kinds of methods to deal with scheduling problems with undetermined parameters: reactive scheduling and proactive scheduling (also preventive scheduling). 21 For reactive scheduling, an original schedule is obtained in a deterministic manner. Whenever there are unexpected events, it handles uncertainty by generating updated schedules in time. Due to the short-sighted nature in reactive scheduling, the global optimality is not guaranteed. In proactive scheduling, the system never regenerates any updated schedules during the schedule’s implementation stage because the generated schedule in proactive paradigm is capable to hedge against uncertainty.
Although novel methods in dealing with uncertainty have been suggested, such as Petri nets 22 and chance-constrained programming, 23 meta-heuristic-based approaches in addressing the stochastic IPPS problem have seldom been reported. In this article, we focus on the IPPS problem with uncertain processing times using proactive scheduling paradigm to guarantee the global optimality. The objective is to minimize the total completion time (makespan). We deduce a novel mathematical model for the stochastic IPPS problem. Due to the complexity of the problem, a memetic algorithm (MA) is developed to address this problem while fluctuations in processing times are captured by a set of processing time scenarios. We consider two measures, the expected makespan measure 24 and the worst-case deviation measure, 25 respectively, in individual evaluation in MA. Experimental results show that the proposed MA can generate satisfactory schedules to cope with fluctuations in processing times.
The rest of the article is structured as follows. The next section gives the description of the IPPS problem and the mathematical model. In section “Robust scheduling models,” the two performance measures will be introduced. Section “The MA” presents the details of the proposed MA. Computational results with discussions will be reported in section “Experiments with discussions.” The last section gives conclusions.
The IPPS problem with mathematical modeling
Problem description
The IPPS problem can be defined as follows: 26 given a set of n parts (jobs) to be processed on m machines with operations including alternative manufacturing resources, select the suitable manufacturing resources and sequence the operations so as to determine a schedule in which the precedence constraints among operations can be satisfied and the corresponding objectives can be achieved. In short, this problem can be regarded as “job shop scheduling problems with routing and process plan flexibility.” 4 Jobs to be processed in the IPPS problem are described by network graphs as illustrated in Figure 1(a).
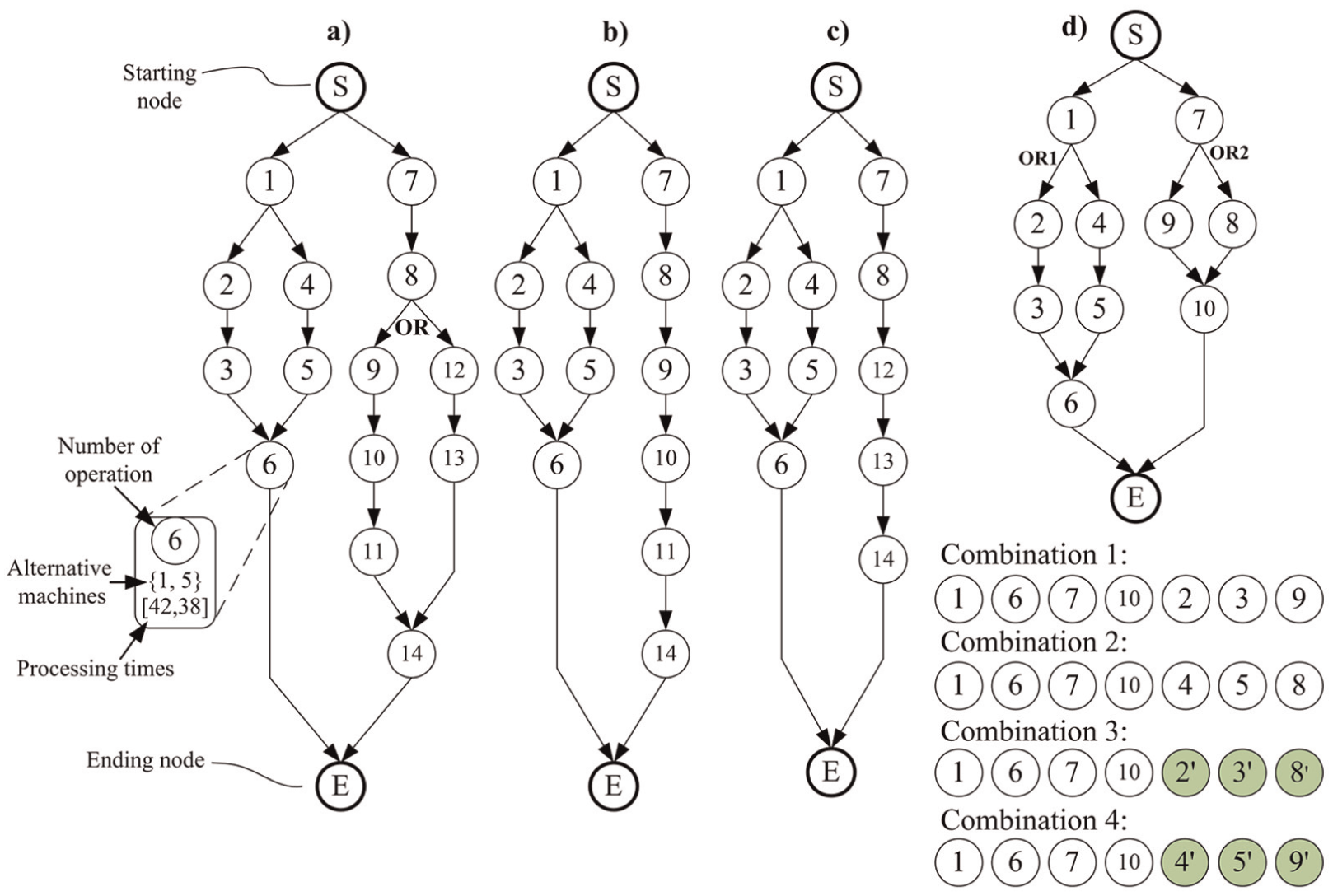
Network graph representations: a) a network graph representation of a job, b-c) two combinations of the network graph in a) and d) an example of generating combinations from a network graph with two OR nodes.
In a network graph, the starting node and the ending node are two dummy nodes. A process plan for a job begins at the starting node and ends at the ending node. In an operation node, the operation number with its alternative machines and corresponding processing times are specified. For operation 6 in Figure 1(a), it can be processed by machine 1 or 5 with processing times 42 or 38. An arc coming from node A to node B implies that operation B should follow operation A directly or indirectly. Moreover, if a bifurcation is marked with “OR” (called an OR node), this means that one and only one OR link path of the two should be traversed. In other cases, the two link paths of a bifurcation should be traversed. For the network of the job in Figure 1(a), feasible paths (9-10-11) and (12-13) are two OR link paths. Two possible process plans in Figure 1(a) are (7→1→8→4→2→12→3→5→13→6→14) and (1→2→3→4→5→6→7→8→12→13→14).
In classical (flexible) job shop scheduling problems (FJSP), the number of operations belonging to a certain job is predefined, and each operation should be processed by a machine. More importantly, each job has a fixed operation sequence (e.g. O1→O2→O3→…). This implies that operation Oi + 1 should be scheduled after Oi and before Oi + 2 in any case. However, the IPPS problem is a more flexible problem because the precedence relationship of some operations is not fixed (e.g. there is no precedence relationship between operations 2 and 4 in Figure 1(a)). Moreover, some operations may not be selected if an OR link path is not selected.
Mathematical modeling
Our MILP model is developed based on network graphs instead of pre-generated process plans. The term “(operation) combination” is very important in modeling this problem. By judging the corresponding OR nodes in a network graph, a job’s operation combination can be formed by picking several operations (not all the operations in a network graph) without taking operation precedence relationships into account. For instance, the job in Figure 1(a) has only two operation combinations as shown in Figure 1(b) and (c), respectively: combination (1-8, 12-14) and combination (1-11, 14). These two combinations can be judged by the OR node in Figure 1(a). Furthermore, additional operation nodes should be added if there are more than one OR nodes. In Figure 1(d), there are four combinations, where operations 2′, 3′, 4′, 5′, 8′, and 9′ are newly added. The newly added operations have the same precedence relationships and available machines together with processing times as the original operations. The proposed model is based on some basic assumptions as follows:
Jobs and machine tools are independent and available at time zero.
Job preemption is not allowed, and each machine can handle only one job at a time. Different operations of one job cannot be processed simultaneously.
Once a job is finished, it will be immediately transferred to another machine with transportation time neglected.
Setup time of an operation is included in the processing time.
Processing times of operations are not deterministic.
We first establish a model using deterministic processing times; then, the robust mathematical model will be presented based on the deterministic version.


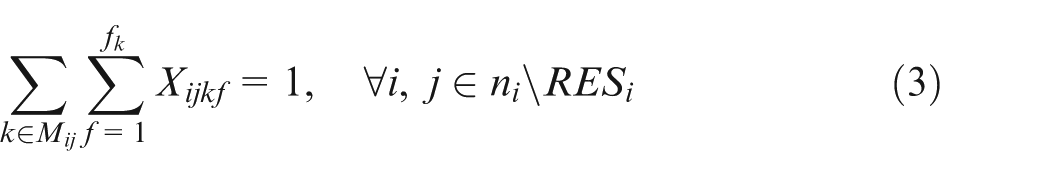
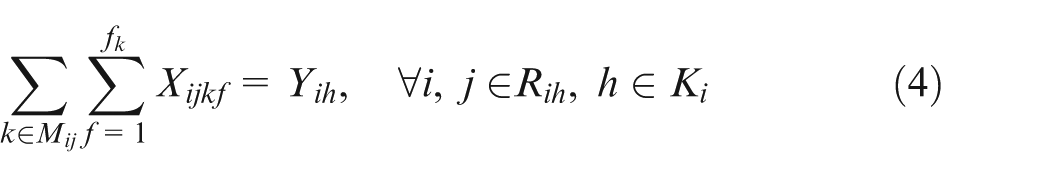
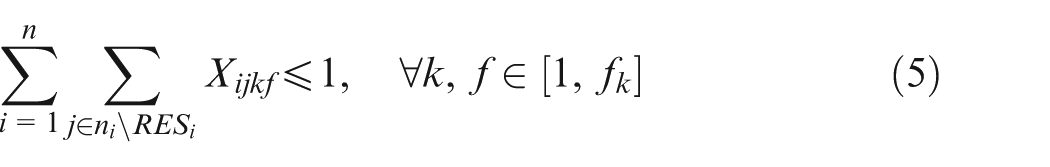
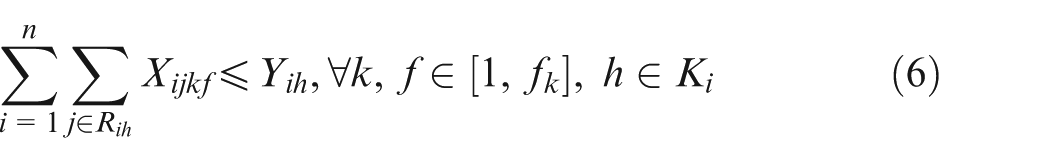
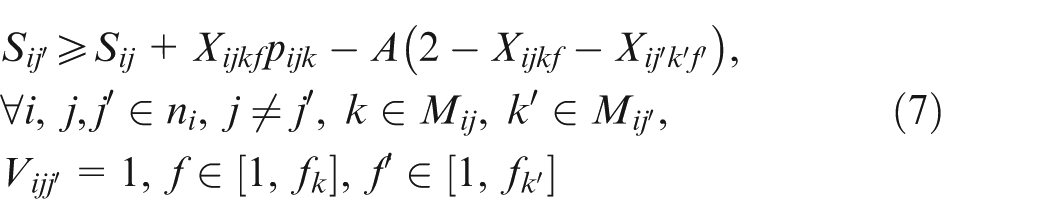
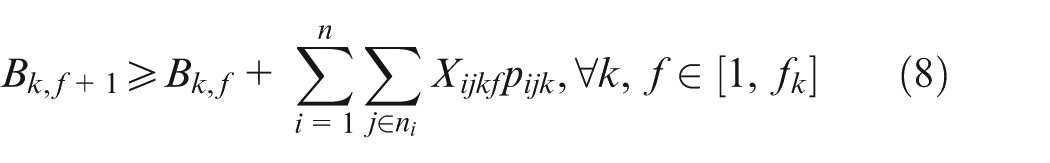
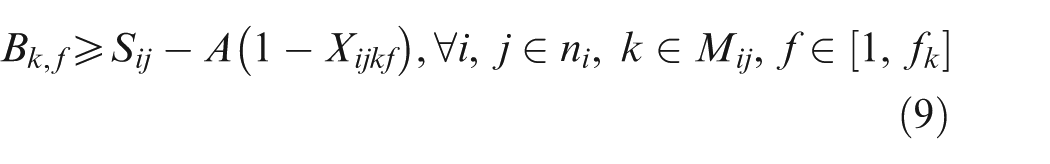
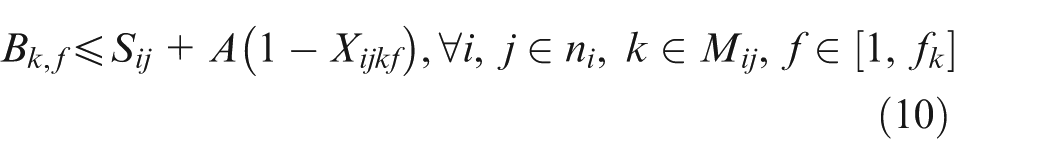
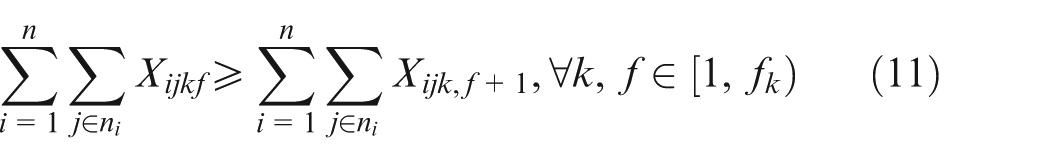
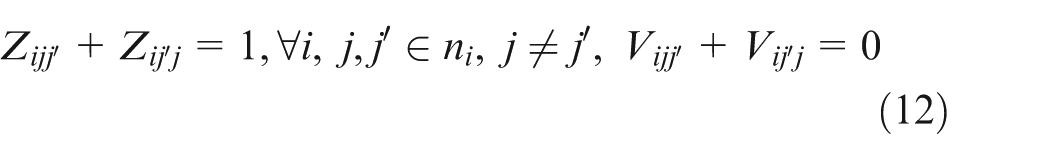
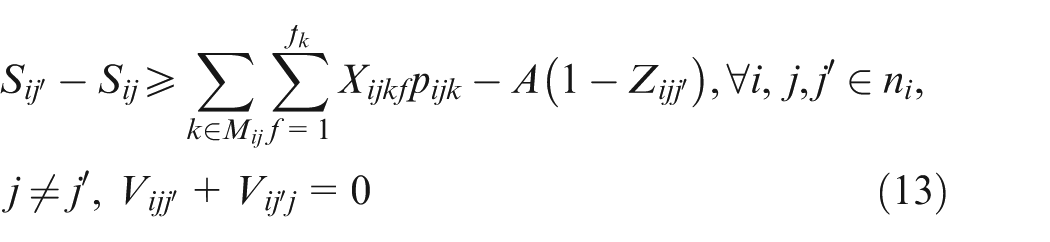
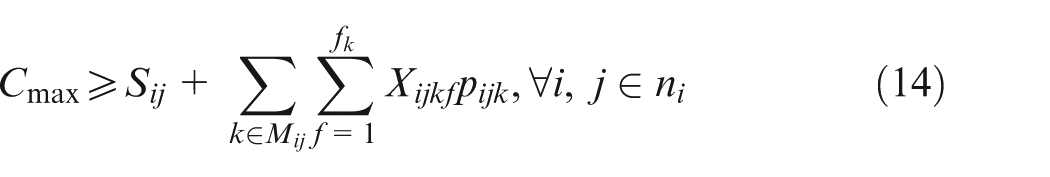
Constraint set (2) specifies that only one combination should be chosen for each job. Constraint sets (3) and (4) state that each selected operation of each job can be only assigned one and only one position on an available machine. Constraint sets (5) and (6) make sure that each position on each machine can handle at most one operation. Constraint set (7) schedules two operations of the same job; the two operations have a sequence relation. Constraint set (8) means that the starting time of a subsequent position on one machine should not be earlier than the completion time of the previous one. Constraint sets (9) and (10) couple machine starting times and job starting times. Constraint set (11) requires every operation on one machine to be arranged with the front to back order. Constraint sets (12) and (13) schedule two operations that have no precedence relationship. Finally, constraint set (14) determines the makespan of the schedule. Constraint sets (2–14) above are about deterministic case; in considering undetermined processing times, the following constraints should be added based on the conception of robust scheduling and the robust optimization approach.27,28 We consider the bounded and symmetric uncertainty in modeling the stochastic IPPS problem.
Bounded and symmetric uncertainty
In this paradigm, a “true” value
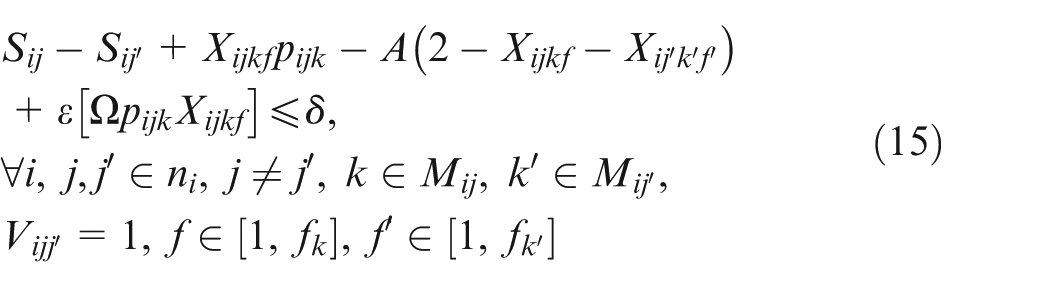
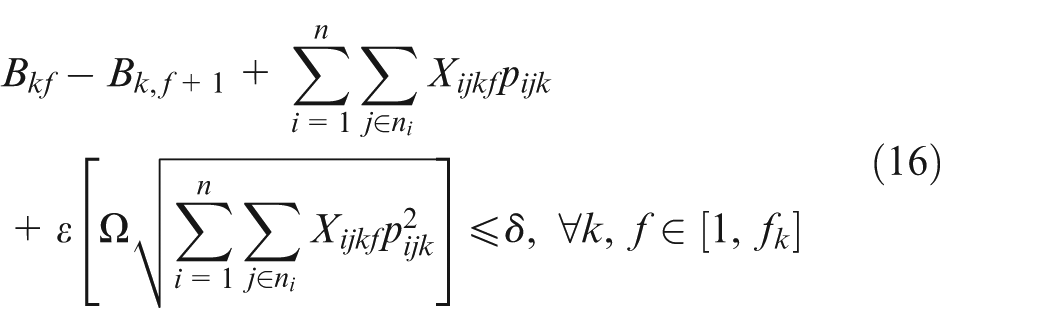
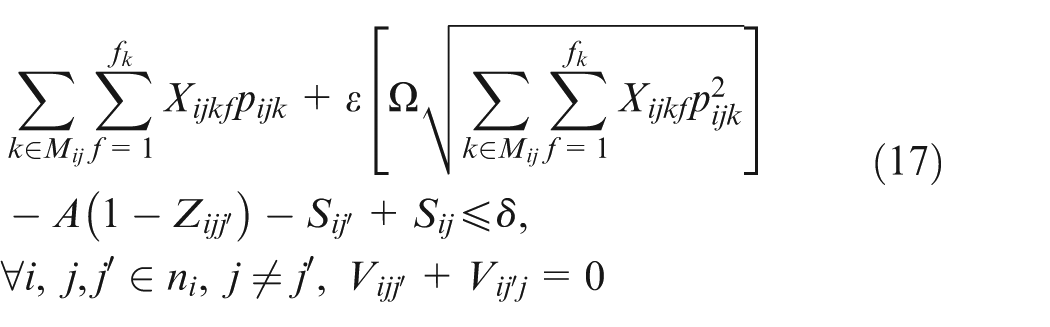
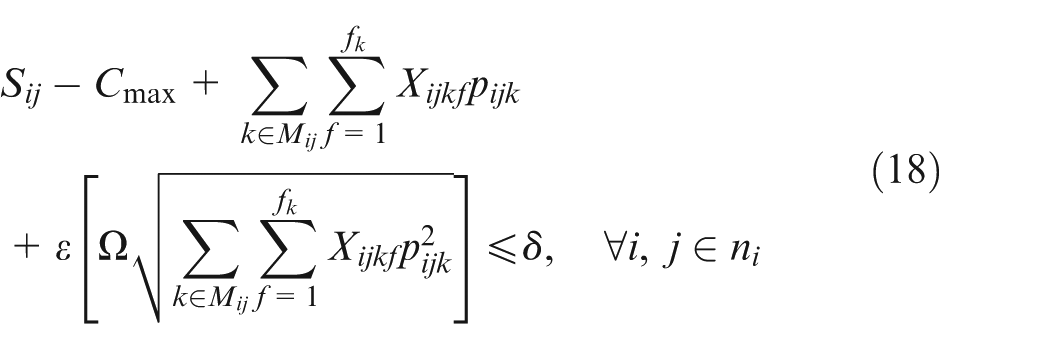
In constraint sets (15, 16, 17, and 18),
Robust scheduling models
The idea behind the method that deals with uncertain processing times in this article is to determine a schedule whose performance is more satisfactory than a schedule without considering robustness with potential realizations of processing times to hedge against the prevailing processing time uncertainty. The performance measure of interest is makespan. Two measures that consider the system performance over all potential realizations of job processing times are adopted and compared. One measure of schedule robustness is about the expected performance and the other focuses on the worst-case deviation over all scenarios.
The uncertain processing time can be described through a set of scenarios Λ, and each scenario
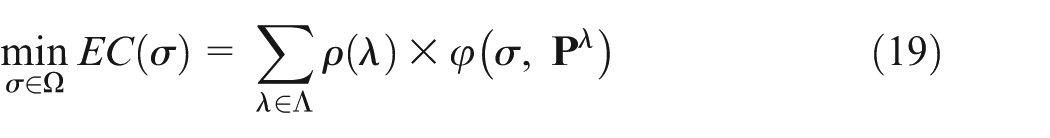
Thus, the optimal expected performance can be denoted as
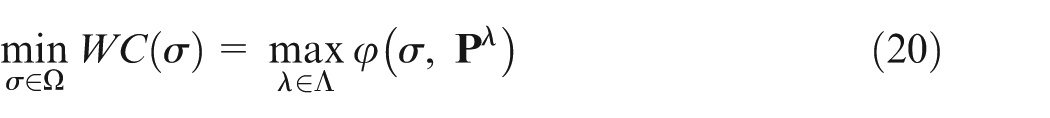
The optimal worst performance can be denoted as
The MA
Encoding and decoding
The chromosome structure is illustrated in Figure 2. In our problem, a chromosome consists of a scheduling string, some process plan strings, and corresponding operation strings. The scheduling string adopts an operation-based coding scheme.
29
It is a permutation of job numbers with each job number appearing exactly
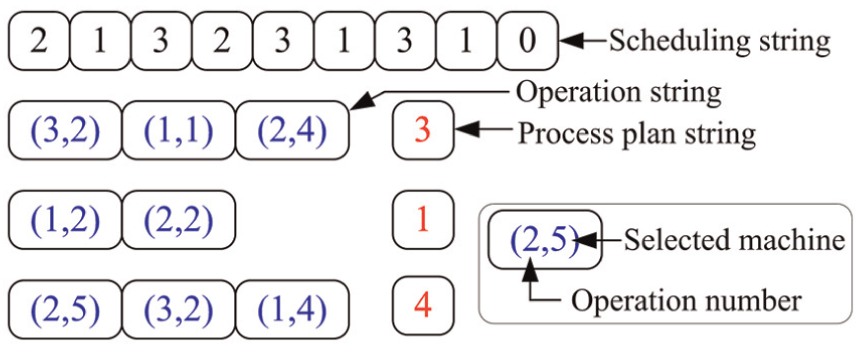
The coding scheme.
The active scheduling procedure 31 summarized as follows is adopted in the decoding process.
Step 1: For each number in the scheduling string, determine the corresponding job and operation if the number is not equal to 0: if the number
Step 2: Find out the operation
Step 3: Assign this operation on the predefined machine
Step 3.1: Check whether there is a time slot on
Step 3.2: If there is a time slot and
Step 3.3: If there is no available time slot, append the operation at the end of the machine with the starting time
Step 4: Go to Step 1 for next operation till the operations are all scheduled.
Genetic operators
Figure 3 illustrates the crossover procedure. Position-based crossover method is adopted. Randomly select some jobs and exchange the operation strings together with corresponding process plan strings of the selected jobs in two individuals; other operation strings and process plan strings in both individuals are kept still. Then, two empty scheduling strings O1, O2 are initialized. The genes in parent 1, which reflect the unselected jobs, are passed on to the same positions as in the offspring 1 (O1). These genes are removed from parent 2 (P2), and the remaining elements are copied into the undetermined positions in O1 in the same order as they appear in P2. A repairing procedure is adopted to resolve the illegitimacy; it deletes redundant symbols or adds necessary symbols after checking the actual number of operations of each selected job. Figure 3(a) gives an example. Last two jobs are selected, and a “0” is filled in a position in offspring 2 (O2) to avoid infeasibility.
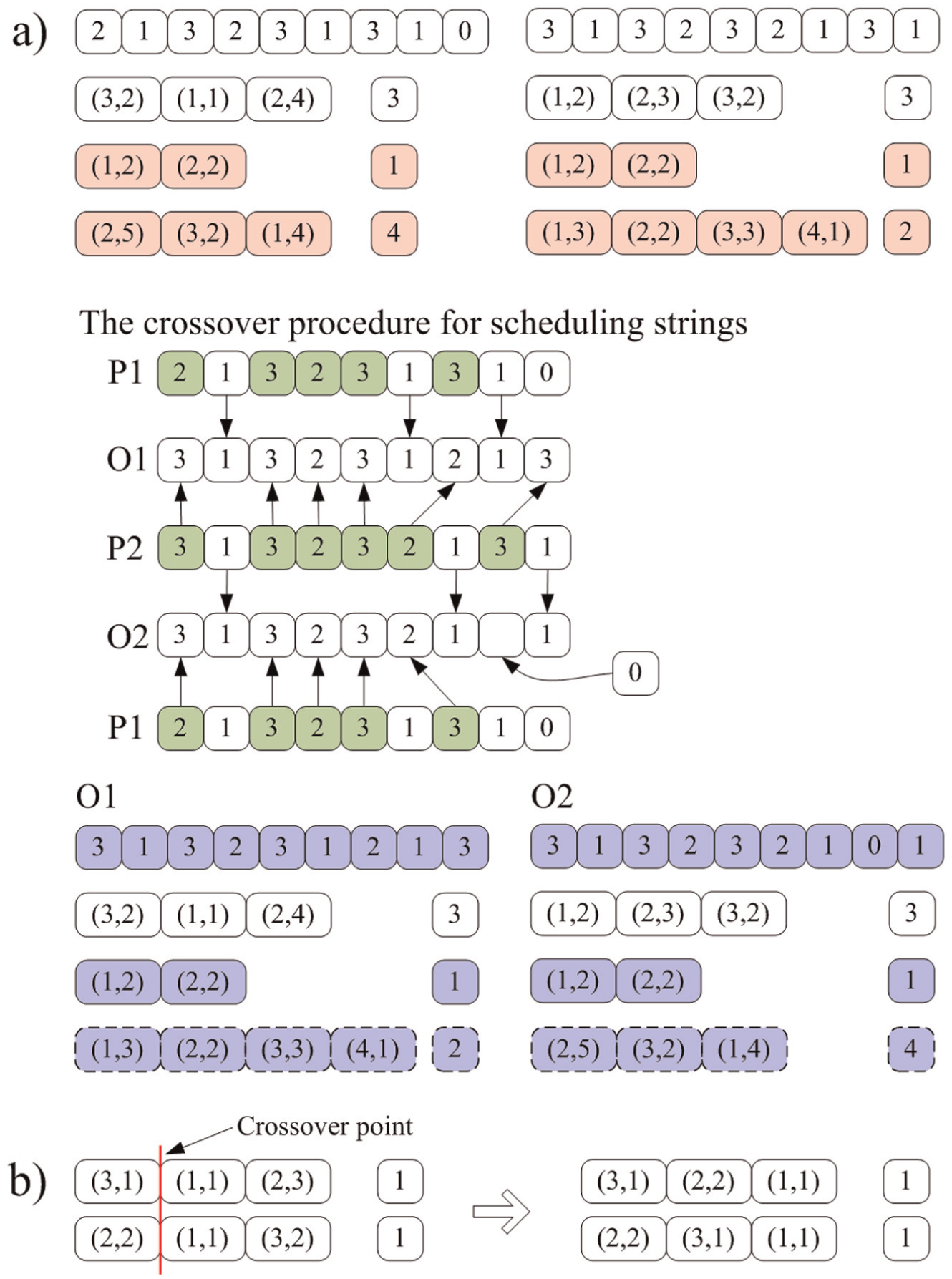
Crossover operators: a) the first crossover operator and b) the second crossover operator.
Different with the case in job shop scheduling problem (JSP) or FJSP where the processing sequence is fixed; in the IPPS problem, the same operation combination of a job can have different permutations. Our proposed chromosome structure allows the MA to take this advantage by performing the second crossover operator as shown in Figure 3(b). An order crossover (OX)-based one-point crossover is performed between two operation strings for the same job in two individuals. The two jobs in both individuals should have the same number in the process plan strings (they have the same operation combination). Two new feasible operation stings are generated with new feasible permutations.
For the selection operator, a simple tournament selection is adopted. The mutation procedure is performed by changing a machine for an operation and swapping two numbers in two different positions in the scheduling string.
Local search algorithm
Embedding local search methods into a meta-heuristic algorithm is a highly respected way. 32 In our algorithm, we employ the variable neighborhood search (VNS) algorithm to improve the population’s overall performance. In VNS, two neighborhood structures are adopted. A neighborhood structure combines the special knowledge of a certain problem to facilitate an effective and slight perturbation in an individual. These two adopted neighborhood structures have been successfully applied to the FJSP. The first one is the N5 neighborhood structure. 33 It is famous for its high cost performance because only swapping the first and (or) last two operations in a critical block is performed. The second one is proposed by Mastrolilli and Gambardella 34 (referred to as Nopt neighborhood structure); it tries to remove an operation that is on a critical path to another machine to break the critical path.
VNS tries to optimize an individual using one neighborhood structure continuously till there is no further improvement. Then, it jumps to the second neighborhood. If the individual is improved by the second neighborhood, it goes back to the first neighborhood to repeat the above process. Otherwise, the VNS algorithm is terminated. The procedure of the proposed MA is presented in Figure 4. The parameters Ns, Np, and N in Figure 4 denote the number of scenarios, individuals, and iterations, respectively.
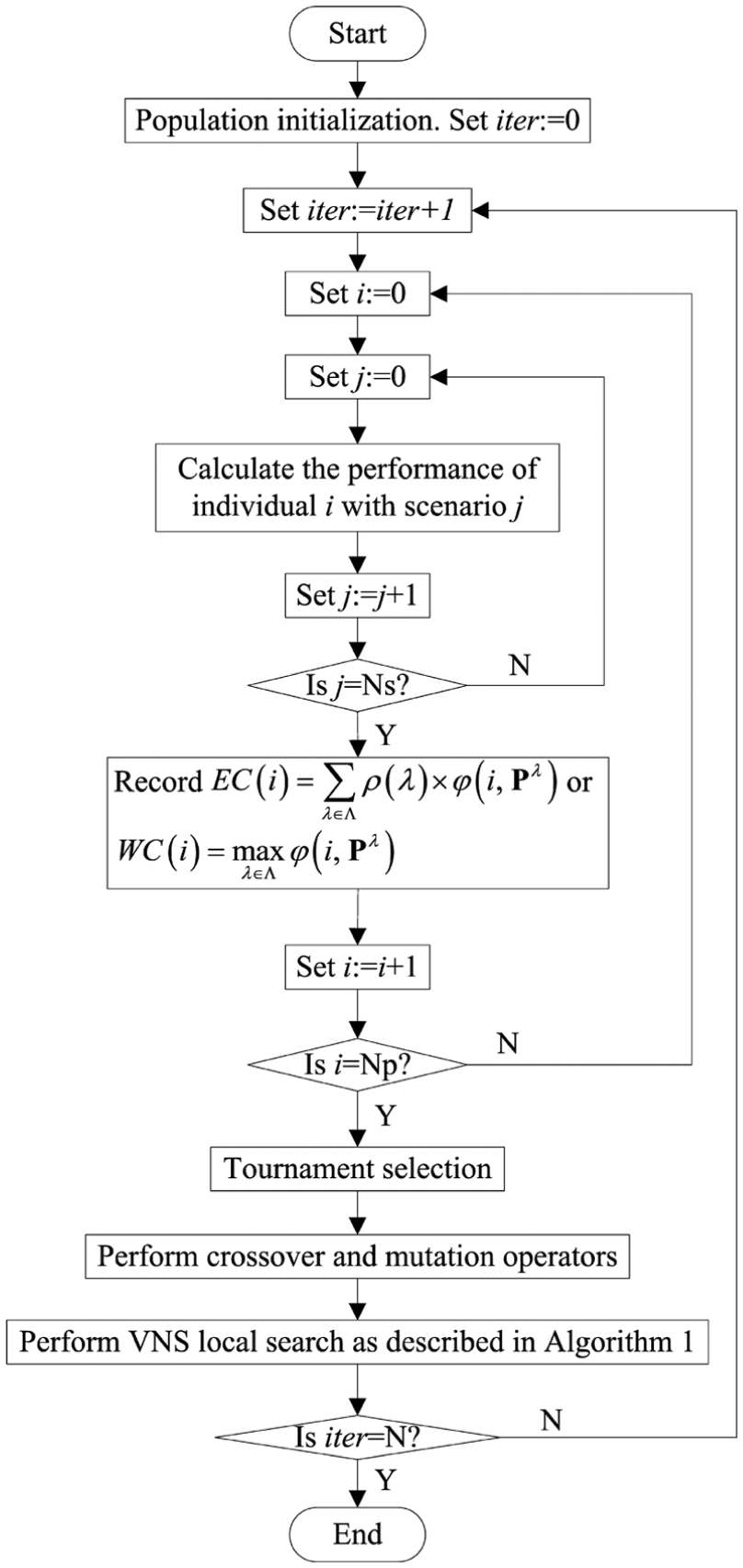
The flowchart of the proposed memetic algorithm.
Experiments with discussion
To study the effect of the two performance measures and obtain robust schedules, we adopt the well-known benchmark instances proposed by Kim et al.
35
The bounded and symmetric uncertainty paradigm is considered in our experiments. In this paradigm, the actual processing time of an operation is distributed around its mean value randomly and symmetrically. We consider two types of fluctuations in processing times: small fluctuation and large fluctuation. The two types of fluctuations are controlled by the tightness factor β. Furthermore, we assume that the actual processing time of an operation
In the proposed MA, 400 individuals are employed and the algorithm terminates after 400 iterations. In addition, the crossover probability is set to 0.7. The whole algorithm is programmed in C++ language; all the experiments are carried out on a PC with an Intel i5-3470 3.2 GHz CPU and 4 GB of memory.
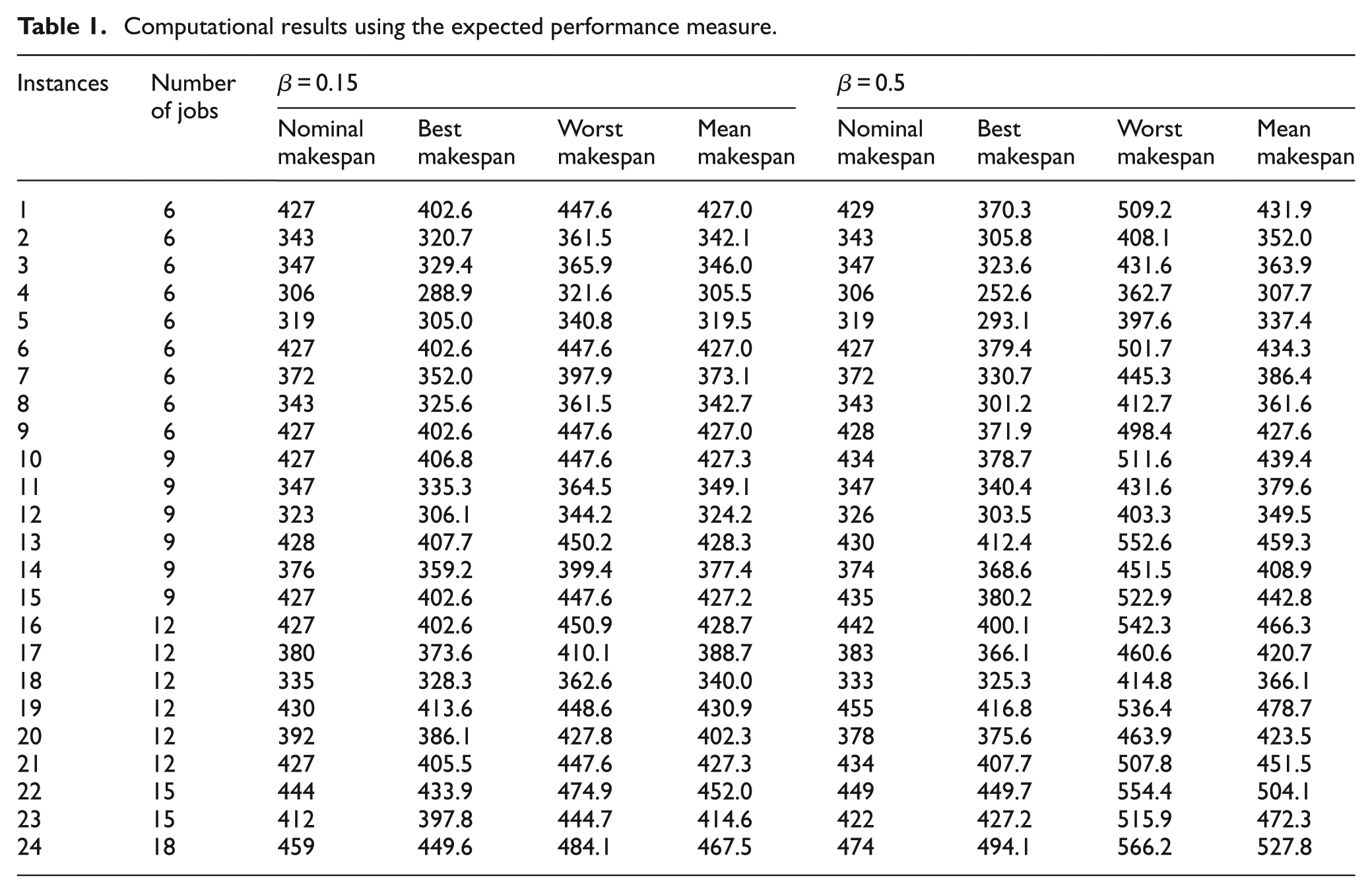
As mentioned above, two measures of schedule robustness, namely the expected performance and the worst-case deviation, are adopted and compared. Tables 1 and 2 present the nominal makespan values, the maximum makespan values, the minimum makespan values, and the mean makespan values of the 24 benchmark instances with the ECM model (the expected performance measure) and the WCM model (the worst-case deviation measure), respectively.
Computational results using the expected performance measure.
Computational results using the worst-case deviation measure.
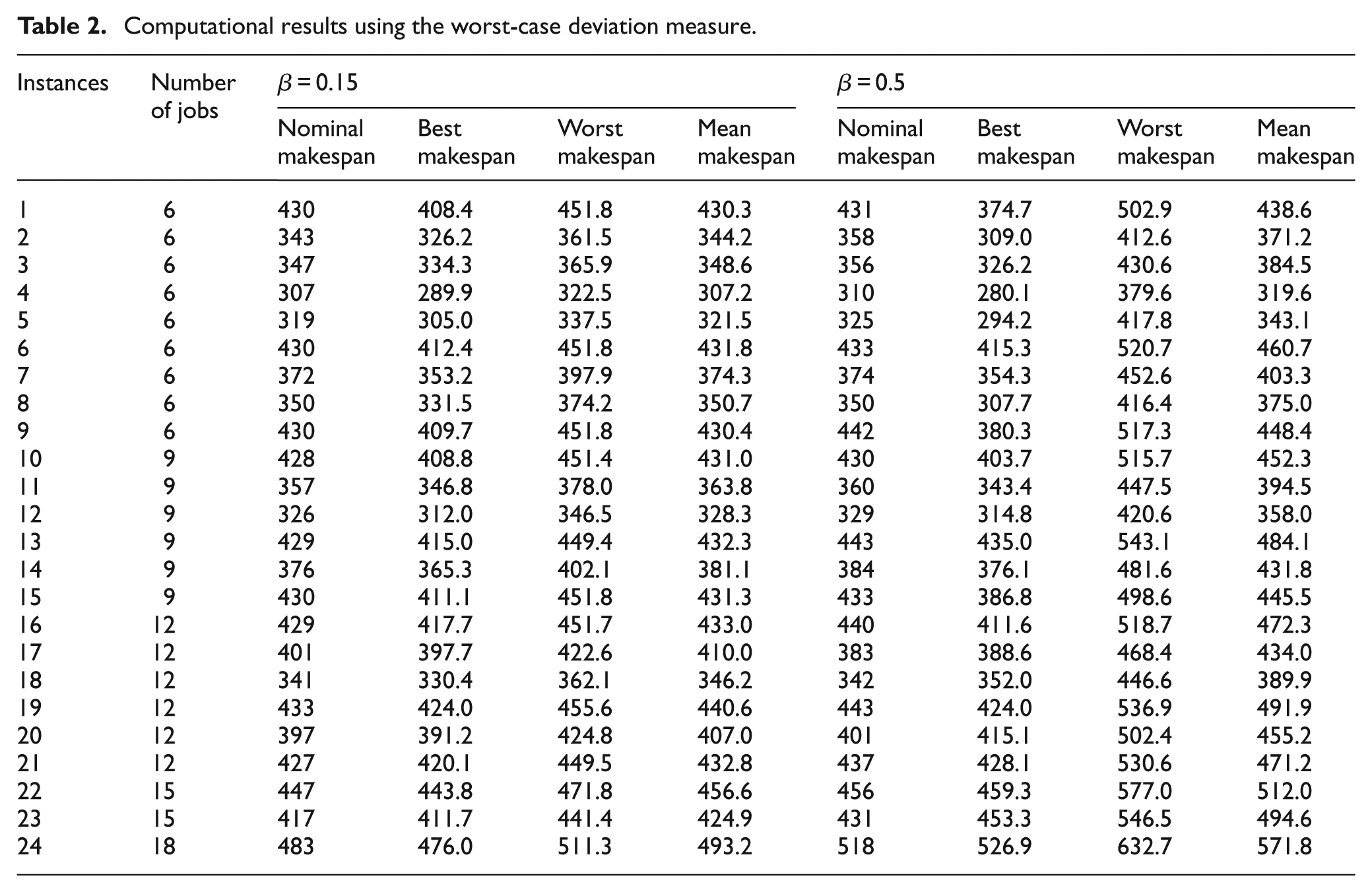
As presented in both Tables 1 and 2, the makespan values of 100 scenarios fall within the ranges around corresponding mean makespan values. For the small fluctuation case (β = 0.15) in both tables, it seems that the average makespan values of 100 scenarios do not deviate much from corresponding nominal makespan values. For the large fluctuation case (β = 0.5), however, the average makespan values of large-scale instances in both tables deviate largely from the corresponding nominal makespan values. The reason behind this is that large fluctuations in processing times lead to more elusive situations in determining the makespan. Moreover, it can be perceived from both tables that the nominal makespan values in the large fluctuation case (β = 0.5) are generally larger than the ones in the small fluctuation case (β = 0.15). This stems from the selection procedure in the proposed MA because the selection operator in our algorithm is guided by the expected performance measure or the worst-case deviation measure instead of the nominal makespan measure.
Figures 5 and 6 give two Gantt charts with the same scheduling scheme of the first instance with nominal and actual processing times, respectively. An instance in Kim’s benchmark is constructed with several jobs taken from all the 18 jobs. There are six jobs (jobs 1–3 and jobs 10–12) in the first instance. Corresponding job IDs are given in both Gantt charts for all the six jobs (note that six job IDs in both Gantt charts are 1, 2, 3, 10, 11, and 12, and jobs are marked with different colors). It can be seen that the permutation of operations on the same machine and the sequence of operations belonging to the same job remain unchanged although the processing times are different in the two cases. The makespan 417.1 in Figure 6 is shorter than the nominal version (427). However, in some cases, it may be larger than the nominal one.
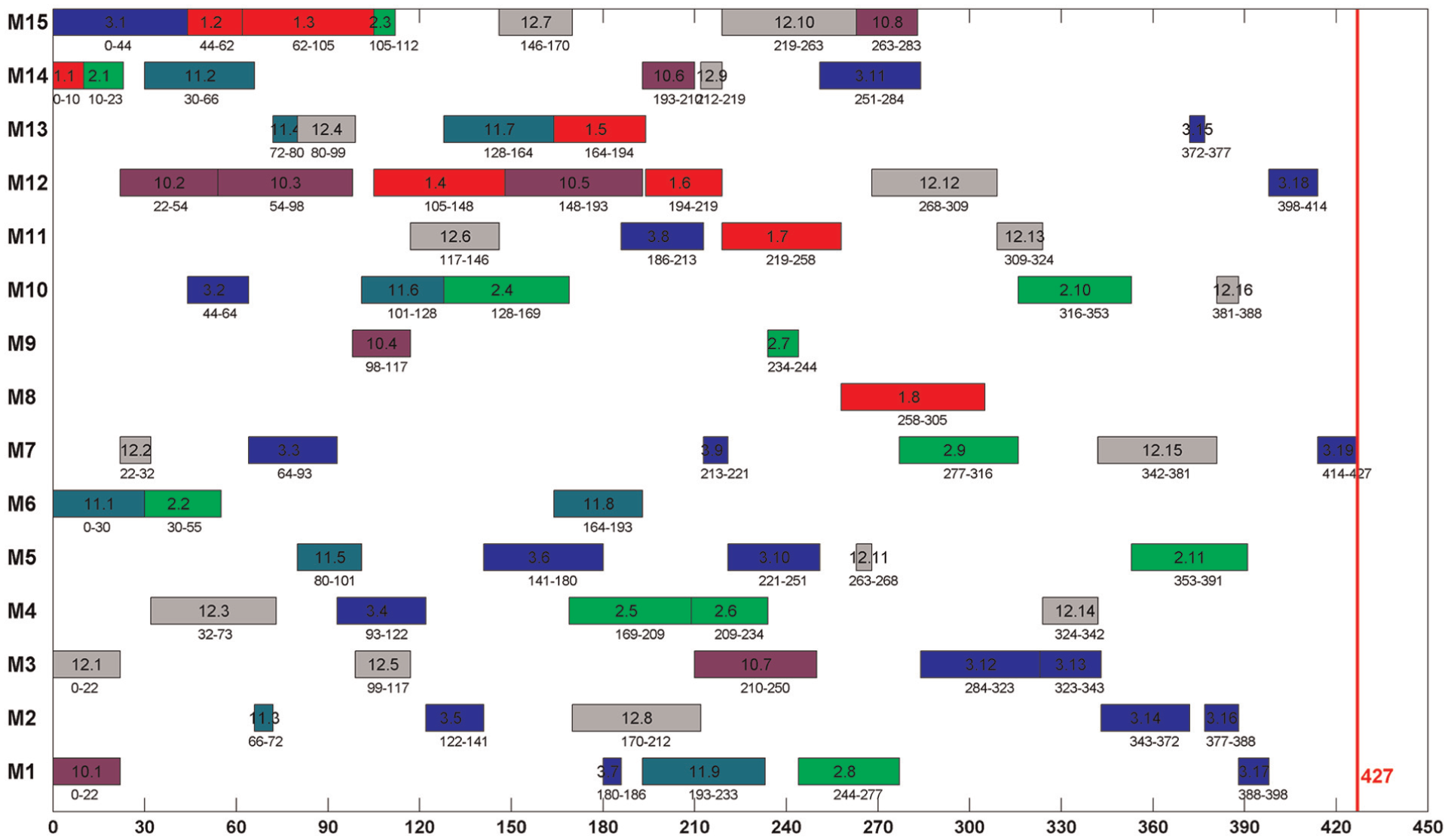
The Gantt chart of the first instance with nominal processing times.
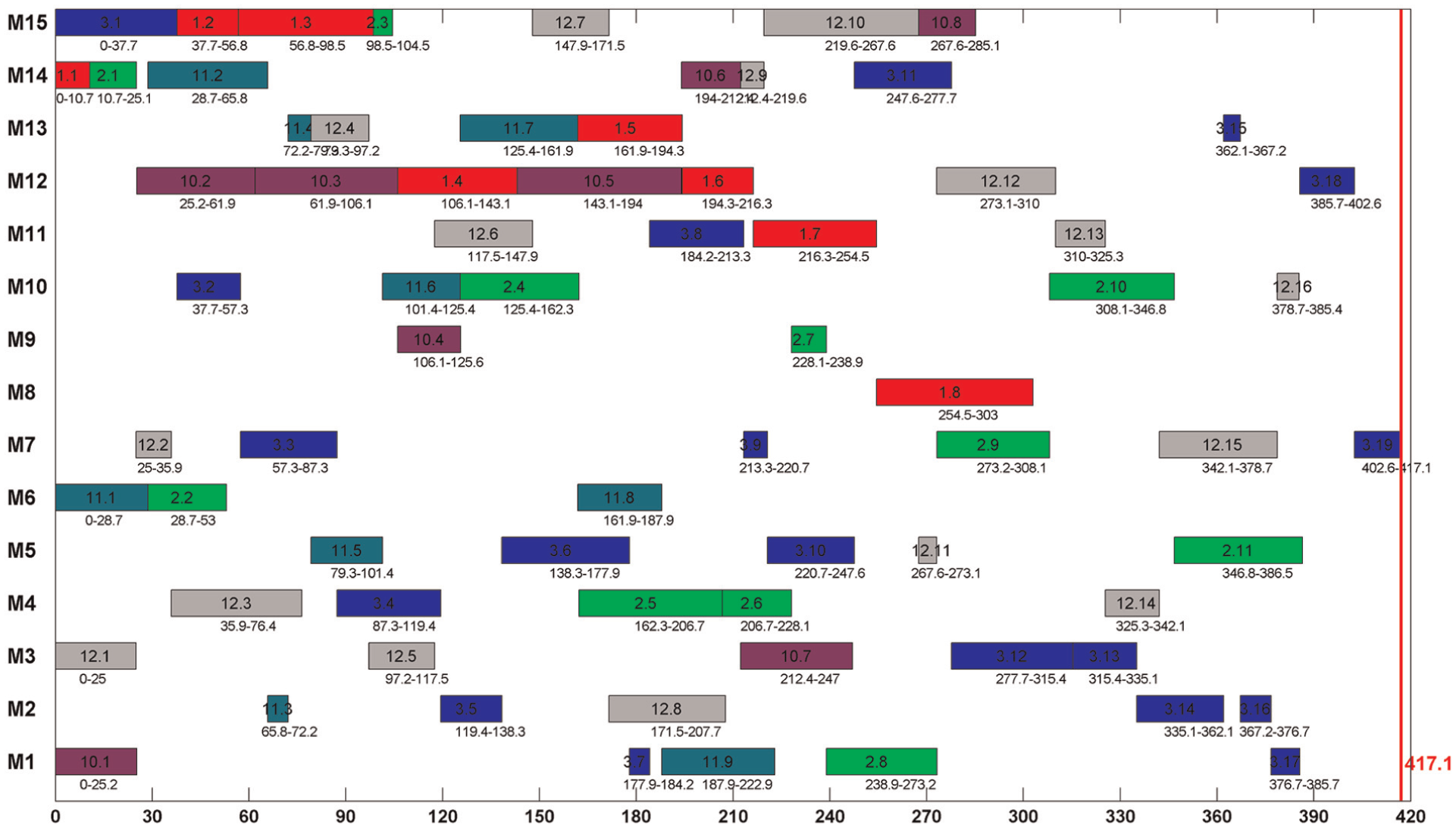
The Gantt chart of the first instance with actual processing times.
Figure 7 shows the boxplots of small-scale, medium-scale, and large-scale instances (represented by instance 1, instance 12, and instance 24) in both the small and large fluctuation cases. According to Figure 7 and Tables 1 and 2, the ECM model that adopts expected performance measure is better than the WCM model that adopts worst-case deviation measure. More importantly, the ECM model shows especial talent in capturing a robust schedule for large-scale instances.
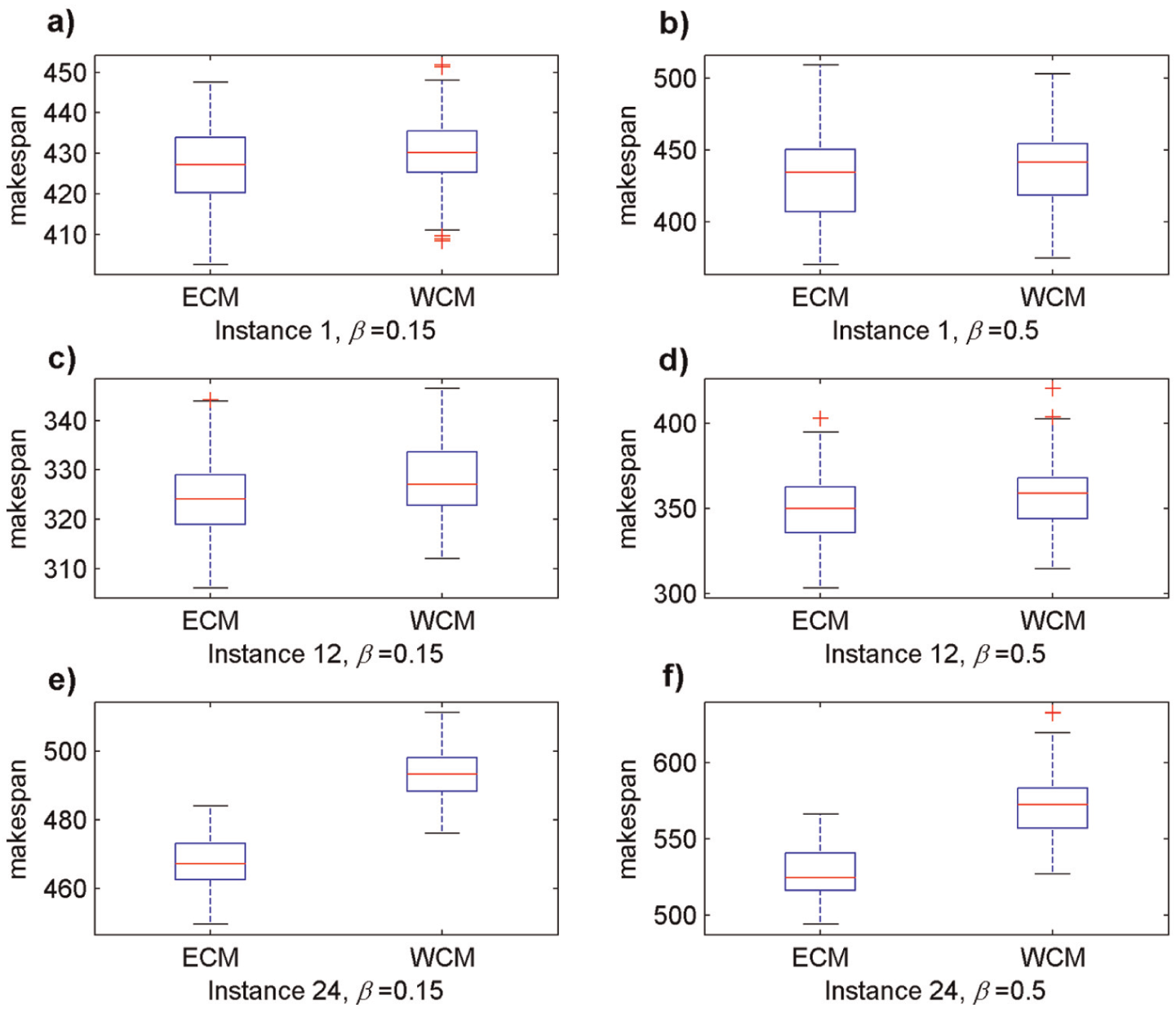
The boxplots of instances 1, 12, and 24: a-b) the boxplots of instance 1 in small and large fluctuation cases respectively, c-d) the boxplots of instance 12 in small and large fluctuation cases respectively and e-f) the boxplots of instance 24 in small and large fluctuation cases respectively.
In the following, visual comparisons are given between different schedules that generated with and without considering robustness to show the advantage of the proposed scenario-based MA. Using the same instances as above (instances 1, 12, and 24), we plot the boxplots as shown in Figure 8. It can be seen from Figure 8 that the medians of the makespan values with the ECM model are all less than those of the schedules that consider deterministic processing times only. An extreme case is depicted in Figure 8(e): the worst makespan value in 100 scenarios using the ECM model is even better than the best makespan value of the schedule that considers deterministic processing times only.
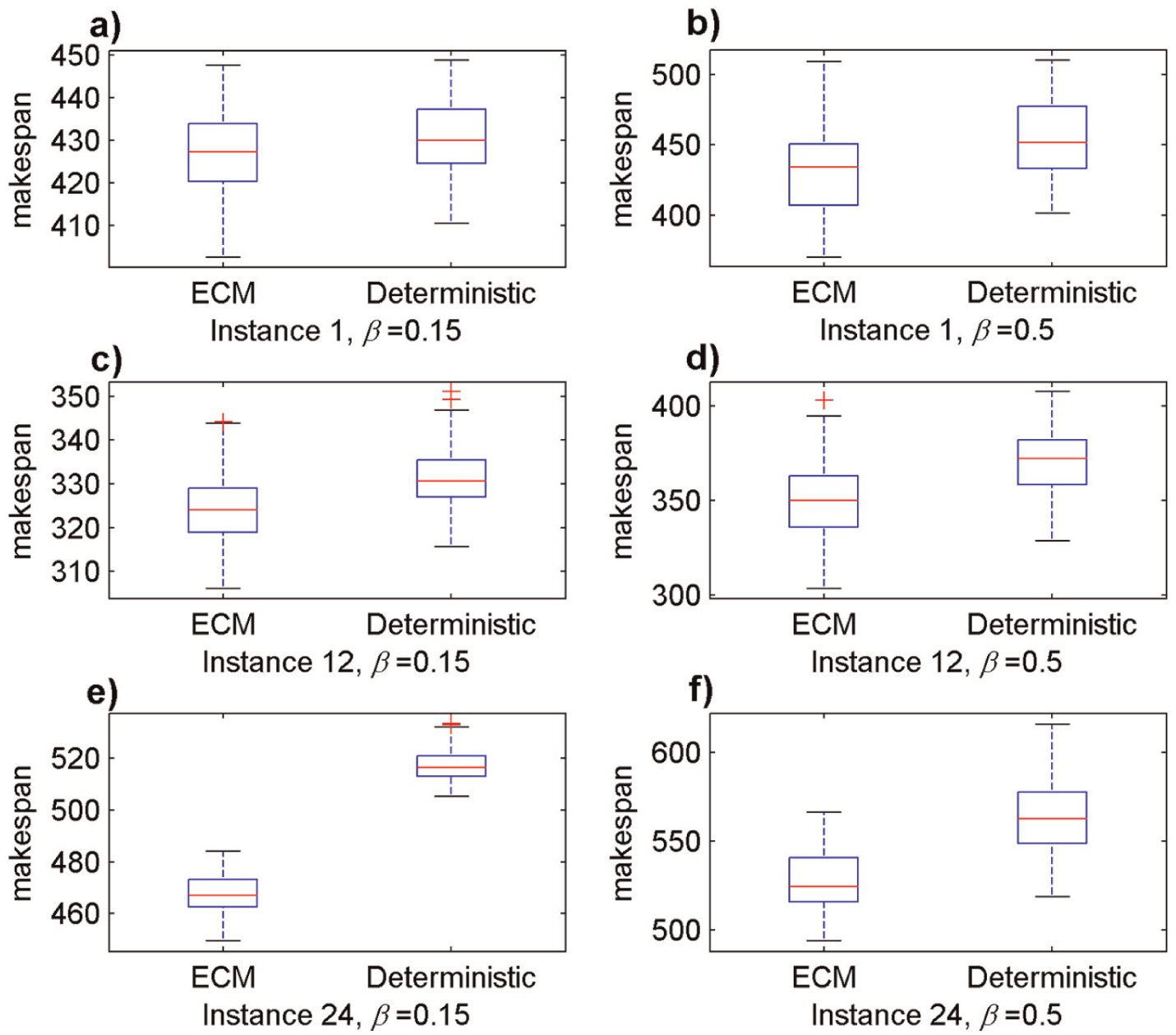
Comparisons between the schedules with and without considering robustness: a-b) the boxplots of instance 1 in small and large fluctuation cases respectively, c-d) the boxplots of instance 12 in small and large fluctuation cases respectively and e-f) the boxplots of instance 24 in small and large fluctuation cases respectively.
Conclusion
In this article, we establish a mathematical model for the stochastic IPPS problem. Due to the complexity of the problem, we suggest a VNS-based MA to address the IPPS problem with fluctuations in processing times to adjust to real-world situations. Effective neighborhood structures are employed in VNS and the uncertainty in processing times is captured by a set of scenarios. The proposed MA is tested on typical benchmark instances to evaluate its performance with two performance measures. Computational results show that the expected makespan measure performs better than the worst-case deviation measure and the proposed method exhibits high performance in large-scale instances.
Footnotes
Appendix 1
Acknowledgements
The authors express their special appreciation to all authors in “References” section due to their support for the article. The authors also thank the anonymous referees for their insightful and valuable suggestions and comments to improve this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
This research is supported by the Funds for International Cooperation and Exchange of the National Natural Science Foundation of China (Grant No. 51561125002), National Natural Science Foundation of China (Grant Nos 51275190, 51405075 and 51575211), and the Fundamental Research Funds for the Central Universities (HUST: 2014TS038).