
Abstract
Manufacturing systems are constrained by one or more bottlenecks. Reducing bottlenecks improves the entire system. Finding bottlenecks, however, is a difficult task. In this study, a new bottleneck detection method based on theory of constrains and sensitivity analysis is presented to overcome the disadvantages of existing bottleneck identification methods for a job shop. First, a bottleneck index matrix is obtained by examining the sensitivity of system production performance to the capacity of each machine. Technique for order preference by similarity to ideal solution is then employed to calculate the comprehensive bottleneck index of each machine. Based on the calculation result, bottleneck machine clusters under different hierarchies are obtained through hierarchical cluster analysis. The designed identification approach, as a prior-to-run method, can identify bottleneck machine clusters under different hierarchies before the overall system circulation, thereby providing good guidance for subsequent production optimization. Finally, a set of job-shop scheduling problem benchmarks with different scales is selected for comparison between the proposed approach and existing approaches, such as, the shifting bottleneck detection method, the bottleneck detection method based on orthogonal experiment, and the bottleneck cluster identification method. By comparison, the proposed approach is proven to be credible and superior.
Keywords
Introduction
The production volatility and processing dependency of production systems, as well as limited manufacturing resources, inevitably lead to bottlenecks that restrict the maximization of system throughput. 1 Each manufacturing system has bottlenecks that constrain its performance. According to theory of constraints (TOC), bottlenecks control the circulation of the entire system; the output rate of bottlenecks determines that of the system. 2 In many studies,3–5 bottlenecks have been regarded as important characteristic information that may be utilized to accelerate the appearance of the optimal scheduling solution. In most situations, the final throughput of manufacturing systems can be improved within a relatively short time if bottleneck machines are well scheduled and controlled. Therefore, identifying system bottlenecks rapidly and accurately is a key to bottleneck management and a prerequisite to production management and process control. However, how to define the bottleneck and how to design an easily implemented bottleneck detection method are still problematic at present.
Finding bottlenecks is a difficult task. Cox and Spencer, 6 for example, simply recommend that “the best approach is often to go to the production floor and ask knowledgeable employees.” Several traditional approaches define and identify bottlenecks through production features, such as equipment load and queue lengths of unprocessed jobs in front of each machine. The entity with the highest load5,7 or the longest queue length8,9 is considered to be the system bottleneck. This method is simple and can be implemented easily. However, in cases wherein the utilizations of different machines are the same or very similar or the buffers of several machines overflow simultaneously, identifying which machine is the bottleneck is difficult. In addition, in some systems, machines with the highest load are not the real bottlenecks.10,11 Machine load can mostly be regarded as a priori information in bottleneck identification.
Some system-theoretical approaches have been proposed for bottleneck detection. Li et al. 12 proposed a data driven bottleneck detection method which utilized the blockage and starvation probabilities and buffer content records in production line to detect bottleneck. Sengupta et al. 13 analyzed the inter-departure time from different machines to identify and rank the bottlenecks. The machine with the minimum total time spent in blocked-up and blocked-down states is the number one bottleneck machine. Ching et al. 14 presented a bottleneck detection method using the frequencies of machine blockages and starvations in assembly systems. These system-theoretical approaches usually need to accumulate and process a lot of production data to detect bottlenecks, such as the blockage possibilities/time/frequencies or the starvation possibilities/time/frequencies of each machine, and the inter-departure time of each machine. They can detect bottlenecks only if manufacturing systems have run for a long time. The bottleneck detection process of system-theoretical approaches is very complicated. Usually they are used in production lines that consist of machines arranged in consecutive order and buffers separating each of the two adjacent machines. It is not easy for the system-theoretical bottleneck detection approaches to be implemented in the more complex job-shop environment.
Roser et al.15,16 divided all possible states of machines into two groups, being either active states or inactive states and proposed the shifting bottleneck detection method (SB-DM). The machine with the longest average active period is considered to be the bottleneck. This method can be easily implemented and is reliable in detecting bottlenecks in a job shop. However, it requires a long time to obtain the information describing the change in the status of the different machines.
Chiang et al.17,18 and Kuo et al.19,20 employed sensitivity analysis to identify bottlenecks in production lines. The bottleneck in a production line is understood as a machine that impedes system performance in the strongest manner. The difficulty of sensitivity analysis rapidly increases with system complexity, thereby limiting its application in complex systems, such as a job shop; this method is only used in a flow shop currently. Kasemset et al. 7 also mentioned a sensitivity index. After identifying the system bottleneck candidates by measuring a set of indicators of each machine, including utilization rate, production bottleneck rate, and processing and utilization factors, the judgment whether multiple bottlenecks exist was performed by adding bottleneck candidates and measuring the corresponding effect on system output. The sensitivity index was used in this study only to determine the existence of multiple bottlenecks.
Most existing bottleneck detection methods are posterior-to-run approaches which detect bottlenecks after a production system has run or the scheduling scheme to be used has already been generated. Consequently, the guidance of the obtained bottleneck knowledge to production optimization is greatly weakened. Zhai et al.10,21 proposed a prior-to-run identification method based on orthogonal experiment Bottleneck Detection Method based on Orthogonal Experiment (BDM-OE); this method can locate system bottlenecks before production task execution by performing typical orthogonal experiments constructed by orthogonal layouts and dispatching rules. However, the reliability of the results greatly depends on whether the orthogonal layouts used are appropriate. Constructing suitable orthogonal layouts for cases that consist of numbers of machines is a complex and difficult task. In addition, different orthogonal layouts must be created for different cases. These disadvantages greatly weaken the adaptability and flexibility of this method. Zhang and Wu22,23 also designed a prior-to-run bottleneck identification method, which is based on constraint transformation for job-shop scheduling. A new optimization model which relaxed the capacity constraints for the machines of the original scheduling problem was initially proposed. A simulated annealing algorithm was then applied to solve the newly defined model. Based on the optimization result, the bottleneck characteristic value of each machine was calculated to identify system bottlenecks before manufacturing systems run. However, the newly defined optimization model, like the original scheduling problem, is also a combinatorial optimization problem. Thus, obtaining its optimal solution, which is the foundation of bottleneck detection, is a difficult task. This greatly reduces the efficiency of the method.
In this study, a new prior-to-run bottleneck detection method for a job shop is proposed according to the basic principle that bottlenecks control the operation of the entire system. The method is implemented by performing sensitivity analysis on the relationship between the capacity of each machine and the corresponding outcome objective values by analyzing the simulation data of scheduling problems. For different production systems, this approach can rapidly and simply identify bottleneck machine clusters under different hierarchies by performing a unified measurement on the sensitivity of system production performance to machine capacity before task execution, and thus it provides good guidance for subsequent production optimization.
Bottleneck machine identification
Definition of bottleneck machines
In a job shop, factors that affect system performance can be divided into internal factors (e.g. machine capacities and process routings), external factors (e.g. raw material supply, production tasks change, and order delivery time), and random factors (e.g. equipment failure and personnel changes). Without considering the effects of external and random factors because of their high unpredictability, internal factors, particularly machine capacities, have significant and direct effect on system performance. In practical scheduling problems, there often exist machines with such properties: compared with other machines, these machines can produce a more significant impact on the final scheduling performance. In other words, in the event that the capacities of other machines are all fixed, moderate changes of the capacity of this machine will lead to comparatively larger variations of the final scheduling objective value, which indicates that the room for optimization and improvement is also relatively large for such machines. Machines with such characteristics are referred to as “bottleneck machines” in this study and defined as follows.
Definition 1
Consider m is the number of machines in a certain production system. Let ci (i = 1, 2, …, m) denote the production capacity of machine i under certain production tasks, and f denote the value of one of the scheduling objectives that measure system performance. The sensitivity of f to ci can be calculated by equation (1)

According to TOC, ei quantifiably describes the likelihood that machine i is the bottleneck and is referred to as bottleneck index.
Definition 2
If
Calculation of bottleneck index matrix
Based on the preceding explanation, a bottleneck machine identification method is developed by analyzing the simulation data of scheduling problems. The algorithm performs sensitivity analysis on the relationship between the capacity of each machine and the corresponding outcome objective values.
To calculate the bottleneck index of each machine, capacity variation
In a determined scheduling case (i.e. the number of jobs, number of machines, processing route of each job, and processing time of each process are all determined), assume that a set of n jobs are to be processed on a set of m machines under the following basic assumptions: (1) the raw materials required are adequate in the production system, (2) no change will occur in the production tasks, (3) all machines will not break down within the production cycle, (4) all machines are available and all jobs can be processed at t = 0, (5) each job has a fixed processing route and each process has a fixed processing time, (6) all machines are independent from each other. i∈M = {1,2, …, m} is the machine mark number and A = {A1, A2, …, Ai, …, Am} is the machine set. Pi is the process set on machine Ai.
Let us suppose that the current simulation data set Ω
j
contains Nj solutions to the discussed scheduling problem, and these solutions are rapidly generated through the combination of dispatching rules, which is one of the most easily implemented and efficient scheduling methods. Element

The variation of machine capacity in the jth simulation
For machine Ai, change the processing time of all the processes in set Pi by

According to the definition of bottleneck machines, the bottleneck index of machine Ai when capacity changes by

The bottleneck index matrix of m machines in the jth simulation can be obtained by conducting the same operation separately to other machines with the same

To avoid accidental factors that may occur in a single simulation and to investigate the bottleneck characteristics of each machine comprehensively, a total of μ simulations are conducted and different
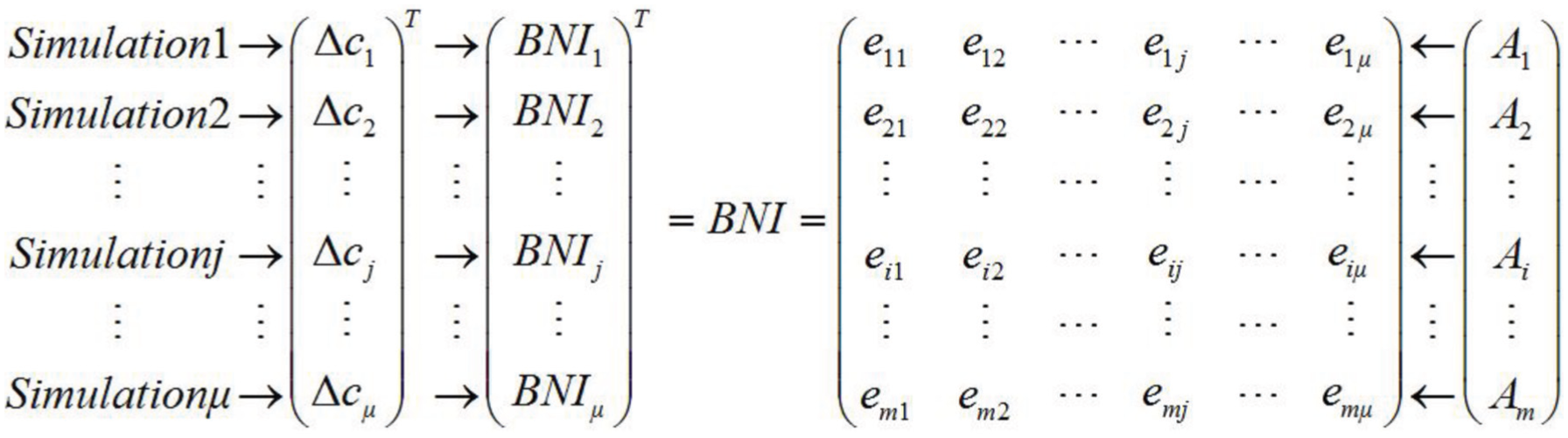
Interpretation of BNI.
Calculation of comprehensive bottleneck index based on technique for order preference by similarity to ideal solution
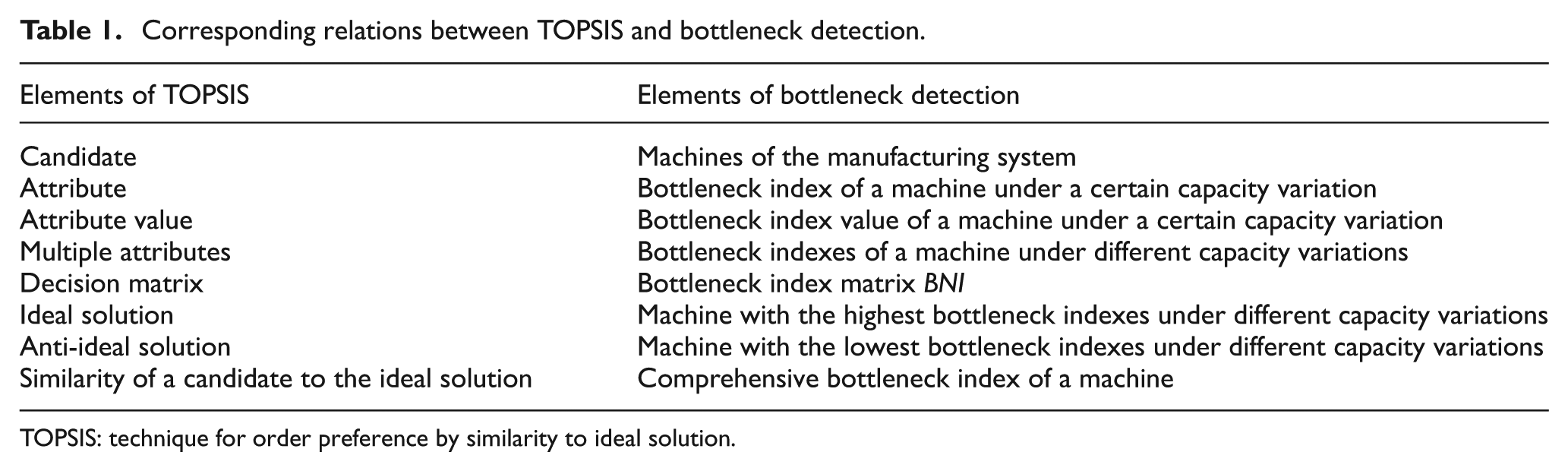
Technique for order preference by similarity to ideal solution (TOPSIS) is a method for multiple attribute decision that involves the following basic procedures: (1) specifying the decision problem by giving the candidates, attributes, performances of each candidate under each attribute, and construct the decision matrix; (2) finding out the ideal solution and the anti-ideal solution of the discussed decision issue; (3) calculating the similarity of each candidate to the ideal solution by considering its distances to the ideal solution and to the anti-ideal solution, and (4) sorting all the candidates according to their similarities to the ideal solution and obtaining the preferred solution that is closest to the ideal solution and farthest from the anti-ideal solution. In this study, each machine is considered as a candidate of the bottleneck identification issue, and the bottleneck index values of the machine under different capacity variations are regarded as the attribute values of the candidate under different attributes. In this manner, the similarities of each candidate (each machine) to the ideal solution (an ideal machine with the highest bottleneck indexes under different capacity variations) can be calculated using TOPSIS. This similarity is referred to as the comprehensive bottleneck index of the machine. The corresponding relations between the elements of TOPSIS and the elements of bottleneck detection are shown in Table 1, and taking BNI as the decision matrix, the procedures to obtain the comprehensive bottleneck index are as follows:
Step 1. Normalizing bottleneck index matrix BNI.
Let
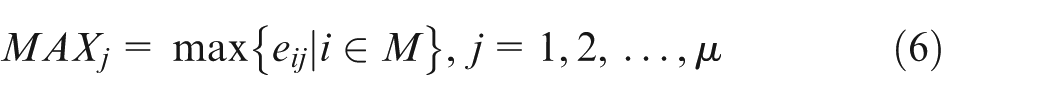
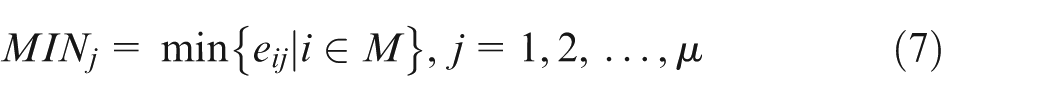


The bottleneck index matrix BNI will be transformed into the standardized BNI′ through transforming
Step 2. Finding out the ideal solution and the anti-ideal solution
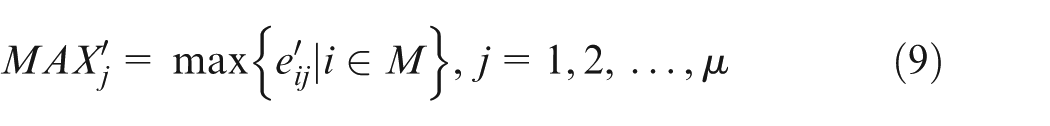
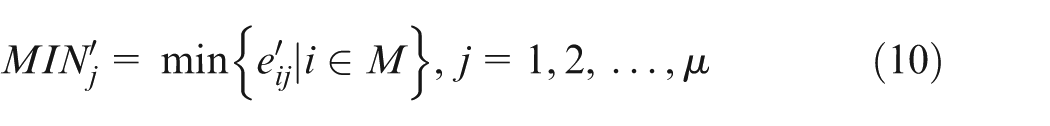
The ideal solution
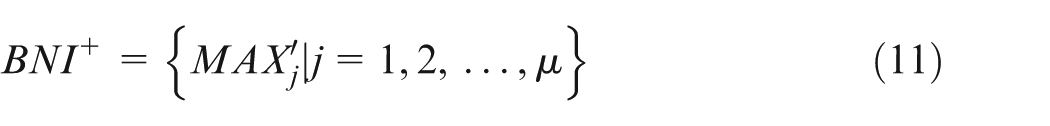
The anti-ideal solution
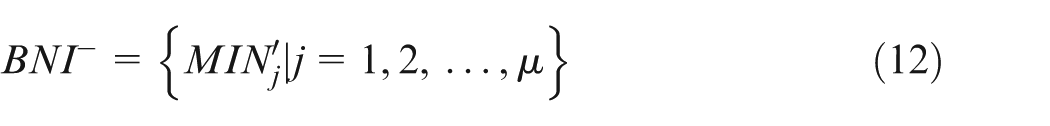
Step 3. Calculating the Euclidean distance from machine Ai to the ideal solution
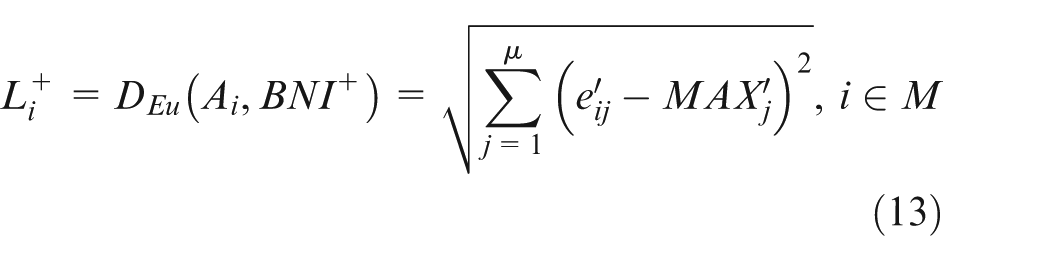
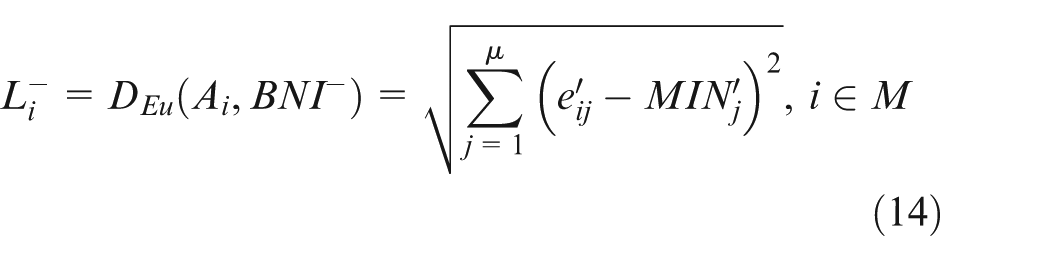
Step 4. Calculating the similarity of machine Ai to the ideal solution as equation (15) and referring the results Ei as the comprehensive bottleneck index of machine Ai

Thus, the comprehensive bottleneck index matrix of m machines CBNI is obtained

Corresponding relations between TOPSIS and bottleneck detection.
TOPSIS: technique for order preference by similarity to ideal solution.
Comprehensive bottleneck index is calculated by integrating the bottleneck characteristic knowledge gained from μ simulations. It can eliminate accidental factors that may occur in a single simulation. Hence, bottleneck characteristics can be fully reflected. The identification results based on this index are satisfactory and convincing.
Identification of bottleneck machine clusters based on hierarchical clustering analysis
Considering the fact that there exist primary and secondary relationships among bottleneck machines, Wang et al.11,24 proposed a set of innovative concepts, including machine cluster, bottleneck cluster (BC), primary bottleneck cluster (PBC), and PBC order, and established a job-shop bottleneck cluster detection method (BC-DM) that uses clustering analysis to output bottleneck machine clusters under different hierarchies. Different from determining the bottleneck sets by a subjectively given size, the cluster method makes the size more reasonable and objective.
After obtaining the comprehensive bottleneck index matrix CBNI, hierarchical clustering analysis is employed in this study to identify bottleneck machine clusters under different hierarchies. The workflow is shown in Figure 2.
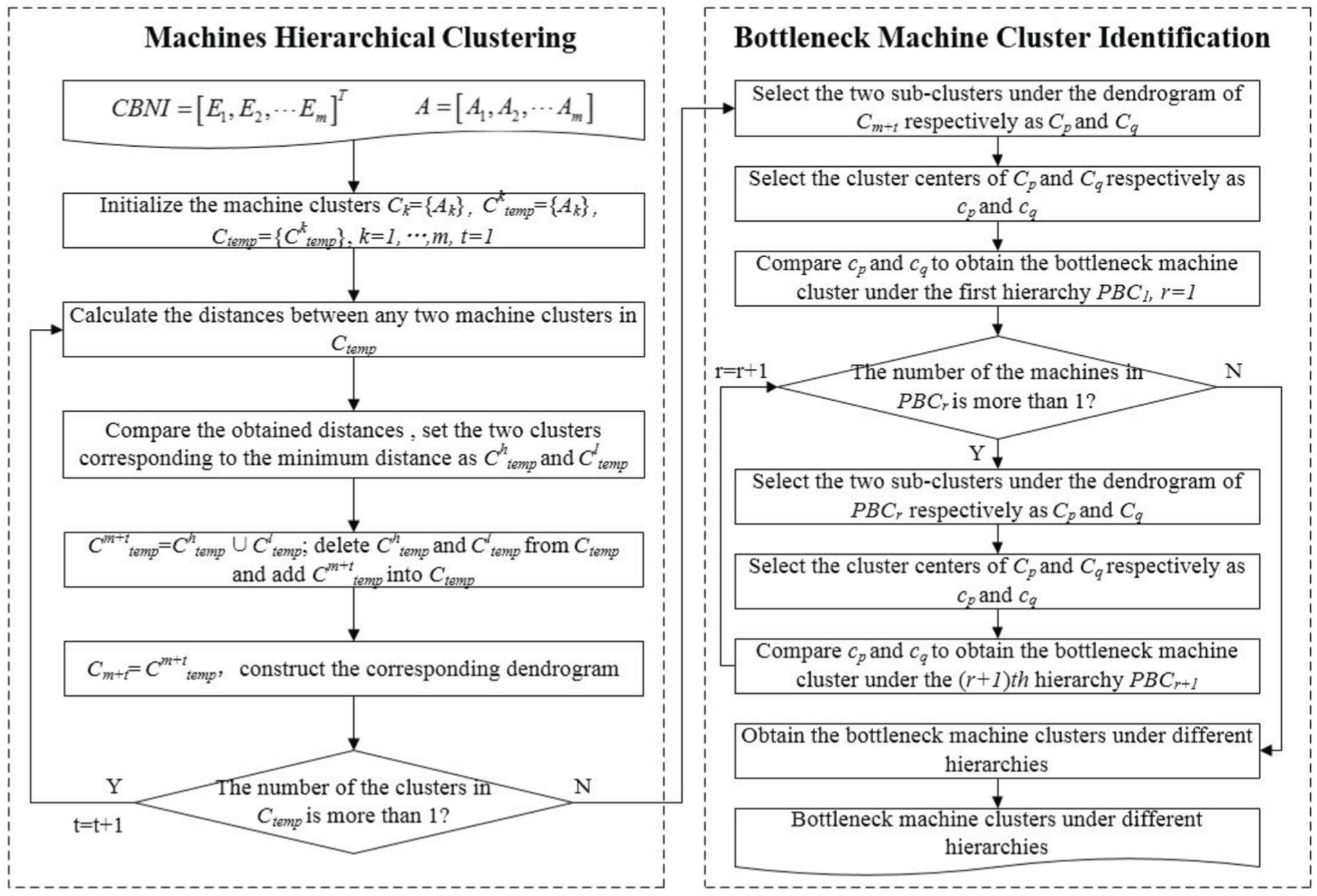
Bottleneck machine cluster identification through machine’s hierarchical clustering.
It can be seen from Figure 2 that m machines in A are first hierarchically clustered according to their comprehensive bottleneck indexes in CBNI. During the process, the distance between two machine clusters Cp and Cq is defined as the distance between the two machines that are separate from the two clusters and are closest to each other in the comprehensive bottleneck index. That is
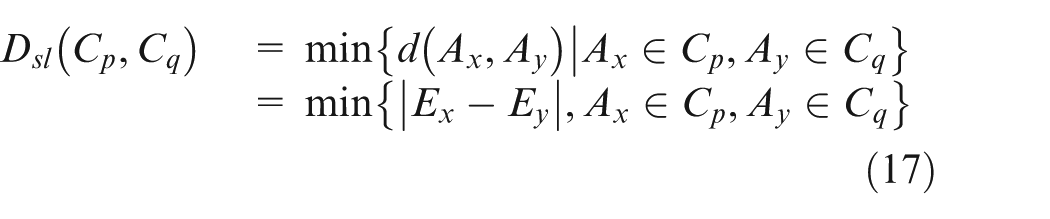
Bottleneck machine cluster identification is then conducted based on the final result of machine hierarchical clustering Cm+t and the corresponding dendrogram. In this process, the cluster center of a machine cluster is defined as the machine with the highest comprehensive bottleneck index in this cluster. The cluster centers of two machine clusters are compared, and the machine cluster with the cluster center that has a higher comprehensive bottleneck index is selected as the bottleneck machine cluster under a certain hierarchy.
The entire workflow of the proposed detection method is shown in Figure 3. The basic procedures are described as follows:
Step 1. Make the discussed bottleneck identification case specific by giving the job number n, machine number m, processing route of each job, and processing time of each process. Set the total number of simulations μ. j denotes the simulation mark number, j = 1.
Step 2. If
Step 3. For machine Ai, change the processing time of all the processes in Pi into
Step 4. If
Step 5. Calculate the comprehensive bottleneck index matrix CBNI based on BNI with TOPSIS.
Step 6. Conduct hierarchical cluster analysis to identify the bottleneck machine clusters under different hierarchies based on CBNI.
Step 7. Terminate and output the final results.
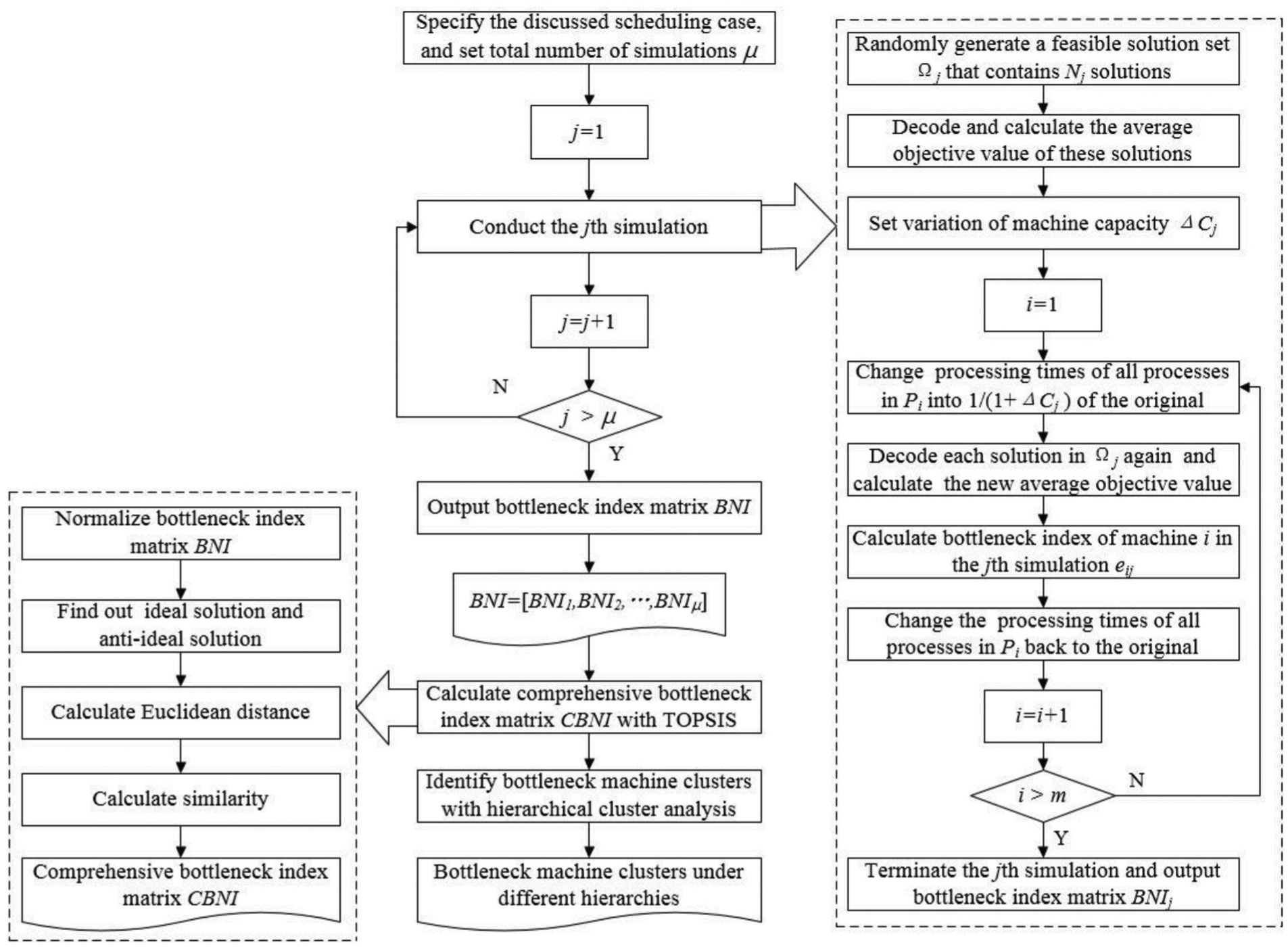
Bottleneck identification workflow based on TOC and sensitivity analysis.
Computational example studies and discussions
Computational examples
To illustrate the effectiveness and performance of the designed method in this study, we adopt job-shop scheduling benchmark instances for simulation, including different scales of 50, 75, 100, 200, and 300 operations. Each scale contains 4 instances, that is, 20 instances in all. The simulation details of each instance (such as the number of machines, number of jobs, number of operations, processing time for each operation, and processing routine) are available at http://people.brunel.ac.uk/~mastjjb/jeb/orlib/files/jobshop1.txt. Minimizing the makespan that is frequently used is selected as the scheduling objective. The number of feasible solutions randomly generated in each simulation is set as Nj = 200 for benchmarks with processes less than or equal to 100 and Nj = 400 for benchmarks with processes more than 100. Bottleneck identification will be conducted from two aspects,
Identification results of the proposed method.
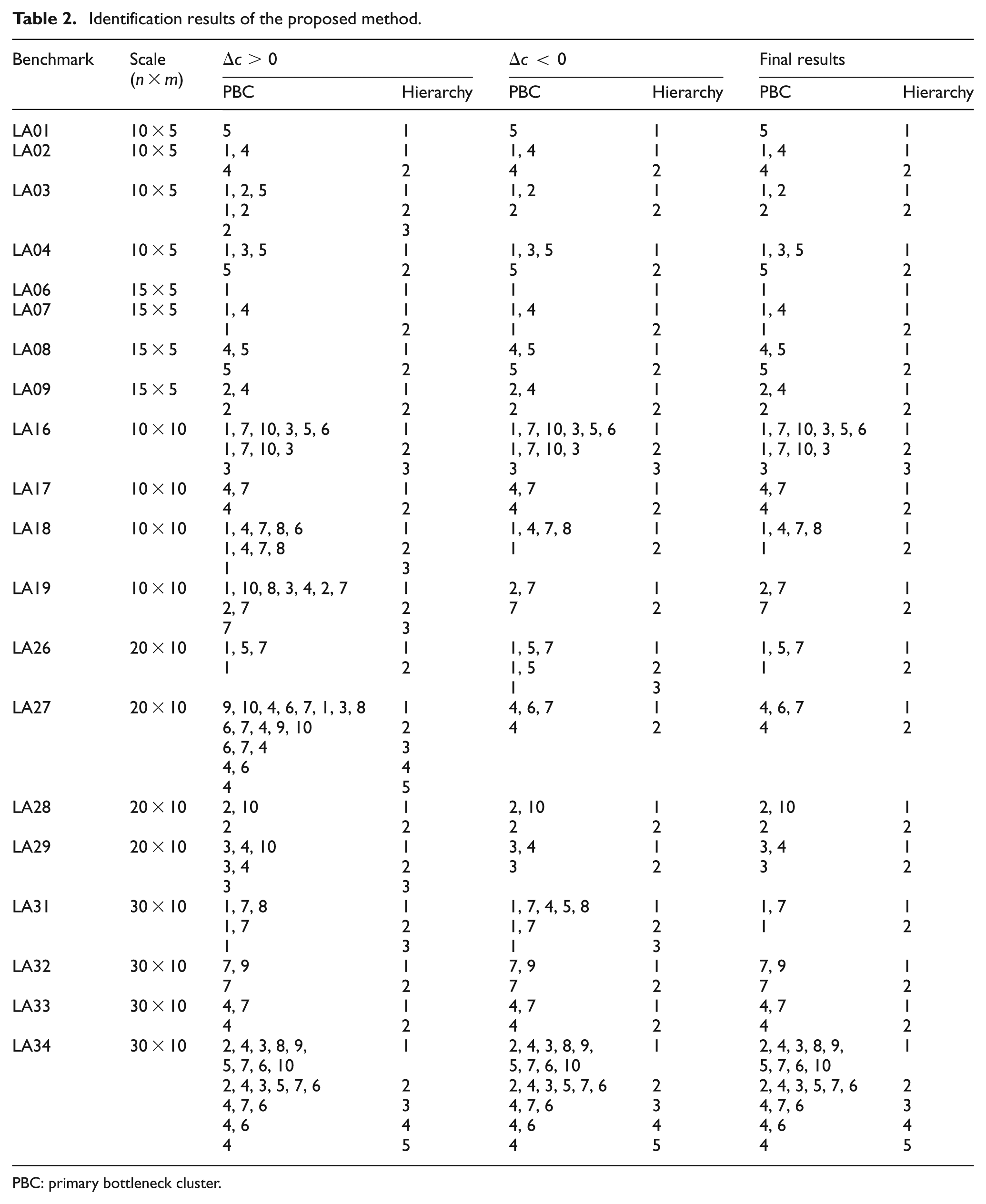
PBC: primary bottleneck cluster.
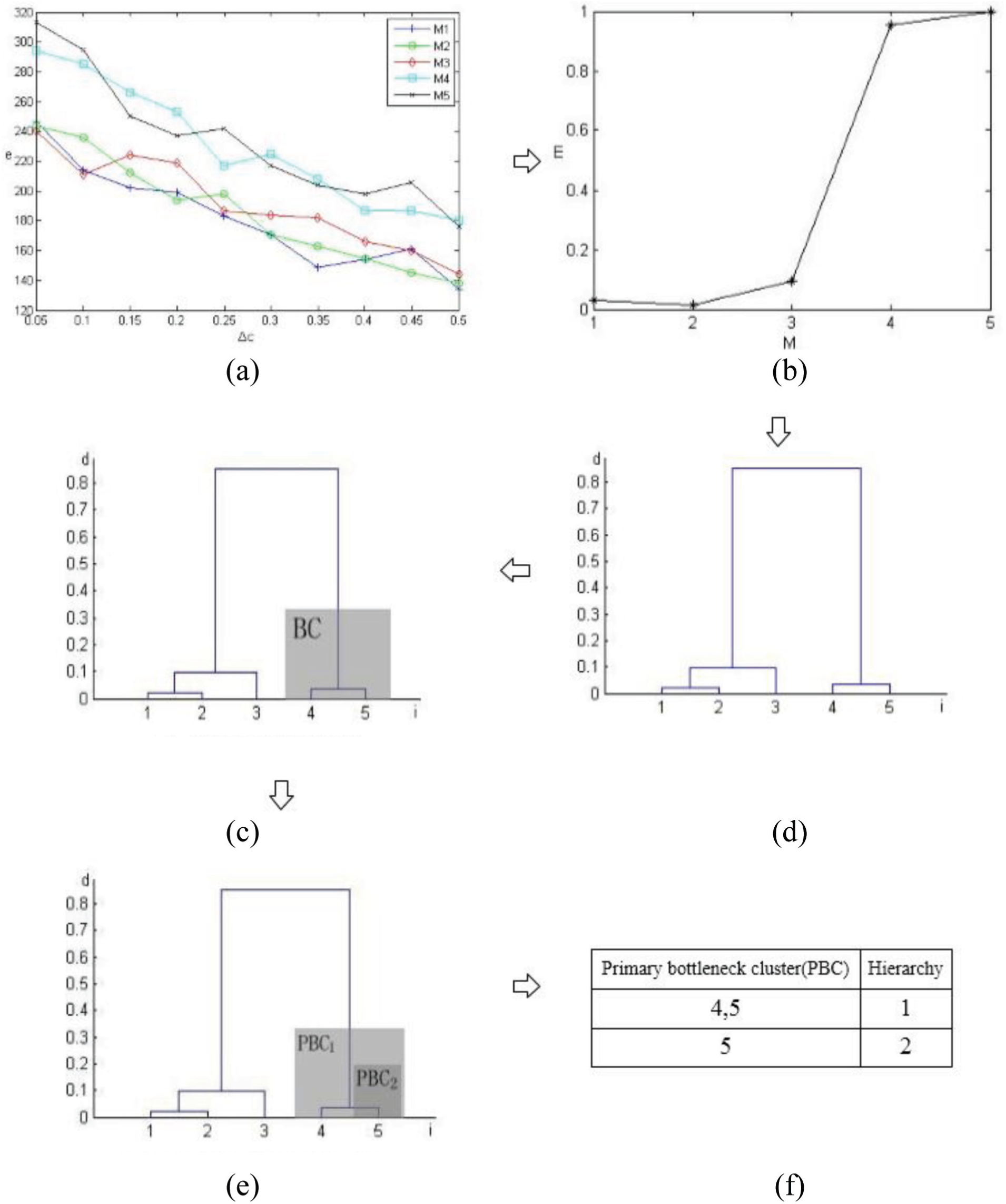
Detailed bottleneck identification process of LA08: (a) bottleneck index of each machine in LA08, (b) comprehensive bottleneck index of each machine in LA08, (c) hierarchical clustering dendrogram of LA08, (d) bottleneck cluster (BC), (e) primary bottleneck cluster (PBC2), and (f) final results.
The identification results of the proposed methods are compared with those of several existing approaches in literature: (1) BDM-OE, 10 (2) SB-DM, 15 and (3) BC-DM. 11 The results are presented in Table 3.
Comparison of the results of four methods.
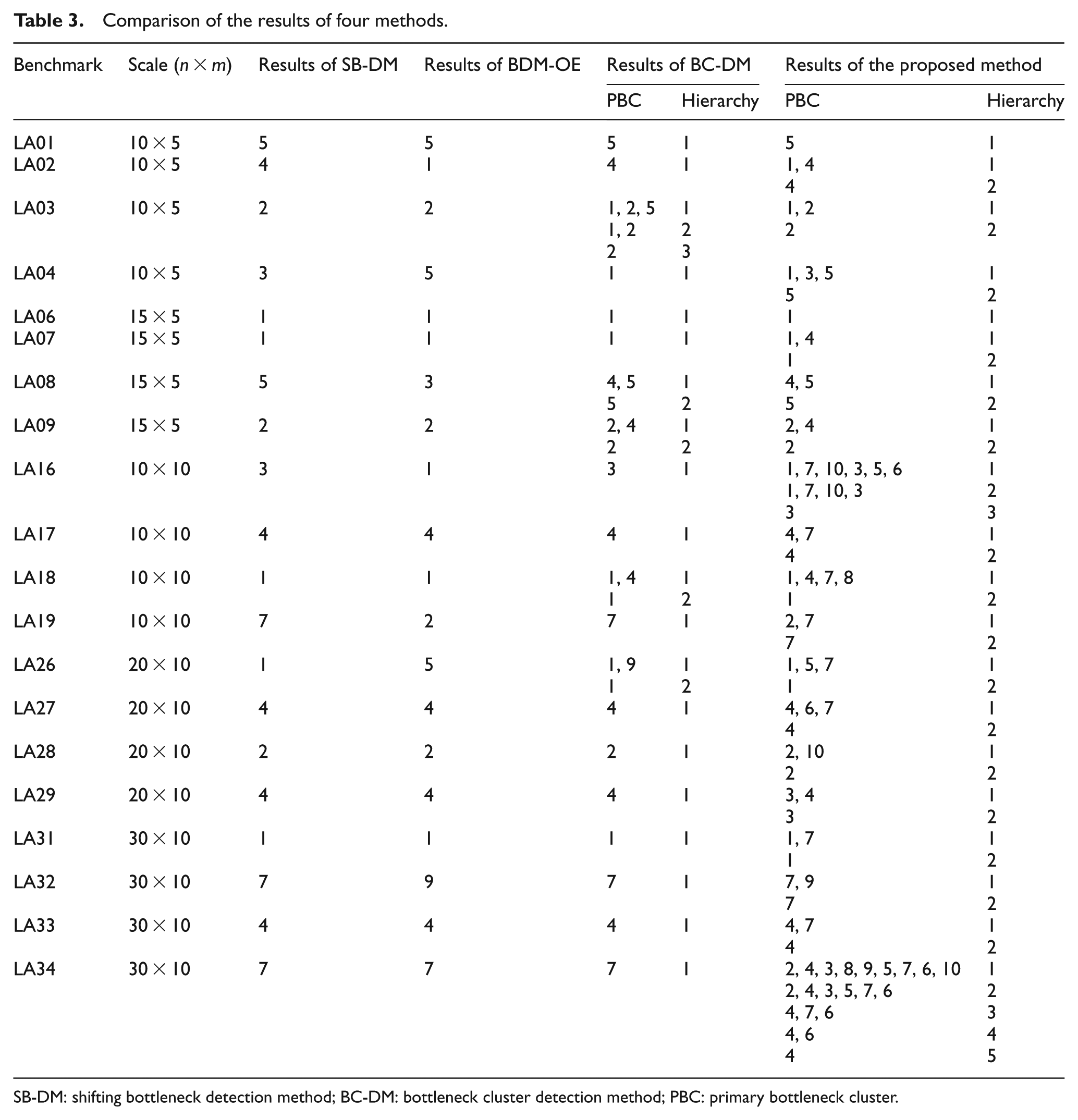
SB-DM: shifting bottleneck detection method; BC-DM: bottleneck cluster detection method; PBC: primary bottleneck cluster.
Results discussion
Table 3 shows that the results of the proposed method are consistent with those of SB-DM for most scheduling benchmarks, with a consistency rate of 87.5%. In identifying BC under the highest hierarchy, which is the most important bottleneck knowledge, the coincidence rate between the results of the proposed method and those of BC-DM is 90%. Thus, the proposed method is feasible and effective.
The slight difference in detection results from those of the other methods is attributed to the difference in data foundations and production indicators used (Table 4). The proposed method can be conducted without the optimal scheduling scheme. Its data foundation is a set of feasible scheduling schemes that are randomly generated, whereas SB-DM and BC-DM work based on the obtained optimal or suboptimal scheduling scheme obtained by optimization algorithms. The proposed method locates bottlenecks based on the sensitivity of production performance to the capacities of each machine, whereas SB-DM determines the bottleneck based on the duration a machine is active without interruption in the optimal scheduling scheme and BC-DM bases identification on production data of each machine, including workload, utilization rate, and average active time. Differences in data foundation and identification indicators determine that the slight variances in the recognition result cannot be avoided.
Comparison of data foundation and production indicators used in the three methods.

SB-DM: shifting bottleneck detection method; BC-DM: bottleneck cluster detection method.
Notably, the proposed method is superior to the other two methods on computational complexity and efficiency. As posterior-to-run identification methods, SB-DM and BC-DM, can only be applied after the production system has run or the optimal scheduling scheme to be used has already been generated. However, the gain of the optimal scheduling scheme largely depends on the selected optimization algorithm and related parameters, and most job-shop scheduling problems have been shown to be non-deterministic polynomial-time (NP)-hard in the strong sense and still considered to be very difficult combinatorial optimization problems. Thus, the relatively high requirement of the two methods on data foundations considerably reduces their recognition efficiency.
The proposed method is a prior-to-run identification method and only requires feasible scheduling schemes as data foundations. The main procedures, including the random generation of feasible scheduling schemes, changing processing time of processes, encoding, and decoding, are very simple. Hence, identifying bottlenecks takes less time and the longest running time does not exceed 10 s. Therefore, the proposed method has great advantages on efficiency.
Compared with BDM-OE, which is also a prior-to-run identification method, the proposed method has unique advantages. BDM-OE conducts identification by performing several typical orthogonal experiments without knowing the optimal scheduling scheme. However, the reliability of the results highly depends on whether the orthogonal layouts used are appropriate. In addition, different orthogonal layouts need to be created for different cases, and the construction of orthogonal layouts is very complex, especially for cases consisting of numbers of machines. As the number of machines increases, constructing the appropriate orthogonal layouts becomes increasingly difficult, which greatly restricts the application of the method in large-scale scheduling cases and weakens its adaptability and flexibility.
Based on the basic principles of TOC, the proposed method conducts bottleneck identification by examining the sensitivity of system performance to machine capacities. For identification cases of all sizes, bottlenecks can be located through unified procedures and operations without individualized processes. Thus, the method has greater adaptability and flexibility.
Conclusion and outlook
This study initially defines bottleneck machines in a job shop based on the basic principle of TOC that bottlenecks control operations of the whole system. With an eye to internal factors that have impact on system performance, this definition is in favor of identifying system bottlenecks from the global point of view by conducting an overall performance-oriented measurement in each machine. Consequently, this method provides good guidance for subsequent production optimization.
To overcome the disadvantages of existing bottleneck detection methods for a job shop, including complex recognition algorithms and poor guidance caused by posterior-to-run recognition, a prior-to-run method based on TOC and sensitivity analysis is designed based on the foundation of bottleneck identification. A bottleneck index matrix is first obtained by measuring the sensitivity of system performance to the capacity of each machine. TOPSIS is then employed to calculate the comprehensive bottleneck index. Based on the calculation results, BCs under different hierarchies are obtained through hierarchical cluster analysis. Finally, 20 benchmarks of job-shop scheduling problems are selected to compare the proposed approach with several existing approaches, that is, SB-DM, BDM-OE, and BC-DM, to illustrate the effectiveness and performance of the designed method. The comparison shows that the proposed approach is largely consistent with other popular methods in the recognition results, but could be conducted with less complexity because of its simple and unified procedures. Moreover, its data foundations are easier to obtain. Therefore, the proposed method is feasible and superior. BCs under different hierarchies can be quickly identified before the overall system circulation by using the proposed method, thereby providing considerable valuable information for managers of production systems to improve the overall system performance.
After achieving bottleneck machine identification under a steady production state, future research will consider the influence of dynamic random events on bottleneck identification and the multi-objective and multi-resource characteristics of bottlenecks, as well as focus on bottleneck identification and prediction oriented toward multiple objectives and multiple resources under the background of bottleneck shifting.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research is supported by the National Natural Science Foundation of China (NSFC) under grant no. 51205429 and the National Science and Technology Pillar Program during the 12th Five-year Plan Period of China under grant no. 2012BAF01B01.